Information Evolution and Organisations

Capgemini UK, Forge End, Woking, Surrey GU21 6DB, UK
Information 2019, 10(12), 393; https://0-doi-org.brum.beds.ac.uk/10.3390/info10120393
Submission received: 26 October 2019
/
Revised: 7 December 2019
/
Accepted: 8 December 2019
/
Published: 12 December 2019
(This article belongs to the Section Information Theory and Methodology)
Abstract
:In a changing digital world, organisations need to be effective information processing entities, in which people, processes, and technology together gather, process, and deliver the information that the organisation needs. However, like other information processing entities, organisations are subject to the limitations of information evolution. These limitations are caused by the combinatorial challenges associated with information processing, and by the trade-offs and shortcuts driven by selection pressures. This paper applies the principles of information evolution to organisations and uses them to derive principles about organisation design and organisation change. This analysis shows that information evolution can illuminate some of the seemingly intractable difficulties of organisations, including the effects of organisational silos and the difficulty of organisational change. The derived principles align with and connect different strands of current organisational thinking. In addition, they provide a framework for creating analytical tools to create more detailed organisational insights.
1. Introduction
As the world becomes more digital, the success of all types of organisation depends more and more on how good they are at processing information. This is not just a narrow issue about technology, but about organisations as information processing entities. At the same time, it is becoming more important for organisations to respond effectively to a changing environment [1,2], so a static view of information is not enough. However, organisations are finding this challenge difficult. Davenport and Spanyi have reported that [3], “companies are beginning to report high failure rates for digital transformation, similar to failure rates for large-scale transformation in general. There are too many legacy systems, too much technical debt, and too many functional and business unit data silos to overcome.” So, how can we relate ideas about organisations and how they change [4,5] to ideas about information processing and how it changes?
This paper considers that question and links information evolution [6,7,8,9,10] to principles about organisation design and organisation change. Information evolution is based on two underlying ideas, namely, information connection and adaptation to the environment. The idea that information is connected surfaces in many different fields. The World Wide Web is a (very) large-scale example. With respect to people, Kahneman [11] talks about ideas being connected in “associative memory”. Within his work on social network analysis [12], Granovetter discussed the nature of connections. In [13], the authors say: “By embracing the networked nature of organisations, and the challenge of changing what is highly connected, we […] increase the chances that it will ultimately succeed.” Numerous techniques for modelling information (including Bayesian networks, causal networks, dataflow diagrams, class diagrams, and knowledge graphs, to select just a few) are based on showing connections of different types.
Adapting to the environment is also very widely discussed. It is at the heart of natural selection [14], but, more recently, it has been embraced in many fields. Is his analysis of culture, Schein said that [15] “the culture of a group can be defined as the accumulated shared learning of that group as it solves its problems of external adaptation and internal integration.” Quine [16] discusses the “field of force whose boundary conditions are experience.” In [17], Christian says that “natural selection [has] equipped large organisms with a desire for more information, because good information [is] vital to their success. [...] Decision-making works at several different levels in brainy creatures. Some decisions need to be made quickly...” As this quote implies, adapting to the environment requires trade-offs. Simon [18] uses this idea in his concept of bounded rationality. As described in [13], this is “the theory that when people make decisions, their rationality is limited (bounded) by the difficulty of the decision problem, their own cognitive limitations, and the time available to make the decision.” Simon invented the term “satisficing” to embrace the concept of doing what is good enough. Many authors, starting with Ferrero [19], and then Zipf [20], have captured a related idea, namely, the “principle of least effort”, especially as it concerns searching for information.
Section 2 summarises some of the key ideas about information evolution. More detail, derived from [6,7], is provided in Appendix A, which explores the underlying concepts and explains the diagramming conventions.
Based on these ideas, Section 3 develops a connection-related model of information processing that shows how information evolution applies to organisations. One of the themes throughout the paper is that the way in which information is structured constrains how it can be used. This means that we need to think carefully about the model and ensure that it does not inadvertently constrain thinking. Accordingly, the model used is generic and enables an integrated analysis. To use current terminology in the IT world [21], it combines the ability to do both functional and non-functional analysis. Using the model, Section 4 considers information measures (like pace, friction, and quality) and how they can be affected.
Section 5 and Section 6 apply this model to organisations and organisational change, respectively. They show that information evolution can illuminate some of the seemingly intractable difficulties of organisations, including the effects of organisational silos and the difficulty of organisational change. Many established organisational principles can be derived directly from information evolution.
Information evolution provides an integrated framework for analysing organisations as information processing entities. The approach unites disparate ideas expressed in the literature [4,5] and addresses fundamental challenges that organisations face to ensure their longevity.
The developed principles link directly to information connection models and the associated information measures. This opens the possibility of developing information evolution models of the effects of organisational silos and organisational change on information measures. This will be the topic of further research.
2. Information Evolution Overview
Information evolution is based on a model of information that is sufficiently general to support discussions about the nature of information [6,7], different measures of information (like truth, for example) [7], its relationship with meaning [8], different models of inference [9], digital transformation [22], and artificial intelligence [10,23]. Appendix A summarises some technical elements and introduces a diagramming approach. This section highlights some of the key ideas.
Interaction: As Christian says in [17], “we have seen that all living organisms are informavores. They collect information, process it, and act on it.” More generally, interacting entities (IEs), like people, animals, organisations, political parties, organisational teams, or computer systems, interact with their environments to achieve favourable outcomes either directly or via other entities. To improve the likelihood of favourable outcomes and reduce the likelihood of unfavourable outcomes, they need to be able to connect environment states with potential actions and subsequent outcomes. Information, in a variety of forms of information artefacts (IAs), enables this connection.
Selection pressures: The combinatorial challenge associated with these connections is huge [10], so IEs make trade-offs and use shortcuts. The selection pressures of the environment (i.e., everything outside the IE that affects any interaction) determine the outcome of interactions and the effectiveness of the trade-offs.
Ecosystem conventions: IEs in different environments are subject to different selection pressures and so different information ecosystems develop, each with their own conventions that embed the trade-offs and the ways in which information is processed. We simply call them “ecosystems” where the meaning is clear. Examples include the worlds of finance managers, banking systems, mathematicians, and graph theorists. As these examples show, IEs may belong to more than one ecosystem and ecosystems may be nested and more specialised depending on the selection pressures under consideration.
The application of ecosystem conventions to a type of environmental challenge is called a viewpoint [8,9]. A viewpoint encapsulates how one or more IEs (which we call a group) will collect information and use information processing patterns for a range of inputs (where the word patterns is used in the information technology sense [24]). Business processes or different mathematical techniques are examples of viewpoints.
Separation: Information is based on connections between the properties of elements of the physical world, but various techniques have evolved to enable it to be used independently. For example:
- The use of symbols separates information from the physical world;
- Ecosystem conventions separate symbols from types of representation (so words can be written or spoken, for example);
- Ecosystem conventions separate processing (and the making of connections) from types of IE (so computers can automate some human activities, for example);
- Communication separates information from a physical location (so information can be duplicated at a distance).
In this way, the evolution of ecosystem conventions progressively separates information from the processes that generate it.
Information measures: The effectiveness of information in supporting favourable outcomes is determined by three measures: Pace, friction and quality [6,7]. Different ecosystem conventions embed different trade-offs between these. Since humans are instinctively poor at assessing information quality [11], we often need to be explicit when analysing it. Many ecosystems (e.g., science and law) have conventions about how quality is addressed involving elements of review or challenge. Quality can be subdivided into several attributes, as described in Appendix A.
Fitness: Fitness measures how effectively an IE can achieve favourable outcomes in its environment. There are the following three levels of fitness:
- Level 1 (narrow fitness): Associated with a single interaction;
- Level 2 (broad fitness): Associated with multiple interactions (of the same or different types) and the consequent need to manage and prioritise resources between the different types. This is the type of fitness linked to specialisation, for example;
- Level 3 (adaptiveness): Associated with environment change and the consequent need to adapt.
3. Viewpoints and Information Processing
All information processing has a viewpoint (using the terminology employed in [8,9]). This is routine in day-to-day life, for example:
- With the same evidence, different political parties reach very different conclusions about the right course of action;
- In legal cases, the prosecution and defence represent different viewpoints in response to the same evidence;
- Business processes and applications encapsulate an organisational response to certain circumstances;
- Even in science, there are divisive debates about the merit of hypotheses (this is represented, for example, in Kuhn’s paradigm shifts [25]).
Ecosystem conventions encode approaches to information that have withstood selection pressures. For any type of environment state, the conventions are encoded in a viewpoint that defines what an IE or group of IEs is trying to achieve, the type of information processing steps that may be required, and how they relate to each other. The viewpoint may be as simple as “try to find out more” or, at the other extreme, it may correspond to a very detailed plan. The viewpoint may define any or all of the following:
- The overall outcome(s) desired;
- Any interim outcomes to be achieved;
- Actions and interactions required to deliver the outcomes;
- The groups of IEs involved and what they will do (a group may include one IE or more);
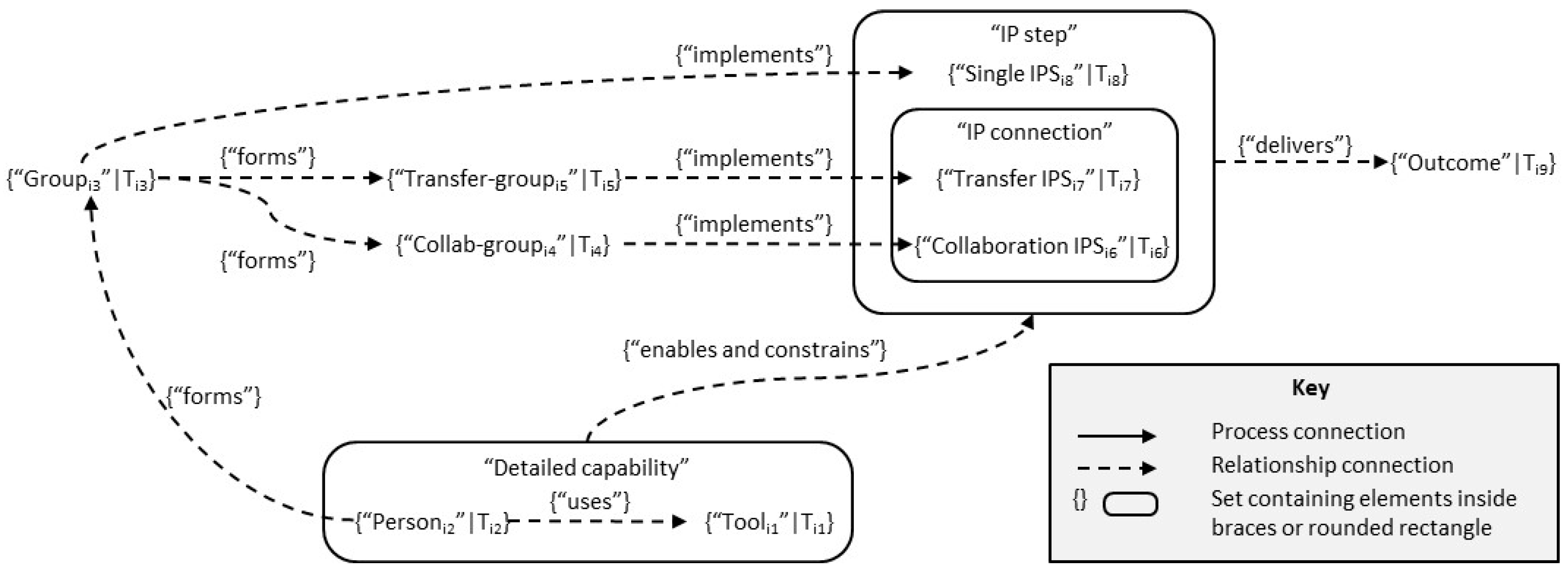
- The individual information processing steps (IP steps) carried out by each group, how the steps relate to each other, how groups collaborate, and how information is transferred between them.
In principle, an implementation of a viewpoint could continue indefinitely, but it makes sense to consider one as completing when it is tested against the environment, which is the convention used below. Examples include the publication of a mathematics paper or the completion of an end-to-end business process.
Because IEs can be nested in groups (e.g., people work in teams that may form parts of organisational units), we need to be clear in each case what is the group under consideration and what is “the environment” for that group. For example, in a business programme, the viewpoint encompasses the whole programme, but different groups implement different parts of the plan.
Viewpoints are divided into information processing (IP) steps, each of which includes a continuous piece of information processing carried out by a single group (potentially just one IE). An IP step embeds the conventions and shortcuts generated by selection trade-offs [10]. An individual IP step is completed when the group:
- Achieves the desired interim outcome;
- Engages in an interaction with one or more other groups;
- Transfers information to another group;
- Is unable to complete the processing for some reason.
A group performing an IP step is different from any general set of IEs for two reasons. The IEs in a group work together (they interact) on specific activities and a group can organise and schedule its own activities (within some constraints). For reasons that we will discuss in Section 5, groups are likely to develop their own conventions for processing information, and, as such, form an ecosystem of their own.
Using the conventions described in Appendix A, we can build models of IP steps and viewpoints, which we can call IP step patterns and viewpoint patterns. Because we are interested in the range of information measures, including pace, friction, and quality, we need these patterns to include the elements that might impact the measures. One of the results below is that the structure of an information artefact (IA) constrains its use under the influence of selection pressures, so that is a trap we need to avoid.
We want to take an IE-centric view, so we need to consider different ways in which an IE can engage with information. The first is the most obvious, namely, an IE can take some inputs and generate one or more new IAs. An IE can look for information. Here, we can distinguish between routine IE or ecosystem information that can be obtained immediately (here, we call this “find”) and other searches, for which there is a significant delay, or for which the process is not clear (here, we call this “search”). An IE can notify other IEs or be notified itself. Or, in some cases, it may not be able to complete the processing and may need to transfer information to another IE (for example, when a team escalates a decision to superiors or gets approval via some form of governance).
We can consider a single IP step to represent a single focus of attention for an IE or group that uses common working memory [6] and that which does not require non-immediate interaction with other IEs. As such, it will include “find” but not “search”, for example. Between different IP steps conducted by different IEs or groups, some or all working memory may be lost. While processing information, an IE may update its own viewpoint pattern and develop a rationale for the outputs produced (which we call an output connection model (OCM)). Updating the viewpoint pattern represents the natural process of obtaining a better understanding of how to best achieve the outcome desired, or even if that outcome should be changed. The OCM supports the potential need to pass on the rationale to further IP steps, potentially with other groups.
If we are to consider information measures generally, we need to think about the following activities for each IP step:
- Scheduling the processing for the IP step. Here, the IE may well be engaged in other IP steps or have higher priority IP steps to consider first and only then will it be ready to process the information;
- Assessing the inputs to decide what information to collate and what information processing models to apply (i.e., how to process the information to achieve the desired IP step outcome);
- Apply the relevant models;
- Testing whether the result meets the selection pressures and, if not, deciding whether to continue processing, transfer the processing to another IP step, look for more information or wait for more inputs;
- Reacting to external events during the processing;
- Generating IAs as instructions to create the outputs, notifications, and state changes required to deliver the desired outcome.
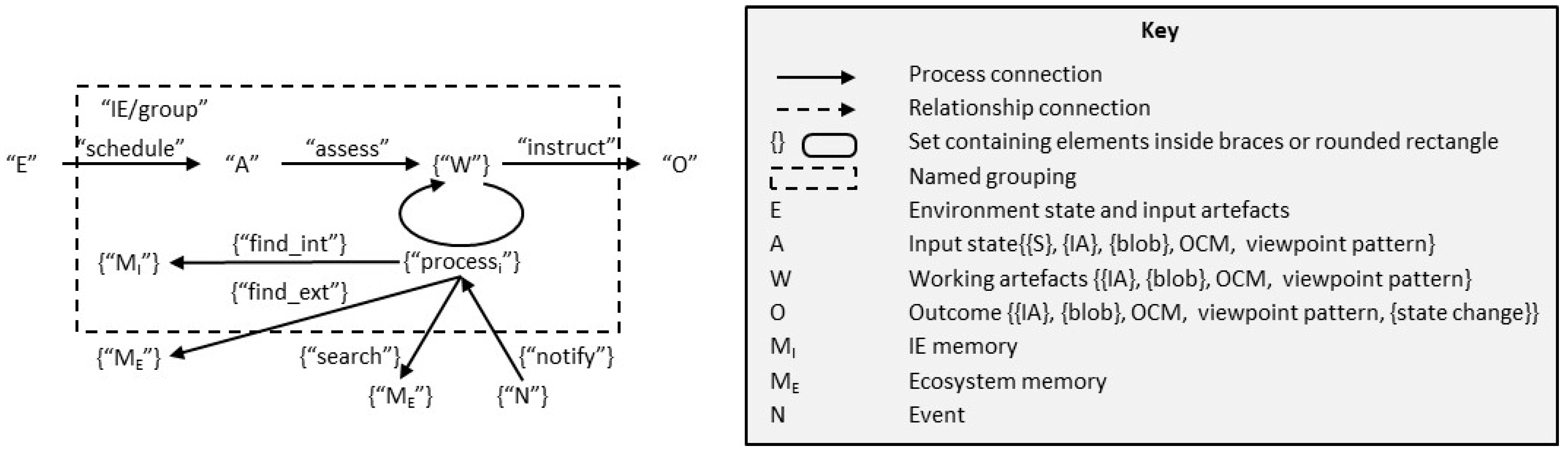
These elements are shown in Figure 1. The figure uses conventions for showing information connections, which are described in Appendix A and summarised in the key. Connections of two types are used in diagrams of this type, namely, process connections (in which a process converts one state to another) and relationship connections (which show a relationship between two sets). A blob (where the word is used in IT, derived from “binary large object”) is an artefact that does not use ecosystem symbolic content but satisfies some ecosystem conventions so it can be processed within the ecosystem. Examples include digital images or video.
An IP step pattern may describe activities that might not conventionally be considered as information processing. These include collaboration involving different groups or the transfer of information and control between groups (including the escalation, approval, or provision of more information). Other IP steps require just a single group. This subdivision highlights those types of information processing (collaboration and transfer) that connect groups. The nature of these connections plays a significant role in the discussion below, when we look at organisational silos and the connections between groups.
Note that once the environment is in a state (E) with particular properties (e.g., receipt of a message by an IE), an IP step will be triggered. This means that we can model a viewpoint pattern as shown in Figure 2.
So, different groups of IEs (perhaps including people and computer systems) carry out a variety of IP steps, and the set of these IP steps form the information processing activities of the viewpoint. In Figure 2, we have used space-time constraints (indicated by “|T”) to indicate that the various relationships indicated may vary (differently) in terms of location and time.
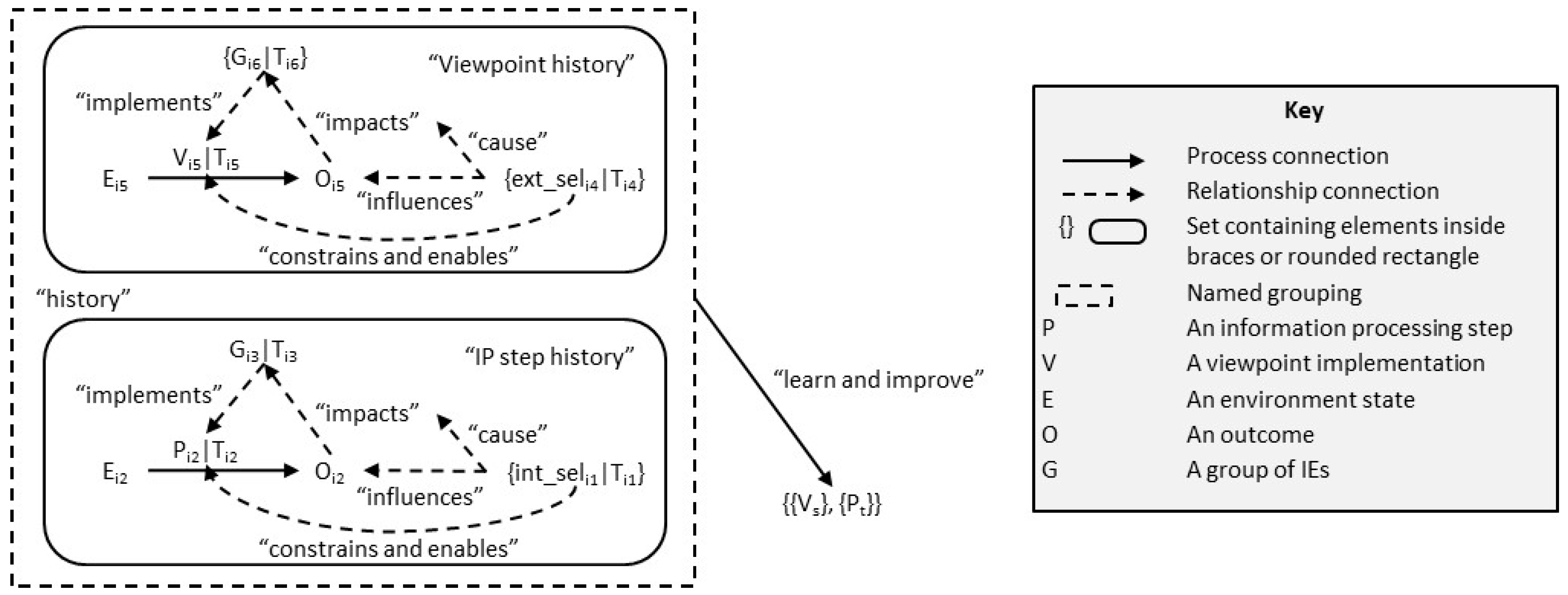
We have described the importance of selection pressures, and Figure 3 describes how they relate to IP steps and viewpoints. Selection pressures impact groups as a result of outcomes, but they also influence the desired outcomes themselves. Selection pressures also constrain and enable the implementation of IP steps and viewpoints. They make some activities easier and others harder. Together, these factors form a basis for learning and improvement.
The figure differentiates between levels of selection pressures. The selection pressures of the environment affect each IE or group, but the nature of that environment differs for different groups. The selection pressures on a business are different from the selection pressures on a person in that business and, similarly, the selection pressures for a viewpoint may be different from those of an IP step. In the figure, they are referred to as external and internal selection pressures (to match the organisational terminology used later).
4. Information Measures
The evolution of information in ecosystems results in information processing and artefacts that are good enough (or else the IEs would not achieve favourable enough outcomes). We can measure “good enough” by looking at some information measures. An IP step or viewpoint has the following three high-level measures:
- Pace: How fast IAs are produced. This is important because the environment may demand a response in a given time or may prioritise early responses;
- Friction: How many resources are used. This is important because any IE has limited resources;
- Quality: How well the IAs meet the requirements of the environment.
Pace and friction are conceptually straightforward. Pace can be measured in time units. Friction is more complicated, but, just as accounting conventions can allocate a cost to activities, we assume that friction is also reducible to a number in suitable units (e.g., financial units for organisations, calories for physical activities). Quality is not so straightforward. It is broken down into separate categories, described in Appendix A and in more detail in [6,7].
There is one final question we need to consider for groups of IEs: Are they all trying to do the same thing? We can capture this in the following measure:
- Alignment: This measures the degree to which the outcomes that different IEs are aiming to achieve are the same.
4.1. Information Evolution and Measures
IP step and viewpoint patterns will change their nature over time under the influence of selection pressures. Initially, they may be undefined and exploratory, and at the other extreme they may be completely prescriptive and algorithmic (and this can be seen in the detail of the viewpoint pattern). As they are exercised, their usage becomes embedded in the ecosystem conventions and, where appropriate, shortcuts become incorporated [10]. By analogy with “muscle memory”, we can call this connection memory. Here, the ecosystem conventions become embedded and the rationale for the conventions may be lost.
During this process, there will be improvements in fitness. However, level 2 and 3 fitness takes longer to assess and establish than level 1 fitness, and quality is a measure of the eventual outcome of a process, whereas pace and friction are attributes of the process itself. So, it takes longer to assess and establish quality conventions associated with level 2 and 3 fitness, and, in that period, pace and friction selection pressures still apply. Therefore, we can assert the following principle, referred to as the quality reduction principle: In the absence of appropriate selection pressures, pace and friction will be improved at the expense of quality (especially level 2 and 3 quality), since their effect is applied sooner and more directly.
4.2. Information Conversion
The need to relate different ecosystems (e.g., finance and IT departments in organisations) highlights a potential difficulty, namely, that of information conversion. Information processing is often concerned with creating new types of information, but, in some cases, the processed information directly concerns the source. Examples include:
- Information transferred from one IE to another;
- Translated information;
- Information that describes how an entity of some kind has changed (as is the case with organisational change);
- Information that describes when the same thing is described from different viewpoints (as is the case with software development) and information has to be converted between them.
Information conversion, in this sense, may not be possible with any degree of quality. For instance, it is not possible to translate sensibly between quantum mechanics and Latin. Even when it is possible, it may be difficult, and so it will be highly subject to selection pressures. In this section, we examine information conversion and its impact on different levels of fitness and quality.
We can map information conversion on a simple two by two grid, as shown in Table 1. One dimension identifies whether different ecosystems are involved. The other indicates whether the information is intended to change.
Note that transferring information is different from the transmission of information described by Shannon [28]. The difference here is that there may be context (working memory in the IP step pattern above) and rationale (the OCM in IP step pattern) to consider as well. Both context and rationale may be important for high quality interpretation in the IE, in which the information is transferred but some or all information may be assumed rather than transmitted.
The other quadrants in the table (translation and transformation) have the following additional dimensions to consider:
- Structure similarity: How closely different information structures map to each other within the same or different ecosystems;
- Content similarity: How closely the content chunks in one ecosystem relate to the other (for example, do they relate to the same properties in the same way?);
- Interpretation similarity: How closely interpretations in the different ecosystems can map to each other (for example, interpretations in physics, relating theory to experiment, need to be very rigorous, whereas political debate does not meet the same criteria).
Consider just the first of these. Even if different IAs in the same ecosystem contain the same information in some sense (the amount of information is discussed in [7]), then selection pressures may still apply to them differently. For example, in language terms, one may be very badly written and difficult to understand. This gives us the information structure principle: The structure of an IA constrains its effect under the influence of selection pressures. The principle of least effort [19,20] shows how important this can be, and, more recently, information architecture [29] is an example of its application in delivering online services.
The conversion process depends on the complexity of the IA to be translated and the degree to which each of the dimensions above applies. Conversion requires relationship connections between the source and target with respect to structure, content, and interpretation. The similarity of different ecosystems determines the nature of this relationship connectivity. When they are similar, the connectivity may be one-to-one and straightforward. However, when they are dissimilar, the relationship may relate sets of subsets in the source to various different sets of subsets in the target, depending on the context. This implies a much higher degree of connectivity and may imply a level of computational complexity somewhere between linear and exponential (in the very worst case). This is an example of the combinatorial problem with information discussed in [10]. Finally, the conversion process, in itself, may affect the timeliness of the information. Thus, we have the ecosystem conversion principle: If IEs (including groups) are in different ecosystems, then interaction between them incurs higher friction than if they are in the same ecosystem. The degree of friction depends on the degree of similarity between the ecosystems.
When we consider the impact of selection pressures, the ecosystem conversion principle has the following corollary, with evolution following the course of “good enough” least resistance. This is the ecosystem interaction principle: Without appropriate selection pressures, trade-offs will minimise inter-ecosystem interaction.
The ecosystem conversion and ecosystem interaction principles pose the following question: How can the difficulties of information conversion be overcome? One approach is to use the (relatively) high connectivity that exists inside IEs to perform the conversion inside an IE. This is the approach taken in automated language translation software and in specific organisational roles, like user research, business analysis, or software design (these roles are about converting information from one ecosystem to another).
When the connectivity is not available in a group, then the connectivity has to be provided by high-quality interaction between groups. In human terms, this is collaboration [30].
These two ideas address individual information conversions, but a complementary approach is to reduce the number of conversions. One possibility is to change a many-to-many problem to a many-to-one-to-many problem, but a more extreme version of this is to create a new group and, with it, a new ecosystem. This is the approach taken in agile software development [31] and the product management and business platform approaches being introduced [32]. In these cases, since the conversions will be repeated many times, the overhead of creating a new ecosystem makes sense.
The combination of these ideas gives us the conversion quality principle: There are the following strategies available to maintain information quality in information conversion:
- Performing information conversion within an IE;
- Using collaboration between groups to improve connectivity where the connection memory is not strong enough to maintain the required information measures;
- Reducing the number of conversions required.
4.3. Viewpoint Information Measures
Discussing information conversion opens up the following wider question: How can we improve information measures? Figure 1, Figure 2 and Figure 3 show that there are several mechanisms available here.
High quality input is required to achieve high quality output for the whole viewpoint. However, this is a result that fights human intuition. As Kahneman says [11], in relation to the system he named “system 1” (the automatic processing of information in humans): “What you see is all there is.” In other words, people instinctively deal with the information in front of them rather than assessing its quality. In addition, high-quality input is also required for each IP step throughout a viewpoint. Introducing the OCM into the model in Figure 1 highlights one of the characteristic difficulties, namely, the continuity of the rationale and information throughout the viewpoint and between IP steps. Creating outputs and interpreting inputs uses resources, and, as such, in the absence of suitable selection pressures, the information produced in an IP step will not be fully transferred through the viewpoint. This may threaten the quality of the outcome and is why the continuity of involvement with people is so often considered essential.
One of Deming’s 14 principles [33] is this: “Cease dependence on inspection to achieve quality. Eliminate the need for inspection on a mass basis by building quality into the product in the first place.” This applies equally to information processing. Here, the principle avoids reworking and the consequent potential reduction of quality as trade-offs begin to take effect (perhaps as a result of the quality reduction principle). We can rephrase Deming’s principle in the following terms: The continuous application of selection pressures should be built into each IP step and viewpoint. This approach, as indicated in Figure 3, will also ensure learning and improvement. It also leads to improvements in alignment (all IEs contributing to a viewpoint implementation need to be working towards the same outcome).
It is clear from Figure 1 that anything that takes an IE out of its normal flow will impact pace and friction. So, interruptions (in the form of event notifications) and the need to transfer control will both have an impact.
Together, these points give us the measure improvement principle: The following approaches will improve information measures in viewpoints:
- Ensuring high-quality input to the viewpoint and each IP step;
- Applying selection pressures continuously through each IP step;
- Learning and improving;
- Minimising interruptions to the viewpoint and each IP step;
- Implementing conversion quality strategies, as described in the conversion quality principle.
5. Information Evolution and Organisations
Based on the ideas developed so far, we can now focus more on organisational thinking. Here, the discussion is divided into two. This section considers business architecture and the next section considers organisational change.
First, we consider what fitness means in terms of organisations, for instance, how organisations develop structures and mechanisms to try to align activities with the objectives of the organisation and the environment. These internal selection pressures act on the information processing of the various groups in the organisation. One implication is the development of organisational silos and their impact on organisational activities (including the so-called “Conway’s law” [34]).
5.1. Internal Selection Pressures
It has been recognised for a long time that fitness and organisational theory are linked. For example, Scott [35] describes contingency theory in the following manner: “The best way to organise depends on the nature of the environment to which the organisation must relate.” Schein [15] says that “the culture of a group can be defined as the accumulated shared learning of that group as it solves its problems of external adaptation and internal integration...”
Organisations try to align the activities of people and teams with organisational objectives and the environment by using a variety of mechanisms, which are described below (note that different techniques are used for computer systems [21]). We call these defined selection drivers. These mechanisms, in themselves, exert selection pressures that we can call internal selection pressures (to distinguish them from the external environment and its selection pressures). As well as indicating desirable outcomes and the impact of achieved outcomes, internal selection pressures also include enablers and constraints, which have a large influence on pace and friction. The greater the impact of constraints, the greater the need for strong quality selection pressures (as described in the conversion quality principle) to promote good quality. In this sense, the management of internal selection pressures incorporates elements of the theory of constraints [36]. For a group, external dependencies (and their associated enablers and constraints) create selection pressures. We can express these ideas in the internal selection principle: Internal selection pressures affect desired outcomes and the impact of those outcomes, and depend on enablers and constraints, including cultural and other dependencies.
In turn, we consider several internal selection pressures below.
Organisation structure: On the face of it, an organisational structure should not create selection pressures. However, organisational silos will alter selection pressures on other parts of the organisation by enabling or constraining activities. This is discussed in more detail below.
Process design: Business processes are the organisational representation of viewpoint patterns. As such, they enable those ways of working which are aligned with the processes and constrain others. These are forms of selection pressure.
Performance management: According to the UK professional body for HR, “performance management is the activity and set of processes that aim to maintain and improve employee performance in line with an organisation’s objectives” [37]. Thus, the purpose of performance management is to define a set of internal selection pressures. Any associated incentives will affect the desired outcomes of people and groups and their overall alignment.
Governance: Organisational governance can be defined as “a system by which an organisation makes and implements decisions in pursuit of its objectives” [38]. These decisions affect the allocation of budgets and numerous other facets of organisational life and so define internal selection pressures. As the authors say in [13]: “Budgets, and the way they are created in large and midsized companies, are one of the biggest inhibitors of cross-functional execution”.
Contracts: Contracts define the relationships between organisations and the ways in which those relationships should work. More generally, contracts exert selection pressures by defining desired outcomes, enabling certain processes and relationships, and constraining others.
Technology: One of the great advantages of information technology can be that it can reduce friction and increase pace. So, again, technology exerts selection pressures by enabling some activities while constraining others (e.g., when information is hard to retrieve).
Some of these mechanisms may be easier to implement or change than others, however, generally, change is hard, both in terms of implementing new technology [39] and changing the organisation [4,5]. One of the reasons for this is the effect of culture, which is an internal selection pressure, usually created as a by-product. As Schein says [15]: “The culture of a group can be defined as the accumulated shared learning of that group as it solves its problems of external adaptation and internal integration; which has worked well enough to be considered valid and, therefore, to be taught to new members as the correct way to perceive, think, feel, and behave in relation to those problems.” Because culture determines how the other factors are treated in the detail of daily activities, it has a particularly powerful effect. In the quote attributed to Drucker: “Culture eats strategy for breakfast”. Public statements of desired outcomes and behaviour are not enough. Schein cautions [15] that “we will observe in many organisations espoused values that reflect the desired behaviour but are not reflected in observed behaviour.”
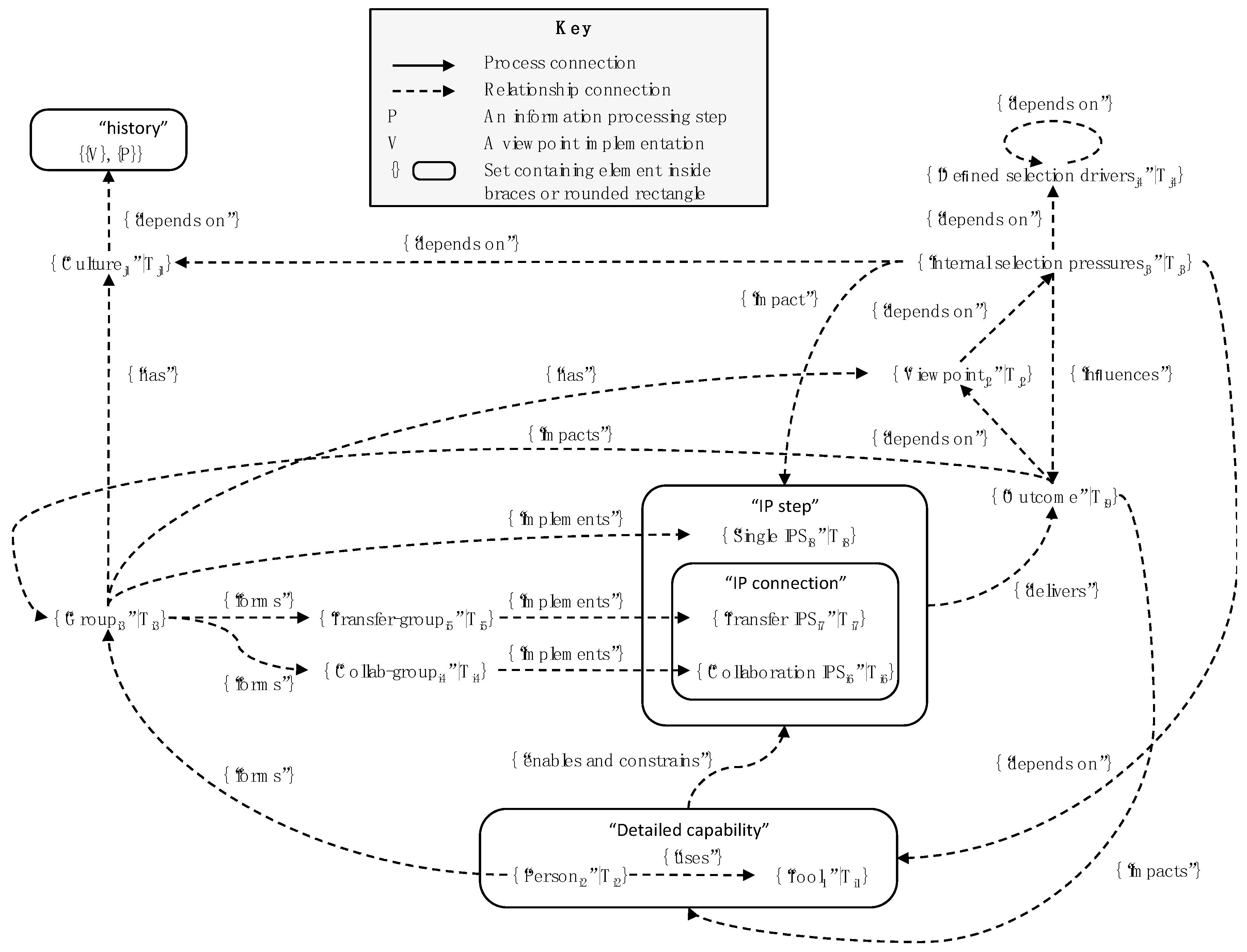
Figure 4 shows how internal selection pressures relate to IP steps. One of the key implications of the figure is that the effects can be complicated and rely on history (especially through the impact of culture) as well as recent outcomes.
But, given this complexity, how well do the internal selection pressures support the achievement of the objectives of the organisation? We can analyse the issues in terms of Figure 1, Figure 2 and Figure 4. External selection pressures operate on the entire outcome (including, potentially, states not explicitly addressed in internal selection pressures), but, by contrast, defined selection drivers often have one or more of the following characteristics:
- Too broad: For combinatorial reasons, defined selection drivers divide the potential outcomes into a relatively small set of categories, each of which include various outcomes that external selection pressures would differentiate between;
- Limited: They only apply to some of the outcome and, especially, may not consider level 3 fitness at all;
- Untimely: They may be subject to annual (or less frequent) updates which are out of step with the environment;
- Unintegrated: They may not be designed as a coherent whole or integrate effectively, and so the outcomes they support may contradict each other;
- Gamed: Womack and Jones [40] quote the case study of a Texan builder who “got rid of individual sales commissions (‘which destroy quality consciousness’) and eliminated the traditional ‘builder bonus’ for his construction superintendents (who were qualifying for the ‘on-time completion’ bonus by making side deals with customers on a ‘to-be-done-later’ list)”;
- Subject to surrogation: Surrogation is a human failing, in which people get metrics confused with what is being measured. This is discussed in [41], in which the authors include the following example: “A company selects ‘delighting the customer’ as a strategic objective and decides to track progress on it using customer survey scores. […] But somehow, employees start thinking the strategy is to maximize survey scores, rather than to deliver a great customer experience.” Surrogation is an example of the development of ecosystem conventions;
- Inadequate with respect to culture: Culture acts in the minutiae of daily activities and the powerful connection memory it induces is difficult to overcome [15].
The authors of [41] provide a crisp summary of the issues (with respect to performance management): “An obsession with the numbers can sink your strategy.” We can summarise the position in the following principle:
The selection inadequacy principle: Without additional mechanisms, the defined selection drivers are unlikely to be a reliable proxy for external selection pressures.
This applies to adaptiveness especially, so we can also state the following principle:
The adaptiveness selection principle: If an organisation has not reflected the need for adaptiveness fully in its internal selection pressures (including culture), then its chances of responding effectively to changes in the environment are reduced.
5.2. Ecosystems and Silos
The definition of groups comes with two immediate implications. Groups are responsible, in part at least, for the scheduling of their own activities. In the absence of wider coordination (and the selection pressures implied), any connection with another group will not be optimised to meet the schedule of that other group. Therefore, even if they are otherwise equal, inter-group process connections will have reduced pace and increased friction compared to intra-group process connections.
Groups are also likely to evolve ways of working and process connections to minimise friction within the group (e.g., through colocation, common information structures, and common channels of communication). So, it is likely that inter-group process connections will have additional higher friction than intra-group connections.
These factors are enough to provide selection pressures that minimise inter-group connections. Over time, the likelihood increases (in the absence of other selection pressures) that the structures of the information managed in the groups will require more conversion and that different groups will make different trade-offs. This increases the friction and reduces the pace of further process connections. In addition, different groups may also combine the conventions from different ecosystems, bringing the additional difficulties of information conversion (e.g., the ecosystem conversion and ecosystem interaction principles) into play.
This process is mutually reinforcing, where the greater the difference between the groups, the greater the selection pressures to maintain or increase the distance (in the absence of other selection pressures). This leads to the following principle:
The group silo principle: In the absence of appropriate selection pressures, groups will form silos incorporating their own conventions (ecosystems of their own) that limit external connectivity. In turn, this will limit activities that require high connectivity to those within the group.
This causes well-known, if unintended, consequences. For example: “Most business leaders cite organisational silos as a major obstacle in executing a transformation” [30].
A corollary of the group silo principle is “Conway’s law” [34]. As Conway says: “Given any design team organisation, there is a class of design alternatives which cannot be effectively pursued by such an organisation because the necessary communication paths do not exist. Therefore, there is no such thing as a design group which is both organised and unbiased.”
More generally, we have the following principle:
The organisation structure principle: In the absence of other selection pressures, selection pressures relating to organisation structure will constrain the interaction patterns and outputs of an organisation so that they reflect the organisation structure.
In his biography of Steve Jobs, Walter Isaacson [42] discussed this question when considering Apple and Sony: “Sony worried about cannibalization. If it built a music player and service that made it easy for people to share digital songs, that might hurt sales of its record division. One of Jobs’s business rules was to never be afraid of cannibalizing yourself. ‘If you do not cannibalize yourself, someone else will,’ [Steve Jobs] said. So even though an iPhone might cannibalize sales of an iPod, or an iPad might cannibalize sales of a laptop, that did not deter him.”
Since the result applies to any ecosystems that have some element of distance between them, there is an even more general result, namely, the ecosystem distance principle: For ecosystems that already exist, then, in the absence of suitable selection pressures, their degree of similarity will be maintained or decreased.
5.3. Information Processing Trends
Figure 4 raises some business architecture questions, but answers to these questions depend on some contextual questions, for instance, how changeable is the environment? How important are the dependencies between groups?
The first of these has been widely addressed and is the focus of digital transformation initiatives [1], but the environment is changing faster than is comfortable for many organisations [2].
Where business requirements are clear and technology capabilities are available, then technology provides a good mechanism for providing information. However, in more complex cases, or when there is change, people in other groups will need to be involved. In this case, the conversion quality principle demonstrates that a collaborative approach will be needed, which introduces the group collaboration principle: Where there is insufficient connection memory (for example, in the case of change), collaborative relationships between groups are required to maintain information quality.
The use of big data, data enrichment, machine learning, and AI techniques [23,43] and the number of services available online, mean that, increasingly, business processes are using data not traditionally collected and processed within existing ecosystem conventions. So, we can state the following principle:
The external information principle: The nature of information used in business processes is progressively relying on information from outside the ecosystem.
These two principles can be summarised more generally in the following principle:
The group connection principle: Good quality information requires that the connections between groups should be managed explicitly, as well as the groups themselves.
This point matches the following comment in [13]: “While the resources you are connecting are obviously valuable, they are just half of the equation. The other half, the connections, play just as big a role.”
5.4. Viewpoint Patterns and Business Architecture
As the discussion above has highlighted, dependencies between groups and information conversion are key design issues. Dependencies between groups have been greatly studied. For example, Thompson [44] describes sequential, pooled and reciprocal types of interdependency. These issues are also discussed in [13], where the authors discuss how to address “the entangled realities of scale, interdependence, and dynamism found in today’s incumbents.” In this section, we will discuss different viewpoint patterns, for instance, how different groups can relate in the delivery of some outcome in a changing environment.
Consider the question in relation to two dimensions, specifically, the degree of integration of the groups (whether they form a joint ecosystem or not) and the frequency with which external selection pressures are applied. These dimensions allow us to test two key issues: The impact of dependencies between groups and the achievement of the right information measures.
In Table 2, the rows show the rate of external interaction and the columns show the degree of integration of groups (from not-at-all to the creation of a joint group with representation from the others). The table shows the different (extreme) examples. In pattern A, groups can operate in parallel or sequentially.
There are some straightforward conclusions from this analysis. Since internal selection pressures are not likely to match external selection pressures (the selection inadequacy principle) then, especially if the environment is subject to high rates of change, high external interaction will be required to maintain good quality. In addition, if different ecosystems are involved, then the conversion quality, measure improvement, and group silo principles imply that a joint ecosystem will be the most effective way of managing the quality difficulties associated with information conversion. This gives us the viewpoint pattern principle: Pattern D (in Table 2) is the most likely to achieve good quality in the case of a high rate of environment change and a requirement for multi-ecosystem information processing.
This explains why there is trend towards pattern D in high change environments, such as those that require regular changes to technology or processes. Pattern D corresponds to agile and DevOps forms of IT organisation [45], and more generally to the concept of a business platform discussed by McKinsey [32]. The sequential form of pattern A corresponds to the traditional “waterfall” IT development approach, and the analysis above shows the inherent quality risks associated with that approach.
6. Organisational Change
Organisations need to make changes, but as Lawrence says [46]: “One of the most baffling and recalcitrant of the problems which business executives face is employee resistance to change.” Many authors have explored this topic [4,5], and the fundamental nature of change is well understood (if not so well practiced). Kotter [47] said: “Too many managers do not realise that transformation is a process.” In [13], the authors express it like this: “...Executives fundamentally misunderstand transformation in the context of today’s large organisations. [...] Transformation is not an event; it’s an essential and perpetual task of leadership. To quote Ben Franklin, ‘when you’re finished changing, you’re finished.’”
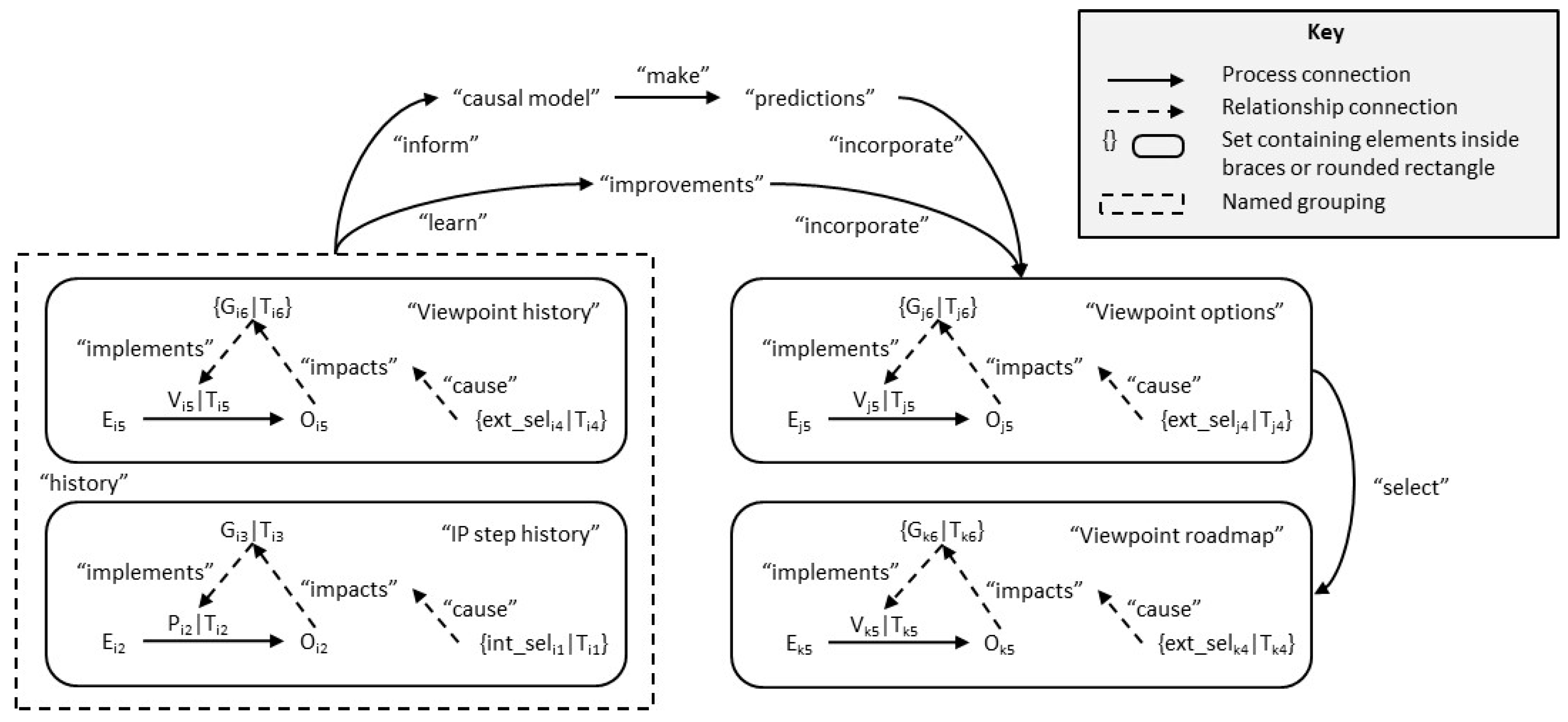
Figure 5 shows the processes in defining change. Changes can be driven by two separate mechanisms: Learning from history and predicting the future.
One difference between them is that predicting the future requires some kind of model of the future environment. Here, historical trends can be extrapolated but historical data alone are usually not sufficient [48]. For simplicity, the process of defining the causal models, a difficult part of the process, has been omitted from the figure.
Figure 4 and Figure 5 show the connectedness of change. As the authors have said in [13]: “We maintain that every major transformation challenge a practitioner faces [...] is an intrinsically networked activity that involves many different organisational resources working together.” In this section, we analyse this aspect of connectedness based on the idea that organisation change requires, converting the old view of the organisation into the new view both in definition and implementation (as discussed in Section 4). This conversion has, in itself, a viewpoint pattern, so we can use the ideas above to analyse it.
However, before we consider how to change, we discuss why ecosystems resist change, how to avoid change (by building in flexibility), and how to minimise the extent of change (by decoupling dependencies).
6.1. Ecosystem Inertia
We can expect organisational change to be difficult. It suffers from a more general phenomenon called ecosystem inertia [8,9,10,22]. Ecosystem conventions take time to develop and may not keep up with the rate of change in the environment. Existing conventions may not suit the changed environment and may reduce an IE’s chances of favourable outcomes. There are examples of this in many disciplines, for example:
- Kuhn’s discussion of paradigm shifts in science [25];
- “Change resistance” in organisations, for example [46]: “One of the most baffling and recalcitrant problems which business executives face is employee resistance to change”;
- “The natural state of companies as they grow and mature is always towards more disorder” [13], and this disorder makes change harder;
- The “digital divide” [49], as some people find it difficult to keep up with changing digital technology.
It is straightforward to see why this is so. Establishing a new process connection and then exercising it will incur more friction and increased pace than just simply exercising it, especially when it has been exercised before and there is connection memory involving many dependencies. This applies to a single IE and even more so at a group or ecosystem level. The greater the number of dependencies, the greater the friction and, as Figure 4 shows, there may be many such dependencies. As a result, level 1 and 2 selection pressures will resist change.
The second reason is the uncertainty of rationale. Change needs a clear rationale (e.g., a business case for an organisation), but, in a changing environment, prediction is uncertain. Uncertainty is an attribute of poor information quality and this poor quality constrains decision-making.
In organisational terms, the selection pressures (for and against) are linked to Lewin’s force field concept [50]. As Schein has made clear, [15] cultures may embed barriers to change, for example, those summarised by Moss Kanter [51].
We can describe ecosystem inertia in the following terms of the ecosystem inertia principle: In the absence of a sufficient shift in selection pressures from level 1 and 2 towards level 3, change will be resisted. Even where sufficient selection pressures exist, any change will take time to come into effect.
6.2. Flexibility
Change is only required when viewpoint implementations are not able to process information with the required measures. Whether change is needed depends on the set of environment states that each IP step can successfully process (with the required measures) without changing the viewpoint. We call this set the domain of the IP step and, correspondingly, the domain of the viewpoint.
It may well be the case that outside the domain of an IP step, process dependencies will be invoked (for example, to escalate to a supervisor in a contact centre) or it may just be that ecosystem conventions are violated (for example, the viewpoint takes too long or is not performed to the required quality). Taking our cue from Figure 1, it is clear that a well-defined IP step pattern needs to maintain consistency between the following three factors:
- The environment state that triggers the IP step;
- The domain of the IP step;
- The triggering of process connections for inputs that cannot be processed within the ecosystem conventions.
Selection trade-offs will naturally eliminate the need to deal with inputs outside of those received (the first two of these). So, in the absence of level 3 selection pressures, the domains of viewpoints and IP steps will not support change. This gives us the following principle.
The flexibility principle: In the absence of level 3 selection pressures, viewpoints and IP steps will become inflexible and change will become more difficult.
6.3. Dependencies and Decoupling
The number of connections shown in Figure 4 illustrates the difficulty of change. A variety of approaches to this have been discussed using the term “loose coupling”. In the technology world, loose coupling is a characteristic of some technology architectures [53], but loose coupling has also been analysed in relation to organisations. Weick [54] first introduced the term, and later, with Orton [55], reviewed the different uses in the organisational literature. They say that: “The concept of loose coupling allows theorists to posit that any system, in any organisational location, can act on both a technical level, which is closed to outside forces (coupling produces stability), and an institutional level, which is open to outside forces (looseness produces flexibility).” In this quote, coupling relates to level 1 and 2 fitness and looseness relates to level 3 fitness, but there is an obvious tension between them, leading to the following principle:
The fitness dilemma principle: Level 1 and 2 fitness require process connections with good connection memory, but level 3 fitness requires the ability to break certain connections.
In [13], the authors address this dilemma and “recommend moving past a conventional functional orientation to a connected ‘organisational fabric’ overlaid on the existing company hierarchy”. We can analyse the different dimensions of this topic by considering Figure 4, which highlights the following different sources of coupling:
- Definition dependency: When one IA is defined in terms of another (e.g., when performance management is defined according to organisation structure);
- Connection memory: When strong connection memory creates a dependency (this is the effect of culture, for example, in which the culture of groups, and therefore their performance, depends on history);
- Viewpoint pattern: When a viewpoint requires group activities to act in concert (this is the use of the term “dependency” in project management terms and applies to the relationship between IP steps in a viewpoint pattern).
Table 3 shows how these sources of coupling can apply to the relevant elements in Figure 4 and, therefore, how the options available for decoupling can support level 3 fitness.
We summarise this as the decoupling principle: The impact of change is reduced if different elements of the business architecture are decoupled.
6.4. Organisational Change and Information Evolution
Many different approaches to organisational change have been defined [4,5], but as the authors explain in [56], when considering different approaches: “The content of change management is reasonably correct.” Therefore, we can use any well-established approach to understand the relationship with the ideas in this paper.
Consider the table “Eight Steps to Transforming Your Organization”, created by Kotter [47], which summarises the stages required to be successful with organisational change. Table 4 shows how Kotter’s description of the stages of change relate to information evolution.
Table 4 shows that information evolution is directly relevant to organisational change and this section examines the relationship in more detail. We can give the discussion an information evolution focus by observing Figure 4 and considering the effect of change as information conversion. Any change process will convert a current instance of this pattern into one or more future instances (see Figure 5). In terms of the change itself, we can consider it as a viewpoint instance by addressing the following questions:
- What are the impacts of selection pressures on the change itself?
- What is the impact of silos on the change process?
- What is the quality of the change and how does it relate to the scope of the change?
- What are appropriate patterns for the change viewpoint?
- How can the difficulty of change be reduced?
Just like any other activity, a change process is subject to selection pressures. Unless the selection pressures are appropriate, as the quality reduction principle implies, quality will suffer (and, in this case, the change will not achieve the outcomes required). So, getting the selection pressures right is a prerequisite to successful change (many of Kotter’s points in Table 4 support this). We can express this by invoking the concept of a change ecosystem. This is an ecosystem in which the conventions and enablers associated with successful change are embedded. Using this idea, we can express the adaptiveness principle in the following way:
The change ecosystem principle: Organisations subject to change should build a change ecosystem, including a culture that supports change, appropriate internal selection pressures, and mechanisms to reduce the friction of change.
As the authors say in [56], “most studies show a 60–70% failure rate for organisational change, a statistic that has stayed constant from the 1970s to the present.” They attribute this to the following reason: “The content of change management is reasonably correct, but the managerial capacity to implement it has been woefully underdeveloped.” In the language of this paper, they are pointing out the lack of one of the ingredients of a change ecosystem. The title of [57] expresses a related point: “To get people to change, make change easy.” Without a change ecosystem, ecosystem inertia driven by internal selection pressures will work against change, and without a change ecosystem, the internal selection pressures themselves are going to be difficult to change.
However, a change ecosystem requires practice. If an organisation has not developed good connection memory with respect to change, then even the right selection pressures will not have had a chance to develop suitable change ecosystem conventions. This gives us the following principle:
The change connection principle: Effective change, and the development of a change ecosystem, needs repetition and continuous attention, or else the change connection memory will decay and the likelihood of future success with change will diminish.
Change commonly needs to integrate different ecosystems (for example, in order to implement a new application to support some business processes) and is therefore subject to the difficulties of information conversion that have been discussed in Section 4. The organisation of the change can therefore be subject to the effects of the group silo principle, and as such, we have the following principle:
The change silo principle: If a change initiative is carried out by a separate group, then, without an established change ecosystem and appropriate selection pressures, the change initiative will be subject to silo effects and will require a highly collaborative approach.
Analysis of Figure 4 (with respect to one or more target states) shows that the quality of a change can depend on each connection in the figure. Where connections are especially strong (e.g., with respect to culture [15]), they will have a large impact on the quality of the change and that impact is likely not to be understood. So, quality depends on the scope of the change, and we have the following principle:
The change scope principle: Change needs to address all of the dependency connections (including culture and internal selection pressures) as well as the immediate objects of the change. If it does not, then the quality of the change is likely to be reduced and the change is less likely to be effective. More than this, the reasons for the ineffectiveness will not be fully understood, and the implementation of a change ecosystem will be inhibited.
This principle is supported by exhortations in the literature. For example, in [58], the authors say: “The need to shift mind-sets is the biggest block to successful transformations. The key lies in making the shift both individual and institutional at the same time.” The authors go on to examine the dependencies and constraints that may have an effect.
The viewpoint pattern principle shows that pattern D in Table 2 is most appropriate for high levels of change and complex information processing. This corresponds with the business platform idea described by McKinsey [32], in which an agile delivery model is used to provide incremental change.
However, as Figure 4 implies, the overall approach also needs to change the connections between groups (the collaborative and transfer IP steps) to improve fitness. In [32], the authors realise the need for connection as well. They describe a mission control group, which would “act as the design authority and oversight team” for the other groups. In [13], the authors “recommend that you introduce orchestration as a mode of execution that sits astride the existing [organisation] structure. Imagine enveloping the current [organisation] chart with a virtual organisational fabric, with weak and strong connections, supported by digital business agility, which makes a connected approach to change possible.” The authors are at pains to point out that this fabric cannot behave as a silo. Therefore, we can state the following principle:
The orchestration principle: In a changing environment, change needs to be built into the business-as-usual business architecture and culture (in line with the degree of change and information conversion requirements), and a change ecosystem must be developed. This requires an understanding of balanced level 1/2/3 fitness requirements and the ability to orchestrate:
- The improvement of the change ecosystem;
- Improved connections between groups (to improve overall fitness and reduce constraints and friction).
7. Conclusions
Information evolution provides an integrated framework for analysing organisations as information processing entities. The approach unites disparate ideas expressed in the literature [4,5] and addresses fundamental challenges that organisations face to ensure their longevity. The present paper shows that the following important organisational ideas can be derived from information evolution principles:
- Organisations are information processing entities that require the right balance between level 1, 2, and 3 fitness in response to external selection pressures;
- In a rapidly changing environment, organisations need to develop a change ecosystem throughout the organisation (with the associated culture, internal selection pressures, and enablers) to support the required rate of change;
- In a rapidly changing environment, organisations need a business architecture with the following ingredients:
- Long-term groups conforming to pattern D in Table 2;
- Stable activities that do not require pattern D;
- One-off initiatives;
- Continuous connection orchestration.
These themes unite disparate ideas expressed in the literature and address fundamental challenges that organisations face to ensure their longevity. Table 5 expresses these themes as organisational principles and relates them to the results in the paper.
The degree to which each of these principles applies depends on the balance required between level 1, 2 and 3 fitness, which is part of the first principle in Table 5.
These principles directly link to information connection models and the associated information measures. This opens the possibility of developing information evolution models of the effects of organisational silos and organisational change on information measures. This will be the topic of further research.
Funding
This research received no external funding.
Acknowledgments
The author would like to think Paul O’Sullivan for many useful discussions in the early development of this paper.
Conflicts of Interest
The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A. Information Evolution and Information Connection
This Appendix summarises and collates key information evolution ideas (from [6,7,8,9,10]) and shows how the ideas in the main paper relate to the underlying principles of information evolution. The following are discussed:
- What information is and what we mean by information connection;
- Conventions for drawing information connection diagrams (in the form used in the main paper);
- Measures of information.
Appendix A.1. Information and Information Connections
If we want to model information connections, then we need to be clear about we mean by an information connection. This section pieces together the following different components of the picture:
- The physical world, properties, and values;
- Ecosystem content, including the symbolic representation of information;
- Different types of content, including chunks (to express the constraints under consideration, nouns, adjectives, and verbs are all examples in the case of human language) and assertions about the relationships between chunks (like sentences);
- How content is interpreted in terms of the physical world;
- Different types of connection.
Finally, this leads to a discussion of the modelling approach.
A slice is a contiguous subset of space-time. A slice can correspond to an entity at a point in time (or more properly, within a very short interval of time), a fixed piece of space over a fixed period of time or, much more generally, an event that moves through space and time. This definition allows great flexibility in discussing information. By using slices rather than space and time separately, we can apply a common approach in different cases. For example, slices are sufficiently general to support a common discussion of both nouns, verbs, the past, and the future.
Each slice has a set of properties, and for each property, p, there is a measurement process (μp) within an ecosystem that takes the slice as an input and generates the value of the property for the slice. Note that this, like many of the ideas below, is ecosystem specific. Two ecosystems may consider the same properties and measurement, but they are not guaranteed to. Think of Latin and quantum mechanics as examples that express properties of the physical world in very different ways.
Properties can be used to constrain the slices under consideration. Suppose that pi is a property, vi is a range of values of the property, and P is a Boolean function of (pi = vi), 1 ≤ i ≤ n. It is a space-time constraint if all of the pi are space-time properties. Suppose that ti are space-time constraints. We can define (pi | ti) in which pi is measured at ti. If T = {ti: 1 ≤ i ≤ n}, then we can call this constraint P| T. Where the context is clear we can call such a constraint an outcome. An outcome may include IAs or blobs (which may be subject to very complicated constraints).
In different ecosystems, different modelling tools are used to define these constraints. Examples of this include human languages, programming languages, and mathematics. Each can describe individual constraints that we call chunks. Chunks constrain the set of slices under consideration and each modelling tool has its own syntax for this. Table A1 shows some examples.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table A1.
Modelling tools, chunks and assertions.
| Modelling Tool | Example Chunks | Example Assertions |
|---|---|---|
| English Language | “John”, “lives in Rome” | “John lives in Rome” |
| Mathematics | “planar graphs”, “four-colourable” | “Planar graphs are four-colourable” |
However, being able to define constraints is not enough. We also need to be able to relate them to each other. We call these relationships assertions (see Table A1), corresponding to sentences in language. Chunks and assertions are different kinds of content. Chunks specify constraints and assertions make hypotheses about the relationships between constraints. They relate to the physical world differently. The interpretations of chunks correspond to sets of slices created using the following operators to create the constraints: ∩, ∪, \, c (where Ac is the absolute complement of A). By contrast, interpretations of assertions use set containment and equality comparisons (⊆, ⊇, ⊂, ⊃, =, ≠).
An instruction is a particular form of assertion. When we apply the ideas above then an instruction is just an assertion about the relationship between an environment state (including the instructions), one or more actors (performing the instructions), a process (implementing the instructions on a trigger in the environment state), and an outcome (the intended result of the instructions). In different cases, elements of the relationship may be assumed (for example, a computer is assumed in programming languages).
We use the term content to include both chunks and assertions, but how does content relate to other slices? Here, we consider chunks first. Any chunk can relate to slices in the following three ways:
- The slice representing the content itself;
- C-interpretation: The set of slices corresponding to the chunk under the standard ecosystem interpretation (c stands for chunk); this may not be trivial, for example, “i” references specific content when it is about the square root of minus one and the c-interpretation, and, in that case, will only relate to the relevant mathematical slices;
- R-interpretation: The set of slices that the chunk references under an interpretation (r stands for reference). Where just the term “interpretation” is used, it means r-interpretation.
Note how this definition supports content interpretation which is the interpretation of content in terms of other content rather than events. Since interpretation relates content to slices, if those slices can also be interpreted as content in the ecosystem, then interpretation can be disconnected from the physical world. This is how pure mathematics operates, for example. Content interpretation has limitations [8,9,10], but this flexibility enables the representation and manipulation of abstractions (including, even, difficult abstractions, like i or infinity) or counter-factuals [48] separately from any relationship with the physical world. The examination of the relationship with the physical world can be pursued separately, where appropriate, through a variety of disciplines (including science).
Information is a list of assertions (called a passage in [6]), meeting the conventions of an ecosystem. Assertions hypothesise connections between the values of properties of sets of slices. Content chunks constrain the properties and values under consideration and therefore, when interpreted, can be mapped to sets of slices that assertions relate.
As well as general properties of slices, we are interested in slices that correspond to more complicated structures and, in particular, blobs and IAs. So, we can write an outcome as a set in the following way: {{Si},{Bj},{Ik}}|T, or [{Si},{Bj},{Ik}]|T, where the square brackets represent a list and where Si are slices, Bj are blobs, and Ik are IAs, each constrained in some way, for some defined ranges of i, j, k, and where the measurements take place in subsets of space-time constraint T. We can generalise this also to include Boolean functions of sets and lists.
Note that each of these can be expressed as (potentially complicated) chunks, but we need to be careful here. We are using set notation freely, but in some modelling tools (like language) that is not part of the convention. This is acceptable because we are (implicitly) defining a new ecosystem, that of a metamodel, which represents other ecosystems.
When we are discussing patterns (in the sense in which the term is used in the paper above), we can use metamodel elements so long as we are clear that they do not necessarily represent ecosystem content. Here, we need to be aware that implicit referencing bedevils discussions about information and can lead to interpretation tangling [8,9], in which conventions linked to one ecosystem are inadvertently applied to another.
Any assertion represents a connection between constraints. However, is this the same as the wider question of information connection? Can all connections be represented as assertions? We are interested in three types of connection (always with respect to an ecosystem) that we can define in the following ways:
- Process connection: There is a process, recognised within the ecosystem, that produces one outcome when acting on another outcome;
- Relationship connection: There is a process, recognised within the ecosystem, that establishes whether or not a set of slices satisfies a relationship with a particular value;
- Property connection: There is a process, recognised within the ecosystem, that establishes the value that a set of slices has for a particular property.
If these can be expressed as assertions, then we have what we need.
In this list, it is clear that properties form a special case of relationships. A process connection is also a form of relationship. We can describe it in the following way: There is a process, recognised within the ecosystem, that establishes whether or not a set of slice constraints (divided into an input set, a process and an output set) satisfies a relationship. So, process connections are also relationships.
However, of course, each of these are assertions from the form of their definitions. The assertion makes a connection between the input constraint (defining the input sets) and the relationship constraint (sets of slices that generate a particular value when the relationship process is applied).
Therefore, in any ecosystem, all relationships can be represented as assertions and all assertions are relationships, and so this provides clarity about what we mean by an information connection. Of course, the processes implied by the definitions do not actually have to exist. An assertion is a hypothesis subject to information quality limitations [7,8,9].
The natural way to model connections is to use graphs. These are sufficient in most cases, but there are occasions [6,7] when slightly more generality is needed. A graph makes a division into vertices and edges, in which edges represent connections, but there are some occasions in which a method to model the connections of connections is desired. Graphs cannot support this, so we need a slightly more general construct in which connections of connections are supported. Here, we call them linnets (where “linnet” is short for “linked net”. Other obvious terms, like supergraph or hypergraph, are already used).
Also, we need to reason both about the way in which the model is constructed and also about what is being modelled. To keep these distinct, we use the notion of a pointer. Here, we define a pointer to be the tuple of c = (l, v, S), for which:
- l is a label: Lab (c);
- S is a set which is the set of all possible values of the pointer: Cont (c);
- v is the value (a member of S or ∅).
- An unrooted linnet C is a tuple (V, E, N) which satisfies the following conditions:
- There is a set of pointers P with unique labels LP;
- V ⊆ LP is a finite set that we call vertices;
- E ⊆ LP is a finite set that we call connectors;
- V and E are disjoint;
- N is the set of connections of D where N ⊆ {(a, e, b): a, b ∈ V ∪ E, e ∈ E};
- If e ∈ E and (a, e, b), (a’, e, b’) ∈ N, then a = a’ and b = b’.
The vertices, connectors, and connections of C are known as V(C), E(C) and N(C), respectively.
We define the proximity of a vertex to be 0. If (e1, e, e2) is a connection, then the proximity of e, prox (e), is defined as follows: If (e1, e, e2) is a connection, then prox (e) = min(prox (e1), prox (e2)) + 1, where min is undefined if either prox (e1) or prox (e2) is undefined. A connector is rooted if its proximity is defined. A linnet is an unrooted linnet, in which all connectors are rooted. So, in a linnet, all connectors connect back to vertices eventually. We can move past this technicality, if needed, by defining vertices as connections that loop back to themselves, but since we want to draw diagrams with points and lines, the definition here is sufficient.
Appendix A.2. Information Connection Diagrams
Linnets provide the tool for modelling connections, and we can use pointers to differentiate between reasoning about the linnet itself and reasoning about the modelled ecosystem. The pointer labels are used for the definition of the linnet and the values of the pointers are used for the objects we want to model. So, if we are drawing the linnet, the pointer labels usually have little relevance. To express the same concept differently, there are different ecosystems involved, namely, the modelling ecosystem (about the linnet) and the modelled ecosystem or ecosystems.
As mentioned above, we want to represent patterns as well as content, so we will use quotes (“”) for content and represent metamodel concepts without quotes. Under some circumstances, we may want to represent a whole linnet (C) as part of a larger linnet (D). In this case, we can construct a linnet C’ with one additional vertex labelled something like linnet_C, with a connector to each of V(C) and E(C). The vertex linnet_C will participate in D, but we can access C through the connectors from linnet_C. We can use a similar mechanism to model lists or sets.
Processes take one outcome to another, so we can represent them as in Figure A1a. Figure A1b shows the assertion “John ran to the shops” in the same form. In this version, “John” is a property of “ran to”, “the shops” is a type of destination, and the starting state is unspecified. We can add space-time constraints in diagrams where they are needed, but otherwise they are not required.
Figure A1.
Process connections.

We can extend properties (of a slice) to relationships between slices, as above. In this case, a relationship is the outcome of an ecosystem measurement (μ“relationship”), as shown in Figure A2a. The outcome is an IA that expresses the value. To simplify this, we can write relationships as a dotted line (as in Figure A2b), or when the relationship is between two sets of slices, we can write it as in Figure A2c.
Figure A2.
Relationship connections.

We can also use patterns for connectors. Figure A3 shows two different examples. In Figure A3a, the sets on either side of the connector are treated as single entities (so {“IEi”} is in {“Gj”}). In Figure A3b, there are (unspecified) connectors between elements of the sets (so elements in {“IEi”} are in elements of {“Gj”}).
Figure A3.
Connector patterns.

Where we want to consider a set that will not conveniently fit within braces, then we can use a rounded box, as in Figure 2, representing a set that contains a number of elements defined by what is in the box.
Finally, when we want to reference a linnet without including all of the additional connectors required (as discussed above), we can use a square box, as in the box named “history” in Figure 3. This is a mechanism for naming and analysing a particular grouping or subset of a diagram.
Appendix A.3. Information Measures
The evolution of information in ecosystems results in information processing and IAs that are good enough. We can measure “good enough” using three high-level measures:
- Pace: How fast outcomes are produced. This is important because the environment may demand a response in a given time or may prioritise early responses;
- Friction: How many resources are used. This is important because any IE has limited resources;
- Quality: How well the outcomes meet the requirements of the environment. This is an important factor in determining the favourability of the outcome.
Pace and friction are conceptually straightforward. Pace can be measured in time units. Friction is more complicated but, just as accounting conventions can allocate a cost to activities, we assume that friction is also reducible to a number in suitable units (e.g., financial for organisations, calories for physical activities).
Quality is more complicated to establish, but it has been defined in detail in [6,7], based on the conventions of scientific measurement. The first question to establish is what is quality measured against? The definitions in [6,7] are based on ecosystem conventions, specifically, how closely the information outcome corresponds to the notion of quality established in the ecosystem conventions. This is the default, but in some cases (perhaps when we are looking at environmental change, where the conventions lag behind the needs of the environment) we may need to consider other targets.
Quality breaks down into the following elements for chunks:
- Accuracy: This measures how closely the interpretation of any chunk matches the ecosystem interpretation (defined by the ecosystem conventions);
- Precision: This measures the extent to which interpretations of the chunk are the same in different circumstances (where they are intended to be the same);
- Resolution: This measures whether one interpretation can discriminate more finely than another;
- Coverage: This measures the number of properties of slices that are incorporated in a chunk and how tightly each value constrains the property (this is a measure of the modelling tool rather than the interpretation);
- Timeliness: This measures the difference between the time of measurement of the slice properties under consideration and the time of interpretation.
Unlike pace and friction, the first four of these measures do not necessarily correspond to a number or conform to a total order [7], so we cannot necessarily compare the quality of two IAs directly.
The quality of assertions depends both on the quality of the relevant chunks and the quality of the interpreted relation between them. In that sense, an assertion is a hypothesis that different interpretations may confirm or refute to different extents. We can capture this extent in the following measure:
- Plausibility: This measures the extent to which the set theoretical relation associated with the assertion corresponds to the actual set relationship of the interpreted chunks.
Figure A4 (copied from [7]) helps to explain this idea. The vertical axis relates to the chunk quality and assumes that the two chunks are of comparable quality, but, with that caveat, it shows some interesting zones, marked A, B, C, and D. (The vertical axis is only indicative, since chunk quality is not a total order.)
Figure A4.
Plausibility and chunk quality.

Zone A represents assertions that are most likely to be true (in an ecosystem sense), specifically, those that are plausible and supported by high chunk quality. Zone C represents assertions that can be considered contradictions, specifically, those that have an assertion relation that does not correspond to a high-quality interpreted relation between the chunks. Zones B and D correspond to low chunk quality and are correspondingly unreliable. The dotted line shows increasing reliability of plausibility (or perhaps we should call it trustworthiness).
There is one final question we need to consider for groups of IEs: Are they all trying to do the same thing? We can capture this in the following measure:
- Alignment: This measures the degree to which outcomes with different IEs are aiming to achieve are the same thing.
References
- Westerman, G.; Bonnet, D.; McAfee, A. Leading Digital: Turning Technology into Business Transformation; Harvard Business Review Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Buvat, J.; Puttur, R.K.; Bonnet, D.; Slatter, M.; Westerman, G.; Crummenert, C. Understanding Digital Mastery Today; Capgemini Digital Transformation Institute, 2018; Available online: https://www.capgemini.com/wp-content/uploads/2018/07/Digital-Mastery-DTI-report_20180704_web.pdf (accessed on 10 December 2019).
- Davenport, T.H.; Spanyi, A. Digital Transformation Should Start with Customers. MIT Sloan Review. October 2019. Available online: https://0-sloanreview-mit-edu.brum.beds.ac.uk/article/digital-transformation-should-start-with-customers/ (accessed on 10 December 2019).
- Barnard, M.; Stoll, N. Organisational Change Management: A Rapid Literature Review; Centre for Understanding Behaviour Change: Bristol, UK, 2010; Available online: http://www.bristol.ac.uk/media-library/sites/cubec/migrated/documents/pr1.pdf (accessed on 10 December 2019).
- Rosenbaum, D.; More, E.; Steane, P. Planned organisational change management: Forward to the past? An exploratory literature review. J. Organ. Chang. Manag. 2018, 31, 286–303. [Google Scholar] [CrossRef]
- Walton, P. A Model for Information. Information 2014, 5, 479–507. [Google Scholar] [CrossRef] [Green Version]
- Walton, P. Measures of Information. Information 2015, 6, 23–48. [Google Scholar] [CrossRef] [Green Version]
- Walton, P. Information and Meaning. Information 2016, 7, 41. [Google Scholar] [CrossRef] [Green Version]
- Walton, P. Information and Inference. Information 2017, 8, 61. [Google Scholar] [CrossRef] [Green Version]
- Walton, P. Artificial Intelligence and the Limitations of Information. Information 2018, 9, 332. [Google Scholar] [CrossRef] [Green Version]
- Kahneman, D. Thinking, Fast and Slow; Macmillan: London, UK, 2011. [Google Scholar]
- Granovetter, M.S. The Strength of Weak Ties. Am. J. Sociol. 1973, 78, 1360–1380. [Google Scholar] [CrossRef] [Green Version]
- Wade, M.; Noronha, A.; Macaulay, J.; Barber, J. Orchestrating Transformation: How to Deliver Winning Performance with a Connected Approach to Change; DBT Center Press: Lausanne, Switzerland, 2019. [Google Scholar]
- Darwin, C. On the Origin of Species by Means of Natural Selection, or the Preservation of Favoured Races in the Struggle for Life; John Murray: London, UK, 1859. [Google Scholar]
- Schein, E.H.; Schein, P. Organizational culture and leadership; John Wiley and Sons, Inc.: Hoboken, NJ, USA, 2017. [Google Scholar]
- Quine, W.V.O. Two Dogmas of Empiricism, Reprinted in from a Logical Point of View, 2nd ed.; Harvard University Press: Cambridge, MA, USA, 1951; pp. 20–46. [Google Scholar]
- Christian, D. Origin Story: A Big History of Everything; Little, Brown and Company: New York, NY, USA, 2018. [Google Scholar]
- Simon, H. Bounded Rationality and Organizational Learning. Organ. Sci. 1991, 2, 125–134. [Google Scholar] [CrossRef]
- Ferrero, G. L’inertie mentale et la loi du moindre effort. Revue Philosophique de la France et de l’Étranger 1894, 37, 169–182. [Google Scholar]
- Zipf, G.K. Human Behavior and the Principle of Least Effort; Addison-Wesley Press: Boston, MA, USA, 1949. [Google Scholar]
- Sommerville, I. Software Engineering; Addison-Wesley: Harlow, UK, 2010. [Google Scholar]
- Walton, P. Digital Information and Value. Information 2015, 6, 733–749. [Google Scholar] [CrossRef] [Green Version]
- Dwivedi, Y.K.; Hughes, L.; Ismagilova, E.; Aarts, G.; Coombs, C.; Crick, T.; Duan, Y.; Dwivedi, R.; Edwards, J.; Eirug, A.; et al. Artificial Intelligence (AI): Multidisciplinary Perspectives on Emerging Challenges, Opportunities, and Agenda for Research, Practice and Policy. Int. J. Inf. Manag. 2019. [Google Scholar] [CrossRef]
- Avgeriou, P.; Uwe, Z. Architectural patterns revisited: A pattern language. In Proceedings of the 10th European Conference on Pattern Languages of Programs (EuroPlop 2005), Bavaria, Germany, 6–10 July 2005. [Google Scholar]
- Kuhn, T.S. The Structure of Scientific Revolutions, 2nd ed.; University of Chicago Press: Chicago, IL, USA, 1970. [Google Scholar]
- DeBrusk, C. The Risk of Machine-Learning Bias (And How to Prevent It). MIT Sloan Manag. Rev. March 2018. Available online: https://0-sloanreview-mit-edu.brum.beds.ac.uk/article/the-risk-of-machine-learning-bias-and-how-to-prevent-it/ (accessed on 10 December 2019).
- Miller, A. Want Less-Biased Decision? Use Algorithms. Harv. Bus. Rev. July 2018. Available online: https://hbr.org/2018/07/want-less-biased-decisions-use-algorithms (accessed on 10 December 2019).
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423, 623–656. [Google Scholar] [CrossRef] [Green Version]
- Rosenfeld, L.; Morville, P. Information Architecture for the World Wide Web; O’Reilly & Associates: Sebastopol, CA, USA, 1998. [Google Scholar]
- Casciaro, T.; Edmondson, A.C.; Jang, S. Cross-Silo Leadership. HBR. May-June 2019. Available online: https://hbr.org/2019/05/cross-silo-leadership (accessed on 10 December 2019).
- Beck, K.; Beedle, M.; van Bennekum, A.; Cockburn, A.; Cunningham, W.; Fowler, M.; Grenning, J.; Highsmith, J.; Hunt, A.; Jeffries, R.; et al. Manifesto for Agile Software Development. Available online: http://www.agilemanifesto.org (accessed on 10 December 2019).
- Bossert, O.; Desmet, D. The Platform Play: How to Operate Like a Tech Company. McKinsey Digital. February 2019. Available online: https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/the-platform-play-how-to-operate-like-a-tech-company (accessed on 10 December 2019).
- Deming, W.E. Out of the Crisis; Massachusetts Institute of Technology, Center for Advanced Engineering Study; Cambridge University Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Conway, M.E. How Do Committees Invent? Datamation; Thompson Publications: Chicago, IL, USA, 1988. [Google Scholar]
- Scott, W.R. Organizations: Rational, Natural, and Open Systems; Englewood Cliffs: Bergen County, NJ, USA; Prentice Hall Inc.: Upper Saddle River, NJ, USA, 1981. [Google Scholar]
- Cox, J.; Goldratt, E.M. The Goal: A Process of Ongoing Improvement; North River Press: Croton-on-Hudson, NY, USA, 1986. [Google Scholar]
- Performance Management: An Introduction. Available online: https://www.cipd.co.uk/knowledge/fundamentals/people/performance/factsheet (accessed on 10 December 2019).
- International Standard on Social Responsibility. Available online: https://asq.org/quality-resources/iso-26000 (accessed on 10 December 2019).
- Dwivedi, Y.K.; Wastell, D.; Laumer, S.; Henriksen, H.Z.; Myers, M.D.; Bunker, D.; Elbanna, A.; Ravishankar, M.N.; Srivastava, S.C. Research on information systems failures and successes: Status update and future directions. Inf. Syst. Front. 2015, 17, 143–157. [Google Scholar] [CrossRef] [Green Version]
- Womack, J.P.; Jones, D.T. Lean Thinking—Banish Waste and Create Wealth in your Corporation; Simon & Schuster: New York, NY, USA, 1996. [Google Scholar]
- Harris, M.; Tayler, B. Don’t Let Metrics Undermine Your Business. Harvard Business Review. 2019. Available online: https://hbr.org/2019/09/dont-let-metrics-undermine-your-business (accessed on 10 December 2019).
- Isaacson, W. Steve Jobs; Simon & Schuster: New York, NJ, USA; Toronto, ON, Canada, 2011. [Google Scholar]
- Capgemini Report. TechnoVision 2018: The Impact of AI. Available online: https://www.capgemini.com/technovision-2018-the-impact-of-ai/ (accessed on 10 December 2019).
- Thompson, J.D. Organisations in Action. Social Science Bases of Administrative Theory; McGraw Hill: New York, NY, USA, 1967. [Google Scholar]
- Kim, G.; Debois, P.; Willis, J.; Humble, J. The Devops Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations; IT Revolution Press: Portland, OR, USA, 2016. [Google Scholar]
- Lawrence, P.R. How to Deal with Resistance to Change. Harv. Bus. Rev. 1954, 32, 49–57. [Google Scholar] [CrossRef]
- Kotter, J.P. Leading Change: Why Transformation Efforts Fail. Harv. Bus. Rev. January 2007. Available online: https://hbr.org/2007/01/leading-change-why-transformation-efforts-fail (accessed on 10 December 2019).
- Pearl, J.; MacKenzie, D. The Book of Why: The New Science of Cause and Effect; Basic Books: New York, NY, USA, 2018. [Google Scholar]
- Norris, P. Digital Divide: Civic Engagement, Information Poverty and the Internet Worldwide; Cambridge University Press: New York, NY, USA, 2001. [Google Scholar]
- Lewin, K. Field Theory in Social Science; Harper and Row: Manhattan, NY, USA, 1951. [Google Scholar]
- Moss Kanter, R. Ten Reasons People Resist Change. Harv. Bus. Rev. September 2012. Available online: https://hbr.org/2012/09/ten-reasons-people-resist-chang (accessed on 10 December 2019).
- Allman, E. Managing Technical Debt. Commun. ACM 2012, 55, 50–55. [Google Scholar] [CrossRef]
- Ford, N.; Parsons, R.; Kua, K. Building Evolutionary Architectures: Support Constant Change; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Weick, K.E. Educational Organizations as Loosely Coupled Systems. Adm. Sci. Q. 1976, 21, 1–19. [Google Scholar] [CrossRef]
- Orton, J.D.; Weick, K.E. Loosely coupled systems: A reconceptualization. Acad. Manag. Rev. 1990, 15, 203–223. [Google Scholar] [CrossRef] [Green Version]
- Ashkenas, R. Change Management Needs to Change. Harv. Bus. Rev. April 2013. Available online: https://hbr.org/2013/04/change-management-needs-to-cha (accessed on 10 December 2019).
- Luna, T.; Cohen, J. To Get People to Change, Make Change Easy. Harv. Bus. Rev. December 2017. Available online: https://hbr.org/2017/12/to-get-people-to-change-make-change-easy (accessed on 10 December 2019).
- Keller, S.; Schaninger, B. Getting Personal about Change. McKinsey Quarterly. August 2019. Available online: https://www.mckinsey.com/business-functions/organization/our-insights/getting-personal-about-change (accessed on 10 December 2019).
Figure 1.
Information processing step pattern.

Figure 2.
Viewpoint pattern.

Figure 3.
IP steps, viewpoints and selection pressures.

Figure 4.
Internal selection pressures and dependencies.

Figure 5.
Defining change.

Table 1.
Different types of information conversion.
| No Change Intended | Change Intended | |
|---|---|---|
| Same Ecosystem | Transfer | Transform |
| Different Ecosystem | Translate | Transform |
Table 2.
Viewpoint pattern drivers.
| No Integration | Joint Ecosystem | |
|---|---|---|
| High External Interaction | B Requires an iterative approach. Requires high levels of collaboration between groups. | D Requires an iterative approach. Requires the overhead of establishing a joint ecosystem. |
| Low External Interaction | A Separate groups can operate in series or parallel. | C Requires the overhead of establishing a joint ecosystem. |
Table 3.
Organisational dependence and decoupling.
| Figure 4 Reference | Decoupling Approaches |
|---|---|
| Defined Selection Drivers | Defining selection drivers independently of each other. Incorporating selection drivers that focus on connections as well as silos. |
| Culture | Making change part of the culture. |
| TransferIPS CollaborationIPS (these are shown in Figure 4) | Designing groups and viewpoint patterns to reduce the need for information conversion. Designing groups and viewpoint patterns to reduce the need for information transfer. Creating a collaborative culture. |
| CoreIPS | These can either be treated as atomic or expanded out, and the same overall analysis is applied at the next level down. |
| Groups | Decoupling people from groups has an inbuilt difficulty, namely, the continuity of knowledge, but there are several approaches to be used with care because of the potential impact on quality:
|
| Tools | Enabling the separation of information from its generation (see Section 2). Reducing the need for extensive training for tools by incorporating good user research and user experience design. Making access to training straightforward (e.g., computer-based training). |
Table 4.
Kotter’s stages and information evolution.
| Kotter Stage | Information Evolution Relationship |
|---|---|
| Establish a Sense of Urgency | Understand selection pressures, trends, and opportunities. Align leaders with desired outcomes. |
| Form a Powerful Guiding Coalition | Ensure alignment to desired outcomes. Collaborate to avoid the effects of silos. |
| Create a Vision | Define the outcomes and viewpoint for the change. |
| Communicate the Vision | Communicate the change viewpoint to ensure alignment more widely. Use the leadership to start to change dependencies (including culture). |
| Empower Others to Act on the Vision | Implement selection pressures aligned with the change. Encourage the implementation of the required dependencies (including culture). |
| Plan for and Create Short-Term Wins | Implement the change viewpoint pattern. Implement selection pressures aligned with the change. Improve change connection memory. Encourage the implementation of the required dependencies (including culture). |
| Consolidate Improvements and Produce More Change | Reinforce selection pressures aligned with the change. Implement the change viewpoint pattern and update the change viewpoint pattern. Improve change connection memory. Encourage the implementation of the required dependencies (including culture). |
| Institutionalize New Approaches | Reinforce selection pressures aligned with the change. Improve change connection memory. Encourage the implementation of the required dependencies (including culture). |
Table 5.
Organisational principles.
| Principle | Commentary |
|---|---|
| Align Internal Selection Pressures with External Selection Pressures |
|
| Create a Change Ecosystem |
|
| Create an Adaptive Business Architecture |
|
| Manage One-Off Change Adaptively |
|
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Walton, P. Information Evolution and Organisations. Information 2019, 10, 393. https://0-doi-org.brum.beds.ac.uk/10.3390/info10120393
AMA Style
Walton P. Information Evolution and Organisations. Information. 2019; 10(12):393. https://0-doi-org.brum.beds.ac.uk/10.3390/info10120393
Chicago/Turabian StyleWalton, Paul. 2019. "Information Evolution and Organisations" Information 10, no. 12: 393. https://0-doi-org.brum.beds.ac.uk/10.3390/info10120393
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.