
X23D—Intraoperative 3D Lumbar Spine Shape Reconstruction Based on Sparse Multi-View X-ray Data

Abstract
:1. Introduction
2. Materials and Methods
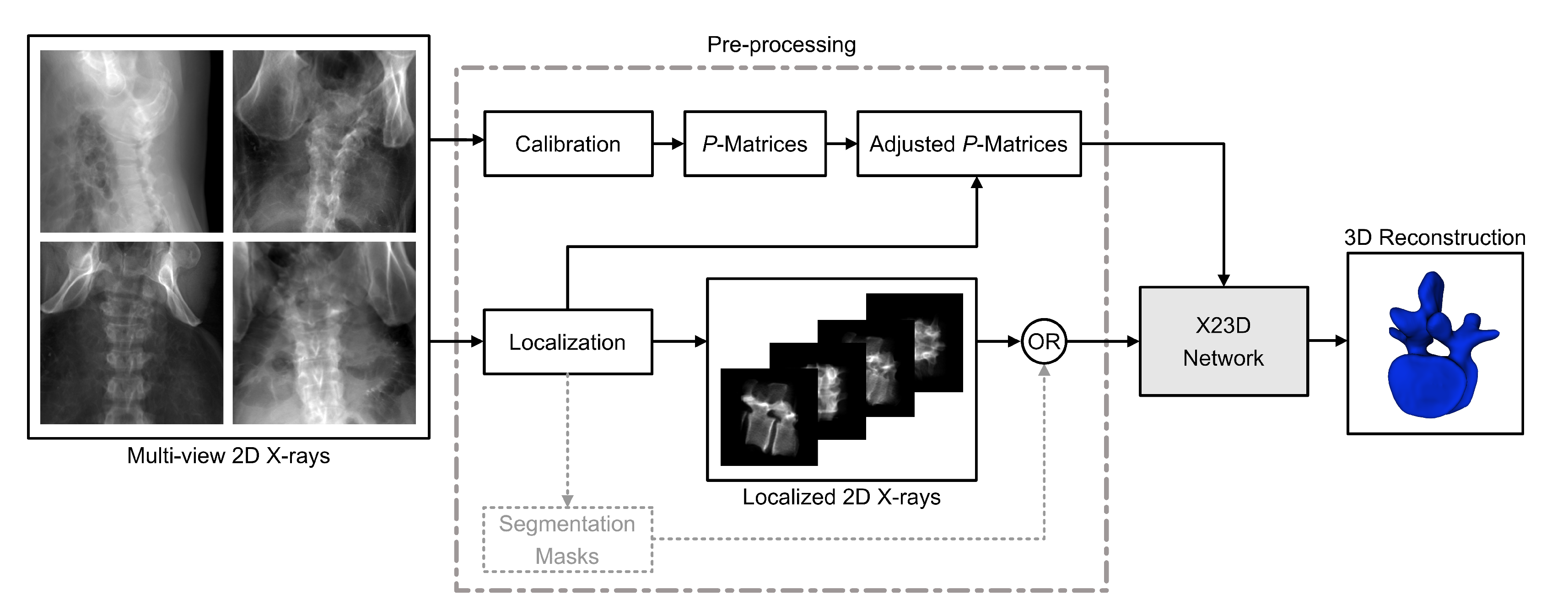
2.1. Input Data and Pre-Processing
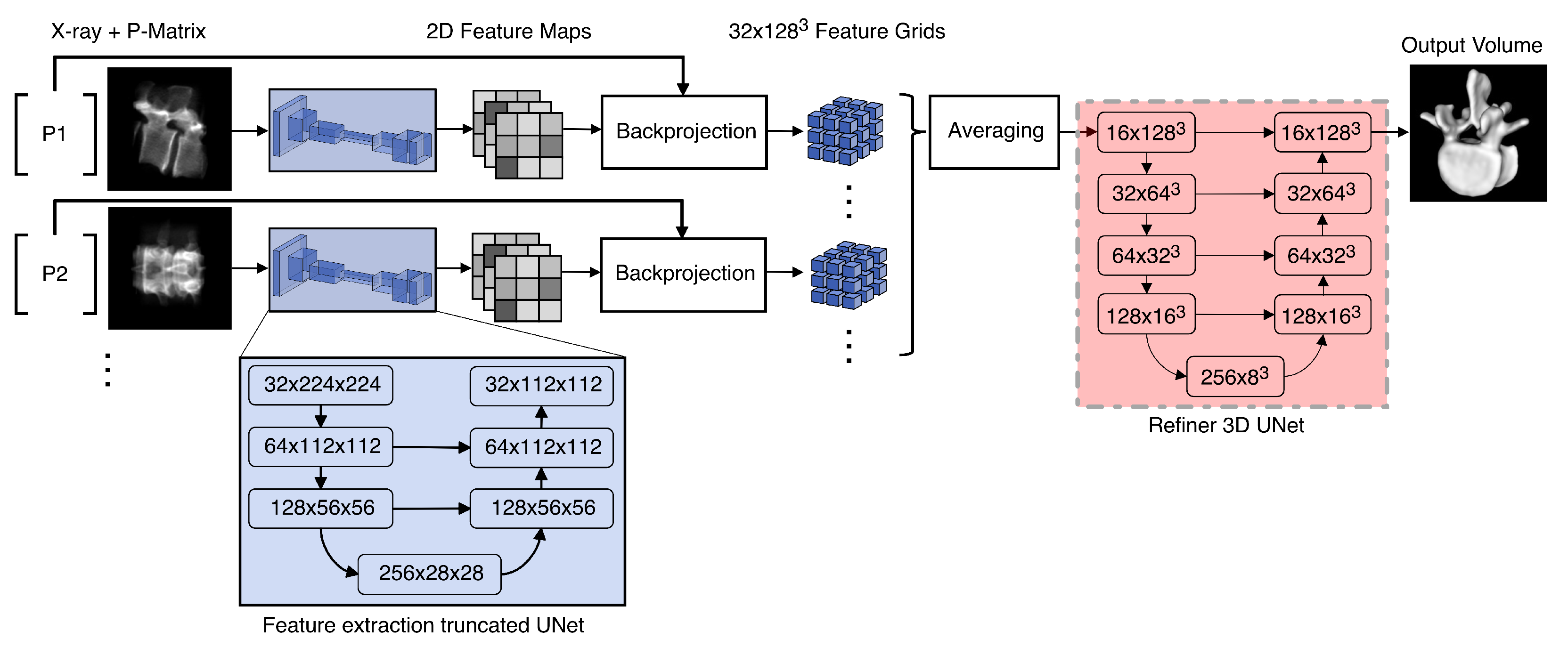
2.2. X23D Network Architecture
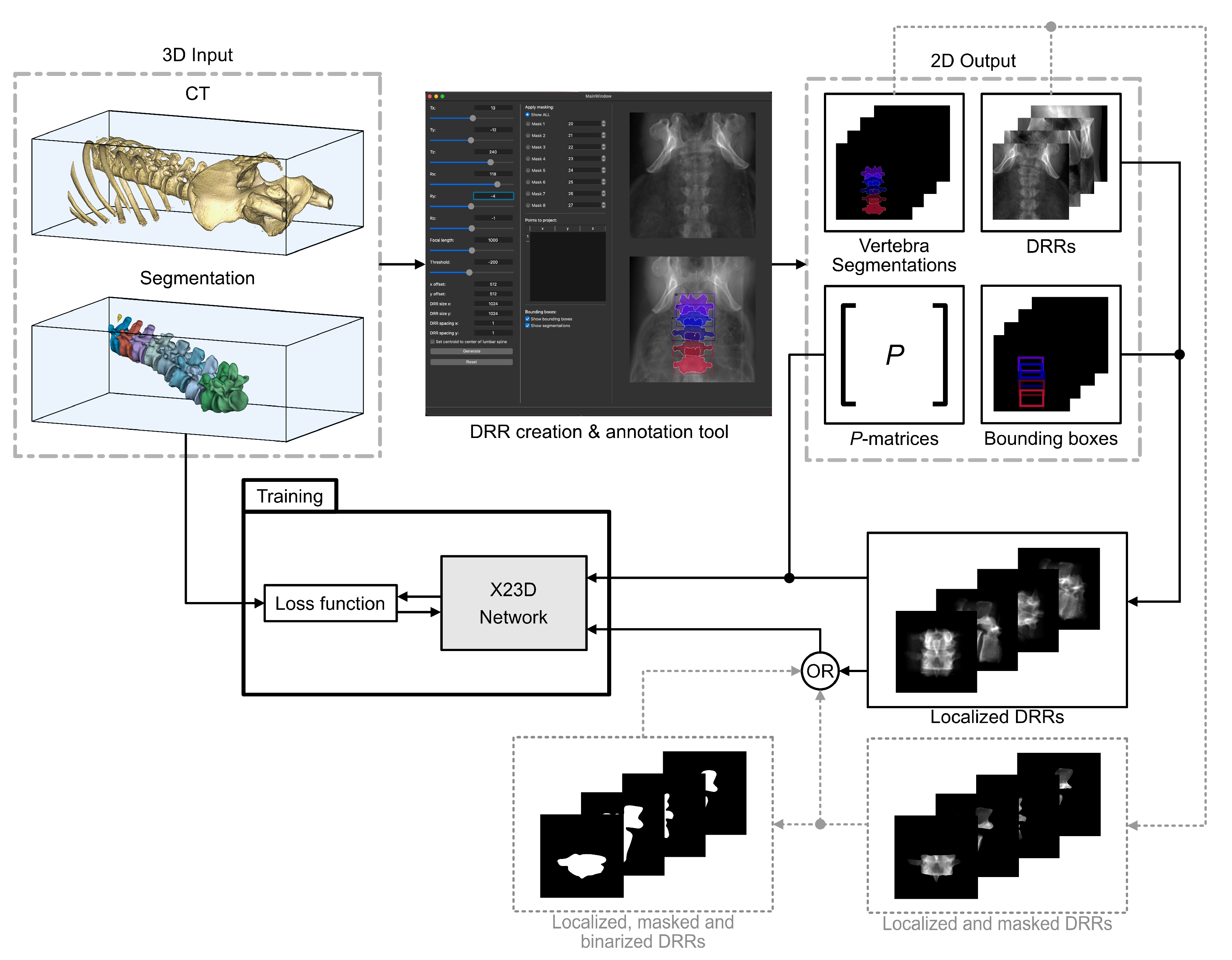
2.3. Data Generation and Training
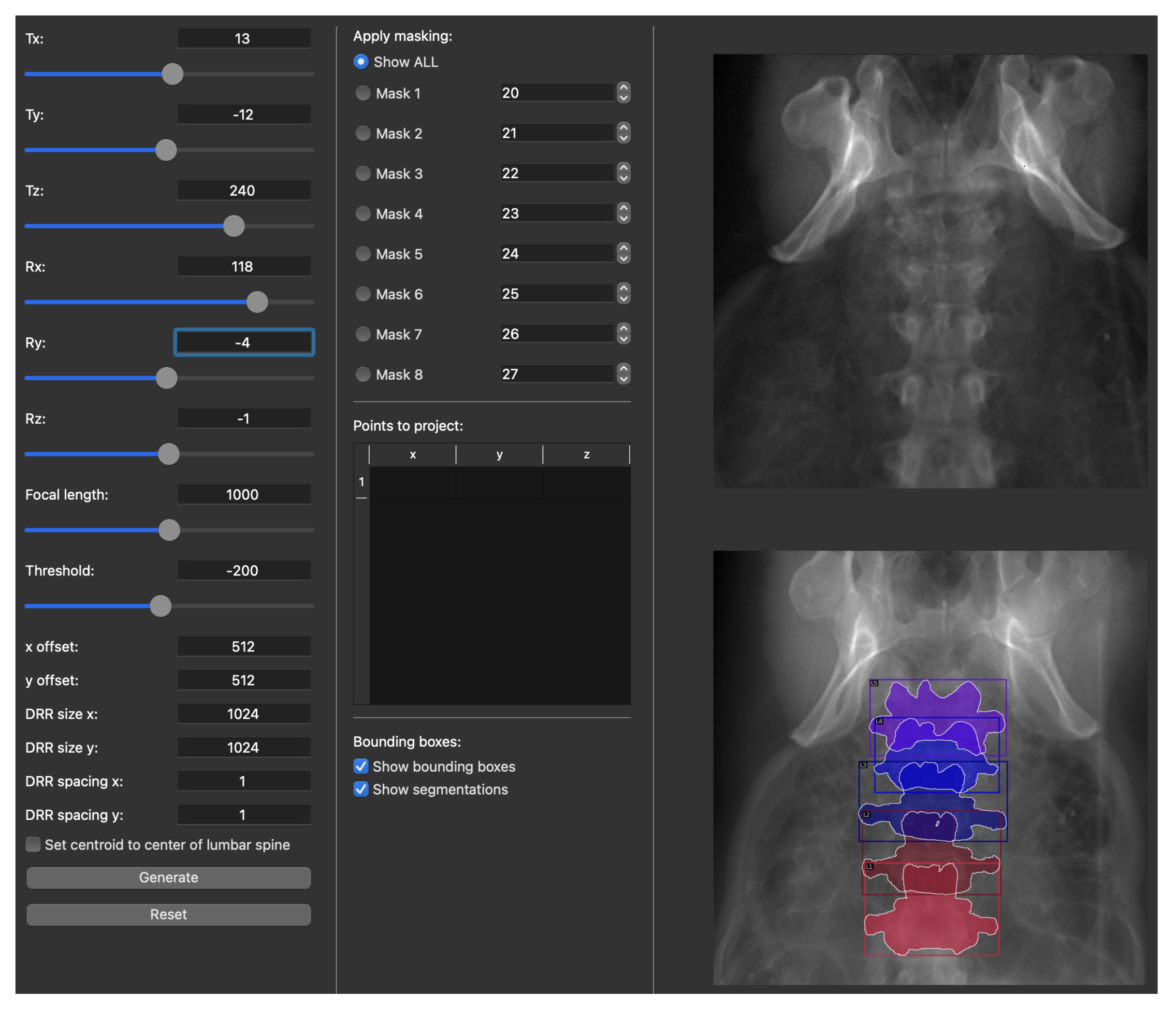
2.3.1. X-ray Simulation
- Full-size 2D DRR images generated from different view angles (more details about the view angles are provided in Section 2.3.2).
- The corresponding P-matrices expressing the intrinsic and the extrinsic parameters.
- 2D vertebral bounding boxes.
- 2D vertebral segmentation masks.
- Automatically localized 2D DRRs that were cropped down to a single vertebra using the bounding boxes in item 3.
- Automatically segmented localized 2D DRRs consisting of the bone and the background classes.
- Adjusted -matrices expressing the cropping effect.
2.3.2. View Angles
- AP: included three images—one strict anterior–posterior image and two images with deviation in the sagittal plane.
- Lateral: included four images—two strict lateral images from each side and an additional two images with deviation in the coronal plane.
- Oblique: included four images—two oblique shots with separation from the AP in the sagittal plane and two additional shots with separation from the AP in the same fashion.
- Miscellaneous: included nine shots from poses with deviations in two planes that could not be assigned to the previously defined categories.
2.3.3. Train–Validation–Test Split
2.4. Performance Evaluation
- Segmented grayscale: these localized images were created by applying the 2D segmentation masks (as described in item 6 in the list above) onto the unsegmented localized images (Figure 5b).
- Segmented binary: these localized images were created by thresholding the segmented grayscale images (Figure 5c).
2.5. Statistical Evaluation
2.6. Coding Platform, Hardware and Training Hyperparameters
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASD | Average Surface Distance |
| CAS | Computer-Assisted Surgical |
| CBCT | Cone-Beam Computed Tomography |
| CT | Computed Tomography |
| DRR | Digitally Reconstructed Radiograph |
| GRU | Gated Recurrent Unit |
| ITK | Insight Toolkit |
| LSM | Learnt Stereo Machines |
| ML | Machine Learning |
| SSM | Statistical Shape Model |
References
- Medress, Z.A.; Jin, M.C.; Feng, A.; Varshneya, K.; Veeravagu, A. Medical malpractice in spine surgery: A review. Neurosurg. Focus FOC 2020, 49, E16. [Google Scholar] [CrossRef] [PubMed]
- Farshad, M.; Bauer, D.E.; Wechsler, C.; Gerber, C.; Aichmair, A. Risk factors for perioperative morbidity in spine surgeries of different complexities: A multivariate analysis of 1009 consecutive patients. Spine J. 2018, 18, 1625–1631. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gelalis, I.D.; Paschos, N.K.; Pakos, E.E.; Politis, A.N.; Arnaoutoglou, C.M.; Karageorgos, A.C.; Ploumis, A.; Xenakis, T.A. Accuracy of pedicle screw placement: A systematic review of prospective in vivo studies comparing free hand, fluoroscopy guidance and navigation techniques. Eur. Spine J. 2012, 21, 247–255. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, Y.H.; Niu, C.C.; Hsieh, M.K.; Tsai, T.T.; Chen, W.J.; Lai, P.L. Cage positioning as a risk factor for posterior cage migration following transforaminal lumbar interbody fusion—An analysis of 953 cases. BMC Musculoskelet. Disord. 2019, 20, 260. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amato, V.; Giannachi, L.; Irace, C.; Corona, C. Accuracy of pedicle screw placement in the lumbosacral spine using conventional technique: Computed tomography postoperative assessment in 102 consecutive patients. J. Neurosurg. Spine 2010, 12, 306–313. [Google Scholar] [CrossRef]
- Gertzbein, S.D.; Robbins, S.E. Accuracy of pedicular screw placement in vivo. Spine 1990, 15, 11–14. [Google Scholar] [CrossRef]
- Laine, T.; Mäkitalo, K.; Schlenzka, D.; Tallroth, K.; Poussa, M.; Alho, A. Accuracy of pedicle screw insertion: A prospective CT study in 30 low back patients. Eur. Spine J. 1997, 6, 402–405. [Google Scholar] [CrossRef] [Green Version]
- Hicks, J.M.; Singla, A.; Shen, F.H.; Arlet, V. Complications of pedicle screw fixation in scoliosis surgery: A systematic review. Spine 2010, 35, E465–E470. [Google Scholar] [CrossRef]
- Nevzati, E.; Marbacher, S.; Soleman, J.; Perrig, W.N.; Diepers, M.; Khamis, A.; Fandino, J. Accuracy of pedicle screw placement in the thoracic and lumbosacral spine using a conventional intraoperative fluoroscopy-guided technique: A national neurosurgical education and training center analysis of 1236 consecutive screws. World Neurosurg. 2014, 82, 866–871. [Google Scholar] [CrossRef]
- Landham, P.R.; Don, A.S.; Robertson, P.A. Do position and size matter? An analysis of cage and placement variables for optimum lordosis in PLIF reconstruction. Eur. Spine J. 2017, 26, 2843–2850. [Google Scholar] [CrossRef]
- Kraiwattanapong, C.; Arnuntasupakul, V.; Kantawan, R.; Keorochana, G.; Lertudomphonwanit, T.; Sirijaturaporn, P.; Thonginta, M. Malposition of Cage in Minimally Invasive Oblique Lumbar Interbody Fusion. Case Rep. Orthop. 2018, 2018, 9142074. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Learch, T.J.; Massie, J.B.; Pathria, M.N.; Ahlgren, B.A.; Garfin, S.R. Assessment of pedicle screw placement utilizing conventional radiography and computed tomography: A proposed systematic approach to improve accuracy of interpretation. Spine 2004, 29, 767–773. [Google Scholar] [CrossRef] [PubMed]
- Ferrick, M.R.; Kowalski, J.M.; Simmons, E.D., Jr. Reliability of roentgenogram evaluation of pedicle screw position. Spine 1997, 22, 1249–1252. [Google Scholar] [CrossRef] [PubMed]
- Choma, T.J.; Denis, F.; Lonstein, J.E.; Perra, J.H.; Schwender, J.D.; Garvey, T.A.; Mullin, W.J. Stepwise methodology for plain radiographic assessment of pedicle screw placement: A comparison with computed tomography. Clin. Spine Surg. 2006, 19, 547–553. [Google Scholar] [CrossRef]
- Mason, A.; Paulsen, R.; Babuska, J.M.; Rajpal, S.; Burneikiene, S.; Nelson, E.L.; Villavicencio, A.T. The accuracy of pedicle screw placement using intraoperative image guidance systems: A systematic review. J. Neurosurg. Spine 2014, 20, 196–203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tonetti, J.; Boudissa, M.; Kerschbaumer, G.; Seurat, O. Role of 3D intraoperative imaging in orthopedic and trauma surgery. Orthop. Traumatol. Surg. Res. 2020, 106, S19–S25. [Google Scholar] [CrossRef] [PubMed]
- Sati, M.; Bourquin, Y.; Berlemann, U.; Nolte, L.P. Computer-assisted technology for spinal cage delivery. Oper. Tech. Orthop. 2000, 10, 69–76. [Google Scholar] [CrossRef]
- Strong, M.J.; Yee, T.J.; Khalsa, S.S.S.; Saadeh, Y.S.; Swong, K.N.; Kashlan, O.N.; Szerlip, N.J.; Park, P.; Oppenlander, M.E. The feasibility of computer-assisted 3D navigation in multiple-level lateral lumbar interbody fusion in combination with posterior instrumentation for adult spinal deformity. Neurosurg. Focus 2020, 49, E4. [Google Scholar] [CrossRef]
- Wang, M.; Li, D.; Shang, X.; Wang, J. A review of computer-assisted orthopaedic surgery systems. Int. J. Med. Robot. Comput. Assist. Surg. 2020, 16, 1–28. [Google Scholar] [CrossRef]
- Guéziec, A.; Kazanzides, P.; Williamson, B.; Taylor, R.H. Anatomy-based registration of CT-scan and intraoperative X-ray images for guiding a surgical robot. IEEE Trans. Med. Imaging 1998, 17, 715–728. [Google Scholar] [CrossRef]
- Sundar, H.; Khamene, A.; Xu, C.; Sauer, F.; Davatzikos, C. A novel 2D-3D registration algorithm for aligning fluoro images with 3D pre-op CT/MR images. In Proceedings of the Medical Imaging 2006: Visualization, Image-Guided Procedures, and Display, San Diego, CA, USA, 11–16 February 2006; Volume 6141, p. 61412K. [Google Scholar]
- Esfandiari, H.; Anglin, C.; Guy, P.; Street, J.; Weidert, S.; Hodgson, A.J. A comparative analysis of intensity-based 2D–3D registration for intraoperative use in pedicle screw insertion surgeries. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 1725–1739. [Google Scholar] [CrossRef] [PubMed]
- Penney, G.P.; Batchelor, P.G.; Hill, D.L.; Hawkes, D.J.; Weese, J. Validation of a two-to three-dimensional registration algorithm for aligning preoperative CT images and intraoperative fluoroscopy images. Med. Phys. 2001, 28, 1024–1032. [Google Scholar] [CrossRef] [PubMed]
- Miao, S.; Wang, Z.J.; Liao, R. A CNN regression approach for real-time 2D/3D registration. IEEE Trans. Med. Imaging 2016, 35, 1352–1363. [Google Scholar] [CrossRef] [PubMed]
- Varnavas, A.; Carrell, T.; Penney, G. Fully automated 2D–3D registration and verification. Med. Image Anal. 2015, 26, 108–119. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.N.; Fan, Y.; Hao, D.J. Risk factors for robot-assisted spinal pedicle screw malposition. Sci. Rep. 2019, 9, 3025. [Google Scholar] [CrossRef] [Green Version]
- Härtl, R.; Lam, K.S.; Wang, J.; Korge, A.; Kandziora, F.; Audigé, L. Worldwide survey on the use of navigation in spine surgery. World Neurosurg. 2013, 79, 162–172. [Google Scholar] [CrossRef]
- Tian, N.F.; Huang, Q.S.; Zhou, P.; Zhou, Y.; Wu, R.K.; Lou, Y.; Xu, H.Z. Pedicle screw insertion accuracy with different assisted methods: A systematic review and meta-analysis of comparative studies. Eur. Spine J. 2011, 20, 846–859. [Google Scholar] [CrossRef] [Green Version]
- Beck, M.; Mittlmeier, T.; Gierer, P.; Harms, C.; Gradl, G. Benefit and accuracy of intraoperative 3D-imaging after pedicle screw placement: A prospective study in stabilizing thoracolumbar fractures. Eur. Spine J. 2009, 18, 1469–1477. [Google Scholar] [CrossRef] [Green Version]
- Costa, F.; Cardia, A.; Ortolina, A.; Fabio, G.; Zerbi, A.; Fornari, M. Spinal Navigation: Standard Preoperative Versus Intraoperative Computed Tomography Data Set Acquisition for Computer-Guidance SystemRadiological and Clinical Study in 100 Consecutive Patients. Spine 2011, 36, 2094–2098. [Google Scholar] [CrossRef]
- Hollenbeck, J.F.; Cain, C.M.; Fattor, J.A.; Rullkoetter, P.J.; Laz, P.J. Statistical shape modeling characterizes three-dimensional shape and alignment variability in the lumbar spine. J. Biomech. 2018, 69, 146–155. [Google Scholar] [CrossRef]
- Furrer, P.R.; Caprara, S.; Wanivenhaus, F.; Burkhard, M.D.; Senteler, M.; Farshad, M. Patient-specific statistical shape modeling for optimal spinal sagittal alignment in lumbar spinal fusion. Eur. Spine J. 2021, 30, 2333–2341. [Google Scholar] [CrossRef] [PubMed]
- Yu, W.; Tannast, M.; Zheng, G. Non-rigid free-form 2D–3D registration using a B-spline-based statistical deformation model. Pattern Recognit. 2017, 63, 689–699. [Google Scholar] [CrossRef] [Green Version]
- Baka, N.; Kaptein, B.L.; de Bruijne, M.; van Walsum, T.; Giphart, J.; Niessen, W.J.; Lelieveldt, B.P. 2D–3D shape reconstruction of the distal femur from stereo X-ray imaging using statistical shape models. Med. Image Anal. 2011, 15, 840–850. [Google Scholar] [CrossRef] [PubMed]
- Aubert, B.; Vazquez, C.; Cresson, T.; Parent, S.; de Guise, J.A. Toward automated 3D spine reconstruction from biplanar radiographs using CNN for statistical spine model fitting. IEEE Trans. Med. Imaging 2019, 38, 2796–2806. [Google Scholar] [CrossRef] [PubMed]
- Shen, L.; Zhao, W.; Xing, L. Patient-specific reconstruction of volumetric computed tomography images from a single projection view via deep learning. Nat. Biomed. Eng. 2019, 3, 880–888. [Google Scholar] [CrossRef]
- Ying, X.; Guo, H.; Ma, K.; Wu, J.; Weng, Z.; Zheng, Y. X2CT-GAN: Reconstructing CT from biplanar X-rays with generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10619–10628. [Google Scholar]
- Kasten, Y.; Doktofsky, D.; Kovler, I. End-to-end convolutional neural network for 3D reconstruction of knee bones from bi-planar X-ray images. In Proceedings of the International Workshop on Machine Learning for Medical Image Reconstruction, Lima, Peru, 8 October 2020; Springer: Cham, Switzerland. [Google Scholar]
- Li, R.; Niu, K.; Wu, D.; Vander Poorten, E. A Framework of Real-time Freehand Ultrasound Reconstruction based on Deep Learning for Spine Surgery. In Proceedings of the 10th Conference on New Technologies for Computer and Robot Assisted Surgery, Barcelona, Spain, 28–30 September 2020. [Google Scholar]
- Uneri, A.; Goerres, J.; De Silva, T.; Jacobson, M.W.; Ketcha, M.D.; Reaungamornrat, S.; Kleinszig, G.; Vogt, S.; Khanna, A.J.; Wolinsky, J.P.; et al. Deformable 3D-2D Registration of Known Components for Image Guidance in Spine Surgery. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016, Athens, Greece, 17–21 October 2016; Ourselin, S., Joskowicz, L., Sabuncu, M.R., Unal, G., Wells, W., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 124–132. [Google Scholar]
- Dufour, P.A.; Abdillahi, H.; Ceklic, L.; Wolf-Schnurrbusch, U.; Kowal, J. Pathology hinting as the combination of automatic segmentation with a statistical shape model. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Nice, France, 1–5 October 2012; Springer: Berlin, Germany, 2012; pp. 599–606. [Google Scholar]
- Tatarchenko, M.; Richter, S.R.; Ranftl, R.; Li, Z.; Koltun, V.; Brox, T. What do single-view 3d reconstruction networks learn? In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3405–3414. [Google Scholar]
- Kar, A.; Häne, C.; Malik, J. Learning a multi-view stereo machine. Adv. Neural Inf. Process. Syst. 2017, 2017, 365–376. [Google Scholar]
- Liebmann, F.; Roner, S.; von Atzigen, M.; Scaramuzza, D.; Sutter, R.; Snedeker, J.; Farshad, M.; Fürnstahl, P. Pedicle screw navigation using surface digitization on the Microsoft HoloLens. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 1157–1165. [Google Scholar] [CrossRef]
- Lieberman, I.H.; Kisinde, S.; Hesselbacher, S. Robotic-assisted pedicle screw placement during spine surgery. JBJS Essent. Surg. Tech. 2020, 10, e0020. [Google Scholar] [CrossRef]
- Amiri, S.; Wilson, D.R.; Masri, B.A.; Anglin, C. A low-cost tracked C-arm (TC-arm) upgrade system for versatile quantitative intraoperative imaging. Int. J. Comput. Assist. Radiol. Surg. 2014, 9, 695–711. [Google Scholar] [CrossRef]
- Chintalapani, G.; Jain, A.K.; Burkhardt, D.H.; Prince, J.L.; Fichtinger, G. CTREC: C-arm tracking and reconstruction using elliptic curves. In Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Anchorage, AK, USA, 23–28 June 2008; IEEE: Washingotn, USA, 2008; pp. 1–7. [Google Scholar]
- Navab, N.; Bani-Hashemi, A.R.; Mitschke, M.M.; Holdsworth, D.W.; Fahrig, R.; Fox, A.J.; Graumann, R. Dynamic geometrical calibration for 3D cerebral angiography. In Proceedings of the Medical Imaging 1996: Physics of Medical Imaging, Newport Beach, CA, USA, 10–15 February 1996; SPIE: Bellingham, WA, USA, 1996; Volume 2708, pp. 361–370. [Google Scholar]
- Esfandiari, H.; Martinez, J.F.; Alvarez, A.G.; Guy, P.; Street, J.; Anglin, C.; Hodgson, A.J. An automated, robust and closed form mini-RSA system for intraoperative C-Arm calibration. In Proceedings of the CARS 2017—Computer Assisted Radiology and Surgery, Barcelona, Spain, 20–24 June 2017; Volume 12 (Suppl. S1), pp. S37–S38. [Google Scholar] [CrossRef] [Green Version]
- Kausch, L.; Thomas, S.; Kunze, H.; Privalov, M.; Vetter, S.; Franke, J.; Mahnken, A.H.; Maier-Hein, L.; Maier-Hein, K. Toward automatic C-arm positioning for standard projections in orthopedic surgery. Int. J. Comput. Assist. Radiol. Surg. 2020, 15, 1095–1105. [Google Scholar] [CrossRef]
- Esfandiari, H.; Andreß, S.; Herold, M.; Böcker, W.; Weidert, S.; Hodgson, A.J. A Deep Learning Approach for Single Shot C-Arm Pose Estimation. CAOS 2020, 4, 69–73. [Google Scholar]
- Al Arif, S.M.R.; Knapp, K.; Slabaugh, G. Fully automatic cervical vertebrae segmentation framework for X-ray images. Comput. Methods Programs Biomed. 2018, 157, 95–111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sa, R.; Owens, W.; Wiegand, R.; Chaudhary, V. Fast scale-invariant lateral lumbar vertebrae detection and segmentation in X-ray images. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1054–1057. [Google Scholar]
- Wang, L.; Xie, C.; Lin, Y.; Zhou, H.Y.; Chen, K.; Cheng, D.; Dubost, F.; Collery, B.; Khanal, B.; Khanal, B.; et al. Evaluation and comparison of accurate automated spinal curvature estimation algorithms with spinal anterior-posterior X-ray images: The AASCE2019 challenge. Med. Image Anal. 2021, 72, 102115. [Google Scholar] [CrossRef] [PubMed]
- Otake, Y.; Schafer, S.; Stayman, J.; Zbijewski, W.; Kleinszig, G.; Graumann, R.; Khanna, A.; Siewerdsen, J. Automatic localization of vertebral levels in x-ray fluoroscopy using 3D-2D registration: A tool to reduce wrong-site surgery. Phys. Med. Biol. 2012, 57, 5485. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mushtaq, M.; Akram, M.U.; Alghamdi, N.S.; Fatima, J.; Masood, R.F. Localization and Edge-Based Segmentation of Lumbar Spine Vertebrae to Identify the Deformities Using Deep Learning Models. Sensors 2022, 22, 1547. [Google Scholar] [CrossRef]
- Kim, K.C.; Cho, H.C.; Jang, T.J.; Choi, J.M.; Seo, J.K. Automatic detection and segmentation of lumbar vertebrae from X-ray images for compression fracture evaluation. Comput. Methods Programs Biomed. 2021, 200, 105833. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Deng, Y.; Wang, C.; Hui, Y.; Li, Q.; Li, J.; Luo, S.; Sun, M.; Quan, Q.; Yang, S.; Hao, Y.; et al. CTSpine1K: A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography. arXiv 2021, arXiv:2105.14711. [Google Scholar]
- Goitein, M.; Abrams, M.; Rowell, D.; Pollari, H.; Wiles, J. Multi-dimensional treatment planning: II. Beam’s eye-view, back projection, and projection through CT sections. Int. J. Radiat. Oncol. Biol. Phys. 1983, 9, 789–797. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, September 6–12 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Knapitsch, A.; Park, J.; Zhou, Q.Y.; Koltun, V. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Trans. Graph. 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Xie, H.; Yao, H.; Zhang, S.; Zhou, S.; Sun, W. Pix2Vox++: Multi-scale context-aware 3D object reconstruction from single and multiple images. Int. J. Comput. Vis. 2020, 128, 2919–2935. [Google Scholar] [CrossRef]
- McCormick, M.M.; Liu, X.; Ibanez, L.; Jomier, J.; Marion, C. ITK: Enabling reproducible research and open science. Front. Neuroinformatics 2014, 8, 13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lowekamp, B.; Chen, D.; Ibanez, L.; Blezek, D. The Design of SimpleITK. Front. Neuroinformatics 2013, 7, 45. [Google Scholar] [CrossRef] [PubMed]
- Pérez-García, F.; Sparks, R.; Ourselin, S. TorchIO: A Python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images in deep learning. Comput. Methods Programs Biomed. 2021, 208, 106236. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Falcon, W.; Borovec, J.; Wälchli, A.; Eggert, N.; Schock, J.; Jordan, J.; Skafte, N.; Bereznyuk, V.; Harris, E.; Murrell, T.; et al. Pytorchlightning/pytorch-lightning: 0.7.6 Release. Zenodo, 15 May 2020. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [Green Version]
- Tunçer, N.; Kuyucu, E.; Sayar, Ş.; Polat, G.; Erdil, İ.; Tuncay, İ. Orthopedic surgeons’ knowledge regarding risk of radiation exposition: A survey analysis. SICOT-J 2017, 3, 29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moore, C.; Liney, G.; Beavis, A.; Saunderson, J. A method to produce and validate a digitally reconstructed radiograph-based computer simulation for optimisation of chest radiographs acquired with a computed radiography imaging system. Br. J. Radiol. 2011, 84, 890–902. [Google Scholar] [CrossRef] [Green Version]
- Shiode, R.; Kabashima, M.; Hiasa, Y.; Oka, K.; Murase, T.; Sato, Y.; Otake, Y. 2D–3D reconstruction of distal forearm bone from actual X-ray images of the wrist using convolutional neural networks. Sci. Rep. 2021, 11, 15249. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
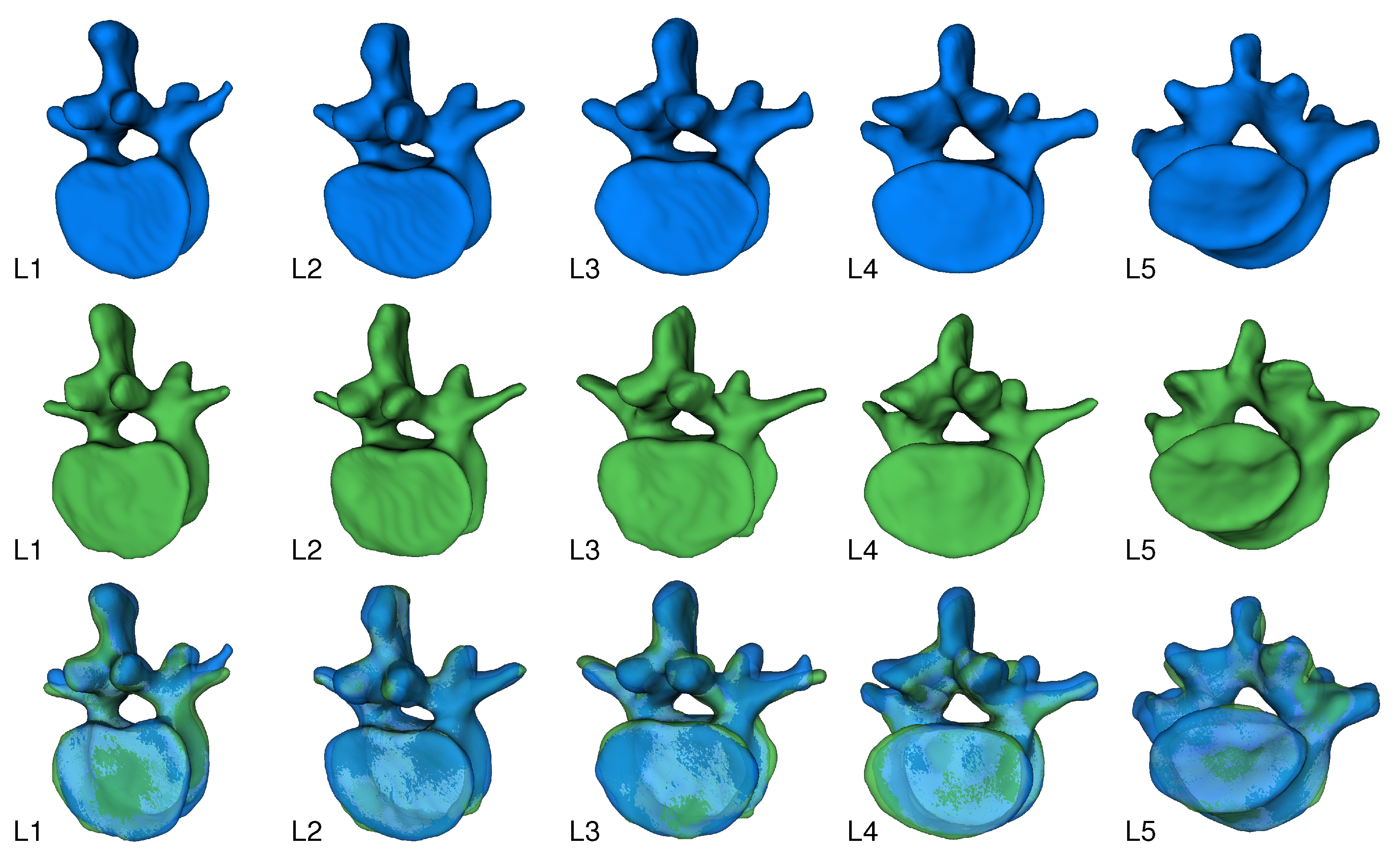{kind=link}
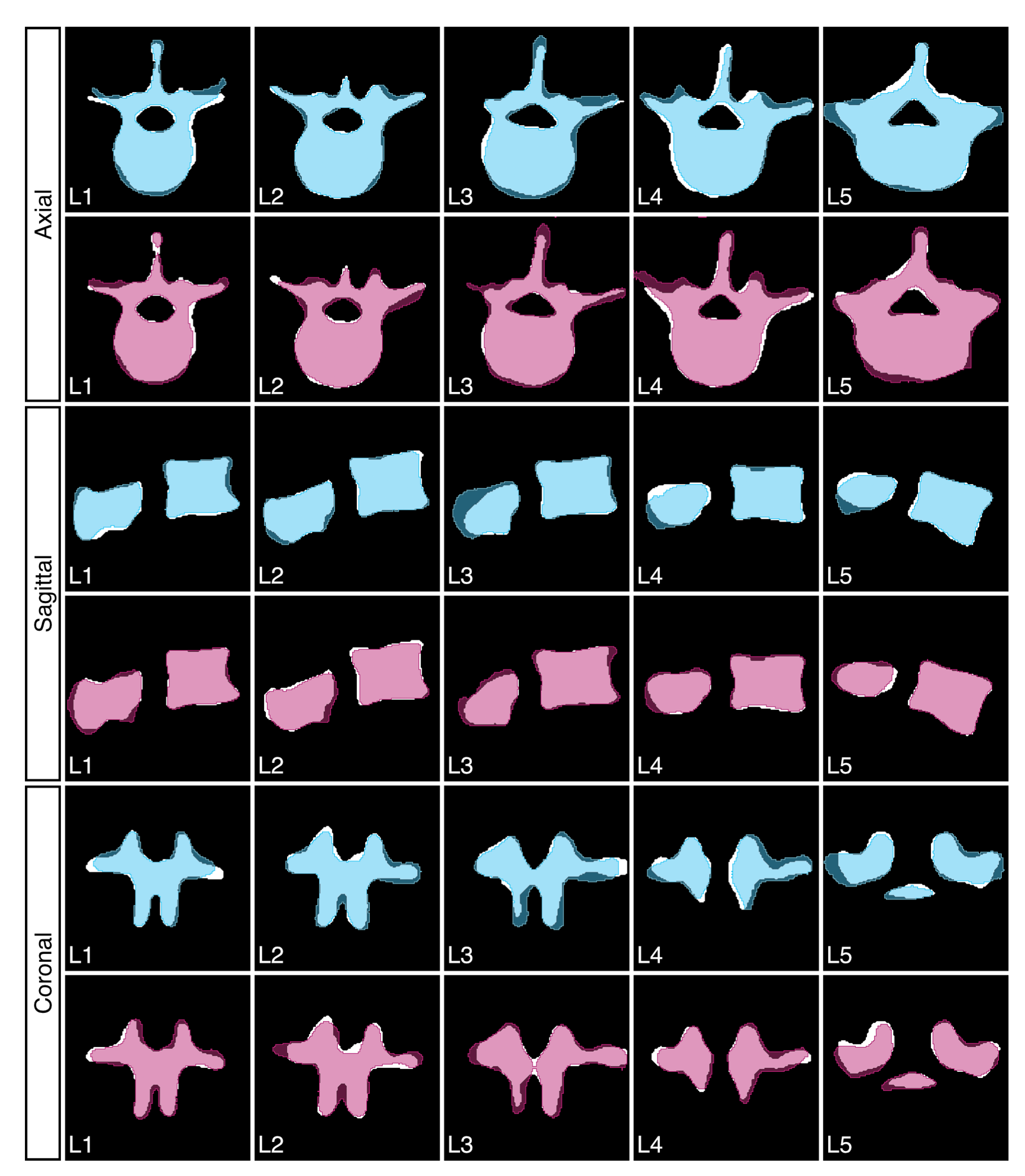{kind=link}
{kind=link}
| Unsegmented | Segmented | Pix2Vox++ (Seg.) | ||||||
|---|---|---|---|---|---|---|---|---|
| Grayscale | Binary | Binary-Aug. | ||||||
| #Views | 4 | 8 | 4 | 8 | 4 | 4 | 4 | 8 |
| F1 score | 0.88 ± 0.03 | 0.89 ± 0.04 | 0.89 ± 0.03 | 0.91 ± 0.02 | 0.90 ± 0.02 | 0.91 ± 0.02 | 0.85 ± 0.05 | 0.86 ± 0.06 |
| Surface score | 0.71 ± 0.11 | 0.67 ± 0.12 | 0.73 ± 0.10 | 0.69 ± 0.10 | 0.70 ± 0.10 | 0.72 ± 0.09 | 0.58 ± 0.12 | 0.58 ± 0.12 |
| IoU | 0.89 ± 0.03 | 0.89 ± 0.03 | 0.90 ± 0.02 | 0.91 ± 0.02 | 0.90 ± 0.03 | 0.91 ± 0.02 | 0.86 ± 0.04 | 0.87 ± 0.04 |
| HD95 (mm) | 2.83 ± 1.72 | 3.21 ± 1.84 | 2.31 ± 0.94 | 3.79 ± 4.51 | 2.43 ± 0.92 | 2.20 ± 0.66 | 3.74 ± 2.01 | 3.76 ± 1.90 |
| ASD (mm) | 0.73 ± 0.36 | 0.84 ± 0.43 | 0.67 ± 0.21 | 1.02 ± 0.66 | 0.73± 0.20 | 0.73 ± 0.18 | 1.01 ± 0.44 | 0.99 ± 0.39 |
| 4-Views | |||||
|---|---|---|---|---|---|
| L1 | L2 | L3 | L4 | L5 | |
| F1 score | 0.89 ± 0.03 | 0.90 ± 0.02 | 0.89 ± 0.03 | 0.88 ± 0.03 | 0.86 ± 0.04 |
| Surface score | 0.75 ± 0.09 | 0.76 ± 0.09 | 0.73 ± 0.09 | 0.69 ± 0.11 | 0.62 ± 0.11 |
| IoU | 0.90 ± 0.02 | 0.90 ± 0.02 | 0.89 ± 0.02 | 0.89 ± 0.03 | 0.87 ± 0.03 |
| HD95 (mm) | 2.39 ± 1.05 | 2.39 ± 1.12 | 2.87 ± 1.79 | 3.10 ± 2.46 | 3.38 ± 1.60 |
| ASD (mm) | 0.64 ± 0.18 | 0.62 ± 0.16 | 0.67 ± 0.16 | 0.81 ± 0.65 | 0.90 ± 0.30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jecklin, S.; Jancik, C.; Farshad, M.; Fürnstahl, P.; Esfandiari, H. X23D—Intraoperative 3D Lumbar Spine Shape Reconstruction Based on Sparse Multi-View X-ray Data. J. Imaging 2022, 8, 271. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging8100271
Jecklin S, Jancik C, Farshad M, Fürnstahl P, Esfandiari H. X23D—Intraoperative 3D Lumbar Spine Shape Reconstruction Based on Sparse Multi-View X-ray Data. Journal of Imaging. 2022; 8(10):271. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging8100271
Chicago/Turabian StyleJecklin, Sascha, Carla Jancik, Mazda Farshad, Philipp Fürnstahl, and Hooman Esfandiari. 2022. "X23D—Intraoperative 3D Lumbar Spine Shape Reconstruction Based on Sparse Multi-View X-ray Data" Journal of Imaging 8, no. 10: 271. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging8100271