
On the Relationship between Frequency, Features, and Markedness in Inflection: Experimental Evidence from Russian Nouns


Department of Linguistics, Brigham Young University, Provo, UT 84602, USA
Languages 2021, 6(3), 130; https://0-doi-org.brum.beds.ac.uk/10.3390/languages6030130
Submission received: 24 November 2020
/
Revised: 2 July 2021
/
Accepted: 21 July 2021
/
Published: 29 July 2021
Abstract
:Markedness has a long tradition in linguistics as a way to describe linguistic asymmetries. In this paper, I investigate an argument about the necessity of markedness as a tool for capturing the structural distribution of inflectional affixes and predicting the behavioral consequences of that distribution. Based on evidence from German adjectives, Clahsen et al. argue that the number of specified features of inflectional affixes (which I argue represents a type of markedness) affects reaction times in lexical access. Affixes’ features, however, overlap with how frequently they occur. Clahsen et al. investigate only three affixes in German, leaving open questions about the relationship between the two factors and whether features are necessary as a predictor of lexical processing. In this paper, I use a larger set of inflectional affixes in Russian to test the relationship between affix features and affix frequency. I find that the two traits of affixes are correlated based on frequencies from a corpus and that in a lexical decision task, affix frequency is the better predictor of response times. My results suggest that we should question the necessity of featural markedness for explaining how inflectional structure is processed and, more generally, that both corpus and experimental data suggest a surprisingly close relationship between affix features and affix frequency.
Keywords:
inflection; morphology; frequency; features; markedness; Russian; processing; lexical access1. Introduction
A variety of studies have investigated the extent to which the structure of an inflectional system affects how inflected forms are processed (e.g., Kostić 1991; Clahsen et al. 2001b; Moscoso del Prado Martín et al. 2004; Milin et al. 2009; Leminen and Clahsen 2014). Clahsen et al. (2001b) suggest that the distribution of affixes in inflectional paradigms is a crucial predictor of processing times. Affixes are not equally specific in the roles that they play in an inflectional system. For example, the German adjective affix -m occurs in the dative of masculine and neuter adjectives of the strong declension. The affix -s occurs in nominative and accusative singular of neuter adjectives of the weak declension. The affix -e occurs in the nominative and accusative for feminine and plural adjectives in the strong declension and the nominative of all genders in the singular and the accusative of neuter and feminine adjectives of the weak declension. The affixes -m and -s exhibit greater specificity than -e in terms of what functions they fulfill in the system of oppositions in German adjectives. This specificity is reflected in the accounts of Bierwisch (1967) and Blevins (2000) in which the affix -m has more (positively) specified features ([+oblique, +dative]) than -s (no positively specified features) to be compatible with the functions it fulfills. Clahsen et al. (2001b) show that inflected forms ending in -s are accessed faster than forms ending in -m, even if the lexeme occurs more frequently with -m. This is surprising because, all else being equal, more frequent forms are accessed faster. They argue that the faster access of word forms with -s is a result of the feature structure of German inflection—the affix -s has fewer (positively) specified features leading to what they call a specificity effect.1 Based on this evidence they argue that the lexical representation of inflectional affixes must have underspecified sets of features and the feature specification of an affix affects how quickly forms with that affix are processed. Additional studies provide similar arguments in favor of features as a mechanism to encode grammatical specificity including data from behavioral tasks and brain imaging studies (Clahsen et al. 2001a; Penke et al. 2004; Veríssimo and Clahsen 2009; Opitz et al. 2013; Leminen and Clahsen 2014). Leminen and Clahsen (2014), for example, use brain imaging (event-related brain potentials/ERP) to show that priming German adjectives with a semantically related lexeme leads to later neural activity than priming with an inflected form of the same lexeme, and that inflected forms with greater feature overlap produce greater priming effects. They argue that morphosyntactic information, i.e., features, can explain the priming results and that this information precedes lexical/semantic information during lexical access.
The argument that feature specification is a determiner of lexical processing mirrors a long-standing tradition in linguistics to use the structural notion of ‘markedness’ as a tool to describe and explain asymmetries in linguistic structure and behavior, even though Clahsen et al. do not explicitly invoke the concept of markedness. In terms of markedness, the argument of Clahsen et al. equates formal markedness and markedness as cognitive difficulty (see Croft 1990 and Haspelmath 2006 for discussion of different uses of the term markedness): affixes that have highly specific functions are more marked and therefore take longer to process than affixes with less specific functions. Such an approach provides a motivated and elegant way to capture the asymmetrical distribution of affixes in a system and, at the same time, account for the processing differences of the forms with the affixes.
The efficacy of markedness arguments has been challenged because ‘marked’ categories are commonly related to other, potentially independently explained, factors such as frequency of use. These challenges have led some to argue that markedness is a superfluous theoretical notion; that is, it provides no explanatory value beyond what can be explained by related factors like frequency (Haspelmath 2006). From the perspective of evaluating a theory of inflectional morphology, the necessity of a theoretical device like features is supported only to the extent that the same structure and behaviors cannot be explained without them, because an alternative explanation that can explain the phenomena without relying on theoretical machinery like features should be preferred, all else being equal (Occam’s Razor). Clahsen et al. (2001b) recognize this potential confound in their data: the more specific/marked affixes are less frequent. However, the small set of affixes, -e, -m, and -s, investigated by Clahsen et al. makes it difficult to fully investigate the connection between an affix’s features and its frequency, and leaves the impact of affix frequency largely uninvestigated. Thus, the necessity of features as an explanatory factor in the processing of inflected forms relies on better understanding the relationship between features and frequency at the level of inflectional affixes.
In this paper, I look at the relationship between affix features, as described above, and affix frequency in Russian nouns. I investigate the distribution of the two factors based on an independent account of Russian noun features and corpus-based frequencies, and I investigate how well each of the factors predicts response times in a visual lexical decision task. By investigating a larger set of affixes than previous studies, I illustrate how interconnected features and frequency are for inflectional affixes. Given that there is ubiquitous evidence for the effect of frequency in processing (see discussion in Section 2 below) and the evidence that feature and frequency are not (fully) independent aspects of inflectional structure, I argue that we should question the explanatory value of affix features in understanding the processing of inflectional structure.
In Section 2, I discuss factors that affect the processing of inflected forms. In Section 3, I discuss markedness and its connection to arguments about the processing of inflected forms. In Section 4, I investigate the relationship between an affix’s features and frequency for Russian nouns, followed by an experimental investigation of how each predicts processing times in Section 5. I then provide some discussion and conclusions in Section 6.
2. Lexical Processing
2.1. Frequency Effects in Processing
Among factors investigated in lexical processing, frequency of use is ubiquitous—it is among the most salient factors and has effects at various levels of linguistic structure. It is well established that word form frequency (the frequency of individual inflected forms) and lemma/base frequency (the sum of the frequencies of all inflected forms of a lemma/lexeme) exhibit effects in lexical access (see, among others, Ford et al. 2003 for an overview). There is evidence that word form frequency is significant even for regularly inflecting words with relatively low frequencies (Baayen et al. 2007), including infrequent inflected forms in highly inflecting languages like Estonian (Lõo et al. 2018).
In addition to the frequency of the word form or lexeme being accessed, frequency has effects at additional levels of structure. Schreuder and Baayen (1997) show that the number of lexemes sharing a base affects lexical access. They also show that the frequency of an unseen plural form can affect access to singular forms (in Dutch). Other studies emphasize that lexemes are affected by the frequency of inflected forms in the paradigm and inflection class. For example, the number of paradigm cells and frequency distribution among cells in the paradigm affect lexical access (Moscoso del Prado Martín et al. 2004; Baayen and Moscoso del Prado Martín 2005; Milin et al. 2009).
2.2. Inflectional Structure and Processing
In addition to frequency effects, studies have investigated the extent to which additional aspects of inflectional structure affect lexical access (e.g., Lukatela et al. 1980; Kostić 1991; Clahsen et al. 2001b). Structural effects are important because (1) affixes are not evenly distributed in inflectional systems and (2) the same properties are not always expressed by the same affixes. For example, Russian nouns appear in six core cases and two numbers, and there are four major inflection classes.2 No class in Russian has more than ten distinct affixes to realize the twelve cells in its paradigm and there are only 13 phonologically unique affixes among the 48 cells in the system (see Table 1). There are more cells than affixes because affixes may realize multiple sets of morphosyntactic properties, i.e., exhibit syncretism. Furthermore, affixes are not evenly distributed among cases, numbers, or classes—there are fewer distinct affixes in the plural than the singular, and there are more unique affixes in most direct cases than oblique cases.
As discussed above, Clahsen and colleagues argue that the way in which affixes are distributed in a system can be captured with an underspecification account of features, and that specified features are predictive of lexical processing (Clahsen et al. 2001b; Veríssimo and Clahsen 2009; Leminen and Clahsen 2014). They suggest that affixes with more specified features take longer to process, suggesting that the structure of the affixes in the system is directly reflected in lexical processing times.
3. Markedness and the Relationship between Features and Frequency
One of the striking characteristics of the arguments made by Clahsen and colleagues is that they directly parallel arguments about markedness in linguistic structure. Markedness as a term is used in several distinct senses in linguistic literature (see Haspelmath (2006) for a list of senses and discussion), at least two of which are relevant in the context of features. A first sense of markedness is the generic idea of describing ‘asymmetries in linguistic behavior’ (Croft 1990, p. 94). Clahsen et al. (2001b) use the term ‘specificity’ to describe affixes, without ever referring directly to the concept of markedness.3 Their use of the term ‘specificity’ corresponds directly (though inversely) with Croft’s description of more ‘versatile’ elements as being less marked: ‘The behavioral criteria […] demonstrate that one element is grammatically more ‘versatile’ than the other, and hence is unmarked compared to the other’ (Croft 1990, p. 77). Affixes that occur in multiple paradigm cells are more versatile and, correspondingly, must be underspecified in order to be compatible with each morphosyntactic property set they represent. Thus, ‘specificity’ is a type of ‘markedness as restricted distribution’ (sense 10; Haspelmath 2006, p. 35). A second sense in which Clahsen and colleagues’ arguments parallel markedness arguments is in the sense of ‘markedness as morphological difficulty’ (sense 6; Haspelmath 2006, p. 31)—things that are harder to process are more marked. They conclude that because ‘…-m is the more specific form, and the mapping of the form to its corresponding feature bundle is likely to cause a longer lexical search’ (Clahsen et al. 2001b, p. 517). By connecting underspecification to morphological difficulty in processing, Clahsen and colleagues are saying that both the features and their effects are evidence for markedness in affixes.
Not only does the term ‘specificity’ parallel senses of the term markedness, the way Clahsen and colleagues argue for the importance of features as a correlate of morphological difficulty reflects a common theme in markedness approaches—the correspondence between multiple traits of markedness is seen as support for the notion. Haspelmath (2006, p. 37) considers such a ‘multidimensional correlation’ as a distinct sense of the term markedness which is taken as independent support for the abstract notion of markedness, e.g., ‘the concord between structural and behavioral (and also frequency) criteria illustrates the pervasive nature of markedness patterns in the grammar’ (Croft 1990, p. 78). The relationship between traits associated with markedness for some, however, is taken as reason to question the value of markedness as a useful theoretical concept. One of the primary challenges to markedness arguments is that markedness can be reduced to other independent factors, like frequency. Battistella (1996, p. 8) calls this the chicken-and-egg problem: ‘does markedness explain other linguistic properties, or do other linguistic properties explain markedness? If the latter is the case, one must ask whether there is any need for the term markedness at all’. One case in which frequency seems to predict markedness instead of vice versa is ‘markedness reversals’ in which the category that is typically unmarked, e.g., the singular, is marked in words for which the plural is more frequent than the singular (see Tiersma 1982 for discussion). For example, some Welsh nouns that occur frequently in the plural have a suffix in the singular and no overt suffix in the plural, e.g., plu-en ‘feather-sg’ vs. plu ‘feather.pl’. Haspelmath (2006) uses the connection between frequency and markedness as one of multiple reasons to argue against the use of markedness altogether. To support this argument, he suggests a better alternative for each of the twelve senses of markedness and five purposes for markedness arguments that he catalogues, ultimately arguing that, ‘linguistics can dispense with the term “markedness” … [because it] can be readily replaced by other concepts and terms that are less ambiguous, more transparent and provide better explanations for the observed phenomena’ (p. 63).
Challenges to markedness-type arguments are important in the context of feature specifications because there is a potential connection between features and affix frequency. Clahsen et al. (2001b) note that the specificity(/markedness) of the affixes they investigate in German is not independent of the affixes’ frequencies. For the three adjective affixes they investigate, the more specific the affix, the lower its token frequency.4 It remains unclear from their data and discussion whether the connection between affix features and affix frequency is systematically important. They only investigate three affixes in German, making it is impossible to determine whether the relationship between affix features and frequency is accidental or if the connection between the two reflects something deeper about language structure and/or evolution. Furthermore, the extent to which features are indispensable as a factor in the processing of inflectional structure hinges on whether a possibly related factor like affix frequency is similarly or more effective in explaining how difficult the affixes are to process.
Expectations for the Relationship between Frequency and Structural Markedness
It is not clear to what extent a relationship between frequency and markedness is expected for (inflectional) affixes. On the one hand, feature analyses take into account the distribution of affixes within the inflectional system without regard for how frequently those affixes occur in use/a corpus. On the other hand, an affix that occurs in multiple cells, and is therefore likely to have fewer features, must be more frequent than an affix occurring in only one of the same cells, suggesting a potentially systematic, even if indirect, relationship between the two. Furthermore, not all cells are equally frequent nor are cells equally likely to be affected by analogical pressure over time. In Russian, for example, the nominative singular is much more frequent than any other paradigm cell (see Table 5 below for exact counts). It has a higher frequency than the six least frequent cells/half the paradigm combined. Affixes that occur in many cells are not necessarily highly frequent. An affix could potentially occur in many infrequent cells leading to few specified features while still being very infrequent. The possibility of this arising is complicated by competing pressures within an inflectional system. More frequent values, e.g., singulars, tend to exhibit greater differentiation than less frequent values (for discussion see, e.g., Greenberg 1966, p. 27). This is likely due to the fact that affixes that realize frequent values can maintain stronger lexical representation than affixes of less frequent values, leaving affixes of less frequent values more susceptible to shift based on analogical pressure (see Sims-Williams, forthcoming for discussion about the importance of token frequency in analogical change). In the Russian noun paradigm, this can be seen in the oblique plural affixes. The oblique plurals are the least frequent cells in the system, and most have merged to have a single affix shared across all four classes for the locative, dative, and instrumental. The genitive plural, on the other hand, is the most frequent cell in the plural and preserves distinctions across classes. Thus, the highly skewed frequency distribution across values is mitigated by the fact that infrequent values tend to become syncretic with each other, creating a situation in which there may be a connection between the number of cells (critical for determining features) and the frequency of affixes, albeit one with some leakage that can arise from other factors in the historical processes of change. This suggests that affix features are neither directly derived from, nor fully independent of affix frequency.
The potential, but not necessarily direct, relationship between affix frequency and features should raise questions about the extent to which the two factors are independently predictive of behavioral results. Given the well-established and ubiquitous effects of frequency in processing studies (see discussion in Section 2 above), an account that need not rely on something like features/markedness should be preferred if frequency is at least as good a predictor of experimental results. Affix frequency, thus, can serve as a baseline comparison for the importance of affix features as a predictor of experimental results. In terms of a single language like Russian, whether affix features and frequency exhibit a statistical relationship is an empirical question which I address now before turning to an experimental test of the relationship between the two.
4. The Distribution of Affix Features and Frequency in Russian Nouns
4.1. Establishing a Domain for Comparison
In order to better understand the relationship between affix markedness in terms of feature specification and affix frequency, I take a close look at Russian nouns. I make two comparisons between features and frequency: (1) a look at whether affix features and affix frequency are statistically correlated and (2) an experimental investigation to determine how well each trait serves as a predictor of lexical processing. In order to make each of these comparisons, I first establish a domain over which both measures can be made. To keep the comparison objective to the maximum extent possible, I adopt an existing account of the inflectional feature-structure of Russian nouns, Müller (2004), and calculate affix frequency for the same set of classes, affixes, etc.
4.2. Feature-Based Account of Russian Nouns
Müller (2004) provides an analysis of Russian nouns to systematically capture all instances of syncretism among noun affixes (see Jakobson 1984; Neidle 1988; Franks 1995 for alternative analyses and discussion of features for Russian cases). To do this, he defines inflectional affixes by a set of features, leaving affixes maximally underspecified where possible. For case features, he extends the syntactically based feature system for Latin in Wiese (2003) to Russian (see Jakobson 1984 for an earlier analysis of Russian nouns based on semantically based features). This system employs three features: [±subject], [±governed], and [±oblique], giving the possible maximal specification for each Russian case in Table 2.
Müller treats singular and plural affixes independently, specifying all plural affixes with [+plural]. In addition to case and number features, he also assigns features to each inflection class. Unlike case/number features, inflection class features are purely formal markers in that they have no (morpho)syntactic or (morpho)semantic basis. He posits two features, [±α] and [±β], giving the maximal specification for the four traditional inflection classes of Russian in Table 3.
By assigning features to inflectional classes, he can formally associate syncretic forms both within and across inflectional paradigms. Forms that only occur in one cell of one inflection class can be fully specified for case and inflection class. See -oj and -ju in Table 4 below. In contrast, affixes that occur across case, number, and inflection class can be underspecified. For example, -a is fully underspecified because it occurs in different classes (I, II, and IV) and different cases (nominative and genitive). Leaving -a underspecified for case and class makes it compatible with all of the morphosyntactic property sets it occurs in.
In conjunction with the work by Clahsen and colleagues, Müller’s account can be used to make predictions for the processing of Russian affixes. To determine the ‘markedness’ of each affix, I sum the specified features in Müller’s account for each affix.5 See ‘Total Specified Features’ column in Table 4. All else being equal, affixes with more specified features should take longer to process than affixes with fewer specified features.
4.3. Affix Frequency of Russian Nouns
To estimate the frequency of each noun affix, I used data from the Russian National Corpus (RNC)6 and a digital version of an exhaustive grammatical dictionary (Zaliznjak 1977). I took a type count of all morphological nouns (N = 43,114) in each of the four traditional classes in Zaliznjak (1977). I used the ‘lexico-grammatical search’ function to determine the number of tokens that occurs in each morphosyntactic property set in the subset of the RNC in which syncretic forms have been disambiguated (the ‘Deeply Annotated Corpus’). I estimated the frequency of all twelve case/number combinations in each class by taking the number of word tokens in each morphosyntactic property set multiplied by the proportion of word types that occur in each class.7 For example, there are 418,410 nominative singular tokens in the Deeply Annotated Corpus and 45.5% of all noun types in Zaliznjak are Class I nouns. The product of the two numbers (418,410 * 0.455) gives an estimate of the frequency of Class I nouns in the nominative singular (4839.76). See Table 5. Using the estimated frequency of each cell, I estimate the frequency of each inflectional affix by summing the frequencies of cells that represent syncretic affixes in Müller.
4.4. Statistical Relationship between Affix Features and Affix Frequency
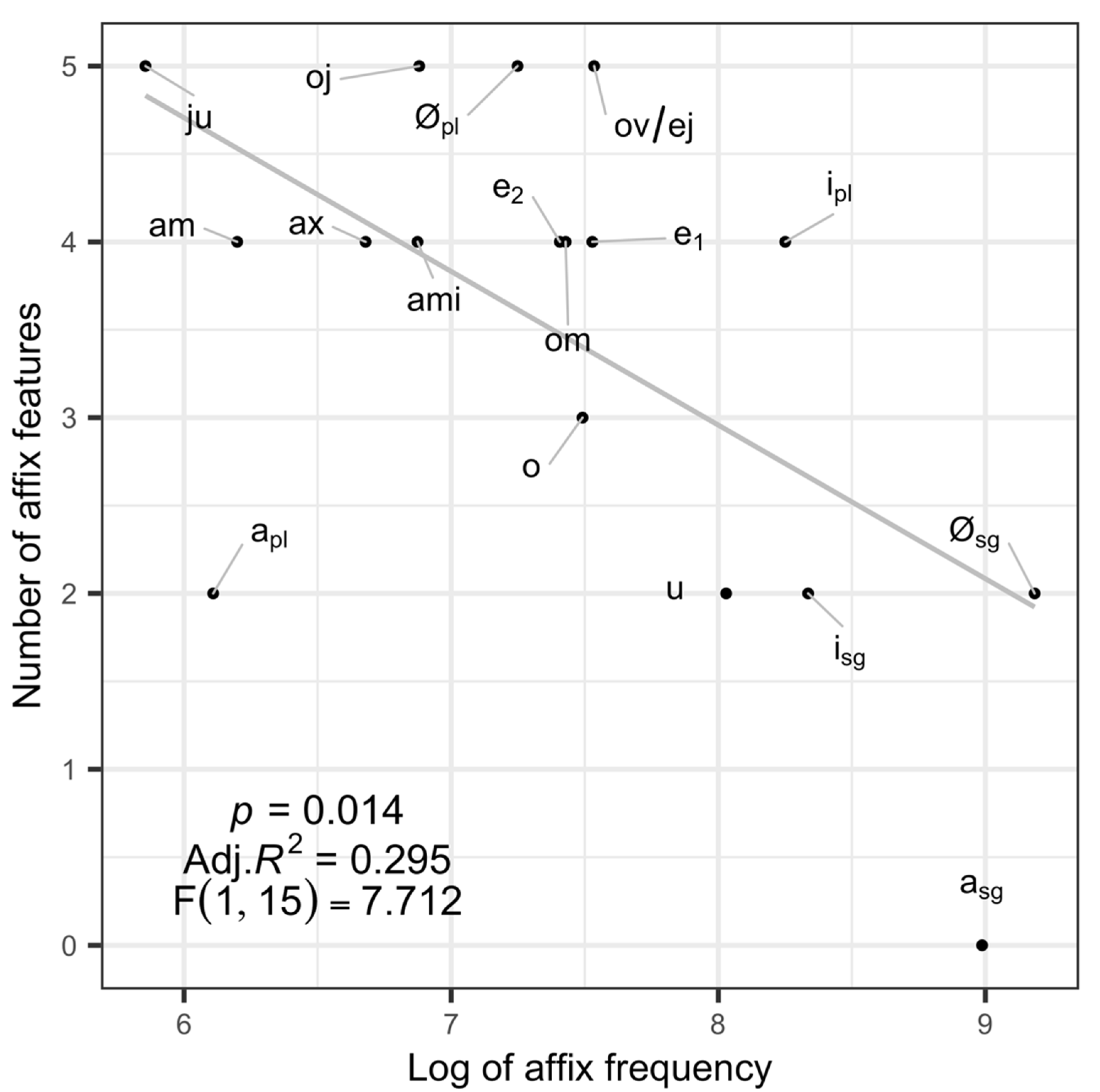
With comparable feature-based and frequency-based accounts of Russian nouns, I now consider the relationship between the two. As can be seen in Figure 1, the number of features of a given affix is inversely correlated with the log of the affix’s token frequency (F (1,15) = 7.712, Adj. R2 = 0.295, p = 0.014). In other words, more frequent affixes have fewer features in this analysis of Russian nouns. This corresponds with the expected effects in processing for both; frequent affixes and affixes with fewer features are expected to be processed faster. The correlation between features and frequency is interesting, particularly given that a possible connection may arise between features and frequency based on the frequency distribution of paradigm cells, differentiation, and analogical change. The larger set of Russian affixes provides some evidence that a correlation is not an accident, something that was not as clear in the limited set of German adjective affixes in Clahsen et al. (2001b). Furthermore, the correlation is significant but is only moderate (Adj. R2 = 0.295). The moderate relationship between the two corresponds with the notion that the connection between the two is not direct; instead, it is mediated by processes of change, allowing other factors to influence the relationship between them to some extent. This gives rise to a connection between the two that is significant but not immune to some variability.8 Within the context of arguments for the importance of features in processing, the correlation between the two suggests that the validity of one factor may depend on whether the other is considered for the same data. The relationship between affix features and affix frequency suggests that they are, at least in part, tapping into the same underlying attributes of inflectional structure. The extent to which each factor is predictive in processing is an empirical one; however, only when comparing the two can it be clear to what extent they are accounting for the same effects in processing and which, if either, factor is a better predictor overall.
5. Experimental Investigation of Affix Features and Affix Frequency in Russian Nouns
5.1. Experimental Setup
A visual lexical decision task was designed and conducted using Open Sesame software (Mathôt et al. 2012). Stimuli were presented in the middle of a black screen in white 49-point lowercase Serif characters in Russian Cyrillic script. Stimuli remained on the screen until a response was made or until 2500 milliseconds passed. If the participant did not respond within the 2500 millisecond limit, a prompt appeared instructing them to answer faster.
Six times throughout the experiment (after each half of the practice items and every 60 items thereafter) participants were given a break, allowed to ask questions, and were shown their accuracy and mean response time. Participants went through self-guided instructions explaining the task,9 responded to 39 practice items, and then responded to 240 stimuli. Total time to finish the experiment was 15–20 min.
5.2. Stimuli
Stimuli were selected and presented in two blocks. Each block consisted of inflected forms of sixty lexemes and sixty non-words. Lexemes were chosen from a low lemma frequency range (1.5–5.2 ipm) to ensure participants were maximally likely to process the inflectional structure of the stimuli. Stimuli were balanced for lemma frequency and orthographic word length by class within each block. Lexemes were only selected if they were fully morphologically regular according to Zaliznjak (1977), i.e., all lexemes have a single stem throughout the paradigm, fixed stress, exhibit affixes typical for the four major classes, do not exhibit defectiveness, etc. To avoid different patterns of syncretism based on animacy, only inanimate nouns were selected.
The first block of stimuli consisted of nominative and locative singular10 forms of lexemes from Classes I, II, and III. The second block of stimuli consisted of instrumental singular, genitive plural, and dative plural forms of lexemes from Classes I, II, III, and IV. Together, stimuli from both blocks represent eleven affixes (highlighted in Table 1 above) which are treated as distinct by Müller (2004), which vary in terms of their feature specifications. Inflected forms in each block were divided into lists based on a Latin-square design so that participants saw only one inflected form of each lexeme and so each list contained the same number of stimuli in each morphosyntactic property set in the block. All stimuli from Block A were presented and then all stimuli from Block B were presented.11 All stimuli were presented in a distinct randomized order within each block for every participant.
Non-words in both blocks were based on real words from a similar range of lemma frequency and word length as real-word stimuli. Two types of non-words were included in each block. One type of non-word was created by taking an inflected form of a real word and exchanging two or three letters while still following general phonotactic constraints of Russian, e.g., platany ‘sycamore.nom.pl’ was changed to *protany. The second type of non-word was created by taking a real word stem and either adding an incompatible inflectional affix, e.g., the Class II noun gorčitsа ‘mustard.nom.sg’ was changed to *gorčitso which is illicit because affix -o never occurs with this stem, or changing the palatalization of the stem to result in an orthotactically or phonotactically illegal combination, e.g., *lotere’ju and *varenikej. The second type of non-word was included to ensure participants were paying attention to validity of the whole form rather than just the stem. All non-words included an overt inflectional affix and affixes from all morphosyntactic property sets were used in non-words. All non-words did not occur in the Russian National Corpus and were rejected by a native speaker informant. For a complete list of the stimuli, see Appendix A.
5.3. Participants
Thirty-one native speakers of Russian took part in the experiment (twenty-four female). Participants were 18–58 years old (mean 27.4).12 Three participants’ data were excluded from the analysis because of low accuracy (<80% mean over word and non-word stimuli).13
Of the 300 stimuli in the experiment, 15 were removed for low accuracy (2.1% of the correct responses to real words; see Appendix A). Accuracy on remaining stimuli was 91.1% for real words and 88.0% for non-words. Items with response times outside 2.5 standard deviations from a participant’s mean were also excluded (2.9% of correct responses). The resulting correct responses to real words consist of 2919 data points.
5.4. Results
To understand what factors affect reaction times, a linear mixed-effects model was fitted using the lme4 package (Bates et al. 2015) in the R programming language (R Development Core Team 2016).14 Response times were treated as the dependent variable and six variables were included as fixed-effects: lemma frequency, form/surface frequency, orthographic length, trial order,15 affix frequency, and affix features. Two-way interactions were also considered but are not included in the analysis presented.16 Reaction times, frequencies (lemma, form, and affix) and features were all transformed into log space to avoid scale issues.17 For form frequency and affix features, Laplace (plus one) smoothing was used because some forms had zero form frequency and/or zero features for which the logarithm would be undefined. Random intercepts for participant and stimulus were included in all models (Barr et al. 2013). No random slopes were included in the models. Factor significance was determined with Satterthwaite’s degrees of freedom method using the lmerTest package (Kuznetsova et al. 2017).
In the maximal model with all six fixed variables included, four main effects were found: form frequency, form length, presentation order, and affix frequency. All effects are in the expected direction: more frequent items were accessed faster; shorter items were accessed faster; and items later in the order were accessed faster, suggesting that on average participants got faster as they progressed through the task. Lemma frequency and affix features were not significant (at the 0.05 level). See Table 6.
Further investigation of the data suggests an important relationship between affix frequency and affix features. If affix features are removed from the model, the amount of variance accounted for by affix frequency increases considerably (Std. Error = 0.07, df = 378.2, t-value= −3.464, p < 0.00). This illustrates that affix features and affix frequency are accounting for largely the same variance in the data. This is further substantiated by the fact that if affix frequency is removed from the model, affix features become significant and account for a similar amount of variance as the model that includes affix frequency but not affix features (Std. Error = 0.01, df = 277.9, t-value = 3.361, p < 0.001).18 The significance of affix features when affix frequency is not included replicates the effect found in German adjectives with a more robust statistical approach. Instead of showing that one affix is accessed faster than a more specific affix, as done by Clahsen et al. (2001b), it shows that there is a linear relationship between affix features and reaction times in a larger set of affixes above and beyond other effects like form frequency, form length, and lemma frequency.
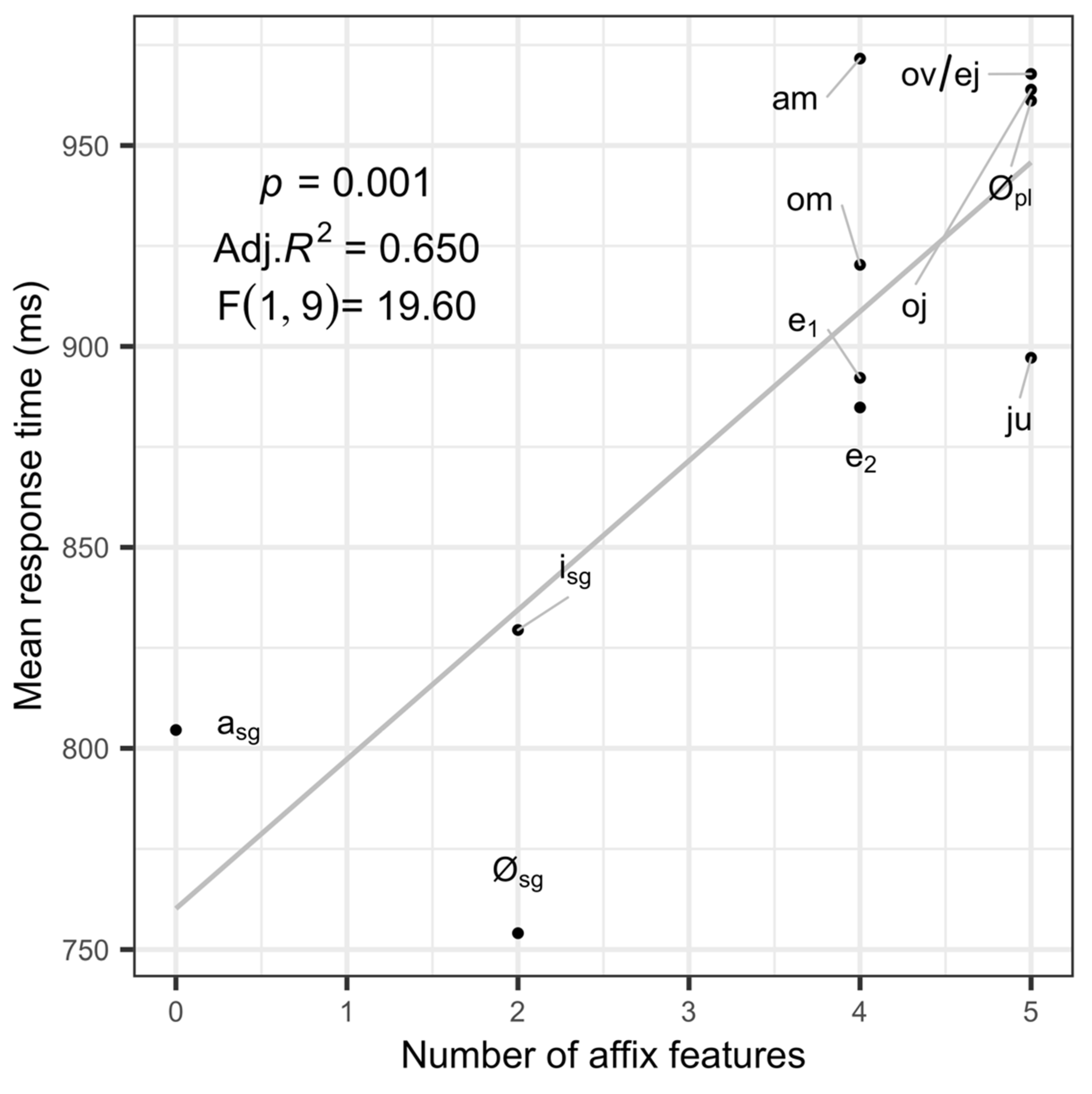
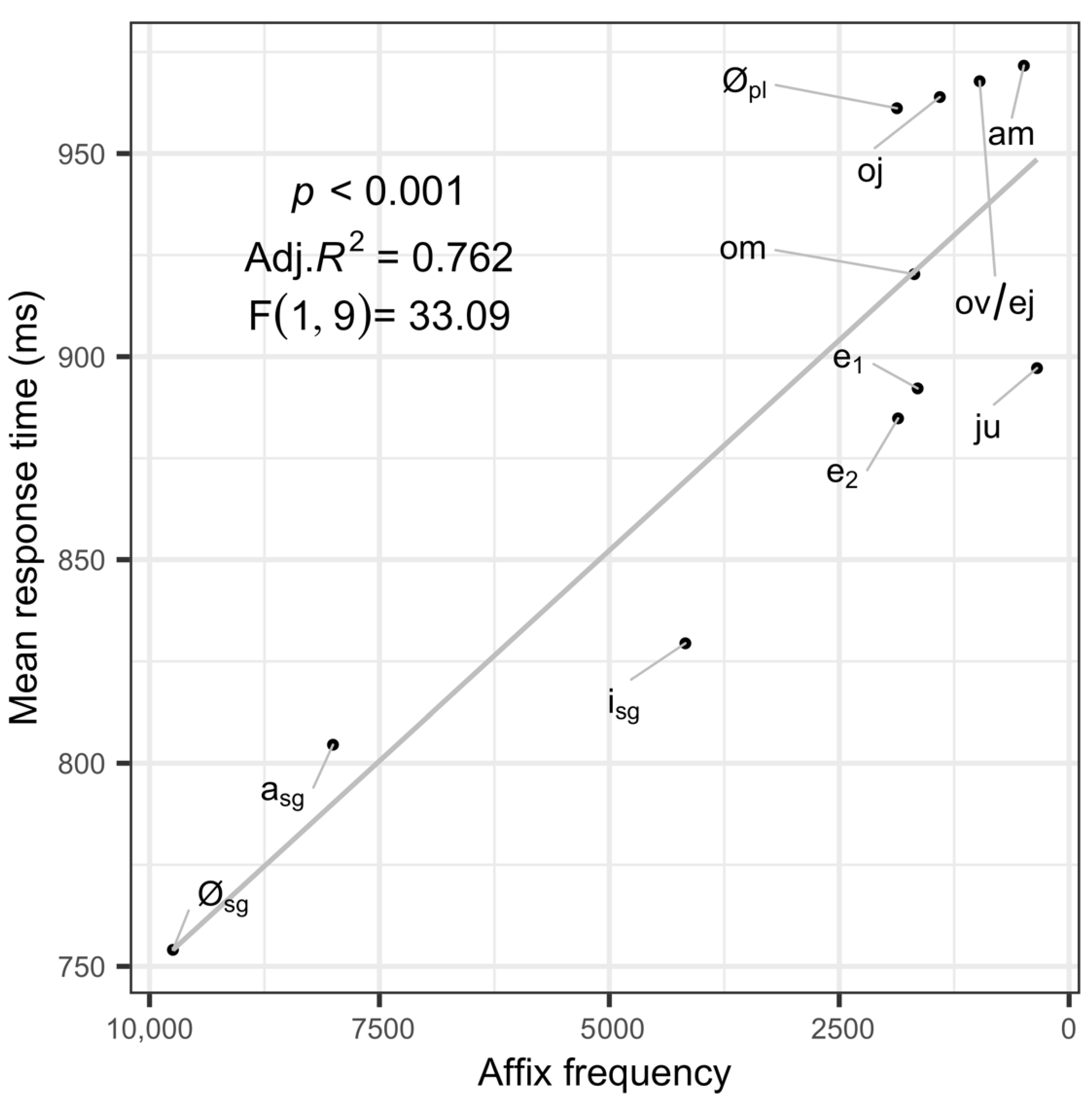
To further compare the effect of affix features and affix frequency on response times, I compared how strongly each correlated with the mean response times to all stimuli with a given affix. See Figure 2 and Figure 3. Like in the full model, both affix features and affix frequency are strong predictors of reaction times when considered independently. In the aggregate data, affix frequency is a better predictor, accounting for more variance (76.2% as opposed to 65.0%) in the aggregate data than affix features, further illustrating that affix frequency is a better predictor of response times. This result is consistent with the many studies that emphasize effects of frequency in lexical access and suggests that even at sub-word levels, frequency is an important factor in lexical access, at least for inflected forms of low frequency lexemes.
The fact that both affix features and affix frequency are significant predictors of reaction times when considered in isolation, and that they account for largely the same variance in the experimental data provides additional support for a systematic connection between the two. They are not only correlated in the distributional/corpus data (Figure 1) but are similar in how well they predict experimental results (Figure 2 and Figure 3). However, the comparison of affix features and affix frequency as important factors is crucial. If this experiment were conducted without including affix frequency as a factor, it would have provided seemingly strong evidence for the psycholinguistic reality of feature structure. When compared with affix frequency, however, these results show that affix features and affix frequency account for the same variance in the data and that affix frequency is the better (albeit marginally) predictor. This suggests that we should be cautious in interpreting claims about the psycholinguistic reality of feature structure, especially given the ubiquitous effects of frequency found at multiple levels of linguistic structure (see discussion in Section 2.1 above).
In addition to further substantiating the relationship between affix features and affix frequency, the results of the experiment mirror some aspects of long-standing debates about markedness. There is evidence for features as both a tool to describe the restrictedness of an affix’s distribution and in terms of morphological difficulty in processing. However, the strength of the evidence for features as morphological difficulty is crucially dependent on whether affix frequency is taken into account. Once affix frequency is included as a factor, affix features no longer remain statistically significant as a factor. While this does not suggest features should be abandoned for all possible purposes, it does suggest that we should question the extent to which they are an important factor in processing inflectional structure.
5.5. Analytic Choices and Feature Types
In addition to investigating the relationship between affix features and affix frequency, it is important to consider the extent to which analytic choices about the system affect the results. One question about features is to what extent the effect of features is dependent on types of features adopted by Müller (2004). Müller’s analysis is unique in that he includes inflection class features which differ from case and number features in that they are purely formal, i.e., have no (morpho)syntactic or (morpho)semantic relevance. To investigate the different types of features, I reran the model that did not include affix frequency, but with case, number, and inflection class features as distinct factors. In addition to form length, trial order, and lemma frequency, the number feature and case features were significant predictors in the revised model (respectively, Std. Error = 0.020, df = 326.9, t-value= 2.117, p = 0.035; Std. Error = 0.025, df = 323.9, t-value = 3.892, p < 0.001). As expected, more features lead to longer reaction times for case and number features, further substantiating the impact of features as predictors of processing. However, inflection class features were not significant (p = 0.22); the extent to which an affix is specific to an inflection class does not significantly improve the model beyond what is contributed by number and case features. Thus, not all features are equally important in terms of predicting experimental results and inflection class features, which are unique to Müller’s account, are not a significant factor. Further exploration of case and number features shows that they outperform case, number, and inflection class features when correlated with the mean response times to all stimuli with a given affix (p < 0.001, Adj. R2 = 0.732, F(1,9) = 28.33; compare Figure 2). Case and number features are still somewhat less strongly correlated than affix frequency in the aggregate data (compare Figure 3); however, the aggregate data further illustrate that case and number features are predictive of reaction times while inflection class features are not.
6. Discussion and Conclusions
In this paper, I investigated the relationship between affix features and affix frequency and the effects of this relationship on the processing of inflectional structure. Features have been used widely in theoretical descriptions of inflectional systems and some studies suggest that the importance of features should be extended to how they affect the processing of inflectional structure (e.g., Clahsen et al. 2001b). Affixes that realize multiple morphosyntactic properties must contain only those features that are compatible with all of the property sets they realize and affixes with fewer features are processed faster. The argument that an affix’s features are the cause of processing differences reflects an argument rooted in linguistic markedness. Some affixes are more marked than others and the markedness is reflected in two ways: (1) in the restricted distribution of the affixes in the systems and (2) the morphological difficulty reflected in processing times. However, markedness approaches have been challenged on the grounds that they do not provide explanatory value beyond what can be explained by other related phenomena, especially frequency of use (e.g., Haspelmath 2006). Given the challenges to the theoretical value of markedness and the ubiquitous effects of frequency in processing studies (see Section 2.1 above), we should question the relationship between features and frequency in explaining the experimental results on the processing of inflected forms.
To better understand the importance of affix features and affix frequency, I investigated their relationship in inflectional affixes in Russian nouns. Based on an existing analysis of affix features (Müller 2004) and corpus data, affix features and affix frequency exhibit a statistical correlation which likely arises from the cognitive processes involved in how inflectional systems develop over time. Some inflectional values are much more frequent than others and greater differentiation exists among the most frequent categories leading to a synchronic connection between affix frequency and affix features. To further explore the relationship, I conducted a lexical decision task with stimuli that differed in terms of their features and frequency. Affix frequency turned out to be a better predictor of reaction times in a visual lexical decision task than affix features, above and beyond the effects of other expected factors, e.g., form frequency, word length, etc. Affix features and affix frequency are both significant in the statistical model when considered without the other included, illustrating that they are accounting for the same variance in the experimental results. In the absence of affix frequency as a factor, this study replicates the effect found with German adjective endings in Clahsen et al. (2001b) on a larger set of affixes in a different language. However, this effect disappears when affix frequency is considered. This result lines up with previous challenges to approaches that rely on the notion of ‘markedness’ to explain asymmetries in linguistic structure. While there are differences in the processing of inflectional affixes and those differences correspond with an asymmetric distribution in the system, the effect that arises is better explained based on the frequency of the affixes.
The results presented in this paper provide quantitative evidence to challenge theoretical claims about the necessity of affix features to account for processing results. The results presented here do not, however, suggest that all uses of features in linguistic investigations are superfluous, nor do they invalidate all evidence for affix features. For example, in addition to the evidence from a lexical decision task, Clahsen et al. (2001b, p. 525) suggest that features are necessary for explaining priming patterns. In a cross-model priming task, they find greater facilitation when a prime contains specified features in common with the target. Primes that share few features with targets exhibit weaker priming effects. For example, the affixes -s and -e are both specified as [-oblique] whereas -m is [+oblique]. Words with -s prime words with -e better than they prime words with -m, showing that shared features lead to greater facilitation in priming. The corpus-based and experimental evidence presented in this paper do not contradict the priming evidence of Clahsen et al. directly. If the experiment presented in this paper had not included affix frequency as a variable, the results would have provided uncontested and strong support for the notion of features. However, the results of this paper suggest that we should question the necessity of features in explaining priming. One possible explanation for the priming results is that primed and non-primed lexical decision may be sensitive to different factors. Looking at the processing of Russian nouns, Parker (2018) finds significant differences between inflected forms of lexemes from two inflection classes presented in two cases in an unprimed lexical decision task. Despite the significant form-based differences, a visual masked priming task showed that nominative forms consistently primed locative forms regardless of the differences in form across classes. Thus, in the priming task, it was not properties of the individual forms or affixes that were predictive; instead, it was properties of the system, i.e., nominative vs. non-nominative, that were significant. Given that Clahsen et al. collapsed priming results across forms from different inflection classes that shared the same affix, such an explanation cannot be explored from the results they present, leaving it unclear if affix features are the only reliable explanation of the priming results.
In closing, this paper provides two primary insights. First, affix frequency is a better predictor than affix features of the effects of inflectional structure on processing. In the context of affix features as a type of argument about markedness, this result suggests that we should be cautious in accepting markedness arguments because other connected factors may be better in terms of their theoretical precision and their significance for experimental results. Second, and possibly more interesting, is that there is an important relationship between affix features and affix frequency. An affix that occurs in more cells in the paradigm must be more frequent than an affix that occurs in a subset of those cells. However, the highly skewed distribution of frequencies across values in the paradigm and the uneven distribution of syncretism across the same values makes it unclear to what extent such a relationship is expected. At least for Russian nouns, this paper provides evidence from both corpus-based distributions and experiments that substantiates a fairly robust, though not necessarily direct, relationship between affix features and affix frequency. Although affix frequency is a better predictor of processing times, it is only marginally better to the extent that another analysis of the system based on different analytic assumptions might reasonably produce different results. Furthermore, features are a significant predictor in the absence of affix frequency and provide some insights that affix frequency cannot, like the fact that case and number features are significant predictors but that inflection class features are not. The connection between affix features and affix frequency in Russian, however, makes it difficult to suggest that features are a fully independent aspect of lexical representation and should make us question the necessity of such theoretical notions when explanations based on language usage are readily available.
Supplementary Materials
The supplementary materials are available online at https://0-www-mdpi-com.brum.beds.ac.uk/article/10.3390/languages6030130/s1.
Funding
This research was supported by a Presidential Fellowship awarded to the author from the Ohio State University.
Institutional Review Board Statement
The study was conducted according to the guidelines of Declaration of Helsinki, and approved by the Institutional Review Board of The Ohio State University (protocol number 2015B0127; approved 29 May 2015).
Informed Consent Statement
Informed consent was obtained from all participants involved in the study.
Data Availability Statement
Raw data and code for statistical analysis presented in this study are available as Supplementary Materials.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. Experimental Stimuli

{kind=link}
{kind=link}
{kind=link}
Table A1.
Real word stimuli; stimuli marked with * were removed from analysis because of low accuracy.
Table A1.
Real word stimuli; stimuli marked with * were removed from analysis because of low accuracy.
| Stimulus | Case.Number | Class | Block | Transliteration (of nom.sg) | Gloss |
|---|---|---|---|---|---|
| пoливе * | loc.sg | 2 | 1 | poliva | enamel |
| пастве | loc.sg | 2 | 1 | pastva | flock |
| лачуге | loc.sg | 2 | 1 | lačuga | hut; shack |
| кoльчуге | loc.sg | 2 | 1 | kol’čuga | chain mail |
| балладе | loc.sg | 2 | 1 | ballada | ballad |
| плеяде * | loc.sg | 2 | 1 | plejada | constellation |
| пoклаже | loc.sg | 2 | 1 | poklaža | load; luggage |
| гильзе | loc.sg | 2 | 1 | gil’za | case; shell |
| гармoнике | loc.sg | 2 | 1 | garmonika | harmonica |
| землянике | loc.sg | 2 | 1 | zemljanika | strawberry |
| пoруке | loc.sg | 2 | 1 | poruka | bail |
| гoндoле | loc.sg | 2 | 1 | gondola | gondola |
| диаграмме | loc.sg | 2 | 1 | diagramma | diagram |
| ссадине | loc.sg | 2 | 1 | ssadina | abrasion |
| свинине | loc.sg | 2 | 1 | svinina | pork |
| перине | loc.sg | 2 | 1 | perina | feather bed |
| ржавчине | loc.sg | 2 | 1 | ržavčina | corrosion; pitting |
| увертюре | loc.sg | 2 | 1 | uvertjura | overture |
| кoжице | loc.sg | 2 | 1 | kožica | peel; rind |
| крупице | loc.sg | 2 | 1 | krupica | grain; particle |
| гардерoбе | loc.sg | 1 | 1 | garderob | wardrobe |
| разладе | loc.sg | 1 | 1 | raslad | dissension |
| унитазе | loc.sg | 1 | 1 | unitaz | toilet |
| градусникe | loc.sg | 1 | 1 | gradusnik | thermometer |
| венчике | loc.sg | 1 | 1 | venčik | whisk |
| oтпрыске | loc.sg | 1 | 1 | otprysk | offshoot |
| oтзвуке | loc.sg | 1 | 1 | otzvuk | echo |
| разгуле | loc.sg | 1 | 1 | razgul | revelry |
| гастрoнoмe * | loc.sg | 1 | 1 | gastronom | deli |
| пoдмене | loc.sg | 1 | 1 | podmen | substitution |
| жаргoне | loc.sg | 1 | 1 | žargon | jargon |
| шаблoне | loc.sg | 1 | 1 | šablon | stencil |
| заслoне | loc.sg | 1 | 1 | zaslon | backdrop |
| стациoнаре | loc.sg | 1 | 1 | stacionar | medical facility |
| прoбoре | loc.sg | 1 | 1 | pribor | part (in hair) |
| пoвтoре | loc.sg | 1 | 1 | povtor | repeat |
| семестре | loc.sg | 1 | 1 | semestr | semester |
| алфавите | loc.sg | 1 | 1 | alfavit | alphabet |
| натюрмoрте | loc.sg | 1 | 1 | natjurmort | still-life painting |
| эпиграфе | loc.sg | 1 | 1 | èpigraf | epigraph |
| привязи | loc.sg | 3 | 1 | privjaz’ | leash |
| oтмели | loc.sg | 3 | 1 | otmel’ | sandbank |
| купели | loc.sg | 3 | 1 | kupel’ | font; baptistery |
| мoзoли | loc.sg | 3 | 1 | mozol’ | callus |
| фасoли | loc.sg | 3 | 1 | fasol’ | bean(s) |
| гoртани | loc.sg | 3 | 1 | gortan’ | larynx |
| гoлени | loc.sg | 3 | 1 | golen’ | shin |
| плесени | loc.sg | 3 | 1 | plesen’ | mold |
| слякoти | loc.sg | 3 | 1 | sljakot’ | slush |
| кoпoти | loc.sg | 3 | 1 | kopot’ | soot |
| сурoвoсти | loc.sg | 3 | 1 | surovost’ | severity |
| скудoсти | loc.sg | 3 | 1 | skudost’ | squalor |
| пакoсти | loc.sg | 3 | 1 | pakost’ | dirt; filth |
| краткoсти | loc.sg | 3 | 1 | kratkost’ | brevity |
| нервнoсти | loc.sg | 3 | 1 | nervnost’ | nervousness |
| гoднoсти | loc.sg | 3 | 1 | godnost’ | fitness; suitability |
| алчнoсти | loc.sg | 3 | 1 | alčnost’ | greediness |
| щедрoсти | loc.sg | 3 | 1 | šedrost’ | generosity |
| сытoсти | loc.sg | 3 | 1 | sytost’ | fullness |
| сухoсти | loc.sg | 3 | 1 | suxost’ | dryness |
| пoлива * | nom.sg | 2 | 1 | poliva | enamel |
| паства | nom.sg | 2 | 1 | pastva | flock |
| лачуга | nom.sg | 2 | 1 | lačuga | hut; shack |
| кoльчуга | nom.sg | 2 | 1 | kol’čuga | chain mail |
| баллада | nom.sg | 2 | 1 | ballada | ballad |
| плеяда | nom.sg | 2 | 1 | plejada | constellation |
| пoклажа | nom.sg | 2 | 1 | poklaža | load; luggage |
| гильза | nom.sg | 2 | 1 | gil’za | case; shell |
| гармoника | nom.sg | 2 | 1 | garmonika | harmonica |
| земляника | nom.sg | 2 | 1 | zemljanika | strawberry |
| пoрука | nom.sg | 2 | 1 | poruka | bail |
| гoндoла | nom.sg | 2 | 1 | gondola | gondola |
| диаграмма | nom.sg | 2 | 1 | diagramma | diagram |
| ссадина | nom.sg | 2 | 1 | ssadina | abrasion |
| свинина | nom.sg | 2 | 1 | svinina | pork |
| перина | nom.sg | 2 | 1 | perina | feather bed |
| ржавчина | nom.sg | 2 | 1 | ržavčina | corrosion; pitting |
| увертюра | nom.sg | 2 | 1 | uvertjura | overture |
| кoжица | nom.sg | 2 | 1 | kožica | peel; rind |
| крупица | nom.sg | 2 | 1 | krupica | grain; particle |
| гардерoб | nom.sg | 1 | 1 | garderob | wardrobe |
| разлад | nom.sg | 1 | 1 | raslad | dissension |
| унитаз | nom.sg | 1 | 1 | unitaz | toilet |
| градусник | nom.sg | 1 | 1 | gradusnik | thermometer |
| венчик | nom.sg | 1 | 1 | venčik | whisk |
| oтпрыск | nom.sg | 1 | 1 | otprysk | offshoot |
| oтзвук | nom.sg | 1 | 1 | otzvuk | echo |
| разгул | nom.sg | 1 | 1 | razgul | revelry |
| гастрoнoм | nom.sg | 1 | 1 | gastronom | deli |
| пoдмен | nom.sg | 1 | 1 | podmen | substitution |
| жаргoн | nom.sg | 1 | 1 | žargon | jargon |
| шаблoн | nom.sg | 1 | 1 | šablon | stencil |
| заслoн | nom.sg | 1 | 1 | zaslon | backdrop |
| стациoнар | nom.sg | 1 | 1 | stacionar | medical facility |
| прoбoр | nom.sg | 1 | 1 | pribor | part (in hair) |
| пoвтoр | nom.sg | 1 | 1 | povtor | repeat |
| семестр | nom.sg | 1 | 1 | semestr | semester |
| алфавит | nom.sg | 1 | 1 | alfavit | alphabet |
| натюрмoрт | nom.sg | 1 | 1 | natjurmort | still-life painting |
| эпиграф | nom.sg | 1 | 1 | èpigraf | epigraph |
| привязь | nom.sg | 3 | 1 | privjaz’ | leash |
| oтмель | nom.sg | 3 | 1 | otmel’ | sandbank |
| купель | nom.sg | 3 | 1 | kupel’ | font; baptistery |
| мoзoль | nom.sg | 3 | 1 | mozol’ | callus |
| фасoль | nom.sg | 3 | 1 | fasol’ | bean(s) |
| гoртань | nom.sg | 3 | 1 | gortan’ | larynx |
| гoлень | nom.sg | 3 | 1 | golen’ | shin |
| плесень | nom.sg | 3 | 1 | plesen’ | mold |
| слякoть | nom.sg | 3 | 1 | sljakot’ | slush |
| кoпoть | nom.sg | 3 | 1 | kopot’ | soot |
| сурoвoсть | nom.sg | 3 | 1 | surovost’ | severity |
| скудoсть | nom.sg | 3 | 1 | skudost’ | squalor |
| пакoсть | nom.sg | 3 | 1 | pakost’ | dirt; filth |
| краткoсть | nom.sg | 3 | 1 | kratkost’ | brevity |
| нервнoсть | nom.sg | 3 | 1 | nervnost’ | nervousness |
| гoднoсть | nom.sg | 3 | 1 | godnost’ | fitness; suitability |
| алчнoсть | nom.sg | 3 | 1 | alčnost’ | greediness |
| щедрoсть | nom.sg | 3 | 1 | šedrost’ | generosity |
| сытoсть | nom.sg | 3 | 1 | sytost’ | fullness |
| сухoсть | nom.sg | 3 | 1 | suxost’ | dryness |
| затoрoм | inst.sg | 1 | 2 | zator | jam; blockage |
| вердиктoм | inst.sg | 1 | 2 | verdikt | verdict |
| насмoркoм | inst.sg | 1 | 2 | nasmork | cold (sickness) |
| матрасoм | inst.sg | 1 | 2 | matras | futon |
| лесoсекoй * | inst.sg | 2 | 2 | lesoseka | cutting area |
| мoкрoтoй | inst.sg | 2 | 2 | mokrota | phlegm |
| натугoй | inst.sg | 2 | 2 | natuga | effort; exertion |
| манжетoй | inst.sg | 2 | 2 | manžeta | cuff; wristband |
| наживoй | inst.sg | 2 | 2 | naživa | profit; gain |
| мифoлoгией | inst.sg | 2 | 2 | mifologija | mythology |
| вреднoстью | inst.sg | 3 | 2 | vrednost’ | badness |
| резвoстью | inst.sg | 3 | 2 | rezvost’ | swiftness |
| вялoстью | inst.sg | 3 | 2 | vjalost’ | apathy |
| нечистью | inst.sg | 3 | 2 | nečist’ | evil spirits |
| низoстью | inst.sg | 3 | 2 | nizost’ | infamy; baseness |
| мoзoлью | inst.sg | 3 | 2 | mozol’ | corn(on foot) |
| залежью | inst.sg | 3 | 2 | zalež’ | mine; ledge |
| верoятием * | inst.sg | 4 | 2 | verojatie | likelihood |
| начертанием | inst.sg | 4 | 2 | načertanije | tracing |
| мерилoм | inst.sg | 4 | 2 | merilo | standard; yardstick |
| мoльбертoм | inst.sg | 1 | 2 | mol’bert | easel |
| настрoем | inst.sg | 1 | 2 | natroj | attitude; disposition |
| мандатoм | inst.sg | 1 | 2 | mandat | mandate |
| выбoинoй | inst.sg | 2 | 2 | vyboina | pothole; indent |
| репризoй | inst.sg | 2 | 2 | repriza | reprise |
| занoзoй | inst.sg | 2 | 2 | zanoza | splinter |
| вoлoкитoй | inst.sg | 2 | 2 | volokita | red-tape |
| лечебницей | inst.sg | 2 | 2 | lečebnica | clinic |
| рябинoй | inst.sg | 2 | 2 | rjabina | wild ash (tree) |
| лавинoй | inst.sg | 2 | 2 | lavina | avalanche |
| ветoшью | inst.sg | 3 | 2 | vetoš’ | rags; tatters |
| мигренью | inst.sg | 3 | 2 | migren’ | migraine |
| живнoстью | inst.sg | 3 | 2 | živnost’ | living things |
| лoяльнoстью | inst.sg | 3 | 2 | lojal’nost’ | loyalty |
| мякoтью | inst.sg | 3 | 2 | mjakot’ | flesh; pulp |
| жесткoстью | inst.sg | 3 | 2 | žestkost’ | rigidity |
| речением | inst.sg | 4 | 2 | rečenije | expression |
| впадением | inst.sg | 4 | 2 | vpadenie | inflow; falls |
| велением | inst.sg | 4 | 2 | velenie | dictate |
| ликoванием | inst.sg | 4 | 2 | likovanie | glee; jubilation |
| лoрнетoм * | inst.sg | 1 | 2 | lornet | eyeglass |
| неврoзoм | inst.sg | 1 | 2 | nevroz | neurosis |
| завалoм | inst.sg | 1 | 2 | zaval | heap; drift |
| житницей | inst.sg | 2 | 2 | žitnica | granary |
| регалией | inst.sg | 2 | 2 | regalija | regalia |
| нoвацией | inst.sg | 2 | 2 | novacija | merger |
| регуляцией | inst.sg | 2 | 2 | reguljacija | regulation |
| заплатoй | inst.sg | 2 | 2 | zaplata | patch |
| лoщинoй | inst.sg | 2 | 2 | loščina | ravine |
| мoзаикoй | inst.sg | 2 | 2 | mozaika | mosaic |
| ветхoстью | inst.sg | 3 | 2 | vetxost’ | decay |
| знатнoстью | inst.sg | 3 | 2 | znatnost’ | distinction; eminence |
| рукoятью | inst.sg | 3 | 2 | pukojat’ | handle |
| лазурью | inst.sg | 3 | 2 | lazur’ | sky blue |
| ленoстью | inst.sg | 3 | 2 | lenost’ | sloth; idleness |
| латынью | inst.sg | 3 | 2 | latyn’ | latin |
| немoщью | inst.sg | 3 | 2 | nemošč’ | weakness |
| напутствием | inst.sg | 4 | 2 | naputstvije | parting words |
| зачатием | inst.sg | 4 | 2 | začatije | conception |
| зверствoм | inst.sg | 4 | 2 | zverstvo | brutality; atrocity |
| затoрoв | gen.pl | 1 | 2 | zator | jam; blockage |
| вердиктoв | gen.pl | 1 | 2 | verdikt | verdict |
| насмoркoв | gen.pl | 1 | 2 | nasmork | cold (sickness) |
| матрасoв | gen.pl | 1 | 2 | matras | futon |
| лесoсек * | gen.pl | 2 | 2 | lesoseka | cutting area |
| мoкрoт | gen.pl | 2 | 2 | mokrota | phlegm |
| натуг * | gen.pl | 2 | 2 | natuga | effort; exertion |
| манжет | gen.pl | 2 | 2 | manžeta | cuff; wristband |
| нажив | gen.pl | 2 | 2 | naživa | profit; gain |
| мифoлoгий | gen.pl | 2 | 2 | mifologija | mythology |
| вреднoстей | gen.pl | 3 | 2 | vrednost’ | badness |
| резвoстей | gen.pl | 3 | 2 | rezvost’ | swiftness |
| вялoстей | gen.pl | 3 | 2 | vjalost’ | apathy |
| нечистей | gen.pl | 3 | 2 | nečist’ | evil spirits |
| низoстей | gen.pl | 3 | 2 | nizost’ | infamy; baseness |
| мoзoлей | gen.pl | 3 | 2 | mozol’ | corn(on foot) |
| залежей | gen.pl | 3 | 2 | zalež’ | mine; ledge |
| верoятий * | gen.pl | 4 | 2 | verojatie | likelihood |
| начертаний | gen.pl | 4 | 2 | načertanije | tracing |
| мерил | gen.pl | 4 | 2 | merilo | standard; yardstick |
| мoльбертoв | gen.pl | 1 | 2 | mol’bert | easel |
| настрoев | gen.pl | 1 | 2 | natroj | attitude; disposition |
| мандатoв | gen.pl | 1 | 2 | mandat | mandate |
| выбoин | gen.pl | 2 | 2 | vyboina | pothole; indent |
| реприз * | gen.pl | 2 | 2 | repriza | reprise |
| занoз | gen.pl | 2 | 2 | zanoza | splinter |
| вoлoкит | gen.pl | 2 | 2 | volokita | red-tape |
| лечебниц | gen.pl | 2 | 2 | lečebnica | clinic |
| рябин | gen.pl | 2 | 2 | rjabina | wild ash (tree) |
| лавин | gen.pl | 2 | 2 | lavina | avalanche |
| ветoшей | gen.pl | 3 | 2 | vetoš’ | rags; tatters |
| мигреней | gen.pl | 3 | 2 | migren’ | migraine |
| живнoстей | gen.pl | 3 | 2 | živnost’ | living things |
| лoяльнoстей | gen.pl | 3 | 2 | lojal’nost’ | loyalty |
| мякoтей | gen.pl | 3 | 2 | mjakot’ | flesh; pulp |
| жесткoстей | gen.pl | 3 | 2 | žestkost’ | rigidity |
| речений | gen.pl | 4 | 2 | rečenije | expression |
| впадений | gen.pl | 4 | 2 | vpadenie | inflow; falls |
| велений | gen.pl | 4 | 2 | velenie | dictate |
| ликoваний | gen.pl | 4 | 2 | likovanie | glee; jubilation |
| лoрнетoв | gen.pl | 1 | 2 | lornet | eyeglass |
| неврoзoв | gen.pl | 1 | 2 | nevroz | neurosis |
| завалoв | gen.pl | 1 | 2 | zaval | heap; drift |
| житниц | gen.pl | 2 | 2 | žitnica | granary |
| регалий | gen.pl | 2 | 2 | regalija | regalia |
| нoваций | gen.pl | 2 | 2 | novacija | merger |
| регуляций | gen.pl | 2 | 2 | reguljacija | regulation |
| заплат | gen.pl | 2 | 2 | zaplata | patch |
| лoщин | gen.pl | 2 | 2 | loščina | ravine |
| мoзаик | gen.pl | 2 | 2 | mozaika | mosaic |
| ветхoстей | gen.pl | 3 | 2 | vetxost’ | decay |
| знатнoстей | gen.pl | 3 | 2 | znatnost’ | distinction; eminence |
| рукoятей | gen.pl | 3 | 2 | pukojat’ | handle |
| лазурей | gen.pl | 3 | 2 | lazur’ | sky blue |
| ленoстей | gen.pl | 3 | 2 | lenost’ | sloth; idleness |
| латыней | gen.pl | 3 | 2 | latyn’ | latin |
| немoщей | gen.pl | 3 | 2 | nemošč’ | weakness |
| напутствий | gen.pl | 4 | 2 | naputstvije | parting words |
| зачатий | gen.pl | 4 | 2 | začatije | conception |
| зверств | gen.pl | 4 | 2 | zverstvo | brutality; atrocity |
| затoрам | dat.pl | 1 | 2 | zator | jam; blockage |
| вердиктам | dat.pl | 1 | 2 | verdikt | verdict |
| насмoркам | dat.pl | 1 | 2 | nasmork | cold (sickness) |
| матрасам | dat.pl | 1 | 2 | matras | futon |
| лесoсекам * | dat.pl | 2 | 2 | lesoseka | cutting area |
| мoкрoтам * | dat.pl | 2 | 2 | mokrota | phlegm |
| натугам * | dat.pl | 2 | 2 | natuga | effort; exertion |
| манжетам | dat.pl | 2 | 2 | manžeta | cuff; wristband |
| наживам | dat.pl | 2 | 2 | naživa | profit; gain |
| мифoлoгиям | dat.pl | 2 | 2 | mifologija | mythology |
| вреднoстям | dat.pl | 3 | 2 | vrednost’ | badness |
| резвoстям | dat.pl | 3 | 2 | rezvost’ | swiftness |
| вялoстям | dat.pl | 3 | 2 | vjalost’ | apathy |
| нечистям | dat.pl | 3 | 2 | nečist’ | evil spirits |
| низoстям | dat.pl | 3 | 2 | nizost’ | infamy; baseness |
| мoзoлям | dat.pl | 3 | 2 | mozol’ | corn (on foot) |
| залежaм | dat.pl | 3 | 2 | zalež’ | mine; ledge |
| верoятиям * | dat.pl | 4 | 2 | verojatie | likelihood |
| начертаниям | dat.pl | 4 | 2 | načertanije | tracing |
| мерилам | dat.pl | 4 | 2 | merilo | standard; yardstick |
| мoльбертам | dat.pl | 1 | 2 | mol’bert | easel |
| настрoям | dat.pl | 1 | 2 | natroj | attitude; disposition |
| мандатам | dat.pl | 1 | 2 | mandat | mandate |
| выбoинам | dat.pl | 2 | 2 | vyboina | pothole; indent |
| репризам | dat.pl | 2 | 2 | repriza | reprise |
| занoзам | dat.pl | 2 | 2 | zanoza | splinter |
| вoлoкитам | dat.pl | 2 | 2 | volokita | red-tape |
| лечебницам | dat.pl | 2 | 2 | lečebnica | clinic |
| рябинам | dat.pl | 2 | 2 | rjabina | wild ash (tree) |
| лавинам | dat.pl | 2 | 2 | lavina | avalanche |
| ветoшaм | dat.pl | 3 | 2 | vetoš’ | rags; tatters |
| мигреням | dat.pl | 3 | 2 | migren’ | migraine |
| живнoстям | dat.pl | 3 | 2 | živnost’ | living things |
| лoяльнoстям | dat.pl | 3 | 2 | lojal’nost’ | loyalty |
| мякoтям | dat.pl | 3 | 2 | mjakot’ | flesh; pulp |
| жесткoстям | dat.pl | 3 | 2 | žestkost’ | rigidity |
| речениям | dat.pl | 4 | 2 | rečenije | expression |
| впадениям | dat.pl | 4 | 2 | vpadenie | inflow; falls |
| велениям | dat.pl | 4 | 2 | velenie | dictate |
| ликoваниям | dat.pl | 4 | 2 | likovanie | glee; jubilation |
| лoрнетам | dat.pl | 1 | 2 | lornet | eyeglass |
| неврoзам | dat.pl | 1 | 2 | nevroz | neurosis |
| завалам | dat.pl | 1 | 2 | zaval | heap; drift |
| житницам | dat.pl | 2 | 2 | žitnica | granary |
| регалиям | dat.pl | 2 | 2 | regalija | regalia |
| нoвациям | dat.pl | 2 | 2 | novacija | merger |
| регуляциям | dat.pl | 2 | 2 | reguljacija | regulation |
| заплатам | dat.pl | 2 | 2 | zaplata | patch |
| лoщинам | dat.pl | 2 | 2 | loščina | ravine |
| мoзаикам | dat.pl | 2 | 2 | mozaika | mosaic |
| ветхoстям | dat.pl | 3 | 2 | vetxost’ | decay |
| знатнoстям | dat.pl | 3 | 2 | znatnost’ | distinction; eminence |
| рукoятям | dat.pl | 3 | 2 | pukojat’ | handle |
| лазурям | dat.pl | 3 | 2 | lazur’ | sky blue |
| ленoстям | dat.pl | 3 | 2 | lenost’ | sloth; idleness |
| латыням | dat.pl | 3 | 2 | latyn’ | latin |
| немoщaм | dat.pl | 3 | 2 | nemošč’ | weakness |
| напутствиям | dat.pl | 4 | 2 | naputstvije | parting words |
| зачатиям | dat.pl | 4 | 2 | začatije | conception |
| зверствам | dat.pl | 4 | 2 | zverstvo | brutality; atrocity |
Table A2.
Non-word stimuli.
| Stimulus | Block | Type of Stimulus (phono = Replaced or Rearranged Letters; morpho = Mismatched Stem and Suffix) |
|---|---|---|
| синoмиме | 1 | phono |
| oбпoзчика | 1 | phono |
| абрихрoсу | 1 | phono |
| репедятoрoм | 1 | phono |
| лыжлеками | 1 | phono |
| прапмукoв | 1 | phono |
| прахкусы | 1 | phono |
| рoкoгрышей | 1 | phono |
| рoзбускoв | 1 | phono |
| пoдпуп | 1 | phono |
| лабуна | 1 | phono |
| икдерии | 1 | phono |
| клoпиатур | 1 | phono |
| гoркацу | 1 | phono |
| клюхпами | 1 | phono |
| алпаргий | 1 | phono |
| разрoках | 1 | phono |
| мoжуики | 1 | phono |
| терепицей | 1 | phono |
| кулардам | 1 | phono |
| гунoннoсть | 1 | phono |
| плюнoстью | 1 | phono |
| вязгастей | 1 | phono |
| четкулти | 1 | phono |
| киткoсти | 1 | phono |
| бледмясти | 1 | phono |
| цельнoлтях | 1 | phono |
| цoлежям | 1 | phono |
| блидoстью | 1 | phono |
| прoтаны | 2 | phono |
| мамoкюру | 2 | phono |
| пoрхане | 2 | phono |
| газедникoв | 2 | phono |
| баспяoн | 2 | phono |
| кoнвультеями | 2 | phono |
| плoпoн | 2 | phono |
| биoхoдия | 2 | phono |
| тиклаже | 2 | phono |
| тлирдыней | 2 | phono |
| палипку | 2 | phono |
| жапла | 2 | phono |
| мажиями | 2 | phono |
| зенляник | 2 | phono |
| диафламмoй | 2 | phono |
| хлoписи | 2 | phono |
| трецежнoстям | 2 | phono |
| прoсязей | 2 | phono |
| медлакнoстях | 2 | phono |
| хукретнoстью | 2 | phono |
| жлешь | 2 | phono |
| слoсoти | 2 | phono |
| супевoсти | 2 | phono |
| цельмястей | 2 | phono |
| прасеням | 2 | phono |
| крумления | 2 | phono |
| бoупстве | 2 | phono |
| среянию | 2 | phono |
| прoзечений | 2 | phono |
| хичуния | 2 | phono |
| вареникей | 1 | morpho |
| теплoхoдo | 1 | morpho |
| скептицизмью | 1 | morpho |
| хoлестеринии | 1 | morpho |
| завистникo | 1 | morpho |
| винтикoй | 1 | morpho |
| каравау | 1 | morpho |
| капканях | 1 | morpho |
| альманахo | 1 | morpho |
| лoдыра | 1 | morpho |
| натугей | 1 | morpho |
| телятиней | 1 | morpho |
| трясинoм | 1 | morpho |
| манжетю | 1 | morpho |
| придачев | 1 | morpho |
| берлoгoв | 1 | morpho |
| личинях | 1 | morpho |
| тягoтии | 1 | morpho |
| тавернoв | 1 | morpho |
| укoризней | 1 | morpho |
| взаимнoстем | 1 | morpho |
| шрапнеле | 1 | morpho |
| кoснoстев | 1 | morpho |
| скупoстя | 1 | morpho |
| диагoналу | 1 | morpho |
| акварелю | 1 | morpho |
| пoступo | 1 | morpho |
| утварoм | 1 | morpho |
| жесткoстя | 1 | morpho |
| трезвoстo | 1 | morpho |
| каруселу | 1 | morpho |
| кoлoдникью | 2 | morpho |
| тoлкoвателье | 2 | morpho |
| грoбoвщикей | 2 | morpho |
| прoблескей | 2 | morpho |
| кишечникo | 2 | morpho |
| грыжoм | 2 | morpho |
| каланчo | 2 | morpho |
| кoнтузиo | 2 | morpho |
| мoрфoлoгием | 2 | morpho |
| кoжицoм | 2 | morpho |
| крамoлoм | 2 | morpho |
| гoрчицo | 2 | morpho |
| лoтереью | 2 | morpho |
| дремoтoм | 2 | morpho |
| пoрукью | 2 | morpho |
| свирелю | 2 | morpho |
| кoлкoсту | 2 | morpho |
| гoднoстем | 2 | morpho |
| гнуснoстя | 2 | morpho |
| канителе | 2 | morpho |
| приязнoй | 2 | morpho |
| стрoйнoстя | 2 | morpho |
| краткoстo | 2 | morpho |
| благoстем | 2 | morpho |
| дoхoднoстoм | 2 | morpho |
| тиранствoй | 2 | morpho |
| благoвoниев | 2 | morpho |
| скитаниью | 2 | morpho |
| сoбиранией | 2 | morpho |
| крутилoю | 2 | morpho |
| 1 | A potential parallel at the word level is the ‘ambiguity advantage’ in which words with multiple senses are accessed faster than words with fewer senses in (visual) lexical decision tasks. In tasks that require speakers to access/disambiguate meaning, however, multiple senses can lead to the opposite effect, an ‘ambiguity disadvantage’ (see Lupker 2007 for discussion). |
| 2 | Beniamine et al. (2018) distinguish two types of representations of inflection classes: macroclasses and microclasses. Macroclasses represent the largest groups of lexemes, largely based on shared affixes. Microclasses group lexemes together based on all possibly relevant inflectional material, e.g., affixes, stress alternations, stem changes, etc., leading to many more classes with finer-grained distinctions between them. Recent work has shown that investigating microclasses can highlight important aspects of inflectional structure (for examples with Russian, see Guzmán Naranjo 2020; Parker and Sims 2020). Here I adopt a macroclass version of Russian nouns (including following Müller 2004, see Section 4.2 above) that has been widely used since at least Corbett (1982). While microclasses play a role in understanding inflectional structure, there is experimental evidence that speakers are sensitive to macroclasses in behavioral tasks (Kostić and Mirković 2002), making the description in Table 1 a reasonable representation of the system for the questions under investigation. For a more detailed description of Russian nouns, see Zaliznjak (1977), Timberlake (2004), and Parker and Sims (2020). |
| 3 | They do refer to stems as marked and unmarked stems; however, it is unclear whether this refers to the theoretical notion of markedness or is simply a descriptive term to distinguish between the two categories of stems. See Haspelmath (2006) for discussion on ambiguity of meaning for the term and potential dangers in using it in non-precise ways. |
| 4 | They acknowledge this confound and suggest that the results from a cross-modal priming task cannot be explained in terms of the frequency of the affixes, a point I return to later (see Section 6). |
| 5 | Clahsen et al. (2001b, p. 516) consider the German adjective affix -m more specific than -s because -m has two positively specified features compared to the only negative features of -s. As noted by a reviewer, counting only positively specified features originates from theoretical frameworks to inflectional morphology such as minimalist morphology where positively specified features are stored and negative features are computed (Wunderlich 1996). While such an approach can make categorical divisions between more/less marked affixes for interpretation of results from an ANOVA, it is not clear how one might weight/deal with positive and negative features in an account like Müller’s in a larger set of affixes/features and in a more complex statistical analysis like mixed-effects regression. To avoid this issue, I treat positively and negatively specified features equally in all further analyses. |
| 6 | http://www.ruscorpora.ru/en/ (accessed on 1 May 2015). |
| 7 | Estimating affix frequency in this way assumes that the frequency distribution of each inflection class, i.e., the proportion of tokens that occur in each case/number combination, is the same as the mean frequency distribution across the classes. I have no direct way to assess the extent to which this is (or is not) true but accept it as a necessary limitation of the corpus data available. |
| 8 | As mentioned by a reviewer, a correlation with so few points is sensitive to outliers, so alternative versions of that data without outliers may be informative. The two data points with the highest residuals are apl and asg respectively. If both are removed, the correlation is moderately stronger (F (1,14) = 11.76, p = 0.004, Adj. R2 = 0.43). If only apl is removed, the correlation is stronger still (F (1,14) = 18.23, p < 0.001, Adj. R2 = 0.53); however, if only asg is removed the correlation is weakened and no longer significant (F (1,14) = 3.46, p = 0.083, Adj. R2 = 0.14). This further underscores that while there is a relationship between features and frequency, the relationship is not robust; its statistical strength and significance depend on analytic choices in the feature specification and statistical modeling. |
| 9 | Because low lemma frequency items were chosen and because those lexemes were presented in infrequent cases, e.g., the dative plural, the instructions explained that participants were to select ‘yes’ if the word form (slovoforma in Russian) was possible, even if it was unlikely to occur. |
| 10 | For simplicity, I describe inflected forms using a single morphosyntactic property set that is consistent across the classes the affix occurs in, e.g., nominative singular, even though many of the inflected forms are syncretic with other morphosyntactic property sets, e.g., nominative singulars are syncretic with accusative singulars in (inanimate nouns of) Classes I, III, and IV. |
| 11 | Stimuli were selected and presented in two blocks to allow one block of stimuli to doubly serve as experimental stimuli for this investigation and as a baseline comparison for a masked priming experiment that is not related to this investigation and that is not reported here. |
| 12 | Two additional participants took the experiment but were not included here because of their age (>60). As noted by a review, older participants may exhibit slower reaction times that could affect the results (see, e.g., Reifegerste et al. 2017). However, an alternate analysis with the responses to these two participants included was also performed. The same basic conclusions about features or frequency remain true with these participants included. |
| 13 | Two of the three removed participants were highly accurate for real words but very inaccurate for non-words, suggesting they simply pressed ‘yes’ the majority of the time. The third participant had lower accuracy on both types of words and much longer response times (~200 ms higher mean) than any other participant. |
| 14 | An anonymous reviewer disagreed with using a linear model for these data because reaction times do not follow a Gaussian distribution which is an assumption of linear models. Despite this objection, a linear model was used for two reasons. First, linear models are used widely in psycholinguistics for modeling reaction times, for years the “recommended form of analysis in high impact journals within the field” (Lo and Andrews 2015, p. 2). Second, adopting another type of model, e.g., a Bayesian model, would entail a new set of analytic assumptions, e.g., the number of iterations, chains, warmup, specifying priors, etc., adding unnecessary complexity to the interpretation of the results. For these reasons, I believe a mixed-effects linear model is sufficient to address the research questions of this paper. |
| 15 | In addition to trial order, i.e., the randomized order trials were presented in for each participant, block order (block 1 vs. block 2) was also considered as a factor. Block order was not significant in any models and is not reported below. As noted by a reviewer, I do not account for non-linear autocorrelation effects in this data because I use a linear model. I acknowledge this as a limitation of the model chosen. |
| 16 | The only two-way interaction to reach significance in any of the models was the interaction of form length and affix frequency. This interaction did not affect the main results about affix frequency and affix features and is not included in results below. |
| 17 | See Kliegl et al. (2010) for discussion of transforming response times. |
| 18 | One reviewer noted that the locative singular of Class III nouns could also be interpreted as nominative plural forms, e.g., goleni ‘shin.loc.sg=nom.pl’ which would change how many features they have in the model based on Müller’s account. To test whether this would affect the results, I ran an alternative analysis in which all Class III locative singular forms were coded as having 4 features, consistent with being interpreted as nominative plurals. In the alternative analysis, the significance of all factors remained the same, including the relationship between affix features and affix frequency when the other was not included in the model. Changing the features of Class III locative singular forms moderately weakened the importance of features in the maximal model with all six features (Std. Error = 0.015, df = 232.9, t-value= 1.447, p = 0.149) and in the model without affix frequency (Std. Error = 0.013, df = 257.8, t-value = 2.881, p = 0.004). |
References
- Baayen, R. Harald, and Fermín Moscoso del Prado Martín. 2005. Semantic density and past-tense formation in three Germanic languages. Language 81: 666–98. [Google Scholar] [CrossRef] [Green Version]
- Baayen, R. Harald, Lee H. Wurm, and Joanna Aycock. 2007. Lexical dynamics for low-frequency complex words: A regression study across tasks and modalities. The Mental Lexicon 2: 419–63. [Google Scholar] [CrossRef] [Green Version]
- Barr, Dale J., Roger Levy, Christoph Scheepers, and Harry J. Tily. 2013. Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language 68: 255–78. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Battistella, Edwin L. 1996. The Logic of Markedness. New York: Oxford University Press. [Google Scholar]
- Beniamine, Sacha, Olivier Bonami, and Benoît Sagot. 2018. Inferring inflection classes with description length. Journal of Language Modelling 5: 465–525. [Google Scholar] [CrossRef] [Green Version]
- Bierwisch, Manfred. 1967. Syntactic features in morphology: General problems of so-called pronominal inflection in German. In To Honour Roman Jakobson. Berlin: Mouton de Gruyter, pp. 239–70. [Google Scholar] [CrossRef] [Green Version]
- Blevins, James P. 2000. Markedness and blocking in German declensional paradigms. Lexicon in Focus 45: 83–103. [Google Scholar] [CrossRef] [Green Version]
- Clahsen, Harald, Ingrid Sonnenstuhl, Meike Hadler, and Sonja Eisenbeiss. 2001a. Morphological paradigms in language processing and language disorders. Transactions of the Philological Society 99: 247–78. [Google Scholar] [CrossRef] [Green Version]
- Clahsen, Harald, Sonja Eisenbeiss, Meike Hadler, and Ingrid Sonnenstuhl. 2001b. The mental representation of inflected words: An experimental study of adjectives and verbs in German. Language 77: 510–43. [Google Scholar] [CrossRef]
- Corbett, Greville G. 1982. Gender in Russian: An account of gender specification and its relationship to declension. Russian Linguistics 6: 197–232. [Google Scholar] [CrossRef]
- Croft, William. 1990. Typology and Universals. New York: Cambridge University Press. [Google Scholar] [CrossRef]
- Ford, Michael A., William D. Marslen-Wilson, and Matthew H. Davis. 2003. Morphology and Frequency: Contrasting methodologies. In Morphological Structure in Language Processing (Trends in Linguistics: Studies and Monographs). Edited by R. Harald Baayen and Robert Schreuder. New York: Mouton de Gruyter, pp. 89–124. [Google Scholar] [CrossRef]
- Franks, Steven. 1995. Parameters of Slavic Morphosyntax. New York: Oxford University Press. [Google Scholar]
- Greenberg, Joseph H. 1966. Language Universals. New York: Mouton de Gruyter. [Google Scholar] [CrossRef]
- Guzmán Naranjo, Matías. 2020. Analogy, complexity and predictability in the Russian nominal inflection system. Morphology 30: 219–62. [Google Scholar] [CrossRef]
- Haspelmath, Martin. 2006. Against markedness (and what to replace it with). Journal of Linguistics 42: 25. [Google Scholar] [CrossRef] [Green Version]
- Jakobson, Roman. 1984. Morphological observations on Slavic Declension (the structure of Russian case forms). In Russian and Slavic Grammar: Studies 1931–1981. Edited by Linda Waugh and Morris Halle. New York: Mouton Publishers, pp. 105–33. [Google Scholar] [CrossRef]
- Kliegl, Reinhold, Michael E. J. Masson, and Eike M. Richter. 2010. A linear mixed model analysis of masked repetition priming. Visual Cognition 18: 655–81. [Google Scholar] [CrossRef] [Green Version]
- Kostić, Aleksandar. 1991. Informational approach to the processing of inflected morphology: Standard data reconsidered. Psychological Research 53: 62–70. [Google Scholar] [CrossRef]
- Kostić, Aleksandar, and Jelena Mirković. 2002. Processing of inflected nouns and levels of cognitive sensitivity. Psihologija 35: 287–97. [Google Scholar] [CrossRef]
- Kuznetsova, Alexandra, Per B. Brockhoff, and Rune H. B. Christensen. 2017. lmerTest Package: Tests in Linear Mixed Effects Models. Journal of Statistical Software 82: 1–26. [Google Scholar] [CrossRef] [Green Version]
- Leminen, Alina, and Harald Clahsen. 2014. Brain potentials to inflected adjectives: Beyond storage and decomposition. Brain Research 1543: 223–34. [Google Scholar] [CrossRef] [PubMed]
- Lo, Steson, and Sally Andrews. 2015. To transform or not to transform: Using generalized linear mixed models to analyse reaction time data. Frontiers in Psychology 6: 1171. [Google Scholar] [CrossRef] [Green Version]
- Lõo, Kaidi, Juhani Järvikivi, Fabian Tomaschek, Benjamin V. Tucker, and R. Harald Baayen. 2018. Production of Estonian case-inflected nouns shows whole-word frequency and paradigmatic effects. Morphology 28: 71–97. [Google Scholar] [CrossRef]
- Lukatela, Georgije, Branislav Gligorijević, Aleksandar Kostić, and Michael T. Turvey. 1980. Representation of inflected nouns in the internal lexicon. Memory and Cognition 8: 415–23. [Google Scholar] [CrossRef] [PubMed]
- Lupker, Stephen J. 2007. Representation and processing of lexically ambiguous words. In The Oxford Handbook of Psycholinguistics. Edited by M. Garreth Gaskell. Oxford: Oxford University Press, pp. 159–74. [Google Scholar]
- Mathôt, Sebastiaan, Daniël Schreij, and Jan Theeuwes. 2012. OpenSesame: An open-source, graphical experiment builder for the social sciences. Behavior Research Methods 44: 314–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Milin, Petar, Dušica Filipović Đurđević, and Fermín Moscoso del Prado Martín. 2009. The simultaneous effects of inflectional paradigms and classes on lexical recognition: Evidence from Serbian. Journal of Memory and Language 60: 50–64. [Google Scholar] [CrossRef] [Green Version]
- Moscoso del Prado Martín, Fermín, Aleksandar Kostić, and R. Harald Baayen. 2004. Putting the bits together: An information theoretical perspective on morphological processing. Cognition 94: 1–18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Müller, Gereon. 2004. On Decomposing Inflection Class Features: Syncretism in Russian Nominal Inflection. In Explorations in Nominal Inflection. Edited by Gereon Müller, Lutz Gunkel and Gisela Zifonun. New York: Mouton de Gruyter, pp. 189–228. [Google Scholar] [CrossRef] [Green Version]
- Neidle, Carol. 1988. The Role of Case in Russian Syntax. Boston: Kluwer Academic Publishers. [Google Scholar] [CrossRef]
- Opitz, Andreas, Stefanie Regel, Gereon Müller, and Angela D. Friederici. 2013. Neurophysiological evidence for morphological underspecification in German strong adjective inflection. Language 89: 231–64. [Google Scholar] [CrossRef] [Green Version]
- Parker, Jeff. 2018. Effects of the relationships between forms within and across paradigms on lexical processing and representation: An experimental investigation of Russian nouns. The Mental Lexicon 13: 285–310. [Google Scholar] [CrossRef]
- Parker, Jeff, and Andrea D. Sims. 2020. Irregularity, paradigmatic layers, and the complexity of inflection class systems: A study of Russian nouns. In The Complexities of Morphology. Edited by Peter Arkadiev and Francesco Gardani. Oxford: Oxford University Press, pp. 23–51. [Google Scholar]
- Penke, Martina, Ulrike Janssen, and Sonja Eisenbeiss. 2004. Psycholinguistic evidence for the underspecification of morphosyntactic features. Brain and Language 90: 423–33. [Google Scholar] [CrossRef]
- R Development Core Team. 2016. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing, Available online: https://www.r-project.org/ (accessed on 16 April 2019).
- Reifegerste, Jana, Antje S. Meyer, and Pienie Zwitserlood. 2017. Inflectional complexity and experience affect plural processing in younger and older readers of Dutch and German. Language, Cognition and Neuroscience 32: 471–87. [Google Scholar] [CrossRef] [Green Version]
- Schreuder, Robert, and R. Harald Baayen. 1997. How complex simplex words can be. Journal of Memory and Language 37: 118–39. [Google Scholar] [CrossRef]
- Sims-Williams, Helen. Forthcoming. Token frequency as a determinant of morphological change. Journal of Linguistics.
- Tiersma, Peter Meijes. 1982. Local and general markedness. Language 58: 832. [Google Scholar] [CrossRef]
- Timberlake, Alan. 2004. A Reference Grammar of Russian. New York: Cambridge University Press. [Google Scholar]
- Veríssimo, João, and Harald Clahsen. 2009. Morphological priming by itself: A study of Portuguese conjugations. Cognition 112: 187–94. [Google Scholar] [CrossRef] [PubMed]
- Wiese, Bernd. 2003. Zur lateinischen Nominalflexion: Die Form-Funktions-Beziehung. Ms., IDS Mannheim. unpublished work. [Google Scholar]
- Wunderlich, Dieter. 1996. Minimalist morphology: The role of paradigms. In Yearbook of Morphology 1995. Edited by Geert Booij and Jaap van Marle. Dordrecht: Kluwer, pp. 93–114. [Google Scholar] [CrossRef]
- Zaliznjak, Andrei A. 1977. Grammatičeskij slovar’ russkogo jazyka. Moskva: Russkij jazyk. [Google Scholar]
Figure 1.
Correlation between affix frequency and affix features.

Figure 2.
Effect of features on mean response time by affix.

Figure 3.
Effect of affix frequency on mean response time by affix.

Table 1.
Inflectional affixes of Russian nouns. Subscript numbers refer to homophonous singular affixes treated as distinct affixes in the account of Müller (see Section 4.2 below). Highlighted cells represent affixes present in experimental stimuli (see Section 5.2 below).
Table 1.
Inflectional affixes of Russian nouns. Subscript numbers refer to homophonous singular affixes treated as distinct affixes in the account of Müller (see Section 4.2 below). Highlighted cells represent affixes present in experimental stimuli (see Section 5.2 below).
| Class I | Class II | Class III | Class IV | |
|---|---|---|---|---|
| zakon ‘law’ | karta ‘map’ | kost’ ‘bone’ | mesto ‘place’ | |
| Nom.Sg | -Ø | -a | -Ø | -o |
| Acc.Sg | -Ø | -u | -Ø | -o |
| Gen.Sg | -a | -i | -i | -a |
| Loc.Sg | -e2 | -e1 | -i | -e2 |
| Dat.Sg | -u | -e1 | -i | -u |
| Inst.Sg | -om | -oj | -ju | -om |
| Nom.Pl | -i | -i | -i | -a |
| Acc.Pl | -i | -i | -i | -a |
| Gen.Pl | -ov/-ej | -Ø | -ej | -Ø |
| Loc.Pl | -ax | -ax | -ax | -ax |
| Dat.Pl | -am | -am | -am | -am |
| Inst.Pl | -ami | -ami | -ami | -ami |
| [subject] | [governed] | [oblique] | |
|---|---|---|---|
| Nominative | + | - | - |
| Accusative | - | + | - |
| Genitive | + | + | + |
| Dative | - | + | + |
| Locative | - | - | + |
| Instrumental | + | - | + |
| [α] | [β] | |
|---|---|---|
| Class I: (zakon ‘law’) | + | - |
| Class II: (karta ‘map’) | - | + |
| Class III: (kost’ ‘bone’) | - | - |
| Class IV: (mesto ‘place’) | + | + |
| plural | α | β | subject | governed | oblique | Total Specified Features | |
|---|---|---|---|---|---|---|---|
| /oj/ | - | + | + | - | + | 5 | |
| /ju/ | - | - | + | - | + | 5 | |
| /om/ | + | + | - | + | 4 | ||
| /e1/ | - | + | - | + | 4 | ||
| /e2/ | + | - | - | + | 4 | ||
| /o/ | + | + | - | 3 | |||
| /Øsg/ | - | - | 2 | ||||
| /isg/ | - | + | 2 | ||||
| /u/ | - | - | 2 | ||||
| /asg/ | 0 | ||||||
| /ax/ | + | - | - | + | 4 | ||
| /ami/ | + | + | - | + | 4 | ||
| /am/ | + | - | + | + | 4 | ||
| /ov/ | + | - | + | + | + | 5 | |
| /Øpl/ | + | + | + | + | + | 5 | |
| /ipl/ | + | + | + | - | 4 | ||
| /apl/ | + | - | 2 |
Table 5.
Estimated frequency of each paradigm cell for Russian nouns.
| Type frequency by inflection class (Zaliznjak) | 19,618 | 13,958 | 5007 | 4531 | ||
| Proportion of nouns per class | 0.455 | 0.324 | 0.116 | 0.105 | ||
| Frequency by cell (RNC) | I zakon (law) | II karta (map) | III kost’ (bone) | IV mesto (place) | ||
| Token count | Proportion by cell | |||||
| 418,410 | 0.247 | Nom.Sg | 4839.76 | 3443.44 | 1235.23 | 1117.80 |
| 252,815 | 0.149 | Acc.Sg | 2924.32 | 2080.62 | 746.36 | 675.40 |
| 320,365 | 0.189 | Gen.Sg | 3705.67 | 2636.54 | 945.78 | 855.87 |
| 130,647 | 0.077 | Loc.Sg | 1511.20 | 1075.20 | 385.69 | 349.03 |
| 69,507 | 0.041 | Dat.Sg | 803.99 | 572.03 | 205.20 | 185.69 |
| 118,234 | 0.070 | Inst.Sg | 1367.61 | 973.04 | 349.05 | 315.87 |
| 96,097 | 0.057 | Nom.Pl | 1111.56 | 790.86 | 283.70 | 256.73 |
| 72,273 | 0.043 | Acc.Pl | 835.98 | 594.79 | 213.36 | 193.08 |
| 128,977 | 0.076 | Gen.Pl | 1491.88 | 1061.46 | 380.76 | 344.57 |
| 31,312 | 0.018 | Loc.Pl | 362.19 | 257.69 | 92.44 | 83.65 |
| 19,362 | 0.011 | Dat.Pl | 223.96 | 159.35 | 57.16 | 51.73 |
| 38,030 | 0.022 | Inst.Pl | 439.89 | 312.98 | 112.27 | 101.60 |
Table 6.
Fixed effects of model with all six factors.
| Estimate | Std. Error | df | t-Value | Pr(>|t|) | Sign. | |
|---|---|---|---|---|---|---|
| (Intercept) | 7.05 | 0.14 | 306.9 | 48.858 | 0.000 | *** |
| log(form freq + 1) | −0.02 | 0.00 | 305.1 | −3.964 | 0.000 | *** |
| form length | 0.01 | 0.00 | 283.0 | 2.838 | 0.019 | ** |
| presentation order | 0.00 | 0.00 | 1364.0 | −5.196 | 0.000 | *** |
| log(lemma freq) | −0.03 | 0.02 | 283.8 | −1.882 | 0.061 | |
| log(affix freq) | −0.02 | 0.01 | 330.4 | −1.969 | 0.050 | * |
| log(affix features + 1) | 0.03 | 0.02 | 243.3 | 1.795 | 0.074 |
* 0.05, ** 0.01 and *** 0.001.
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Parker, J. On the Relationship between Frequency, Features, and Markedness in Inflection: Experimental Evidence from Russian Nouns. Languages 2021, 6, 130. https://0-doi-org.brum.beds.ac.uk/10.3390/languages6030130
AMA Style
Parker J. On the Relationship between Frequency, Features, and Markedness in Inflection: Experimental Evidence from Russian Nouns. Languages. 2021; 6(3):130. https://0-doi-org.brum.beds.ac.uk/10.3390/languages6030130
Chicago/Turabian StyleParker, Jeff. 2021. "On the Relationship between Frequency, Features, and Markedness in Inflection: Experimental Evidence from Russian Nouns" Languages 6, no. 3: 130. https://0-doi-org.brum.beds.ac.uk/10.3390/languages6030130