3. An Overview of ChatGPT
Three different versions of GPT, i.e., GPT-1, GPT-2, GPT-3, and GPT-4 were released by OpenAI in the past. The four versions of GPT differ in size. Each new version was trained by scaling up the data and parameters.
Table 1 shows the different parameters used by the three versions of GPT and the different features each version supports [
12,
13].
ChatGPT was developed on top of the GPT-3 language model using reinforcement learning from human feedback (RLHF). The initial model was trained using supervised fine-tuning, where human AI trainers participated in conversations, playing both the role of the user and an AI assistant. The trainers were provided with model-generated suggestions to assist them in composing their responses. ChatGPT and InstructGPT are both variants of the GPT language model, but they have different focuses and training data. InstructGPT is specifically designed for generating instructional text and providing step-by-step guidance, while ChatGPT is a more general-purpose conversational AI model that can be used for a variety of text-based tasks.
A new dialogue dataset was created by combining the InstructGPT dataset, which was transformed into a dialogue format, with other dialogue data. This new dataset was used to fine-tune both ChatGPT and InstructGPT, allowing them to perform better in dialogue-based tasks. Overall, while both models are based on the GPT architecture, they have different strengths and use cases. InstructGPT is ideal for tasks that require providing detailed instructions, while ChatGPT is better suited for generating natural language responses in conversational settings.
ChatGPT uses reinforcement learning to fine-tune the model, and the data are collected for comparison, consisting of multiple model responses ranked by quality. The data are gathered from conversations between AI trainers and the chatbot. The trainer selects a randomly selected model-generated message, samples, and ranks during this process. Using reward models, it is fine-tuned by using Proximal Policy Optimization, and the process is repeated several times [
14].
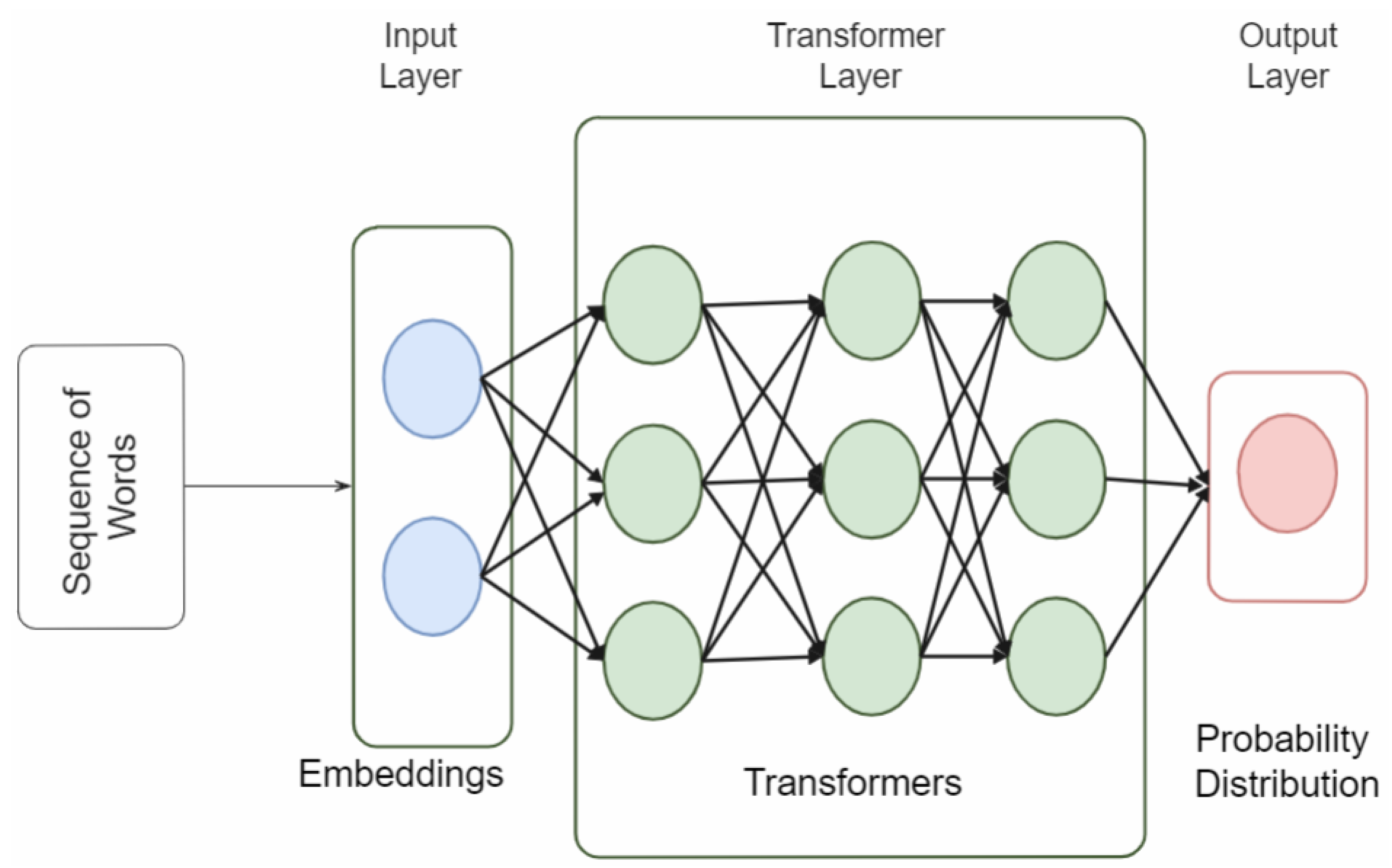
Figure 1 shows the basic model used to train ChatGPT, and the steps are listed as follows:
The input layer takes in a sequence of words and converts them into numerical representations called embeddings. The embeddings are passed to the transformer layers.
The transformer layers are made up of multi-head self-attention mechanisms and feed-forward neural networks. The self-attention mechanisms allow the model to focus on specific parts of the input when generating a response, while the feed-forward neural networks allow the model to learn and extract features from the input.
The transformer layers are stacked on top of each other and are connected through residual connections. This allows the model to learn and extract features at different levels of abstraction.
The GPT models are built on Google’s transformer architecture, which was introduced in 2017 through the paper “Attention is all you need” [
15]. Within the field of natural language processing (NLP), researchers have explored various algorithms to address challenges in human language, including morphological variations, synonyms, homonyms, syntactic and semantic ambiguity, co-references, pronouns, negations, alignment, and intent. While earlier computational linguistics methods (such as grammatical, symbolic, statistical approaches, and early deep-learning models like LSTM) faced limitations in resolving these issues, transformers emerged as a successful solution.
Transformers, specifically through their advanced mechanism called multi-head self-attention, have demonstrated the ability to automatically detect and handle many linguistic phenomena mentioned above. This capability is a result of being exposed to vast amounts of human language data.
The original transformer architecture consists of an encoder and a decoder, which effectively handle complex sequence-to-sequence patterns involving both left- and right-side context sensitivity—common in natural language. Both the encoder and decoder comprise multiple feed-forward layers that employ the self-attention technique mentioned earlier. The number of these layers typically ranges from 12 to 24, depending on the model’s complexity and can go up to 128 in the largest GPT-4 model. These layers have been proven to be able to capture various levels of linguistic ambiguity and complexity, encompassing punctuation, morphology, syntax, semantics, and more intricate interactions. Essentially, by being exposed to language data, these models swiftly learn the essential components of the standard NLP pipeline. ChatGPT can be used for a wide range of applications, as shown in
Table 2.
These are just a few examples of the many possible applications of ChatGPT where it can be useful [
1,
16]. However, there are several limitations of ChatGPT, as given in
Table 3.
4. A Comparative Study of ChatGPT and Other Language Generation Models
Language generation models are an important area of research in the field of NLP. For example, ChatGPT can generate human-like text and perform a variety of NLP tasks. However, it is not the only model available for language generation. Other models such as GPT-2, GPT-3, BERT, RoBERTa, T5, XLNet, Megatron, and ALBERT have also been developed and have shown good performance in language generation and other NLP tasks [
17]. Many studies have been conducted to compare the performance of various language models, including ChatGPT [
18].
There are several research studies with an emphasis on language processing models and differences in the quality of outputs. A recent comparative study of GPT-2 and GPT-3 language models by researchers at the Indian Institute of Technology compared the performance of GPT-2 and GPT-3 [
19]. The study looks at the quality of the language generated with the two models, as well as their ability to complete a variety of NLP tasks. The study concludes that GPT-3 outperforms GPT-2 in terms of language generation quality and task completion accuracy.
Another study that may be relevant is a comparative study of GPT-3 and BERT language models [
20,
21]. This study compared the performance of GPT-3 with BERT, which is another state-of-the-art language model developed by Google [
22]. The study looked at the ability of the two models to complete a variety of natural language understanding tasks and concluded that GPT-3 outperforms BERT in many cases [
23], but BERT is better in certain tasks such as named entity recognition [
24]. Here are a few examples of tasks where GPT-3 has been found to outperform BERT in the scope of these relevant studies:
Language generation: GPT-3 has been found to generate more fluent and natural-sounding language than BERT in several studies. This is likely due to GPT-3’s larger model size and training data, which allows it to capture more nuanced relationships between words and phrases [
23].
Question answering: GPT-3 has been found to be more accurate than BERT in answering questions based on a given context. This is likely due to GPT-3’s ability to generate text, which allows it to provide more detailed and informative answers [
25].
Text generation: GPT-3 has been found to generate more coherent and coherently written text than BERT in several studies. This is likely due to GPT-3’s ability to generate text, which allows it to generate more complete and well-formed sentences [
26].
Text completion: GPT-3 has been found to be more accurate than BERT in completing the text, especially in the case of long-form text such as articles and essays [
27].
Summarization: GPT-3 has been found to generate more fluent and informative summaries than BERT in several studies. This is likely due to GPT-3’s ability to understand and analyze the content of a text, which allows it to generate more accurate and informative summaries [
13,
28].
Sentiment analysis: GPT-3 has been found to be more accurate than BERT in determining the sentiment of text, such as whether the text expresses a positive, negative, or neutral sentiment [
29].
Text classification: GPT-3 has been found to be more accurate than BERT in classifying text into different categories, such as news articles, social media posts, and customer reviews [
30].
Dialogue systems: GPT-3 has been found to be more accurate than BERT in generating natural and coherent responses in dialogue systems such as chatbots [
31].
It is important to note that while GPT-3 has been found to outperform BERT in many cases, BERT is better in certain tasks such as named entity recognition, which is a task of identifying and classifying named entities in a given text [
32].
Table 4 provides a comparison of popular language models based on various criteria such as model name, training data, model size, structure, performance, advantages, and disadvantages. The table includes information on models such as GPT-2, GPT-3, GPT-4, BERT, RoBERTa, T5, XLNet, Megatron, and ALBERT. It shows the amount of data used to train the model and the number of parameters, the structure of the model, and its performance on certain tasks. It also highlights the advantages and disadvantages of each model, such as computational cost, memory requirements, and ease of fine-tuning.
Table 4 can be used as a reference for choosing the appropriate model for a particular task and to understand the trade-offs between the different models [
33].
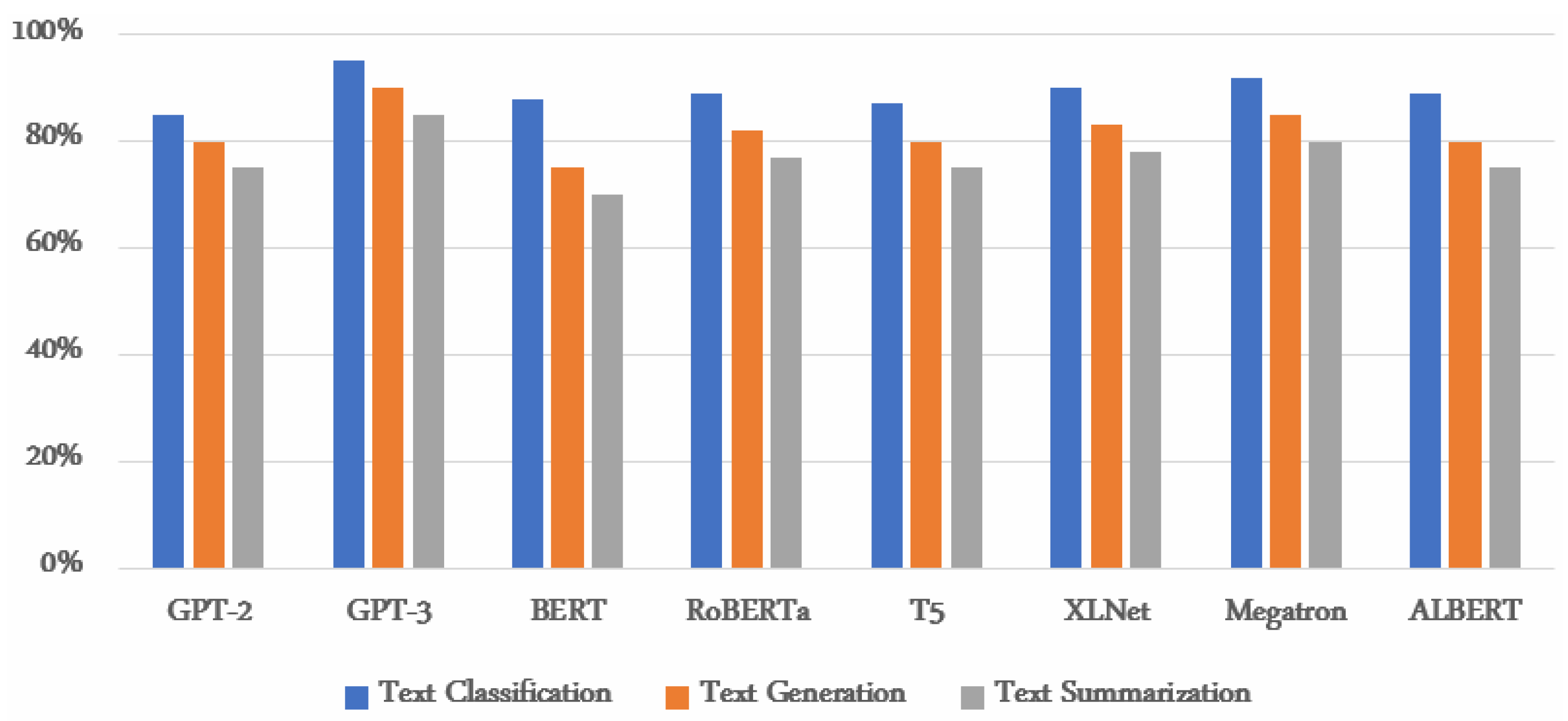
Figure 2 compares the performance of GPT-2, GPT-3, BERT, RoBERTa, T5, XLNet, Megatron, and ALBERT on text classification, text generation, and text summarization tasks. The figure lists the name of the language model in the horizontal line and the performance of each model on different tasks in the vertical line. The performance is presented as a percentage and ranges from 0 to 100%.
According to this
Figure 2, GPT-3, XLNet, and Megatron have the highest performance across all tasks, with average performance of 95%, 90%, and 92%, respectively. While GPT-2, BERT, RoBERTa, and T5 have similar performances, with average performance of 85%, 85%, 85%, and 87%, respectively, and ALBERT has the lowest performance, with an average performance of 89% [
34].
The performance percentages show how well the language model performed on each task. We evaluated the model by asking it to classify, summarize, and generate text. Human judges assessed the results based on accuracy, fluency, and coherence. The evaluation was quick and simple, using a metric of simplicity.
GPT-4 is a powerful language model that can process text, photos, and videos. This makes it a versatile tool for marketers, organizations, and individuals alike. GPT-3, on the other hand, is better at processing language but struggles with complex multimedia inputs like video. GPT-4 is also better at understanding and producing different dialects and reacting to the emotions represented in text. For example, GPT-4 can detect and respond to a user expressing sadness or anger in a way that feels more intimate and sincere. GPT-4’s ability to handle dialects is one of its most impressive features. Dialects are local or cultural variants of a language, and GPT-4 can understand and produce them with ease.
Another advantage of GPT-4 is its ability to synthesize data from multiple sources to answer complex questions. GPT-3 may have difficulty making connections to answer complex questions, but GPT-4 can easily do so by drawing on information from a variety of sources. In addition to its other strengths, GPT-4 is also capable of producing creative content with greater coherence. For example, GPT-4 can create a short story with a strong storyline and character development, whereas GPT-3 may struggle to keep the narrative consistent and coherent.
Finally, GPT-4 has a maximum token limit of 32,000 tokens, or 25,000 words. This is a significant increase from GPT-3’s maximum token limit of 4000 tokens, or 3125 words. This means that GPT-4 can generate more complex and detailed text than GPT-3.
6. ChatGPT and Privacy Concerns: An Analysis
As with any form of digital technology, there are potential risks associated with using ChatGPT, particularly in terms of privacy [
39,
40]. One of the main concerns with ChatGPT is the potential for it to be used to generate sensitive or personal information [
41]. Since ChatGPT is trained on a large amount of data, it can potentially generate information that is private or sensitive, such as medical records [
40], financial information, or personal details.
One of the potential risks associated with using ChatGPT is the possibility of the model being used to generate sensitive information without the consent of the individuals involved [
42]. For example, ChatGPT could be used to generate fake conversations or emails that appear to be from real people, which could be used to commit fraud or impersonate individuals. Additionally, ChatGPT could be used to generate sensitive information such as medical diagnoses or financial transactions, which could be used to exploit individuals or steal their identities [
16,
43]. The potential for ChatGPT to be used for malicious purposes highlights the need for strong privacy regulations and oversight in the development and use of these models.
Another potential risk is the possibility of the model being used to target individuals with personalized phishing, scams, or other malicious activities. For example, an attacker can use ChatGPT to generate a personalized message that looks like it came from a bank, or from a person the victim trusts, to obtain sensitive information or money from the victim [
44]. Furthermore, ChatGPT could be used to generate offensive or fake content, which could be used to spread misinformation or incite violence. To mitigate these risks, it is important to ensure that the data used to train the model are properly protected and that the model is only used for legitimate purposes.
One of the technical concerns with ChatGPT is that it can memorize and reproduce personal information from the dataset it was fine-tuned on. This is because ChatGPT is a neural network with a large number of parameters that allow it to learn patterns from the data. In other words, if the fine-tuning data contain personal information such as credit card numbers, social security numbers, and phone numbers, ChatGPT could potentially generate similar information in its outputs. There have been several reported cases of ChatGPT and other language generation models potentially compromising personal information. Here are a few examples related to ChatGPT:
Researchers at OpenAI found that GPT-3 [
45], which is the latest version of ChatGPT, could generate responses that were indistinguishable from the human-written text. They trained the model on a diverse range of internet text and fine-tuned it on specific tasks such as language translation, question answering, and summarization. They found that GPT-3 could perform these tasks with high accuracy, often requiring only a single example to learn the task. This raises concerns about the potential for GPT-3 to be used to create phishing emails or other malicious content that can lead to personal information being compromised.
In another case, the researchers at the AI Ethics Lab found that fine-tuning a language model on a dataset containing personal information [
46], such as emails and text messages, can result in the model memorizing and reproducing that personal information. They fine-tuned a version of GPT-2 on a dataset of private emails and found that the model was able to generate private information such as phone numbers and email addresses with high accuracy. These examples serve to highlight the potential risks that arise when utilizing language generation models such as ChatGPT. If these models are fine-tuned using datasets that include sensitive personal information, there is a possibility of compromising data privacy and experiencing a breach.
It is worth noting that these studies highlight the importance of careful curation and pre-processing of training data and the need for appropriate data security measures when fine-tuning the model to ensure that personal information is not compromised. Furthermore, these studies also stress the importance of monitoring and evaluating the model’s performance to detect any potential privacy issues and to take necessary actions [
45].
Table 5 provides a brief overview of the technical measures that can be taken to mitigate the risk of ChatGPT generating personal information when fine-tuned on such data. It is worth mentioning that the effectiveness of these measures would depend on the specific use case and the data used, and the best approach to mitigate the risks would be a combination of technical, organizational, and legal measures.
10. Evaluating the Performance of ChatGPT on Different Languages and Domains
ChatGPT is trained on a variety of text databases such as Common Crawl [
61], WebText2 [
62], Wikipedia, Books1 and Books2 [
63], etc., so it is able to understand and generate text in a variety of languages. However, it is primarily designed to understand and generate text in English. ChatGPT is able to communicate in multiple languages. Indeed, it uses a deep learning model known as a transformer architecture [
15], which is a neural network-based language model that has demonstrated success in natural language processing tasks. The model can learn the patterns and structures of multiple languages because it has been trained on a big corpus of text data in many different languages. Comprehending the underlying grammatical and semantic rules of each language enables the model to generate human-like text in a variety of languages.
The model can be adjusted to function in certain languages or dialects and can handle a variety of input formats, including text, speech, or graphics. This is accomplished by modifying the model’s parameters to conform to a given entity’s features. The model may also produce fresh text in the same languages by applying the knowledge it has gained from the training data. This is accomplished by creating new text that is cohesive and grammatically sound utilizing the underlying patterns and structures that it has learned throughout the training process. Additionally, the model can be adjusted to fit particular use cases, such as giving translations or responding to queries. This can be accomplished by using a dataset created especially for that use case to train the model on.
ChatGPT performance was evaluated in different domains such as ophthalmology [
64], medicine [
65], programming [
66], etc. In ophthalmology, two well-known multiple choice question banks from the high stakes Ophthalmic Knowledge Assessment Program (OKAP) exam to assess ChatGPT’s precision in the ophthalmology question-answering domain. The assessment sets ranged in difficulty from low to moderate and included recall, interpretation, and practical and clinical decision-making issues. In the two 260-question simulated tests, ChatGPT’s accuracy was 55.8% and 42.7%, respectively. The highest outcomes were in general medicine, whereas the worst outcomes were in neuro-ophthalmology, ophthalmic pathology, and intraocular malignancies. Its performance varied between subspecialties. These results are encouraging, but they also imply that ChatGPT may need to specialize through domain-specific pre-training in order to perform better in ophthalmology subspecialties. In medicine, ChatGPT was evaluated on the USMLE, which consists of three exams (Step 1, Step 2CK, and Step 3). Without any extra instruction or reinforcement, ChatGPT passed all three exams with a score at or around the passing mark. Furthermore, ChatGPT’s explanations displayed a high degree of concordance and insight. These findings imply that massive language models may be able to support clinical decision-making as well as medical education.
In programming [
66], ChatGPT is quite good at fixing software flaws, but its main advantage over other approaches and AI models is its special capacity for communication with people, which enables it to increase the accuracy of an answer. ChatGPT was tested by researchers from Johannes Gutenberg University Mainz and University College London against “standard automated program repair techniques” and two deep-learning approaches to program repairs: CoCoNut from researchers at the University of Waterloo, Canada, and Codex, OpenAI’s GPT-3-based model that powers GitHub’s Copilot paired programming auto code-completion service. It is not new that ChatGPT may be used to address coding issues, but the researchers emphasize that its special ability to communicate with people provides it with a potential advantage over other methods and models. The researchers used the QuixBugs bug-fixing benchmark to evaluate ChatGPT’s performance. The researchers manually verified whether the suggested answer was accurate after running ChatGPT against 40 Python-only QuixBugs bugs. They asked the question four times because the accuracy of ChatGPT’s responses often vary. ChatGPT tied CoCoNut (19) and Codex (19) in resolving 19 of the 40 Python problems (21). However, only seven of the problems were resolved using conventional APR techniques. The researchers found that ChatGPT had a success rate of 77.5% with subsequent conversations.
In terms of natural languages, ChatGPT supports at least 95 languages including English, French, Greek, German, Hindi, Arabic, Mandarin, etc. It is important to remember that the performance of the model will differ based on the language and level of complexity of the text being created.

 ,
, 


{kind=link}
{kind=link}