Integrated Question-Answering System for Natural Disaster Domains Based on Social Media Messages Posted at the Time of Disaster


1
Graduate School of Science and Technology, Tokai University, Kanagawa 259-1292, Japan
2
School of Information Science and Technology, Tokai University, Kanagawa 259-1292, Japan
*
Author to whom correspondence should be addressed.
Information 2020, 11(9), 456; https://0-doi-org.brum.beds.ac.uk/10.3390/info11090456
Submission received: 28 August 2020
/
Revised: 10 September 2020
/
Accepted: 18 September 2020
/
Published: 21 September 2020
(This article belongs to the Special Issue Knowledge Management, Trust and Communication in the Era of Social Media)
Abstract
:Natural disasters are events that humans cannot control, and Japan has suffered from many such disasters over its long history. Many of these have caused severe damage to human lives and property. These days, numerous Japanese people have gained considerable experience preparing for disasters and are now striving to predict the effects of disasters using social network services (SNSs) to exchange information in real time. Currently, Twitter is the most popular and powerful SNS tool used for disaster response in Japan because it allows users to exchange and disseminate information quickly. However, since almost all of the Japanese-related content is also written in the Japanese language, which restricts most of its benefits to Japanese people, we feel that it is necessary to create a disaster response system that would help people who do not understand Japanese. Accordingly, this paper presents the framework of a question-answering (QA) system that was developed using a Twitter dataset containing more than nine million tweets compiled during the Osaka North Earthquake that occurred on 18 June 2018. We also studied the structure of the questions posed and developed methods for classifying them into particular categories in order to find answers from the dataset using an ontology, word similarity, keyword frequency, and natural language processing. The experimental results presented herein confirm the accuracy of the answer results generated from our proposed system.
1. Introduction
Information is essential, especially in times of disaster. In recent years, numerous people have come to enjoy new ways to exchange information and share situations via texts, images, videos, and sounds using social network services (SNSs). Some of these social media tools, which have become essential to the lives of many people, were developed to support various types of events, especially those related to disasters. Since Japan is frequently struck by natural disasters, the Japanese people have accumulated a vast wealth of survival experience and have learned effective ways to stay abreast of various disaster-related events using social media as real-time tools for exchanging information. For example, just 10 min after the Osaka Northern Earthquake occurred at 07:58 a.m. on 18 June 2018, more than 270,000 tweets that included the Japanese word “地震” (earthquake) were posted [1].
In such situations, SNS information updates can help increase survival possibilities because they often include real-time data collected from on-site users in the disaster areas, news on help being provided by government agencies, or other knowledge that should be widely publicized [2]. In this regard, with more than 45 million active users, Twitter is the most widely utilized SNS in Japan. The information and knowledge sharing is not stimulated by imposing structures and tools but by rich social interaction and its immersion in practice [3]. When information is exchanged together, information and knowledge are created through the interaction between people [4]. Therefore, the most helpful information at the time of disasters, such as safe places and useful services, can be obtained from people who exchange various information using social networks.
It is well known that numerous tweets are posted when disasters occur [5] because information and communication technology can enhance the speed of knowledge sharing by lowering temporal and spatial barriers between users [6]. However, since almost all such information is initially unconfirmed, it cannot be used immediately. Instead, it must await clarification, which means the content and meaning must be considered appropriately before it can be included in an emergency dataset. Furthermore, even though a variety of disaster mitigation systems have been created and are now in use in Japan, those systems primarily support the Japanese public using the Japanese language, which means that they are inaccessible to foreigners who do not understand Japanese. With that point in mind, we have been working on developing a system to support foreigners residing in Japan, which is expected to be useful for assisting them in obtaining necessary real-time information during disasters.
More specifically, in this paper, we report on the proposed integrated framework for a question-answering (QA) scheme in disaster domains that is based on an information provision system. To accomplish this, we collected a dataset of more than nine million tweets from Twitter on 18 June 2018, when the Osaka North Earthquake occurred [7]. After that, we classified these social media messages using an ontology, word similarity, and keyword frequency, and then we evaluated the natural language processing results to organize those messages into ten categories. The results were then statistically compared with the keyword used to classify each category [8].
In the next phase, we used tokenization and keyword stemming to develop and classify questions using those same social media messages. Then, keywords were extracted from those messages and reformatted into questions that allowed the system to understand what the questioner wanted to determine. Then, those question-related keywords were compared with the most frequently used keywords in the social media content dataset, and group keywords were assigned to categories associated with the question types. Then, answers that have previously been discovered to those questions are presented. All these processes work together to help us develop a system that can answer and respond to question-related problems using social media. Then, we verified the accuracy of the proposed QA process by calculating the confusion matrix of the result.
2. Related Work
Numerous researchers have studied QA systems in the search for ways to solve related problems in different domains, and they have presented a variety of different methods for improving the accuracy of the question-classification process. However, there are several differences in the resulting answers. For example, using applied research, Tripti et al. [9] proposed a hybrid QA system that uses machine learning (ML) to perform question classification through patterns. To accomplish this, they studied the syntactic structure of questions and conducted an experiment involving 500 medical questions. The resulting process was found to be helpful when assigning a suitable question category and identifying appropriate keywords.
In another study, Agarwal et al. [10] introduced an on-the-fly conceptual network model by applying intelligent indexing algorithms to a concept network to improve answer generation. Those researchers also proposed a framework based on a dynamic self-evolving concept network. Meanwhile, Sunny et al. [11] proposed a community QA system and a question recommendation system using the k-nearest neighbors (KNN) and Naïve Bayes algorithms. This system can determine the redundancy of questions with similar meanings on the system, and it ranks the resulting answer using “likes” and “comments” received from users.
Separately, Lin-Qin et al. [12] present an integrated framework for Chinese language intelligent QA in restricted domains. This model is implemented using a convolutional neural network, a bidirectional long short-term memory network, and question pair matching to perform QA processing. In still another study, Kanokorn et al. [13] proposed an information extraction process for both questions and answers that uses the Thai language and a related corpus. This research resulted in a web-based QA system whose answers are factoids extracted from Thai Wikipedia articles.
In addition to research on QA processes, other researchers have proposed methods to analyze social media and create disaster-assistance systems. For example, the Disaster Information Tweeting System (DITS) and the Disaster Information Mapping System (DIMS) are currently among the most popular mobile web-based applications used in Japan. These applications use a Twitter account to link with geolocation data and hashtags to obtain and share disaster information among participating users [14].
Similarly, the DETSApp English language mobile disaster app is an applied research application that can display real-time scenario contents related to disaster events accurately using images posted on Twitter. The image process works with a near-duplicate image detection algorithm and summarization using associated textual information [15]. Additionally, the DISAster-information ANAlyzer (DISAANA) and the Disaster-information SUMMarizer (D-SUMM) are mutually-supporting Japanese language web-based apps that use Twitter as an information source. Working together, DISAANA provides a list of answers related to location and information, while D-SUMM summarizes the disaster reports [16].
3. Methodology
Numerous disaster-related studies using various ML algorithms have been carried out for purposes such as data classification, prediction, and/or evacuation route planning. However, there have only been a few studies that have systematically analyzed recent developments, particularly in relation to disaster management or disaster knowledge management [17]. With that point in mind, this study explores a method for implementing a QA system in natural disaster domains that works by extracting disaster information from social media messages.
To accomplish this, we collected a dataset and performed a few necessary classification pre-processing procedures, i.e., message tokenization and keyword similarity identification, etc., in order to classify tweet sentences in the same manner as outlined in our previous research [5]. Next, we separated the system framework into three main phases. The first phase involves separating the question sentences via tokenization, classifying the questions by type, and then comparing them with previous questions with the KNN algorithms. The second step involves classifying question-related keywords by a computing ontology and WordNet similarity. After that, the keyword matching process is implemented to analyze the dataset discussed in our previous research. Then, in the third stage, we create an answer by selecting keyword compatibility and ranking the most frequent social media retweets.
3.1. Classification Algorithm
Since our proposed system uses natural sentences as input, the question-classification algorithms used are important. The system itself can be divided into the classification algorithm based on syntactic structures and the classification algorithm based on interrogative words. The syntactic structure classification algorithm, which works by extracting reasonable features from sentences, improves classification accuracy because proper syntactic structures are essential for controlling word combinations in sentences. Hence, the algorithm is used to analyze each word’s role to understand the meaning of the question.
The classification algorithm, which is based on interrogative words, works by analyzing the interrogative word in a sentence. This method is used to solve the problem that occurs when syntax analysis rules are very complex, because it is difficult to cover all grammar rules. However, the classification result can be limited to a relatively small range [18].
3.2. KNN Algorithm
The KNN algorithm, which is an algorithm in the supervised learning group, is a highly beneficial ML algorithm that is used to group data (classification). This algorithm uses various methods to decide which classes can replace new conditions or cases by checking certain numbers and determining cases where they are the same or close to each other by calculating the total number of conditions. It is used for classification and regression when classifying an unknown dataset, which is primarily based on the similarity of neighboring results [19]. The KNN algorithm does not need training data to implement classification. Instead, the algorithm works by identifying the most relevant questions from sample document groups [20].
3.3. Statistic Similarity
Statistic similarity, which is a method that can be used to calculate the similarity between questions, works using a low-dimensional vector with only a few words in one sentence. This method compares questions based on the question word set. More specifically, in a situation where two questions are given as Q1 = [word A, word B, and word C] and Q2 = [word A, word D, and word E], we can define the word set as follows: QS = Q1UQ2.
The QS word set contains all the distinct words in Q1 and Q2. Thus, a vector v that can represent each question follows Q1 = V1 = {1,1,1,0,0} and Q2 = V2 = {0,0,1,1,1}. If the word does not appear in this question, the value of the component is set to 0. If the word appears in this question, its value is equal to its frequency in the question [21]. As a result, we can measure the statistic similarity by Formula (1) below.
3.4. Word Similarity on WordNet
WordNet, which is an English word database that focuses on the relationships between words, consists of nouns, verbs, adjectives, and adverbs. Related words are linked via synonym sets (synsets). More specifically, WordNet is an ontology in which more than 100,000 words have been collected that is used primarily to find similarities (upper and lower position, synonyms, properties, causes, etc.) between keywords, after which it presents similarity scores with percentages [22,23,24].
The WordNet similarity equation compares two words by finding the root words of both and then obtains a similarity score for each word. The comparison result between the two words will be a score from zero to one. A score of one indicates a 100% relationship, while a score close to one indicates a firm relationship probability. In contrast, a score of zero or close to zero indicates that the two words are unrelated despite their similarity. In this research, after separating the question’s sentence into keywords, we explore the meaning and relationship among words via WordNet similarity.
3.5. Confusion Matrix
A confusion matrix is a tool used to measure the ability and accuracy rate of an ML process or system. The matrix uses four values: True Positive (TP), which means the program’s actual predictions and data are true; True Negative (TN), which means the program’s actual predictions and data are false; False Positive (FP), which means the program makes a correct prediction, but the actual data is false; and False Negative (FN), in which the program prediction is false, but the actual data is true. [25,26,27]. We measure the results produced by the system using three criteria:
- Accuracy: The predicted accuracy matches what actually happens. The accuracy formula is (TP + TN)/(TP + TN + FP + FN).
- Precision: Correct and true predictions are compared with true predictions, but what happens is not true. The precision formula is TP/(TP + FP).
- Recall: The true prediction accuracy compared to the number of occurrences where both the prediction and occurrence are true. The recall formula is TP/(TP + FN).
It is necessary to measure the model or result in each step before developing or using it in various fields.
4. Framework Design
4.1. Framework of Our Proposed Integrated QA System
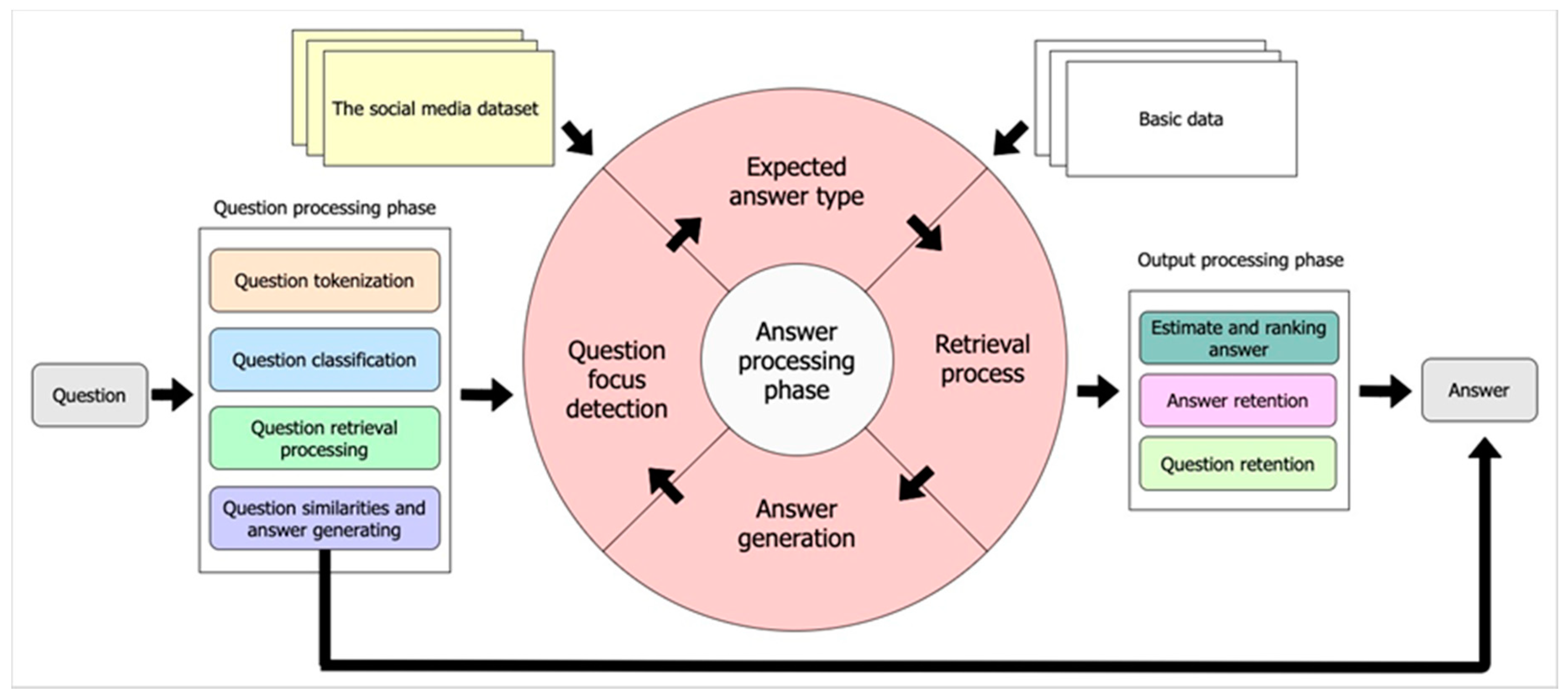
The systematic framework of our proposed integrated QA system for use in a natural disaster is divided into three main steps: the question processing phase, the answer processing phase, and the output processing phase, as shown in Figure 1. The first step takes an input question received from a user and goes through question processing to analyze the sentence. This process separates the question sentences into keywords and classifies the question by type. Next, the results are explored in the answer-processing phase, where matching between the keywords and the dataset takes place. This is the process where the answer is extracted from the database.
To facilitate answer creation, the system’s database maintains important data in two parts: parts extracted from the social media dataset during our previous research [8] and basic data such as location, contact, and coordinate information. By comparing the question keywords with the dataset keywords and basic supplemental data, answer sets can be produced.
Next, we rank the answer result and estimate the possibility of a correct answer. The output result is most likely the closest related to the question the user wants to be answered. In the final step that follows, both the question and the answer are recorded in the database so they can be immediately available if the same question is asked in the future.
4.2. Question Processing Phase Framework
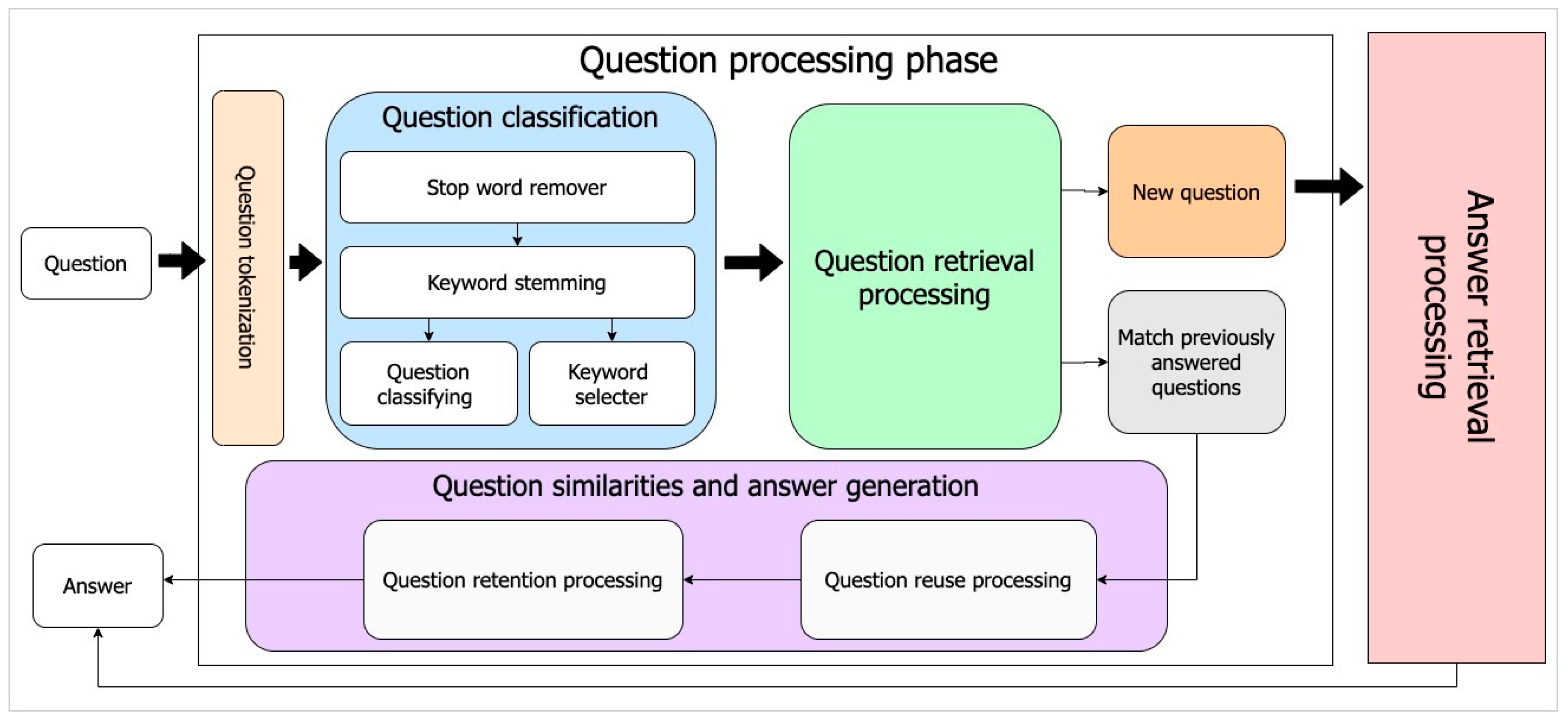
The first step of the proposed framework is the question-processing phase, during which the questions are analyzed and classified. Internal procedures such as tokenization, stop word remover, keyword stemming, question classification, and keyword selection are completed in this question analyzing process. Specifically, this process receives question messages from users, separates the structural components of those questions, and removes the unimportant components
The next process separates the sentence into words to identify the question by type and category. After that—but before sending the keyword result to the next step—the system will begin question retrieval processing. This process checks the submitted question for similarities by comparing it with previous questions contained in the database. If a question has already been asked, the system will engage the reuse and retention processes to retrieve the previous answer and reuse it for the current question. However, if it is a new question, the system will forward it to the answer-processing phase, as shown in Figure 2.
4.3. Framework Part of Answer Retrieval Processing and Answer Output
The second and third steps of the framework are the answer processing and output processing phases. The answer retrieval processing phase involves taking keywords from the previous process and using them to analyze the question by type (what, where, when, why, how, which, and whom) and then specifying the answer categories in which the expected answers should be located.
For example, if the question contains the word “where”, it indicates that the user is asking about a location, so the system will retrieve place location information and calculate the distance between that location and the user in order to create an answer, which it will then forward to the user. However, if the question type is “what” or “how”, the system will go through the matching process between the question keywords and dataset keywords to extract potential answers.
After obtaining the answer result set, the system creates an answer based on keyword compatibility and the social media content ranking that indicates the highest correct probability. The result is sent to the user in the answer output step, and both the question and answer are added to the database for reuse, as shown in Figure 3.
5. Experiments
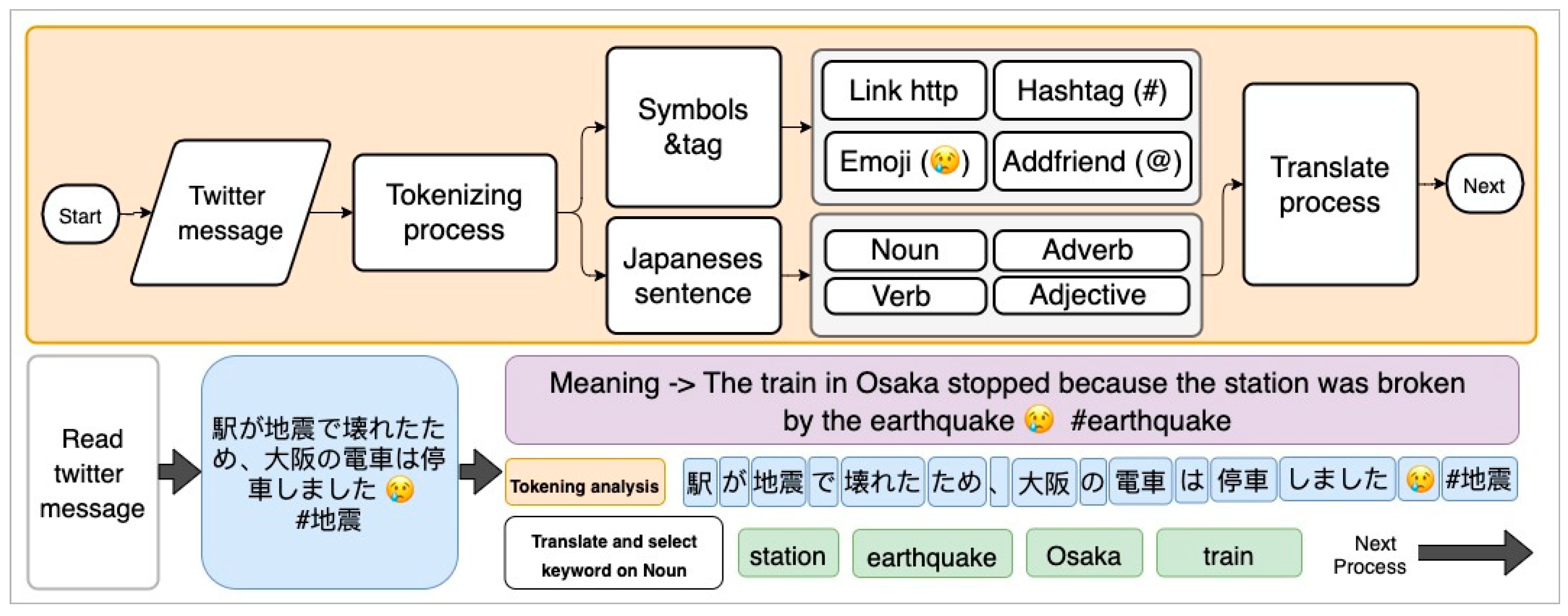
This section will explain how the system works by following the framework steps discussed above. More specifically, we describe how we collect and analyze necessary information from social media, perform data classification, and use the QA system answering process. The Twitter application programming interface (API) is used to access data in the JavaScript Object Notation (JSON) String form [28]. After that, all of the keywords are translated from Japanese into English in order to facilitate understanding while preparing for the next step, as shown in Figure 4.
5.1. Data Classification of Social Media Messages
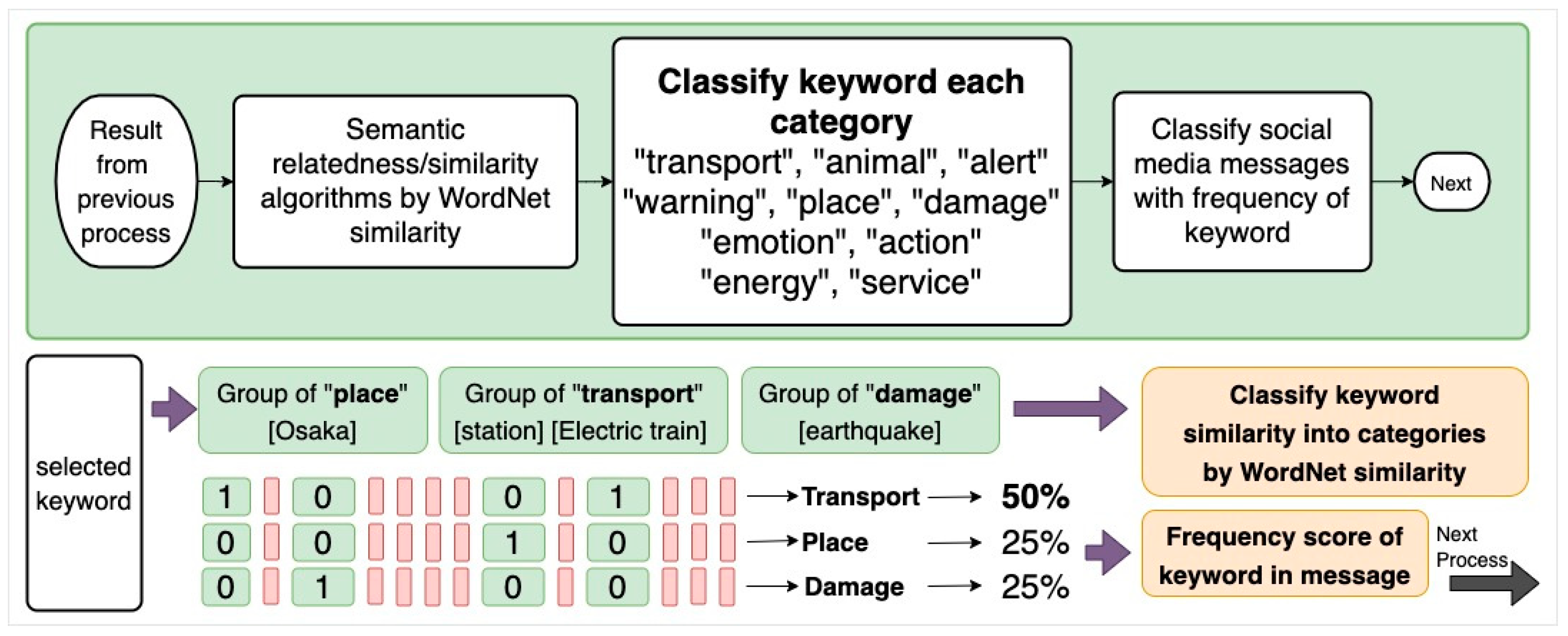
After the data gathering process, we selected ten English words to create ten categories by focusing on contents that must be known in relation to three main topics: before a disaster occurs, during a disaster, and after a disaster. Lists are compiled related to transportation (travel information, and vehicles), animals (human, pets, and other live animals), alerts (information during and after the disaster), warnings (cautions and self-preservation efforts before a disaster), places (buildings and/or other locations), damages (effects and violence caused by disasters), emotions (feeling and ideas), actions (activities during the disaster), energy (energy information), and services (available assistance and information sharing services).
Next, to classify questions sentences by type, they are compared to all ten categories in order to determine similarities. WordNet calculates a keyword similarity score by using an ontology to compare the compatibility of tweet dataset keywords and ten categories. For example, “Cat” has a higher compatibility with the category “animal” than the other categories. Moreover, it also counts how frequently the words of each category are used in the sentence [8], as shown in Figure 5.
5.2. Question Processing
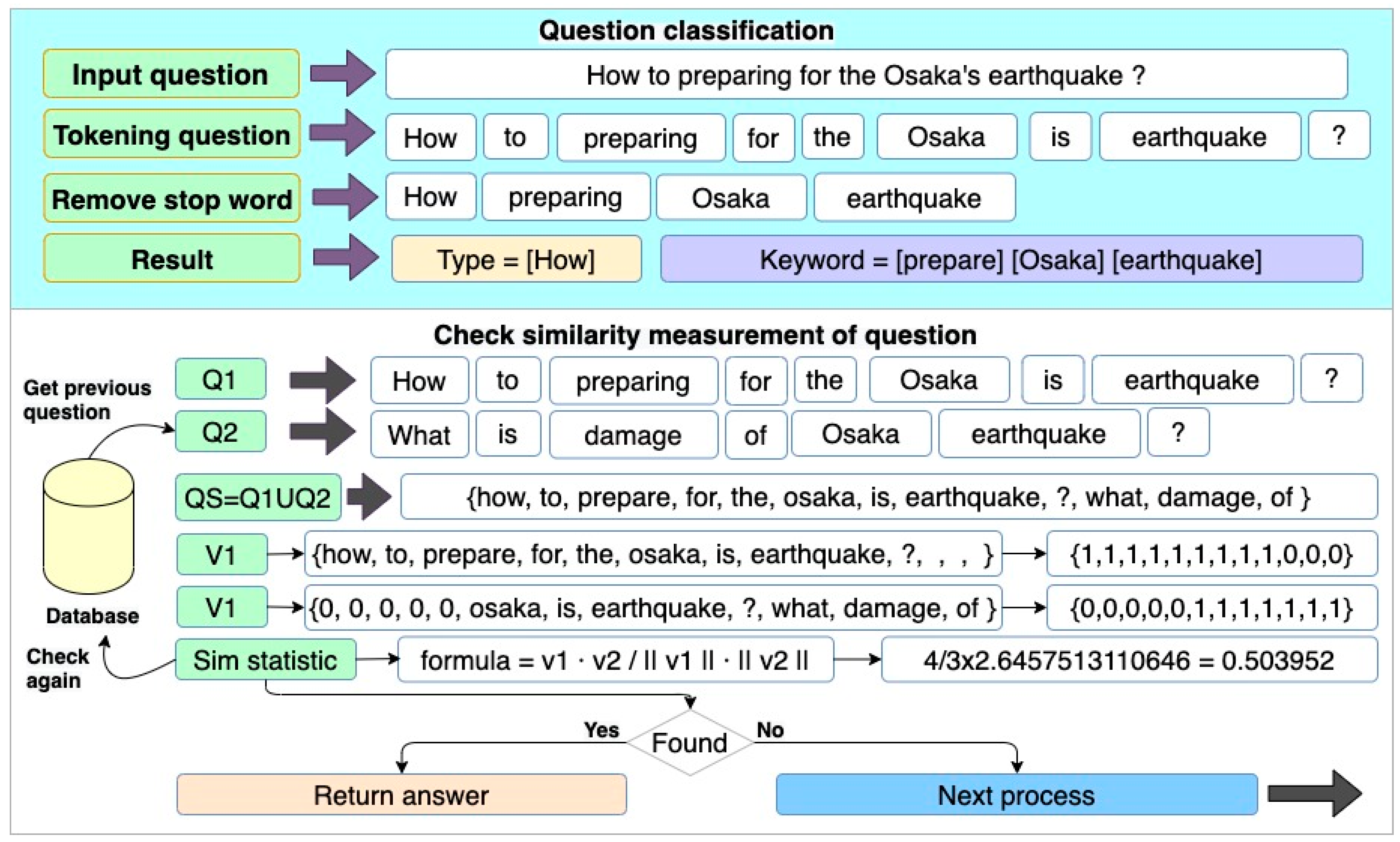
Based on the framework above, the first step is to split the sentences into words via tokenization processing. For example, the question message, “How to prepare for the Osaka’s earthquake?” will become [How] [to] [preparing] [for] [the] [Osaka] [is] [earthquake] [?]. The next step is the word removal process because words from tokenization have conjunctions, prepositions, or words that cannot be filtered, such as “a”, “an”, “the”, “from”, “for”, and “in”.
After that, the next process is stemming the keywords from the result [How] [preparing] [Osaka] [earthquake]. Since English words have added endings such as “-ing”, “-ion”, “-tion”, “-s”, “-es”, “ed”, it is necessary to convert those words to standard form via keyword stemming. The result of [preparing] becomes [prepare]. After this process, we get the question type = [How] and using the keyword selector get = [prepare] [Osaka] [earthquake] for the next step.
Before sending results to the answer processing step, the question processing will check the similarity measurement of the question by calculating the weighted sum of feature distance. We use KNN retrieval to find all of the closest previous questions in the database and then calculate the closeness between each keyword of the previous and new questions. For example, in Question 1, [How] [to] [prepare] [for] [the] [Osaka] [is] [earthquake] [?] and Question 2, [What] [is] [damage] [of] [Osaka] [earthquake] [?]. The statistic similarity is QS = Q1UQ2 = {how, to, prepare, for, the, Osaka, is, earthquake, ?, what, damage, of}. The resulting vector of similarity is v1 = {1,1,1,1,1,1,1,1,1,0,0,0} and v2 = {0,0,0,0,0,1,1,1,1,1,1,1}.
Next, we use the sim statistic formula obtained from the formula = v1 · v2/|| v1 || · || v2 ||, from which we then obtain a result equal to 0.5039, which means these two questions differ. If the system finds a match using a previous question, it will return the same answer to the user, as shown in Figure 6.
However, if there are many similar questions, such as Question 1, “How to prepare for the earthquake?” and Question 2, “How to prepare for the typhoon?”, the calculation result is 0.857, and the vector is not equal. In this case, it is necessary to use WordNet to compare the different keywords from the vector to identify more similarities.
5.3. Answer Retrieval Processing and Answer Output
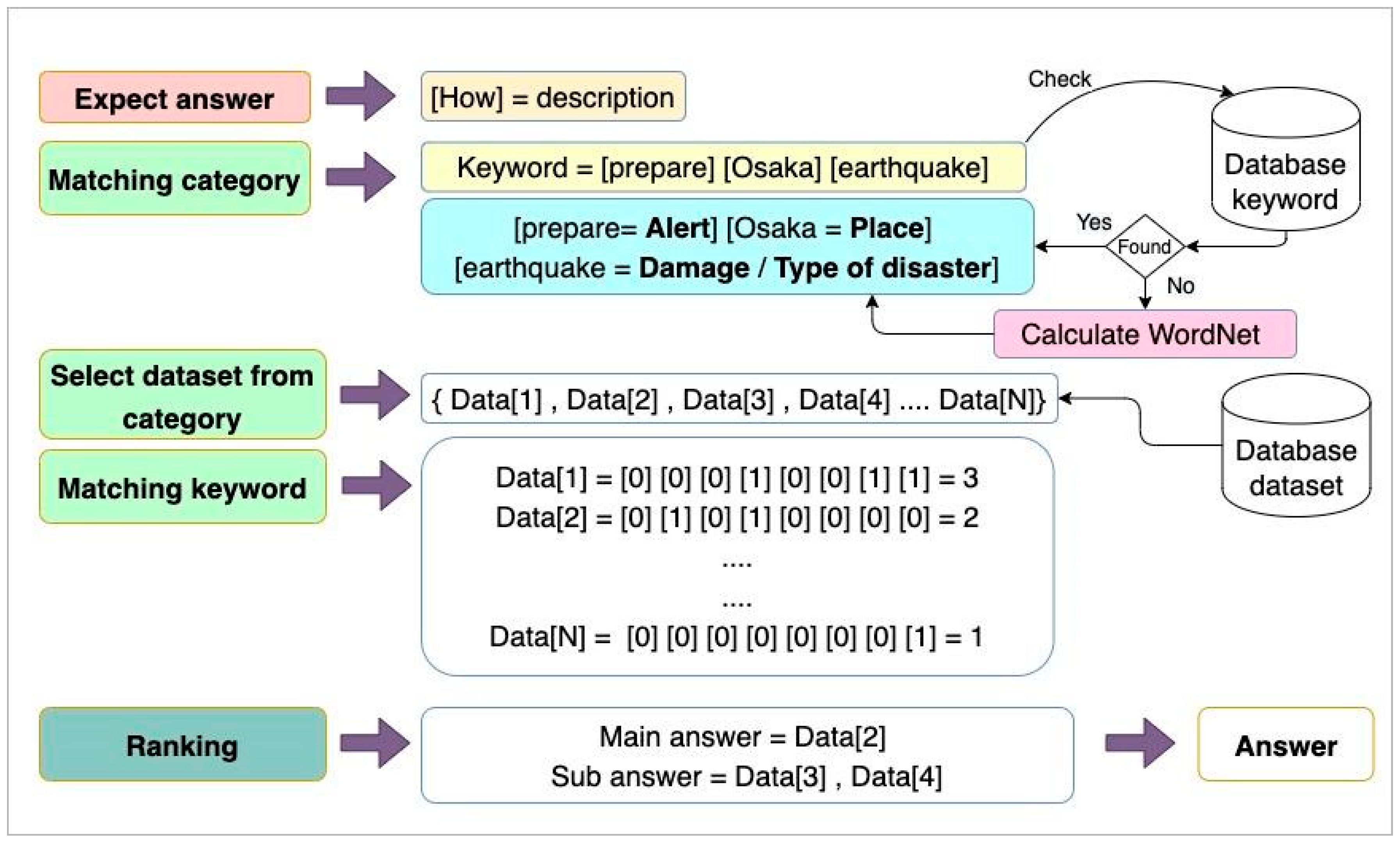
After categorizing the question similarities and differences, research work begins on the different results. The next step is to use the question keywords to find the answer. This process begins with classification, during which the question’s keyword is matched with the keywords of the ten predetermined dataset categories from the database of our previous work.
However, if no keyword match is found in the database, WordNet similarity recalculations will be performed to find the keyword’s score. After determining the question category, the score with the highest value in that category will be used to retrieve the dataset information.
In our experiments, we compared data compatibility by finding the answer that contained the most relevant words to the primary question keyword. For example, in the question, “How to prepare for the earthquake?”, The main keyword is “prepare”. Therefore, the system will retrieve the answer that has the most keyword matches or similar meanings.
The system will also pull up ten unique items and arrange them by the number of retweets from the highest to the lowest. In this process, we also eliminate spam and information that cannot be used from the data. Then, we select the first rank as the primary answer and supplement that answer by two other items as spares in case the first item is an incorrect answer.
For example, the result for the question, “How to prepare for the earthquake?” is the tweet “地震発生後余震への備え - 断水に備えお風呂に水を貯める - 停電に備え懐中電灯の用意 - 食器棚の扉にはガムテープで食器が落ちない工夫を - 家族同じ部屋で休む - 枕元に避難リュックとスニーカーを準備 - 避難リュックの中身は飲み水、ラジオ、マスク、軍…” “Preparing for aftershocks after an earthquake, - Prepare extra water to avoid running out. - Prepare a flashlight for use in case of power failure. - Use tape to prevent dishes from falling on the cupboard door. - Have all family members rest in the same room. - Prepare evacuation backpacks and sneakers, and keep them at your bedside. - The contents of the evacuation backpack are drinking water, radio, mask, army...” (as shown in Figure 7).
5.4. Retrieval Performance and Evaluation Results
In this section, we describe the experimental results used to evaluate question retrieval accuracy and answer retrieval performance based on precision, recall, and accuracy. When evaluating the accuracy of question retrieval performance, we tested the accuracy of question calculation similarities using a confusion matrix. To accomplish this, we created 100 questions, 50 of which were listed as previous questions, and another 50 questions that were new, and then verified the results. All 100 questions were used in each experiment. If the system found a previous question, the system will send the previous answer. If the system encounters a new question, it will be saved and sent to the next process where the prediction result and actual question will be compared. The results are as follows (see Table 1).
Based on those results, the accuracy score of calculation similarities in the question retrieval performance is presented. As can be seen from the table, the accuracy can be as high as 88%. Then, we analyzed the accuracy imperfections caused by words that cannot be calculated via WordNet similarities such as place names or transliterated words.
These include questions such as, “How about Kansai in Osaka’s earthquake?” and “How about trains in Osaka’s earthquake?” Those questions should refer to the same answer, but the system cannot determine whether the words “Kansai” are the same or different from “train”. In addition, the questions “What is the damage of the city?” and “What is the damage of Osaka city?” should also refer to the same answer because the database only contains the Osaka earthquake dataset.
When evaluating the answer retrieval performance accuracy, we used the same 100 questions mentioned above and investigated the answers found for all 100 questions. When some questions could not be answered, such as the question, “How to prepare for a typhoon?”, no answer could be shown because the dataset only contained Osaka earthquake data. Therefore, we focused solely on the results of matching answers from the Twitter dataset that were directly or somewhat related to the questions, because some Twitter messages contained useful information but not enough to answer those questions (see Table 2).
With an accuracy score of 77%, this experiment showed that the system was reasonably capable of finding answers that matched the dataset. However, we found that some results did not directly match the answers because of two factors. The first factor was that the questions and answer categories used in the classification process were too small and should be increased according to the data group. The second factor is that the dataset’s contents were insufficient because the results were extracted using the Japanese word “地震” (earthquake), which is not specific to certain question groups.
Therefore, in our future research, we intend to explore more dataset groups in order to gain in-depth information on topics such as rescues, preparations, services (free or charged), and shelters. Furthermore, since the dataset’s contents were insufficient, some questions produced different calculation results but still obtained the same answer.
These included questions such as “What was the magnitude of Osaka’s earthquake?” and “What time did the Osaka’s earthquake happen?” Those questions got the same answer “18日7時58分頃、大阪府で最大震度6弱を観測する地震がありました。震源地は大阪府北部、M5.9。” This is translated as, “At around 07:58 on the 18th, there was an earthquake in Osaka Prefecture that produced a maximum seismic intensity of 6 or less. The epicenter was M5.9 in northern Osaka.” This result occurred because the content of a large number of the retweeted Twitter messages related to that earthquake included the time, location, and damage information.
6. Discussion
The question-answering system proposed in this study is based on the dataset that we collected from social media in the event of natural disasters. This research aims to develop a system to support foreigners residing in Japan to obtain necessary real-time information during disasters. We have developed a system that continuously develops the previous study in which we investigated the social media messages from Twitter. We extracted sentences based on keywords and classify social media messages. We think that the crucial component of the system is the size of the social media dataset and the preciseness of the sentence classification. Specifically, we used the ontologies to classify texts as keywords to related categories in the classification process.
Moreover, the number of categories is important because it is used to calculate the meaning of the sentence by ontology and word similarity. After all, messages in social networks, such as Twitter, have only 140–280 characters. It is difficult to find the meaning of a sentence when the number of words is insufficient. Therefore, increasing the accuracy of finding the sentence’s meaning depends on the number of categories and further improved ontology databases.
The system proposed in this paper is designed to only be used in the event of a disaster. For building a good system, it is important to consider ease of use and familiarity in the event of disasters. From that perspective, we think that it is desirable to improve our system to be a dual-purpose information system, which is capable of continuous use during normal times and natural disasters [29,30]. Since users utilize the system for collecting information daily, they can collect information without confusion when a disaster occurs.
7. Conclusions and Future Work
Herein, as part of efforts aimed at developing a disaster information provision system, we proposed an integrated framework for integrated QA processing and proposed a method that can be used to classify questions and answers in disaster domains. In the presented experimental results, we showed that the sentence patterns for typical questions are inappropriate for practical development because they generate numerous question types and are prone to typographical errors. Accordingly, as part of efforts to reduce problems and increase user speed, it will be necessary to develop a wizard-type interface for creating questions or shortcut buttons for entering important questions.
Our research also found that the accuracy of the classified questions and answers depends on the number of categories defined and the number of answer datasets. Thus, in future research, it will be useful to increase the number of categories that affect disaster content in order to increase the accuracy of the result. Moreover, the results of comparisons with other keyword datasets or the use of another disaster dataset can be expected to increase the accuracy percentage. All these research results help us develop a system that can answer and respond to question-related problems using social media, which can contributing to building a system to support foreigners residing in Japan to assist them in obtaining necessary real-time information during disasters in the future.
Author Contributions
Conceptualization, K.K. and O.U.; methodology, K.K. and O.U.; software, K.K. and O.U.; validation, K.K. and O.U.; formal analysis, K.K.; investigation, K.K.; resources, K.K.; data curation, K.K.; writing—original draft preparation, K.K. and O.U.; writing—review and editing, K.K. and O.U.; visualization, K.K. and O.U.; supervision, K.K. and O.U.; project administration, K.K. and O.U.; funding acquisition, O.U. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by funding of JSPS KAKENHI (Grant Number 18K11553) and the Tokai University General Research Organization.
Acknowledgments
We thank our colleagues from Osamu Uchida laboratory who provided a dataset of Tweets related to the Osaka North Earthquake occurred on 18 June 2018.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yamada, S.; Utsu, K.; Uchida, O. An Analysis of Tweets during the 2018 Osaka North Earthquake in Japan—A Brief Report. In Proceedings of the 5th International Conference on Information and Communication Technologies for Disaster Management (ICT-DM’2018), Sendai, Japan, 4–7 December 2018; IEEE: Piscataway Township, NJ, USA, 2019; ISBN 978-1-5386-6638-8. [Google Scholar] [CrossRef]
- Utsu, K.; Uchida, O. Analysis of Rescue Request and Damage Report Tweets Posted During 2019 Typhoon Hagibis. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2020. [Google Scholar] [CrossRef]
- Van den Hooff, B.; Huysman, M. Managing knowledge sharing: Emergent and engineering approaches. Inf. Manag. 2009, 46, 1–8. [Google Scholar] [CrossRef]
- Josef, D.; Francesco, C.; Jaroslav, R. Complex Network Analysis for Knowledge Management and Organizational Intelligence. J. Knowl. Econ. 2020, 11, 405–424. [Google Scholar] [CrossRef]
- Nishikawa, S.; Uchida, O.; Utsu, K. Analysis of Rescue Request Tweets in the 2018 Japan Floods. In Proceedings of the 2019 International Conference on Information Technology and Computer Communications (ITCC), Singapore, 16–18 August 2019; pp. 29–36, ISBN 978-1-4503-7228-2. [Google Scholar] [CrossRef]
- Hendriks, P. Why share knowledge? The influence of ICT on the motivation for knowledge sharing. Knowl. Process Manag. 1999, 6, 91–100. [Google Scholar] [CrossRef]
- Kemavuthanon, K.; Uchida, O. Social Media Messages during Disasters in Japan: An Empirical Study of 2018 Osaka North Earthquake in Japan. In Proceedings of the 2019 IEEE 2nd International Conference on Information and Computer Technologies (ICICT), Kahului, HI, USA, 14–17 March 2019; IEEE: Piscataway Township, NJ, USA, 2019; pp. 199–203. ISBN 978-1-7281-3323-2. [Google Scholar] [CrossRef]
- Kemavuthanon, K.; Uchida, O. Classification of Social Media Messages Posted at the Time of Disaster. In Proceedings of the IFIP Advances in Information and Communication Technology (ITDRR 2019), Kyiv, Ukraine 3–4 December 2019; Springer: Cham, Switzerland, 2020; pp. 212–226. ISBN 978-3-030-48939-7. [Google Scholar] [CrossRef]
- Dodiya, T.; Jain, S. Question classification for medical domain Question Answering system. In Proceedings of the 2016 IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE), une, India, 19–21 December 2016; IEEE: Piscataway Township, NJ, USA, 2017; pp. 204–207. ISBN 978-1-5090-3745-2. [Google Scholar] [CrossRef]
- Agarwal, A.; Sachdeva, N.; Yadav, R.K.; Udandarao, V.; Mittal, V.; Gupta, A.; Mathur, A. EDUQA: Educational Domain Question Answering System Using Conceptual Network Mapping. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway Township, NJ, USA, 2019; pp. 8137–8141. ISBN 978-1-4799-8131-1. [Google Scholar] [CrossRef] [Green Version]
- Shah, S.S.; Bavaskar, T.S.; Ukhale, S.S.; Patil, R.A.; Kalyankar, A.S. Answer Ranking in Community Question Answer (QA) System and Questions Recommendation. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; IEEE: Piscataway Township, NJ, USA, 2019; ISBN 978-1-5386-5257-2. [Google Scholar] [CrossRef]
- Cai, L.; Wei, M.; Zhou, S.; Yan, X. Intelligent Question Answering in Restricted Domains Using Deep Learning and Question Pair Matching. IEEE Access 2020, 8, 32922–33293. [Google Scholar] [CrossRef]
- Trakultaweekoon, K.; Thaiprayoon, S.; Palingoon, P.; Rugchatjaroen, A. The First Wikipedia Questions and Factoid Answers Corpus in the Thai Language. In Proceedings of the 2019 14th International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP), Chiang Mai, Thailand, 30 October–1 November 2019; IEEE: Piscataway Township, NJ, USA, 2020; ISBN 978-1-7281-5631-6. [Google Scholar] [CrossRef]
- Uchida, O.; Kosugi, M.; Endo, G.; Funayama, T.; Utsu, K.; Tajima, S.; Tomita, M.; Kajita, Y.; Yamamoto, Y. A Real-Time Information Sharing System to Support Self-, Mutual-, and Public-Help in the Aftermath of a Disaster Utilizing Twitter. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2016, E99–A, 1551–1554. [Google Scholar] [CrossRef]
- Layek, A.K.; Pal, A.; Saha, R.; Mandal, S. DETSApp: An App for Disaster Event Tweets Summarization using Images Posted on Twitter. In Proceedings of the 2018 Fifth International Conference on Emerging Applications of Information Technology (EAIT), Kolkata, India, 12–13 January 2018; IEEE: Piscataway Township, NJ, USA, 2018; ISBN 978-1-5386-3719-7. [Google Scholar] [CrossRef]
- Mizuno, J.; Tanaka, M.; Ohtake, K.; Jong-Hoon, O.; Kloetzer, J.; Chikara, H.; Torisawa, K. WISDOM X, DISAANA and D-SUMM: Large-scale NLP Systems for Analyzing Textual Big Data. In Proceedings of the 26th International Conference on Computational Linguistics: System Demonstrations, Osaka, Japan, 11–16 December 2016; pp. 263–267. [Google Scholar]
- Nunavath, V.; Goodwin, M. The Use of Artificial Intelligence in Disaster Management-A Systematic Literature Review. In Proceedings of the 2019 International Conference on Information and Communication Technologies for Disaster Management (ICT-DM), Paris, France, 18–20 December 2019; IEEE: Piscataway Township, NJ, USA, 2020; pp. 1–8. ISBN 978-1-7281-4920-2. [Google Scholar] [CrossRef]
- Li, H.; Wang, N.; Hu, G.; Yang, W. PGM-WV: A context-aware hybrid model for heuristic and semantic question classification in question-answering system. In Proceedings of the 2017 International Conference on Progress in Informatics and Computing (PIC), Nanjing, China, 15–17 December 2017; IEEE: Piscataway Township, NJ, USA, 2018; pp. 240–244. ISBN 978-1-5386-1978-0. [Google Scholar] [CrossRef]
- Singh, K.; Nagpal, R.; Sehgal, R. Exploratory Data Analysis and Machine Learning on Titanic Disaster Dataset. In Proceedings of the 2020 10th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 29–31 January 2020; IEEE: Piscataway Township, NJ, USA, 2020; pp. 320–326. ISBN 978-1-7281-2791-0. [Google Scholar] [CrossRef]
- Gosavi, J.; Jagdale, B.N. Answer Selection in Community Question Answering Portals. In Proceedings of the 2018 IEEE Punecon, Pune, India, 30 November–2 December 2018; IEEE: Piscataway Township, NJ, USA, 2019; ISBN 978-1-5386-7278-5. [Google Scholar] [CrossRef]
- Song, W.; Feng, M.; Gu, N.; Wenyin, L. Question Similarity Calculation for FAQ Answering. In Proceedings of the Semantics, Knowledge and Grid, Third International Conference on, Xian, Shan Xi, China, 29–31 October 2007; pp. 298–301, ISBN 0-7695-3007-9. [Google Scholar] [CrossRef]
- Li, H.; Tian, Y.; Ye, B.; Cai, Q. Comparison of Current Semantic Similarity Methods in WordNet. In Proceedings of the 2010 International Conference on Computer Application and System Modeling (ICCASM 2010), Taiyuan, China, 22–24 October 2010; IEEE: Piscataway Township, NJ, USA, 2010; pp. 408–411. ISBN 978-1-4244-7237-6. [Google Scholar] [CrossRef]
- Hasi, N.-U. The Automatic Construction Method of Mongolian Lexical Semantic Network Based on WordNet. In Proceedings of the 2012 Fifth International Conference on Intelligent Networks and Intelligent Systems (ICINIS), Tianjin, China, 1–3 November 2012; IEEE: Piscataway Township, NJ, USA, 2012; pp. 220–223. ISBN 978-1-4673-3083-1. [Google Scholar] [CrossRef]
- Pedersen, T.; Patwardhan, S.; Michelizzi, J. WordNet:Similarity-Measuring the Relatedness of Concepts. In Proceedings of the Nineteenth National Conference on Artificial Intelligence, San Jose, CA, USA, 25–29 July 2004; AAAI Press: San Francisco, CA, USA, 2004; pp. 1024–1025. ISBN 978-0-262-51183-4. [Google Scholar]
- Kale, S.; Padmadas, V. Sentiment Analysis of Tweets Using Semantic Analysis. In Proceedings of the 2017 International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 17–18 August 2017; IEEE: Piscataway Township, NJ, USA, 2018; ISBN 978-1-5386-4008-1. [Google Scholar] [CrossRef]
- Vekariya, D.V.; Limbasiya, N.R. A Novel Approach for Semantic Similarity Measurement for High Quality Answer Selection in Question Answering using Deep Learning Methods. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; IEEE: Piscataway Township, NJ, USA, 2020; pp. 518–522. ISBN 978-1-7281-5197-7. [Google Scholar] [CrossRef]
- Janssens, O.; Slembrouck, M.; Verstockt, S.; Hoecke, S.V.; Walle, R.V. Real-time Emotion Classification of Tweets. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2013), Niagara Falls, ON, Canada, 25–28 August 2013; IEEE: Piscataway Township, NJ, USA, 2014; pp. 1430–1431. ISBN 978-1-4503-2240-9. [Google Scholar] [CrossRef]
- Riyadh, A.Z.; Alvi, N.; Talukder, K.H. Exploring Human Emotion via Twitter. In Proceedings of the 2017 20th International Conference of Computer and Information Technology (ICCIT), Dhaka, Banglades, 22–24 December 2017; IEEE: Piscataway Township, NJ, USA, 2017; pp. 22–24. ISBN 978-1-5386-1150-0. [Google Scholar] [CrossRef]
- Kosugi, M.; Utsu, K.; Yamamoto, Y.; Uchida, O. A Twitter-Based Disaster Information Sharing System. In Proceedings of the 2019 IEEE 4th International Conference on Computer and Communication Systems (ICCCS), Singapore, 23–25 February 2019; IEEE: Piscataway Township, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Okazaki, R.; Hirotomo, M.; Mohri, M.; Shiraishi, Y. Dual-Purpose Information Sharing System for Direct User Support in Both Ordinary and Emergency Times. IPSJ J. 2013, 55, 1778–1786. (In Japanese) [Google Scholar]
Figure 1.
An overview framework of the integrated question answering system in natural disaster.

Figure 2.
The system framework in part of the question-processing phase.

Figure 3.
The system framework in part of answer processing and output processing.

Figure 4.
Tweets tokenizing and analysis process.

Figure 5.
Classification of social media messages process.

Figure 6.
Question processing phase.

Figure 7.
Answer processing phase.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Question retrieval performance accuracy.
| Accuracy | Precision | Recall | |
|---|---|---|---|
| Confusion Matrix Score | 0.883 | 0.98 | 0.75 |
Table 2.
Answer retrieval performance accuracy.
| Accuracy | Precision | Recall | |
|---|---|---|---|
| Confusion Matrix Score | 0.776 | 0.82 | 0.863 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Kemavuthanon, K.; Uchida, O. Integrated Question-Answering System for Natural Disaster Domains Based on Social Media Messages Posted at the Time of Disaster. Information 2020, 11, 456. https://0-doi-org.brum.beds.ac.uk/10.3390/info11090456
AMA Style
Kemavuthanon K, Uchida O. Integrated Question-Answering System for Natural Disaster Domains Based on Social Media Messages Posted at the Time of Disaster. Information. 2020; 11(9):456. https://0-doi-org.brum.beds.ac.uk/10.3390/info11090456
Chicago/Turabian StyleKemavuthanon, Kemachart, and Osamu Uchida. 2020. "Integrated Question-Answering System for Natural Disaster Domains Based on Social Media Messages Posted at the Time of Disaster" Information 11, no. 9: 456. https://0-doi-org.brum.beds.ac.uk/10.3390/info11090456
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.