
Digital Synesthesia in Heritage and Second Language Writing during Collaborative and Individual Digital Storytelling


Department of Language and Literature, William Carey University, Hattiesburg, MS 39401, USA
Languages 2022, 7(3), 222; https://0-doi-org.brum.beds.ac.uk/10.3390/languages7030222
Submission received: 3 May 2021
/
Revised: 21 July 2022
/
Accepted: 1 August 2022
/
Published: 22 August 2022
(This article belongs to the Special Issue L2/HL Writing and Technology)
Abstract
:Using the social semiotic multimodal approach, this study compared the transformation and transduction moves of eight Spanish heritage language learners (SHLs) and six second-language learners (L2s) as they composed collaborative and individual digital stories (DSs) in an undergraduate advanced Spanish writing class. The research analyzed the learners’ composing processes regarding digital synesthesia when working collaboratively and individually as they integrated written, oral, aural, and visual semiotic resources. The data revealed that SHLs demonstrated more frequent and more complex digital synesthesia than did their L2 classmates during their quest for digital multimodality in Spanish, indicating improvement via task repetition in frequency and variety of integrated modes.
1. Introduction
In language classrooms, an emerging pedagogical activity is digital storytelling (DST), a particular genre that combines writing and multimodal literacies (e.g., Elola and Oskoz 2017; Lundby 2008; Malita and Martin 2010; Oskoz and Elola 2014; Yang 2012). A digital story (DS) is a narrative that requires “the integration of text, images, and sounds” (Oskoz and Elola 2014, p. 179), and their use provides an avenue for equipping learners in the development of these literacies as they simultaneously gain a world language, integrating computer-assisted language learning (CALL) and second language acquisition (SLA) in a purposeful way (Ortega 2017). This integration of modes in a digital composition is digital synesthesia, and the process includes transformation, changing a text from one genre to another, as when digital composers transform a narrative to a much shorter voice-over script, and transduction, changing from one mode to another, as when they replace some of the original text with another mode, such as an image (Kress 2003). This study looked specifically at the integration of multimodal elements in collaborative and individual, digital compositions composed by two demographics, Spanish heritage learners (SHLs) and second language learners (L2s).
2. Literature Review
2.1. Digital Storytelling and Digital Synesthesia
A digital story (DS) is a narrative that requires the use of multiple modes, including, but not limited to, image, music, voice recording, sound effects, and text-on-screen. Language learners compose a story, find a focal moment in the story, transform the text narrative into voice-over script highlighting the focal moment, which they read and record. They gather into small groups to listen and to give and receive feedback. The composers integrate other semiotic resources, such as images and sound, and edit their digital compositions after again receiving feedback from a small group of peers. The genre in its inception treated an autobiographical moment of importance in the life of the storyteller; therefore, the individual writer was always at the center (StoryCenter Website n.d.; Lambert 2013). Therefore, this form was constrained previously by the use of the first-person narrator who recounted a personal experience, the use of still images and video, a soundtrack with a length under five minutes, and a focus on the process more than the product (for a detailed description of step-by-step DS creation, see Lambert 2013, pp. 37–38). Oskoz and Elola (2016a) broadened this concept by implementing the possibility of telling someone else’s story by giving participants the option to use third-person narrators as they transformed their academic essays to DSs since the students may not have had personal experiences within the scope of the immigration topics being treated. This departure from the first-person point of view also allows for the possibility for collaborative composition. Storch (2013) defines a collaborative composition as “an activity where there is a shared and negotiated decision-making process and a shared responsibility for the production of a single text” (p. 3). Another broadening technique is the use of interviews since all composers may not have a first-person knowledge of a topic.
As the learners compose, they make decisions using the affordances offered by technology, such as Creative Commons and other image and audio file repositories, which contains files which are licensed to the public with a simple attribution to the creator. They gather digital files containing image and sound, which they then integrate into the digital version of the story, using a program or platform for video creation (Lambert 2013). Hafner refers to this integration of modes as the practice as “remix” in which learners appropriate and recombine digital elements to innovate (Hafner 2015). Kress (2003) described the process of multimodal composition as including the transformation, or changing from one genre to another (e.g., from a 500-word written narration, which uses only words to tell the story, to a 250-word voice-over script, which is combined with the addition of multiple modes to do so). This multimodal affordance available with technological tools is transduction, or changing from one mode to another (e.g., from written text to audio sound effect) as a method to achieve economy in the transformation. The integration of disparate modes is called digital synesthesia, the study of which is underrepresented in the literature, and nonexistent when comparing collaborative and individual DSs composed by two different demographics, L2s and SHLs.
2.2. Digital Storytelling in Educational Research
Regarding L2 writing, studies have shown that the writing process has the potential to promote learning not just in monomodal texts but also in multimodal texts, such as those created through DST, with the help of new technologies (Ortega 2017). A review of the current literature on multimodality and new tools reveals that most research pertaining to L2 digital writing has looked at affective factors, such as identity, agency, and voice; for example, Davis (2005) found that DS construction aided identity construction; Fokides’ (2016) case study revealed that the participant exhibited more agency in the classroom setting after sharing her story with her peers; Hull and Katz (2006) also detailed case studies which found that both subjects negotiated their identities and shaped a positive self-image during DS production leading to new self-perception; and Jiang et al. (2020) found that an ethnic minority student felt more empowered in her language-learning role as a digital composer and class expert on her home culture. Others looked at collaborative construction as well as some linguistic gains (e.g., Nishioka 2016; Yang and Wu 2012; Jiang 2017; Akoto 2021).
Other researchers have examined the affordances of individual and collaborative multimodal composing; Jiang (2017) connected the affordances offered by technology to positive impacts on language learning and overall literacy. Chan et al. (2017) utilized a case study with three students to explore the factors influencing growth in digital literacies. They found that DSs fomented gains in digital skills as well as student engagement and motivation. Additionally, Akoto (2021) looked at learners’ self-reported perceptions on the positives and negatives of using Google Docs as a collaborative platform for multimodal composition, finding that such collaboration positively impacts feedback, idea generation, and community building within the collaboration. However, no study to date has compared the creation of an individual digital story with that of a collaborative digital story, using the same learners during one term.
2.3. Analyzing Multimodal Compositions
In modern society where virtual communication is possible in more than the linguistic mode, first- and second-language teachers and researchers are beginning to embrace the use and study of nonlinguistic modes, such as images, sounds, videos, hyperlinks, color and even font choice (e.g., Kress 2003; Yang 2012). The social semiotic multimodal approach (SSMA) seeks to analyze the digital composer’s choices of modes and analyze their relationships within the greater text. According to Jewitt (2017), SSMA focuses on “mapping how modal resources are used by people in a given community/social context…sign-making as a social process” (p. 33). Kress (2010) spoke to the notions of transformation, defined as “the processes of meaning change through reordering of the elements in a text or other semiotic object” within the same mode, for example, a change of order in the sequence of events by using of flashbacks or a change of genre from a narrative to a script, and transduction, which is “moving meaning-making material from one mode to another” (Kress 2010, pp. 129, 125). With transduction, there is a substitution of one mode for another, such as replacing text with an image. In this way, the choices composers make allow them to make new meanings within the context of a socially situated act and endow them with communicative and creative agency, based on interests and the perceived purpose of the communication (Kress 2003; Yang 2012). Research using SSMA in the L2 context typically explores the use of semiotic tools in digital multimodal compositions. Some major studies regarding DST examine identity and semiotic choices (Hull and Nelson 2005); narrative viewpoints (Liang 2015); digital tools, artifacts, and linguistic choices (Oskoz and Elola 2016a).
Nelson (2006) examined how factors such as social context, technology, and ideology influence the project design in multimodal texts composed by five undergraduate L2 language learners of English in an American university. He found that multimodal composers felt that they used digital synaesthesia to enhance their multimedia essays, but also felt that, at times, their available resources limited their choices and caused them to adjust their visions for the projects and, in a way, to negotiate meaning via “semiotic material across modes” (p. 71). In Oskoz and Elola (2016a), six advanced Spanish learners first wrote two expository and two argumentative essays, which served as the basis of the DSs they would later create. They analyzed the writers’ use of artifacts and tools in transduction and transformation moves across modes. They noted that writers found it necessary to adjust their plans for the projects as they attempted to integrate additional visual or aural elements and tools to the written word. Yang (2012) also found an evolving use of semiotic resources in the DST process. In her study, two EFL undergraduate students studying to be English teachers developed multimodal texts, which required multiple redesigning and reimagining due to difficulties that emerged when using multimodal tools, resulting in their perceptions and products being shaped by self-perceived or practical degree of skill with technological tools and available materials.
2.4. Collaborative and HL Writing
Collaborative writing is becoming more common in the academic setting, as educators explore and experience the benefits of the shared writing experience (Wigglesworth and Storch 2012). With the joint participation of more than one writer in the second language carrying out a single written task, the explicit knowledge writers may draw upon is multiplied and co-constructed, potentially allowing the learners access to more vocabulary, more ideas for content, and more accuracy, and also yielding potentially more complex texts (e.g., Storch and Wigglesworth 2007; Storch 2011; Ortega 2017; Watanabe and Swain 2007). Collective scaffolding, which occurs when one or both learners supply missing pieces of the linguistic puzzle, allows the learners to combine their linguistic resources (Donato 1994). In Sadik (2008), collaborative success emerged as eight classes of middle-school EFL learners formed groups, which wrote creative DSs using textbook topics. Interviews reported that teachers thought that DST was a source of enrichment as a classroom tool, promoting creativity and motivation. Student gains included an opportunity to think deeply about their topics to produce a story that demonstrated their understanding of the concepts and mastery of digital literacies by using DS-making tools.
Studies looking specifically at collaborative writing in classrooms with two demographics, L2 and HL learners, also appear in the literature. Spanish in the United States is a minority language with more than 37 million speakers nationwide and with potential exposure outside the classroom dependent on regional demographics (González-Barrera and López 2013). As such, it is quite common for classes to be a mix of traditional L2s, native Spanish speakers or recent arrivals, and SHLs. Valdés (2000) defines a heritage speaker as someone who grew up in a home where the language of the home is not the dominant language of the society and “who speaks or merely understands the heritage language (HL), and who is to some degree bilingual in [the dominant language] and the heritage language” (p. 1). Research on collaborative writing with HL participants is not abundant, and the majority of the studies used mixed dyads composed of one HL and one L2 (e.g., Blake and Zyzik 2003; Bowles 2011; Valentín-Rivera 2016; also see Torres and Vargas and Hurtado and Gastañaga’s articles in this Special Issue). Examples of research aims include a quest to find which demographic benefits most in a mixed dyad (Blake and Zyzik 2003), the exploration of the dynamics of mixed pairs (Bowles 2011), and the examination of corrective feedback as an artifact in collaborative writing (Valentín-Rivera 2016). Conversely, Walls (2018) looked at both mixed and matched dyads. Using SCT, Walls (2018) studied eight mixed dyads of HL–L2 and matched dyads of HL–HL, and L2–L2 undergraduate lower-level learners who collaborated during a writing task. She found that in matched dyads of HL–HL learners, participants collaborated on the writing and in resolving language issues and took turns being the expert. However, in the mixed dyads of HL–L2 learners, the HL members tended not to relinquish the role of expert and consulted print materials or resolved issues by talking to themselves rather than rely on the L2 partner, leading her to question the benefits of mixed dyads. Huang et al. (2017) also found that disparate levels of L2 learners did not correlate to gains across the board. They found that young EFL learners who were low- to mid-proficiency benefited, but the high-proficiency learners who were paired with partners at lower levels show fewer gains in motivation as well as digital literacies. To date, the collaborative and individual DST processes and products have not been studied using pairs matched by demographic and by similar language level.
2.5. The Present Study
This study emerged from a larger project, which also fully situated the collaborative and individual processes, products and perceptions of language learners within an activity system as described in Activity Theory (Leont’ev 1978) and which contributed an assessment rubric for measuring the complexity and accuracy of multimodal compositions. Based on DS’ potential for promoting learning, the larger study also explored the multimodal modifications L2 and HL learners make when adapting their simple narratives into a digital format while working collaboratively on a story inspired by research on a general topic of immigration, and then individually, writing a story dealing with the immigrant experience inspired by an immigrant interview. The present study examines digital synesthesia, considering the transduction moves of image, sound, and other elements that language learners as DS composers integrate to transform simple text narratives to digital compositions. The following describes the materials and methods, data sources, analysis of the texts, results, and discussion. To analyze the text and digital products, the investigation utilizes the tenets of the SSMA to explore patterns of transformation and transduction, using the following research questions:
- How do language learners navigate multimodality (e.g., integrating technologies of text, image and sound in transformation and transduction moves) during individual and collaborative tasks?
- What elements characterize any differences (e.g., greater frequency and/or variety of transduction moves) the SHL learners and L2 learners exhibit in their navigation of multimodality?
3. Materials and Methods
3.1. Participants
The participants in this study were 14 students taking an upper-level Spanish class in a large university in the southwestern United States. They came from an intact class of advanced composition for Spanish majors and minors titled Writing Literacies in Context: Identity and Resistance. The class explored that context through the lens of immigration. The class included other writing activities besides the two DSs. The initial 18 class members were paired using leveling procedures, which included the abridged language placement test from Servicio Internacional de Evaluación de la Lengua Española, or SIELE test, found in Supplementary S1, and a background questionnaire followed by an in-class writing sample, found in Supplementary S2. The pairs were composed of either two SHLs or two L2 learners to compare the two demographics represented in the study. Two dyads were removed for not meeting all requirements.
The age of the students ranged from 20 to 27 years with a median age of 21.93 years. As detailed in Table 1, the pre-project questionnaire revealed that eight participants were HLs of Spanish, four of which could be classified as narrow (generation 1.5 or 2nd generation), one as broad (3rd generation with receptive knowledge of Spanish in childhood) and three very broad (3rd or 4th generation with limited or very limited exposure to Spanish in childhood). The heritage group contained two simultaneous learners who reported learning Spanish and English concurrently, three sequential learners who learned English once they started primary school, and three who reported learning Spanish after starting school. Among the six L2 participants were one Brazilian national and one HL of Portuguese, who formed one pair. The other four were L2 learners who were native speakers of English. All participants were asked at what age they began learning English and Spanish, and their answers can be seen in the fourth column under onset of Spanish/English in Table 1. Table 1 also contains the score on the abridged SIELE, rank on in-class diagnostic writing sample (18 = best), and number of words per error (WPE) in the writing sample as can be seen in the last three columns.
3.2. The Tasks
Because traditionally DS storytellers write from first-person point of view (Lambert 2013), the two tasks in the current study necessitated a departure from that stricture, as participants co-wrote the collaborative DSs, eliminating the possibility of an autobiographical point of view, and which also was more inclusive of some of the L2 learners who professed a lack of personal experience with immigration. Rather, participants fictionalized an element drawn from their team’s research in collaborative DS in the first half of the semester and a personal interview with an immigrant in individual DSs in the second half of the semester. The process for each task began by composing a simple, chronological narrative. Writers then transformed these simple narratives into something more complex: the collaborative and individual DSs.
Task 1. After reading articles regarding immigration issues, watching videos, and discussing the issues with classmates, students composed narrative stories dealing with their chosen issue while working in collaborative pairs. Each pair was to produce one simple narrative and one DS. They were responsible for working collaboratively with their partners throughout the process. They were expected to help one another and to contribute equally to prewriting activities, accumulation of multimodal elements, and content generation within a Google document, construction of the multimodal story in the online platform WeVideo, and troubleshooting of technical issues. They were also expected to participate in peer editing activities with other pairs.
Task 2. The students created a DS individually. Each participant produced one simple narrative and one DS. Rather than basing the story solely on research, the students created a fictionalized story inspired by interviews they each made with a Hispanic immigrant. Although participants may have received cooperative help from one another, each was responsible for his or her own product at every stage of task 2.
The context built by the assignments was that of creating a YouTube channel designed to educate the Spanish-speaking public on immigration issues. Participants also knew from the outset that the entire class would be viewing the DSs. They later found that a team of judges would decide the winning collaborative DS and honorable mention. They were also encouraged to enter their work in an undergraduate conference, showcasing student work in a multidisciplinary gathering. The individual DSs were also judged, and first through third places as well as two honorable mentions were awarded by outside judges. Supplementary S3 contains the task assignments while Supplementary S4 outlines the task schedule by weeks. These procedures were informed by multiple sources, which delineate procedures particular to digital storytelling, including Oskoz and Elola (2016b), Frazel (2010), Castañeda (2013), and Lambert (2013).
3.3. Data Sources
The SIELE Test. Many Spanish language practitioners regard the disparaged but ubiquitous excerpt from Diplomas de Español como Lengua Extranjera or DELE test as outdated and Eurocentric.1 However, a new test, the SIELE claims to bridge the gaps left gaping by its predecessor.2 At present, no research study that has used this test was found, unlike the DELE. The research project used parts of the practice test provided by the website, which includes sections on reading comprehension, listening comprehension, written expression and interaction, and spoken expression and interaction. The abbreviated test used 22 of the 38 items from the section on reading comprehension to reduce the time needed from 60 to 35 min after the testing time parameters were confirmed in a pilot study. The partial version, which includes five short readings, one longer reading, and one 12-item cloze passage, can be found in Supplementary S1. Scores from this abridged version of the SIELE, along with a writing sample, were used to provide insight into the approximate levels of the students in the class to form collaborative pairs of participants with similar language levels. Hence, this abridged form of the SIELE was not used to establish proficiency nor for placement, but rather for leveling to establish the pairs.
The background questionnaire. This instrument was adapted from Torres (2013). The information was used to determine the demographics, to describe the participants and to form the collaborative pairs. In forming the SHL pairs, the classroom instructor, the program director, and the researcher took into consideration the family generation within the United States for SHLs, using information supplied in the background questionnaire. For example, besides having similar scores in the leveling measures and details from the background questionnaire, Amelia and Victoria (Pair 2) also seemed the most balanced in their bilingualism of all the SHLs. All other SHLs appeared to be English dominant with several exhibiting many L2 learner behaviors across skill sets, such as grammar and syntax. Evidence of similar levels was used in the pair formation.
The simple narratives, voice-over scripts, and DSs. The text compositions were analyzed to examine the transformation of the simple narratives to the voice-over scripts. Those documents developed in Google Docs were then compared to the DSs to examine digital synesthesia and the potential transduction moves made as composers converted text passages into other modes, such as sound and image. When it was time to begin the DSs for each task, the researcher created a collaborative project for each DS in a professional account for WeVideo, the collaborative online platform used for building the DSs. She then invited the students to join the collaboration created for each by sending them a project invitation via email.
In the WeVideo online platform, the students were able to layer tracks for image and audio as well as the other technical modifications, such as stretching images for longer play, transitions between images, image overlay, addition of pauses to the voice-over tracks, and fade in or out for audio tracks. In the platform, it was also easy to see the time sequences for each element. Having all the images in one sightline made analyzing them much easier than viewing them one-by-one in the video form; additionally, the video version was also available in the online version in the top right quadrant of the screen. The version history also made it possible to view the date and time stamp of each saved version, as well as who saved it; however, the platform did not indicate how long the student worked on each version as can be seen in the version histories in Google Docs.
Reflections and Surveys (See Supplementary S5 and S6). The students wrote reflections and answered specific survey questions at various points during the two tasks. In additional Google documents created for the reflections of each participant during the creation of the collaborative and individual DS processes and products, participants wrote reflection journals at three points during the collaborative and at four points in the individual DS creation process as part of the qualitative data. The Google document provided them with topics and specific questions as prompts for their reflections. For example, students were asked about which elements they converted to other modes (images, sounds, music) to economize their words. In the Midterm and Final Surveys, after the completion of the collaborative and individual DSs, students completed surveys to assess their choices during the DST process and to discover how having a collaborative partner or not impacted their processes and products. Surveys were made of twenty-four open-ended questions. In the final survey, for example, they were asked if being familiar with the DST process from the collaborative task impacted the process for the second task.
The Semi-Structured Interviews. During the last few days of the semester, students participated in individual, semi-structured interviews, which the researcher recorded and then transcribed verbatim. Questions included topics on skill development, project collaboration, and final thoughts on collaborative DST versus individual DST. The springboard questions are in Supplementary S7.
The Researcher Field Notes and Instructor Reflections (See Supplementary S5). The classroom instructor wrote a post-project reflection for each DS sequence, using the prompts. For example, one question asked if she noticed any differences between the performances in the two tasks and between the L2s and SHLs during the composition of the DSs. The researcher wrote weekly field notes during the investigation regarding the details of the class events and observations about class behaviors and was available for the out-of-class tech help sessions at regularly scheduled times each week and by appointment.
3.4. Analysis
The simple text narratives and voice-over scripts (as well as the DSs) were analyzed to extrapolate patterns in transformation and transduction as well as additions and deletions made between versions. Tables detailing moves involving transformation tracked the changes the participants made to adapt the simple narratives to the voice-over scripts. To conduct this analysis, the researcher created parallel-text tables, of which Table 2 is an example. The tables separated the texts into corresponding sections with the middle column describing the types of changes observed. An example is Olivia’s individual DS (Pair 5). In the first passage of the simple narrative, she includes more description of Raquel and the setting. In the voice-over script for the individual DS, she reduces the corresponding text by 45 words or 73.8%. These calculations were completed for the entirety of each text narrative and script to determine the transformation made by each L2 and SHL composer.
Tables, such as the example in Table 3, detailing moves involving transduction tracked the replacement of text statements in the simple narratives with information supplied via a different mode, such as image or sound in the DS, resulting in multimodality. To determine this, the researcher made an inventory of all images, text-on-screen, and sound files by looking at the files for each DS in the WeVideo platform and describing them in tables (example in Table 4). Then, an attempt was made to determine if these modes replaced passages in the simple narrative or if they simply enhanced elements present in the voice-over script. Using the individual DS mentioned above, Olivia (Pair 5) replaced the physical description of the American student with a photo of a blond woman walking down the street as seen in Table 3.
Table 2 and Table 3 also revealed simple deletions or additions between modes. Some participants simply deleted passages from the simple narrative in the voice-over script and digital compositions rather than use another mode (e.g., images or sounds) to substitute text. At other times, participants added passages to the voice recordings in DSs that were not present in the simple narratives. This was also determined by the parallel-text tables. As seen in Table 2 and Table 3 above, Olivia did not use a different mode to replace the name of Raquel’s university, her major, her “caderas meciéndose/swaying hips”, or the description of the actions of the passersby. She simply deleted that information. This emerged as the predominant method of transformation for the L2 digital composers. Additionally, some took the opportunity to make changes to their narratives by adding detail that was not present in the original text narratives.
The researcher also created an inventory of silence, voice-over tracks, music, and sound effects in chronological order and with durations expressed by beginning and ending minute/second of each element in the DSs. Column two recorded the duration of notable silences. Column three recorded the duration of voice-over tracks, including turn taking. Column four included the duration and changes in the music track(s). Column five recorded the type and duration of sound effects used. This table informed complexity in the mode of sound. Table 4 is an example for one pair’s collaborative and individual DSs. These tables aided in identifying sound as a possible transduction move.
The researcher then was able to create transduction tables, indicating a change by the use of transduction moves in which language learners replaced passages from the simple narratives with other modes, such as image and sound, in the finished DSs. Table 3 and Table 4 included images with implicit meanings. The implicit images were figurative in nature or did not correspond literally with the spoken text and, thus, were additive rather than illustrative. Later, Table 4 also included any comments made by the participants in the qualitative data. Table 5 is an example for one pair’s collaborative DS and other qualitative data.
The researcher then created a table tracking the word count of the simple narratives and the voice-over scripts to compare the collaborative and individual texts to examine how well writers were able to stay within task parameters with and without a partner (see Table 6 in the results section). The semi-structured interview contained a question in which writers were asked to account for maintaining, increasing or decreasing their word counts between tasks. Another table tabulated the types of transductions moves participants mentioned making in the qualitative data (see Table 7 below), and finally, a table tracking the number and type of transduction moves made by pairs and individuals was made (see Table 8 below).
4. Results
The data served to illuminate patterns of transformation and transduction and to answer the research questions regarding how language learners navigated the DST process and multimodality by transforming the text of their simple narratives into voice-over scripts and by integrating text, image and sound during transduction moves as they navigate the affordances of multimodal technologies during individual and collaborative tasks and, in each of these elements, what typified any differences (e.g., greater frequency and/or variety of transduction moves) the SHL learners and L2 learners exhibited in their navigation of multimodality.
4.1. Transforming the Text of Simple Narratives into the Voice-Over Script
In both tasks, participants were required to transform the collaborative 500–700-word simple narrative into a 250–300-word voice-over script, and they were urged in class and in the guidance of the Google document not to go over 300 words. In the collaborative task, seven participants reported in their written reflections that they focused on isolating and maintaining the most important points of the narrative decided via discussion among partners, as when Mason (Pair 5) stated, “We looked at our story and chose what needed to be kept for an emotional appeal as well as solid information to back up our topic”. His partner concurred when Charlee said, “We worked together…[going] through the whole narrative and decided what was crucial information”. Four of fourteen mentioned “cutting” or “condensing” the simple narrative, and both members of Pair 4 mentioned changing the point of view for part of the voice-over script. William (Pair 4) mentioned a shift in point of view from the father in the simple narrative to the son in the voice-over script. He recalled, “We shifted from focusing on the son, Armando, [in the story] to Mateo [the father in the story], because after talks with [the instructor] we thought it would add more drama”. He continued, “When it came to the voice-over itself we split it up, using myself as a 1st person perspective to add depth to the story, and [Emma--his SHL partner] was the one to set the scene and explained the plot information in order to move the story along”.
Using word count, one element of transformation, results show that all seven pairs of language learners were successful in meeting the minimum word count of 500 for the collaborative simple narrative, while four of seven pairs were unsuccessful in transforming the voice-over script to the maximum word count of 300 or less, as instructed in class and within the guidance of the Google document; however, these were over by no more than 32 words. This contrasts sharply with the totals for the second task, the individual DS, as can be seen in Table 6. SHLs were slightly more productive than the L2s in total word count in the simple narratives and slightly more able to condense their stories into the voice-over scripts, as can be seen in the first columns of Table 6 below.
Four participants also cited preliminary plans for using images and sounds as they wrote their voice-over script. The writing guide in Google Docs defined transduction and encouraged them to contemplate possible transduction moves as they transformed the narrative to script. Olivia and Abigail (Pair 5) mentioned using the idea of transduction during the transformation process. Olivia wrote, “For the most part it was just picking words that we could omit and then replacing them with pictures and other things”. Abigail concurred, “We also decided which parts we could explain through pictures and which parts we could use through sound”.
As with the collaborative DS, participants were required to transform the 500–700-word individual simple narrative into a 250–300-word individual voice-over script. While four of the fourteen language learners were unsuccessful in meeting the minimum word count for the individual simple narratives, seven were unsuccessful in transforming the individual voice-over script to the maximum word count; two exceeded by more than 160 words. As can be seen in Table 6 below, compositions exceeding the task parameters are in bold and justified to the right, and compositions not reaching task parameters are in italics and justified to the left.
None of the collaborative compositions were under the word count parameters, while seven of the twenty-eight individual compositions were short. As noted in the table above, four SHLs complained specifically about having to cut or sacrifice detail in the individual voice-over script, and three of those exceeded the word-count parameters. Two L2s made that complaint, but only one of those two exceeded the maximum. In fact, Olivia (Pair 5) complained; however, she came under the suggested minimum by 18 words.
4.2. Structuring the Multimodal Text: Transduction
The second reflection occurred after students completed the rough drafts of the collaborative DS multimodal composition. Question 2 asked them about ways in which they accomplished transduction: “Which elements did you convert to other modes (images, sounds, music) in order to economize your words?” Respondents referred to images, music, voice effects, sound effects and text-on-screen. All fourteen respondents mentioned the use of images for transduction. Only two of the six L2s, Mason and Charlee (Pair 6), mentioned transduction through music. Conversely, five SHLs of eight did so: Maria (Pair 1), Amelia (Pair 2), both Noah and Avery (Pair 3), and William (Pair 4). Two from each demographic said they used sound effects to replace text, and only one L2 said she used text-on-screen to economize. However, evidence of their professed transduction efforts was not always obvious in the digital compositions.
Regarding the substitution with image, Abigail (Pair 5) explained, “We did this … by changing the description of the red-headed teacher to a picture of the teacher. The description was then rendered useless, and we were able to cut that part out”. William (Pair 4) explained their deliberate use of image, sounds, and silence when he stated, “The main way we used pictures and sounds to convey a meaning is when Mateo is picked up by the police. At this point, we used a lack of music and a pause of [silence] before the sirens and sounds of jail bars being closed are played”. This pause in the music and use of sound effects in the collaborative DS corresponded to the pause in the voice-over script after his partner Emma, the narrator, said, “Era un día normal en mayo cuando…./It was a normal day in May when…” and before his character stated, “En un segundo, todo de mi futuro cambia./In a second, my whole future changes”. William continues to explain the lack of music as his first-person narration continues, “Then for my narrative, there is no music again so there’s only one thing to focus on, adding to the intensity and conveying that sense of unknowing”.
Clearly, not all digital composers understood the transduction concept at this point despite having heard explanations in class and having an explanation in the task guidance. Both partners in two pairs and one partner in another pair only referred to images and sounds as complementing the words of the voice-over script rather than additive or substituting elements of the original simple narrative. For example, Noah (Pair 3) said, “I told my partner that we should first listen to our audio and write down images that we would imagine as the script played out. This way, we would have images that the listener would most likely be thinking of as the script went on”. Liam (Pair 7) responded, “Mainly we are just using sound effects and pictures to reinforce what is said”.
The fifth reflection followed the completion of the rough drafts of the individual DSs, and participants responded to the question, “What changed between the narrative form of the digital story and the final script with images and sound?” Six of the fourteen, as indicated by the asterisks in Table 7 below, referred to cutting out details or words to achieve the transformation between individual simple narrative and voice-over script, including Mason (Pair 6) who only reduced his word count by 29 words. Four of those six respondents did not mention replacing the cut passages with images or sound. Six of the fourteen reported replacing words with sounds, images and video. Sofia (Pair 1) incorporated all three; she stated, “I focused a lot on taking words away and working more with visuals. …a lot of scenes had to be cut in order to stay within time limits. … I attempted to balance this a bit with other background sounds and music shifts. Of course, I also took a risk in adding video to part of my story”. Abigail (Pair 5) specified multiple modes she used to replace text: “The final script used images and sound to consolidate the number of words used. I utilized a ringing sound and a door shutting sound to exemplify the effects of the story without using too many descriptive words. I also used a map to show where José’s parents moved without using extra words to portray this”.
In the reflections, students were asked specifically about their use of transduction. After the collaborative DS process, only four of fourteen participants made mention of plans for the substitutions of another mode for words in the simple narrative. At this stage in the individual DS process, six of the fourteen participants mentioned substitutions of another mode for words.
The total transduction moves during the collaboration were seven and increased to 50 in the individual DSs. Sofia (Pair 1) accounted for 26 transduction moves in her individual DS, as seen in Table 8 below.
Mason and Charlee (Pair 6) did not show any clear evidence of transduction as a team or as individuals, whereas Pair 1 exhibited 29 transduction moves across both tasks. Though a statistical analysis was not advisable due to the scarcity of data and the wide range of scores, the raw data did yield interesting trends. For example, SHLs accounted for 87.72% of all transduction moves, and L2s only accounted for 12.28%, which will be discussed further in the discussion section below.
4.3. Navigating the Affordances of Multimodal Technologies
The WeVideo platform proved to be an exceptional tool for the integration of modes in a DS. In WeVideo, the digital composers could layer as many visual and audio tracks as they desired, resulting in digital synesthesia (Kress 2000). For example, some participants even layered images, thereby creating a new image; however, no one overlapped music tracks even if they created separate lines for each in WeVideo. In Figure 1, Abigail (Pair 5) used four layers of media, visible across the bottom of the screen capture: (a) Video 2 with images (including the beginning title slide and the credits not pictured but at the end); (b) Voice with the voice-over recording; (c) Music with two audio tracks of music; and (d) Sound Effects with audio clips of a door closing and a cell phone ringing.
Like Abigail’s, most DSs contained four media tracks; although, some contained overlapping images rather than sound effects. For example, Liam and Luca (Pair 7) used an image of a single-family house with an image of U.S. dollar signs ($$) superimposed on the image, to reinforce the idea that owning a house is expensive in the United States. All DSs contained at least three separate tracks: one for images, voice-over recordings, and music. Only Sofia (Pair 1) inserted a fifth type of track using layers of text-on-screen over images. The use of multiple layers of media did not, however, always result in transduction. Transduction occurs when digital composers use one mode to replace another. For example, in Abigail’s story above in Figure 1 above, the blue vertical line intersects a point in the story in which the picture of a telephone complements the sound effect of a ringing telephone at the point that Abigail’s recorded voice-over states, “Después de mucho tiempo, José recibió una llamada./After a long time, José received a call”. This was not an example of transduction because the exact sentence also appeared in her original narrative; therefore, the image and sound effect were not additive in that they did not supply information missing from the voice-over recording but present in the original text. Most of the additional modes complemented or illustrated rather than substituted text. Some multimodal elements may have substituted language ideation occurring during the development of the digital version, but was missing in the original text narratives. It is possible, for example, that Abigail could have selected the image of the telephone with the idea that her character’s parents interrupted a homework session with the call, which would make the image additive. However, the point of comparison was the simple narrative from Google Docs, the recorded voice-over script, and the digital composition in WeVideo; Abigail’s individual simple narrative did not contain information on what her character was doing when he received the call, making it impossible to code as transduction. Participants could also add movement to their images by adding transitions between images. The classroom instructor explained the transition tools during class, and 100% of the participants used transitions during their DSs.
All DSs also contained music tracks; although, a few suspended the music at some point in favor of using silence for effect. Many used only one music track for the entire DS, and a few even inserted the same track a second time when it did not last for the length of the DS. Some with two music tracks waited until the credits to play the second track, while others used a second, third, or even fourth track to match the storyline with a particular song to set the mood or to change the story’s tone. Noah (Pair 3) mentioned adding three tracks in his collaborative DS, and later he added four to his individual DS; he explained his use in the individual DS, “The music reflected the mood and pace of my story. I also utilized certain music to highlight moments that I wanted the audience to pay attention to. I did this by changing tracks, alternating volume, or even cutting out music completely”. However, it was difficult to say that music replaced text in the simple narrative, which would have comprised a transduction move. Only three clear instances of transduction from written language to musical tracks emerged, and all three were in two individual DSs produced by two SHLs. For instance, Victoria replaced “viven felices/they live happily” with festive Mexican music in her individual DS.
While no one added video footage to the collaborative DSs, three did so for the individual DSs. Noah (Pair 3) and Mason (Pair 6) used videos that they found on the internet. They may have noticed that one of the example DSs from the pilot contained video footage, or they may have realized the possibility independently while using WeVideo. Conversely, Sofia (Pair 1) asked the instructor for permission to use video, recruited an actor, and self-produced seven of her own video clips. The video footage from Sofia’s individual DS were among the clearest examples of transduction in the project. All but one of her video clips could be directly linked to passages in the simple narrative that were missing from the voice-over script as can be seen in Table 9. To clarify, her actor never spoke, and the video footage itself had no sound. The sounds of the DS were the voice-over track, the music tracks and the four sound effects.
Sofia stated that her use of video occurred when her character was moving forward and that she switched to still images when he faced obstacles due to his lack of English-language skills, adding an interesting layer that she acknowledged might have been lost on the viewers. Sofia, an SHL, was the only participant exhibiting transduction from language to video.
In sum, participants used the available affordances of a variety of modes including images, video, sound effects (e.g., siren, telephone ring), and text-on-screen to replace text passages present in the simple narratives—elements that were removed from the voice-over scripts and that reappeared in the DSs via other modalities. Transduction was defined for the participants in class and in the writing prompts for the voice-over script; however, using transduction moves was not on the grading rubric and, therefore, was not specifically required. As a result, not all participants showed clear evidence of transduction between the simple narrative and DS tasks. In the collaborative task, Pairs 6 (Mason and Charlee) and 7 (Liam and Luca) did not clearly use transduction. Five participants, Noah (Pair 3), William (Pair 4), Mason and Charlee (Pair 6), and Liam (Pair 7) did not clearly use transduction in the individual task.
Pairs used images in transduction moves five times in the collaborative DSs, whereas individuals used images in transduction moves 29 times. Sofia (Pair 1) used self-produced video six times to replace text in the individual simple narrative. There was no clear evidence of transduction using sound effects or text-on-screen in the collaborative DSs, whereas individuals used sounds in transduction moves 11 times, and Sofia (Pair 1) used text-on-screen in transduction moves four times. For example, Sofia layered three modes to replace language from the individual simple narrative, as seen in Table 10 below.
The research questions sought to explore how the composers navigated multimodality using digital tools in the collaborative and individual products as well as the behaviors of the different demographics within the class, specifically, how they used modalities during the synesthesia. After completing their original narrative stories, the participants were tasked with economy of text during the transformation of the simple narrative to the voice-over script in that they had to keep their voice-over scripts under a maximum number of words. As they transformed one written text into another, they planned for the integration of the diverse modes of image and sound beyond the spoken words of the audio recordings of their written voice-over scripts. The use of some of these images and sounds resulted in the occurrence of transduction moves in which they substituted words from the simple narrative with visual elements and sound within the multimodal digital composition.
5. Discussion
Regarding the transformation of the simple narratives to the voice-over scripts, collaborative partners stayed very close to task parameters; however, the majority of the individual writers did not seem able or chose not to stay within prescribed word counts, mostly by exceeding the word count for the scripts. This willingness to forgo parameters could result from lack of partner accountability or lack of dialogue between collaborators on ways to reduce the word count. Writers also seemed more preoccupied with “cutting content” rather than following the guidelines, which encouraged replacing text with other modes.
Regarding structuring the multimodal text and navigating multimodality, one of the most salient conclusions evident in this research is that multimodality did not necessarily mean that the participants rendered clear evidence that they utilized these modes to achieve transduction by substituting passages from the original text versions of the narratives with other modes in the digital versions in WeVideo. This difficulty in putting the concept of transduction into practice is hinted at in Nelson’s study (Nelson 2006), which found that participants struggle in their manipulation of semiotic resources to convey deeper meanings and is confirmed by Elola and Oskoz (2017), who also found that transduction can be difficult for learners to accomplish, even when explained. Rather than configuring the words, images, and sounds in such a way that each holds a part of a message in counterpoint, each element is incomplete without the others, and most of the collaborative DS composers held a line of melody with the elements working in unison, each sharing the same message. Without the second task, transduction would barely be noticeable. Possible reasons for its relative absence in the first task may include lack of understanding of the concept or lack of motivation for the deep thinking required in a more complex design.
Although transduction in the collaborative DSs was almost nonexistent, the individual digital compositions contained many more occurrences of transduction. Collaborative DSs only exhibited seven clear transduction moves, while individual DSs contained fifty, with Sofia (Pair 1) accounting for 26. In the collaborative project, all participants complained of having to cut content from the simple narratives to accommodate the guidelines of the task, and that appeared to be the way most pairs achieved economy in the transformation process, with only one sound effect and six images to substitute language. The increased number and the greater variety of modes used in substitution in the individual DS indicated growth in using diverse methods for economy; although, many still complained about having to cut detail and content, indicating a possible progress in understanding the concept of transmodal movements. This greater use of transduction in the second project may be due to just that, a better concept of using multiple modes effectively via the practice effect of task repetition. Manchón (2014) cited the benefits of oral task repetition for language acquisition and suggested the possible extension of benefits for language acquisition from the repetition of a written task and continued instruction. The same could be true for developing synesthetic skills during multimodal task repetition. By this time in the second task, the participants had seen and heard the definition and examples multiple times in the classroom setting as well as the task guidance in Google Docs and individual writing conferences, highlighting the importance of the practice needed to develop expertise in multimodal design and the need for improvement in its instruction.
When considering demographics, the SHLs created many more transduction moves than the L2s, 87.72%, or more than seven to one, and with half of all the L2 population having no clear transduction moves of any kind. All three of these L2 participants acknowledged the use of images for economy in their reflections, revealing a conscious effort to combine different modes to share their message, whereas others simply visualized the action of the script and looked for images that illustrated those mental images, resulting in illustrative rather than additive images. The composers may have ignored the task guidance, which instructed them to ponder and identify passages that could be replaced with images and sound before writing the script, or they were simply focused on cutting language and forgot that option. The SHLs also used a greater variety of transduction modes, including images, video, sound effects, music and text-on-screen, while the L2s only revealed clear substitutions using images.
Why were the L2 participants for the most part unable or unwilling to transform their texts by transduction or “movement between and across modes” (Newfield 2017, p. 103)? They clearly expressed frustration with what they perceived as the necessity to cut content and detail. The researcher’s field notes recorded details on two separate occasions when L2 participants complained openly in class of having to cut material from the simple narrative, and, each time, the instructor coached them on possible transduction moves by re-explaining the concept of transduction and giving examples. The qualitative data from the participants also mentioned that the instructor suggested transduction moves as an alternative to simple text reduction in some of the instructor’s face-to-face feedback sessions. The L2s appeared to understand the concept, but this apparent understanding did not translate to practice. Almost all images and sounds were illustrative rather than additive, as with Abigail’s DS (Pair 5) seen previously in Figure 1. In such a small sample size (L2s: n = 6), it is impossible to generalize, but it may have been due to individual differences or preferences among the participants, lack of task engagement, or, perhaps, inability or unwillingness to deal with the increased cognitive load required in the transduction process (Newfield 2017). This notion of language learners having a limited capacity or a maximum cognitive load was advanced by Skehan (1998), who posited that the brain can handle only attend to a limited amount of detail at any one time. The language skills of the L2 learners may have been taxed to the point that they chose not to expend the extra energy on the deep thinking required to achieve transduction. As mentioned previously, transduction was not a requirement but a suggestion; therefore, L2 learners, who were more focused on task completion and grade, did not have that incentive to encourage them. Only one of the L2s, Olivia (Pair 5), highly rated and boasted of her writing skills in Spanish, and she and her partner Abigail were responsible for all but one of the L2 transduction moves; perhaps her view of herself as a masterful L2 writer may have been an individual difference affecting the outcome. This notion is strengthened by the fact that Sofia (Pair 1) was responsible for many of the transduction moves for the SHLs. Sofia also considered herself a strong writer, and she prided herself on the lengths she went to in the crafting of her story. Olivia also indicated a level of engagement in her individual DS not present for many of the L2s, in that she intended for the person she interviewed to view the story he had inspired. Another possible variable is that, although the stories were not autobiographical, SHLs still identified with the characters in their DSs, resulting in a vicarious identity-building and sense of empowerment, evident in Davis (2005), Hull and Katz (2006) and Jiang et al. (2020).
Still images were the greatest source of transduction from the text to the digital compositions. This is not surprising since digital composers used a whopping 380 images, which included stock photographs, candid photographs, self-made photographs, clipart, maps, and emoticons. In the qualitative data, many participants often spoke about substituting language with images, revealing an understanding and application of the concept in their efforts to economize their words in the digital version. For instance, Abigail recalled that she “used a map to show where José’s parents moved without using extra words to portray this”. A few studies have looked specifically at transduction and the use of images in DSs (Hull and Nelson 2005; Nelson 2006; Oskoz and Elola 2016a; Yang 2012), but none have accounted for the rate of transduction moves using images as compared to illustrative images or their frequency as compared to other transduction moves. The deliberate depth of thinking involved in making these choices is what Newfield (2017) refers to as the “transmodal moment” (p. 103), and not all participants appeared to grasp or to invest in its completion.
Although presented as an option, most composers did not utilize text-on-screen beyond a title and the credits. Only Sofia’s (Pair 1) contained text-on-screen to replace language and information from the simple narrative, establishing setting and time of day. Conversely, the use of video rather than still images was not presented specifically, but three used video footage in the individual DSs. Although not a requirement, all of the participants enhanced their DSs by adding movement to at least some of their images by using the digital tools available in WeVideo. These tools made it possible to add transitions between images to soften the change from one image to another, such as the fading in and out of the image. Another tool used widely was a pan-in or pan-out feature, which meant that the image could start with the full image and slowly focus in on one element of the image, such as a face, or vice versa. The students were shown how to use these tools during class time. However, the addition of video by Sofia (Pair 1), Noah (Pair 3), and Mason (Pair 6), rather than still images, is an example of innovation on the part of these individuals in the development of digital skills, as found in Chan et al. (2017), who found that “students may develop their creativity and innovation in expressing their ideas with digital media” (p. 13).
Although a distant second in the types of transduction moves, the digital composers embraced the use of sound effects in the individual task, more than quadrupling their use of sound effects from the collaborative DSs to the individual DSs. These sound effects, or non-musical sounds, such as an audio clip of a siren or the chatter of children on a playground, added to the realism of the composition. The presentation of the first DSs was a very high moment in the class, and this may have translated to including a non-required element in the second by observing the dramatic impact of sound effects in the collaborative DS by Emma and William (Pair 4), who used a siren and the slam of a cell door at the detention of the first-person narrator. Mason (Pair 6) remarked that he liked Pair 4’s collaborative DS “…because of the use of sound effects to stress the situation and add flavor”. Since sound effects were not required for the DSs, their increased use may have correlated with a higher level of motivation and engagement in the second task, as when Semones (2001) found that levels of motivation rose during the DST process. Sadik (2008) also found that DST promoted creativity and motivation, which could be connected to this willingness to add an additional layer to the stories, illustrated by Pair 1’s Maria who stated, “I was able to add sound effects which made my digital story stand out compared to others who chose not to incorporate sounds into their stories”. Additionally, as in Chan et al. (2017), growing ease with the technology as the participants had more practice with WeVideo may have been a factor, resulting in more intricate digital compositions due to task repetition. A counterpoint might have helped to gauge if the increase is due to task repetition or to working individually. When separated by demographic, the SHLs used many more sound effects than the L2s (18 to 5, respectively).
Despite the higher number of sound effects used, the majority served to enhance the language of the recorded voice-over script rather than to replace passages in the simple narratives. Clear connection to transduction from language to sound effect was only present in three DSs, all created by SHLs: the collaborative DS by Pair 4 mentioned above and two individual DSs, Pair 4’s Emma (airplane taking off) and Pair 1’s Sofia (wind, shoppers, door slam, and construction tools). There is a dearth of research specifically addressing the use of sound effects to achieve transduction and multimodal synesthesia in digital compositions, except for Oskoz and Elola (2016a), who found that DS composers used inflection, repetition and pauses to replace connectors between sentences. However, the initial plan for transduction, as with other transmodal moments, most likely needs to occur during the process of text transformation from the simple narrative to the voice-over script, and if the composers fail to do so at that point in the process, it may not happen at all. Transduction does not happen accidentally, but rather by deliberate choices that multimodal composers make as they construct the digital versions. In this project, once the target number of words emerged from the transformation process, the need for transduction ended; therefore, any changes after that point would be the result of desiring to add more words to the voice-over script recording and finding a way to replace passages at that point. However, these participants were more likely to extend the voice-over script beyond the maximum word count, as Liam (Pair 7) did when he submitted a shorter voice-over script in the text version for grading, but added passages in the recorded version, highlighting that half the participants were unable to transform their simple narratives into voice-over scripts, which fit the parameters of the task by going over the maximum word count allowed.
Another surprise was the difficulty in attaching a musical passage or track change as a substitution for words in the simple narratives. Most of the time the language of the voice-over script also indicated the change in tone. Very few clear instances of transduction from written language to musical tracks emerged, and all were in two individual DSs produced by two SHLs. Many studies on DST mention the use of music as an additional layer (e.g., Chan et al. 2017; Huang et al. 2017; Yang 2012), but most describe the use of background music in terms of simply setting the mood for the DS rather than specifically noting musical passages as transduction moves replacing text. Although setting the mood could be perceived as a form of transduction, the music seemed to complement the text of the voice-over script rather than replace it.
Lastly, was the unique case of Pair 1’s SHL Sofia, who was one of the top writers in the class. The depth of thought and planning that Sofia incorporated in the execution of her individual DS was unparalleled. Sofia considers herself a writer, so, that she would meticulously craft her words was unsurprising, but her DS showed evidence of that same meticulousness in the crafting of the nonverbal modes, some of which she admitted were lost on the viewers. As mentioned earlier, she used still images when her character hit roadblocks in communication, but used self-created video footage when her character was moving forward toward the accomplishment of his goals. Also mentioned previously, Sofia was the source of almost half of all instances of transduction, which shows a deep level of understanding of the concept of transduction moves, which Kress (2010) suggested indicate agency in the multimodal designer. Also surprising was the variety of types of transduction moves. Sofia used all of the moves mentioned in the task guidelines (image, music, sound effects, and text-on-screen) as well as the silent video she self-produced to replace text. The greatest surprise of all was that the outside judges, who were familiar with the DS process and products, did not recognize Sofia’s DS as a class winner, and only Abigail (Pair 5), who heard Sofia mention all the time she spent on it, mentioned it as a favorite because she recognized the time and effort invested once she viewed the DS. This lack of recognition could have come from the judges’ privileging the overall impact of the DS rather than the intricacy of design. If the intended outcome within the activity system was digital literacy in the L2, then Sofia was the winner, but somehow, her effort did not translate into a DS that was recognized as the multilayered, complex multimodal product it was. Nelson (2006) stated,
However, power tools do not necessarily a carpenter make, to coin a phrase. To engage Synaesthesia in its truly creative sense, one must not only understand the tools and the codes of the new media age; one must understand how to recombine these communication resources so as to bend them to her/his expressive will.p. 72
Sofia acknowledged that some of her imagery was most likely lost on the viewers and that her choice to keep the pacing slow in an effort to communicate the monotony of her character’s days may have been a misfire, which may have been the main reason her individual DS did not stand out: it seemed very slow. In other words, Sofia’s weakness was that she did not have a sense of how the slow pace would affect the classroom community and judges. Perhaps if she had had a collaborative partner or more practice, this weakness could have been addressed and she would have realized that she needed to make adjustments to heighten the impact of her story.
When considering the demographics separately, the SHLs produced text and digital compositions that were more complex in their design than those of the L2s in the variety and quantity of transduction moves in their process of transformation from simple narrative to digital compositions. This willingness to add transduction could stem from their language skills as typical SHLs, which may have allowed them to manage the tasks in such a way that allowed them the time to increase the intricacy of their multimodal products. This addition of additive elements in the individual products was most likely due to the SHLs’ strength and confidence in their linguistic skills that made up for the lack of a partner, the connectedness the SHLs felt toward their content, and/or the L2s’ focus on fulfilling, but not necessarily exceeding, the tasks’ parameters: barely producing the required number of words in text documents and not adding complex elements, which were not required, to the digital texts. In fact, some L2s accounted for their reduced output by saying that it was hard to generate content alone, and others said that they were anticipating having to cut content for the individual voice-over script to comply with the directive to economize because they were concerned with the graded product and not necessarily the ungraded process. While the SHLs seemed more invested in the DSs as an opportunity to share a meaningful message that was close to their hearts, the L2s were more focused on the composing process as a series of tasks to complete and grades to earn; although, their emotional investment seemed to rise in the individual project, due to the requirement of a personal interview. The L2s also seemed more resistant to the inclusion of DST in the curriculum, perhaps because they felt less connected to their content and more focused on the tasks; although, their emotional investment seemed to grow with the interviews included in the second task. Conversely, the SHLs seemed to view the DSs as a meaningful activity with a purpose worthy of their time and effort, most likely due to their connection to the cultural content of their research and interviews. Therefore, educators should find ways to enhance the presentation of DST as a valuable genre and include additional means of enhancing task engagement for L2 composers.
6. Conclusions
In an effort to enhance the potential for transduction moves in the DS products, educators may need to guide the DS composers to deeper thinking and more complex design during the transformation process by including a step requiring them to practice transduction as a classroom activity and then to examine and to mark their own simple narratives for specific passages that could be replaced with another mode, such as image, sound effect, music change, or text-on-screen. This deeper understanding of the process of creating synesthesia, or the integration of semiotic modes, in multimodal texts might then be instrumental in the composition of more complex DSs, and thereby lead to the development of digital literacies (Kress 2003; Nelson 2006). This would lead to richer texts and clarity regarding the intentions of the digital composer in future research of this type by making the creator’s intentions clearer to the researcher.
Limitations in this project include the small sample size, the absence of a counterbalanced design that may have affected the results due to the practice effect of task repetition. Future studies could find ways to mitigate these limitations. Since the data came from a small, intact class, which was taking part in other class activities, such as grammar study, the constraints on the research tasks included the impossibility of including a task counterpoint, meaning that half the participants could do the individual task followed by the collaborative second and vice versa. The structure of the class and the small number of dyads made that inadvisable, especially since the study also separated the population into the two demographics. As such, the decision to have the students carry out the collaborative task first and the individual second was guided by the literature. Various studies have already established that collaborative texts tend to be of greater quality (e.g., Elola and Oskoz 2010; Valentín-Rivera 2016); therefore, to offset a possible double advantage of collaboration and task repetition, the participants did the collaborative task first followed by the individual.
Applied linguistics needs more investigations into the use of multimodal writing during the process of second language acquisition and, more specifically, the benefits of collaborative multimodal composition. Current scholarship has not fully explored its effectiveness. Pedagogically, DST offers an academic activity that includes digital literacies in the L2. Adding the collaborative element enhances 21st Century skill development and offers the L2 learners an opportunity to scaffold their technological skills, resulting in products that are potentially more complex in the design of their multimodal texts than those they produce individually, and leading to multimodal and linguistic development and, consequently, improving the practices of multiliteracies as they improve language skills. Furthermore, more research is needed to operationalize and to connect DST to L2 development and to measure students’ multiliteracy gains via multimodal task-based projects, which extend beyond the qualitative and include the quantitative (Forceville 2010; Oskoz and Elola 2016b). Using SSMA as a theoretical framework, this research project attempted to add to the scholarship in this new direction in our rapidly changing world of global communication by comparing the processes and products by which SHL and L2 composers achieve synesthesia, which are crucial to multimodal composition.
Supplementary Materials
The following supporting information can be downloaded at: https://0-www-mdpi-com.brum.beds.ac.uk/article/10.3390/languages7030222/s1.
Funding
This research received no external funding.
Institutional Review Board Statement
The study was conducted according to the guidelines of the Declaration of Helsinki, and approved by the Institutional Review Board of Texas Tech University.
Informed Consent Statement
Written informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Data supporting reported results can be found in the office of Dr. Idoia Elola, Professor of Spanish & Applied Linguistics & Second Language Studies at Texas Tech University.
Conflicts of Interest
The author declares no conflict of interest.
| 1 | This statement is based on anecdotal evidence provided by the professorate at Texas Tech University. |
| 2 | The website https://cursosinternacionales.usal.es/en/what-difference-between-siele-and-dele (accessed on 24 October 2016) contrasts the two tests. |
References
- Akoto, Miriam. 2021. Collaborative Multimodal Writing via Google Docs: Perceptions of French FL Learners. Languages 6: 140. [Google Scholar] [CrossRef]
- Blake, Robert J., and Eve C. Zyzik. 2003. Who’s helping whom?: Learner/heritage-speakers’ networked discussions in Spanish. Applied Linguistics 24: 519–44. [Google Scholar] [CrossRef]
- Bowles, Melissa A. 2011. Exploring the role of modality: L2-heritage learner interactions in the Spanish language classroom. Heritage Language Journal 8: 30–65. [Google Scholar] [CrossRef]
- Castañeda, Martha E. 2013. I am proud that I did it and it’sa piece of me”: Digital storytelling in the foreign language classroom. CALICO Journal 30: 44–62. [Google Scholar] [CrossRef]
- Chan, Banny S. K., Daniel Churchill, and Thomas K. F. Chiu. 2017. Digital literacy learning in higher education through digital storytelling approach. Journal of International Education Research (JIER) 13: 1–16. [Google Scholar] [CrossRef]
- Davis, Alan. 2005. Co-authoring identity: Digital storytelling in an urban middle school. THEN: Technology, Humanities, Education & Narrative 1. [Google Scholar]
- Donato, Richard. 1994. Collective scaffolding in second language learning. Vygotskian Approaches to Second Language Research, 33–56. [Google Scholar]
- Elola, Idoia, and Ana Oskoz. 2010. Collaborative writing: Fostering foreign language and writing conventions development. Language Learning & Technology 14: 51–71. [Google Scholar]
- Elola, Idoia, and Ana Oskoz. 2017. Writing with 21st century social tools in the L2 classroom: New literacies, genres, and writing practices. Journal of Second Language Writing 36: 52–60. [Google Scholar] [CrossRef]
- Fokides, Emmanuel. 2016. Using autobiographical digital storytelling for the integration of a foreign student in the school environment. A case study. Journal of Information Technology Education: Innovations in Practice 15: 99–115. [Google Scholar] [CrossRef]
- Forceville, Charles J. 2010. The Routledge Handbook of Multimodal Analysis: Carey Jewitt. London: Routledge, 340p, pp. 2604–8. ISBN 13 978-0-415-43437-9. [Google Scholar]
- Frazel, Midge. 2010. Digital Storytelling Guide for Educators. Washington, DC: International Society for Technology in Education. [Google Scholar]
- González-Barrera, Ana, and Mark Hugo López. 2013. Spanish Is the Most Spoken Non-English language in US Homes, Even among Non-Hispanics. Pew Research Center. Available online: https://www.pewresearch.org/fact-tank/2013/08/13/spanish-is-the-most-spoken-non-english-language-in-u-s-homes-even-among-non-hispanics/ (accessed on 26 March 2017).
- Hafner, Christoph A. 2015. Remix culture and English language teaching: The expression of learner voice in digital multimodal compositions. Tesol Quarterly 49: 486–509. [Google Scholar] [CrossRef]
- Huang, Yun-Yin, Chen-Chung Liu, Yu Wang, Chin-Chung Tsai, and Hung-Ming Lin. 2017. Student engagement in long-term collaborative EFL storytelling activities: An analysis of learners with English proficiency differences. Journal of Educational Technology & Society 20: 95–109. [Google Scholar]
- Hull, Glynda A., and Mark Evan Nelson. 2005. Locating the semiotic power of multimodality. Written Communication 22: 224–61. [Google Scholar] [CrossRef] [Green Version]
- Hull, Glynda A., and Mira-Lisa Katz. 2006. Crafting an agentive self: Case studies of digital storytelling. Research in the Teaching of English, 43–81. [Google Scholar]
- Jewitt, Carey. 2017. An introduction to multimodality. In The Routledge Handbook of Multimodal Analysis. Edited by Carey Jewitt. London: Routledge/Taylor & Francis Group, pp. 15–30. [Google Scholar]
- Jiang, Lianjiang. 2017. The affordances of digital multimodal composing for EFL learning. Elt Journal 71: 413–22. [Google Scholar] [CrossRef]
- Jiang, Lianjiang, Miaoyan Yang, and Shulin Yu. 2020. Chinese ethnic minority students’ investment in English learning empowered by digital multimodal composing. TESOL Quarterly 54: 954–79. [Google Scholar] [CrossRef]
- Kress, Gunther R. 2003. Literacy in the New Media Age. London: Routledge. [Google Scholar]
- Kress, Gunther R. 2010. Multimodality: A Social Semiotic Approach to Contemporary Communication. London: Routledge. [Google Scholar]
- Kress, Gunther. 2000. Design and transformation: New theories of meaning. In Multiliteracies: Literacy Learning and the Design of Social Futures. Edited by Courtney Cazden and Bill Cope. London: Routledge, pp. 153–61. [Google Scholar]
- Lambert, Joe. 2013. Digital Storytelling: Capturing Lives, Creating Community. London: Routledge. [Google Scholar]
- Leont’ev, A. 1978. Activity, Consciousness, and Personality. Hoboken: Prentice-Hall. [Google Scholar]
- Liang, Mei-Ya. 2015. Viewpoints in multimodal storytelling: From sensation to narration. Language & Communication 42: 23–35. [Google Scholar]
- Lundby, Knut. 2008. Digital Storytelling, Mediatized Stories: Self-Representations in New Media. Bern: Peter Lang. [Google Scholar]
- Malita, Laura, and Catalin Martin. 2010. Digital storytelling as web passport to success in the 21st century. Procedia-Social and Behavioral Sciences 2: 3060–64. [Google Scholar] [CrossRef] [Green Version]
- Manchón, Rosa M. 2014. The distinctive nature of task repetition in writing. Implications for theory, research, and pedagogy. ELIA 14: 13–41. [Google Scholar] [CrossRef] [Green Version]
- Nelson, Mark Evan. 2006. Mode, meaning, and synaesthesia in multimedia L2 writing. Language Learning & Technology 10: 56–76. [Google Scholar]
- Newfield, Denise. 2017. Transformation, transduction and the transmodal moment. In The Routledge Handbook of Multimodal Analysis. Edited by Carey Jewitt. London: Routledge/Taylor & Francis Group, pp. 100–13. [Google Scholar]
- Nishioka, Hiromi. 2016. Analysing language development in a collaborative digital storytelling project: Sociocultural perspectives. System 62: 39–52. [Google Scholar] [CrossRef]
- Ortega, Lourdes. 2017. New CALL-SLA research interfaces for the 21st century: Towards equitable multilingualism. Calico Journal 34: 283–316. [Google Scholar] [CrossRef]
- Oskoz, Ana, and Idoia Elola. 2014. Integrating digital stories in the writing class: Towards a 21st century literacy. Digital Literacies in Foreign Language Education: Research, Perspectives, and Best Practices 14: 179–200. [Google Scholar]
- Oskoz, Ana, and Idoia Elola. 2016a. Digital stories: Bringing multimodal texts to the Spanish writing classroom. ReCALL: The Journal of EUROCALL 28: 326. [Google Scholar] [CrossRef]
- Oskoz, Ana, and Idoia Elola. 2016b. Digital stories: Overview. Calico Journal 33. [Google Scholar] [CrossRef]
- StoryCenter Website. n.d. Our Story. Available online: https://www.storycenter.org/history (accessed on 27 October 2017).
- Sadik, Alaa. 2008. Digital storytelling: A meaningful technology-integrated approach for engaged student learning. Educational Technology Research and Development 56: 487–506. [Google Scholar] [CrossRef]
- Semones, Lara. 2001. Collaboration, computer mediation, and the foreign language writer. The Clearing House 74: 308–12. [Google Scholar] [CrossRef]
- Skehan, Peter. 1998. A Cognitive Approach to Language Learning. Oxford: Oxford University Press. [Google Scholar]
- Storch, Neomy. 2011. Collaborative writing in L2 contexts: Processes, outcomes, and future directions. Annual Review of Applied Linguistics 31: 275–88. [Google Scholar] [CrossRef]
- Storch, Neomy. 2013. Collaborative Writing in L2 Classrooms. Bristol: Multilingual Matters, vol. 31. [Google Scholar]
- Storch, Neomy, and Gillian Wigglesworth. 2007. Writing tasks: The effects of collaboration. In Investigating Tasks in Formal Language Learning. Bristol: Multilingual Matters, pp. 157–77. [Google Scholar]
- Torres, Julio Rubén. 2013. Heritage and Second Language Learners of Spanish: The Roles of Task Complexity and Inhibitory Control. Ph.D. dissertation, Georgetown University, Washington, DC, USA. [Google Scholar]
- Valdés, Guadalupe. 2000. Introduction. In Spanish for Native Speakers: AATSP Professional Development Series Handbook for Teachers K-16 (Vol. 1). Edited by Guadalupe Valdés. New York: AATSP. [Google Scholar]
- Valentín-Rivera, Laura. 2016. Activity theory in Spanish mixed classrooms: Exploring corrective feedback as an artifact. Foreign Language Annals 49: 615–34. [Google Scholar] [CrossRef]
- Walls, Laura C. 2018. The effect of dyad type on collaboration: Interactions among heritage and second language learners. Foreign Language Annals 51: 638–57. [Google Scholar] [CrossRef]
- Watanabe, Yuko, and Merrill Swain. 2007. Effects of proficiency differences and patterns of pair interaction on second language learning: Collaborative dialogue between adult ESL learners. Language Teaching Research 11: 121–42. [Google Scholar] [CrossRef]
- Wigglesworth, Gillian, and Neomy Storch. 2012. Feedback and writing development through collaboration: A socio-cultural approach. L2 Writing Development: Multiple Perspectives 6: 69–101. [Google Scholar]
- Yang, Ya-Ting C., and Wan-Chi I. Wu. 2012. Digital storytelling for enhancing student academic achievement, critical thinking, and learning motivation: A year-long experimental study. Computers & Education 59: 339–52. [Google Scholar]
- Yang, Yu-Feng Diana. 2012. Multimodal composing in digital storytelling. Computers and Composition 29: 221–38. [Google Scholar] [CrossRef]
Figure 1.
Screen capture of Abigail’s synesthesia in her individual DS in WeVideo.


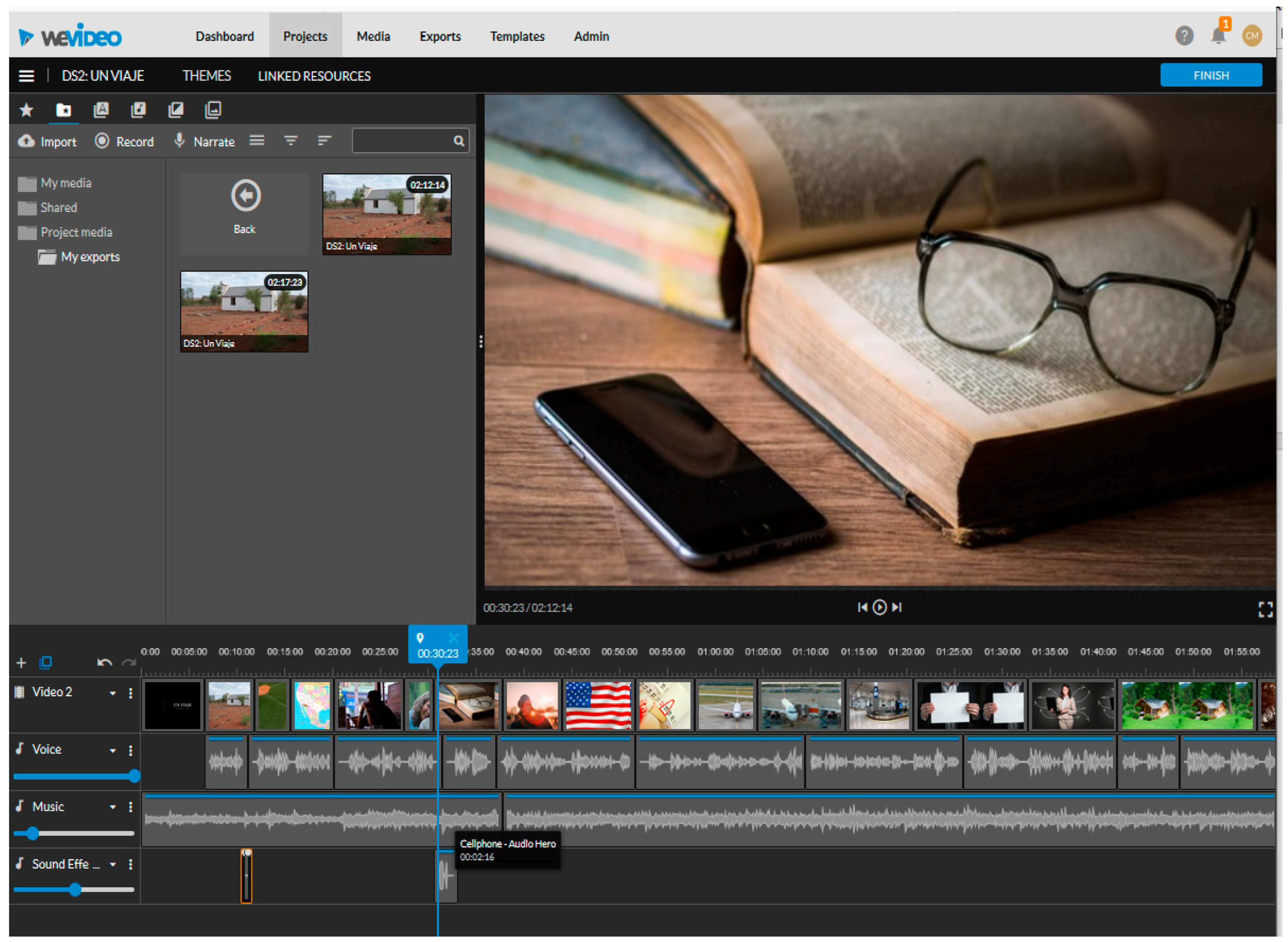{kind=link}
Table 1.
The Collaborative pairs with pseudonyms. The numbers and shading indicate the pairings.
| pseudonym | age | SHL/L2. Generation, Broad/Narrow | Onset of Spanish/English | Leveling | ||
| SIELE | Rank | WPE | ||||
| Spanish Heritage Language Learners | ||||||
| 1a Maria | 20 | SHL 2nd gen., narrow | 0yrs/0yrs, simultaneous | 16/22 | 7 | 7.9 |
| 1b Sofia | 22 | SHL 1st gen-@6mos or gen. 1.5, narrow | 0yrs/5yrs, sequential | 16/22 | 16 | 14.4 |
| 2a Amelia | 24 | SHL 2nd gen., narrow | 0yrs/0yrs, simultaneous | 19/22 | 18 | 23.3 |
| 2b Victoria | 27 | SHL 2nd gen., narrow | 0yrs/6yrs, sequential | 17/22 | 17 | 37.3 |
| 3a Noah | 20 | SHL 3rd gen., broad/receptive | 0yrs/0yrs, simultaneous, L2 like | 12/22 | 4 | 5.5 |
| 3b Avery | 21 | SHL 3rd gen., very broad | 16yrs/0yrs, L2 like | 8/22 | 2 | 2.3 |
| 4a Emma | 23 | SHL 4th gen., very broad | 12yrs/0yrs, L2 like | 15/22 | 14 | 22.5 |
| 4b William | 23 | SHL 4th gen., very broad | 8yrs/0yrs, L2 like | 10/22 | 5 | 8 |
| Second Language Learners | ||||||
| 5a Olivia | 20 | L2 | 13yrs/0yrs | 14/22 | 15 | 36.5 |
| 5b Abigail | 21 | L2 | 14yrs/0yrs | 9/22 | 11 | 37 |
| 6a Mason | 22 | L2 | 12yrs/0yrs | 11/22 | 6 | 11.1 |
| 6b Charlee | 21 | L2 | 13yrs/0yrs | 11/22 | 8 | 11.9 |
| 7a Liam | 20 | L3 (HL Portuguese) | 13yrs/0yrs | 17/22 | 10 | 16.7 |
| 7b Luca | 23 | L3 (Brazilian national) | 11yrs/6yrs | 17/22 | 9 | 11.6 |
Table 2.
Partial parallel-text table: Olivia’s individual DS *.
| Passage from the simple narrative | Types of changes | Passage from the voiceover script |
| La mujer rubia caminaba por la calle mexicana, sus caderas meciéndose de lado a lado como las palmas en el viento. Todos los hombres la miraban con ojos enamorados mientras ella los pasaba. Se llama Raquel. Era una estudiante de los Estados Unidos que estudió la enseñanza en La Universidad de Texas, pero este verano ella estuvo estudiando en Monterrey, México. Translation: The blond woman walked along the Mexican street, her hips swaying from side to side like palm trees in the wind. All the men looked at her with enamored eyes as she passed by. Her name is Raquel. She was a student from the United States, who was studying education at the University of Texas, but this summer she was studying in Monterrey Mexico. 61 words | reduced 73.8% deleted: blond (transduced to image in DS) physical description, passersby, major, school | Raquel caminaba por la calle mexicana. Era una estudiante americana estudiando en Monterrey durante el verano. Translation: Raquel walked along the Mexican street. She was an American student studying in Monterrey for the summer. 16 words |
* Blue indicates an element was substituted by another mode in the DS; red indicates notable changes, and italics indicates deleted passages.
Table 3.
Example of transduction: Olivia’s individual DS.
| Passage from the Individual Simple Narrative | Passage from the Individual Voice-Over Script | Image from the Individual DS |
|---|---|---|
| La mujer rubia caminaba por la calle mexicana, sus caderas meciéndose de lado a lado como las palmas en el viento. Todos los hombres la miraban con ojos enamorados mientras ella los pasaba. Se llama Raquel. * See translations in Table 2. | Raquel caminaba por la calle mexicana. |  |
Table 4.
Pair 5: example inventory of sounds.
| DSs: Types of Sound Elements Used: Music (Type/Variety), Sound Effects, etc. Minute.Second | ||||
|---|---|---|---|---|
| No Sound | Voice-Over | Music | Sound Effects | |
| Coll. DS: Olivia/Abigail | 0.04–0.28 A 0.31–1.08 O 0.10–1.18 A 1.20–1.56 O 1.58–2.36 A 2.38–2.42 O | 0.00–3.02 chill acoustic guitar w/keyboard fade down/up | 0.13–0.17 very faint airplane noise | |
| Indiv. DS: Olivia | 0.07–1.51 | 0.00–3.28 romantic piano, fade down/up | ||
| Indiv. DS: Abigail | 0.06–0.30 0.34–2.00 | 0.00–0.37 somber piano music 0.34–2.12 upbeat ukulele | 0.10–0.11 door slam 0.30–0.33 cell phone ring | |
Table 5.
Pair 4: example table of transduction moves and implicit images.
| Trans-Duction Moves | Word/Phrase/Sentence from Simple Narrative Missing in DS | Closest Corresponding Word/Phrase/Sentence of Voice-over | Images | Sounds | Text-on-Screen |
|---|---|---|---|---|---|
| Coll. DS: Emma/William | Durante el viaje de treinta minutos a la hacienda, un coche sin marcar encendió sus luces y la vida de Armando y Mateo cambió por siempre./During the 30-min trip home, an unmarked car turned on its lights, and the life of Armando and Mateo changed forever. | Mateo: En un segundo, todo de mi futuro cambia./In a second, all my future changes. |  | siren | |
| reflection | “…we wanted to tell the story without saying it, so we used photos that invoke a common response for all audience members, such as implying an arrest by showing a police car”. Emma’s comment | ||||
Table 6.
Word count for transformation of simple narrative to voice-over script. P1–4 = SHLs; P5–7 = L2s.
Table 6.
Word count for transformation of simple narrative to voice-over script. P1–4 = SHLs; P5–7 = L2s.
| Pairs | Collaborative simple narrative: (500–700 words) | Collaborative Voiceover script (250–300 words) | Name | Individual simple narrative (500–700 words) | Individual voiceover script (250–300 words) |
| short/in range/long | short/in range/long | short/in range/long | short/in range/long | ||
| P1 | 833 | 309 | Maria | 705 | 344 |
| Sofia * | 787 | 359 | |||
| P2 | 677 | 267 | Amelia | 509 | 300 |
| Victoria | 737 | 468 | |||
| P3 | 550 | 289 | Noah * | 475 | 298 |
| Avery * | 596 | 309 | |||
| P4 | 587 | 329 | Emma * | 640 | 319 |
| William | 703 | 248 | |||
| P5 | 669 | 316 | Olivia * | 632 | 232 |
| Abigail | 363 | 243 | |||
| P6 | 631 | 332 | Mason * | 508 | 479 |
| Charlee | 559 | 282 | |||
| P7 | 615 | 271 | Liam | 484 | 324 |
| Luca | 291 | 296 |
* Complained about having to cut length/detail (see below).
Table 7.
Using images and sound to replace text in the individual simple narrative.
| Comments for collaborative DS and individual DS transduction of narrative to voiceover script. | |||||||||
| collaborative DS | individual DS | ||||||||
| Pair | Name | sounds | images | video | Name | sounds | images | video | |
| SHL | Pair 1 | Maria | Maria | ✔ | ✔ | ||||
| Sofia | Sofia * | ✔ | ✔ | ✔ | |||||
| Pair 2 | Amelia | ✔ | Amelia | ||||||
| Victoria | Victoria | ||||||||
| Pair 3 | Noah * | Noah * | |||||||
| Avery * | Avery * | ||||||||
| Pair 4 | Emma * | Emma * | |||||||
| William | ✔ | William | ✔ | ✔ | |||||
| L2 | Pair 5 | Olivia * | ✔ | Olivia * | ✔ | ✔ | |||
| Abigail * | ✔ | ✔ | Abigail | ✔ | ✔ | ||||
| Pair 6 | Mason * | Mason * | |||||||
| Charlee * | Charlee | ||||||||
| Pair 7 | Liam | Liam | |||||||
| Luca | Luca | ✔ | |||||||
* Mentioned having to cut text length/detail in the voice-over script.
Table 8.
Summary of the number of transduction moves across tasks.
Task | All/ All moves | Images | Video | Sound Effects | Music | Text-on-screen | ||||||
| SHL | L2 | SHL | L2 | SHL | L2 | SHL | L2 | SHL | L2 | |||
| Coll. DS1 | 7 | 4 | 2 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | |
| Indiv. DS2 | 50 | 24 | 5 | 6 | 0 | 8 | 3 | 11 | 0 | 4 | 0 | |
| Totals | 57 | 28 | 7 | 6 | 0 | 9 | 3 | 12 | 0 | 4 | 0 | |
| Pair Data: Transduction moves in collaborative DS | ||||||||||||
| Pairs | All moves | Images | Video | Sound Effects | Music | Text on Screen | ||||||
| P1 | 1 | 1 | 0 | 0 | 0 | 0 | ||||||
| P2 | 1 | 1 | 0 | 0 | 0 | 0 | ||||||
| P3 | 1 | 1 | 0 | 0 | 0 | 0 | ||||||
| P4 | 2 | 1 | 0 | 1 | 0 | 0 | ||||||
| P5 | 2 | 2 | 0 | 0 | 0 | 0 | ||||||
| P6 | 0 | 0 | 0 | 0 | 0 | 0 | ||||||
| P7 | 0 | 0 | 0 | 0 | 0 | 0 | ||||||
| Pair Data: Transduction moves in individual DS | ||||||||||||
| Name | All moves | Images | Video | Sound Effects | Music | Text-on-Screen | ||||||
| P1 | Maria | 2 | 2 | 0 | 0 | 0 | 0 | |||||
| Sofia | 26 | 10 | 6 | 4 | 2 | 4 | ||||||
| P2 | Amelia | 2 | 2 | 0 | 0 | 0 | 0 | |||||
| Victoria | 5 | 4 | 0 | 0 | 1 | 0 | ||||||
| P3 | Noah | 0 | 0 | 0 | 0 | 0 | 0 | |||||
| Avery | 2 | 2 | 0 | 0 | 0 | 0 | ||||||
| P4 | Emma | 8 | 4 | 0 | 4 | 0 | 0 | |||||
| William | 0 | 0 | 0 | 0 | 0 | 0 | ||||||
| P5 | Olivia | 3 | 3 | 0 | 0 | 0 | 0 | |||||
| Abigail | 1 | 1 | 0 | 0 | 0 | 0 | ||||||
| P6 | Mason | 0 | 0 | 0 | 0 | 0 | 0 | |||||
| Charlee | 0 | 0 | 0 | 0 | 0 | 0 | ||||||
| P7 | Liam | 0 | 0 | 0 | 0 | 0 | 0 | |||||
| Lucas | 1 | 1 | 0 | 0 | 0 | 0 | ||||||
Table 9.
Examples of Sofia’s transduction using self-produced video footage.
| Word/Phrase/Sentence from Simple Narrative Missing in DS | Closest Corresponding Word/Phrase/Sentence of Voice-Over | Still Images from Videos Replacing Narrative Text |
|---|---|---|
| Son las siete de la mañana./It’s seven o’clock in the morning. | --none-- |  |
| Puede contar varias costillas asomándose de su cuerpo gastado./He can count some of his ribs sticking out of his worn-out body. | --none-- |  |
| Tomó un hielo del congelador y lo puso contra su dedo reflexionando en el día./He took a piece of ice from the freezer and put it on his thumb [while] reflecting on the day. | --none-- |  |
Table 10.
Sofia’s transduction through digital synesthesia.
| Word/Phrase/Sentence from Simple Narrative Missing in DS | Closest Corresponding Word/Phrase/Sentence of Voice-Over | Images Replacing | Sound Effects Replacing | Text-on-Screen Replacing |
|---|---|---|---|---|
| Son las nueve cuando al fin sale de la tienda con sus compras./It’s 9:00 when he finally leaves the store with his purchases. | --none-- |  | * sounds of grocery store * |  |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Maqueda, C.H. Digital Synesthesia in Heritage and Second Language Writing during Collaborative and Individual Digital Storytelling. Languages 2022, 7, 222. https://0-doi-org.brum.beds.ac.uk/10.3390/languages7030222
AMA Style
Maqueda CH. Digital Synesthesia in Heritage and Second Language Writing during Collaborative and Individual Digital Storytelling. Languages. 2022; 7(3):222. https://0-doi-org.brum.beds.ac.uk/10.3390/languages7030222
Chicago/Turabian StyleMaqueda, Cheryl H. 2022. "Digital Synesthesia in Heritage and Second Language Writing during Collaborative and Individual Digital Storytelling" Languages 7, no. 3: 222. https://0-doi-org.brum.beds.ac.uk/10.3390/languages7030222