A Comparison of Classification Techniques to Predict Brain-Computer Interfaces Accuracy Using Classifier-Based Latency Estimation †

 ,
, 
Abstract
:
1. Introduction
- (i)
- LS provided the best overall performance on the dataset used in CBLE’s original article [11],
- (ii)
- In a classifier comparison study [19] SWLDA provided the overall best performance, and
- (iii)
- A recent study [20] showed that SAE provided the best overall performance on their dataset for P300 speller. But SAE has not been used to estimate latency jitter to our knowledge.
2. Methods
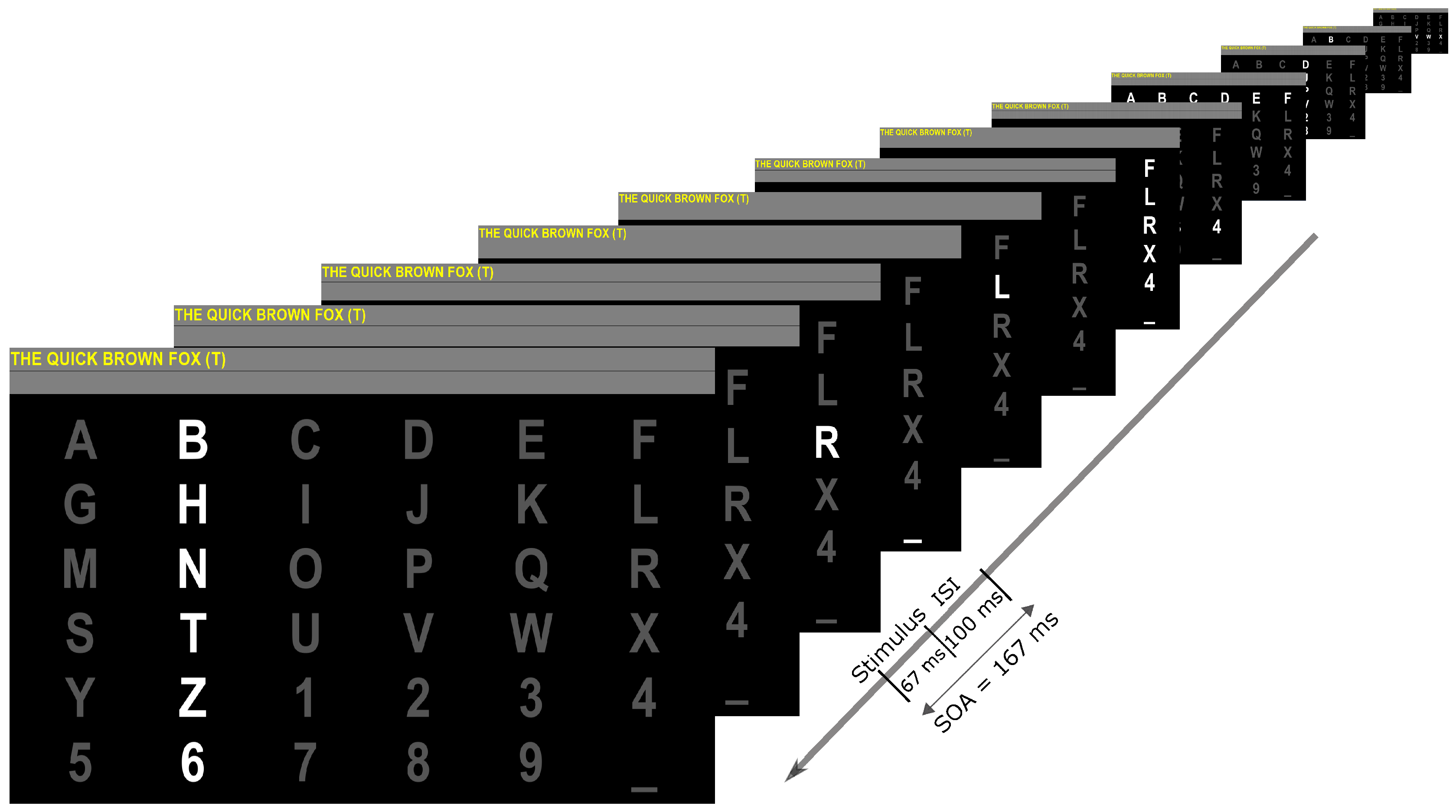
2.1. Experimental Setup
2.2. Participants
2.3. EEG Pre-Processing
2.4. Classification Strategy
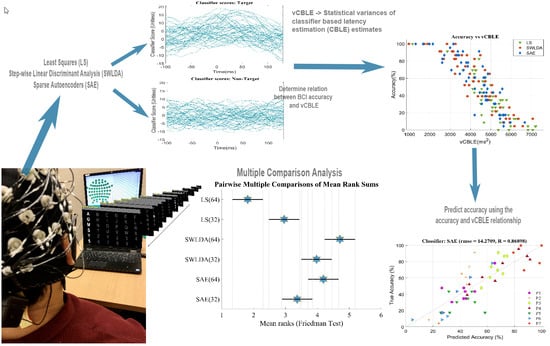
2.4.1. Classifier-Based Latency Estimation (CBLE)
2.4.2. Least Squares (LS)
2.4.3. Step-Wise Linear Discriminant Analysis (SWLDA)
2.4.4. Sparse Autoencoder
2.4.5. Parameter Selection
2.5. Performance Evaluation
3. Results
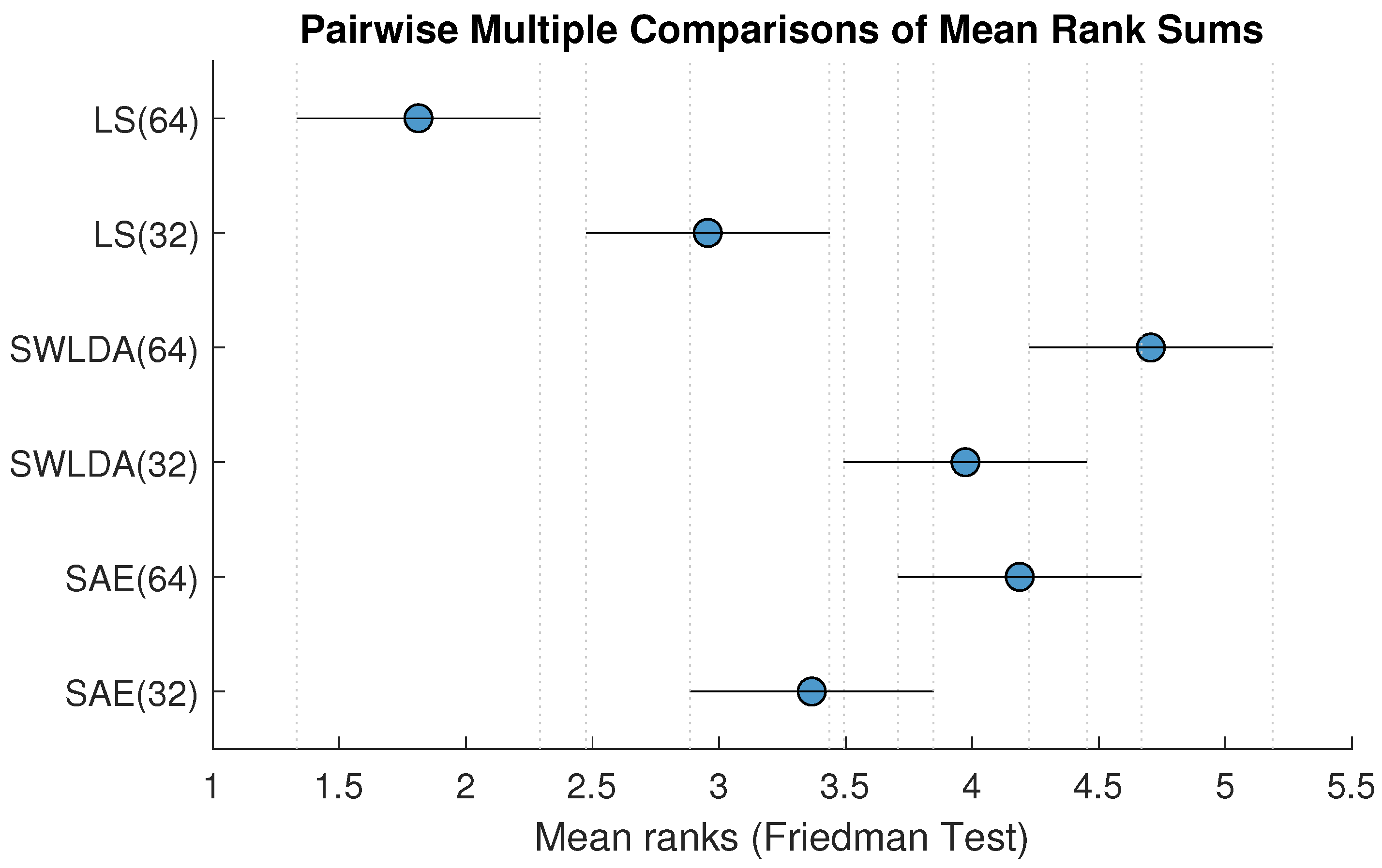
3.1. Friedman Test with Post Hoc Analysis
3.2. Wilcoxon Signed-Ranks Test
3.3. Effect of Number of Electrodes
- LS: The accuracy using all channels is significantly worse than using a reduced set of channels.
- SWLDA: The set of all channels performed better than the reduced channel set, but the difference was not significant.
- SAE: The set of all channels performed better than the reduced channel set, with the difference close to but above the usual significance threshold (adjusted p = 0.068, below 0.05 without Bonferroni correction).
3.4. Effect of Classification Method
- SWLDA vs. SAE: SWLDA slightly outperformed SAE, but the different was highly non-significant (p-value 1).
- SAE vs. LS: SAE significantly outperformed LS (adjusted p-value ). The significant difference is also observed in Figure 2.
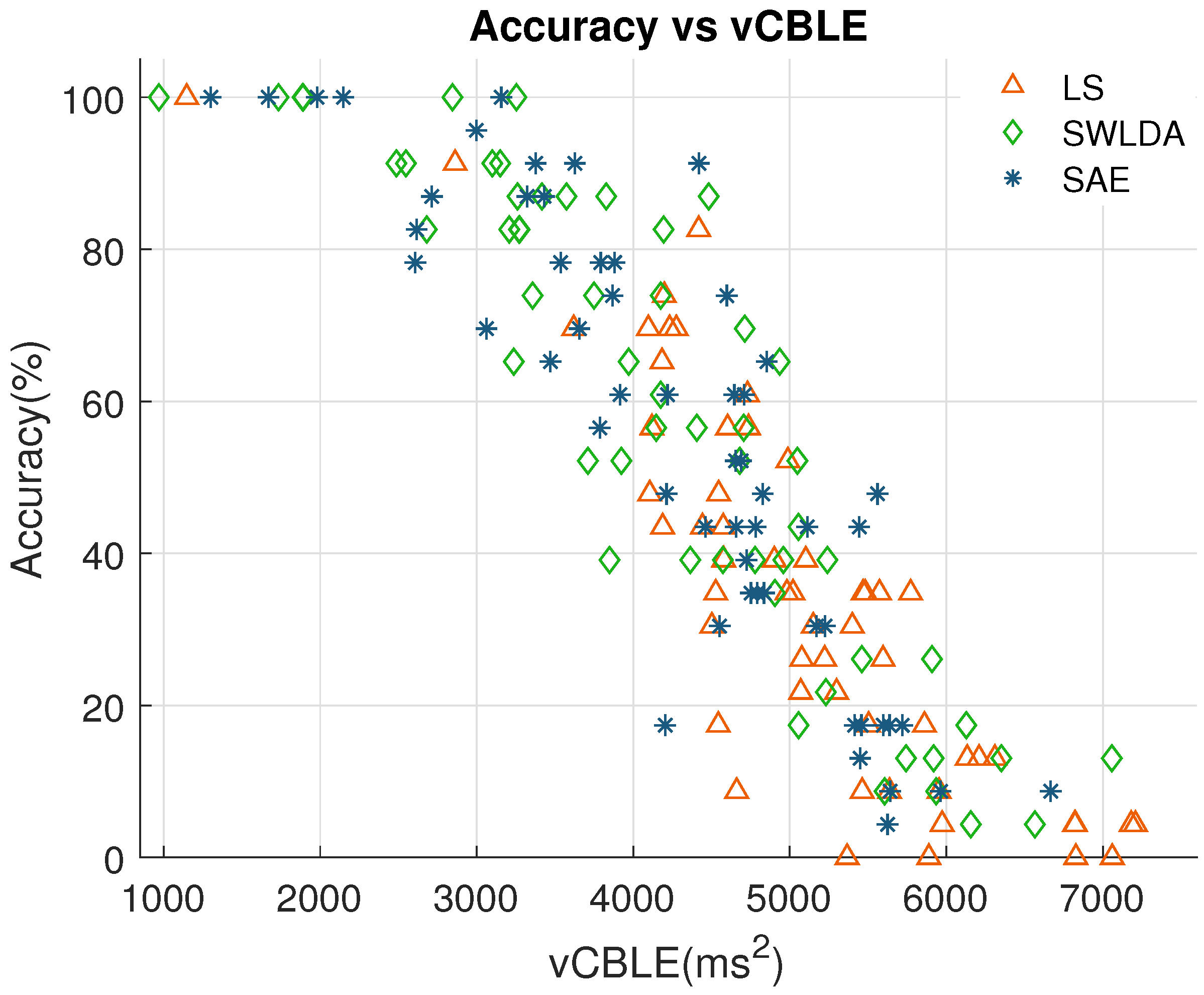
3.5. Relation between BCI Accuracy and P300 Latency Variations
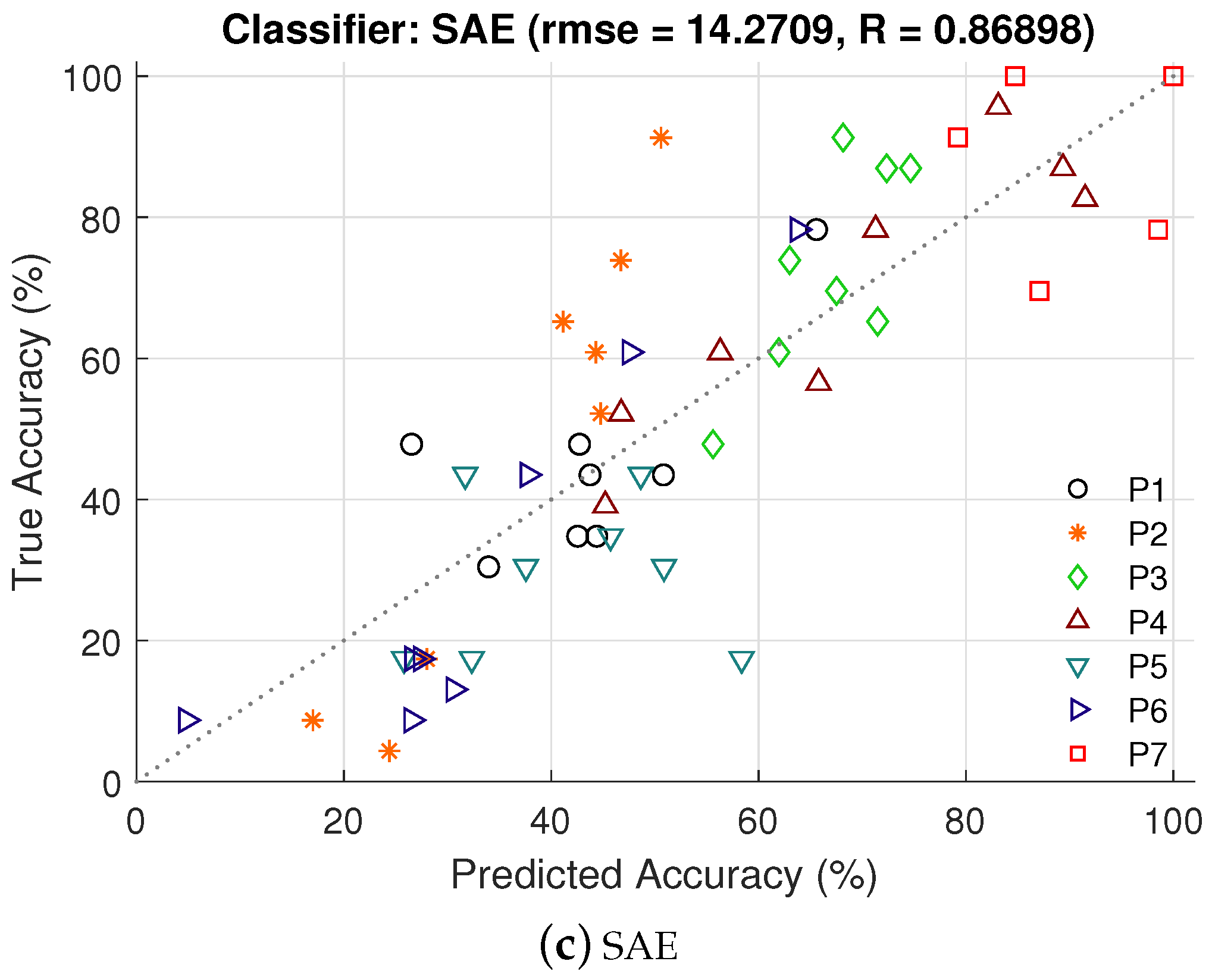
3.6. Predicting BCI Accuracy from vCBLE
4. Discussion
4.1. Limitations
4.2. Future Work
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AE | Autoencoder |
| ANOVA | Analysis of Variance |
| BCI | Brain-computer interface |
| CBLE | Classifier-based latency estimation |
| ERP | Event-related potential |
| ITR | Information transfer rate |
| LDA | Linear discriminant analysis |
| LS | least-squares |
| SAE | Sparse autoencoders |
| SOA | Stimulus onset asynchrony |
| SWLDA | Stepwise linear discriminant analysis |
| vCBLE | Statistical variance of the CBLE |
References
- Shih, J.J.; Krusienski, D.J.; Wolpaw, J.R. Brain-computer interfaces in medicine. Mayo Clin. Proc. 2012, 87, 268–279. [Google Scholar] [CrossRef] [Green Version]
- Paszkiel, S. Analysis and Classification of EEG Signals for Brain-Computer Interfaces; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Farwell, L.A.; Donchin, E. Talking off the top of your head: Toward a mental prosthesis utilizing event-related brain potentials. Electroencephalogr. Clin. Neurophysiol. 1988, 70, 510–523. [Google Scholar] [CrossRef]
- Bianchi, L.; Liti, C.; Piccialli, V. A new early stopping method for p300 spellers. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 1635–1643. [Google Scholar] [CrossRef]
- Donchin, E.; Spencer, K.M.; Wijesinghe, R. The mental prosthesis: Assessing the speed of a P300-based brain-computer interface. IEEE Trans. Rehabil. Eng. 2000, 8, 174–179. [Google Scholar] [CrossRef] [Green Version]
- Guger, C.; Daban, S.; Sellers, E.; Holzner, C.; Krausz, G.; Carabalona, R.; Gramatica, F.; Edlinger, G. How many people are able to control a P300-based brain-computer interface (BCI)? Neurosci. Lett. 2009, 462, 94–98. [Google Scholar] [CrossRef]
- Fjell, A.M.; Rosquist, H.; Walhovd, K.B. Instability in the latency of P3a/P3b brain potentials and cognitive function in aging. Neurobiol. Aging 2009, 30, 2065–2079. [Google Scholar] [CrossRef]
- Polich, J.; Kok, A. Cognitive and biological determinants of P300: An integrative review. Biol. Psychol. 1995, 41, 103–146. [Google Scholar] [CrossRef]
- Yagi, Y.; Coburn, K.L.; Estes, K.M.; Arruda, J.E. Effects of aerobic exercise and gender on visual and auditory P300, reaction time, and accuracy. Eur. J. Appl. Physiol. Occup. Physiol. 1999, 80, 402–408. [Google Scholar] [CrossRef]
- Polich, J. Updating P300: An integrative theory of P3a and P3b. Clin. Neurophysiol. 2007, 118, 2128–2148. [Google Scholar] [CrossRef] [Green Version]
- Thompson, D.E.; Warschausky, S.; Huggins, J.E. Classifier-based latency estimation: A novel way to estimate and predict BCI accuracy. J. Neural Eng. 2012, 10, 016006. [Google Scholar] [CrossRef] [Green Version]
- Aricò, P.; Aloise, F.; Schettini, F.; Salinari, S.; Mattia, D.; Cincotti, F. Influence of P300 latency jitter on event related potential-based brain-computer interface performance. J. Neural Eng. 2014, 11, 035008. [Google Scholar] [CrossRef]
- Li, R.; Keil, A.; Principe, J.C. Single-trial P300 estimation with a spatiotemporal filtering method. J. Neurosci. Methods 2009, 177, 488–496. [Google Scholar] [CrossRef]
- D’Avanzo, C.; Schiff, S.; Amodio, P.; Sparacino, G. A Bayesian method to estimate single-trial event-related potentials with application to the study of the P300 variability. J. Neurosci. Methods 2011, 198, 114–124. [Google Scholar] [CrossRef]
- Mowla, M.R.; Huggins, J.E.; Thompson, D.E. Enhancing P300-BCI performance using latency estimation. Brain-Comput. Interfaces 2017, 4, 137–145. [Google Scholar] [CrossRef]
- Ye, J. Least squares linear discriminant analysis. In Proceedings of the 24th international conference on Machine Learning, ACM, Corvalis, OR, USA, 20–24 June 2007; pp. 1087–1093. [Google Scholar]
- Lee, K.; Kim, J. On the equivalence of linear discriminant analysis and least squares. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Mowla, M.R. Applications of Non-Invasive Brain-Computer Interfaces for Communication and Affect Recognition. Ph.D. Thesis, Kansas State University, Manhattan, KS, USA, 2020. [Google Scholar]
- Krusienski, D.J.; Sellers, E.W.; Cabestaing, F.; Bayoudh, S.; McFarland, D.J.; Vaughan, T.M.; Wolpaw, J.R. A comparison of classification techniques for the P300 Speller. J. Neural Eng. 2006, 3, 299. [Google Scholar] [CrossRef] [Green Version]
- Vařeka, L.; Mautner, P. Stacked autoencoders for the P300 component detection. Front. Neurosci. 2017, 11, 302. [Google Scholar] [CrossRef] [Green Version]
- Schalk, G.; McFarland, D.J.; Hinterberger, T.; Birbaumer, N.; Wolpaw, J.R. BCI2000: A general-purpose brain-computer interface (BCI) system. IEEE Trans. Biomed. Eng. 2004, 51, 1034–1043. [Google Scholar] [CrossRef]
- Rakotomamonjy, A.; Guigue, V. BCI competition III: Dataset II-ensemble of SVMs for P300 speller. IEEE Trans. Biomed. Eng. 2008, 55, 1147–1154. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Krusienski, D.J.; Sellers, E.W.; McFarland, D.J.; Vaughan, T.M.; Wolpaw, J.R. Toward enhanced P300 speller performance. J. Neurosci. Methods 2008, 167, 15–21. [Google Scholar] [CrossRef] [Green Version]
- Olshausen, B.A.; Field, D.J. Sparse coding with an overcomplete basis set: A strategy employed by V1? Vis. Res. 1997, 37, 3311–3325. [Google Scholar] [CrossRef] [Green Version]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Wolpaw, J.R.; Ramoser, H.; McFarland, D.J.; Pfurtscheller, G. EEG-based communication: Improved accuracy by response verification. IEEE Trans. Rehabil. Eng. 1998, 6, 326–333. [Google Scholar] [CrossRef]
- Dal Seno, B.; Matteucci, M.; Mainardi, L.T. The utility metric: A novel method to assess the overall performance of discrete brain-computer interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 2009, 18, 20–28. [Google Scholar] [CrossRef]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Hochberg, J.; Tamhane, A.C. Multiple Comparison Procedures; John Wiley & Sons: Hoboken, NJ, USA, 1987. [Google Scholar]
- Marascuilo, L.A.; McSweeney, M. Nonparametric post hoc comparisons for trend. Psychol. Bull. 1967, 67, 401. [Google Scholar] [CrossRef]
- Gibbons, J.D.; Chakraborti, S. Nonparametric Statistical Inference; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Kvam, P.H.; Vidakovic, B. Nonparametric Statistics with Applications to Science and Engineering; John Wiley & Sons: Hoboken, NJ, USA, 2007; Volume 653. [Google Scholar]
- Benavoli, A.; Corani, G.; Mangili, F. Should we really use post-hoc tests based on mean-ranks? J. Mach. Learn. Res. 2016, 17, 152–161. [Google Scholar]
- Wilcoxon, F. Individual comparisons by ranking methods. Biom. Bull. 1945, 1, 80–83. [Google Scholar] [CrossRef]
- Kaufmann, T.; Schulz, S.; Grünzinger, C.; Kübler, A. Flashing characters with famous faces improves ERP-based brain–computer interface performance. J. Neural Eng. 2011, 8, 056016. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dutt-Mazumder, A.; Huggins, J.E. Performance comparison of a non-invasive P300-based BCI mouse to a head-mouse for people with SCI. Brain-Comput. Interfaces 2020, 1–10. [Google Scholar] [CrossRef]
- Eidel, M.; Kübler, A. Wheelchair Control in a Virtual Environment by Healthy Participants Using a P300-BCI Based on Tactile Stimulation: Training Effects and Usability. Front. Hum. Neurosci. 2020, 14, 265. [Google Scholar] [CrossRef] [PubMed]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Session | Sentence to Spell |
|---|---|
| THE QUICK BROWN FOX | |
| 01 | THANK YOU FOR YOUR HELP |
| THE DOG BURIED THE BONE | |
| MY BIKE HAS A FLAT TIRE | |
| 02 | I WILL MEET YOU AT NOON |
| DO NOT WALK TOO QUICKLY | |
| YES. YOU ARE VERY SMART | |
| 03 | HE IS STILL ON OUR TEAM |
| IT IS QUITE WINDY TODAY |
| Methods | LS(64) | LS(32) | SWLDA(64) | SWLDA(32) | SAE(64) |
|---|---|---|---|---|---|
| LS(32) | 1.55 *** | - | - | - | - |
| SWLDA(64) | *** | *** | - | - | - |
| SWLDA(32) | *** | *** | 0.543 | - | - |
| SAE(64) | *** | 0.0047 ** | 1 | 1 | - |
| SAE(32) | *** | 1 | ** |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mowla, M.R.; Gonzalez-Morales, J.D.; Rico-Martinez, J.; Ulichnie, D.A.; Thompson, D.E. A Comparison of Classification Techniques to Predict Brain-Computer Interfaces Accuracy Using Classifier-Based Latency Estimation . Brain Sci. 2020, 10, 734. https://0-doi-org.brum.beds.ac.uk/10.3390/brainsci10100734
Mowla MR, Gonzalez-Morales JD, Rico-Martinez J, Ulichnie DA, Thompson DE. A Comparison of Classification Techniques to Predict Brain-Computer Interfaces Accuracy Using Classifier-Based Latency Estimation . Brain Sciences. 2020; 10(10):734. https://0-doi-org.brum.beds.ac.uk/10.3390/brainsci10100734
Chicago/Turabian StyleMowla, Md Rakibul, Jesus D. Gonzalez-Morales, Jacob Rico-Martinez, Daniel A. Ulichnie, and David E. Thompson. 2020. "A Comparison of Classification Techniques to Predict Brain-Computer Interfaces Accuracy Using Classifier-Based Latency Estimation " Brain Sciences 10, no. 10: 734. https://0-doi-org.brum.beds.ac.uk/10.3390/brainsci10100734