1. Introduction
Diabetic nephropathy (DKD) is a multifactorial microvascular complication of diabetes mellitus (DM) [
1]. Declining kidney function of DM patients may manifest itself with or without notable proteinuria, leading to chronic kidney disease and end-stage renal disease in some patients over an average time span of several years [
2,
3]. In the clinical practice around the world, formal diagnosis of DKD almost exclusively relies on invasive renal biopsy, and only a limited proportion of DM patients with renal impairment undergoes biopsy. For this reason, there has been a long-standing interest in introducing circulating biomarkers as a diagnostic criterion or a monitoring tool for clinical management of the diseases beyond the current gold standard, i.e., estimated glomerular filtration rate (eGFR) and its past trajectories calculated from serum creatinine or cystatin-C with adjustments for age, gender, and race, and urine albumin/creatinine ratio (uACR). As discussed in recent extensive reviews of diagnostic biomarkers of DKD [
4] and clinical management [
5], a growing body of evidence from prospective and cross-sectional studies supports the utility of plasma or urinary protein markers originating from various anatomical sites of origin, such as cystatin C [
6,
7], copeptin [
8], kidney injury molecule-1 (KIM-1) [
9,
10], neutrophil gelatinase-associated lipocalin (NGAL) [
7], TNF receptors, as well as microRNAs.
Metabolomics studies have also contributed to the repertoire of candidate biomarkers for non-diabetic chronic kidney disease (CKD) such as IgA nephropathy, revealing amino acids and their metabolites, tryptophan metabolites, uric acid and other purine metabolites, oxidative stress, and lipids and acylcarnitines as promising markers [
11]. However, the presence of DM influences the circulating levels of metabolites and the search for DKD-specific markers may require the direct comparison of healthy non-DM subjects, DM patients with normal renal function, and DKD patients. Moreover, in contrast to the plasma proteomics studies for DKD biomarker discovery, most discovery-phase metabolomics studies were conducted before 2015. This was an era when untargeted mass spectrometry used to be performed without systematic MS/MS fragmentation, with compound identification depending on the precursor ion information and proprietary libraries from instrument vendors. MS technology and bioinformatics software have substantially advanced over the past few years, and it is worth revisiting the global identification of compounds and semi-quantification by untargeted LC-MS in this arena.
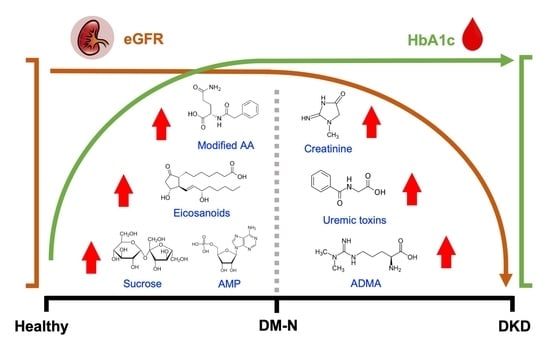
To address these gaps, we applied a modern untargeted metabolomics workflow to a cross-sectional case control study of 90 participants. Here we compare metabolite levels among healthy controls (N = 30), DM patients with normal renal function (DM-N, average eGFR 108.6 mL/min/1.73m2, N = 30), and DM patients with early nephropathy patients (DKD, average eGFR 72.6 mL/min/1.73m2, N = 30). We first employed data-dependent acquisition (DDA) MS to all ninety plasma samples to achieve a high rate of MS/MS-based identification. We subsequently re-analyzed the samples using data-independent acquisition (DIA) MS for consistent semi-quantification across all samples.
In addition, we demonstrate a network-based multivariate data analysis approach as a feature exploration tool for the identification of differential metabolites for DM-N and DKD. This approach is particularly useful for the analysis of omics data sets in which the measurements are highly correlated. At the same time, however, we emphasize that the technical advances presented in this work do not address the fact that the data are generated from a cross-sectional case study, and refrain from interpreting the altered metabolite levels between groups as causal agents in the pathogenesis of DM and DKD.
In what follows, we structured the groups comparisons in two stages. To identify the changes in plasma levels of metabolites and lipids, we first compared the 60 DM patients to the 30 control, and later compared the 30 DKD subjects and the 30 DM-N patients. In parallel, we first undertook traditional differential analysis using univariate hypothesis testing, and repeated the analysis for metabolite panel selection for the two stages using the supervised multivariate analysis. We describe these results in more detail below.
3. Discussion
In this work, we used DDA (IDA) acquisition to create a customized MS/MS spectral library, and subsequently performed DIA (SWATH-MS) analysis for reproducible re-identification and semi-quantification across a large number of samples. This workflow of combining both DDA and DIA from the same samples was seamlessly carried out by a data processing software MetaboKit [
13], with the help of reference MS/MS spectral libraries that constantly evolve and are made publicly available to the metabolomics and lipidomics research community by various parties. However, we note that it is not always necessary to perform DDA on all samples. In routine practice, samples pooled from a selected subset of samples often provide enough information to build a spectral library with DDA. Thereafter, as long as the same type of LC system is used, the MetaboKit software assists the user to build a maturing customized spectral library, with which future analysis can be performed using DIA only for semi-quantification.
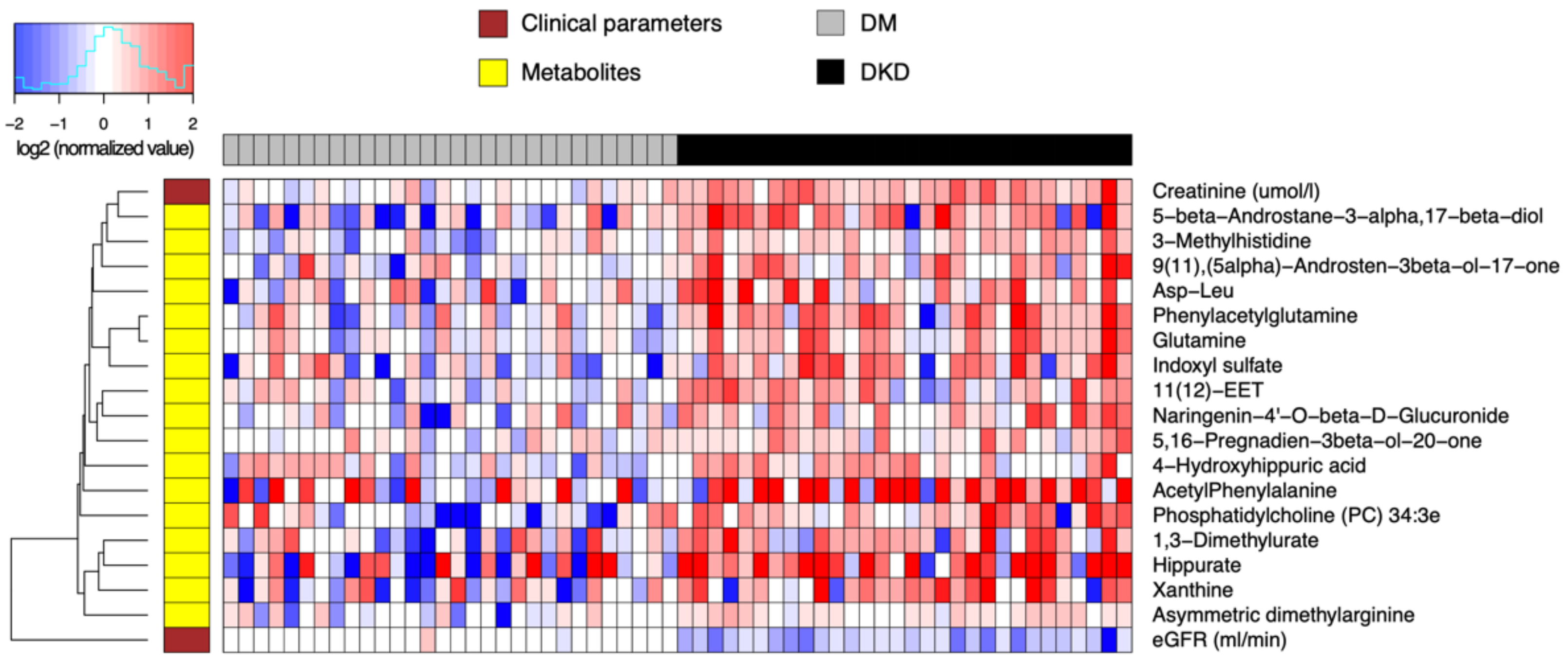
We also showcased a network-based multivariate analysis framework via iOmicsPASS, rather than the conventional hypothesis testing-based filtering and interpretation of data or multivariable regression modeling approaches that often fail to deal with the multicollinearity problem in correlated high-dimensional data sets. However, it is important to note that we used the method as a feature exploration tool to capture significantly discriminative, correlated variations from a systems biology point of view, and the reported network signatures of DM and DKD, reported in
Figure 3 and
Figure 4, respectively, were not validated in independent cohorts. It is thus possible that a good proportion of weak edges, i.e. those with partial correlations close to zero, may not be reproduced if the partial correlation network analysis were to be repeated in independent data sets, and the nodes connected by thin edges (weak co-expression scores) may not be selected in future data sets. However, we expect the major hubs in the networks, such as AMP and ADMA, to be highly discriminative features of the network signatures in other studies.
A number of plasma and urine metabolomics studies in DKD and non-diabetic CKD have previously been conducted using GC-MS or LC-MS techniques [
18,
19,
20]. Most metabolites we reported to be associated with DKD, or closely related metabolites, have already been captured with concordant directions of change by respective studies, including compounds involved in urea and ammonia metabolism and excretion [
21], gut microbiome-associated tryptophan metabolism [
22], uremic toxins [
23,
24,
25,
26], glutamate and PAG excretion in urine [
27], and uremic solutes also produced by the gut microbiome [
24,
28]. On the other hand, our metabolome coverage had a limitation of its own. For example, our experiment did not capture some of the well-known free fatty acids and organic acids and intermediates from renal organic ion transport and mitochondrial activity such as TCA cycle, as previously reported [
11,
20]. In certain compounds, the direction of changes we observed in our experiments (e.g., glucuronide, hippuric acid) was inconsistent with those reported in a previous urine metabolomics study [
29], although it is possible that the changes in blood and urine may not always coincide.
Several interesting observations arose from our data. First, the circulating level of AMP is elevated in subjects with DM with a high correlation with HbA1c. The increase in the plasma levels of adenine nucleotides insinuates subsequent overactivation of the fuel-sensing enzyme AMP-activated protein kinase (AMPK) in insulin resistant individuals [
30,
31], or AMP elevation may predate the hyperglycemia as an upstream regulator of glucose uptake in the whole body [
32,
33]. Therefore, assays of AMPK activity in relevant tissues such as skeletal muscle and the plasma AMP/ATP ratio in the same hyperglycemic person’s blood sample may be important complementary information to insulin sensitivity and insulin resistance assays for more detailed diagnosis of DM. However, we acknowledge that our data were generated from plasma samples collected from a cross-sectional case control study with skewed age distribution between the groups, and thus the association of AMP elevation with DM is confounded by the older age in the DM patients.
Second, we observed that plasma levels of indole-3-propionic acid (IPA) and indole-3-lactic acid (ILA) are elevated in DM-N and DKD patients, both metabolized from tryptophan by gut flora. It was previously shown that, in a prospective study of at-risk Finnish individuals, higher levels of IPA were associated with lower risk of type 2 diabetes and serum CRP-based low-grade inflammation levels [
34]. Similarly, ILA has been linked to amelioration of salt-sensitive hypertension [
35]. In the context of cross-sectional case–control study, we can deduce that the elevated levels of IPA and ILA in the subjects with DM are likely the microbiome-mediated response to the treatments for improved glycemic control.
Last, we observed increased levels of a few lysophosphatidylethanolamine (LPE) and phosphatidylamine (PE) species and decreased levels of ether-linked phosphatidylethanolamine species as well as other lysophospholipids of different head groups in DM-N and DKD. It is likely that this change in balance in the phospholipid composition has to do with systemic dyslipidemia, and has little to do with localized perturbation of lipid efflux, uptake, and metabolism in kidney tissues in the case of DKD [
36,
37]. Although the methanol-based metabolite extraction still resulted in a decent coverage of eicosanoids, sterol lipids, phospholipids and some ceramides, a shortcoming of our current study is that we did not detect the majority of triglycerides and cholesteryl esters. Despite this drawback, the biochemical assay data in
Table 1 suggest that only the total triglyceride level is elevated in DM and DKD, but LDL, HDL, and total cholesterol levels are more or less equivalent to the controls. We therefore speculate that even the composition of individual TG species would not have provided additional information delineating the difference between DM-N and DKD in the current study cohort. We leave this aspect of investigation to future research.
4. Materials and Methods
Metabolite extraction. In this process, 800 µL of ice cold methanol was added to 200 µL of each plasma sample. The mixtures were incubated at −20 °C for 60 min to precipitate proteins and centrifuge at 16,000 g at 4 °C for 10 min. The supernatants were divided into two aliquots and dried in a vacuum concentrator. Quality control (QC) samples were prepared by pooling equal volume of all plasma samples in this study to monitor the stability and repeatability during LC-MS analysis and the same protocol was used for metabolite extraction from QC samples.
LC-MS/MS analysis. Metabolite analysis was performed on an ACQUITY I-class UPLC system (Waters, Milford, MA, US) coupled to a TripleTOF 5600 fitted with a DuoSpray ion source (SCIEX, Foster, CA, US). Each sample was reconstituted in 30 µL of 95/5 water/methanol (v/v) and 5 µL was injected for each analysis in the positive mode and negative ionization mode, with both information-dependent acquisition (IDA) and sequential windows acquisition of all theoretical fragment ion mass spectra (SWATH-MS). Samples were injected in a randomized order and a QC sample was injected after every 10 samples. Mass calibration was automatically performed after every 20 injections by the automated calibration delivery system.
Reverse phase liquid chromatography and positive ionization mode. The column used for positive ionization mode was a Waters HSS T3 2.1 mm × 100 mm, 1.8 µm. Mobile phase A was 0.1% formic acid in 5% acetonitrile and mobile phase B was 0.1% formic acid in 95% acetonitrile. The gradient profile was 2% B from 0 to 1 min, 50% B at 8 min, 98% B from 13 min to 15 min and 2% B at 15.1 min to 20 min. The flow rate was set to 0.4 mL/min. The temperature of the column oven and auto-sampler was set to 40 °C and 4 °C, respectively. The source voltage was 5500 V.
Reverse phase liquid chromatography and negative ionization mode. The column used for analysis in the negative ionization mode was a Waters BEH C18 2.1 mm × 100 mm, 1.7 µm column. Mobile phase A was 5 mM ammonium bicarbonate in 5% acetonitrile and mobile phase B was 5 mM ammonium bicarbonate in 95% acetonitrile. The gradient profile was 2% B from 0 to 1 min, 50% B at 8 min, 98% B from 13 min to 15 min and 2% B at 15.1 min to 20 min. The flow rate was set to 0.4 ml/min. The temperature of the column oven and auto-sampler was set to 45 °C and 4 °C, respectively. The source voltage was 4500 V.
IDA (DDA) acquisition. Each IDA duty cycle contained one TOF MS survey scan (180 ms) followed by 20 MS/MS scans (40 ms). The mass ranges of TOF MS and MS/MS scans were 100 to 1000 and 30 to 1000 m/z, respectively. The following IDA parameters were applied: dynamic background subtraction, charge monitoring to exclude multiply charge ions and isotopes and dynamic exclusion of former target ions for s. Ramped collision energies of 20 to 40 V and −20 to −40 V were applied for positive and negative MS/MS scans, respectively.
SWATH-MS (DIA) acquisition. Each SWATH duty cycle contained one TOF MS survey scan (150 ms) followed by 36 SWATH scans (20 ms each). The fragment ion window for SWATH was from 100 to 1000 m/z in steps of 25 Da. The mass range of TOF MS and SWATH scans were 100 to 1000 and 30 to 1000 m/z, respectively. Ramped collision energies of 20 to 40 V and −20 to −40 V were applied for positive and negative MS/MS SWATH scans, respectively.
MetaboKit analysis [
13]. IDA files were processed for spectral library construction using the NIST2014, HMDB [
38], MassBank [
39], LipidBlast (main and fork) [
40] as reference libraries. For peak extract, we considered ion chromatograms spanning between 3 and 100 s. For compound identification, precursor ion
m/z should match the theoretical monoisotopic mass within 15 ppm. For MS/MS-based scoring, the modified dot product score was required to be at least 0.5, and at least two fragment ions must match peaks in the reference spectra within 30 ppm. This process generates an MS1-based peak area table as well as a custom MS/MS library with matching records to the reference libraries.
For the SWATH-MS analysis, we trimmed the raw data by removing all peaks with an intensity value of 1000 or below. The length of ion chromatograms was limited to 3 to 100 s, as in the IDA analysis. Using the custom library created above [
12], we rolled up the peak areas of the top six most intense fragment ions to derive a semi-quantitative value for individual compounds. Ion chromatograms of fragment ions were required to have at least 0.5 Pearson correlation with the ion chromatograms of the corresponding precursor ion, with the dot product score at the apex of the elution to be 0.5 and above. This time point was also required to be within 20 s from the RT marked for each record in the custom library.
Statistical analysis. Log-transformed (base 2) peak areas of precursor ions from the SWATH-MS analysis were used as semi-quantitative data for metabolites. Univariate differential expression analysis (t-test with multiple testing correction by
q-value [
41]), univaraite linear regression analysis, heatmap visualizations, and sparse Gaussian graphical model estimation (glasso) for deriving sparse inverse covariance matrix were performed using glasso package in R [
16]. The estimated inverse covariance matrix was converted into a partial correlation matrix, and metabolite pairs (nodes) with non-zero partial correlations were connected by lines (edges) to form the partial correlation network.
Network-based multivariate classification analysis with iOmicsPASS. Using this network as the background, supervised classification analysis was performed by the iOmicsPASS software [
17] to identify subnetwork signatures of DM-N and DKD groups from 87 and 59 samples, respectively, after dropping the outliers. In iOmicsPASS, the co-expression score of an edge for a given sample is derived from the z-scores of the two connected nodes. If the partial correlation between the nodes is positive, the edge score for that sample is calculated as the sum of the two z-scores. If the partial correlation is negative, the edge score is the difference between the two z-scores, whichever node was named first in the network input file. Hence, the interpretation of up and down between groups depends on the order of appearance of the nodes, and therefore it is important to reaffirm the abundance levels of individual nodes for proper interpretation in the latter case. The subnetworks for individual comparison groups (DM-N and DKD in
Figure 3 and DKD in
Figure 4) were then visualized using Cyotpscape software. In the networks, an edge was colored in red if the partial correlation between the two nodes was positive, and in blue if the partial correlation was negative. The thickness of edges was proportional to the magnitude of the group centroid values, i.e., the discriminative co-expression score reported by the supervised classifier in iOmicsPASS.
Author Contributions
Conceptualization, H.C. and L.Z.; methodology, G.T., Y.G., L.Z., H.C.; software, G.T., H.W.L.K., H.C.; formal analysis, Y.M.T., Y.G., G.T., H.W.L.K., K.P.C.; investigation, C.M.K., E.S.T.; resources, C.M.K., E.S.T., K.P.C.; data curation, Y.M.T., G.T., K.P.C., H.C.; writing—original draft preparation, H.C.; writing—review and editing, Y.M.T., C.M.K., E.S.T., L.Z., H.C.; visualization, Y.M.T., H.C.; supervision, L.Z., K.P.C., H.C.; funding acquisition, K.P.C., E.S.T., L.Z., H.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by grants from Singapore Ministry of Education (MOE2016-T2-1-001), Singapore National Medical Research Council (NMRC/CG/M009/2017 to H.C., E.S.T.; NMRC/OF-LCG/DYNAMO/2017 to E.S.T.), Singapore National Medical Research Council (NMRC/CG/SERI/2017 to L.Z.), Venerable Yen Pei-NKF research grant (NKFRC/2015/07/06 to C.M.K.), and A*STAR (IAF-ICP I1901E0040 to H.C.). Authors also thank SingHealth Foundation for supporting the proteomics core facility at Singapore Eye Research Institute.
Institutional Review Board Statement
Ethical approval for the samples for control group was received from Domain Specific Review Board of the National Healthcare Group in Singapore (NHG DSRB Reference No. 2015/01262). Ethical approval for the DM group (both DM-N and DKD) was received from Domain Specific Review Board of the National Healthcare Group in Singapore (NHG DSRB Reference No. 2015/01239). The study was conducted according to the guidelines of the Declaration of Helsinki.
Informed Consent Statement
Informed consent was obtained from all subjects before participation in the studies mentioned above.
Data Availability Statement
Interested users may contact the corresponding author for the access to raw mass spectrometry data (
[email protected]).
Conflicts of Interest
The authors declare no conflict of interest.
References
- KDOQI. KDOQI Clinical Practice Guidelines and Clinical Practice Recommendations for Diabetes and Chronic Kidney Disease. Am. J. Kidney Dis. 2007, 49 (Suppl. 2), S12–S154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gross, J.L.; de Azevedo, M.J.; Silveiro, S.P.; Canani, L.H.; Caramori, M.L.; Zelmanovitz, T. Diabetic nephropathy: Diagnosis, prevention, and treatment. Diabetes Care 2005, 28, 164–176. [Google Scholar] [CrossRef] [Green Version]
- Schena, F.P.; Gesualdo, L. Pathogenetic mechanisms of diabetic nephropathy. J. Am. Soc. Nephrol. 2005, 16 (Suppl. 1), S30–S33. [Google Scholar] [CrossRef] [PubMed]
- Colhoun, H.M.; Marcovecchio, M.L. Biomarkers of diabetic kidney disease. Diabetologia 2018, 61, 996–1011. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, H.; Liu, S.; Bastacky, S.I.; Wang, X.; Tian, X.J.; Zhou, D. Diabetic kidney diseases revisited: A new perspective for a new era. Mol. Metab. 2019, 30, 250–263. [Google Scholar] [CrossRef]
- Barr, E.L.; Maple-Brown, L.J.; Barzi, F.; Hughes, J.T.; Jerums, G.; Ekinci, E.I.; Ellis, A.G.; Jones, G.R.; Lawton, P.D.; Sajiv, C.; et al. Comparison of creatinine and cystatin C based eGFR in the estimation of glomerular filtration rate in Indigenous Australians: The eGFR Study. Clin. Biochem. 2017, 50, 301–308. [Google Scholar] [CrossRef] [Green Version]
- Bjornstad, P.; Pyle, L.; Cherney, D.Z.I.; Johnson, R.J.; Sippl, R.; Wong, R.; Rewers, M.; Snell-Bergeon, J.K. Plasma biomarkers improve prediction of diabetic kidney disease in adults with type 1 diabetes over a 12-year follow-up: CACTI study. Nephrol Dial. Transplant. 2018, 33, 1189–1196. [Google Scholar] [CrossRef]
- Pikkemaat, M.; Melander, O.; Bengtsson Bostrom, K. Association between copeptin and declining glomerular filtration rate in people with newly diagnosed diabetes. The Skaraborg Diabetes Register. J. Diabetes Complicat. 2015, 29, 1062–1065. [Google Scholar] [CrossRef]
- Sabbisetti, V.S.; Waikar, S.S.; Antoine, D.J.; Smiles, A.; Wang, C.; Ravisankar, A.; Ito, K.; Sharma, S.; Ramadesikan, S.; Lee, M.; et al. Blood kidney injury molecule-1 is a biomarker of acute and chronic kidney injury and predicts progression to ESRD in type I diabetes. J. Am. Soc. Nephrol. 2014, 25, 2177–2186. [Google Scholar] [CrossRef]
- Panduru, N.M.; Sandholm, N.; Forsblom, C.; Saraheimo, M.; Dahlstrom, E.H.; Thorn, L.M.; Gordin, D.; Tolonen, N.; Waden, J.; Harjutsalo, V.; et al. Kidney injury molecule-1 and the loss of kidney function in diabetic nephropathy: A likely causal link in patients with type 1 diabetes. Diabetes Care 2015, 38, 1130–1137. [Google Scholar] [CrossRef] [Green Version]
- Hocher, B.; Adamski, J. Metabolomics for clinical use and research in chronic kidney disease. Nat. Rev. Nephrol 2017, 13, 269–284. [Google Scholar] [CrossRef]
- Chen, G.; Walmsley, S.; Cheung, G.C.M.; Chen, L.; Cheng, C.Y.; Beuerman, R.W.; Wong, T.Y.; Zhou, L.; Choi, H. Customized Consensus Spectral Library Building for Untargeted Quantitative Metabolomics Analysis with Data Independent Acquisition Mass Spectrometry and MetaboDIA Workflow. Anal. Chem. 2017, 89, 4897–4906. [Google Scholar] [CrossRef] [PubMed]
- Narayanaswamy, P.; Teo, G.; Ow, J.R.; Lau, A.; Kaldis, P.; Tate, S.; Choi, H. MetaboKit: A comprehensive data extraction tool for untargeted metabolomics. Mol. Omics 2020, 16, 436–447. [Google Scholar] [CrossRef] [PubMed]
- Teo, G.; Kim, S.; Tsou, C.C.; Collins, B.; Gingras, A.C.; Nesvizhskii, A.I.; Choi, H. mapDIA: Preprocessing and statistical analysis of quantitative proteomics data from data independent acquisition mass spectrometry. J. Proteomics 2015, 129, 108–120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, T.; Zhang, H.; Zhao, T.; Zhang, X.; Lu, J.; Yin, T.; Liang, Q.; Wang, Y.; Luo, G.; Lan, H.; et al. Intrarenal metabolomics reveals the association of local organic toxins with the progression of diabetic kidney disease. J. Pharm Biomed. Anal. 2012, 60, 32–43. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 2008, 9, 432–441. [Google Scholar] [CrossRef] [Green Version]
- Koh, H.W.L.; Fermin, D.; Vogel, C.; Choi, K.P.; Ewing, R.M.; Choi, H. iOmicsPASS: Network-based integration of multiomics data for predictive subnetwork discovery. NPJ Syst. Biol. Appl. 2019, 5, 22. [Google Scholar] [CrossRef] [Green Version]
- Abbiss, H.; Maker, G.L.; Trengove, R.D. Metabolomics Approaches for the Diagnosis and Understanding of Kidney Diseases. Metabolites 2019, 9, 34. [Google Scholar] [CrossRef] [Green Version]
- Darshi, M.; Van Espen, B.; Sharma, K. Metabolomics in Diabetic Kidney Disease: Unraveling the Biochemistry of a Silent Killer. Am. J. Nephrol. 2016, 44, 92–103. [Google Scholar] [CrossRef]
- Sharma, K.; Karl, B.; Mathew, A.V.; Gangoiti, J.A.; Wassel, C.L.; Saito, R.; Pu, M.; Sharma, S.; You, Y.H.; Wang, L.; et al. Metabolomics reveals signature of mitochondrial dysfunction in diabetic kidney disease. J. Am. Soc. Nephrol. 2013, 24, 1901–1912. [Google Scholar] [CrossRef]
- Weiner, I.D.; Mitch, W.E.; Sands, J.M. Urea and Ammonia Metabolism and the Control of Renal Nitrogen Excretion. Clin. J. Am. Soc. Nephrol. 2015, 10, 1444–1458. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hirayama, A.; Nakashima, E.; Sugimoto, M.; Akiyama, S.; Sato, W.; Maruyama, S.; Matsuo, S.; Tomita, M.; Yuzawa, Y.; Soga, T. Metabolic profiling reveals new serum biomarkers for differentiating diabetic nephropathy. Anal. Bioanal Chem. 2012, 404, 3101–3109. [Google Scholar] [CrossRef]
- Ng, D.P.; Salim, A.; Liu, Y.; Zou, L.; Xu, F.G.; Huang, S.; Leong, H.; Ong, C.N. A metabolomic study of low estimated GFR in non-proteinuric type 2 diabetes mellitus. Diabetologia 2012, 55, 499–508. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koppe, L.; Fouque, D.; Soulage, C.O. The Role of Gut Microbiota and Diet on Uremic Retention Solutes Production in the Context of Chronic Kidney Disease. Toxins 2018, 10, 155. [Google Scholar] [CrossRef] [Green Version]
- Van den Brand, J.A.; Mutsaers, H.A.; van Zuilen, A.D.; Blankestijn, P.J.; van den Broek, P.H.; Russel, F.G.; Masereeuw, R.; Wetzels, J.F. Uremic Solutes in Chronic Kidney Disease and Their Role in Progression. PLoS ONE 2016, 11, e0168117. [Google Scholar] [CrossRef] [PubMed]
- Mutsaers, H.A.; Engelke, U.F.; Wilmer, M.J.; Wetzels, J.F.; Wevers, R.A.; van den Heuvel, L.P.; Hoenderop, J.G.; Masereeuw, R. Optimized metabolomic approach to identify uremic solutes in plasma of stage 3-4 chronic kidney disease patients. PLoS ONE 2013, 8, e71199. [Google Scholar] [CrossRef] [Green Version]
- Posada-Ayala, M.; Zubiri, I.; Martin-Lorenzo, M.; Sanz-Maroto, A.; Molero, D.; Gonzalez-Calero, L.; Fernandez-Fernandez, B.; de la Cuesta, F.; Laborde, C.M.; Barderas, M.G.; et al. Identification of a urine metabolomic signature in patients with advanced-stage chronic kidney disease. Kidney Int. 2014, 85, 103–111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Niewczas, M.A.; Sirich, T.L.; Mathew, A.V.; Skupien, J.; Mohney, R.P.; Warram, J.H.; Smiles, A.; Huang, X.; Walker, W.; Byun, J.; et al. Uremic solutes and risk of end-stage renal disease in type 2 diabetes: Metabolomic study. Kidney Int. 2014, 85, 1214–1224. [Google Scholar] [CrossRef] [Green Version]
- Van der Kloet, F.M.; Tempels, F.W.; Ismail, N.; van der Heijden, R.; Kasper, P.T.; Rojas-Cherto, M.; van Doorn, R.; Spijksma, G.; Koek, M.; van der Greef, J.; et al. Discovery of early-stage biomarkers for diabetic kidney disease using ms-based metabolomics (FinnDiane study). Metabolomics 2012, 8, 109–119. [Google Scholar] [CrossRef] [Green Version]
- Ruderman, N.B.; Carling, D.; Prentki, M.; Cacicedo, J.M. AMPK, insulin resistance, and the metabolic syndrome. J. Clin. Investig. 2013, 123, 2764–2772. [Google Scholar] [CrossRef] [PubMed]
- Jeon, S.M. Regulation and function of AMPK in physiology and diseases. Exp. Mol. Med. 2016, 48, e245. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Z.; Zhao, Y.; Zhao, M.; Wang, S.; Hua, Z.; Zhang, J. The plasma 5’-AMP acts as a potential upstream regulator of hyperglycemia in type 2 diabetic mice. Am. J. Physiol. Endocrinol. Metab. 2012, 302, E325–E333. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Zhao, Y.; Sun, Q.; Yang, Y.; Gao, Y.; Ge, W.; Liu, J.; Xu, X.; Zhang, J. An Intermediary Role of Adenine Nucleotides on Free Fatty Acids-Induced Hyperglycemia in Obese Mice. Front. Endocrinol. 2019, 10, 497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tuomainen, M.; Lindstrom, J.; Lehtonen, M.; Auriola, S.; Pihlajamaki, J.; Peltonen, M.; Tuomilehto, J.; Uusitupa, M.; de Mello, V.D.; Hanhineva, K. Associations of serum indolepropionic acid, a gut microbiota metabolite, with type 2 diabetes and low-grade inflammation in high-risk individuals. Nutr. Diabetes 2018, 8, 35. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Hou, Y.; Wang, G.; Zheng, X.; Hao, H. Gut Microbial Metabolites of Aromatic Amino Acids as Signals in Host-Microbe Interplay. Trends Endocrinol. Metab. 2020, 31, 818–834. [Google Scholar] [CrossRef] [PubMed]
- Herman-Edelstein, M.; Scherzer, P.; Tobar, A.; Levi, M.; Gafter, U. Altered renal lipid metabolism and renal lipid accumulation in human diabetic nephropathy. J. Lipid. Res. 2014, 55, 561–572. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wahl, P.; Ducasa, G.M.; Fornoni, A. Systemic and renal lipids in kidney disease development and progression. Am. J. Physiol. Renal. Physiol. 2016, 310, F433–F445. [Google Scholar] [CrossRef] [Green Version]
- Wishart, D.S.; Tzur, D.; Knox, C.; Eisner, R.; Guo, A.C.; Young, N.; Cheng, D.; Jewell, K.; Arndt, D.; Sawhney, S.; et al. HMDB: The Human Metabolome Database. Nucleic. Acids Res. 2007, 35, D521–D526. [Google Scholar] [CrossRef] [PubMed]
- Horai, H.; Arita, M.; Kanaya, S.; Nihei, Y.; Ikeda, T.; Suwa, K.; Ojima, Y.; Tanaka, K.; Tanaka, S.; Aoshima, K.; et al. MassBank: A public repository for sharing mass spectral data for life sciences. J. Mass Spectrom. 2010, 45, 703–714. [Google Scholar] [CrossRef]
- Kind, T.; Liu, K.H.; Lee, D.Y.; DeFelice, B.; Meissen, J.K.; Fiehn, O. LipidBlast in silico tandem mass spectrometry database for lipid identification. Nat. Methods 2013, 10, 755–758. [Google Scholar] [CrossRef] [Green Version]
- Storey, J.D. The positive false discovery rate: A Bayesian interpretation and the q-value. Ann. Stat. 2003, 31, 2013–2035. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}