

Using ChatGPT and Persuasive Technology for Personalized Recommendation Messages in Hotel Upselling



Abstract
:1. Introduction
2. Preliminaries
2.1. ChatGPT
2.1.1. Capabilities and Functionality of ChatGPT
2.1.2. GPT Versions and Technologies Involved
2.2. Persuasive Technology
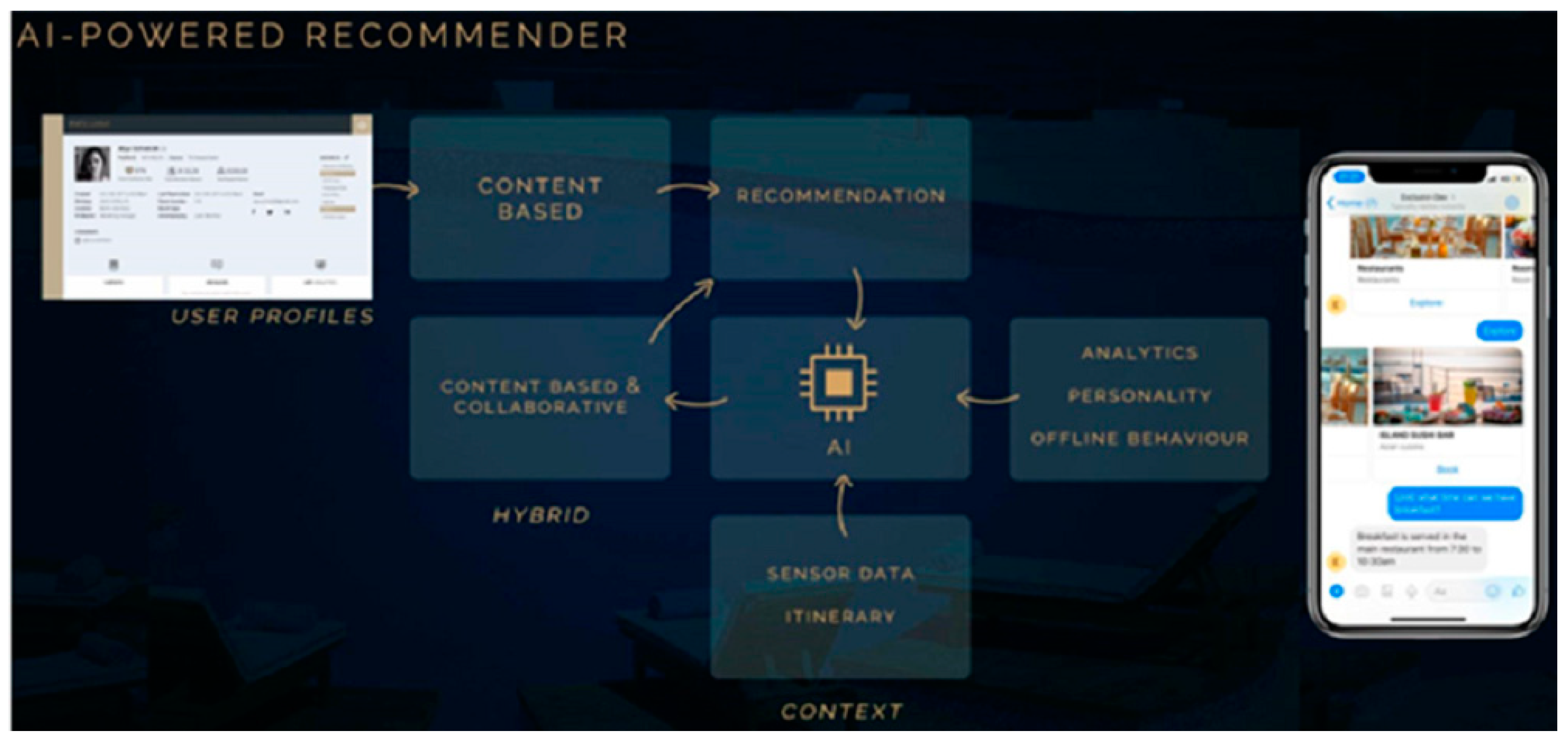
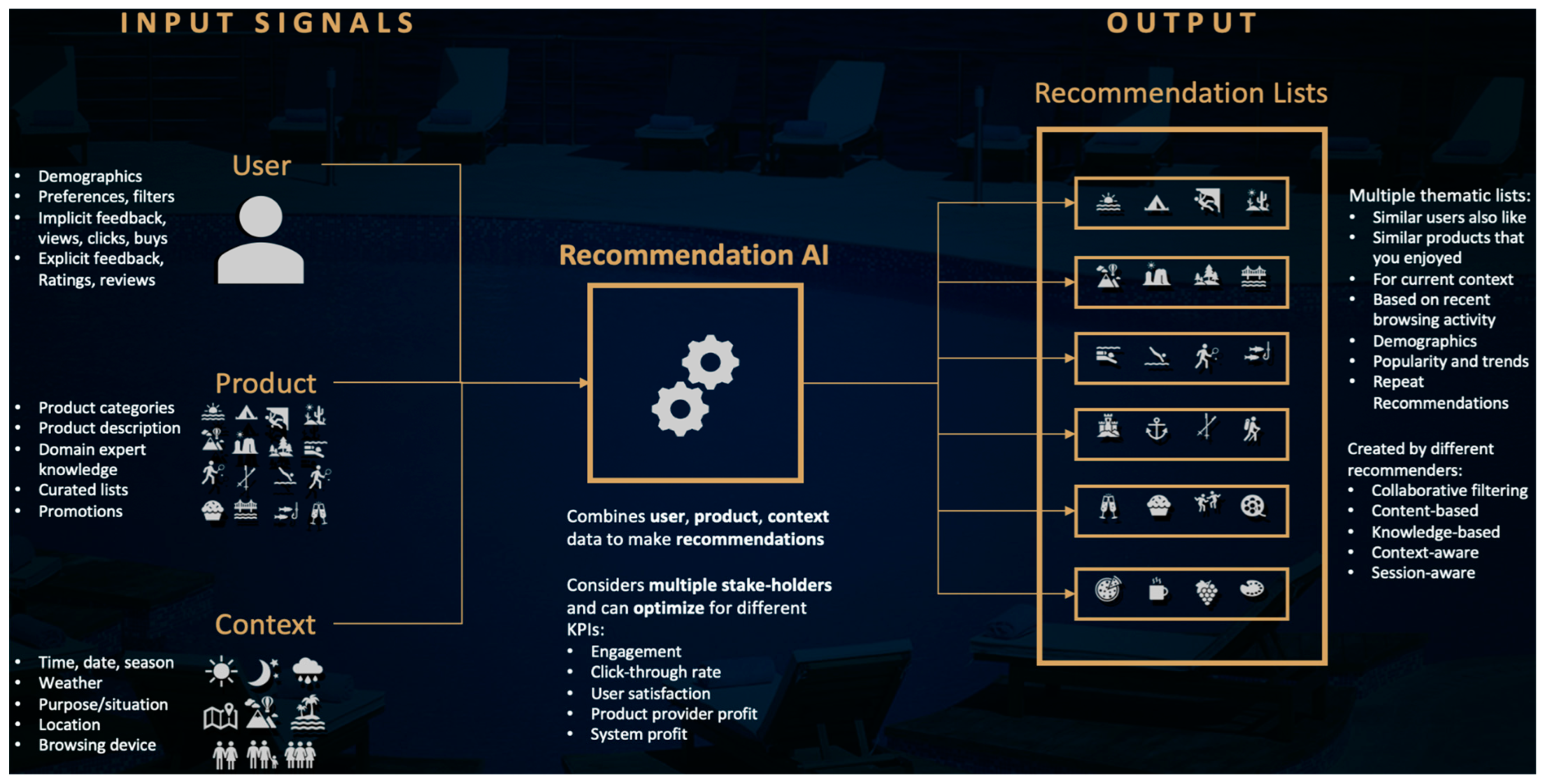
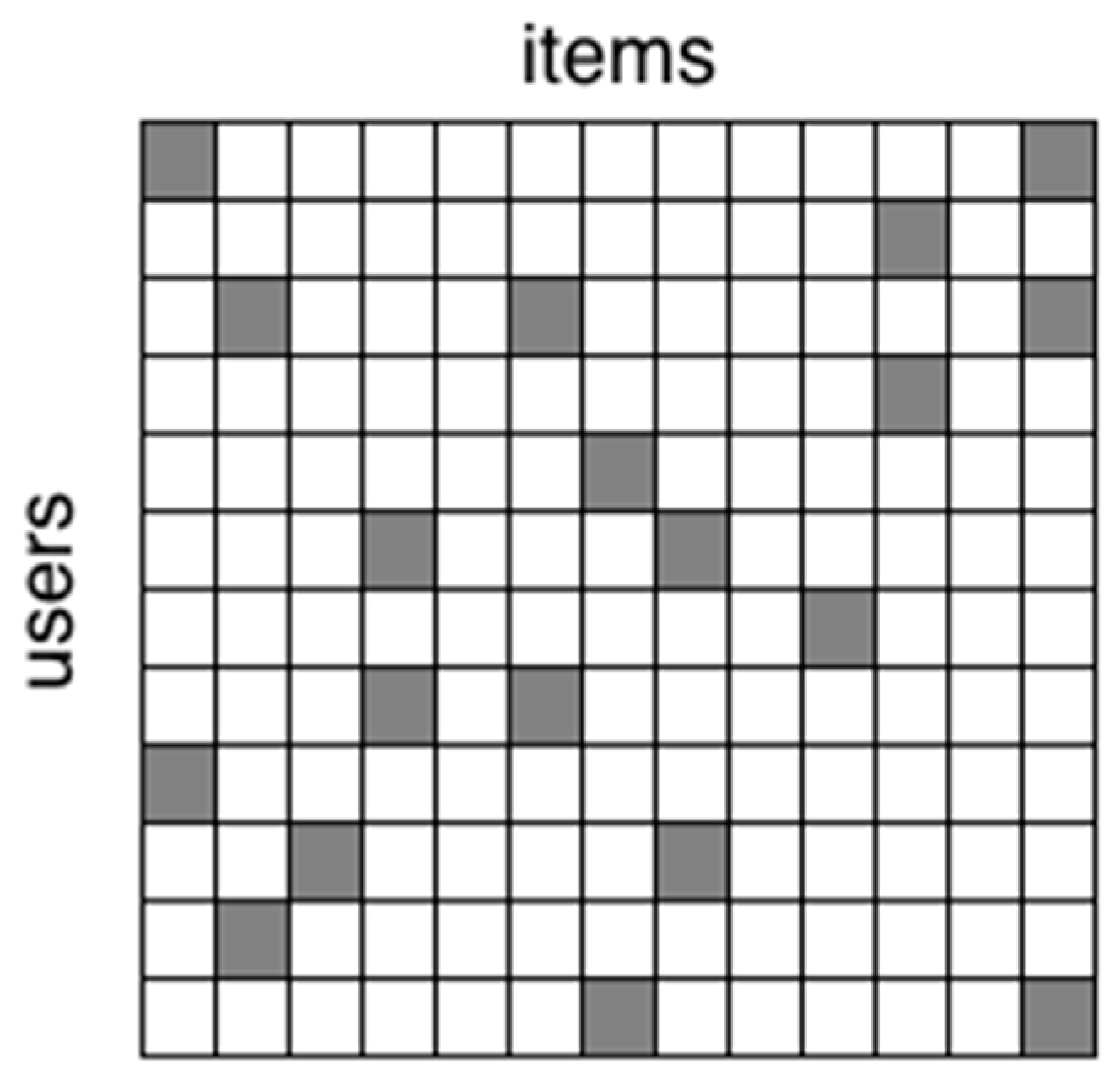
2.3. Recommender Systems
- User-to-item relationship: This relationship is influenced by the user profiling scheme and the user’s explicitly documented preferences for a specific type of item (e.g., a product or service).
- Item-to-item relationship: This relationship is based on the similarity or complementarity of the characteristics or items’ descriptions.
- User-to-user relationship: This relationship describes users who may have similar preferences as far as specific elements are concerned, such as location, age group, mutual friends, etc.
3. Related Work
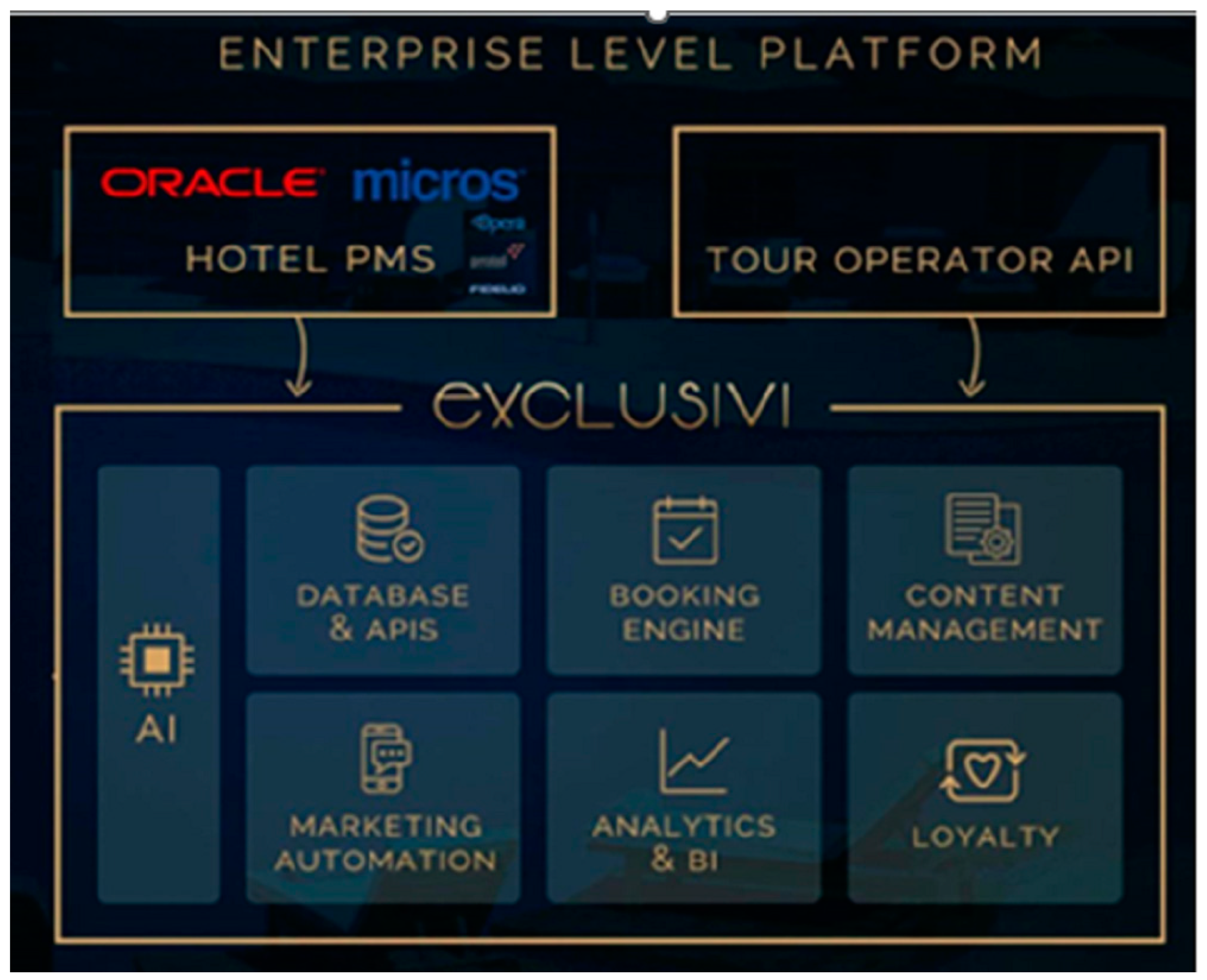
4. The Proposed Methodology
4.1. Description of the Recommendation System
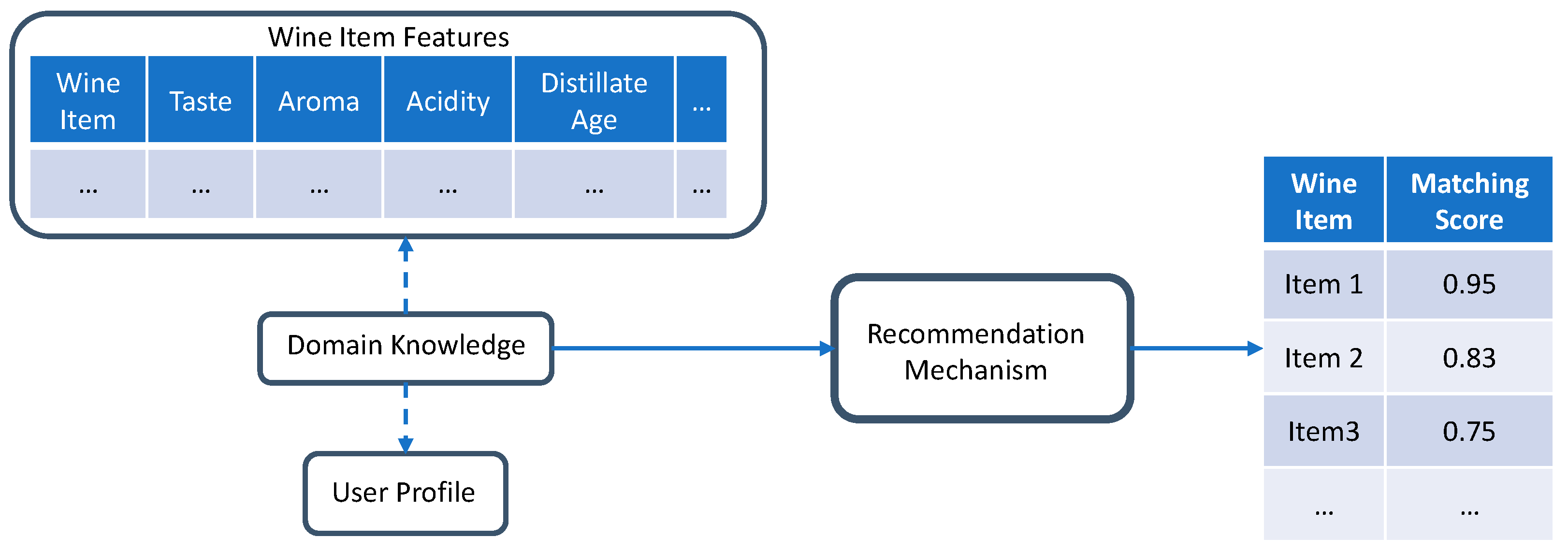
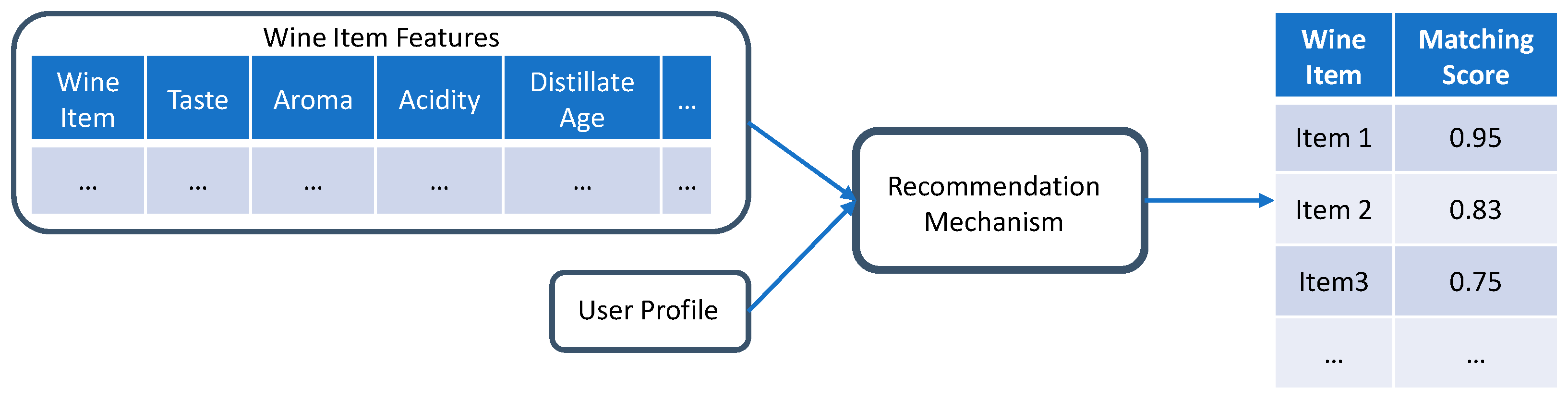
4.1.1. Knowledge-Based Recommendation Strategy
4.1.2. Content-Based Recommendation Strategy
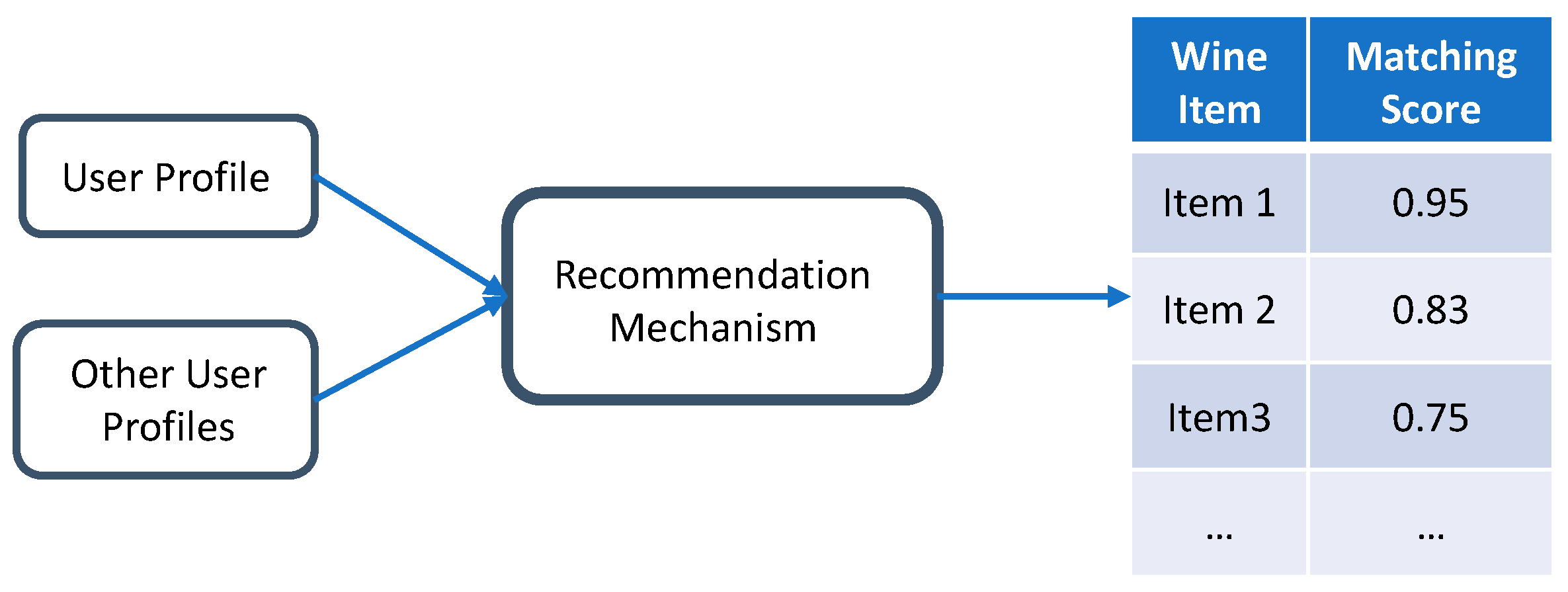
4.1.3. Collaborative-Filtering-Based Recommendation Strategy
4.1.4. Examples Illustrating Upsell’s Recommender System
- (1)
- /wine/kbr?acm={acm} is used with the knowledge-based recommender algorithm for a specific reservationNumber. This is executed every time a user chooses to answer a quiz (preference extraction). The service returns recommendations for that user.
- (2)
- /wine/cbr?acm={acm} is used with the content-based recommender algorithm for a specific reservation number. It is executed every time a user provides feedback on a purchased wine. The service returns recommendations for that user.
- (3)
- /wine/uucf?acm={acm} is used with the user–user CF recommender for all reservations (reservationNumber). It is executed every time a user provides feedback on a purchased wine. The service returns recommendations to all users rather than to just the ones who provided feedback. This is because in collaborative filtering, one user’s recommendations depend on the feedback of users with similar preferences.
- (4)
- /wine/iicf?acm={acm} is used with user–user collaborative filtering for all reservations (reservationNumber). This is executed whenever a user provides feedback to a purchased wine. The service returns recommendations for all users rather than only for the one who gave feedback. The {acm} variable refers to the accommodation identity (id), i.e., a specific hotel of a network of hotel units, while the reservationNumber refers to the visitor’s id. Table 1 and Table 2 depict the invocation of the services /wine/kbr?acm={acm} and /wine/cbr?acm={acm}, respectively. Table 3 gives the response of the invocation of the services /wine/uucf?acm={acm} and /wine/iicf?acm={acm}, which is a GET method.
- (1)
- /pos/iicf is used with the item–item CF recommender for a specific order.
- (2)
- /pos/pop is used with the content-based recommender for a specific order. This is also performed whenever a recommendation is requested for a specific order.
- (3)
- /pos/update_state?acm={acm} is used to update the state of a specific recommendation. It is run periodically to update the information that the recommendation algorithms rely on to derive their recommendations.
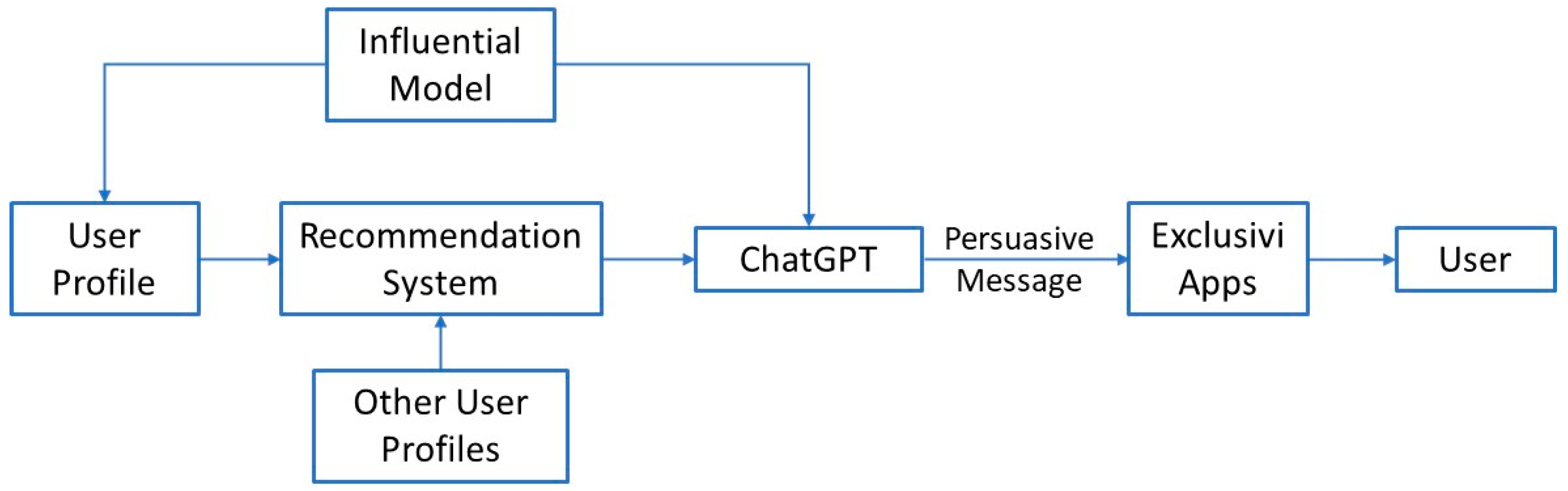
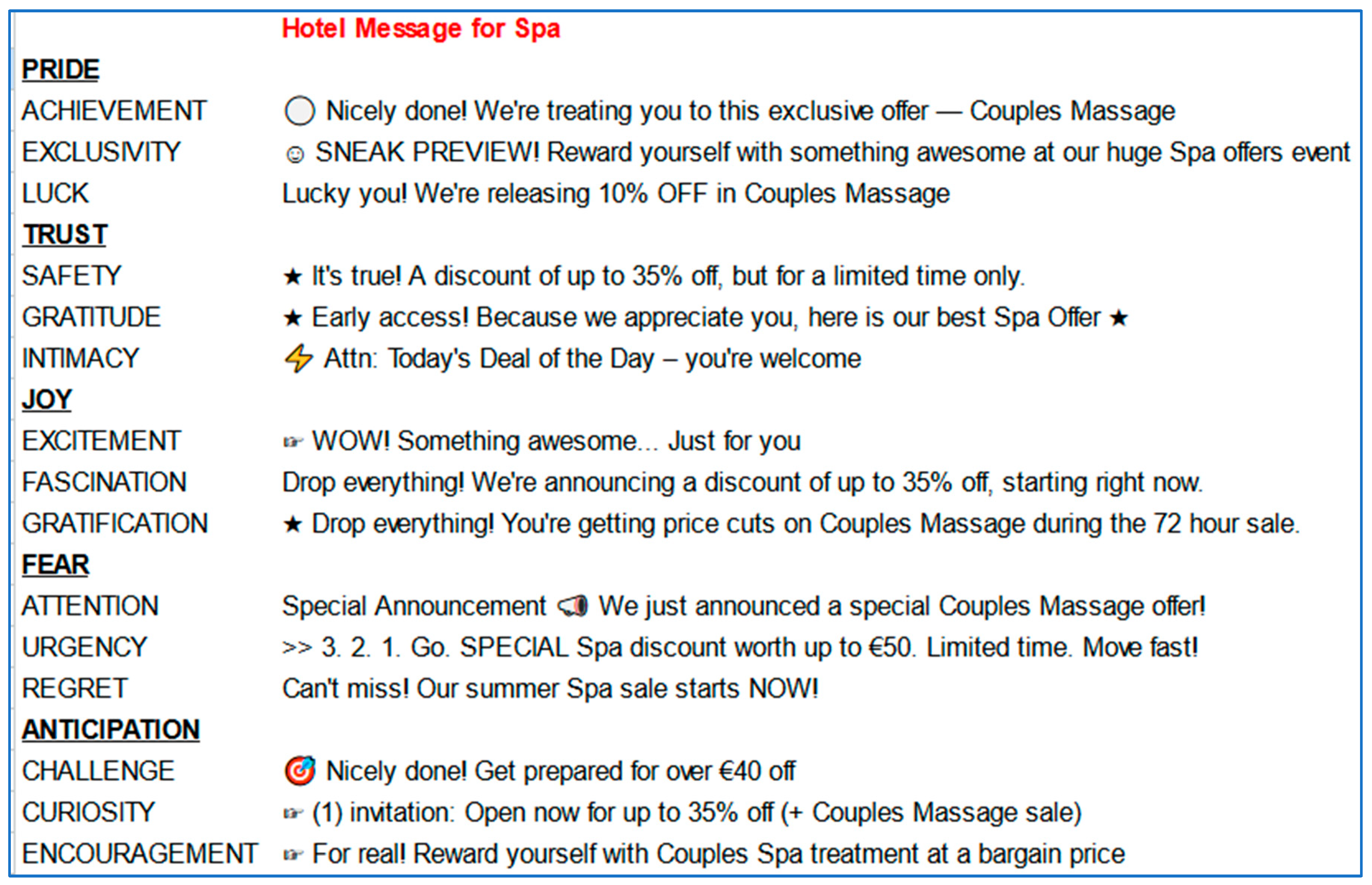
4.2. Recommendations Using ChatGPT and Persuasive Technology
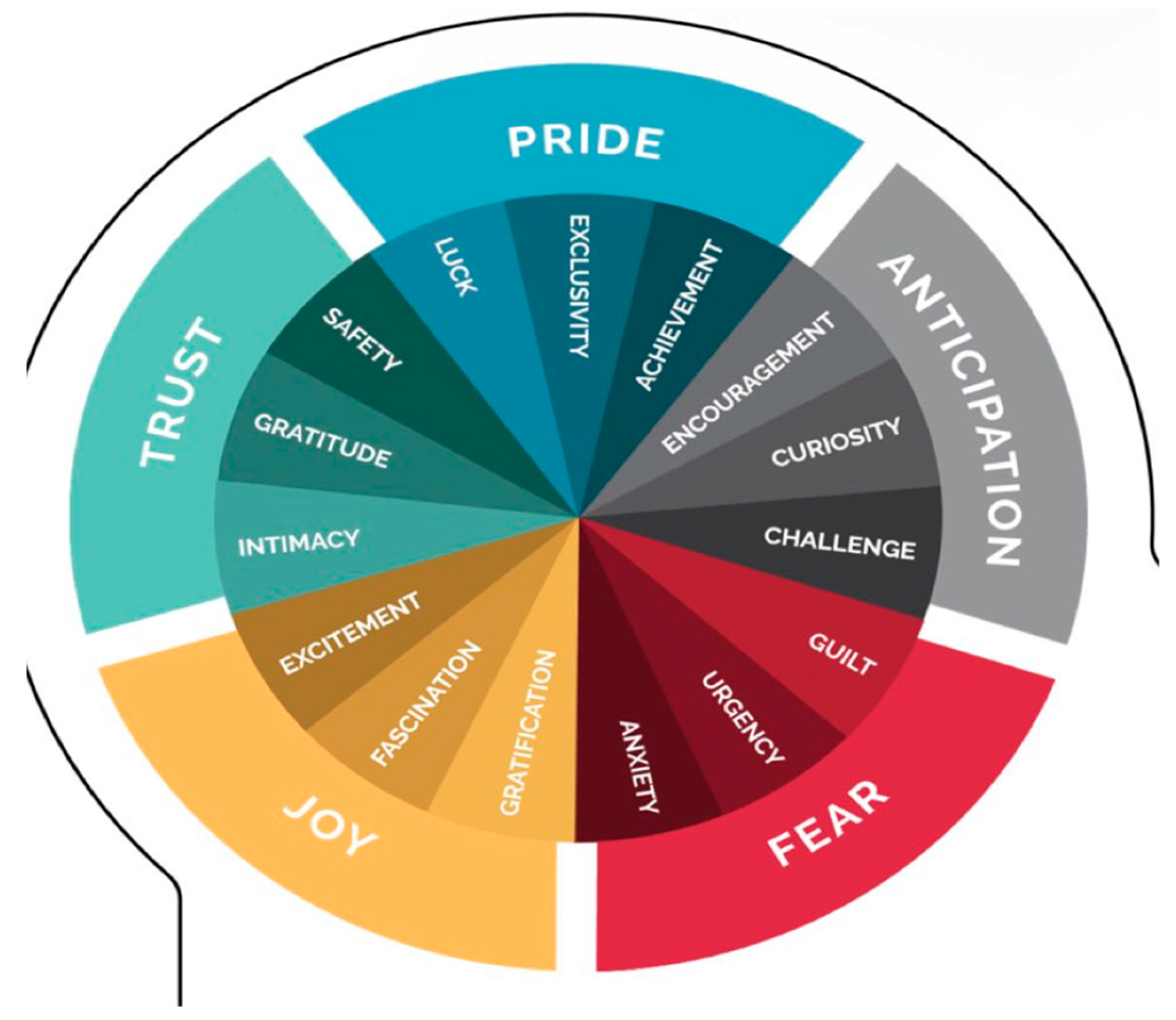
- Joy = {Gratification, Fascination, and Excitement}
- Trust = {Intimacy, Gratitude, and Safety}
- Pride = {Luck, Exclusivity, and Achievement}
- Anticipation = {Encouragement, Curiosity, and Challenge}
- Fear = {Guilt, Urgency, and Anxiety}
| Algorithm 1 Principles’ Ranking Process |
| (Step 1). According to the functionality of the tool, when a guest logs in to the hotel’s Wi-Fi or mobile app, she automatically receives a pop-up with ads for the hotel’s services, like spas or restaurants. Each ad corresponds to one of the five emotion categories of Persado’s wheel. Based on the resulting impressions and clicks, the guest is assigned to one of the elements of the EC set (i.e., one of Persado’s emotion categories). (Step 2). . (Step 3). . (Step 4). . |
5. Experimental Analysis
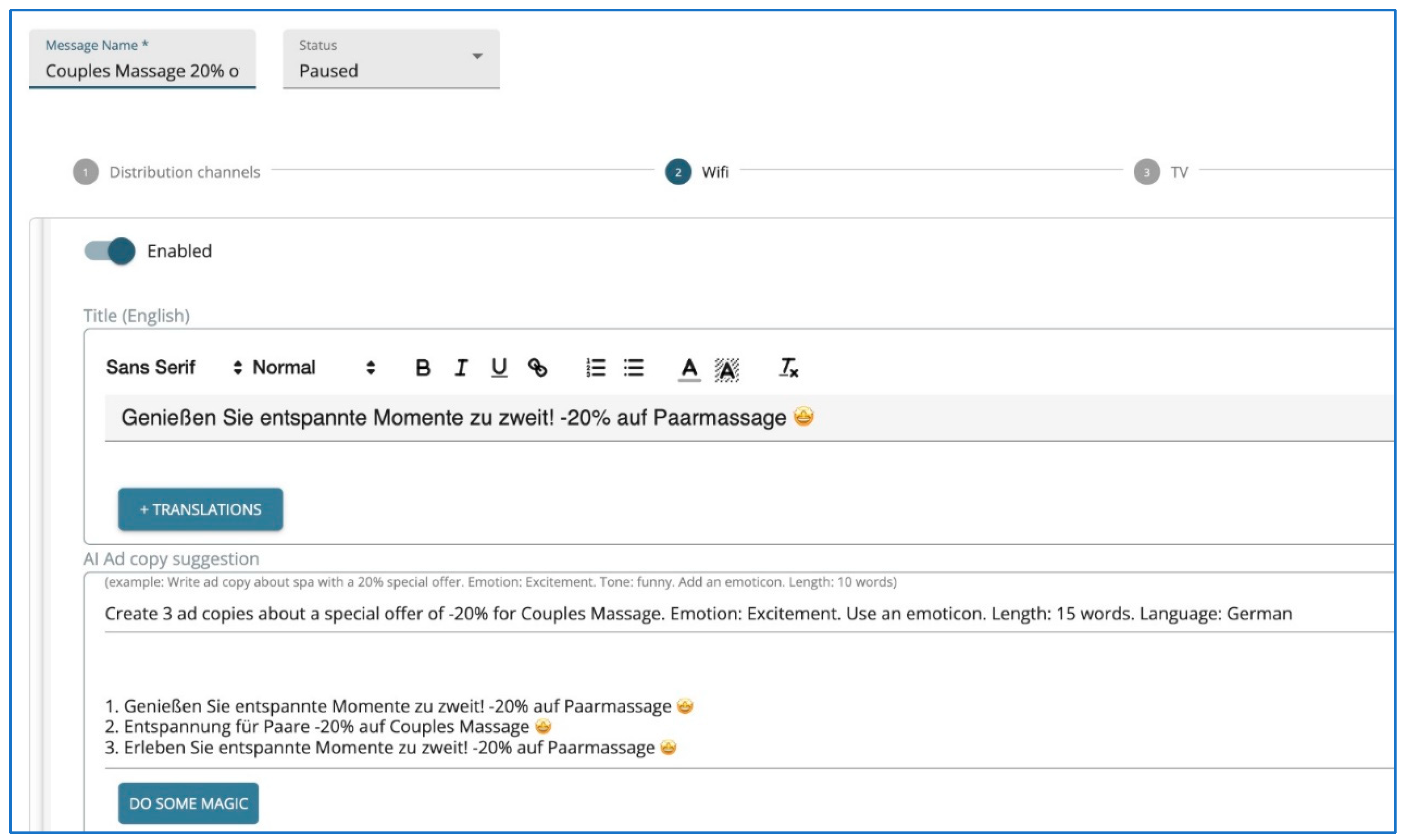
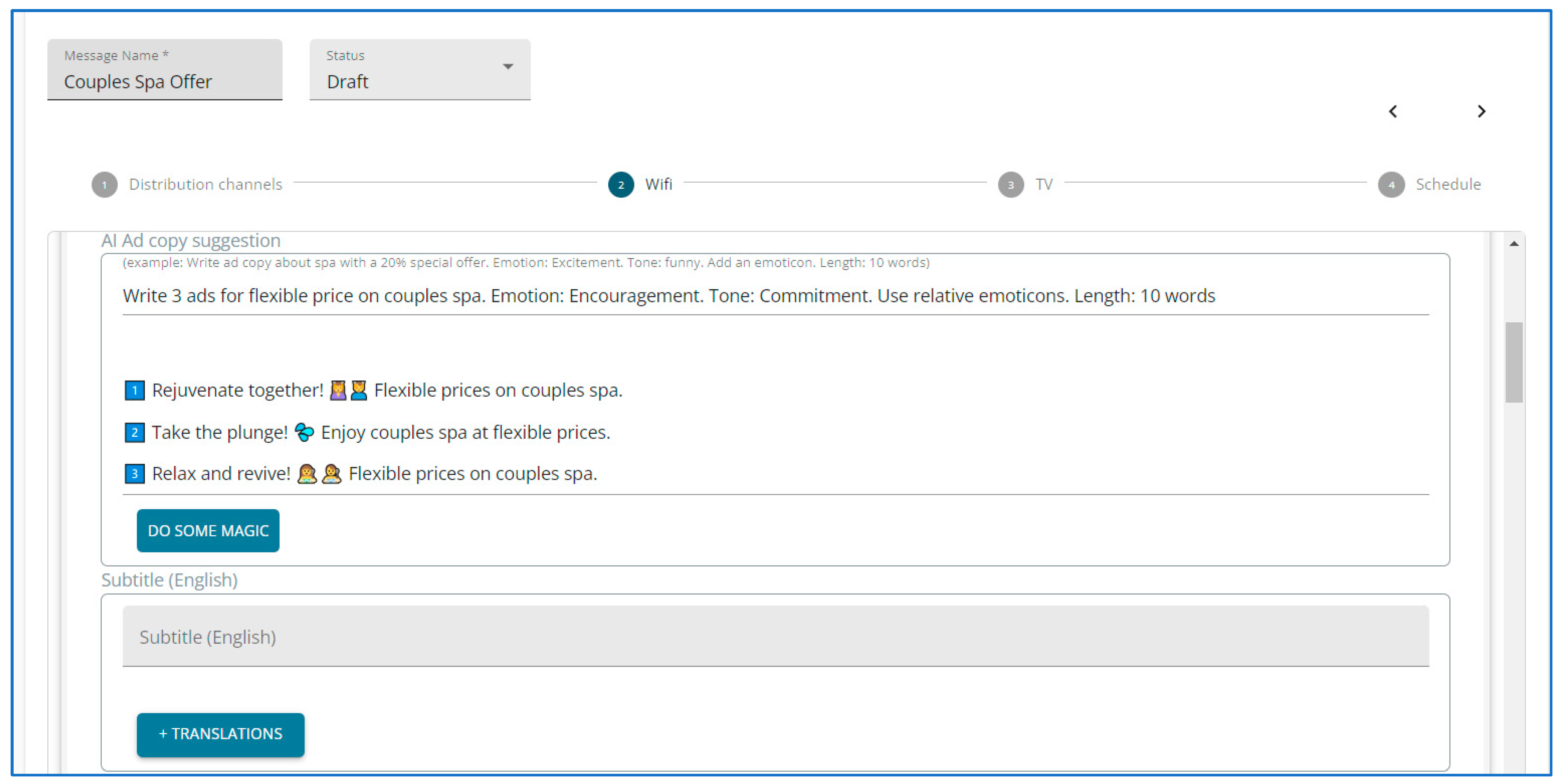
“Create 3 ad copies about a special offer of −20% (Task) for Couples Massage (Topic), with excitement (Emotion), and funny (Tone), Use an emoticon, in 15 words (Length), in German (Language)”
6. Challenges and Ethical Considerations and the Role of the Mediator in User Experience
6.1. Challenges and Ethical Considerations
- Privacy: ChatGPT, being data-driven, requires vast amounts of user data for training, which may include sensitive information about these users. Recommender systems that leverage LLMs need to handle user data with the utmost care to safeguard user privacy. Collecting and storing user data must comply with relevant data protection regulations, e.g., GDPR, and data anonymization techniques should be employed to minimize the risk of data breaches.
- Fairness and Bias: ChatGPT learns from large data sets, which can inadvertently perpetuate human biases that are present in the data. If these biases are not carefully identified and mitigated, the recommendations generated by ChatGPT may be biased towards certain groups or demographics, e.g., black people. This can lead to unfair treatment, discrimination, or the exclusion of particular individuals or communities. Ethical recommender systems should be designed to mitigate biases and promote fairness in their recommendations.
- User Autonomy: Persuasive technology, including recommender systems, should respect the autonomy of users. While personalized recommendations can enhance user experiences, they must not be manipulative in their intent. Users should have the option to control and customize the level of personalization they desire, with clear and transparent mechanisms for opting in or out of persuasive features.
- Transparency and Explainability: ChatGPT is often considered a “black box” model, meaning its decision-making processes can be challenging to interpret and understand. For ethical recommender systems, it is crucial to provide explanations for the recommendations that are offered to users. Users have the right to know why specific recommendations are being made and how their data are being utilized to generate those suggestions.
- Trust and User Perception: Integrating ChatGPT into persuasive recommender systems may lead to concerns about trust and user perception. If users feel that the system is exploiting their data or manipulating their choices, they may lose trust in the technology and the service provider. Ethical communication and transparency about the technology’s capabilities and limitations are essential to build and maintain user trust.
- Security and Adversarial Attacks: ChatGPT, like any AI model, may be vulnerable to adversarial attacks, where malicious actors attempt to manipulate the system’s output by inputting specific crafted data. Ensuring robust security measures to protect against such attacks is crucial for maintaining the system’s integrity and user trust.
6.2. The Role of the Mediator in User Experience
- Establishing Trust: Related to what we have already stated in the ethical considerations, when users feel that the AI system understands and cares about their concerns, they are more likely to trust the system’s recommendations. Empathy can help to build this trust, making users more receptive to the persuasive techniques employed by the AI.
- Enhancing Communication: An empathetic ChatGPT can better interpret user inquiries, providing more accurate and relevant responses. This can lead to a more engaging and satisfying user experience.
- Emotional Connection: Empathy in ChatGPT can create an emotional connection between the user and the AI system. This connection can lead to increased user satisfaction and a higher likelihood of booking a hotel or buying a hotel product/service through the AI platform (e.g., eXclusivi).
- Increased Conversion Rate: Empathy in ChatGPT can make users feel understood and valued, which, when combined with persuasive techniques, can increase the likelihood of users following through with hotel bookings.
- Improved User Satisfaction: An empathetic AI that provides personalized and relevant recommendations can lead to higher user satisfaction, resulting in repeat bookings and positive word of mouth.
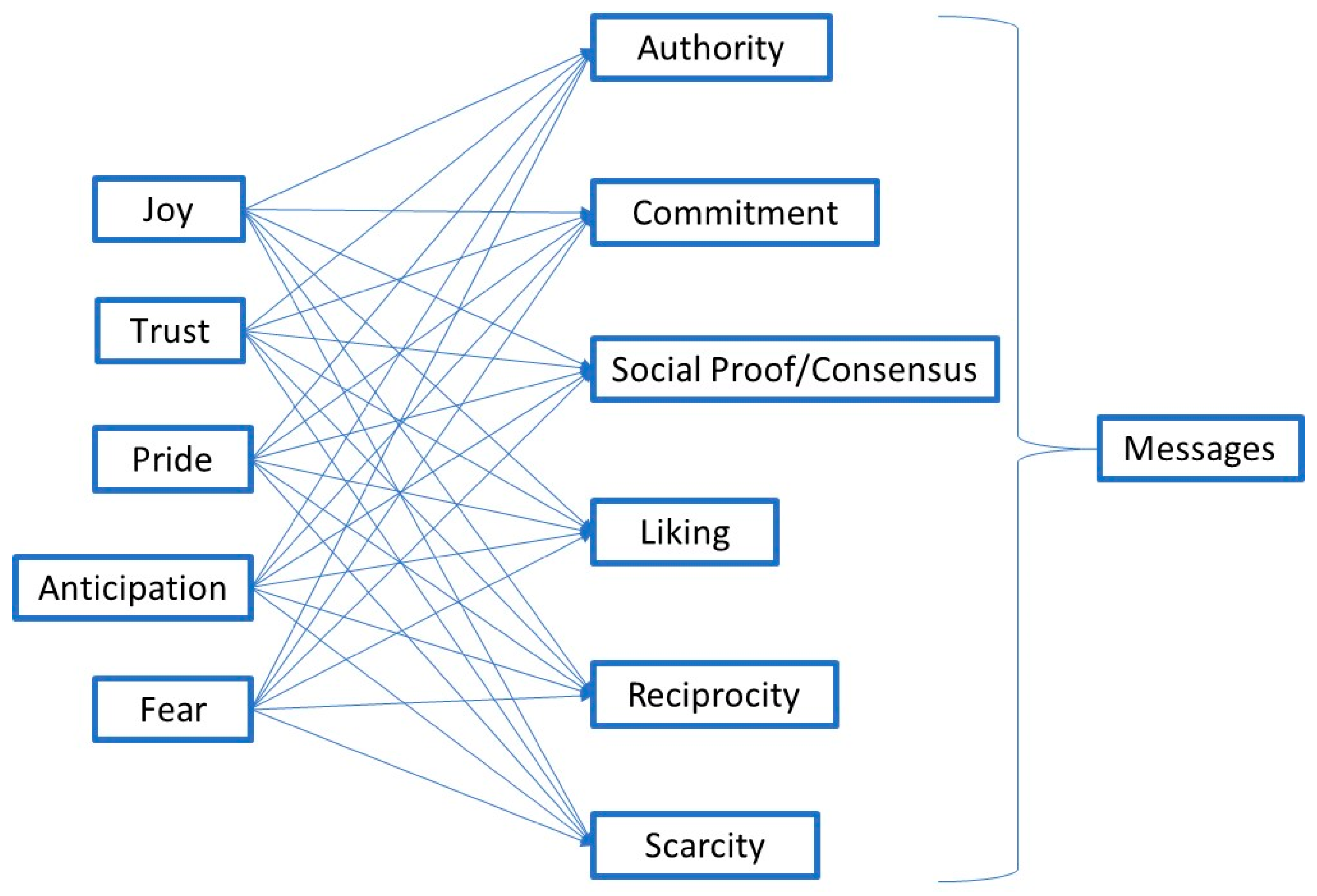
- Higher Engagement: Persuasive techniques like social proof and scarcity can increase user engagement with the AI system, leading to more extensive interactions and potentially more bookings.
- Potential Ethical Concerns: While persuasive technology can be effective, there are ethical considerations regarding how far it should go in influencing user behavior. Striking a balance between persuasion and user autonomy is crucial to avoid manipulative practices.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hui, T.L.T.; Au, N.; Law, R. Customer experiences with hotel smartphone: A case study of Hong Kong hotels. In Information and Communication Technologies in Tourism 2016; Inversini, A., Schegg, R., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 455–466. [Google Scholar]
- Ivanov, S.; Seyitoglu, F.; Markova, M. Hotel managers’ perceptions towards the use of robots: A mixed-methods approach. Inf. Technol. Tour. 2020, 22, 505–535. [Google Scholar] [CrossRef]
- Padma, P.; Ahn, J. Guest satisfaction & dissatisfaction in luxury hotels: An application of big data. Int. J. Hosp. Manag. 2020, 84, 102318. [Google Scholar]
- Buhalis, D.; Cheng, E.S.Y. Exploring the use of chatbots in hotels: Technology providers’ perspective. In Information and Communication Technologies in Tourism 2020; Neidhardt, J., Wörndl, W., Eds.; Springer Nature: Cham, Switzerland, 2020; pp. 231–242. [Google Scholar]
- Morosan, C.; DeFranco, A. Using interactive technologies to influence guests’ unplanned dollar spending in hotels. Int. J. Hosp. Manag. 2019, 82, 242–251. [Google Scholar] [CrossRef]
- Han, S.H.; Lee, L.; Edvardsson, B.; Verma, R. Mobile technology adoption among hotels: Managerial issues and opportunities. Tour. Manag. Perspect. 2021, 38, 100811. [Google Scholar] [CrossRef]
- Yang, H.; Song, H.; Cheung, C.; Guan, J. How to enhance hotel guests’ acceptance and experience of smart hotel technology: An examination of visiting intentions. Int. J. Hosp. Manag. 2021, 97, 103000. [Google Scholar] [CrossRef]
- Peng, Y. A survey on modern recommendation system based on big data. arXiv 2022, arXiv:2206.02631. [Google Scholar]
- Guerra-Montenegro, J.; Sanchez-Medina, J.; Lana, I.; Sanchez-Rodriguez, D.; Alonso-Gonzalez, I.; Del Ser, J. Computational intelligence in the hospitality industry: A systematic literature review and a prospect of challenges. Appl. Soft Comput. 2021, 102, 107082. [Google Scholar] [CrossRef]
- Fogg, B.J. Persuasive Technology: Using Computers to Change What We Think and Do; Morgan Kaufmann: San Francisco, CA, USA, 2002. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223v10. [Google Scholar]
- Ray, P.P. ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things Cyber-Phys. Syst. 2023, 3, 121–154. [Google Scholar] [CrossRef]
- Wu, T.; He, S.; Liu, J.; Sun, S.; Liu, K.; Han, Q.-L.; Tang, Y. A brief overview of ChatGPT: The history, status quo and potential future development. IEEE/CAA J. Autom. Sin. 2023, 10, 1122–1136. [Google Scholar] [CrossRef]
- Wang, Y.; Pan, Y.; Yan, M.; Su, Z.; Luan, T.H. A survey on ChatGPT: AI–generated contents, challenges, and solutions. arXiv 2023, arXiv:2305.18339v1. [Google Scholar] [CrossRef]
- Jiao, W.X.; Wang, W.X.; Huang, J.-T.; Wang, X.; Tu, Z.P. Is ChatGPT a good translator? Yes with GPT-4 as the engine. arXiv 2023, arXiv:2301.08745. [Google Scholar]
- Lund, B.D.; Wang, T. Chatting about ChatGPT: How may AI and GPT impact academia and libraries? Libr. Hi Tech News 2023, 3, 26–29. [Google Scholar] [CrossRef]
- Qin, C.; Zhang, A.; Zhang, Z.; Chen, J.; Yasunaga, M.; Yang, D. Is Chat GPT a general-purpose natural language processing task solver? arXiv 2023, arXiv:2302.06476. [Google Scholar]
- Du, H.; Teng, S.; Chen, H.; Ma, J.; Wang, X.; Gou, C.; Li, B.; Ma, S.; Miao, Q.; Na, X.; et al. Chat with ChatGPT on intelligent vehicles: An IEEE TIV perspective. IEEE Trans. Intell. Veh. 2023, 8, 2020–2026. [Google Scholar] [CrossRef]
- Sallam, M. ChatGPT utility in healthcare education, research, and practice: Systematic review on the promising perspectives and valid concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef] [PubMed]
- Ali, S.R.; Dobbs, T.D.; Hutchings, H.A.; Whitaker, I.S. Using ChatGPT to write patient clinic letters. Lancet Digit Health 2023, 5, e179–e181. [Google Scholar] [CrossRef] [PubMed]
- Haleem, A.; Javaid, M.; Singh, R.P. An era of ChatGPT as a significant futuristic support tool: A study on features, abilities, and challenges. BenchCouncil Trans. Benchmarks Stand. Eval. 2022, 2, 100089. [Google Scholar] [CrossRef]
- Pu, D.; Demberg, V. ChatGPT vs human-authored text: Insights into controllable text summarization and sentence style transfer. arXiv 2023, arXiv:2306.07799v1. [Google Scholar]
- Hassani, H.; Silva, E.S. The role of ChatGPT in data science: How AI-assisted conversational interfaces are revolutionizing the field. Big Data Cogn. Comput. 2023, 7, 62. [Google Scholar] [CrossRef]
- Kolides, A.; Nawaz, A.; Rathor, A.; Beeman, D.; Hashmi, M.; Fatima, S.; Berdik, D.; Al-Ayyoub, M.; Jararweh, Y. Artificial intelligence foundation and pre-trained models: Fundamentals, applications, opportunities, and social impacts. Simul. Model. Pract. Theory 2023, 126, 102754. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, C.; Li, C.; Qiao, Y.; Zheng, S.; Dam, S.K.; Zhang, M.; Kim, J.U.; Kim, S.T.; Choi, J.; et al. One small step for generative AI, one giant leap for AGI: A complete survey on ChatGPT in AIGC era. arXiv 2023, arXiv:2304.06488v1. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805v2. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. arXiv 2022, arXiv:2201.11903. [Google Scholar]
- Wang, B.; Min, S.; Deng, X.; Shen, J.; Wu, Y.; Zettlemoyer, L.; Sun, H. Towards understanding chain-of-thought prompting: An empirical study of what matters. arXiv 2023, arXiv:2212.10001v2. [Google Scholar]
- Xu, B.; Yang, A.; Lin, J.; Wang, Q.; Zhou, C.; Zhang, Y.; Mao, Z. ExpertPrompting: Instructing large language models to be distinguished experts. arXiv 2023, arXiv:2305.14688v1. [Google Scholar]
- Xian, Y.; Schiele, B.; Akata, Z. Zero-shot learning—The good, the bad and the ugly. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3077–3086. [Google Scholar]
- Liu, Z.; Chen, C.; Wang, J.; Chen, M.; Wu, B.; Che, X.; Wang, D.; Wang, Q. Chatting with GPT-3 for zero-shot human-like mobile automated GUI testing. arXiv 2023, arXiv:2305.09434v1. [Google Scholar]
- Bragg, J.; Cohan, A.; Lo, K.; Beltagy, I. FLEX: Unifying evaluation for few-shot NLP. arXiv 2021, arXiv:2107.07170v2. [Google Scholar]
- Ziegler, D.M.; Stiennon, N.; Wu, J.; Brown, T.B.; Radford, A.; Amodei, D.; Christiano, P.; Irving, G. Fine-tuning language models from human preferences. arXiv 2019, arXiv:1909.08593v2. [Google Scholar]
- MacGlashan, J.; Ho, M.K.; Loftin, R.; Peng, B.; Wang, G.; Roberts, D.L.; Taylor, M.E.; Littman, M.L. Interactive learning from policy-dependent human feedback. arXiv 2023, arXiv:1701.06049v2. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. Highresolution image synthesis with latent diffusion models. arXiv 2022, arXiv:2112.10752v2. [Google Scholar]
- Hagendorff, T.; Fabi, S.; Kosinski, M. Machine intuition: Uncovering human-like intuitive decision-making in GPT-3.5. arXiv 2022, arXiv:2212.05206. [Google Scholar]
- Oinas-Kukkonen, H.; Harjumaa, M.A. Systematic framework for designing and evaluating persuasive systems. Lect. Notes Comput. Sci. 2008, 5033, 164–176. [Google Scholar]
- Perfetti, C. Guiding Users with Persuasive Design: An Interview with Andrew Chak. UX Articles by UIE, 2003. Available online: https://articles.uie.com/chak_interview/ (accessed on 15 January 2023).
- Chiu, M.-C.; Chang, S.-P.; Chang, Y.-C.; Chu, H.-H.; Chen, C.C.-H.; Hsiao, F.-H.; Ko, J.-C. Playful bottle: A mobile social persuasion system to motivate healthy water intake. In Proceedings of the 11th International Conference on Ubiquitous Computing (UbiComp’09), Orlando, FL, USA, 30 September–3 October 2009; pp. 185–194. [Google Scholar]
- Halko, S.; Kientz, J.A. Personality and Persuasive Technology: An Exploratory Study on Health-Promoting Mobile Applications. Lect. Notes Comput. Sci. 2010, 6137, 150–161. [Google Scholar]
- Lieto, A.; Vernero, F. Influencing the others’ minds: An experimental evaluation of the use and efficacy of fallacious-reducible arguments in web and mobile technologies. PsychNology J. 2014, 12, 87–105. [Google Scholar]
- Gena, C.; Grillo, P.; Lieto, A.; Mattutino, C.; Vernero, F. When personalization is not an option: An in-the-wild study on persuasive news recommendation. Information 2019, 10, 300. [Google Scholar] [CrossRef]
- Augello, A.; Citta, G.; Gentile, M.; Lieto, A. A Storytelling Robot managing Persuasive and Ethical Stances via ACT-R: An Exploratory Study. Int. J. Soc. Robot. 2021. [Google Scholar] [CrossRef]
- Cialdini, R.B. Harnessing the science of persuasion. Harv. Bus. Rev. 2001, 79, 72–81. [Google Scholar]
- Alslaity, A.; Tran, T. On the impact of the application domain on users’ susceptibility to the six weapons of influence. Lect. Notes Comput. Sci. 2020, 12064, 3–15. [Google Scholar]
- Mintz, J.; Aagaard, M. The application of persuasive technology to educational settings. Educ. Technol. Res. Dev. 2012, 60, 483–499. [Google Scholar] [CrossRef]
- Kembellec, G.; Chartron, G.; Saleh, I. Recommender Systems; John Wiley & Sons Inc.: Hoboken, NJ, USA, 2014. [Google Scholar]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutierrez, A. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to recommender systems handbook. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P.B., Eds.; Springer: New York, NY, USA, 2011; pp. 1–35. [Google Scholar]
- Barranco, M.J.; Noguera, J.M.; Castro, J.; Martinez, L. A context-aware mobile recommender system based on location and trajectory. In Management Intelligent Systems; Casillas, J., Martinez-Lopez, F.J., Rodriguez, J.M.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 153–162. [Google Scholar]
- Chicaiza, J.; Valdiviezo-Diaz, P. A comprehensive survey of knowledge graph-based recommender systems: Technologies, development, and contributions. Information 2021, 12, 232. [Google Scholar] [CrossRef]
- Veloso, B.M.; Leal, F.; Malheiro, B.; Burguillo, J.C. On-line guest profiling and hotel recommendation. Electron. Commer. Res. Appl. 2019, 34, 100832. [Google Scholar] [CrossRef]
- Veloso, B.M.; Leal, F.; Malheiro, B.; Burguillo, J.C. A 2020 perspective on “Online guest profiling and hotel recommendation”: Reliability, scalability, traceability and transparency. Electron. Commer. Res. Appl. 2020, 40, 100957. [Google Scholar] [CrossRef]
- Neuhofer, B.; Buhalis, D.; Ladkin, A. Smart technologies for personalized experiences: A case study in the hospitality domain. Electron Mark. 2015, 25, 243–254. [Google Scholar] [CrossRef]
- Leal, L.; Malheiro, B.; Burguillo, J.C. Incremental hotel recommendation with inter-guest trust and similarity post-filtering. In New Knowledge in Information Systems and Technologies: WorldCIST’19 2019; Rocha, A., Adeli, H., Reis, L., Costanzo, S., Eds.; Springer Nature: Cham, Switzerland, 2019; Volume 930, pp. 262–272. [Google Scholar]
- Tai, Y.-F.; Wang, Y.-C.; Luo, C.-C. Technology- or human-related service innovation? Enhancing customer satisfaction, delight, and loyalty in the hospitality industry. Serv. Bus. 2021, 15, 667–694. [Google Scholar] [CrossRef]
- Nor1. Available online: https://www.oracle.com/corporate/acquisitions/nor1/ (accessed on 17 February 2023).
- Young, A. Nor1′s PRiME Decision Platform with Real-Time Merchandising Banners Driving Double-Digit Conversion Rate for Hotels. Available online: https://www.hospitalitynet.org/news/4094347.html (accessed on 23 January 2023).
- Yoon, D.; Kim, Y.-K.; Fu, R.J.C. How can hotels’ green advertising be persuasive to consumers? An information processing perspective. J. Hosp. Tour. Manag. 2020, 45, 511–519. [Google Scholar] [CrossRef]
- Díaz, Ε; Koutra, C. Evaluation of the persuasive features of hotel chains websites: A latent class segmentation analysis. Int. J. Hosp. Manag. 2013, 34, 338–347. [Google Scholar] [CrossRef]
- eXclusivi. Available online: https://exclusivi.com/contactless/ (accessed on 12 December 2022).
- Oracle Opera Hotel Property Management. Available online: https://www.oracle.com/uk/hospitality/hotel-property-management/ (accessed on 20 May 2023).
- Fidelio Suit 8. Available online: http://www.micros.rs/en/fidelio-suite-8.html (accessed on 25 May 2023).
- Protel Net. Available online: https://www.protel.net/ (accessed on 11 April 2023).
- Pylon Hospitality. Available online: https://www.pylon.gr/product.aspx?id=2047&mID=1048,1056 (accessed on 22 April 2023).
- Orange PMS. Available online: https://www.orangepms.com/ (accessed on 10 June 2023).
- Persado. Available online: https://www.businesswire.com/news/home/20151210005927/en/Persado-Releases-Annual-Emotional-Rankings-Report (accessed on 20 November 2022).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Post | Response |
|---|---|
| { “_id”: “5b0e5ee02ab79c0001557144”, “accommodationId”: “smp”, “reservationNumber”: “151792”, “profileName”: “Bernd”, “preferences”: { “color”: “2”, “tannins”: “2”, “fruitness”: “1”, “acidity”: “1”, “body”: “1”, “earthy”: “2”, “spices”: “2”, “herbal”: “2”, “floral”: “2”, “oaky”: “1”, “price”: “less_60” }, “dateTime”: “2018-05-30T11:20:48.000+03:00”, “_class”: “com.infamous.persistence.documents.wineProfiles. models.WineProfile” } | { “accommodationId”: “smp”, “recommendedWines”: [ “DI_MIN_PAL_WIN_46”, “DI_MIN_PAL_WIN_33” ], “reservationNumber”: “151792”, “timestamp”: “2018-07-10T11:44:12.856229”, “type”: “kbr” } |
| Post | Response |
|---|---|
| { “id”: “5b4329beb9d8210001c446a2”, “accommodationId”: “blv”, “reservationNumber”: “30000184099”, “dateTime”: { “dayOfYear”: 190, “dayOfWeek”: “MONDAY”, “month”: “JULY”, “dayOfMonth”: 9, “year”: 2018, “monthValue”: 7, “hour”: 12, “minute”: 24, “nano”: 366000000, “second”: 14, “chronology”: { “calendarType”: “iso8601”, “id”: “ISO” } }, “ratings”: [ { “id”: “wine”, “rating”: “7” } ], “profileName”: “EECKHOUT,”, “wineId”: “DI_BLV_WIN_LIS_17”, “restaurantId”: “DI_BLV_THE_PI1”, “dateTimeLong”: 1531128254 } | { “accommodationId”: “blv”, “recommendedWines”: [ “DI_MIN_PAL_WIN_46”, “DI_MIN_PAL_WIN_33” ], “reservationNumber”: “151792”, “timestamp”: “2018-07-10T11:44:12.856229”, “type”: “cbr” } |
| Response |
|---|
| { “accommodationId”: “blv”, “recommendedWines”: [ { “list”: [ “DI_BLV_WIN_LIS_37”, “DI_BLV_WIN_LIS_20” ], “reservationId”: “30000184099” }, { “list”: [ “DI_BLV_WIN_LIS_37”, “DI_BLV_WIN_LIS_20” ], “reservationId”: “30000194074” }, { “list”: [ “DI_BLV_WIN_LIS_37”, “DI_BLV_WIN_LIS_20” ], “reservationId”: “blv” } ], “timestamp”: “2018-07-10T11:44:12.856229”, “type”: “uucf” } |
| Post | Response |
|---|---|
| { “id”: “5b4329beb9d8210001c446a2”, “accommodationId”: “blv”, “reservationNumber”: “30000184099”, “dateTime”: { “dayOfYear”: 190, “dayOfWeek”: “MONDAY”, “month”: “JULY”, “dayOfMonth”: 9, “year”: 2018, “monthValue”: 7, “hour”: 12, “minute”: 24, “nano”: 366000000, “second”: 14, “chronology”: { “calendarType”: “iso8601”, “id”: “ISO” } }, “ratings”: [ { “id”: “wine”, “rating”: “7” } ], “profileName”: “EECKHOUT,”, “wineId”: “DI_BLV_WIN_LIS_17”, “restaurantId”: “DI_BLV_THE_PI1”, “dateTimeLong”: 1531128254 } | { “accommodationId”: “blv”, “recommendedWines”: [ “DI_MIN_PAL_WIN_46”, “DI_MIN_PAL_WIN_33” ], “reservationNumber”: “151792”, “timestamp”: “2018-07-10T11:44:12.856229”, “type”: “cbr” } |
| Response |
|---|
| { “itemDict”: [ { “id”: “DI_ROY_MIN_COF_72”, “value”: 30 }, { “id”: “DI_ROY_MIN_COF_39”, “value”: 32 } ], “posixTime”: 1532375562, “r”: [ [ ] ] } |
| Joy | Trust | |||||
|---|---|---|---|---|---|---|
| Impressions | Clicks | CTR | Impressions | Clicks | CTR | |
| Authority | 1611 | 35 | 2.173 | 1723 | 71 | 4.121 |
| Commitment | 1843 | 68 | 3.690 | 2122 | 102 | 4.807 |
| Social Proof/Consensus | 1899 | 71 | 3.739 | 2109 | 89 | 4.220 |
| Liking | 1657 | 72 | 4.345 | 1978 | 92 | 4.651 |
| Reciprocity | 1533 | 33 | 2.153 | 1699 | 43 | 2.531 |
| Scarcity | 1522 | 64 | 4.205 | 1922 | 48 | 2.497 |
| Pride | Anticipation | |||||
|---|---|---|---|---|---|---|
| Impressions | Clicks | CTR | Impressions | Clicks | CTR | |
| Authority | 1623 | 68 | 4.190 | 1892 | 77 | 4.070 |
| Commitment | 1957 | 79 | 4.037 | 2091 | 78 | 3.730 |
| Social Proof/Consensus | 2091 | 84 | 4.017 | 1863 | 93 | 4.992 |
| Liking | 1799 | 73 | 4.058 | 2326 | 118 | 5.073 |
| Reciprocity | 2079 | 97 | 4.666 | 2223 | 103 | 4.633 |
| Scarcity | 1967 | 89 | 4.525 | 2395 | 102 | 4.259 |
| Fear | |||
|---|---|---|---|
| Impressions | Clicks | CTR | |
| Authority | 2012 | 84 | 4.175 |
| Commitment | 1718 | 88 | 5.122 |
| Social Proof/Consensus | 1802 | 82 | 4.550 |
| Liking | 1988 | 101 | 5.080 |
| Reciprocity | 1845 | 57 | 3.089 |
| Scarcity | 1703 | 52 | 3.053 |
| Joy | Trust | Pride | Anticipation | Fear |
|---|---|---|---|---|
| 1. Liking | 1. Commitment | 1. Reciprocity | 1. Liking | 1. Commitment |
| 2. Scarcity | 2. Liking | 2. Scarcity | 2. Social Proof/Consensus | 2. Liking |
| 3. Social Proof/Consensus | 3. Social Proof/Consensus | 3. Authority | 3. Reciprocity | 3. Social Proof/Consensus |
| 4. Commitment | 4. Authority | 4. Liking | 4. Scarcity | 4. Authority |
| 5. Authority | 5. Reciprocity | 5. Commitment | 5. Authority | 5. Reciprocity |
| 6. Reciprocity | 6. Scarcity | 6. Social Proof/Consensus | 6. Commitment | 6. Scarcity |
| Emotion | Impressions | Clicks | ctr | % Increase in Emotion’s ctr vs. Control’s ctr | |
|---|---|---|---|---|---|
| Pride | Achievement | 27,988 | 1484 | 5.302% | 31% |
| Exclusivity | 31,378 | 1485 | 4.733% | 17% | |
| Luck | 29,932 | 1386 | 4.630% | 14% | |
| Trust | Safety | 31,276 | 1413 | 4.518% | 12% |
| Gratitude | 28,244 | 1308 | 4.631% | 14% | |
| Intimacy | 29,788 | 1697 | 5.697% | 41% | |
| Joy | Excitement | 31,504 | 1069 | 3.393% | −16% |
| Fascination | 31,804 | 1278 | 4.018% | −1% | |
| Gratification | 29,524 | 1122 | 3.800% | −6% | |
| Fear | Attention | 29,571 | 1407 | 4.758% | 17% |
| Urgency | 28,184 | 1257 | 4.460% | 10% | |
| Regret | 28,206 | 1022 | 3.623% | −11% | |
| Anticipation | Challenge | 28,992 | 1132 | 3.905% | −4% |
| Curiosity | 29,068 | 1314 | 4.520% | 12% | |
| Encouragement | 31,708 | 1255 | 3.958% | −2% | |
| Control Message | 27,674 | 1121 | 4.051% | 0% | |
| Emotion | Impressions | Clicks | Reservations | rrt | % Increase in Emotion’s rrt vs. Control’s rrt | |
|---|---|---|---|---|---|---|
| Pride | Achievement | 27,988 | 1484 | 54 | 3.639% | 36% |
| Exclusivity | 31,378 | 1485 | 51 | 3.434% | 28% | |
| Luck | 29,932 | 1386 | 36 | 2.597% | −3% | |
| Trust | Safety | 31,276 | 1413 | 33 | 2.335% | −13% |
| Gratitude | 28,244 | 1308 | 39 | 2.982% | 11% | |
| Intimacy | 29,788 | 1697 | 66 | 3.889% | 45% | |
| Joy | Excitement | 31,504 | 1069 | 36 | 3.368% | 26% |
| Fascination | 31,804 | 1278 | 33 | 2.582% | −4% | |
| Gratification | 29,524 | 1122 | 39 | 3.476% | 30% | |
| Fear | Attention | 29,571 | 1407 | 60 | 4.264% | 59% |
| Urgency | 28,184 | 1257 | 45 | 3.580% | 34% | |
| Regret | 28,206 | 1022 | 33 | 3.229% | 21% | |
| Anticipation | Challenge | 28,992 | 1132 | 30 | 2.650% | −1% |
| Curiosity | 29,068 | 1314 | 45 | 3.425% | 28% | |
| Encouragement | 31,708 | 1255 | 39 | 3.108% | 16% | |
| Control Message | 27,674 | 1121 | 30 | 2.676% | 0% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Remountakis, M.; Kotis, K.; Kourtzis, B.; Tsekouras, G.E. Using ChatGPT and Persuasive Technology for Personalized Recommendation Messages in Hotel Upselling. Information 2023, 14, 504. https://0-doi-org.brum.beds.ac.uk/10.3390/info14090504
Remountakis M, Kotis K, Kourtzis B, Tsekouras GE. Using ChatGPT and Persuasive Technology for Personalized Recommendation Messages in Hotel Upselling. Information. 2023; 14(9):504. https://0-doi-org.brum.beds.ac.uk/10.3390/info14090504
Chicago/Turabian StyleRemountakis, Manolis, Konstantinos Kotis, Babis Kourtzis, and George E. Tsekouras. 2023. "Using ChatGPT and Persuasive Technology for Personalized Recommendation Messages in Hotel Upselling" Information 14, no. 9: 504. https://0-doi-org.brum.beds.ac.uk/10.3390/info14090504