
A Tutorial on How to Conduct Meta-Analysis with IBM SPSS Statistics

1
Education Faculty, Harran University, Sanliurfa 63190, Turkey
2
Education Faculty, Gaziantep University, Gaziantep 27310, Turkey
*
Authors to whom correspondence should be addressed.
Psych 2022, 4(4), 640-667; https://0-doi-org.brum.beds.ac.uk/10.3390/psych4040049
Submission received: 21 August 2022
/
Revised: 15 September 2022
/
Accepted: 15 September 2022
/
Published: 22 September 2022
(This article belongs to the Special Issue Computational Aspects and Software in Psychometrics II)
Abstract
:Meta-analysis has started to take place among the most used methodologies in psychological research. Such a technique allows researchers to combine the data sets obtained from several individual studies on the same topic and thus is particularly useful for finding solutions to controversial issues that cannot be solved with individual studies. This paper presents a detailed tutorial of the IBM SPSS software, which enables one to implement the statistical analyses for meta-analysis. Examples are also provided to highlight the main analyses conducted in the meta-analysis. The tutorial ends by discussing the differences between IBM SPSS capabilities and those of other software packages.
1. Introduction
Scientific research is a cumulative process in which each scientist makes unique contributions to their area of study. After a certain period of time, these individual studies may reveal different findings about the subject studied. When we look at the research on a particular subject as a whole, we may not be able to see whether the methods applied or developed are really effective. An example of this situation was experienced in the field of psychotherapy in the 1950s. In 1952, Hans Eysenck initiated a fierce debate in clinical psychology by publishing a study arguing that psychotherapy had no beneficial effect on patients [1]. By the mid-1970s, hundreds of psychotherapy studies had produced a dizzying array of positive, neutral, and negative results, and reviews of these studies failed to settle the debate. To evaluate Eysenck’s claim, Gene V. Glass calculated an overall mean value for 375 psychotherapy studies by statistically standardizing the differences between treatment and control groups. Smith and Glass [2] published their findings in a journal and showed that psychotherapy was actually an effective practice. Glass called this method “meta-analysis”. Despite criticism from some scientists [3], meta-analysis is now accepted as an appropriate method of statistically summarizing the results of individual quantitative studies in the behavioral, social, and health sciences [4]. Although the term meta-analysis was first used by Glass in 1976, the first meta-analysis in the sense of combining quantitative studies is attributed to Pearson [5], who analyzed data from five studies on the correlations between inoculation and immunity and mortality. In the late 1970s and early 1980s, following Glass’s work, among others, Rosenthal [6], Glass, McGaw and Smith [7], Hedges [8,9], Hunter, Schmidt, and Jackson [10], and Light and Pillemar [11] popularized meta-analysis and further developed the statistical methods necessary for its application.
It is known as systematic review, in which scientists systematically review the results from a large number of studies and synthesize the results in order to make inferences about the typical findings and sources of variability between studies. Over the past 40 years, there has been a large increase in the use of systematic reviews in both medicine and the social sciences, including psychology and education. The focus on evidence-based practice in many professions has increased interest in understanding both the known and unknown parts of important interventions and clinical practice [12]. Systematic reviews promise a transparent and repeatable method for summarizing the literature to help improve both policy decisions and the design of new studies. Although systematic reviews have a certain potential, this potential is also observed to be compromised by inadequate methods and misinterpretation of results [12]. In short, a systematic review is a critical evaluation to seek the answer to a focused question in the light of available research. However, meta-analysis differs from systematic review in that it only focuses on quantitative studies. The present study focuses on the meta-analysis method, which was developed based on quantitative research and has emerged as a methodological and statistical approach to draw conclusions from the empirical literature.
Meta-analysis is a quantitative method used to combine the results of multiple studies into a single conclusion. The term “meta-analysis” was first coined by Gene Glass in 1976 as the statistical analysis of a large collection of analysis results from individual studies for the purpose of integrating the findings [13] (p. 3). A meta-analysis collects quantitative results from multiple studies and draws conclusions about the overall effect between studies. In doing so, it does not look at what results the original studies found. The word “meta” is used because it is a kind of research of research or analysis of analysis [13]. To put it briefly, it is a systematic quantitative research method to reveal the big picture of a topic. In order to conduct a meta-analysis study, Glass suggested using the effect size value when combining the findings of multiple studies correctly [13,14]. Any standardized index (standardized mean difference, correlation, and odds ratio) can be used as an effect size as long as it is comparable between studies, independent of the sample, and indicates the size and direction of the effect. The effect size is the value that makes meta-analysis possible. The effect size is taken as the “dependent variable” in the meta-analysis and results in a comparable statistic as it is obtained by standardizing between studies.
The general purpose of meta-analysis is to combine the results of individual studies to reach summary conclusions about a research question. It is used to calculate a summary estimate of effect size, to explore the causes of differences in effects between studies, and to identify heterogeneity in the effects (or differences in risk) of the intervention in different subgroups. It is worth mentioning here that the meta-analysis calculates the weighted average of the effect size, not the arithmetic mean between studies. It is an approach that gives more weight to more precise estimates. In other words, it gives greater weight to studies with a large sample size. The weighting factor is equal to 1/(standard error)2. Studies with a low standard error (i.e., large sample size) contribute more to the overall average estimated as a result of the meta-analysis.
In meta-analysis, the overall average estimate can be typically obtained with either a fixed-effect or random-effects model. The model assuming that the parameter measuring the effect size is the same in all studies is called the “fixed-effect” model. The model that allows this parameter to act as a random variable that takes different values from one study to another is called the “random-effects” model. The fixed effect model and the random-effects model make different assumptions and apply different weights in the calculation of the average effect size. There is only one source of variation (i.e., the sampling error) in the fixed-effect model. That is, the difference between each effect size is due to the difference in sample size, and the population effect size is the same for each study. It is assumed that each effect size value in the study comes from a fixed population. On the other hand, there are two sources of variation in the random-effects model. The random-effects model assumes that each observed effect size differs from the population mean by an individual-level sampling error plus a value representing other sources of variability assumed to be randomly distributed. Although there are different ways of performing meta-analysis, the most common and popular approaches are those offered by Hunter and Schmidt [10,15,16], Glass [7,13], and Hedges and Olkin [17]. All three approaches aim to transform the results of individual studies into a common measure.
An excellent literature review is at the heart of the meta-analysis. A common threat to literature reviews and meta-analyses is known as publication bias. The term “publication bias” is often used to express that statistically significant results are more likely to be presented and published than non-significant and null results [18]. Publication bias is a systematic error that occurs in a statistical inference conditioned on gaining publication status [19]. As a matter of fact, published studies alone do not represent all studies in a research area. This situation is also called the file drawer problem [20]. It is seen as a threat because it adds systematic error to the meta-analysis. This threat arises because studies that have not found a statistically significant effect (or have not found the expected effect) are less likely to be published and therefore less likely to be available to the meta-analyst. Lipsey and Wilson [21] provided evidence for publication bias by showing that published studies had a larger mean effect size than unpublished studies. A study group included in a meta-analysis may be over-representative of published studies, as it is much easier to identify and screen published studies than unpublished studies that were never written due to negative or null findings. Another source of bias is the presence of gray literature [22]. This includes conference presentations, technical reports, or obscure publications, and is kept between the drawer and the publication process. This situation is also referred to as “fugitive literature” by Rosenthal [23]. In order to eliminate publication bias, a comprehensive search should be conducted to find these missing studies. To counter this threat, one should seek to obtain unpublished work (for example, dissertations and conference proceedings) that will either eliminate this threat or at least allow one to assess the magnitude of this bias. That is, the primary way to avoid publication bias in meta-analysis is to include both published and unpublished studies. Card (2011) states six methods that can be used to examine whether there is a publication bias. These are moderator analysis, funnel plot, fail-safe N, regression analysis, trim and fill, and weighted selection methods. Apart from these, there is another method proposed by Begg and Mazumdar [24] based on rank correlations.
1.1. Steps of Meta-Analysis
Researchers who want to perform these analyses through meta-analysis should follow certain steps. Although it is presented in different ways in many sources, the steps required to perform a meta-analysis can be listed as follows:
- The research question should be formulated.
- A decision should be made on how to select appropriate studies from the collected studies.
- Appropriate studies should be collected according to research questions and keywords.
- Quality control/sensitivity analyses should be done.
- The effect size to be used in the selected studies should be decided and calculated for each study.
- The data should be pooled and a summary measure and confidence interval should be calculated.
- Additional analyses (heterogeneity, publication bias, etc.) should be done.
- Moderator analyses for moderator variables should be performed.
- Results should be interpreted and inferences should be made.
- In addition, the details of the above-mentioned steps should be reported together with the meta-analysis findings.
Meta-analysis is used extensively in education, psychology, health, and several other areas to summarize the results of individual studies conducted on the same topic. This method helps researchers to estimate the mean effect size using the effect size and variance (or standard error) values from each individual study. While this method may seem straightforward, statistical analyses of meta-analysis data resulting from individual studies often present great challenges. Thus, several software packages have been developed for this purpose.
1.2. Software Options
Meta-analysis studies are very demanding in terms of both data collection and data analysis. It is a very time-consuming process to identify the studies that will be included in the meta-analysis and to extract the necessary information for calculating the effect size. In light of the summary information obtained, calculating the effect size value for each study and obtaining the overall mean is another time-consuming step where researchers with poor statistical knowledge are likely to make mistakes. Unfortunately, while the creation of the data file specified here is mandatory by the researcher himself, there are several software packages developed to perform the second step, the data analysis process. Researchers have two options when it comes to software that can be used—using specialized software designed for meta-analysis (e.g., Comprehensive Meta-Analysis) or using statistical software designed for general purposes (e.g., SPSS).
In the literature, several standalone software packages have been made available, especially for meta-analysis. Commercial packages include MetaWin [25] and Comprehensive Meta-Analysis (CMA) [26]. DSTAT [27] and Advanced Basic Meta-analysis [28] are other commercial software programs that are less well-known than MetaWin and CMA. In addition to these software packages, free meta-analysis specific software packages are also available, including RevMan (Review Manager), MetaGenyo [29], MetaStat [30], Meta-Analysis [31], META (Meta-Analysis Easy to Answer) [32], and OpenMeta [Analyst] [33].
Some of the existing software packages have also been expanded for meta-analysis. Examples of these packages are MIX 2.0 [34], metaXL [35], and MetaEasy [36] add-ins developed for Excel. Functions and macros have also been prepared for meta-analysis in Stata [37]. Using the proc mixed command, meta-analysis can be conducted through the SAS program [38]. Various meta-analysis packages are also available in R [39] including meta [40], metafor [41], rmeta [42], robumeta [43] and metaSEM [44]. Detailed information about other meta-analysis packages in the R program can be found in the study of Polanin, Hennessy and Tanner-Smith [45]. A module called MAJOR in Jamovi, developed by Kyle Hamilton, allows users to conduct a meta-analysis using different types of input (e.g., effect sizes, correlation coefficients). Similarly, another open-source statistical software called JASP can also be used for meta-analysis. The engine behind these two software packages comes from the R package metafor. In addition, some macros have been developed to conduct meta-analysis using the SPSS program [4,46]. The existing SPSS macros, however, currently only provide limited capabilities for conducting analyses and enable researchers to conduct only main analyses (i.e., mean ES, subgroup analyses, and meta-regression analyses). Publication bias and other graphical options (e.g., forest plot and funnel plot) were not available in these SPSS macros (see also [47]). SPSS macros also require researchers to write SPSS syntax, which would be cumbersome for most practitioners. Very recently, IBM SPSS introduced a point-and-click meta-analysis menu with Version 28. Although many programs have been developed in the literature, the SPSS program remains the first choice for many researchers. Thus, researchers familiar with using SPSS may want to conduct the statistical analyses required for meta-analysis via SPSS. To date, no study has been conducted on how to conduct meta-analysis with IBM SPSS. The tutorial in this study provides guidance for students and researchers who originally plan to use IBM SPSS for meta-analysis of the data collected from individual studies.
1.3. Properties of IBM SPSS Statistics
It is possible to conduct most of the analyses required for meta-analysis studies using IBM SPSS Statistics with Version 28 (SPSS28). The trial version of SPSS28 can be downloaded from the official website (https://www.ibm.com/products/spss-statistics) (accessed on 31 July 2022). After clicking the “Try SPSS Statistics at no cost” link, to start the trial period, you should enter some information (e.g., name, e-mail address). With this information, you can obtain an IBMid and code. With this code you can set up SPSS28 on your PC. The trial period is limited to 30 days. After the trial period, one may want to purchase the software.
Whether you have the demo or the full version, SPSS28 has several procedures, including mean effect size calculation, heterogeneity statistics, publication bias, and moderator analyses.
1.3.1. Main Analyses
There are three main submenus under the Meta Analysis menu of SPSS28: Continuous Outcomes, Binary Outcomes, and Meta Regression. Users can perform meta-analysis with either continuous or binary outcomes on raw data. In addition, similar analyses can be performed when the pre-calculated effect size data are available with continuous or binary outcomes. These are presented in the Continuous Outcomes and Binary Outcomes submenus. The users with summary data (e.g., N, mean, and SD) should use the Raw Data submenu, and the users with pre-calculated effect sizes (ES and its variance) should use the Pre-calculated Effect Size submenu. Both fixed-effect and random-effects models are available under the model section. Users can also conduct subgroup analyses under these menus.
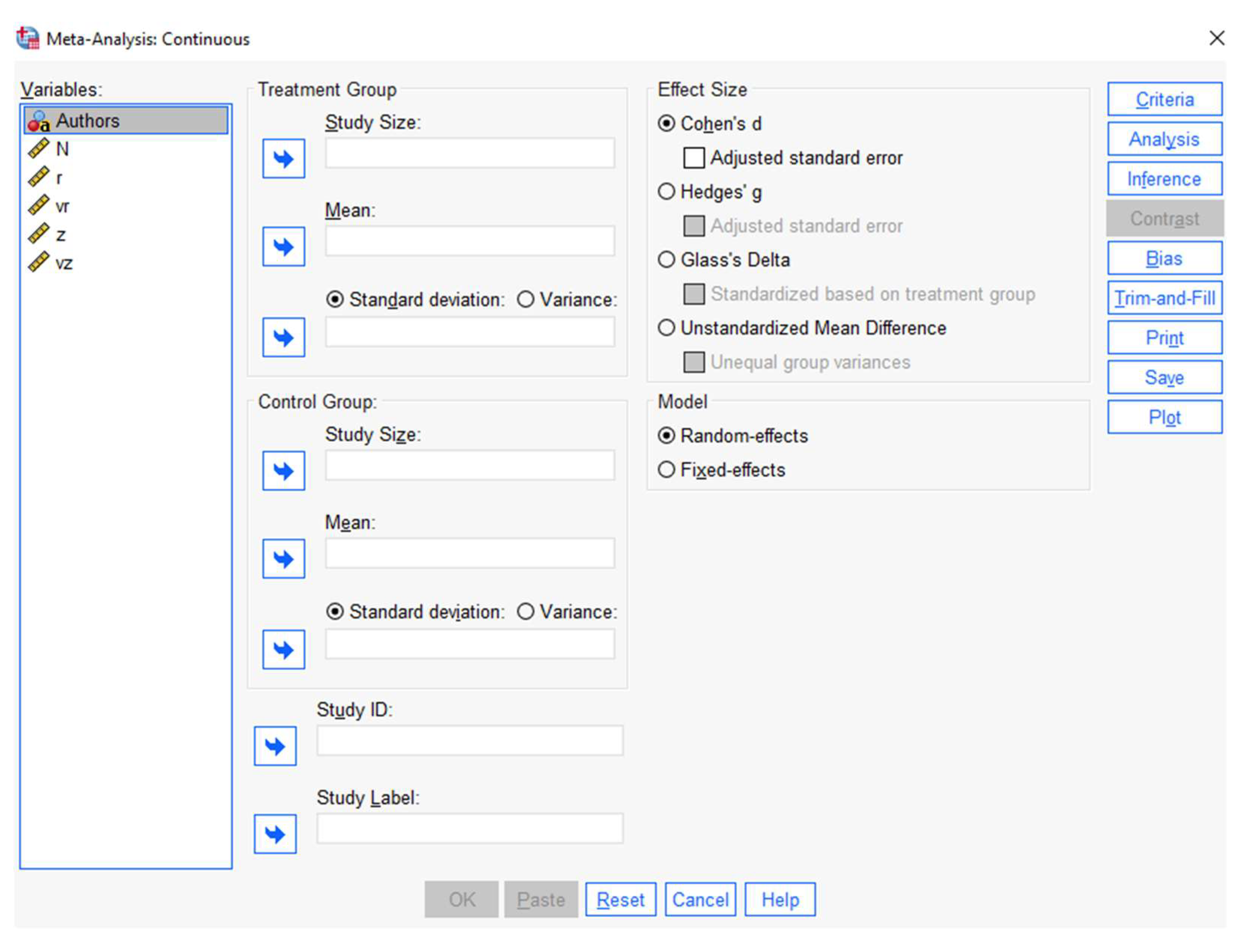
When the Raw Data submenu of the Continuous Outcomes menu is selected, the Effect Size section has four types of effect size indices: Unstandardized mean difference, Cohen’s d, Hedges’ g, and Glass’ delta. In addition to Study ID, the summary statistics required for meta-analyses are sample size, mean, and standard deviation (or variance) values for both control and treatment groups. When the Raw Data submenu of the Binary Outcomes menu is selected, the Effect Size section has four types of effect size indices: Log Odds Ratio, Peto’s Log Odds Ratio, Log Risk Ratio, and Risk Difference. In addition to Study ID, the summary statistics required for meta-analyses are success and failure rates for both control and treatment groups. When the Pre-Calculated Effect Size submenu of the Continuous Outcomes or Binary Outcomes menus is selected, the Effect Size and its standard error or variance should be selected. In addition, one of the effect size types (Log Odds Ratio, Peto’s Log Odds Ratio, Log Risk Ratio, and Risk Difference) should be selected for binary outcomes data.
Whichever of the data entry types aforementioned above you choose, you can modify several options, including Criteria, Analysis, Inference, Contrast, Bias, Trim-and-Fill, Print, Save, and Plot menus (see Figure 1). The Criteria dialog has several options for confidence interval, missing data, iteration, and convergence. Cumulative analysis and subgroup analysis can be selected under the Analysis submenu. Estimator type and standard error adjustment can be determined under the Inference dialog. Currently, there are seven estimators available in SPSS: Restricted maximum likelihood (REML), which is the default, Maximum likelihood (ML), Empirical Bayes, Hedges, Hunter–Schmidt, DerSimonian–Laird, and Sidik–Jonkman. The standard error adjustment dialog includes three options: no adjustment, Apply the Knapp–Hartung adjustment, and Apply the truncated Knapp–Hartung adjustment. As mentioned on the IBM website, the Contrast dialog provides settings for controlling the contrast test for meta-analysis with continuous outcomes on raw data that are provided in the active data set for the estimation of the effect size.
1.3.2. Publication Bias Analyses
Several analyses for publication bias assessment can be applied in SPSS28. Egger’s regression test can be applied via Bias dialog, while the trim-and-fill method can be performed with the Trim-and-Fill dialog. A funnel plot can also be obtained in SPSS28 to examine whether the relationship between standard errors and effect sizes shows a symmetrical shape. In addition to Funnel Plot, several plots, including Forest Plot, Cumulative Forest Plot, Bubble Plot, and Galbraith Plot, can be created via this Plot dialog. The Print dialog can be used to show test of homogeneity and heterogeneity statistics in the output screen. The Print dialog also enables users to print effect size and prediction intervals. Lastly, the Save dialog can be used to save several statistics including individual effect size, standard error, confidence interval lower bound, confidence interval upper bound, p-value, study weight, and percentage of study weight (Please visit IBM website for more details: https://www.ibm.com/docs/en/spss-statistics/SaaS?topic=features-meta-analysis) (accessed on 30 July 2022).
1.3.3. Subgroup Analyses and Meta-Regression
SPSS28 enables users to conduct both subgroup analyses and meta-regression. Subgroup analysis can be selected under the Analysis submenu. In order to conduct a subgroup analysis, users need to add the variables of interest (categorical moderator) from the ‘Variables’ box into the ‘Subgroup Analysis’ box. Using the Meta Regression submenu, users can perform meta-regression analyses by selecting the effect size, standard error (or variance and weight), factor(s), and covariate(s). Categorical moderators are listed in factor(s) and numeric variables are listed in covariate(s). The Meta Regression submenu has some of the dialogs mentioned above: Criteria, Inference, Print, Save, and Plot. While options under the Criteria and Inference dialogs remain the same, the Print dialog allows users to display exponentiated statistics and model coefficient tests. Save dialog enables users to save several statistics, including predicted values, standard error of predicted values, confidence interval lower bound, confidence interval upper bound, residuals, standard error of residuals, leverages, fixed linear predictions, standard error of fixed linear predictions, best linear unbiased predictions (BLUPs), and standard error of BLUPs. A Bubble plot can also be created using the Plot dialog under the Meta Regression submenu.
1.4. Steps of Conducting Meta-Analysis in IBM SPSS Statistics
- Step 1: Prepare your data set
In order to conduct a meta-analysis, the effect size and variance (or standard error) of each individual study should be collected or calculated. Sometimes, researchers may have only summary data instead. SPSS28 allows users to save data as pre-calculated effect size or summary data. The researchers planning to perform a meta-analysis based on continuous data should collect sample size (N), mean, and SD values for both the control and treatment groups of each study. The researchers planning to perform a meta-analysis based on binary data should collect success and failure rates for both the control and treatment groups of each study. However, the researchers planning to perform a meta-analysis based on correlation should collect correlation and sample size for each individual study. Then, Pearson correlation coefficients should be transformed to Fisher’s z values. In addition, the variance or standard error of Fisher’s z values should be computed. For continuous and binary data, pre-calculated effect size and its variance or standard error can also be calculated and saved in a data set. Table 1 shows an example data file for pre-calculated effect size for correlation data. The example data file for raw data (means, SDs, and Ns) is demonstrated in Table 2. Each variable measured is represented by a column, and each measurement of that variable is represented by a row in what is known as a wide data format. A variable representing study ID would usually be placed in the first column, followed by the variables defining the effect size and its variance, or summary variables. Study in tables are explained in Supplementary Materials.
- Step 2: Open IBM SPSS Statistics and import your data set
Researchers either prepare data sets in the SPSS program or save them in other file formats such as MS Excel. In the case of other data formats, the data file should be imported into the SPSS program. For example, to import the meta-analysis data from Excel to SPSS:
- Select File > Import Data > Excel.
It is important to click on the “read variable names from first row of data” box when you have the variable names on the first row of Excel file. As an alternative, users can enter the data on the blank page opened in the variable and data view sections in the SPSS program.
- Step 3: Open Meta Analysis menu
The Meta Analysis procedure performs meta-analysis on the data in the active data set in order to estimate the overall effect size. To open the Meta Analysis menu (see Figure 2):
- Select Analyze > Meta Analysis.
- Step 4: Calculate mean effect size
There are several options under the Meta Analysis menu. As a result, the researchers should choose the option that best fits their data set and research question. The choice depends on the data type (continuous or binary) and whether it is summary or pre-calculated effect size. To be able to analyze a continuous raw data set:
- Select Analyze > Meta Analysis > Continuous Outcomes > Raw Data…
- Add the variables of the treatment group (sample size, mean, and SD) into the ‘Treatment Group’ box
- Add the variables of the control group (sample size, mean, and SD) into the ‘Control Group’ box
- Add the identifying variable (Authors’ names) into the ‘Study ID’ box
- Select the effect size type (Cohen’s d, Hedges’ g, Glass’ delta, Unstandardized Mean Difference) in the ‘Effect Size’ box
- Select the model type (fixed-effect or random-effects) under the ‘Model’ box
- Click ‘OK’
Similar steps can be followed for binary data sets. Users need to add success and failure variables into the treatment group and control group boxes. The effect size type would be one of the following: Logg Odds Ratio, Peto’s Logg Odds Ratio, Logg Risk Ratio, and Risk Difference.
To be able to calculate the mean effect size with pre-calculated effect sizes:
- Select Analyze > Meta Analysis > Binary Outcomes > Pre-Calculated Effect Size
- Select the effect size type (Logg Odds Ratio, Peto’s Logg Odds Ratio, Logg Risk Ratio, and Risk Difference) in the ‘Effect Size’ box
- Add the effect size variable (e.g., Logg Odds Ratio) into the ‘Effect Size’ box
- Add the variance variable into the ‘Variance’ box
- Alternatively, add the standard error variable into the ‘Standard Error’ box
- Add the identifying variable (Authors’ names) into the ‘Study ID’ box
- Select the model type (fixed-effect or random-effects) under the ‘Model’ box
- Click ‘OK’
When these steps are applied, the mean effect size and other statistics will be shown in three tables (Meta-Analysis Summary, Case Processing Summary, and Effect Size Estimates) as a part of the output. The table labeled as ‘Effect Size Estimates’ shows the mean effect size, its standard error, Z-value, two-tailed p-value, and 95% confidence interval.
- Step 5: Check heterogeneity
One of the important analyses requires an assessment of heterogeneity. This can be checked with several statistics, including Q-statistics, Tau-squared, H-squared, and I-squared in SPSS28. To be able to obtain heterogeneity statistics:
- Select Analyze > Meta Analysis > Continuous Outcomes > Raw Data…
- Click on the ‘Print’ dialog
- Check the dialog boxes labeled as ‘Test of homogeneity’ and ‘Heterogeneity measures’
- Click ‘Continue’ to go back to the main screen
- Click ‘OK’
When these steps are applied, the heterogeneity statistics in two tables (Test of Residual Homogeneity and Residual Heterogeneity) will be shown in the output.
- Step 6: Create plots
Another way of checking the heterogeneity is to create some plots. For example, a forest plot can be examined to do a visual assessment of heterogeneity. To be able to create a forest plot:
- Select one of the input screens under the Meta Analysis menu
- For example, Select Analyze > Meta Analysis > Continuous Outcomes > Raw Data
- Click on the ‘Plot’ dialog
- Select ‘Forest Plot’
- Check the dialog box under the ‘Display Columns’
- Decide ‘Position of plot column’, ‘Annotations’, and ‘Reference lines’
- Click ‘Continue’ to go back to the main screen
- Click ‘OK’
When these steps are applied, the forest plot will be shown in the output. Other plots, including cumulative forest plot, bubble plot, funnel plot, and Galbraith plot, can be obtained using the ‘Plot’ dialog under the Meta Analysis menu.
- Step 7: Assess publication bias
A meta-analyst should ensure that publication bias is not an issue for the studies included in the meta-analysis. This can be examined using several statistics in SPSS28, including funnel plot, Egger’s regression test, and trim-and-fill methods. The funnel plot can be obtained using the ‘Plot’ dialog described in the previous step. To be able to perform Egger’s regression test:
- Select one of the input screens under the Meta Analysis menu
- For example, Select Analyze > Meta Analysis > Continuous Outcomes > Raw Data
- Click on the ‘Bias’ dialog
- Select ‘Egger’s regression-based test’
- Check the dialog boxes under the ‘Include intercept in regression’ and ‘Estimates statistics based on t-distribution’
- Click ‘Continue’ to go back to the main screen
- Click ‘OK’
When these steps are applied, the results of the Egger’s regression test will be shown in the output. To be able to perform trim-and-fill method:
- Select one of the input screens under the Meta Analysis menu
- For example, Select Analyze > Meta Analysis > Continuous Outcomes > Raw Data
- Click on the ‘Trim-and-Fill’ dialog
- Select ‘Estimate number of missing studies’
- Check the dialog boxes under the ‘Side to Impute Studies’ as left or right. Another option is to click on ‘Determined by the slopes of Egger’s test’
- Other options can be determined by clicking the boxes under ‘Method’, ‘Iteration Process’
- Click ‘Continue’ to go back to the main screen
- Click ‘OK’
When these steps are applied, the results of the trim-and-fill method will be shown in the output.
- Step 8: Perform subgroup analyses
A meta-analyst should examine the possible source of heterogeneity in the case of lack of homogeneity among the individual studies. To do this, subgroup analyses can be applied using the categorical moderators (e.g., publication type) collected from individual studies. To be able to perform subgroup analysis:
- Select one of the input screens under the Meta Analysis menu
- For example, Select Analyze > Meta Analysis > Continuous Outcomes > Raw Data
- Click on the ‘Analysis’ dialog
- Add the variables of interest (categorical moderator) from the ‘Variables’ box into the ‘Subgroup Analysis’ box
- Click ‘Continue’ to go back to the main screen
- Click ‘OK’
When these steps are applied, the results of the subgroups of the categorical variable will be shown in the output. For each category, the table labeled as ‘Effect Size Estimates for Subgroup Analysis’ will show the mean effect size, its standard error, Z-value, two-tailed p-value, and 95% confidence interval and prediction interval. Overall results will be reported in the last row of the table.
- Step 9: Perform meta-regression analyses
Another way of examining the possible source of heterogeneity is to conduct a meta-regression analysis using continuous (e.g., mean age of the sample) and categorical moderators (e.g., publication type) collected from individual studies. However, subgroup analysis can be done with only categorical variables. With meta-regression analysis, researchers can analyze both continuous and categorical moderators. This method also allows us to include more than one moderator in the regression model. To be able to perform meta-regression analysis:
- Select Analyze > Meta Analysis > Meta Regression
- Add the effect size variable (e.g., Cohen’s d) from the ‘Variables’ box into the ‘Effect size’ box
- Add the effect size variance from the ‘Variables’ box into the ‘Variance’ box. Alternatively, one can use the standard error or weight of the effect size
- Add the variables of interest (continuous moderator) from the ‘Variables’ box into the ‘Covariate(s)’ box
- Add the variables of interest (categorical moderator) from the ‘Variables’ box into the ‘Factor(s)’ box
- Click ‘Continue’ to go back to the main screen
- Click ‘OK’
When these steps are applied, the results of the meta-regression analysis will be shown in the tables (Model Summary, Case Processing Summary, Model Coefficient Test, and Parameter Estimates) as a part of the output. The table labeled as ‘Parameter Estimates’ shows the regression coefficient, its standard error, t-value, two-tailed p-value, and 95% confidence interval. As mentioned above, the Meta Regression submenu has several dialogs, including Criteria, Inference, Print, Save, and Plot. These dialogs can be used to obtain additional information such as bubble plots, diagnostic statistics, etc.
2. Empirical Examples
2.1. Example 1 (Standardized Mean Difference)
In this section, we will present an example of applying a standardized mean difference-based meta-analysis containing two group comparisons. For this purpose, we used the sample data retrieved from Çırak Kurt, Yıldırım, and Cücük’s [49] study (see Table 2). The sample data set includes student achievement comparisons in blended learning and face-to-face learning environments. Additionally, the data set includes only 14 studies and post-test scores of students. Çırak Kurt et al. [49] collected sample size, mean, and standard deviation values for experimental (blended learning) and control (face-to-face learning) groups.
With the values presented in Table 2, the Cohen’s d value (standardized mean difference) can be calculated for each study as follows:
Cohen’s d value is calculated by dividing the difference between means by the pooled standard deviation (SDpooled) that can be calculated as below:
where and are sample sizes of control and treatment groups and and are variances. For Cohen’s d, the standard error can be calculated as below:
Another standardized mean difference index is named Hedges’ g, which applies a correction for bias due to small sample sizes as follows:
Although Glass’ delta is a less preferred effect size, it is used in some studies. Glass’ delta assumes that the standard deviations are different between groups. Additionally, Glass’ delta only uses the standard deviation of the control group [50]. Glass’ delta and its variance can be calculated as follows:
The sample analyses here were conducted with Hedges’ g value. However, similar analyses can be applied with Cohen’s d and Glass’ delta. To obtain a mean Hedges’ g value, there are two data entry options in SPSS: raw data or pre-calculated effect sizes. If one calculates effect size values from online platforms (e.g., https://www.campbellcollaboration.org/research-resources/effect-size-calculator.html) (accessed on 30 July 2022), the following steps can be used:
- Select Analyze > Meta Analysis > Continuous Outcomes > Pre-Calculated Effect Size
An easier way to do this is to conduct the analysis using raw data when you have the data ready as entered in Excel. For this option, the following steps can be used (see Figure 3):
- Select File > Open > Data
- Select “Files of Type” as “Excel”
- Find the data > Open
- Select Analyze > Meta Analysis > Continuous Outcomes > Raw Data (see Figure 4)
Figure 4.
Meta-analysis with Raw Data.

- Add the variables of the treatment group (sample size, mean, and SD) into the ‘Treatment Group’ box
- Add the variables of the control group (sample size, mean, and SD) into the ‘Control Group’ box
- Add the identifying variable (Authors’ names [Study]) into the ‘Study ID’ box
- Select the effect size type as ‘Hedges’ g’ in the ‘Effect Size’ box
- Select the model type ‘Random-effects’ under the ‘Model’ box
- Open ‘Print’ Dialogue > Select the ‘Test of homogeneity’ and ‘Heterogeneity Measures’ > Click ‘Continue’ (see Figure 5)
- Open ‘Plot’ Dialogue > Select ‘Forest Plot’ box and all the ‘Display Columns’ boxes > Click ‘Continue’
- Click ‘OK’ (see Figure 6)
When these steps are applied, the outputs will be presented in the new window as in Figure 7.
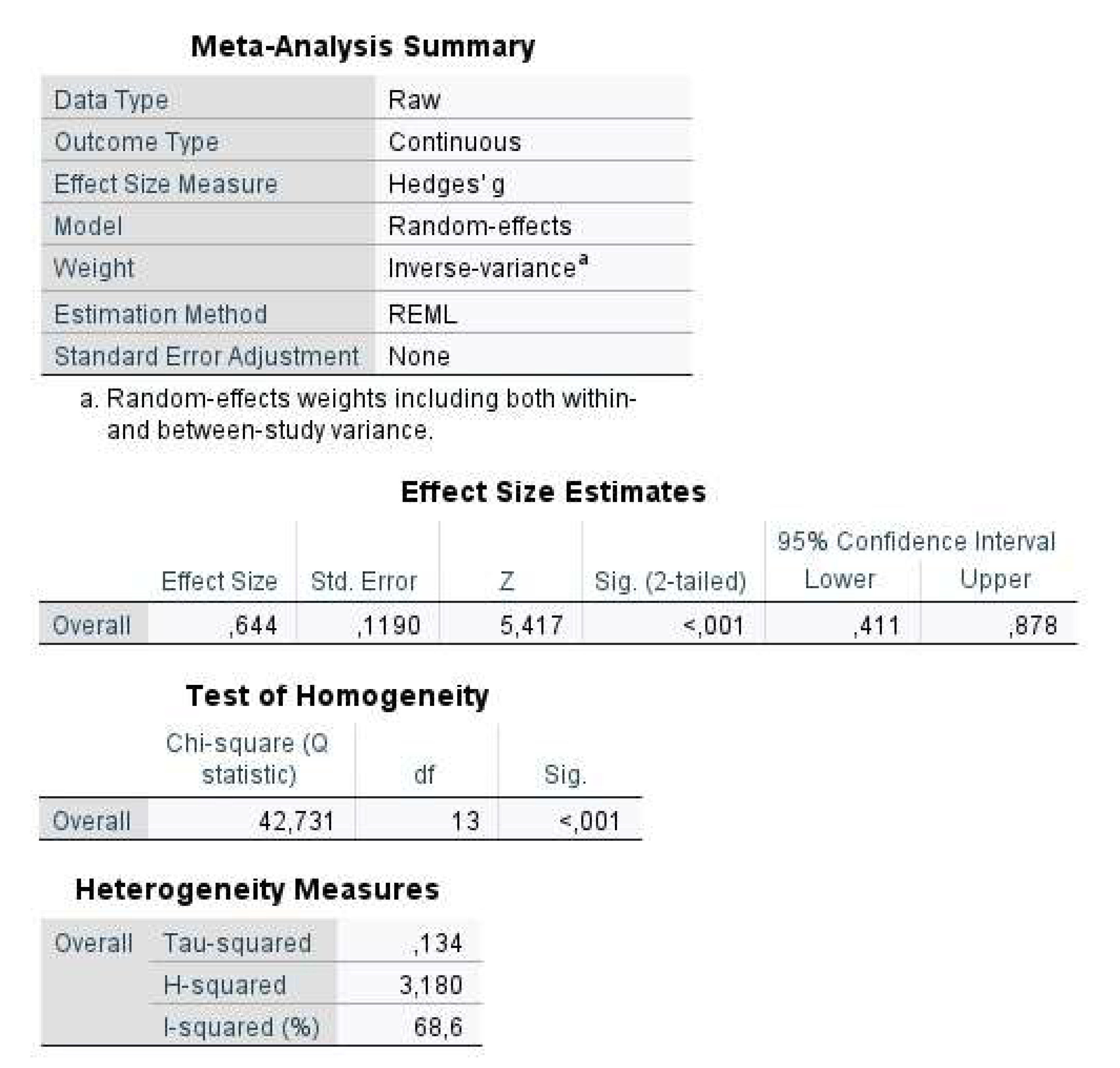
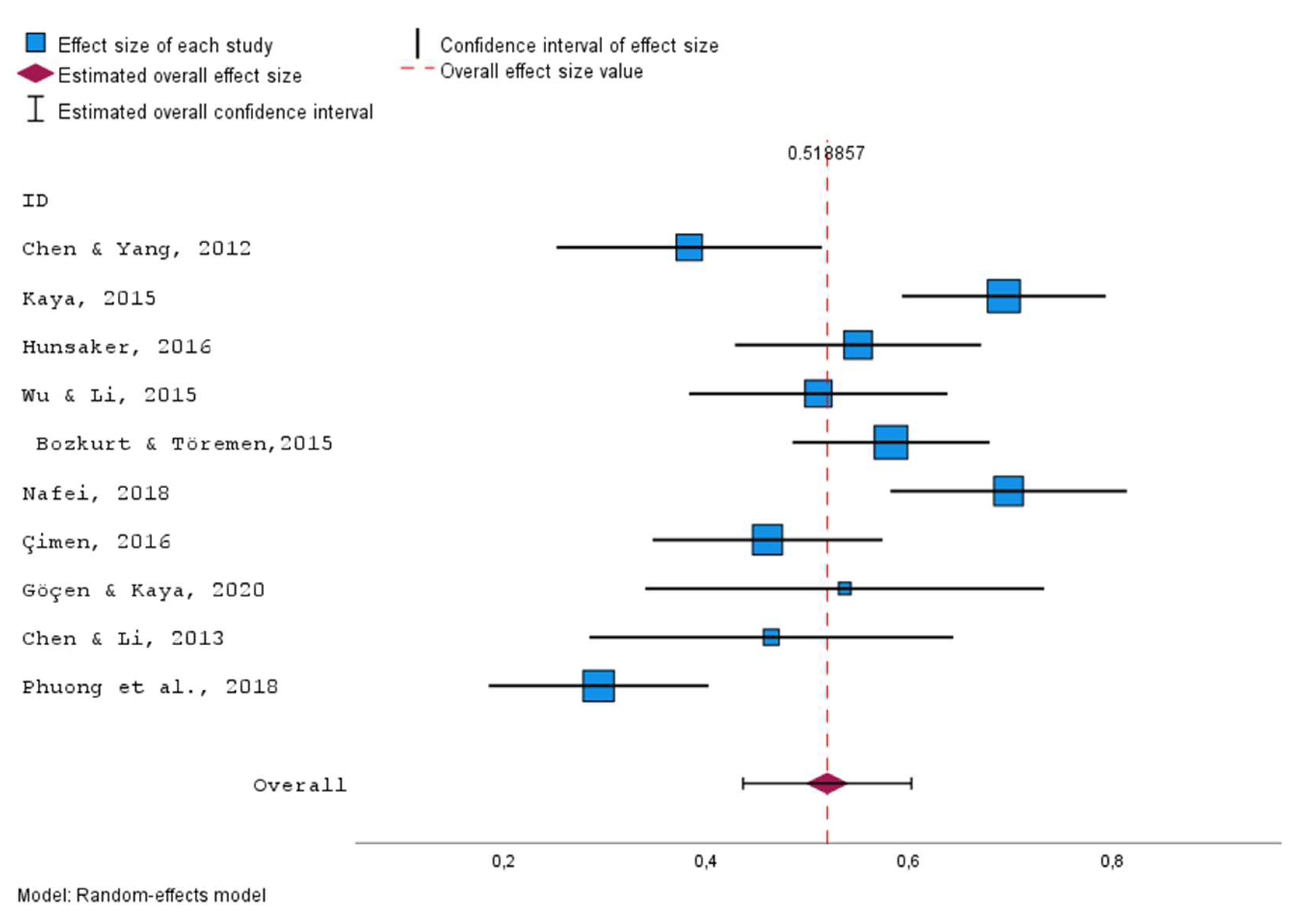
Figure 7 shows that the mean effect size estimate was 0.644 (95% CI:.411,.878) and statistically significant (p < 0.001). The estimated Hedges’ g value (0.644) corresponds to a medium-level positive effect according to Cohen [51]. For heterogeneity, Q-statistics, Tau-squared, H-squared, and I-squared values should be examined. The Q-statistics (Q = 42.731, df = 13, p < 0.001) was found to be statistically significant. In addition, Tau-squared, H-squared, and I-squared values were found to be 0.134, 3.18, and 68.6, respectively. As a result, there is a statistically significant heterogeneity between studies. Another way of checking the heterogeneity is to create a forest plot (see Figure 8). As shown in Figure 8, individual studies appeared to be distributed heterogeneously. In this case, researchers may want to conduct the moderator analysis that will be shown in Example 3.
2.2. Example 2 (Odds Ratio)
In the previous example, it was explained how to conduct the meta-analysis with continuous variables. In this section, how to conduct a meta-analysis using an odds ratio or risk ratio is demonstrated. There are treatment and control groups (as in the previous one) in meta-analyses based on odds ratio or risk ratio, but the data is binary. In this type of meta-analysis, studies that report numbers showing whether an event has occurred or not within two groups are included. For this purpose, we used the sample data retrieved from Cummings and Del Beccaro’s [52] study. This data set is presented in Table 3.
The sample data set contains the infected and total numbers of treatment and control group subjects. In seven studies included in the meta-analysis, it was examined whether a simple wound could cause infection with or without antibiotics. Using the data of Roberts and Teddy [53], the odds ratio and log (odds ratio) calculation can be conducted based on the values presented in Table 4.
Using the information presented in Table 4, the odds ratio and its logarithm (log odds ratio) are calculated as follows:
The variance of the odds ratio index is calculated as follows:
The odds ratio was calculated as 0.706, indicating that the infection rate among those who use antibiotics is lower than those who do not use antibiotics. The critical odds ratio value is 1.00. Since the odds ratio value is less than 1, the interpretation was made like this.
The risk ratio, log (risk ratio) values, and its variance can be calculated as below.
In addition, meta-analysis can also be conducted with the risk ratio value, but, in this example, we will use the odds ratio. Like in the previous example, there are two options in SPSS: raw data or pre-calculated effect sizes. In the case of pre-calculated effect size values, one can follow these steps:
- Select Analyze > Meta Analysis > Binary Outcomes > Pre-Calculated Effect Size
- An easier way to do this is to conduct the analysis using raw data when you have the data ready as entered in Excel. For this option, the following steps can be used.
- Select File > Open > Data
- Find the data > Open
- Select Analyze > Meta Analysis > Binary Outcomes > Raw Data
- Add the variables of the experimental group (success and failure) into the ‘Treatment Group’ box
- Add the variables of the control group (success and failure) into the ‘Control Group’ box
- Add the identifying variable (Authors’ names [Study]) into the ‘Study ID’ box
- Select the effect size type as ‘Log Odds Ratio’ in the ‘Effect Size’ box
- Select the model type ‘Random-effects’ under the ‘Model’ box
- Open ‘Print’ Dialogue > Select the ‘Test of homogeneity’ and ‘Heterogeneity Measures’ > Click ‘Continue’ (see Figure 9)
- Open ‘Plot’ Dialogue > Select ‘Forest Plot’ box and all ‘Display Columns’ boxes > Select ‘Overall effect size’ box > Click ‘Continue’
- Click ‘OK’ (see Figure 10)
When these steps are applied, the outputs will be presented in the new window as in Figure 11.
As seen in Figure 11, the mean effect size estimate was found to be −0.127 (95% CI: −0.534, 0.281) and statistically non-significant (p = 0.542). Additionally, for heterogeneity, Q-statistics, Tau-squared, H-squared, and I-squared values should be examined. The Q-statistics (Q = 4.923, df = 6, p = 0.554) value was found to be statistically non-significant. In addition, Tau-squared, H-squared, and I-squared values were estimated to be 0.004, 1.012, and 1.2, respectively. The forest plot is presented in Figure 12.
2.3. Example 3 (Correlation)
In this example, we will show you how to conduct a meta-analysis based on correlational data. Correlational meta-analyses are used to find the overall correlation estimate between two continuous variables. For example, researchers may want to examine the relationship between schizotypy and creativity as in Acar and Sen [54]. In this case, a meta-analyst should collect Pearson correlation and sample size values. However, Pearson correlation (r) cannot be used directly in meta-analysis due to its dependency on its own variance (see [4]). Thus, Pearson correlation values should be transformed to Fisher’s z values using the following equation [55]:
where r represents the Pearson correlation value. In addition, the variance of the Fisher’s Z-transformed correlations can be calculated as
where n represents the sample size. The SPSS program does not have an option to calculate Fisher’s Z-transformed correlations and its variance. Thus, the users need to compute these values. A simple-to-use Excel function called FISHER() can be used for this purpose. Another option would be using online calculators (https://www.campbellcollaboration.org/research-resources/effect-size-calculator.html) (accessed on 30 July 2022). The sample data set presented in Table 1 was used for this empirical example. The data set in Table 1 was taken from Göçen and Şen [48] that showed the overall relationship between organizational commitment and spiritual leadership. Only ten studies were drawn from the original study and are presented in Table 1. As you can see, Fisher’s Z-transformed correlations (z) and their variances (vz) are presented in Table 1. There are four moderator variables (i.e., country, region, sector, and female percent) in addition to sample size (n), Pearson correlation (r), and its variance (vr) (see Figure 13). As always, a variable of study ID was presented in the first column. The screenshot of this data set in SPSS is demonstrated in Figure 13.
To perform the necessary analyses, one has to open the data in SPSS and click on the Meta Analysis menu. For this purpose, the following steps should be performed in the SPSS menu:
- Select Analyze > Meta Analysis > Continuous Outcomes > Pre-Calculated Effect Size
- Add the effect size variable (e.g., z) into the ‘Effect Size’ box
- Add the variance variable (e.g., vz) into the ‘Variance’ box
- Add the identifying variable (e.g., authors) into the ‘Study ID’ box
- Select the model type as random-effects under the ‘Model’ box
- Click ‘OK’ (see Figure 14)
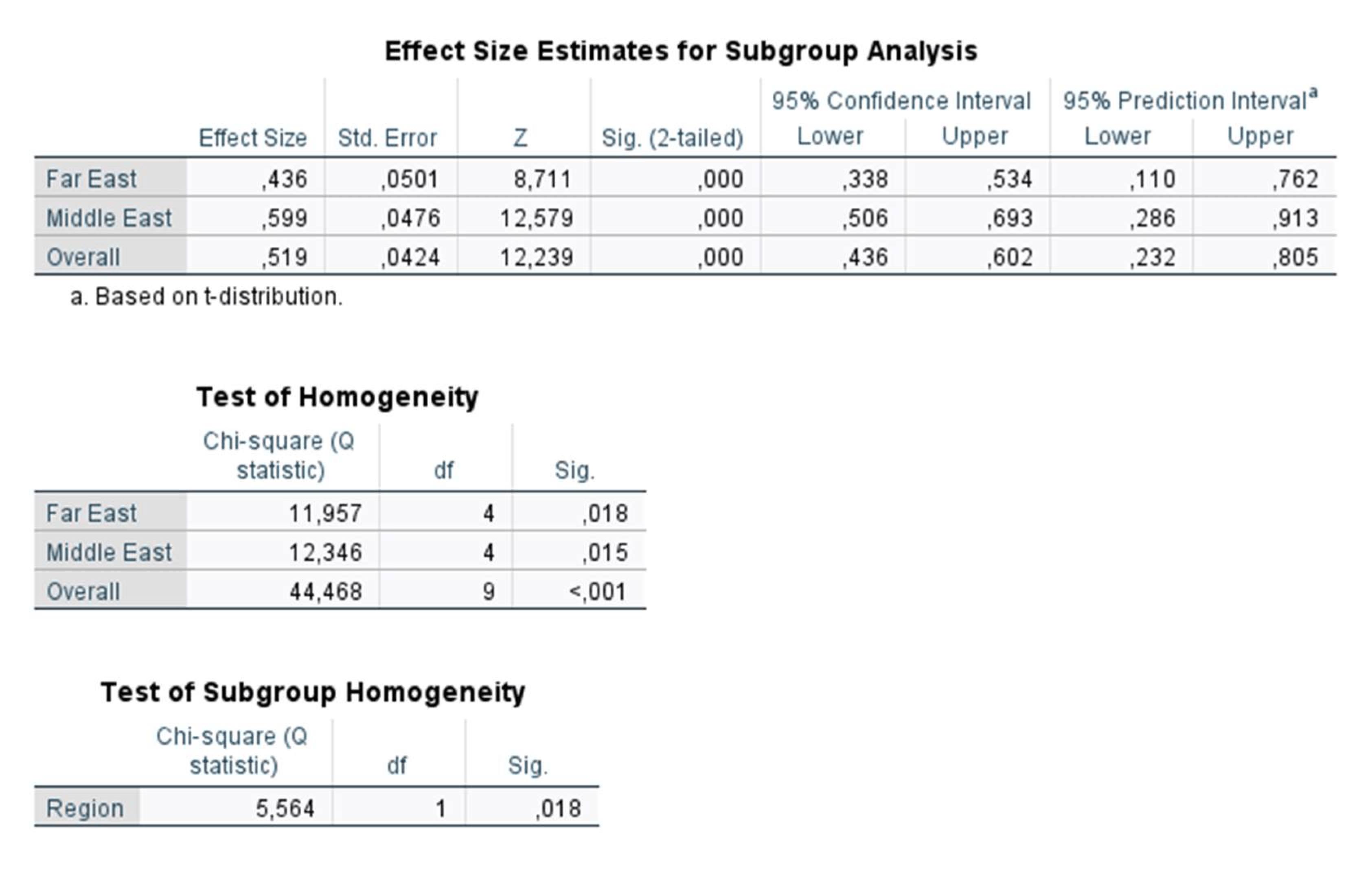
When these steps are applied, the mean effect size estimate can be obtained as 0.519 (95% CI: 0.436, 0.602). This estimate was found to be statistically significant (p < 0.001). In order to interpret this value, one needs to retransform this mean value into Pearson correlation. This can be achieved with the following formula:
Alternatively, an easy-to-use Excel function called FISHERINV() can be used for this purpose. As applied in Excel, FISHERINV(0.519) yields the mean effect size as 0.477 in terms of Pearson correlation. To perform the heterogeneity analyses, one has to click on the ‘Print’ dialog on the main screen shown in Figure 14. The boxes called ‘test of homogeneity’ and ‘heterogeneity statistics’ should be checked. When the necessary analyses were performed in SPSS, the Q-statistics value was found to be 44.468 (df = 9, p < 0.001). In addition, Tau-squared, H-squared, and I-squared values were found to be 0.014, 4.534, and 77.9, respectively. As a result, there is a significant and a large amount of heterogeneity between studies. As stated above, the ‘Plot’ dialog can be used to obtain several plots, including forest plots and funnel plots. The forest plot presented in Figure 15 also shows the heterogeneity between studies.
Publication bias was also assessed using the funnel plot presented in Figure 16. To perform Egger’s test, the ‘Bias’ dialog was used, and the intercept value was estimated as 0.607 (p = 0.014). When the ‘Trim-and-fill’ dialog was selected, the results suggested that no imputation was needed based on the slopes of Egger’s test. Thus, publication bias was not a concern for the example data set.
Given the statistically significant heterogeneity, it would be a good idea to conduct subgroup analysis and moderator analysis. The final part of this example shows the application of moderator analyses with categorical (region) and continuous (female proportion) variables listed in Table 1. To perform the subgroup analysis, one needs to open the ‘Analysis’ dialog when the screen presented in Figure 14 is open. Under the ‘Analysis’ dialog, you need to add the categorical variable (e.g., region) into the ‘Subgroup Analysis’ box (see Figure 17).
The results of subgroup analysis with region variable are presented in Figure 18. As shown in Figure 18, there is a statistically significant difference between the mean effect size values of studies conducted in the Far East and the Middle East (Q(1) = 5.564, p = 0.018). The average effect size for studies that were conducted in the Middle East (.599) was significantly higher than the average effect size for studies that were conducted in the Far East (0.436). Additionally, the variance within the Far East studies indicated statistically significant heterogeneity (QW = 11.957, df = 4, p = 0.018), similar to the variance within Middle East studies (QW = 12.346, df = 4, p = 0.015).
To perform the meta-regression analysis with both categorical and continuous variables, the following steps should be performed in the SPSS menu:
- Select Analyze > Meta Analysis > Meta Regression
- Add the effect size variable (e.g., z) into the ‘Effect Size’ box
- Add the variance variable (e.g., vz) into the ‘Variance’ box
- Add the continuous variable (e.g., FemalePercent) into the ‘Covariate(s)’ box
- Add the categorical variable (e.g., Region) into the ‘Factor(s)’ box
- Select the model type as random-effects under the ‘Model’ box
- Click ‘OK’ (see Figure 19)
The results of the meta-regression analysis with female percentage are presented in Figure 20. Meta-regression analyses were performed with a random-effects model using unrestricted maximum likelihood estimation. As shown in Figure 20, results of meta-regression analysis suggested that none of these variables (region and female percentage) were statistically significant predictors of the relationship between organizational commitment and spiritual leadership (p > 0.05).
3. Conclusions
The present article is meant to provide a general overview of the capabilities of the IBM SPSS software package for conducting meta-analysis. Therefore, this tutorial article introduced readers to the key features of IBM SPSS Statistics. The steps of meta-analysis using IBM SPSS were described and demonstrated over three examples. In summary, this tutorial covered the following technical considerations necessary for the meta-analysis application in IBM SPSS: creating data sets includes measures of effect sizes and their variances as well as study identifiers, choosing appropriate options, estimating the mean effect sizes (Hedges’ g, odds ratio, and correlation), checking the heterogeneity, creating the plots, assessment of publication bias, and conducting moderator analyses via subgroup analysis and meta-regression model.
As it is known, several software packages are used for meta-analysis. Among these software packages, there are those that are used only for meta-analysis, those that work as a submenu of comprehensive software, macros, and statistical packages, paid or free ones. IBM SPSS is a comprehensive but paid statistical program that offers a 30-day trial version. While some of the statistical analyses for meta-analysis were possible with SPSS Macros until the latest version (see [47]), a meta-analysis submenu was added into SPSS28. It would be useful to compare IBM SPSS with other meta-analysis software packages to better understand its features. A comparison of the capabilities of the IBM SPSS, CMA, and metafor packages for conducting meta-analyses is presented in Table 5 as in [56]. As shown in Table 5, IBM SPSS can be considered in between the CMA and R metafor package in terms of the meta-analysis capabilities. There are several options for meta-analysis applications. In addition to other properties not listed in Table 5, IBM SPSS has most of the features listed in Table 5. For example, IBM SPSS Statistics has options for Glass’ delta, which is not available in most of the other packages. Another positive aspect is that it allows analysis by entering both raw data and pre-calculated effect size. However, its current version does not have options for likelihood ratio tests and permutation tests as in the metafor package. Another limitation of IBM SPSS is that it does not allow simultaneous analysis of different data formats as in CMA software. Perhaps one of the most important shortcomings in SPSS28 is the ability to calculate the effect size for only one measurement (e.g., posttest) of the two groups in the standardized mean difference. In this case, it is necessary to calculate the effect size with online calculation tools and enter pre-calculated effect sizes into the SPSS28. Despite these limitations, it is clear that IBM SPSS will be among the main programs to be preferred by meta-analysis practitioners for future research in psychology and other areas. This is mainly because it is relatively straightforward and user-friendly, so this tutorial is intended to be a basic guide for first-time users who wish to familiarize themselves with the meta-analysis capabilities of IBM SPSS.
We hope that this presentation, along with the screenshots and available data presented in tables, helps psychological researchers to learn and appropriately apply meta-analyses in IBM SPSS. We also hope this tutorial article fosters increased awareness, knowledge, and skills in relation to meta-analysis and sparks further enthusiasm for adding meta-analysis to the methodological toolbox in psychology and other areas.
Supplementary Materials
The following supporting information can be downloaded at: https://0-www-mdpi-com.brum.beds.ac.uk/article/10.3390/psych4040049/s1.
Author Contributions
S.S.: Conceptualization, Methodology, Writing, and Formal Analysis. I.Y.: Methodology, Formal Analysis, Writing—Review and Editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Eysenck, H.J. The Effects of Psychotherapy: An Evaluation. J. Consult. Psychol. 1952, 16, 319–324. [Google Scholar] [CrossRef] [PubMed]
- Smith, M.L.; Glass, G.V. Meta-Analysis of Psychotherapy Outcome Studies. Am. Psychol. 1977, 32, 752–760. [Google Scholar] [CrossRef] [PubMed]
- Eysenck, H.J. An Exercise in Mega-Silliness. Am. Psychol. 1978, 33, 517. [Google Scholar] [CrossRef]
- Lipsey, M.W.; Wilson, D.B. Practical Meta-Analysis; Applied social research methods series; Sage Publications: Thousand Oaks, CA, USA, 2001; ISBN 978-0-7619-2167-7. [Google Scholar]
- Pearson, K. Report on Certain Enteric Fever Inoculation Statistics. BMJ 1904, 3, 1243–1246. [Google Scholar]
- Rosenthal, R. Combining Results of Independent Studies. Psychol. Bull. 1978, 85, 185–193. [Google Scholar] [CrossRef]
- Glass, G.V.; McGaw, B.; Smith, M.L. Meta-Analysis in Social Research; Sage Publications: Beverly Hills, CA, USA, 1981; ISBN 978-0-8039-1633-3. [Google Scholar]
- Hedges, L.V. Fitting Categorical Models to Effect Sizes from a Series of Experiments. J. Educ. Stat. 1982, 7, 119. [Google Scholar] [CrossRef]
- Hedges, L.V. A Random Effects Model for Effect Sizes. Psychol. Bull. 1983, 93, 388–395. [Google Scholar] [CrossRef]
- Hunter, J.E.; Schmidt, F.L.; Jackson, G.B. Meta-Analysis: Cumulating Research Findings across Studies; Studying organizations: Innovations in methodology; Sage: Beverly Hills, CA, USA, 1982; ISBN 978-0-8039-1864-1. [Google Scholar]
- Light, R.J.; Pillemer, D.B. Summing Up: The Science of Reviewing Research; Harvard University Press: Cambridge, MA, USA, 1984; ISBN 978-0-674-85430-7. [Google Scholar]
- Pigott, T.D. Advances in Meta-Analysis; Statistics for social and behavioral sciences; Springer: New York, NY, USA, 2012; ISBN 978-1-4614-2277-8. [Google Scholar]
- Glass, G.V. Primary, Secondary, and Meta-Analysis of Research. Educ. Res. 1976, 5, 3–8. [Google Scholar] [CrossRef]
- Glass, G.V. Integrating Findings: The Meta-Analysis of Research. Rev. Res. Educ. 1977, 5, 351. [Google Scholar] [CrossRef]
- Hunter, J.E.; Schmidt, F.L. Methods of Meta-Analysis: Correcting Error and Bias in Research Findings; Sage: Thousand Oaks, CA, USA, 2004; ISBN 978-1-4416-5498-4. [Google Scholar]
- Schmidt, F.L.; Hunter, J.E. Development of a General Solution to the Problem of Validity Generalization. J. Appl. Psychol. 1977, 62, 529–540. [Google Scholar] [CrossRef]
- Hedges, L.V.; Olkin, I. Statistical Methods for Meta-Analysis; Academic Press: Orlando, FL, USA, 1985; ISBN 978-0-12-336380-0. [Google Scholar]
- Petitti, D.B. Meta-Analysis, Decision Analysis, and Cost-Effectiveness Analysis: Methods for Quantitative Synthesis in Medicine, 2nd ed.; Monographs in Epidemiology and Biostatistics; Oxford University Press: New York, NY, USA, 2000; ISBN 978-0-19-513364-6. [Google Scholar]
- Begg, C.B.; Berlin, J.A. Publication Bias: A Problem in Interpreting Medical Data. J. R. Stat. Society. Ser. A (Stat. Soc.) 1988, 151, 419. [Google Scholar] [CrossRef]
- Rosenthal, R. The File Drawer Problem and Tolerance for Null Results. Psychol. Bull. 1979, 86, 638–641. [Google Scholar] [CrossRef]
- Lipsey, M.W.; Wilson, D.B. The Efficacy of Psychological, Educational, and Behavioral Treatment: Confirmation from Meta-Analysis. Am. Psychol. 1993, 48, 1181–1209. [Google Scholar] [CrossRef] [PubMed]
- Conn, V.S.; Valentine, J.C.; Cooper, H.M.; Rantz, M.J. Grey Literature in Meta-Analyses. Nurs. Res. 2003, 52, 256–261. [Google Scholar] [CrossRef]
- Rosenthal, R. Meta-Analytic Procedures for Social Research; Applied Social Research Methods Series; Sage Publications: Beverly Hills, CA, USA, 1984; ISBN 978-0-8039-2033-0. [Google Scholar]
- Begg, C.B.; Mazumdar, M. Operating Characteristics of a Rank Correlation Test for Publication Bias. Biometrics 1994, 50, 1088. [Google Scholar] [CrossRef]
- Rosenberg, M.S.; Adams, D.C.; Gurevitch, J. MetaWin: Statistical Software for Meta-Analysis with Resampling Tests; Sinauer Assoc: Sunderland, MA, USA, 1997; ISBN 978-0-87893-773-8. [Google Scholar]
- Borenstein, M.; Hedges, L.V.; Higgins, J.P.T.; Rothstein, H.R. Comprehensive Meta-Analysis; Biostat: Englewood, NJ, USA, 2005. [Google Scholar]
- Johnson, B.T.; Wood, T.D. DSTAT 2.00: Software for Meta-Analysis; Lawrence Erlbaum Assoc Inc.: Storrs, CT, USA, 2006. [Google Scholar]
- Mullen, B. Advanced BASIC Meta-Analysis; L. Erlbaum Associates: Hillsdale, NJ, USA, 1989; ISBN 978-0-8058-0502-4. [Google Scholar]
- Martorell-Marugan, J.; Toro-Dominguez, D.; Alarcon-Riquelme, M.E.; Carmona-Saez, P. MetaGenyo: A Web Tool for Meta-Analysis of Genetic Association Studies. BMC Bioinform. 2017, 18, 563. [Google Scholar] [CrossRef]
- Rudner, L. Meta-Stat: Software to Aid in the Meta-Analysis of Research Findings; ERIC Clearinghouse on Assessment. ERIC Clearinghouse on Assessment and Evaluation Department of Measurement, Statistics and Evaluation, University of Maryland: College Park, MD, USA, 2002. [Google Scholar]
- Schwarzer, R. Manual for Meta-Analysis Programs. 1996. Available online: userpage.fu-berlin.de/~health/manual.pdf (accessed on 30 July 2022).
- Kenny, D.A. Meta-Analysis: Easy to Answer. 1999. Available online: http://davidakenny.net/meta.htm (accessed on 30 July 2022).
- Wallace, B.C.; Schmid, C.H.; Lau, J.; Trikalinos, T.A. Meta-Analyst: Software for Meta-Analysis of Binary, Continuous and Diagnostic Data. BMC Med. Res. Methodol. 2009, 9, 80. [Google Scholar] [CrossRef]
- Bax, L.; Yu, L.-M.; Ikeda, N.; Moons, K.G. A Systematic Comparison of Software Dedicated to Meta-Analysis of Causal Studies. BMC Med. Res. Methodol. 2007, 7, 40. [Google Scholar] [CrossRef]
- Barendregt, J.J.; Suhail, A.D. MetaXL User Guide Version 5.3. 2016. Available online: https://www.epigear.com/index_files/metaxl.html (accessed on 30 July 2022).
- Kontopantelis, E.; Reeves, D. MetaEasy: A Meta-Analysis Add-In for Microsoft Excel. J. Stat. Softw. 2009, 30, 1–25. [Google Scholar] [CrossRef]
- Palmer, T.M.; Sterne, J.A.C. (Eds.) Meta-Analysis in Stata: An Updated Collection from the Stata Journal, 2nd ed.; StataCorp LP: College Station, TX, USA, 2016; ISBN 978-1-59718-147-1. [Google Scholar]
- Van Houwelingen, H.C.; Arends, L.R.; Stijnen, T. Advanced Methods in Meta-Analysis: Multivariate Approach and Meta-Regression. Stat. Med. 2002, 21, 589–624. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing. 2022. Available online: https://cran.r-project.org/web/packages/meta/meta.pdf (accessed on 30 July 2022).
- Schwarzer, G. Package ‘Meta’; The R Foundation for Statistical Computing. 2022. Available online: https://cran.r-project.org/web/packages/meta/meta.pdf (accessed on 30 July 2022).
- Viechtbauer, W. Metafor: Meta-Analysis Package for R. 2015. Available online: https://cran.r-project.org/web/packages/meta/meta.pdf (accessed on 30 July 2022).
- Lumley, T. Rmeta: Meta-Analysis. 2009. Available online: https://cran.r-project.org/web/packages/meta/meta.pdf (accessed on 30 July 2022).
- Fisher, Z.; Tipton, E. Robumeta: An R-Package for Robust Variance Estimation in Meta-Analysis. arXiv 2015, arXiv:1503.02220. [Google Scholar]
- Cheung, M.W.-L. MetaSEM: An R Package for Meta-Analysis Using Structural Equation Modeling. Front. Psychol. 2015, 5, 1521. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Polanin, J.R.; Hennessy, E.A.; Tanner-Smith, E.E. A Review of Meta-Analysis Packages in R. J. Educ. Behav. Stat. 2017, 42, 206–242. [Google Scholar] [CrossRef]
- Field, A.P.; Gillett, R. How to Do a Meta-Analysis. Br. J. Math. Stat. Psychol. 2010, 63, 665–694. [Google Scholar] [CrossRef] [PubMed]
- Şen, S. How to Do Meta-Analysis with SPSS? HEJ 2019, 4, 21–49. [Google Scholar] [CrossRef]
- Göçen, A.; Şen, S. Spiritual Leadership and Organizational Citizenship Behavior: A Meta-Analysis. SAGE Open 2021, 11, 215824402110407. [Google Scholar] [CrossRef]
- Çirak Kurt, S.; Yildirim, İ.; Cücük, E. Harmanlanmış Öğrenmenin Akademik Başarı Üzerine Etkisi: Bir Meta-Analiz Çalışması. HUJE 2017, 33, 776–802. [Google Scholar] [CrossRef]
- Marfo, P.; Okyere, G.A. The Accuracy of Effect-Size Estimates under Normals and Contaminated Normals in Meta-Analysis. Heliyon 2019, 5, e01838. [Google Scholar] [CrossRef]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; L. Erlbaum Associates: Hillsdale, NJ, USA, 1988; ISBN 978-0-8058-0283-2. [Google Scholar]
- Cummings, P.; Del Beccaro, M.A. Antibiotics to Prevent Infection of Simple Wounds: A Meta-Analysis of Randomized Studies. Am. J. Emerg. Med. 1995, 13, 396–400. [Google Scholar] [CrossRef]
- Roberts, A.H.N.; Teddy, P.J. A Prospective Trial of Prophylactic Antibiotics in Hand Lacerations. Br. J. Surg. 2005, 64, 394–396. [Google Scholar] [CrossRef]
- Acar, S.; Sen, S. A Multilevel Meta-Analysis of the Relationship between Creativity and Schizotypy. Psychol. Aesthet. Creat. Arts 2013, 7, 214–228. [Google Scholar] [CrossRef]
- Borenstein, M.; Hedges, L.V.; Higgins, J.P.T.; Rothstein, H. Introduction to Meta-Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2011; ISBN 978-1-119-55837-8. [Google Scholar]
- Viechtbauer, W. Conducting Meta-Analyses in R with the Metafor Package. J. Stat. Softw. 2010, 36, 1–48. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Screenshot of the Continuous Outcomes Submenu.

Figure 2.
SPSS Meta Analysis Menu.

Figure 3.
Open Data Menu.

Figure 5.
Data Identification Menu.

Figure 6.
Forrest Plot Menu.

Figure 7.
Outputs.

Figure 8.
Forest Plot.

Figure 9.
Data identification menu.

Figure 10.
Forest Plot Menu.

Figure 11.
Output for Binary Data.

Figure 12.
Forest Plot for Binary Data.

Figure 13.
Dataset.

Figure 14.
Data Identification Menu.

Figure 15.
Forest Plot for Correlation Data.

Figure 16.
Funnel Plot for Correlation Data.

Figure 17.
Subgroup Analysis Screen.

Figure 18.
Results of Subgroup Analysis with Region Variable.

Figure 19.
Data Identification Menu for Meta Regression.

Figure 20.
Results of Meta-regression Analysis with Female Percentage.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Sample Dataset for Correlation and Moderator Analyses [48].
Table 1.
Sample Dataset for Correlation and Moderator Analyses [48].
| Study | n | r | vr | Country | Region | Business | Female % | z | vz |
|---|---|---|---|---|---|---|---|---|---|
| Chen & Yang, 2012 | 227 | 0.365 | 0.003 | Taiwan | FE | Others | 49.4 | 0.383 | 0.004 |
| Kaya, 2015 | 383 | 0.600 | 0.001 | Turkey | ME | Education | 50.5 | 0.693 | 0.003 |
| Hunsaker, 2016 | 263 | 0.500 | 0.002 | South Korea | FE | Others | 33 | 0.549 | 0.004 |
| Wu & Li, 2015 | 239 | 0.470 | 0.003 | Taiwan | FE | Others | 38.6 | 0.510 | 0.004 |
| Bozkurt & Töremen, 2015 | 409 | 0.524 | 0.001 | Turkey | ME | Education | 52.81 | 0.582 | 0.002 |
| Nafei, 2018 | 285 | 0.603 | 0.001 | Egypt | ME | Others | 60 | 0.698 | 0.004 |
| Çimen, 2016 | 301 | 0.430 | 0.002 | Turkey | ME | Education | 56.48 | 0.460 | 0.003 |
| Göçen & Kaya, 2020 | 102 | 0.490 | 0.006 | Turkey | ME | Education | 22.56 | 0.536 | 0.010 |
| Chen & Li, 2013 | 122 | 0.433 | 0.006 | China | FE | Others | 0.8 | 0.464 | 0.008 |
| Phuong et al., 2018 | 329 | 0.285 | 0.003 | Vietnam | FE | Others | 45 | 0.293 | 0.003 |
Note. n = Sample size, r = Pearson correlation, vr = variance of Pearson r, z = Fisher z, vz = variance of Fisher z.
Table 2.
Sample Raw Dataset [49] for Standardized Mean Difference Example.
Table 2.
Sample Raw Dataset [49] for Standardized Mean Difference Example.
| Study | Blended n | Blended Mean | Blended SD | Face-to-Face n | Face-to-Face Mean | Face-to-Face SD |
|---|---|---|---|---|---|---|
| Unsal, 2007 | 24 | 31 | 2.5 | 22 | 31.05 | 2.82 |
| Turkcapar, 2011 | 28 | 18.14 | 3.67 | 28 | 15.89 | 4.67 |
| Aygun, 2011 | 35 | 18.91 | 2.72 | 36 | 15.23 | 4.003 |
| Aksogan, 2011 | 32 | 53.8 | 11.9 | 31 | 50.25 | 16.76 |
| Yapici, 2011 | 47 | 25.11 | 5.04 | 60 | 19.08 | 2.657 |
| Yildiz, 2011 | 36 | 8.41 | 0.996 | 35 | 7.6 | 1.03 |
| Turk, 2012 | 51 | 71.57 | 13.47 | 64 | 58.36 | 14.28 |
| Saritepeci, 2012 | 52 | 12.36 | 4.11 | 55 | 10.25 | 4.1 |
| Demirkol, 2012 | 27 | 78.7 | 13.05 | 27 | 72.22 | 9.12 |
| Akgündüz, 2013a | 25 | 20.44 | 5.874 | 24 | 15.792 | 6.29 |
| Akgündüz, 2013b | 25 | 18.08 | 6.211 | 24 | 15.792 | 6.29 |
| Pesen, 2014a | 38 | 32.23 | 2.87 | 38 | 29.86 | 2.56 |
| Pesen, 2014b | 41 | 28.17 | 3.77 | 41 | 28.43 | 3.16 |
| Kahyaoglu, 2014 | 25 | 31.44 | 3.78 | 25 | 26 | 8.14 |
Table 3.
Sample data set for binary meta-analysis [52].
Table 3.
Sample data set for binary meta-analysis [52].
| Publication | Antibiotic (Infected) | Antibiotic (Uninfected) | Antibiotic (Total) | Control (Infected) | Control (Uninfected) | Control (Total) |
|---|---|---|---|---|---|---|
| Beelsey, 1975 | 1 | 63 | 64 | 1 | 64 | 65 |
| Day, 1975 | 12 | 44 | 56 | 4 | 52 | 56 |
| Roberts, 1977 | 18 | 187 | 205 | 12 | 88 | 100 |
| Hutton, 1978 | 10 | 132 | 142 | 9 | 134 | 143 |
| Worlock, 1980 | 5 | 66 | 71 | 2 | 32 | 34 |
| Grossman, 1981 | 2 | 172 | 174 | 1 | 90 | 91 |
| Thirlby, 1983 | 16 | 211 | 227 | 17 | 255 | 272 |
Table 4.
Sample Data for Calculation Odds Ratio [53].
Table 4.
Sample Data for Calculation Odds Ratio [53].
| Infected | Uninfected | Total | |
|---|---|---|---|
| Treatment group | 18 | 187 | 205 |
| Control group | 12 | 88 | 100 |
| Total | 30 | 275 | 305 |
Table 5.
Comparison of the Capabilities of the IBM SPSS, CMA, and Metafor Packages for Conducting Meta-analyses.
Table 5.
Comparison of the Capabilities of the IBM SPSS, CMA, and Metafor Packages for Conducting Meta-analyses.
| IBM SPSS | CMA | Metafor | |
|---|---|---|---|
| Model fitting: | |||
| Fixed-effect models | yes | yes | yes |
| Random-effects models | yes | yes | yes |
| Heterogeneity estimator | various | various | various |
| Mantel–Hanszel method | yes | yes | yes |
| Peto’s method | yes | yes | yes |
| Plotting: | |||
| Forest plots | yes | yes | yes |
| Funnel plots | yes | yes | yes |
| Radial plots | yes | no | yes |
| L’Abbe plots | yes | no | no |
| Q-Q normal plots | yes | no | yes |
| Moderator analyses: | |||
| Categorical moderators | single * | single | multiple |
| Continuous moderators | multiple * | multiple | multiple |
| Mixed-effects models | yes | yes | yes |
| Testing/Confidence Intervals: | |||
| Knapp and Hartung adjustment | yes | yes | yes |
| Likelihood ratio tests | no | no | yes |
| Permutation tests | no | no | yes |
| Other: | |||
| Leave-one-out analysis | no | yes | yes |
| Influence diagnostics | yes | yes | yes |
| Cumulative meta-analysis | yes | yes | yes |
| Tests for funnel plot asymmetry | yes | yes | yes |
| Trim-and-fill method | yes | yes | yes |
| Selection models | no | no | no |
| Prediction interval | yes | no | yes |
* The number of moderators that can be analyzed simultaneously.
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Sen, S.; Yildirim, I. A Tutorial on How to Conduct Meta-Analysis with IBM SPSS Statistics. Psych 2022, 4, 640-667. https://0-doi-org.brum.beds.ac.uk/10.3390/psych4040049
AMA Style
Sen S, Yildirim I. A Tutorial on How to Conduct Meta-Analysis with IBM SPSS Statistics. Psych. 2022; 4(4):640-667. https://0-doi-org.brum.beds.ac.uk/10.3390/psych4040049
Chicago/Turabian StyleSen, Sedat, and Ibrahim Yildirim. 2022. "A Tutorial on How to Conduct Meta-Analysis with IBM SPSS Statistics" Psych 4, no. 4: 640-667. https://0-doi-org.brum.beds.ac.uk/10.3390/psych4040049