
IoT-Based Framework for COVID-19 Detection Using Machine Learning Techniques
1
Department of Physics, Faculty of Education, University of Misan, Maysan 62001, Iraq
2
Faculty of Basic Education, University of Misan, Maysan 62001, Iraq
3
Department of Computer Engineering, Faculty of Information Technology, Imam Ja’afar Al-Sadiq University, Maysan 10011, Iraq
*
Author to whom correspondence should be addressed.
Sci 2024, 6(1), 2; https://0-doi-org.brum.beds.ac.uk/10.3390/sci6010002
Submission received: 20 October 2023
/
Revised: 17 December 2023
/
Accepted: 21 December 2023
/
Published: 23 December 2023
Abstract
:Current advancements in the technology of the Internet of Things (IoT) have led to the proliferation of various applications in the healthcare sector that use IoT. Recently, it has been shown that voice signal data of the respiratory system (i.e., breathing, coughing, and speech) can be processed through machine learning techniques to detect different diseases of this system such as COVID-19, considered an ongoing global pandemic. Therefore, this paper presents a new IoT framework for the identification of COVID-19 based on breathing voice samples. Using IoT devices, voice samples were captured and transmitted to the cloud, where they were analyzed and processed using machine learning techniques such as the naïve Bayes (NB) algorithm. In addition, the performance of the NB algorithm was assessed based on accuracy, sensitivity, specificity, precision, F-Measure, and G-Mean. The experimental findings showed that the proposed NB algorithm achieved 82.97% accuracy, 75.86% sensitivity, 94.44% specificity, 95.65% precision, 84.61% F-Measure, and 84.64% G-Mean.
1. Introduction
In the voice analysis area, classification of an illness can be made possible by using particular features of voice signals [1]. Hence, this area has become a significant topic for research since it can decrease laborious work in the classification of voice pathologies [2]. The healthcare field is considered an active application for the IoT, where IoT technology has been employed in various medical applications due its many features. For instance, the IoT is employed in remote health surveillance; monitoring of blood pressure; monitoring of oxygen saturation; care of the elderly; monitoring of chronic diseases; management and control of wheelchairs; and fitness schedules. Figure 1 illustrates IoT devices recently used in the healthcare sector. In addition, several healthcare, diagnostic, and imaging devices can be regarded as smart devices which play a vital part in IoT [3]. The incorporation of IoT into healthcare fields is predicted to minimize healthcare service charges, as well as enhance quality of life and improve the user experience. According to the perspective of healthcare organizations, the technology of IoT holds the prospect of reducing a device’s downtime via remote service provision. Correspondingly, the IoT is able to precisely specify the times for reloading supplies for various devices for the purpose of performing continued and flexible processes. Additionally, the IoT delivers effective and practical scheduling of specified resources in order to guarantee the provision of the most suitable services and rest for patients [4].
Due to the significance of the healthcare field, combining the cloud and IoT within healthcare holds the potential for extensive applications in both societal and daily life, with a particular focus on the healthcare domain [6]. These applications can flourish by embracing cloud and IoT technologies. For instance, there are several uses for patients with chronic conditions who need long-term monitoring [7], when the provision of constant surveillance can be critical. Cloud computing can provide massive storage and high processing power while also ensuring security [8].
Along with IoT and cloud services in healthcare applications, machine learning (ML) introduces several approaches that may aid in addressing prognostic and diagnostic difficulties in various medical areas [9]. These techniques have been employed in discriminating between two or more classes of disease [10]. Also, ML techniques are extensively employed in diverse domains, for instance in image identification in the healthcare field [11]; language classification [12,13]; identification of voice pathology [14,15]; classification of spam emails [16]; and vehicle detection [17].
Furthermore, ML techniques have been used in many medical applications such as COVID-19 detection [18]; lung cancer detection [19]; voice pathology classification [20]; breast cancer detection [21]; and diabetes disease detection [22,23]. One of the most dangerous illnesses facing the world recently is COVID-19 [24]. On 11 March 2020 this virus was declared a worldwide pandemic by the World Health Organization (WHO) [25]. COVID-19 is regarded as a new infectious illness and can cause death [26]. Consequently, it is imperative to exploit the features of IoT, ML and the cloud for use in the healthcare sector generally and in COVID-19 detection in particular. The general symptoms of COVID-19 comprise loss of taste or smell, gastrointestinal symptoms, muscle pain, shortness of breath, and joint pain [27]. The most prevalent symptoms of COVID-19 are dry coughs, fatigue, and fever [28]. Most systems of COVID-19 detection are performed using x-ray images, whereas voice analysis of COVID-19 patients has not gained much attention. Therefore, this paper presents a new IoT framework based on machine learning techniques for the detection of COVID-19 by using breathing voice signals. The main aims of this paper are as follows:
- Propose a new IoT framework based on machine learning techniques for the detection of COVID-19 by using breathing voice signals.
- Use mel-frequency cepstral coefficients (MFCCs) to extract the needed features from breathing voice signals and the naïve Bayes (NB) algorithm to classify whether the input voice signal is positive or negative.
- Evaluate the proposed work based on several of the most common evaluation measurements—accuracy, sensitivity, specificity, precision, F-Measure, and G-Mean.
- Compare the proposed NB algorithm against the SVM and RF algorithms in the detection of the COVID-19 by using breathing voice signals.
- Compare the performance of the proposed work, in terms of accuracy, with recent studies that used the same dataset.
The remainder of the current paper is organised as follows: Section 2 provides a review of previous work relevant to the current study. Section 3 presents the materials and proposed methods, and Section 4 presents the experiment setup and discussion of results. Finally, Section 5 illustrates the conclusion of this research.
2. Related Works
There are different types of data on the respiratory system, such as coughing, speech, breathing, and sneezing. These data can be analyzed and processed through ML techniques for the purpose of identifying diseases of the respiratory system [29]. Here, we will present a brief review of ML methods and techniques that have been used in the detection of COVID-19. The short-time magnitude spectrogram features (SRMSF) and the ResNet18 algorithm were presented and implemented for the identification of COVID19 in [30]. In this method, the cough voice samples of the Coswara database were used for the training and testing of the ResNet18 algorithm. The best area under curve (AUC) result was 0.72.
Furthermore, the work in [31] has been suggested as a method for detecting COVID-19 based on voice samples. In this work, mel-filter bank features (MFBF) technique is employed to extract audio features. Subsequently, these features are fed to a support vector machine (SVM) for the purpose of identifying the voice samples as either healthy class or COVID-19 class. The voice samples were collected from YouTube for training and testing the SVM classifier. According to the experimental findings, the highest obtained result for detection accuracy was 88.60%.
The study in [32], has been presented as a system of COVID-19 detection. In this system, several handcrafted features were implemented, while a logistic regression (LR) algorithm was used as a classifier to separate voice features into healthy or COVID-19. There were two types of voice samples used for training and testing the LR classifier. The first type of voice sample was for cough samples, whilst the second type of voice sample was for breath samples. These two types of voice samples were collected from a crowd-sourced database. The experimental outcomes demonstrated that the best results showing precision using cough voice samples and breath voice samples were 80.00% and 69.00%, respectively.
The authors in [33] studied and analyzed the sustained phonation of the vowel /i/, number counting, and deep breathing for the detection of COVID-19. In addition, these three types of voice samples were collected from the DiCOVA database. The authors used various features such as harmonics, super-vectors, MFCC, and formats. In addition, they used the SVM classifier for differentiating the COVID-19 samples from healthy samples. The experimental results showed that the SVM classifier was able to recognize COVID-19 samples with AUC scores of 0.734 and 0.717 for cross-validation and testing, respectively. However, the results obtained via this method were not encouraging.
The work in [34] was presented as a method to differentiate people who were infected by COVID-19 from healthy people. Voice samples for the healthy class and COVID-19 class were collected in India. In the database, there were 152 samples which were affected by COVID-19 (i.e., positive cases) and 1143 samples which were healthy cases (i.e., negative cases). Pre-processing was implemented and the features extracted using MFCC technique. The oversampling was also conducted on the extracted features for the purpose of increasing detection accuracy. According to the experimental outcomes, the highest achieved accuracy was 92%, which was obtained by K-NN classifier.
In [35], the authors conducted an experimental study to assess the effectiveness of bottleneck feature extraction and transfer learning in the identification of COVID-19 using audio recordings of coughs, breaths, and speech. Furthermore, they utilized a dataset that included various sounds such as coughs, sneezes, speech, and background noise, but lacked COVID-19 labels. Initially, the authors pre-trained three deep neural networks, namely CNN, LSTM, and Resnet50. Subsequently, they fine-tuned these pre-trained networks using smaller datasets that contained labelled instances of COVID-19 associated with coughing. In addition, they utilized these pre-trained networks as bottleneck feature extractors. The experimental findings indicated that a Resnet50 classifier trained through this transfer learning approach consistently demonstrated excellent or near-optimal performance across all datasets. It achieved an AUC of 0.98 for the cough set, 0.94 for the breath set, and 0.92 for the speech set.
Another study used a cough dataset for the assessment of COVID-19 [36]. This study aimed to employ an automatic speech identification system based on hidden Markov models (HMMs) to analyze cough signals and determine whether they originated from individuals who were healthy or COVID-19 patients. The method was developed as a customizable model that utilizes HMMs, MFCC, Gaussian mixture models (GMMs), and a dataset of cough recordings from both healthy and sick volunteers. The proposed approach successfully categorized a dry cough with a sensitivity ranging from 85.86% to 91.57%. It could also distinguish between a dry cough and a cough associated with COVID-19 symptoms with a specificity ranging from 5% to 10%.
The work in [37] focused on distinguishing between healthy individuals and those infected with COVID-19 by utilizing cough recordings. It built upon the previously successful application of the bag-of-words (BoW) classifier in biometric scenarios involving ECG signals. The evaluation measurements included accuracy in discrimination, F1-score, AUC, and sensitivity. A comprehensive series of tests was carried out using two crowd-sourced datasets: COUGHVID (consisting of 250 subjects per class) and COVID-19 Sounds (comprising 450 subjects per class, recorded in a medical setting). To enhance data quality, the authors applied specific preprocessing procedures to clean the recordings and selected audio segments that exclusively contained pure cough sounds. The work also introduced new developments related to the impact of both input and output fusion techniques on classification performance. Additionally, the proposed work has overtaken the CNN algorithm in identifying COVID-19. The results showed that the BoW algorithm achieved the highest accuracy of 74.3%, 71.4% sensitivity, 75.4% F1-score, and 82.6% AUC using the COUGHVID dataset. However, the obtained results are still not encouraging in terms of detecting and identifying COVID-19 instances.
The research in [38] proposed an automatic COVID-19 detection system using cough voice data. The proposed system was based on the utilization of several features extraction techniques such as spectral centroid (SC), zero-crossing rate (ZCR), mel-frequency cepstral coefficients (MFCC), and long short-term memory (LSTM) classifier. The assessment of the proposed system was conducted on a cough voice corpus that was collected from 20 COVID-19 patients (8 female and 12 male) and 60 healthy speakers (20 female and 40 male). In addition, the collected cough voice dataset was divided into 30% for testing and 70% for training. The experimental results showed that the best performance achieved was with the utilization of MFCC features and LSTM classifier, where it hits a precision of 99.30%.
Additionally, an application for the detection of COVID-19 was proposed in [39]. The proposed application was built using the short-time Fourier transform (STFT) features and decision forest (DF) classifier. The evaluation of the proposed application was conducted based on speech data. The experiment’s outcomes showed that the proposed application attained results with an accuracy of 73.17%. Table 1 illustrates the related work of the current study. Based on all the above-mentioned studies, we can summarize the limitations as follows:
- The outcomes of most previous works are still not encouraging and require more enhancement regarding the accuracy rate.
- Most of the previous studies have been evaluated based on limited evaluation measurements.
3. Proposed Method
The proposed method comprises four steps for the detection of COVID-19. The first step refers to the use of database voice samples. The second step is the use of the IoT framework. The third step refers to the feature extraction technique. Finally, the fourth step denotes the classification technique for identifying the COVID-19 class from the healthy class. Figure 2 depicts the overall flowchart of the proposed method for detecting COVID-19 using voice data. The following subsections will provide explanations for each of these steps individually.
3.1. Database
In this work, we trained and tested the proposed method using the corona hack respiratory sound dataset (CHRSD). The voice signals of this dataset were collected from Kaggle [35]. This voice database comprises numerous types of respiratory sounds. For example, shallow breath, count fast; deep breath, count normal; heavy cough; and vowels (i.e., /a/, /e/, /o/). Each type of respiratory sound contains voice signals for COVID-19-infected people and healthy people. Furthermore, in our proposed method, we selected all breath samples for the detection of COVID-19 in both classes—healthy and COVID-19. We used a balanced voice database, with 78 voices for the COVID-19 category and 78 voices for the healthy category. Thus, the total number in the database was156. The voice database was split into 70% and 30% for training and testing processes, respectively.
3.2. IoT Framework
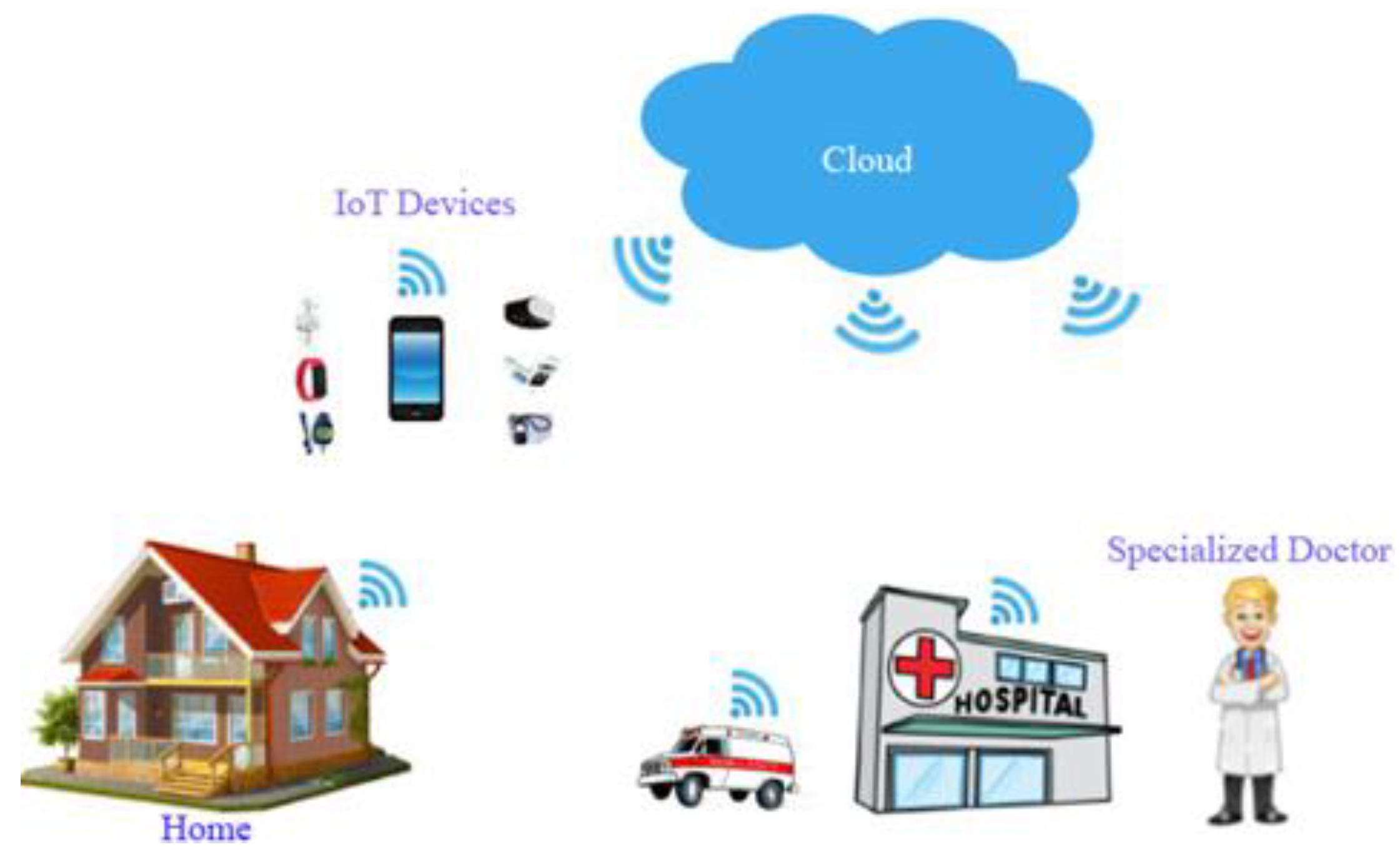
The proposed IoT framework/model, merged with cloud computing, aimed to diagnose COVID-19 via testing obtained voice samples of the vowel /a/. Figure 3 presents the procedures of the proposed IoT framework using IoT devices for capturing and uploading the user’s voice to the cloud, where the voice signal was processed and analyzed.
The proposed IoT framework can be useful for patients who are suffering from COVID-19 to self-diagnose using their voice. Some patients may have difficulty getting to hospitals or clinics for a medical examination for various reasons, such as distance from home and problems obtaining appointments at short notice; others may think that their hoarseness is not life endangering. Nonetheless, early diagnosis is imperative for this kind of disease in order to determine if there are any problems with vocal folds. Using our proposed IoT framework, recording the process of a patient’s voice for voice diagnosis can be made easier by using IoT devices such as smartphones. Hence, the proposed IoT framework presents not only a simpler and easier process of self-diagnosis for patients but can also motivate them to regularly check their voice when they have any hoarseness or voice disorder. The recorded voice can then be sent to the cloud for further processing and classification into COVID-19 class or healthy class by using the machine learning technique.
3.3. Feature Extraction
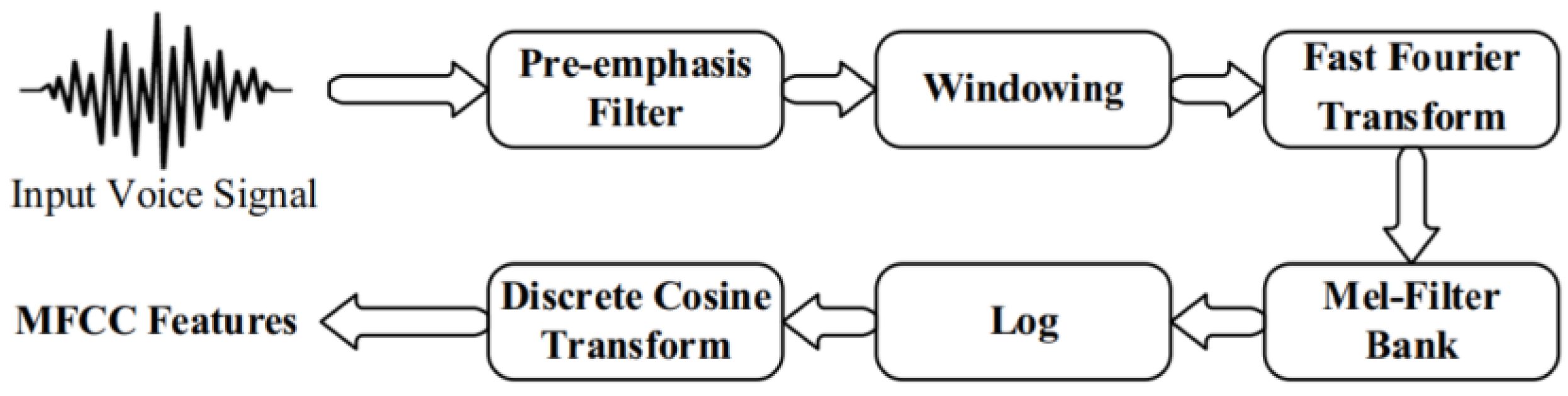
In this study, voice features were extracted using the MFCC technique based on performing various stages. These stages included pre-emphasis, windowing, FFT (fast Fourier transform), mel filter bank, log, and DCT (discrete cosine transform). The diagram of the MFCC technique is shown Figure 4. In the pre-emphasis stage, the energy of the voice samples were increased at a higher frequency. The windowing stage refers to splitting the voice signals into frames.
In addition, the FFT stage denotes converting the voice sample from the time field into a frequency field. Subsequently, the mel filter bank is involved for the purpose of converting frequencies of the voice signals from Hz to mel as shown in the following equation:
The DCT was implemented to convert the log mel spectrum into a time field. Therefore, each voice signal was converted into a sequence of attributes.
3.4. Classification
The naïve Bayes (NB) algorithm was used in the classification process for the purpose of identifying voice samples into the COVID-19 category and the healthy category. It is worth stating that the NB algorithm has been implemented extensively in prediction and diagnostic tasks, where the performance of the NB algorithm has been proven efficient and shown to achieve higher results compared to other algorithms [41]. Furthermore, the NB algorithm can perform well based on a small number of instances for determining subjects. In addition, the NB algorithm is easy to implement. In the NB algorithm, the attribute values of the feature in a category are presumed to be independent of others, known as class conditional independence. In the NB algorithm, the attributes of a class c are indicated as a group of {f1, f2 … fn} = (x) which represents the feature vector of voice signal samples. In addition, the probability P(c∣x) denotes the probability of a new voice signal. It can be computed by employing the Bayes equation:
The parameters of the equation are:
- ○
- P(c|x) is the posterior probability of class (c) given predictor (x).
- ○
- P(c) is the prior probability of class.
- ○
- P(x|c) is the likelihood which is the probability of the predictor given class.
- ○
- P(x) is the prior probability of the predictor.
The process of classification can easily be defined in three simple steps: (a) create a frequency table from the dataset; (b) establish a likelihood table by specifying the probabilities; and (c) utilize the Bayesian equation to measure the post-class probability. The prediction outcome is the class with the highest posterior probability.
4. Experimental Results
The voice samples in this work were gathered from the CHRSD database for both classes, COVID-19 and healthy. In this database, there are different types of respiratory categories. In the proposed work, we used all breathing categories for both classes in order to identify COVID-19. The database used in this work was balanced—there were 78 voice samples for each class. Hence, the total number of all samples in the database was 156. The voice database was split into 70% and 30% for training and testing processes, respectively. In the training set, there were 109 voice samples, with 47 voice samples in the testing set. The experiment was conducted utilizing the Python 3 programming language on a PC (Windows 10). The NB algorithm was assessed in terms of common evaluation measurements: accuracy (Acc), sensitivity (Sen), specificity (Spe), precision (Pre), F-Measure (F-M), and G-Mean (G-M). These performance measurements were computed using the following equations [42,43,44,45,46]:
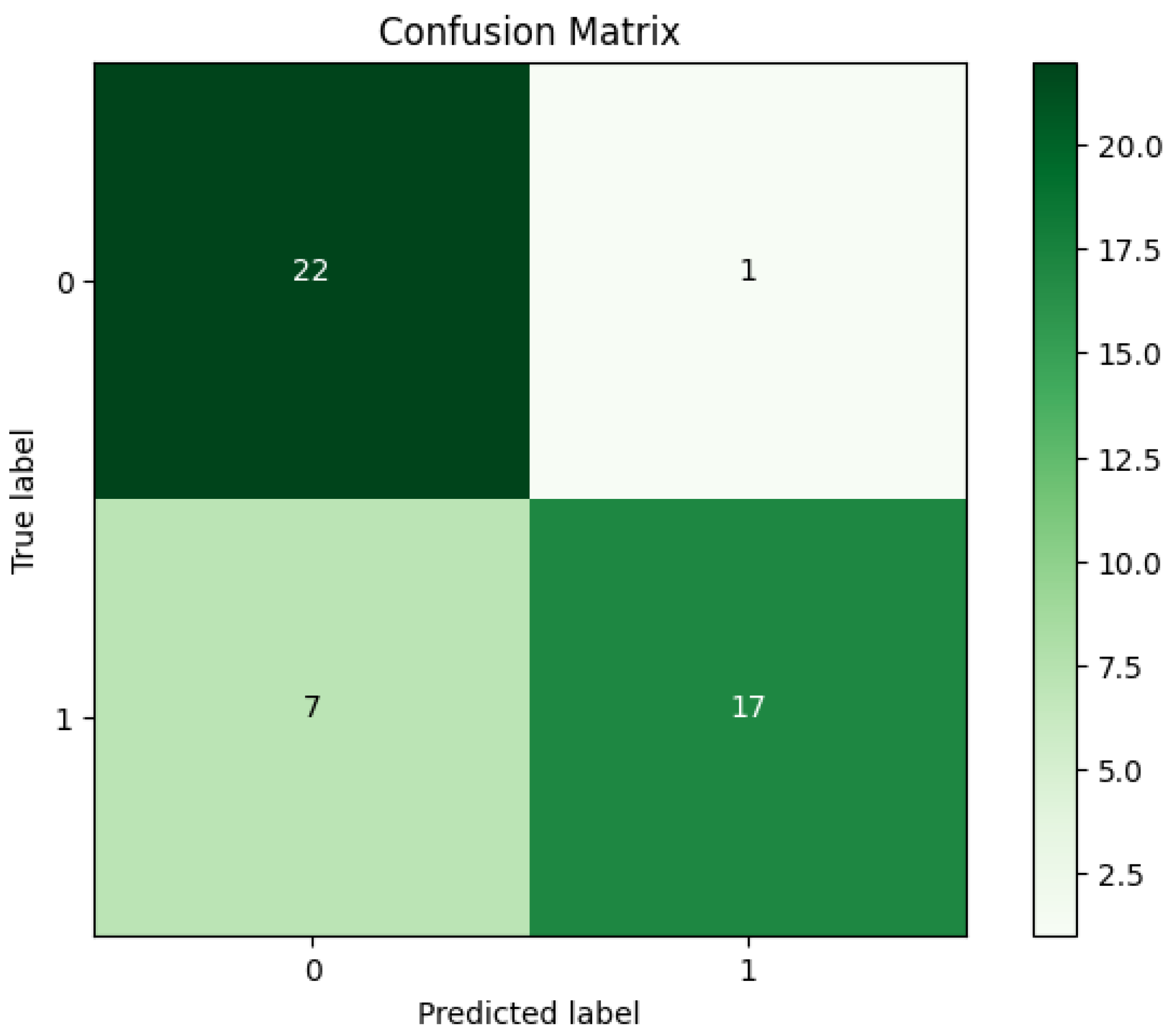
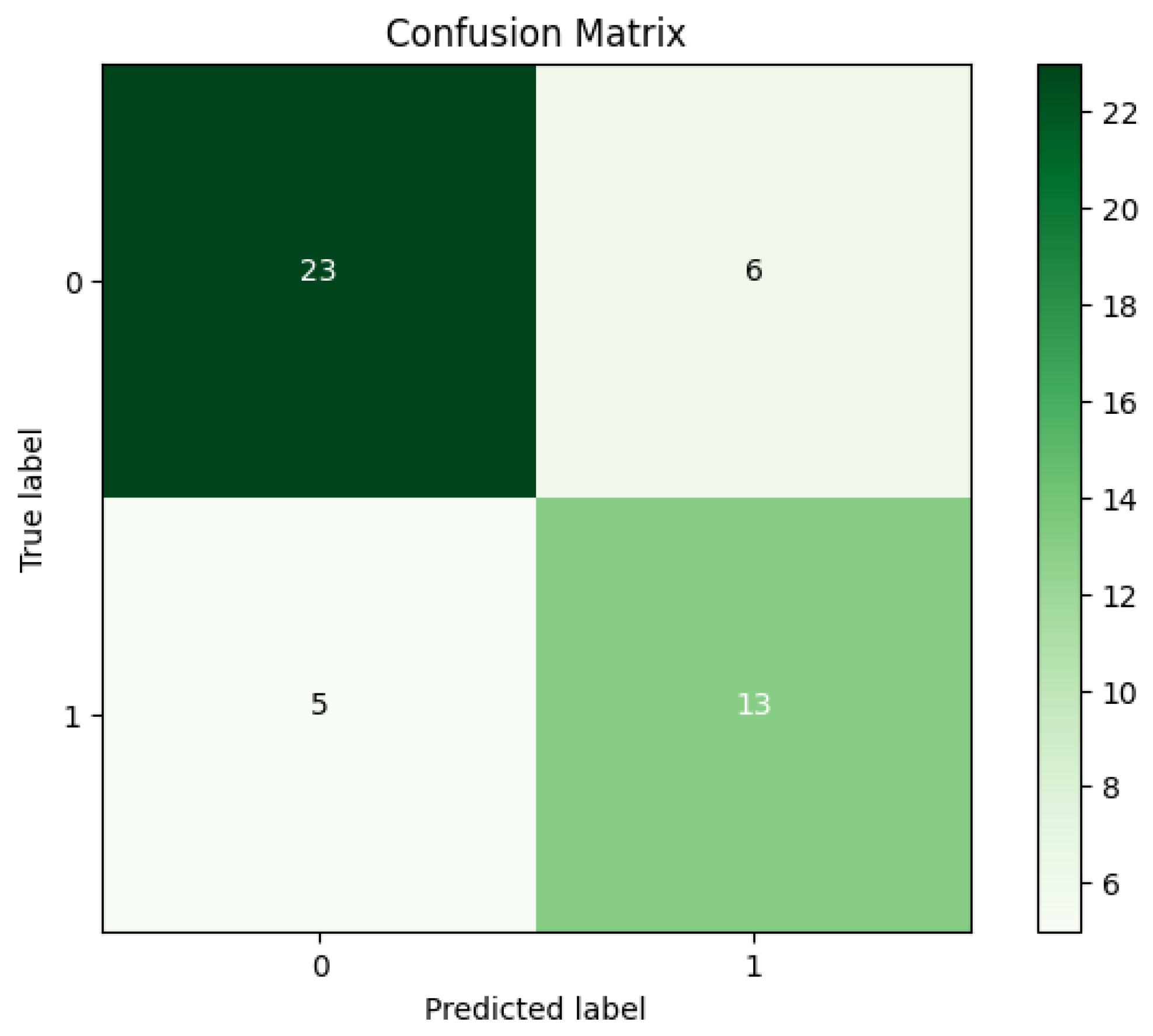
where TP refers to true positive; TN denotes true negative; and FP and FN indicate false positive and false negative, respectively. The experimental results in Table 2 demonstrate that the proposed method using the NB algorithm achieved 82.97% Acc, 75.86% Sen, and 94.44% Spe. Furthermore, the achieved results for the Pre, F-M, and G-M were 95.65%, 84.61%, and 84.64%, respectively. In addition, Figure 5 exhibits the confusion matrix for the NB algorithm.
Additionally, based on the confusion matrix for the NB algorithm’s best outcomes shown in Figure 5, we can observe the following: (a) it was a clear indication that the proposed NB algorithm on the CHRSD database was able to accurately classify 22 out of 23 COVID-19 samples, and (b) the proposed NB algorithm was capable of accurately classifying 17 out of 23 healthy samples.
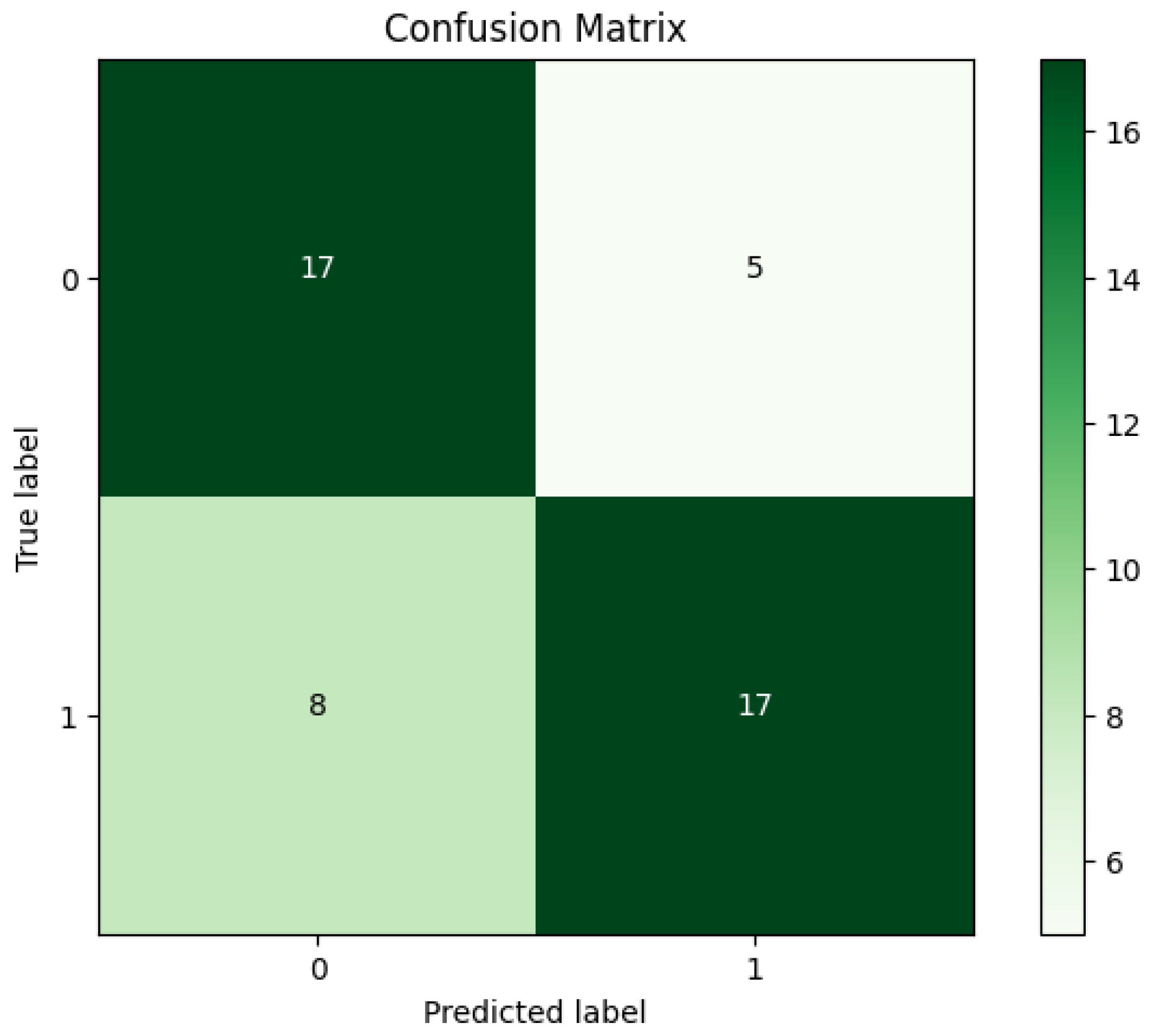
Moreover, additional experiments were conducted utilizing the SVM and RF algorithms on the same CHRSD database. Table 3 shows all the experimental results of both SVM and RF algorithms. The experimental outcomes in Table 3 reveal that the SVM algorithm achieved 76.60% Acc, 82.14% Sen, 68.42% Spe, 79.31% Pre, 80.70% F-M, and 74.97% G-M. Furthermore, the RF algorithm attained 72.34% Acc, 68.00% Sen, 77.27% Spe, 77.27% Pre, 72.34% F-M, and 72.49% G-M. Figure 6 and Figure 7 show the confusion matrices for the SVM and RF algorithms. Further, Figure 8 depicts the comparison results of the proposed NB algorithm against the SVM and RF in COVID-19 detection.
Based on the results in Table 2 and Table 3 and Figure 5, Figure 6, Figure 7 and Figure 8, it is clear that the proposed NB algorithm outperformed both the SVM and RF algorithms. The highest accuracy rate achieved by the proposed NB algorithm was 82.97% while the highest accuracy rate achieved by the SVM and RF algorithms were 76.60% and 72.34%, respectively.
In addition, we evaluated and compared the NB algorithm with other methods in [47,48,49], in terms of the detection accuracy in identifying COVID-19. These methods have been presented in the detection of COVID-19 based on all breath samples. Also, these methods used the same database that we used in the proposed NB algorithm in order to perform a fair comparison. Table 4 shows the comparison between the proposed NB algorithm with other methods in the detection of COVID-19. The experimental findings demonstrate that the proposed NB algorithm outperformed its comparatives in the detection of COVID-19 based on all breath samples.
Even though the results in Table 3 demonstrate that the proposed NB algorithm outperformed all of its peers in terms of classification accuracy rate, there are still some limitations of the current work, which are as follows:
The current work has been evaluated on a small dataset which may affect the detection accuracy rate.
The evaluation of the present work in terms of execution time has been ignored.
This research focused on classifying the respiratory system voice data into two classes (COVID-19/healthy) only, and other lung illnesses were ignored.
5. Conclusions
This paper presents a new IoT framework based on a machine-learning algorithm for the detection of COVID-19 using breathing voice signals. IoT devices have been used to capture voice signals from users and then send them to the cloud. In the cloud, voice signals can be processed and analyzed using naïve Bayes (NB), one of the machine learning techniques. The voice samples for this study were gathered from the CHRSD database, with a balanced number of samples for each class—healthy and COVID-19 with each class having 78 voice samples. Furthermore, the NB algorithm was evaluated using six different evaluation measurements: accuracy, sensitivity, specificity, precision, F-Measure, and G-Mean. The results demonstrated that the NB algorithm achieved 82.97% accuracy, 75.86%, sensitivity, 94.44% specificity, 95.65% precision, 84.61% F-Measure, and 84.64% G-Mean. However, the current work is still suffering from some limitations which can be illustrated as follows: (i) evaluation of the current work was based on a small dataset, and (ii) the present work has ignored the evaluation of the proposed NB algorithm in terms of execution time. Therefore, in future work we plan to evaluate the proposed work on a bigger dataset alongside an evaluation of execution time. In addition, we would consider the classification of other lung illnesses using respiratory system voice data. Moreover, we would test the use of different classifiers for the detection of COVID-19 based on various voice types of the respiratory system such as vowels, speech, and coughing.
Author Contributions
Conceptualization, G.F.K.A.-M. and A.S.A.-K.; methodology, G.F.K.A.-M.; software, A.S.A.-K.; validation, G.F.K.A.-M., A.S.A.-K. and T.J.S.; formal analysis, T.J.S.; investigation, A.S.A.-K.; resources, G.F.K.A.-M.; data curation, T.J.S.; writing—original draft preparation, T.J.S.; writing—review and editing, A.S.A.-K.; visualization, A.S.A.-K.; supervision, T.J.S.; project administration, A.S.A.-K.; funding acquisition, A.S.A.-K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Latif, S.; Qadir, J.; Qayyum, A.; Usama, M.; Younis, S. Speech technology for healthcare: Opportunities, challenges, and state of the art. IEEE Rev. Biomed. Eng. 2020, 14, 342–356. [Google Scholar] [CrossRef] [PubMed]
- Kanase, N.V.; Pangoankar, S.A.; Panat, A.R. A Robust Approach of Estimating Voice Disorder Due to Thyroid Disease. In Advances in Signal and Data Processing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 157–168. [Google Scholar]
- Pradhan, B.; Bhattacharyya, S.; Pal, K. IoT-based applications in healthcare devices. J. Healthc. Eng. 2021, 2021, 6632599. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.M.; Nooruddin, S.; Karray, F.; Muhammad, G. Internet of Things: Device Capabilities, Architectures, Protocols, and Smart Applications in Healthcare Domain. IEEE Internet Things J. 2022, 10, 3611–3641. [Google Scholar] [CrossRef]
- Al-Dhief, F.T.; Latiff, N.M.A.A.; Malik, N.N.N.A.; Salim, N.S.; Baki, M.M.; Albadr, M.A.A.; Mohammed, M.A. A survey of voice pathology surveillance systems based on internet of things and machine learning algorithms. IEEE Access 2020, 8, 64514–64533. [Google Scholar] [CrossRef]
- Alshamrani, M. IoT and artificial intelligence implementations for remote healthcare monitoring systems: A survey. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 4687–4701. [Google Scholar] [CrossRef]
- He, R.; Liu, H.; Niu, Y.; Zhang, H.; Genin, G.M.; Xu, F. Flexible miniaturized sensor technologies for long-term physiological monitoring. npj Flex. Electron. 2022, 6, 20. [Google Scholar] [CrossRef]
- Vellela, S.S.; Balamanigandan, R.; Praveen, S.P. Strategic Survey on Security and Privacy Methods of Cloud Computing Environment. J. Next Gener. Technol. 2022, 2, 70–78. [Google Scholar]
- Baker, S.; Xiang, W. Artificial Intelligence of Things for Smarter Healthcare: A Survey of Advancements, Challenges, and Opportunities. IEEE Commun. Surv. Tutor. 2023, 25, 1261–1293. [Google Scholar] [CrossRef]
- Chavda, V.P.; Patel, K.; Patel, S.; Apostolopoulos, V. Artificial Intelligence and Machine Learning in Healthcare Sector. Bioinform. Tools Pharm. Drug Prod. Dev. 2023, 285–314. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; Al-Dhief, F.T.; Omar, K.; Hamzah, F.A. Optimised genetic algorithm-extreme learning machine approach for automatic COVID-19 detection. PLoS ONE 2020, 15, e0242899. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; AL-Dhief, F.T. Spoken language identification based on optimised genetic algorithm–extreme learning machine approach. Int. J. Speech Technol. 2019, 22, 711–727. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; Nazri, M.Z.A.; AL-Dhief, F.T. Grey wolf optimization-extreme learning machine for automatic spoken language identification. Multimed. Tools Appl. 2023, 82, 27165–27191. [Google Scholar] [CrossRef]
- AL-Dhief, F.T.; Latiff, N.M.A.A.; Malik, N.N.N.A.; Sabri, N.; Baki, M.M.; Albadr, M.A.A.; Abbas, A.F.; Hussein, Y.M.; Mohammed, M.A. Voice Pathology Detection Using Machine Learning Technique. In Proceedings of the 2020 IEEE 5th International Symposium on Telecommunication Technologies (ISTT), Shah Alam, Malaysia, 9–11 November 2020; IEEE: New York, NY, USA, 2020; pp. 99–104. [Google Scholar]
- Mohammed, M.A.; Abdulkareem, K.H.; Mostafa, S.A.; Khanapi Abd Ghani, M.; Maashi, M.S.; Garcia-Zapirain, B.; Oleagordia, I.; Alhakami, H.; Al-Dhief, F.T. Voice Pathology Detection and Classification Using Convolutional Neural Network Model. Appl. Sci. 2020, 10, 3723. [Google Scholar] [CrossRef]
- Mohammed, M.A.; Mostafa, S.A.; Obaid, O.I.; Zeebaree, S.R.; Abd Ghani, M.K.; Mustapha, A.; Fudzee, M.F.M.; Jubair, M.A.; Hassan, M.H.; Ismail, A.; et al. An anti-spam detection model for emails of multi-natural language. J. Southwest Jiaotong Univ. 2019, 54. [Google Scholar] [CrossRef]
- Abbas, A.F.; Sheikh, U.U.; AL-Dhief, F.T.; Mohd, M.N.H. A Comprehensive Review of Vehicle Detection Using Computer Vision. Submitt. TELKOMNIKA Telecommun. Comput. Electron. Control J. 2020, 19, 838–850. [Google Scholar] [CrossRef]
- Salam, M.A.; Taha, S.; Ramadan, M. COVID-19 detection using federated machine learning. PLoS ONE 2021, 16, e0252573. [Google Scholar]
- Radhika, P.; Nair, R.A.; Veena, G. A comparative study of lung cancer detection using machine learning algorithms. In Proceedings of the 2019 IEEE International Conference on Electrical, Computer and Communication Technologies (ICECCT), Coimbatore, India, 20–22 February 2019; IEEE: New York, NY, USA, 2019; pp. 1–4. [Google Scholar]
- Al-Dhief, F.T.; Baki, M.M.; Latiff, N.M.A.A.; Malik, N.N.N.A.; Salim, N.S.; Albader, M.A.A.; Mahyuddin, N.M.; Mohammed, M.A. Voice pathology detection and classification by adopting online sequential extreme learning machine. IEEE Access 2021, 9, 77293–77306. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Ayob, M.; Tiun, S.; AL-Dhief, F.T.; Arram, A.; Khalaf, S. Breast cancer diagnosis using the fast learning network algorithm. Front. Oncol. 2023, 13, 1150840. [Google Scholar] [CrossRef]
- Mujumdar, A.; Vaidehi, V. Diabetes prediction using machine learning algorithms. Procedia Comput. Sci. 2019, 165, 292–299. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Ayob, M.; Tiun, S.; Al-Dhief, F.T.; Hasan, M.K. Gray wolf optimization-extreme learning machine approach for diabetic retinopathy detection. Front. Public Health 2022, 10, 925901. [Google Scholar] [CrossRef]
- Atlam, M.; Torkey, H.; El-Fishawy, N.; Salem, H. Coronavirus disease 2019 (COVID-19): Survival analysis using deep learning and Cox regression model. Pattern Anal. Appl. 2021, 24, 993–1005. [Google Scholar] [CrossRef] [PubMed]
- Asghar, N.; Mumtaz, H.; Syed, A.A.; Eqbal, F.; Maharjan, R.; Bamboria, A.; Shrehta, M. Safety, efficacy, and immunogenicity of COVID-19 vaccines; a systematic review. Immunol. Med. 2022, 45, 225–237. [Google Scholar] [CrossRef] [PubMed]
- Azarpazhooh, M.R.; Morovatdar, N.; Avan, A.; Phan, T.G.; Divani, A.A.; Yassi, N.; Stranges, S.; Silver, B.; Biller, J.; Belasi, M.T.; et al. COVID-19 pandemic and burden of non-communicable diseases: An ecological study on data of 185 countries. J. Stroke Cerebrovasc. Dis. 2020, 29, 105089. [Google Scholar] [CrossRef] [PubMed]
- Rofail, D.; McGale, N.; Podolanczuk, A.J.; Rams, A.; Przydzial, K.; Sivapalasingam, S.; Mastey, V.; Marquis, P. Patient experience of symptoms and impacts of COVID-19: A qualitative investigation with symptomatic outpatients. BMJ Open 2022, 12, e055989. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Chen, Z.; Nie, Y.; Ma, Y.; Guo, Q.; Dai, X. Identification of symptoms prognostic of COVID-19 severity: Multivariate data analysis of a case series in Henan Province. J. Med. Internet Res. 2020, 22, e19636. [Google Scholar] [CrossRef]
- Belkacem, A.N.; Ouhbi, S.; Lakas, A.; Benkhelifa, E.; Chen, C. End-to-end AI-based point-of-care diagnosis system for classifying respiratory illnesses and early detection of COVID-19: A theoretical framework. Front. Med. 2021, 8, 585578. [Google Scholar] [CrossRef]
- Bagad, P.; Dalmia, A.; Doshi, J.; Nagrani, A.; Bhamare, P.; Mahale, A.; Rane, S.; Agarwal, N.; Panicker, R. Cough against COVID: Evidence of COVID-19 signature in cough sounds. arXiv 2020, arXiv:2009.08790. [Google Scholar]
- Ritwik, K.V.S.; Kalluri, S.B.; Vijayasenan, D. COVID-19 patient detection from telephone quality speech data. arXiv 2020, arXiv:2011.04299. [Google Scholar]
- Brown, C.; Chauhan, J.; Grammenos, A.; Han, J.; Hasthanasombat, A.; Spathis, D.; Xia, T.; Cicuta, P.; Mascolo, C. Exploring automatic diagnosis of COVID-19 from crowdsourced respiratory sound data. arXiv 2020, arXiv:2006.05919. [Google Scholar]
- Ritwik, K.V.S.; Kalluri, S.B.; Vijayasenan, D. COVID-19 Detection from Spectral Features on the DiCOVA Dataset. In Proceedings of the 22nd Annual Conference of the International Speech Communication Association, Brno, Czech Republic, 30 August–3 September 2021; pp. 936–940. Available online: https://pesquisa.bvsalud.org/global-literature-on-novel-coronavirus-2019-ncov/resource/pt/covidwho-1535020?lang=en (accessed on 20 December 2023).
- Bhuvaneswari, A. An Ensemble Method for COVID-19 Positive Cases Detection using Machine Learning Algorithms. In Proceedings of the 2022 Second International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 21–22 April 2022; IEEE: New York, NY, USA, 2022; pp. 1–9. [Google Scholar]
- Pahar, M.; Klopper, M.; Warren, R.; Niesler, T. COVID-19 detection in cough, breath and speech using deep transfer learning and bottleneck features. Comput. Biol. Med. 2022, 141, 105153. [Google Scholar] [CrossRef]
- Hamidi, M.; Zealouk, O.; Satori, H.; Laaidi, N.; Salek, A. COVID-19 assessment using HMM cough recognition system. Int. J. Inf. Technol. 2023, 15, 193–201. [Google Scholar] [CrossRef] [PubMed]
- Pavel, I.; Ciocoiu, I.B. COVID-19 Detection from Cough Recordings Using Bag-of-Words Classifiers. Sensors 2023, 23, 4996. [Google Scholar] [CrossRef] [PubMed]
- Hassan, A.; Shahin, I.; Alsabek, M.B. COVID-19 detection system using recurrent neural networks. In Proceedings of the 2020 International Conference on Communications, Computing, Cybersecurity, and Informatics (CCCI), Sharjah, United Arab Emirates, 3–5 November 2020; IEEE: New York, NY, USA, 2020; pp. 1–5. [Google Scholar]
- Usman, M.; Gunjan, V.K.; Wajid, M.; Zubair, M. Speech as A Biomarker for COVID-19 detection using machine learning. Comput. Intell. Neurosci. 2022, 2022, 6093613. [Google Scholar] [CrossRef] [PubMed]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; Al-Dhief, F.T.; Abdali, T.-A.N.; Abbas, A.F. Extreme learning machine for automatic language identification utilizing emotion speech data. In Proceedings of the 2021 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Kuala Lumpur, Malaysia, 12–13 June 2021; IEEE: New York, NY, USA, 2021; pp. 1–6. [Google Scholar]
- Alwateer, M.; Almars, A.M.; Areed, K.N.; Elhosseini, M.A.; Haikal, A.Y.; Badawy, M. Ambient healthcare approach with hybrid whale optimization algorithm and Naïve Bayes classifier. Sensors 2021, 21, 4579. [Google Scholar] [CrossRef] [PubMed]
- Albadr, M.A.A.; Tiun, S. Spoken language identification based on particle swarm optimisation–extreme learning machine approach. Circuits Syst. Signal Process. 2020, 39, 4596–4622. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Tiun, S.; Al-Dhief, F.T. Evaluation of machine translation systems and related procedures. ARPN J. Eng. Appl. Sci. 2018, 13, 3961–3972. [Google Scholar]
- Albadr, M.A.A.; Tiun, S.; Al-Dhief, F.T.; Sammour, M.A. Spoken language identification based on the enhanced self-adjusting extreme learning machine approach. PLoS ONE 2018, 13, e0194770. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; AL-Dhief, F.T.; Omar, K.; Maen, M.K. Speech emotion recognition using optimized genetic algorithm-extreme learning machine. Multimed. Tools Appl. 2022, 81, 23963–23989. [Google Scholar] [CrossRef]
- Albadra, M.A.A.; Tiuna, S. Extreme learning machine: A review. Int. J. Appl. Eng. Res. 2017, 12, 4610–4623. [Google Scholar]
- Chowdhury, M.E.; Ibtehaz, N.; Rahman, T.; Mekki, Y.M.S.; Qibalwey, Y.; Mahmud, S.; Ezeddin, M.; Zughaier, S.; Al-Maadeed, S.A.S. QUCoughScope: An artificially intelligent mobile application to detect asymptomatic COVID-19 patients using cough and breathing sounds. arXiv 2021, arXiv:2103.12063. [Google Scholar]
- Dash, T.K.; Mishra, S.; Panda, G.; Satapathy, S.C. Detection of COVID-19 from speech signal using bio-inspired based cepstral features. Pattern Recognit. 2021, 117, 107999. [Google Scholar]
- Muguli, A.; Pinto, L.; Sharma, N.; Krishnan, P.; Ghosh, P.K.; Kumar, R.; Bhat, S.; Chetupalli, S.R.; Ganapathy, S.; Ramoji, S.; et al. DiCOVA Challenge: Dataset, task, and baseline system for COVID-19 diagnosis using acoustics. arXiv 2021, arXiv:2103.09148. [Google Scholar]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; Al-Dhief, F.T. Particle Swarm Optimization-Based Extreme Learning Machine for COVID-19 Detection. Cogn. Comput. 2022, 1–16. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
IoTs in the healthcare sector [5].
Figure 1.
IoTs in the healthcare sector [5].

Figure 2.
Flowchart of the proposed method for COVID-19 detection.

Figure 3.
The proposed IoT framework for capturing voice signals using IoT devices.

Figure 4.
The MFCC technique [40].
Figure 4.
The MFCC technique [40].

Figure 5.
The confusion matrix of the NB algorithm.

Figure 6.
The confusion matrix for the SVM algorithm.

Figure 7.
The confusion matrix for the RF algorithm.

Figure 8.
The comparison results of the proposed NB algorithm against the SVM and RF in COVID-19 detection.
Figure 8.
The comparison results of the proposed NB algorithm against the SVM and RF in COVID-19 detection.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
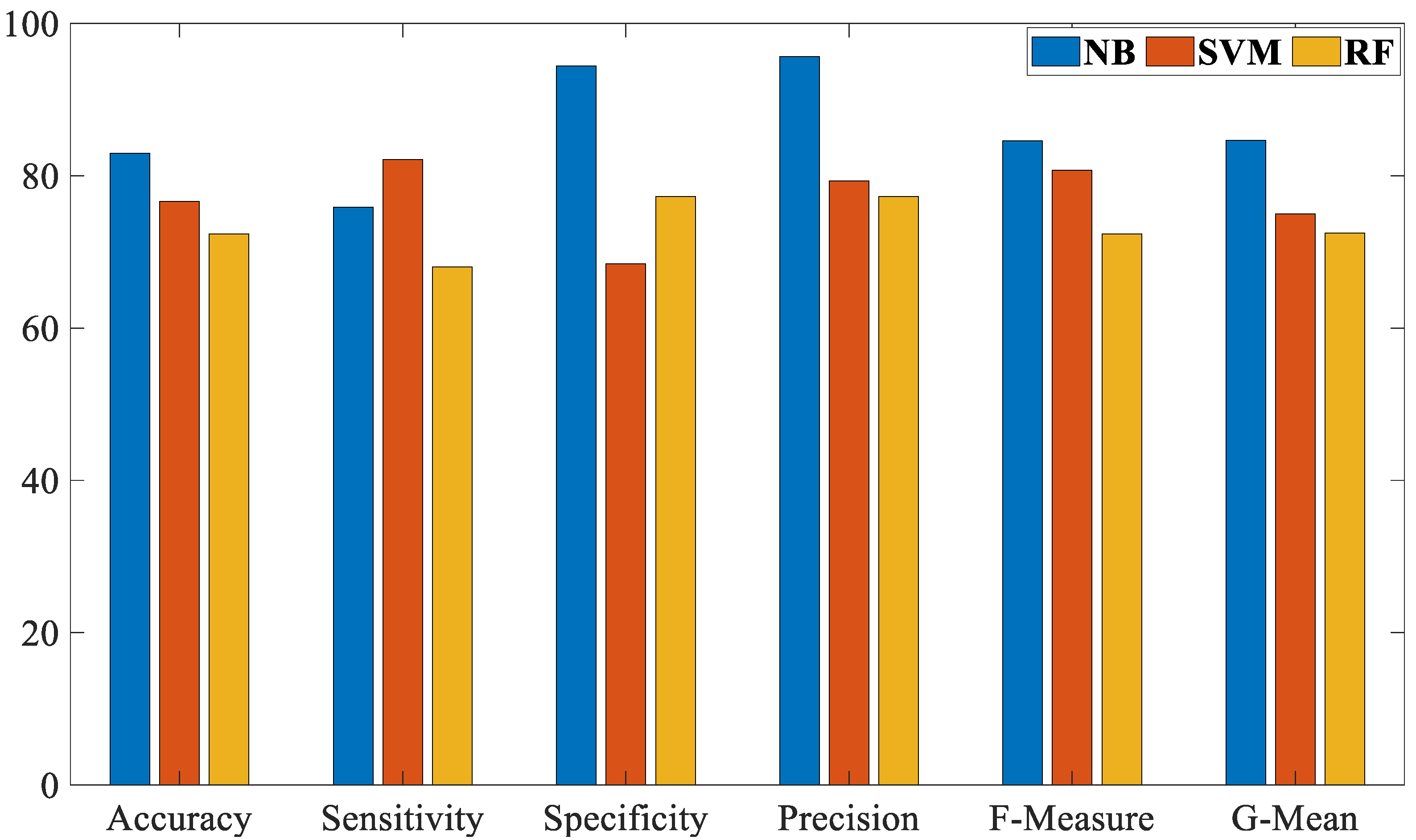{kind=link}
Table 1.
Summary of related work.
| Ref. | Modality/Parameters | Features Extraction | Classifier | Results |
|---|---|---|---|---|
| [30] | Cough | SRMSF | ResNet18 | 0.72 AUC |
| [31] | Speech | MFBF | SVM | 88.60% accuracy |
| [32] | Cough and breath | Several handcrafted features | LR | 80.00% accuracy using cough voice data and 69.00% accuracy using breath voice data |
| [33] | Vowel /i/, number counting, and deep breathing | harmonics, super-vectors, MFCC, and formats | SVM | 0.734 and 0.717 AUC for cross-validation and testing, respectively. |
| [34] | Speech | MFCC | K-NN | 92% accuracy |
| [35] | speech, breath, and cough | MFCC | Resnet50, CNN, and LSTM | The best AUC results were achieved by the Resnet50, where it obtained 0.98 (coughs), 0.94 (breaths), and 0.92 (speech). |
| [36] | cough | MFCC | GMM | Sensitivity ranging from 85.86% to 91.57%. |
| [37] | Cough | MFCC | BoW | 74.3% accuracy, 71.4% sensitivity, 75.4% F1-score, and 82.6% AUC. |
| [38] | Cough | SC, ZCR, and MFCC | LSTM | 99.30% precision |
| [39] | speech | STFT | DF | 73.17% accuracy |
Table 2.
The best results achieved by the proposed NB algorithm in the detection of COVID-19.
| Acc | Sen | Spe | Pre | F-M | G-M |
|---|---|---|---|---|---|
| 82.97% | 75.86% | 94.44% | 95.65% | 84.61% | 84.64% |
Table 3.
The best results achieved by the SVM and RF algorithms in the detection of COVID-19.
| SVM Algorithm | |||||
|---|---|---|---|---|---|
| Acc | Sen | Spe | Pre | F-M | G-M |
| 76.60% | 82.14% | 68.42% | 79.31% | 80.70% | 74.97% |
| RF Algorithm | |||||
| Acc | Sen | Spe | Pre | F-M | G-M |
| 72.34% | 68.00% | 77.27% | 77.27% | 72.34% | 72.49% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Al-Khaleefa, A.S.; Al-Musawi, G.F.K.; Saeed, T.J. IoT-Based Framework for COVID-19 Detection Using Machine Learning Techniques. Sci 2024, 6, 2. https://0-doi-org.brum.beds.ac.uk/10.3390/sci6010002
AMA Style
Al-Khaleefa AS, Al-Musawi GFK, Saeed TJ. IoT-Based Framework for COVID-19 Detection Using Machine Learning Techniques. Sci. 2024; 6(1):2. https://0-doi-org.brum.beds.ac.uk/10.3390/sci6010002
Chicago/Turabian StyleAl-Khaleefa, Ahmed Salih, Ghazwan Fouad Kadhim Al-Musawi, and Tahseen Jebur Saeed. 2024. "IoT-Based Framework for COVID-19 Detection Using Machine Learning Techniques" Sci 6, no. 1: 2. https://0-doi-org.brum.beds.ac.uk/10.3390/sci6010002