
Using Learned Health Indicators and Deep Sequence Models to Predict Industrial Machine Health †


Abstract
:1. Introduction
2. Methods
2.1. Data
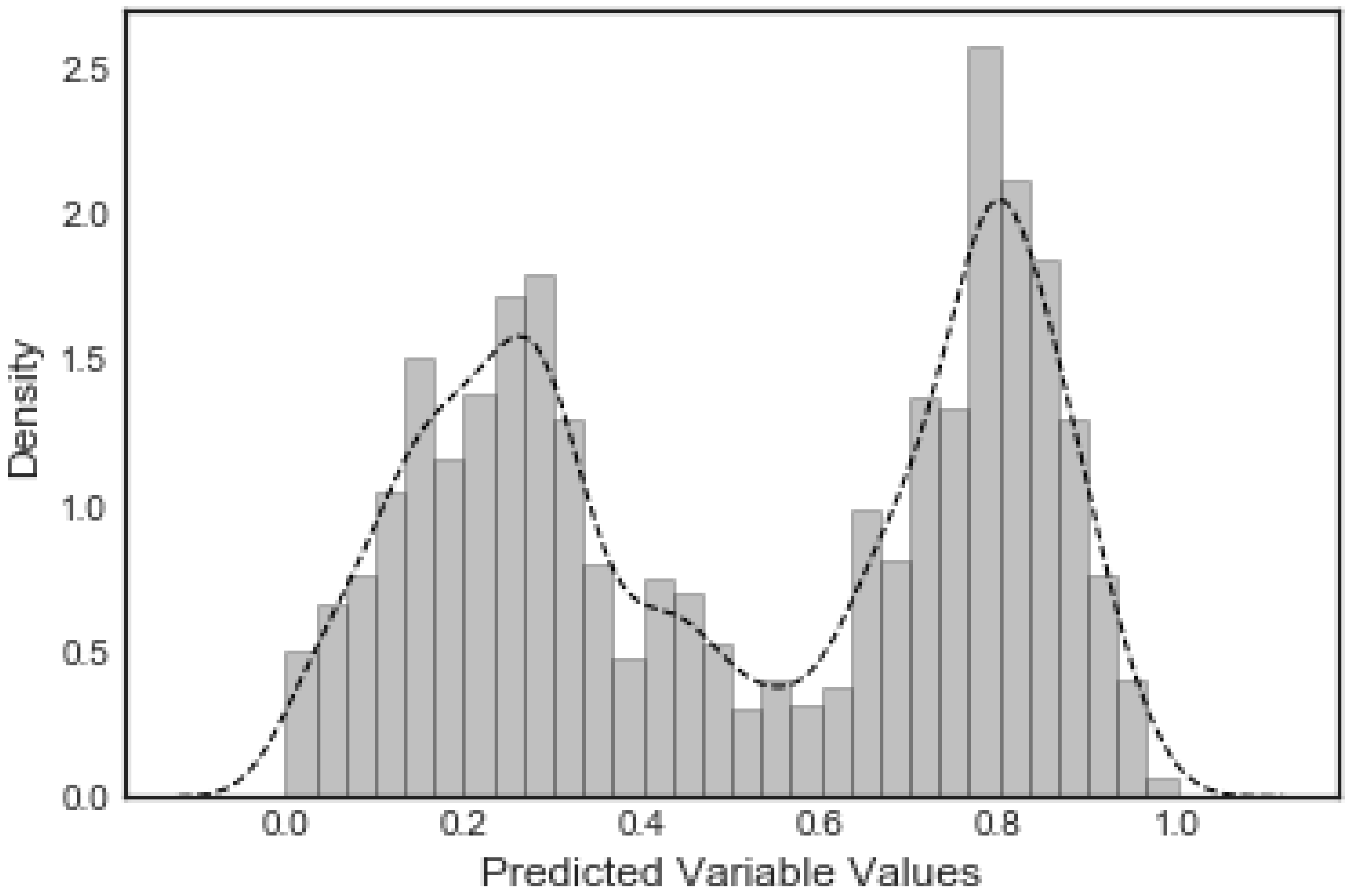
2.2. The Predicted Variable
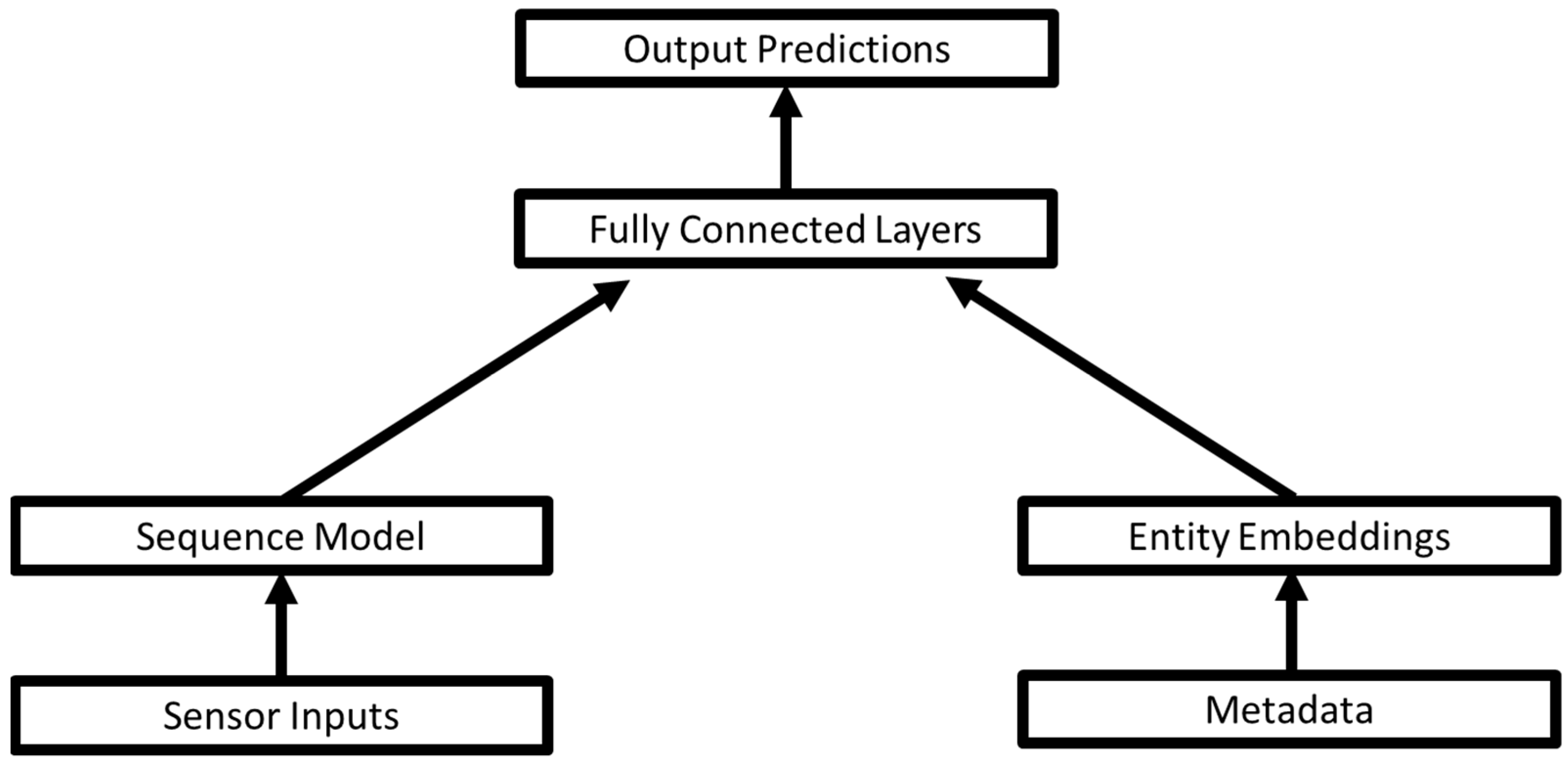
2.3. Modelling
3. Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, R.; Wang, D.; Yan, R.; Mao, K.; Shen, F.; Wang, J. Machine Health Monitoring Using Local Feature-Based Gated Recurrent Unit Networks. IEEE Trans. Ind. Electron. 2017, 65, 1539–1548. [Google Scholar] [CrossRef]
- Lund, D.; MacGillivray, C.; Turner, V.; Morales, M. Worldwide and Regional Internet of Things (IoT) 2014–2020 Forecast: A Virtuous Circle of Proven Value and Demand; International Data Corporation: Framingham, MA, USA, 2014. [Google Scholar]
- Lei, Y.; Jia, F.; Lin, J.; Xing, S.; Ding, S.X. An intelligent fault diagnosis method using unsupervised feature learning towards mechanical big data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Yin, S.; Li, X.; Gao, H.; Kaynak, O. Data-Based Techniques Focused on Modern Industry: An Overview. IEEE Trans. Ind. Electron. 2015, 62, 657–667. [Google Scholar] [CrossRef]
- Chen, Z.; Fang, H.; Chang, Y. Weighted data-driven fault detection and isolation: A subspace-based approach and algorithms. IEEE Trans. Ind. Electron. 2016, 63, 3290–3298. [Google Scholar] [CrossRef]
- Jardine, A.K.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, J.; Yan, R.; Mao, K. Machine health monitoring with LSTM networks. In Proceedings of the 10th International Conference on Sensing Technology (ICST), Nanjing, China, 11–13 November 2016; pp. 1–6. [Google Scholar]
- Liu, Z.; Jia, Z.; Vong, C.M.; Bu, S.; Han, J.; Tang, X. Capturing high-discriminative fault features for electronics-rich analog system via deep learning. IEEE Trans. Ind. Inform. 2017, 13, 1213–1226. [Google Scholar] [CrossRef]
- He, M.; He, D. Deep Learning Based Approach for Bearing Fault Diagnosis. IEEE Trans. Ind. Appl. 2017, 53, 3057–3065. [Google Scholar] [CrossRef]
- Janssens, O.; Van De Walle, R.; Loccufier, M.; Van Hoecke, S. Deep Learning for Infrared Thermal Image Based Machine Health Monitoring. IEEE/ASME Trans. Mechatronics 2017, 23, 151–159. [Google Scholar] [CrossRef] [Green Version]
- Jiang, G.; He, H.; Xie, P.; Tang, Y. Stacked Multilevel-Denoising Autoencoders: A New Representation Learning Approach for Wind Turbine Gearbox Fault Diagnosis. IEEE Trans. Instrum. Meas. 2017, 66, 2391–2402. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Networks 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In Proceedings of the NIPS Workshop on Deep Learning, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Cho, E.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Conference for Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Gallicchio, C.; Micheli, A. Deep echo state network (DeepESN): A brief survey. arXiv 2017, arXiv:1712.04323. [Google Scholar]
- Jaeger, H.; Haas, H. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. Science 2004, 304, 78–80. [Google Scholar] [CrossRef] [Green Version]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Fawaz, H.I.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.-A.; Petitjean, F. InceptionTime: Finding AlexNet for time series classification. Data Min. Knowl. Discov. 2020, 34, 1–27. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-ResNet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep transformer models for time series forecasting: The influenza prevalence case. arXiv 2020, arXiv:2001.08317. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Amihai, I.; Chioua, M.; Gitzel, R.; Kotriwala, A.M.; Pareschi, D.; Sosale, G.; Subbiah, S. Modeling Machine Health Using Gated Recurrent Units with Entity Embeddings and K-Means Clustering. In Proceedings of the IEEE 16th International Conference on Industrial Informatics, Porto, Portugal, 18–20 July 2018; pp. 212–217. [Google Scholar]
- Liu, L.; Chen, S.; Zhang, F.; Wu, F.X.; Pan, Y.; Wang, J. Deep convolutional neural network for automatically segmenting. Neural Comput. Appl. 2020, 32, 6545–6558. [Google Scholar] [CrossRef]
- Karim, F.; Majumdar, S.; Darabi, H.; Chen, S. LSTM Fully Convolutional Networks for Time Series Classification. IEEE Access 2018, 6, 1662–1669. [Google Scholar] [CrossRef]
- Stetco, A.A. Wind Turbine operational state prediction: Towards featureless, end-to-end predictive maintenance. In Proceedings of the International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 4422–4430. [Google Scholar]
- Duan, J.S. A novel ResNet-based model structure and its applications in machine health monitoring. J. Vib. Control 2021, 27, 1036–1050. [Google Scholar] [CrossRef]
- Liu, R.; Wang, F.; Yang, B.; Qin, S.J. Multiscale Kernel Based Residual Convolutional Neural Network for Motor Fault Diagnosis Under Nonstationary Conditions. IEEE Trans. Ind. Informatics 2020, 16, 3797–3806. [Google Scholar] [CrossRef]
- Zhang, W. Aero-engine remaining useful life estimation based on 1-dimensional FCN-LSTM neural networks. In Proceedings of the 2019 IEEE Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random forests. In Ensemble Machine Learning; Zhang, C., Ma, Y., Eds.; Springer: Boston, MA, USA, 2012; pp. 157–175. [Google Scholar]
- Painsky, A.; Wornell, G. on the universality of the logistic loss function. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 936–940. [Google Scholar]
- Cheng, G.; Berkhahn, F. Entity embeddings of categorical variables. arXiv 2016, arXiv:1604.06737. [Google Scholar]
- de Brébisson, A.; Simon, É.; Auvolat, A.; Vincent, P.; Bengio, Y. Artificial neural networks applied to taxi destination prediction. arXiv 2015, arXiv:1508.00021. [Google Scholar]
- Prechelt, L. Early stopping-but when? In Neural Networks: Tricks of the Trade; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 55–69. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [Green Version]
- Oliphant, T.E. Python for scientific computing. Comput. Sci. Eng. 2007, 9, 10–20. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Chow, M.-Y.; Tipsuwan, Y.; Hung, J. Neural-network-based motor rolling bearing fault diagnosis. IEEE Trans. Ind. Electron. 2000, 47, 1060–1069. [Google Scholar] [CrossRef] [Green Version]
- Samanta, B.; Al-Balushi, K. Artificial neural network based fault diagnostics of rolling element bearings using time-domain features. Mech. Syst. Signal Process. 2003, 17, 317–328. [Google Scholar] [CrossRef]
- Aminian, M.; Aminian, F. Neural-network based analog-circuit fault diagnosis using wavelet transform as preprocessor. IEEE Trans. Circuits Syst. II Analog. Digit. Signal Process. 2000, 47, 151–156. [Google Scholar] [CrossRef]
- Su, H.; Chong, K.T. Induction machine condition monitoring using neural network modeling. IEEE Trans. Ind. Electron. 2007, 54, 241–249. [Google Scholar] [CrossRef]
- Samir, K.; Takehisa, Y. A review on the application of deep learning in system health management. Mech. Syst. Signal Process. 2018, 107, 241–265. [Google Scholar]
- Toh, G.; Park, J. Review of vibration-based structural health monitoring using deep learning. Appl. Sci. 2020, 10, 1680. [Google Scholar] [CrossRef]
- Zheng, S.; Ristovski, K.; Farahat, A.; Gupta, C. Long short-term memory network for remaining useful life estimation. In Proceedings of the IEEE International Conference on Prognostics and Health Management (ICPHM), Dallas, TX, USA, 19–21 June 2017; pp. 88–95. [Google Scholar]
- Yuan, M.; Wu, Y.; Li, L. Fault diagnosis and remaining useful life estimation of aero engine using LSTM neural network. In Proceedings of the IEEE International Conference on Aircraft Utility Systems (AUS), Beijing, China, 10–12 October 2016; pp. 135–140. [Google Scholar]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. Multi-sensor prognostics using unsupervised health index based on LSTM Encoder-Decoder. arXiv 2016, arXiv:1608.06154. [Google Scholar]
- Chen, Y.; Peng, G.; Zhu, Z.; Li, S. A novel deep learning method based on attention mechanism for bearing remaining useful life prediction. Appl. Soft Comput. 2020, 86, 105919. [Google Scholar] [CrossRef]
- Xia, T.; Song, Y.; Zheng, Y.; Pan, E.; Xi, L. An ensemble framework based on convolutional bi-directional LSTM with multiple time windows for remaining useful life estimation. Comput. Ind. 2020, 115, 103182. [Google Scholar] [CrossRef]
- He, M.; Zhou, Y.; Li, Y.; Wu, G.; Tang, G. Long short-term memory network with multi-resolution singular value decomposition for prediction of bearing performance degradation. Measurement 2020, 156, 107582. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Wang, J.; Mao, K. Learning to monitor machine health with convolutional bi-directional LSTM networks. Sensors 2017, 17, 273. [Google Scholar] [CrossRef] [PubMed]
- Tao, Y.; Wang, X.; Sanches, R.V.; Yang, S.; Bai, Y. Spur gear fault diagnosis using a multilayer gated recurrent unit approach with vibration signal. IEEE Access 2019, 7, 56880–56889. [Google Scholar] [CrossRef]
- Guo, L.; Gao, H.; Huang, H.; He, X.; Li, S. Multifeatures fusion and nonlinear dimension reduction for intelligent bearing condition monitoring. Shock Vib. 2016, 2016, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional Neural Network Based Fault Detection for Rotating Machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Babu, G.S.; Zhao, P.; Li, X.L. Deep convolutional neural network based regression approach for estimation of remaining useful life. In Proceedings of the International Conference on Database Systems for Advanced Applications, Dallas, TX, USA, 16–19 April 2016; pp. 214–228. [Google Scholar]
- Chen, Z.; Shang, L.; Zhou, M. A FP-CNN method for aircraft fault prognostics. In Proceedings of the 3rd International Conference on Automation, Mechanical Control and Computational Engineering (AMCCE), Dalian, China, 12–13 May 2018; pp. 571–579. [Google Scholar]
- Wang, J.; Zhuang, J.; Duan, L.; Cheng, W. A multi-scale convolutional neural network for featureless fault diagnosis. In Proceedings of the 2016 International Symposium of Flexible Automation (ISFA), Cleveland, OH, USA, 1–3 August 2016; pp. 1–6. [Google Scholar]
- Guennemann, N.; Pfeffer, J. Predicting defective engines using convolutional neural networks on temporal vibration signals. In Proceedings of the First International Workshop on Learning with Imbalanced Domains: Theory and Applications, Skopje, Macedonia, 22 September 2017; pp. 92–102. [Google Scholar]
- de Oliveira, M.; Monteiro, A.; Vieira, F.J. A new structural health monitoring strategy based on PZT sensors and convolutional neural networks. Sensors 2018, 18, 2955. [Google Scholar] [CrossRef] [Green Version]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A New Convolutional Neural Network-Based Data-Driven Fault Diagnosis Method. IEEE Trans. Ind. Electron. 2017, 65, 5990–5998. [Google Scholar] [CrossRef]
- Abdeljaber, O.; Avci, O.; Kiranyaz, S.; Gabbouj, M.; Inman, D.J. Real-time vibration-based structural damage detection using one-dimensional convolutional neural networks. J. Sound Vib. 2017, 388, 154–170. [Google Scholar] [CrossRef]
- Han, T.; Liu, C.; Yang, W.; Jiang, D. A novel adversarial learning framework in deep convolutional neural network for intelligent diagnosis of mechanical faults. Knowl. Based Syst. 2019, 165, 474–487. [Google Scholar] [CrossRef]
- Dong, H.; Yang, L.; Li, H. Small fault diagnosis of front-end speed controlled wind generator based on deep learning. WSEAS Trans. Circuits Syst. 2016, 15, 64–72. [Google Scholar]
- Lin, Y.; Nie, Z.-H.; Ma, H.-W. Structural Damage Detection with Automatic Feature-Extraction through Deep Learning. Comput. Civ. Infrastruct. Eng. 2017, 32, 1025–1046. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Baur, M.; Albertelli, P.; Monno, M. a review of prognostics and health management of machine tools. the international J. Adv. Manuf. Technol. 2020, 107, 2843–2863. [Google Scholar] [CrossRef]
- Alshorman, O.; Irfan, M.; Saad, N.; Zhen, D.; Haider, N.; Glowacz, A.; Alshorman, A. A Review of Artificial Intelligence Methods for Condition Monitoring and Fault Diagnosis of Rolling Element Bearings for Induction Motor. Shock. Vib. 2020, 2020, 1–20. [Google Scholar] [CrossRef]
- Thoppil, N.M.; Vasu, V.; Rao, C.S.P. Deep learning algorithms for machinery health prognostics using time-series data: A review. J. Vib. Eng. Technol. 2021. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Model | Class 1 Accuracy | Class 2 Accuracy | Overall Accuracy | F1 | MCC |
|---|---|---|---|---|---|
| BiGRU | 85.05 | 89.6 | 87.33 | 0.876 | 0.747 |
| BiGRU, no entity embed-dings | 78.06 | 92.7 | 85.4 | 0.864 | 0.715 |
| BiGRU, no penultimate FC | 78.2 | 91.8 | 85.0 | 0.860 | 0.707 |
| Only BiGRU | 78.36 | 91.1 | 84.7 | 0.856 | 0.7 |
| Transformer | 90.90 | 85.78 | 90.26 | 0.880 | 0.768 |
| Res-CNN | 94.10 | 87.38 | 93.26 | 0.904 | 0.817 |
| FCN | 93.87 | 90.24 | 93.42 | 0.919 | 0.842 |
| Inception-time | 94.63 | 87.76 | 93.77 | 0.909 | 0.826 |
| ResNet | 95.68 | 85.7 | 94.43 | 0.902 | 0.818 |
| Random-forests | 98.59 | 81.29 | 89.47 | 0.890 | 0.811 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amihai, I.; Kotriwala, A.; Pareschi, D.; Chioua, M.; Gitzel, R. Using Learned Health Indicators and Deep Sequence Models to Predict Industrial Machine Health. Eng. Proc. 2021, 5, 7. https://0-doi-org.brum.beds.ac.uk/10.3390/engproc2021005007
Amihai I, Kotriwala A, Pareschi D, Chioua M, Gitzel R. Using Learned Health Indicators and Deep Sequence Models to Predict Industrial Machine Health. Engineering Proceedings. 2021; 5(1):7. https://0-doi-org.brum.beds.ac.uk/10.3390/engproc2021005007
Chicago/Turabian StyleAmihai, Ido, Arzam Kotriwala, Diego Pareschi, Moncef Chioua, and Ralf Gitzel. 2021. "Using Learned Health Indicators and Deep Sequence Models to Predict Industrial Machine Health" Engineering Proceedings 5, no. 1: 7. https://0-doi-org.brum.beds.ac.uk/10.3390/engproc2021005007