We now focus on the applicability of the MOLBL model in a concrete statistical setting.
3.1. Estimation with Simulation
As developed in [
23], the parameters
,
and
of the MOLBL model can be estimated via the maximum likelihood method. That is, based on
n data supposed to be drawn from the MOLBL distribution, say
, the maximum likelihood estimates (MLEs) of
,
and
, say
,
and
, respectively, are defined by
where
is the likelihood function of the model, that is
The log-likelihood function as well as the related score equations can be found in [
23]. However, it is worth mentioning that the MLEs
,
and
have no closed-form expressions. For practical purposes, they can be determined numerically by the use of statistical software. Here, we employ the R software with the package named maxLik (see [
37]).
As a new contribution, we conduct a simulation study to check the asymptotic behavior of the MLEs of the model using Newton–Raphson method. The algorithm used in this simulation study is as follows.
- Step 1:
We chose the number of replications denoted by N.
- Step 2:
We chose the sample size denoted by n, the values of the parameters , , and an initial value denoted by .
- Step 3:
We generate a value denoted by u from a random variable with the unit uniform distribution.
- Step 4:
We update
by using the Newton formula in the following way:
- Step 5:
For a small enough tolerance limit denoted by , if , we store as a sample from MOLBL distribution.
- Step 6:
Otherwise, if then, set and go to Step 3.
- Step 7:
Repeat Steps 3–6 n times to obtain , respectively.
- Step 8:
Compute the MLEs of the parameters.
- Step 9:
Repeat Steps 3–8 N times to generate N MLEs.
The results are obtained from
replications. In each replication, a random sample of size
, 120, 200, 300 and 800 is generated for different combinations of
,
and
. Here, the considered values of
,
and
are
,
,
,
and
.
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6 list the average MLEs, biases and the corresponding mean squared errors (MSEs). We recall that the average MLEs of
,
and
are given by
respectively, the biases of
,
and
are
respectively, and the MSEs of
,
and
are
respectively.
The values in
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6 show that, as the sample size increases, the MSEs of the estimates of the parameters tend to zero and the average estimates of the parameters tend closer to the true parameter values. One can notice that the convergence is slow for the estimation of
. This can be explained by the fact that it is taken relatively large in our experiments, i.e., at 5, 8 and 10. The overall numerical convergence can certainly be improved by using modern algorithms, such as the Simulated Annealing (SANN) described in [
38]. Indeed, the SANN method guarantees a convergence that does not depend on the initial values, even when several local extrema are present. Further details and applications of this method can be found in [
39]. Alternatively, Bayesian estimation can be investigated in a similar manner to the former Lomax distribution, as performed in [
8]. However, these methods require additional developments that we leave for future work.
3.2. Applications to Four Data Sets
This section provides new applications to explore the potential of the MOLBL model with other six well known competitive models, namely the power Lomax (POLO) (see [
19]), exponentiated Lomax (EXLO) (see [
14]), Marshall–Olkin length-biased exponential (MOLBE) (see [
40]), length-biased Lomax (LBLO), original Weibull and original Lomax models. The MOLBL, POLO and EXLO models have three parameters, whereas the MOLBE, LBLO, Weibull and Lomax models have two parameters. The pdfs of these competitive models are shown below.
The pdf of the POLO model is
and
for
.
The pdf of the EXLO model is
and
for
.
The pdf of the LBLO model is given as Equation (
2), that is
and
for
.
The pdf of the MOLBE model is
and
for
.
The pdf of the Weibull model is
and
for
.
The pdf of the Lomax model is specified by Equation (
1), that is
and
for
.
Four data sets were considered and analyzed, chosen for their interests as well as their different statistical natures (right-skewed, left-skewed, high peak, etc.) The model parameters were classically estimated by the maximum likelihood method, as described in
Section 3.1 for the MOLBL model. Then, we compared the considered models by taking into account the AIC, CAIC, BIC, HQIC,
,
, KS and the p-value of the corresponding KS test. The best model is the one with the smallest values for the AIC, CAIC, BIC, HQIC,
,
, KS and the greatest value for the
p-value of the KS test.
Data set 1: The data were extracted from [
41]. It represents the survival times of a group of patients suffering from Head and Neck cancer disease and treated using radiotherapy. The data are as follows: 6.53, 7, 10.42, 14.48, 16.10, 22.70, 34, 41.55, 42, 45.28, 49.40, 53.62, 63, 64, 83, 84, 91, 108, 112, 129, 133, 133, 139, 140, 140, 146, 149, 154, 157, 160, 160, 165, 146, 149, 154, 157, 160, 160, 165, 173, 176, 218, 225, 241, 248, 273, 277, 297, 405, 417, 420, 440, 523, 583, 594, 1101, 1146, 1417.
Table 7 shows the MLEs of the parameters of the considered models, with their standard errors.
Table 8 indicates the values of the AIC, CAIC, BIC, HQIC,
,
, KS and
p-value of the considered models.
From
Table 8, it is clear the MOLBL model is the best, with the smallest values for the AIC with AIC
, CAIC with CAIC
, BIC with BIC
, with HQIC with HQIC
,
with
,
with
, KS with KS
and the greatest value for the
p-value (
p).
Data set 2: The data were taken from [
42]. They represent the life of fatigue fracture of Kevlar 49/epoxy strands that are subject to a constant pressure at the 90% stress level until the strand failure. The data are as follows: 0.0251, 0.0886, 0.0891, 0.2501, 0.3113, 0.3451, 0.4763, 0.5650, 0.5671, 0.6566, 0.6748, 0.6751, 0.6753, 0.7696, 0.8375, 0.8391, 0.8425, 0.8645, 0.8851, 0.9113, 0.9120, 0.9836, 1.0483, 1.0596, 1.0773, 1.1733, 1.2570, 1.2766, 1.2985, 1.3211, 1.3503, 1.3551, 1.4595, 1.4880, 1.5728, 1.5733, 1.7083, 1.7263, 1.7460, 1.7630, 1.7746, 1.8275, 1.8375, 1.8503, 1.8808, 1.8878, 1.8881, 1.9316, 1.9558, 2.0048, 2.0408, 2.0903, 2.1093, 2.1330, 2.2100, 2.2460, 2.2878, 2.3203, 2.3470, 2.3513, 2.4951, 2.5260, 2.9911, 3.0256, 3.2678, 3.4045, 3.4846, 3.7433, 3.7455, 3.9143, 4.8073, 5.4005, 5.4435, 5.5295, 6.5541, 9.0960.
Table 9 shows the MLEs of the parameters of the considered models, with their standard errors.
Table 10 indicates the values of the AIC, CAIC, BIC, HQIC,
,
, KS and
p-value of the considered models.
From
Table 10, the MOLBL model is revealed to be the best, with the smallest values for the AIC with AIC
, CAIC with CAIC
, BIC with BIC
, with HQIC with HQIC
,
with
,
with
, KS with KS
and the greatest value for the
p-value (
p).
Data set 3: The data were taken from [
43]. The data represent the survival times of 72 guinea pigs infected with virulent tubercle bacilli. The data are as follows: 0.1, 0.33, 0.44, 0.56, 0.59, 0.72, 0.74, 0.77, 0.92, 0.93, 0.96, 1, 1, 1.02, 1.05, 1.07, 1.07, 1.08, 1.08, 1.08, 1.09, 1.12, 1.13, 1.15, 1.16, 1.2, 1.21, 1.22, 1.22, 1.24, 1.3, 1.34, 1.36, 1.39, 1.44, 1.46, 1.53, 1.59, 1.6, 1.63, 1.63, 1.68, 1.71, 1.72, 1.76, 1.83, 1.95, 1.96, 1.97, 2.02, 2.13, 2.15, 2.16, 2.22, 2.3, 2.31, 2.4, 2.45, 2.51, 2.53, 2.54, 2.54, 2.78, 2.93, 3.27, 3.42, 3.47, 3.61, 4.02, 4.32, 4.58, 5.55.
Table 11 shows the MLEs of the parameters of the considered models, with their standard errors.
Table 12 indicates the values of the AIC, CAIC, BIC, HQIC,
,
, KS and
p-value of the considered models.
Table 12 confirms that the MOLBL model is more efficient in adaptive capacity, having the smallest values for the AIC with AIC
, CAIC with CAIC
, BIC with BIC
, with HQIC with HQIC
,
with
,
with
, KS with KS
and the greatest value for the
p-value (
p).
Data set 4: The data were taken from [
44]. They represent the survival data on the death times of psychiatric patients admitted to the University of Iowa hospital. The data are as follows: 1, 1, 2, 22, 30, 28, 32, 11, 14, 36, 31, 33, 33, 37, 35, 25, 31, 22, 26, 24, 35, 34, 30, 35, 40, 39.
Table 13 shows the MLEs of the parameters of the considered models, with their standard errors.
Table 14 indicates the values of the AIC, CAIC, BIC, HQIC,
,
, KS and
p-value of the considered models.
Based on
Table 14, it is flagrant that the MOLBL model is preferable among all, with the smallest values for the AIC with AIC
, CAIC with CAIC
, BIC with BIC
, with HQIC with HQIC
,
with
,
with
, KS with KS
and the greatest value for the p-value (
p).
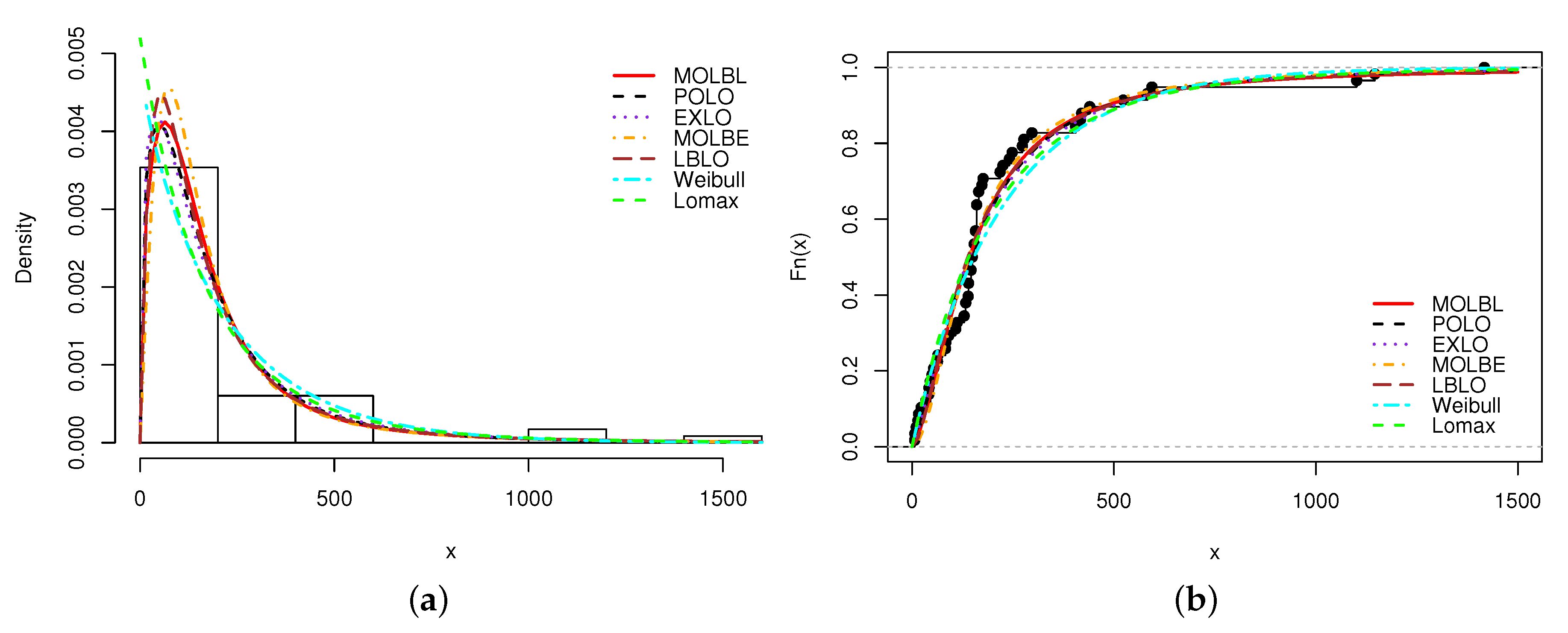
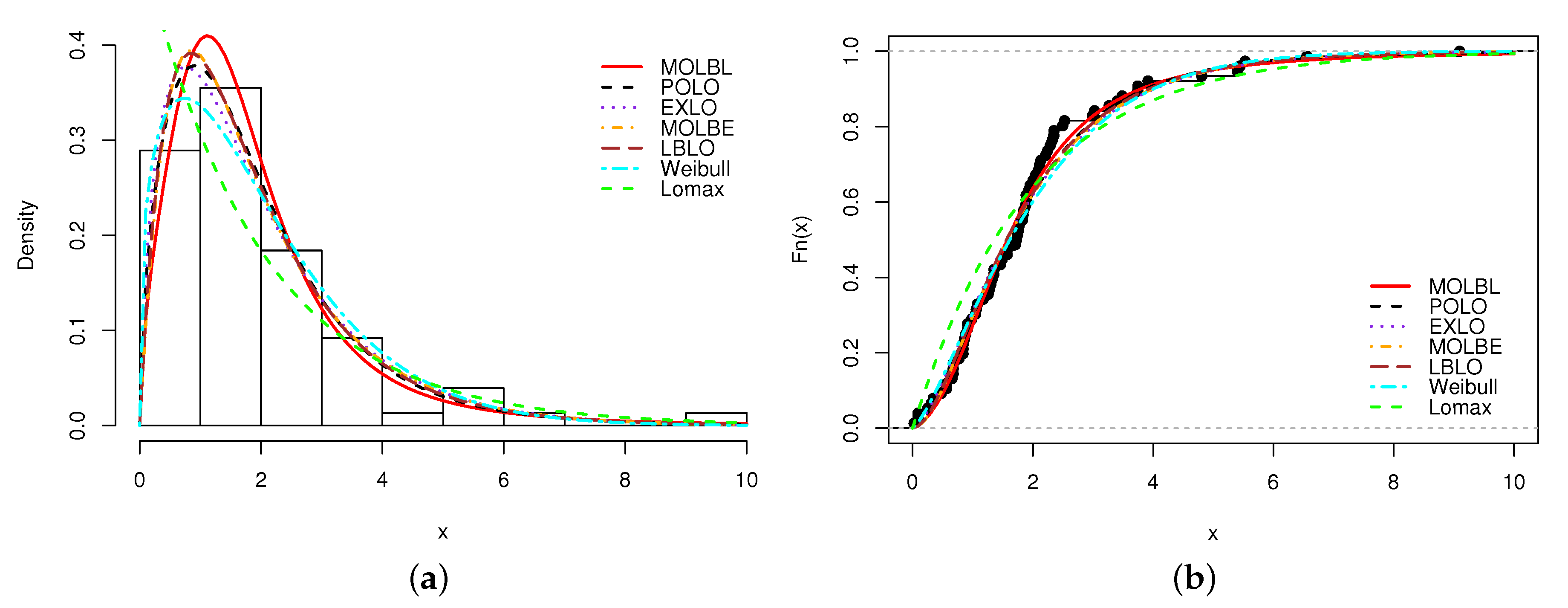
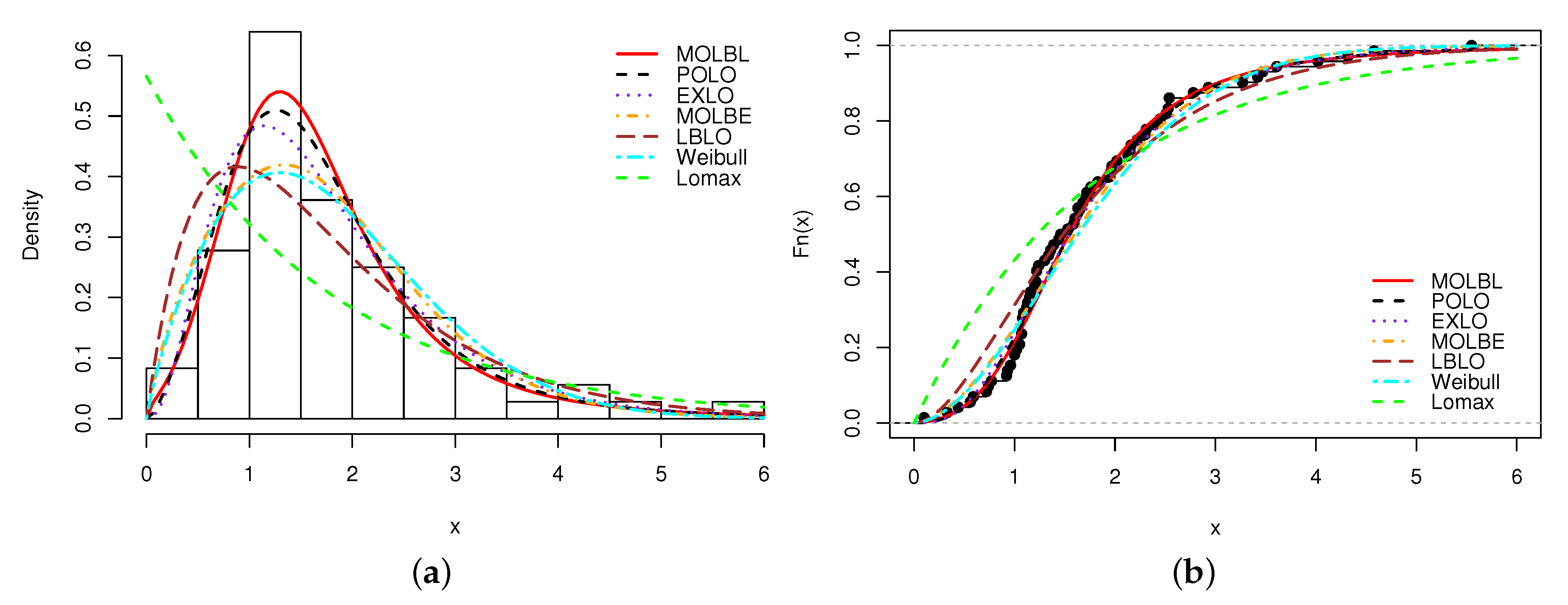
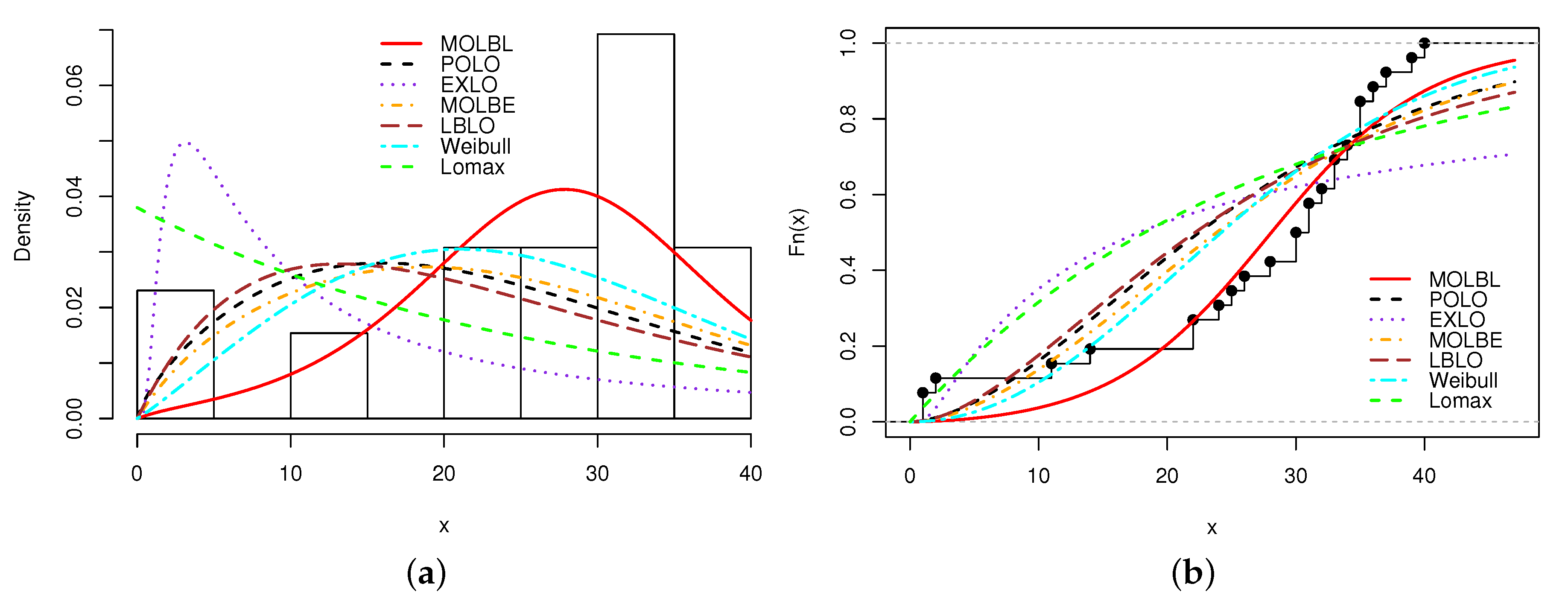
A graphical analysis is now performed, showing the fitted pdfs and cdfs of all the models. The fitted pdfs are superposed over the corresponding histogram of the data, and the estimated cdfs are superposed over the corresponding empirical cdf of the data. The plots are displayed in
Figure 1,
Figure 2,
Figure 3 and
Figure 4, for Data sets 1, 2, 3 and 4, respectively.
In all the figures, we see that the MOLBL model better adjusted the empirical objects, making enough pliancy to adapt to the right or left skewness property of the data, as well as versatile peakness.







{kind=link}
{kind=link}
{kind=link}
{kind=link}