Recently, many researchers in the field of sentiment analysis have used a supervised machine learning algorithm as their clustering module and primary classification, such as the work in [
8]. These methods classified and displayed user-created texts that contained the sentiment using n-gram features as well as the bag-of-words (BOW) technique, and they were occasionally combined [
9]. The n-gram characteristics have been developed to address the shortcomings of the simple BOW model, such as the fact that it ignores grammatical structures and word order [
10]. When using n-gram features, there is a significant disadvantage, particularly when n ≥ 3, in that the feature distance output is remarkably high dimensional. As a result, feature selection algorithms have been used extensively in recent studies [
11] to overcome this disadvantage. Users’ sentiments can be extracted from their text using a variety of algorithms, including SVM, Naive Bayes (NB), and artificial neural networks (ANN). Several methods, including that in [
12], have demonstrated good performance in this area. When using supervised approaches, one of the challenges that can arise is that they are often slow and require a large amount of time throughout the training process. There have been numerous approaches based on the unsupervised lexicon that have been proposed to address these issues, including those in [
8,
13]. These methods are quick, scalable, and simple to implement. On the other hand, they rely largely on vocabulary, which has resulted in them being less accurate when compared to their supervised counterparts [
13,
14]. There have been very few researchers who have taken advantage of the advantages offered by both lexicon-based and supervised-based approaches and then merged them in a variety of ways, as cited by [
14,
15]. For sentiment analysis, Zhang et al. [
16] presented an approach that is divided into two parts at the entity level of tweets. Having a high recall rate is the first step in the process, which is achieved through the use of the supervised approach. The second phase is a high-precision lexical method that is built on the previous stage. According to [
17], machine learning methods and lexicon-based sentiment analysis have been combined in a concept-based sentiment analysis model that has been presented. When compared to simply statistical methods, their method was more accurate and justified, and its ability to discern the polarity or strength of sentiment was superior to lexicon-based methods.
2.3. AWD-LSTM
ASGD weight-dropped LSTM or AWD-LSTM uses drop connect and a variant of average-SGD (NT-ASGD) combined with many additional famous regularization approaches. AWD-LSTM is the architecture used by ULMFIT for its language modeling tasks [
7,
19]. As shown in
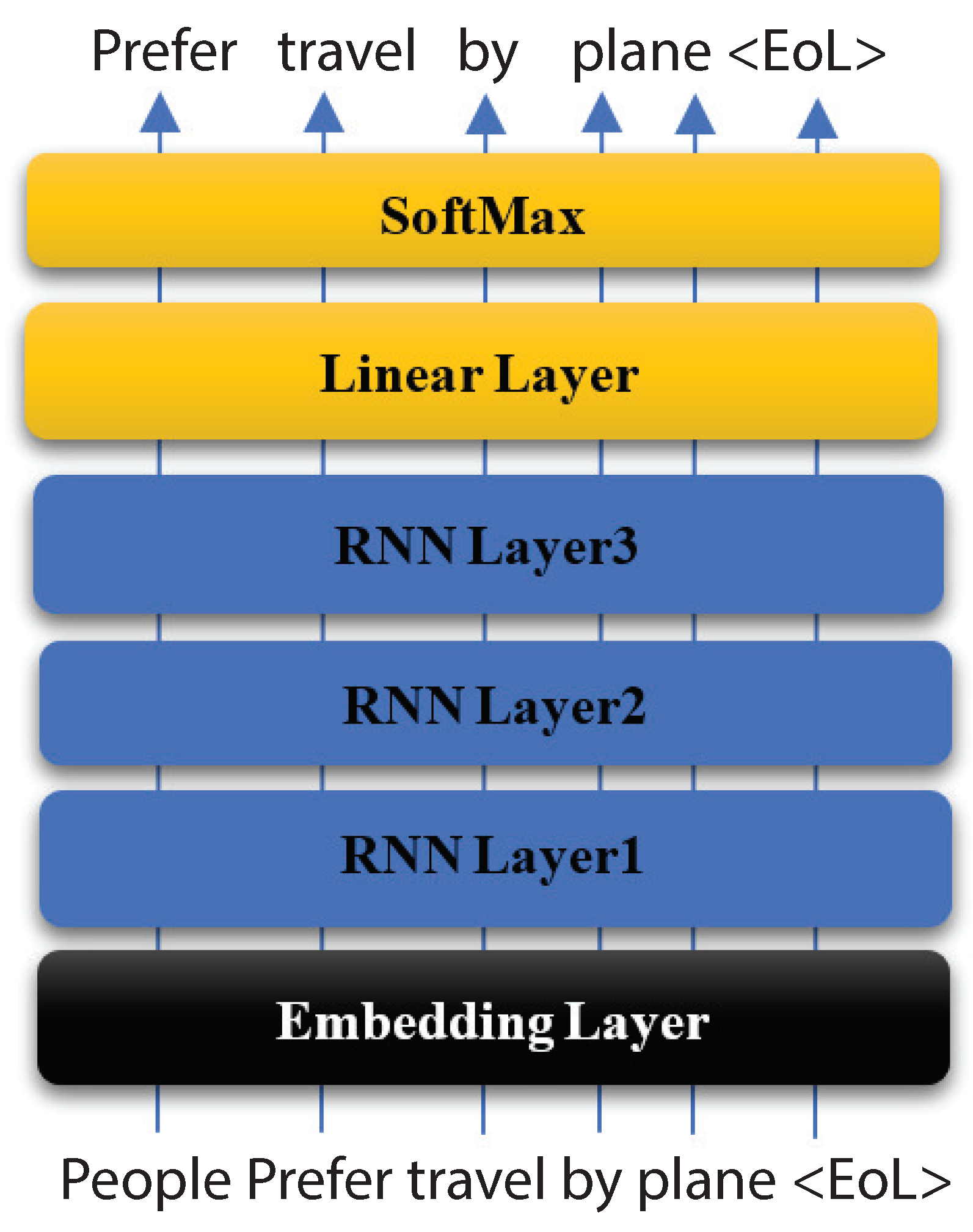
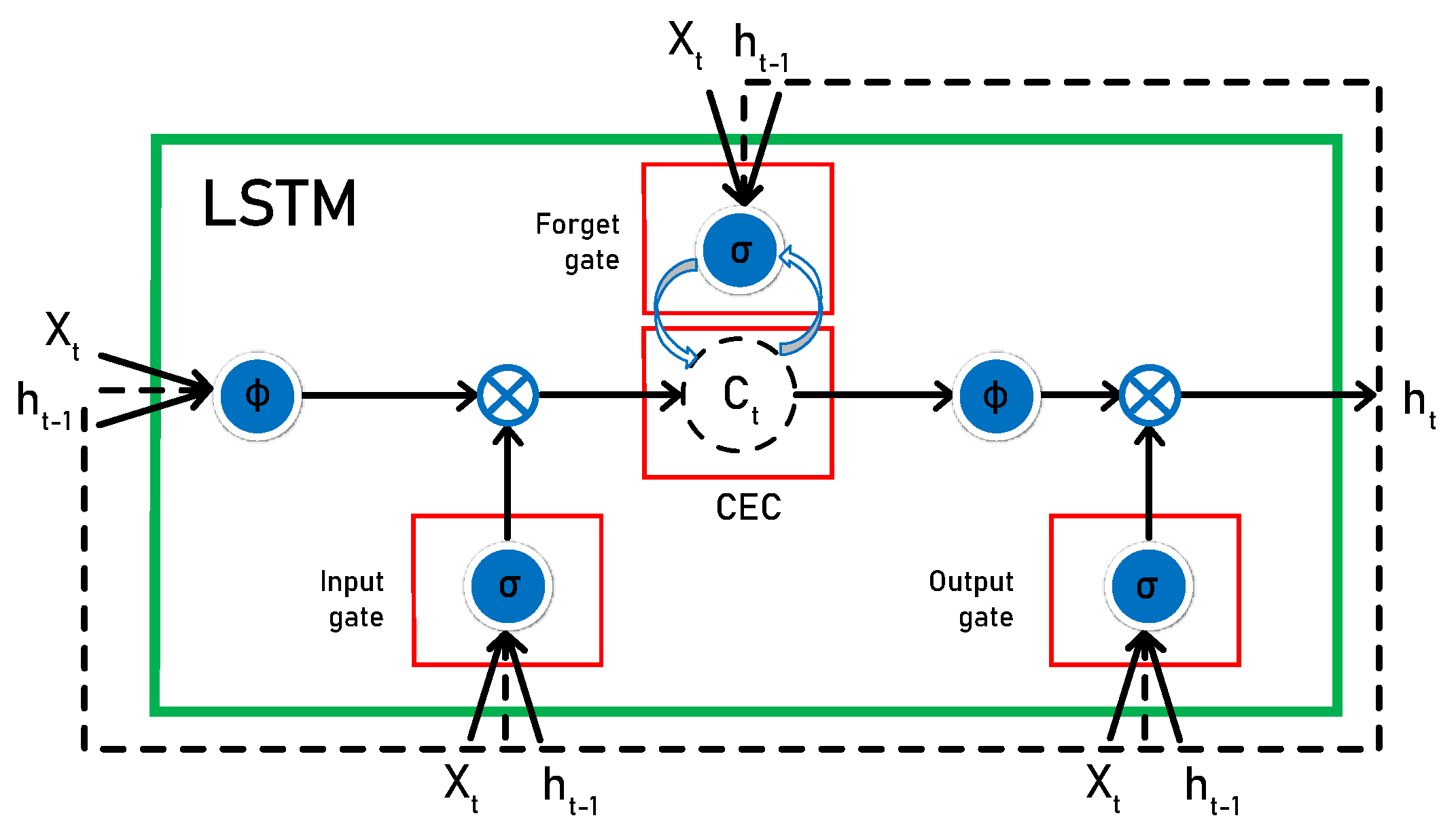
Figure 2, the repeating LSTM module consists of four interacting layers. The general LSTM unit is formed from a cell, an input gate, an output gate, and a forget gate. LSTM can perform many operations such as language modeling, character-level neural machine translation, and sentiment classification.
The following Equation (
1) is the mathematical formulation to express LSTM:
where (
) are weight matrices;
() is the vector input to time step t;
() is the current exposed hidden state;
() is the memory cell state;
and (⨀) is the element-wise multiplication.
2.4. Support Vector Machine (SVM)
The main conception of SVM is to categorize information separately using hyperplane to increase the margin among them to the maximum. SVM is commonly used in learning classification algorithms based on statistical learning theory (SLT), which is a theoretical paradigm for machine learning that draws on statistics and functional analysis. SLT has been successfully applied in various areas, including computer vision, voice recognition, and bioengineering. SVM has high classification accuracy and excellent performance; thus, it is popularly widely used in problems classifications [
20].
SVM is one of the effective ML algorithms for regression and classification and sentiment detection [
21]. SVM is one of the most popular classifiers due to its capability to achieve higher generality performance whenever the dimension embedding of the input features space is very high. The purpose of SVM is to discover the most suitable classification function to differentiate between members of the two classes in the training data. The SVM classification uses structural risk reduction to create a hyperplane for the exclusion of positives from a group of negative instances. SVM aims to separate data points and evaluate each data point category into a hyperplane. SVM maximizes the margin between support vectors because separating all classes is necessary [
22]. SVM is commonly used to solve many problems in the real world, including intrusion recognition, image processing, text classification, etc. Initially, SVM was designed to classify the binary classes. Later, the examples were expanded to multiple classes. In binary classification, the classification task is the data points classification task of a given dataset of instances into two separate sets and defines whether they have some features or not. Many real-world tasks have been used to the binary classification task in its implementation, where the response to some query is either a yes or no: for example, object detection, figuring out relations to a specific class of the instance, face detection, or intrusion detection. The mathematical basis of the SVM algorithm is presented in the binary classification task in two cases: linear divisible and non-linear divisible cases. In a case that is non-linear divisible, there is one or more than one hyperplane that may split the two categories represented by the training data. The well-known query is how to select the most suitable hyperplane that would get the best out of the accuracy performance on test data. The best answer is to exploit the boundary between support vectors that splitting the positive and negative points into the training data. Then, the most suitable hyperplane is the one that evenly splits the boundary between the two classes.
2.5. Long Short-Term Memory (LSTM)
LSTM is an extension of RNN. The vanishing of gradients in the training of vanilla RNN was proposed. It has a special memory mechanism that gives it an advantage over the vanilla RNN. The memory mechanism enables the network to capture long-term dependencies, in particular the LSTM appraoch in [
23], which succeeded in minimizing dimensionality and outstanding performing concerning the precise classification of opinion. Reducing the input functions is an important task for the classification of sentiment based on machine learning techniques. Therefore, the suggested method could be a promising solution for better classification with scalability. The proposed approach would be particularly suitable for applications that have a large dataset such as the detection of sentiment for product and service reviews.
Tarasov [
24] used a long short-term model for the sentiment of the restaurant reviewers for RNNs. Several approaches are used to compare the gathering results using the following techniques: simple recurrent neural networks, logistic regression, bidirectional RNNs, and bidirectional long-term memory. Deep bidirectional LSTM with numerous hidden layers yielded the best performance across all RNN models.
A vector representation of single words can be considered as a system training parameter to simplify the analysis of the general model text data. Thus, we can initiate values for single words with random values of vector representations to replicate certain variables. Tai et al. [
25] performed the LSTM to solve identifications of the romantic phrases extracted from film reviews and estimation of somaticizing sentence pair’s tasks.
Socher et al. [
26] presented the Treebank sentiment and recursive neural tensor networks to solve their feeling detection project. In the case of single-sentence positive/negative cataloging, by using recursive neural tensor networks, performance increased from 80% to 85%.
The prediction of fine-grained feeling labels for all sentences was 80.7% higher than the 9.7% increase with a bag of features for approaches, such as SVM and Naive Bayes using the recursive neural tensor network process. Neural networks are effective for managing text data analysis tasks as variants in the LSTM model. The use of these models is an innovative approach to describe the social networking emotions of users.
The idea with LSTM is to have a self-regulating flow of information through the cells that can be forgotten or modified based on the information input to the cell. Therefore, some extra parameters have been added to each recurrent cell to enable the RNN to propagate information and overcome optimization issues. The added parameters, as shown in
Figure 3, act as filters to allow the cell to select which information is worth remembering and which is worth forgetting.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}