
Predicting Emotional Valence of People Living with the Human Immunodeficiency Virus Using Daily Voice Clips: A Preliminary Study

 ,
,
Abstract
:1. Introduction
1.1. PLHIV and Depression
1.2. Depression Interventions for PLHIV
1.3. Research Objectives
- To collect PLHIV’s voice data using their mobile devices,
- To screen critical voice features using statistic methods of correlation and analysis of variance (ANOVA),
- To test AI modeling for discriminating PLHIV’s emotional valence and compare the effectiveness of the two statistical methods.
2. Material and Methods
2.1. Study Design and Setting
2.2. Participants and Sampling
2.3. Data Collection
2.4. Data Processing and Feature Screening
2.5. Modeling
3. Results
3.1. Collected Data
3.2. Critical Features Using Correlation and ANOVA
3.3. Model Performance
3.4. Decision Tree
4. Discussion
4.1. Limitations of Collected Data
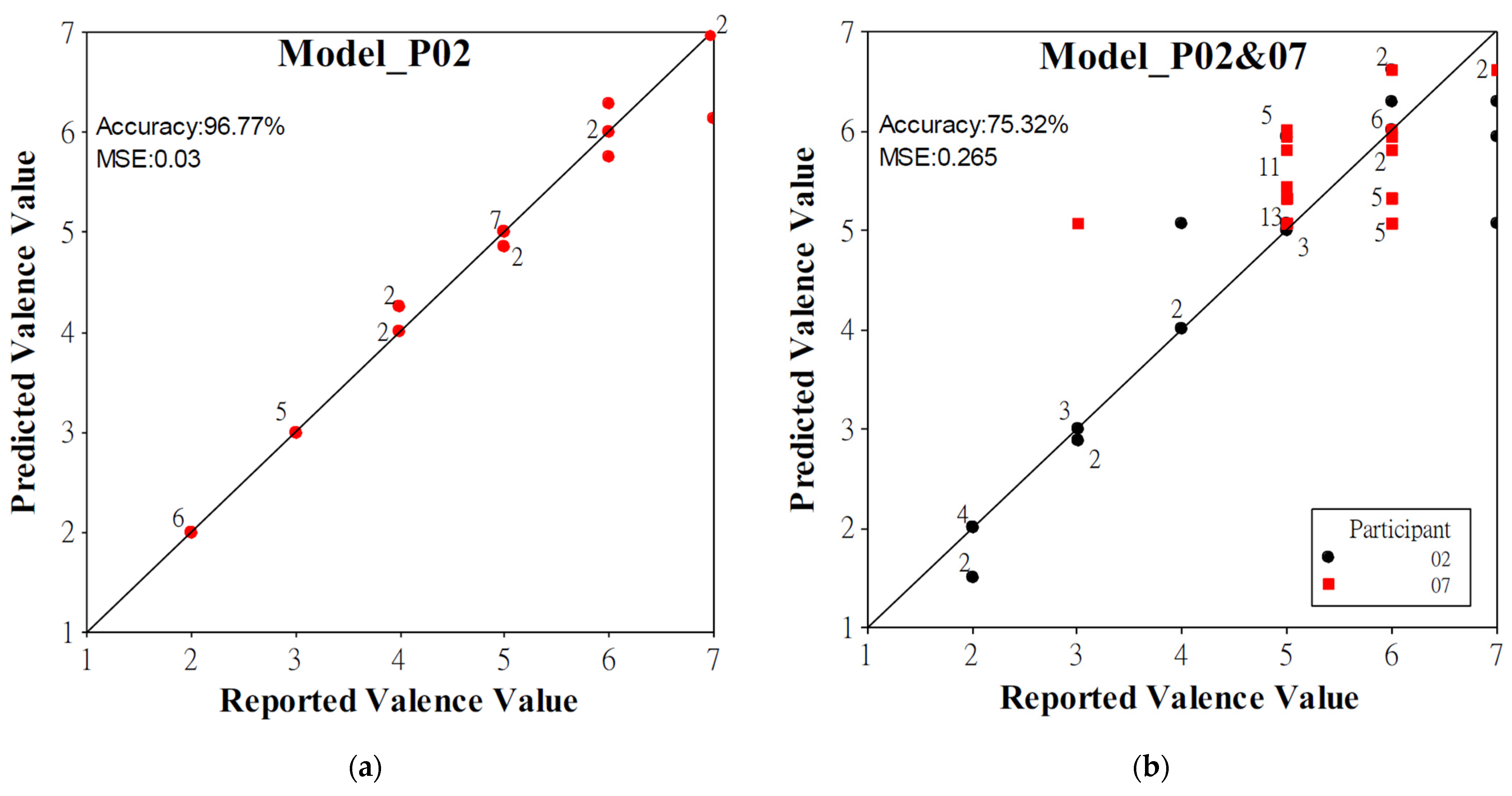
4.2. Model Performance When Using the Modeling Data of Participants 2 and 7
4.3. Comparisons of Screened Voice Features
4.4. Contribution and Future Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Ruffieux, Y.; Lemsalu, L.; Aebi-Popp, K.; Calmy, A.; Cavassini, M.; Fux, C.A.; Günthard, H.F.; Marzolini, C.; Scherrer, A.; Vernazza, P.; et al. Mortality from suicide among people living with HIV and the general Swiss population: 1988–2017. J. Int. AIDS Soc. 2019, 22, e25339. [Google Scholar] [CrossRef] [PubMed]
- Ciesla, J.A.; Roberts, J.E. Meta-analysis of the relationship between HIV infection and risk for depressive disorders. Am. J. Psychiatry 2001, 158, 725–730. [Google Scholar] [CrossRef]
- Cook, J.A.; Burke-Miller, J.K.; Steigman, P.J.; Schwartz, R.M.; Hessol, N.A.; Milam, J.; Merenstein, D.J.; Anastos, K.; Golub, E.T.; Cohen, M.H. Prevalence, comorbidity, and correlates of psychiatric and substance use disorders and associations with HIV risk behaviors in a multisite cohort of women living with HIV. AIDS Behav. 2018, 22, 3141–3154. [Google Scholar] [CrossRef]
- Grov, C.; Golub, S.A.; Parsons, J.T.; Brennan, M.; Karpiak, S.E. Loneliness and HIV-related stigma explain depression among older HIV-positive adults. AIDS Care 2010, 22, 630–639. [Google Scholar] [CrossRef] [PubMed]
- Zeng, C.; Li, L.; Hong, Y.A.; Zhang, H.; Babbitt, A.W.; Liu, C.; Li, L.; Qiao, J.; Guo, Y.; Cai, W. A structural equation model of perceived and internalized stigma, depression, and suicidal status among people living with HIV/AIDS. BMC Public Health 2018, 18, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Rubin, L.H.; Maki, P.M. HIV, depression, and cognitive impairment in the era of effective antiretroviral therapy. Curr. HIV/AIDS Rep. 2019, 16, 82–95. [Google Scholar] [CrossRef] [PubMed]
- Arseniou, S.; Arvaniti, A.; Samakouri, M. HIV infection and depression. Psychiatry Clin. Neurosci. 2014, 68, 96–109. [Google Scholar] [CrossRef]
- Wang, T.; Fu, H.; Kaminga, A.C.; Li, Z.; Guo, G.; Chen, L.; Li, Q. Prevalence of depression or depressive symptoms among people living with HIV/AIDS in China: A systematic review and meta-analysis. BMC Psychiatry 2018, 18, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Padilla, M.; Frazier, E.L.; Carree, T.; Shouse, R.L.; Fagan, J. Mental health, substance use and HIV risk behaviors among HIV-positive adults who experienced homelessness in the United States–Medical Monitoring Project, 2009–2015. AIDS Care 2020, 32, 594–599. [Google Scholar] [CrossRef]
- Miller, T.R.; Halkitis, P.N.; Durvasula, R. A biopsychosocial approach to managing HIV-related pain and associated substance abuse in older adults: A review. Ageing Int. 2019, 44, 74–116. [Google Scholar] [CrossRef]
- Treisman, G.; Angelino, A. Interrelation between psychiatric disorders and the prevention and treatment of HIV infection. Clin. Infect. Dis. 2007, 45, S313–S317. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yousuf, A.; Arifin, S.R.M.; Musa, M.L.M.R. Depression and HIV disease progression: A mini-review. Clin. Pract. Epidemiol. Ment. Health CP EMH 2019, 15, 153. [Google Scholar] [CrossRef] [PubMed]
- Wojna, V.; Nath, A. Challenges to the diagnosis and management of HIV dementia. AIDS Read. 2006, 16, 615–616, 621. [Google Scholar]
- Babiloni, C.; Vecchio, F.; Buffo, P.; Onorati, P.; Muratori, C.; Ferracuti, S.; Roma, P.; Battuello, M.; Donato, N.; Pellegrini, P.; et al. Cortical sources of resting-state EEG rhythms are abnormal in naïve HIV subjects. Clin. Neurophysiol. 2012, 123, 2163–2171. [Google Scholar] [CrossRef] [PubMed]
- Cook, J.A.; Grey, D.; Burke, J.; Cohen, M.H.; Gurtman, A.C.; Richardson, J.L.; Wilson, T.E.; Young, M.A.; Hessol, N.A. Depressive symptoms and AIDS-related mortality among a multisite cohort of HIV-positive women. Am. J. Public Health 2004, 94, 1133–1140. [Google Scholar] [CrossRef]
- Keiser, O.; Spoerri, A.; Brinkhof, M.W.; Hasse, B.; Gayet-Ageron, A.; Tissot, F.; Christen, A.; Battegay, M.; Schmid, P.; Bernasconi, E.; et al. Suicide in HIV-infected individuals and the general population in Switzerland, 1988–2008. Am. J. Psychiatry 2010, 167, 143–150. [Google Scholar] [CrossRef]
- Catalan, J.; Harding, R.; Sibley, E.; Clucas, C.; Croome, N.; Sherr, L. HIV infection and mental health: Suicidal behaviour–systematic review. Psychol. Health Med. 2011, 16, 588–611. [Google Scholar] [CrossRef]
- Shim, E.-J.; Lee, S.H.; Kim, N.J.; Kim, E.S.; Bang, J.H.; Sohn, B.K.; Park, H.Y.; Son, K.-L.; Hwang, H.; Lee, K.-M.; et al. Suicide risk in persons with HIV/AIDS in South Korea: A partial test of the interpersonal theory of suicide. Int. J. Behav. Med. 2019, 26, 38–49. [Google Scholar] [CrossRef] [PubMed]
- Brown, L.A.; Majeed, I.; Mu, W.; McCann, J.; Durborow, S.; Chen, S.; Blank, M.B. Suicide risk among persons living with HIV. AIDS Care 2021, 33, 616–622. [Google Scholar] [CrossRef]
- Kumar, S.; Nilsen, W.; Pavel, M.; Srivastava, M. Mobile health: Revolutionizing healthcare through transdisciplinary research. Computer 2012, 46, 28–35. [Google Scholar] [CrossRef]
- Swendeman, D.; Ramanathan, N.; Baetscher, L.; Medich, M.; Scheffler, A.; Comulada, W.S.; Estrin, D. Smartphone self-monitoring to support self-management among people living with HIV: Perceived benefits and theory of change from a mixed-methods, randomized pilot study. J. Acquir. Immune Defic. Syndr. 2015, 69, S80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- van Luenen, S.; Garnefski, N.; Spinhoven, P.; Kraaij, V. Guided internet-based intervention for people with HIV and depressive symptoms: A randomised controlled trial in the Netherlands. Lancet HIV 2018, 5, e488–e497. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Guo, Y.; Hong, Y.A.; Zhu, M.; Zeng, C.; Qiao, J.; Xu, Z.; Zhang, H.; Zeng, Y.; Cai, W. Mechanisms and effects of a WeChat-based intervention on suicide among people living with HIV and depression: Path model analysis of a randomized controlled trial. J. Med. Internet Res. 2019, 21, e14729. [Google Scholar] [CrossRef] [Green Version]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A Database of German Emotional Speech. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Gangamohan, P.; Kadiri, S.R.; Yegnanarayana, B. Analysis of emotional speech—A review. In Toward Robotic Socially Believable Behaving Systems-Volume I; Springer: Berlin/Heidelberg, Germany, 2016; pp. 205–238. [Google Scholar]
- Williamson, J.R.; Young, D.; Nierenberg, A.A.; Niemi, J.; Helfer, B.S.; Quatieri, T.F. Tracking depression severity from audio and video based on speech articulatory coordination. Comput. Speech Lang. 2019, 55, 40–56. [Google Scholar] [CrossRef]
- Wang, S.; Ling, X.; Zhang, F.; Tong, J. Speech Emotion Recognition Based on Principal Component Analysis and Back Propagation Neural Network, Proceedings of the 2010 International Conference on Measuring Technology and Mechatronics Automation, Changsha, China, 3–14 March 2010; IEEE: New York, NY, USA, 2010; pp. 437–440. [Google Scholar]
- Shah, A.F.; Krishnan, V.V.; Sukumar, A.R.; Jayakumar, A.; Anto, P.B. Speaker Independent Automatic Emotion Recognition from Speech: A Comparison of MFCCs and Discrete Wavelet Transforms, Proceedings of the 2009 International Conference on Advances in Recent Technologies in Communication and Computing, Kottayam, India, 27–28 October 2009; IEEE: New York, NY, USA, 2009; pp. 528–531. [Google Scholar]
- Mishra, H.K.; Sekhar, C.C. Variational. In Gaussian Mixture Models for Speech Emotion Recognition. Proceedings of the 2009 Seventh International Conference on Advances in Pattern Recognition, Kolkata, India, 4–6 February 2009; IEEE: New York, NY, USA, 2009; pp. 183–186. [Google Scholar]
- Wu, C.-H.; Liang, W.-B. Emotion recognition of affective speech based on multiple classifiers using acoustic-prosodic information and semantic labels. IEEE Trans. Affect. Comput. 2010, 2, 10–21. [Google Scholar]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V.; Ellsworth, P. Emotion in the Human Face: Guidelines for Research and an Integration of Findings; Elsevier: Amsterdam, The Netherlands, 2013; Volume 11. [Google Scholar]
- Ekman, P. Basic emotions. In Handbook of Cognition and Emotion; John Wiley & Sons: Sussex, UK, 1999; Volume 98, p. 16. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.-C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335. [Google Scholar] [CrossRef]
- Liu, Z.-T.; Li, K.; Li, D.-Y.; Chen, L.-F.; Tan, G.-Z. Emotional Feature Selection of Speaker-Independent Speech Based on Correlation Analysis and Fisher, Proceedings of the 2015 34th Chinese Control Conference (CCC), Hangzhou, China, 28–30 July 2015; IEEE: New York, NY, USA, 2015; pp. 3780–3784. [Google Scholar]
- EI Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 4, 572–587. [Google Scholar] [CrossRef]
- Taiwan Centers for Disease Control. AIDS Statistics. 2021. Available online: https://www.cdc.gov.tw/En/Category/MPage/kt6yIoEGURtMQubQ3nQ7pA (accessed on 2 September 2021).
- Leung, C.; Wing, Y.; Kwong, P.; Shum, A.L.K. Validation of the Chinese-Cantonese version of the Hospital Anxiety and Depression Scale and comparison with the Hamilton Rating Scale of Depression. Acta Psychiatr. Scand. 1999, 100, 456–461. [Google Scholar] [CrossRef]
- Schuller, B.; Steidl, S.; Batliner, A. The Interspeech 2009 Emotion Challenge. In Proceedings of the Tenth Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009. [Google Scholar]
- Young, S.; Evermann, G.; Gales, M.; Hain, T.; Kershaw, D.; Liu, X.; Moore, G.; Odell, J.; Ollason, D.; Povey, D. The HTK book. Camb. Univ. Eng. Dep. 2002, 3, 12. [Google Scholar]
- Cao, W.-H.; Xu, J.-P.; Liu, Z.-T. Speaker-Independent Speech Emotion Recognition Based on Random Forest Feature SELECTION ALGOrithm, Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; IEEE: New York, NY, USA, 2017; pp. 10995–10998. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | n | % |
|---|---|---|
| Sample size | 16 | 100 |
| Age | ||
| Mean (years) | 34.53 | ― |
| SD (years) | 5.72 | ― |
| Sex | ||
| Male | 16 | 100 |
| Occupational State | ||
| Employed (stable) | 6 | 37.5 |
| Employed (unstable) | 6 | 37.5 |
| Self-employed | 1 | 6.25 |
| Unemployed | 3 | 18.75 |
| Drugs even taken | ||
| Amphetamine | 7 | 43.75 |
| Gamma-hydroxybutyrate | 3 | 18.75 |
| Rush | 2 | 12.5 |
| Took within 3 months | 7 | 43.75 |
| Never took | 9 | 56.25 |
| Period between diagnosis of HIV infection | ||
| Mean (years) | 7.87 | ― |
| SD (years) | 4.26 | ― |
| Anxiety | ||
| Definite (score 11–21) | 5 | 31.25 |
| Doubtful (score 8–10) | 3 | 18.75 |
| No (score 07) | 8 | 50 |
| Mean (score) | 7.63 | ― |
| SD (score) | 5.91 | ― |
| Depression | ||
| Definite (score 11–21) | 5 | 31.25 |
| Doubtful (score 8–10) | 4 | 25 |
| No (score 0–7) | 7 | 43.75 |
| Mean (score) | 7.69 | ― |
| SD (score) | 4.17 | ― |
| Effects | Original Descriptors (d) | Delta Regression Coefficients of Descriptors (d’) | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | SD | Skewness | Kurtosis | Max Value | Min Value | Max Position | Min Position | Range | Offset | Slope | MSE | Mean | SD | Skewness | Kurtosis | Max Value | Min Value | Max Position | Min Position | Range | Offset | Slope | MSE | ||
| RMS | ^ | ^ | |||||||||||||||||||||||
| ZCR | ^ | ^ | ^ | * | * | ||||||||||||||||||||
| F0 | |||||||||||||||||||||||||
| HNR | ^ | ||||||||||||||||||||||||
| MFCC | 1 | ^ | |||||||||||||||||||||||
| 2 | ^ | ||||||||||||||||||||||||
| 3 | * | ||||||||||||||||||||||||
| 4 | ^ | ||||||||||||||||||||||||
| 5 | * | * | |||||||||||||||||||||||
| 6 | ^ | ^ | |||||||||||||||||||||||
| 7 | |||||||||||||||||||||||||
| 8 | ^ | ||||||||||||||||||||||||
| 9 | |||||||||||||||||||||||||
| 10 | |||||||||||||||||||||||||
| 11 | * | ||||||||||||||||||||||||
| 12 | * | ||||||||||||||||||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, R.F.; Cheng, S.-H.; Liu, Y.-P.; Chen, C.-P.; Wang, Y.-J.; Chang, S.-Y. Predicting Emotional Valence of People Living with the Human Immunodeficiency Virus Using Daily Voice Clips: A Preliminary Study. Healthcare 2021, 9, 1148. https://0-doi-org.brum.beds.ac.uk/10.3390/healthcare9091148
Lin RF, Cheng S-H, Liu Y-P, Chen C-P, Wang Y-J, Chang S-Y. Predicting Emotional Valence of People Living with the Human Immunodeficiency Virus Using Daily Voice Clips: A Preliminary Study. Healthcare. 2021; 9(9):1148. https://0-doi-org.brum.beds.ac.uk/10.3390/healthcare9091148
Chicago/Turabian StyleLin, Ray F., Shu-Hsing Cheng, Yung-Ping Liu, Cheng-Pin Chen, Yi-Jyun Wang, and Shu-Ying Chang. 2021. "Predicting Emotional Valence of People Living with the Human Immunodeficiency Virus Using Daily Voice Clips: A Preliminary Study" Healthcare 9, no. 9: 1148. https://0-doi-org.brum.beds.ac.uk/10.3390/healthcare9091148