
Deep-SDM: A Unified Computational Framework for Sequential Data Modeling Using Deep Learning Models
 , ,
, ,
Abstract
:- A simplified and scalable framework for implementing deep learning model architectures: LSTM, GRU, and CNN for sequential data modeling.
- Extensive, automated, and data-driven approach for hyperparameter tuning.
- Numerous subroutines for data exploration, input preparation, model construction, hyperparameter tuning, statistical validation, and results visualization.
- Tracks every intermediate and final result.
- Implements robust model selection strategies and performs statistical analysis to validate the conclusions.
1. Introduction
- Scalable Framework: It is a simplified and scalable framework for implementing deep learning model architectures: LSTM, GRU, and CNN for sequential data modelling.
- Unified Pipeline: The framework handles multiple machine learning tasks, such as data exploration, input preparation, model construction, hyperparameter tuning, statistical validation, and results visualization. These activities are integrated together to make a unified framework.
- Optimization Methodology: It provides an extensive, automated, and data-driven approach for hyperparameter tuning to select the optimal parameter of the model.
- Ease of Use: Every intermediate and final result is accessed through the objects or can be stored in a separate file for future purposes.
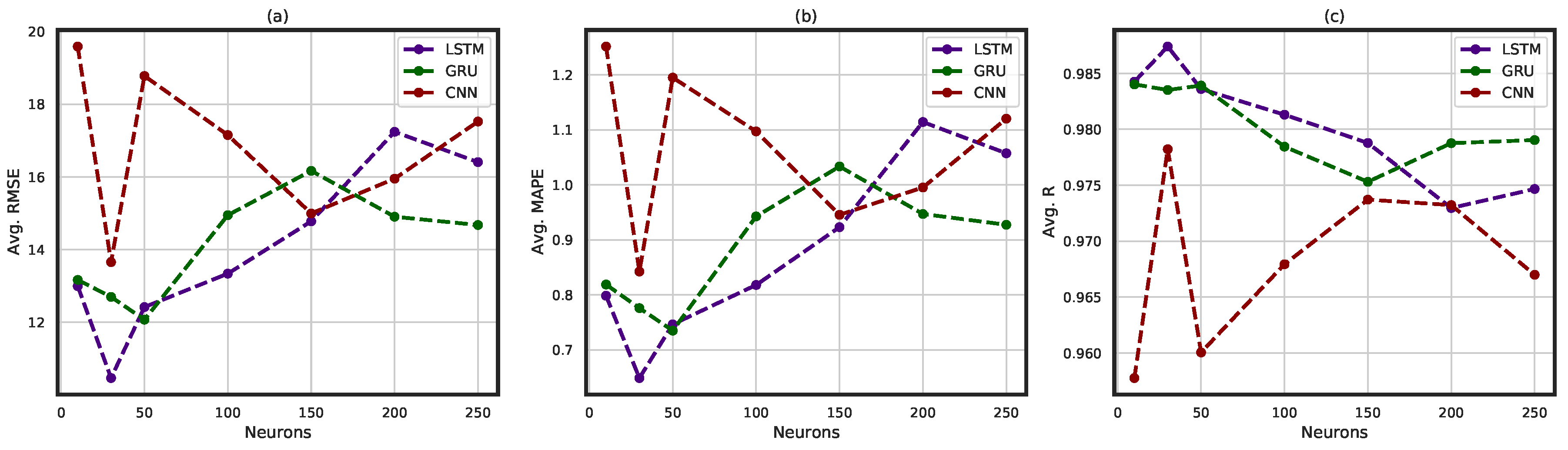
- Model Validation: The framework implements robust model selection strategies and performs statistical analysis to validate the conclusions. Root Mean Squared Error (RMSE), Mean Absolute Percentage Error (MAPE), and Correlation Coefficient (R) are the evaluation metrics for model selection.
2. Related Work
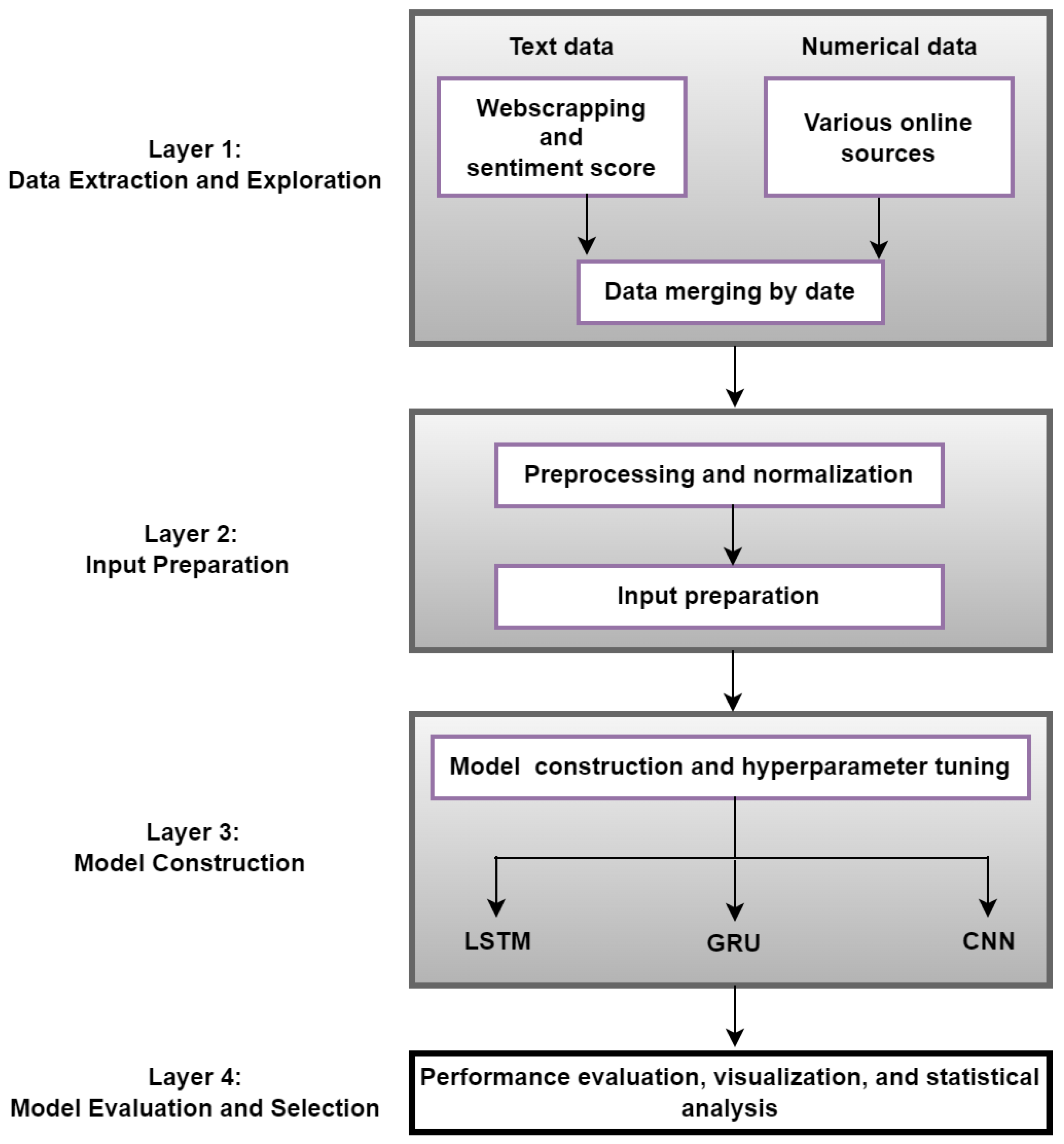
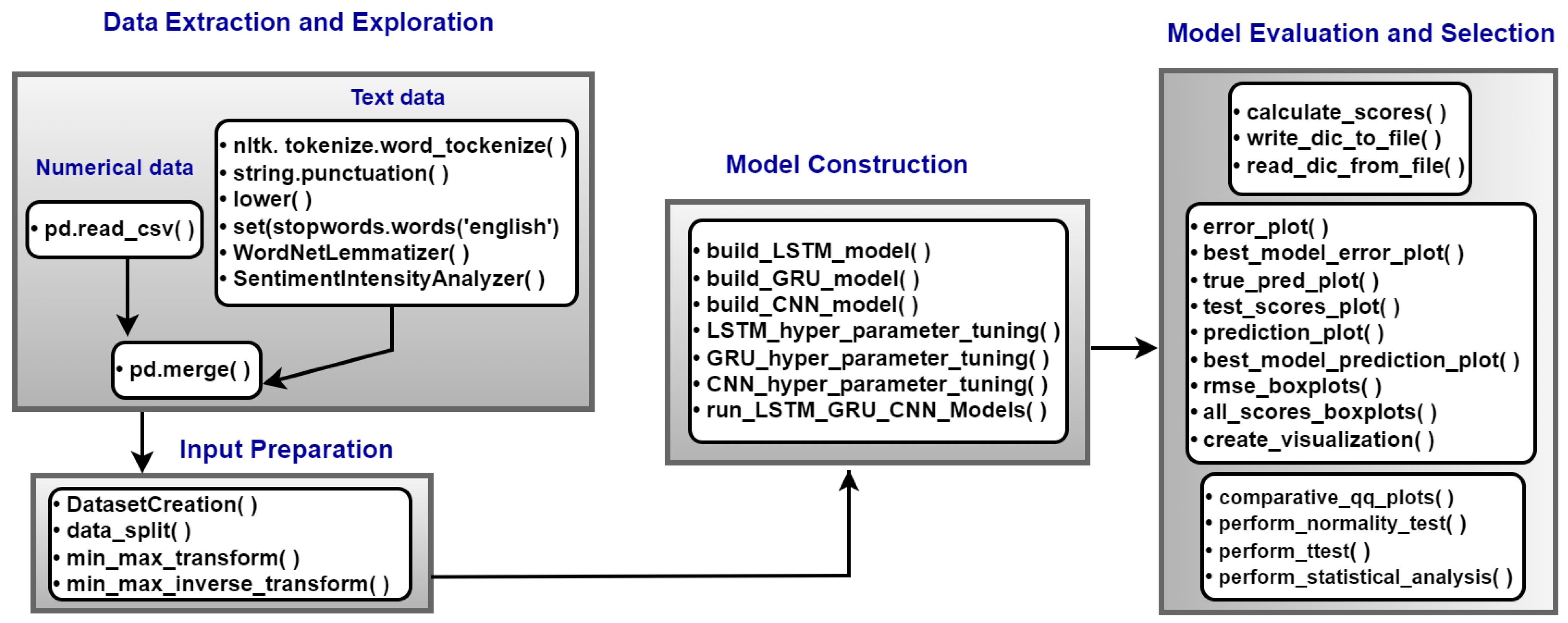
3. Methods and Functionalities
- :
- True value;
- :
- The average value of the original sequence;
- :
- Predicted value;
- :
- Average value of predicted sequence;
- n:
- Number of observations.
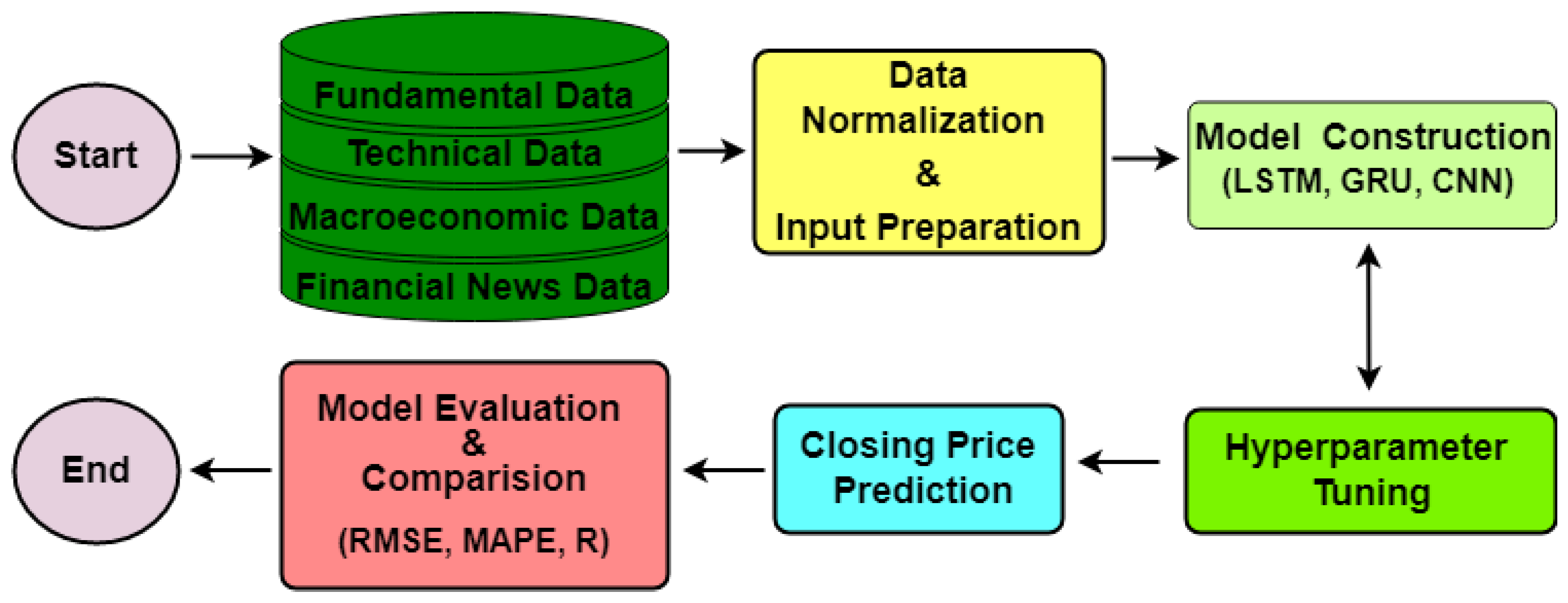
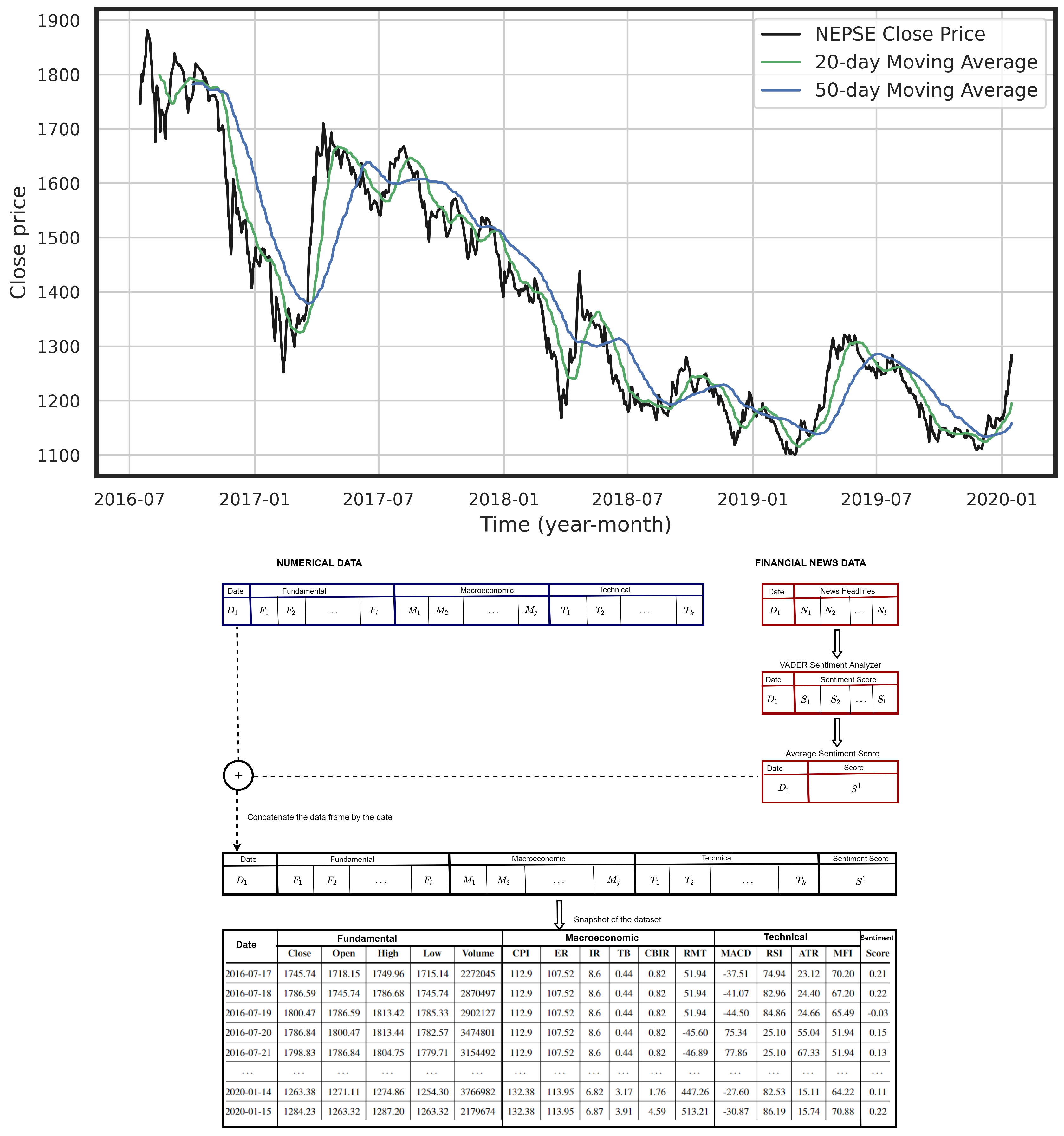
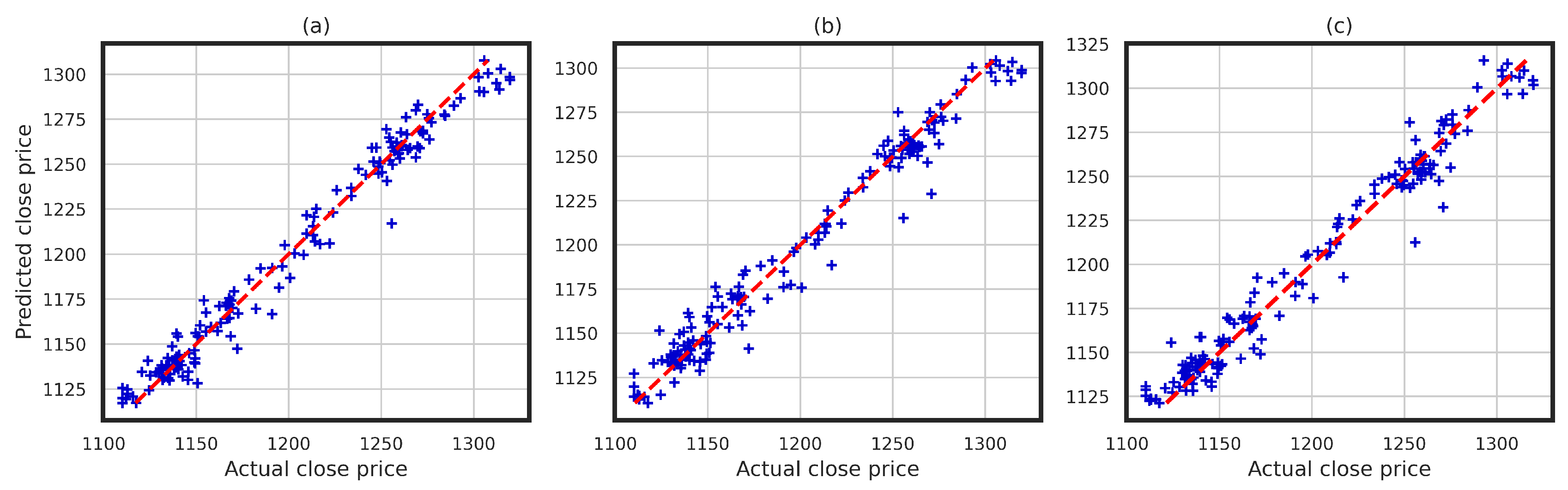
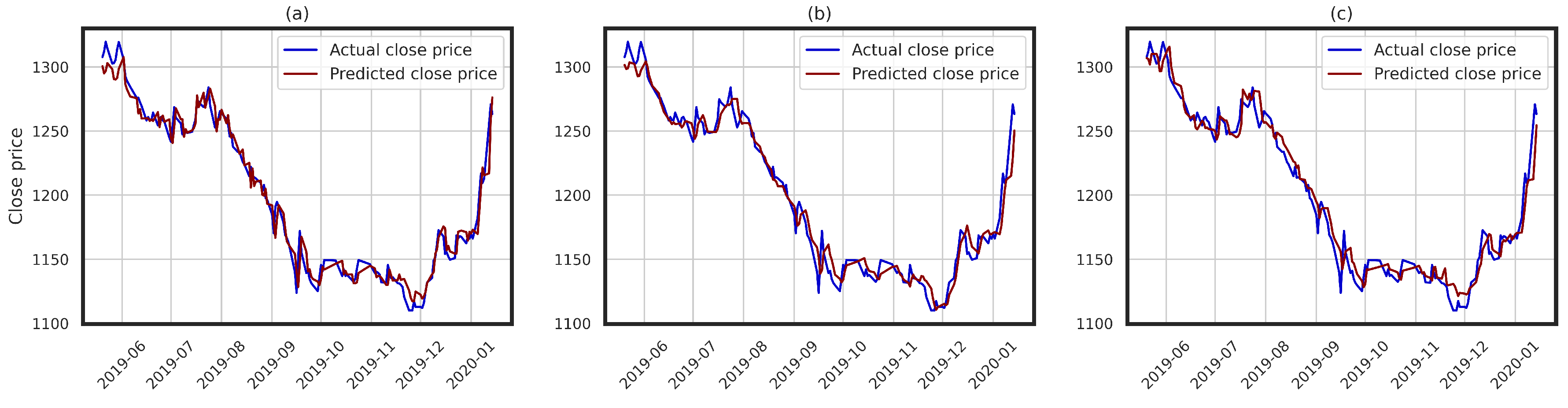
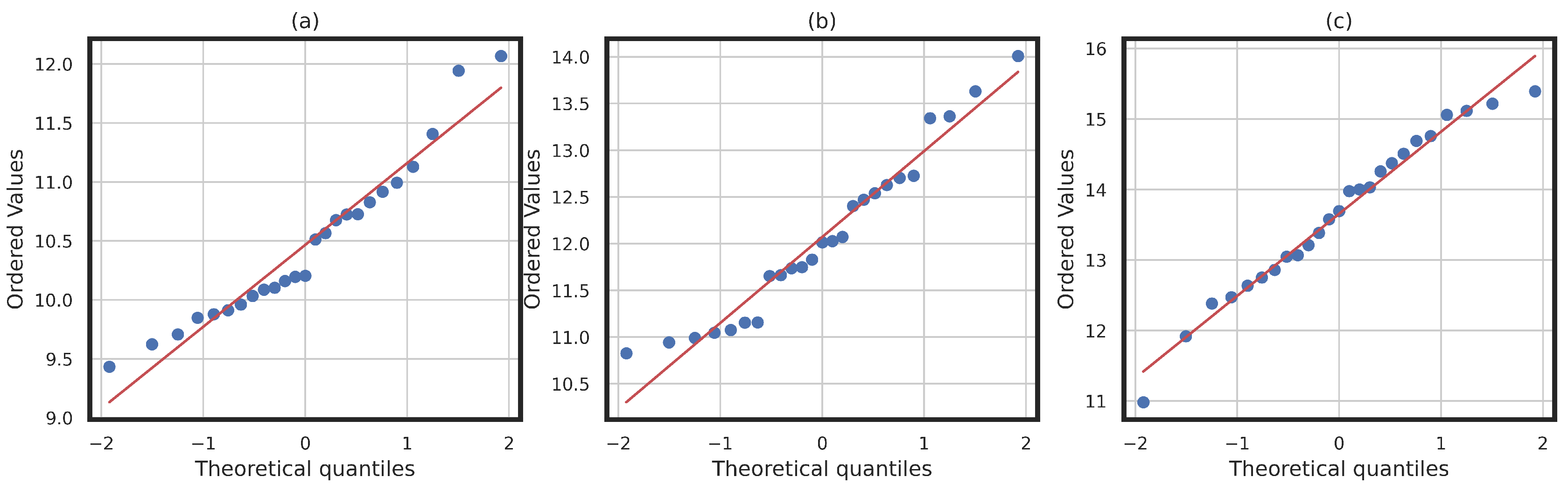
4. Implementation of the Proposed Framework: Illustrative Example
5. Impact on Related Fields
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of Neurons/Filters | LSTM | GRU | CNN | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Optimizer | Learning Rate | Batch Size | Optimizer | Learning Rate | Batch Size | Optimizer | Learning Rate | Batch Size | |
| 10 | Adam | 0.01 | 16 | Adam | 0.001 | 4 | Adagrad | 0.01 | 8 |
| 30 | Adam | 0.1 | 16 | Adagrad | 0.01 | 8 | Adagrad | 0.1 | 8 |
| 50 | Adam | 0.001 | 16 | Adagrad | 0.01 | 16 | Adagrad | 0.01 | 16 |
| 100 | Adagrad | 0.01 | 16 | Adagrad | 0.001 | 8 | Adagrad | 0.01 | 16 |
| 150 | Adagrad | 0.001 | 4 | Adagrad | 0.001 | 16 | Adagrad | 0.01 | 16 |
| 200 | Adagrad | 0.001 | 16 | Adagrad | 0.001 | 16 | Adagrad | 0.01 | 16 |
| 250 | Adagrad | 0.001 | 16 | Adagrad | 0.001 | 16 | Adagrad | 0.001 | 8 |
| Models | No. of Neurons | Optimizer | Learning Rate | Batch Size |
|---|---|---|---|---|
| LSTM | 30 | Adam | 0.1 | 16 |
| GRU | 50 | Adagrad | 0.01 | 16 |
| CNN | 30 | Adagrad | 0.1 | 8 |



References
- Alkhatib, K.; Khazaleh, H.; Alkhazaleh, H.A.; Alsoud, A.R.; Abualigah, L. A new stock price forecasting method using active deep learning approach. J. Open Innov. Technol. Mark. Complex. 2022, 8, 96. [Google Scholar] [CrossRef]
- Mandal, M.; Vipparthi, S.K. An empirical review of deep learning frameworks for change detection: Model design, experimental frameworks, challenges and research needs. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6101–6122. [Google Scholar] [CrossRef]
- Bao, W.; Yue, J.; Rao, Y. A deep learning framework for financial time series using stacked autoencoders and long-short term memory. PLoS ONE 2017, 12, e0180944. [Google Scholar] [CrossRef] [PubMed]
- Yan, B.; Aasma, M. A novel deep learning framework: Prediction and analysis of financial time series using CEEMD and LSTM. Expert Syst. Appl. 2020, 159, 113609. [Google Scholar]
- Du, S.; Li, T.; Yang, Y.; Horng, S.J. Deep air quality forecasting using hybrid deep learning framework. IEEE Trans. Knowl. Data Eng. 2019, 33, 2412–2424. [Google Scholar] [CrossRef]
- Dahal, K.R.; Pokhrel, N.R.; Gaire, S.; Mahatara, S.; Joshi, R.P.; Gupta, A.; Banjade, H.R.; Joshi, J. A comparative study on effect of news sentiment on stock price prediction with deep learning architecture. PLoS ONE 2023, 18, e0284695. [Google Scholar] [CrossRef] [PubMed]
- Gilik, A.; Ogrenci, A.S.; Ozmen, A. Air quality prediction using CNN+ LSTM-based hybrid deep learning architecture. Environ. Sci. Pollut. Res. 2022, 29, 11920–11938. [Google Scholar] [CrossRef]
- Somu, N.; MR, G.R.; Ramamritham, K. A deep learning framework for building energy consumption forecast. Renew. Sustain. Energy Rev. 2021, 137, 110591. [Google Scholar] [CrossRef]
- Wen, S.C.; Yang, C.H. Time series analysis and prediction of nonlinear systems with ensemble learning framework applied to deep learning neural networks. Inf. Sci. 2021, 572, 167–181. [Google Scholar] [CrossRef]
- Yang, J.; Li, S.; Wang, Z.; Dong, H.; Wang, J.; Tang, S. Using deep learning to detect defects in manufacturing: A comprehensive survey and current challenges. Materials 2020, 13, 5755. [Google Scholar] [CrossRef]
- Malhan, R.; Gupta, S.K. The Role of Deep Learning in Manufacturing Applications: Challenges and Opportunities. J. Comput. Inf. Sci. Eng. 2023, 23, 060816. [Google Scholar] [CrossRef]
- Jamwal, A.; Agrawal, R.; Sharma, M. Deep learning for manufacturing sustainability: Models, applications in Industry 4.0 and implications. Int. J. Inf. Manag. Data Insights 2022, 2, 100107. [Google Scholar] [CrossRef]
- Sahu, S.K.; Mokhade, A.; Bokde, N.D. An Overview of Machine Learning, Deep Learning, and Reinforcement Learning-Based Techniques in Quantitative Finance: Recent Progress and Challenges. Appl. Sci. 2023, 13, 1956. [Google Scholar] [CrossRef]
- Huang, J.; Chai, J.; Cho, S. Deep learning in finance and banking: A literature review and classification. Front. Bus. Res. China 2020, 14, 1–24. [Google Scholar] [CrossRef]
- Abdel-Jaber, H.; Devassy, D.; Al Salam, A.; Hidaytallah, L.; El-Amir, M. A review of deep learning algorithms and their applications in healthcare. Algorithms 2022, 15, 71. [Google Scholar] [CrossRef]
- Kaul, D.; Raju, H.; Tripathy, B. Deep learning in healthcare. In Deep Learning in Data Analytics: Recent Techniques, Practices and Applications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 97–115. [Google Scholar]
- Othman, N.A.; Abdel-Fattah, M.A.; Ali, A.T. A Hybrid Deep Learning Framework with Decision-Level Fusion for Breast Cancer Survival Prediction. Big Data Cogn. Comput. 2023, 7, 50. [Google Scholar] [CrossRef]
- Roy, B.; Malviya, L.; Kumar, R.; Mal, S.; Kumar, A.; Bhowmik, T.; Hu, J.W. Hybrid Deep Learning Approach for Stress Detection Using Decomposed EEG Signals. Diagnostics 2023, 13, 1936. [Google Scholar] [CrossRef] [PubMed]
- Ko, K.K.; Jung, E.S. Improving Air Pollution Prediction System through Multimodal Deep Learning Model Optimization. Appl. Sci. 2022, 12, 10405. [Google Scholar] [CrossRef]
- Kothadiya, D.; Bhatt, C.; Sapariya, K.; Patel, K.; Gil-González, A.B.; Corchado, J.M. Deepsign: Sign language detection and recognition using deep learning. Electronics 2022, 11, 1780. [Google Scholar] [CrossRef]
- Forootan, M.M.; Larki, I.; Zahedi, R.; Ahmadi, A. Machine learning and deep learning in energy systems: A review. Sustainability 2022, 14, 4832. [Google Scholar] [CrossRef]
- Olu-Ajayi, R.; Alaka, H.; Sulaimon, I.; Sunmola, F.; Ajayi, S. Building energy consumption prediction for residential buildings using deep learning and other machine learning techniques. J. Build. Eng. 2022, 45, 103406. [Google Scholar] [CrossRef]
- Altalak, M.; Ammad uddin, M.; Alajmi, A.; Rizg, A. Smart agriculture applications using deep learning technologies: A survey. Appl. Sci. 2022, 12, 5919. [Google Scholar] [CrossRef]
- Islam, M.M.; Adil, M.A.A.; Talukder, M.A.; Ahamed, M.K.U.; Uddin, M.A.; Hasan, M.K.; Sharmin, S.; Rahman, M.M.; Debnath, S.K. DeepCrop: Deep learning-based crop disease prediction with web application. J. Agric. Food Res. 2023, 14, 100764. [Google Scholar] [CrossRef]
- Nagaraj, N.; Gururaj, H.L.; Swathi, B.H.; Hu, Y.C. Passenger flow prediction in bus transportation system using deep learning. Multimed. Tools Appl. 2022, 81, 12519–12542. [Google Scholar] [CrossRef] [PubMed]
- Ravi, C.; Tigga, A.; Reddy, G.T.; Hakak, S.; Alazab, M. Driver identification using optimized deep learning model in smart transportation. ACM Trans. Internet Technol. 2022, 22, 84. [Google Scholar] [CrossRef]
- Sayal, A.; Chaithra, N.; Jha, J.; Trilochan, B.; Kalyan, G.V.; Priya, M.S.; Gupta, V.; Memoria, M.; Gupta, A. Visual Sentiment Analysis Using Machine Learning for Entertainment Applications. In Proceedings of the 2023 International Conference on IoT, Communication and Automation Technology (ICICAT), Gorakhpur, India, 23–24 June 2023; pp. 1–8. [Google Scholar]
- Chou, C.H.; Su, Y.S.; Hsu, C.J.; Lee, K.C.; Han, P.H. Design of desktop audiovisual entertainment system with deep learning and haptic sensations. Symmetry 2020, 12, 1718. [Google Scholar] [CrossRef]
- Nasseri, M.; Falatouri, T.; Brandtner, P.; Darbanian, F. Applying Machine Learning in Retail Demand Prediction—A Comparison of Tree-Based Ensembles and Long Short-Term Memory-Based Deep Learning. Appl. Sci. 2023, 13, 11112. [Google Scholar] [CrossRef]
- Giri, C.; Chen, Y. Deep learning for demand forecasting in the fashion and apparel retail industry. Forecasting 2022, 4, 565–581. [Google Scholar] [CrossRef]
- Zhang, X.; Guo, F.; Chen, T.; Pan, L.; Beliakov, G.; Wu, J. A Brief Survey of Machine Learning and Deep Learning Techniques for E-Commerce Research. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 2188–2216. [Google Scholar] [CrossRef]
- Alzahrani, M.E.; Aldhyani, T.H.; Alsubari, S.N.; Althobaiti, M.M.; Fahad, A. Developing an intelligent system with deep learning algorithms for sentiment analysis of E-commerce product reviews. Comput. Intell. Neurosci. 2022, 2022, 3840071. [Google Scholar] [CrossRef]
- Bhandari, H.N.; Rimal, B.; Pokhrel, N.R.; Rimal, R.; Dahal, K.R.; Khatri, R.K. Predicting stock market index using LSTM. Mach. Learn. Appl. 2022, 9, 100320. [Google Scholar] [CrossRef]
- Chen, H.; Engkvist, O.; Wang, Y.; Olivecrona, M.; Blaschke, T. The rise of deep learning in drug discovery. Drug Discov. Today 2018, 23, 1241–1250. [Google Scholar] [CrossRef]
- Fan, C.; Sun, Y.; Zhao, Y.; Song, M.; Wang, J. Deep learning-based feature engineering methods for improved building energy prediction. Appl. Energy 2019, 240, 35–45. [Google Scholar] [CrossRef]
- He, Y.; Wu, P.; Li, Y.; Wang, Y.; Tao, F.; Wang, Y. A generic energy prediction model of machine tools using deep learning algorithms. Appl. Energy 2020, 275, 115402. [Google Scholar] [CrossRef]
- Lu, W.; Li, J.; Wang, J.; Qin, L. A CNN-BiLSTM-AM method for stock price prediction. Neural Comput. Appl. 2021, 33, 4741–4753. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, J.; Wang, X.; Gao, M.; Guo, B.; Gao, M.; Liu, J.; Yu, Y.; Wang, L.; Kong, W.; et al. Prediction of drug efficacy from transcriptional profiles with deep learning. Nat. Biotechnol. 2021, 39, 1444–1452. [Google Scholar] [CrossRef] [PubMed]
- Sarwar, M.A.; Kamal, N.; Hamid, W.; Shah, M.A. Prediction of diabetes using machine learning algorithms in healthcare. In Proceedings of the 2018 24th International Conference on Automation and Computing (ICAC), Newcastle upon Tyne, UK, 6–7 September 2018; IEEE: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Mohan, S.; Mullapudi, S.; Sammeta, S.; Vijayvergia, P.; Anastasiu, D.C. Stock price prediction using news sentiment analysis. In Proceedings of the 2019 IEEE Fifth International Conference on Big Data Computing Service and Applications (BigDataService), Newark, CA, USA, 4–9 April 2019; IEEE: New York, NY, USA, 2019; pp. 205–208. [Google Scholar]
- Abdullah, S.S.; Rahaman, M.S.; Rahman, M.S. Analysis of stock market using text mining and natural language processing. In Proceedings of the 2013 International Conference on Informatics, Electronics and Vision (ICIEV), Dhaka, Bangladesh, 17–18 May 2013; IEEE: New York, NY, USA, 2013; pp. 1–6. [Google Scholar]
- Schumaker, R.P.; Chen, H. Textual analysis of stock market prediction using breaking financial news: The AZFin text system. ACM Trans. Inf. Syst. (TOIS) 2009, 27, 1–19. [Google Scholar] [CrossRef]
- Bhandari, H.N.; Rimal, B.; Pokhrel, N.R.; Rimal, R.; Dahal, K.R. LSTM-SDM: An integrated framework of LSTM implementation for sequential data modeling. Softw. Impacts 2022, 14, 100396. [Google Scholar] [CrossRef]
- Pokhrel, N.R.; Dahal, K.R.; Rimal, R.; Bhandari, H.N.; Khatri, R.K.; Rimal, B.; Hahn, W.E. Predicting nepse index price using deep learning models. Mach. Learn. Appl. 2022, 9, 100385. [Google Scholar] [CrossRef]
- Livieris, I.E.; Stavroyiannis, S.; Pintelas, E.; Pintelas, P. A novel validation framework to enhance deep learning models in time-series forecasting. Neural Comput. Appl. 2020, 32, 17149–17167. [Google Scholar] [CrossRef]
- Chen, W.; Shi, K. A deep learning framework for time series classification using Relative Position Matrix and Convolutional Neural Network. Neurocomputing 2019, 359, 384–394. [Google Scholar] [CrossRef]
- Du, S.; Li, T.; Horng, S.J. Time series forecasting using sequence-to-sequence deep learning framework. In Proceedings of the 2018 9th International Symposium on Parallel Architectures, Algorithms and Programming (PAAP), Taipei, Taiwan, 26–28 December 2018; pp. 171–176. [Google Scholar]
- Khorram, A.; Khalooei, M.; Rezghi, M. End-to-end CNN+ LSTM deep learning approach for bearing fault diagnosis. Appl. Intell. 2021, 51, 736–751. [Google Scholar] [CrossRef]
- Wang, J.; Li, R.; Li, R.; Fu, B.; Chen, D.Z. Hmckrautoencoder: An interpretable deep learning framework for time series analysis. IEEE Trans. Emerg. Top. Comput. 2022, 10, 99–111. [Google Scholar] [CrossRef]
- Buda, T.S.; Caglayan, B.; Assem, H. Deepad: A generic framework based on deep learning for time series anomaly detection. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Melbourne, VIC, Australia, 3–6 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 577–588. [Google Scholar]
- Laptev, N.; Amizadeh, S.; Flint, I. Generic and scalable framework for automated time-series anomaly detection. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1939–1947. [Google Scholar]
- Li, Z.; Kang, L.; Zhou, L.; Zhu, M. Deep learning framework with time series analysis methods for runoff prediction. Water 2021, 13, 575. [Google Scholar] [CrossRef]
- Yao, L.; Zhang, Y.; Li, W.; Chung, C.R.; Guan, J.; Zhang, W.; Chiang, Y.C.; Lee, T.Y. DeepAFP: An effective computational framework for identifying antifungal peptides based on deep learning. Protein Sci. 2023, 32, e4758. [Google Scholar] [CrossRef] [PubMed]
- Yang, S. A novel study on deep learning framework to predict and analyze the financial time series information. Future Gener. Comput. Syst. 2021, 125, 812–819. [Google Scholar] [CrossRef]
- Niu, T.; Wang, J.; Lu, H.; Yang, W.; Du, P. Developing a deep learning framework with two-stage feature selection for multivariate financial time series forecasting. Expert Syst. Appl. 2020, 148, 113237. [Google Scholar] [CrossRef]
- Ye, R.; Dai, Q. A novel transfer learning framework for time series forecasting. Knowl.-Based Syst. 2018, 156, 74–99. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gülçehre, Ç.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Cao, J.; Li, Z.; Li, J. Financial time series forecasting model based on CEEMDAN and LSTM. Phys. A Stat. Mech. Appl. 2019, 519, 127–139. [Google Scholar] [CrossRef]
- Capinha, C.; Ceia-Hasse, A.; Kramer, A.M.; Meijer, C. Deep learning for supervised classification of temporal data in ecology. Ecol. Inform. 2021, 61, 101252. [Google Scholar] [CrossRef]
- Alshahrani, H.M.; Al-Wesabi, F.N.; Al Duhayyim, M.; Nemri, N.; Kadry, S.; Alqaralleh, B.A. An automated deep learning based satellite imagery analysis for ecology management. Ecol. Inform. 2021, 66, 101452. [Google Scholar] [CrossRef]
- Li, H.; Fan, Y. Interpretable, highly accurate brain decoding of subtly distinct brain states from functional MRI using intrinsic functional networks and long short-term memory recurrent neural networks. NeuroImage 2019, 202, 116059. [Google Scholar] [CrossRef]
- Rimal, R.; Brannon, M.; Wang, Y.; Yang, X. Comparative study of various machine learning methods on ASD classification. Int. J. Data Sci. Anal. 2023, 1–15. [Google Scholar] [CrossRef]
- Wang, D.; Su, J.; Yu, H. Feature extraction and analysis of natural language processing for deep learning English language. IEEE Access 2020, 8, 46335–46345. [Google Scholar] [CrossRef]
- Lavanya, P.; Sasikala, E. Deep learning techniques on text classification using Natural language processing (NLP) in social healthcare network: A comprehensive survey. In Proceedings of the 2021 3rd International Conference on Signal Processing and Communication (ICPSC), Coimbatore, India, 13–14 May 2021; pp. 603–609. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar] [CrossRef]
- Lu, J.; Tan, L.; Jiang, H. Review on convolutional neural network (CNN) applied to plant leaf disease classification. Agriculture 2021, 11, 707. [Google Scholar] [CrossRef]
- Mohammadpour, L.; Ling, T.C.; Liew, C.S.; Aryanfar, A. A survey of CNN-based network intrusion detection. Appl. Sci. 2022, 12, 8162. [Google Scholar] [CrossRef]
- Dhillon, A.; Verma, G.K. Convolutional neural network: A review of models, methodologies and applications to object detection. Prog. Artif. Intell. 2020, 9, 85–112. [Google Scholar] [CrossRef]
- Joloudari, J.H.; Hussain, S.; Nematollahi, M.A.; Bagheri, R.; Fazl, F.; Alizadehsani, R.; Lashgari, R.; Talukder, A. BERT-deep CNN: State of the art for sentiment analysis of COVID-19 tweets. Soc. Netw. Anal. Min. 2023, 13, 99. [Google Scholar] [CrossRef]
- Marques, G.; Agarwal, D.; De la Torre Díez, I. Automated medical diagnosis of COVID-19 through EfficientNet convolutional neural network. Appl. Soft Comput. 2020, 96, 106691. [Google Scholar] [CrossRef] [PubMed]
- McKinney, W. Pandas: A foundational Python library for data analysis and statistics. Python High Perform. Sci. Comput. 2011, 14, 1–9. [Google Scholar]
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions, Sydney, NSW, Australia, 17 July 2006; pp. 69–72. [Google Scholar]
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 216–225. [Google Scholar]
- Mollenhauer, D.; Atzmueller, M. Sequential Exceptional Pattern Discovery Using Pattern-Growth: An Extensible Framework for Interpretable Machine Learning on Sequential Data. In Proceedings of the XI-ML@ KI, Bamberg, Germany, 21 September 2020. [Google Scholar]
- Ostmeyer, J.; Cowell, L. Machine learning on sequential data using a recurrent weighted average. Neurocomputing 2019, 331, 281–288. [Google Scholar] [CrossRef]


| Info: Code Metadata and Environmental Setup | Description |
|---|---|
| Current code version | Version 1.0 |
| Permanent link to code/repository used for this code version | https://github.com/mlrg2020/Deep-SDM |
| Permanent link to Reproducible Capsule | https://codeocean.com/capsule/3410053/tree/v1 |
| Legal Code License | MIT License |
| Compilation requirements, operating environments, and dependencies | Code can be executed in Anaconda or Google Colab |
| Support email for questions | [email protected] |
| Machine Configuration | Google Colab with NVIDIA-SMI 495.44 GPU |
| Environment | Python 3.6.0, TensorFlow, and Keras APIs |
| Architecture | LSTM, GRU, and CNN |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pokhrel, N.R.; Dahal, K.R.; Rimal, R.; Bhandari, H.N.; Rimal, B. Deep-SDM: A Unified Computational Framework for Sequential Data Modeling Using Deep Learning Models. Software 2024, 3, 47-61. https://0-doi-org.brum.beds.ac.uk/10.3390/software3010003
Pokhrel NR, Dahal KR, Rimal R, Bhandari HN, Rimal B. Deep-SDM: A Unified Computational Framework for Sequential Data Modeling Using Deep Learning Models. Software. 2024; 3(1):47-61. https://0-doi-org.brum.beds.ac.uk/10.3390/software3010003
Chicago/Turabian StylePokhrel, Nawa Raj, Keshab Raj Dahal, Ramchandra Rimal, Hum Nath Bhandari, and Binod Rimal. 2024. "Deep-SDM: A Unified Computational Framework for Sequential Data Modeling Using Deep Learning Models" Software 3, no. 1: 47-61. https://0-doi-org.brum.beds.ac.uk/10.3390/software3010003