
Teasing Apart Silvopasture System Components Using Machine Learning for Optimization

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
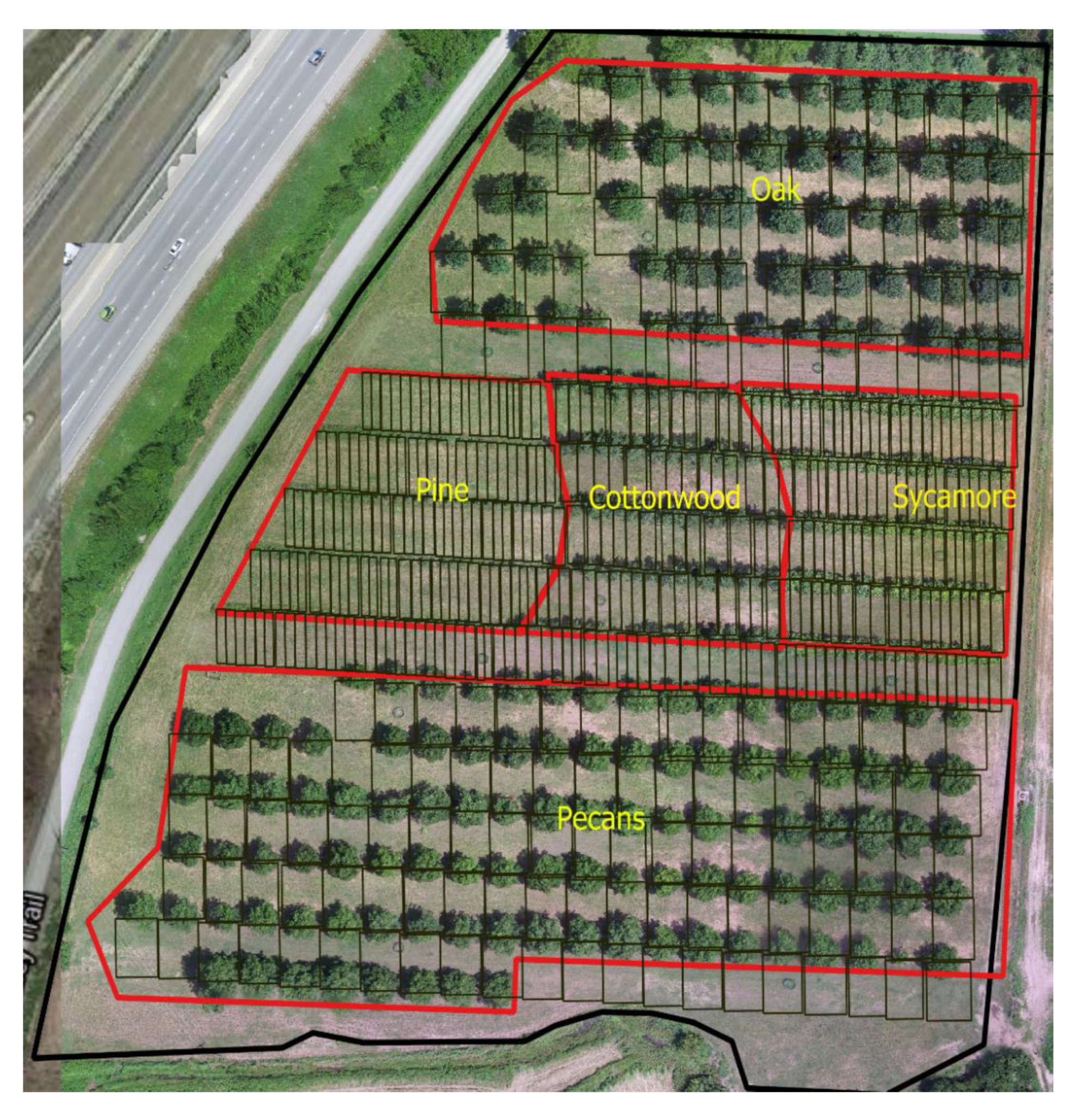
2.1. Site and Experiment Description
2.2. Sampling and Processing for Silvopasture Variables
2.3. Data Preprocessing for Analysis
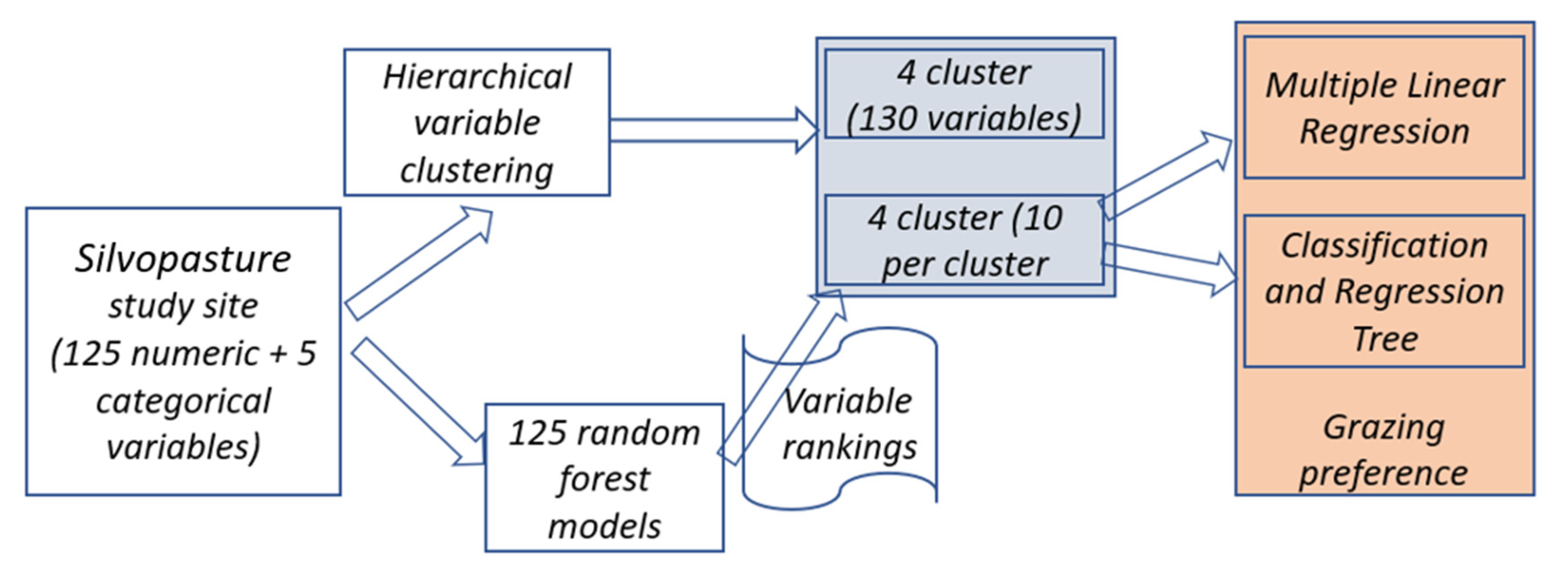
2.4. Machine Learning Approach to Identify Important Variables in a Silvopasture System
2.4.1. Grouping Similar Variables Using Hierarchical Variable Clustering
2.4.2. Variable of Importance Using Random Forest Model
2.5. Animal Grazing Preference Modeling Using Variables Selected by RF-Based Variable Ranking Method
3. Results
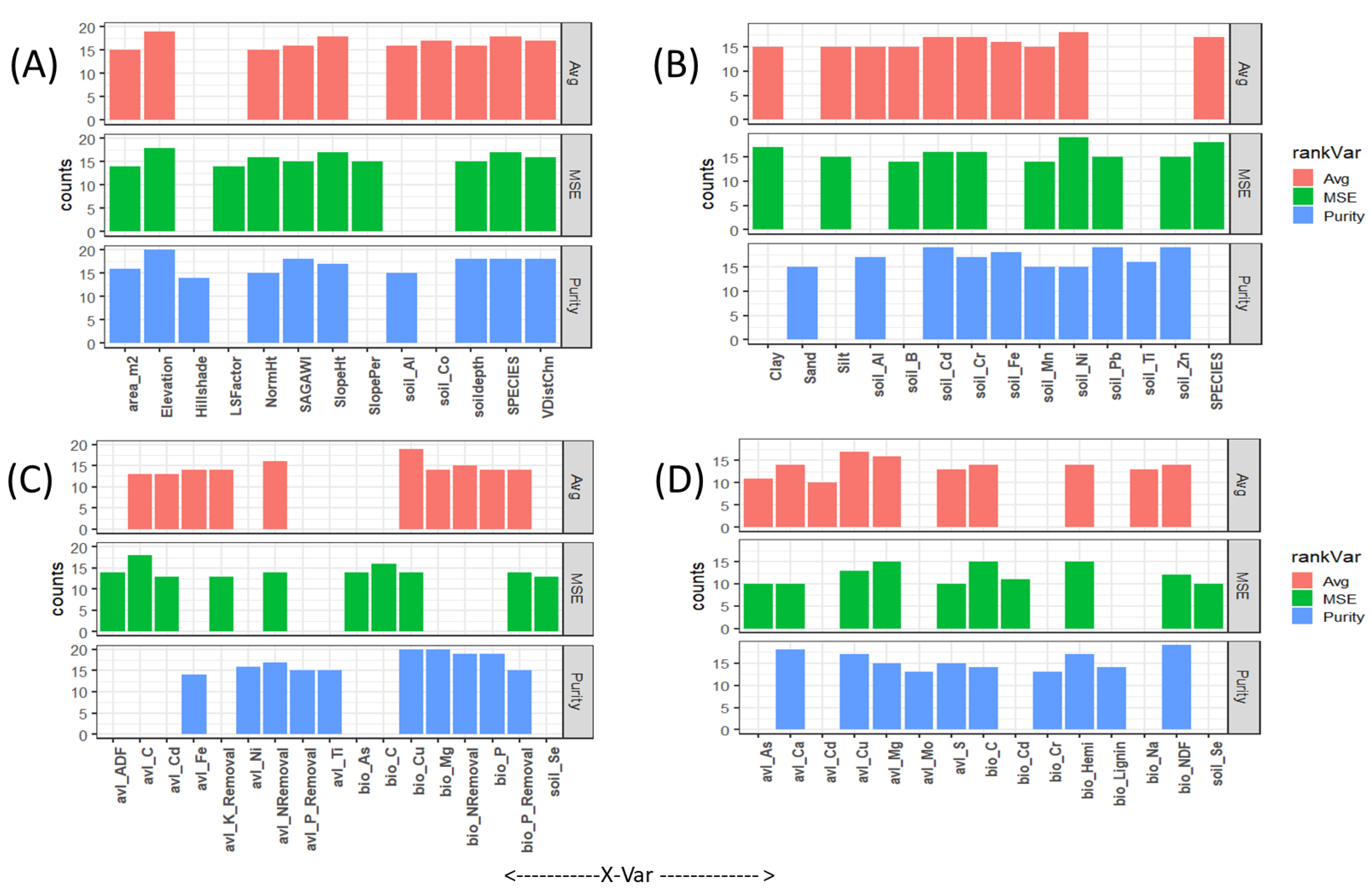
3.1. Grouping Variables Together Using Hierarchical Clustering Method
3.2. Important Variables Using Random Forest Method
3.3. Linear Regression-Based Interpretation of Selected Variables for Animal Grazing Preference
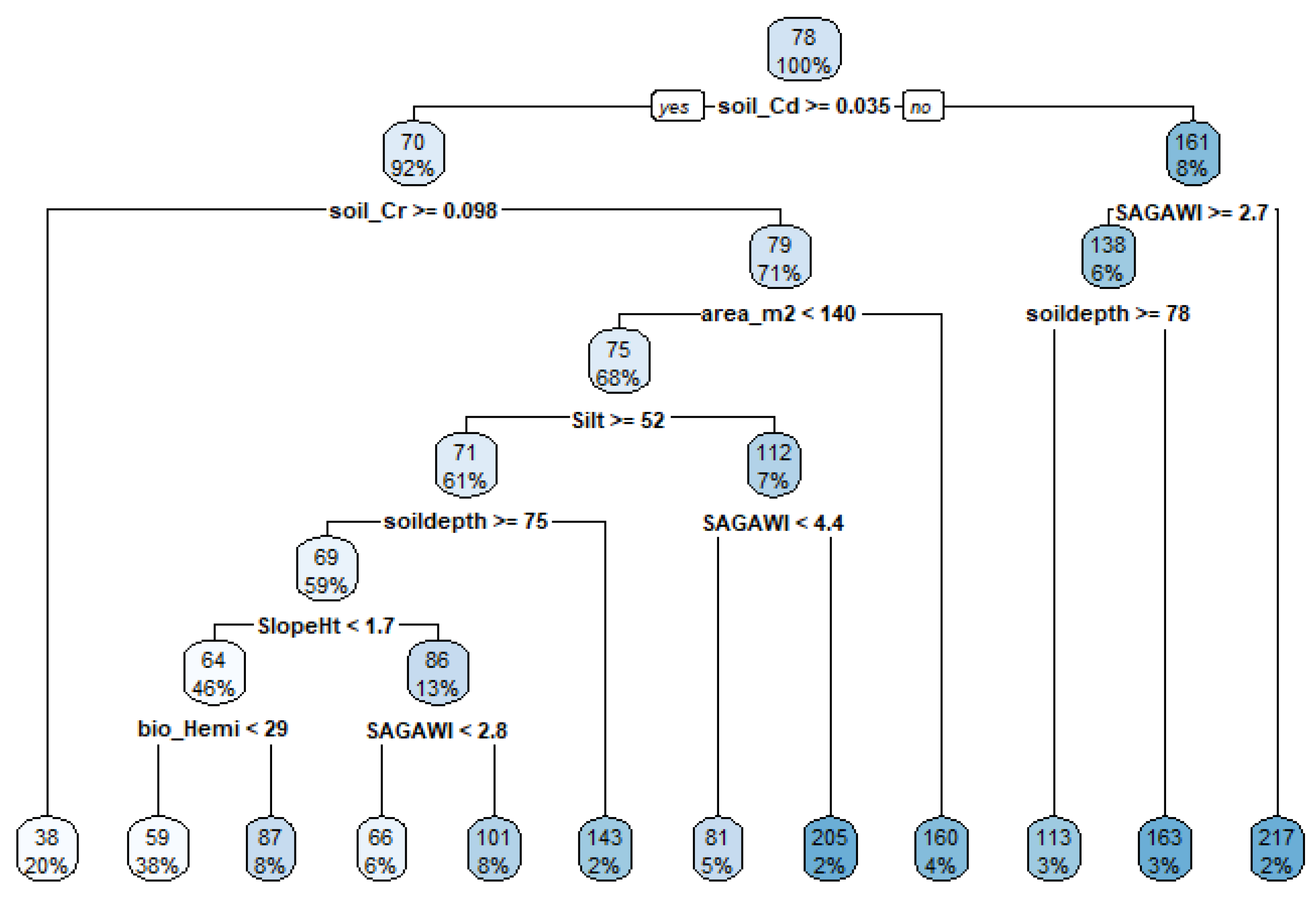
3.4. CART-Based Interpretation of the Selected Variables for Grazing Preference
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
References
- Cardinael, R.; Chevallier, T.; Cambou, A.; Béral, C.; Barthès, B.G.; Dupraz, C.; Durand, C.; Kouakoua, E.; Chenu, C. Increased soil organic carbon stocks under agroforestry: A survey of six different sites in France. Agric. Ecosyst. Environ. 2017, 236, 243–255. [Google Scholar] [CrossRef] [Green Version]
- Pinho, R.C.; Miller, R.P.; Alfaia, S.S. Agroforestry and the improvement of soil fertility: A view from Amazonia. Appl. Environ. Soil Sci. 2012, 2012, 616383. [Google Scholar] [CrossRef]
- Jose, S. Agroforestry for ecosystem services and environmental benefits: An overview. Agrofor. Syst. 2009, 76, 1–10. [Google Scholar] [CrossRef]
- Schroeder, P. Agroforestry systems: Integrated land use to store and conserve carbon. Clim. Res. 1993, 3, 53–60. [Google Scholar] [CrossRef]
- Bzdok, D.; Altman, N.; Krzywinski, M. Statistics versus machine learning. Nat. Methods 2018, 15, 233–234. [Google Scholar] [CrossRef]
- Samuel, A.L. Some studies in machin learning using the game of checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Cioffi, R.; Travaglioni, M.; Piscitelli, G.; Petrillo, A.; De Felice, F. Artificial intelligence and machine learning applications in smart production: Progress, trends and directions. Sustainability 2020, 12, 492. [Google Scholar] [CrossRef] [Green Version]
- John, G.H.; Langley, P. Static versus dynamic sampling for data mining. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining; AAAI Press: Portland, OR, USA, 1996. [Google Scholar]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Kalogirou, S.; Wolf, E. Less is more: Optimizing classification performance through feature selection in a very-high-resolution remote sensing object-based urban application. GIScience Remote Sens. 2018, 55, 221–242. [Google Scholar] [CrossRef]
- Bzdok, D. Classical statistics and statistical learning in imaging neuroscience. Front. Neurosci. 2017, 11, 543. Available online: https://www.frontiersin.org/articles/10.3389/fnins.2017.00543/full (accessed on 18 July 2021). [CrossRef]
- Wang, S.; McCormick, T.H.; Leek, J.T. Methods for correcting inference based on outcomes predicted by machine learning. Proc. Natl. Acad. Sci. USA 2020, 117, 30266–30275. [Google Scholar] [CrossRef]
- Morr, P.E. Age of acquisition, imagery, recall, and the limitations of multiple-regression analysis. Mem. Cogn. 1981, 9, 277–282. [Google Scholar] [CrossRef] [Green Version]
- Porter, A.L.; Connolly, T.; Heikes, R.G.; Park, C.Y. Misleading indicators: The limitations of multiple linear regression in formulation of policy recommendations. Policy Sci. 1981, 13, 397–418. [Google Scholar] [CrossRef]
- Adhikari, K.; Owens, P.R.; Ashworth, A.J.; Sauer, T.J.; Libohova, Z.; Richter, J.L.; Miller, D.M. Topographic controls on soil nutrient variations in a silvopasture system. Agrosystems Geosci. Environ. 2018, 1, 180008. [Google Scholar] [CrossRef]
- Sauer, T.J.; Coblentz, W.K.; Thomas, A.L.; Brye, K.R.; Brauer, D.K.; Skinner, J.V.; Brahana, J.V.; DeFauw, S.L.; Hays, P.D.; Moffitt, D.C.; et al. Nutrient cycling in an agroforestry alley cropping system receiving poultry litter or nitrogen fertilizer. Nutr. Cycl. Agroecosystem 2015, 101, 167. [Google Scholar] [CrossRef]
- DeFauw, S.L.; Brye, K.R.; Sauer, T.J.; Hays, P. Hydraulic and physiochemical properties of a hillslope soil assemblage in the Ozark highlands. Soil Sci. Soc. Am. J. 2014, 179, 107–117. [Google Scholar] [CrossRef]
- Thomas, A.L.; Brauer, D.K.; Sauer, T.J.; Coggeshall, M.V.; Ellersieck, M.R. Cultivar influences early rootstock and scion survival of grafted black walnut. J. Am. Pomol. Soc. 2008, 62, 3–12. [Google Scholar]
- Ashworth, A.J.; Kharel, T.; Sauer, T.; Adams, T.C.; Philipp, D.; Thomas, A.; Owens, P.R. Spatial Monitoring Technologies for Coupling the Soil-Plant-Water-Animal Nexus. Sci. Rep. 2021. in review. [Google Scholar]
- Ashworth, A.J.; Adams, T.C.; Kharel, T.P.; Philipp, D.; Owens, P.R.; Sauer, T.J. Root Decomposition in Silvopastures is Influenced by Grazing, Fertility, and Grass Species. Agrosystems Geosci. Environ. 2021. [Google Scholar] [CrossRef]
- Blake, G.R.; Hartge, K.H. Bulk density. In Methods of Soil Analysis, Part 1—Physical and Mineralogical Methods, 2nd ed.; Agronomy Monograph, 9; Klute, A., Ed.; American Society of Agronomy—Soil Science Society of America: Madison, WI, USA, 1986; pp. 363–382. [Google Scholar]
- Niyigena, V.; Ashworth, A.J.; Nieman, C.; Achara, M.; Coffey, K.P.; Philipp, D.; Meadors, L.; Sauer, T.J. Factors affecting sugar accumulation and fluxes in warm- and cool-season forages grown in a silvopastoral system. Agronomy 2021, 11, 354. [Google Scholar] [CrossRef]
- Dhakal, M.; West, C.P.; Villalobos, C.; Sarturi, J.O.; Deb, S.K. Trade-off between nutritive value improvement and crop water use for alfalfa-grass system. Crop Sci. 2020, 60, 1711–1723. [Google Scholar] [CrossRef] [Green Version]
- Gurmessa, B.; Ashworth, A.J.; Yang, Y.; Savin, M.; Moore, P.A., Jr.; Ricke, S.; Pedretti, G.C.E.F.; Cocco, S. Variations in bacterial community structure and antimicrobial resistance gene abundance in cattle manure and poultry litter. Environ. Res. 2021, 197, 111011. [Google Scholar] [CrossRef]
- Gurmessa, B.; Ashworth, A.J.; Yang, Y.; Adhikari, K.; Savin, M.; Owens, P.R.; Sauer, T.; Pedretti, E.F.; Cocco, S.; Corti, G. Soil bacterial diversity based on management and topography in a silvopastoral system. Appl. Soil Ecol. 2021, 163, 103918. [Google Scholar] [CrossRef]
- Hijmans, R.J. Raster: Geographic data analysis and modeling. R package version 2.9-23. 2019. Available online: https://CRAN.R-project.org/package=raster (accessed on 15 December 2020).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: https://www.R-project.org/ (accessed on 10 December 2020).
- Chavent, M.; Kuentz-Simonet, V.; Liquet, B.; Saracco, J. ClustOfVar: An R pakage for the clustering of variables. J. Stat. Softw. Am. Stat. Assoc. 2012, 50, 6809. [Google Scholar]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–208. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and regression by randomforest. R News 2002, 2, 18–22. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002; ISBN 0-387-95457-0. [Google Scholar]
- Therneau, T.; Atkinson, B. Rpart: Recursive Partitioning and Regression Trees; R package version 4.1-15. 2019. Available online: https://CRAN.R-project.org/package=rpart (accessed on 15 December 2020).
- Marten, G.C. The animal -plant complex in forage palatability phenomena. J. Anim. Sci. 1973, 46, 1470–1477. [Google Scholar] [CrossRef]
- Willms, W. Spring forage selection by tame Mule deer on Big Sagebrush range, British Columbia. J. Range Manag. 1978, 31, 192–199. [Google Scholar] [CrossRef]
- Cambardella, C.A.; Moorman, T.; Novak, J.; Parkin, T.; Karlen, D.; Turco, R.; Konopka, A.E. Field scale variability of soil properties in central Iowa soils. Soil Sci. Soc. Am. J. 1994, 58, 1501–1511. [Google Scholar] [CrossRef]
- Brown, D.J.; Clayton, M.K.; McSweeney, K. Potential terrain controls on soil color, texture contrast and grain-size deposition for the original catena landscape in Uganda. Geoderma 2004, 122, 51–72. [Google Scholar] [CrossRef]
- Mehnatkesh, A.; Ayoubi, S.; Jalalian, A.; Sahrawat, K.L. Relationships between soil depth and terrain attributes in a semi arid hilly region in western Iran. J. Mt. Sci. 2013, 10, 163–172. [Google Scholar] [CrossRef]
- Umali, B.P.; Oliver, D.P.; Forrester, S.; Chittleborough, D.J.; Hutson, J.L.; Kookana, R.S.; Ostendorf, B. The effect of terrain and management on the spatial variability of soil properties in an apple orchard. Catena 2012, 93, 38–48. [Google Scholar] [CrossRef]
- Franzen, D.W.; Nanna, T.; Norvell, W.A. A survey of soil attributes in North Dakota by landscape position. Agron. J. 2006, 98, 1015–1022. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster 1 | Score | Cluster 2 | score | Cluster 3 | Score | Cluster 4 | Score |
|---|---|---|---|---|---|---|---|
| SPECIES | 0.82 | soil_Cd | 0.86 | bio_P_Removal | 0.88 | bio_NDF | 0.90 |
| SAGAWI | 0.77 | soil_Cr | 0.85 | bio_Mg | 0.83 | avl_Ca | 0.90 |
| NormHt | 0.63 | soil_Pb | 0.79 | bio_P | 0.80 | Forage_spp | 0.87 |
| SlopePer | 0.61 | soil_Ti | 0.70 | avl_P_Removal | 0.74 | avl_Cu | 0.87 |
| SlopeHt | 0.60 | soil_Cu | 0.69 | bio_NRemoval | 0.68 | avl_Na | 0.82 |
| soildepth | 0.59 | soil_As | 0.69 | avl_Ni | 0.68 | avl_Mo | 0.77 |
| area_m2 | 0.57 | soil_Fe | 0.66 | bio_Mo | 0.67 | bio_Hemi | 0.73 |
| MRVBF | 0.57 | soil_Al | 0.62 | avl_NRemoval | 0.66 | avl_S | 0.69 |
| X1b | 0.55 | Sand | 0.61 | bio_K_Removal | 0.65 | bio_Ca | 0.66 |
| Hillshade | 0.55 | soil_Mo | 0.57 | bio_Cu | 0.65 | bio_S | 0.60 |
| VWC1 | 0.50 | soil_Ca | 0.55 | avl_Co | 0.63 | avl_Mg | 0.55 |
| TreeHeight | 0.48 | soil_Se | 0.55 | avl_Fe | 0.61 | bio_Na | 0.55 |
| Wetness | 0.44 | pH | 0.48 | bio_N | 0.60 | avl_Zn | 0.55 |
| DBH | 0.44 | soil_Mn | 0.45 | avl_K_Removal | 0.56 | bio_Mn | 0.51 |
| Elevation | 0.43 | Silt | 0.42 | Fertilizer | 0.56 | bio_Lignin | 0.50 |
| soil_Co | 0.39 | soil_Zn | 0.40 | avl_Pb | 0.56 | bio_Cd | 0.46 |
| VDistChn | 0.35 | X15b | 0.40 | avl_Mn | 0.56 | Carb | 0.43 |
| Clay | 0.35 | soil_P | 0.35 | avl_Ti | 0.54 | bio_Pb | 0.28 |
| bio_Cr | 0.33 | soil_S | 0.33 | avl_Al | 0.54 | avl_Lignin | 0.28 |
| bio_As | 0.32 | soil_Ni | 0.23 | avl_Yield | 0.54 | bio_Ash | 0.24 |
| LOI | 0.29 | avl_Hemi | 0.21 | avl_Ash | 0.54 | bio_C | 0.22 |
| bio_Se | 0.28 | avl_ADF | 0.20 | avl_P | 0.48 | bio_B | 0.21 |
| LSFactor | 0.28 | CN | 0.19 | avl_Cr | 0.44 | bio_Ti | 0.17 |
| soil_B | 0.26 | X0.33b | 0.13 | bio_Zn | 0.40 | bio_Al | 0.15 |
| TFU | 0.26 | grz_hr_ha | 0.12 | bio_Yield | 0.32 | bio_Fe | 0.14 |
| EC | 0.19 | soil_Na | 0.12 | LAI | 0.27 | avl_As | 0.11 |
| avl_N | 0.18 | X3b | 0.00 | bio_Co | 0.27 | bio_ADF | 0.10 |
| N | 0.18 | soil_Mg | 0.00 | PAR | 0.25 | avl_Se | 0.06 |
| MidSlope | 0.17 | soil_K | 0.00 | avl_Cd | 0.23 | ||
| Aspect | 0.17 | avl_C | 0.21 | ||||
| ValleyDep | 0.16 | Density | 0.15 | ||||
| Suagr | 0.15 | bio_Ni | 0.12 | ||||
| FlowAccum | 0.14 | Temp | 0.07 | ||||
| C | 0.10 | avl_B | 0.02 | ||||
| CO2 | 0.09 | ||||||
| MRRTF | 0.08 | ||||||
| avl_K | 0.07 | ||||||
| bio_K | 0.06 | ||||||
| avl_NDF | 0.01 |
| Variables | Coefficient | ANOVA-p > F | VIF | |
|---|---|---|---|---|
| Intercept | −4025 | - | ||
| SlopeHt | −34 * | 0.00 | 6.8 | |
| SAGAWI | 12.0 * | 0.00 | 3.8 | |
| NormHt | 242 * | 0.00 | 9.7 | |
| soil_Ni | −28 * | 0.30 | 2.5 | |
| soil_Cd | 923 * | 0.00 | 4.0 | |
| soil_Cr | −1383 * | 0.00 | 8.4 | |
| soil_Fe | 29 * | 0.01 | 4.2 | |
| soil_Mn | −36 * | 0.00 | 4.9 | |
| bio_Cu | −73 * | 0.00 | 4.3 | |
| avl_NRemoval | 4 * | 0.04 | 6.0 | |
| avl_Fe | 11 * | 0.70 | 5.2 | |
| bio_P | −782 * | 0.00 | 7.1 | |
| avl_C | 90 * | 0.00 | 4.6 | |
| avl_Ca | 166 * | 0.04 | 5.0 | |
| grz_hr_ha | Mean | 77.7 | ||
| SD | 58.0 | |||
| N | 415 |
| Factors | Grazing Hour | Soil Cd | Soil Cr | Tree Coverage | SAGAWI | Soil Depth | Biomass p Removal | Biomass Mg | Biomass NDF | Forage Mass Ca |
|---|---|---|---|---|---|---|---|---|---|---|
| h ha−1 AU−1 | mg kg−1 | mg kg−1 | m2 | Index | cm | mg kg−1 | mg kg−1 | % | mg kg−1 | |
| Tree Species | ||||||||||
| Cottonwood | 76.4 b,c,† | 0.07 a | 0.11 a | 57.2 c | 4.66 a | 96.2 a | 6.26 a,b | 1474 a | 62.7 b | 5440 a,b |
| Oak | 68.5 b,c | 0.05 b | 0.09 b | 105.0 b | 3.99 c | 85.4 c | 6.48 a | 1427 b | 63.2 a | 5258 c |
| Pecan | 103.3 a | 0.05 b | 0.08 c | 132.0 a | 4.81 a | 91.1 b | 6.29 a | 1382 c | 63.1 a | 5216 c |
| Pine | 80.8 b | 0.04 c | 0.06 d | 28.8 d | 3.46 d | 82.1 d | 6.28 a | 1457 a | 62.6 b | 5363 b |
| Sycamore | 58.5 c | 0.03 d | 0.09 b | 61.5 c | 4.28 b | 83.2 d | 5.86 b | 1441 a,b | 62.5 b | 5529 a |
| Fertilizer | ||||||||||
| Fertilized | 71.1 b | 0.04 b | 0.08 b | 76.8 a | 4.29 a | 87.9 a | 4.65 b | 1597 a | 63.0 a | 5222 b |
| Control | 83.9 a | 0.06 a | 0.09 a | 77.0 a | 4.19 a | 87.3 a | 7.82 a | 1275 b | 62.6 b | 5500 a |
| Wetness | ||||||||||
| Aquic | 51.8 b | 0.06 a | 0.10 a | 77.0 a | 4.60 a | 92.9 a | 6.05 b | 1419 b | 62.7 a | 5381 a |
| Udic | 103.2 a | 0.04 b | 0.07 b | 76.9 a | 3.88 b | 82.3 b | 6.42 a | 1453 a | 62.9 a | 5342 a |
| Grass Treatments | ||||||||||
| Orchardgrass | 53.9 b | 0.06 a | 0.09 a | 77.3 a | 4.07 b | 87.4 a | 6.56 a | 1509 a | 60.8 b | 6015 a |
| Native grass | 101.1 a | 0.04 b | 0.08 b | 76.5 a | 4.41 a | 87.8 a | 5.91 b | 1363 b | 64.8 a | 4708 b |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kharel, T.P.; Ashworth, A.J.; Owens, P.R.; Philipp, D.; Thomas, A.L.; Sauer, T.J. Teasing Apart Silvopasture System Components Using Machine Learning for Optimization. Soil Syst. 2021, 5, 41. https://0-doi-org.brum.beds.ac.uk/10.3390/soilsystems5030041
Kharel TP, Ashworth AJ, Owens PR, Philipp D, Thomas AL, Sauer TJ. Teasing Apart Silvopasture System Components Using Machine Learning for Optimization. Soil Systems. 2021; 5(3):41. https://0-doi-org.brum.beds.ac.uk/10.3390/soilsystems5030041
Chicago/Turabian StyleKharel, Tulsi P., Amanda J. Ashworth, Phillip R. Owens, Dirk Philipp, Andrew L. Thomas, and Thomas J. Sauer. 2021. "Teasing Apart Silvopasture System Components Using Machine Learning for Optimization" Soil Systems 5, no. 3: 41. https://0-doi-org.brum.beds.ac.uk/10.3390/soilsystems5030041