
Fault Detection of Bearing: An Unsupervised Machine Learning Approach Exploiting Feature Extraction and Dimensionality Reduction



Abstract
:1. Introduction
2. Materials and Methods
2.1. Background
2.1.1. Feature Extraction
- (i)
- Time domain: mean, standard deviation, rms (root mean square), peak value, peak-to-peak value, shape indicator, skewness, kurtosis, crest factor, clearance indicator, etc.
- (ii)
- Frequency domain: mean frequency, central frequency, energy in frequency bands, etc.
- (iii)
- Time-frequency domain: entropy are usually extracted by Wavelet Transform, Wavelet Packet Transform, and empirical model decomposition.
2.1.2. Dimensionality Reduction
2.1.3. Anomaly Detection (AD) and Isolation Forest (IF)
2.2. Methodology
2.2.1. Data Acquisition and Feature Extraction
2.2.2. Dimensionality Reduction, Fault Detection, and Feature Trend Analysis
2.3. Experimental Procedure
2.3.1. Tests and Analysis Approaches
2.3.2. Hyperparameter Tuning and Evaluation Metrics
3. Results and Discussion
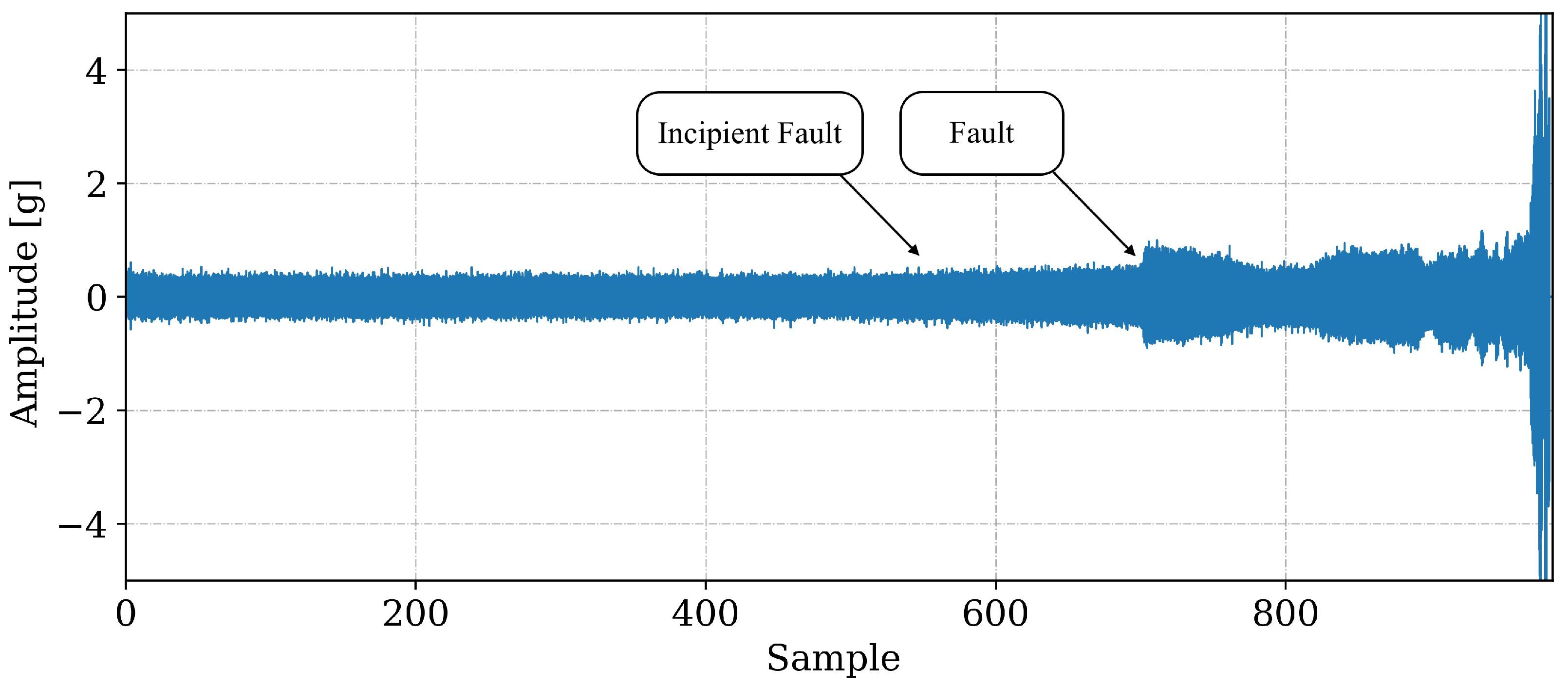
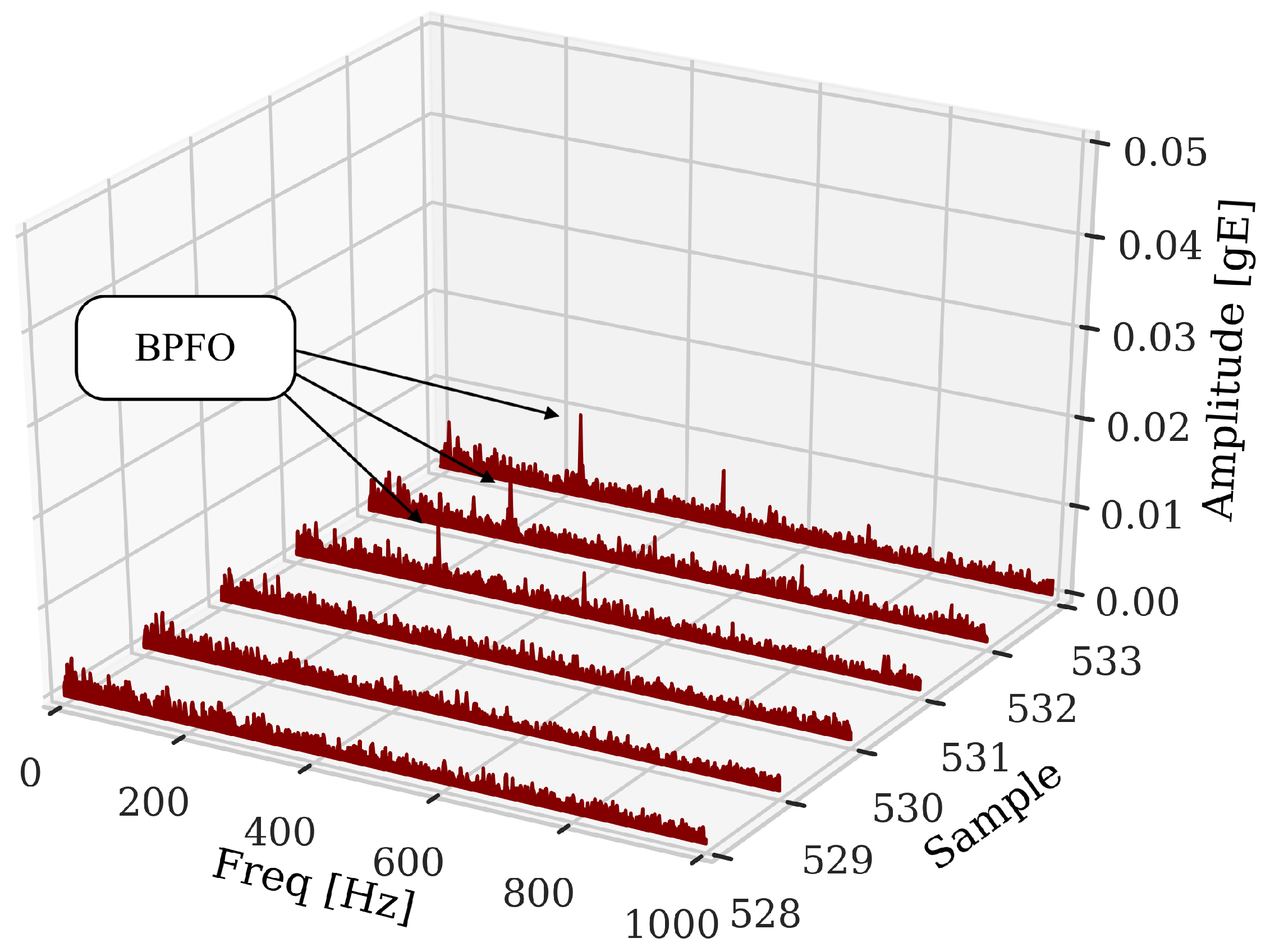
3.1. Data Exploration
3.2. Fault Detection: Anomaly Detection
3.3. Trend Analysis: Extracted Features
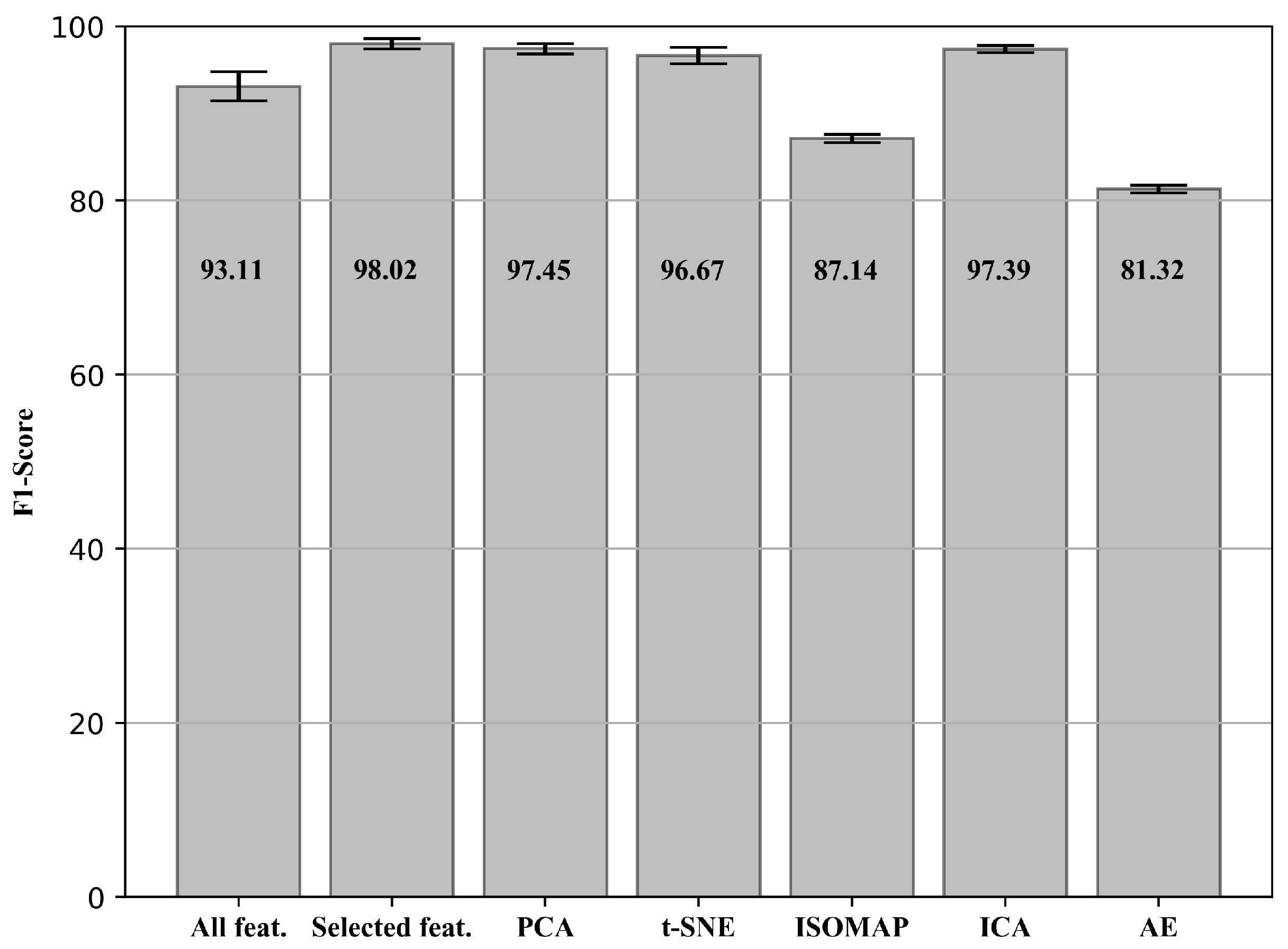
3.4. Trend Analysis: Extracted Features with Reduced Dimension
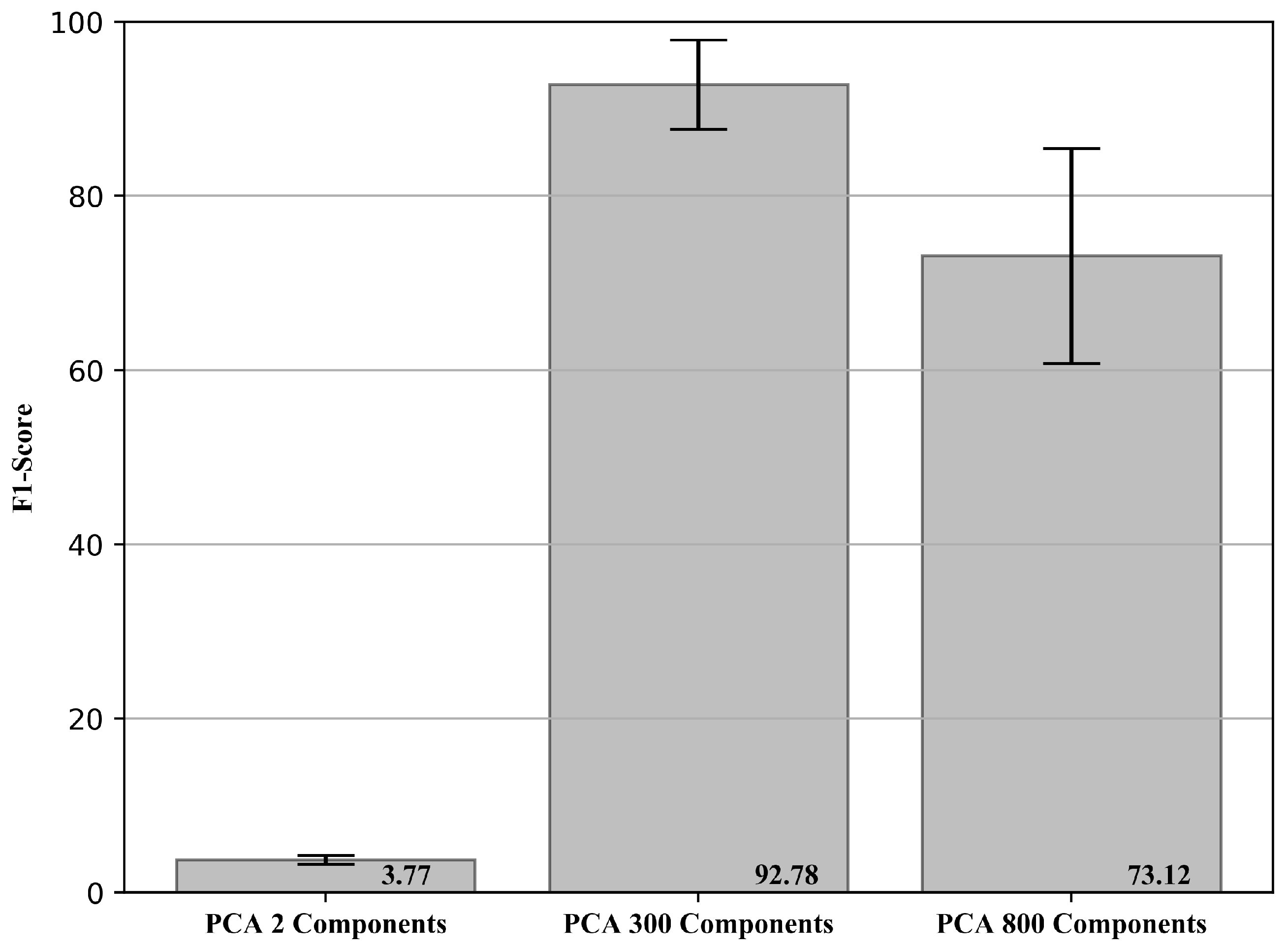
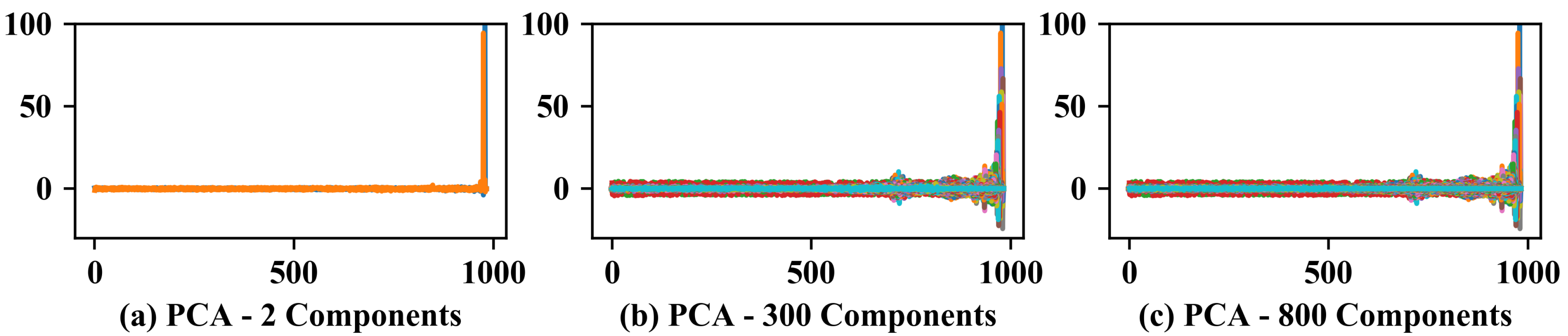
3.5. Dimensionality Reduction in the Raw Signal
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lei, Y.; Lin, J.; He, Z.; Zuo, M.J. A review on empirical mode decomposition in fault diagnosis of rotating machinery. Mech. Syst. Signal Process 2013, 35, 108–126. [Google Scholar] [CrossRef]
- Bousdekis, A.; Magoutas, B.; Apostolou, D.; Mentzas, G. Review, analysis and synthesis of prognostic-based decision support methods for condition based maintenance. J. Intell. Manufact. 2018, 29, 1303–1316. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Stetco, A.; Dinmohammadi, F.; Zhao, X.; Robu, V.; Flynn, D.; Barnes, M.; Keane, J.; Nenadic, G. Machine learning methods for wind turbine condition monitoring: A review. Renew. Energy 2019, 133, 620–635. [Google Scholar] [CrossRef]
- Zocco, F.; Maggipinto, M.; Susto, G.A.; McLoone, S. Greedy Search Algorithms for Unsupervised Variable Selection: A Comparative Study. 2021. Available online: http://xxx.lanl.gov/abs/2103.02687 (accessed on 21 October 2021).
- Ciabattoni, L.; Ferracuti, F.; Freddi, A.; Monteriù, A. Statistical Spectral Analysis for Fault Diagnosis of Rotating Machines. IEEE Trans. Ind. Electron. 2018, 65, 4301–4310. [Google Scholar] [CrossRef]
- Wei, Y.; Li, Y.; Xu, M.; Huang, W. A Review of Early Fault Diagnosis Approaches and Their Applications in Rotating Machinery. Entropy 2019, 21, 409. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brito, L.C.; Susto, G.A.; Brito, J.N.; Duarte, M.A.V. An Explainable Artificial Intelligence Approach for Unsupervised Fault Detection and Diagnosis in Rotating Machinery. Mech. Syst. Signal Process 2022, 163, 108105. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis; Springer: New York, NY, USA, 1986. [Google Scholar]
- Strange, H.; Zwiggelaar, R. Open Problems in Spectral Dimensionality Reduction; Springer Briefs in Computer Science; Springer: Berlin, Germany, 2014. [Google Scholar]
- Tenenbaum, J.; de Silva, V.; Langford, J. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2322. [Google Scholar] [CrossRef]
- VanDerMaaten, L.; Hinton, G. Visualizing Data Using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Jutten, C.; Hérault, J. Blind separation of sources, part I: An adaptive algorithm based on neuromimetic architecture. Signal Process. 1991, 24, 1–10. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA,, 2016; Available online: http://www.deeplearningbook.org (accessed on 21 October 2021).
- Zhao, Y.; Nasrullah, Z.; Li, Z. PyOD: A Python Toolbox for Scalable Outlier Detection. J. Mach. Learn. Res. 2019, 20, 1–7. [Google Scholar]
- Hawkins, D. Identification of Outliers; Chapman and Hall: New York, NY, USA, 1980. [Google Scholar]
- Barbariol, T.; Feltresi, E.; Susto, G.A. Self-Diagnosis of Multiphase Flow Meters through Machine Learning-Based Anomaly Detection. Energies 2020, 13, 3136. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 5–19 December 2008; pp. 413–422. [Google Scholar]
- Bolón Canedo, V.; Sánchez Maroño, N.; Alonso Betanzos, A. A review of feature selection methods on synthetic data. Knowl. Inf. Syst. 2013, 34, 483–519. [Google Scholar] [CrossRef]
- Zhang, K.; Li, Y.; Scarf, P.; Ball, A. Feature selection for high-dimensional machinery fault diagnosis data using multiple models and Radial Basis Function networks. Neurocomputing 2011, 74, 2941–2952. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Q.; Chen, M.; Sun, Y.; Qin, X.; Li, H. A two-stage feature selection and intelligent fault diagnosis method for rotating machinery using hybrid filter and wrapper method. Neurocomputing 2018, 275, 2426–2439. [Google Scholar] [CrossRef]
- Lei, Y.; Zuo, M.J. Gear crack level identification based on weighted K nearest neighbor classification algorithm. Mech. Syst. Signal Process. 2009, 23, 1535–1547. [Google Scholar] [CrossRef]
- Li, Y.; Yang, Y.; Li, G.; Xu, M.; Huang, W. A fault diagnosis scheme for planetary gearboxes using modified multi-scale symbolic dynamic entropy and mRMR feature selection. Mech. Syst. Signal Process. 2017, 91, 295–312. [Google Scholar] [CrossRef]
- Singh, M.; Shaik, A.G. Faulty bearing detection, classification and location in a three-phase induction motor based on Stockwell transform and support vector machine. Measurement 2019, 131, 524–533. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]
- Diallo, M.; Mokeddem, S.; Braud, A.; Frey, G.; Lachiche, N. Identifying Benchmarks for Failure Prediction in Industry 4.0. Informatics 2021, 8, 68. [Google Scholar] [CrossRef]
- Lee, J.; Qiu, H.; Yu, G.; Lin, J. Bearing Dataset. IMS; University of Cincinnati, NASA Ames Prognostics Data Repository, Rexnord Technical Services: Moffett Field, CA, USA, 2007. Available online: https://ti.arc.nasa.gov/tech/dash/pcoe/prognostic-data-repository/#bearing (accessed on 14 November 2021).
- Qiu, H.; Lee, J.; Lin, J.; Yu, G. Wavelet filter-based weak signature detection method and its application on rolling element bearing prognostics. J. Sound Vib. 2006, 289, 1066–1090. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Description | Features | Description |
|---|---|---|---|
| Absolute Energy | Root Mean Square (rms) | ||
| Kurtosis | Skewness | ||
| Global value from envelope analysis peak-to-peak | Crest Factor | ||
| Principal Frequency | Wavelet sub band entropy | ||
| Ball Pass Frequency Outer (BPFI) | Ball Pass Frequency Inner (BPFO) | ||
| Ball Spin Frequency (BSF) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brito, L.C.; Susto, G.A.; Brito, J.N.; Duarte, M.A.V. Fault Detection of Bearing: An Unsupervised Machine Learning Approach Exploiting Feature Extraction and Dimensionality Reduction. Informatics 2021, 8, 85. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8040085
Brito LC, Susto GA, Brito JN, Duarte MAV. Fault Detection of Bearing: An Unsupervised Machine Learning Approach Exploiting Feature Extraction and Dimensionality Reduction. Informatics. 2021; 8(4):85. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8040085
Chicago/Turabian StyleBrito, Lucas Costa, Gian Antonio Susto, Jorge Nei Brito, and Marcus Antonio Viana Duarte. 2021. "Fault Detection of Bearing: An Unsupervised Machine Learning Approach Exploiting Feature Extraction and Dimensionality Reduction" Informatics 8, no. 4: 85. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8040085