1. Introduction
Forest fires are a natural hazard that significantly affects Iran’s forest areas due to their widespread environmental, economic, and social impacts. Forest fires are also considered as the leading force damaging forest resources, and they happen periodically in different severities [
1]. Additionally, forest fires have increased due to an increase in the global temperature, the population, and human activities in forest areas [
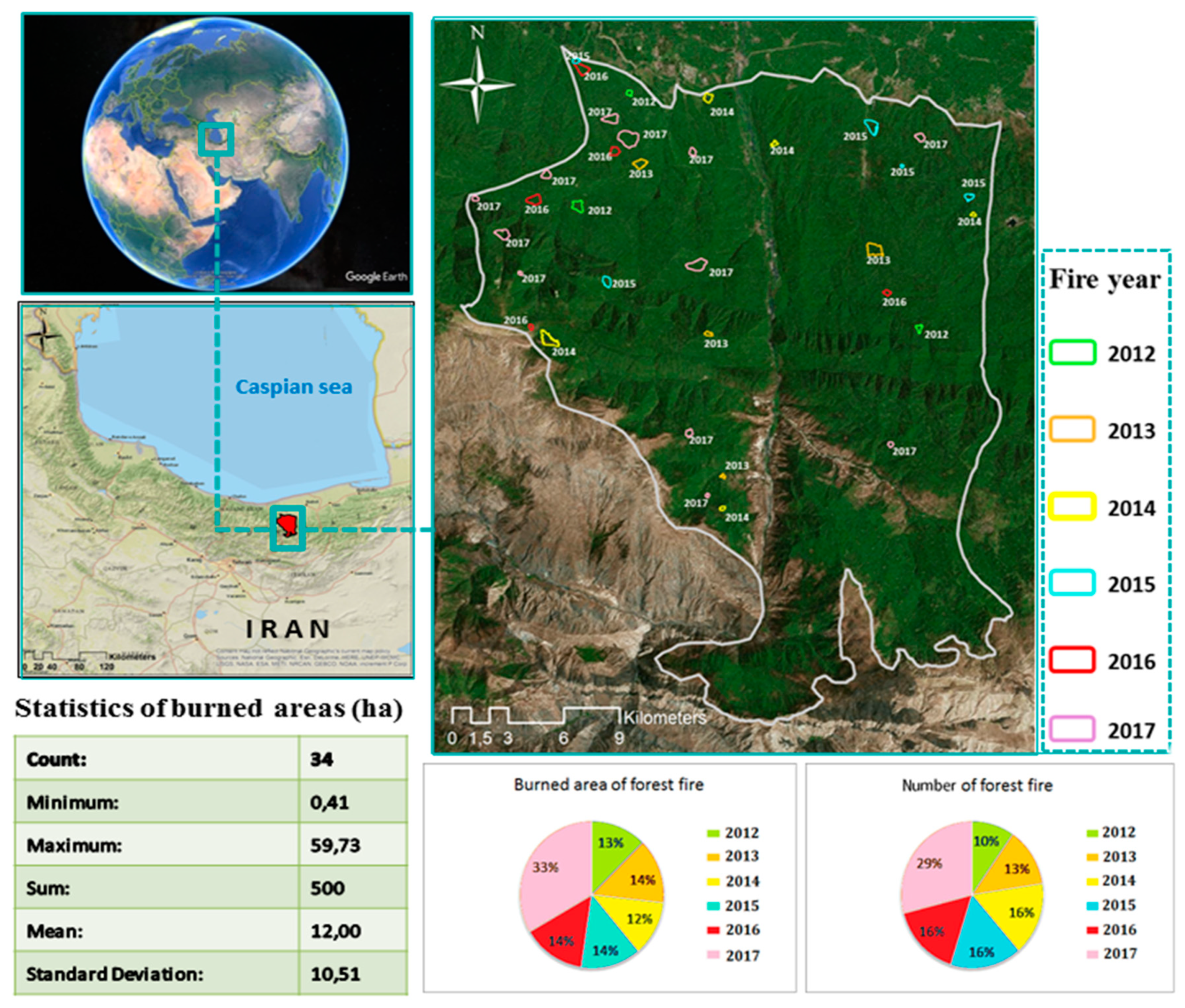
2]. In our study area, upward trends in both the number of forest fire events and burned areas are confirmed from 2012 until 2017. Forest fires cause some permanent alterations to forest areas, such as a reduction of plant communities and biodiversity, which can accelerate the deforestation processes [
3]. However, there are also some advantages of forest fires, e.g., the elimination of harmful microorganisms, fungi, insects, and herbal disease, and soil enrichment by the nutrients and minerals released from the remaining ash [
4]. However, there is no doubt that forest fires are a potential risk with economic and social consequences for the population who live in the forest areas [
1]. A forest fire, like any natural hazard, demonstrates the potential threat from a natural process [
5]. Northern Iran has approximately 1.2 million hectares and more than 300 hectares have burned annually. Most of these fires happen on the ground surface and affect young trees more often than old ones [
6]. Thus, small trees and regeneration are largely affected and consequently, forest fire is considered as one of the main reasons of deforestation and desertification in northern Iran. Despite the high forest fire frequency in this area, there are no comprehensive susceptibility and risk analysis studies. Our study of the forest fire susceptibility in the northern forests of Iran is therefore timely and necessary. The use of the most recent spatial modelling approaches shall improve our knowledge on this problem and the results shall support fire management in this area.
The term risk is applied frequently for predicting uncertain future events of extreme consequences. Risk mapping focuses on low-probability, high-consequence adverse events that are stochastic in space. Risk assessment should be conducted when the predicted results are uncertain, but can be estimated [
7]. Forest fire risk is assessed based on a scale of the probability that forest fires will occur and have destructive impacts on the population [
8]. In other words, forest fire risk can be defined as the probability of devastating consequences, or likely losses (deaths, injuries, properties), caused by an interplay of forest fires and vulnerable communities in a given area [
9]. Moreover, considering the indicators of social vulnerability to natural hazards is a relatively small part of both social and spatial research, especially in administrations worldwide [
10]. In the present study, the forest fire risk mapping is used for identifying locations which bear the chance of loss, determined from estimates of forest fire susceptibility and social/infrastructural vulnerability.
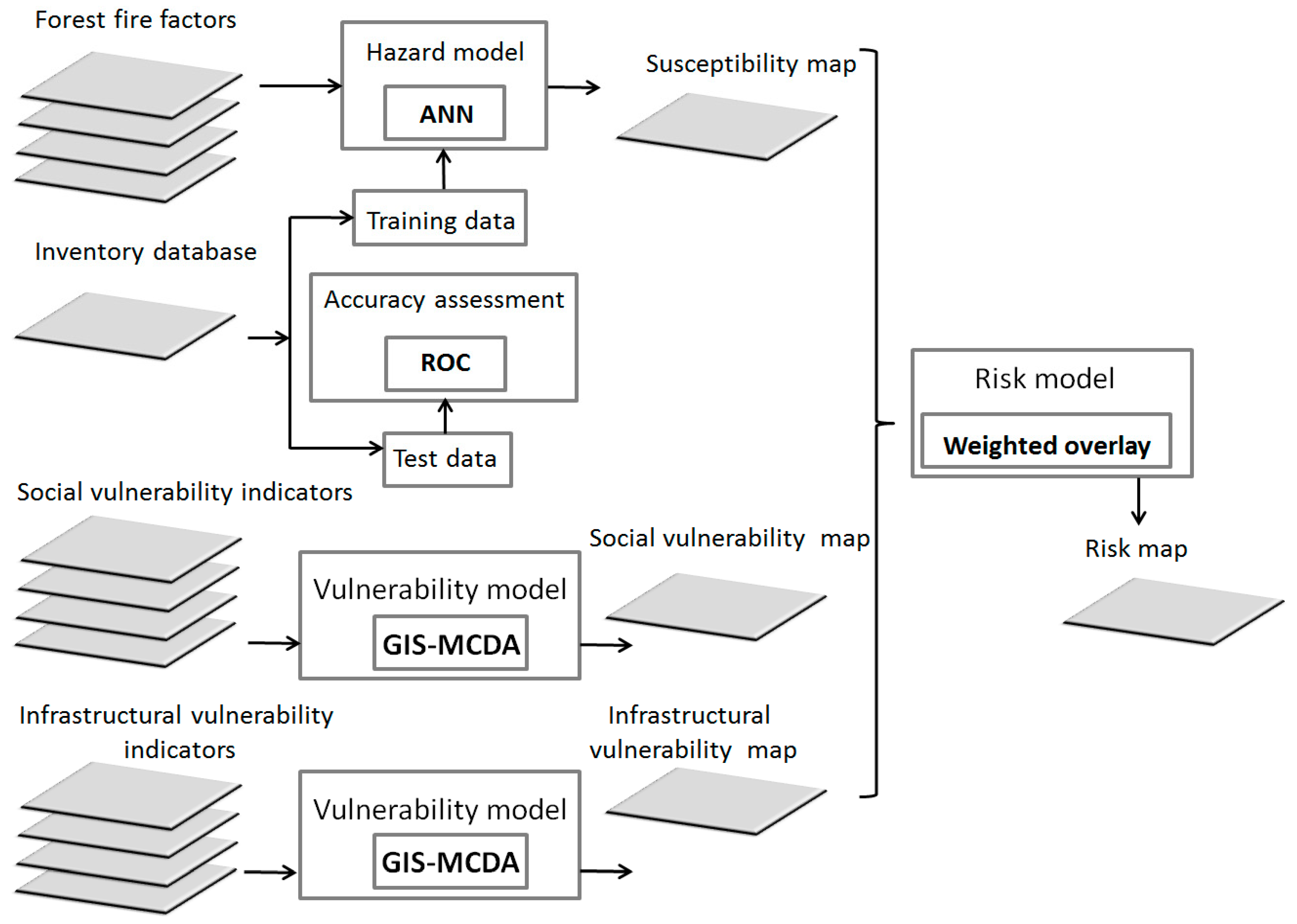
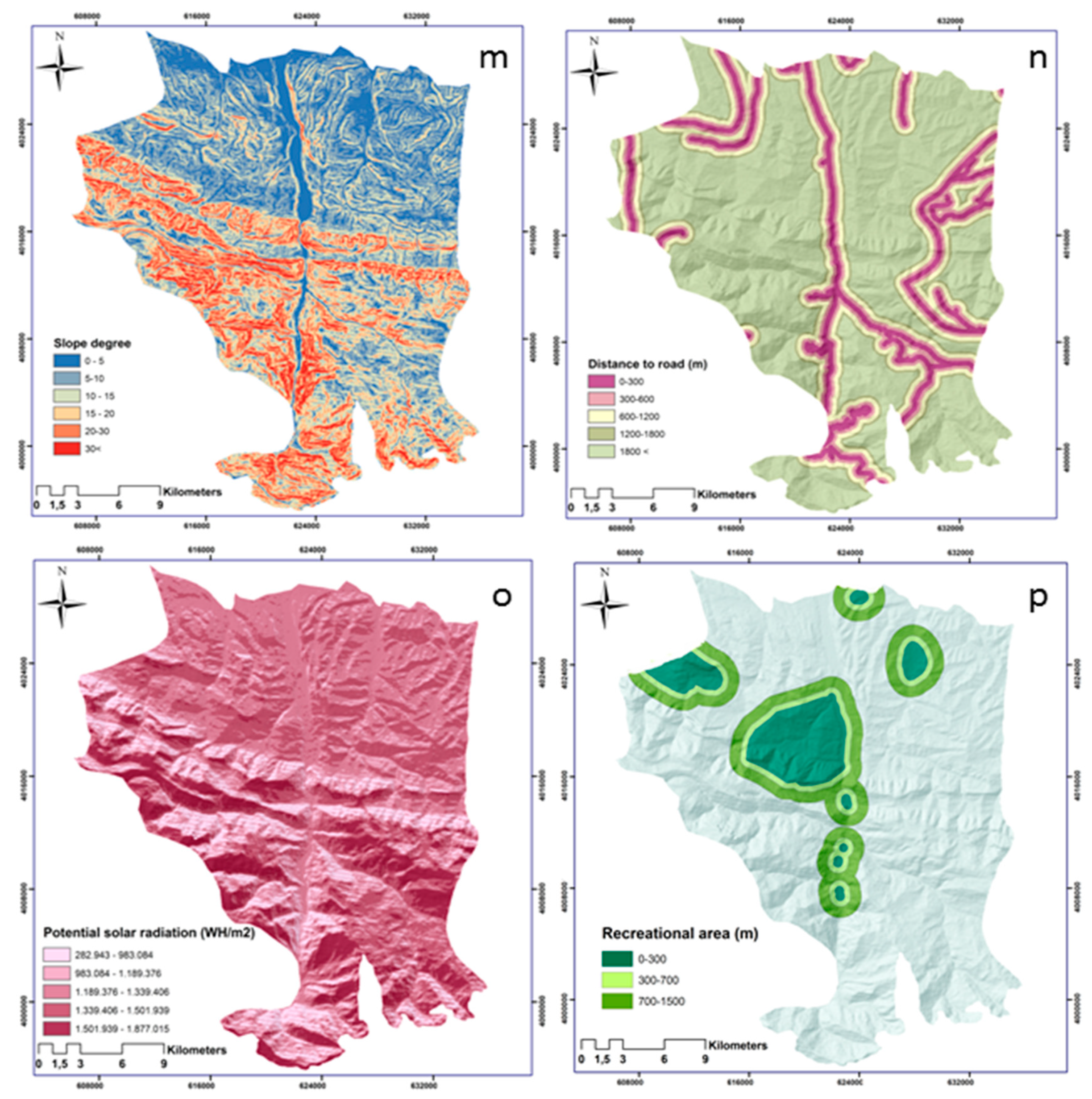
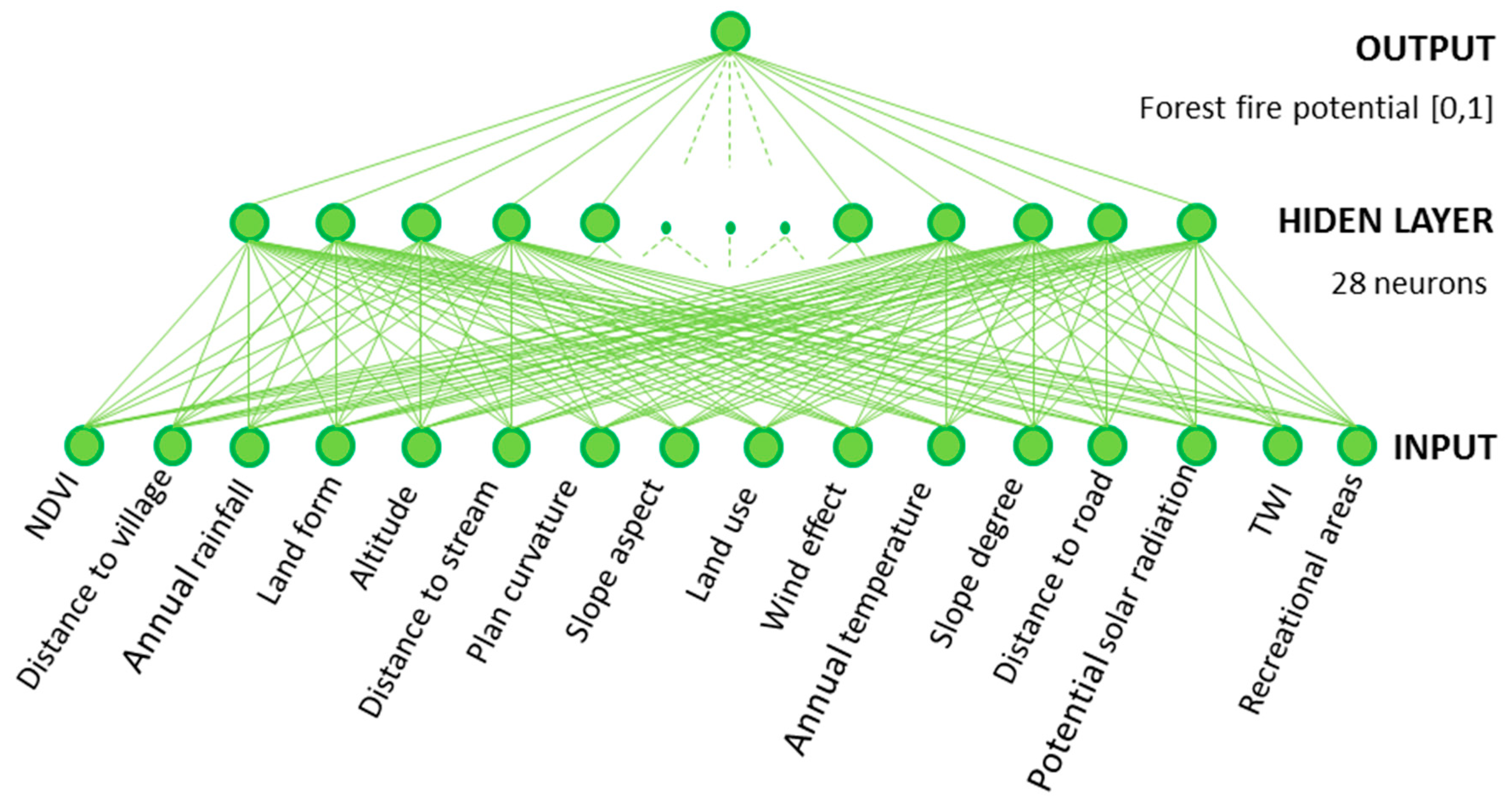
The main aim of the present study is the forest fire risk mapping using environmental, social and infrastructure variables. For this goal, we required both socially vulnerable and susceptible areas to forest fires. Thus, a forest fire susceptibility map, or hazard map (in a more general expression), was generated considering sixteen relevant factors (i.e., topographic, meteorological, and human-made factors). In addition to the environmental variables, the human activity is also considered, as the conditioning factor plays a vital role in the forest fire susceptibility. Data from geographic information systems (GIS) and remote sensing (RS) is required for any natural hazard susceptibility mapping [
11,
12,
13,
14,
15]. In addition to using relevant input data, an appropriate methodology is needed for useful hazard mapping. Vulnerability mapping concerning natural hazards is a multi-faceted procedure. Several aspects of vulnerability, including infrastructural and social indicators, should be considered in the final vulnerability map [
16]. Generally, a clear understanding of the social issues of forest fire susceptibility, susceptibility and management are required to evaluate the damages to valued assets and resources and human life losses caused by forest fires [
17,
18]. Management of forest fire protection and estimating the responding costs is also paramount [
19]. Although environmental variables (e.g., topography, temperature, vegetation) help assess the potential occurrence of forest fires, they are not sufficient for predicting where and to which extent forest fires can impact people or damage constructions [
20,
21]. Therefore, an ideal effort for forest fire prevention and risk mitigation must not only consider environmental variables, but also the different levels of social vulnerability of communities within residential areas in the study area. The social vulnerability can be determined from social systems and census data [
22].
Demand for mapping the risky areas has grown as forest fires have increasingly affected populations and the environment. Universally, the growing frequency and damage from forest fires has resulted in many new studies. Based on the literature, there are two main methods and techniques for this aim, namely, data-based (machine learning (ML)) and knowledge-based methods that have been proposed and evaluated. Several studies used knowledge-based methods for forest fire susceptibility mappings, such as fuzzy logic [
23,
24], the analytic hierarchy process (AHP) [
25,
26] and the analytical network process [
27]. However, ML methods such as logistic regression [
5], artificial neural networks (ANN) [
28,
29,
30], and Random Forest [
31] are also conventional for mapping the susceptible areas of forest fires. Predicting the susceptible areas of any natural hazard has always been considered as an environmental management need [
32]. Researchers attempt to turn this need into a systematic methodology based on well-established models and mathematical theories. They have also been increasingly developing/applying multivariate data analysis methods from both data mining and ML fields for predicting the susceptible areas of natural hazard based on previous distribution patterns and relevant factors [
33]. In this study, we used the capabilities of an ANN method for predicting areas which potentially have a higher probability of forest fires. The forest fire inventory dataset includes the location of ignition and also the burned area. Therefore, the susceptibility map can represent a measure of the likelihood of ignition and the probability of spreading of forest fires based on the trained ANN method. At the same time, we generated both social and infrastructural vulnerability maps based on related vulnerabilities’ indexes. Vulnerability is defined as the potential effect of a threat and considers the adaptive and endurance capacity of the affected units over time [
7]. A wildfire vulnerability assessment of a forest area considers how populations can respond and adapt to the threat. Generally, the vulnerability of a place depends on various social indicators that have been considered by several studies, such as education level, age, unemployment rate, gender, accessibility to health centres, housing tenancy, and accessibility to government facilities [
9,
18,
34,
35,
36,
37,
38]. These social indicators usually describe social inequities among people, which are presumed to increase a society’s vulnerability to natural hazards [
8]. Although in some areas in the world people living close to forest areas may be rich, in Iran, and most likely in the majority of cases, this population tends to be poorer. In the latter case, social vulnerability is relatively high since it is more difficult to recover from the impact of a hazard [
39]. These people are also more sensitive to the threat of any natural hazards, such as forest fire occurrences, because socially vulnerable residents are generally less able to deal with threats from nature [
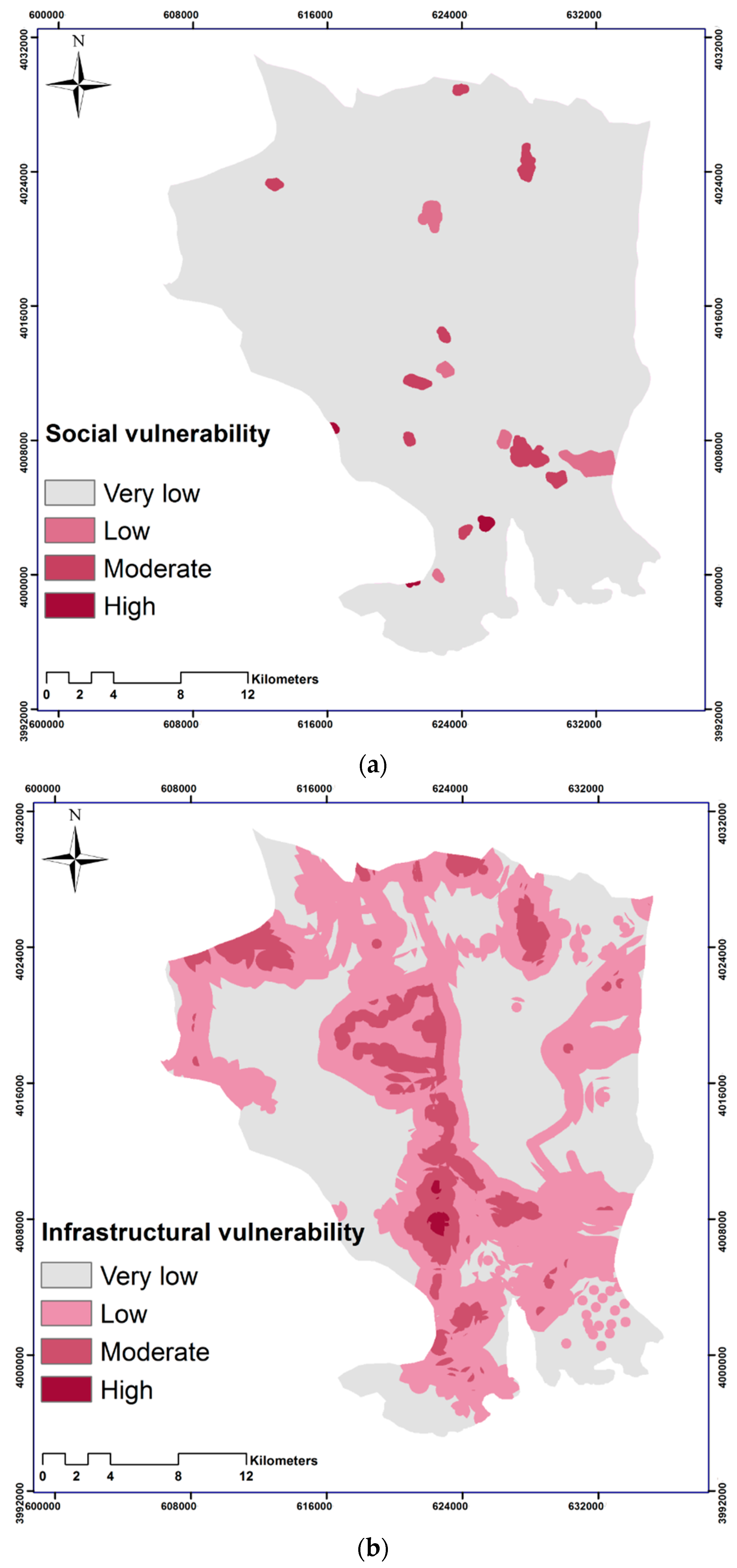
18]. We used 22 social indicators and 11 infrastructural indicators for mapping both social and infrastructural vulnerabilities.
GIS-based multi-criteria decision analysis (GIS-MCDA) was used for both weighting and data aggregation. GIS-MCDA is a useful modelling methodology in the spatial sciences that can consider data with their spatial information [
40]. Capabilities of GIS and MCDA have been well combined to solve a wide range of spatial problems [
41]. The integration of MCDAs with the capabilities of GIS provides a smart spatial modelling methodology for identifying the relative significance of indicators [
42]. AHP is one of the most commonly used methods in GIS-MCDA approaches [
43]. This method supports the weighting process based on experts’ judgments, which are organized in pairwise comparison matrices. The high knowledge of experts plays a crucial role in preparing useful pairwise comparison matrices [
44].The resulting vulnerability maps indicate the elements-at-risk. However, the forest fire susceptibility mapping results in a map depicting hazardous areas [
9]. A simple map overlay within the GIS environment was used to generate the risk map. Overlaying the social vulnerability map with the hazard map is a common approach for risk map generation that is used in several studies [
8,
18,
45,
46]. Our study considered both social vulnerabilities and the map of natural hazards susceptibility, resulting in a more comprehensive risk assessment of forest fire in the study area. Risk analysis provides scientists and managers with a better understanding about the location and potential effects of forest fires on the economy, society and the environment [
7]. Risk mapping can transparently address the management of issues, which are existing in the forestry areas and the mitigation of adverse consequences of forest fires.
5. Discussion and Conclusion
Mapping the forest fire risk posed to human life and properties is an essential component of emergency land management, forest fire prevention, mitigation of adverse impacts, and response and recovery management [
83]. As already discussed in the introduction section, forest fire susceptibility maps have often been used to priorities investments in forest fire prevention, and also for preparation planning. However, even considering social vulnerabilities leads to more effective forest fire risk management [
84]. Since such risk maps can illustrate the location of the elements-at-risk, besides communities who have a lower capacity to deal with the fire and the spatial correlations between communities and fires, they are also more useful for land managers and firefighters for emergency planning in combating fires in real time. Therefore, a comprehensive forest fire mitigation and disaster management plan should concentrate on areas where there is an overlap between populations and their more vulnerable properties and a higher forest fire risk. In this regard, the forest fire susceptibility map of our study was generated using environmental variables. We considered the most available factors and prepared them as input data for the model. Training and testing data were generated using field survey GPS polygons and MODIS hotspot data. The field survey was done by the SWOAC [
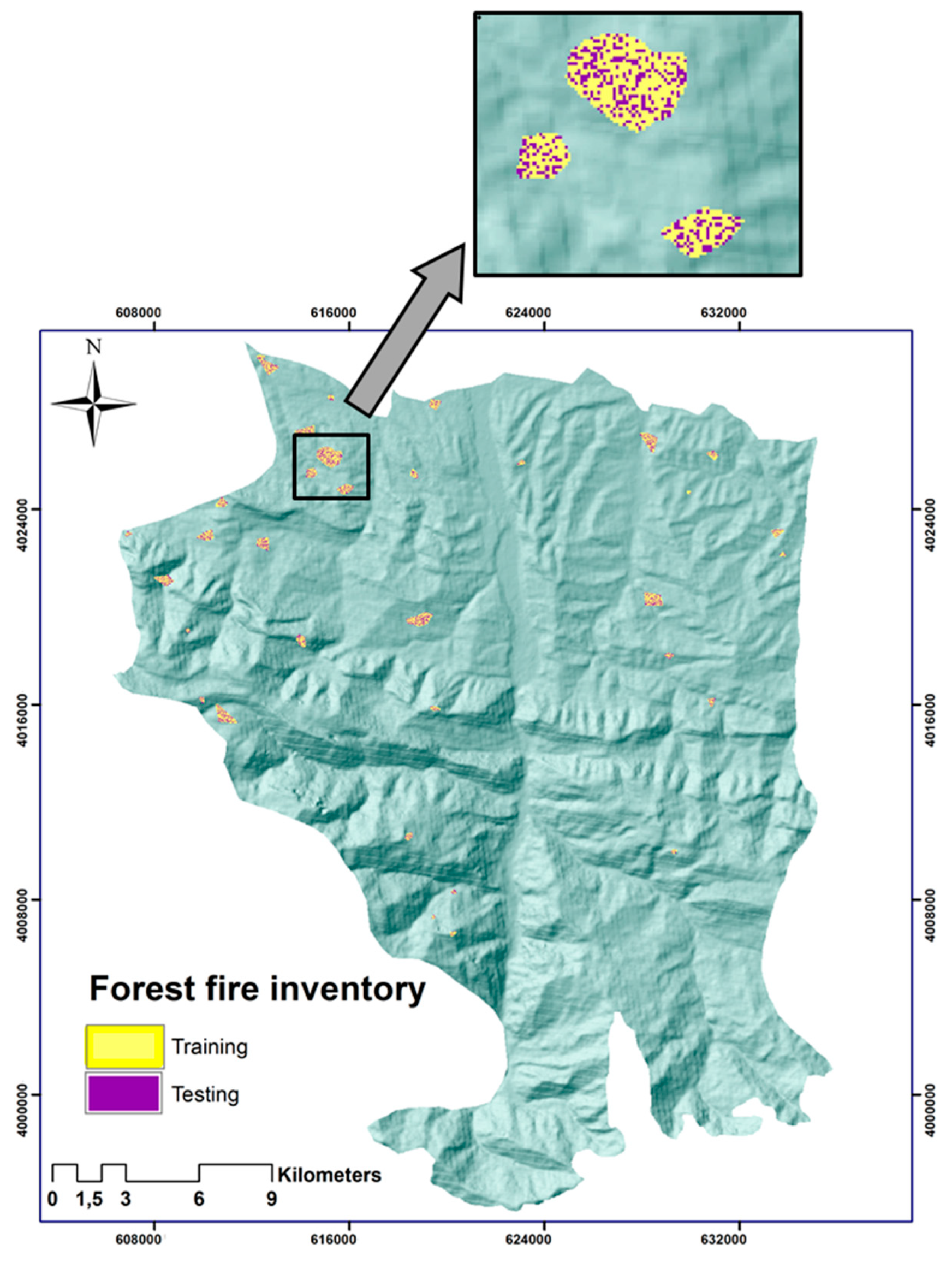
52]. According to the literature, a wide range of approaches have been used to predict areas with potential susceptibility to forest fires. Thus, different methods have been applied by various researchers to explore the potential role of relative factors that point to fire events. In this research, we generated a model using an ANN method with an MLP architecture that was trained with the BPA through ten-fold CV. The main limitation that we faced in this study was the dataset used. The fire inventory was from MODIS with a resolution of 1000 m while the resolution of the condition factors was 30 m. The dataset from the SWOAC includes the polygons with detailed borders. However, this documentation does not include small forest fires. Therefore, for the cases of the extensive wildfires, we considered the GPS polygons rather than those of from MODIS. Still, for the small events, the MODIS dataset was applied. Thus, the dataset of the MODIS is more accurate in terms of the number of the forest fires. The GPS dataset is more reliable regarding the shape of the polygons of burned areas because of the low resolution of MODIS. Consequently, the integration of both sources resulted in a more reliable inventory dataset of the location and the extension area of the wildfires. Nevertheless, the resolution of the resulting inventory dataset was not the same as that of the input data. Therefore, this difference in the resolution resulted in some uncertainties, which are difficult to quantify.
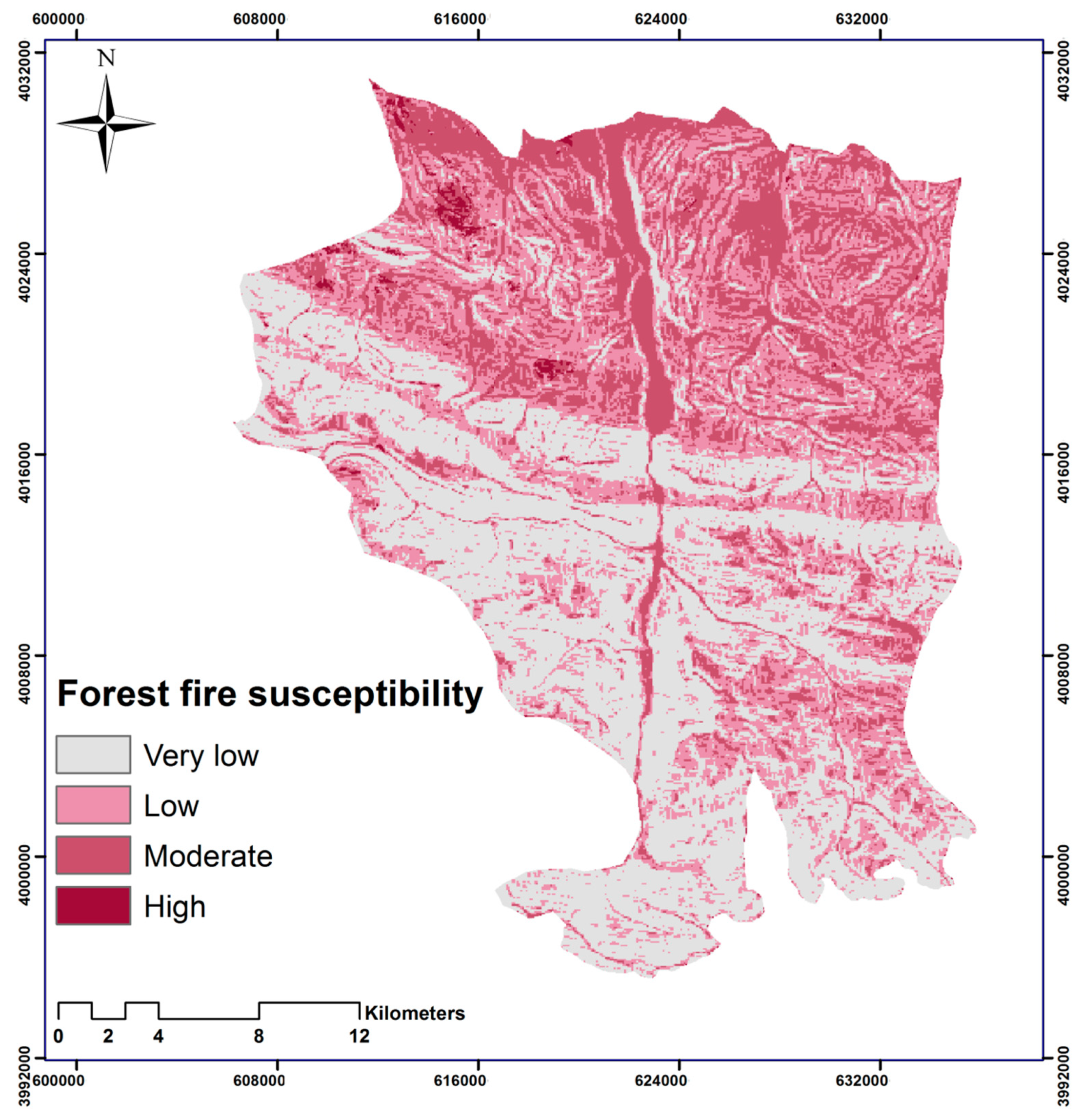
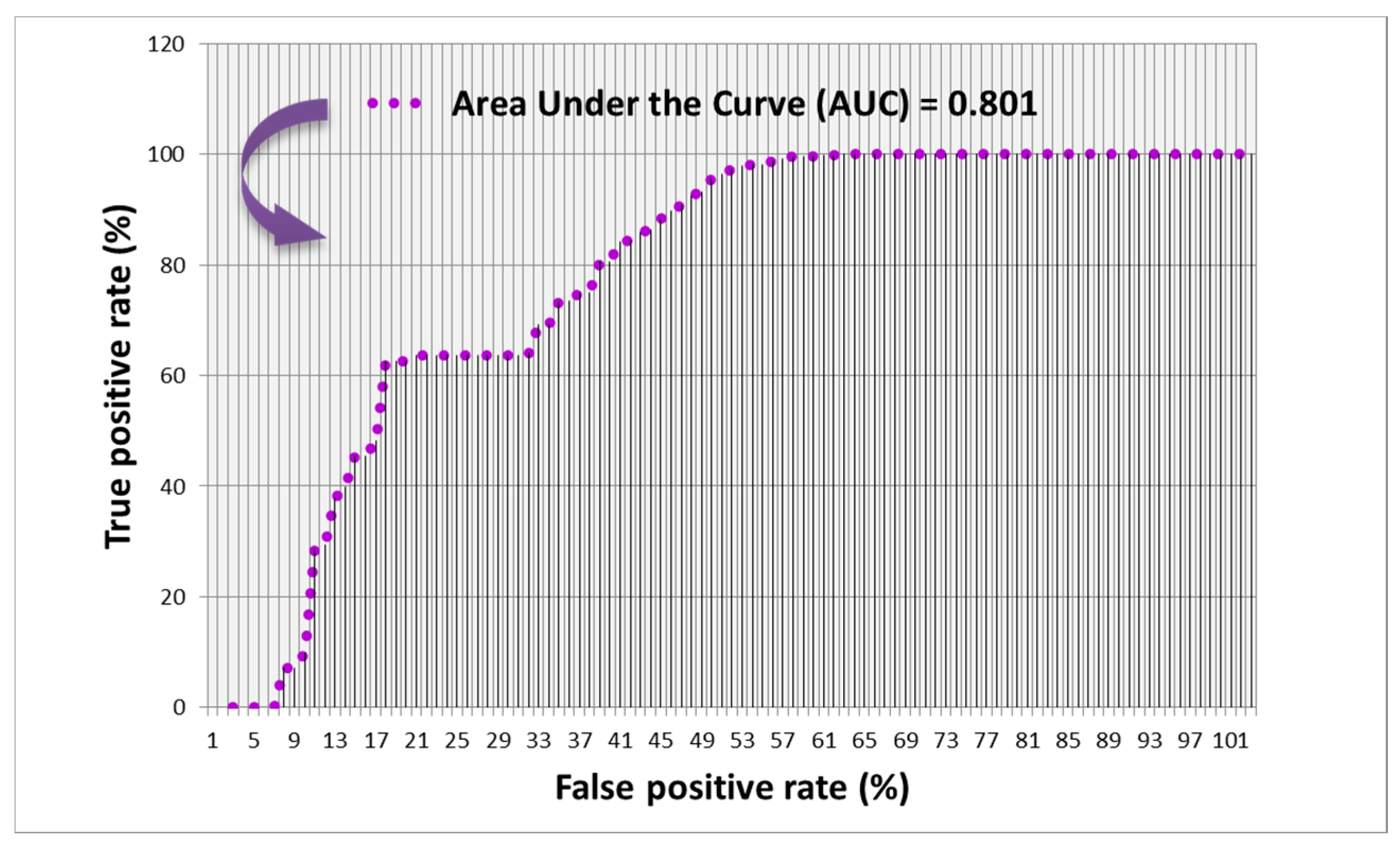
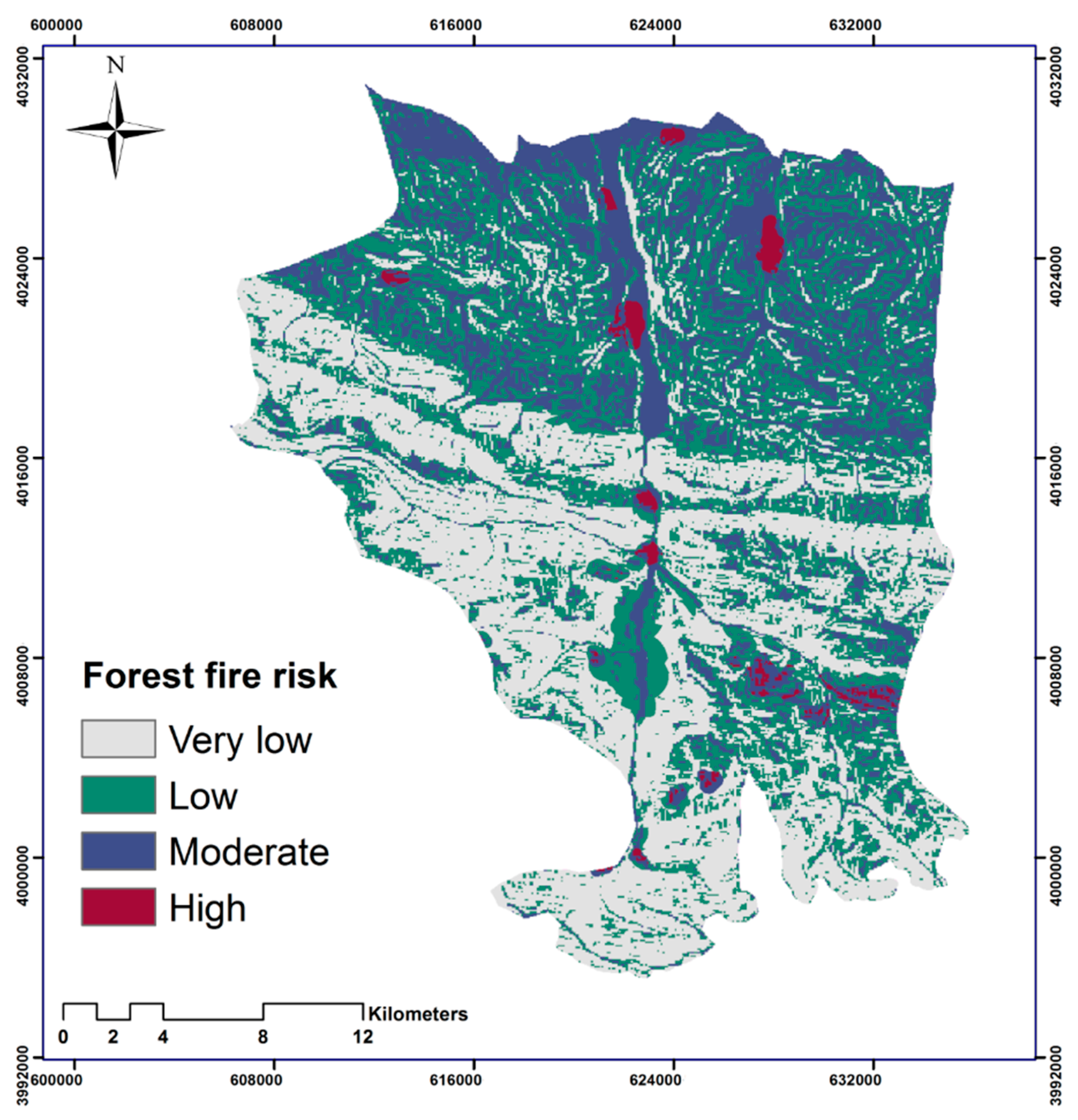
The model was developed and trained based on the previous forest fire events between 2012 and 2017, and the relevant factors contributing to the forest fire. The performance of the model was evaluated by the RMSE, and the resulting forest fire susceptibility map was validated using the ROC curve. Both of these measures showed acceptable accuracies of the results of the model. The resulting forest fire susceptibility map with the highest accuracy revealed that the southern part of our study area is more susceptible to forest fires in the future. This matter illustrates that the factors of annual rainfall and annual mean temperature play an important role by creating extreme dryness, which is a crucial factor determining forest fires [
85]. The areas with high forest fire susceptibility also have a close spatial correlation with the previously recorded forest fire events.
Although environmental variables contributing to the forest fire played an essential role in the assessment of susceptible forest fire areas, they are not the only reason for both forest fire susceptibility and risk. As some of the forest fires in in our case study are reported to be a result of human activity and the local people in particular SWOAC [
52], considering the areas and some specific sites of human activity such as recreational areas can help to have a better understanding of the results of the forest fire susceptibility and risk. The distance from population concentration is considered to be relevant to human activity. Therefore, the closer regions to the settlements and population concentration can indicate a higher presence of human activity and consequently more susceptibility and risk of forest fire [
31]. Thus, the population density and social vulnerability indicators were used, which were gained from different sources and, mostly, from census data. We also consider the areas with infrastructural valued assets and resources that are recognized as public/private properties. All indicators were weighted and ranked using expert knowledge and pairwise comparison matrices. Mostly, local experts were asked to contribute to this study, and they are mentioned in the acknowledgements section. The reason for selecting local experts to weight the indicators is that they are more familiar with the existing situation in our study area. These experts have different field backgrounds, like geography, geomorphology, meteorology, and wildlife. The selection of social vulnerability indicators may have some limitations, and the authors cannot be sure to have considered all relevant indicators that determine social vulnerability. However, we tried to localise the information that defines vulnerability in our case study. The social vulnerability generally depends on different characteristics, e.g., the country that the study area is located in, government support, and social features. Thus, the indicators may vary among different nations. The average life expectancy of houses, for instance, is a range between 10 and 15 years in our case study area. As this measure depends on the materials and different standards that are used for buildings, it may vary in other countries and even states. However, the concept of social vulnerability is a stable concept, and a large segment of the indicators are the same in different communities (e.g., age, gender and occupation). As we used the most relevant factors regarding forest fires and a large number of social/infrastructural vulnerability indicators, the performed methodology can easily be generalized and adapted to different locations like Australia, California, and Spain – i.e., fire-prone areas. Thus, the transferability of the method only requires minor changes and localization regarding social vulnerability indicators.
The novelty of our study is using both data-based ML and knowledge-based multi-criteria decision analyses for producing the forest fire risk map. Although there are several instances of using these methodologies separately for risk map generation, we provide an integration of using both methods for this aim. The reasons for using different methods for forest fire susceptibility mapping and the production of social/infrastructural vulnerability maps were described in
Section 4.3. Our results emphasize the importance of considering a social/infrastructural vulnerability assessment when creating forest fire risk maps. Both resulting susceptibility and vulnerability maps were overlayed and analysed to understand how they correspond.
We propose that our future research can consider biodiversity and its contributing role in forest fires. For the detection of different tree species, convolutional neural networks can be applied. This method is a deep learning method, but it consists of a more significant number of various layers and requires a massive amount of training data. We also want to use other ML methods such as support vector machines and random forest for forest fire susceptibility modelling and mapping purposes.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}