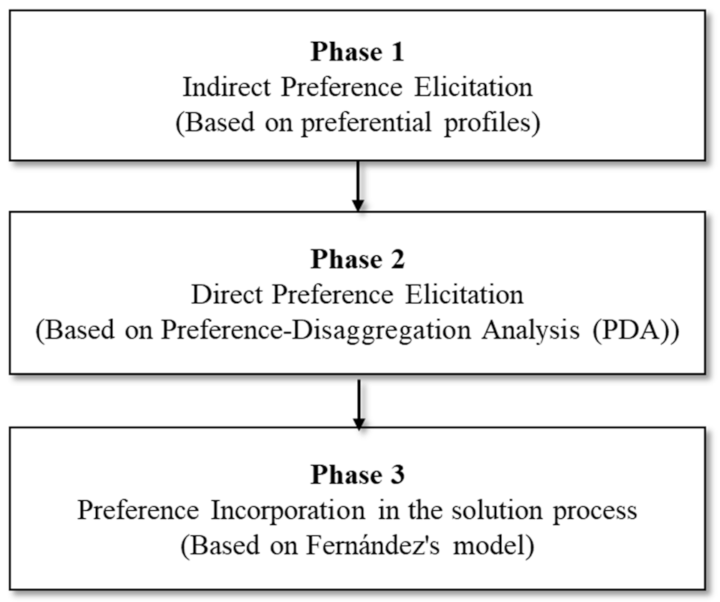
This section describes the experimental process that evaluates P-HMCSGA. The process analyzes the algorithm in two experiments. The first experiment analyzes the effect of the profile of a decision maker in the search process. The second experiment studies the error variability of initial reference solutions and their impact on final solutions.
The experimental design tested the approach, in each experiment, on three different profiles, one configuration for the involved algorithms and six instances of the project portfolio problem (PPP). The performance of P-HMCSGA was measured using five different indicators that reflect how well it approximates the Pareto front with and without preferences and how well it adjusts the portfolios to the specified profiles.
4.4. Quality Indicators to Evaluate Solutions
This work uses five different indicators to evaluate the performance of the proposed P-HMCSGA algorithm. These metrics are detailed in the remainder of this section.
Indicator
NDA measures the non-dominance proportion achieved over an approximated Pareto front (PF)
A. Equation (13) computes this indicator as to the quotient of the size of the set of non-dominated solutions
F0 produced by P-HMCSGA and the size of set
A.
Indicator
PSOA measures the proportion between non-strictly outranked solutions (i.e., solutions that are hard to distinguish by preference according to a specific DM (see
Section 2) and an approximated PF
A. Equation (14) computes this indicator as the quotient of the size of the approximated non-strict-outranked frontier
FNSO produced by P-HMCSGA and the size of the set
A.
Indicator PC measures the percentage of maximum cardinality achieved by the solutions reported by P-HMCSGA. Equation (15) computes it as the quotient between the number of supported projects in a portfolio, sp, and the estimated maximum projects that could ever be supported, ems.
Indicator PES (previously established projects) measures the proportion of the DM’s previously established projects that are found in a portfolio generated by P-HMCSGA. Equation (16) computed as the quotient between ep, i.e., the number of projects in a portfolio that are wanted by the DM, and EP (established projects), the maximum number of wanted projects.
Finally, indicator PAR (project in area/region) is the proportion of supported projects that goes in agreement with the area/region desired in the portfolio and established by the DM. Equation (17) measures this proportion as the quotient between EAR, the number of projects in the portfolio constructed by P-HMCSGA that satisfied the area and region conditions of the DM and q, the number of projects in the instance that satisfy the area and region conditions established by the DM.
The NDA and PSOA are referred to as general quality indicators because they measure the quality of a strategy based on their closeness to the PF or the RoI, the general metric evaluations for multi-criteria algorithms. The indicators PC, PES and PAR are indicators of specific quality because they measure how well the portfolios constructed have respected the preferences established by a particular preference profile.
4.5. Experiment 1: Effect of the Profile of a Decision Maker in the Search Process
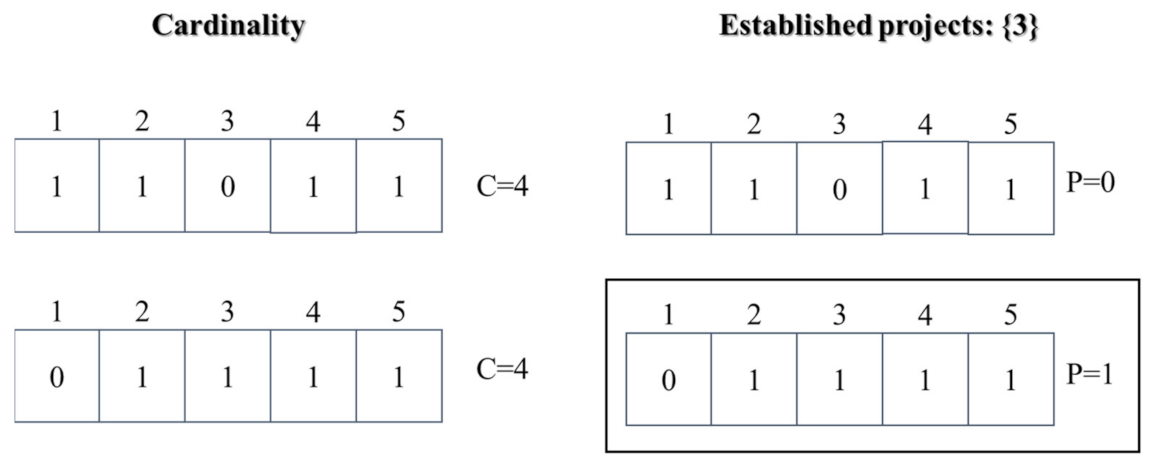
This experiment was carried out based on the idea that if the solutions are presented to two decision makers with different profiles, these may be good for one decision maker and they may not be good for another, or perhaps only some. An example is shown in
Figure 7, where, for a DM that seeks to maximize the number of projects included in the portfolio, both solutions satisfy that requirement, but if these same solutions are presented to a DM whose profile establishes that project number 3 must be supported, the first solution is definitely not acceptable because it does not include this.
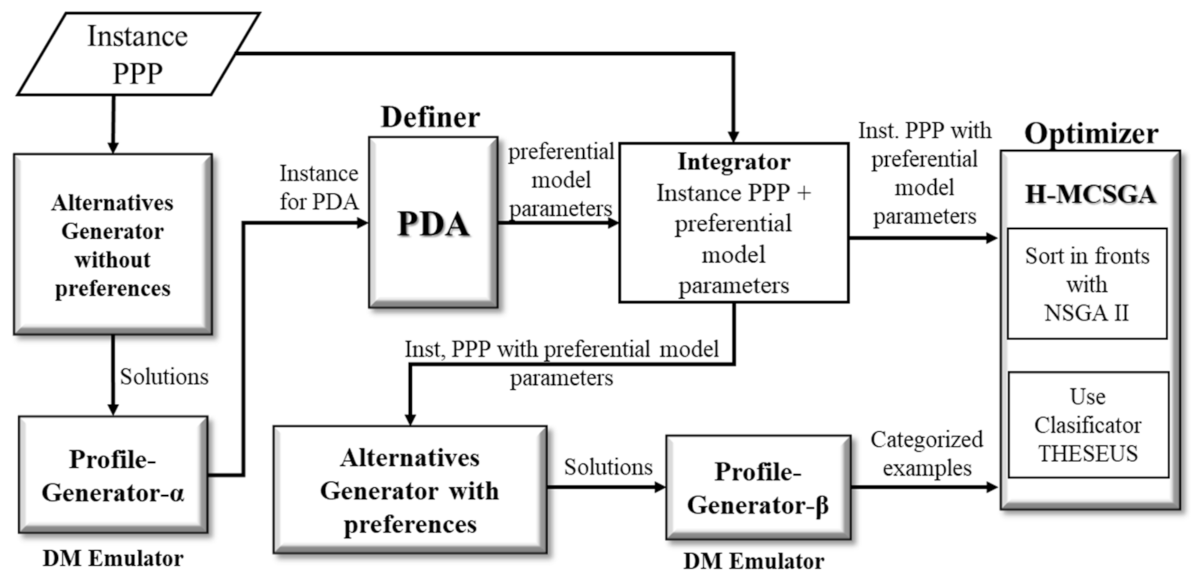
From the above, an experiment was designed, the process of which is shown in
Figure 8. There, it illustrates that P-HMCSGA solves each instance using each of the
n profiles (the configurations of the approaches are according to those defined in
Section 4.2). With the results, a matrix of size
n ×
n is formed. The set of solutions produced using each profile
i is compared against the other profiles
j in order to estimate how well the satisfaction of a profile
i by P-HMCSGA behaves in comparison with other profiles
j not considered at the moment. Hence, a cell (
i,
j) contains the number of portfolios that satisfies profiles
i and
j.
Appendix A and
Appendix B show the complete set of results derived from experimenting with the considered set of instances; the remainder of the sections presents a summary based on selected cases.
Table 3 shows the different DM profiles considered in the experiment for all the instances. Each profile defines two values: the expected value, which is the desired amount of elements required to satisfy a DM completely, and the minimum accepted, which is the minimum number of elements necessary to consider a solution as satisfactory. The maximum found shows the best match obtained from a portfolio constructed by P-HMCSGA.
Table 4 shows the matrix obtained for the concentration of the results of the evaluations in the profiles. The row leads the profile used by P-HMCSGA to approximate the RoI. The column shows how the best value obtained by fixing the profile behaves in other profiles. The value in parenthesis indicates the best value in the compared profile; the value outside is the number of solutions that obtained that value.
The results from
Table 4 show that the highest number of solutions coincide with the main diagonal; this demonstrates that the use of profiles in the search process of P-HMCSGA indeed pursues the construction of portfolios that satisfy such preference conditions.
Table 5 shows the results from the measurements established by the indicators defined in
Section 4.4. Again, the highest scores are in the main diagonal and are achieved when the indicator matches the profile used during the search process. These results corroborate the fact that the use of profiles favors the construction of solutions that satisfy a DM’s preferences.
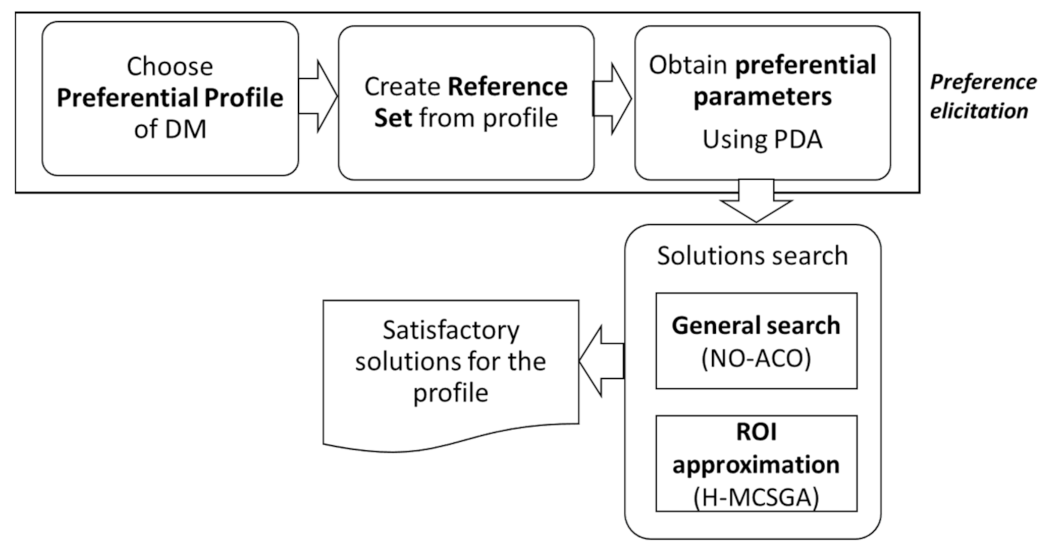
Figure 9 illustrates the process used to identify the approximate Pareto front and non-strict outranked sets from P-HMCSGA on each profile. There, all the solutions considered satisfactory for each profile were concentrated in bags of satisfactory solutions, sets of non-repeated solutions that satisfy non-dominance or non-strictly outrank conditions.
Table 6 summarizes the measurements on the
ND and
NSO indicators obtained from the cardinality profile. Using P-HMCSGA to approximate the PF and the RoI on instance o9p100_1, under the cardinality profile, the set
A of reported portfolios was of size 99. The numbers of portfolios that satisfy the cardinality, established projects and area-region profiles are shown in row one and columns 3, 5 and 7, respectively.
The proportion of non-dominated solutions on each profile is shown in row 2 and columns 4, 6 and 8. The proportion of non-strictly outranked solution on each profile is shown in row 3 and columns 4, 6 and 8. The results show that if we use cardinality in the profile, the best measures for indicators ND and NSO are obtained when comparing against the same cardinality.
Table 7 summarizes the measurements on the
ND and
NSO indicators obtained from the established projects profile. Using P-HMCSGA to approximate the PF and the RoI on instance o9p100_1, under the established projects profile, the set
A of reported portfolios was of size 38. The numbers of portfolios that satisfy the cardinality, established projects and area-region profiles are shown in row one and columns 3, 5 and 7, respectively. The proportion of non-dominated solutions on each profile is shown in row 2 and columns 4, 6 and 8. The proportion of non-strictly outranked solution on each profile is shown in row 3 and columns 4, 6 and 8. The results show that if we use established projects in the profile, the best measures for indicators
ND and
NSO are obtained when comparing against the same established projects.
Table 8 summarizes the measurements on the
ND and
NSO indicators obtained from the area-region profile. Using P-HMCSGA to approximate the PF and the RoI on instance o9p100_1, under the area-region profile, the set
A of reported portfolios was of size 56. The numbers of portfolios that satisfy the cardinality, established projects and area-region profiles are shown in row one and columns 3, 5 and 7, respectively. The proportion of non-dominated solutions on each profile is shown in row 2 and columns 4, 6 and 8. The proportion of non-strictly outranked solution on each profile is shown in row 3 and columns 4, 6 and 8. The results show that if we use established projects in the profile, the best measures for indicators
ND and
NSO are obtained when comparing against the same area-region.
Table 6,
Table 7 and
Table 8 show that the percentage of solutions remaining satisfactory (non-dominated and non-strictly outranked) is very high in the solutions obtained from the parameter configuration corresponding to the specified profile. When the search was not configurated according to the interesting profile, it obtains few solutions (which were not repeated). Both complementary results show that the search direction depends on the preference profile established by the DM. The solutions obtained from the configuration of specific parameters for the profile are good in dominance and outranking. Besides, using these parameters, it is possible to find a greater number of satisfactory solutions for the profile.
4.6. Experiment 2: Error Variability of Initial Reference Solutions and Its Impact on Final Solutions
The objective of this experiment is to analyze how the quality of an initial reference set affects the performance of P-HMCSGA. For this purpose, the implementation of the algorithm considers the use of two types of reference sets. The low-quality reference set (denoted “Low”) has solutions around the minimum value in a profile that is considered satisfactory for a DM. The high-quality reference set (denoted “Good”) has solutions close to the maximum value possible of satisfaction for the chosen profile. The experiment compares the final set of solutions produced by P-HMCSGA using each of the reference sets in terms of the level of satisfaction of the profile and the number of solutions produced. The results show that using a robust reference set formed by solutions of high quality improves the performance of P-HMCSGA and allows it to find solutions that better satisfy the preferential profile.
For this experiment, the configuration of P-HMCSGA was in accordance with the values in
Table 1, except for the number of executions of the generation of alternatives without preferences that were set to 1 for simplicity. The instance considered for the experiment was o9p100_1. The profile used was established projects and it fixes 15 projects as the desire by the DM (expected column in
Table 9); Also, in addition, it considers as satisfactory any solution having a subset of at least 11 of such projects (minimum accepted column in
Table 9). The low-quality reference has 20 portfolios or solutions; from them, two contain 12 of the desired 15 projects and the remaining ones contain only 11 projects. The high-quality reference set (or robust reference set) also has 20 portfolios; however, three of them have all the desired projects and 17 of them have 14.
Table 9 also shows the maximum number of desired projects that could be found in a solution constructed by P-HMCSGA in the experiment; those solutions could only be found using a reference set of high quality.
Table 10 shows the results of this experiment. In row 1, the column “Maximum in RS
” shows the composition of the reference sets Low and Good; the column “Finals” shows the composition of the satisfactory solutions found by P-HMCSGA. In both columns, the notation
X(
Y) indicates that there are
X solutions having
Y desire projects from the 15 considered in the profile. In row 2, the best value achieved according to the PES indicator is shown, considering the composition of the portfolios reported and 15 as the maximum number of desired projects, EP. It is important to note the contrast of the solutions obtained using reference sets with different qualities. The significant variations in the quality of solutions obtained are evident, favoring the results of the robust reference set; this situation is due to the fact that there are far more solutions with a greater number of desired projects involved in the portfolios and also because those solutions present the highest value in PES, indicating that they are closer to the DM’s profile than the others.
Finally,
Table 11 shows the summary of the dominance comparison of the solutions found using the different referent sets. In the case of the final solutions obtained using the low-quality reference set, of the six of the acceptable solutions according to the preference profile, five remained non-dominated. On the other hand, the use of the high-quality reference set presents a larger number of non-dominated solutions (97.73% of all those reported) all also being satisfactory to the DM.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








