
HOSVD-Based Algorithm for Weighted Tensor Completion


Department of Mathematics, University of California, Los Angeles, CA 90095, USA
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
J. Imaging 2021, 7(7), 110; https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging7070110
Submission received: 15 May 2021
/
Revised: 17 June 2021
/
Accepted: 2 July 2021
/
Published: 7 July 2021
Abstract
:Matrix completion, the problem of completing missing entries in a data matrix with low-dimensional structure (such as rank), has seen many fruitful approaches and analyses. Tensor completion is the tensor analog that attempts to impute missing tensor entries from similar low-rank type assumptions. In this paper, we study the tensor completion problem when the sampling pattern is deterministic and possibly non-uniform. We first propose an efficient weighted Higher Order Singular Value Decomposition (HOSVD) algorithm for the recovery of the underlying low-rank tensor from noisy observations and then derive the error bounds under a properly weighted metric. Additionally, the efficiency and accuracy of our algorithm are both tested using synthetic and real datasets in numerical simulations.
1. Introduction
In many data-rich domains such as computer vision, neuroscience, and social networks, tensors have emerged as a powerful paradigm for handling the data deluge. In recent years, tensor analysis has gained more and more attention. To a certain degree, tensors can be viewed as the generalization of matrices to higher dimensions, and thus multiple questions from matrix analysis extend naturally to tensors. Similar to matrix decomposition, the problem of tensor decomposition (decomposing an input tensor into several less complex components) has been widely studied both in theory and application (see e.g., [1,2,3]). Thus far, the problem of low-rank tensor completion, which aims to complete missing or unobserved entries of a low-rank tensor, is one of the most actively studied problems (see e.g., [4,5,6,7]). It is noteworthy that, as caused by various unpredictable or unavoidable reasons, multidimensional datasets are commonly raw and incomplete, and thus often only a small subset of entries of tensors are available. It is, therefore, natural to address the above issue using tensor completion in modern data-driven applications, in which data are naturally represented as a tensor, such as image/video inpainting [5,8], link-prediction [9], and recommendation systems [10], to name a few.
In the past few decades, the matrix completion problem, which is a special case of tensor completion, has been extensively studied. In matrix completion, there are mature algorithms [11], theoretical foundations [12,13,14] and various applications [15,16,17,18] that pave the way for solving the tensor completion problem in high-order tensors. Recently, Foucart et al. [19] proposed a simple algorithm for matrix completion for general deterministic sampling patterns, and raised the following questions: given a deterministic sampling pattern and corresponding (possibly noisy) observations of the matrix entries, what type of recovery error can we expect? In what metric? How can we efficiently implement recovery? These were investigated in [19] by introducing an appropriate weighted error metric for matrix recovery of the form , where M is the true underlying low-rank matrix, refers to the recovered matrix, and H is a best rank-1 matrix approximation for the sampling pattern . In this regard, similar questions arise for the problem of tensor completion with deterministic sampling patterns. Unfortunately, as is often the case, moving from the matrix setting to the tensor setting presents non-trivial challenges, and notions such as rank and SVD need to be re-defined and re-evaluated. We address these extensions for the completion problem here.
Motivated by the matrix case, we propose an appropriate weighted error metric for tensor recovery of the form , where is the true underlying low-rank tensor, is the recovered tensor, and is an appropriate weight tensor. For the existing work, the error is only limited to the form , which corresponds to the case that all the entries of are 1, where can be considered to be a CP rank-1 tensor. It motivates us to rephrase the questions mentioned above as follows.
Main questions. Given a sampling pattern , and noisy observations on , for what rank-one weight tensor can we efficiently find a tensor so that is small compared to ? And how can we efficiently find such weight tensor , or determine that a fixed has this property?
1.1. Contributions
Our main goal is to provide an algorithmic tool, theoretical analysis, and numerical results that address the above questions. In this paper, we propose a simple weighted Higher Order Singular Value Decomposition (HOSVD) method. Before we implement the weighted HOSVD algorithm, we first appropriately approximate the sampling pattern with a rank one tensor . We can achieve high accuracy if is small, where denotes the element-wise inverse. Finally, we present empirical results on synthetic and real datasets. The simulation results show that when the sampling pattern is non-uniform, the use of weights in the weighted HOSVD algorithm is essential, and the results of the weighted HOSVD algorithm can provide a very good initialization for the total variation minimization algorithm which can dramatically reduce the iterative steps without lose the accuracy. In doing so, we extend the weighted matrix completion results of [19] to the tensor setting.
1.2. Organization
The paper is organized as follows. In Section 2, we give a brief review of related work and concepts for tensor analysis, instantiate notations, and state the tensor completion problem under study. Our main results are stated in Section 3 and the proofs are provided in Appendix A and Appendix B. The numerical results are provided and discussed in Section 4.
2. Related Work, Background, and Problem Statement
In this section, we give a brief overview of the works that are related to ours, introduce some necessary background information about tensors, and finally give a formal statement of tensor completion problem under study. The related work can be divided into two lines: that based on matrix completion problems, which leads to a discussion of weighted matrix completion and related work, and that based on tensor analysis, in which we focus on CP and Tucker decompositions.
2.1. Matrix Completion
The matrix completion problem is to determine a complete matrix M from its partial entries on a subset . We use to denote the matrix whose entries are 1 on and 0 elsewhere so that the entries of are equal to those of the matrix M on , and are equal to 0 elsewhere, where ⊡ denotes the Hadamard product. There are various works that aim to understand matrix completion with respect to the sampling pattern . For example, the works in [20,21,22] relate the sampling pattern to a graph whose adjacency matrix is given by and show that as long as the sampling pattern is suitably close to an expander, efficient recovery is possible when the given matrix M is sufficiently incoherent. Mathematically, the task of understanding when there exists a unique low-rank matrix M that can complete as a function of the sampling pattern is very important. In [23], the authors give conditions on under which there are only finitely many low-rank matrices that agree with , and the work of [24] gives a condition under which the matrix can be locally uniquely completed. The work in [25] generalized the results of [23,24] to the setting where there is sparse noise added to the matrix. The works [26,27] study when rank estimation is possible as a function of a deterministic pattern . Recently, [28] gave a combinatorial condition on that characterizes when a low-rank matrix can be recovered up to a small error in the Frobenius norm from observations in and showed that nuclear minimization will approximately recover M whenever it is possible, where the nuclear norm of M is defined as with the non-zero singular values of M.
All the works mentioned above are in the setting where recovery of the entire matrix is possible, but in many cases full recovery is impossible. Ref. [29] uses an algebraic approach to answer the question of when an individual entry can be completed. There are many works (see e.g., [30,31]) that introduce a weight matrix for capturing the recovery results of the desired entries. The work [21] shows that, for any weight matrix, H, there is a deterministic sampling pattern and an algorithm that returns using the observation such that is small. The work [32] generalizes the algorithm in [21] to find the “simplest” matrix that is correct on the observed entries. Succinctly, their works give a way of measuring which deterministic sampling patterns, , are “good” with respect to a weight matrix H. In contrast to these two works, [19] is interested in the problem of whether one can find a weight matrix H and create an efficient algorithm to find an estimate for an underlying low-rank matrix M from a sampling pattern and noisy samples such that is small.
In particular, one of our theoretical results is that we generalize the upper bounds for weighted recovery of low-rank matrices from deterministic sampling patterns in [19] to the upper bound of tensor weighted recovery. The details of the connection between our result and the matrix setting result in [19] is discussed in Section 3.
2.2. Tensor Completion Problem
Tensor completion is the problem of filling in the missing elements of partially observed tensors. Similar to the matrix completion problem, low rankness is often a necessary hypothesis to restrict the degrees of freedom of the missing entries for the tensor completion problem. Since there are multiple definitions of the rank of a tensor, this completion problem has several variations.
The most common tensor completion problems [5,33] may be summarized as follows (we will define the different ranks subsequently, see further on in this section).
Definition 1
(Low-rank tensor completion (LRTC) [7]). Given a low-rank (CP rank, Tucker rank, or other ranks) tensor and sampling pattern Ω, the low-rank completion of is given by the solution of the following optimization problem:
where denotes the specific tensor rank assumed at the beginning.
In the literature, there are many variants of LRTC but most of them are based on the following questions:
- (1)
- (2)
- (3)
- Under what conditions can one expect to achieve a unique and exact completion (see e.g., [34])?
In the rest of this section, we instantiate some notations and review basic operations and definitions related to tensors. Then some tensor decomposition-based algorithms for tensor completion are stated. Finally, a formal problem statement under study will be presented.
2.2.1. Preliminaries and Notations
Tensors, matrices, vectors, and scalars are denoted in different typeface for clarity below. In the sequel, calligraphic boldface capital letters are used for tensors, capital letters are used for matrices, lower boldface letters for vectors, and regular letters for scalars. The set of the first d natural numbers is denoted by . Let and , represents the element-wise power operator, i.e., . denotes the tensor with 1 on and 0 otherwise. We use to denote the tensor with for all . Moreover, we say that if the entries of are sampled randomly with the sampling set such that with probability . We include here some basic notions relating to tensors, and refer the reader to e.g., [2] for a more thorough survey.
Definition 2
(Tensor). A tensor is a multidimensional array. The dimension of a tensor is called the order (also called the mode). The space of real tensors of order n and size is denoted as . The elements of a tensor are denoted by .
An n-order tensor can be matricized in n ways by unfolding it along each of the n modes. The definition for the matricization of a given tensor is stated below.
Definition 3
(Matricization/unfolding of a tensor). The mode-k matricization/unfolding of tensor is the matrix, which is denoted as , whose columns are composed of all the vectors obtained from by fixing all indices except for the k-th dimension. The mapping is called the mode-k unfolding operator.
Example 1.
Let with the following frontal slices:
then the three mode-n matricizations are
Definition 4
(Folding operator). Suppose that is a tensor. The mode-k folding operator of a matrix , denoted as , is the inverse operator of the unfolding operator.
Definition 5
(∞-norm). Given , the norm is defined as
The unit ball under the ∞-norm is denoted by .
Definition 6
(Frobenius norm). The Frobenius norm for a tensor is defined as
Definition 7
(Max-norm for matrix). Given , the max-norm for X is defined as
Definition 8
(Product operations).
- Outer product: Let . The outer product among these n vectors is a tensor defined as:The tensor is of rank one if it can be written as the outer product of n vectors.
- Kronecker product of matrices: The Kronecker product of and is denoted by . The result is a matrix of size defined by
- Khatri-Rao product: Given matrices and , their Khatri-Rao product is denoted by . The result is a matrix of size defined bywhere and stand for the i-th column of A and B respectively.
- Hadamard product: Given , their Hadamard product is defined by element-wise multiplication, i.e.,
- Mode-k product: Let and , the multiplication between on its mode-k with U is denoted as with
Given , we use to denote the CP representation of tensor , i.e.,
where means the j-th column of the matrix M.
Different from the case of matrices, the rank of a tensor is not presently well understood. Additionally, the task of computing the rank of a tensor is an NP-hard problem [40]. Next we introduce an alternative definition of the rank of a tensor, which is easy to compute.
Definition 10
(Tensor Tucker rank [39]). Let . The tuple is called the Tucker rank of the tensor , where . We use to denote the cone of tensors with Tucker rank .
2.2.2. CP-Based Method for Tensor Completion
The CP decomposition was first proposed by Hitchcock [1] and further discussed in [43]. The formal definition of the CP decomposition is the following.
Definition 11
(CP decomposition). Given a tensor , its CP decomposition is an approximation of n loading matrices , , such that
where r is a positive integer denoting an upper bound of the rank of and is the i-th column of matrix . If we unfold along its k-th mode, we have
Here the ≈ sign means that the algorithm should find an optimal with the given rank such that the distance between the low-rank approximation and the original tensor, , is minimized.
Given an observation set , the main idea to implement tensor completion for a low-rank tensor is to conduct imputation based on the equation
where is the interim low-rank approximation based on the CP decomposition, is the recovered tensor used in next iteration for decomposition, and . For each iteration, we usually estimate the matrices using the alternating least squares optimization method (see e.g., [44,45,46]).
2.2.3. HOSVD-Based Method for Tensor Completion
The Tucker decomposition was proposed by Tucker [47] and further developed in [48,49].
Definition 12
(Tucker decomposition). Given an n-order tensor , its Tucker decomposition is defined as an approximation of a core tensor multiplied by n factor matrices , along each mode, such that
where is a positive integer denoting an upper bound of the rank of the matrix .
If we unfold along its k-th mode, we have
Tucker decomposition is a widely used tool for tensor completion. To implement Tucker decomposition, one popular method is called the higher-order SVD (HOSVD) [47]. The main idea of HOSVD is:
- Unfold along mode k to obtain matrix ;
- Find the economic SVD decomposition of ;
- Set to be the first columns of ;
- .
If we want to find a Tucker rank approximation for the tensor via HOSVD process, we just replace by the first columns of .
2.2.4. Tensor Completion Problem under Study
In our setting, it is supposed that is an unknown tensor in or . Fix a sampling pattern and the weight tensor . Our goal is to design an algorithm that gives provable guarantees for a worst-case , even if it is adapted to .
In our algorithm, the observed data are , where are i.i.d. Gaussian random variables. From the observations, the goal is to learn something about . In this paper, instead of measuring our recovered results with the underlying true tensor in a standard Frobenius norm , we are interested in learning using a weighted Frobenius norm, i.e., to develop an efficient algorithm to find so that
is as small as possible for some weight tensor . When measuring the weighted error, it is important to normalize appropriately to understand the meaning of the error bounds. In our results, we always normalize the error bounds by . It is noteworthy that
which gives a weighted average of the per entry squared error. Generally, our problem can be formally stated below.
| Problem: Weighted Universal Tensor Completion Parameters:
Goal: Design an efficient algorithm with the following guarantees:
|
Remark 1
(Strictly positive ). The requirement that is strictly greater than zero is a generic condition. In fact, if for some , some mode k with index of is zero, then we can reduce the problem to a smaller one by ignoring that mode k with index .
3. Main Results
In this section, we state informal versions of our main results. With fixed sampling pattern and weight tensor , we can find by solving the following optimization problem:
or
where with
It is known that solving (2) is NP-hard [40]. However, there are some polynomial time algorithms to find approximate solutions for (2) such that the approximation is (empirically) close to the actual solution of (2) in terms of the Frobenius norm. In our numerical experiments, we solve (2) via the CP-ALS algorithm [43]. To solve (3), we use the HOSVD process [48]. Assume that has Tucker rank . Let
and set to be the left singular vector matrix of . Then the estimated tensor is of the form
In the following, we call this the weighted HOSVD algorithm.
3.1. General Upper Bound
Suppose that the optimal solution for (2) or (3) can be found, we would like to give an upper bound estimations for with some proper weight tensor .
Theorem 1.
Let have strictly positive entries, and fix . Suppose that has rank r for problem (2) or Tucker rank for problem (3), and let be the optimal solutions for (2) or (3). Suppose that . Then with probability at least over the choice of ,
Recall here, and as defined in Section 2.2.1 and .
Notice that the upper bound in Theorem 1 is for the optimal output for problems (2) and (3), which is general. However, the upper bound in Theorem 1 contains no rank information of the underlying tensor . To introduce the rank information of the underlying tensor , we restrict our analysis for Problem (3) by considering the HOSVD process in the sequel.
3.2. Results for Weighted HOSVD Algorithm
In this section, we begin by giving a general upper bound for the weighted HOSVD algorithm.
3.2.1. General Upper Bound for Weighted HOSVD
Theorem 2
(Informal, see Theorem A1). Let have strictly positive entries, and fix . Suppose that has Tucker rank . Suppose that and let be the estimate of the solution of (3) via the HOSVD process. Then
with high probability over the choice of , where
and means that for some universal constant .
Remark 2.
The upper bound in [19] suggests , where and , where is obtained by considering the truncated SVD decompositions. Notice that in our result, when , the upper bound becomes with . Since in our work is much bigger than the in [19], the bound in our work is weaker than the one in [19]. The reason is that in order to obtain a general bound for all tensor, the fact that the optimal approximations for a given matrix in the spectral norm and Frobenious norm are the same cannot be applied.
3.2.2. Case Study: When
To understand the bounds mentioned above, we also study the case when such that is small for . Even though the samples are taken randomly in this case, our goal is to understand our upper bounds for deterministic sampling pattern . To make sure that is small, we need to assume that each entry of is not too small. For this case, we have the following main results.
Theorem 3
(Informal, see Theorems A2 and A7). Let be a CP rank-1 tensor so that for all we have . Suppose that .
- Upper bound: Then the following holds with high probability.For our weighted HOSVD algorithm , for any Tucker tensor with , returns so that with high probability over the choice of ,where and .
- Lower bound: If additionally, is flat (the entries of are close), then for our weighted HOSVD algorithm , there exists some so that with probability at least over the choice of ,where , , and is some constant to measure the “flatness" of .
Remark 3.
The formal statements in Theorems A2 and A7 are more general than the statements in Theorem 3.
4. Experiments
4.1. Simulations for Uniform Sampling Pattern
In this section, we test the performance of our weighted HOSVD algorithm when the sampling pattern arises from uniform random sampling. Consider a tensor of the form , where and . Let be a Gaussian random tensor with and be the sampling pattern set according to uniform sampling. In this simulation, we compare the results of numerical experiments for using the HOSVD algorithm to solve
and
where and .
First, we generate a synthetic sampling set with sampling rate SR and find a weight tensor by solving
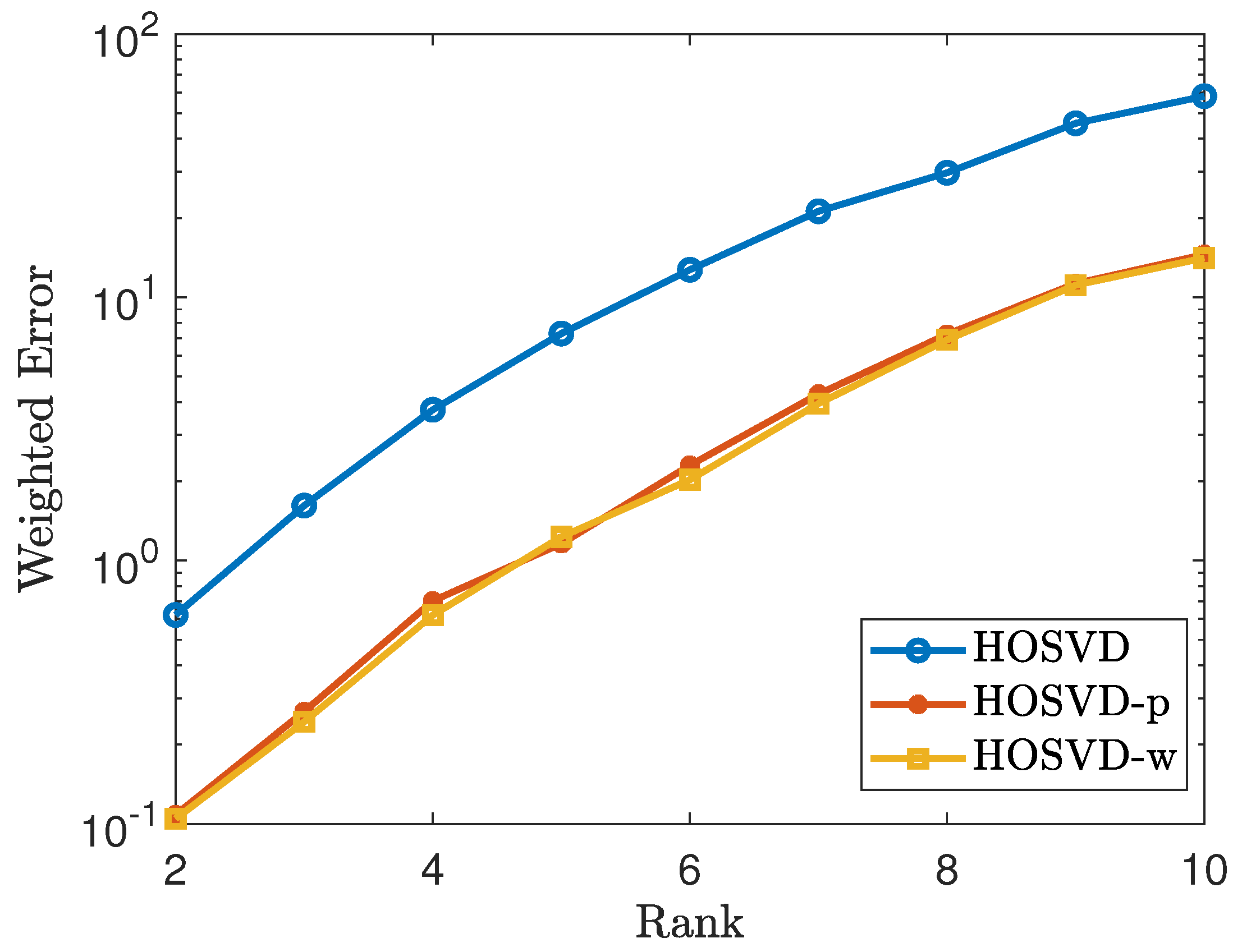
via the alternating least squares method for the non-negative CP decomposition. Next, we generate synthetic tensors of the form with with , where , and r varies from 2 to 10. Then we add mean zero Gaussion random noise with variance so that a new tensor is generated, which is denoted by . Then we solve the tensor completion problems (4), (5) and (6) by the HOSVD procedure. For each fixed low-rank tensor, we average over 20 tests. We measure error using the weighted Frobenius norm. The simulation results are reported in Figure 1 and Figure 2. Figure 1 shows the results for the tensor of size and Figure 2 shows the results for the tensor of size , where the weighted error is of the form . These figures demonstrate that using our weighted samples performs more efficiently than using the original samples. For the uniform sampling case, the p weighted samples and weighted samples exhibit similar performance.
4.2. Simulation for Non-Uniform Sampling Pattern
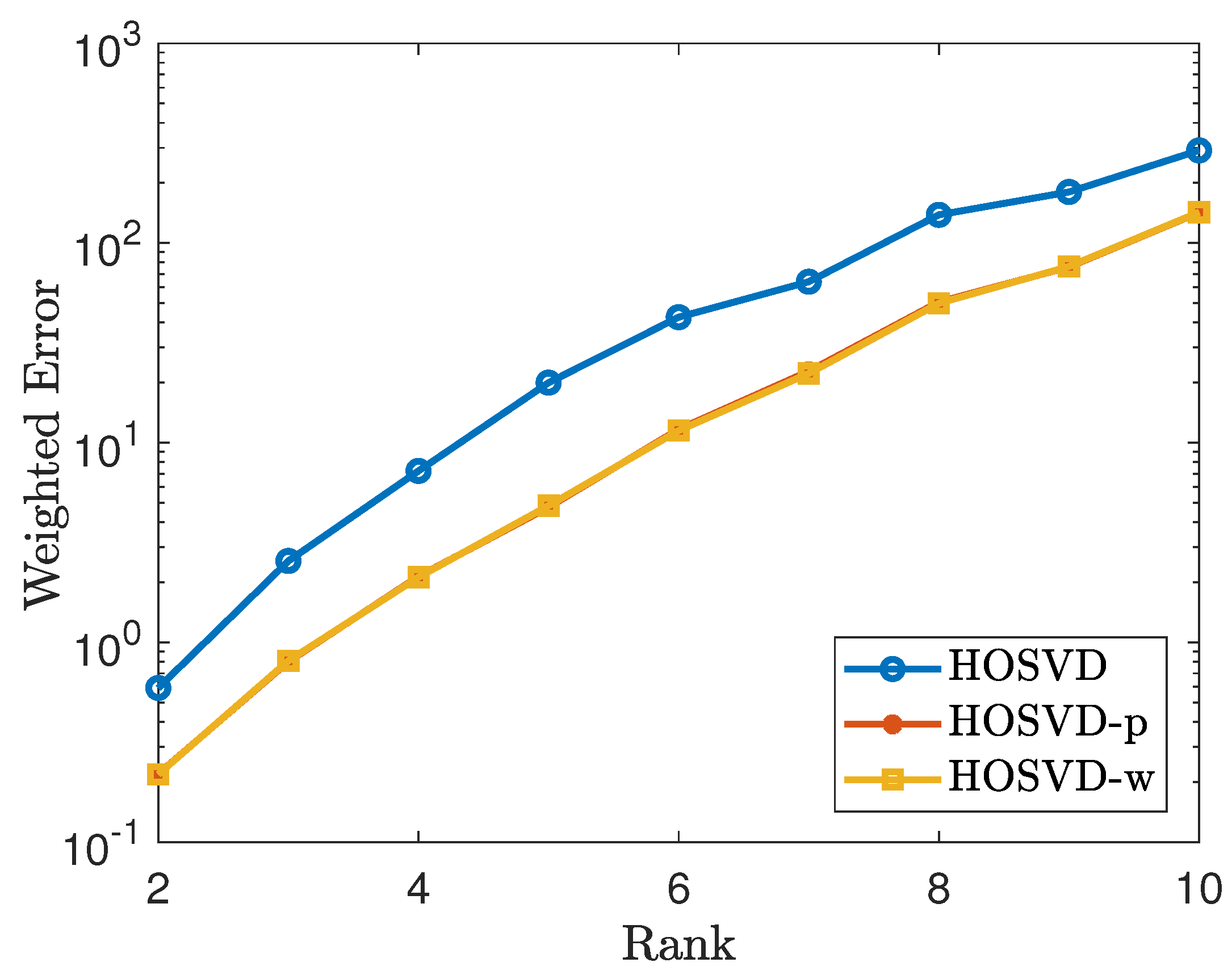
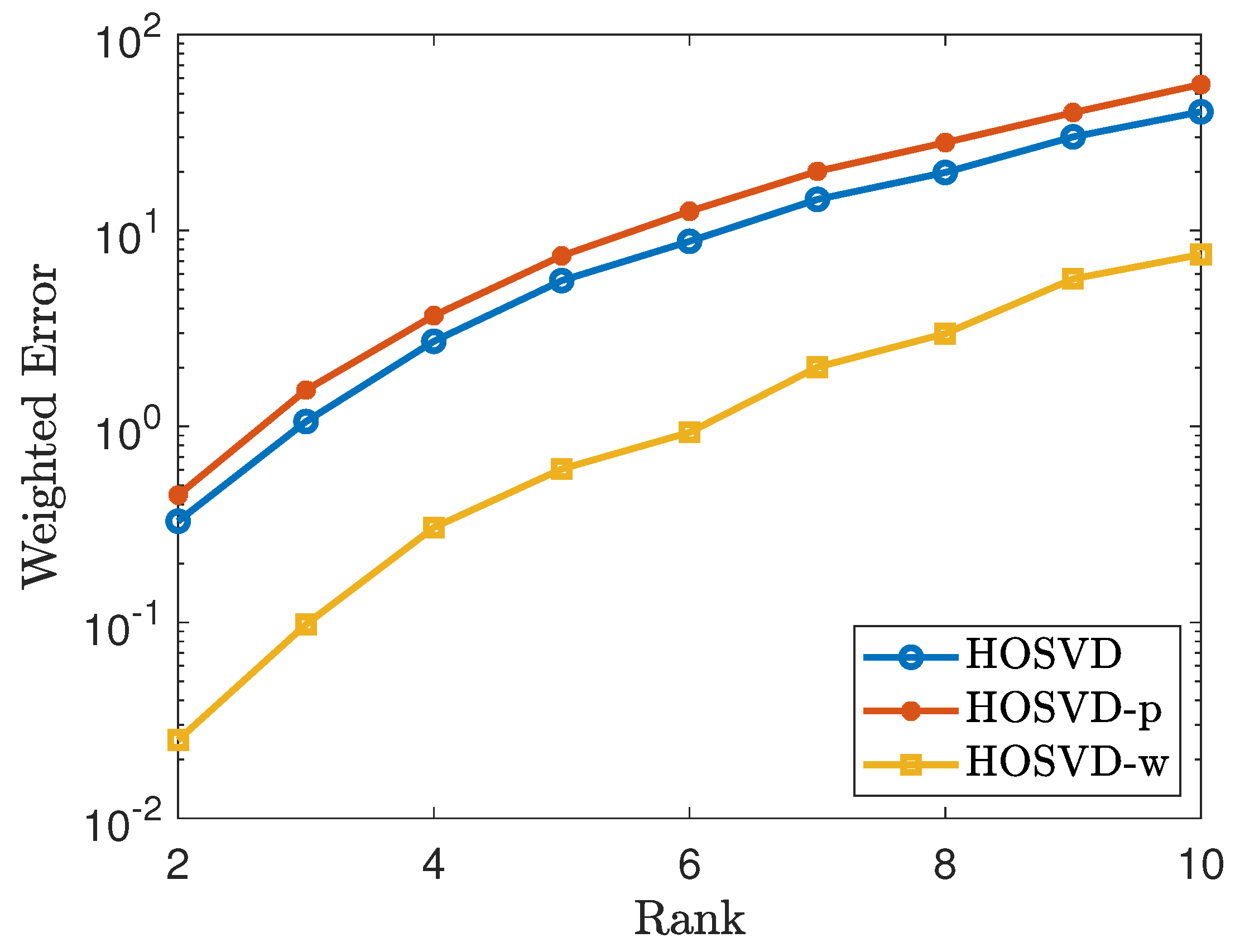
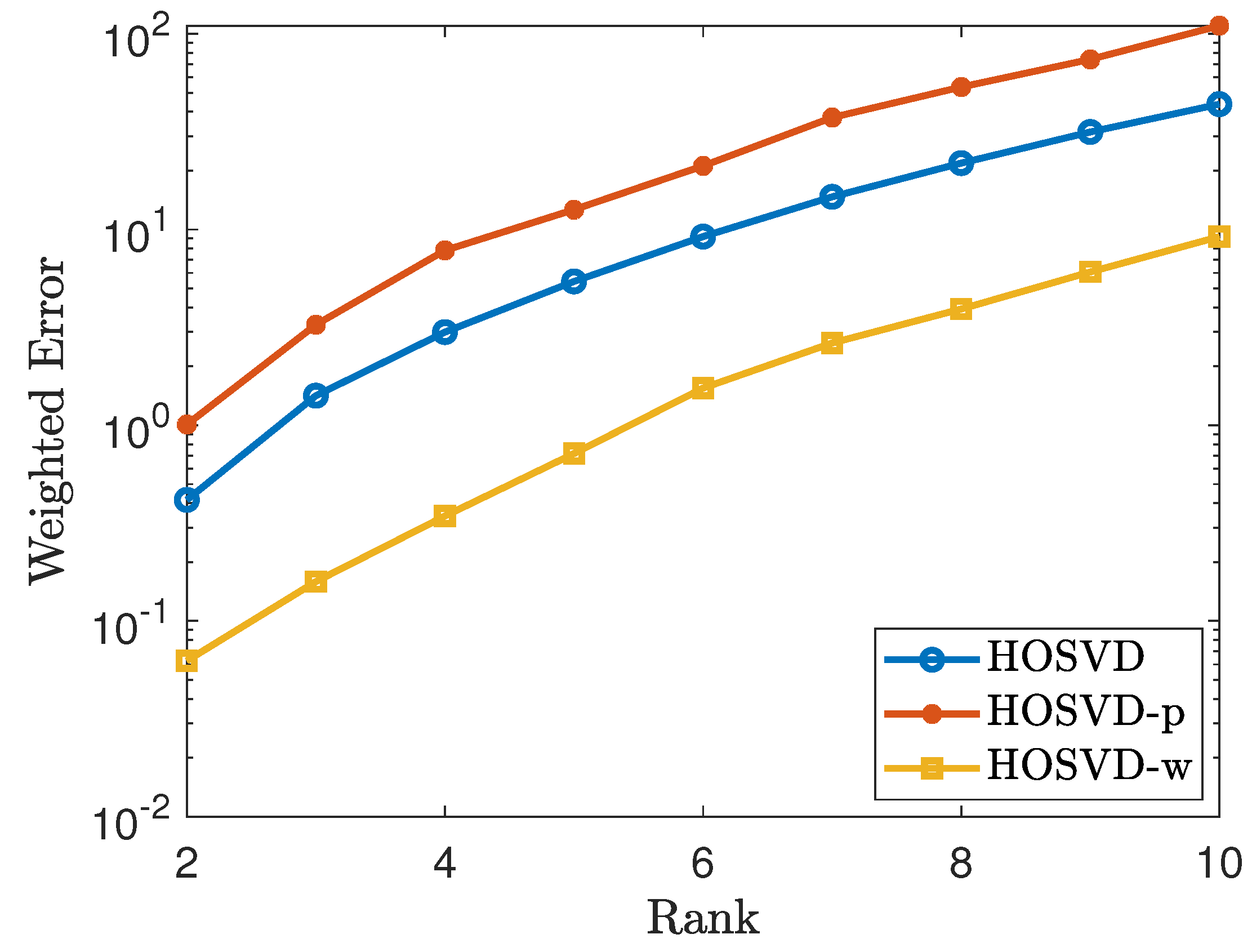
To generate a non-uniform sampling pattern with sampling rate , we first generate a CP rank 1 tensor of the form , where . Let . Then we repeat the process as in Section 4.1. The simulation results are shown in Figure 3 and Figure 4. As shown in figures, the results using our proposed weighted samples perform more efficiently than using the p weighted samples.
Remark 4.
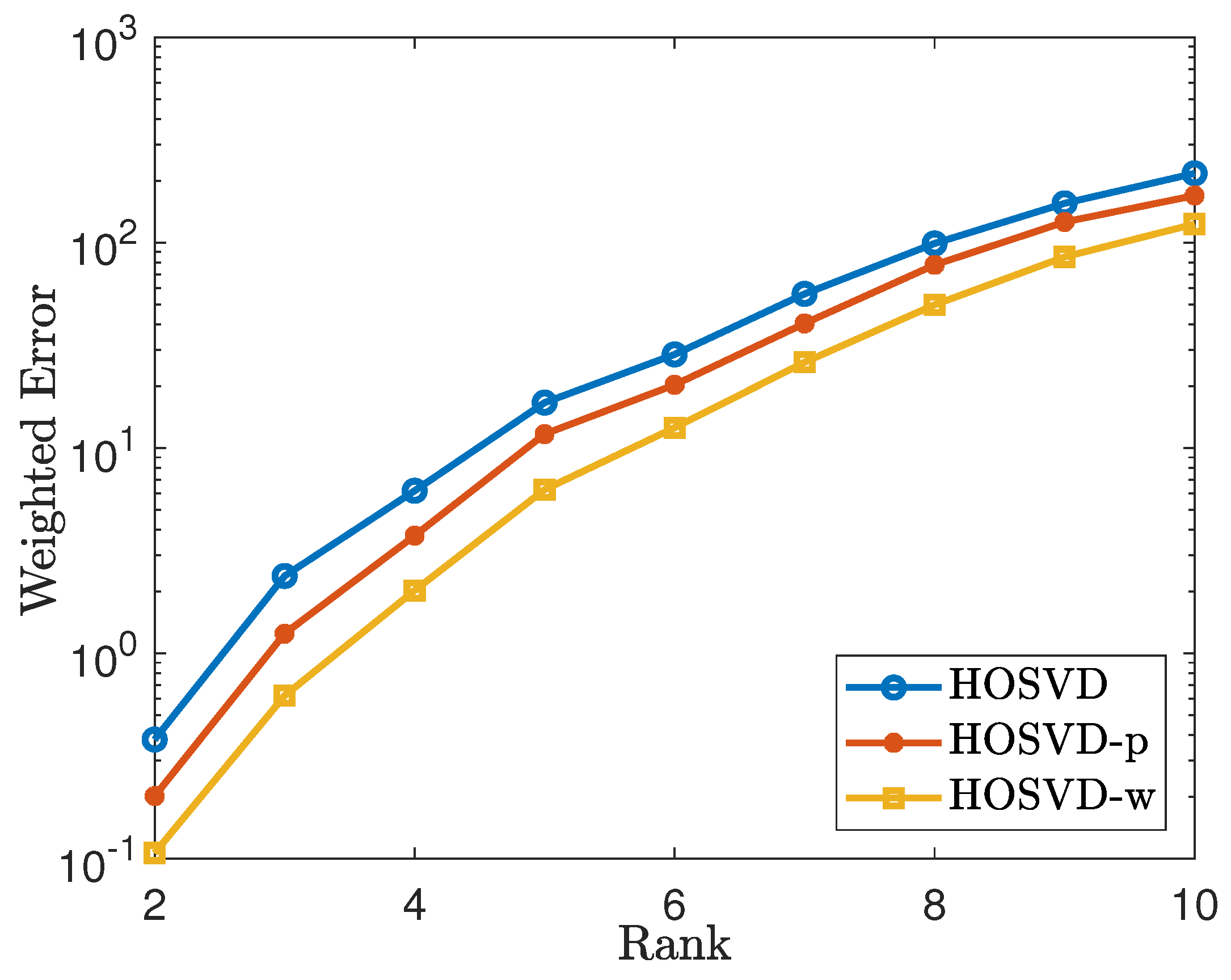
When we use the HOSVD procedure to solve (4), (5), and (6), we need (an estimate of) the Tucker rank as input. Instead of inputting the real rank of the true tensor, we could also use the rank that is estimated by considering the decay of the singular values for the unfolded matrices of the sampled tensor as the input rank, which we call SV-rank. The simulation results for the non-uniform sampling pattern with SV-rank as input are reported in Figure 5. The simulation shows that the weighted HOSVD algorithm performs more efficiently than using the p weighted samples or the original samples. Comparing Figure 5 with Figure 3, we could observe that using the estimated rank as input for HOSVD procedure performs even better than using the real rank as input. This observation motivates a way to find a “good" rank as input for HOSVD procedure.
Remark 5.
We only provide guarantees on the performance in the weighted Frobenius norm, (as we report the weighted error ), our procedures exhibit good empirical performance even in the usual relative error when the Tucker rank of the tensor is relatively low. However, we observe that the advantages of weighted HOSVD scheme tend to be diminished in terms of relative error when the Tucker rank increases. This result is not surprising since the entries are treated unequally in scheme (6). Therefore we leave the investigation on relative error and the tensor rank for future work.
4.3. Test for Real Data
In this section, we test our weighted HOSVD algorithm for tensor completion on three videos, see [50]. The dataset is the tennis-serve data from an Olympic Sports Dataset [51]. One can download the dataset from http://vision.stanford.edu/Datasets (accessed date 10 May 2021). There are a lot of videos in the zip file and we only choose three of them: “d2P_zx_JeoQ_00120_00515.seq” (video 1), “gs3sPDfbeg4_00082_00229.seq”(video 2), and “VADoc-AsyXk_00061_ 0019.seq” (video 3). The three videos are color video. In our simulation, we use the same setup as the one in [50], and choose 30 frames evenly from each video. For each frame, the size is scaled to , so each video is transformed into a 4-D tensor data of size . The first frame of each video after preprocessing is illustrated in Figure 6.
We implement the experiments for different sampling rates of , , , and to generate uniform and non-uniform sampling patterns . In our implementation, we use the SV-rank of as the input rank. According to the generated sampling pattern, we find a weight tensor and find estimates and by considering (4) and (6) respectively, using the input Tucker rank . The entries on and are forced to be the observed data. The Signal to Noise Ratio (SNR)
are computed and the simulation results are reported in Table 1 and Table 2. As shown in the tables, applying HOSVD process to (6) can give a better result than applying HOSVD process to (4) directly regardless of the uniformity of the sampling pattern.
Finally, we test the proposed weighted HOSVD algorithm on real candle video data named “candle_4_A” [52] (The dataset can be downloaded from the Dynamic Texture Toolbox in http://0-www-vision-jhu-edu.brum.beds.ac.uk/code/ (accessed date 10 May 2021). We have tested the relation between the relative errors and the sampling rates using as the input rank for HOSVD algorithm. The relative errors are presented in Figure 7. The simulation results also show that the proposed weighted HOSVD algorithm can implement tensor completion efficiently.
4.4. The Application of Weighted HOSVD on Total Variation Minimization
As shown in the previous simulations, the weighted HOSVD decomposition can provide better results for tensor completion by comparing with HOSVD. There are a bunch of algorithms that are Sensitive to initialization. Additionally, real applications may have higher requirements for accuracy. Therefore, it is meaningful to combine our weighted HOSVD with other algorithms in order to further improve the performance. In this section, we would consider the application of weighted HOSVD decomposition on the total variation minimization algorithm. As a traditional approach, the total variation minimization (TVM), is broadly applied in studies about image recovery and denoising. While the earliest research could trace back to 1992 [53]. The later studies combined TVM and other low rank approximation algorithms such as Nuclear Norm Minimization (see e.g., [54,55,56]) and HOSVD (e.g., [57,58,59]) in order to achieve better performance in image and video completion tasks.
Motivated by the matrix TV minimization, we proposed the tensor TV minimization which is summarized in Algorithm 1. In Algorithm 1, the Laplacian operator computes the divergence of all-dimension gradients for each entry of the tensor. The shrink operator simply moves the input towards 0 with distance , or formally defined as:
For the initialization of in Algorithm 1, we assign to be the output of the result from HOSVD-w.
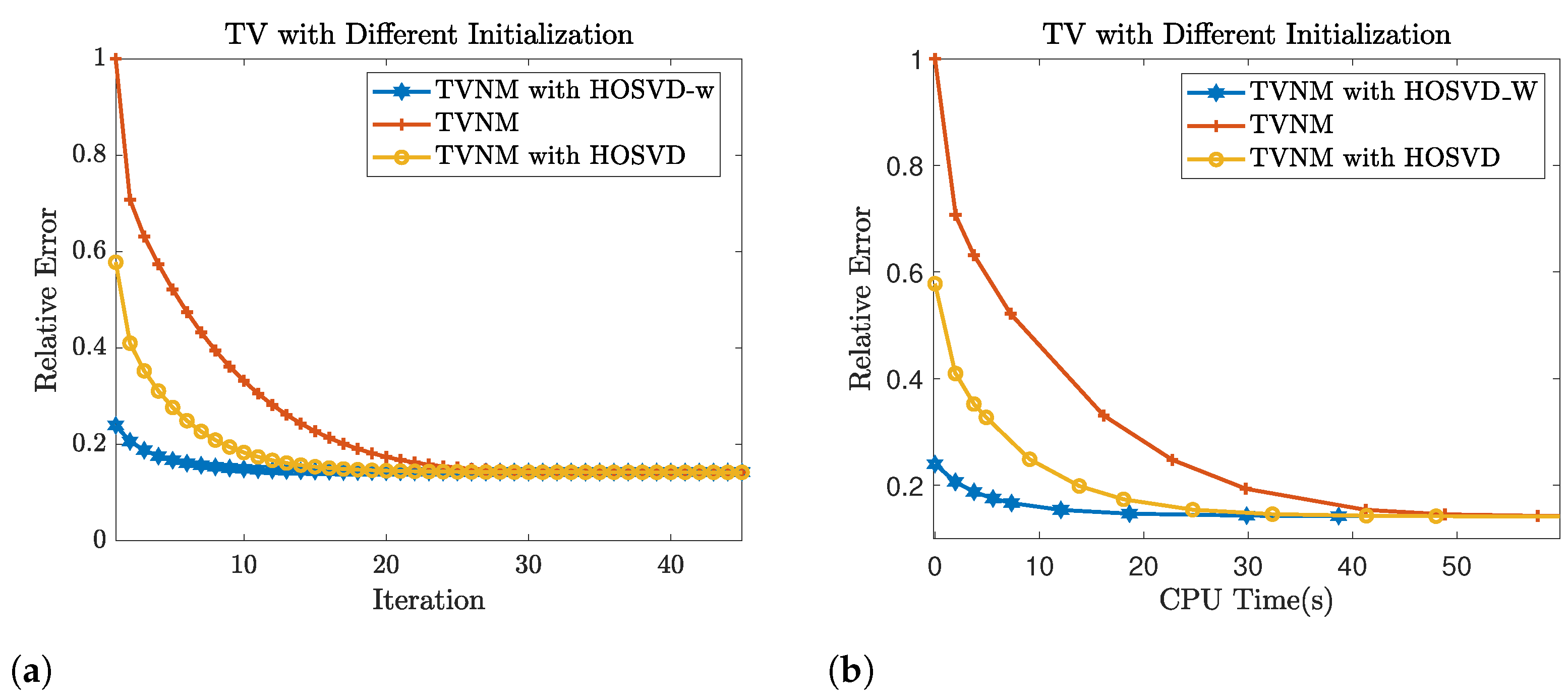
Applying the same experiment setting as in Section 4.3, we evaluate the performance of the cocktail approach as well as the regular HOSVD approach. We report the simulation results in Table 1 and we measure the performances by considering the signal to noise ratio(SNR). As shown in Table 1, the total variation minimization could be applied to further improve the result of (6). Specifically, the TVM with as initialization performs similar to TVM with HOSVD-w as initialization when the observed rate is high, but the HOSVD-w initialization could improve the performance of TVM when the observed rate is very low (e.g., 10%). Additionally, we compared the decay of relative error for using the weighted HOSVD output as initialization and the default initialization (). The iterative results are shown in Figure 8, and it shows that using the result from weighted HOSVD as an initialization could notably reduce the iterations of TV-minimization for achieving the convergence threshold ().
| Algorithm 1: TV Minimization for Tensor. |
 |
5. Conclusions
In this paper, we propose a simple but efficient algorithm named the weighted HOSVD algorithm for recovering an underlying low-rank tensor from noisy observations. For this algorithm, we provide upper and lower error bounds that measure the difference between the estimates and the true underlying low-rank tensor. The efficiency of our proposed weighted HOSVD algorithm is also shown by numerical simulations. Additionally, the result of our weighted HOSVD algorithm can be used as an initialization for the total variation minimization algorithm, which shows that using our method as an initialization for the total variation minimization algorithm can increasingly reduce the iterative steps leading to improved overall performance in reconstruction (see our conference paper [60]). It would be interesting for future work to combine the weighted HOSVD algorithm with other algorithms to achieve more accurate results for tensor completion in many settings.
Author Contributions
Conceptualization, L.H. and D.N.; Formal analysis, L.H.; Funding acquisition, D.N.; Methodology, L.H.; Project administration, Z.C., L.H. and D.N.; Supervision, L.H. and D.N.; Validation, Z.C., L.H. and D.N.; Visualization, Z.C. and L.H.; Writing—original draft, Z.C. and L.H.; Writing—review & editing, Z.C., L.H. and D.N. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by NSF DMS and NSF BIGDATA .
Data Availability Statement
In this work, the following the pre-existing reference databases have been used for our evaluations: tennis-seve dataset ([50,51]) and candel video data ([52]).They are publicly available at: http://vision.stanford.edu/Datasets/OlympicSports/ (accessed date 10 May 2021); http://0-www-vision-jhu-edu.brum.beds.ac.uk/code/ (accessed date 10 May 2021).
Acknowledgments
The authors take pleasure in thanking Hanqin Cai, Keaton Hamm, Armenak Petrosyan, Bin Sun, and Tao Wang for comments and suggestions on the manuscript.
Conflicts of Interest
The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A. Proof for Theorem 1
In this appendix, we provide the proof for Theorem 1.
Proof of Theorem
Let .
Thus, we have that
Next, let’s estimate . Notice that
Recall that . By choosing , we have that
We conclude that with probability at least ,
Plugging this into (A1) proves the theorem. □
Appendix B. Proof of Theorems 2 and 3
In this appendix, we provide the proofs for the results related with the weighted HOSVD algorithm. The general upper bound for weighted HOSVD in Theorem 2 is restated in Appendix B.1 and its proof is also presented there. If the sampling pattern is generated according to the weight tensor , the related results in Theorem 3 are illustrated in Appendix B.2.
Appendix B.1. General Upper Bound for Weighted HOSVD Algorithm
Theorem A1.
Let have strictly positive entries, and fix . Suppose that has Tucker rank . Suppose that and let
where are obtained by HOSVD approximation process, where . Then with probability at least over the choice of ,
where
Proof.
Recall that and . First we have the following estimations.
Notice that
Therefore, we have
Next, to estimate for .
Let us consider the case when . Other cases can be derived similarly. Using the fact that has rank and , we conclude that
To bound , we consider
where is the -th standard basis vector of .
Please note that
Therefore,
Similarly,
By ([61] Theorem 1.5), for any ,
We conclude that with probability at least , we have
Similarly, we have
with
with probability at least , for .
Plugging all these into (A2), we can obtain the bound in our theorem. □
Next we are going to study the special case when the sampling set .
Appendix B.2. Case Study: Ω∼W
In this section, we would provide upper and lower bounds for the weighted HOSVD algorithm.
Appendix B.2.1. Upper Bound
First, let us understand the bounds and in the case when for .
Lemma A1.
Let be a CP rank-1 tensor so that all with . Suppose that so that for each , with probability , independently for each . Then with probability at least over the choice of Ω, we have for
and
Proof.
Fix . Bernstein’s inequality yields
and
Set , then we have
and
Hence, by taking a union bound,
Similarly, we have
Combining all these inequalities above, with probability at least , we have
Next we would bound in (A3). First of all, let’s consider . Set . Then
Notice that
Since , then
Similarly,
In addition,
Then, the matrix Bernstein Inequality ([61] Theorem 1.4) gives
Let , then we have
Similarly,
for all .
Thus, with probability at least , we have
Lemma A2.
Let . Then with probability at least , over the choice of Ω
Proof.
Please note that
which is the sum of zero-mean independent random variables. Observe that and
By Bernstein’s inequality,
Set , then we have
□
Next let us give the formal statement for the upper bounds in Theorem 3.
Theorem A2.
Let be a CP rank-1 tensor so that for all we have . Suppose that we choose each independently with probability to form a set . Then with probability at least
For the weighted HOSVD Algorithm named , returns for any Tucker rank tensor with so that with probability at least over the choice of ,
Proof.
This is directly from Theorem A1, Lemmas A1 and A2. □
Appendix B.2.2. Lower Bound
To deduce the lower bound, we have to construct a finite subset S in the cone so that we can approximate the minimal distance between two different elements in S. Before we prove the lower bound, we need the following theorems and lemmas.
Theorem A3
(Hanson-Wright inequality). There is some constant so that the following holds. Let be a vector with mean-zero, independent entries, and let F be any matrix which has zero diagonal. Then
Theorem A4
(Fano’s Inequality). Let be a collection of densities on , and suppose that . Suppose there is some such that for any , . Then
The following lemma specializes Fano’s Inequality to our setting, which is a generalization of ([19] Lemma 19). In the following lemma, we show that for any reconstruction algorithm on a set , with probability no less than , there exists some elements in K such that the weighted reconstruction error is bounded below by some quantity, where the quantity is independent of the algorithm.
Lemma A3.
Let , and let be a finite subset of K so that . Let be a sampling pattern. Let and choose
and suppose that
Let be a tensor whose entries are i.i.d., . Let be any weight tensor.
Then for any algorithm that takes as input for and outputs an estimate to , there is some so that
with probability at least .
Proof.
Consider the set
which is a scaled version of S. By our assumption, .
Recall that the Kullback–Leibler (KL) divergence between two multivariate Gaussians is given by
where , .
Specializing to , with
Suppose that is as in the statement of the lemma. Define an algorithm so that for any if there exists such that
then set (notice that if such exists, then it is unique), otherwise, set .
Then by the Fano’s inequality, there is some so that
If , then , and so
Finally, we observe that
which completes the proof. □
To understand the lower bound in (A5), we construct a specific finite subset S for the cone of Tucker rank tensors in the following lemma.
Lemma A4.
There is some constant c so that the following holds. Let and be sufficiently large. Let K be the cone of Tucker rank tensors with , be any CP rank-1 weight tensor, and be any CP rank-1 tensor with . Write and , and
Let
There is a set so that
- The set has size , for
- for all .
- for all .
Proof.
Let be a set of random -valued tensors chosen uniformly at random with replacement, of size . Choose to be determined below for all .
Let
First of all, we would estimate and . Please note that
where the expectation is over the random choice of . Then by Markov’s inequality,
We also have
By Hoeffding’s inequality, we have
Using the fact that and a union bound over all values of , we conclude that
Thus, for a tensor , the probability that both of and hold is at least . Thus, by a Chernoff bound it follows that with probability at least for some constant C, there are at least tensors such that all of these hold. Let be the set of such ’s. The set guaranteed in the statement of the lemma will be , which satisfies both item 1 and 2 in the lemma and is also contained in .
Thus, we consider item 3: we are going to show that this holds for S with high probability, thus in particularly it will hold for , and this will complete the proof of the lemma.
Fix , and write
where is the vectorization of . Thus, each entry of is independently 0 with probability or with probability each. Rearranging the terms, we have
where denotes the diagonal matrix with on the diagonal.
To understand (A6), we need to understand the matrix . The diagonal of this matrix is . We will choose the matrix for so that the off-diagonal terms are small. □
Theorem A5.
There are matrices for such that:
- (a)
- (b)
Having chosen matrices for , we can now analyze the expression (A6).
Theorem A6.
There are constants so that with probability at least
we have
Proof.
We break into two terms:
For the first term (I), we will use the Hanson-Wright Inequality (see Theorem A3). In our case, the matrix . The Frobenius norm of this matrix is bounded by
The operator norm of F is bounded by
Thus, the Hanson-Wright inequality implies that
Plugging in , and replacing the constant c with a different constant , we have
Next we turn to the second term . We write
and bound the error term with high probability. Observe that is a zero-mean subgaussian random variable, and thus satisfies for all t > 0 that
for some constant . Thus, for any we have
Thus,
By a union of bound over all of the points in S, we establish items 1 and 3 of the lemma. □
Now we are ready to prove the lower bound in Theorem 3. First we give a formal statement for the lower bound in Theorem 3 by introducing the constant to characterize the “flatness” of .
Theorem A7
(Lower bound for low-rank tensor when is flat and ). Let be a CP rank-1 tensor so that all with , so that
Suppose that we choose each independently with probability to form a set . Then with probability at least over the choice of Ω, the following holds:
Let and let be the cone of the tensor with Tucker rank . For any algorithm that takes as input and outputs a guess for , for and , then there is some so that
with probability at least over the randomness of and the choice of . Above c, C are constants which depend only on .
Proof.
Let , so that .
We instantiate Lemma A4 with and being the tensor whose entries are all 1. Let S be the set guaranteed by Lemma A4. We have
and
We also have
for . Using the assumption that are flat, the size of the set S is bigger than or equal to
where depends on c and C. Set
Observe that and
so this is a legitimate choice of in Lemma A3. Next, we verify that . Indeed, we have
so , and every element of has Tucker rank by construction.
Then Lemma A3 concludes that if works on , then there is a tensor so that
Additionally, by Lemma A2, we conclude that
where depends on the above constants. □
Remark A1.
Consider the special case when with . Then we can consider the reconstruction of S in Lemma A4 with , being the tensor whose entries are all 1, , and which implies that and . Thus, we have
which has the same bound as the one in ([19] Lemma 28).
References
- Hitchcock, F.L. The expression of a tensor or a polyadic as a sum of products. J. Math. Phys. 1927, 6, 164–189. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Zare, A.; Ozdemir, A.; Iwen, M.A.; Aviyente, S. Extension of PCA to higher order data structures: An introduction to tensors, tensor decompositions, and tensor PCA. Proc. IEEE 2018, 106, 1341–1358. [Google Scholar] [CrossRef] [Green Version]
- Ge, H.; Caverlee, J.; Zhang, N.; Squicciarini, A. Uncovering the spatio-temporal dynamics of memes in the presence of incomplete information. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 1493–1502. [Google Scholar]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor completion for estimating missing values in visual data. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 208–220. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Shang, F.; Cheng, H.; Cheng, J.; Tong, H. Factor matrix trace norm minimization for low-rank tensor completion. In Proceedings of the 2014 SIAM International Conference on Data Mining, Philadelphia, PA, USA, 24–26 April 2014; pp. 866–874. [Google Scholar]
- Song, Q.; Ge, H.; Caverlee, J.; Hu, X. Tensor Completion Algorithms in Big Data Analytics. ACM Trans. Knowl. Discov. Data 2019, 13, 1–48. [Google Scholar] [CrossRef]
- Kressner, D.; Steinlechner, M.; Vandereycken, B. Low-rank tensor completion by Riemannian optimization. BIT Numer. Math. 2014, 54, 447–468. [Google Scholar] [CrossRef] [Green Version]
- Ermiş, B.; Acar, E.; Cemgil, A.T. Link prediction in heterogeneous data via generalized coupled tensor factorization. Data Min. Knowl. Discov. 2015, 29, 203–236. [Google Scholar] [CrossRef]
- Symeonidis, P.; Nanopoulos, A.; Manolopoulos, Y. Tag recommendations based on tensor dimensionality reduction. In Proceedings of the 2008 ACM Conference on Recommender Systems, Lausanne, Switzerland, 23–25 October 2008; pp. 43–50. [Google Scholar]
- Cai, J.F.; Candès, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Cai, T.T.; Zhou, W.X. Matrix completion via max-norm constrained optimization. Electron. J. Stat. 2016, 10, 1493–1525. [Google Scholar] [CrossRef]
- Candes, E.J.; Plan, Y. Matrix completion with noise. Proc. IEEE 2010, 98, 925–936. [Google Scholar] [CrossRef] [Green Version]
- Candès, E.J.; Recht, B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009, 9, 717. [Google Scholar] [CrossRef] [Green Version]
- Amit, Y.; Fink, M.; Srebro, N.; Ullman, S. Uncovering shared structures in multiclass classification. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 17–24. [Google Scholar]
- Cai, H.; Cai, J.F.; Wang, T.; Yin, G. Accelerated Structured Alternating Projections for Robust Spectrally Sparse Signal Recovery. IEEE Trans. Signal Process. 2021, 69, 809–821. [Google Scholar] [CrossRef]
- Gleich, D.F.; Lim, L.H. Rank aggregation via nuclear norm minimization. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 60–68. [Google Scholar]
- Liu, Z.; Vandenberghe, L. Interior-point method for nuclear norm approximation with application to system identification. SIAM J. Matrix Anal. Appl. 2009, 31, 1235–1256. [Google Scholar] [CrossRef]
- Foucart, S.; Needell, D.; Pathak, R.; Plan, Y.; Wootters, M. Weighted matrix completion from non-random, non-uniform sampling patterns. IEEE Trans. Inf. Theory 2020, 67, 1264–1290. [Google Scholar] [CrossRef]
- Bhojanapalli, S.; Jain, P. Universal matrix completion. arXiv 2014, arXiv:1402.2324. [Google Scholar]
- Heiman, E.; Schechtman, G.; Shraibman, A. Deterministic algorithms for matrix completion. Random Struct. Algorithms 2014, 45, 306–317. [Google Scholar] [CrossRef]
- Li, Y.; Liang, Y.; Risteski, A. Recovery guarantee of weighted low-rank approximation via alternating minimization. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2358–2367. [Google Scholar]
- Pimentel-Alarcón, D.L.; Boston, N.; Nowak, R.D. A characterization of deterministic sampling patterns for low-rank matrix completion. IEEE J. Sel. Top. Signal Process. 2016, 10, 623–636. [Google Scholar] [CrossRef] [Green Version]
- Shapiro, A.; Xie, Y.; Zhang, R. Matrix completion with deterministic pattern: A geometric perspective. IEEE Trans. Signal Process. 2018, 67, 1088–1103. [Google Scholar] [CrossRef] [Green Version]
- Ashraphijuo, M.; Aggarwal, V.; Wang, X. On deterministic sampling patterns for robust low-rank matrix completion. IEEE Signal Process. Lett. 2017, 25, 343–347. [Google Scholar] [CrossRef] [Green Version]
- Ashraphijuo, M.; Wang, X.; Aggarwal, V. Rank determination for low-rank data completion. J. Mach. Learn. Res. 2017, 18, 3422–3450. [Google Scholar]
- Pimentel-Alarcón, D.L.; Nowak, R.D. A converse to low-rank matrix completion. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 96–100. [Google Scholar]
- Chatterjee, S. A deterministic theory of low rank matrix completion. arXiv 2019, arXiv:1910.01079. [Google Scholar]
- Király, F.J.; Theran, L.; Tomioka, R. The algebraic combinatorial approach for low-rank matrix completion. arXiv 2012, arXiv:1211.4116. [Google Scholar]
- Eftekhari, A.; Yang, D.; Wakin, M.B. Weighted matrix completion and recovery with prior subspace information. IEEE Trans. Inf. Theory 2018, 64, 4044–4071. [Google Scholar] [CrossRef] [Green Version]
- Negahban, S.; Wainwright, M.J. Restricted strong convexity and weighted matrix completion: Optimal bounds with noise. J. Mach. Learn. Res. 2012, 13, 1665–1697. [Google Scholar]
- Lee, T.; Shraibman, A. Matrix completion from any given set of observations. In Proceedings of the Advances in Neural Information Processing Systems, Red Hook, NY, USA, 5–10 December 2013; pp. 1781–1787. [Google Scholar]
- Gandy, S.; Recht, B.; Yamada, I. Tensor completion and low-n-rank tensor recovery via convex optimization. Inverse Probl. 2011, 27, 025010. [Google Scholar] [CrossRef] [Green Version]
- Ashraphijuo, M.; Wang, X. Fundamental conditions for low-CP-rank tensor completion. J. Mach. Learn. Res. 2017, 18, 2116–2145. [Google Scholar]
- Barak, B.; Moitra, A. Noisy tensor completion via the sum-of-squares hierarchy. In Proceedings of the Conference on Learning Theory, New York, NY, USA, 23–26 June 2016; pp. 417–445. [Google Scholar]
- Jain, P.; Oh, S. Provable tensor factorization with missing data. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1431–1439. [Google Scholar]
- Goldfarb, D.; Qin, Z. Robust low-rank tensor recovery: Models and algorithms. SIAM J. Matrix Anal. Appl. 2014, 35, 225–253. [Google Scholar] [CrossRef] [Green Version]
- Mu, C.; Huang, B.; Wright, J.; Goldfarb, D. Square deal: Lower bounds and improved relaxations for tensor recovery. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 73–81. [Google Scholar]
- Hitchcock, F.L. Multiple invariants and generalized rank of a p-way matrix or tensor. J. Math. Phys. 1928, 7, 39–79. [Google Scholar] [CrossRef]
- Kruskal, J.B. Rank, decomposition, and uniqueness for 3-way and N-way arrays. In Multiway Data Analysis; North-Holland Publishing Co.: Amsterdam, The Netherlands, 1989; pp. 7–18. [Google Scholar]
- Acar, E.; Yener, B. Unsupervised multiway data analysis: A literature survey. IEEE Trans. Knowl. Data Eng. 2008, 21, 6–20. [Google Scholar] [CrossRef]
- Sidiropoulos, N.D.; De Lathauwer, L.; Fu, X.; Huang, K.; Papalexakis, E.E.; Faloutsos, C. Tensor decomposition for signal processing and machine learning. IEEE Trans. Signal Process. 2017, 65, 3551–3582. [Google Scholar] [CrossRef]
- Carroll, J.D.; Chang, J.J. Analysis of individual differences in multidimensional scaling via an N-way generalization of “Eckart-Young” decomposition. Psychometrika 1970, 35, 283–319. [Google Scholar] [CrossRef]
- Bro, R. PARAFAC. Tutorial and applications. Chemom. Intell. Lab. Syst. 1997, 38, 149–172. [Google Scholar] [CrossRef]
- Kiers, H.A.; Ten Berge, J.M.; Bro, R. PARAFAC2—Part I. A direct fitting algorithm for the PARAFAC2 model. J. Chemometr. 1999, 13, 275–294. [Google Scholar] [CrossRef]
- Tomasi, G.; Bro, R. PARAFAC and missing values. Chemom. Intell. Lab. Syst. 2005, 75, 163–180. [Google Scholar] [CrossRef]
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef] [PubMed]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef] [Green Version]
- Kroonenberg, P.M.; De Leeuw, J. Principal component analysis of three-mode data by means of alternating least squares algorithms. Psychometrika 1980, 45, 69–97. [Google Scholar] [CrossRef]
- Fang, Z.; Yang, X.; Han, L.; Liu, X. A sequentially truncated higher order singular value decomposition-based algorithm for tensor completion. IEEE Trans. Cybern. 2018, 49, 1956–1967. [Google Scholar] [CrossRef] [PubMed]
- Niebles, J.C.; Chen, C.W.; Li, F.F. Modeling temporal structure of decomposable motion segments for activity classification. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 392–405. [Google Scholar]
- Ravichandran, A.; Chaudhry, R.; Vidal, R. Dynamic Texture Toolbox. 2011. Available online: http://www.vision.jhu.edu (accessed on 10 May 2021).
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, Q.; Jin, J.; Shen, Y. Structure tensor total variation-regularized weighted nuclear norm minimization for hyperspectral image mixed denoising. Signal Process. 2017, 131, 202–219. [Google Scholar] [CrossRef]
- Madathil, B.; George, S.N. Twist tensor total variation regularized-reweighted nuclear norm based tensor completion for video missing area recovery. Inf. Sci. 2018, 423, 376–397. [Google Scholar] [CrossRef]
- Yao, J.; Xu, Z.; Huang, X.; Huang, J. Accelerated dynamic MRI reconstruction with total variation and nuclear norm regularization. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 635–642. [Google Scholar]
- Wang, Y.; Peng, J.; Zhao, Q.; Leung, Y.; Zhao, X.L.; Meng, D. Hyperspectral image restoration via total variation regularized low-rank tensor decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 1227–1243. [Google Scholar] [CrossRef] [Green Version]
- Ji, T.Y.; Huang, T.Z.; Zhao, X.L.; Ma, T.H.; Liu, G. Tensor completion using total variation and low-rank matrix factorization. Inf. Sci. 2016, 326, 243–257. [Google Scholar] [CrossRef]
- Li, X.; Ye, Y.; Xu, X. Low-rank tensor completion with total variation for visual data inpainting. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Chao, Z.; Huang, L.; Needell, D. Tensor Completion through Total Variation with Initialization from Weighted HOSVD. In Proceedings of the Information Theory and Applications, San Diego, CA, USA, 2–7 February 2020. [Google Scholar]
- Tropp, J.A. User-friendly tail bounds for sums of random matrices. Found. Comput. Math. 2012, 12, 389–434. [Google Scholar] [CrossRef] [Green Version]
- Lancaster, P.; Farahat, H. Norms on direct sums and tensor products. Math. Comp. 1972, 26, 401–414. [Google Scholar] [CrossRef]
Figure 1.
Tensor of size using the uniform sampling pattern: plots the errors of the form . The lines labeled as HOSVD, HOSVD-p and HOSVD-w represent the results for solving (4), (5) and (6), respectively.

Figure 2.
Tensor of size using the uniform sampling pattern: plots the errors of the form . The lines labeled as HOSVD, HOSVD-p and HOSVD-w represent the results for solving (4), (5) and (6), respectively.

Figure 3.
Tensor of size using the non-uniform sampling pattern: plots the errors of the form . The lines labeled as HOSVD, HOSVD-p and HOSVD-w represent the results for solving (4), (5) and (6), respectively.

Figure 4.
Tensor of size using the non-uniform sampling pattern: plots the errors of the form . The lines labeled as HOSVD, HOSVD-p and HOSVD-w represent the results for solving (4), (5) and (6), respectively.

Figure 5.
Tensor of size using the non-uniform sampling pattern and with the SV-rank as the input rank: plots the errors of the form .
Figure 5.
Tensor of size using the non-uniform sampling pattern and with the SV-rank as the input rank: plots the errors of the form .

Figure 6.
The first frame of videos [50].
Figure 6.
The first frame of videos [50].

Figure 7.
Relation between relative error and sampling rate for the dataset “candle_4_A” using as the input rank for HOSVD process. The left figure records the relative error for the uniform sampling pattern and the right figure for the non-uniform sampling pattern. The sampling error stands for the relative error between the original video and the video with masked entries estimated to be zeros, hence should approximately equal to , where SR is the sampling rate.
Figure 7.
Relation between relative error and sampling rate for the dataset “candle_4_A” using as the input rank for HOSVD process. The left figure records the relative error for the uniform sampling pattern and the right figure for the non-uniform sampling pattern. The sampling error stands for the relative error between the original video and the video with masked entries estimated to be zeros, hence should approximately equal to , where SR is the sampling rate.

Figure 8.
Convergence comparison between total variation minimization (TVM) with HOSVD-w, , and HOSVD as initialization on video 1 with SR = 50%: (a) the relative error vs. number of iterations. (b) the relative error v.s. total computational CPU time(initialization + completion).
Figure 8.
Convergence comparison between total variation minimization (TVM) with HOSVD-w, , and HOSVD as initialization on video 1 with SR = 50%: (a) the relative error vs. number of iterations. (b) the relative error v.s. total computational CPU time(initialization + completion).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Signal to noise ratio (SNR) and elapsed time (in second) for Higher Order Singular Value Decomposition (HOSVD) and HOSVD-w on video data with uniform sampling pattern. The HOSVD-w and HOSVD-p behave very similar for uniform sampling hence we integrate the results into one column.
Table 1.
Signal to noise ratio (SNR) and elapsed time (in second) for Higher Order Singular Value Decomposition (HOSVD) and HOSVD-w on video data with uniform sampling pattern. The HOSVD-w and HOSVD-p behave very similar for uniform sampling hence we integrate the results into one column.
| Video | SR | Input Rank | HOSVD-w+TV | HOSVD | HOSVD-w/HOSVD-p | TVM |
|---|---|---|---|---|---|---|
 | 10% | 13.29 (16.3 s) | 1.27 (3.74 s) | 10.15 (11.4 s) | 13.04 (41.3 s) | |
| 30% | 16.96 (14.0 s) | 4.26 (4.01 s) | 12.05 (7.23 s) | 17.05 (29.7 s) | ||
| 50% | 19.60 (12.2 s) | 8.21 (2.99 s) | 14.59 (7.03 s) | 19.68 (23.8 s) | ||
| 80% | 24.90 (11.5 s) | 17.29 (6.55 s) | 19.75 (8.08 s) | 25.01 (18.1 s) | ||
 | 10% | 10.98 (13.1 s) | 1.19 (4.20 s) | 7.88 (8.76 s) | 10.89 (42.2 s) | |
| 30% | 14.44 (16.1 s) | 4.11 (3.80 s) | 10.40 (7.51 s) | 14.50 (31.4 s) | ||
| 50% | 16.95 (15.3 s) | 7.85 (5.86 s) | 12.84 (7.64 s) | 16.96 (26.6 s) | ||
| 80% | 22.21 (15.1 s) | 16.51 (7.24 s) | 18.64 (8.45 s) | 22.19 (18.4 s) | ||
 | 10% | 12.34 (16.1 s) | 1.22 (2.73 s) | 8.46 (9.88 s) | 12.23 (45.7 s) | |
| 30% | 17.10 (15.3 s) | 4.24 (3.17 s) | 11.62 (7.62 s) | 17.19 (35.3 s) | ||
| 50% | 20.44 (12.3 s) | 8.20 (3.92 s) | 14.54 (5.85 s) | 20.49 (28.9 s) | ||
| 80% | 26.80 (12.4 s) | 18.03 (8.40 s) | 21.38 (8.93s) | 26.71 (20.9 s) |
Table 2.
Signal to noise ratio (SNR) for HOSVD and HOSVD-w on video data with non-uniform sampling pattern.
Table 2.
Signal to noise ratio (SNR) for HOSVD and HOSVD-w on video data with non-uniform sampling pattern.
| Video | SR | Input Rank | HOSVD | HOSVD-w | HOSVD-p |
|---|---|---|---|---|---|
 | 10% | 1.09 | 10.07 | 5.56 | |
| 30% | 3.74 | 11.81 | 7.53 | ||
| 50% | 7.05 | 13.22 | 10.73 | ||
| 80% | 15.76 | 19.60 | 17.39 | ||
 | 10% | 1.13 | 8.04 | 4.33 | |
| 30% | 3.79 | 10.13 | 6.80 | ||
| 50% | 7.15 | 12.57 | 10.14 | ||
| 80% | 14.81 | 18.55 | 16.31 | ||
 | 10% | 1.09 | 8.31 | 4.73 | |
| 30% | 3.76 | 11.05 | 6.87 | ||
| 50% | 7.18 | 13.78 | 9.99 | ||
| 80% | 15.88 | 20.82 | 16.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chao, Z.; Huang, L.; Needell, D. HOSVD-Based Algorithm for Weighted Tensor Completion. J. Imaging 2021, 7, 110. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging7070110
AMA Style
Chao Z, Huang L, Needell D. HOSVD-Based Algorithm for Weighted Tensor Completion. Journal of Imaging. 2021; 7(7):110. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging7070110
Chicago/Turabian StyleChao, Zehan, Longxiu Huang, and Deanna Needell. 2021. "HOSVD-Based Algorithm for Weighted Tensor Completion" Journal of Imaging 7, no. 7: 110. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging7070110
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.