
Applying Self-Supervised Learning to Medicine: Review of the State of the Art and Medical Implementations



Abstract
:1. Introduction
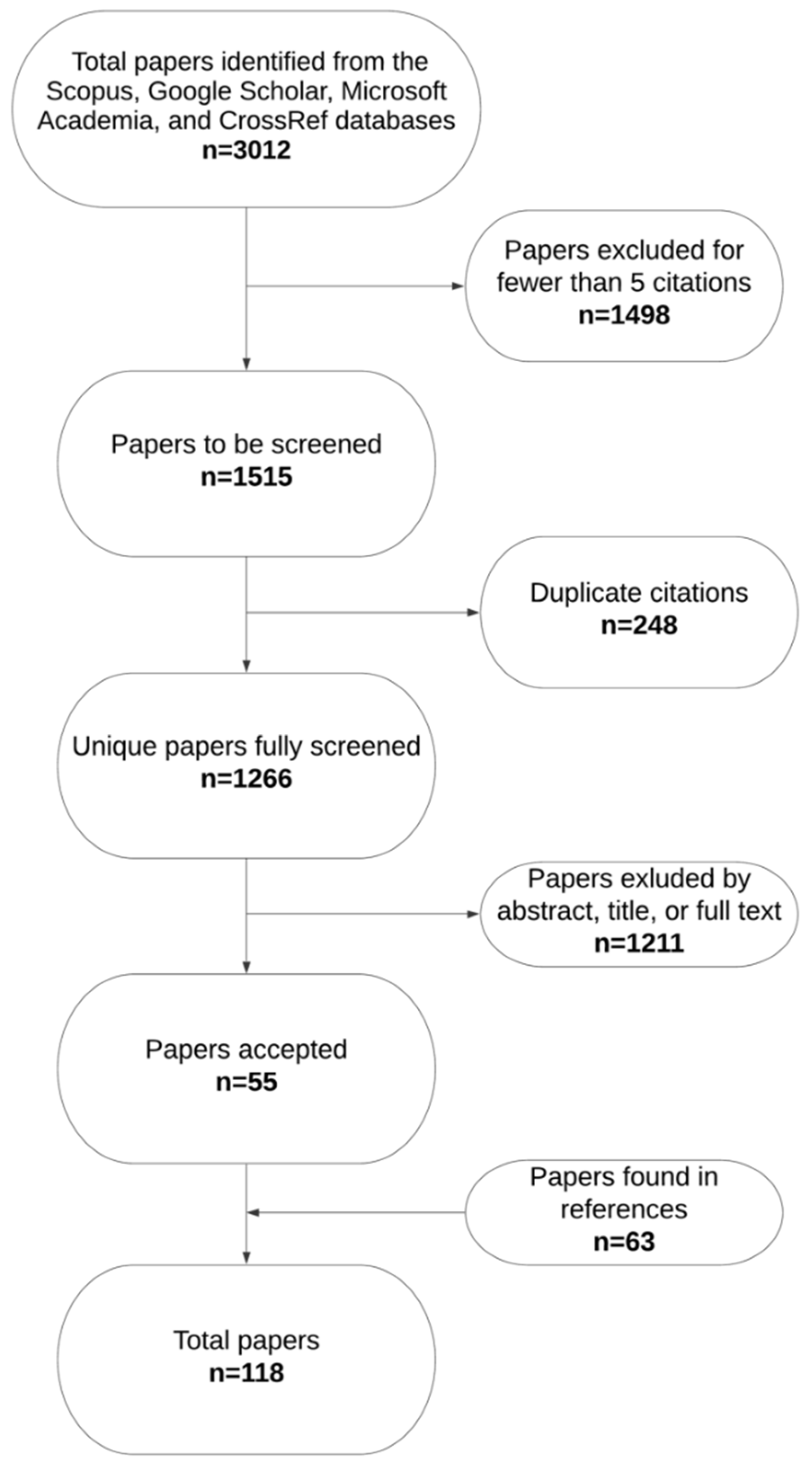
2. Materials and Methods
2.1. Study Outline
2.2. Data Acquisition
3. Review
3.1. Background: From Convolutional Neural Networks to Self-Supervised Learning
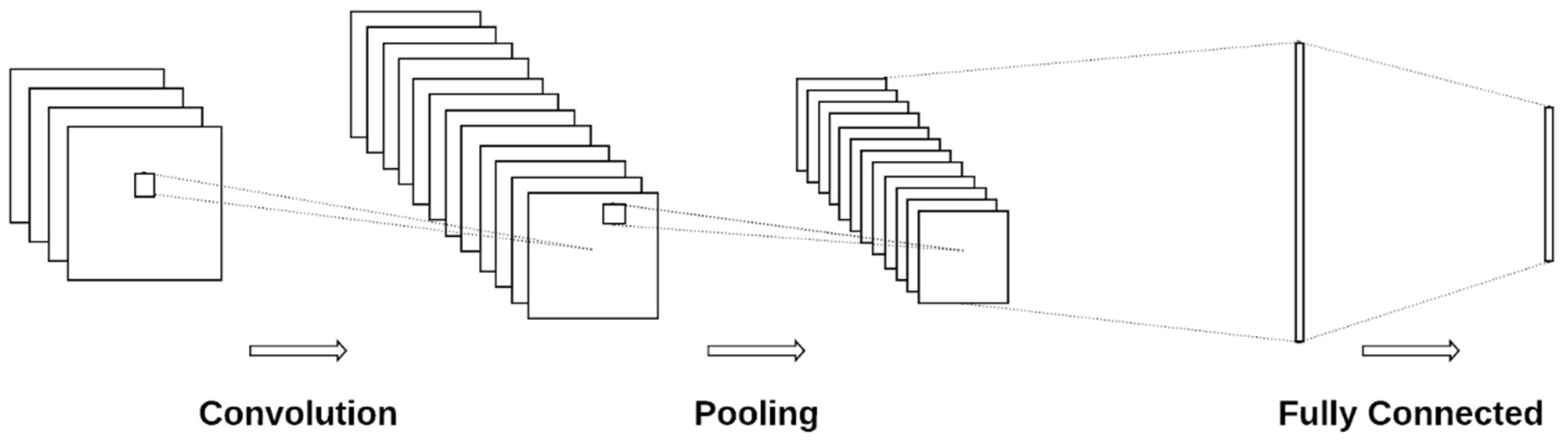
3.1.1. Convolutional Neural Networks
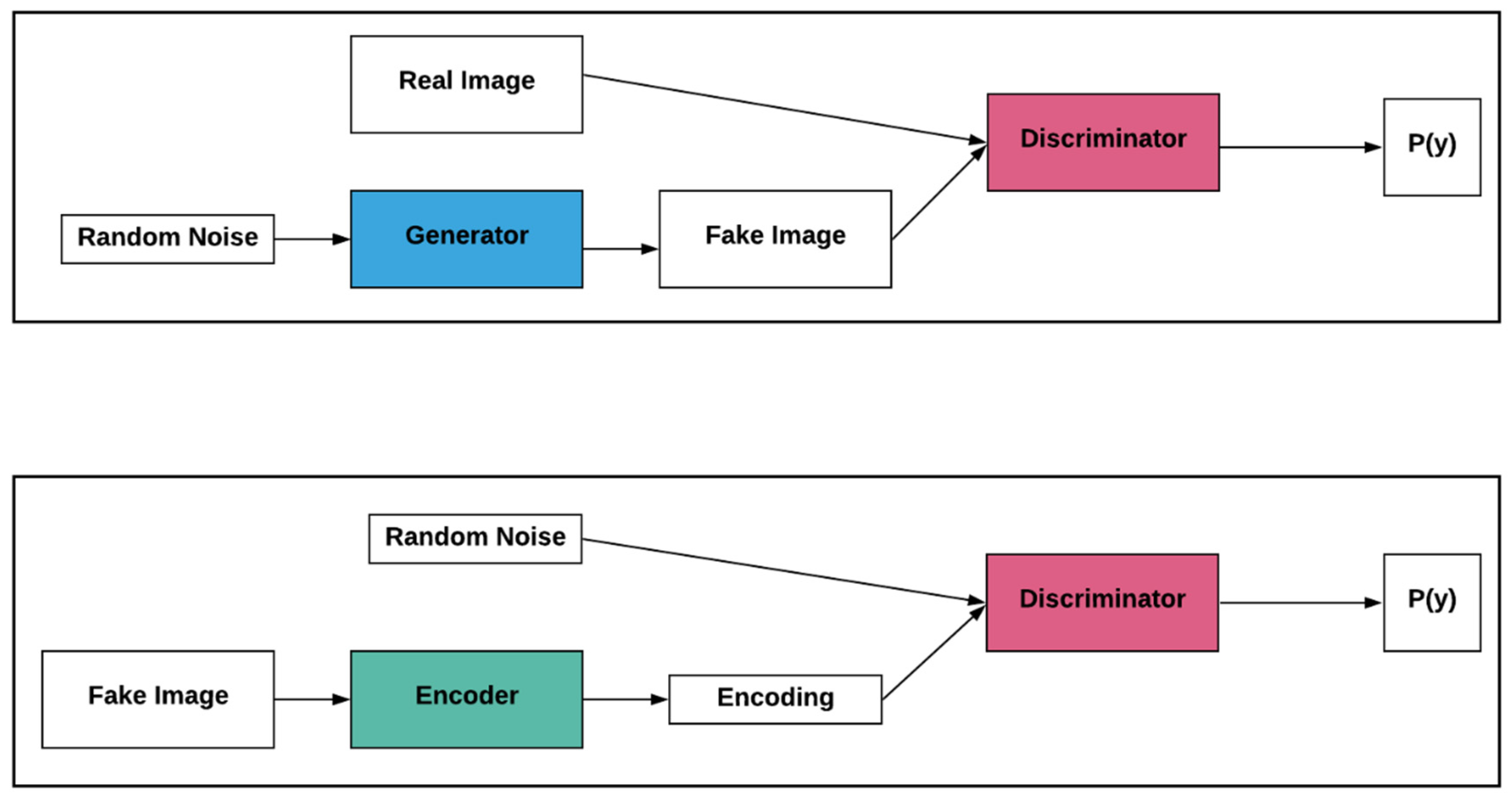
3.1.2. Generative Adversarial Networks and Adversarial Learning
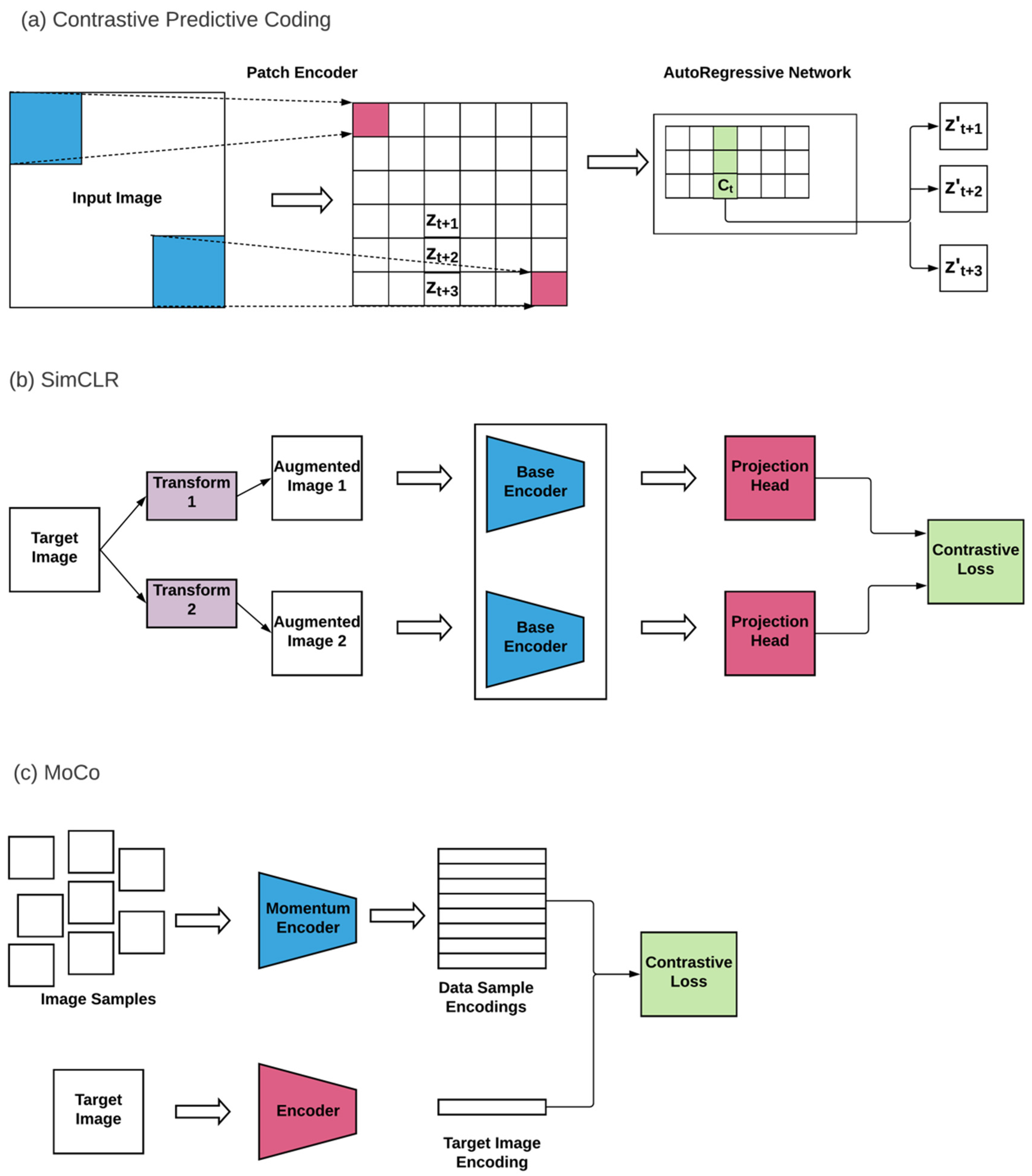
3.1.3. Contrastive Learning
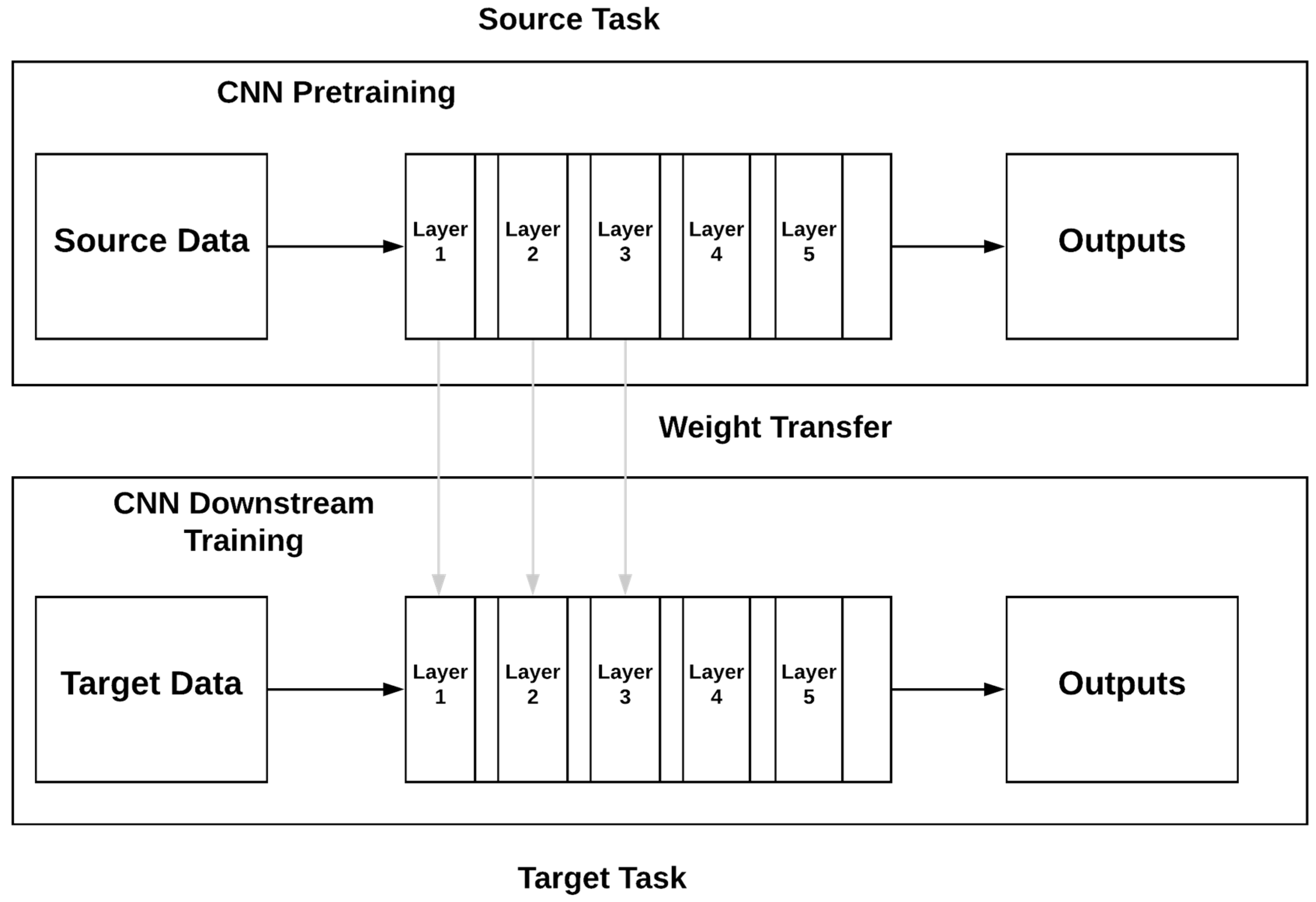
3.1.4. Transfer Learning
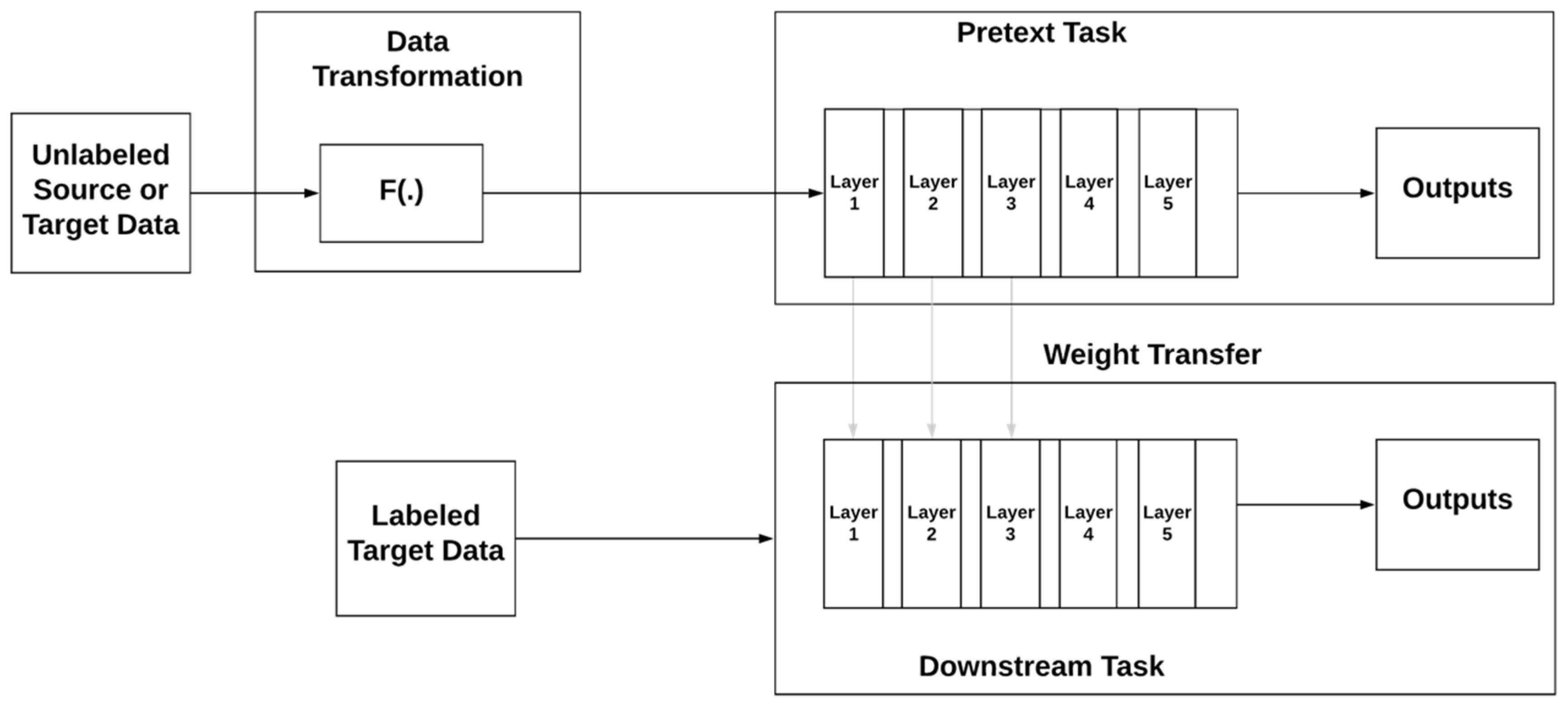
3.1.5. Self-Supervised Learning
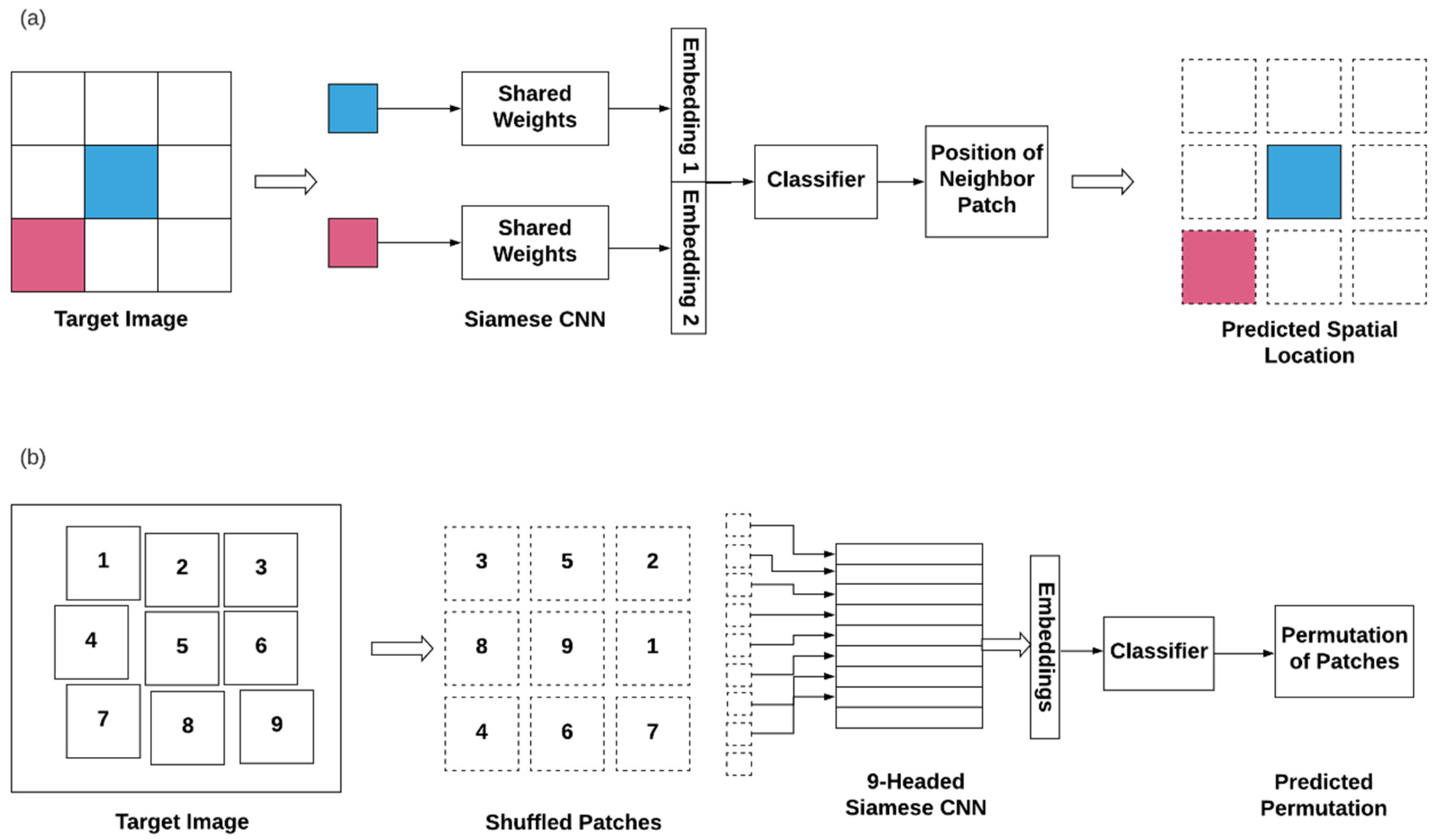
3.2. Self-Supervised Learning—Pixel to Scalar
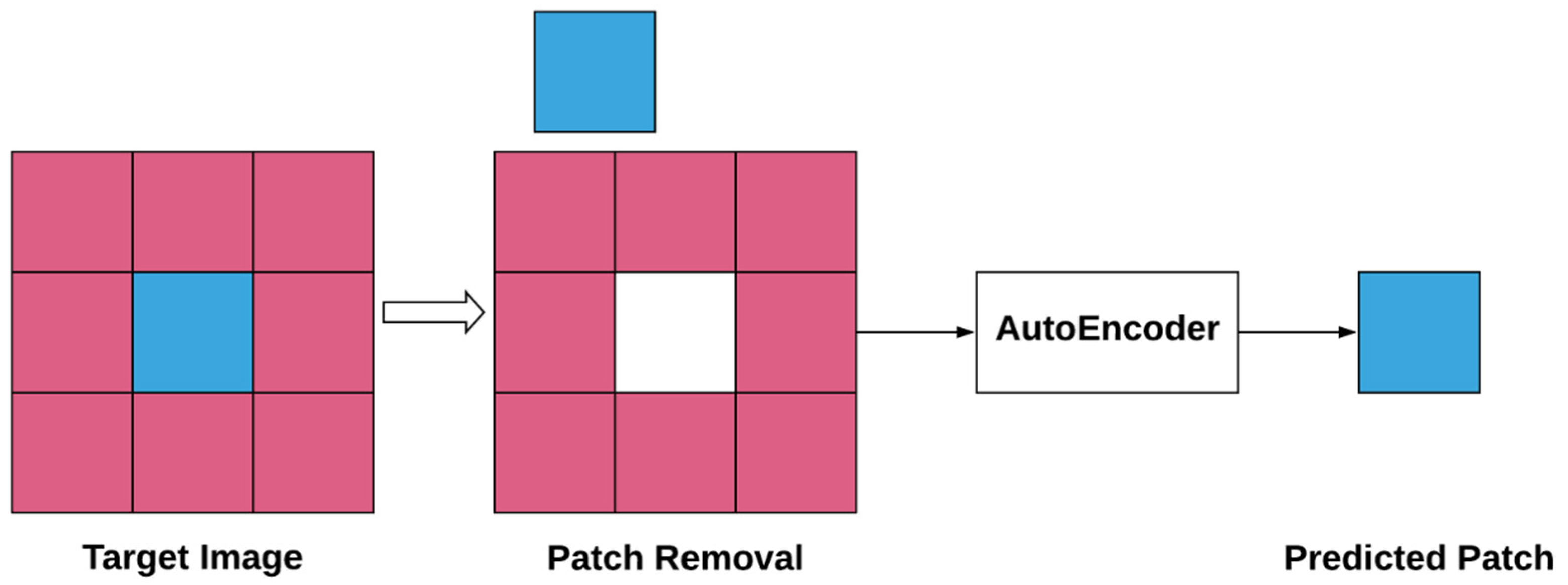
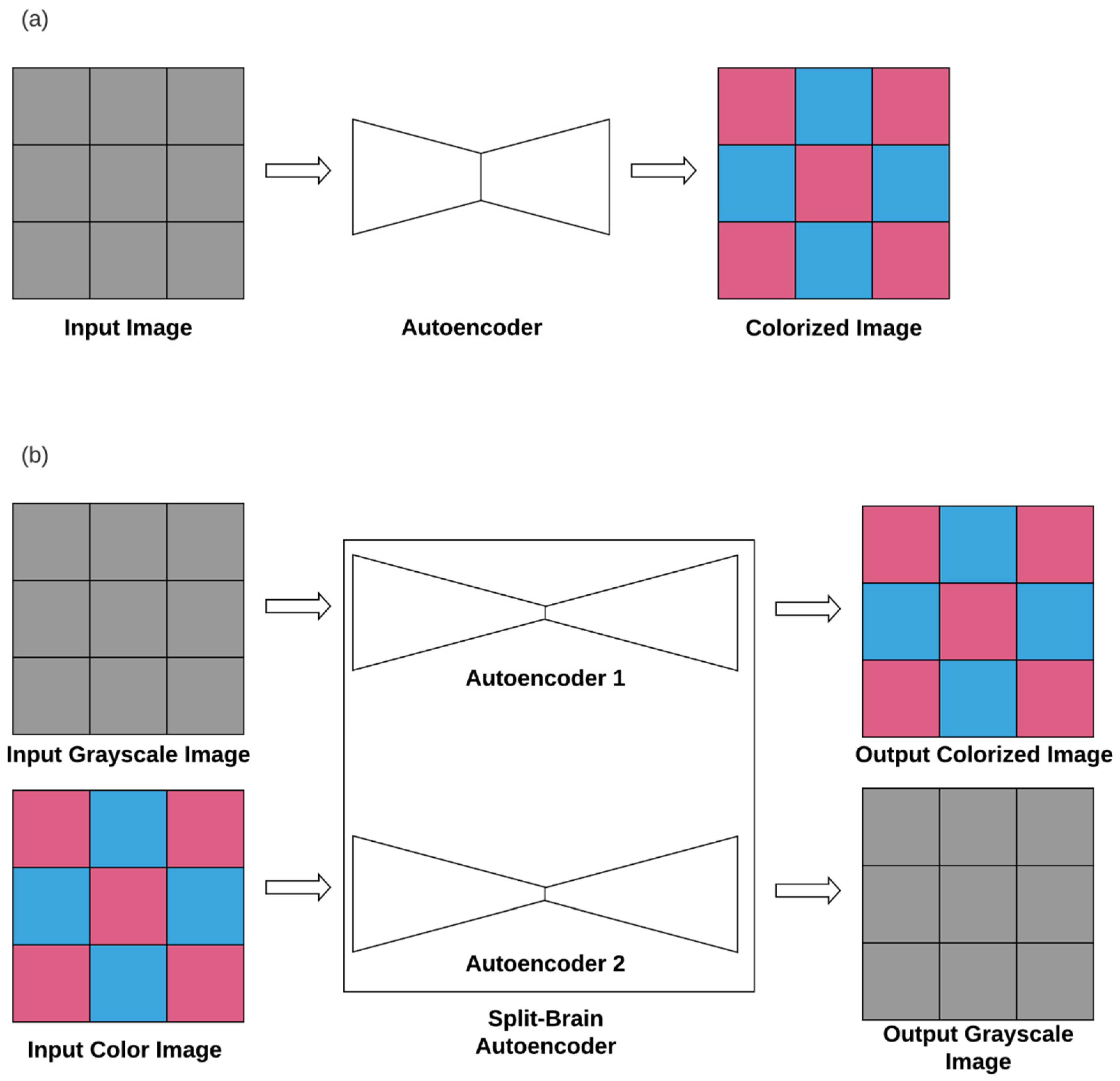
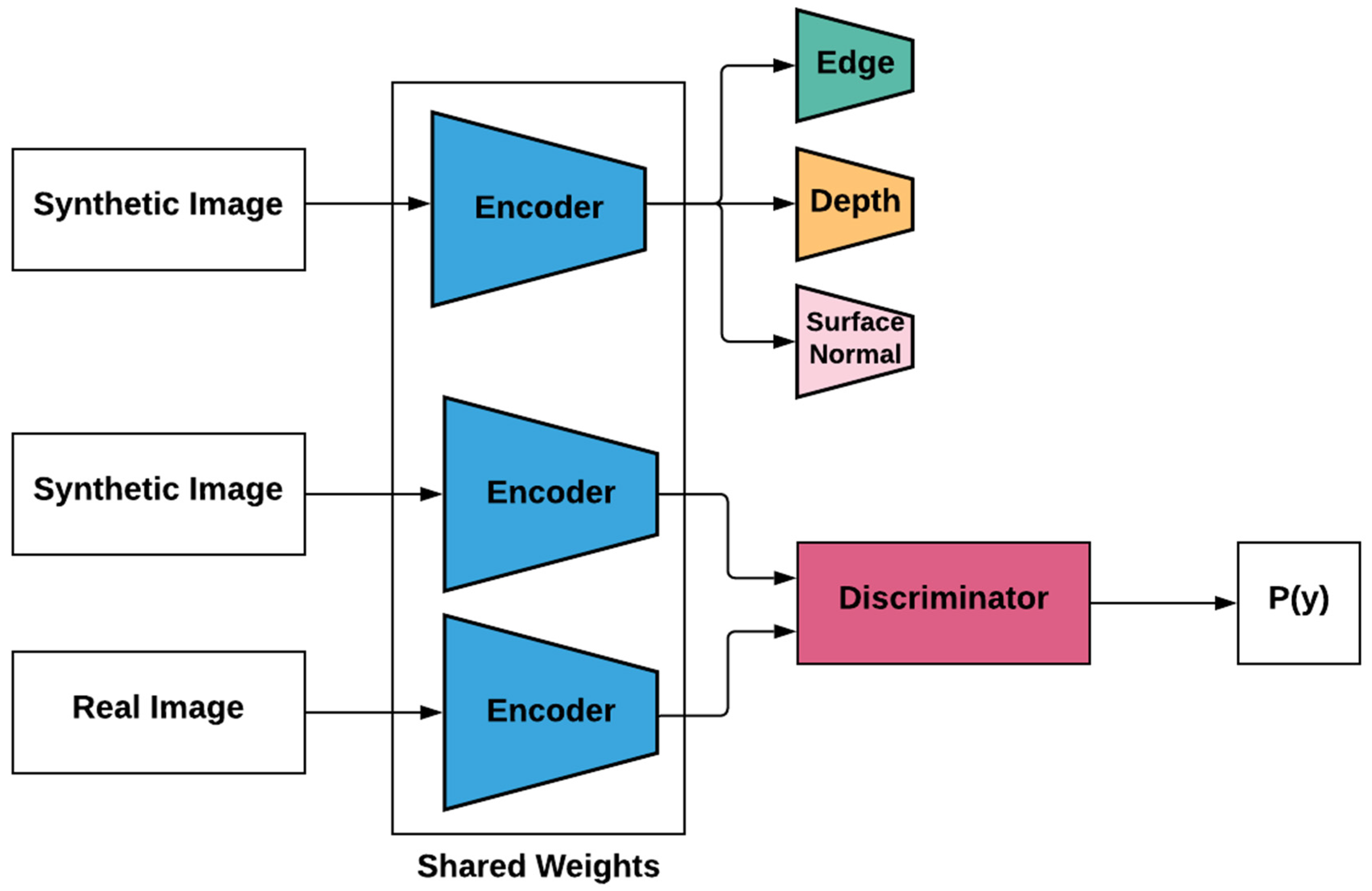
3.3. Self-Supervised Learning—Pixel to Pixel
3.4. Self-Supervised Learning—Adversarial Learning
3.5. Self-Supervised Learning—Contrastive Learning
3.6. Self-Supervised Learning in Medicine
3.6.1. Selected Applications in Medicine
3.6.2. Selected Applications in Pathology
4. Discussion
- The totality of the pretext tasks we reviewed was manually crafted by experts, required domain expertise as well as ML knowledge, and involved a large number of trials and experimentations. We think there is an opportunity to formulate this as an optimization problem, conceptually very similar to the search for an optimal architecture for a deep learning problem. Given enough examples of pretext tasks (e.g., building blocks), and provided that hardware prices continue to decrease, it could be possible to compose these building blocks autonomously. This process would consist of creating new pretext task pipelines, running them, and benchmarking these pretext pipelines either against related problems/datasets. In doing so, a researcher would gain insight into what would and would not potentially work on the new problem/dataset at hand. Optionally, a researcher could run these models directly on the new data. A small manual curation effort would be required to label a few cases from each generated dataset and apply the pretrained models to new problems (i.e., new objective functions) and new datasets.
- Again, focusing on optimizing pretext tasks, another potentially useful direction is the development of a way to balance generating and benchmarking new computationally intensive pretext tasks (as detailed above) while minimizing the total compute the cost of the entire search, or minimizing the computational cost of most successful pretext task. For example, consider the scenario where there are two pretext tasks whose benchmark differs by a single-digit performance percentage. With the difference in their performance being negligible, the pretext task that entails the least expensive computation (e.g., grayscale could be preferred over tile reconstruction) should be prioritized. This could be useful in areas where computational resources are limited (e.g., edge ML or battery-operated devices), for example, in the medical device area.
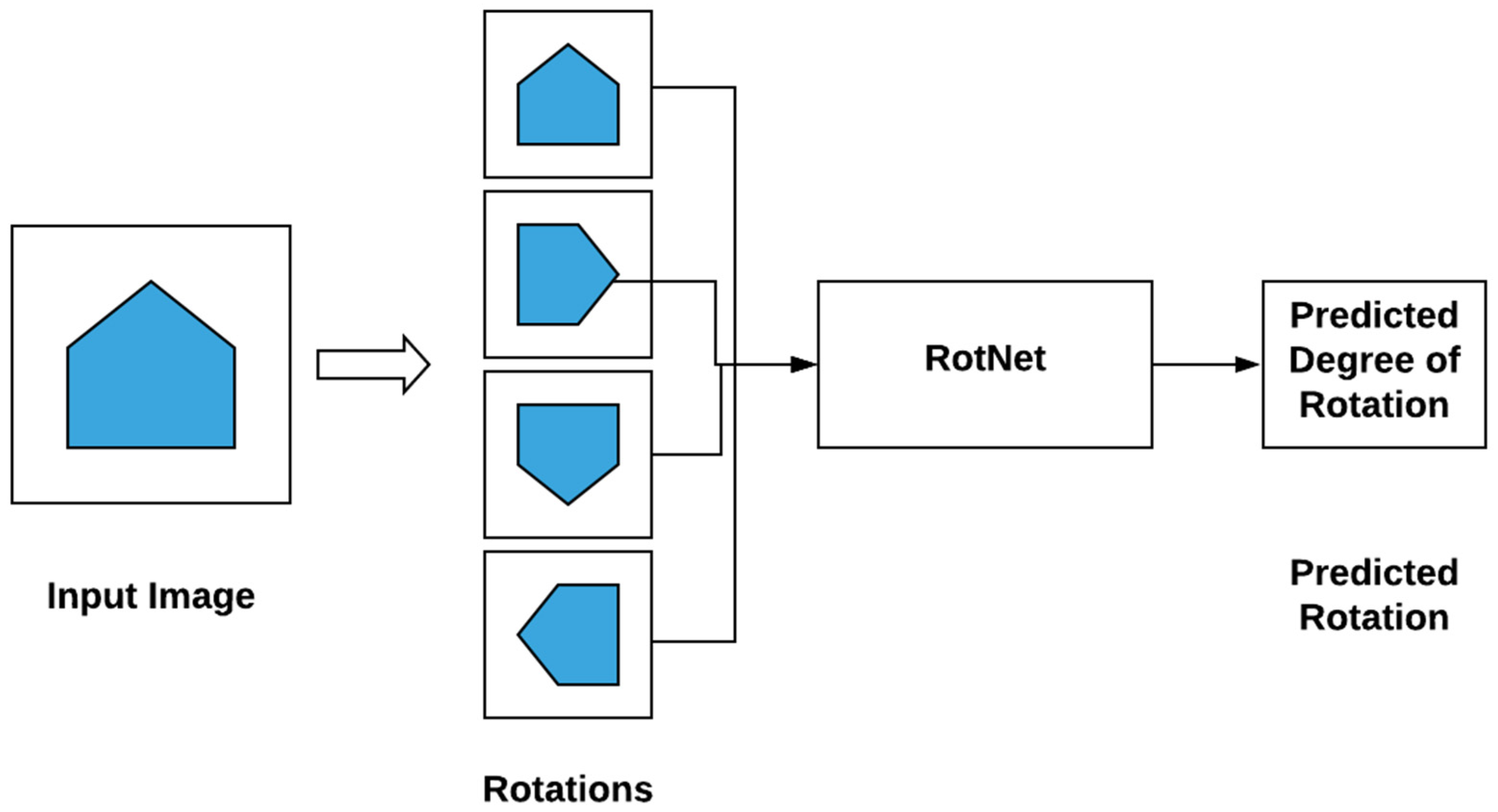
- Direct specification of inductive biases. Instead of implicitly choosing inductive biases by designing pretext tasks and augmentations, these biases could be incorporated directly into model architectures and training regimes, thus potentially improving the performance and training efficiency of SSL. For instance, a random rotation data augmentation step could be replaced by a rotation-invariant network architecture such as RotNet [38] to enforce the rotational symmetry directly. This approach has previously been applied to the histopathology domain, in which images are known to be rotation invariant [119] This may also serve to mitigate a potential pitfall of SSL, where chosen pretext tasks or augmentations may implicitly introduce unwanted inductive biases. Further work in this direction is needed to design model architectures that respect more complex invariances in features such as color jittering or image deformation.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- LeCun, Y.; Haffner, P.; Bottou, L.; Bengio, Y. Object recognition with gradient-based learning. In Shape, Contour and Grouping in Computer Vision; Springer: Berlin/Heidelberg, Germany, 1999; pp. 319–345. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bau, D.; Zhou, B.; Khosla, A.; Oliva, A.; Torralba, A. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Girshick, R.; Dollár, P. Rethinking imagenet pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.; Grosse, R.; Ranganath, R.; Ng, A.Y. Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal QC, Canada, 14–18 June 2009; pp. 609–616. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; Red Hook: New York, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Yi, X.; Walia, E.; Babyn, P. Generative adversarial network in medical imaging: A review. Med. Image Anal. 2019, 58, 101552. [Google Scholar] [CrossRef] [Green Version]
- Kazeminia, S.; Baur, C.; Kuijper, A.; van Ginneken, B.; Navab, N.; Albarqouni, S.; Mukhopadhyay, A. GANs for medical image analysis. Artif. Intell. Med. 2020, 109, 101938. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature Verification Using a”Siamese” Time Delay Neural Network. In Advances in Neural Information Processing Systems; AT&T Bell Laboratories: Holmdel, NJ, USA, 1994; pp. 737–744. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 539–546. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Hénaff, O.J.; Srinivas, A.; De Fauw, J.; Razavi, A.; Doersch, C.; Eslami, S.; Oord, A.v.d. Data-efficient image recognition with contrastive predictive coding. arXiv 2019, arXiv:1905.09272. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge 2007 (VOC2007) Results. Int. J. Comput. Vis. 2007, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable are Features in Deep Neural Networks? In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS ’14), Montreal, QC, Canada, 8–13 December 2014; pp. 3320–3328. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. Decaf: A deep convolutional activation feature for generic visual recognition. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 647–655. [Google Scholar]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Gadepalli, K.; Norouzi, M.; Dahl, G.E.; Kohlberger, T.; Boyko, A.; Venugopalan, S.; Timofeev, A.; Nelson, P.Q.; Corrado, G.S. Detecting cancer metastases on gigapixel pathology images. arXiv 2017, arXiv:1703.02442. [Google Scholar]
- Tajbakhsh, N.; Hu, Y.; Cao, J.; Yan, X.; Xiao, Y.; Lu, Y.; Liang, J.; Terzopoulos, D.; Ding, X. Surrogate Supervision for Medical Image Analysis: Effective Deep Learning from Limited Quantities of Labeled Data. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 1251–1255. [Google Scholar]
- Liu, J.T.; Glaser, A.K.; Bera, K.; True, L.D.; Reder, N.P.; Eliceiri, K.W.; Madabhushi, A. Harnessing non-destructive 3D pathology. Nat. Biomed. Eng. 2021, 5, 203–218. [Google Scholar] [CrossRef]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; Van Der Maaten, L. Exploring the limits of weakly supervised pretraining. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Noroozi, M.; Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In Proceedings of European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 69–84. [Google Scholar]
- Santa Cruz, R.; Fernando, B.; Cherian, A.; Gould, S. Deeppermnet: Visual permutation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Carlucci, F.M.; D’Innocente, A.; Bucci, S.; Caputo, B.; Tommasi, T. Domain generalization by solving jigsaw puzzles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Dosovitskiy, A.; Springenberg, J.T.; Riedmiller, M.; Brox, T. Discriminative unsupervised feature learning with convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 June 2014; pp. 766–774. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised representation learning by predicting image rotations. arXiv 2018, arXiv:1803.07728. [Google Scholar]
- Zhai, X.; Oliver, A.; Kolesnikov, A.; Beyer, L. S4l: Self-supervised semi-supervised learning. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1476–1485. [Google Scholar]
- Feng, Z.; Xu, C.; Tao, D. Self-supervised representation learning by rotation feature decoupling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10364–10374. [Google Scholar]
- Gidaris, S.; Bursuc, A.; Komodakis, N.; Pérez, P.; Cord, M. Boosting few-shot visual learning with self-supervision. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 8059–8068. [Google Scholar]
- Sayed, N.; Brattoli, B.; Ommer, B. Cross and learn: Cross-modal self-supervision. In German Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 228–243. [Google Scholar]
- Agrawal, P.; Carreira, J.; Malik, J. Learning to see by moving. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 37–45. [Google Scholar]
- Zeng, A.; Yu, K.-T.; Song, S.; Suo, D.; Walker, E.; Rodriguez, A.; Xiao, J. Multi-view self-supervised deep learning for 6d pose estimation in the amazon picking challenge. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1383–1386. [Google Scholar]
- Huh, M.; Liu, A.; Owens, A.; Efros, A.A. Fighting fake news: Image splice detection via learned self-consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Liu, X.; Van De Weijer, J.; Bagdanov, A.D. Leveraging unlabeled data for crowd counting by learning to rank. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7661–7669. [Google Scholar]
- Liu, X.; Van De Weijer, J.; Bagdanov, A.D. Exploiting unlabeled data in cnns by self-supervised learning to rank. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1862–1878. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Lin, Y.; Dong, X.; Yan, Y.; Bian, W.; Yang, Y. Progressive learning for person re-identification with one example. IEEE Trans. Image Process. 2019, 28, 2872–2881. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Tzeng, E.; Darrell, T.; Efros, A.A. Unsupervised domain adaptation through self-supervision. arXiv 2019, arXiv:1909.11825. [Google Scholar]
- Ballard, D.H. Modular Learning in Neural Networks. In AAAI; University of Rochester: Rochester, NY, USA, 1987; pp. 279–284. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Learning Representations for Automatic Colorization. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 577–593. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful Image Colorization. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 649–666. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Split-brain autoencoders: Unsupervised learning by cross-channel prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1058–1067. [Google Scholar]
- Doersch, C.; Zisserman, A. Multi-task self-supervised visual learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2051–2060. [Google Scholar]
- Zou, W.; Zhu, S.; Yu, K.; Ng, A.Y. Deep Learning of Invariant Features via Simulated Fixations in Video. In Advances in Neural Information Processing Systems; Stanford University: Stanford, CA, USA, 2012; pp. 3203–3211. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Pathak, D.; Girshick, R.; Dollár, P.; Darrell, T.; Hariharan, B. Learning features by watching objects move. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2701–2710. [Google Scholar]
- Wiles, O.; Koepke, A.; Zisserman, A. Self-supervised learning of a facial attribute embedding from video. arXiv 2018, arXiv:1808.06882. [Google Scholar]
- Lai, Z.; Xie, W. Self-supervised learning for video correspondence flow. arXiv 2019, arXiv:1905.00875. [Google Scholar]
- Zhu, A.Z.; Yuan, L.; Chaney, K.; Daniilidis, K. EV-FlowNet: Self-supervised optical flow estimation for event-based cameras. arXiv 2018, arXiv:1802.06898. [Google Scholar]
- Sundermeyer, M.; Marton, Z.-C.; Durner, M.; Brucker, M.; Triebel, R. Implicit 3d orientation learning for 6d object detection from rgb images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 699–715. [Google Scholar]
- Jakab, T.; Gupta, A.; Bilen, H.; Vedaldi, A. Unsupervised learning of object landmarks through conditional image generation. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018; pp. 4016–4027. [Google Scholar]
- Ma, F.; Cavalheiro, G.V.; Karaman, S. Self-supervised sparse-to-dense: Self-supervised depth completion from lidar and monocular camera. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3288–3295. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 3828–3838. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Mordvintsev, A.; Olah, C.; Tyka, M. Inceptionism: Going Deeper into Neural Networks. Available online: https://ai.googleblog.com/2015/06/inceptionism-going-deeper-into-neural.html (accessed on 17 June 2015).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 2172–2180. [Google Scholar]
- Tian, Y.; Peng, X.; Zhao, L.; Zhang, S.; Metaxas, D.N. CR-GAN: Learning complete representations for multi-view generation. arXiv 2018, arXiv:1806.11191. [Google Scholar]
- Jenni, S.; Favaro, P. Self-supervised feature learning by learning to spot artifacts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2733–2742. [Google Scholar]
- Chen, T.; Zhai, X.; Ritter, M.; Lucic, M.; Houlsby, N. Self-supervised gans via auxiliary rotation loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12154–12163. [Google Scholar]
- McCloskey, M.; Cohen, N.J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 1989; Volume 24, pp. 109–165. [Google Scholar]
- French, R.M. Catastrophic forgetting in connectionist networks. Trends Cogn. Sci. 1999, 3, 128–135. [Google Scholar] [CrossRef]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, B.; Tenenbaum, J. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 82–90. [Google Scholar]
- Lin, D.; Fu, K.; Wang, Y.; Xu, G.; Sun, X. MARTA GANs: Unsupervised representation learning for remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2092–2096. [Google Scholar] [CrossRef] [Green Version]
- Ren, Z.; Jae Lee, Y. Cross-domain self-supervised multi-task feature learning using synthetic imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 762–771. [Google Scholar]
- Singh, S.; Batra, A.; Pang, G.; Torresani, L.; Basu, S.; Paluri, M.; Jawahar, C. Self-Supervised Feature Learning for Semantic Segmentation of Overhead Imagery. BMVC 2018, 1, 4. [Google Scholar]
- Bachman, P.; Hjelm, R.D.; Buchwalter, W. Learning representations by maximizing mutual information across views. arXiv 2019, arXiv:1906.00910. [Google Scholar]
- Wang, X.; Gupta, A. Unsupervised learning of visual representations using videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2794–2802. [Google Scholar]
- Zeng, A.; Song, S.; Nießner, M.; Fisher, M.; Xiao, J.; Funkhouser, T. 3dmatch: Learning local geometric descriptors from rgb-d reconstructions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1802–1811. [Google Scholar]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3733–3742. [Google Scholar]
- Zhuang, C.; Zhai, A.L.; Yamins, D. Local aggregation for unsupervised learning of visual embeddings. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6002–6012. [Google Scholar]
- Sharma, V.; Tapaswi, M.; Sarfraz, M.S.; Stiefelhagen, R. Self-supervised learning of face representations for video face clustering. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive multiview coding. arXiv 2019, arXiv:1906.05849. [Google Scholar]
- Trinh, T.H.; Luong, M.-T.; Le, Q.V. Selfie: Self-supervised pretraining for image embedding. arXiv 2019, arXiv:1906.02940. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Jamaludin, A.; Kadir, T.; Zisserman, A. Self-supervised learning for spinal MRIs. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2017; pp. 294–302. [Google Scholar]
- Alex, V.; Vaidhya, K.; Thirunavukkarasu, S.; Kesavadas, C.; Krishnamurthi, G. Semisupervised learning using denoising autoencoders for brain lesion detection and segmentation. J. Med. Imaging 2017, 4, 041311. [Google Scholar] [CrossRef]
- Spitzer, H.; Kiwitz, K.; Amunts, K.; Harmeling, S.; Dickscheid, T. Improving cytoarchitectonic segmentation of human brain areas with self-supervised siamese networks. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2018; pp. 663–671. [Google Scholar]
- Amunts, K.; Zilles, K. Architectonic mapping of the human brain beyond Brodmann. Neuron 2015, 88, 1086–1107. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Sinha, A.; Unberath, M.; Ishii, M.; Hager, G.D.; Taylor, R.H.; Reiter, A. Self-supervised learning for dense depth estimation in monocular endoscopy. In OR 2.0 Context-Aware Operating Theaters, Computer Assisted Robotic Endoscopy, Clinical Image-Based Procedures, and Skin Image Analysis; Springer: Berlin/Heidelberg, Germany, 2018; pp. 128–138. [Google Scholar]
- Ross, T.; Zimmerer, D.; Vemuri, A.; Isensee, F.; Wiesenfarth, M.; Bodenstedt, S.; Both, F.; Kessler, P.; Wagner, M.; Müller, B. Exploiting the potential of unlabeled endoscopic video data with self-supervised learning. Int. J. Comput. Assist. Radiol. Surg. 2018, 13, 925–933. [Google Scholar] [CrossRef] [Green Version]
- Leonard, S.; Sinha, A.; Reiter, A.; Ishii, M.; Gallia, G.L.; Taylor, R.H.; Hager, G.D. Evaluation and stability analysis of video-based navigation system for functional endoscopic sinus surgery onin vivoclinical data. IEEE Trans. Med. Imaging 2018, 37, 2185–2195. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Qin, C.; Bai, W.; Schlemper, J.; Petersen, S.E.; Piechnik, S.K.; Neubauer, S.; Rueckert, D. Joint learning of motion estimation and segmentation for cardiac MR image sequences. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Cheng, J.; Tsai, Y.-H.; Wang, S.; Yang, M.-H. Segflow: Joint learning for video object segmentation and optical flow. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 686–695. [Google Scholar]
- Tsai, Y.-H.; Yang, M.-H.; Black, M.J. Video segmentation via object flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3899–3908. [Google Scholar]
- Bai, W.; Chen, C.; Tarroni, G.; Duan, J.; Guitton, F.; Petersen, S.E.; Guo, Y.; Matthews, P.M.; Rueckert, D. Self-supervised learning for cardiac mr image segmentation by anatomical position prediction. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2019; pp. 541–549. [Google Scholar]
- Zhou, Z.; Sodha, V.; Siddiquee, M.M.R.; Feng, R.; Tajbakhsh, N.; Gotway, M.B.; Liang, J. Models genesis: Generic autodidactic models for 3d medical image analysis. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Colorization as a proxy task for visual understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6874–6883. [Google Scholar]
- Rawat, R.R.; Ortega, I.; Roy, P.; Sha, F.; Shibata, D.; Ruderman, D.; Agus, D.B. Deep learned tissue “fingerprints” classify breast cancers by ER/PR/Her2 status from H&E images. Sci. Rep. 2020, 10, 1–13. [Google Scholar]
- Hayakawa, T.; Prasath, V.S.; Kawanaka, H.; Aronow, B.J.; Tsuruoka, S. Computational Nuclei Segmentation Methods in Digital Pathology: A Survey. Arch. Comput. Methods Eng. 2019, 28, 1–13. [Google Scholar] [CrossRef]
- Gildenblat, J.; Klaiman, E. Self-supervised similarity learning for digital pathology. arXiv 2019, arXiv:1905.08139. [Google Scholar]
- Lu, A.X.; Kraus, O.Z.; Cooper, S.; Moses, A.M. Learning unsupervised feature representations for single cell microscopy images with paired cell inpainting. PLoS Comput. Biol. 2019, 15, e1007348. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Wang, Y.; Wang, G.; Liu, J. Fast and robust segmentation of white blood cell images by self-supervised learning. Micron 2018, 107, 55–71. [Google Scholar] [CrossRef]
- Yamamoto, Y.; Tsuzuki, T.; Akatsuka, J.; Ueki, M.; Morikawa, H.; Numata, Y.; Takahara, T.; Tsuyuki, T.; Tsutsumi, K.; Nakazawa, R. Automated acquisition of explainable knowledge from unannotated histopathology images. Nat. Commun. 2019, 10, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Tellez, D.; Litjens, G.; van der Laak, J.; Ciompi, F. Neural image compression for gigapixel histopathology image analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 567–578. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, B.; Tang, Y.; Eric, I.; Chang, C.; Fan, Y.; Lai, M.; Xu, Y. Unsupervised learning for cell-level visual representation in histopathology images with generative adversarial networks. IEEE J. Biomed. Health Inform. 2018, 23, 1316–1328. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Lu, M.Y.; Chen, R.J.; Wang, J.; Dillon, D.; Mahmood, F. Semi-supervised histology classification using deep multiple instance learning and contrastive predictive coding. arXiv 2019, arXiv:1910.10825. [Google Scholar]
- Veeling, B.S.; Linmans, J.; Winkens, J.; Cohen, T.; Welling, M. Rotation equivariant cnns for digital pathology. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2018; pp. 210–218. [Google Scholar]
- Zhai, X.; Puigcerver, J.; Kolesnikov, A.; Ruyssen, P.; Riquelme, C.; Lucic, M.; Djolonga, J.; Pinto, A.S.; Neumann, M.; Dosovitskiy, A. A large-scale study of representation learning with the visual task adaptation benchmark. arXiv 2019, arXiv:1910.04867. [Google Scholar]
- Goyal, P.; Mahajan, D.; Gupta, A.; Misra, I. Scaling and benchmarking self-supervised visual representation learning. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6391–6400. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Classification (mAP) | Detection (mAP) | Segmentation (mIoU) |
|---|---|---|---|
| Pretrained ImageNet | 79.9 | 59.1 | 48.0 |
| Context Prediction | 65.3 | 51.1 | - |
| Jigsaw Puzzle | 67.6 | 53.2 | 37.6 |
| Visual Permutation Net | 69.4 | 49.5 | 37.9 |
| RotNet | 73.0 | 54.4 | 39.1 |
| Semi-Supervised Rotnet | 74.3 | 57.5 | 45.3 |
| Algorithm | Classification (mAP) | Detection (mAP) | Segmentation (mIoU) |
|---|---|---|---|
| ImageNet Pretrained (Baseline) | 79.9 | 59.1 | 48.0 |
| Context Encoder | 56.5 | 44.5 | 29.7 |
| Image Colorization | 65.6 | 46.9 | 35.6 |
| GAN Colorization | 65.9 | - | 38.4 |
| Split-Brain AutoEncoders | 67.1 | 46.7 | 36.0 |
| Algorithm | Classification (mAP) | Detection_07 (mAP) | Detection_12 (mAP) |
|---|---|---|---|
| ImageNet Pretrained (Baseline) | 79.9 | 56.8 | 56.5 |
| Adversarial Feature Learning | 58.6 | 46.2 | 44.9 |
| Cross-Domain SSL | 68.0 | 52.6 | 50.0 |
| Author | Algorithm | Accuracy |
|---|---|---|
| Zhuang et al. [87] | Local Aggregation | 60.2 |
| He et al. [11] | MoCo | 60.6 |
| Hénaff et al. [20] | CPC | 63.8 |
| Chen et al. [31] | SimCLR | 69.3 |
| He et al. [32] | MoCo2 | 71.1 |
| Paper | Task | Metric | Supervised Training | Self-Supervised Training |
|---|---|---|---|---|
| Gildenblat et al. [111] | Separation of Tiles | ADDR | 1.38 | 1.5 |
| Tumor Tile Retrieval | Ratio of Retrieved Tumor Tiles | 26% | 34% | |
| Hu et al. [116] | Image-Level Classification | Precision | 0.910 | 0.952 |
| Recall | 0.959 | 0.963 | ||
| F-Score | 0.931 | 0.947 | ||
| Lu et al. [118] | H&E Classification | Accuracy | 86.0 ± 4.64 | 95.0 ± 2.65 |
| AUC | 0.939 ± 0.240 | 0.968 ± 0.022 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chowdhury, A.; Rosenthal, J.; Waring, J.; Umeton, R. Applying Self-Supervised Learning to Medicine: Review of the State of the Art and Medical Implementations. Informatics 2021, 8, 59. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8030059
Chowdhury A, Rosenthal J, Waring J, Umeton R. Applying Self-Supervised Learning to Medicine: Review of the State of the Art and Medical Implementations. Informatics. 2021; 8(3):59. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8030059
Chicago/Turabian StyleChowdhury, Alexander, Jacob Rosenthal, Jonathan Waring, and Renato Umeton. 2021. "Applying Self-Supervised Learning to Medicine: Review of the State of the Art and Medical Implementations" Informatics 8, no. 3: 59. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8030059