1. Introduction
With the rapid development of Internet technology, people are exposed to vast amounts of text information every day such as news, blogs, reports, papers, etc. When we are faced with a large amount of disorganized information, quickly and accurately locating the required information becomes a problem to be solved. Automatic text summarization provides an efficient solution to this task. Text summarization can create a shorter version containing the main idea of the source text automatically. We can judge whether an article is interesting to us based on the shorter version. This can greatly reduce the time consumed in retrieving information.
Text summarization is generally divided into two branches, namely, extractive and abstractive. Extractive summarization selects some sentences from the source text to compose a summary. Abstractive summarization is based on the semantics of the source text to generate novel sentences as the summary. Abstractive summarization is thus more difficult than copying sentences from the source text, and most of the work in the past has been focused on extractive summarization [
1,
2,
3,
4].
However, in recent years, abstractive summarization based on deep learning has also made great progress. The current popular abstractive model is mostly carried out under the framework of encoder and decoder. In order to improve the accuracy of the decoder, Bahdanau et al. [
5] added an attention mechanism to the encoder-decoder framework and produced state-of-the-art performance in machine translation (MT). Due to the similarities between MT and text summarization, the subsequent text summarization follows the model of MT. Under the framework, the encoder reads the source text and understands the semantics of the text, the decoder generates summary words, and the attention mechanism is responsible for aligning the input and the output information to make the output more reliable. Despite the similarities, abstractive summarization is a very different problem from MT. The decoder must receive all contents of the source text in MT, however, in text summarization, the decoder only needs the important information from the source text to generate a summary. Humans also write summaries like this. Before the summary is generated, the important information is first extracted, and then during the process of writing a summary, only the important information is considered. A good summary should be concise and have high saliency, namely, containing more key information. However, based on the current abstractive model, the summary generation is based on all contents of the source text. Under this condition, when the source text contains plenty of information irrelevant to the summary, the encoder cannot correctly represent the semantics of the text. This means that the decoder is influenced by this irrelevant information, thereby resulting in the saliency of the summary declining. As shown in
Figure 1, the generated summary has poor saliency.
Based on the above discussion, in order to reduce the interference of the irrelevant information for the decoder, thereby improving the saliency of generated summary, this paper proposes an attentive information extraction model. This model is also proposed with reference to the way that humans write summaries. During the process of people writing a summary, they first read and understand the source text; then they will outline the important information and filter the information that is useless to the summary; next, they compare the important information with true semantics to ensure that the outlined information is correct; finally, they will write summaries. The current attentional encoder-decoder model is able to read and understand the source text as well as write a summary. However, preliminarily outlining the important information and ensuring the correctness of important information have not been realized. Thus, we firstly use an extra attention mechanism, namely, a multi-layer perceptron (MLP) network, to obtain the important information after the encoder and before the decoder. The important information is the skeleton of the source text. Furthermore, the semantic information between the reference summary and the source text is consistent, so we calculate semantic similarity scores between the reference summary and the extracted important information to ensure the correctness of the extracted information. In order to further enhance the ability of the MLP network, we maximize the similarity score to encourage high semantic similarity between the reference summary and the source text. As one of the targets of the abstractive model is to maximize the probability of target words, we think the decoder has good writing ability. We skip the decoder to maximize the score so that the encoder’s semantic expression capabilities and the ability of the MLP network to extract information are improved as much as possible without affecting the ability of the decoder writing a summary. Our model extracts the important information before the decoder and the decoder generates summaries according to the important information. It cannot be influenced by the irrelevant information, therefore it can capture the main idea of the source text more completely and accurately, thus the saliency of the summary is higher.
We conduct experiments on the CNN/Daily Mail and DUC-2004 datasets. Our model achieved a 42.01 ROUGE-1 f-score and 33.94 ROUGE-1 recall, respectively, and outperformed the state-of-the-art abstractive model on the same datasets. In addition, by anonymous and subjective human evaluation, the saliency of the summary generated by our model was further enhanced. The readability of the summary generated by our model was stronger than the baseline model.
2. Related Work
The current abstractive model was carried out based on an encoder-decoder model [
6]. This model was originally used in the field of MT. In order to improve the accuracy of the decoder, Bahdanau et al. [
5] added the attention mechanism to the model and obtained state-of-the-art results in MT. Due to the strong similarity between text summarization and MT tasks, the current popular text summarization models mostly followed this structure.
In the early days of text summarization studies, most of the work was done around extractive summarization [
1,
2,
3,
4,
7,
8,
9]. However, in recent years, the study of text summarization mainly focused on abstractive summarization. Rush et al. [
10] proposed a data-driven network model to generate summaries. They used the convolutional neural network (CNN) to encode the source text and used a neural language model to decode a summary. State-of-the-art results were obtained on the DUC-2004 and Gigawords datasets. In an extension of this work, Chopra et al. [
11] used Recurrent neural network (RNN) instead of the neural language model in the decoder, resulting in further improvement in the datasets. As RNN can better represent serialized data, Nallapati et al. [
12] implemented both the encoder and the decoder using a RNN and constructed a multi-sentence summarization of the dataset CNN/Daily Mail.
Under the framework of an attentional encoder and decoder, researchers began to solve the problem of repeatability, poor readability, and out-of-vocabulary (OOV) words. Vinyals et al. [
13] used the pointer mechanism in the encoder-decoder network model to solve the OOV problem. Experiments have proved that the mechanism can achieve good results. Gu et al. [
14], Gulcehre et al. [
15], and Nallapati et al. [
12] also adopted the pointer mechanism on abstractive summarization to solve the OOV problem. See et al. [
16] used a similar mechanism to generate summaries. In order to solve the problem of repeatability, the coverage mechanism [
17] was introduced. Experiments achieved state-of-the-art results on the CNN/Daily Mail datasets. Suzuki et al. [
18] mitigated the repeatability of summaries by evaluating the upper bound frequency of each target word in the encoder and controlling the output word in the decoder. Nema et al. [
19] dealt with the sentences input into the model so that they were orthogonal to each other, thereby reducing the repeatability of the generated summaries. Li et al. [
20] added latent structured information to the decoder and introduced an editing vector [
21] to edit the generated summary, thereby enhancing the readability of the summary. Recently, Paulus et al. [
22] applied reinforcement learning (RL) to generate a summary and adopted the attention mechanism inside the decoder.
In addition, Xu [
23] used a multi-layer perceptron (MLP) model inside the encoder to predict the weight of each sentence in the source text. This model reduced the interference of irrelevant sentences when generating summaries. Zhou et al. [
24] also adopted a MLP model after the encoder to weaken the irrelevant information and improve the model performance. Ma et al. [
25] added a similarity comparison module between the generated summaries and the original text after the decoder to improve the semantic relevance of the summary. Ma et al. [
26] combined text sentiment classification with text summarization tasks and proposed a hierarchical end-to-end model with a highway network, which achieved good experimental results on the Amazon online review dataset. In another experiment by Ma et al. [
27], they proposed a supervised learning model to improve the ability of encoder text representation, thereby improving the result of summarization. Hsu et al. [
28] combined extractive and abstractive summarization to generate a summary, this improved the informativity and readability of summaries. Lin et al. [
29] controlled the information flow from encoder to decoder to improve the semantic relevance of the summary. Li et al. [
30] also combined extractive with abstractive models to generate summaries and improve the informativity of the summary. Celikyilmaz et al. [
31] presented deep communicating agents in an encoder-decoder architecture to address the challenges of representing a long document for abstractive summarization. Under the conditions of solving the problem of OOV words and repeatability, our model refers to the idea of Zhou et al. [
24], adopting an extra attention mechanism to extract the important information. In order to ensure the correctness of the extracted information and enhance the ability of extra attention mechanisms, we calculate semantic similarity between the reference summary and the extracted information, and maximize the similarity score to encourage high similarity between the reference summary and the extracted information. Experiments show that our model outperformed the state-of-the-art abstractive model and the saliency of the summary generated by our model was further enhanced.
Author Contributions
X.X. conceived the idea, performed the experiments and wrote the paper. Y.W. provided the ideas for the experiments. L.J. helped build the experimental environment. G.X., X.F. and L.W. provided writing guidance. Besides, Y.W. and L.J. also helped revise the paper.
Funding
This work was funded by the Pre-research Project (Grant No.: 31510010502), and the Research of Nuclear emergency Application Technology and Application Demonstration (Grant No.: 41-Y30B12-9001-17/18).
Acknowledgments
We are thankful to Key Laboratory of Spatial Information Processing and Applied System Technology, Chinese Academy of Sciences for providing support in the experimental condition. Thanks for Hermann et al. to provide the raw data. And thanks for all authors to their efforts.
Conflicts of Interest
The authors have no relevant financial interests in this article and no potential conflicts of interest to disclose. Research data is some public datasets.
References
- Cheng, J.; Lapata, M. Neural summaryzation by extracting sentences and words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 484–494. [Google Scholar]
- Cao, Z.; Chen, C.; Li, W.; Li, S.; Wei, F.; Zhou, M. TGSum: Build Tweet Guided Multi-Document Summarization Dataset. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2906–2912. [Google Scholar]
- Yang, Y.; Bao, F.; Nenkova, A. Detecting (un) important content for single-document news summarization. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; pp. 707–712. [Google Scholar]
- Isonuma, M.; Fujino, T.; Mori, J.; Matsuo, Y.; Sakata, I. Extractive summarization using multi-task learning with document classification. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2101–2110. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv, 2014; arXiv:1409.0473. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems Conference, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Cao, Z.; Wei, F.; Dong, L.; Li, S.; Zhou, M. Ranking with Recursive Neural Networks and Its Application to Multi-Document Summarization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–29 January 2015; pp. 2153–2159. [Google Scholar]
- Nallapati, R.; Zhai, F.; Zhou, B. SummaRuNNer: A Recurrent Neural Network Based Sequence Model for Extractive Summarization of Documents. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017; pp. 3075–3081. [Google Scholar]
- Cao, Z.; Li, W.; Li, S.; Wei, F.; Li, Y. Attsum: Joint learning of focusing and summarization with neural attention. arXiv, 2016; arXiv:1604.00125. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A neural attention model for abstractive sentence summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 379–389. [Google Scholar]
- Chopra, S.; Auli, M.; Rush, A.M. Abstractive sentence summarization with attentive recurrent neural networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 93–98. [Google Scholar]
- Nallapati, R.; Zhou, B.; Gulcehre, C.; Xiang, B. Abstractive text summarization using sequence-to-sequence rnns and beyond. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 280–290. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. In Proceedings of the Advances in Neural Information Processing Systems Conference, Montreal, QC, Canada, 7–12 December 2015; pp. 2692–2700. [Google Scholar]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O. Incorporating copying mechanism in sequence-to-sequence learning. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1631–1640. [Google Scholar]
- Gulcehre, C.; Ahn, S.; Nallapati, R.; Zhou, B.; Bengio, Y. Pointing the unknown words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 140–149. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1073–1083. [Google Scholar]
- Tu, Z.; Lu, Z.; Liu, Y.; Liu, X.; Li, H. Modeling coverage for neural machine translation. arXiv, 2016; arXiv:1601.04811. [Google Scholar]
- Suzuki, J.; Nagata, M. Cutting-off Redundant Repeating Generations for Neural Abstractive Summarization. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; pp. 291–297. [Google Scholar]
- Nema, P.; Khapra, M.; Laha, A.; Ravindran, B. Diversity driven attention model for query-based abstractive summarization. arXiv, 2017; arXiv:1704.08300. [Google Scholar]
- Li, P.; Lam, W.; Bing, L.; Wang, Z. Deep Recurrent Generative Decoder for Abstractive Text Summarization. arXiv, 2017; arXiv:1708.00625. [Google Scholar]
- Guu, K.; Hashimoto, T.B.; Oren, Y.; Liang, P. Generating Sentences by Editing Prototypes. arXiv, 2017; arXiv:1709.08878. [Google Scholar]
- Paulus, R.; Xiong, C.; Socher, R. A deep reinforced model for abstractive summarization. arXiv, 2017; arXiv:1705.04304. [Google Scholar]
- Xu, J. Improving Social Media Text Summarization by Learning Sentence Weight Distribution. arXiv, 2017; arXiv:1710.11332. [Google Scholar]
- Zhou, Q.; Yang, N.; Wei, F.; Zhou, M. Selective encoding for abstractive sentence summarization. arXiv, 2017; arXiv:1704.07073. [Google Scholar]
- Ma, S.; Sun, X.; Xu, J.; Wang, H.; Li, W.; Su, Q. Improving semantic relevance for sequence-to-sequence learning of Chinese social media text summarization. arXiv, 2017; arXiv:1706.02459. [Google Scholar]
- Ma, S.; Sun, X.; Lin, J.; Ren, X. A Hierarchical End-to-End Model for Jointly Improving Text Summarization and Sentiment Classification. arXiv, 2018; arXiv:1805.01089. [Google Scholar]
- Ma, S.; Sun, X.; Lin, J.; Wang, H. Autoencoder as Assistant Supervisor: Improving Text Representation for Chinese Social Media Text Summarization. arXiv, 2018; arXiv:1805.04869. [Google Scholar]
- Hsu, W.T.; Lin, C.K.; Lee, M.Y.; Min, K.; Tang, J.; Sun, M. A Unified Model for Extractive and Abstractive Summarization using Inconsistency Loss. arXiv, 2018; arXiv:1805.06266. [Google Scholar]
- Lin, J.; Sun, X.; Ma, S.; Su, Q. Global Encoding for Abstractive Summarization. arXiv, 2018; arXiv:1805.03989. [Google Scholar]
- Li, C.; Xu, W.; Li, S.; Gao, S. Guiding Generation for Abstractive Text Summarization Based on Key Information Guide Network. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 55–60. [Google Scholar]
- Celikyilmaz, A.; Bosselut, A.; He, X.; Choi, Y. Deep communicating agents for abstractive summarization. arXiv, 2018; arXiv:1803.10357. [Google Scholar]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. In Proceedings of the Advances in Neural Information Processing Systems Conference, Montreal, QC, Canada, 7–12 December 2015; pp. 1693–1701. [Google Scholar]
- Over, P.; Dang, H.; Harman, D. DUC in context. Inf. Process. Manag. 2007, 43, 1506–1520. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Workshop on Text Summarization Branches Out, Post-Conference Workshop of ACL 2004, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Fan, A.; Grangier, D.; Auli, M. Controllable Abstractive Summarization. arXiv, 2017; arXiv:1711.05217. [Google Scholar]
- Li, P.; Bing, L.; Lam, W. Actor-critic based training framework for abstractive summarization. arXiv, 2018; arXiv:1803.11070. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.S.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
Figure 1.
An example of abstractive text summarization. Green font is the key information in the source text. Red font is the key information obtained by current abstractive model.
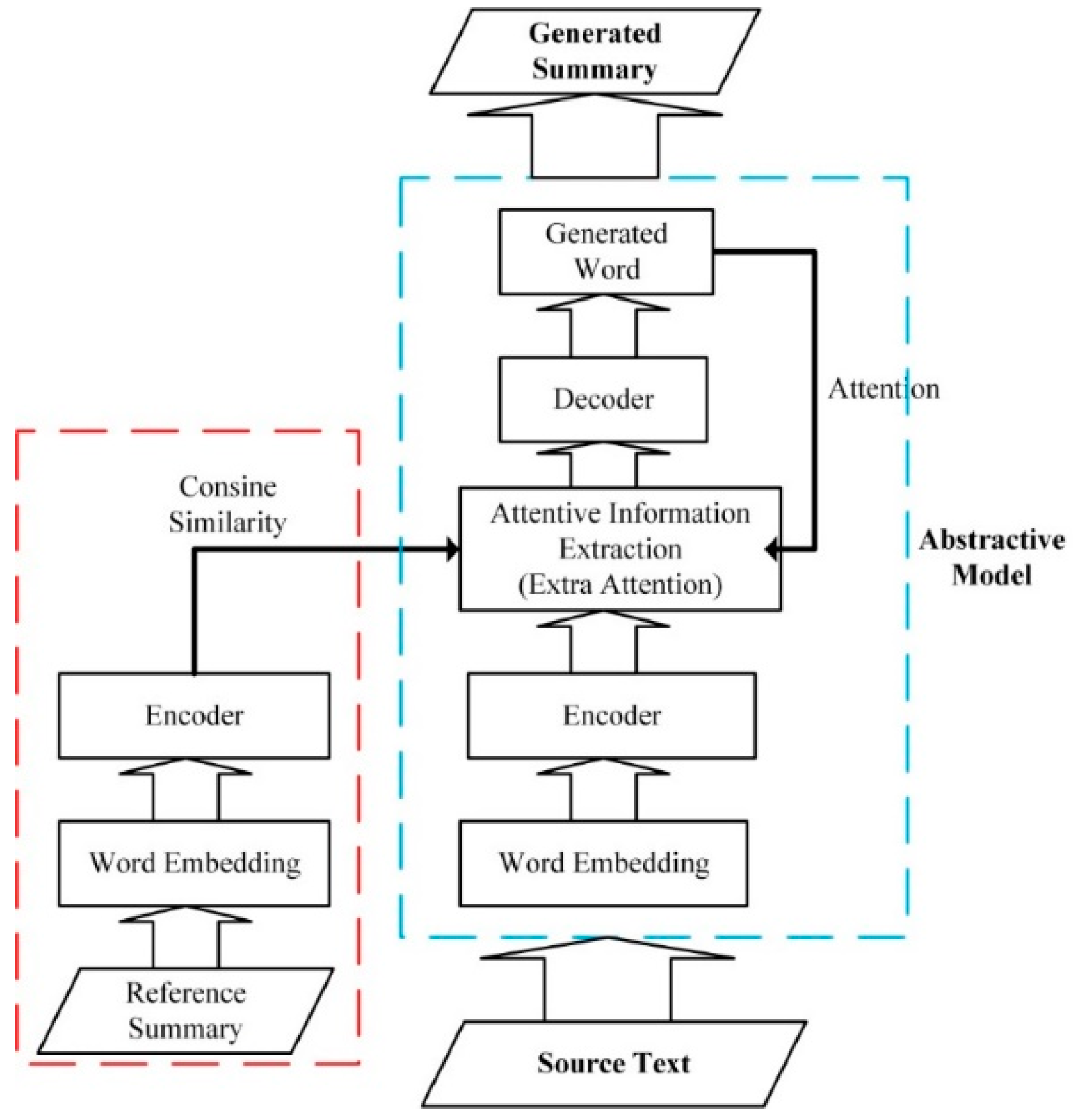
Figure 2.
The flow diagram of our model. At the training stage, the Generated Summary in the figure does not exist. Our target is to train an abstractive model, namely, the part drawn by the blue dotted line. At the test stage, our input is only the source text and the part represented by the red dotted line does not exist, the output is the summary generated using the abstractive model.
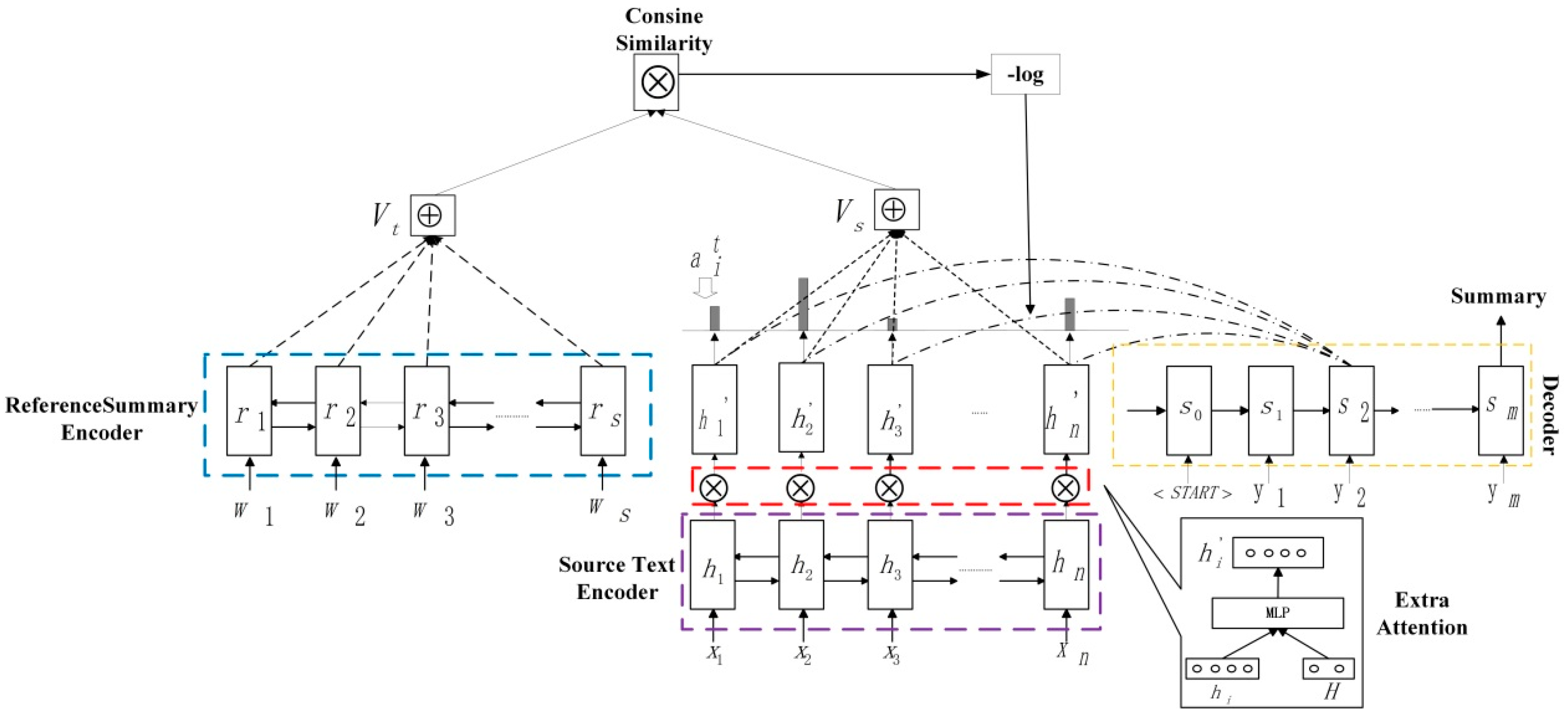
Figure 3.
Our proposed model. Before the decoder, an extra attention mechanism is used to extract important information and compare the similarity of the reference summary and the extracted information to ensure the correctness of the necessary information. In order to enhance the ability of the extra attention mechanism in extracting information, the similarity score is fed back to the network, skipping the decoder.
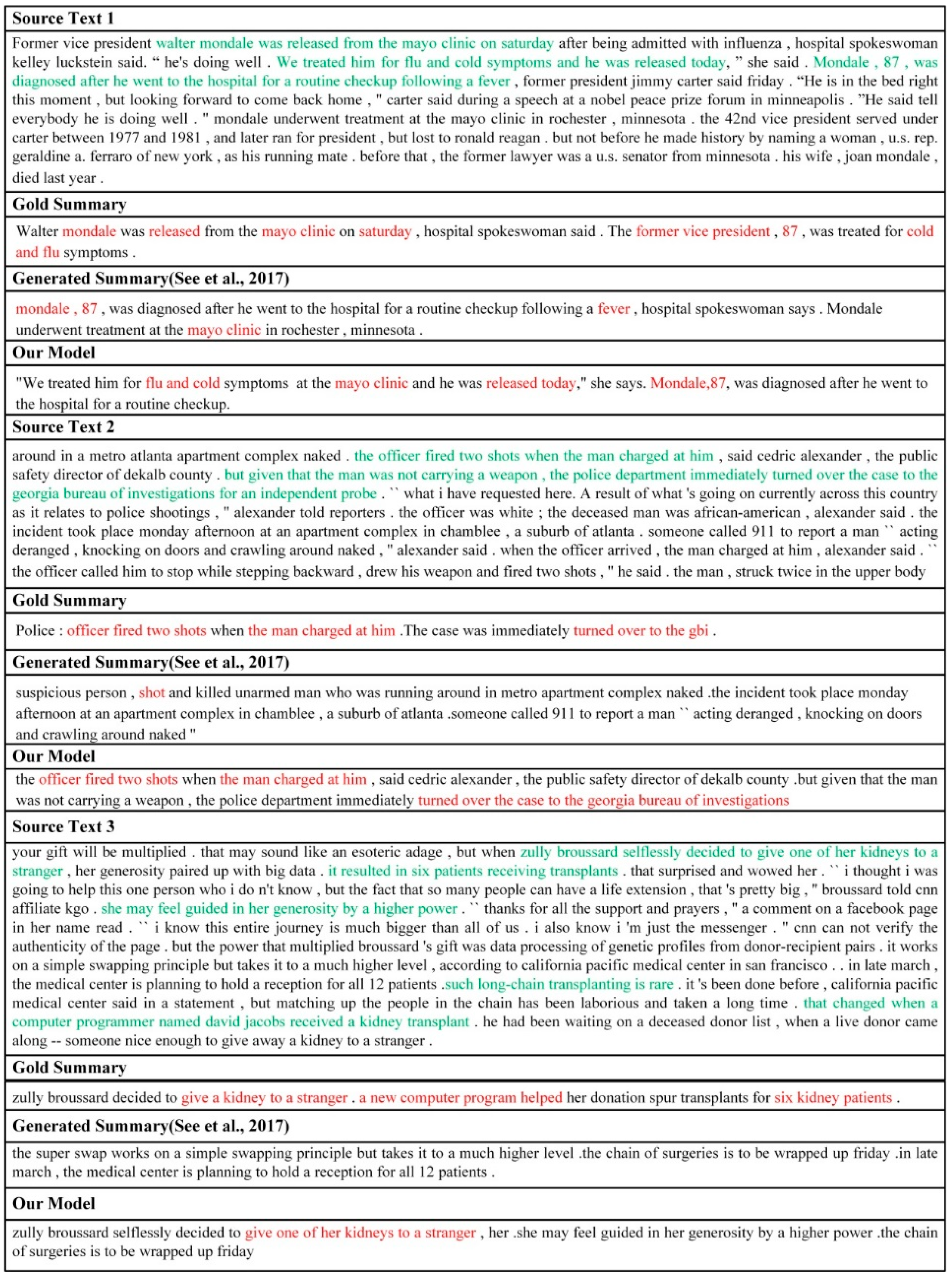
Figure 4.
Examples of abstractive summarization. Green font is the key information of the source text and red font represents the effective information generated by the abstractive model. The source text (1–3) represents original texts, the gold summary is the reference summary, the generated summary is the summary by the model of See et al. [
16] and our model represents the summary by our proposed model.
Figure 5.
The weight heat map. The word in the picture is the source text. The darker color has greater weight and corresponding word is more important. The reference summary was “Cambodian government rejects opposition’s call for talks abroad”. The generated summary by our model was “Cambodian leader Hun Sen rejected opposition parties demands for talks outside the country”.
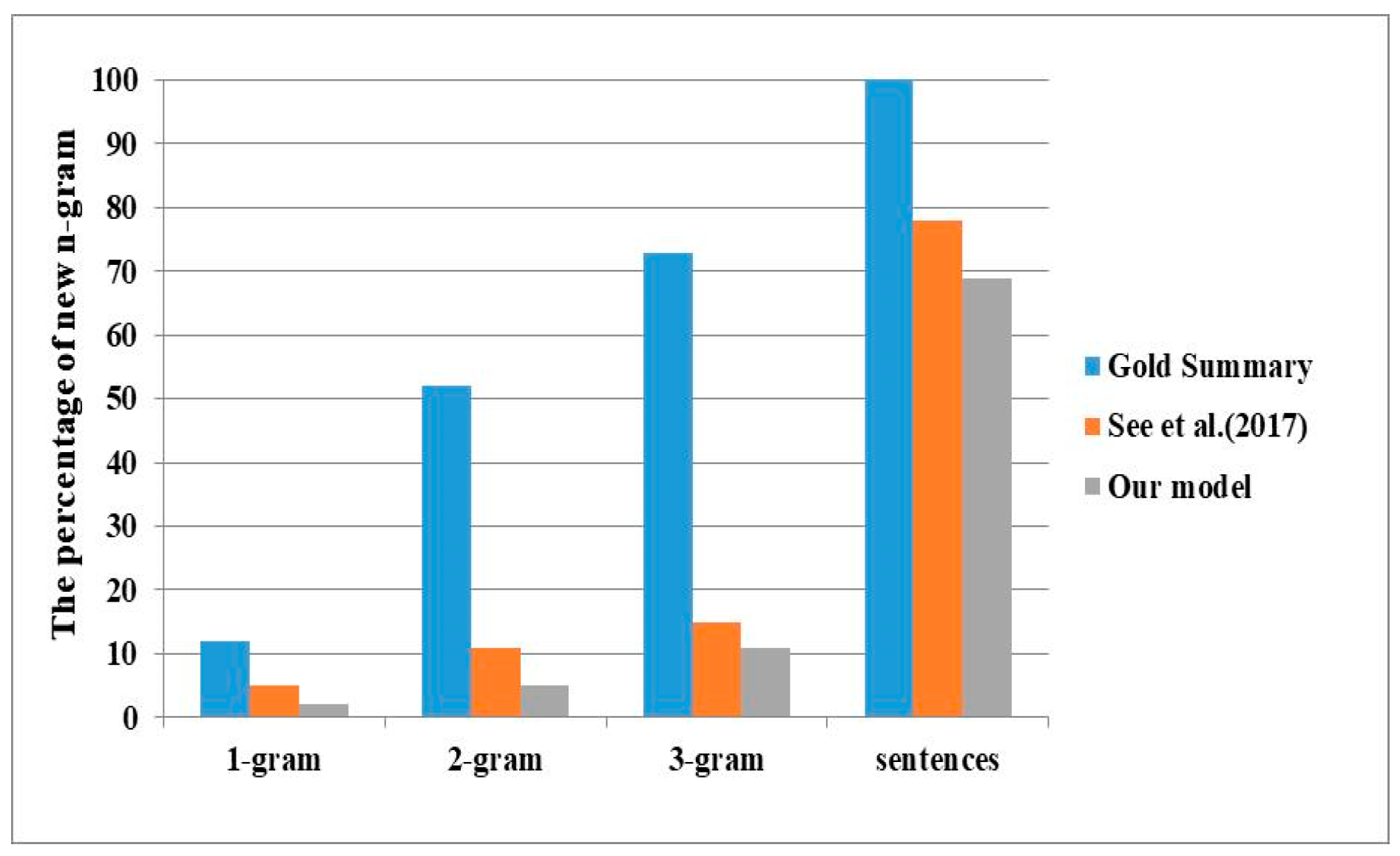
Figure 6.
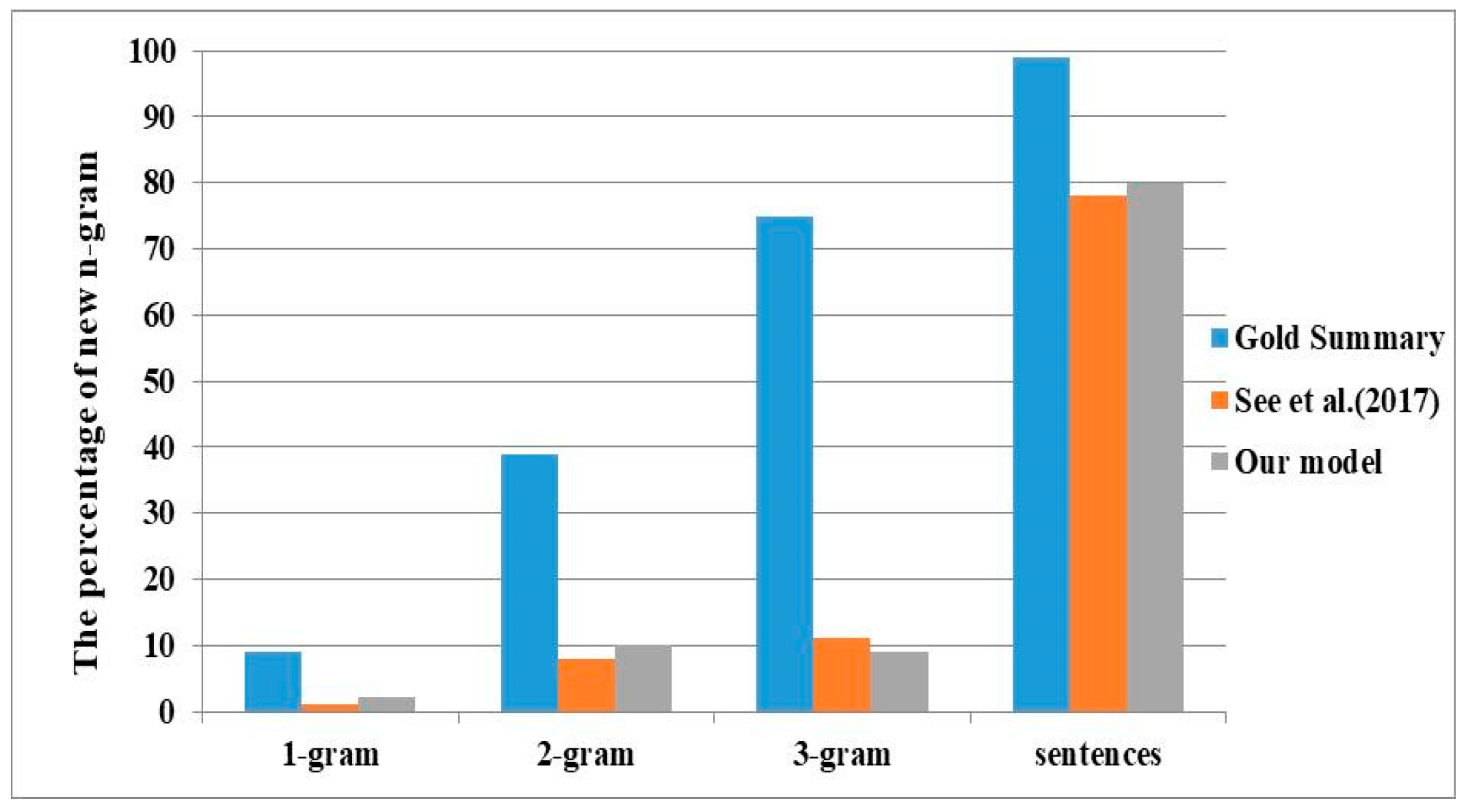
The percentage of new n-grams for CNN/Daily Mail. Larger percentage indicates stronger abstraction.
Figure 7.
The percentage of new n-grams for DUC 2004. Larger percentage indicates stronger abstraction.
Table 1.
Our model parameters at the training stage. Max_enc_steps and Max_dec_steps are the allowed maximum length of the source text input encoder and the generated summary, respectively.
| Model Parameters | Values |
|---|
| Hidden dimension | 256 |
| Embedding dimension | 128 |
| Vocabulary size | 50K |
| Max_enc_steps | 400 |
| Max_dec_steps | 100 |
| Batch size | 16 |
| Beam size | 4 |
| Learning rate | 0.15 |
| 1 |
| 0.001 |
Table 2.
Saliency scoring criteria. Relevance indicates the informativity of the summary by the model (our model or See et al. [
16] model). Score is from 0 to 5 and higher scores are better. Higher score indicates higher saliency.
| Relevance | Score |
|---|
| No relevance | 0 |
| Little relevance | 1 |
| A little relevance | 2 |
| Relevance | 3 |
| A lot of relevance | 4 |
| Great relevance | 5 |
Table 3.
Readability Scoring Criteria. Higher score indicates stronger readability. Score is from 1 to 5 and higher scores are better.
| Syntax | Grammar | Score |
|---|
| Very Poor | Very Bad | 1 |
| Poor | Bad | 2 |
| Barely Acceptable | Barely Acceptable | 3 |
| Good | Good | 4 |
| Very good | Very Good | 5 |
Table 4.
ROUGE F1 on CNN/Daily Mail. All our ROUGE scores have a 95% confidence interval in the official ROUGE script.
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|
| Maximum Likelihood | | | |
| Words-lv2k-temp-att | 35.46 | 13.30 | 32.65 |
| Pointer-Generator + Coverage | 39.53 | 17.28 | 36.38 |
| ML, with intra-attention | 38.30 | 14.81 | 35.49 |
| Controlled summarization | 39.75 | 17.29 | 36.54 |
| End2end w/inconsistency loss | 40.68 | 17.97 | 37.13 |
| Attentive Information Extraction (Ours) | 42.01 | 20.09 | 38.78 |
| Reinforcement Learning | | | |
| DCA MLE + SEM | 41.11 | 18.21 | 36.03 |
| DCA MLE + SEM + RL | 41.69 | 19.47 | 37.92 |
Table 5.
ROUGE recall on DUC-2004. All our ROUGE scores have a 95% confidence interval in the official ROUGE script.
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|
| ABS+ | 28.18 | 8.49 | 23.81 |
| Words-lv5k-1sent | 28.61 | 9.42 | 25.24 |
| C2R + Atten | 28.97 | 8.26 | 24.06 |
| SEASS | 29.21 | 9.56 | 25.51 |
| AC-ABS | 32.03 | 10.99 | 27.86 |
| Attentive Information Extraction (Ours) | 33.94 | 8.99 | 28.44 |
Table 6.
Saliency evaluation results. See et al. [
16] is the summary generated by the model of See et al. [
16] and our model is the summary generated by our model.
| Summary | Evaluator 1 | Evaluator 2 | Evaluator 3 | Average Score |
|---|
| See et al. [16] | 3 | 2.86 | 3.22 | 3.03 |
| Our model | 3.5 | 3.12 | 3.36 | 3.33 |
Table 7.
Readability evaluation results. See et al. [
16] is the summary generated by the model of See et al. [
16] and our model is the summary generated by our model. A/B: A represents the score of the syntax and B indicates the score of the grammar.
| Summary | Evaluator 1 | Evaluator 2 | Evaluator 3 | Average Score |
|---|
| See et al. [16] | 4.23/2.97 | 4.09/3.01 | 4.50/3.22 | 4.27/3.07 |
| Our model | 4.31/3.08 | 4.28/3.20 | 4.71/3.53 | 4.43/3.27 |
Table 8.
Results for DUC-2004. +Max_dec_steps (25/30/35) represents setting different lengths for Max_dec_steps.
| Our Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|
| +Max_dec_steps 25 | 33.94 | 8.99 | 28.44 |
| +Max_dec_steps 30 | 36.96 | 9.75 | 30.69 |
| +Max_dec_steps 35 | 39.14 | 10.26 | 32.17 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}