1. Introduction
In supervised classification, the goal is to tag an image with one class name based on its content. In the beginning of the 2000s, the leading approaches were based on feature coding. Among the most employed coding-based methods, there are the bag of words model (BoW) [
1], the vector of locally aggregated descriptors (VLAD) [
2,
3], the Fisher score (FS) [
4] and the Fisher vectors (FV) [
5,
6,
7]. The success of these methods is based on their main advantages. First, the information obtained by feature coding can be used in a wide variety of applications, including image classification [
5,
8,
9], text retrieval [
10], action and face recognition [
11], etc. Second, combined with powerful local handcrafted features, such as SIFT, they are robust to transformations like scaling, translation, or occlusion [
11].
Nevertheless, in 2012, the ImageNet Large Scale Visual Recognition Challenge has shown that Convolutional Neural Networks [
12,
13] (CNNs) can outperform FV descriptors. Since then, in order to take advantage of both worlds, some hybrid classification architectures have been proposed to combine FV and CNN [
14]. For example, Perronnin et al. have proposed to train a network of fully connected layers on the FV descriptors [
15]. Another hybrid architecture is the deep Fisher network composed by stacking several FV layers [
16]. Some authors have proposed to extract convolutional features from different layers of the network, and then to use VLAD or FV encoding to encode features into a single vector for each image [
17,
18,
19]. These latter features can also be combined with features issued from the fully connected layers in order to improve the classification accuracy [
20].
At the same time, many authors have proposed to extend the formalism of encoding to features lying in a non-Euclidean space. This is the case of covariance matrices that have already demonstrated their importance as descriptors related to array processing [
21], radar detection [
22,
23,
24,
25], image segmentation [
26,
27], face detection [
28], vehicle detection [
29], or classification [
11,
30,
31,
32], etc. As mentioned in [
33], the use of covariance matrices has several advantages. First, they are able to merge the information provided by different features. Second, they are low dimensional descriptors, independent of the dataset size. Third, in the context of image and video processing, efficient methods for fast computation are available [
34].
Nevertheless, since covariance matrices are positive definite matrices, conventional tools developed in the Euclidean space are not well adapted to model the underlying scatter of the data points which are covariance matrices. The characteristics of the Riemannian geometry of the space
of
symmetric and positive definite (SPD) matrices should be considered in order to obtain appropriate algorithms. The aim of this paper is to introduce a unified framework for BoW, VLAD, FS and FV approaches, for features being covariance matrices. In the recent literature, some authors have proposed to extend the BoW and VLAD descriptors to the LE and affine invariant Riemannian metrics. This yields to the so-called Log-Euclidean bag of words (LE BoW) [
33,
35], bag of Riemannian words (BoRW) [
36], Log-Euclidean vector of locally aggregated descriptors (LE VLAD) [
11], extrinsic vector of locally aggregated descriptors (E-VLAD) [
37] and intrinsic Riemannian vector of locally aggregated descriptors (RVLAD) [
11]. All these approaches have been proposed by a direct analogy between the Euclidean and the Riemannian case. For that, the codebook used to encode the covariance matrix set is the standard k-means algorithm adapted to the LE and affine invariant Riemannian metrics.
Contrary to the BoW and VLAD-based coding methods, a soft codebook issued from a Gaussian mixture model (GMM) should be learned for FS or FV encoding. This paper aims to present how FS and FV can be used to encode a set of covariance matrices [
38]. Since these elements do not lie on an Euclidean space but on a Riemannian manifold, a Riemannian metric should be considered. Here, two Riemannian metrics are used: the LE and the affine invariant Riemannian metrics. To summarize, we provide four main contributions:
First, based on the conventional multivariate GMM, we introduce the log-Euclidean Fisher score (LE FS). This descriptor can be interpreted as the FS computed on the log-Euclidean vector representation of the covariance matrices set.
Second, we have recently introduced a Gaussian distribution on the space
: the Riemannian Gaussian distribution [
39]. This latter allows the definition of a GMM on the space of covariance matrices and an Expectation Maximization (EM) algorithm can hence be considered to learn the codebook [
32]. Starting from this observation, we define the Riemannian Fisher score (RFS) [
40] which can be interpreted as an extension of the RVLAD descriptor proposed in [
11].
The third main contribution is to highlight the impact of the Fisher information matrix (FIM) in the derivation of the FV. For that, the Log-Euclidean Fisher Vectors (LE FV) and the Riemannian Fisher Vectors (RFV) are introduced as an extension of the LE FS and the RFS.
Fourth, all these coding methods will be compared on two image processing applications consisting of texture and head pose image classification. Some experiments will also be conducted in order to provide fairer comparison between the different coding strategies. It includes some comparisons between anisotropic and isotropic models. An estimation performance analysis of the dispersion parameter for covariance matrices of large dimension will also be studied.
As previously mentioned, hybrid architectures can be employed to combine FV with CNN. The adaptation of the proposed FV descriptors to these architecture is outside the scope of this paper but will remain one of the perspective of this work.
The paper is structured as follows.
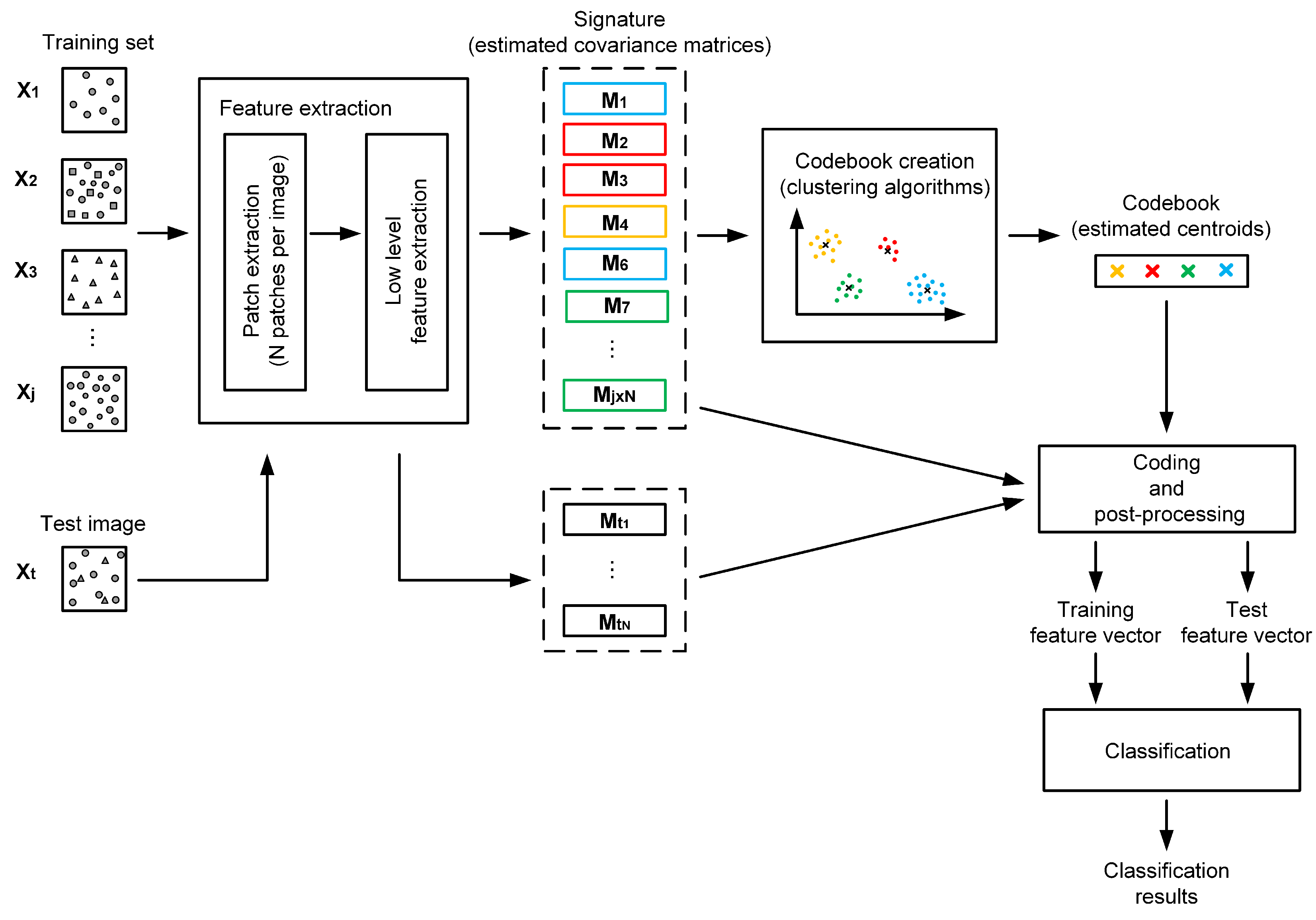
Section 2 introduces the workflow presenting the general idea of feature coding-based classification methods.
Section 3 presents the codebook generation on the manifold of SPD covariance matrices.
Section 4 introduces a theoretical study of the feature encoding methods (BoW, VLAD, FS and FV) based on the LE and affine invariant Riemannian metrics.
Section 5 shows two applications of these descriptors to texture and head pose image classification. In addition, finally,
Section 6 synthesizes the main conclusions and perspectives of this work.
4. Feature Encoding Methods
Given the extracted codebook, the purpose of this part is to project the feature set of SPD matrices onto the codebook elements. In other words, the initial feature set is expressed using the codewords contained in the codebook.
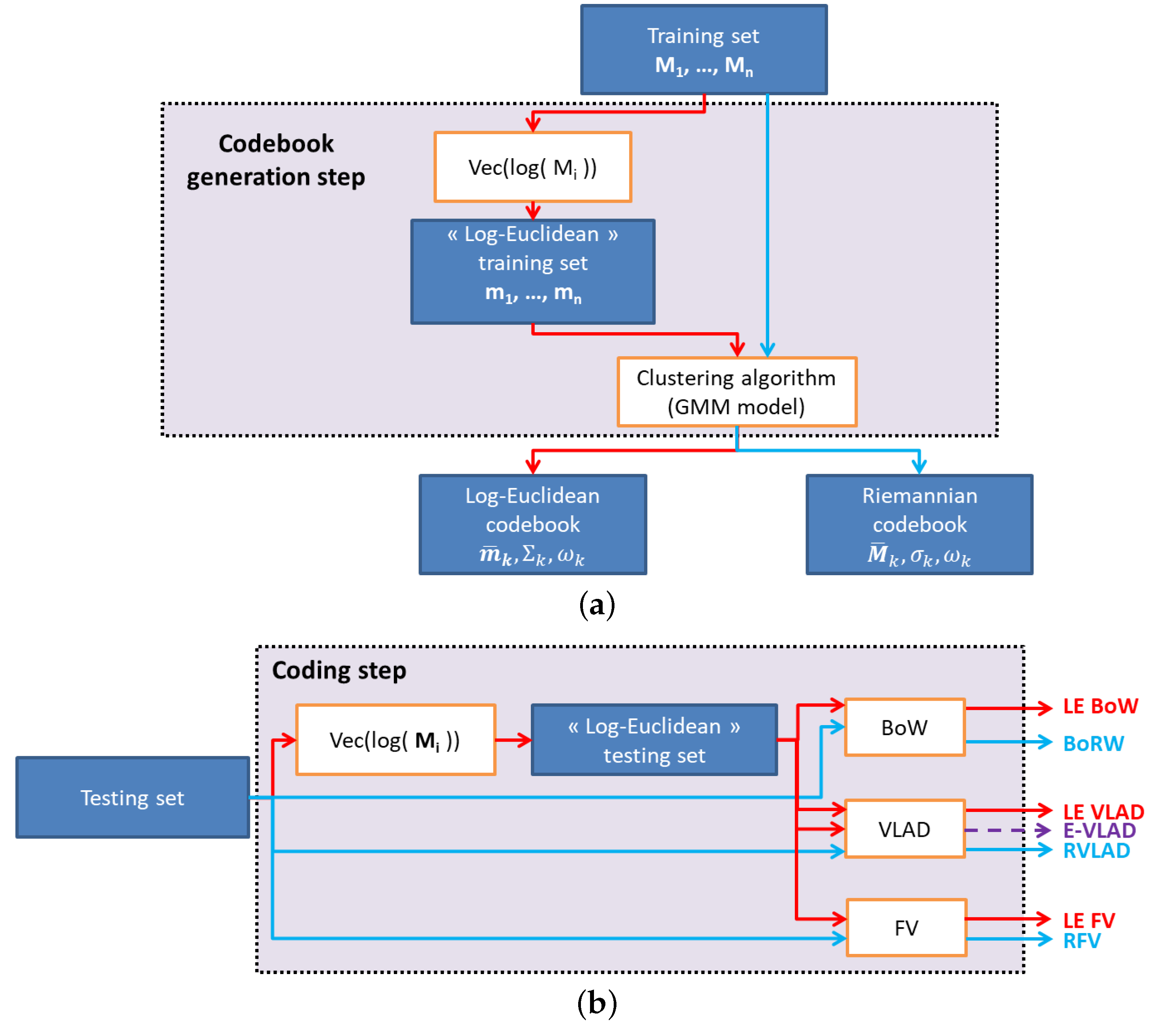
Figure 2 draws an overview of the relation between the different approaches based on the BoW, VLAD and FV models. The LE-based metric approaches appear in red while the affine invariant ones are displayed in blue. The E-VLAD descriptor is displayed in purple since it considers the Riemannian codebook combined with LE representation of the features.
4.1. Bag of Words Descriptor
One of the most common encoding methods is represented by the BoW model. With this model, a set of features is encoded in an histogram descriptor obtained by counting the number of features which are closest to each codeword of the codebook. In the beginning, this descriptor has been employed for text retrieval and categorization [
10,
55], by modeling a text with an histogram containing the number of occurrences of each word. Later on, the BoW model has been extended to visual categorization [
56], where images are described by a set of descriptors, such as SIFT features. In such case, the “words” of the codebook are obtained by considering a clustering algorithm with the standard Euclidean metric. Recently, the BoW model has been extended to features lying in a non-Euclidean space, such as SPD matrices. In this context, two approaches have been proposed based respectively on the LE and affine invariant Riemannian metrics:
the log-Euclidean bag of words (LE BoW) [
33,
35].
the bag of Riemannian words (BoRW) [
36].
These two descriptors have been employed successfully for different applications, including texture and human epithelial type 2 cells classification [
36], action recognition [
33,
35].
4.1.1. Log-Euclidean Bag of Words (LE BoW)
The LE BoW model has been considered in [
33,
35]. First, the space of covariance matrices is embedded into a vector space by considering the LE vector representation
given in (
1). With this embedding, the LE BoW model can be interpreted as the BoW model in the LE space. This means that codewords are elements of the log-Euclidean codebook detailed in
Section 3.1. Next, each observed SPD matrix
is assigned to cluster
k of closest codeword
to compute the histogram descriptor. The vicinity is evaluated here as the Euclidean distance between the LE vector representation
and the codeword
.
The LE BoW descriptor can also be interpreted by considering the Gaussian mixture model recalled in (
2). In such case, each feature
is assigned to the cluster
k, for
according to:
where
is the multivariate Gaussian distribution given in (
3). In addition, two constraints are assumed
:
the homoscedasticity assumption:
the same weight is given to all mixture components:
4.1.2. Bag of Riemannian Words (BoRW)
This descriptor has been introduced in [
36]. Contrary to the LE BoW model, the BoRW model exploits the affine invariant Riemannian metric. For that, it considers the Riemannian codebook detailed in
Section 3.2. Then, the histogram descriptor is computed by assigning each SPD matrix to the cluster
k of the closest codebook element
, the proximity being measured with the geodesic distance recalled in (
8).
As for the LE BoW descriptor, the definition of the BoRW descriptor can be obtained by the Gaussian mixture model, except that the RGD model defined in (
12) is considered instead of the multivariate Gaussian distribution. Each feature
is assigned to the cluster
k, for
according to:
In addition, the two previously cited assumptions are made, that are the same dispersion and weight are given to all mixture components.
It has been shown in the literature that the performance of BoW descriptors depends on the codebook size, best results being generally obtained for large dictionaries [
5]. Moreover, BoW descriptors are based only on the number of occurrences of each codeword from the dataset. In order to increase the classification performances, second order statistics can be considered. This is the case of VLAD and FV that are presented next.
4.2. Vectors of Locally Aggregated Descriptors
VLAD descriptors have been introduced in [
2] and represent a method of encoding the difference between the codewords and the features. For features lying in a Euclidean space, the codebook is composed by cluster centroids
obtained by clustering algorithm on the training set. Next, to encode a feature set
, vectors
containing the sum of differences between codeword and feature samples assigned to it are computed for each cluster:
The final VLAD descriptor is obtained as the concatenation of all vectors
:
To generalize this formalism to features lying in a Riemannian manifold, two theoretical aspects should be addressed carefully, which are the definition of a metric to describe how features are assigned to the codewords, and the definition of subtraction operator for these kind of features. By addressing these aspects, three approaches have been proposed in the literature:
the log-Euclidean vector of locally aggregated descriptors (LE VLAD) [
11].
the extrinsic vector of locally aggregated descriptors (E-VLAD) [
37].
the intrinsic Riemannian vector of locally aggregated descriptors (RVLAD) [
11].
4.2.1. Log-Euclidean Vector of Locally Aggregated Descriptors (LE VLAD)
This descriptor has been introduced in [
11] to encode a set of SPD matrices with VLAD descriptors. In this approach, VLAD descriptors are computed in the LE space. For this purpose, (
24) is rewritten as:
where the LE representation
of
belongs to the cluster
if it is closer to
than any other element of the LE codebook. The proximity is measured here according to the Euclidean distance between the LE vectors.
4.2.2. Extrinsic Vector of Locally Aggregated Descriptors (E-VLAD)
The E-VLAD descriptor is based on the LE vector representation of SPD matrices. However, contrary to the LE VLAD model, this descriptor uses the Riemannian codebook to define the Voronoï regions. It yields that:
where
belongs to the cluster
if it is closer to
according to the affine invariant Riemannian metric. Note also that here
is the LE vector representation of the Riemannian codebook element
.
To speed-up the processing time, Faraki et al. have proposed in [
37] to replace the affine invariant Riemannian metric by the Stein metric [
57]. For this latter, computational cost to estimate the centroid of a set of covariance matrices is less demanding than with the affine invariant Riemannian metric since a recursive computation of the Stein center from a set of covariance matrices has been proposed in [
58].
Since this approach exploits two metrics, one for the codebook creation (with the affine invariant Riemannian or Stein metric) and another for the coding step (with the LE metric), we referred it as an extrinsic method.
4.2.3. Riemannian Vector of Locally Aggregated Descriptors (RVLAD)
This descriptor has been introduced in [
11] to propose a solution for the affine invariant Riemannian metric. More precisely, the geodesic distance [
47] recalled in (
8) is considered to measure similarity between SPD matrices. The affine invariant Riemannian metric is used to define the Voronoï regions) and the Riemannian logarithm mapping [
48] is used to perform the subtraction on the manifold. It yields that for the RVLAD model, the vectors
are obtained as:
where
is the Riemannian logarithm mapping defined in (
11). Please note that the vectorization operator
is used to represent
as a vector.
As explained in [
2], the VLAD descriptor can be interpreted as a simplified non probabilistic version of the FV. In the next section, we give an explicit relationship between these two descriptors which is one of the main contribution of the paper.
4.3. Fisher Vector Descriptor
Fisher vectors (FV) are descriptors based on Fisher kernels [
59]. FV measures how samples are correctly fitted by a given generative model
. Let
, be a sample of
N observations. The FV descriptor associated to
is the gradient of the sample log-likelihood with respect to the parameters
of the generative model distribution, scaled by the inverse square root of the Fisher information matrix (FIM).
First, the gradient of the log-likelihood with respect to the model parameter vector
, also known as the Fisher score (FS)
[
59], should be computed:
As mentioned in [
5], the gradient describes the direction in which parameters should be modified to best fit the data. In other words, the gradient of the log-likelihood with respect to a parameter describes the contribution of that parameter to the generation of a particular feature [
59]. A large value of this derivative is equivalent to a large deviation from the model, suggesting that the model does not correctly fit the data.
Second, the gradient of the log-likelihood can be normalized by using the FIM
[
59]:
where
denotes the expectation over
. It yields that the FV representation of
is given by the normalized gradient vector [
5]:
As reported in previous works, exploiting the FIM
in the derivation of FV yields to excellent results with linear classifiers [
6,
7,
9]. However, the computation of the FIM might be quite difficult. It does not admit a close-form expression for many generative models. In such case, it can be approximated empirically by carrying out a Monte Carlo integration, but this latter can be costly especially for high dimensional data. To solve this issue, some analytical approximations can be considered [
5,
9].
The next part explains how the FV model can be used to encode a set of SPD matrices. Once again, two approaches are considered by using respectively the LE and the affine invariant Riemannian metrics:
4.3.1. Log-Euclidean Fisher Vectors (LE FV)
The LE FV model consists in an approach where the FV descriptors are computed in the LE space. In such case, the multivariate Gaussian mixture model recalled in (
2) is considered.
Let
be the LE representation of the set
. To compute the LE FV descriptor of
, the derivatives of the log-likelihood function with respect to
should first be computed. Let
be the soft assignment of
to the
kth Gaussian component
It yields that, the elements of the LE Fisher score (LE FS) are obtained as:
where
(resp.
) is the
dth element of vector
(resp.
). Please note that to ensure the constraints of positivity and sum-to-one for the weights
, the derivative of the log-likelihood with respect to this parameter is computed by taking into consideration the soft-max parametrization as proposed in [
9,
60]:
Under the assumption of nearly hard assignment, that is the soft assignment distribution
is sharply peaked on a single value of
k for any observation
, the FIM
is diagonal and admits a close-form expression [
9]. It yields that the LE FV of
is obtained as:
4.3.2. Riemannian Fisher Vectors (RFV)
Ilea et al. have proposed in [
40] an approach to encode a set of SPD matrices with FS based on the affine invariant Riemannian metric: the Riemannian Fisher score (RFS). In this method, the generative model is a mixture of RGDs [
39] as presented in
Section 3.2.2. By following the same procedure as before, the RFS is obtained by computing the derivatives of the log-likelihood function with respect to the distribution parameters
. It yields that [
40]:
where
is the Riemannian logarithm mapping in (
11) and
is the derivative of
with respect to
. The function
can be computed numerically by a Monte Carlo integration, in a similar way to the one for the normalization factor
(see
Section 3.2.2).
In these expressions,
represents the probability that the feature
is generated by the
kth mixture component, computed as:
By comparing (
33)–(35) with (
40)–(42), one can directly notice the similarity between the LE FS and the RFS. In these equations, vector difference in the LE FS is replaced by log map function in the RFS. Similarly, Euclidean distance in the LE FS is replaced by geodesic distance in the RFS.
In [
40], Ilea et al. have not exploited the FIM. In this paper, we propose to add this term in order to define the Riemannian Fisher vectors (RFV). To derive the FIM, the same assumption as the one given in
Section 4.3.1 should be made, i.e., the assumption of nearly hard assignment, that is the soft assignment distribution
is sharply peaked on a single value of
k for any observation
. In that case, the FIM is block diagonal and admits a close-form expression detailed in [
61]. In this paper, Zanini et al. have used the FIM to propose an online algorithm for estimating the parameters of a Riemannian Gaussian mixture model. Here, we propose to add this matrix in another context which is the derivation of a descriptor: the Riemannian FV.
First, let’s recall some elements regarding the derivation of the FIM. This block diagonal matrix is composed of three terms, one for the weight, one for the centroid and one for the dispersion.
For the weight term, the same procedure as the one used in the conventional Euclidean framework can employed [
9]. In [
61], they proposed another way to derive this term by using the notation
and observing that
belongs to a Riemannian manifold (more precisely the
-sphere
). These two approaches yield exactly to the same final result.
For the centroid term, it should be noted that each centroid is a covariance matrix which lives in the manifold of symmetric positive definite matrices. To derive the FIM associated to this term, the space should be decomposed as the product of two irreducible manifolds, i.e., where is the manifold of symmetric positive definite matrices with unitary determinant. Hence, each observed covariance matrix can be decomposed as where
- -
is a scalar element lying in .
- -
is a covariance matrix of unit determinant.
For the dispersion parameter, the notation is considered to ease the mathematical derivation. Since this parameter is real, the conventional Euclidean framework is employed to derive the FIM. The only difference is that the Euclidean distance is replaced by the geodesic one.
For more information on the derivation of the FIM for the Riemannian Gaussian mixture model, the interested reader is referred to [
61]. To summarize, the elements of the block-diagonal FIM for the Riemannian Gaussian mixture model are defined by:
where
is the
identity matrix,
and
(resp.
) are the first (resp. the second) order derivatives of the
function with respect to
.
.
Now that the FIM and the FS score are obtained for the Riemannian Gaussian mixture model, we can define the RFV by combining (40) to (42) and (44) to (47) in (31). It yields that:
Unsurprisingly, this definition of the RFV can be interpreted as a direct extension of the FV computed in the Euclidean case to the Riemannian case. In particular (37)–(39) are retrieved when the normalization factor is set to in (48), (50) and (51).
In the end, the RFVs are obtained by concatenating some, or all of the derivatives in (48)–(51). Note also that since (49) is a matrix, the vectorization operator is used to represent it as a vector.
4.3.3. Relation with VLAD
As stated before, the VLAD descriptor can be retrieved from the FV model. In this case, only the derivatives with respect to the central element ( or ) are considered. Two assumptions are also made:
the hard assignment scheme, that is:
where
are the elements assigned to cluster
and
,
the homoscedasticity assumption, that is .
By taking into account these hypotheses, it can be noticed that (
33) reduces to (
26), confirming that LE FV are a generalization of LE VLAD descriptors. The same remark can be done for the approach exploiting the affine invariant Riemannian metric where the RFV model can be viewed as an extension of the RVLAD model. The proposed RFV gives a mathematical explanation of the RVLAD descriptor which has been introduced in [
11] by an analogy between the Euclidean space (for the VLAD descriptor) and the Riemannian manifold (for the RVLAD descriptor).
4.4. Post-Processing
Once the set of SPD matrices is encoded by one of the previously exposed coding methods (BoW, VLAD, FS or FV), a post-processing step is classically employed. In the framework of feature coding, the post-processing step consists in two possible normalization steps: the power and normalization. These operations are detailed next.
4.4.1. Power Normalization
The purpose of this normalization method is to correct the independence assumption that is usually made on the image patches [
7]. For the same vector
, its power-normalized version
is obtained as:
where
, and
is the signum function and
is the absolute value. In practice,
is set to
, as suggested in [
9].
4.4.2. Normalization
This normalization method has been proposed in [
6] to minimize the influence of the background information on the image signature. For a vector
, its normalized version
is computed as:
where
is the
norm.
Depending on the considered coding method, one or both normalization steps are applied. For instance, for VLAD, FS and FV-based methods, both normalizations are used [
36,
40], while for BoW based methods only the
normalization is considered [
33].
4.5. Synthesis
Table 1 draws an overview of the different coding methods. As seen before, two metrics can be considered, namely the LE and the affine invariant Riemannian metrics. This yields to two Gaussian mixture models: a mixture of multivariate Gaussian distributions and a mixture of Riemannian Gaussian distributions. These mixture models are the central point in the computation of the codebook which are further used to encode the features. In this table and in the following ones, the proposed coding methods are displayed in gray.
As observed, a direct parallel can be drawn between the different coding methods (BoW, VLAD, FS and FV). More precisely, it is interesting to note how the conventional coding methods used for descriptors lying in are adapted to covariance matrix descriptors.
6. Conclusions
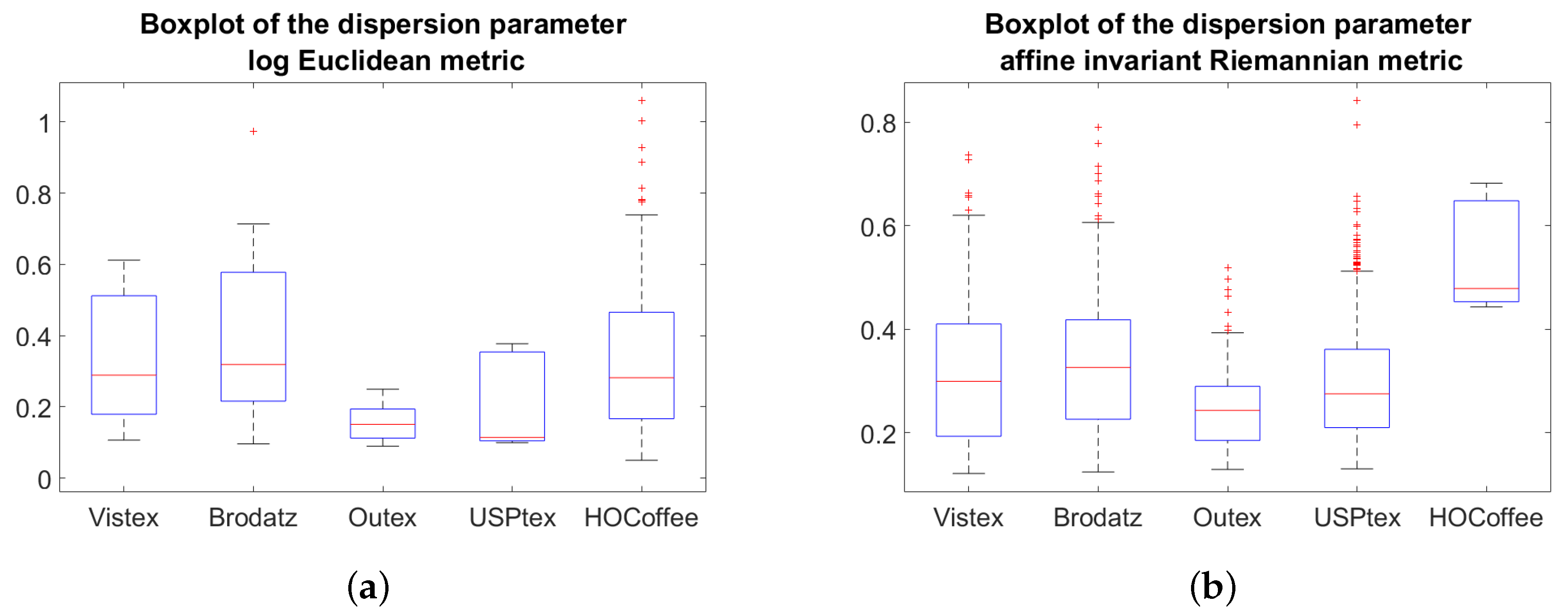
Starting from the Gaussian mixture model (for the LE metric) and the Riemannian Gaussian mixture model (for the affine invariant Riemannian metric), we have proposed a unified view of coding methods. The proposed LE FV and RFV can be interpreted as a generalization of the BoW and VLAD-based approaches. The experimental results have shown that: (i) the use of the FIM in the derivation of the FV allows to improve the classification accuracy, (ii) the proposed FV descriptors outperform the state-of-the-art BoW and VLAD-based descriptors, and (iii) the descriptors based on the LE metric lead to better classification results than those based on the affine invariant Riemannian metric. For this latter observation, the gain observed with the LE metric comes better from the anistropicty of the Gaussian mixture model than on the metric itself. For isotropic models, FV described issued from the affine invariant Riemannian metric leads to better results than those obtained with the LE metric. It is hence expected that the definition of a FV issued from an anistropic Riemannian Gaussian mixture model will improve the performance. This point represents one of the main perspective of this research work.
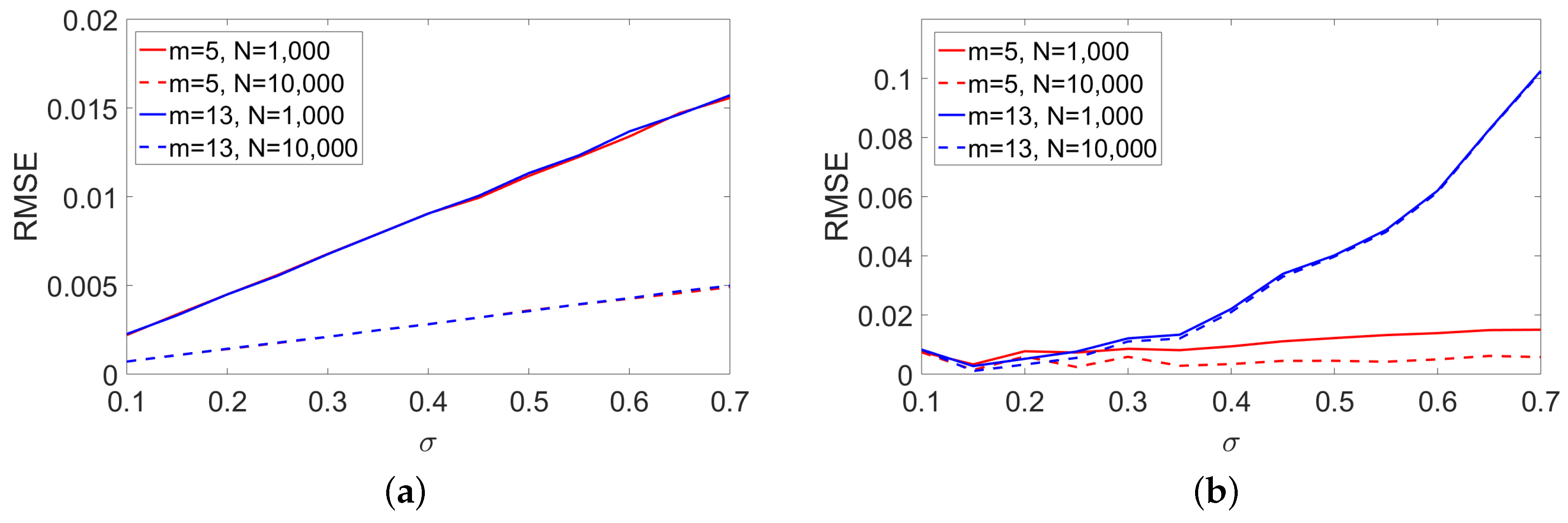
For larger covariance matrices, the last experiment on head pose classification has illustrated the limits of the RFV issued from the Riemannian Gaussian mixture model. It has been shown that the root mean square error of the dispersion parameter can be large for high value of (). In that case, the LE FV are a good alternative to the RFV.
Future works will include the use of the proposed FV coding for covariance matrices descriptors in a hybrid classification architecture which will combine them with convolutional neural networks [
17,
18,
19].










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}