
Conspiracy Thinking, Online Misinformation, and Hate: Insights from an Italian News Story Using Topic Modeling Techniques


Department of Economics, Roma Tre University, 00145 Rome, Italy
Journal. Media 2023, 4(4), 1048-1064; https://0-doi-org.brum.beds.ac.uk/10.3390/journalmedia4040067
Submission received: 7 September 2023
/
Revised: 23 September 2023
/
Accepted: 26 September 2023
/
Published: 15 October 2023
Abstract
:This study delved into the realm of conspiratorial thinking and misinformation on Twitter, examining the case of Silvia Romano, an Italian aid worker who faced online conspiratorial attacks before and after her release. With the increasing prevalence of conspiratorial narratives on social media, this research investigated the interplay between conspiratorial thinking and the dissemination of misinformation. Two datasets comprising Italian tweets were analyzed, aiming to uncover primary topics, detect instances of conspiratorial thinking, explore broader emerging topics beyond Silvia Romano’s case, and examine whether authors of conspiratorial narratives also engage in spreading misinformation. Twitter served as a critical platform for this study, reflecting its evolving role in news dissemination and social networking. The research employed topic modeling techniques and coherence scores to achieve these objectives, addressing challenges posed by the inherent ambiguities in defining conspiratorial narratives. The findings contribute to a deeper understanding of the complex dynamics of conspiratorial thinking and misinformation in the digital age.
1. Introduction
Over the past decade, individuals who have fallen victim to the online realm of conspiratorial thinking have encountered challenges in gaining public acknowledgment of their experiences. This challenge arises from a lack of empirical substantiation for their claims and a legal framework ill-prepared to address their concerns. Unfortunately, their appeals for recognition have often gone unanswered, exacerbating their predicaments. This unintended consequence has been driven by the proliferation of social media, which has significantly expanded people’s freedom of expression. This newfound liberty enables them to share their thoughts and beliefs on a multitude of topics Lewandowsky et al. (2013); Marwick and Lewis (2017); Sunstein (2018).
However, this enhanced freedom also has a downside: some individuals misuse it to propagate conspiratorial narratives, resulting in an increasing volume of such content that more people are exposed to Van Prooijen et al. (2018). Consequently, both online platforms and governments have been exploring potential solutions and countermeasures to address this issue.
Apart from its impact on online discourse, conspiratorial thinking can also have significant consequences in real-life situations, with the boundaries between online and offline manifestations often blurring. Researchers have hypothesized that online conspiratorial narratives may be part of a wider process of harm that can begin on social media and then move to the real/offline world.
Nevertheless, the identification and mitigation of conspiratorial thinking face challenges due to the inherent ambiguities in its definition. Conspiratorial narratives may involve calls for harmful actions against individuals or groups or communication containing inappropriate or offensive language.
This study examined two datasets comprising 35,055 and 1,815,602 Italian tweets, respectively. The smaller dataset focused on tweets related to the release of Silvia Romano, a Milanese woman who volunteered in Kenya, was kidnapped in November 2018, and faced numerous conspiratorial attacks on social media before and after her release. The larger dataset comprised tweets from all users who posted about Silvia Romano’s release and their subsequent activity. The aim was to analyze users engaging in conspiratorial thinking in the first dataset (related to Silvia Romano’s release) and explore any potential connections with the consumption of misinformation in the second dataset (covering all tweets by these users).
Twitter played a significant role in this research, as it has evolved into a platform combining features of news media and social networking Bruns and Moe (2014). Its importance is underscored by extensive literature demonstrating its utility in various fields, from detecting natural disasters and terrorist threats to studying opinion formation on political issues and monitoring public health Buntain et al. (2016); De Santis et al. (2020); Iacomini and Vellucci (2021); Jungherr (2016); Leitner et al. (2021); Mendoza et al. (2018); Pierri et al. (2020). The ongoing global pandemic of coronavirus disease 2019 (COVID-19) has shown that these latter two themes are intertwined. As for Italy, on 11 March 2020, the then Italian Prime Minister Giuseppe Conte ordered a set of severe measures of “social distancing”, stopping nearly all commercial activity and constraining the Italian population at home for safety reasons. As happened in all the countries that were hit the hardest by the COVID-19 pandemic, where social distancing measures were more stringent, people spent an unusual amount of time on social media to stay connected and also to acquire important information mus (n.d.); vic (n.d.); Wiederhold (2020). This tsunami of information also contained misinformation, rumors, and fake news, which spread rapidly through social media platforms, pushing the WHO to declare it as a serious infodemic problem Zarocostas (2020). “We’re not just fighting an epidemic; we’re fighting an infodemic”, declared WHO Director-General Tedros Adhanom Ghebreyesus at the Munich Security Conference on 15 February 2020.
This paper utilized two topic modeling techniques, the biterm topic model (BTM) Yan et al. (2013) and latent Dirichlet allocation (LDA) Blei et al. (2003), to analyze the data. Automatic topic extraction was supplemented by manual analysis aided by coherence scores, which gauged the human interpretability of topics Mimno et al. (2011). To calculate such scores, it is advisable to employ an external corpus to mitigate the effects of unusual term statistics present in tweet collections Boyd-Graber et al. (2014). Common choices for external corpora include the entire collection of English Wikipedia articles and the Associated Press data from the First Text Retrieval Conference (TREC-1) held in November 1992 Harman (1993). However, due to the lack of an Italian corpus suitable for this purpose, an ad hoc corpus was constructed using documents related to kidnapping and terrorism.
The aforementioned discussion led to the following research questions (RQs):
- RQ1.
- What are the primary topics and themes discussed in tweets related to Silvia Romano’s release?
- RQ2.
- Is it possible to differentiate instances of conspiratorial thinking among these discussions?
- RQ3.
- What topics emerge from the analysis of tweets, beyond those discussing Silvia Romano, by users who have engaged in conspiratorial thinking regarding the Italian aid worker?
- RQ4.
- Do the authors of conspiratorial narratives also engage in disseminating misinformation on Twitter?
2. The Datasets
For the current study, two datasets were built through a suitable scraper connected to the standard Twitter Streaming API, accessible upon opening a Twitter developer account. They consisted of, respectively, 35,055 and 1,815,602 tweets. Tweets were retrieved using the R package rtweet Kearney (2019). The first dataset, denoted by , was built on all the tweets in Italian containing the keywords “Silvia Romano”, for a period that spanned from 2020-05-08 at 05:00:00 UTC to 2020-05-16 at 07:30:05 UTC. This was the week of the release of Silvia Romano. The dataset consisted of 35,055 tweets. The number of twitterers who posted this stream of tweets was 18,235. Then, the activities of all these users were monitored, and all their tweets were collected during subsequent weeks. This produced the second dataset of this paper, denoted by . The inspection interval for fell in the weeks from 2020-05-08 01:56:24 UTC to 2020-06-02 12:48:18 UTC. The dataset consisted of 1,815,602 tweets. The tweets were filtered for the Italian language exploiting the specific filtering function available in the Twitter Streaming API.
The collected posts did not include retweets, which we excluded from the search upstream.
3. Methodology
This section describes the tools employed for determining the main topics emerging from tweets about Silvia Romano’s release. These techniques were borrowed from the field of text mining, such as frequency and correlation analysis plus topic modeling.
3.1. Data Preprocessing
In the current study, the adoption of several preprocessing steps was motivated by the aim of reducing the noise present in the data. The adopted preprocessing steps were the following:
- Links, symbols, emojis, punctuation, white spaces, and number removals;
- Lowercase conversion;
- Italian stop-word removals;
- Text tokenization according to “parts of speech tagging”.
The part-of-speech step was carried through UDPipe NLP Toolkit Buchholz and Marsi (2006); Straka and Straková (2017). See also the website of Universal Dependencies CoN (n.d.), as well as Straka and Straková (2017) and the references therein for additional information.
3.2. Topic Modeling
The first step of the topic modeling approach adopted in this paper was the application of the biterm topic model Yan et al. (2013), aka BTM, to the dataset . A BTM learns topics over short texts, like tweets, by directly modeling the generation of all the biterms (i.e., two words co-occurring in the same context) in the whole corpus. In brief, the whole corpus is a mixture of topics, where each biterm is drawn from a specific topic independently. A detailed description of the algorithm can be found in Ref. Yan et al. (2013). To find the topics emerging in collection , the R package provided by Ref. Wijffels (2020) was used.
The second step of the present topic modeling approach was to resort to a latent Dirichlet allocation (LDA) technique Jónsson and Stolee (2015); Silge and Robinson (2017) for the dataset , where tweets were aggregated by author to overcome the poor performance on short documents shown by LDA. The authors of Yan et al. (2013) denoted this variation of the LDA model as LDA-U. The R library provided by Ref. Grün and Hornik (2011), which implements the variational expectation–maximization (VEM) algorithm Blei et al. (2003) for the LDA model, was used to gather experimental data and compared to other models.
Why use LDA for ? LDA is a mechanism employed for topic extraction, which treats documents as probabilistic distribution sets of words or topics. LDA shows poor performance on shorter documents Jónsson and Stolee (2015); Yan et al. (2013). However, this phase aimed to treat twitter users (who tweeted about Silvia Romano) as a probabilistic distribution of topics. This is why a user-based aggregation of tweets was performed. This was conducted before applying the topic modeling technique, and therefore the application of LDA did not present technical contraindications due to the length of the documents.
3.3. Coherence in Topic Models
The coherence score is an automated metric proposed by Mimno et al. (2011) for topic quality evaluation. In each model, it is possible to distinguish between topics that seem to be coherent and topics that seem to be illogical. The coherence score is a way to measure topic quality without relying on human judgments. Given a topic z and its top n words ordered by , the coherence score is defined as
where, for the sake of simplicity, the dependence of top words by z in the RHS is avoided. In the following, the top 10 most likely topic words Boyd-Graber et al. (2014) will be considered (i.e., ).
Let be a function defined as follows. is the count of documents containing the word w concerning the total number of documents, i.e., the document frequency of word w. Moreover, is the count of documents containing both words w and for the total number of documents, i.e., the co-document frequency of words w and . D is the total number of documents in the corpus. There seems to be no corpus in Italian that can be used to compute the counts. For this reason, an ad hoc corpus was built from some books written or translated into Italian Ammaniti (2010); Márquez (2010); Olimpio (2018):
- News of a Kidnapping by Gabriel García Márquez.
- I’m Not Scared by Niccolò Ammaniti.
- Terrorismi: Atlante mondiale del terrore by Guido Olimpio. As far as we know, there is no English translation of this book, which addresses the phenomenon of terrorism on a global scale.
These books were selected because they speak of kidnappings, ransoms, and terrorists and could be similar to the story of Silvia Romano. A problem with the choice of corpus may be that some very technical or specific words are missed.
For this paper, the resulting corpus was provided as a document-term matrix with a term frequency of 26,577 terms in three documents (the aforementioned books) and a sparsity of about 58%.
Lastly, the score function introduced in Mimno et al. (2011),
was adopted. A smoothing count of 1 was included to avoid taking the logarithm of zero.
4. Results
In this section, the results obtained through the techniques described in the previous section are listed and discussed. To increase the clarity and comprehensibility for the reader, the section is split into two subsections devoted to the two datasets of the paper, and .
4.1. Dataset
The dataset was built on all the tweets in Italian containing the keywords “Silvia Romano” during the week of Silvia Romano’s release.
4.1.1. Topic Modeling with BTM
A natural first problem when applying a topic modeling technique concerns the selection of a suitable number of topics. There is no way to address this issue that is the best. For example, the approach adopted by Kuhn (2018) involves studying the trade-off between semantic coherence and exclusivity.
Coherence is based on the document frequency of individual words and the co-document frequency of pairs of distinct words. Such measures can prevent the onset of topics that are misleading in some respects. For example, words may be linked in a chain but not belong to the same topic: the word “raspberry” might be linked to the word “diphthong”, which is also linked to the term “vowel”, but the words “raspberry” and “vowel” should not be assigned to the same topic in a topic model. The solution to this issue through the topic coherence measure was introduced by Mimno et al. (2011).
Table 1 shows the values of topic coherence when applying the BTM to dataset for a number of topics equal to 5. In the following, the i-th topic of dataset D for a number of topics equal to n is denoted by the symbol for .
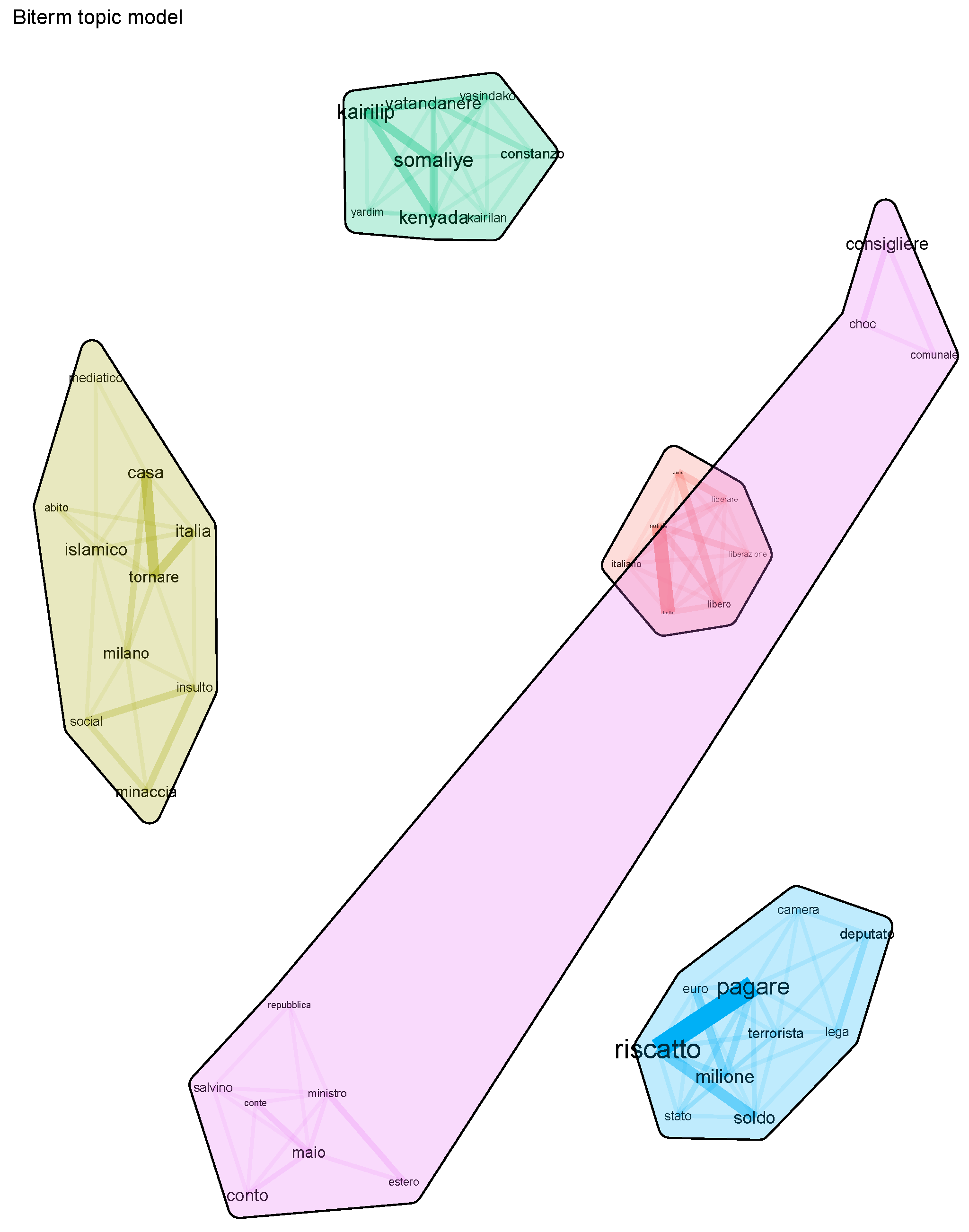
The corresponding topics are shown in Table 2, whereas Figure 1 shows their graphical representation. Table 2 further provides English translations of the terms composing the topics. The topmost and most coherent topic dealt with cyber hate, which, against all odds, immediately greeted the Italian hostage’s release Flick (2020); Povoledo (2020). As documented by Povoledo (2020) in her New York Times article, “the conversion of the young woman, Silvia Romano, to Islam, along with rumors that Italy had paid a ransom for her release, opened the dam to a deluge of insults on social media”. Topic also contained references to the dress worn by Silvia Romano upon disembarking the plane, a green jilbab—a long and loose-fit coat worn by some Muslim women.
The second most coherent topic (Topic ) also dealt with hate, this time from some local politicians—for example, a right-wing municipal councilor ans (n.d.) who posted a photo of Silvia Romano captioned “hang her”. Inevitably, these posts also involved political leaders in the controversy that took place on social networks—Conte, Di Maio, and Salvini were mentioned in the topic. Matteo Salvini is the head of the country’s League party1, Giuseppe Conte served as Prime Minister of Italy from June 2018 until February 2021, and Luigi Di Maio has served as the Minister of Foreign Affairs since 5 September 2019.
Political controversies also emerged from the third most coherent topic, Topic . A League lawmaker described Silvia Romano as a “neo-terrorist” Povoledo (2020), not including the aforementioned rumors that Italy had paid a ransom for her release. All these traits were contained inside Topic .
The other two topics, Topic and Topic , showed a lower semantic coherence. Topic seemed to be a too general topic, even if there were words in it that indicated the public happiness due to the good news of the Italian aid worker’s release. Topic was probably a set of scrap words that the BTM algorithm could not allocate correctly because of the paucity of topics. Anyway, it was possible to find in it a word that could be related to an episode of social hate that physically affected Silvia Romano. The word “bottle” may refer to the bottle thrown at the window of her house by unknown persons Kington (2020).
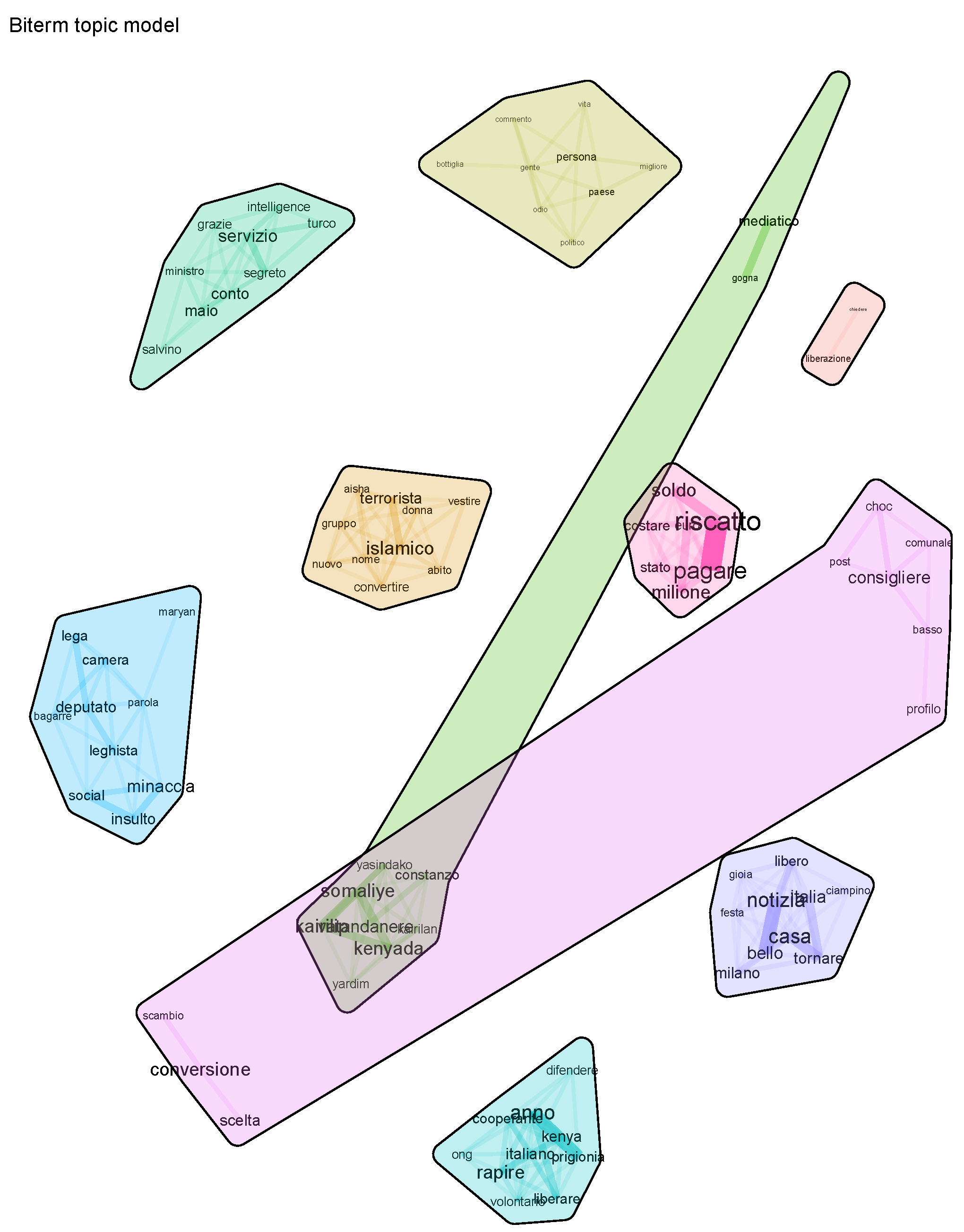
By increasing the number of topics, the situation became clearer. No criterion was followed to select this number, but for the paper’s purposes it was enough to observe again the presence of topics related to cyber hate and political controversies on Twitter. Table 3 shows the values of topic coherence when applying the BTM to dataset for a number of topics equal to 9. The corresponding topics, accompanied by English translations of the Italian words that appeared in them, are shown in Table 4, whereas Figure 2 shows their graphical representation.
The most coherent topic (Topic in this case) dealt again with cyber hate, but not exclusively. Terms like “social” (which in Italian stands for “social media”) and “insult”, referring to hateful messages that occurred on social media platforms (Twitter, in our case), were accompanied by “deputy”; “leghista” (a member or supporter of the League party); and “scuffle” (the translation of “bagarre”, which in Italian is usually used to indicate a situation of political quarrel), instead telling a story of bitter political controversy—remember the League lawmaker who described Silvia Romano as a “neo-terrorist” Povoledo (2020).
Silvia Romano’s clothing, which in the case with five topics appeared among the words of the topic labeled as cyber hate, now has a topic of its own, linked to the conversion of the young woman—Topic . The young woman’s conversion caused controversy and hate phenomena, not only on the web. Topic , which had almost the same coherence as the previous one, described the controversies that emerged from Twitter (ransom, million, terrorist). The difference between Topic and Topic was that, whereas in the first case political news was reported, and this could have been reported in a neutral tone or even criticizing the author of the disrespectful comments (the deputy of the League party), in the second case the words seemed to indicate the controversy spontaneously born from the tweets—for example, there was no indication of political subjects, as occurred in Topic (i.e., the deputy). In this sense, Topic was very similar to Topic .
Topic seemed to tell the story of Silvia Romano, a kidnapped 24-year-old Italian aid worker who was then released after 18 months in captivity in Kenya.
Topic referred again to the bottle thrown at the window of Silvia Romano’s home in Milan. Topic referred to the role of Turkish intelligence in the release of the hostage.
Topic also dealt with hate towards Silvia Romano involving some local politicians (e.g., the aforementioned right-wing municipal councilor). Happiness at the hostage’s release and Silvia Romano’s return home emerged instead from Topic . Topic concerned the release of the hostage.
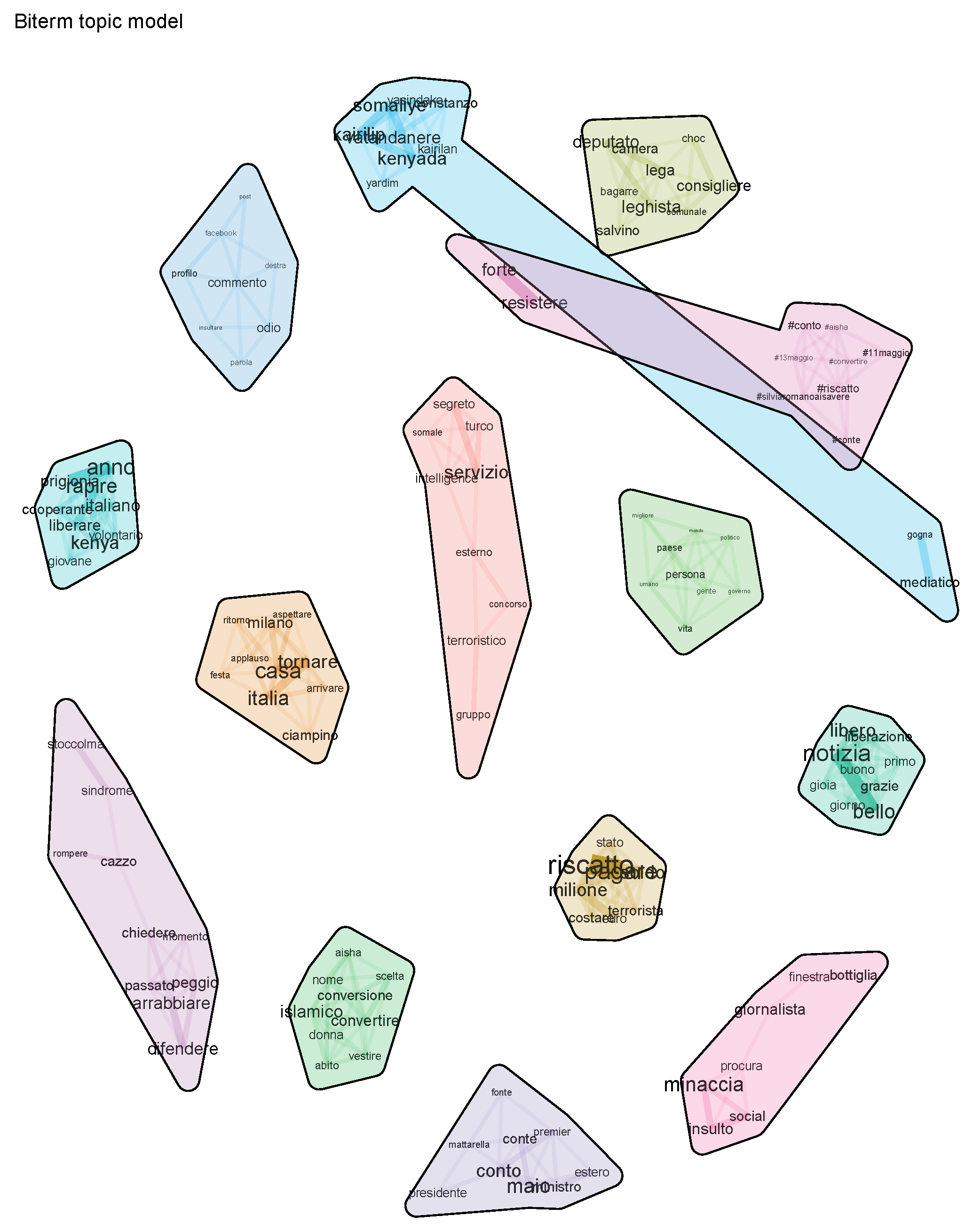
By further increasing the number of topics (see Figure 3), the topic that described the controversies emerging from Twitter (labeled as “controversies” in the case with nine topics) became the most coherent. See Table 5, where, in order not to burden the section too much, only the first three most coherent topics are listed.
4.1.2. Frequency Analysis for
The analysis presented so far therefore answered RQ1 and RQ2. To further answer RQ2, an analysis of the most frequent trigrams that emerged from the corpus was also performed. It was not possible to list all the trigrams resulting from the dataset because there were a large number (a total of 59,499 trigrams), nor did it make sense to report only the most frequent ones because, for example, the first positions were occupied by trigrams such as “libera romano silvia” (translation: “free Silvia Romano”, with a score of 1595) or “liberata romano silvia” (translation: “Silvia Romano freed”, with a score of 497). These were the first two positions and represent general information, in the sense that they do not suggest positive or negative emotions but simply limit themselves to reporting news (in this case, the release of Silvia Romano). The trigram “bentornata romano silvia” (translation: “welcome back Silvia Romano”, with a score of 105) greeted the return home of Silvia Romano with happiness.
However, not all trigrams showed general or positive content. For example, the trigram “costata romano silvia” (translation: “Silvia Romano has cost”, score 74) refers to the rumors that Italy had paid a ransom for Romano’s release, whereas the trigram “romano silvia terrorista” (translation: “Silvia Romano terrorist”, score 71) is related to the political exploitation regarding the conversion of the young woman who was also accused, as reported above, of having become a terrorist.
Among those contained in dataset , the words “costata” (i.e., “has cost”) and “terrorista” (i.e., “terrorist”) appeared in, respectively, 328 and 843 tweets out of 35,055. These tweets mostly concerned the controversy sparked by the League lawmaker who described Silvia Romano as a “neo-terrorist” and the rumors that Italy had paid a ransom for her release Povoledo (2020). The tables provided in the Supplementary Information show, among these, the most cited tweets that represented cyber hate phenomena against Silvia Romano. Similar results could be found, e.g., for the trigram “islamica romano silvia” (translation: “Silvia Romano Islamic”, score 68). The word “islamica” (“Islamic”) appeared in 285 tweets out of 35,055. See the Tables in the Supplementary Information. These tables also show information concerning the “favorite count” field, which provides the number of times the tweet was favorited, representing a sign of strong support for the opinion conveyed by the tweet.
Overall, it is possible to say that the positive or neutral (i.e., journalistic) tones in far outweighed the negative, polemical, and offensive ones. This was related to the positivity of the news, because one could expect that almost everyone would be happy or at least neutral if they learned of the release of a hostage. Nevertheless, thanks to the BTM, the presence of hate speech and controversies was also found. Regarding these findings, the results enclosed in the following sections were obtained.
4.2. Dataset
Dataset contained all the tweets published by the users whose tweets fell within dataset . The observation period followed that of .
4.2.1. Topic Modeling with LDA-U
To obtain the topics that emerged from the analysis of the tweets of Romano’s detractors, a semi-automatic procedure, based on the combination of the BTM and LDA-U techniques, was employed. The procedure comprised the following steps:
- (a)
- Apply the BTM to dataset and obtain a group of topics (say, Group X).
- (b)
- Select the most polemical topic against Silvia Romano among those contained in Group X (say, Topic ).
- (c)
- Detect all the tweets which, with greater probability (assumed to be greater than 0.5), belong to Topic —this was possible because it was assumed Yan et al. (2013) that the topic proportions of a document were equal to the expectation of the topic proportions of biterms generated from the document. This set of tweets was called Set S (a subset of ).
- (d)
- Detect the users who posted the tweets within Set S (say, Set U).
- (e)
- Group by user the tweets in for each user in U.
Topic was that labeled as “controversies” in the case with 13 topics (). It contained the most controversial posts on the release of Silvia Romano. At this point, a new dataset (denoted by , a subset of ) was formed, to which the LDA-U technique was applied. consisted of 216,247 tweets, which were aggregated by 653 users. These were the authors of the aforementioned most controversial posts on the release of Silvia Romano. Figure S1 in the Supplementary Information shows the resulting clustered terms (into 30 topics) obtained from dataset through LDA-U. The topmost topic dealt with coronavirus, which, as one would expect, was a hot topic in May due to the pandemic’s spread in Italy. This was, however, an overall theme that embraced more topics in Figure S1 in the Supplementary Information: 1, 2, 4, 6, 8, 10, 11, 13, 15, 19, 20, 22, 24, 26, 27, 28, 29, 30.
In the following, the symbol denotes the i-th topic learned from dataset .
Topic concerned what has been called, in Italian,“Decreto Rilancio”, a decree-law of 19 May 2020, containing urgent measures in the field of health, labor support, and the economy, as well as social policies related to the epidemiological emergency of COVID-19.
Topic introduced the answers to RQ3 and RQ4. It contained the words “covid”; “trump”; “governo” (i.e., government); “bill” and “gates” (Bill Gates); “virus”; “regime”; and “stato” (i.e., state government). This topic embraced some rumors and conspiracy theories related to the COVID-19 pandemic that were proliferated given the lack of scientific consensus on the virus’s spread. According to a widespread conspiracy theory, Bill Gates used the pandemic as a cover to launch a broad vaccination program to facilitate a global surveillance regime Baines et al. (2021); Eberl et al. (2021); Enders et al. (2020); Fuchs (2021); Gagliardone et al. (2021); Havey (2020); Shahsavari et al. (2020).
Topic contained offensive tweets that used obscene language. This denotes fear, anger, and frustration in the social discussions, as well as conflict and hatred between people who have different opinions. Inappropriate and offensive language deteriorates public discourse and can lead to a more radicalized society Cinelli et al. (2021).
In Topic , the juxtaposition of the words “immigrati” (i.e., immigrant); “migranti” (i.e., migrant); “soldi” (i.e., money); “lavoro” (i.e., job); and “governo” (i.e., government) suggested the presence in dataset of another famous strand of conspiracy theories, resulting from the spread of fallacious racial news, known as “racial hoaxes” Papapicco et al. (2022), able to feed the narrative of immigration promoted by some politicians Cervi et al. (2020) and induce the need for cognitive closure in ordinary citizens Baldner and Pierro (2019). Topic , like the aforementioned Topic , fell into this strand (here, “clandestini” translates to “illegal immigrants”). Linked to them was Topic , focused on the policies pursued by the Lega, which opposes illegal immigration into Italy and the EU as well as the EU’s management of asylum seekers.
Topic was related to the release of Silvia Romano. Here, it was still possible to find the presence of terms that suggested controversy regarding the ransom paid for her release and her conversion. This meant that these controversies did not end in the week of Silvia’s release, but remained in the subsequent weeks.
Other topics related to fake news and hate were and . Together with the previous topics, they formed the following set:
Out of a total of 653 users who posted the most controversial tweets on the release of Silvia Romano, 207 (about 31.7%) used the more offensive words contained in Topic . Of course, these words were not necessarily directed to Silvia Romano. Furthermore, about 23% of these 653 users mentioned words in topics related to rumors and conspiracy theories concerning Bill Gates or racial hoaxes.
Repeating the procedure steps (a)–(e) and substituting (at point (b)) the most polemical topic against Silvia Romano with the most favorable/supportive one towards her (i.e., in English, news, beautiful, free, to free, release, thank you, first, joy, good, day), another dataset was obtained, called . Obviously, and . consisted of 88,635 tweets posted by 857 users (who were the authors of the most favorable/supportive tweets towards Silvia Romano). Figure S2 in the Supplementary Information shows the resulting clustered terms (into 30 topics) obtained from dataset through LDA-U; there seemed to be no records of misinformation in them.
Since LDA modeled each document (i.e., the aggregate tweets by author) as a mixture of topics, it was possible to examine the per-document-per-topic probabilities of aggregate documents in . Then, each aggregate document in was assigned to the topic with the maximum value of . The authors of documents assigned to one of the aforementioned topics in (i.e., those related to fake news and hate) were finally selected. In this way, 271 users were identified and used to refine the search. In dataset , they posted 61,815 tweets. This dataset was called , which was in turn a subset of . In the top 20 of the most active users in , the number of tweets produced varied between 833 and 2005. To date, some of these accounts have been suspended (Twitter suspends accounts that violate the Twitter Rules), whereas some others are still connected to the League party and Matteo Salvini. Users in were on average more active than those in the rest of the dataset, , because the average number of tweets posted per single user in was equal to 228.0996, compared to 118.124 for users in .
To conclude, some topics detected through the application of the BTM to are listed below:
- covid, regione, coronavirus, riaprire, lombardia, morto, plasma (plasma), #iorestoacasa, terapia (therapy);
- bill, gates, sara, cunial, vaccino (vaccine), trump, mondiale, presidente;
- italiani (italians), milioni (millions), pagare (to pay), euro, soldi (money), riscatto (ransom), tassa, miliardi, stato (government);
- clandestini (illegal immigrants), streaming, boss, mafioso, immigrati, sanatoria (sanatorium/regularisation), migranti, bellanova, regolarizzare (to regularize);
- mascherina (mask), piazza, arrestare (to arrest), polizia (police), roma, milano, donna (woman), mondialista (globalist).
These included references to: (i) some alternative debated cures cited by vaccine opponents (plasma therapy) to defeat COVID-19; (ii) the aforementioned conspiracy theory regarding Bill Gates (whereas Sara Cunial is an Italian deputy and former member of the parliamentary group of the Five Star Movement, famous in Italy for her anti-scientific positions on vaccines); (iii) again, the controversy over the ransom paid by the Italian state for the release of Silvia Romano; (iv) the sanatorium proposed by the then Italian minister of agriculture, Teresa Bellanova, which provided for the regularization of foreign workers in Italy and caused considerable controversies; (v) a very general conspiracy theme, containing the term globalist, used as a pejorative in right-wing parties and conspiracy theories Stack (2016) and arguments against masks (also involving supposed abuses committed by police against citizens without masks).
Other topics not listed above referred to the Italian lockdown and to political games (decrees and contrasts between the political leaders of the Democratic Party, Five Star Movement, and League party).
4.2.2. Dataset Two Years Later
After two years, of the 18,235 users, 15,542 remained (82.4%). A possible explanation for this difference is that hateful users were banned more often due to the infringement of Twitter’s guidelines, as conjectured by Ref. Ribeiro et al. (2018). The same is true for “conspiracists”, especially after Twitter adopted stricter policies on COVID-19 vaccine misinformation. The set of users who produced tweets mainly belonging to topics in went from 271 to 222, with a percentage (81.9%) comparable to the rest of the dataset . Deleting the tweets produced by removed accounts, went from 61,815 tweets to 44,539 (70%), while the average number of tweets posted per user in became 200.6261. This new dataset is denoted by . These data were in line with the results of Ref. Ribeiro et al. (2018), according to which hateful users are “power users” in the sense that they tweet more. A similar result could also hold for conspiracists.
Below, some topics detected through the application of the BTM to the new/reduced dataset are listed:
- italiani (italians), milioni (millions), pagare (to pay), euro, soldi (money), riscatto (ransom), governo (government), miliardi, stato (government);
- bill, gates, trump, covid, regione, coronavirus, plasma (plasma), terapia (therapy), donno;
- clandestini (illegal immigrants), boss, mafioso, comunista (communist), immigrati, sanatoria (sanatorium/regularisation), regime (regime);
- mascherina (mask), arrestare (to arrest), polizia (police), roma, milano, piazza, uccidere (to kill), agente (police officer), aggredire (to assault).
These again included references to the ransom paid by the Italian state for the release of Silvia Romano, the regularization proposal for foreign workers in Italy, and anti-mask positions. Bill Gates and covid were still mentioned, but Sara Cunial disappeared, possibly due to the cancellation of accounts that shared her ideas. Unlike the topics detected in , this topic in joined the one containing the mention of plasma therapy, where a reference to Giuseppe De Donno now also appeared. Giuseppe De Donno was an Italian Professor and physician. He was a supporter of plasma remedies to combat COVID-19.
Moreover, the remaining accounts may have also lost some of their tweets due to Twitter Rules violations. By searching status IDs, it was found that of the 61,815 tweets, only 24,185 remained (39.1%). This new dataset is denoted by . The application of the BTM to showed non-relevant topics, focused on political debates, except for the controversies related to the regularization proposal for foreign workers in Italy and the ransom paid for the release of Silvia Romano, which, compared to the corresponding topics in , appeared without any changes in the initial words. Instead, the references to Bill Gates and anti-mask theories disappeared. Although social media polarization and echo chambers could still be found in these topics, the latter results showed the effective work carried out by Twitter to address misinformation on the platform.
5. Conclusions
In this study, a large corpus of almost two million tweets in Italian was collected, containing: (i) posts about the Italian volunteer Silvia Romano during the week of her release, i.e., from 2020-05-08 to 2020-05-16; (ii) all the posts published by the authors of this stream of tweets in the subsequent weeks, spanning from 2020-05-08 to 2020-06-02. The temporal range covered the end of the first COVID-19 lockdown in Italy. This work aimed to characterize the behavior of users engaging in conspiratorial thinking in the first dataset and shed light on the relationship with the consumption of misinformation in the second dataset.
The combined LDA and BTM techniques were able to discover, in an unsupervised fashion, the main emerging terms related to socio-political events (such as discussions of decrees and political disputes), also including terms that were heavily and constantly used, such as the major political leaders’ names.
The implications of this study mainly concern the management of social platforms like Twitter. First, as in Cinelli et al. (2021), this study did not find evidence of a strict relationship between the usage of toxic language (violent, offensive, or simply inappropriate) and involvement in the spread of misinformation on Twitter. Second, users seemed to be prone to use toxic language outside of their echo chamber, targeting the community they perceived to be their opponent. This is in line with recent studies about the polarization of online debates and the stigmatization of users Iacomini and Vellucci (2021). Third, among the tweets posted by the authors of the most controversial posts on the release of Silvia Romano, the presence of mono-thematic debates was not observed. Therefore, there were no serial users/producers of misinformation; instead, these authors seemed to also share other content. Lastly, it should be noted that many of the efforts made by Twitter involved the contradiction of misinformation on the platform. Despite these efforts, after checking the existence of the accounts that had posted the most controversial tweets on the release of Silvia Romano, after almost 2 years from the date of their posting, we found that only around 20% of them were unavailable due to official banning or removal by the author (even though Twitter still removed nearly 60% of these tweets!).
The rest of the political implications were aimed at governments. The past literature explains that during crises, people depend on media to keep updated and receive accurate information Ball-Rokeach and DeFleur (1976). The presence of topics related to anti-vaccine theories showed the difficulties governments face in dealing with individuals’ concerns about vaccine efficacy. The efforts of governments should instead be designed to raise awareness among individuals and include them in civil dialogues, online and offline. The presence of these topics, as well as topics related to racial hoaxes, concerning unfounded rumors of the economic privileges immigrants would enjoy in Italy, represented a pressing need for possible consequences in the real world. Recent measures carried out by the European Parliament have contributed to this direction; it is worth mentioning the provisional political agreement reached on the Digital Services Act (DSA), which follows the principle that what is illegal offline must also be illegal online DSA (n.d.).
We would like to remark that misinformation is often a symptom of deeper socio-political issues rather than their cause. Addressing the symptoms can be helpful, but it should not detract from addressing the root causes or the importance of advocating for access to accurate, transparent, and high-quality information Altay et al. (2023).
The findings of this study must be considered in light of some limitations. This paper discussed concepts such as “hate speech” and “misinformation”. There is a lack of academic consensus on how to measure these concepts (canceled accounts are by no means a proxy for misinformation). Indeed, concerning hate, we adhered here to legal standards (only implicitly). We understand that these standards are ad hoc in abstract cases of legal categorization and may not reflect “scientific” categories in information and communication science or psychology, sociology, etc.; in particular, Silvia’s case represented several categories often targeted on social media that conformed to the legalistic definition of hate speech. Is conspiratorial thinking a form of hate speech? There is clearly an overlap; however, conspiratorial thinking was much more specific in this case study. We could hypothesize two different models of action for the production of conspiratorial tweets. The first model concerned genuine expressions of emotions regarding the topic of Silvia Romano: people who genuinely felt that something unjust had happened. The second model of action properly pertained to misinformation (or humbug): these people expressed concerns about the hypothesis that Silvia Romano could have been sympathetic to terrorists. The difference between these categories of action was crucial for the study. For future work, when analyzing the past tweeting behavior of people expressing concern (rather than hate), one could try to quantify genuine distress about the historical contingency of Silvia Romano (but this approach could also be applied to other news) through the systematic behavior of spreading “concerns” (e.g., about immigration, which we found in our discussion to be relevant).
Another limitation of this paper was that the case of Silvia Romano, as a case study, does not generalize well because the sample of people who tweet in Italian is particularly clustered around certain demographics, which are less representative of the general dynamics involving human behavior compared to collections of tweets in English, French, Spanish, and possibly Arabic, which generalize across many countries. It is not even a representative sample of Italian society: Twitter is less popular in Italy compared to other EU countries. Research on Italian tweets has its own value, but it would require more theoretical effort in future studies, focusing on how misinformation occurs in Italian in contrast to another language and comparing two relatively similar case studies.
Lastly, it is necessary to comment on what was happening at Twitter in the days when this paper was written. The Twitter takeover by billionaire Elon Musk led to important operational changes. Twitter has planned changes to its content moderation policies (e.g., hate speech and the readmission of users previously removed from the platform), which has sparked controversy. It would be interesting to study whether the results highlighted by this paper are still valid in a few months or if, on the contrary, they have been accentuated by the policies of the new Twitter owner.
Supplementary Materials
The following supporting information can be downloaded at: https://0-www-mdpi-com.brum.beds.ac.uk/article/10.3390/journalmedia1010000/s1.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Twitter data were collected by leveraging Twitter’s free streaming API. A Twitter developer account was obtained, as well as the necessary authentication tokens. The dataset is available in compliance with Twitter’s Terms and Conditions (https://developer.twitter.com/en/developer-terms/agreement-and-policy, 6 September 2023), under which I am unable to publicly release the text of the collected tweets. However, I can release those data that respect user privacy, e.g., Tweet IDs, which are unique identifiers tied to specific tweets. The Tweet IDs can be used by researchers to query Twitter’s API and obtain the complete tweet object, including tweet content (text, URLs, hashtags, etc.) and authors’ metadata. They are available from the author on reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
| 1 | The League is a conservative party with no historical ties to pre-existing neo-fascist movements, although this party has the support of individuals who may share far-right political views. |
References
- Altay, Sacha, Manon Berriche, and Alberto Acerbi. 2023. Misinformation on misinformation: Conceptual and methodological challenges. Social Media+ Society 9: 20563051221150412. [Google Scholar] [CrossRef]
- Ammaniti, Niccolò. 2010. Io non ho paura. Torino: Einaudi. [Google Scholar]
- Baines, Annalise, Muhammad Ittefaq, and Mauryne Abwao. 2021. # scamdemic, # plandemic, or # scaredemic: What parler social media platform tells us about COVID-19 vaccine. Vaccines 9: 421. [Google Scholar]
- Baldner, Conrad, and Antonio Pierro. 2019. Motivated prejudice: The effect of need for closure on anti-immigrant attitudes in the united states and italy and the mediating role of binding moral foundations. International Journal of Intercultural Relations 70: 53–66. [Google Scholar] [CrossRef]
- Ball-Rokeach, Sandra.J., and Melvin.L. DeFleur. 1976. A dependency model of mass-media effects. Communication Research 3: 3–21. [Google Scholar] [CrossRef]
- Blei, David M., Andrew Y. Ng, and Michael I. Jordan. 2003. Latent dirichlet allocation. Journal of Machine Learning Research 3: 993–1022. [Google Scholar]
- Boyd-Graber, Jordan, David Mimno, and David Newman. 2014. Care and Feeding of Topic Models: Problems, Diagnostics, and Improvements. CRC Handbooks of Modern Statistical Methods. Boca Raton: CRC Press, pp. 225–54. [Google Scholar]
- Bruns, Axel, and Hallvard Moe. 2014. Structural layers of communication on twitter. Twitter and Society 89: 15–28. [Google Scholar]
- Buchholz, Sabine, and Erwin Marsi. 2006. Conll-x shared task on multilingual dependency parsing. In Proceedings of the Tenth Conference on Computational Natural Language Learning (CoNLL-X), New York NY, USA, June 8–9; pp. 149–64. [Google Scholar]
- Buntain, Cody, Jennifer Golbeck, Brooke Liu, and Gary LaFree. 2016. Evaluating public response to the boston marathon bombing and other acts of terrorism through twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Cologne, Germany, May 18–20; Volume 10, pp. 555–58. [Google Scholar]
- Cervi, Laura, Santiago Tejedor, and Mariana Alencar Dornelles. 2020. When populists govern the country: Strategies of legitimization of anti-immigration policies in salvini’s italy. Sustainability 12: 10225. [Google Scholar] [CrossRef]
- Cinelli, Matteo, Andraž Pelicon, Igor Mozetič, Walter Quattrociocchi, Petra Kralj Novak, and Fabiana Zollo. 2021. Dynamics of online hate and misinformation. Scientific Reports 11: 1–12. [Google Scholar] [CrossRef]
- Conll-u Format. n.d. Available online: https://universaldependencies.org/format.html (accessed on 30 April 2022).
- Coronavirus Quarantine Appears to Be Driving a Global Tiktok Download Boom. n.d. Available online: https://www.musicbusinessworldwide.com/coronavirus-quarantine-appears-to-be-driving-a-global-tiktok-download-boom/ (accessed on 30 April 2022).
- COVID-19: Social Media Use Goes Up as Country Stays Indoors. n.d. Available online: https://www.vicnews.com/news/covid-19-social-media-use-goes-up-as-country-stays-indoors/ (accessed on 30 April 2022).
- De Santis, Enrico, Alessio Martino, and Antonello Rizzi. 2020. An infoveillance system for detecting and tracking relevant topics from italian tweets during the COVID-19 event. IEEE Access 8: 132527–38. [Google Scholar] [CrossRef]
- Digital Services Act: Council and European Parliament Provisional Agreement for Making the Internet a Safer Space for European Citizens. n.d. Available online: https://www.consilium.europa.eu/en/press/press-releases/2022/04/23/digital-services-act-council-and-european-parliament-reach-deal-on-a-safer-online-space/ (accessed on 30 April 2022).
- Eberl, Jakob-Moritz, Robert A Huber, and Esther Greussing. 2021. From populism to the “plandemic”: Why populists believe in covid-19 conspiracies. Journal of Elections, Public Opinion and Parties 31: 272–84. [Google Scholar] [CrossRef]
- Enders, Adam M., Joseph E. Uscinski, Casey Klofstad, and Justin Stoler. 2020. The different forms of COVID-19 misinformation and their consequences. The Harvard Kennedy School Misinformation Review 1: 1–21. [Google Scholar] [CrossRef]
- Flick, Caterina. 2020. Good practices to prevent and counter the spread of illegal hate speech online. In Language, Gender and Hate Speech. Venice: Edizioni Ca’ Foscari, pp. 181–95. [Google Scholar]
- Fuchs, Christian. 2021. Bill gates conspiracy theories as ideology in the context of the COVID-19 crisis. In Communicating COVID-19. Bingley: Emerald Publishing Limited. [Google Scholar]
- Gagliardone, Iginio, Stephanie Diepeveen, Kyle Findlay, Samuel Olaniran, Matti Pohjonen, and Edwin Tallam. 2021. Demystifying the covid-19 infodemic: Conspiracies, context, and the agency of users. Social Media+ Society 7: 20563051211044233. [Google Scholar] [CrossRef]
- Grün, Bettina, and Kurt Hornik. 2011. topicmodels: An R package for fitting topic models. Journal of Statistical Software 40: 1–30. [Google Scholar] [CrossRef]
- Harman, Donna. 1993. Overview of the first text retrieval conference. Paper presented at the National Online Meeting, Gaithersburg, MA, USA, November 4–6; pp. 181–87. [Google Scholar]
- Havey, Nicholas Francis. 2020. Partisan public health: How does political ideology influence support for covid-19 related misinformation? Journal of Computational Social Science 3: 319–42. [Google Scholar] [CrossRef] [PubMed]
- Iacomini, Elisa, and Pierluigi Vellucci. 2021. Contrarian effect in opinion forming: Insights from greta thunberg phenomenon. The Journal of Mathematical Sociology 47: 123–69. [Google Scholar] [CrossRef]
- Jónsson, Elıas, and Jake Stolee. 2015. An Evaluation of Topic Modelling Techniques for Twitter. Toronto: University of Toronto. [Google Scholar]
- Jungherr, Andreas. 2016. Twitter use in election campaigns: A systematic literature review. Journal of Information Technology & Politics 13: 72–91. [Google Scholar]
- Kearney, Michael W. 2019. rtweet: Collecting and analyzing twitter data. Journal of Open Source Software 4: 1829. [Google Scholar] [CrossRef]
- Kington, Tom. 2020. Delight then fury as italy welcomes freed hostage who converted to islam. The Times, May 15. [Google Scholar]
- Kuhn, Kenneth D. 2018. Using structural topic modeling to identify latent topics and trends in aviation incident reports. Transportation Research Part C: Emerging Technologies 87: 105–22. [Google Scholar] [CrossRef]
- Leitner, Stephan, Bartosz Gula, Dietmar Jannach, Ulrike Krieg-Holz, and Friederike Wall. 2021. Understanding the dynamics emerging from infodemics: A call to action for interdisciplinary research. SN Business & Economics 1: 1–18. [Google Scholar]
- Lewandowsky, Stephan, Klaus Oberauer, and Gilles E Gignac. 2013. Nasa faked the moon landing—Therefore, (climate) science is a hoax: An anatomy of the motivated rejection of science. Psychological Science 24: 622–33. [Google Scholar] [CrossRef]
- Márquez, Gabriel García. 2010. Notizia di un Sequestro. Milan: Edizioni Mondadori. [Google Scholar]
- Marwick, Alice E., and Rebecca Lewis. 2017. Media Manipulation and Disinformation Online. Available online: https://citap.unc.edu/publications/media-manipulation-and-disinformation-online/ (accessed on 6 September 2023).
- Mendoza, Marcelo, Bárbara Poblete, and Ignacio Valderrama. 2018. Early tracking of people’s reaction in twitter for fast reporting of damages in the mercalli scale. In International Conference on Social Computing and Social Media. New York: Springer, pp. 247–57. [Google Scholar]
- Mimno, David, Hanna M. Wallach, Edmund Talley, Miriam Leenders, and Andrew McCallum. 2011. Optimizing semantic coherence in topic models. Paper presented at the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, July 27–31; pp. 262–72. [Google Scholar]
- Olimpio, Guido. 2018. Terrorismi: Atlante Mondiale del Terrore. Milan: La Nave di Teseo Editore spa. [Google Scholar]
- Papapicco, Concetta, Isabella Lamanna, and Francesca D’Errico. 2022. Adolescents’ vulnerability to fake news and to racial hoaxes: A qualitative analysis on italian sample. Multimodal Technologies and Interaction 6: 20. [Google Scholar] [CrossRef]
- Pierri, Francesco, Alessandro Artoni, and Stefano Ceri. 2020. Investigating italian disinformation spreading on twitter in the context of 2019 european elections. PLoS ONE 15: e0227821. [Google Scholar] [CrossRef] [PubMed]
- Povoledo, Elisabetta. 2020. Italian hostage’s release erupts into clashes over islam and ransom. The New York Times, May 15. [Google Scholar]
- Probe into Silvia Romano Threats Opened. Available online: https://www.ansa.it/english/news/general_news/2020/05/12/probe-into-silvia-romano-threats-opened-9_8e8314cf-b977-400b-aefb-4acc76d736ab.html (accessed on 30 April 2022).
- Ribeiro, Manoel Horta, Pedro H. Calais, Yuri A. Santos, Virgílio AF Almeida, and Wagner Meira Jr. 2018. Characterizing and detecting hateful users on twitter. In Proceedings of the Twelfth International AAAI Conference on Web and Social Media, Stanford, CA, USA, June 25–28. [Google Scholar]
- Shahsavari, Shadi, Pavan Holur, Tianyi Wang, Timothy R Tangherlini, and Vwani Roychowdhury. 2020. Conspiracy in the time of corona: Automatic detection of emerging covid-19 conspiracy theories in social media and the news. Journal of Computational Social Science 3: 279–317. [Google Scholar] [CrossRef]
- Silge, Julia, and David Robinson. 2017. Text Mining with R: A Tidy Approach. Sebastopol: O’Reilly Media, Inc. [Google Scholar]
- Stack, Liam. 2016. Globalism: A far-right conspiracy theory buoyed by trump. The New York Times, November 14. [Google Scholar]
- Straka, Milan, and Jana Straková. 2017. Tokenizing, pos tagging, lemmatizing and parsing ud 2.0 with udpipe. In Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies. Vancouver: Association for Computational Linguistics, pp. 88–99. [Google Scholar]
- Sunstein, Cass. 2018. # Republic: Divided Democracy in the Age of Social Media. Princeton: Princeton University Press. [Google Scholar]
- Van Prooijen, Jan-Willem, Karen M. Douglas, and Clara De Inocencio. 2018. Connecting the dots: Illusory pattern perception predicts belief in conspiracies and the supernatural. European Journal of Social Psychology 48: 320–35. [Google Scholar] [CrossRef] [PubMed]
- Wiederhold, Brenda K. 2020. Social media use during social distancing. Cyberpsychology, Behavior, and Social Networking 23: 275–76. [Google Scholar] [CrossRef]
- Wijffels, Jan. 2020. BTM: Biterm Topic Models for Short Text, R Package Version 0.3.
- Yan, Xiaohui, Jiafeng Guo, Yanyan Lan, and Xueqi Cheng. 2013. A biterm topic model for short texts. In Proceedings of the 22nd International Conference on World Wide Web. New York: Association for Computing Machinery, pp. 1445–56. [Google Scholar]
- Zarocostas, John. 2020. How to fight an infodemic. The Lancet 395: 676. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Visualization of the biterm topic clusters (5 topics) from the database containing keywords “Silvia Romano”.
Figure 1.
Visualization of the biterm topic clusters (5 topics) from the database containing keywords “Silvia Romano”.

Figure 2.
Visualization of the biterm topic clusters (9 topics) from the database containing keywords “Silvia Romano”.
Figure 2.
Visualization of the biterm topic clusters (9 topics) from the database containing keywords “Silvia Romano”.

Figure 3.
Visualization of the biterm topic clusters (13 topics) from the database containing keywords “Silvia Romano”.
Figure 3.
Visualization of the biterm topic clusters (13 topics) from the database containing keywords “Silvia Romano”.


{kind=link}
{kind=link}
{kind=link}
Table 1.
Topic coherence (5 topics) based on BTM for the database containing keywords “Silvia Romano”.
Table 1.
Topic coherence (5 topics) based on BTM for the database containing keywords “Silvia Romano”.
| Topic | C |
|---|---|
| 11.33947199 | |
| 12.16186511 | |
| 21.4354466 | |
| 23.12297406 | |
| 27.55598819 |
Table 2.
The top 10 most likely topic words for each topic (5 topics) according to BTM in the database containing keywords “Silvia Romano”.
Table 2.
The top 10 most likely topic words for each topic (5 topics) according to BTM in the database containing keywords “Silvia Romano”.
| Topic | Terms | Terms (Translated) | Label |
|---|---|---|---|
| italiano libero liberare liberazione notizia casa bello anno riscatto pagare | italian free to free liberation news home beautiful year ransom to pay | Liberation + Happiness | |
| italia islamico casa tornare milano minaccia social insulto mediatico abito | italy islamic home return milan threat social insult media dress | Cyber hate | |
| somaliye kairilip kenyada vatandanere servizio constanzo yasindako bottiglia kairilan yardim | somaliye kairilip kenyada vatandanere service constanzo yasindako bottle kairilan yardim | A probable garbage topic + Hate | |
| riscatto pagare milione soldo terrorista deputato lega euro camera stato | ransom to pay million money terrorist deputy lega euro chamber state | Political controversies | |
| consigliere conto maio salvini choc ministro estero comunale repubblica conte | councilor bill maio salvini shock minister foreign municipal republic conte | Hate + Voices of Italian politicians |
Table 3.
Topic coherence (9 topics) according to BTM for the database containing keywords “Silvia Romano”.
Table 3.
Topic coherence (9 topics) according to BTM for the database containing keywords “Silvia Romano”.
| Topic | C |
|---|---|
| 12.08473518 | |
| 15.75893508 | |
| 15.92883412 | |
| 16.73976434 | |
| 17.31512848 | |
| 19.8386001 | |
| 23.00519103 | |
| 23.78901918 | |
| 26.5616079 |
Table 4.
The top 10 most likely topic words for each topic (9 topics) according to BTM from the database containing keywords “Silvia Romano”.
Table 4.
The top 10 most likely topic words for each topic (9 topics) according to BTM from the database containing keywords “Silvia Romano”.
| Topic | Terms | Terms (Translated) | Label |
|---|---|---|---|
| libero liberare italiano pagare riscatto casa italia tornare chiedere | free to free italian to pay ransom home italy return to ask | Liberation | |
| persona paese odio gente italiano politico vita bottiglia commento migliore | person country hate people italian politic life bottle comment best | Hate | |
| servizio maio conto italiano salvini grazie turco segreto intelligence ministro | service maio bill italian salvini thanks turkish secret intelligence minister | Intelligence | |
| anno rapire kenya italiano prigionia cooperante liberare difendere volontario ong | year kidnap kenya italian imprisonment cooperating to free protect volunteer ngo | Story | |
| minaccia deputato insulto leghista social camera lega parola maryan bagarre | threat deputy insult leghista social chamber lega word maryan scuffle | Cyber hate + Political controversies | |
| casa notizia italia bello tornare milano libero ciampino gioia festa | home news italy beautiful return milan free ciampino happiness party | Happiness | |
| conversione consigliere scelta libero choc profilo basso scambio comunale post | conversion councilor choice free shock profile little exchange municipal post | Hate + Political controversies | |
| riscatto pagare milione soldo italiano stato costare euro terrorista resistere | ransom to pay million money italian state to cost euro terrorist resist | Controversies | |
| islamico terrorista convertire nome aisha donna nuovo vestire abito gruppo | islamic terrorist convert first name aisha woman new to dress dress group | Change in religious belief + Controversies + Hate |
Table 5.
The top 10 most likely topic words for the 3 most coherent topics (13 topics) according to BTM from the database containing keywords “Silvia Romano”.
Table 5.
The top 10 most likely topic words for the 3 most coherent topics (13 topics) according to BTM from the database containing keywords “Silvia Romano”.
| Topic | Terms | Terms (Translated) | Label | Coherence |
|---|---|---|---|---|
| riscatto pagare milione soldo terrorista italiano costare stato euro liberare | ransom to pay million money terrorist Italian to cost state euro to free | Controversies | 23.00519103 | |
| deputato leghista consigliere lega camera salvini choc bagarre comunale terrorista | deputy leghista councilor lega chamber salvini shock scuffle municipal terrorist | Political controversies | 19.7864841 | |
| persona italiano paese vita gente governo politico migliore umano mondo | person italian country life people government politic best human world | Humanity | 19.68225209 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Vellucci, P. Conspiracy Thinking, Online Misinformation, and Hate: Insights from an Italian News Story Using Topic Modeling Techniques. Journal. Media 2023, 4, 1048-1064. https://0-doi-org.brum.beds.ac.uk/10.3390/journalmedia4040067
AMA Style
Vellucci P. Conspiracy Thinking, Online Misinformation, and Hate: Insights from an Italian News Story Using Topic Modeling Techniques. Journalism and Media. 2023; 4(4):1048-1064. https://0-doi-org.brum.beds.ac.uk/10.3390/journalmedia4040067
Chicago/Turabian StyleVellucci, Pierluigi. 2023. "Conspiracy Thinking, Online Misinformation, and Hate: Insights from an Italian News Story Using Topic Modeling Techniques" Journalism and Media 4, no. 4: 1048-1064. https://0-doi-org.brum.beds.ac.uk/10.3390/journalmedia4040067