
Towards a Semi-Automated Data-Driven Requirements Prioritization Approach for Reducing Stakeholder Participation in SPL Development †


{kind=link}
Abstract
:1. Introduction
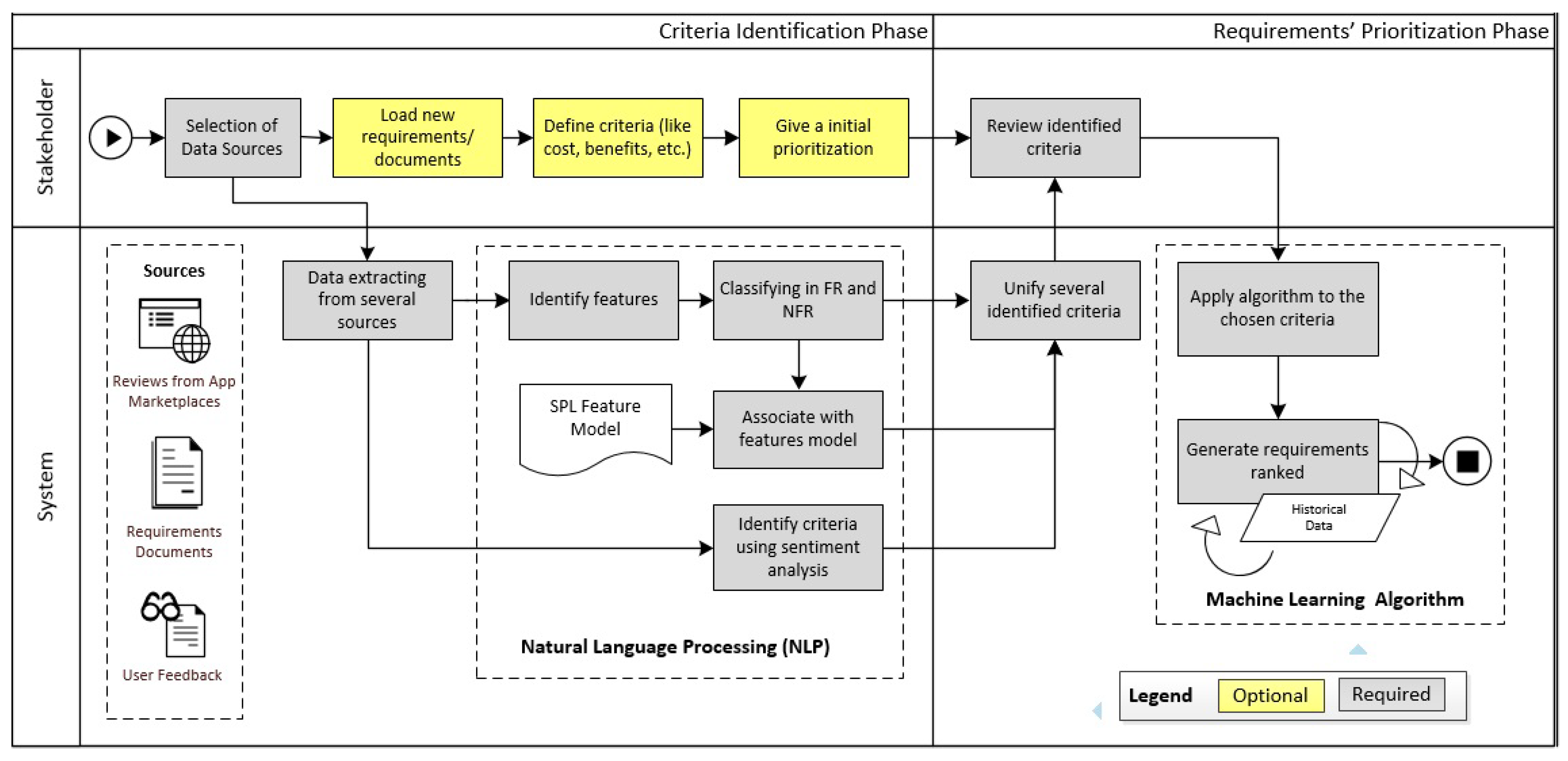
2. A Semi-Automated Data-Driven Requirements Prioritization Process
2.1. Criteria Identification Phase
2.2. Requirements Prioritization Phase
2.3. Datasets
3. Conclusions
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
References
- Hudaib, A.; Masadeh, R.; Qasem, M.H.; Alzaqebah, A. Requirements Prioritization Techniques Comparison. Mod. Appl. Sci. 2018, 12, 62. [Google Scholar] [CrossRef]
- Hujainah, F.; Bakar, R.B.A.; Abdulgabber, M.A.; Zamli, K.Z. Software Requirements Prioritisation: A Systematic Literature Review on Significance, Stakeholders, Techniques and Challenges. IEEE Access 2018, 6, 71497–71523. [Google Scholar] [CrossRef]
- Barenkamp, M.; Rebstadt, J.; Thomas, O. Applications of AI in classical software engineering. AI Perspect. 2020, 2, 1–15. [Google Scholar] [CrossRef]
- Lee, K.; Kang, K.C.; Lee, J. Concepts and guidelines of feature modeling for product line software engineering. In Lecture Notes in Computer Science, Proceedings of the International Conference on Software Reuse, Austin, TX, USA, 15–19 April 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 62–77. [Google Scholar]
- Sayyad Shirabad, J.; Menzies, T. The PROMISE Repository of Software Engineering Databases; School of Information Technology and Engineering, University of Ottawa: Ottawa, ON, Canada, 2005. [Google Scholar]
- Lim, S.L.; Finkelstein, A. StakeRare: Using social networks and collaborative filtering for large-scale requirements elicitation. IEEE Trans. Softw. Eng. 2012, 38, 707–735. [Google Scholar] [CrossRef]
- Cleland-Huang, J.; Mazrouee, S.; Huang, L.; Port, D. nfr [Data Set]; Zenodo: Geneva, Switzerland, 2007. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Limaylla, M.I.; Condori-Fernandez, N.; Luaces, M.R. Towards a Semi-Automated Data-Driven Requirements Prioritization Approach for Reducing Stakeholder Participation in SPL Development. Eng. Proc. 2021, 7, 27. https://0-doi-org.brum.beds.ac.uk/10.3390/engproc2021007027
Limaylla MI, Condori-Fernandez N, Luaces MR. Towards a Semi-Automated Data-Driven Requirements Prioritization Approach for Reducing Stakeholder Participation in SPL Development. Engineering Proceedings. 2021; 7(1):27. https://0-doi-org.brum.beds.ac.uk/10.3390/engproc2021007027
Chicago/Turabian StyleLimaylla, María Isabel, Nelly Condori-Fernandez, and Miguel R. Luaces. 2021. "Towards a Semi-Automated Data-Driven Requirements Prioritization Approach for Reducing Stakeholder Participation in SPL Development" Engineering Proceedings 7, no. 1: 27. https://0-doi-org.brum.beds.ac.uk/10.3390/engproc2021007027