Fundamentals and Applications of Artificial Neural Network Modelling of Continuous Bifidobacteria Monoculture at a Low Flow Rate

 , , and
, , and
Abstract
:1. Introduction
2. Description of Experiments and Statement of the Modelling Task
- -
- x1, duration of the process, (h);
- -
- x2, initial concentration of carbohydrate substrate—oligofructose, (g/L);
- -
- x3, initial concentration of lactic acid, (g/L);
- -
- x4, initial concentration of acetic acid, (g/L);
- -
- x5, initial count of bifidobacteria, (logCFU/mL)).
- -
- Limitation on the choice of a number of possible variants for the neural network architecture;
- -
- Implementation of training and testing algorithms;
- -
- Various levels of modelling errors for the values of variables from different ranges.
3. Materials and Methods
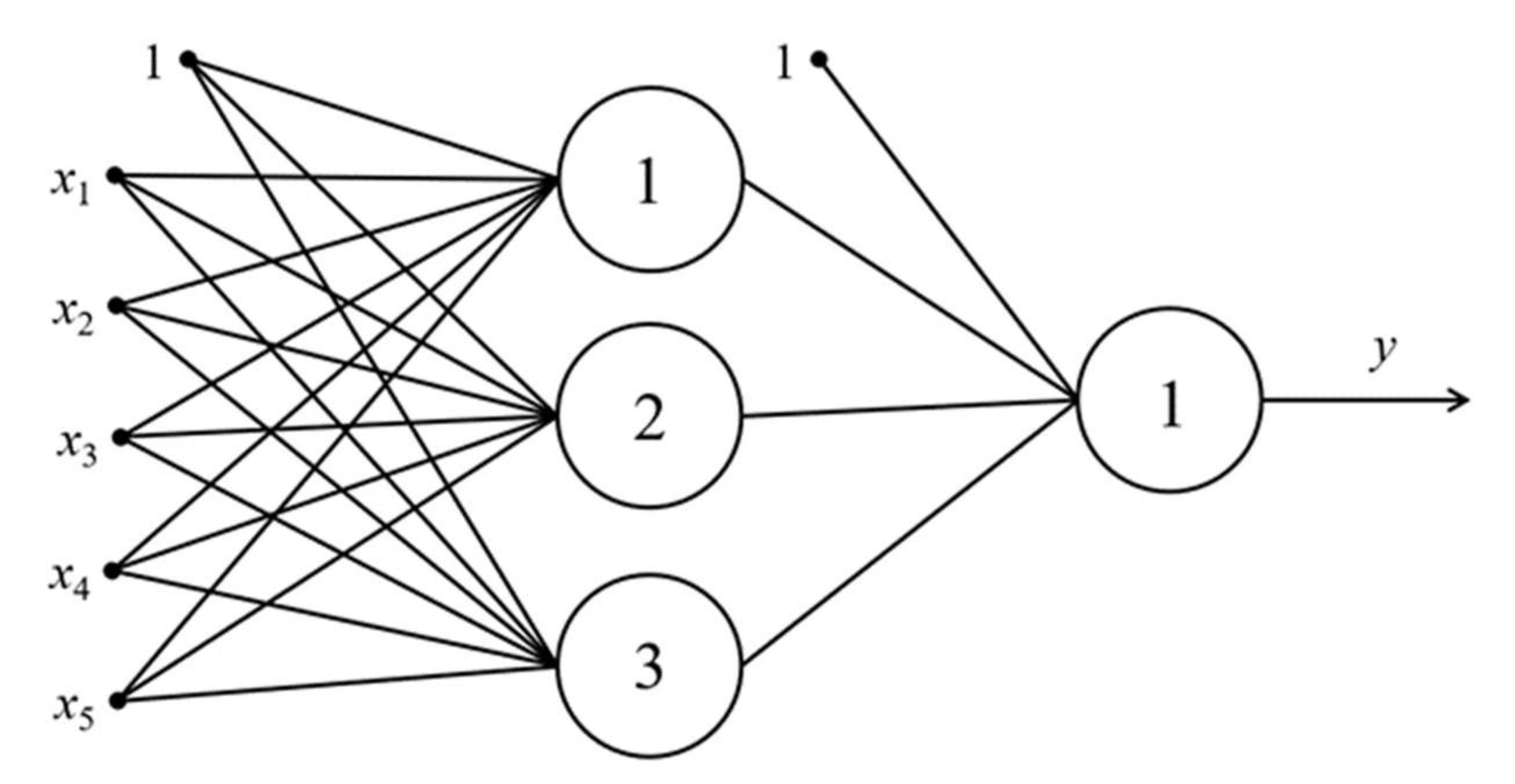
3.1. The Justification of Choice for ANN Architecture
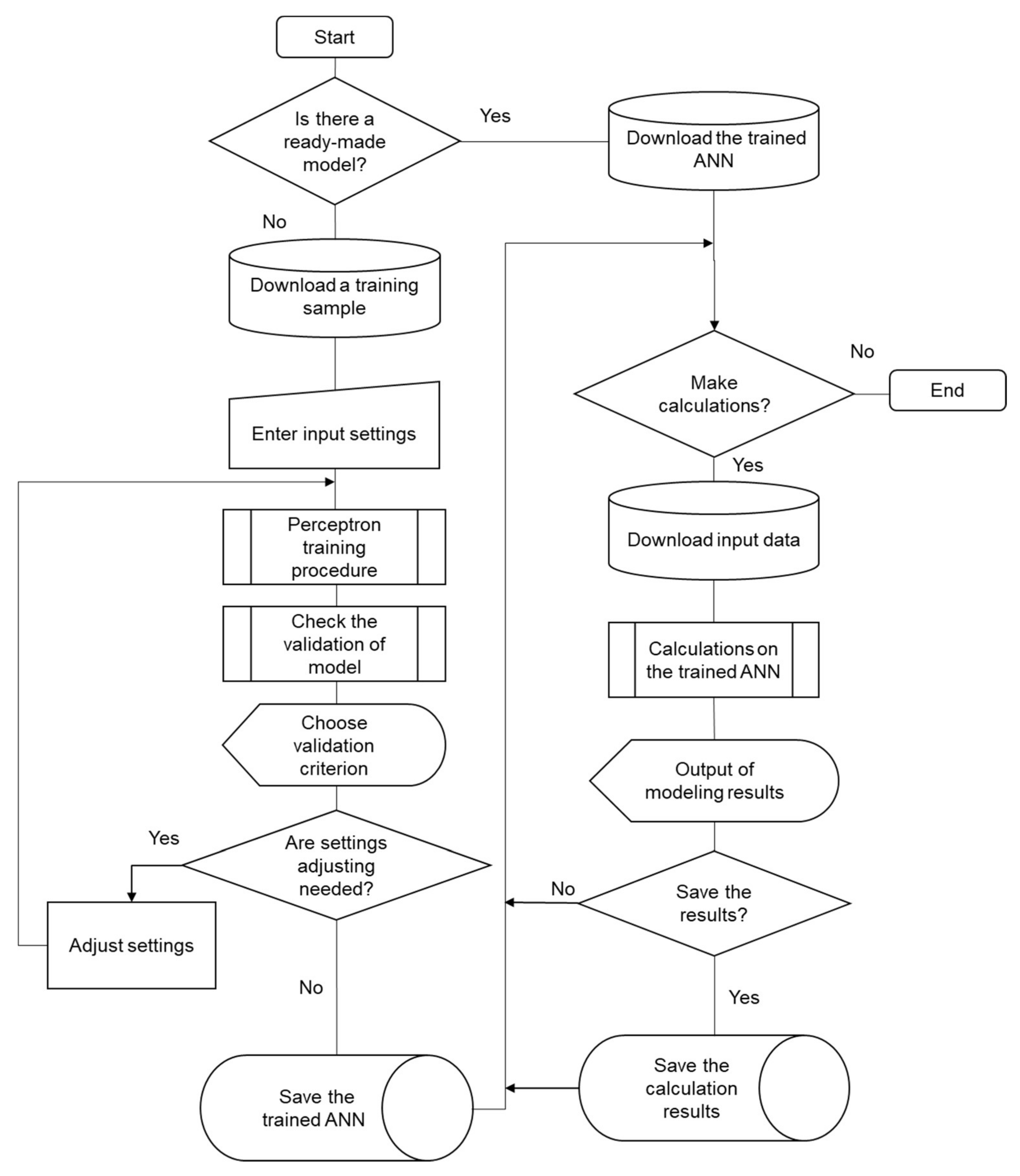
3.2. The Procedure of Settings and Structure Choice for Two-Layer Perceptron. Description of the Algorithm
- If there is no ready, previously configured and trained neural network for calculations, a training sample is formed from the experimental data.
- The initial value of the saturation parameter, the number of hidden neurons and the training rate coefficient are entered.
- The perceptron is trained according to the backpropagation algorithm.
- For the trained perceptron, the validity of the model is estimated for training and testing samples by the calculation of the root-mean-square errors. The share of correctly recognized examples is also defined.
- If the error values exceeded the maximum allowable value of the training algorithm settings, the activation function and/or structure of the perceptron is corrected, and the algorithm continues from step 3.
- If suitable network settings are found, they are stored together with the obtained synaptic coefficient values as a mathematical model for further use.
- If it is necessary to use this model for input data, the signal propagates in the forward direction from the inputs to the outputs of the perceptron. The output values are used for their intended purpose.
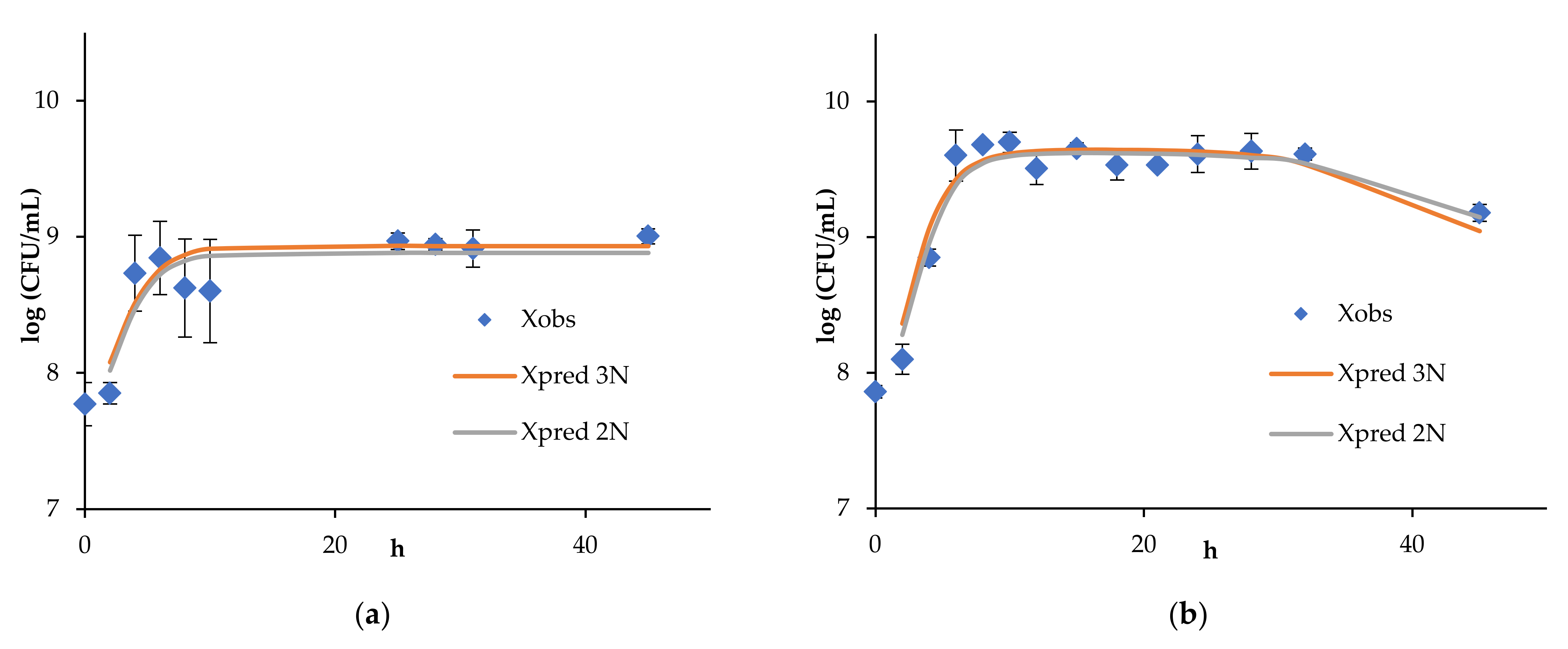
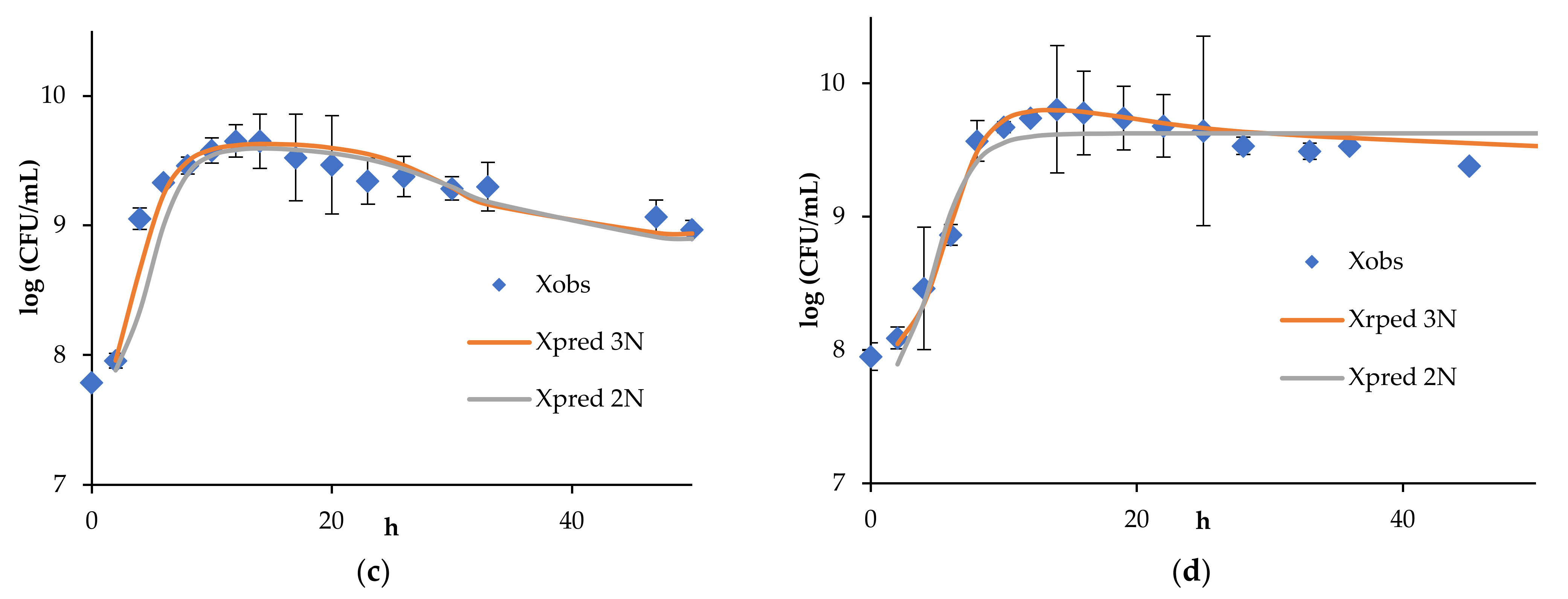
4. Results and Discussion
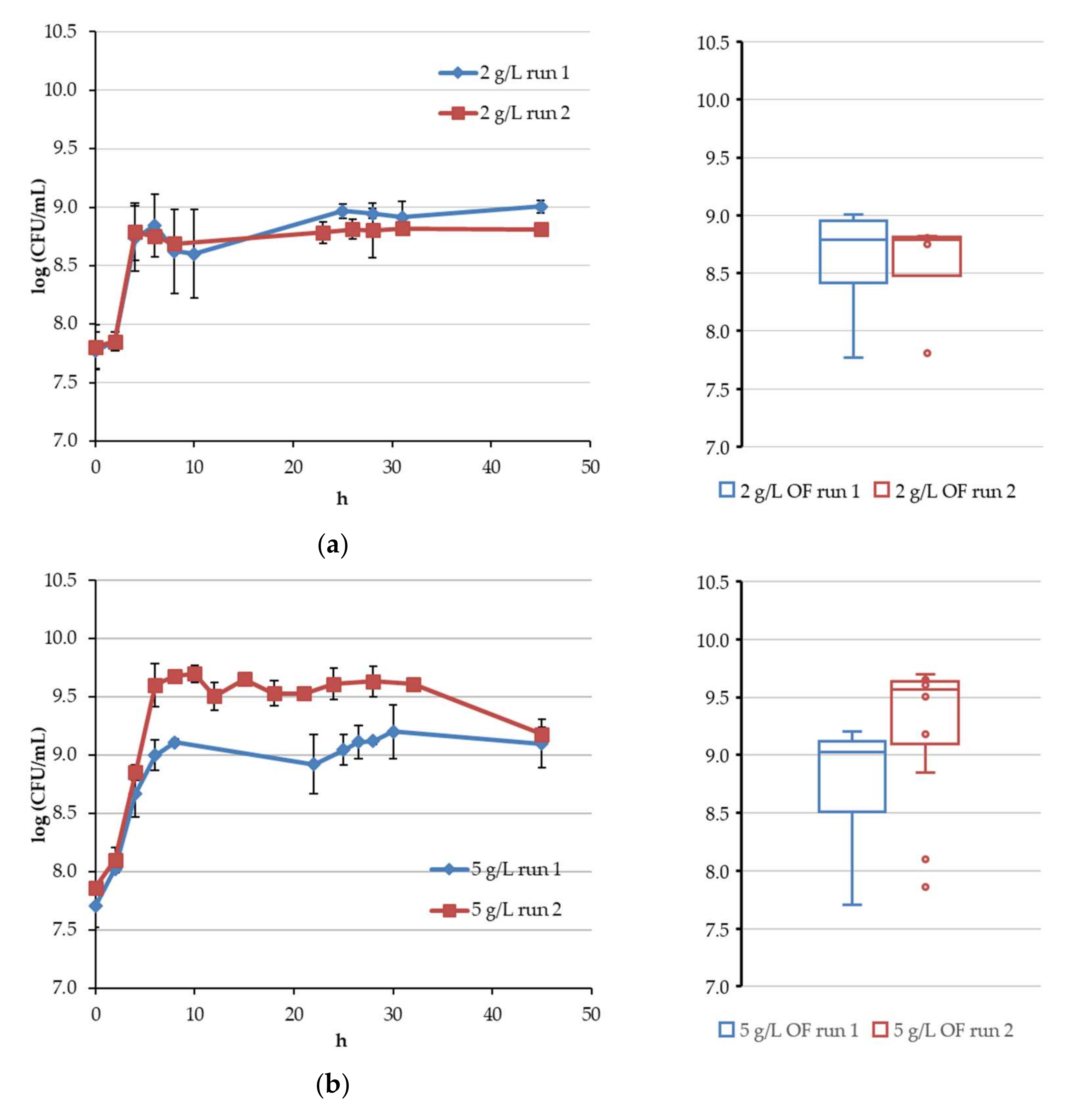
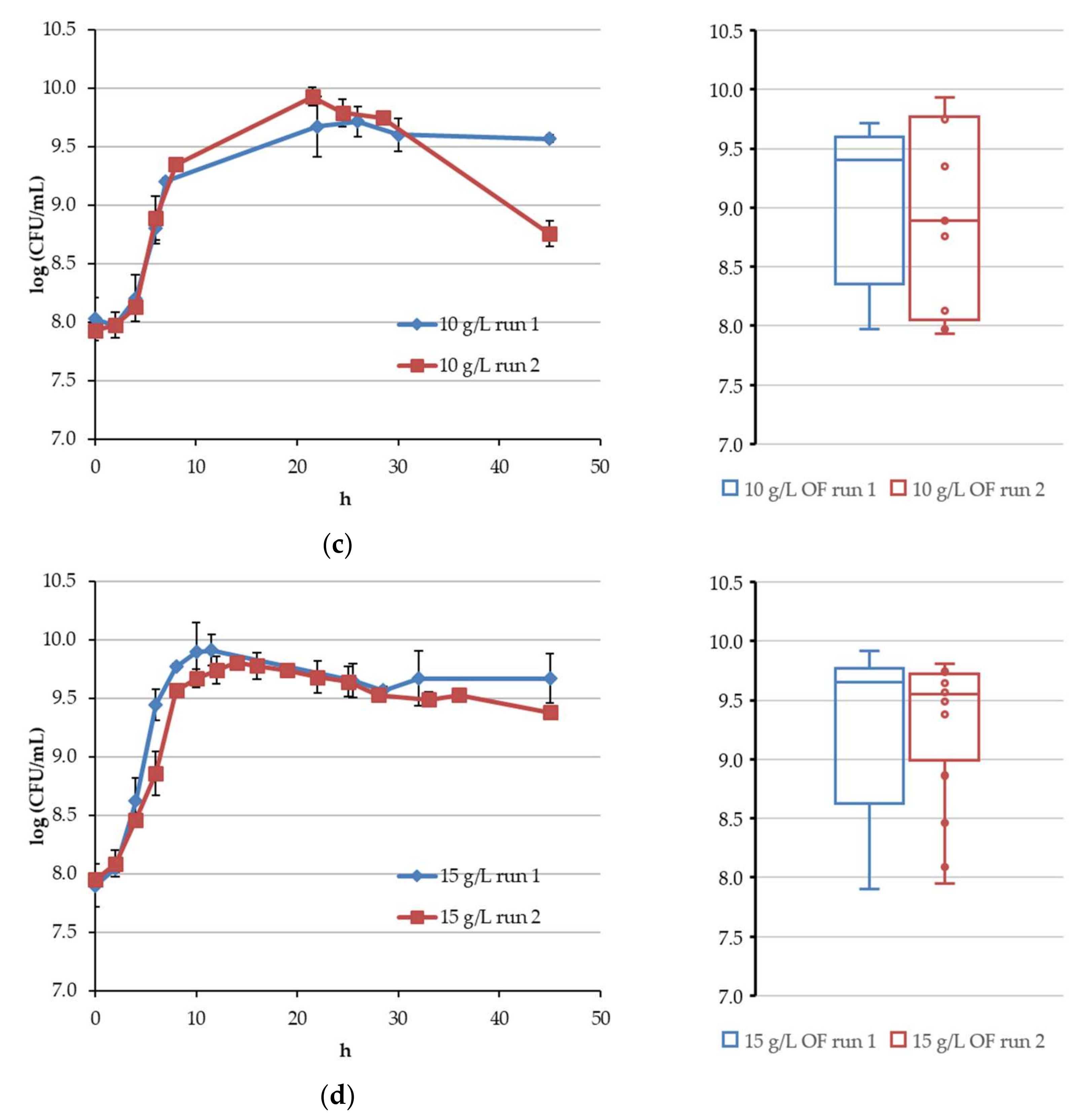
4.1. Continuous Fermentation of Bifidobacteria in Simulated Descending Colon Conditions
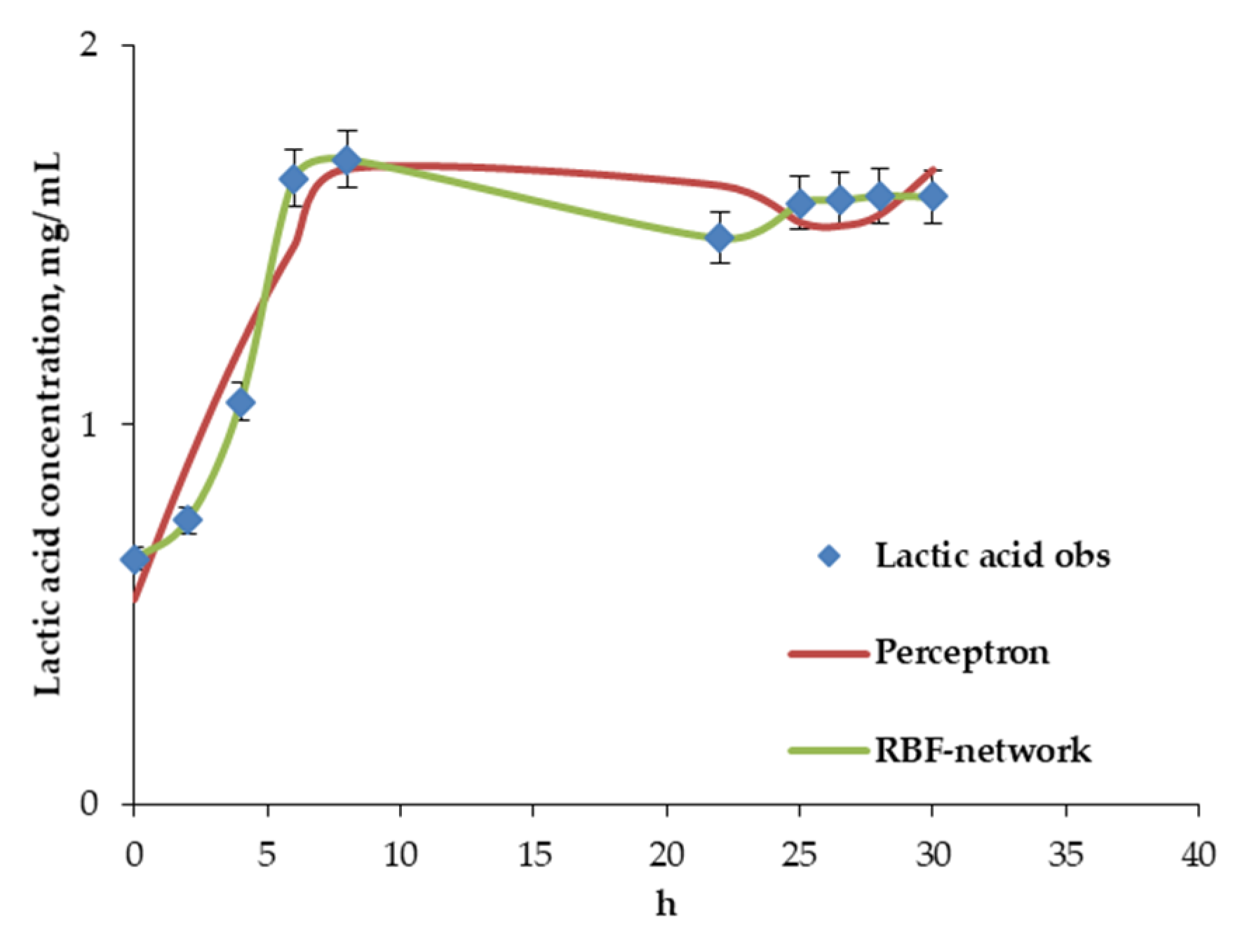
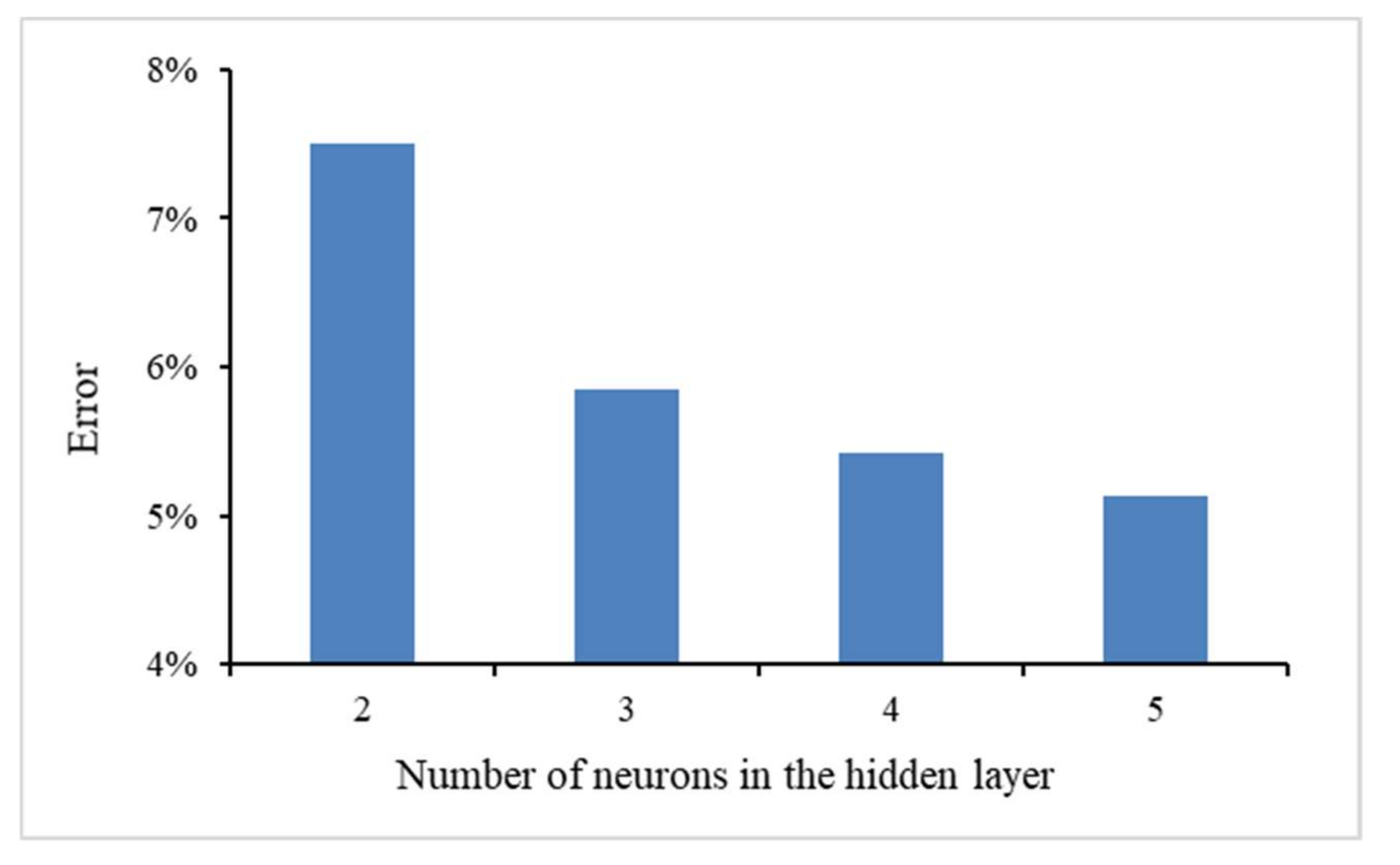
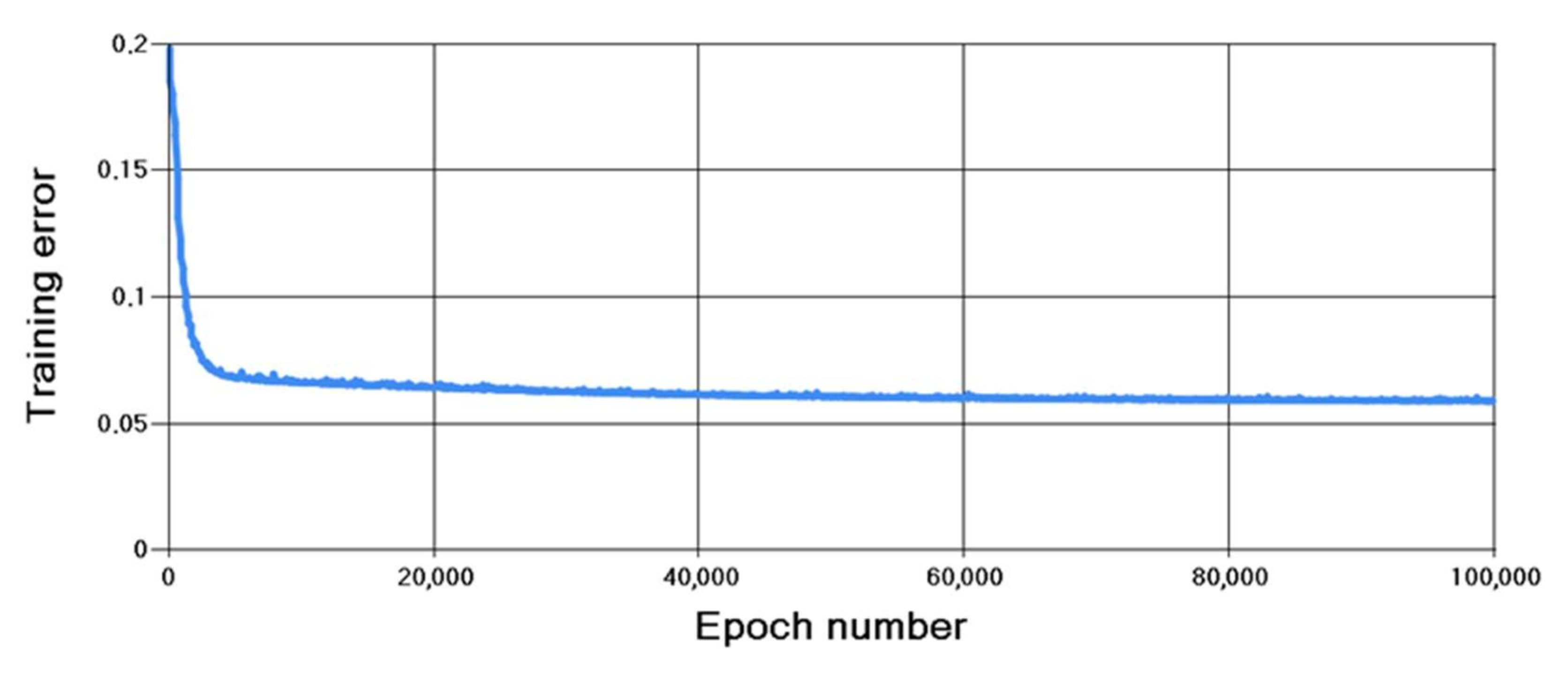
4.2. Results of Algorithm Investigation
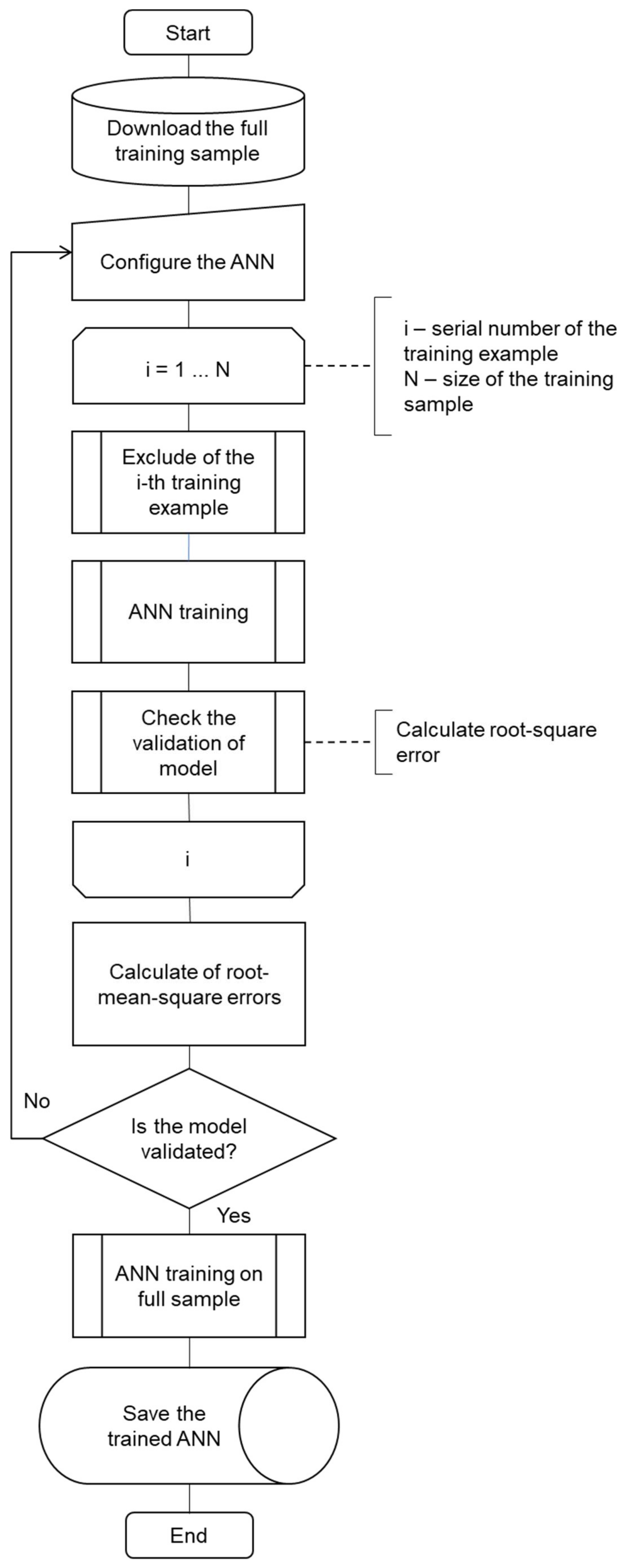
4.3. Features and Algorithm for Testing a Two-Layer Perceptron with a Small Sample Size
- All examples needed to obtain a neural network model are loaded from the experimental results.
- The model settings are selected based on the researcher’s experience.
- The cycle using all examples of the sample is organized. During the cycle:
- -
- One of the examples is excluded from the sample in a definite order;
- -
- The neural network is trained on the basis of the error backpropagation algorithm;
- -
- The correspondence errors between experimental and modelling results of the model are evaluated.
- 4.
- At the end of the cycle, the root-mean-square errors are calculated using experimental and modelling results of the trained networks.
- 5.
- If the root-mean-square errors are satisfactory, a neural network with the same structure and settings is already trained on the full sample (without excluding examples from it), and the resulting model is saved for further use.
- 6.
- If the errors obtained in step 4 were unsatisfactory, the procedure is repeated from step 2 with new settings.
4.4. Artificial Neural Network Model of Continuous Bifidobacteria Monoculture at Low Flow Rate
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bridgman, S.L.; Kozyrskyj, A.L.; Scott, J.A.; Becker, A.B.; Azad, M.B. Gut microbiota and allergic disease in children. Ann. Allergy Asthma Immunol. 2016, 116, 99–105. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gilbert, J.A.; Blaser, M.J.; Caporaso, J.G.; Jansson, J.K.; Lynch, S.V.; Knight, R. Current understanding of the human microbiome. Nat. Med. 2018, 24, 392–400. [Google Scholar] [CrossRef] [PubMed]
- Oh, B.; Boyle, F.; Pavlakis, N.; Clarke, S.; Guminski, A.; Eade, T.; Lamoury, G.; Carroll, S.; Morgia, M.; Kneebone, A.; et al. Emerging Evidence of the Gut Microbiome in Chemotherapy: A Clinical Review. Front. Oncol. 2021, 11, 706331. [Google Scholar] [CrossRef]
- Hill, C.; Guarner, F.; Reid, G.; Gibson, G.R.; Merenstein, D.J.; Pot, B.; Morelli, L.; Canani, R.B.; Flint, H.J.; Salminen, S.; et al. Expert consensus document. The International Scientific Association for Probiotics and Prebiotics consensus statement on the scope and appropriate use of the term probiotic. Nat. Rev. Gastroenterol. Hepatol. 2014, 11, 506–514. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Swanson, K.S.; Gibson, G.R.; Hutkins, R.; Reimer, R.A.; Reid, G.; Verbeke, K.; Scott, K.P.; Holscher, H.D.; Azad, M.B.; Delzenne, N.M.; et al. The International Scientific Association for Probiotics and Prebiotics (ISAPP) consensus statement on the definition and scope of synbiotics. Nat. Rev. Gastroenterol. Hepatol. 2020, 17, 687–701. [Google Scholar] [CrossRef] [PubMed]
- Danne, C.; Rolhion, N.; Sokol, H. Recipient factors in faecal microbiota transplantation: One stool does not fit all. Nat. Rev. Gastroenterol. Hepatol. 2021, 18, 503–513. [Google Scholar] [CrossRef] [PubMed]
- Gibson, G.R.; Cummings, J.H.; Macfarlane, G.T. Use of a three-stage continuous culture system to study the effect of mucin on dissimilatory sulfate reduction and methanogenesis by mixed populations of human gut bacteria. Appl. Environ. Microbiol. 1988, 54, 2750–2755. [Google Scholar] [CrossRef] [Green Version]
- Macfarlane, G.T.; Macfarlane, S.; Gibson, G.R. Validation of a Three-Stage Compound Continuous Culture System for Investigating the Effect of Retention Time on the Ecology and Metabolism of Bacteria in the Human Colon. Microb. Ecol. 1998, 35, 180–187. [Google Scholar] [CrossRef]
- Rosenblatt, F. The Perceptron: A Probabilistic Model For Information Storage and Organization in the Brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [Green Version]
- Wasserman, P.D.; Schwartz, T. Neural networks. II. What are they and why is everybody so interested in them now? IEEE Expert 1988, 3, 10–15. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Açıcı, K.; Asuroglu, T.; Erdas, C.B.; Ogul, H. T4SS Effector Protein Prediction with Deep Learning. Data 2019, 4, 45. [Google Scholar] [CrossRef] [Green Version]
- Zhu, N.; Wang, K.; Zhang, S.; Zhao, B.; Yang, J.; Wang, S. Application of artificial neural networks to predict multiple quality of dry-cured ham based on protein degradation. Food Chem. 2021, 344, 128586. [Google Scholar] [CrossRef] [PubMed]
- Kovarova-Kovar, K.; Gehlen, K.; Kunze, A.; Keller, T.; von Daniken, R.; Kolb, M.; van Loon, A.P.G.M. Application of model-predictive control based on artificial neural networks to optimize the fed-batch process for riboflavin production. J. Biotechnol. 2000, 79, 39–52. [Google Scholar] [CrossRef]
- Oliveira, R.; Peres, J.; de Azevedo, S.F. Hybrid modelling of fermentation processes using artificial neural networks: A study of identification and stability. IFAC Proc. Vol. 2004, 37, 195–200. [Google Scholar] [CrossRef]
- Setoodeh, P.; Jahanmiri, A.; Eslamloueyan, R. Hybrid neural modeling framework for simulation and optimization of diauxie-involved fed-batch fermentative succinate production. Chem. Eng. Sci. 2012, 81, 57–76. [Google Scholar] [CrossRef]
- Ignova, M.; Montague, G.A.; Ward, A.C.; Glassey, J.; Kornfeld, G.; Thomas, C.R. Hybrid modeling and optimisation of industrial fed batch fermentation process. IFAC Proc. Vol. 1998, 31, 271–276. [Google Scholar] [CrossRef]
- Pendashteh, A.R.; Fakhru’l-Razi, A.; Chaibakhsh, N.; Abdullah, L.C.; Madaeni, S.S.; Abidin, Z.Z. Modeling of membrane bioreactor treating hypersaline oily wastewater by artificial neural network. J. Hazard. Mater. 2011, 192, 568–575. [Google Scholar] [CrossRef]
- Antwi, P.; Lic, J.; Meng, J.; Deng, K.; Quashie, F.K.; Li, J.; Boadi, P.O. Feedforward neural network model estimating pollutant removal process within mesophilic upflow anaerobic sludge blanket bioreactor treating industrial starch processing wastewater. Bioresour. Technol. 2018, 257, 102–112. [Google Scholar] [CrossRef] [Green Version]
- Jianfei, L.; Weitie, L.; Xiaolong, C.; Jingyuan, L. Optimization of Fermentation Media for Enhancing Nitrite-oxidizing Activity by Artificial Neural Network Coupling Genetic Algorithm. Chin. J. Chem. Eng. 2012, 20, 950–957. [Google Scholar]
- Williams, C.F.; Walton, G.E.; Jiang, L.; Plummer, S.; Garaiova, I.; Gibson, G.R. Comparative analysis of intestinal tract models. Annu. Rev. Food Sci. Technol. 2015, 6, 329–350. [Google Scholar] [CrossRef] [PubMed]
- Tojo, R.; Suárez, A.; Clemente, M.G.; de los Reyes-Gavilán, C.G.; Margolles, A.; Gueimonde, M.; Ruas-Madiedo, P. Intestinal microbiota in health and disease: Role of bifidobacteria in gut homeostasis. World J. Gastroenterol. 2014, 7, 15163–15176. [Google Scholar] [CrossRef] [PubMed]
- Organji, S.; Abulreesh, H.; Elbanna, K.; Osman, G.; Khider, M. Occurrence and characterization of toxigenic Bacillus cereus in food and infant feces. Asian Pac. J. Trop. Biomed. 2015, 5, 510–514. [Google Scholar] [CrossRef] [Green Version]
- Evdokimova, S.A.; Karetkin, B.A.; Guseva, E.V.; Gordienko, M.G.; Khabibulina, N.V.; Panfilov, V.I.; Menshutina, N.V.; Gradova, N.B. A study and modelling of Bifidobacteria and Bacilli Co-culture Continuous Fermentation under distal intestine simulated conditions. Microorganisms 2022, 10, 929. [Google Scholar] [CrossRef]
- Moody, J.; Darken, C.J. Fast learning in networks of locally tuned processing units. Neural Comput. 1989, 1, 281–294. [Google Scholar] [CrossRef]
- Dreyfus, S.E. Artificial neural networks, back propagation, and the Kelley-Bryson gradient procedure. J. Guid. Control Dyn. 1990, 13, 926–928. [Google Scholar] [CrossRef]
- Meena, G.S.; Gupta, S.; Majumdar, G.C.; Banerjee, R. Growth Characteristics Modeling of Bifidobacterium bifidum Using RSM and ANN. Braz. Arch. Biol. Technol. Int. J. 2011, 54, 1357–1366. [Google Scholar] [CrossRef] [Green Version]
- Meena, G.S.; Majumdar, G.C.; Banerjee, R.; Kumar, N.; Meena, P.K. Growth Characteristics Modeling of Mixed Culture of Bifidobacterium bifidum and Lactobacillus acidophilus using Response Surface Methodology and Artificial Neural Network. Braz. Arch. Biol. Technol. 2014, 57, 962–970. [Google Scholar] [CrossRef] [Green Version]
- Amiri, Z.R.; Khandelwal, P.; Aruna, B.R. Development of acidophilus milk via selected probiotics & prebiotics using artificial neural network. Adv. Biosci. Biotechnol. 2010, 1, 224–231. [Google Scholar] [CrossRef] [Green Version]
- García-Gimeno, R.M.; Hervás-Martínez, C.; Barco-Alcalá, E.; Zurera-Cosano, G.; Sanz-Tapia, E. An Artificial Neural Network Approach to Escherichia coli O157:H7 Growth Estimation. J. Food Sci. 2003, 68, 639–645. [Google Scholar] [CrossRef]
- Ghannam, R.B.; Techtmann, S.M. Machine learning applications in microbial ecology, human microbiome studies, and environmental monitoring. Comput. Struct. Biotechnol. J. 2021, 19, 1092–1107. [Google Scholar] [CrossRef] [PubMed]
- Marcos-Zambrano, L.J.; Karaduzovic-Hadziabdic, K.; Loncar Turukalo, T.; Przymus, P.; Trajkovik, V.; Aasmets, O.; Berland, M.; Gruca, A.; Hasic, J.; Hron, K.; et al. Applications of Machine Learning in Human Microbiome Studies: A Review on Feature Selection, Biomarker Identification, Disease Prediction and Treatment. Front. Microbiol. 2021, 12, 634511. [Google Scholar] [CrossRef] [PubMed]
- Baranwal, M.; Clark, R.L.; Thompson, J.; Sun, Z.; Hero, A.O.; Venturelli, O. Deep Learning Enables Design of Multifunctional Synthetic Human Gut Microbiome Dynamics. bioRxiv 2021. submitted. [Google Scholar] [CrossRef]
- Gradilla-Hernández, M.S.; García-González, A.; Gschaedler, A.; Herrera-López, E.J.; González-Avila, M.; García-Gamboa, R.; Montes, C.Y.; Fuentes-Aguilar, R.Q. Applying Differential Neural Networks to Characterize Microbial Interactions in an Ex Vivo Gastrointestinal Gut Simulator. Processes 2020, 8, 593. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comparison Criterion | Two-Layer Perceptrons | RBF Networks |
|---|---|---|
| Organization of the training algorithm | Multiple repetitions of the training cycle | Single calculation of weight coefficients |
| Possibility of additional training | Yes | No |
| Unambiguity of training results | No | Yes |
| Time of ANN training process | Short | Long |
| Application time of trained ANN | Quickly | Quickly |
| Number of layers with non-linear signal conversion | Two | One |
| Possibility to take training data density into account | No | Yes |
| Input Number (i) | Number of Hidden Neurons (j) | ||
|---|---|---|---|
| 1 | 2 | 3 | |
| 0 | 0.134 | 2.936 | 4.432 |
| 1 | 17.311 | 9.487 | 0.449 |
| 2 | −1.473 | −3.458 | −2.244 |
| 3 | −0.065 | 3.448 | −1.796 |
| 4 | 0.314 | 5.705 | −0.867 |
| 5 | 0.395 | −8.559 | 0.626 |
| Number of Output Neurons (j) | |||
| 0 | 1 | 2 | 3 |
| 1.802 | 2.226 | −0.660 | −3.191 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dudarov, S.; Guseva, E.; Lemetyuynen, Y.; Maklyaev, I.; Karetkin, B.; Evdokimova, S.; Papaev, P.; Menshutina, N.; Panfilov, V. Fundamentals and Applications of Artificial Neural Network Modelling of Continuous Bifidobacteria Monoculture at a Low Flow Rate. Data 2022, 7, 58. https://0-doi-org.brum.beds.ac.uk/10.3390/data7050058
Dudarov S, Guseva E, Lemetyuynen Y, Maklyaev I, Karetkin B, Evdokimova S, Papaev P, Menshutina N, Panfilov V. Fundamentals and Applications of Artificial Neural Network Modelling of Continuous Bifidobacteria Monoculture at a Low Flow Rate. Data. 2022; 7(5):58. https://0-doi-org.brum.beds.ac.uk/10.3390/data7050058
Chicago/Turabian StyleDudarov, Sergey, Elena Guseva, Yury Lemetyuynen, Ilya Maklyaev, Boris Karetkin, Svetlana Evdokimova, Pavel Papaev, Natalia Menshutina, and Victor Panfilov. 2022. "Fundamentals and Applications of Artificial Neural Network Modelling of Continuous Bifidobacteria Monoculture at a Low Flow Rate" Data 7, no. 5: 58. https://0-doi-org.brum.beds.ac.uk/10.3390/data7050058