Intelligence IS Cognitive Flexibility: Why Multilevel Models of Within-Individual Processes Are Needed to Realise This


Abstract
:1. Introduction
Overview
2. Part 1: Building a Case for Intelligence as Cognitive Flexibility
2.1. Entrenched Assumptions
2.1.1. Supposition of Stability
2.1.2. The Ergodic Assumption: History Tells Us Correlations Are Not Enough; Logic Tells Us They Never Were
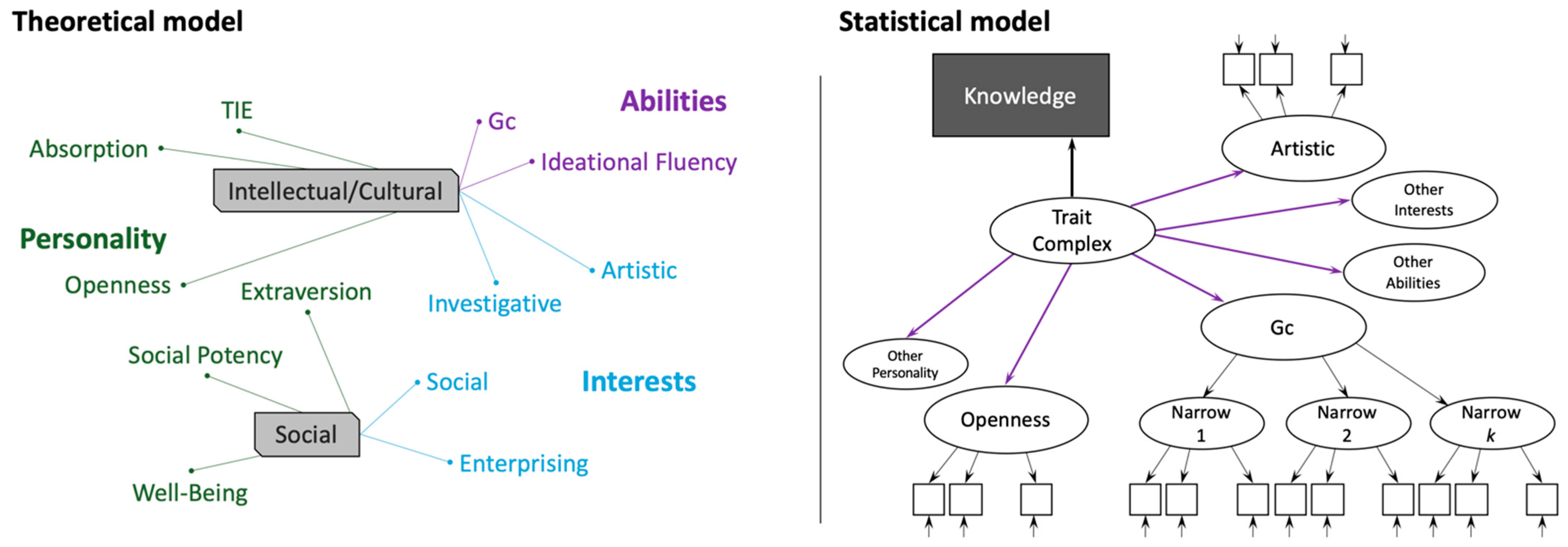
2.1.3. Ontological Status of Reflective vs. Causal- and Composite-Formative Concepts
2.2. Summary of Part 1: Why Intelligence Theorising Has Survived However, Failed to Thrive
3. Part 2: Requirements for A Within-Person Approach to Intelligence
“It is true that the components of individual differences have often been interpreted in terms of cognitive processes, but such an interpretation does not logically follow. The interpretation is necessarily a post hoc interpretation based on the assumptions that processes are directly reflected in individual differences in performances and that correlation between performances defining a factor indicates that a common process is involved.”
3.1. Process-Oriented Accounts
3.1.1. Complexity as the “Ingredient” Process of Intelligence
Complexity vs. Difficulty
3.1.2. Working-Memory Accounts of Intelligence
3.1.3. Relational Binding and Integration Accounts of Intelligence
3.2. Summary of Part 2: Why WM Theory Is Important to Within-Person Process Accounts
4. Part 3: Theory through Task Analysis
4.1. Static Tasks
4.1.1. Theoretically Substantiated Within-Task Manipulation
4.1.2. Within-Task “Interposition”
4.2. Dynamic Tasks
4.2.1. Set-Switching and Card Sorting
4.2.2. Complex Problem Solving (CPS) and Microworlds
4.3. Summary of Part 3: Why Task-Analysis Is Important
5. Part 4: A Case for Multilevel Models in Intelligence Research
5.1. Cognitive Flexibility as Contingent Level 1 Variability in MLM Models
5.1.1. Within- and Between-Individual Parameters of Intelligence as Flexibility
5.1.2. Statistical Advantages of MLM
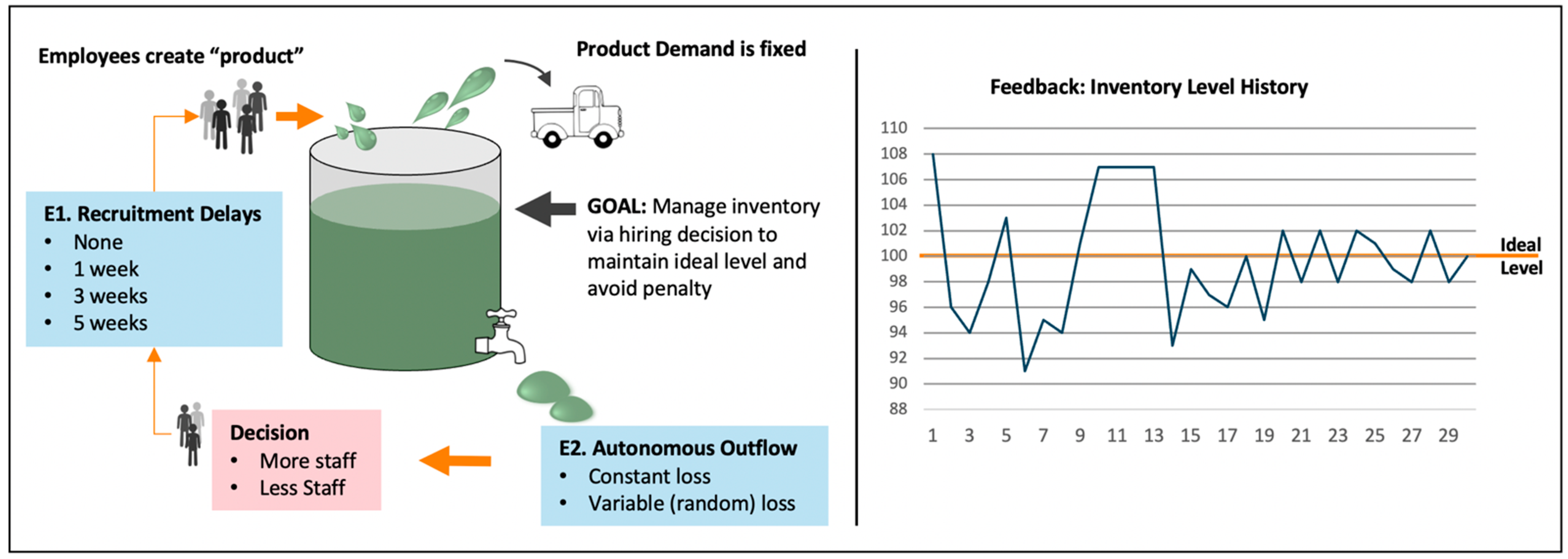
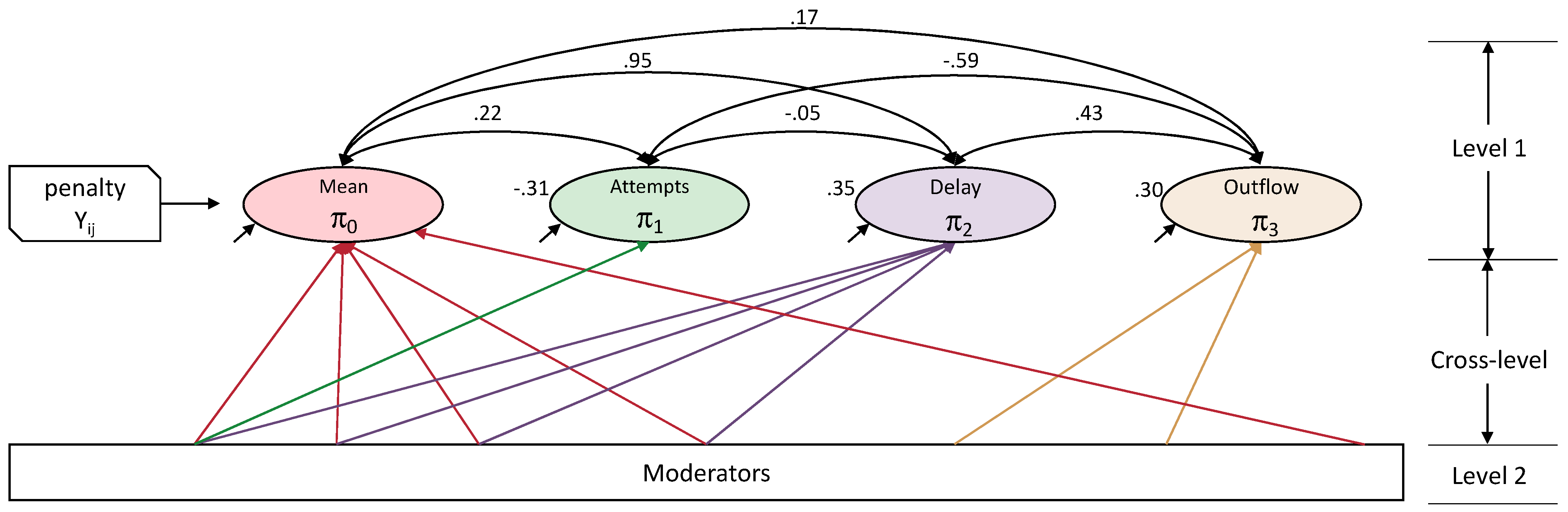
5.2. Microworld Contingency Parameters as Indicators of Cognitive Flexibility: A Case Study
5.3. Summary of Part 4: Why Multilevel Models Are Important
6. Implications and Final Considerations
6.1. Beyond Fluid Intelligence: Why Flexibility Is Relevant to Intelligence Generally, and Other CHC Factors
6.2. Beyond Novelty Processing: Why Flexibility Is Relevant to Routine Reasoning and Cognitive-Capacity
6.3. Beyond Factor-Analysis: Why Methods Matter When Studying Flexibility
6.4. Beyond the Status Quo: The Implications of Getting It Wrong
6.5. Conclusion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1. | The (typically) unquestioned use of the term “manifest variables” to label observed variables is testament to the assumption that individual differences in scores on these variables are the outward manifestation of concomitant individual differences in the latent attribute. |
| 2. | While we prefer to reserve the term “measure” for variables where fundamental measurement properties have been demonstrated (see Michell 1990), in our view, conceiving them as latent variables that happen to have a useful coding metric is more appropriate (see Birney et al. 2022). |
| 3. | The trait-complex example also serves to demonstrate a second point made by Bollen and Diamantopoulos (2017), that reflective latent variables (e.g., extraversion, when appropriately conceived of) can act as composite-formative indicators in other models (such as of trait-complexes). |
| 4. | This is also not to say that with greater understanding, the status of concepts will necessarily move from formative to reflective. Some concepts, maybe most, are by nature and definition, formative. |
| 5. | According to Beckmann (2010; see also Birney et al. 2016) within the framework of person-task-situation interactions, the situation refers to the context or circumstances in which a task is performed. It constitutes a source of complexity in addition to the processing demands posed by the task itself and therefore contributes to the overall complexity and consequently impacts performance. The user-interface, the clarity of instructions, time pressure, or the semanticity of variable labels in a CPS system are examples for such situation components. |
| 6. | Of course, multidimensionality introduces other challenges to measurement that would need to be explicated in the theoretical model. |
| 7. | As well as covariates, as mentioned previously. |
References
- Ackerman, Phillip L. 1996. A theory of adult intellectual development: Process, personality, interests, and knowledge. Intelligence 22: 227–57. [Google Scholar] [CrossRef]
- Ackerman, Phillip L., Margaret E. Beier, and Mary O. Boyle. 2005. Working memory and intelligence: The same or different constructs? Psychological Bulletin 131: 30–60. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ackerman, Phillip L., and Eric D. Heggestad. 1997. Intelligence, personality, and interests: Evidence for overlapping traits. Psychological Bulletin 121: 219–45. [Google Scholar] [CrossRef] [PubMed]
- Ackerman, Phillip L., Ruth Kanfer, and Margaret. E. Beier. 2013. Trait complex, cognitive ability, and domain knowledge predictors of Baccalaureate success, STEM persistence, and gender differences. Journal of Educational Psychology 105: 911–27. [Google Scholar] [CrossRef] [Green Version]
- Arend, Isabel, Roberto Colom, Juan Botella, Maria José Contreras, Victor Rubio, and José Santacreu. 2003. Quantifying cognitive complexity: Evidence from a reasoning task. Personality and Individual Differences 35: 659–69. [Google Scholar] [CrossRef]
- Bateman, Joel E. 2020. Relational Integration in Working Memory: Determinants of Effective Task Performance and Links to Individual Differences in Fluid Intelligence. Sydney: University of Sydney. [Google Scholar]
- Bateman, Joel E., and Damian P. Birney. 2019. The link between working memory and fluid intelligence is dependent on flexible bindings, not systematic access or passive retention. Acta Psychologica 199: 1–12. [Google Scholar] [CrossRef] [PubMed]
- Bateman, Joel E., Damian P. Birney, and Vanessa Loh. 2017. Exploring functions of working memory related to fluid intelligence: Coordination and relational integration. In Proceedings of the 39th Annual Conference of the Cognitive Science Society. Edited by Glenn Gunzelmann, Andrew Howes, Thora Tenbrink and Eddy J. Davelaar. Austin, TX: Cognitive Science Society, pp. 1598–603. [Google Scholar]
- Bateman, Joel E., Kate A. Thompson, and Damian P. Birney. 2019. Validating the relation-monitoring task as a measure of relational integration and predictor of fluid intelligence. Memory & Cognition 47: 1457–68. [Google Scholar]
- Beckmann, Jens F. 1994. Lernen und komplexes Problemlösen. Ein Beitrag zur Konstruktvalidierung von Lerntests [Learning & Complex Problem Solving: A contribution to the validation of learning tests]. Berlin: Holos. [Google Scholar]
- Beckmann, Jens F. 2010. Taming a beast of burden: On some issues with the conceptualisation and operationalisation of cognitive load. Learning and Instruction 20: 250–64. [Google Scholar] [CrossRef]
- Beckmann, Jens F. 2014. The umbrella that is too wide and yet too small: Why Dynamic Testing has still not delivered on the promise that was never made. Journal of Cognitive Education and Psychology 13: 308–23. [Google Scholar] [CrossRef] [Green Version]
- Beckmann, Jens F. 2019. Heigh-Ho: CPS and the seven questions—Some thoughts on contemporary Complex Problem Solving research. Journal for Dynamic Decision Making 5: 1–5. [Google Scholar] [CrossRef]
- Beckmann, Jens F., Damian P. Birney, and Natssia Goode. 2017. Beyond psychometrics: The difference between difficult problem solving and complex problem solving. Frontiers in Psychology: Cognitive Science 8: 1739. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beckmann, Jens F., and Natassi Goode. 2013. The benefit of being naive and knowing it: The unfavourable impact of perceived context familiarity on learning in complex problem solving tasks. Instructional Science 41. [Google Scholar] [CrossRef] [Green Version]
- Beckmann, Jens F., and Jürgen Guthke. 1995. Complex problem solving, intelligence, and learning ability. In Complex Problem Solving: The European Perspective. Edited by Peter A. Frensch and Joachim Funke. New York: Psychology Press, pp. 177–200. [Google Scholar]
- Binet, Alfred. 1905. New methods for the diagnosis of the intellectual level of subnormals. L’Année Psychologique 12: 191–244, (Translated by Kite, Elizabeth S. (1916). The Development of Intelligence in Children. Vineland: Publications of the Training School at Vineland). [Google Scholar]
- Birney, Damian P. 2002. The Measurement of Task Complexity and Cognitive Ability: Relational Complexity in Adult Reasoning. Ph.D. dissertation, University of Queensland, St Lucia, Brisbane, Australia. [Google Scholar]
- Birney, Damian P., Jens F. Beckmann, and Nadin Beckmann. 2019. Within-individual variability of ability and learning trajectories in complex problems. In General and Specific Mental Abilities. Edited by Dennis McFarland. Newcastle upon Tyne: Cambridge Scholars Publishing. [Google Scholar]
- Birney, Damian P., Jens Beckmann, and Yuan-Zhi Seah. 2016. The eye of the beholder: Creativity ratings depend on task involvement, order and methods of evaluation, and personal characteristics of the evaluator. Learning and Individual Differences 51: 400–8. [Google Scholar] [CrossRef] [Green Version]
- Birney, Damian P., Jens F. Beckmann, Nadin Beckmann, and Kit S. Double. 2017. Beyond the intellect: Complexity and learning trajectories in Raven’s Progressive Matrices depend on self-regulatory processes and conative dispositions. Intelligence 61: 63–77. [Google Scholar] [CrossRef]
- Birney, Damian P., Jens F. Beckmann, Nadin Beckmann, Kit S. Double, and Karen Whittingham. 2018. Moderators of learning and performance trajectories in microworld simulations: Too soon to give up on intellect!? Intelligence 68: 128–40. [Google Scholar] [CrossRef]
- Birney, Damian P., Jens F. Beckmann, Nadin Beckmann, and Steven E. Stemler. 2022. Sophisticated statistics cannot compensate for method effects if quantifiable structure is compromised. Frontiers in Psychology: Quantitative Psychology and Measurement 13: 1–13. [Google Scholar] [CrossRef]
- Birney, Damian P., Jens F. Beckmann, Richard Morris, and Sally A. Cripps. 2021. Trajectories of spirals as cognitive flexibility during n-back training. International Journal of Psychophysiology 168: S34–S35. [Google Scholar] [CrossRef]
- Birney, Damian P., and David B. Bowman. 2009. An experimental-differential investigation of cognitive complexity. Psychology Science Quarterly 51: 449–69. [Google Scholar]
- Birney, Damian P., David B. Bowman, Jens F. Beckmann, and Yuan Seah. 2012. Assessment of processing capacity: Latin-square task performance in a population of managers. European Journal of Psychological Assessment 28: 216–26. [Google Scholar] [CrossRef]
- Birney, Damian P., and Graeme S. Halford. 2002. Cognitive complexity of suppositional reasoning: An application of the relational complexity metric to the knight-knave task. Thinking and Reasoning 8: 109–34. [Google Scholar] [CrossRef]
- Birney, Damian P., Graeme S. Halford, and Glenda Andrews. 2006. Measuring the Influence of Relational Complexity on Reasoning: The Development of the Latin Square Task. Educational and Psychological Measurement 66: 146–71. [Google Scholar] [CrossRef] [Green Version]
- Blair, Clancy. 2006. How similar are fluid cognition and general intelligence? A developmental neuroscience perspective on fluid cognition as an aspect of human cognitive ability. Behavioral and Brain Sciences 29: 109–60. [Google Scholar] [CrossRef] [PubMed]
- Bollen, Kenneth A., and Adamantios Diamantopoulos. 2017. In defense of causal-formative indicators: A minority report. Psychological Methods 22: 581–96. [Google Scholar] [CrossRef] [PubMed]
- Borsboom, Denny. 2015. What is causal about individual differences? : A comment on Weinberger. Theory & Psychology 25: 362–68. [Google Scholar]
- Borsboom, Denny, Gideon J. Mellenbergh, and Jaap van Heerden. 2003. The theoretical status of latent variables. Psychological Review 110: 203–19. [Google Scholar] [CrossRef] [Green Version]
- Borsboom, Denny, Gideon J. Mellenbergh, and Jaap van Heerden. 2004. The concept of validity. Psychological Review 111: 1061–71. [Google Scholar] [CrossRef] [PubMed]
- Brose, Annette, Andreas B. Neubauer, and Florian Schmiedek. 2021. Integrating state dynamics and trait change: A tutorial using the example of stress reactivity and change in well-being. European Journal of Personality 36: 180–99. [Google Scholar] [CrossRef]
- Burgess, Gregory C., Jeremy R. Gray, Andrew R. A. Conway, and Todd S. Braver. 2011. Neural mechanisms of interference control underlie the relationship between fluid intelligence and working memory span. Journal of Experimental Psychology: General 140: 674–92. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carpenter, Patricia A., Marcel A. Just, and Peter Shell. 1990. What one intelligence test measures: A theoretical account of the processing in the raven progressive matrices test. Psychological Review 97: 404–31. [Google Scholar] [CrossRef]
- Carroll, John B. 1993. Human Cognitive Abilities: A Survey of Factor-Analytic Studies. Cambridge: Cambridge University Press. [Google Scholar]
- Chuderski, Adam. 2014. The relational integration task explains fluid reasoning above and beyond other working memory tasks. Memory & Cognition 42: 448–463. [Google Scholar] [CrossRef] [Green Version]
- Conway, Andrew R. A., Kristof Kovacs, Han Hao, Kevin P. Rosales, and Jean-Paul Snijder. 2021. Individual differences in attention and intelligence: A united cognitive/psychometric approach. Journal of Intelligence 9: 34. [Google Scholar] [CrossRef] [PubMed]
- Cripps, Edward, Robert E. Wood, Nadin Beckmann, John Lau, Jens F. Beckmann, and Sally A. Cripps. 2016. Bayesian Analysis of Individual Level Personality Dynamics [Original Research]. Frontiers in Psychology 7: 1065. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cronbach, Lee J. 1957. The two disciplines of scientific psychology. American Psychologist 12: 671–84. [Google Scholar] [CrossRef]
- Daneman, Meredyth, and Patricia A. Carpenter. 1980. Individual differences in working memory and reading. Journal of Verbal Learning and Verbal Behaviour 19: 450–66. [Google Scholar] [CrossRef]
- De Boeck, Paul, Laurence Gore, Trinidad González, and Ernesto Martin. 2020. An alternative view on the measurement of intelligence and its history. In The Cambridge Handbook of Intelligence. Edited by Robert J. Sternberg. Cambridge: Cambridge University Press, pp. 44–74. [Google Scholar] [CrossRef]
- Deary, Ian J. 2001. Human intelligence differences: Towards a combined experimental-differential approach. Trends in Cognitive Sciences 5: 164–70. [Google Scholar] [CrossRef]
- Diamond, Adele. 2013. Executive Functions. Annual Review of Psychology 64: 135–68. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dörner, Dietrich. 1986. Diagnostik der operativen Intelligenz [Diagnosis of operative intelligence]. Diagnostica 32: 290–308. [Google Scholar]
- Dörner, Dietrich, and Joachim Funke. 2017. Complex problem solving: What It Is and what It Is not. Frontiers in Psychology 8: 1153. [Google Scholar] [CrossRef]
- Double, Kit S., and Damian P. Birney. 2019. Do confidence ratings prime confidence? Psychonomic Bulletin & Review 26: 1035–42. [Google Scholar] [CrossRef]
- Draheim, Christopher, Jason S. Tsukahara, Jessie D. Martin, Cody A. Mashburn, and Randall W. Engle. 2021. A toolbox approach to improving the measurement of attention control. Journal of Experimental Psychology: General 150: 242–75. [Google Scholar] [CrossRef]
- Ecker, Ullrich K. H., Stephan Lewandowsky, Klaus Oberauer, and Abby E. H. Chee. 2010. The components of working memory updating: An experimental decomposition and individual differences. Journal of Experimental Psychology: Learning Memory and Cognition 36: 170–89. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Elliott, Julian G., Wilma C. M. Resing, and Jens F. Beckmann. 2018. Dynamic assessment: A case of unfulfilled potential? Educational Review 70: 7–17. [Google Scholar] [CrossRef] [Green Version]
- Engle, Randall W. 2002. Working memory capacity as executive attention. Current Directions in Psychological Science 11: 19–23. [Google Scholar] [CrossRef]
- Engle, Randall W., Stephen W. Tuholski, James E. Laughlin, and Andrew R. Conway. 1999. Working memory, short-term memory, and general fluid intelligence: A latent-variable approach. Journal of Experimental Psychology: General 128: 309–31. [Google Scholar] [CrossRef] [PubMed]
- Fogarty, Gerard, and Lazar Stankov. 1982. Competing tasks as an index of intelligence. Personality and Individual Differences 3: 407–22. [Google Scholar] [CrossRef] [Green Version]
- Fried, Eiko. 2020. Lack of theory building and testing impedes progress in the factor and network literature. Psychological Inquiry 31: 271–88. [Google Scholar] [CrossRef]
- Frischkorn, Gidon T., and Claudia C. von Bastian. 2021. In search of the executive cognitive processes proposed by Process-Overlap Theory. Journal of Intelligence 9: 43. [Google Scholar] [CrossRef]
- Funke, Joachim. 1998. Computer-based testing and training with scenarios from complex problem-solving reseach: Advantages and disadvantages. International Journal of Selection and Assessment 6: 90–96. [Google Scholar] [CrossRef] [Green Version]
- Funke, Joachim, Andreas Fischer, and Daniel V. Holt. 2017. When less is less: Solving multiple simple problems is not complex problem solving—A comment on Greiff et al. (2015). Journal of Intelligence 5: 5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Funke, Joachim, Andreas Fischer, and Daniel V. Holt. 2018. Competencies for Complexity: Problem Solving in the Twenty-First Century. In Assessment and Teaching of 21st Century Skills. Educational Assessment in an Information Age. Edited by E. Care, P. Griffin and M. Wilson. Cham: Springer, pp. 41–53. [Google Scholar] [CrossRef]
- Gabales, Leonardo, and Damian P. Birney. 2011. Are the limits in processing and storage capacity common? Exploring the additive and interactive effects of processing and storage load in working memory. Journal of Cognitive Psychology 23: 322–41. [Google Scholar] [CrossRef]
- Gelman, Andrew, Jennifer Hill, and Masanao Yajima. 2012. Why we (usually) don’t have to worry about multiple comparisons. Journal of Research on Educational Effectiveness 5: 189–211. [Google Scholar] [CrossRef] [Green Version]
- Goecke, Benjamin, Florian Schmitz, and Oliver Wilhelm. 2021. Binding costs in processing efficiency as determinants of cognitive flexibility. Journal of Intelligence 9: 18. [Google Scholar] [CrossRef]
- Goff, Maynard, and Phillip L. Ackerman. 1992. Personality-intelligence relations: Assessment of typical intellectual engagement. Journal of Educational Psychology 84: 537–52. [Google Scholar] [CrossRef]
- Gottfredson, Linda S. 1997. Why g matters: The complexity of everyday life. Intelligence 24: 79–732. [Google Scholar] [CrossRef] [Green Version]
- Gottfredson, Linda S. 2018. g theory: How recurring variation in human intelligence and the complexity of everyday tasks create social structure and the democratic dilemma. In The Nature of Human Intelligence. Edited by R. J. Sternberg. Cambridge: Cambridge University Press, pp. 130–51. [Google Scholar]
- Gray, Jeremy R., Christopher F. Chabris, and Todd S. Braver. 2003. Neural mechanisms of general fluid intelligence. Nature Neuroscience 6: 316–22. [Google Scholar] [CrossRef] [PubMed]
- Greiff, Samuel, Matthias Stadler, Philipp Sonnleitner, Christian Wolff, and Romain Martin. 2015. Sometimes less is more: Comparing the validity of complex problem solving measures. Intelligence 50: 100–13. [Google Scholar] [CrossRef]
- Grigorenko, Elena L., and Robert J. Sternberg. 1998. Dynamic testing. Psychological Bulletin 124: 75–111. [Google Scholar] [CrossRef]
- Guthke, Jürgen, and Jens F. Beckmann. 2000. The learning test concept and its application in practice. In Dynamic Assessment: Prevailing Models and Applications (Advances in Cognition and Educational Practice). Edited by Carol S. Lidz and Julian Elliot. Oxford: Elsevier Science, Volume 6, pp. 17–69. [Google Scholar]
- Guthke, Jürgen, Jens F. Beckmann, and Barbara B. Seiwald. 2003. Wie “identisch” sind Arbeitsgedächtnis und Schlußfolgerndes Denken? [How “identical” are working memory and reasoning?]. In Psychologie im Kontext der Naturwissenschaften. Edited by Werner Krause and Bodo Krause. Berlin: Trafo, pp. 149–59. [Google Scholar]
- Guttman, Louis. 1971. Measurement as structural theory. Psychometrika 36: 329–46. [Google Scholar] [CrossRef]
- Halford, Graeme S., Steven Phillips, William H. Wilson, Julie E. McCredden, Glenda Andrews, Damian P. Birney, Rosemary Baker, and John D. Bain. 2007. Relational processing is fundamental to the central executive and is limited to four variables. In The Cognitive Neuroscience of Working Memory: Behavioural and Neural Correlates. Edited by Naoyuki Osaka, Robert H. Logie and Mark D’Esposito. Oxford: Oxford University Press, pp. 261–80. [Google Scholar]
- Halford, Graeme S., and William H. Wilson. 1980. A category theory approach to cognitive development. Cognitive Psychology 12: 356–411. [Google Scholar] [CrossRef] [Green Version]
- Halford, Graeme S., William H. Wilson, and Steven Phillips. 1998. Processing capacity defined by relational complexity: Implications for comparative, developmental, and cognitive psychology. Behavioral and Brain Sciences 21: 803–31. [Google Scholar] [CrossRef]
- Halford, Graeme S., William H. Wilson, and Steven Phillips. 2010. Relational knowledge: The foundation of higher cognition. Trends in Cognitive Sciences 14: 497–505. [Google Scholar] [CrossRef] [PubMed]
- Hearne, Luke J., Damian P. Birney, Luca Cocchi, and Jason B. Mattingley. 2019. The Latin Square Task as a measure of relational reasoning: A replication and assessment of reliability. European Journal of Psychological Assessment, Advance Online Publication 36: 296. [Google Scholar] [CrossRef]
- Horn, John L., and Jennie Noll. 1994. A system for understanding cognitive capabilities: A theory and the evidence on which it is based. In Theories of Intelligence. Edited by Douglas K. Detterman. Norwood: Ablex Publishing Corporation, pp. 151–203. [Google Scholar]
- Jewsbury, Paul A., Stephen C. Bowden, and Milton E. Strauss. 2016. Integrating the switching, inhibition, and updating model of executive function with the Cattell—Horn—Carroll model. Journal of Experimental Psychology: General 145: 220–45. [Google Scholar] [CrossRef] [PubMed]
- Kovacs, Kristof, and Aandrew R. A. Conway. 2016. Process Overlap Theory: A unified account of the general factor of intelligence. Psychological Inquiry 27: 151–77. [Google Scholar] [CrossRef]
- Kyllonen, Patrick C., and Raymond E. Christal. 1990. Reasoning ability is (little more than) working-memory capacity?! Intelligence 14: 389–433. [Google Scholar] [CrossRef]
- Lohman, David F., and Martin J. Ippel. 1993. Cognitive diagnosis: From statistically based assessment toward theory-based assessment. In Test Theory for a New Generation of Tests. Edited by Norman Frederiksen, Robert J. Mislevy and Isaac I. Bejar. Hillsdale: Lawrence Erlbaum Associates, pp. 41–70. [Google Scholar]
- Mackintosh, Nicholas J. 2011. IQ and Human Intelligence, 2nd ed. Oxford: Oxford University Press. [Google Scholar]
- Mayer, John D., and Peter Salovey. 1993. The intelligence of emotional intelligence. Intelligence 22: 89–114. [Google Scholar] [CrossRef]
- Michell, Joel. 1990. An Introduction to the Logic of Psychological Measurement. Hillsdale: Lawrence Erlbaum Associates. [Google Scholar]
- Miyake, Akira, and Naomi P. Friedman. 2012. The nature and organization of individual differences in executive functions: Four general conclusions. Current Directions in Psychological Science 21: 8–14. [Google Scholar] [CrossRef] [PubMed]
- Molenaar, Peter C. M. 2004. Manifesto on psychology as idiographic science: Bringing the person back into scientific psychology, This time forever. Measurement 2: 201–18. [Google Scholar] [CrossRef]
- Molenaar, Peter C. M. 2013. On the necessity to use person-specific data analysis approaches in psychology. European Journal of Developmental Psychology 10: 29–39. [Google Scholar] [CrossRef]
- Navarro, Danielle. 2021. If mathematical psychology did not exist we might need to invent it: A comment on theory building in psychol. Perspectives on Psychological Science 16: 707–16. [Google Scholar] [CrossRef]
- Neisser, Ulric, Gweneth Boodo, Thomas J. Bouchard Jr., A. Wade Boykin, Nathon Brody, Stephen J. Ceci, Diane F. Halpern, John C. Loehlin, Robert Perloff, Robert J. Sternberg, and et al. 1996. Intelligence: Knowns and unknowns. American Psychologist 51: 77–101. [Google Scholar] [CrossRef]
- Oberauer, Klaus. 2013. The focus of attention in working memory—From metaphors to mechanisms. Frontiers in Human Neuroscience 7: 673. [Google Scholar] [CrossRef] [Green Version]
- Oberauer, Klaus. 2021. Towards a theory of working memory. In Working Memory. Edited by Robert H. Logie, Valerie Camos and Nelson Cowan. Oxford: Oxford University Press. [Google Scholar]
- Oberauer, Klaus, and Stephan Lewandowsky. 2016. Control of information in working memory: Encoding and removal of distractors in the complex-span paradigm. Cognition 156: 106–28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oberauer, Klaus, Heinz-Martin Suss, Ralf Schulze, O. Wilhelm, and Werner Wittmann. 2000. Working memory capacity—Facets of a cognitive ability construct. Personality and Individual Differences 29: 1017–45. [Google Scholar] [CrossRef]
- Oberauer, Klaus, Heinz-Martin Suss, Oliver Wilhelm, and N. Sander. 2007. Individual differences in working memory capacity and reasoning ability. In Variation in Working Memory. Edited by Andrew R. A. Conway, Christopher Jarrold, Mchael J. Kane, Akira Miyake and John N. Towse. New York: Oxford University Press, pp. 49–75. [Google Scholar]
- Pedhazuer, Elazar J., and Liora P. Schmelkin. 1991. Measurement, Design, and Analysis: An Integrated Approach. Hillsdale: Lawrence Erlbaum Associates. [Google Scholar]
- Protzko, John. 2017. Effects of cognitive training on the structure of intelligence. Psychonomic Bulletin & Review 24: 1022–31. [Google Scholar] [CrossRef] [Green Version]
- Ravizza, Susan M., and Cameron S. Carter. 2008. Shifting set about task switching: Behavioral and neural evidence for distinct forms of cognitive flexibility. Neuropsychologia 46: 2924–35. [Google Scholar] [CrossRef] [Green Version]
- Schneider, W. Joel, John D. Mayer, and Daniel A. Newman. 2016. Integrating hot and cool intelligences: Thinking broadly about broad abilities. Journal of Intelligence 4: 1. [Google Scholar] [CrossRef]
- Schneider, W. Joel, and Kevin S. McGrew. 2012. The Cattell-Horn-Carroll model of intelligence. In Contemporary Intellectual Assessment: Theories, Tests, and Issues, 3rd ed. Edited by Dawn Flanagan and Patti Harrison. New York: Guilford, pp. 99–144. [Google Scholar]
- Schweizer, Karl. 1996. The speed-accuracy transition due to task complexity. Intelligence 22: 115–28. [Google Scholar] [CrossRef]
- Schweizer, Karl. 2009. Fixed-links models for investigating experimental effects combined with processing strategies in repeated measures designs: A cognitive task as example. Methodology 62: 217–32. [Google Scholar] [CrossRef] [PubMed]
- Schweizer, Karl, Michael Altmeyer, Xuezhu Ren, and M.ichael Schreiner. 2015. Models for the detection of deviations from the expected processing strategy in completing the items of cognitive measures. Multivariate Behavioral Research 50: 544–54. [Google Scholar] [CrossRef]
- Schweizer, Karl, and Wolfgang Koch. 2002. Perceptual processes and cognitive ability. Intelligence 142: 1–26. [Google Scholar] [CrossRef]
- Shipstead, Zach, Tyler L. Harrison, and Randall W. Engle. 2016. Working memory capacity and fluid intelligence: Maintenance and disengagement. Perspectives on Psychological Science 11: 771–79. [Google Scholar] [CrossRef] [Green Version]
- Spilsbury, Georgina, Lazar Stankov, and Richard Roberts. 1990. The effect of a test’s difficulty on its correlation with intelligence. Personality and Individual Differences 11: 1069–77. [Google Scholar] [CrossRef]
- Stadler, Matthias, Nicolas Becker, Markus Gödker, Detlev Leutner, and Samuel Greiff. 2015. Complex problem solving and intelligence: A meta-analysis. Intelligence 53: 92–101. [Google Scholar] [CrossRef]
- Stankov, Lazar. 2000. Complexity, metacognition and fluid intelligence. Intelligence 28: 121–43. [Google Scholar] [CrossRef]
- Stankov, Lazar, and John D. Crawford. 1993. Ingredients of complexity in fluid intelligence. Learning and Individual Differences 5: 73–111. [Google Scholar] [CrossRef]
- Stankov, Lazar, and Anne Cregan. 1993. Quantitative and qualitative properties of an intelligence test: Series completion. Learning and Individual Differences 5: 137–69. [Google Scholar] [CrossRef]
- Steinke, Alexander, and Bruno Kopp. 2020. Toward a computational neuropsychology of cognitive flexibility. Brain Sciences 12: 1000. [Google Scholar] [CrossRef]
- Sternberg, Robert J. 1977a. Component processes in analogical reasoning. Psychological Review 84: 353–78. [Google Scholar] [CrossRef]
- Sternberg, Robert J. 1977b. Intelligence, Information Processing, and Analogical Reasoning: The Componential Analysis of Human Abilities. Hillsdale: Lawrence Erlbaum Associates. [Google Scholar]
- Sternberg, Robert J. 1980. Sketch of a componential subtheory of human intelligence. Behavioral and Brain Science 3: 573–84. [Google Scholar] [CrossRef]
- Sternberg, Robert J. 2020. The Cambridge Handbook of Intelligence, 2nd ed. Edited by Robert J. Sternberg. Cambridge: Cambridge University Press. [Google Scholar] [CrossRef]
- Sternberg, Robert J., Geroge B. Forsythe, Jennifer Hedlund, Joseph Horvath, Richard K. Wagner, Wendy M. Williams, Scott Snook, and Elena L. Grigorenko. 2000. Practical Intelligence in Everyday Life. Cambridge: Cambridge University Press. [Google Scholar]
- Sternberg, Robert J., Chak H. Wong, and Anastasia P. Kreisel. 2021. Understanding and assessing cultural intelligence: Maximum-performance and typical-performance approaches. Journal of Intelligence 9: 45. [Google Scholar] [CrossRef]
- Unsworth, Nash, and Randall W. Engle. 2007a. The nature of individual differences in working memory capacity: Active maintenance in primary memory and controlled search from secondary memory. Psychological Review 114: 104–32. [Google Scholar] [CrossRef] [Green Version]
- Unsworth, Nash, and Randall W. Engle. 2007b. On the division of short-term and working memory: An examination of simple and complex span and their relation to higher order abilities. Psychological Bulletin 133: 1038–66. [Google Scholar] [CrossRef] [Green Version]
- van der Maas, Han, Conor V. Dolan, Raoul P. P. Grasman, Jelte M. Wicherts, Hilde M. Huizenga, and Maartje E. J. Raijmakers. 2006. A dynamical model of General Intelligence: The positive manifold of intelligence by mutualism. Psychological Review 113: 842–61. [Google Scholar] [CrossRef] [PubMed]
- van der Maas, Han, Kees-Jan Kan, Maarten Marsman, and Claire E. Stevenson. 2017. Network models for cognitive development and intelligence. Journal of Intelligence 5: 16. [Google Scholar] [CrossRef] [Green Version]
- Wood, Robert E., Jens F. Beckmann, and Damian P. Birney. 2009. Simulations, learning and real world capabilities. Education + Training 51: 491–510. [Google Scholar] [CrossRef]
- Yu, Calvin, Jens F. Beckmann, and Damian P. Birney. 2019. Cognitive Flexibility as a Meta-Competency. Estudios de Psicología 40: 563–84. [Google Scholar] [CrossRef]
- Ziegler, Matthias, Erik Danay, Moritz Heene, Jens Asendorpf, and Markus Buhner. 2012. Openness, fluid intelligence, and crystallized intelligence: Toward an integrative model. Journal of Research in Personality 46: 173–83. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level 1 X Factors Vary across Occasion and Individuals | Level 1 Z Factors Vary across Occasion, Constant across Individuals | Level 2 Moderators Invariant across Occasion, Vary across Individual |
|---|---|---|
|
|
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Birney, D.P.; Beckmann, J.F. Intelligence IS Cognitive Flexibility: Why Multilevel Models of Within-Individual Processes Are Needed to Realise This. J. Intell. 2022, 10, 49. https://0-doi-org.brum.beds.ac.uk/10.3390/jintelligence10030049
Birney DP, Beckmann JF. Intelligence IS Cognitive Flexibility: Why Multilevel Models of Within-Individual Processes Are Needed to Realise This. Journal of Intelligence. 2022; 10(3):49. https://0-doi-org.brum.beds.ac.uk/10.3390/jintelligence10030049
Chicago/Turabian StyleBirney, Damian P., and Jens F. Beckmann. 2022. "Intelligence IS Cognitive Flexibility: Why Multilevel Models of Within-Individual Processes Are Needed to Realise This" Journal of Intelligence 10, no. 3: 49. https://0-doi-org.brum.beds.ac.uk/10.3390/jintelligence10030049