
Sentiment Analysis of Review Data Using Blockchain and LSTM to Improve Regulation for a Sustainable Market

 , ,
, ,
Abstract
:1. Introduction
- In order to ensure the authenticity and validity of the data, a platform based on blockchain has been developed for data storage. Users can make transactions and post related review information through this platform.
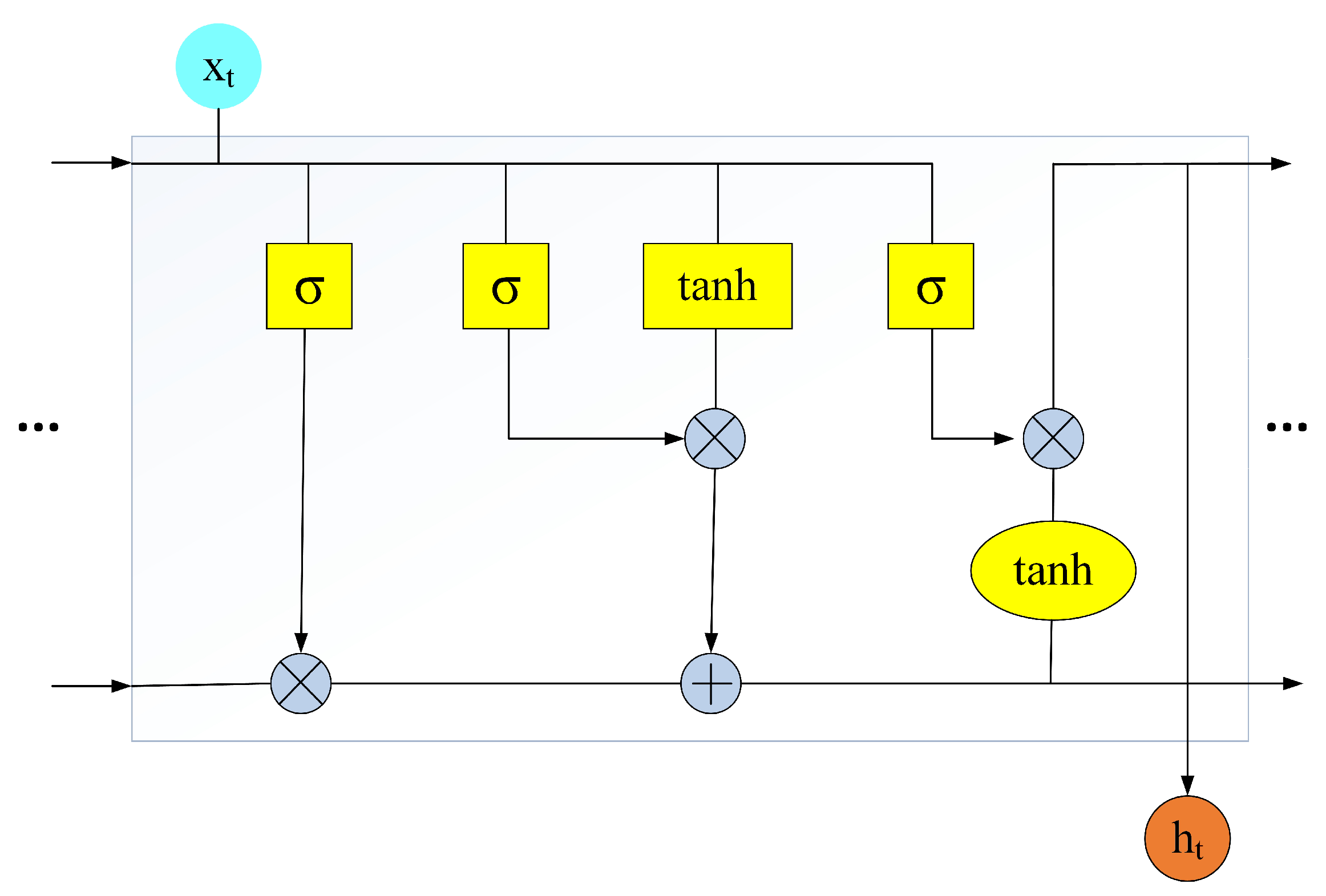
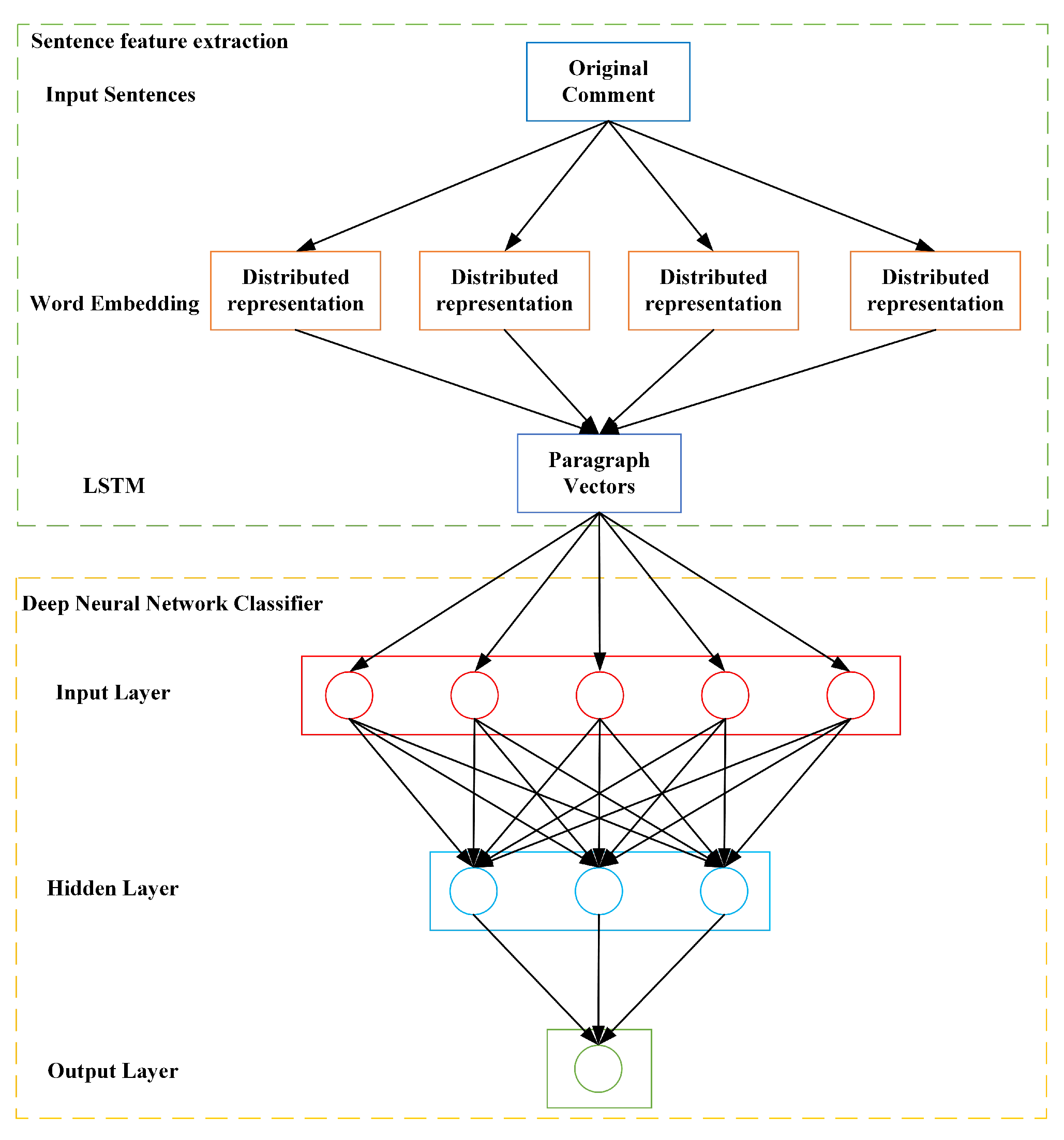
- In order to improve the precision of sentiment analysis, the LSTM model has been improved by an external memory component to process review data containing idioms. Compared with the currently widely used models such as Support Vector Machine (SVM) and Naive Bayes (NB), the improved model shows better performance.
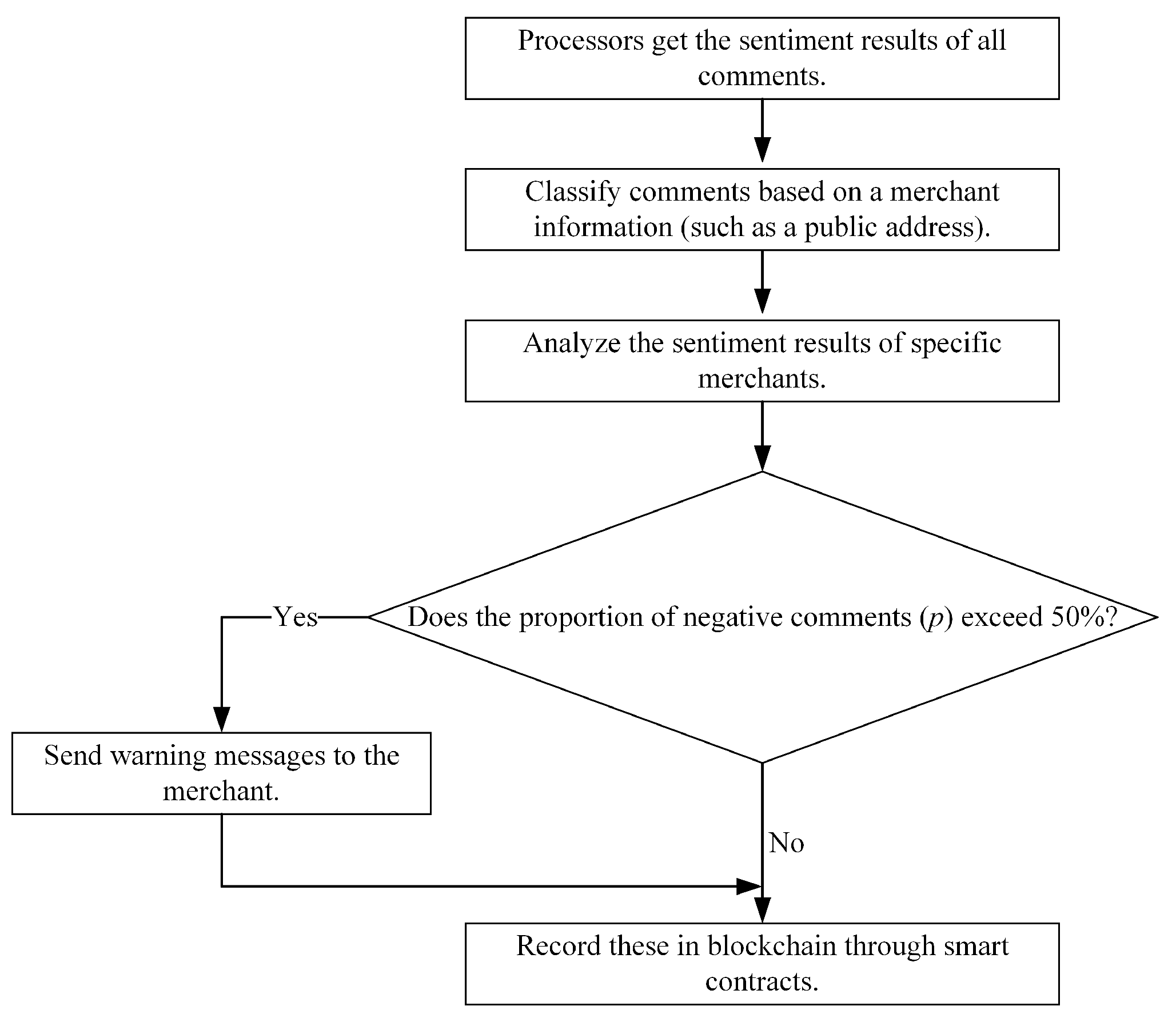
- According to the results of sentiment analysis, the proportion of negative reviews can provide a basis and strategy for regulation. The case study proves the effectiveness of the method used for market regulation.
2. Related Work
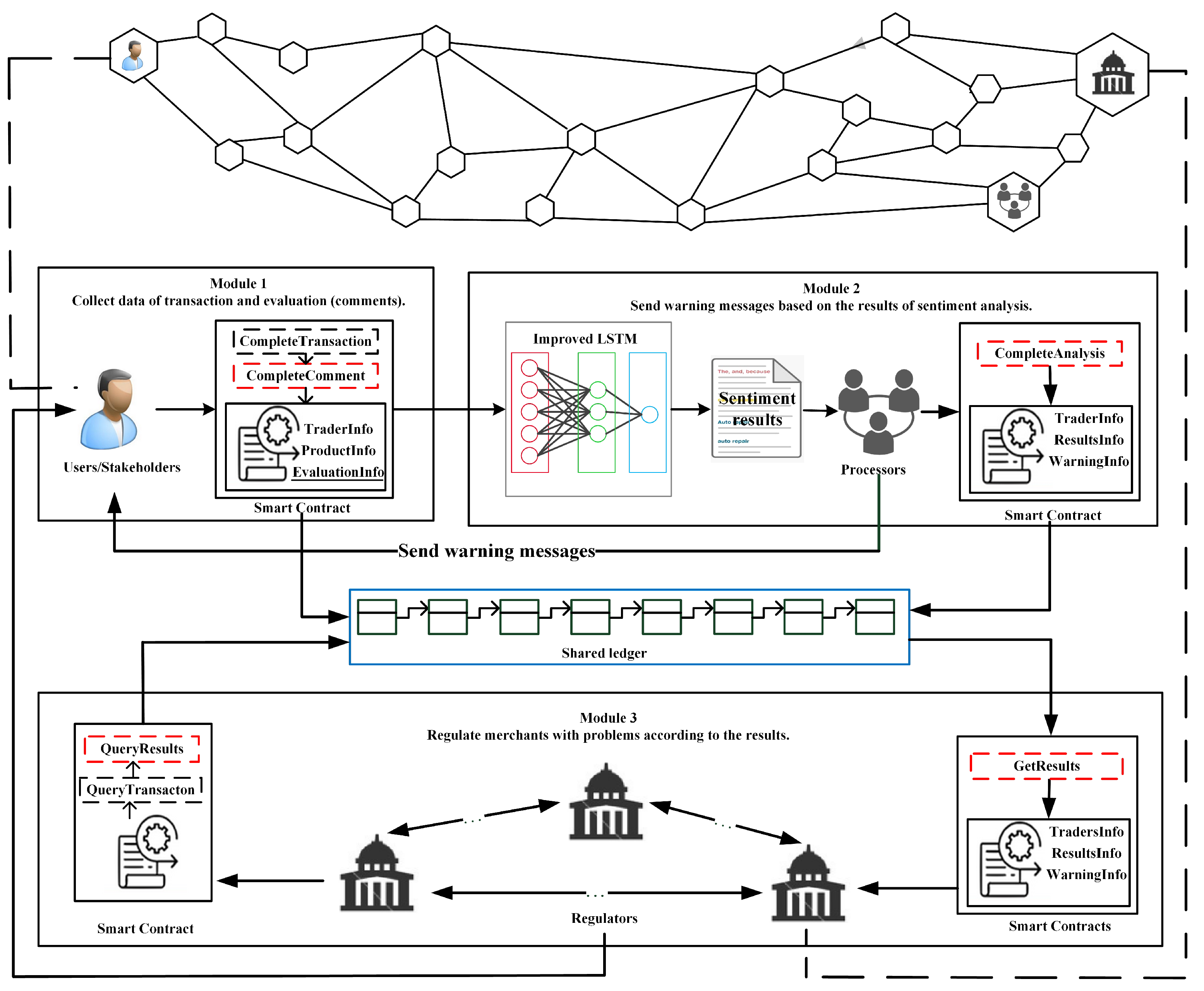
3. Framework
4. Method Implementation
4.1. Transactions and Reviews Based on the Blockchain Network
- sends a message to the blockchain network and defines a transaction in the message;
- accept the by broadcasting;
- Participants in the blockchain verify the legitimacy of the transaction and the transaction is committed.
| Algorithm 1: Participants to finish the review of the transaction. |
 |
| Algorithm 2: Obtaining sentiment analysis results. |
 |
4.2. Sentiment Analysis
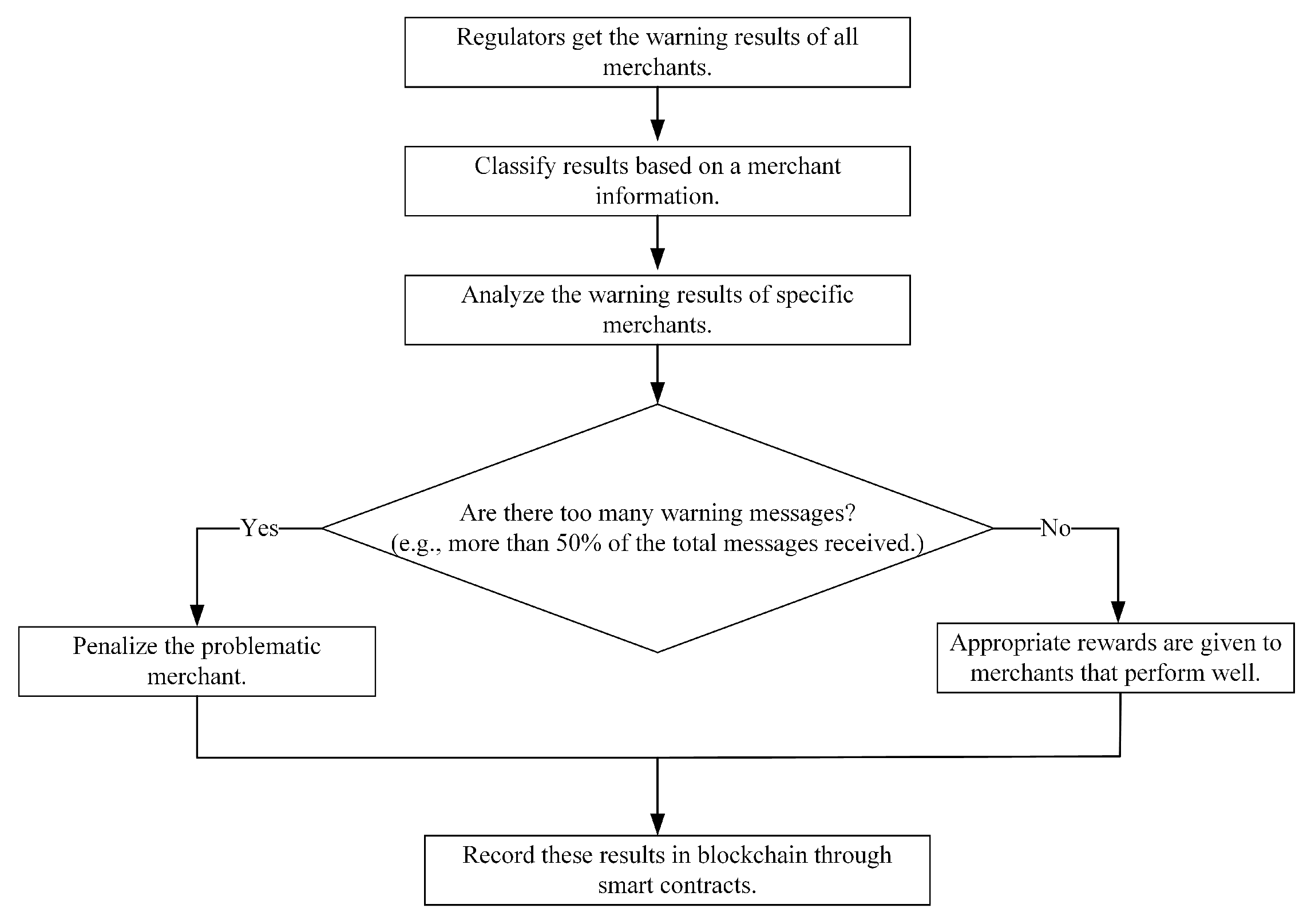
4.3. The Process of Warning and Regulation for Problematic Merchants
5. Experiments
5.1. Experimental Environment and Data
5.2. Experimental Results and Discussion
5.2.1. Metrics for Evaluation
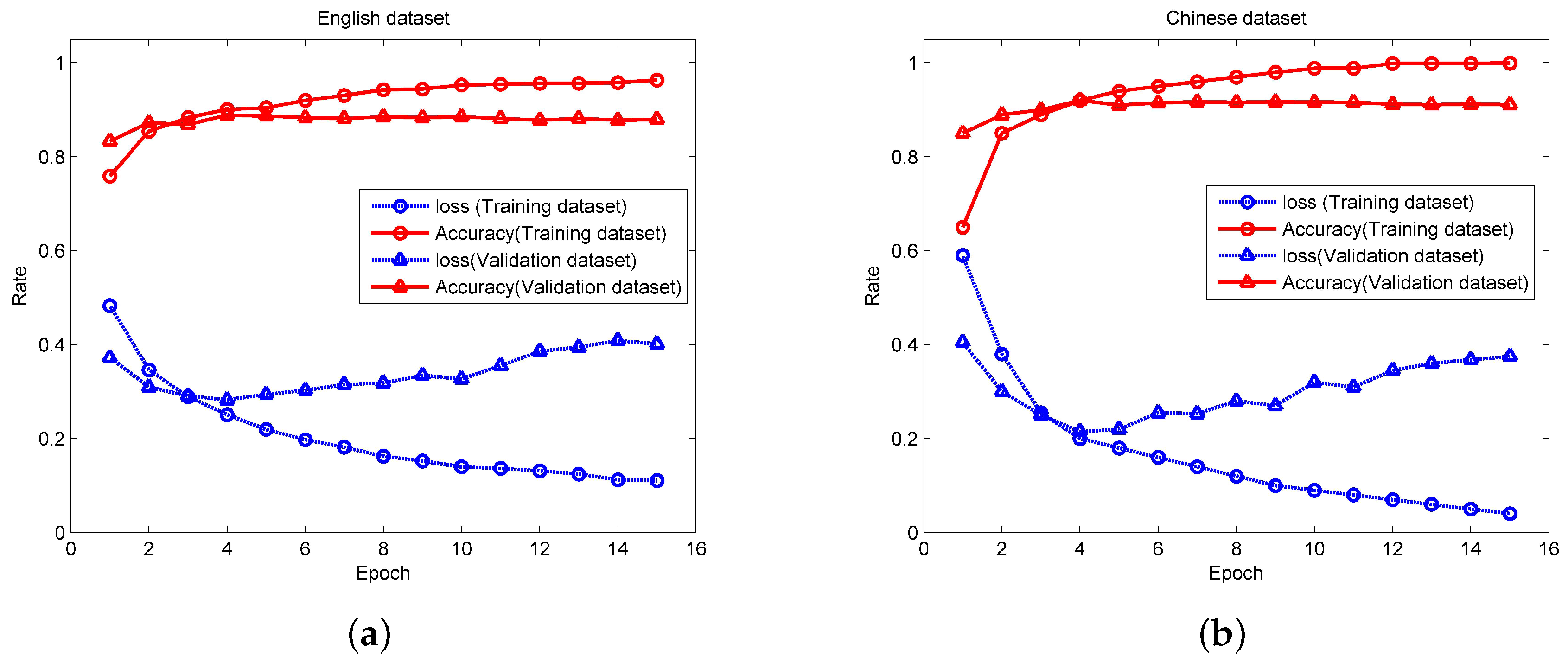
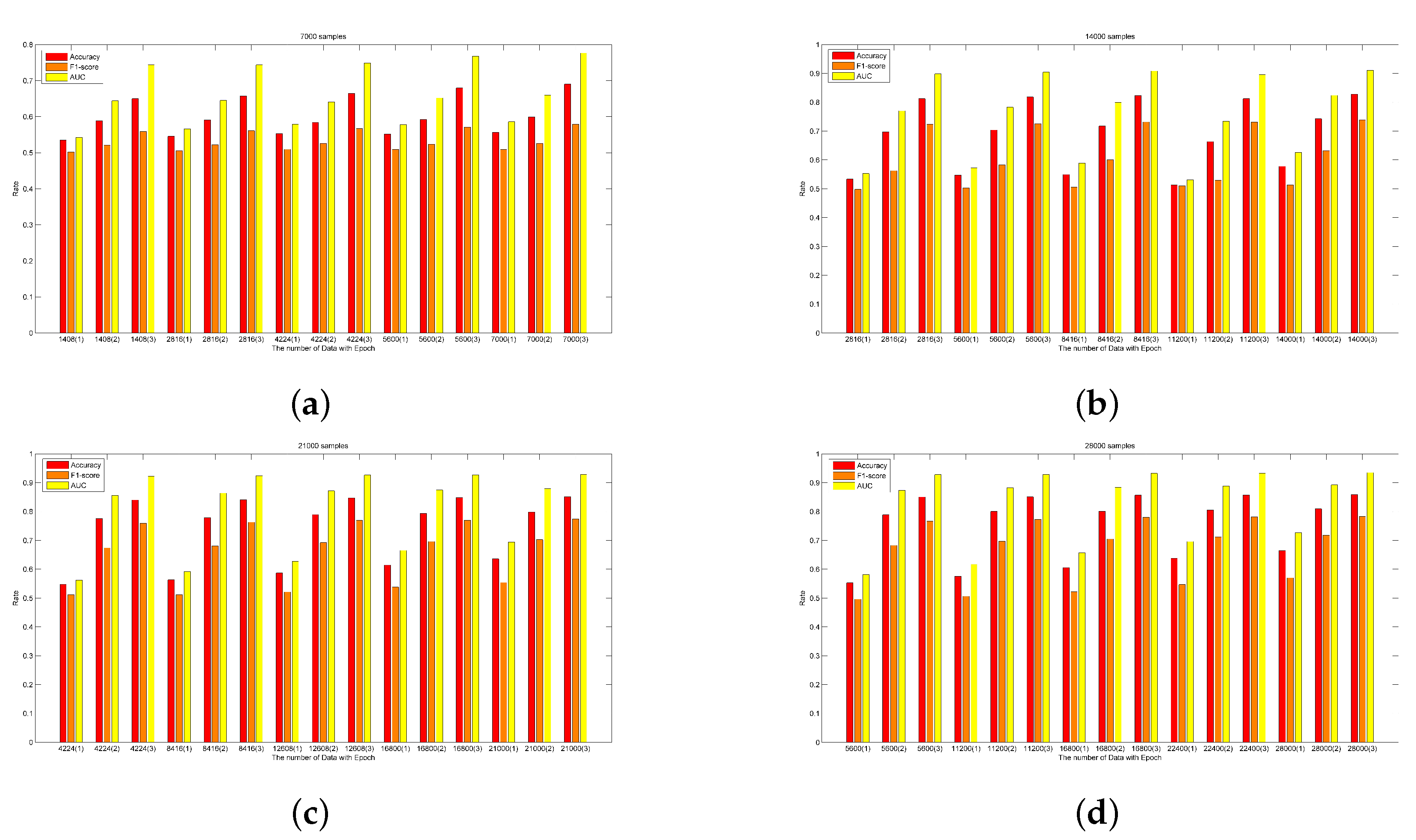
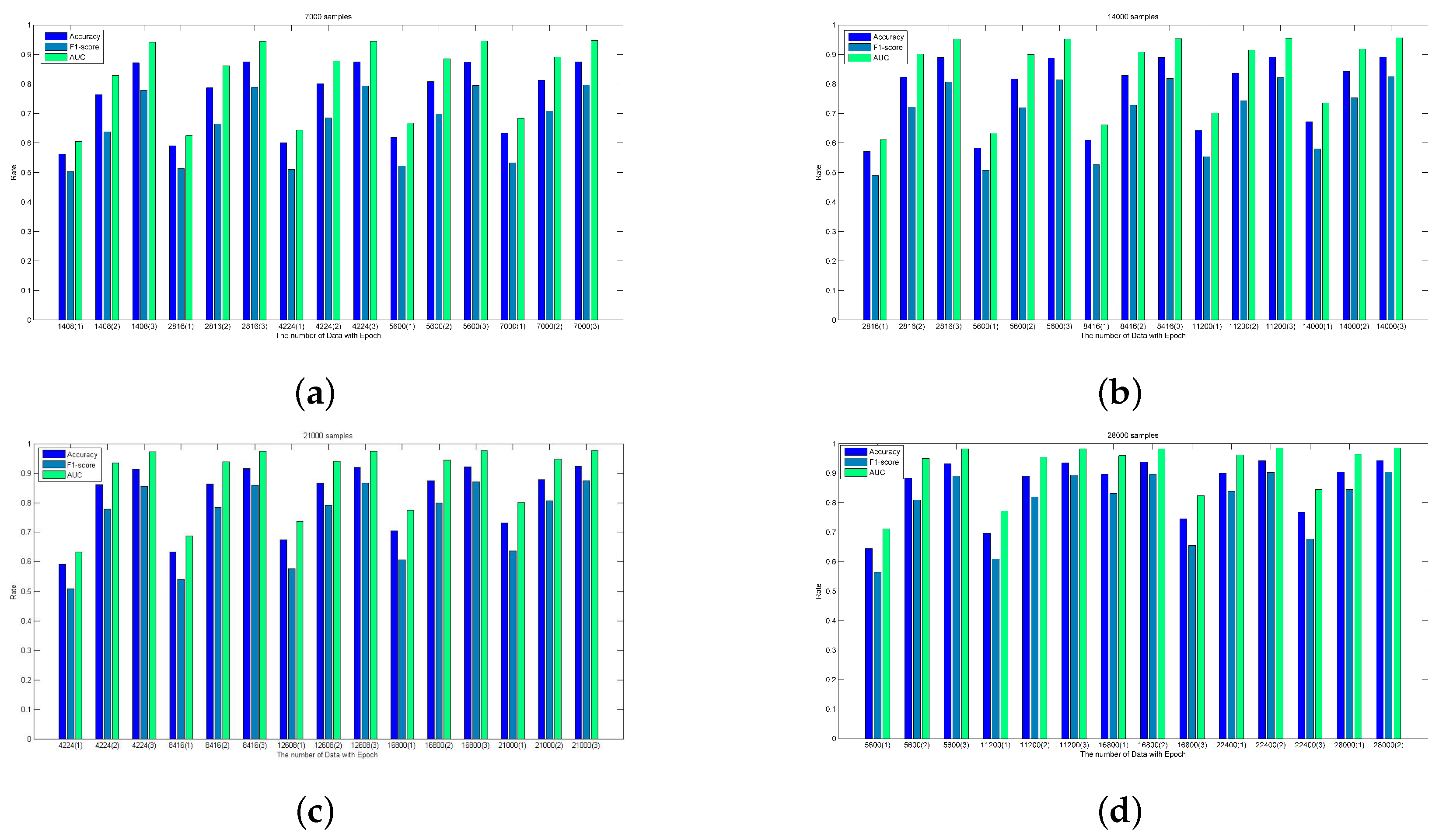
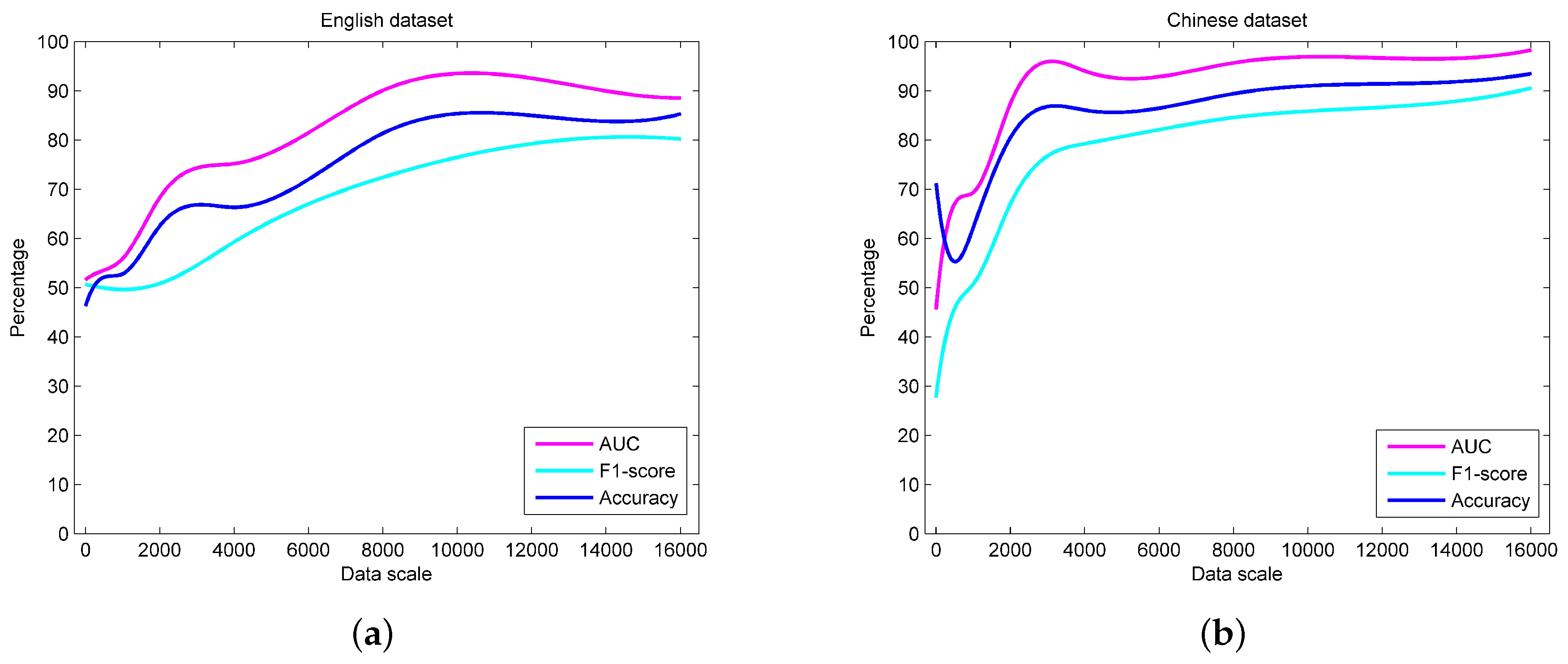
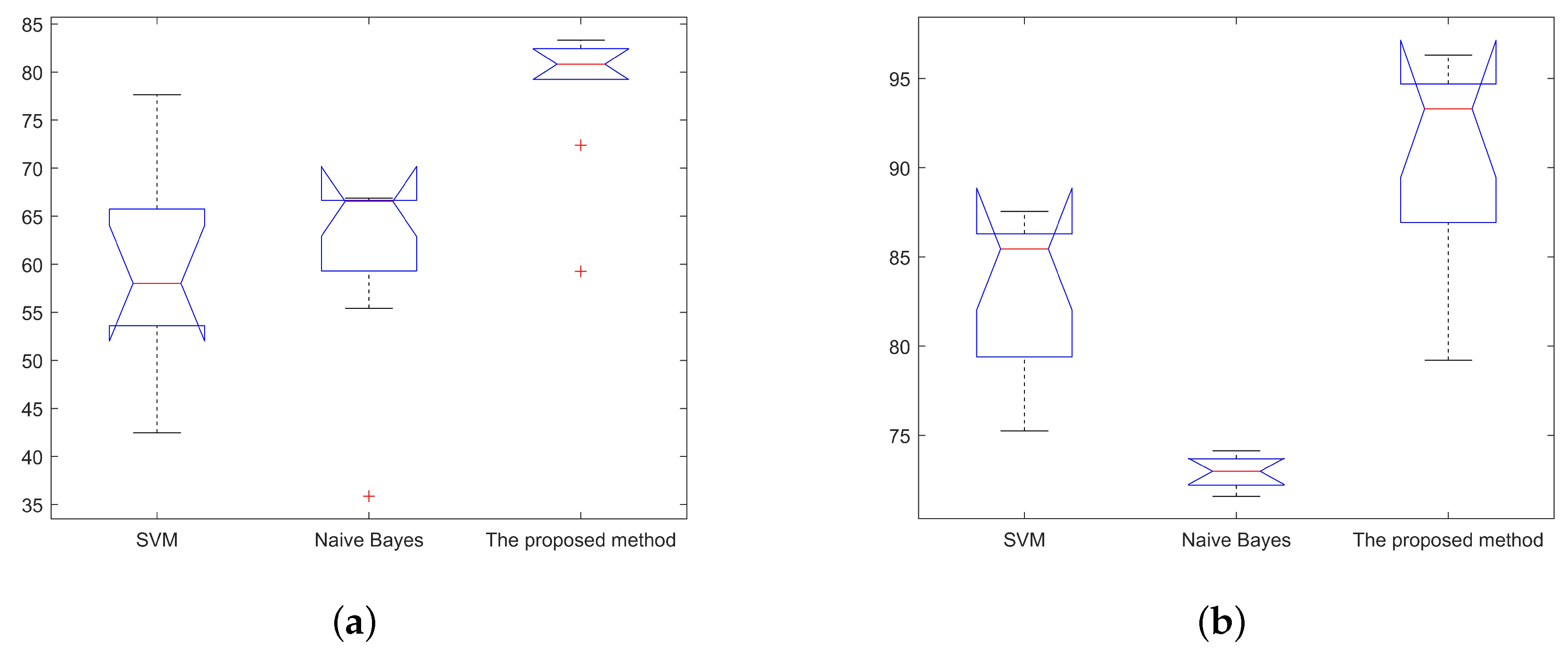
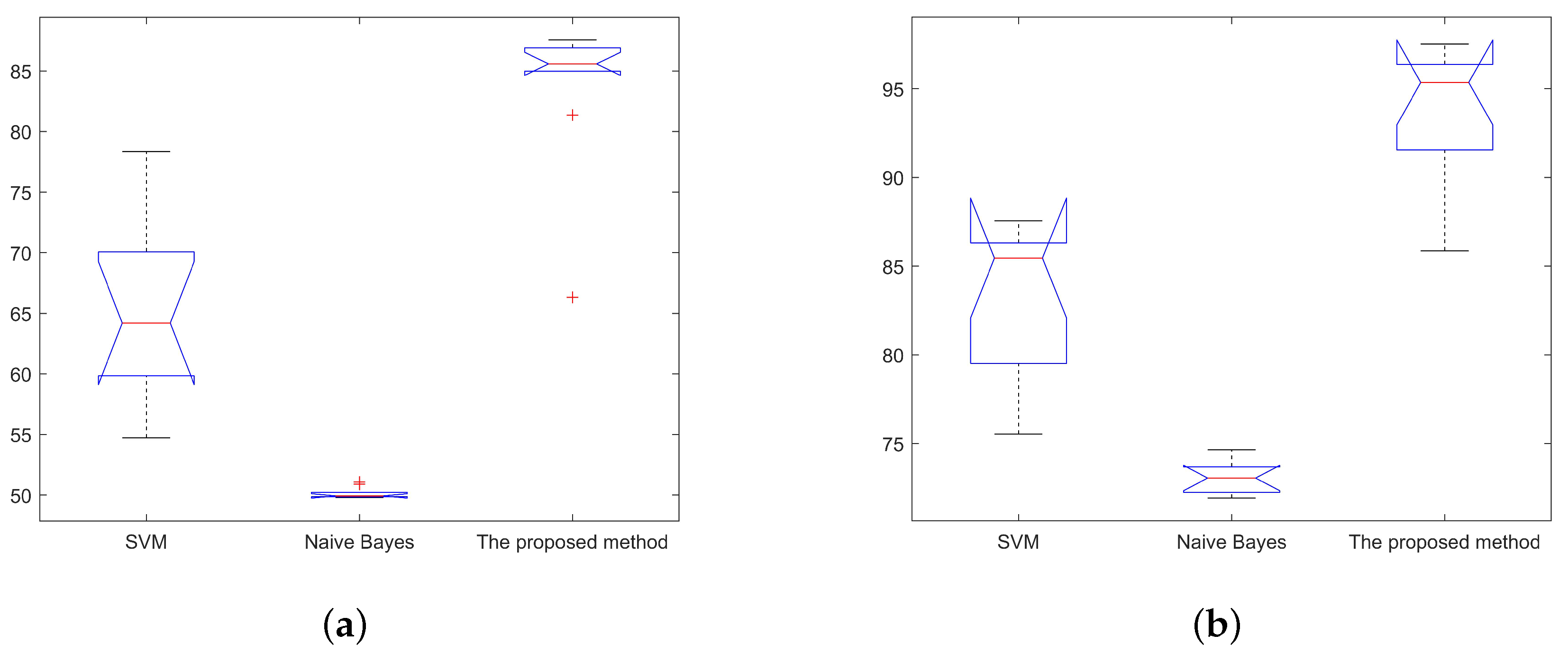
5.2.2. Performance Analysis
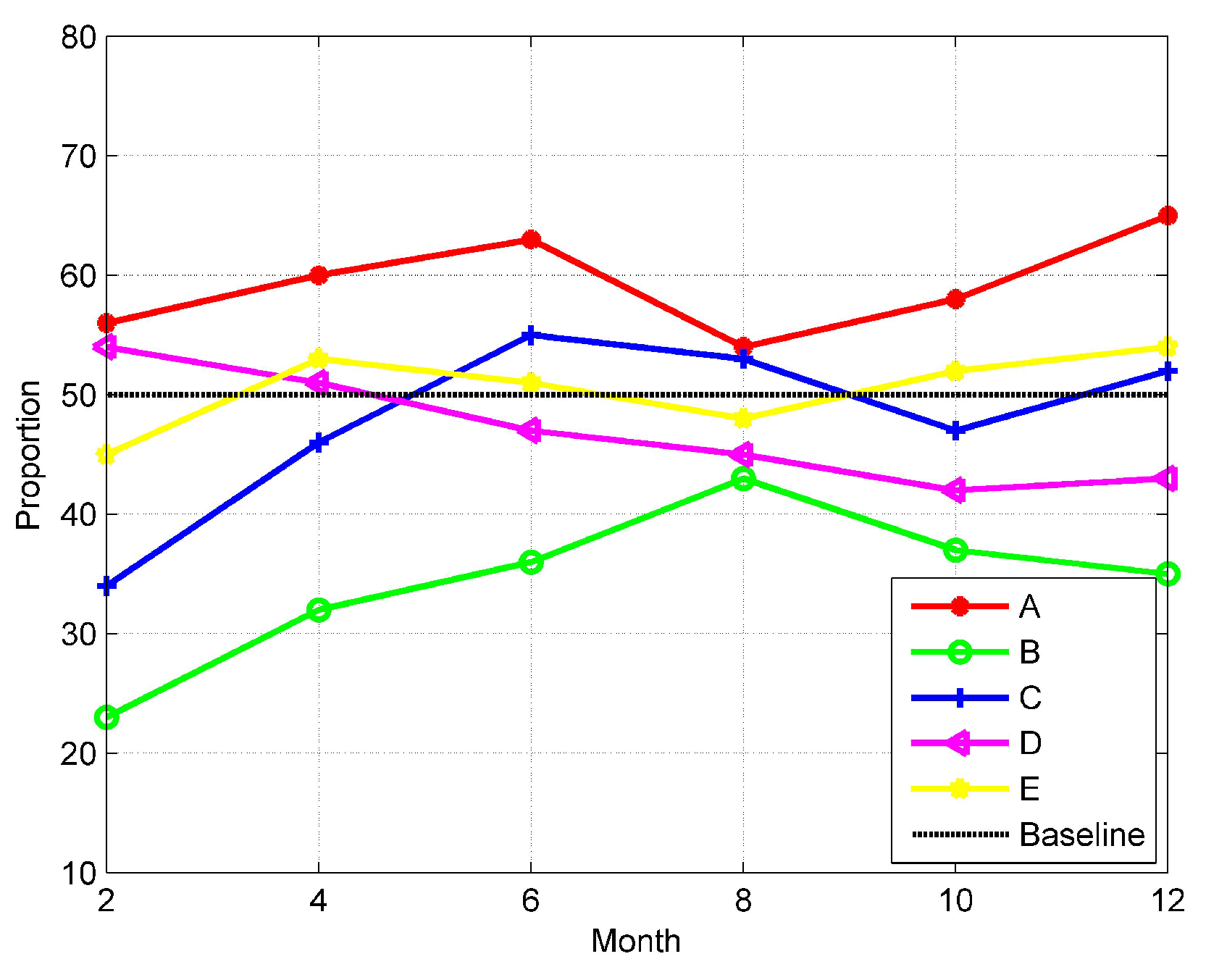
5.2.3. A Case Study
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yadav, A.; Vishwakarma, D.K. Sentiment analysis using deep learning architectures: A review. Artif. Intell. Rev. 2020, 53, 4335–4385. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, A.; Liu, D.; Bian, Y. Customer preferences extraction for air purifiers based on fine-grained sentiment analysis of online reviews. Knowl.-Based Syst. 2021, 228, 107259. [Google Scholar] [CrossRef]
- Jain, P.K.; Pamula, R.; Srivastava, G. A systematic literature review on machine learning applications for consumer sentiment analysis using online reviews. Comput. Sci. Rev. 2021, 41, 100413. [Google Scholar] [CrossRef]
- Zhao, W.; Guan, Z.; Chen, L.; He, X.; Cai, D.; Wang, B.; Wang, Q. Weakly-supervised deep embedding for product review sentiment analysis. IEEE Trans. Knowl. Data Eng. 2017, 30, 185–197. [Google Scholar] [CrossRef]
- Serrano-Guerrero, J.; Olivas, J.A.; Romero, F.P.; Herrera-Viedma, E. Sentiment analysis: A review and comparative analysis of web services. Inf. Sci. 2015, 311, 18–38. [Google Scholar] [CrossRef]
- Sun, S.; Luo, C.; Chen, J. A review of natural language processing techniques for opinion mining systems. Inf. Fusion 2017, 36, 10–25. [Google Scholar] [CrossRef]
- Abdi, A.; Shamsuddin, S.M.; Hasan, S.; Piran, J. Deep learning-based sentiment classification of evaluative text based on multi-feature fusion. Inf. Process. Manag. 2019, 56, 1245–1259. [Google Scholar] [CrossRef]
- Tang, D.; Qin, B.; Liu, T. Deep learning for sentiment analysis: Successful approaches and future challenges. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 292–303. [Google Scholar] [CrossRef]
- Wang, H.; Qin, H.; Zhao, M.; Wei, X.; Shen, H.; Susilo, W. Blockchain-based fair payment smart contract for public cloud storage auditing. Inf. Sci. 2020, 519, 348–362. [Google Scholar] [CrossRef]
- Gong, Y.; van Engelenburg, S.; Janssen, M. A reference architecture for blockchain-based crowdsourcing platforms. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 937–958. [Google Scholar] [CrossRef]
- Ray, P.P.; Dash, D.; Salah, K.; Kumar, N. Blockchain for IoT-based healthcare: Background, consensus, platforms, and use cases. IEEE Syst. J. 2020, 15, 85–94. [Google Scholar] [CrossRef]
- Mao, D.; Hao, Z.; Wang, F.; Li, H. Innovative blockchain-based approach for sustainable and credible environment in food trade: A case study in shandong province, china. Sustainability 2018, 10, 3149. [Google Scholar] [CrossRef] [Green Version]
- Mao, D.; Hao, Z.; Wang, F.; Li, H. Novel automatic food trading system using consortium blockchain. Arab. J. Sci. Eng. 2019, 44, 3439–3455. [Google Scholar] [CrossRef]
- Hao, Z.; Wang, G.; Mao, D.; Zhang, B.; Li, H.; Zuo, M.; Zhao, Z.; Yen, J. A novel method for food market regulation by emotional tendencies predictions from food reviews based on blockchain and saes. Foods 2021, 10, 1398. [Google Scholar] [CrossRef]
- Bodziony, N.; Jemiolo, P.; Kluza, K.; Ogiela, M.R. Blockchain-based address alias system. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 1280–1296. [Google Scholar] [CrossRef]
- Hao, Z.; Mao, D.; Zhang, B.; Zuo, M.; Zhao, Z. A novel visual analysis method of food safety risk traceability based on blockchain. Int. J. Environ. Res. Public Health 2020, 17, 2300. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Xiao, Z.; Liu, Y.; Xu, Y.; Zhou, A.; Zhang, K. Sentiview: Sentiment analysis and visualization for internet popular topics. IEEE Trans.Hum.-Mach. Syst. 2013, 43, 620–630. [Google Scholar] [CrossRef]
- Mao, D.; Hao, Z. A novel sketch-based three-dimensional shape retrieval method using multi-view convolutional neural network. Symmetry 2019, 11, 703. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Niu, J.; Yu, S. Sentidiff: Combining textual information and sentiment diffusion patterns for twitter sentiment analysis. IEEE Trans. Knowl. Data Eng. 2019, 32, 2026–2039. [Google Scholar] [CrossRef]
- Taylor, S.; Kim, T.; Yue, Y.; Mahler, M.; Krahe, J.; Rodriguez, A.G.; Hodgins, J.; Matthews, I. A deep learning approach for generalized speech animation. ACM Trans. Graph. 2017, 36, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Cui, P.; Zhu, W. Deep learning on graphs: A survey. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef] [Green Version]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Tang, B.; He, H.; Baggenstoss, P.M.; Kay, S. A bayesian classification approach using class-specific features for text categorization. IEEE Trans. Knowl. Data Eng. 2016, 28, 1602–1606. [Google Scholar] [CrossRef]
- Goudjil, M.; Koudil, M.; Bedda, M.; Ghoggali, N. A novel active learning method using svm for text classification. Int. J. Autom. Comput. 2018, 15, 290–298. [Google Scholar] [CrossRef]
- Mahajan, D.; Chaudhary, D.K. Sentiment analysis using rnn and google translator. In Proceedings of the 2018 8th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 11–12 January 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 798–802. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Li, D.; Qian, J. Text sentiment analysis based on long short-term memory. In Proceedings of the 2016 First IEEE International Conference on Computer Communication and the Internet (ICCCI), Wuhan, China, 13–15 October 2016; IEEE: iscataway, NJ, USA, 2016; pp. 471–475. [Google Scholar]
- Wang, J.; Cao, Z. Chinese text sentiment analysis using lstm network based on l2 and nadam. In Proceedings of the 2017 IEEE 17th International Conference on Communication Technology (ICCT), Chengdu, China, 27–30 October 2017; IEEE: iscataway, NJ, USA, 2017; pp. 1891–1895. [Google Scholar]
- Alayba, A.M.; Palade, V.; England, M.; Iqbal, R. A combined cnn and lstm model for arabic sentiment analysis. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Hamburg, Germany, 27–30 August 2018; Springer: New York, NY, USA, 2018; pp. 179–191. [Google Scholar]
- Williams, L.; Bannister, C.; Arribas-Ayllon, M.; Preece, A.; Spasić, I. The role of idioms in sentiment analysis. Expert Syst. Appl. 2015, 42, 7375–7385. [Google Scholar] [CrossRef] [Green Version]
- Spasić, I.; Williams, L.; Buerki, A. Idiom-based features in sentiment analysis: Cutting the Gordian knot. IEEE Trans. Affect. Comput. 2017, 11, 189–199. [Google Scholar]
- Pelosi, S. Semantically Oriented Idioms for Sentiment Analysis. A Linguistic Resource for the Italian Language. In Proceedings of the International Conference on Advanced Information Networking and Applications, Caserta, Italy, 15–17 April 2020; Springer: New York, NY, USA; pp. 1069–1077. [Google Scholar]
- Ibrahim, H.S.; Abdou, S.M.; Gheith, M. Sentiment analysis for modern standard Arabic and colloquial. arXiv 2015, arXiv:1505.03105. [Google Scholar] [CrossRef]
- Zarir, A.A.; Oliva, G.A.; Jiang, Z.M.; Hassan, A.E. Developing Cost-Effective Blockchain-Powered Applications: A Case Study of the Gas Usage of Smart Contract Transactions in the Ethereum Blockchain Platform. ACM Trans. Softw. Eng. Methodol. 2021, 30, 1–38. [Google Scholar] [CrossRef]
- Yao, J. Automated sentiment analysis of text data with NLTK. J. Phys. Conf. Ser. 2019, 5, 1187. [Google Scholar] [CrossRef]
- Merity, S.; Keskar, N.S.; Socher, R. Regularizing and optimizing lstm language models. arXiv 2017, arXiv:1708.02182 2017. [Google Scholar]
- McAuley, J.J.; Leskovec, J. From amateurs to connoisseurs: Modeling the evolution of user expertise through online reviews. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 897–908. [Google Scholar]
- Prettenhofer, P.; Stein, B. Cross-language text classification using structural correspondence learning. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 1118–1127. [Google Scholar]
- McAuley, J.; Targett, C.; Shi, Q.; Van Den Hengel, A. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 43–52. [Google Scholar]
- Zhang, W.; Xu, H.; Wan, W. Weakness finder: Find product weakness from chinese reviews by using aspects based sentiment analysis. Expert Syst. Appl. 2012, 39, 10283–10291. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, M.; Zhang, Y.; Lai, G.; Liu, Y.; Zhang, H.; Ma, S. Daily-aware personalized recommendation based on feature-level time series analysis. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1373–1383. [Google Scholar]
- Manaswi, N.K. Understanding and working with Keras. In Deep Learning with Applications Using Python; Apress: Berkeley, CA, USA, 2018; pp. 31–43. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool | Stopwords |
|---|---|
| NLTK | a,about,above,after,again,against,all,am,an,and,any,are,aren’t,as,at,be,because,been,before, being,below,between,both,but,by,can’t,cannot,could,couldn’t,did,didn’t,do,does,doesn’t,doing, don’t,down,during,each,few,for,from,further,had,hadn’t,has,hasn’t,have,haven’t,having,he,he’d, he’ll,he’s,her,here,here’s,hers,herself,him,himself,his,how,how’s,i,i’d,i’ll,i’m,i’ve,if,in, into,is,isn’t,it,it’s,its,itself,let’s,me,more,most,mustn’t,my,myself,no,nor,not,of,off,on,once, only,or,other,ought,our,ours,ourselves,out,over,own,same,shan’t,she,she’d,she’ll,she’s,should, shouldn’t,so,some,such,than,that,that’s,the,their,theirs,them,themselves,then,there,there’s,these, they,they’d,they’ll,they’re,they’ve,this,those,through,to,too,under,until,up,very,was,wasn’t,we,we’d, we’ll,we’re,we’ve,were,weren’t,what,what’s,when,when’s,where,where’s,which,while,who,who’s, whom,why,why’s,with,won’t,would,wouldn’t,you,you’d,you’ll,you’re,you’ve,your,yours, yourself,yourselves |
| Reviews | Reviews Containing Idioms |
|---|---|
| This cake looks nice. (positive) | This cake looks nice, but it cost an arm and a leg! (negative) |
| This product does not look very good. (negative) | This product does not look very good, but it is my cup of tea. (postive) |
| Dataset | Data Set Scale | F1-Score | Accuracy | ||||
|---|---|---|---|---|---|---|---|
| SVM | Naive Bayes | The Proposed Method | SVM | Naive Bayes | The Proposed Method | ||
| English dataset | 4000 | 53.62219 | 59.31077 | 59.27345 | 59.83333 | 50.90278 | 66.31944 |
| 8000 | 61.24075 | 35.85469 | 72.40847 | 65.72917 | 51.07639 | 81.35417 | |
| 12,000 | 58.54958 | 55.40811 | 79.23725 | 63.53241 | 49.84722 | 84.97685 | |
| 16,000 | 50.56394 | 66.86387 | 80.18497 | 58.97222 | 50.22222 | 85.27778 | |
| 20,000 | 54.31992 | 66.48082 | 81.46056 | 61.26667 | 49.79167 | 85.72500 | |
| 24,000 | 71.90217 | 66.56353 | 80.00225 | 74.10417 | 49.88426 | 85.43981 | |
| 28,000 | 57.49231 | 66.74560 | 82.14852 | 64.84921 | 50.08929 | 86.90079 | |
| 32,000 | 65.73920 | 66.64026 | 82.43852 | 70.06597 | 49.97049 | 86.64410 | |
| 36,000 | 77.64720 | 66.53723 | 82.46275 | 78.35802 | 49.85494 | 87.04167 | |
| 40,000 | 42.44256 | 66.54270 | 83.31607 | 54.73611 | 49.86111 | 87.54583 | |
| Chinese dataset | 4000 | 75.24197 | 74.13196 | 79.21657 | 75.53265 | 74.63918 | 85.85567 |
| 8000 | 79.39508 | 71.58752 | 84.54979 | 79.51389 | 71.92361 | 89.57639 | |
| 12,000 | 78.30994 | 73.12014 | 86.93246 | 78.37037 | 73.19907 | 91.55093 | |
| 16,000 | 82.40867 | 73.6837 | 90.77761 | 82.49306 | 73.68403 | 93.67361 | |
| 20,000 | 84.88228 | 72.79004 | 92.74781 | 84.89167 | 72.79444 | 94.99167 | |
| 24,000 | 86.00003 | 72.20354 | 93.83719 | 86.01389 | 72.24306 | 95.7037 | |
| 28,000 | 86.29261 | 73.19657 | 94.41608 | 86.30357 | 73.21825 | 96.31548 | |
| 32,000 | 86.01851 | 72.0971 | 94.68567 | 86.07639 | 72.19271 | 96.36806 | |
| 36,000 | 87.54628 | 72.84717 | 95.74603 | 87.54784 | 72.91358 | 97.18056 | |
| 40,000 | 87.36206 | 73.94975 | 96.31784 | 87.37500 | 73.97917 | 97.51806 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Z.; Hao, Z.; Wang, G.; Mao, D.; Zhang, B.; Zuo, M.; Yen, J.; Tu, G. Sentiment Analysis of Review Data Using Blockchain and LSTM to Improve Regulation for a Sustainable Market. J. Theor. Appl. Electron. Commer. Res. 2022, 17, 1-19. https://0-doi-org.brum.beds.ac.uk/10.3390/jtaer17010001
Zhao Z, Hao Z, Wang G, Mao D, Zhang B, Zuo M, Yen J, Tu G. Sentiment Analysis of Review Data Using Blockchain and LSTM to Improve Regulation for a Sustainable Market. Journal of Theoretical and Applied Electronic Commerce Research. 2022; 17(1):1-19. https://0-doi-org.brum.beds.ac.uk/10.3390/jtaer17010001
Chicago/Turabian StyleZhao, Zhihua, Zhihao Hao, Guancheng Wang, Dianhui Mao, Bob Zhang, Min Zuo, Jerome Yen, and Guangjian Tu. 2022. "Sentiment Analysis of Review Data Using Blockchain and LSTM to Improve Regulation for a Sustainable Market" Journal of Theoretical and Applied Electronic Commerce Research 17, no. 1: 1-19. https://0-doi-org.brum.beds.ac.uk/10.3390/jtaer17010001