

Interpreting Disentangled Representations of Person-Specific Convolutional Variational Autoencoders of Spatially Preserving EEG Topographic Maps via Clustering and Visual Plausibility


Abstract
:1. Introduction
2. Related Work
2.1. Interpreting the VAE Disentangling Representations
2.2. Interpretation of Latent Space for Cluster Analysis
3. Materials and Methods
3.1. Dataset
3.2. EEG Topographic Head Maps Generation
3.3. A Convolutional Variational Autoencoder
- The encoder is a neural network that takes a tensor (as seen in Figure 2C) and defines the approximate posterior distribution , where x is the input tensor and Z is the latent space. The network will create the mean and standard deviation parameters of a factorised Gaussian with the latent space dimension of 25 by simply expressing the distribution as a diagonal Gaussian. This latent space dimension is the minimal dimension that leads to the maximum reconstruction capacity of the input EEG images. A similar experiment has been conducted on the EEG image shape of , where the latent dimension 28 is considered as the minimal dimension that leads to the maximum reconstruction capacity of the input and maximum utility for classification tasks [5]. This architecture (Figure 2C) is made up of three 2D convolutional layers, each followed by a max pooling layer to minimise the dimension of the feature maps. In each convolutional layer, ReLU is employed as the activation function.
- The CNN-VAE decoder is a generative network that takes a latent space Z as input and returns the parameters for the observation’s conditional distribution (as illustrated in the right side of Figure 2C). In this experiment, there are 2 different ways to train the decoder network. One is training it with latent space, utilising all variable values. The other way is to train with latent space where only one variable is active and has the latent sampled value, and all other variable values are set to zero, because zero is the mean of the distribution for each variable in the latent space. Similarly to the encoder network, the decoder is made up of three 2D convolutional layers, each followed by an up-sampling layer to reconstruct the data to the shape of the original input. In each convolutional layer, ReLU is employed as an activation function to regularise the neural network.
- By sampling from the latent distribution described by the encoder’s parameters, the reparameterisation approach is utilised to provide a sample for the decoder. Because the backpropagation method in CNN-VAE cannot flow through a random sample node, sampling activities create a bottleneck. To remedy this, the reparameterisation technique is used to estimate the latent space Z using the decoder parameters plus one more, the parameter:where and are the mean and standard deviation of a Gaussian distribution, respectively, and is random noise used to maintain the stochasticity of Z. The latent space is now created using a function of , , and , allowing the model to backpropagate gradients in the encoder through and while retaining stochasticity through .
- A loss function is used to optimise the CNN-VAEs in order to ensure that the latent space is both continuous and complete, the same as in our previous experiment [5]. Traditional VAE employs the binary cross-entropy loss function in conjunction with the Kullback–Leibler divergence loss, which is a measure of how two probability distributions differ from one another [37]. In this experiment, a new type of divergence known as maximum mean discrepancy (MMD) is introduced. The notion behind MMD is that two distributions are similar if and only if all of their moments are the same. As a result, KL-divergence is used to determine how “different” the moments of two distributions, p(z) and q(z) are from one another [38]. MMD can achieve this effectively using the kernel embedding trick:where can be any universal kernel, such as Gaussian. A kernel can be thought of as a function that compares the “similarity” of two samples. It has a high value when two samples are similar and a low value when they are dissimilar.
3.4. Clustering for Generative Factor Analysis
3.5. Reconstructed EEG Signals
3.6. Models Evaluation
3.6.1. Evaluation of Reconstructed EEG Topographic Maps
- SSIM: This is a perceptual metric that measures how much image quality is lost as a result of processing, including data compression. It is an index of structural similarity (in the real range between two topographic maps (images) [39]). Values close to 1 indicate that the two topographic maps are very structurally similar, whereas values close to 0 indicate that the two images are exceptionally dissimilar and structurally different.
- MAE: The average variance between the significant values in the dataset and the projected values in the same dataset is defined as the mean absolute error (MAE) [40].
- MSE: This is defined as the mean (average) of the square of the difference between the actual and reconstructed values: a lower value indicates a better fit. In this case, the MSE involves the comparison, pixel by pixel, of the original and reconstructed topographic maps [39].
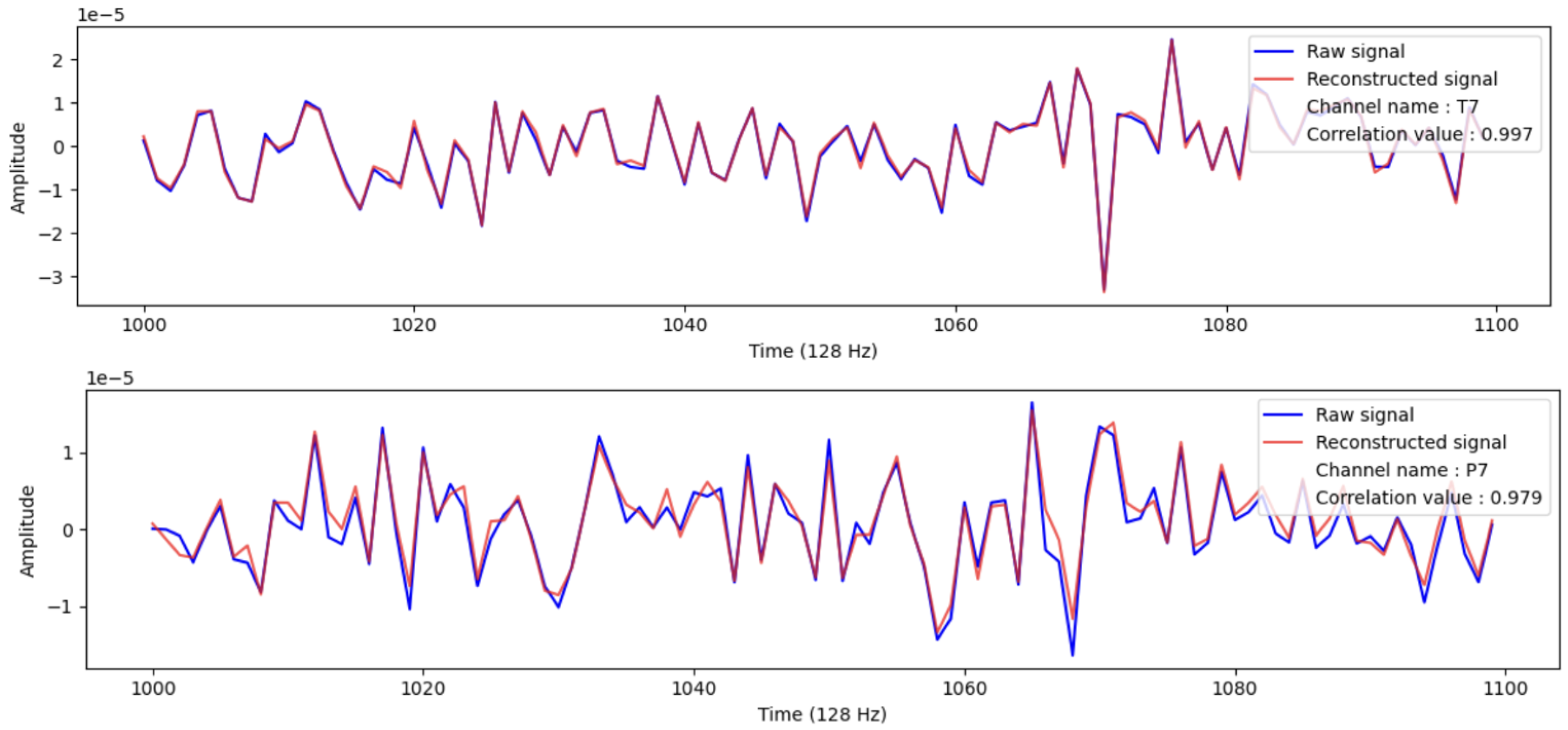
3.6.2. Evaluation of Reconstructed EEG Signals
- Correlation coefficient: The correlation coefficient is a statistical measure of the strength of a two-variable linear relationship. Its values might range between −1 and 1. A positive correlation is represented by a number close to 1 [41].
- Signal-to-noise ratio (SNR): An SNR is a measurement that compares the signal’s real information to the noise in the signal. It is defined as the ratio of the signal power to noise power in a signal [42].The formula for calculating an SNR is
4. Results
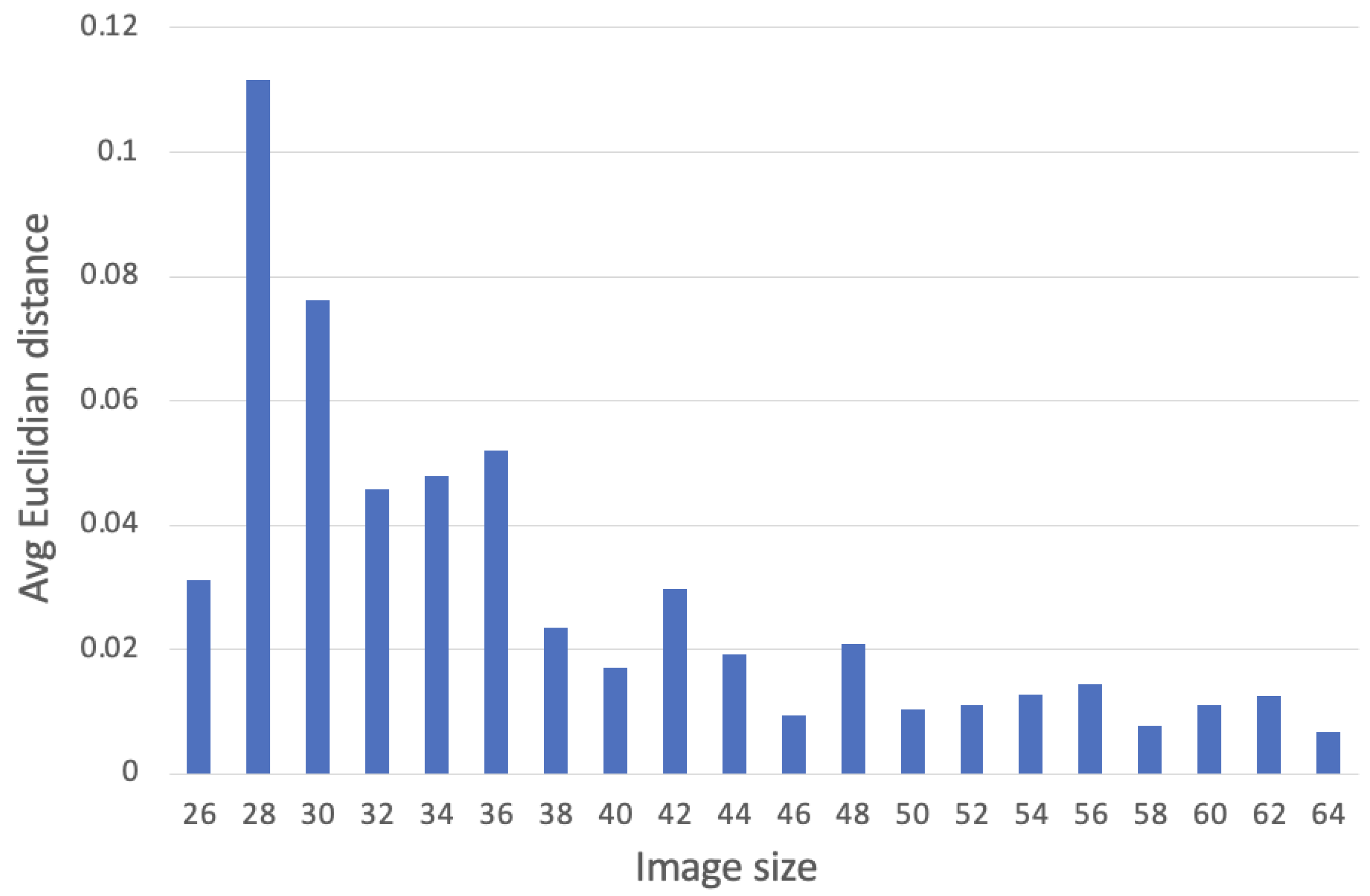
4.1. Examining the Size of the EEG Topographic Maps
4.2. Reconstruction Capacity of CNN-VAE Model
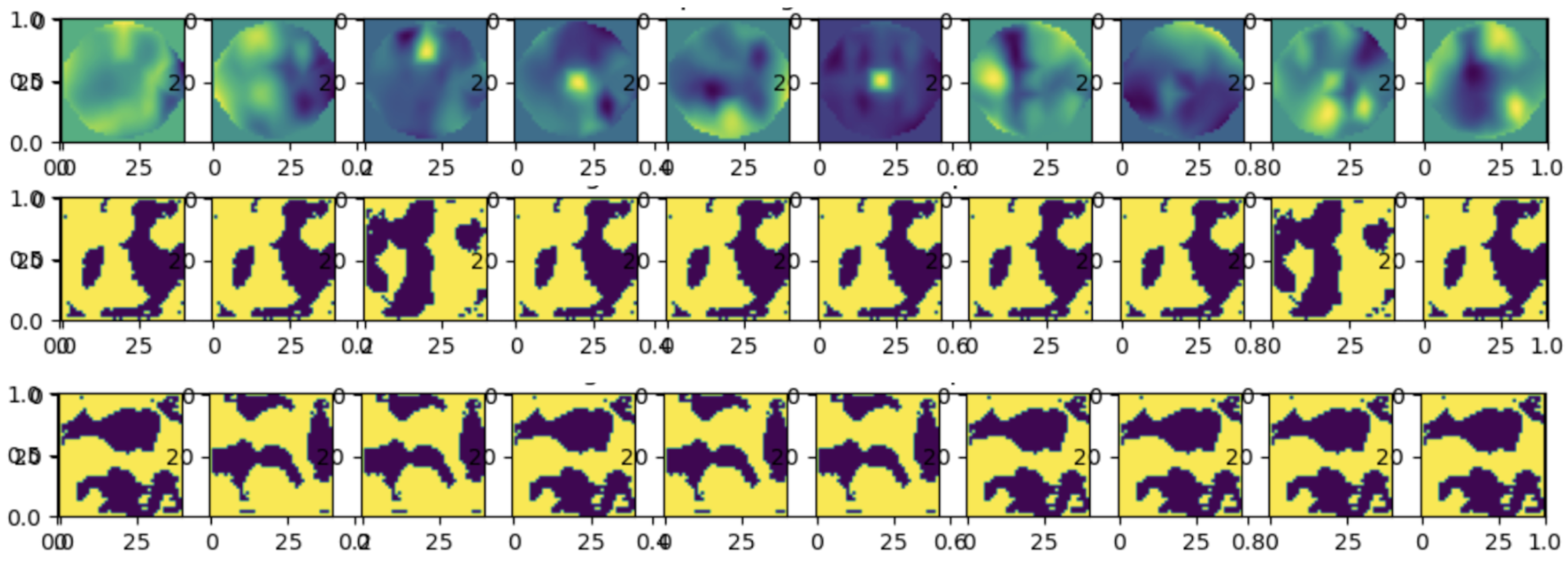
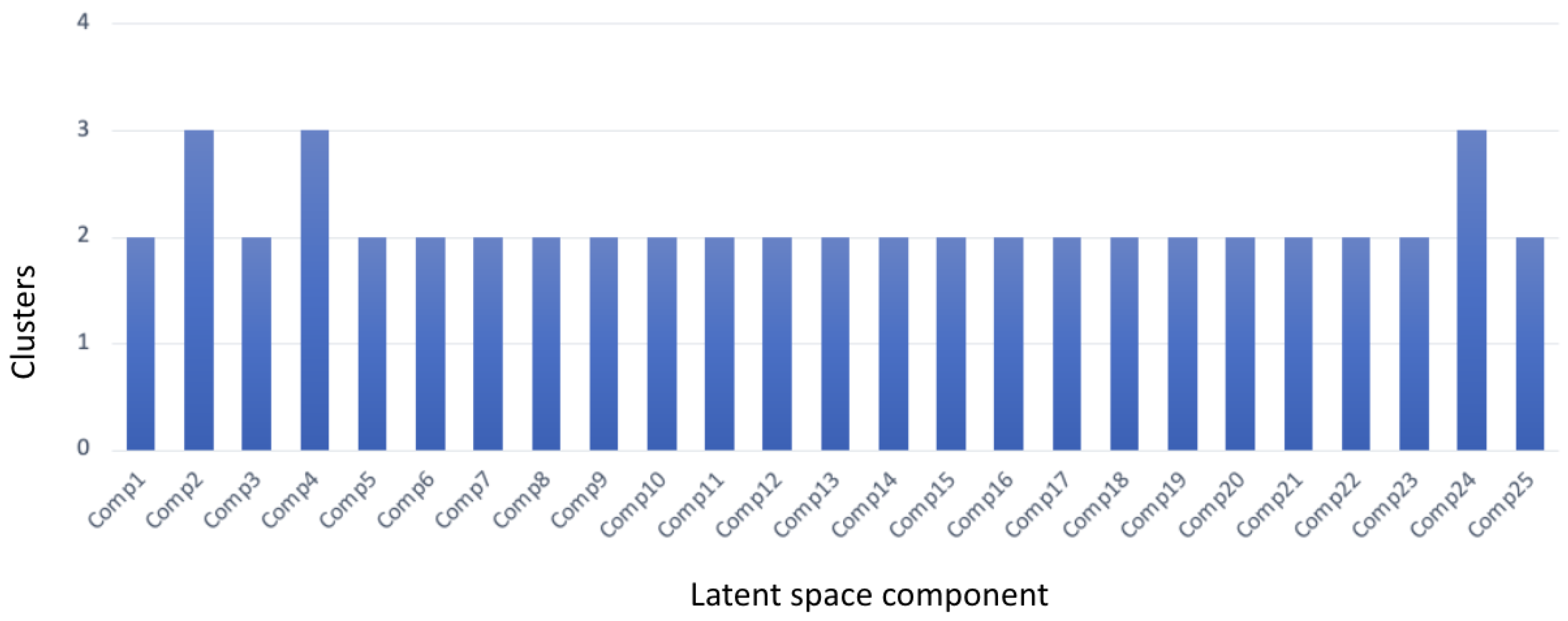
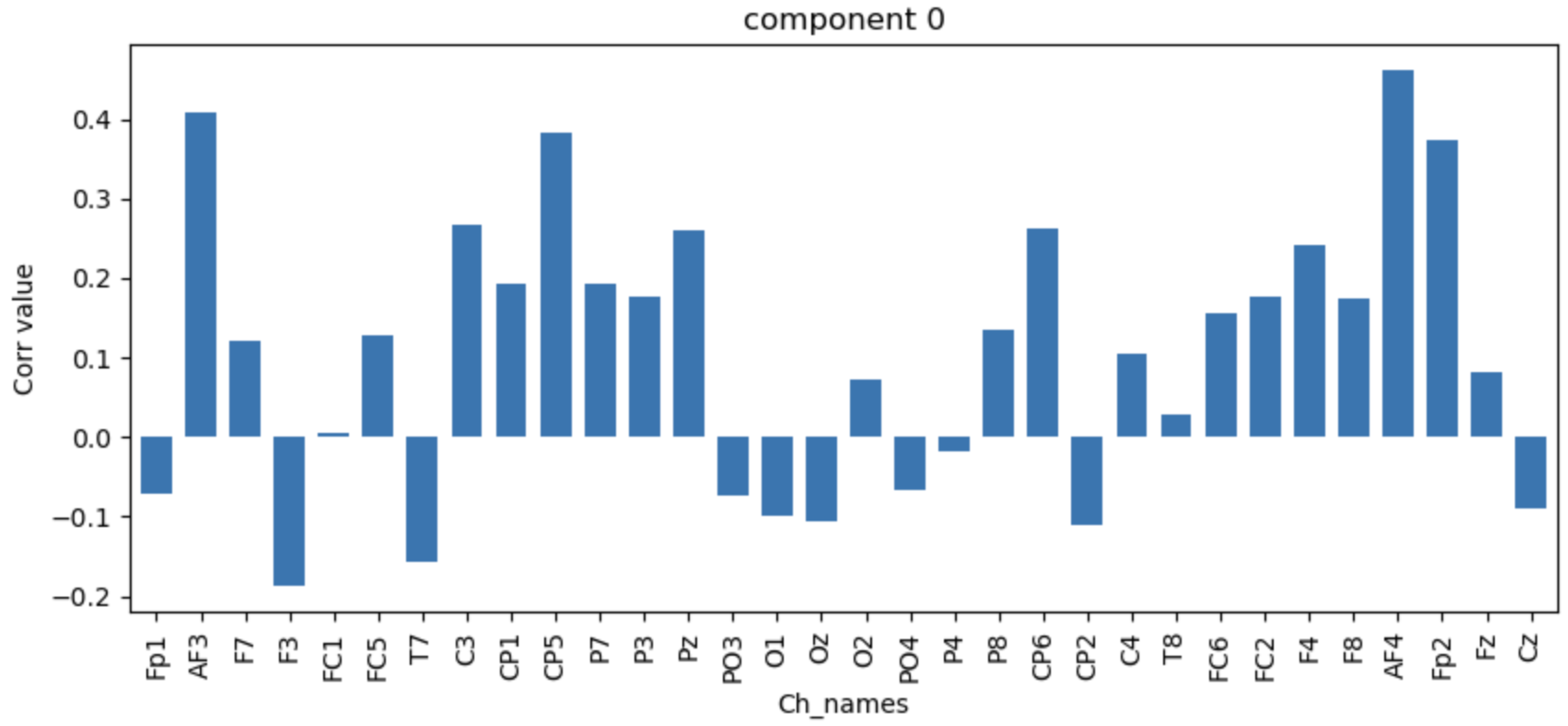
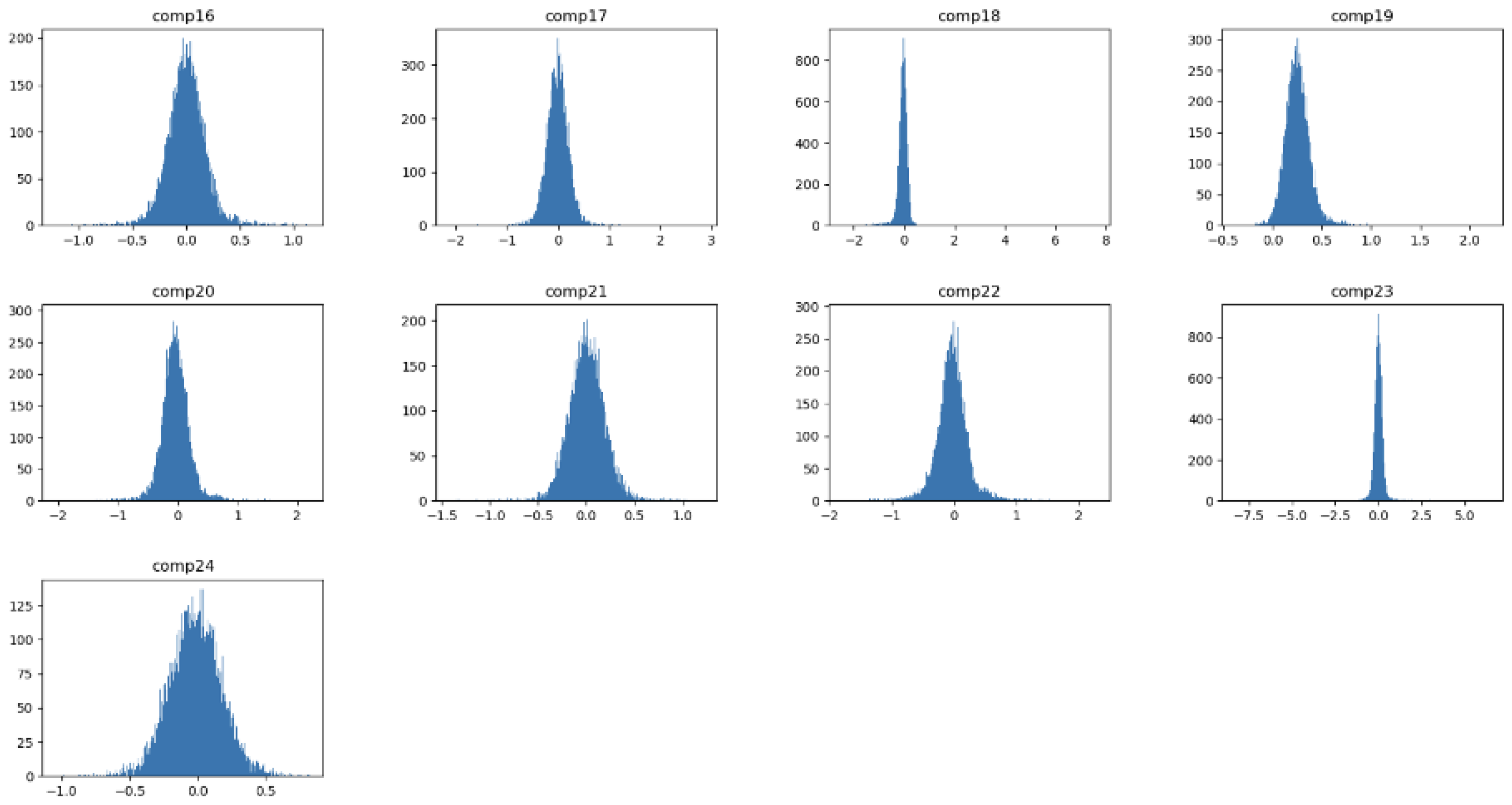
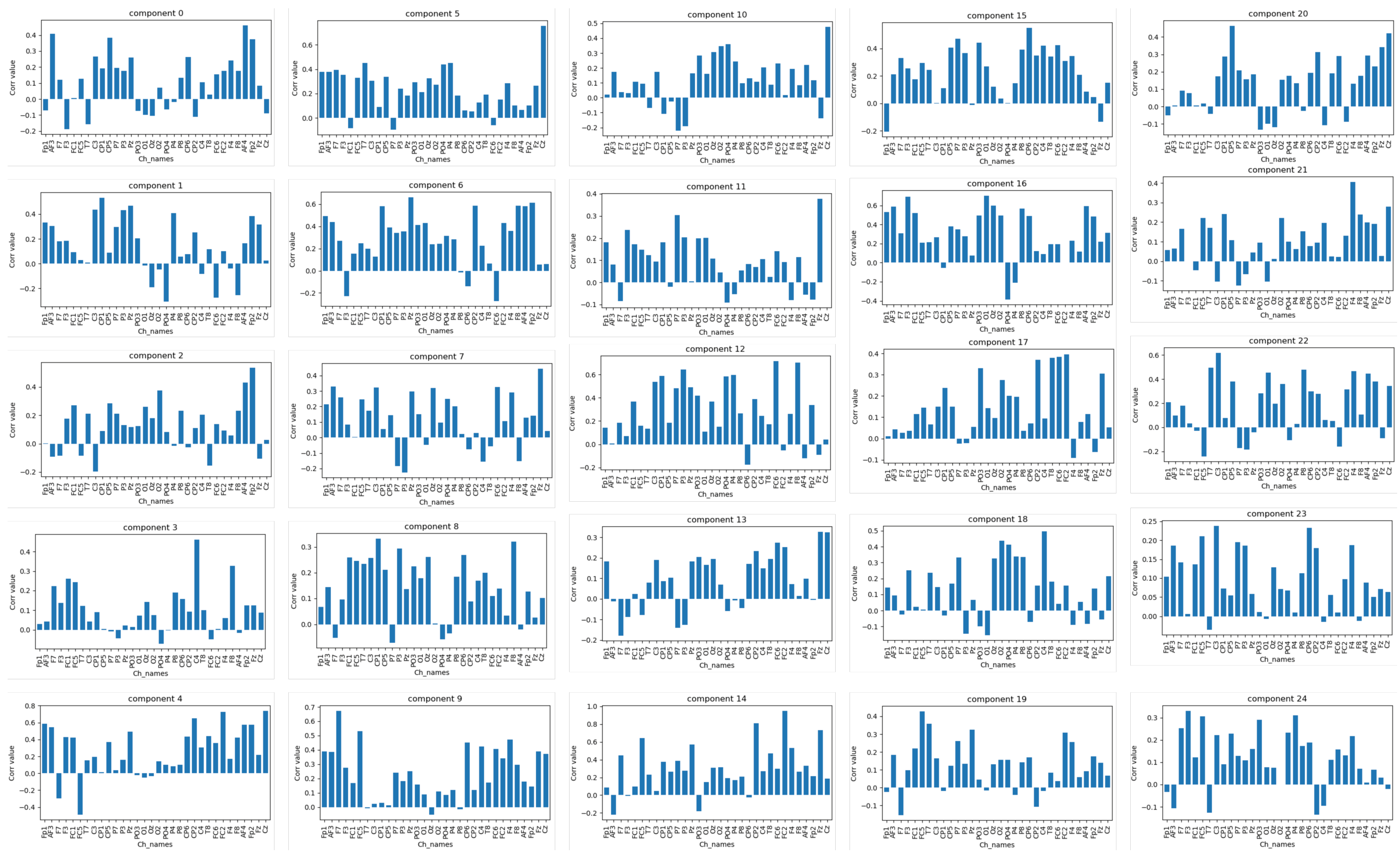
4.3. Interpreting and Visualising the Latent Space
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| EEG | Electroencephalography |
| AE | Autoencoder |
| VAE | Varaiational autoencoder |
| CNN-VAE | Convolutional variational autoencoder |
| SNR | Signal-to-noise ratio |
| XAI | Explainable artificial intelligence |
| SVHN | Street-view house number |
| AR | Attribute-regularized |
| GAN | Generative adversarial network |
| DLS | Disentangling latent space |
| GMM | Gaussian mixture model |
| MMD | Maximum mean discrepancy |
| SSIM | Structural similarity |
| MSE | Mean squared error |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error |
Appendix A




References
- Binnie, C.; Prior, P. Electroencephalography. J. Neurol. Neurosurg. Psychiatry 1994, 57, 1308–1319. [Google Scholar] [CrossRef]
- Khare, S.K.; March, S.; Barua, P.D.; Gadre, V.M.; Acharya, U.R. Application of data fusion for automated detection of children with developmental and mental disorders: A systematic review of the last decade. Inf. Fusion 2023, 99, 101898. [Google Scholar] [CrossRef]
- Hooi, L.S.; Nisar, H.; Voon, Y.V. Comparison of motion field of EEG topo-maps for tracking brain activation. In Proceedings of the 2016 IEEE EMBS Conference on Biomedical Engineering and Sciences (IECBES), Kuala Lumpur, Malaysia, 4–8 December 2016; pp. 251–256. [Google Scholar]
- Anderson, E.W.; Preston, G.A.; Silva, C.T. Using python for signal processing and visualization. Comput. Sci. Eng. 2010, 12, 90–95. [Google Scholar] [CrossRef]
- Ahmed, T.; Longo, L. Examining the Size of the Latent Space of Convolutional Variational Autoencoders Trained With Spectral Topographic Maps of EEG Frequency Bands. IEEE Access 2022, 10, 107575–107586. [Google Scholar] [CrossRef]
- Chikkankod, A.V.; Longo, L. On the dimensionality and utility of convolutional Autoencoder’s latent space trained with topology-preserving spectral EEG head-maps. Mach. Learn. Knowl. Extr. 2022, 4, 1042–1064. [Google Scholar] [CrossRef]
- Anwar, A.M.; Eldeib, A.M. EEG signal classification using convolutional neural networks on combined spatial and temporal dimensions for BCI systems. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 434–437. [Google Scholar]
- Taherisadr, M.; Joneidi, M.; Rahnavard, N. EEG signal dimensionality reduction and classification using tensor decomposition and deep convolutional neural networks. In Proceedings of the 2019 IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP), Pittsburgh, PA, USA, 13–16 October 2019; pp. 1–6. [Google Scholar]
- Miladinović, A.; Ajčević, M.; Jarmolowska, J.; Marusic, U.; Colussi, M.; Silveri, G.; Battaglini, P.P.; Accardo, A. Effect of power feature covariance shift on BCI spatial-filtering techniques: A comparative study. Comput. Methods Programs Biomed. 2021, 198, 105808. [Google Scholar] [CrossRef] [PubMed]
- Klonowski, W. Everything you wanted to ask about EEG but were afraid to get the right answer. Nonlinear Biomed. Phys. 2009, 3, 1–5. [Google Scholar] [CrossRef]
- Lotte, F.; Congedo, M.; Lécuyer, A.; Lamarche, F.; Arnaldi, B. A review of classification algorithms for EEG-based brain–computer interfaces. J. Neural Eng. 2007, 4, R1. [Google Scholar] [CrossRef]
- Bao, G.; Yan, B.; Tong, L.; Shu, J.; Wang, L.; Yang, K.; Zeng, Y. Data augmentation for EEG-based emotion recognition using generative adversarial networks. Front. Comput. Neurosci. 2021, 15, 723843. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Bornschein, J.; Bengio, Y. Reweighted wake-sleep. arXiv 2014, arXiv:1406.2751. [Google Scholar]
- Abdelfattah, S.M.; Abdelrahman, G.M.; Wang, M. Augmenting the size of EEG datasets using generative adversarial networks. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–6. [Google Scholar]
- Hwaidi, J.F.; Chen, T.M. A Noise Removal Approach from EEG Recordings Based on Variational Autoencoders. In Proceedings of the 2021 13th International Conference on Computer and Automation Engineering (ICCAE), Melbourne, Australia, 20–22 March 2021; pp. 19–23. [Google Scholar]
- Li, K.; Wang, J.; Li, S.; Yu, H.; Zhu, L.; Liu, J.; Wu, L. Feature Extraction and Identification of Alzheimer’s Disease based on Latent Factor of Multi-Channel EEG. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 1557–1567. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Li, X.; Zhao, Z.; Song, D.; Zhang, Y.; Pan, J.; Wu, L.; Huo, J.; Niu, C.; Wang, D. Latent factor decoding of multi-channel EEG for emotion recognition through autoencoder-like neural networks. Front. Neurosci. 2020, 14, 87. [Google Scholar] [CrossRef]
- Zheng, Z.; Sun, L. Disentangling latent space for vae by label relevant/irrelevant dimensions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12192–12201. [Google Scholar]
- Peng, X.; Yu, X.; Sohn, K.; Metaxas, D.N.; Chandraker, M. Reconstruction-based disentanglement for pose-invariant face recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1623–1632. [Google Scholar]
- Hsieh, J.T.; Liu, B.; Huang, D.A.; Fei-Fei, L.F.; Niebles, J.C. Learning to decompose and disentangle representations for video prediction. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Wang, S.; Chen, T.; Chen, S.; Nepal, S.; Rudolph, C.; Grobler, M. Oiad: One-for-all image anomaly detection with disentanglement learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Siddharth, N.; Paige, B.; Desmaison, A.; Van de Meent, J.W.; Wood, F.; Goodman, N.D.; Kohli, P.; Torr, P.H. Inducing interpretable representations with variational autoencoders. arXiv 2016, arXiv:1611.07492. [Google Scholar]
- Ramakrishna, S.; Rahiminasab, Z.; Karsai, G.; Easwaran, A.; Dubey, A. Efficient out-of-distribution detection using latent space of β-vae for cyber-physical systems. ACM Trans. Cyber-Phys. Syst. (TCPS) 2022, 6, 1–34. [Google Scholar] [CrossRef]
- Mathieu, E.; Rainforth, T.; Siddharth, N.; Teh, Y.W. Disentangling disentanglement in variational autoencoders. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 4402–4412. [Google Scholar]
- Spinner, T.; Körner, J.; Görtler, J.; Deussen, O. Towards an interpretable latent space: An intuitive comparison of autoencoders with variational autoencoders. In Proceedings of the IEEE VIS, Berlin, Germany, 27 October 2018. [Google Scholar]
- Bryan-Kinns, N.; Banar, B.; Ford, C.; Reed, C.; Zhang, Y.; Colton, S.; Armitage, J. Exploring xai for the arts: Explaining latent space in generative music. arXiv 2022, arXiv:2308.05496 2022. [Google Scholar]
- Pati, A.; Lerch, A. Attribute-based regularization of latent spaces for variational auto-encoders. Neural Comput. Appl. 2021, 33, 4429–4444. [Google Scholar] [CrossRef]
- Dinari, O.; Freifeld, O. Variational-and metric-based deep latent space for out-of-distribution detection. In Proceedings of the 38th Conference on Uncertainty in Artificial Intelligence, Eindhoven, The Netherlands, 1–5 August 2022. [Google Scholar]
- Ding, F.; Yang, Y.; Luo, F. Clustering by directly disentangling latent space. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 341–345. [Google Scholar]
- Mukherjee, S.; Asnani, H.; Lin, E.; Kannan, S. Clustergan: Latent space clustering in generative adversarial networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4610–4617. [Google Scholar]
- Prasad, V.; Das, D.; Bhowmick, B. Variational clustering: Leveraging variational autoencoders for image clustering. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19 July 2020; pp. 1–10. [Google Scholar] [CrossRef]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. Deap: A database for emotion analysis; using physiological signals. IEEE Trans. Affect. Comput. 2011, 3, 18–31. [Google Scholar] [CrossRef]
- Hwaidi, J.F.; Chen, T.M. A Novel KOSFS Feature Selection Algorithm for EEG Signals. In Proceedings of the IEEE EUROCON 2021—19th International Conference on Smart Technologies, Lviv, Ukraine, 6–8 July 2021; pp. 265–268. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes in 2nd International Conference on Learning Representations. In Proceedings of the ICLR 2014-Conference Track Proceedings, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Gretton, A.; Borgwardt, K.; Rasch, M.J.; Scholkopf, B.; Smola, A.J. A kernel method for the two-sample problem. arXiv 2008, arXiv:0805.2368. [Google Scholar]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Schneider, P.; Xhafa, F. Chapter 3—Anomaly detection: Concepts and methods. In Anomaly Detection and Complex Event Processing over IoT Data Streams; Elsevier: Amsterdam, The Netherlands, 2022; pp. 49–66. [Google Scholar]
- Asuero, A.G.; Sayago, A.; González, A. The correlation coefficient: An overview. Crit. Rev. Anal. Chem. 2006, 36, 41–59. [Google Scholar] [CrossRef]
- Hanrahan, C. Noise Reduction in Eeg Signals Using Convolutional Autoencoding Techniques. Master’s Thesis, Technological University Dublin, Dublin, Ireland, 1 September 2019. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comp | SSIM | MSE | MAE | MAPE | SNR | AvgCorr | Cluster |
|---|---|---|---|---|---|---|---|
| C 1-25 | 1.0000 | 0.000000103 | 0.00019 | 0.00042 | 0.36697883 | 0.994 | |
| C1 | 0.9969 | 0.0000375 | 0.00296 | 0.00484 | 0.108 | 0.107 | 2 |
| C2 | 0.9970 | 0.0000369 | 0.00292 | 0.00478 | 0.092 | 0.134 | 3 |
| C3 | 0.9969 | 0.0000374 | 0.00296 | 0.00484 | 0.107 | 0.119 | 2 |
| C4 | 0.9969 | 0.0000376 | 0.00296 | 0.00485 | 1.241 | 0.095 | 3 |
| C5 | 0.9973 | 0.0000309 | 0.00290 | 0.00474 | 0.114 | 0.267 | 2 |
| C6 | 0.9971 | 0.0000341 | 0.00286 | 0.00467 | 0.117 | 0.236 | 2 |
| C7 | 0.9970 | 0.0000353 | 0.00287 | 0.00470 | 0.096 | 0.283 | 2 |
| C8 | 0.9969 | 0.0000373 | 0.00294 | 0.00481 | 0.153 | 0.118 | 2 |
| C9 | 0.9969 | 0.0000374 | 0.00295 | 0.00482 | 0.112 | 0.14 | 2 |
| C10 | 0.9971 | 0.0000352 | 0.00287 | 0.00470 | 0.099 | 0.231 | 2 |
| C11 | 0.9969 | 0.0000373 | 0.00296 | 0.00483 | 0.103 | 0.116 | 2 |
| C12 | 0.9969 | 0.0000376 | 0.00296 | 0.00484 | 0.088 | 0.09 | 2 |
| C13 | 0.9971 | 0.0000351 | 0.00283 | 0.00463 | 0.11 | 0.278 | 2 |
| C14 | 0.9969 | 0.0000377 | 0.00297 | 0.00486 | 0.058 | 0.089 | 2 |
| C15 | 0.9974 | 0.0000295 | 0.00283 | 0.00463 | 0.115 | 0.294 | 2 |
| C16 | 0.9970 | 0.000036 | 0.00285 | 0.00467 | 0.1 | 0.223 | 2 |
| C17 | 0.9970 | 0.0000347 | 0.00280 | 0.00459 | 0.099 | 0.302 | 2 |
| C18 | 0.9969 | 0.0000374 | 0.00296 | 0.00485 | 0.096 | 0.136 | 2 |
| C19 | 0.9969 | 0.0000374 | 0.00295 | 0.00483 | 0.107 | 0.125 | 2 |
| C20 | 0.9969 | 0.0000374 | 0.00295 | 0.00483 | 0.304 | 0.123 | 2 |
| C21 | 0.9970 | 0.0000368 | 0.00294 | 0.00480 | 0.104 | 0.126 | 2 |
| C22 | 0.9970 | 0.0000374 | 0.00296 | 0.00484 | 0.115 | 0.099 | 2 |
| C23 | 0.9970 | 0.0000358 | 0.00291 | 0.00475 | 0.085 | 0.176 | 2 |
| C24 | 0.9969 | 0.0000379 | 0.00298 | 0.00487 | 0.103 | 0.092 | 3 |
| C25 | 0.9969 | 0.0000377 | 0.00297 | 0.00485 | 0.133 | 0.112 | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, T.; Longo, L. Interpreting Disentangled Representations of Person-Specific Convolutional Variational Autoencoders of Spatially Preserving EEG Topographic Maps via Clustering and Visual Plausibility. Information 2023, 14, 489. https://0-doi-org.brum.beds.ac.uk/10.3390/info14090489
Ahmed T, Longo L. Interpreting Disentangled Representations of Person-Specific Convolutional Variational Autoencoders of Spatially Preserving EEG Topographic Maps via Clustering and Visual Plausibility. Information. 2023; 14(9):489. https://0-doi-org.brum.beds.ac.uk/10.3390/info14090489
Chicago/Turabian StyleAhmed, Taufique, and Luca Longo. 2023. "Interpreting Disentangled Representations of Person-Specific Convolutional Variational Autoencoders of Spatially Preserving EEG Topographic Maps via Clustering and Visual Plausibility" Information 14, no. 9: 489. https://0-doi-org.brum.beds.ac.uk/10.3390/info14090489