TwiFly: A Data Analysis Framework for Twitter





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. High-Level Architecture
3.1. Data Collection Module
- Accounts and Users: Management of users and accounts.
- Tweets and Replies: Access to public tweets and replies; ability to post and search for tweets.
- Direct Messages: Access to direct messaging dialogues provided that the users have allowed it; creation of dialogues for use by physical persons or chat-bots
- Ads: Creation of advertising campaign that focuses on topics that have been identified with the use of API.
- Publisher tools and SDKs: Capability of embedding information and Twitter’s function in web pages.
3.2. Storage Module
3.3. Analysis Module
- Calculate the number of tweets based on several filters and criteria: We can calculate the number of tweets available in our database, belonging to or mentioning specific users, containing specific hashtags or text, from a specific location etc.
- Calculate the number of retweets based on several filters and criteria: The same criteria and filters that are applied for tweets can also be applied for retweets.
- Calculate the number of favorites in each tweet.
- Calculate the number of followers for a specific politician.
- Identify the most frequent hashtags used.
- Return the top-k politicians based on several criteria, for example based on their popularity, number of retweets, number of followers, favorites, etc.
- Return the most common hashtags used by each politician.
- Calculate the rate of growth of politician followers for a specific period.
- Identify potential bot accounts: To this direction, we implemented an effective algorithm for identifying machine accounts that are designed to mimic human users, for promoting specific political accounts. Numerous methods for detecting such accounts are already available (see [29] for an overview), however recent findings suggest that the retweeting activity of such automated accounts [30] can be exploited for their identification. Our algorithm, shown in Algorithm 1, is based on the simple idea that bot accounts will retweet a large percentage of the the tweets within a specific amount of time. As such the algorithms initially calculates for all tweets made by a specific twitter account the number of retweets by other accounts, which are performed within a time limit (Lines 5–12). Then, for each individual retweeter, the algorithm calculates the percentage of retweeted tweets (Line 14) and if it exceeds the percentage set by the algorithm it includes the specific account to the list of the potential bots (Line 15). Both the percentage and the time are configurable and can be set by the user. Within our experiments, the percentage was set to 90% and the time was set to 12 h. We manually verified the results of four obvious bots, identifying the high quality of the proposed approach.
| Algorithm 1 Bot detection. |
| 1: procedure detectBot(, , ) 2: 3: 4: 5: for each in do 6: 7: for each for a do 8: if is made within then 9: 10: end if 11: end for 12: end for 13: for each in do 14: if then 15: 16: else 17: 18: end if 19: end for 20: return end procedure |
3.4. Gui
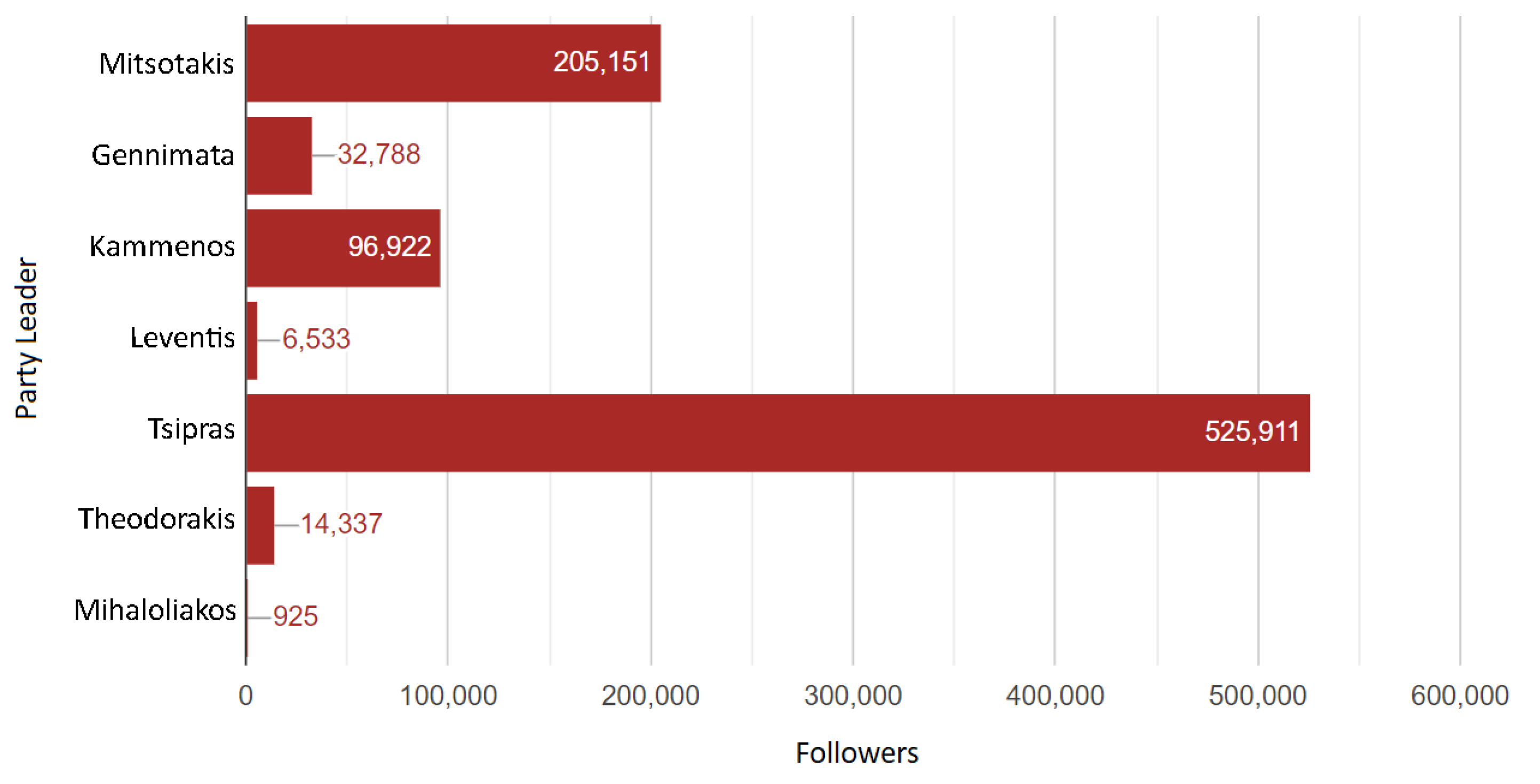
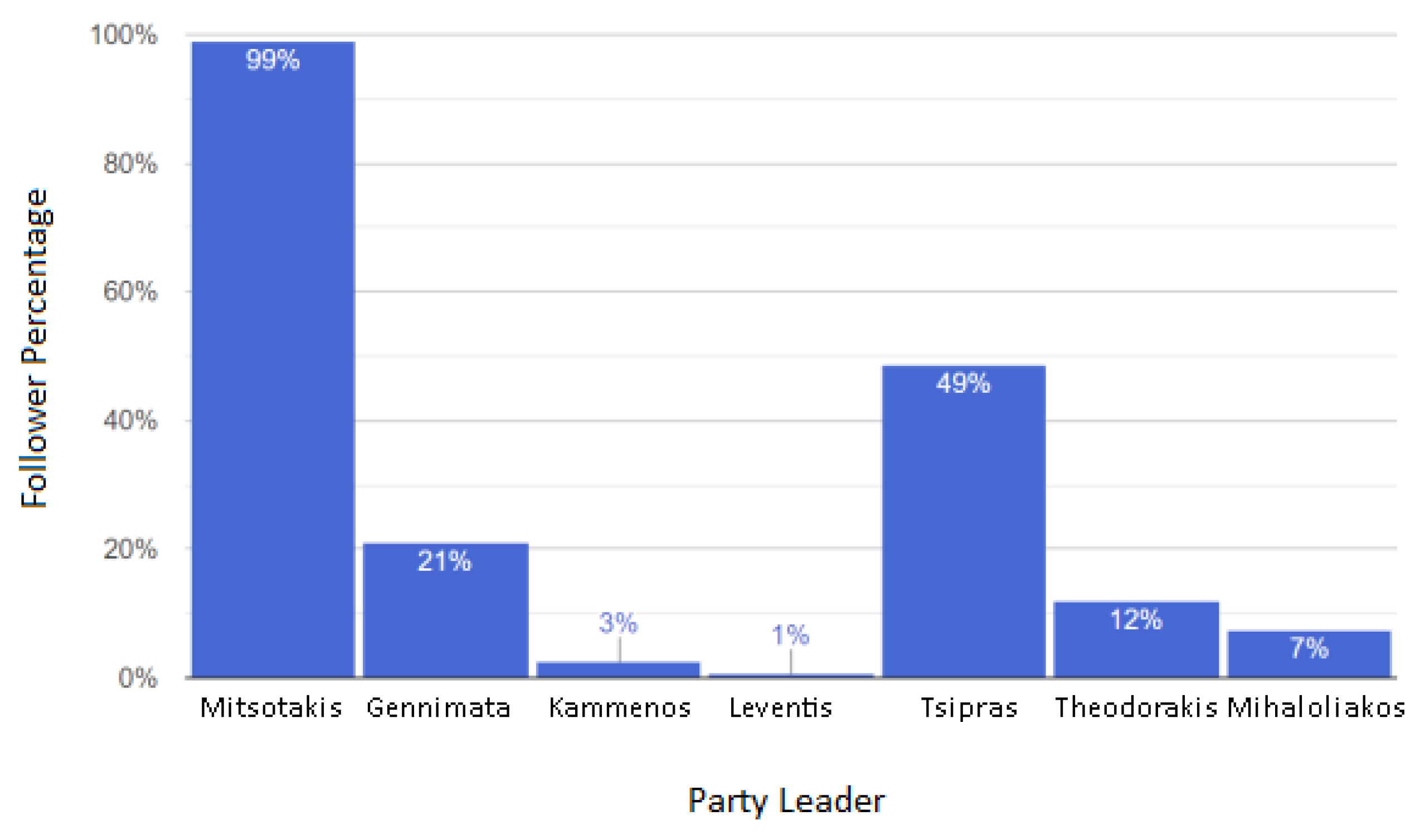
4. Framework Application to the Latest Elections in Greece
Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Stefanidis, K.; Ntoutsi, E.; Kondylakis, H.; Velegrakis, Y. Social-Based Collaborative Filtering. In Encyclopedia of Social Network Analysis and Mining, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef] [Green Version]
- Twitter. Available online: https://en.wikipedia.org/wiki/Twitter (accessed on 1 May 2020).
- Saeed, Z.; Abbasi, R.A.; Maqbool, O.; Sadaf, A.; Razzak, I.; Daud, A.; Aljohani, N.R.; Xu, G. What’s Happening Around the World? A Survey and Framework on Event Detection Techniques on Twitter. J. Grid Comput. 2019, 17, 279–312. [Google Scholar] [CrossRef] [Green Version]
- Ramachandran, D.; Ramasubramanian, P. Event detection from Twitter—A survey. IJWIS 2018, 14, 262–280. [Google Scholar] [CrossRef]
- Gavhane, S.A.; Bhadave, S.B.; Vengatesan, K. Review on Latest Trending Topic Detection in Twitter With Stream Processing (Using Fission Pattern). IJAEC 2019, 10, 43–47. [Google Scholar] [CrossRef]
- Rathan, M.; Hulipalled, V.R.; Venugopal, K.R.; Patnaik, L.M. Consumer insight mining: Aspect based Twitter opinion mining of mobile phone reviews. Appl. Soft Comput. 2018, 68, 765–773. [Google Scholar]
- Sotiriadis, M.D.; van Zyl, C. Electronic word-of-mouth and online reviews in tourism services: The use of twitter by tourists. Electron. Commer. Res. 2013, 13, 103–124. [Google Scholar] [CrossRef]
- Martínez-Rojas, M.; del Carmen Pardo-Ferreira, M.; Rubio-Romero, J.C. Twitter as a tool for the management and analysis of emergency situations: A systematic literature review. Int. J. Inf. Manag. 2018, 43, 196–208. [Google Scholar] [CrossRef]
- Doan, S.; Yang, E.W.; Tilak, S.S.; Li, P.W.; Zisook, D.S.; Torii, M. Extracting health-related causality from twitter messages using natural language processing. BMC Med. Inf. Decision Making 2019, 19-S, 71–77. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weerasinghe, J.; Morales, K.; Greenstadt, R. “Because… I was told… so much”: Linguistic Indicators of Mental Health Status on Twitter. PoPETs 2019, 2019, 152–171. [Google Scholar] [CrossRef] [Green Version]
- Sarma, K.V.; Spiegel, B.M.R.; Reid, W.M.; Chen, S.; Merchant, R.M.; Seltzer, E.; Arnold, C.W. Estimating the Health-Related Quality of Life of Twitter Users Using Semantic Processing. In Proceedings of the MEDINFO 2019: Health and Wellbeing e-Networks for All— Proceedings of the 17th World Congress on Medical and Health Informatics, Lyon, France, 25–30 August 2019; pp. 1065–1069. [Google Scholar]
- Alonso-Muñoz, L.; Marcos-García, S.; Casero-Ripollés, A. Political leaders in (inter)action: Twitter as a strategic communication tool in electoral campaigns. Trípodos 2017, 39, 71–90. [Google Scholar]
- Boynton, G.R.; Cook, J.; Daniels, K.; Dawkins, M.; Kopish, J.; Makar, M.; McDavid, W.; Murphy, M.; Osmundson, J.; Steenblock, T.; et al. The Political Domain Goes to Twitter: Hashtags, Retweets and URLs. Open J. Polit. Sci. 2014, 4, 8–15. [Google Scholar] [CrossRef] [Green Version]
- Cram, L.; Llewellyn, C.; Hill, R.L.; Magdy, W. UK General Election 2017: A Twitter Analysis. arXiv 2017, arXiv:1706.02271. [Google Scholar]
- Budiharto, W.; Meiliana, M. Prediction and analysis of Indonesia Presidential election from Twitter using sentiment analysis. J. Big Data 2018, 5, 51. [Google Scholar] [CrossRef] [Green Version]
- Kusen, E.; Strembeck, M. Politics, sentiments, and misinformation: An analysis of the Twitter discussion on the 2016 Austrian Presidential Elections. Online Soc. Netw. Media 2018, 5, 37–50. [Google Scholar] [CrossRef]
- Caetano, J.A.; Lima, H.S.; Santos, M.F.; Marques-Neto, H.T. Using sentiment analysis to define twitter political users’ classes and their homophily during the 2016 American presidential election. J. Internet Serv. Appl. 2018, 9, 18:1–18:15. [Google Scholar] [CrossRef] [Green Version]
- Evans, H.K.; Brown, K.J.; Wimberly, T. “Delete Your Account”: The 2016 Presidential Race on Twitter. Soc. Sci. Comput. Rev. 2018, 36, 500–508. [Google Scholar] [CrossRef]
- Gervais, B.T.; Evans, H.K.; Russell, A. Fear and Loathing on Twitter: Exploring Negative Rhetoric in Tweets During the 2018 Midterm Election. In The Roads to Congress 2018: American Elections in the Trump Era; Foreman, S.D., Godwin, M.L., Wilson, W.C., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 31–52. [Google Scholar] [CrossRef]
- Christine, B.; Williams, B.I.N. Social Media, Political Marketing and the 2016 US Election. J. Polit. Mark. 2017, 16, 207–211. [Google Scholar]
- Gainous, J.; Wagner, K.M. Tweeting to Power: The Social Media Revolution in American Politics; Oxford University Press: Oxford, UK, 2013. [Google Scholar]
- Wang, L.; Gan, J.Q. Prediction of the 2017 French Election Based on Twitter Data Analysis Using Term Weighting. In Proceedings of the 2018 10th Computer Science and Electronic Engineering Conference, CEEC 2018, University of Essex, Colchester, UK, 19–21 September 2018; pp. 231–235. [Google Scholar]
- Praciano, B.J.G.; da Costa, J.P.C.L.; Maranhao, J.P.A.; de Mendonca, F.L.L.; de Sousa Júnior, R.T.; Prettz, J.B. Spatio-Temporal Trend Analysis of the Brazilian Elections Based on Twitter Data. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops, ICDM Workshops, Singapore, 17–20 November 2018; pp. 1355–1360. [Google Scholar]
- Heredia, B.; Prusa, J.D.; Khoshgoftaar, T.M. Location-Based Twitter Sentiment Analysis for Predicting the U.S. 2016 Presidential Election. In Proceedings of the Thirty-First International Florida Artificial Intelligence Research Society Conference, FLAIRS 2018, Melbourne, FL, USA, 21–23 May 2018; pp. 265–270. [Google Scholar]
- Martin-Gutierrez, S.; Losada, J.C.; Benito, R.M. Recurrent Patterns of User Behavior in Different Electoral Campaigns: A Twitter Analysis of the Spanish General Elections of 2015 and 2016. Complexity 2018, 2018, 2413481:1–2413481:15. [Google Scholar] [CrossRef] [Green Version]
- Yoshida, M.; Toriumi, F. Analysis of Political Party Twitter Accounts’ Retweeters during Japan’s 2017 Election. In Proceedings of the 2018 IEEE/WIC/ACM International Conference on Web Intelligence, WI 2018, Santiago, Chile, 3–6 December 2018; pp. 736–739. [Google Scholar]
- Andriotis, P.; Takasu, A. Emotional Bots: Content-based Spammer Detection on Social Media. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security, WIFS 2018, Hong Kong, China, 11–13 December 2018; pp. 1–8. [Google Scholar]
- Chavoshi, N.; Mueen, A. Model Bots, not Humans on Social Media. In Proceedings of the IEEE/ACM 2018 International Conference on Advances in Social Networks Analysis and Mining, ASONAM 2018, Barcelona, Spain, 28–31 August 2018; pp. 178–185. [Google Scholar]
- Alothali, E.; Zaki, N.; Mohamed, E.A.; Ashwal, H.A. Detecting Social Bots on Twitter: A Literature Review. In Proceedings of the 2018 International Conference on Innovations in Information Technology (IIT), Al Ain, UAE, 18–19 November 2018; pp. 175–180. [Google Scholar]
- Caldarelli, G.; De Nicola, R.; Vigna, F.D.; Petrocchi, M.; Saracco, F. The role of bot squads in the political propaganda on Twitter. arXiv 2019, arXiv:1905.12687. [Google Scholar]










© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chatziadam, P.; Dimitriadis, A.; Gikas, S.; Logothetis, I.; Michalodimitrakis, M.; Neratzoulakis, M.; Papadakis, A.; Kontoulis, V.; Siganos, N.; Theodoropoulos, D.; et al. TwiFly: A Data Analysis Framework for Twitter. Information 2020, 11, 247. https://0-doi-org.brum.beds.ac.uk/10.3390/info11050247
Chatziadam P, Dimitriadis A, Gikas S, Logothetis I, Michalodimitrakis M, Neratzoulakis M, Papadakis A, Kontoulis V, Siganos N, Theodoropoulos D, et al. TwiFly: A Data Analysis Framework for Twitter. Information. 2020; 11(5):247. https://0-doi-org.brum.beds.ac.uk/10.3390/info11050247
Chicago/Turabian StyleChatziadam, Panagiotis, Aftantil Dimitriadis, Stefanos Gikas, Ilias Logothetis, Manolis Michalodimitrakis, Manolis Neratzoulakis, Alexandros Papadakis, Vasileios Kontoulis, Nikolaos Siganos, Dimitrios Theodoropoulos, and et al. 2020. "TwiFly: A Data Analysis Framework for Twitter" Information 11, no. 5: 247. https://0-doi-org.brum.beds.ac.uk/10.3390/info11050247