Comparative Analysis of Complete Chloroplast Genome Sequences of Wild and Cultivated Bougainvillea (Nyctaginaceae)


Abstract
:1. Introduction
2. Results and Discussion
2.1. General Features of Bougainvillea Chloroplast Genomes
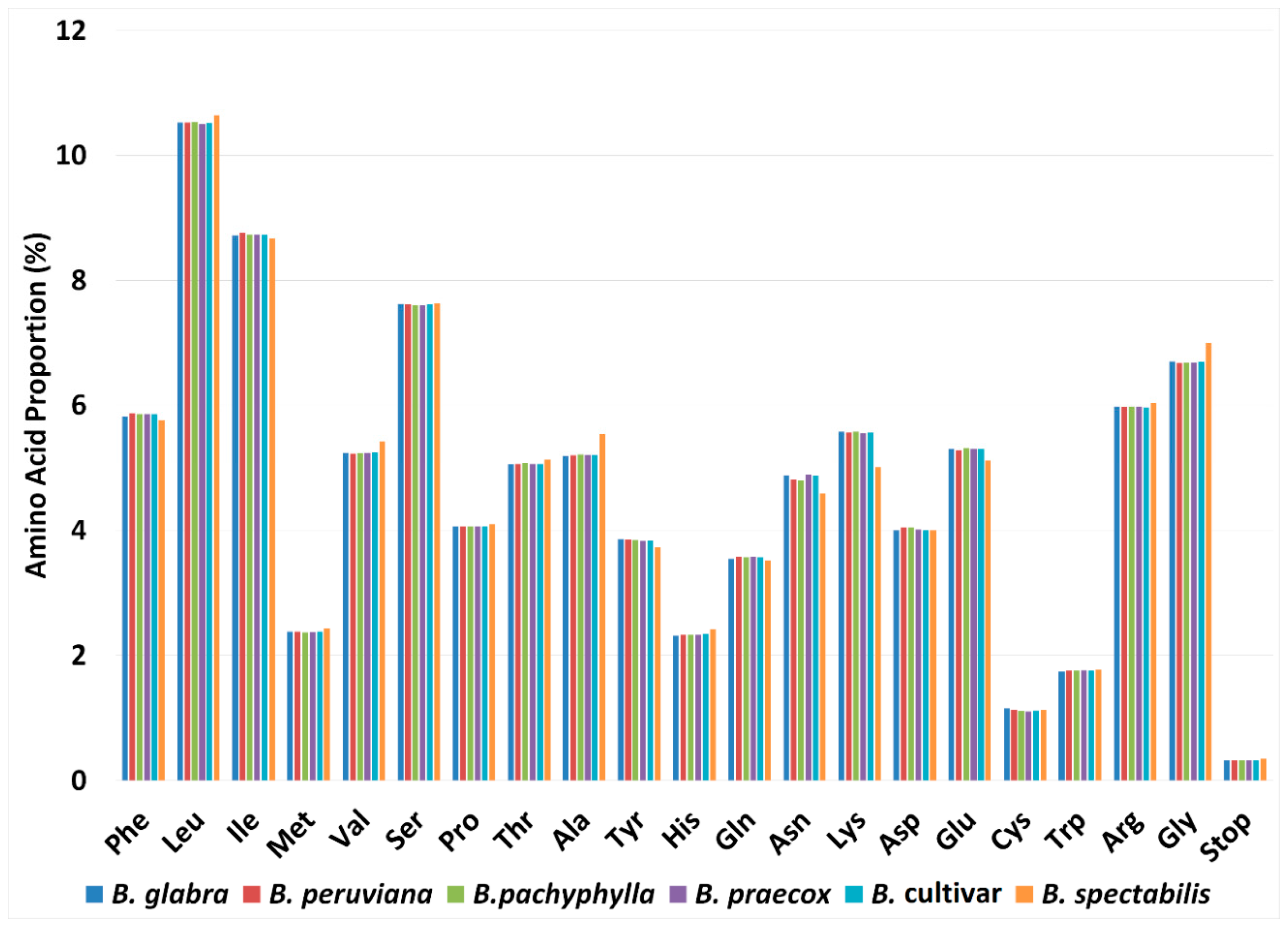
2.2. Codon Usage Analysis
2.3. RNA Editing Sites
2.4. Simple Sequence Repeats and Tandem Repeat Analyses
2.5. IR Contraction and Expansion
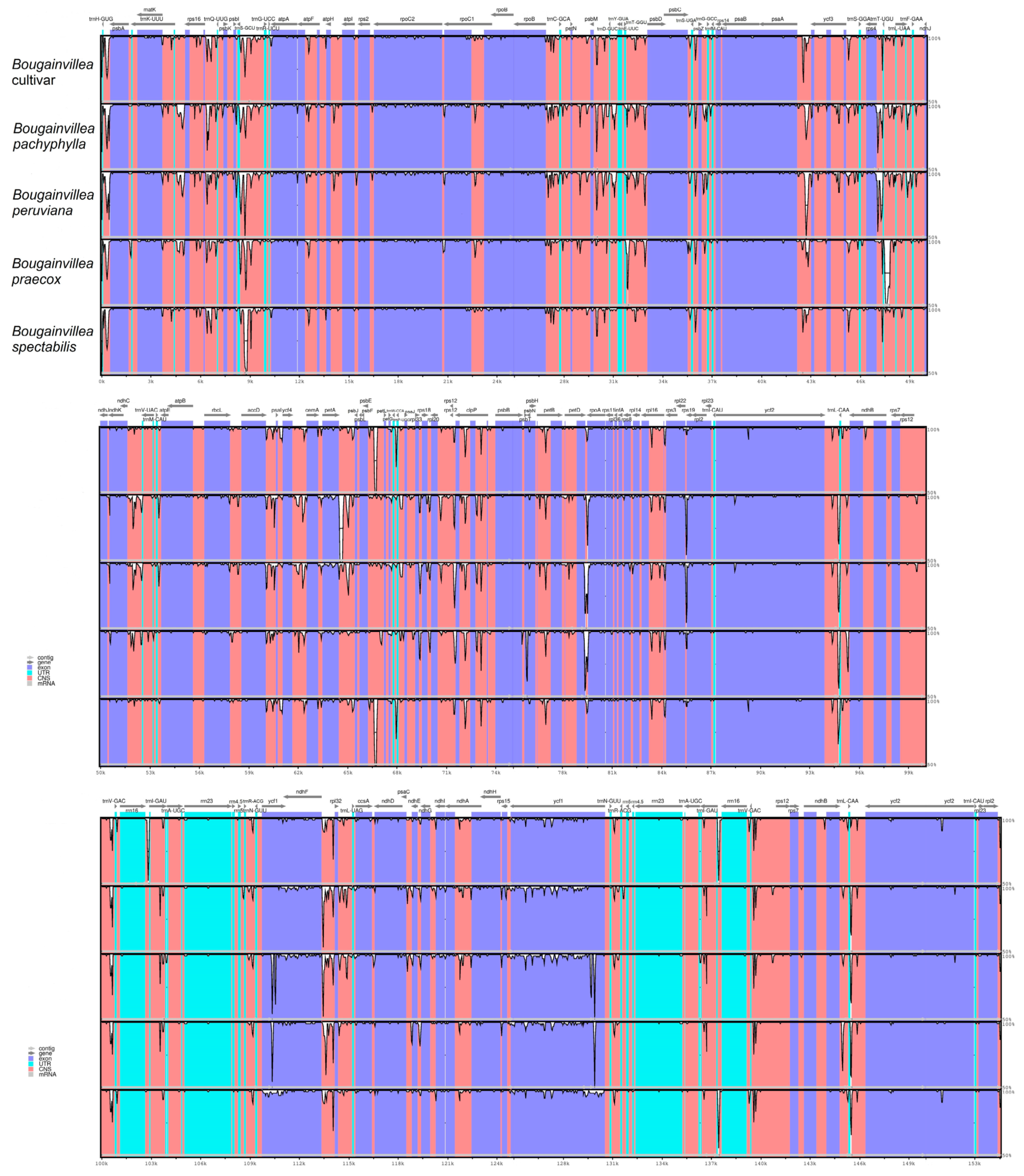
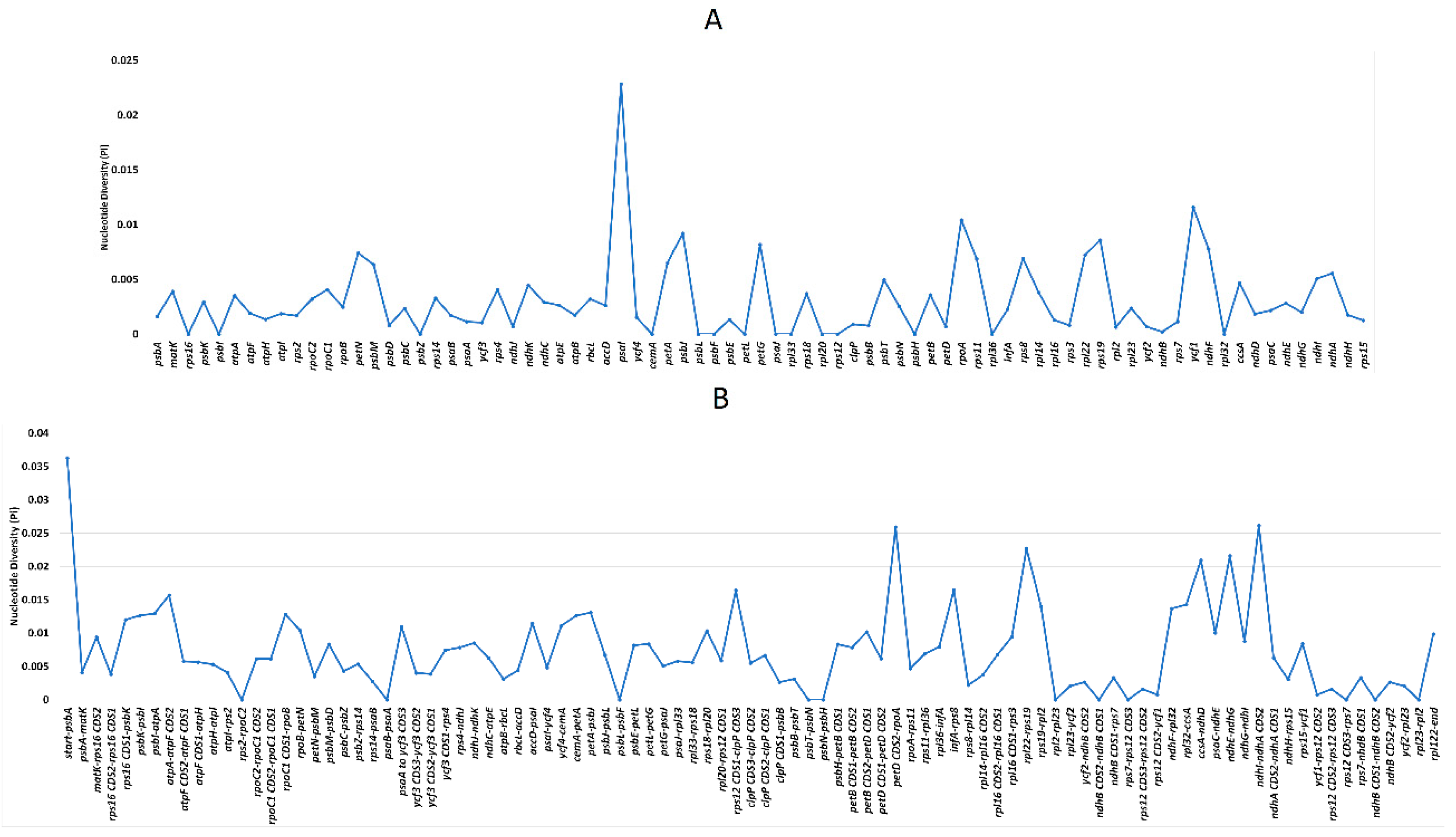
2.6. Sequence Variation Analyses among Bougainvillea cp Genomes
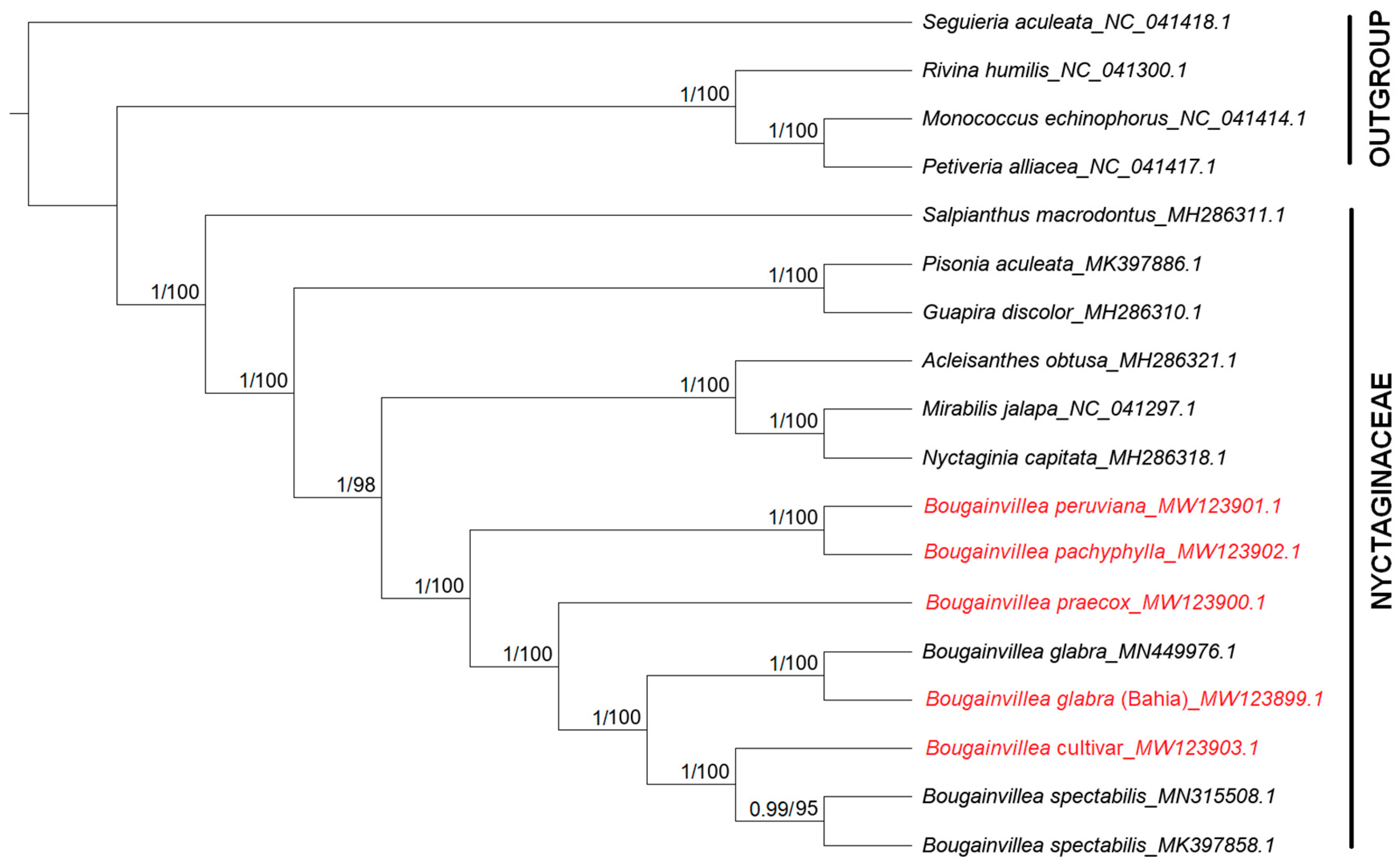
2.7. Phylogenetic Analysis
3. Materials and Methods
3.1. Plant Samples and DNA Extraction
3.2. Chloroplast Genome Sequencing, Assembly, and Annotation
3.3. Codon Usage and RNA Editing Sites Prediction
3.4. Repeat Analysis
3.5. Genome Comparison and Divergence Analyses
3.6. Phylogenetic Analyses
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mabberley, D.J. The Plant Book; Cambridge Univercity Press: Cambridge, UK, 1987; pp. 1–706. [Google Scholar]
- Bittrich, V.; Kühn, U. Nyctaginaceae. In The Families and Genera of Flowering Plants; Kubitzki, K., Rohwer, J.G., Bittrich, V., Eds.; Springer: Berlin, Germany, 1993; Volume 2, pp. 473–486. [Google Scholar]
- Bremer, B.; Bremer, K.; Chase, M.W.; Fay, M.F.; Reveal, J.L.; Soltis, D.E.; Soltis, P.S.; Stevens, P.F.; Anderberg, A.A.; Moore, M.J.; et al. An update of the Angiosperm Phylogeny Group classification for the orders and families of flowering plants: APG II. Bot. J. Linn. Soc. 2003, 141, 399–436. [Google Scholar]
- Kobayashi, K.D.; McConnell, J.; Griffis, J. Bougainvillea. In Ornamentals and Flowers; College of Tropical Agriculture and Human Resources, University of Hawaii: Honolulu, HI, USA, 2007; Volume OF-38, pp. 1–12. [Google Scholar]
- Plants of the World Online. Facilitated by the Royal Botanic Gardens, Kew. Available online: http://www.plantsoftheworldonline.org/ (accessed on 10 October 2020).
- Kulshreshtha, K.; Rai, A.; Mohanty, C.S.; Roy, R.K.; Sharma, S.C. Particulate pollution mitigating ability of some plant species. Int. J. Environ. Res. 2009, 3, 137–142. [Google Scholar]
- Chauhan, P.; Mahajan, S.; Kulshrestha, A.; Shrivastava, S.; Sharma, B.; Goswamy, H.M.; Prasad, G.B.K.S. Bougainvillea spectabilis Exhibits Antihyperglycemic and Antioxidant Activities in Experimental Diabetes. J. Evid. Based Complementary Altern. Med. 2016, 21, 177–185. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abarca-Vargas, R.; Petricevich, V.L. Bougainvillea Genus: A Review on Phytochemistry, Pharmacology, and Toxicology. J. Evid. Based Complementary Altern. Med. 2018, 2018, 9070927. [Google Scholar] [CrossRef] [Green Version]
- Ogunwande, I.A.; Avoseh, O.N.; Olasunkanmi, K.N.; Lawal, O.A.; Ascrizzi, R.; Guido, F. Chemical composition, anti-nociceptive and anti-inflammatory activities of essential oil of Bougainvillea glabra. J. Ethnopharmacol. 2019, 232, 188–192. [Google Scholar] [CrossRef]
- Abarca-Vargas, R.; Petricevich, V.L. Extract from Bougainvillea × buttiana (Variety Orange) Inhibits Production of LPS-Induced Inflammatory Mediators in Macrophages and Exerts a Protective Effect In Vivo. Biomed. Res. Int. 2019, 2019, 2034247. [Google Scholar] [CrossRef] [Green Version]
- Rauf, M.A.; Oves, M.; Rehman, F.U.; Khan, A.R.; Husain, N. Bougainvillea flower extract me.diated zinc oxide’s nanomaterials for antimicrobial and anticancer activity. Biomed. Pharmacother. 2019, 116, 108983. [Google Scholar] [CrossRef]
- Standley, P.C. The Nyctaginaceae and Chenopodiaceae of Northwestern South America; Field Museum of Natural History-Botanical Series: Chicago, IL, USA, 1931; Volume 11, pp. 73–114. [Google Scholar]
- Heimerl, A. Nyctaginaceae. In Engler & Prantl, Naturl. Pflanzenfam, 2nd ed.; W. Engelmann: Leipzig, Germany, 1934; Volume 4, pp. 86–134. [Google Scholar]
- Toursarkissian, M. Las Nictaginaceas argentinas. Revista Museo Argentino de Ciencias Naturales Bernardino Rivadavia. Botanica 1975, 5, 1–83. [Google Scholar]
- Douglas, N.A.; Manos, P.S. Molecular phylogeny of Nyctaginaceae: Taxonomy, biogeography and characters associated with a radiation of xerophytic genera in North America. Am. J. Bot. 2007, 94, 856–872. [Google Scholar] [CrossRef]
- Yao, G.; Jin, J.J.; Lia, H.T.; Yanga, J.B.; Mandalad, V.S.; Croleyd, M.; Mostowd, R.; Douglas, N.A.; Chase, M.W.; Christenhuszg, M.J.M.; et al. Plastid phylogenomic insights into the evolution of Caryophyllales. Mol. Phylogenet. Evol. 2019, 134, 74–86. [Google Scholar] [CrossRef]
- Ni, J.; Lee, S.Y.; Hu, X.; Wang, W.; Zhang, J.; Ruan, L.; Dai, S.; Liu, G. The complete chloroplast genome of a commercially exploited ornamental plant, Bougainvillea glabra (Caryophyllales: Nyctaginaceae). Mitochondrial DNA Part B 2019, 4, 3390–3391. [Google Scholar] [CrossRef] [Green Version]
- Wang, N.; Qiu, M.Y.; Yang, Y.; Li, J.W.; Xou, X.X. Complete chloroplast genome sequence of Bougainvillea spectabilis (Nyctaginaceae). Mitochondrial DNA Part B 2019, 4, 4010–4011. [Google Scholar] [CrossRef] [Green Version]
- Moore, M.J.; Soltis, P.S.; Bell, C.D.; Burleigh, J.G.; Soltis, D.E. Phylogenetic analysis of 83 plastid genes further resolves the early diversification of eudicots. Proc. Natl. Acad. Sci. USA 2010, 107, 4623–4628. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Li, Y.; Cai, Q.; Lin, F.; Huang, P.; Zheng, Y. Development of chloroplast genomic resources for Akebia quinata (Lardizabalaceae). Conserv. Genet. Resour. 2016, 8, 447–449. [Google Scholar] [CrossRef]
- Munyao, J.N.; Dong, X.; Yang, J.X.; Mbandi, E.M.; Wanga, V.O.; Oulo, M.A.; Saina, J.K.; Musili, P.M.; Hu, G.W. Complete Chloroplast Genomes of Chlorophytum comosum and Chlorophytum gallabatense: Genome Structures, Comparative and Phylogenetic Analysis. Plants 2020, 9, 296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwon, E.C.; Kim, J.H.; Kim, N.S. Comprehensive genomic analyses with 115 plastomes from algae to seed plants: Structure, gene contents, GC contents, and introns. Genes Genome 2020, 42, 553–570. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Feng, D.; Song, G.; Wei, X.; Chen, L.; Wu, X.; Li, X.; Zhu, Z. The first intron of rice EPSP synthase enhances expression of foreign gene. Sci. China Life Sci. 2003, 46, 561–569. [Google Scholar] [CrossRef]
- Daniell, H.; Lin, C.; Yu, M.; Chang, W. Chloroplast genomes: Diversity, evolution, and applications in genetic engineering. Genome Biol. 2016, 17, 134. [Google Scholar] [CrossRef] [Green Version]
- Vu, H.T.; Tran, N.; Nguyen, T.H.; Vu, Q.L.; Bui, M.H.; Le, M.T.; Le, L. Complete chloroplast genome of Pahiopedilum delenatii and phylogenetic relationships among Orchidaceae. Plants 2020, 9, 61. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.S.; Chaw, S.M. Evolutionary stasis in Cycad plastomes and the first case of plastome GC-biased gene conversion. Genome Biol. Evol. 2015, 7, 2000–2009. [Google Scholar] [CrossRef] [Green Version]
- Niu, Z.; Xue, Q.; Wang, H.; Xie, X.; Zhu, S.; Liu, W.; Ding, X. Mutational Biases and GC-Biased Gene Conversion AT to GC Content in the Plastomes of Dendrobium Genus. Int. J. Mol. Sci. 2017, 18, 2307. [Google Scholar]
- Knill, T.; Reichelt, M.; Paetz, C.; Gershenzon, J.; Binder, S. Arabidopsis thaliana encodes a bacterial-type heterodimeric isopropylmalate isomerase involved in both Leu biosynthesis and the Met chain elongation pathway of glucosinolate formation. Plant Mol. Biol. 2009, 71, 227–239. [Google Scholar] [CrossRef] [Green Version]
- Hildebrandt, T.M.; Nunes Nesi, A.; Araujo, W.L.; Braun, H.P. Amino Acid Catabolism in Plants. Mol. Plant. 2015, 8, 1563–1579. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marino, S.M.; Gladyshev, V.N. Analysis and functional prediction of reactive cysteine residues. J. Biol. Chem. 2012, 287, 4419–4425. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, D.M.; Zhu, G.F.; Xu, Y.C.; Ye, Y.J.; Liu, J.M. Complete Chloroplast Genomes of Three Medicinal Alpinia Species: Genome Organization, Comparative Analyses and Phylogenetic Relationships in Family Zingiberaceae. Plants 2020, 9, 286. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, X.M.; Wu, S.F.; Ren, D.M.; Zhu, Y.P.; He, F.C. The analysis method and progress in the study of codon bias. Yi Chuan = Hered. 2007, 29, 420–426. [Google Scholar] [CrossRef]
- Zhou, Z.; Dang, Y.; Zhou, M.; Li, L.; Yu, C.H.; Fu, J.; Chen, S.; Liu, Y. Codon usage is an important determinant of gene expression levels largely through its effects on transcription. Proc. Natl. Acad. Sci. USA 2016, 113, E6117–E6125. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Xu, B.; Li, B.; Zhou, Q.; Wang, G.; Jiang, X.; Wang, C.; Xu, Z. Comparative analysis of codon usage patterns in chloroplast genomes of six Euphorbiaceae species. PeerJ 2020, 8, e8251. [Google Scholar] [CrossRef]
- Lee, S.R.; Kim, K.; Lee, B.Y.; Lim, C.E. Complete chloroplast genomes of all six Hosta species occurring in Korea: Molecular structures, comparative, and phylogenetic analyses. BMC Genom. 2019, 20, 833. [Google Scholar] [CrossRef]
- He, P.; Huang, S.; Xiao, G.; Zhang, Y.; Yu, J. Abundant RNA editing sites of chloroplast protein-coding genes in Ginkgo biloba and an evolutionary pattern analysis. BMC Plant Biol. 2016, 16, 257. [Google Scholar] [CrossRef] [Green Version]
- Sasaki, T.; Yukawa, Y.; Miyamoto, T.; Obokata, J.; Sugiura, M. Identification of RNA Editing Sites in Chloroplast Transcripts from the Maternal and Paternal Progenitors of Tobacco (Nicotiana tabacum): Comparative Analysis Shows the Involvement of Distinct Trans-Factors for ndhB Editing. Mol. Biol. Evol. 2003, 20, 1028–1035. [Google Scholar] [CrossRef] [PubMed]
- Yura, K.; Go, M. Correlation between amino acid residues converted by RNA editing and functional residues in protein three-dimensional structures in plant organelles. BMC Plant Biol. 2008, 8, 79. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vieira, M.L.; Santini, L.; Diniz, A.L.; de Freitas Munhoz, C. Microsatellite markers: What they mean and why they are so useful. Genet. Mol. Biol. 2016, 39, 312–328. [Google Scholar] [CrossRef] [PubMed]
- Ebert, D.; Peakall, R. Chloroplast simple sequence repeats (cpSSRs): Technical resources and recommendations for expanding cpSSR discovery and applications to a wide array of plant species. Mol. Ecol. Resour. 2009, 9, 673–690. [Google Scholar] [CrossRef] [PubMed]
- Kumar, P.; Janakiram, T.; Bhat, K.V.; Jain, R.; Prasad, K.V.; Prabhu, K.V. Molecular characterization and cultivar identification in Bougainvillea spp. using SSR markers. Indian J. Agric. Sci. 2014, 84, 1024–1030. [Google Scholar]
- Zhao, Z.; Guo, C.; Sutharzan, S.; Li, P.; Echt, C.S.; Zhang, J.; Liang, C. Genome-wide analysis of tandem repeats in plants and green algae. G3 (Bethesda) 2014, 4, 67–78. [Google Scholar] [CrossRef] [Green Version]
- Verstrepen, K.J.; Jansen, A.; Lewitter, F.; Fink, G.R. Intragenic tandem repeats generate functional variability. Nat. Genet. 2005, 37, 986–990. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Zhang, D.; Ouyang, K.; Chen, X. The complete chloroplast genome of the miracle tree Neolamarckia cadamba and its comparison in Rubiaceae family. Biotechnol. Biotechnol. Equip. 2018, 32, 1314–3530. [Google Scholar] [CrossRef] [Green Version]
- Feng, S.; Zheng, K.; Jiao, K.; Cai, Y.; Chen, C.; Mao, Y.; Wang, L.; Zhan, X.; Ying, Q.; Wang, H. Complete chloroplast genomes of four Physalis species (Solanaceae): Lights into genome structure, comparative analysis, and phylogenetic relationships. BMC Genom. 2020, 20, 242. [Google Scholar] [CrossRef]
- Douglas, N.; Spellenberg, R. A new tribal classification of Nyctaginaceae. Taxon 2010, 59, 905–910. [Google Scholar] [CrossRef]
- Tripathi, S.; Singh, S.; Roy, R.K. Pollen morphology of Bougainvillea (Nyctaginaceae): A popular ornamental plant of tropical and sub-tropical gardens of the world. Rev. Palaeobot. Palynol. 2017, 239, 31–46. [Google Scholar] [CrossRef]
- Standley, P.C. Studies of American Plants; Field Museum of Natural History-Botanical Series: Chicago, IL, USA, 1931; Volume 8, pp. 44–48. [Google Scholar]
- Standley, P.C. Nyctaginaceae. In Flora of Peru; Macbride, J.F., Ed.; Field Museum of Natural History-Botanical Series: Chicago, IL, USA, 1937; Volume 13, pp. 518–546. [Google Scholar]
- Murray, M.G.; Thompson, W.F. Rapid isolation of high molecular weight plant DNA. Nucleic Acids Res. 1980, 8, 4321–4326. [Google Scholar] [CrossRef] [Green Version]
- Patel, R.K.; Jain, M. NGS QC Toolkit: A toolkit for quality control of next generation sequencing data. PLoS ONE 2012, 7, e30619. [Google Scholar] [CrossRef]
- Bankevich, A.; Nurk, S.; Antipov, D.; Gurevich, A.A.; Dvorkin, M.; Kulikov, A.S.; Lesin, V.M.; Nikolenko, S.I.; Pham, S.; Prjibelski, A.D.; et al. SPAdes: A new genome assembly algorithm and its applications to single-cell sequencing. J. Comput. Biol. 2012, 19, 455–477. [Google Scholar] [CrossRef] [Green Version]
- Huang, D.I.; Cronk, Q. Plann: A command-line application for annotating plastome sequences. Appl. Plant Sci. 2015, 3, 1500026. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Shi, L.; Zhu, Y.; Chen, H.; Zhang, J.; Lin, X.; Guan, X. CpGAVAS, an integrated web server for the annotation, visualization, analysis, and GenBank submission of completely sequenced chloroplast genome sequences. BMC Genom. 2012, 13, 715. [Google Scholar] [CrossRef] [Green Version]
- Wyman, S.K.; Jansen, R.K.; Boore, J.L. Automatic annotation of organellar genomes with DOGMA. Bioinformatics 2004, 20, 3252–3255. [Google Scholar] [CrossRef] [Green Version]
- Lagesen, K.; Hallin, P.F.; Rodland, E.; Staerfeldt, H.H.; Rognes, T.; Ussery, D.W. RNAmmer: Consistent annotation of rRNA genes in genomic sequences. Nucleic Acids Res. 2007, 35, 3100–3108. [Google Scholar] [CrossRef]
- Chan, P.P.; Lowe, T.M. tRNAscan-SE: Searching for tRNA genes in genomic sequences. Methods Mol. Biol. 2019, 1962, 1–14. [Google Scholar]
- Greiner, S.; Lehwark, P.; Bock, R. OrganellarGenomeDRAW (OGDRAW) version 1.3.1: Expanded toolkit for the graphical visualization of organellar genomes. Nucleic Acids Res. 2019, 47, W59–W64. [Google Scholar] [CrossRef] [Green Version]
- Kumar, S.; Stecher, G.; Li, M.; Knyaz, C.; Tamura, K. MEGA X: Molecular Evolutionary Genetics Analysis across computing platforms. Mol. Biol. Evol. 2018, 35, 1547–1549. [Google Scholar] [CrossRef] [PubMed]
- Mower, J.P. The PREP suite: Predictive RNA editors for plant mitochondrial genes, chloroplast genes and user-defined alignments. Nucleic Acids Res. 2009, 37, W253–W259. [Google Scholar] [CrossRef] [PubMed]
- Beier, S.; Thiel, T.; Münch, T.; Scholz, U.; Mascher, M. MISA-web: A web server for microsatellite prediction. Bioinformatics 2017, 33, 2583–2585. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Benson, G. Tandem repeats finder: A program to analyze DNA sequences. Nucleic Acids Res. 1999, 27, 573–580. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frazer, K.A.; Pachter, L.; Poliakov, A.; Rubin, E.M.; Dubchak, I. VISTA: Computational tools for comparative genomics. Nucleic Acids Res 2004, 32, W273–W279. [Google Scholar] [CrossRef]
- Katoh, K.; Standley, D.M. MAFFT multiple sequence alignment software version 7: Improvements in performance and usability. Mol. Biol. Evol. 2013, 30, 772–780. [Google Scholar] [CrossRef] [Green Version]
- Librado, P.; Rozas, J. DnaSP v5: A software for comprehensive analysis of DNA polymorphism data. Bioinformatics 2009, 25, 1451–1452. [Google Scholar] [CrossRef] [Green Version]
- Amiryousefi, A.; Hyvönen, J.; Poczai, P. IRscope: An online program to visualize the junction sites of chloroplast genomes. Bioinformatics 2018, 34, 3030–3031. [Google Scholar] [CrossRef]
- Marcais, G.; Delcher, A.L.; Phillippy, A.M.; Coston, R.; Salzberg, S.L.; Zimin, A. MUMmer4: A fast and versatile genome alignment system. PLoS Comput. Biol. 2018, 14, e1005944. [Google Scholar] [CrossRef] [Green Version]
- Kearse, M.; Moir, R.; Wilson, A.; Stones-Havas, S.; Cheung, M.; Sturrock, S.; Buxton, S.; Cooper, A.; Markowitz, S.; Duran, C.; et al. Geneious Basic: An integrated and extendable desktop software platform for the organization and analysis of sequence data. Bioinformatics 2012, 28, 1647–1649. [Google Scholar] [CrossRef]
- Stamatakis, A. RAxML Version 8: A tool for phylogenetic analysis and post-analysis of large phylogenies. Bioinformatics 2014, 30, 1312–1313. [Google Scholar] [CrossRef] [PubMed]
- Trifinopoulos, J.; Nguyen, L.T.; von Haeseler, A.; Minh, B.Q. W-IQ-TREE: A fast online phylogenetic tool for maximum likelihood analysis. Nucleic Acids Res. 2016, 44, W232–W235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miller, M.A.; Pfeiffer, W.; Schwartz, T. Creating the CIPRES science gateway for inference of large phylogenetic trees. In Proceedings of the Gateway Computing Environments Workshop (GCE), New Orleans, LA, USA, 14 November 2010; pp. 1–8. [Google Scholar]
- Ronquist, F.; Huelsenbeck, J.P. MrBayes 3: Bayesian phylogenetic inference under mixed models. Bioinformatics 2003, 19, 1572–1574. [Google Scholar] [CrossRef] [PubMed] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | B. glabra | B. peruviana | B. pachyphylla | B. praecox | B. cultivar | B. spectabilis |
|---|---|---|---|---|---|---|
| Genome size (bp) | 154,536 | 153,966 | 154,062 | 154,306 | 154,520 | 154,541 |
| LSC length (bp) | 85,708 | 85,159 | 85,181 | 85,474 | 85,688 | 85,694 |
| SSC length (bp) | 18,038 | 18,025 | 18,027 | 18,014 | 18,078 | 18,077 |
| IR length (bp) | 25,395 | 25,391 | 25,427 | 25,409 | 25,377 | 25,385 |
| Total no. of genes | 131 | 131 | 131 | 131 | 131 | 131 |
| Protein-coding genes | 86 | 86 | 86 | 86 | 86 | 86 |
| rRNA | 8 | 8 | 8 | 8 | 8 | 8 |
| tRNA | 37 | 37 | 37 | 37 | 37 | 37 |
| Overall GC content (%) | 36.5% | 36.6% | 36.5% | 36.5% | 36.5% | 36.4% |
| GC content in LSC (%) | 34.2% | 34.3% | 34.3% | 34.3% | 34.2% | 34.2% |
| GC content in SSC (%) | 29.5% | 29.6% | 29.6% | 29.5% | 29.5% | 29.5% |
| GC content in IR (%) | 42.8% | 42.8% | 42.8% | 42.8% | 42.8% | 42.7% |
| Gene Category | Gene Names |
|---|---|
| ATP Synthase | atpA, atpB, atpE, atpF *, atpH, atpI |
| NADH dehydrogenase | ndhA *, ndhB(X2) *, ndhC, ndhD, ndhE, ndhF, ndhG, ndhH, ndhI, ndhJ, ndhK |
| Cytochrome b/f complex | petA, petB *, petD *, petG, petL, petN |
| Photosystem I | psaA, psaB, psaC, psaI, psaJ |
| Photosystem II | psbA, psbB, psbC, psbD, psbE, psbF, psbH, psbI, psbJ, psbK, psbL, psbM, psbN, psbT, psbZ |
| RubisCO large subunit | rbcL |
| Ribosomal protein genes (large subunits) | rpl2(x2) *, rpl14, rpl16 *, rpl20, rpl22, rpl23(x2), rpl32, rpl33, rpl36 |
| Ribosomal protein genes (small subunits) | rps2, rps3, rps4, rps7(x2), rps8, rps11, rps12(x2) #, rps14, rps15, rps16 *, rps18, rps19 |
| RNA Polymerase | rpoA, rpoB, rpoC1 *, rpoC2 |
| Ribosomal RNA genes | rrn4.5(X2), rrn5(X2), rrn16(X2), rrn23(X2) |
| Transfer RNA genes | trnI-CAU(x2), trnL-CAA(x2), trnV-GAC(x2), trnI-GAU(x2) *, trnA-UGC(x2) *, trnR-ACG(x2), trnN-GUU(x2), trnL-UAG, trnP-UGG, trnW-CCA, trnM-CAU, trnV-UAC *, trnF-GAA, trnL-UAA *, trnT-UGU, trnS-GGA, trnfM-CAU, trnG-GCC, trnS-UGA, trnT-GGU, trnE-UUC, trnY-GUA, trnD-GUC, trnC-GCA, trnR-UCU, trnG-UCC *, trnS-GCU, trnQ-UUG, trnK-UUU *, trnH-GUG |
| ATP-dependent protease | clpP ** |
| Maturase | matK |
| Hypothetical chloroplast reading frames | ycf1(x2), ycf2(x2), ycf3 **, ycf4 |
| Acetyl-CoA carboxylase | accD |
| C-type cytochrome synthesis gene | ccsA |
| Envelope membrane protein | cemA |
| Translational initiation factor | infA |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bautista, M.A.C.; Zheng, Y.; Hu, Z.; Deng, Y.; Chen, T. Comparative Analysis of Complete Chloroplast Genome Sequences of Wild and Cultivated Bougainvillea (Nyctaginaceae). Plants 2020, 9, 1671. https://0-doi-org.brum.beds.ac.uk/10.3390/plants9121671
Bautista MAC, Zheng Y, Hu Z, Deng Y, Chen T. Comparative Analysis of Complete Chloroplast Genome Sequences of Wild and Cultivated Bougainvillea (Nyctaginaceae). Plants. 2020; 9(12):1671. https://0-doi-org.brum.beds.ac.uk/10.3390/plants9121671
Chicago/Turabian StyleBautista, Mary Ann C., Yan Zheng, Zhangli Hu, Yunfei Deng, and Tao Chen. 2020. "Comparative Analysis of Complete Chloroplast Genome Sequences of Wild and Cultivated Bougainvillea (Nyctaginaceae)" Plants 9, no. 12: 1671. https://0-doi-org.brum.beds.ac.uk/10.3390/plants9121671