Main Influencing Factors of Quality Determination of Collaborative Open Data Pages



1
Department Business Science, Aalen University of Applied Sciences, 73430 Aalen, Germany
2
Department of Information Systems, Poznań University of Economics and Business, 61-875 Poznan, Poland
*
Author to whom correspondence should be addressed.
Information 2020, 11(6), 283; https://0-doi-org.brum.beds.ac.uk/10.3390/info11060283
Submission received: 3 April 2020
/
Revised: 19 May 2020
/
Accepted: 21 May 2020
/
Published: 27 May 2020
(This article belongs to the Special Issue Quality of Open Data)
Abstract
:Collaborative knowledge bases allow anyone to create and edit information online. One example of a resource with collaborative content is Wikipedia. Despite the fact that this free encyclopedia is one of the most popular sources of information in the world, it is often criticized for the poor quality of its content. Articles in Wikipedia in different languages on the same topic, can be created and edited independently of each other. Some of these language versions can provide very different but valuable information on each topic. Measuring the quality of articles using metrics is intended to make open data pages such as Wikipedia more reliable and trustworthy. A major challenge is that the ‘gold standard’ in determining the quality of an open data page is unknown. Therefore, we investigated which factors influence the potentials of quality determination of collaborative open data pages and their sources. Our model is based on empirical data derived from the experience of international experts on knowledge management and data quality. It has been developed by using semi-structured interviews and a qualitative content analysis based on Grounded Theory (GT). Important influencing factors are: Better outcomes, Better decision making, Limitations, More efficient workflows for article creation and review, Process efficiency, Quality improvement, Reliable and trustworthy utilization of data.
1. Introduction
The World Wide Web is characterized by user-generated content which has resulted in various online encyclopedias. The most popular is the free online encyclopedia Wikipedia, which contains more than 51,600,000 million articles in over 300 languages. The English Wikipedia with around 6 million articles is the largest language chapter, followed by the German Wikipedia with over 2.3 million articles [1].
The main feature of the website is the wiki tool, with which viewers can edit the articles directly in the web browser. In traditional encyclopedias, articles are written by experts, but in Wikipedia any web user can write an article. A system that is so open attracts many users who voluntarily write articles and keep them up to date. A major problem is that open access is very difficult to protect from manipulation and vandalism, so for example inaccurate information can be published by opportunistic or inexperienced contributors without any verification [2].
Therefore, a high quality and accuracy of a Wikipedia article cannot be guaranteed. For this reason, Wikipedia has developed several user-oriented approaches for evaluating articles. The users of the platform can mark high quality articles as “featured articles” or “good articles” and mark inferior articles as “articles to be deleted”. However, this system only partially solves the problem, as only a very small part of Wikipedia is rated by them. With a view to improving the rating of articles in online encyclopedias, relevant metrics (or indicators, features, measures) can be developed to determine the quality of Wikipedia articles and their sources [3,4]. Numerous approaches have already been developed on this topic. Current publications focus mainly on technical and mathematical solutions for the development of metrics. Knowledge oriented or economic factors are hardly considered [5,6].
For this purpose, the results of a qualitative study in the form of interviews with international knowledge management experts on the topic “Benefits of metrics for determining the quality of collaborative open data pages and their sources and the main influencing factors” will be presented and explained. The collected data from the semi-structured interviews will be analysed using the Grounded Theory method in order to get verifiable and comprehensible results. The aim of this research paper is to collect interview data from which hypotheses about potentials of determining quality of open data pages can be identified.
In Section 2, the research method and design used in the data collection is explained. Afterwards, the data collection and the selection of experts will be described. Subsequently, the collected data is analyzed and coded, hypotheses are set up with the help of a designed model in Section 3. Finally, the results are summarized. The limitations and the conclusion complete the study. Material in the Appendix A provide more detailed insights.
2. Research Design, Data Collection and Analysis
The following section describes the research design for answering the question: “What are the main influencing factors for determining the quality of collaborative open data pages and their sources?” In this context, Section 2.1 deals with the design of the study, while Section 2.2 provides insights into data collection. In Section 2.3 the analysis of the data is described.
2.1. Research Design
Regarding the research design, the authors chose the methodology of Grounded Theory (GT) according to Glaser and Strauss [7]. GT is a classical evaluation method for generating theories. The explanation as a classical method is therefore based on the fact that it is a “conceptually condensed, methodologically sound and consistent collection of proposals” [8]. In order to develop a theory inductively with GT on the basis of the collected data, several procedures (e.g., iterations) have to be passed through. Characteristic for GT is therefore the constant change in data collection and analysis as well as the subsequent theory development. This methodology aims at the generation of new theories and enables the greatest possible openness towards the subject area to be researched [9]. It should be noted that a literature research is not carried out in advance as this is not part of GT [7,10,11]. It is a systematic collection and evaluation of mainly qualitative data (interview transcripts) with the aim of generating theory. Therefore, it is even essential to treat the research question completely impartially. Furthermore, the GT assumes that an intensive examination of the literature leads to distorted results [7]. The aim of the evaluation is to identify influencing factors and potentials of metrics for determining the quality of collaborative open data pages and their sources, supported by the statements of the interviewed experts [9].
2.2. Data Collection
The qualitative study is based on semi-structured interviews. This is the collection of opinions and evaluations on the research topic from an expert perspective. In this selected form of interview, questions are formulated in advance in the form of an interview guideline. These guidelines only determine the course of the interview in a certain way. The sequence is not absolutely necessary ([12], p. 134f.). The questions are deliberately formulated in an open manner so that the interviewees are not influenced in their answers [13].
First of all, suitable contacts in knowledge management with many years of experience on the subject were sought. Worldwide contacts from various institutions and universities were selected for the survey. The experts were contacted personally by e-mail. Since all personal data must be treated confidentially, a pseudonym was created for all interview partners. The interview guideline was not significantly changed after the pre-test so the answers could be included in the results. The institution of the interviewees with given pseudonyms is shown in Table 1.
With regard to the theoretical sample, the authors applied the iterative approach of Glaser and Strauss [7] in order to address as many knowledge management experts as possible from research institutions at universities and other institutions. This gives us a sufficiently good overview of the various aspects of the topic. From this it can be concluded that the data obtained from the interviews contain a great deal of information. Twelve interviews were conducted with experts from international companies and educational institutions.
The semi-structured interviews lasted an average of 25 min and were conducted between February and March 2019. The interview guideline was sent to the experts in advance. The interviews were structured as follows: First there was a short introduction. Personal and institutional questions were then asked. Finally, this was followed by key questions on the research area. The interviews were digitally recorded and then transcribed.
2.3. Data Analysis
The transcription of the semi-structured interviews was followed by data analysis using the coding method of Strauss and Corbin [14]. This method is divided into open, axial and selective coding [14]. Within the open coding, the answers of the experts are compared with regard to similarities. This led to an initial categorization [14]. Similar expert opinions received an uniform assessment. Using the axial coding method, the authors subcategorized and linked related categories with the same property level and dimension [14]. In this way, the authors assigned the middle categories to the upper categories. Since several user-defined high-level categories were obtained in the data during this procedure, the authors switched to Glaser’s approach [14]. Therefore, the authors have introduced a dependent variable that is the category with the most coherence to all other categories [14]. The dependent variable is comprising the “Potentials of quality determination of collaborative open data pages”. This leads us to further question within the paper: What are the main factors that influence the core category?
In the final step (selective coding), the authors eliminated all concepts not or only weakly associated with the core category [7] and found six main constructs (see Table 2). To improve the quality of collaborative open data pages it is necessary to find coverage gaps. Automated metrics as a quality indicator could separate the articles. Through these metrics the measurement can get improved. To achieve improved outcomes the investigation should give more precise results. In this way the performance could increase. The reliability and trustworthiness of data can improve the whole process. The identification of false and fake data gets better and therefore the quality would improve. Of course, an efficient process has less waste of time and resources. However, it is also possible to uncover cause of problems and have a more efficient data driven organization. With a data driven organization the workflows can get more efficient. In particular, article creation and reviews bring a better service as a provider. As a consequence editors are more satisfied. To get better and faster decision making the information has to be judged. While rating the information and weight of the data, it is possible to categorize according to different quality levels. One statement which brings a negative influence in the model is concerning construct difficulties. It will be hard to find an optimal overview on different open databases to ensure a good quality.
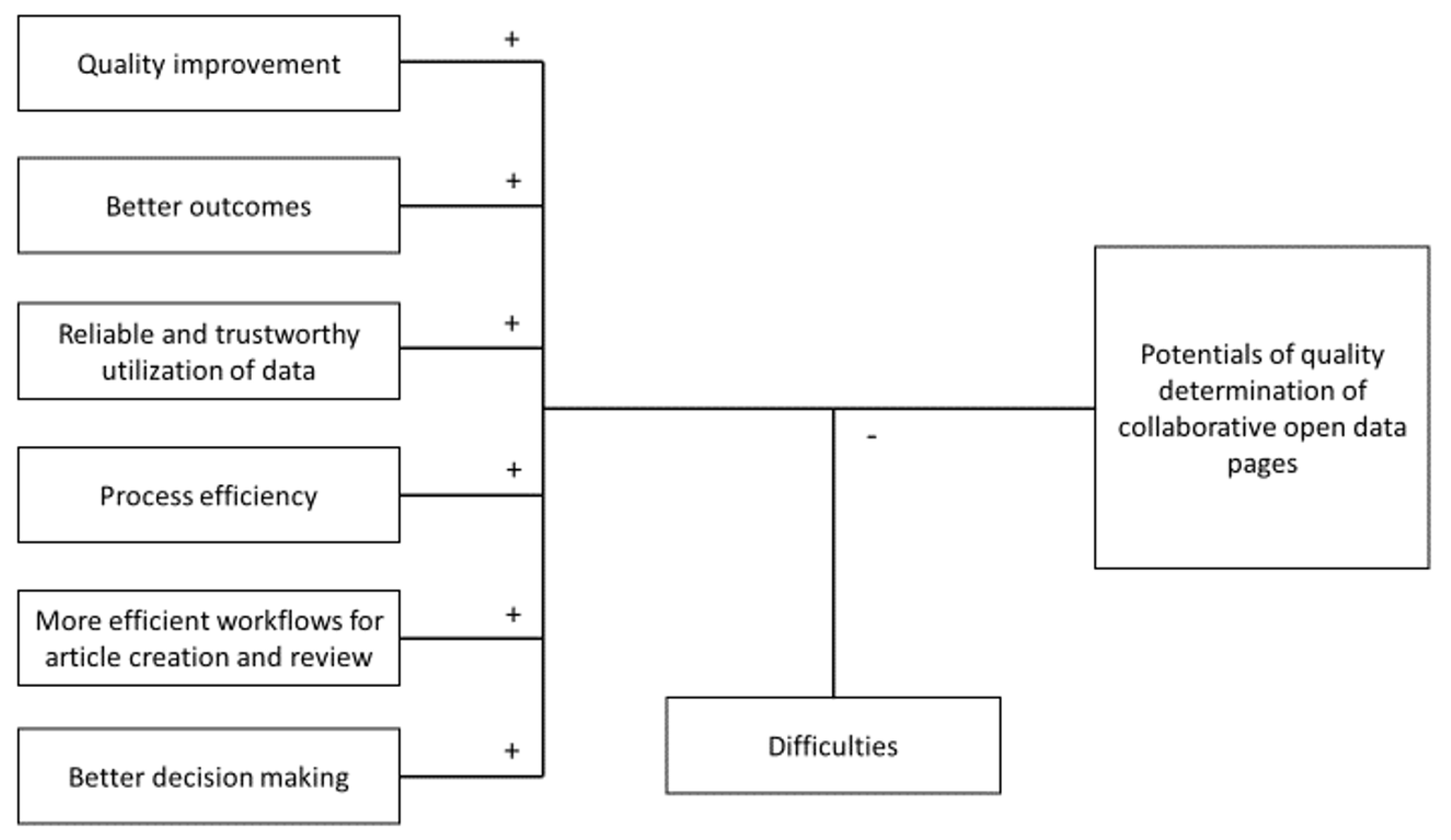
Corresponding answers form the basis for the subsequent generation of hypotheses. This resulted in the derivation of the designed model, consisting of six factors (quality improvement, better outcomes, reliable and trustworthy utilization of data, process efficiency, more efficient workflows for article creation and review, better decision making), which influence the potentials of the quality determination of collaborative open data pages. The “Potentials of quality determination of collaborative open data pages” are thus the dependent variable and core category. The subsequent selective coding serves to eliminate categories that are not or only weakly linked to this core category. All influencing factors are described in more detail in Section 3.
3. The Potentials of Quality Determination of Collaborative Open Data Pages
Based on data analysis with Grounded Theory, the authors defined six parameters which have a positive effect on the potentials of quality determination. The parameters used in the presented model are the results of the interviews, which have been transcribed and afterwards coded and analyzed. The difficulties have a negative impact. The designed model therefore consists of eight constructs (Figure 1).
The description of the parameters is based on the expert statements within the qualitative research. To explain the designed model, each construct is considered in detail. Figure 1 shows the designed model which was developed on the basis of the analyzed interviews. Included are six constructs that have a positive influence on the benefits of metrics to determine the quality of collaborative open data pages and their sources. According to the model, the difficulties reduce the benefits examined. The designed model describes the developed relations between constructs and the dependent variable within the research question.
3.1. Potentials of Quality Determination
As can be seen in the designed model, the quality determination of collaborative open data pages has the following potentials:
- Quality improvement,
- Better outcomes,
- Reliable and trustworthy utilization of data,
- Process efficiency,
- More efficient workflows for article creation and review,
- Better decision making.
There might be also limitations and difficulties in implementation. The following subsections describe the individual potentials and difficulties in detail. In Section 3.9 descriptive contents are listed. These contents are not represented in the construct, but because of their relevance they are described.
3.2. Quality Improvement
A frequently named potential of the quality determination of collaborative open data pages is the resulting quality improvement of these pages. This goes in accordance with the principle ‘improvement through measurement’ or like Stefan said: “What cannot be measured cannot be improved.” Especially automated metrics are considered by some experts to be useful indicators for quality issues. Matthias is convinced that “it is at least possible to improve the quality with machine learning […]” and also Stefan thinks that “automated surface metrics are quite useful as proxies for deeper senses of quality”. But he emphasizes that “values on automated measures can only with caution be taken as indicators for true quality.” An important part of quality improvement is according to some of the experts also “[…] to find coverage gaps in Wikipedia” to achieve a “more complete encyclopedia […]”.
3.3. Better Outcomes
A further potential, which was discussed in a large part of the expert interviews, is better outcomes. If quality can be improved through measurement (Section 3.2), data driven organizations will become more efficient in return “[…] and (so) we have the ability to have better outcomes”. This was confirmed by expert Roland, who specifically addresses the improvement of the “accuracy of outcomes”. Michael confirmed that “high quality information may increase the performance/ outcome of the task and low quality may cause the task to fail.” Another part of better outcomes is, according to some experts, also the possibility of automated knowledge extraction. Because “automated extraction can be used as a baseline and to verify if that what you have is correct.” That is what expert Daniel said in the interview, among other things.
3.4. Reliable and Trustworthy Utilization of Data
Nearly all the experts named the reliable and trustworthy utilization of data as an important potential of the quality determination of collaborative open data pages. Quality determination can be helpful for the “[…] identification of false data” (Anna) and can provide information on whether “[…] some sources (or) some information are reliable” (Karl). “Without any quality determination people may lose the trust into open data pages”, said expert Johannes, who emphasizes the importance of data trustworthiness for people.
3.5. Process Efficiency
The two most important statements regarding process efficiency as a potential of the quality determination of collaborative open data pages are firstly the paradigm ‘Garbage in, garbage out’ and secondly the statement, that the quality determination helps to uncover the root cause of the problem much earlier in the process.
The paradigm ‘Garbage in, garbage out’ was used by many experts to describe the problem of dealing with a bad matter source. Roland stated: “We can waste a lot of time and effort, because we end up doing a lot of work many times, fixing problems and reports instead of fixing the matter source.” Anna also underlines that “as the paradigm ‘garbage in, garbage out’ suggests, one needs to ensure that the quality of data is high such that the outputs of data analyses are valuable”.
This also goes along with discovering the root cause of the problem, rather than, as Roland described, trying to fix the data/information later in the process. Anna thinks that “data quality assessment helps uncover the root cause of the problem which allows one to improve the quality of the data”.
3.6. More Efficient Workflows for Article Creation and Review
Another potential of the quality determination is to allow for more efficient workflows for article creation and review. This includes better service for service providers and higher editor satisfaction. Karl states that automated metrics can help in letting the community know, when to have a look on certain pages. “The metrics will not tell if the page is bad, but metrics can tell, ‘Well this page could have issues, so have a look.’ It is kind of a tool for the collaborative process to draw attention to certain areas.”
Johannes even sees this potential as the most important one: “[…] I think the most interesting potential is as a service provider providing quality determination as a service to their customers”. He names DeepL as one similar example for an automated (translation) platform, which offers their (translation) services to any customer in the business and private sector. For Simon the term ‘Editor satisfaction’ particularly stands out: “Internally [ed.: a potential of quality determination is], more efficient workflows for article creation and review, and thus more editor satisfaction, if they can focus more on things that matter and less on management or irrelevant edits.”
3.7. Better Decision Making
In order to make high quality decisions firstly the information, that your decision is based upon, must be right. Secondly, often times you have to make the decision fast. The quality determination of open data pages facilitates both these points by giving the decision-makers a tool to weight and compare the information.
Richard, for example, says one of the most important potentials of the quality determination is to “weight the data accordingly” and Michael asserts “High quality information may increase the performance/ outcome of the task; low quality may cause the task to fail.”
3.8. Limitations
Anna mentioned a major barrier with not knowing the ‘gold standard’ when determining the quality of an open data page. She says: “We don’t know the real true values (i.e., the gold standard) to determine whether it is a quality issue.”
For Johannes the biggest challenge is checking the correctness of an article, as one would need a verified source. This can be done automatically or by crowd evaluation. However, “in particular, automatically determining correctness (precision) is currently far beyond the ability of automated methods” (Stefan). So both of these methods are limited to a certain extent. Only an evaluation by an expert in the field could really check for the correctness of an article, but as Johannes states, this is “basically impossible”. This is also confirmed by Adrian: “The biggest challenge is around human labor hours. It takes a lot of time and energy to manually assess the quality of an article. Worse, the expertise necessary to assess the complete coverage of a topic is hard-won and thus rare.” He continues, “in the context of using machine classifiers to lessen the cost of human labor hours, the biggest hurdle is the limitation in NLP techniques. It is difficult to have a machine classification model assess the readability of an article. Structural characteristics are much easier to assess.” Johannes even goes as far as saying: “Furthermore, criteria regarding text quality are hard to define and capture even with humans. This is a common problem in natural language generation, where evaluation criteria like fluency are hard to interpret as even humans often do not agree.”
Finally, Stefan summarizes the difficulties in the quality determination of open data pages quite well: “More generally, I believe a challenge of automated metrics is their narrowness, i.e., they only measure a specific quantifiable dimension (e.g., number of references or number of completeness statements), yet these are only proxies for true quality, and only crudely correlate with it. Thus, good values on automated measures can only with caution be taken as indicators for true quality.”
3.9. Descriptive Content
3.9.1. Quality
The experts are unanimous that “Data Quality is […] a multi-dimensional construct and defined as fitness for use. […] Data quality of a free online encyclopedia page can be defined with several different dimensions (e.g., completeness, consistency, trustworthiness) but the use case determines which dimensions are relevant.” This is the opinion of the expert Anna, whose statement represents the majority of the experts. Expert Johannes added that he thinks it is useful to “separate quality into content quality (Correctness, valid sources) and text quality (well written, structure), [because] […] they are both important for a high quality article.”
3.9.2. Metrics
When we asked about possible metrics (indicators) for determining the quality of collaborative open data pages, the experts gave us a huge variety of different answers.
Daniel mentioned that “automated metrics like the size of the page, the number of characters, the number of references or the number of links […] can maybe indicate some quality, but in the end, you need a human to review the text.” This statement coincided with the opinions of many other experts.
In addition to the second part of Daniel’s statement, some experts referred to the current collaborative rating system (Crowd evaluation) of Wikipedia for this question. Expert Alexander suggested to maintain this principle and “[…] borrow (a) reputation system as in Tripadvisor to evaluate the information quality of online encyclopedia, where the users of the information will rate it for its quality.”
The correlation between the proportion of citations per citable text and the quality of those citations is controversial among the experts. While Stefan thinks that “correct and comprehensive pages can easily be written without links and references”, Adrian thinks that the correlation between the citations and article quality is very high. Roland agrees with Adrian’s statement and finds that “the provenance of information is really an important part of quality.” Daniel notes that “having more sources […] is a good thing, but the sources should be verified that they are correct.”
Nearly half of the experts referred directly or indirectly to the editing history of the page as an indicator of its quality. Richard mentioned the “analysis of changes” as a metric for quality. Karl told us that it is important to look (by cross-tracking) “which […] pages are edited by which users. If cross-tracking says high traffic on the page or is there only one author and no one else cared this are indicators.”
Nearly all experts are of the opinion that “SEO tools seem not very well suited for assessing the overall quality of free encyclopedia pages” (Johannes). They “[…] do not think that purely statistical metric[s] can on itself give [information about] the quality of the page” (Karl).
3.9.3. Relevant Groups
The experts agree that almost everyone can benefit from the potential that the quality determination brings. No matter if you are a researcher, student, politician or a data provider.
4. Conclusions
The authors developed a model on the basis of evaluated data that investigates the potential of quality assessment of collaborative open data base pages and their sources. Therefore, the authors first conducted a semi-structured guideline interview to obtain empirical data from international experts in knowledge management. The evaluation of this study is based on Grounded Theory, which uncovered important influencing factors. As a result, the authors found six main factors that can be used as potentials of determining the quality of collaborative open data pages: Quality improvement, better outcomes, reliable and trustworthy utilization of data, process efficiency, more efficient workflows for article creation and review and better decision making.
In addition, the analysis of the data shows that difficulties can arise in determining the quality of collaborative open data base pages, which moderate the influencing factors within the designed model. i.e., there is also an influence on the relationship between each influencing factor (as an independent variable) and the potentials of quality determination of collaborative open data base pages (dependent variable). The full interview transcripts can be obtained from the corresponding author. The interview questions are listed in Table A1.
5. Limitations and Threats to Validity
Nevertheless, there are still some limitations to be considered within the research. First, there are a number of very weak influencing factors that have been neglected in the designed model during the iterative approach of Grounded Theory. Because only a minority of experts have noticed such a factor or other experts argue that this factor does not play an important role for the potentials of quality determination of open data base pages.
The analysis of the results finally revealed that the experts sometimes have very different views on these comprehensive concepts. Another limitation of our qualitative research approach is the focus on a sample of only twelve different international experts. Although the authors tried to put together a representative sample of experts with different expertise in knowledge management, the designed model may differ when interviewing experts with different emphases within knowledge management. As implications for science, the model which was developed serves as the basis for a quantitative approach to validate the relationship between each influencing factor and the potentials of quality determination of collaborative open data base pages.
In a qualitative study using interviews, individual statements from experts are analyzed and their value processed accordingly. Therefore, no hard facts can be generated using statistical models. As a further investigation, a quantitative study can be carried out, which can bring in a larger amount of data by means of a survey and the developed model. This allows hard facts to be analyzed and the subject matter to be examined more closely. It would be interesting to consider another study that is carried out in five or ten years. The comparison could lead to new findings and further research areas.
Author Contributions
Conceptualization, R.-C.H. and W.L.; methodology, R.-C.H.; validation, R.-C.H. and W.L.; formal analysis, R.-C.H.; resources, R.-C.H. and W.L.; writing–original draft preparation, R.-C.H.; writing–review and editing, R.-C.H. and W.L.; visualization, R.-C.H.; supervision, R.-C.H.; project administration, R.-C.H. and W.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
We thank Jennifer Apelt, Maximilian Baun, Pinar Feil, Konstantin Klein, Tobias Oechslein for supporting our research.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A

{kind=link}
Table A1.
Questionnaire for the qualitative interviews “benefits of metrics to determine the quality of collaborative open data pages and their sources”.
Table A1.
Questionnaire for the qualitative interviews “benefits of metrics to determine the quality of collaborative open data pages and their sources”.
| Number | Question |
|---|---|
| 1 | Personal questions |
| 1.1 | Which institution do you work for? |
| 1.2 | What are the main topics you are currently dealing with? |
| 1.3 | Do you already have scientific publications on this topic? |
| 2 | How do you define “quality” of a free online encyclopedia page (e.g., Wikipedia)? |
| 3 | Do you think an evaluation of the quality of all pages in free online encyclopedias is possible? |
| 4 | What are the challenges in determining the quality of collaborative open data pages and their sources? |
| 5 | Do you think the sources (links, references …) of collaborative open data pages are relevant for determining the quality of the pages? |
| 6 | Do you know metrics (indicators) for determining the quality of collaborative open data pages or their sources? |
| 7 | What other metrics or criteria can be used to determine the quality of collaborative open data and their sources? |
| 8 | How do you assess the potential of the metrics of SEO tools (e.g., Sistrix) to determine quality? |
| 9 | What difficulties can appear in the application of (selected) important metrics? |
| 10 | Do you think there are special metrics required regarding different (not collaborative) open data bases (governmental or users data sets)? |
| 11 | For what reasons do you consider the quality determination to be important? |
| 12 | Which potentials result from the quality determination? |
| 13 | Which groups of people could use these potentials for themselves? |
References
- Wikipedia Meta-Wiki. List of Wikipedias. Available online: https://meta.wikimedia.org/wiki/List_of_Wikipedias (accessed on 7 May 2020).
- Lewoniewski, W.; Węcel, K.; Abramowicz, W. Modeling Popularity and Reliability of Sources in Multilingual Wikipedia. Information 2020, 11, 263. [Google Scholar] [CrossRef]
- English Wikipedia. Template: Grading Scheme. Available online: https://en.wikipedia.org/wiki/Template:Grading_scheme (accessed on 7 May 2020).
- Lewoniewski, W. Measures for Quality Assessment of Articles and Infoboxes in Multilingual Wikipedia. In International Conference on Business Information Systems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 619–633. [Google Scholar]
- Lewoniewski, W.; Härting, R.C.; Węcel, K.; Reichstein, C.; Abramowicz, W. Application of SEO Metrics to Determine the Quality of Wikipedia Articles and Their Sources. In Information and Software Technologies; Damaševičius, R., Vasiljevienė, G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 139–152. [Google Scholar]
- Lewoniewski, W.; Węcel, K.; Abramowicz, W. Relative Quality and Popularity Evaluation of Multilingual Wikipedia Articles. Informatics 2017, 4, 43. [Google Scholar] [CrossRef] [Green Version]
- Glaser, B.G.; Strauss, A.L. Grounded Theory: Strategien qualitativer Sozialforschung; im Original Erschienen: 1967; Huber: Bern, Switzerland, 1998. [Google Scholar]
- Strübing, J. Grounded Theory: Zur Sozialtheoretischen und Epistemologischen Fundierung des Verfahrens der Empirisch Begründeten Theoriebildung; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Kühl, S.; Strodtholz, P.; Taffertshofer, A. Handbuch Methoden der Organisationsforschung. In Quantitative und Qualitative Methoden; VS: Wiesbaden, Germany, 2009. [Google Scholar]
- Cresswell, J.W. Qualitative Inquiry and Research Design: Choosing AMONG Five Traditions; SAGE: Thousand Oaks, CA, USA, 1998. [Google Scholar]
- Stern, P.N.; Allen, L.M.; Moxley, P.A. Qualitative research: The nurse as grounded theorist. Health Care Women Int. 1984, 5, 371–385. [Google Scholar] [CrossRef] [PubMed]
- Atteslander, P. Methoden der Empirischen Sozialforschung; Erich Schmidt Verlag: Berlin, Germany, 2010. [Google Scholar]
- Flick, U.; Kardorff, E.V.; Steinke, I. Qualitative Forschung—Ein Handbuch; Rowohlt Taschenbuch Verlag: Hamburg, Germany, 2008. [Google Scholar]
- Straus, A.; Corbin, J. Basics of Qualitative Research: Techniques and Procedures for Developing Grounded Theory; SAGE: Thousand Oaks, CA, USA, 1998. [Google Scholar]
Figure 1.
Designed Model.

Table 1.
Pseudonyms, institutions and countries of the experts.
| Pseudonym | Institution | Country |
|---|---|---|
| Adrian | Computer scientist and a principal research scientist at the Wikimedia Foundation | St. Petersburg |
| Alexander | Faculty of Computer Science, University | Indonesia |
| Andreas | Department of Telecommunications and Information Processing, University | Gent |
| Anna | Institute of Data Science, University | Maastricht |
| Daniel | Department of Computer Science, University | Leipzig |
| Johannes | Department of Computer Science, University | Darmstadt |
| Karl | Applied Computer Science, University | Bamberg |
| Matthias | Information Systems, Business Information Systems and Programming, University | Aalen |
| Michael | Department of Mathematics and Computer Science, University | Florence |
| Richard | Institute of Technology | Israel |
| Roland | School of Computing, University | Dublin |
| Stefan | Institute of Computer Science | Saarbrücken |
Table 2.
Constructs and items of the designed model.
| Construct | Items |
|---|---|
| Quality improvement | Automated metrics as an indicator for quality issues |
| Improvement through measurement | |
| Find coverage gaps | |
| Better outcomes | Accuracy of outcomes |
| Increase the performance | |
| Automated knowledge extraction | |
| Reliable and trustworthy utilization of data | Identification of false data |
| Reliability of data | |
| Data trustworthiness | |
| Process efficiency | Less waste of time and effort |
| Uncover the root cause of the problem | |
| More efficient data driven organizations | |
| More efficient workflows for article creation and review | Insights into their long time behavior |
| Better service for service providers | |
| Editor satisfaction | |
| Better decision making | Information judgement |
| Rate the flood of information, weight the data | |
| Categorization of quality levels | |
| Difficulties | Different open data bases |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Härting, R.-C.; Lewoniewski, W. Main Influencing Factors of Quality Determination of Collaborative Open Data Pages. Information 2020, 11, 283. https://0-doi-org.brum.beds.ac.uk/10.3390/info11060283
AMA Style
Härting R-C, Lewoniewski W. Main Influencing Factors of Quality Determination of Collaborative Open Data Pages. Information. 2020; 11(6):283. https://0-doi-org.brum.beds.ac.uk/10.3390/info11060283
Chicago/Turabian StyleHärting, Ralf-Christian, and Włodzimierz Lewoniewski. 2020. "Main Influencing Factors of Quality Determination of Collaborative Open Data Pages" Information 11, no. 6: 283. https://0-doi-org.brum.beds.ac.uk/10.3390/info11060283
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.