Discrimination of Non-Local Correlations

Facoltà di Informatica, Università della Svizzera italiana, 6900 Lugano, Switzerland
*
Authors to whom correspondence should be addressed.
Entropy 2019, 21(2), 104; https://0-doi-org.brum.beds.ac.uk/10.3390/e21020104
Submission received: 15 December 2018
/
Revised: 11 January 2019
/
Accepted: 17 January 2019
/
Published: 23 January 2019
(This article belongs to the Special Issue Quantum Nonlocality)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:In view of the importance of quantum non-locality in cryptography, quantum computation, and communication complexity, it is crucial to decide whether a given correlation exhibits non-locality or not. As proved by Pitowski, this problem is NP-complete, and is thus computationally intractable unless NP is equal to P. In this paper, we first prove that the Euclidean distance of given correlations from the local polytope can be computed in polynomial time with arbitrary fixed error, granted the access to a certain oracle; namely, given a fixed error, we derive two upper bounds on the running time. The first bound is linear in the number of measurements. The second bound scales with the number of measurements to the sixth power. The former holds only for a very high number of measurements, and is never observed in the performed numerical tests. We, then, introduce a simple algorithm for simulating the oracle. In all of the considered numerical tests, the simulation of the oracle contributes with a multiplicative factor to the overall running time and, thus, does not affect the sixth-power law of the oracle-assisted algorithm.
1. Introduction
Non-local correlations, displayed by certain entangled quantum systems, mark a clear departure from the classical framework made up of well-defined, locally interacting quantities [1]. Besides their importance in foundation of quantum theory, non-local correlations have gained interest as information-processing resources in cryptography [2,3,4,5,6,7,8], randomness amplification [9,10], quantum computation, and communication complexity [11]. In view of their importance, a relevant problem— hereafter called the non-locality problem—is to find a criterion for deciding if observed correlations are actually non-local. Such a criterion is, for example, provided by the Bell inequalities [12]. However, a result by Pitowski [12] suggests that the problem of discriminating between local and non-local correlations is generally intractable. Pitowski proved that deciding membership to the correlation polytope is NP-complete, and is therefore intractable unless NP is equal to P. This result also implies that the opposite problem, deciding whether given correlations are outside the polytope, is not even in NP, unless NP=co-NP—which is believed to be false.
In this paper, we present an algorithm whose numerical tests suggest a polynomial running time for all the considered quantum-correlation problems. More precisely, the algorithm computes the distance from the local polytope. First, we prove that the time cost of computing the distance with an arbitrary fixed error grows polynomially in the size of the problem input (number of measurements and outcomes), granted the access to a certain oracle. Namely, given a fixed error, we derive two upper bounds on the running time. The first bound is linear in the number of measurements. The second bound scales with the number of measurements to the sixth power. The former holds only for a very high number of measurements, and is never observed in the performed numerical tests. Thus, the problem of computing the distance is reduced to determining an efficient simulation of the oracle. Then, we introduce a simple algorithm that simulates the oracle. The algorithm is probabilistic and provides the right answer in a subset of randomized inputs. Thus, to have a correct answer with sufficiently high probability, the simulation of the oracle has to be performed with a suitably high number of initial random inputs. In the numerical tests, the number of random initial trials has pragmatically been chosen such that the simulation of the oracle contributes to the overall running time with a multiplicative factor and, thus, does not affect the sixth-power law of the oracle-assisted algorithm. In all of the performed numerical tests, the overall algorithm always computes the distance within the desired accuracy. The scaling of the running time observed in the tests is compatible with the sixth-power law, derived theoretically.
Similar results have independently been published in [13], almost simultaneously to a first version of this paper [14]. The algorithm in [13] is a modification of Gilbert’s algorithm for minimizing quadratic forms in a convex set. In its original form, the algorithm uses the following strategy for generating a sequence of points, which converge to the minimizer: Given a point of the sequence, a procedure of linear optimization generates another point , such that the next point of the sequence is computed as a convex combination of and . If the convex set is a polytope, the points turn out to be vertices of the polytope. The modified algorithm, introduced in [13], keeps track of the previous vertices , m being some fixed parameter, and computes the next point as convex combination of these points and . In our algorithm, we compute as a convex combination of a suitable set of previously computed vertices, without using the point (Section 5). This difference does not result in substantial computational differences. However, our approach has the advantage of keeping track of the minimal number of vertices required for a convex representation of the optimizer. In particular, in the case of local correlations, the algorithm immediately gives a minimal convex representation of them. This representation provides a certificate, which another party can use for directly proving locality. As another minor difference, our algorithm actually computes the distance from what we will call the local cone. This allows us to eliminate a normalization constraint from the optimization problem.
The paper is organized as follows. In Section 2, we introduce our general scenario. For the sake of simplicity, we will discuss only the two-party case, but the results can be extended to the general case of many parties. After introducing the local polytope in Section 3, we formulate the non-locality problem as a minimization problem; namely, the problem of computing the distance from the local polytope (Section 4). In Section 5, the algorithm is introduced. The convergence and the computational cost are then discussed in Section 6. After introducing the algorithm for solving the oracle, we finally discuss the numerical results in Section 7.
2. Nonsignaling Box
In a Bell scenario, two quantum systems are prepared in an entangled state and delivered to two spatially separate parties; say, Alice and Bob. These parties each perform a measurement on their system and get an outcome. In general, Alice and Bob are allowed to choose among their respective sets of possible measurements. We assume that the sets are finite, but arbitrarily large. Let us denote the measurements performed by Alice and Bob by the indices and , respectively. After the measurements, Alice gets an outcome and Bob an outcome , where and are two sets with cardinality R and S, respectively. The overall scenario is described by the joint conditional probability of getting , given . Since the parties are spatially separate, causality and relativity imply that this distribution satisfies the nonsignaling conditions
where and are the marginal conditional probabilities of r and s, respectively. In the following discussion, we consider a more general scenario than quantum correlations, and we just assume that satisfies the nonsignaling conditions. The abstract machine producing the correlated variables r and s from the inputs a and b will be called the nonsignaling box (briefly, NS-box).
3. Local Polytope
The correlations between the outcomes r and s, associated with the measurements a and b, are local if and only if the conditional probability can be written in the form
where , , and are suitable probability distributions. It is always possible to write the conditional probabilities and as convex combination of local deterministic processes, that is,
where , , , and . Using this decomposition, Equation (2) takes the form of a convex combination of local deterministic distributions. That is,
where and is the Kronecker delta. Equation (5) is known as Fine’s theorem [15]. Thus, a local distribution can always be written as convex combination of local deterministic distributions. Clearly, the converse is also true and a convex combination of local deterministic distributions is local. Therefore, the set of local distributions is a polytope, called a local polytope. As the deterministic probability distributions are not convex combinations of other distributions, they all define the vertices of the local polytope. Thus, there are vertices, each one specified by the sequences and . Let us denote the map from to the associated vertex by . That is, maps the sequences to a deterministic local distribution,
Since the elements of the local polytope are normalized distributions and satisfy the nonsignaling conditions (1), the parameters defining are not independent and the polytope lives in a lower-dimensional subspace. The dimension of this subspace and, more generally, of the subspace of NS-boxes, is equal to [16]
By the Minkowski–Weyl theorem, the local polytope can be represented as the intersection of finitely many half-spaces. A half-space is defined by an inequality
In the case of the local polytope, these inequalities are called Bell inequalities. Given the coefficients , we can choose L such that the inequality is as restrictive as possible. This is attained by imposing that at least one vertex of the local polytope is at the boundary of the half-space; that is, by taking
The oracle, which is central in this work, and introduced later in Section 4, returns the value L from the coefficients .
A minimal representation of a polytope is given by the set of facets of the polytope. A half-space specifies a facet if the associated hyperplane intersects the boundary of the polytope in a set with dimension equal to the dimension of the polytope minus one. A distribution is local if and only if every facet inequality is not violated. Deciding whether some inequality is violated is generally believed to be intractable, due to a result by Pitowski [12], but to test the membership of a distribution to the local polytope can be done in polynomial time, once the vertices—of which the distribution is a convex combination—are known. Thus, deciding membership to the local polytope is an NP problem. Furthermore, the problem is NP-complete [12].
4. Distance from the Local Polytope
The non-locality problem can be reduced to a convex optimization problem, such as the computation of the nonlocal capacity, introduced in [17], and the distance from the local polytope, which can be reduced to a linear program if the norm is employed [18]. Here, we define the distance of a distribution from the local polytope as the Euclidean distance between and the closest local distribution. As mentioned in Section 3 (see Equation (5)), and stated by Fine’s theorem [15], a conditional distribution is local if and only if there is a non-negative function such that
That is, a conditional distribution is local if it is the marginal of a multivariate probability distribution of the outcomes of all the possible measurements, provided that does not depend on the measurements a and b.
The distributions and can be represented as vectors in a -dimensional space. Let us denote them by and , respectively. Given a positive-definite matrix defining the metrics in the vector space, the computation of the distance from the local polytope is equivalent to the minimization of a functional of the form
with respect to , under the constraints that is non-negative and normalized. Namely, the distance is the square root of the minimum of . Hereafter, we choose the metrics so that the functional takes the form
where is some probability distribution. The normalization guarantees that the distance does not diverge in the limit of infinite measurements performed on a given entangled state. In particular, we will consider the case with
Another choice would be to take the distribution maximizing the functional, so that the computation of the distance would be a minimax problem. This case has some interesting advantages, but is more sophisticated and will not be considered here. Since we are interested in a quantity that is equal to zero if and only if is local, we can simplify the problem of computing the distance by dropping the normalization constraint on . Indeed, if the distance is equal to zero, , and thus , are necessarily normalized. Conversely, if the distance is different from zero for every normalized local distribution, it is so also for every unnormalized local distribution. Thus, the discrimination between local and non-local correlation is equivalent to the following minimization problem.
Problem 1.
Let us denote the solution of this problem and the corresponding optimal value by and , respectively. The associated (unnormalized) local distribution is denoted by . The square root of is the minimal distance of from the cone defined as the union of all the lines connecting the zero distribution and an arbitrary point of the local polytope. Let us call this set the local cone. Hereafter, we will consider the problem of computing the distance from the local cone, but the results can be easily extended to the case of the local polytope, so that we will use “local cone” and “local polytope” as synonyms in the following discussion. Note that there are generally infinite minimizers , since lives in a -dimensional space, whereas the functional F depends on through , which lives in a -dimensional space. In other words, since the local polytope has vertices, but the dimension of the polytope is , a (normalized) distribution has generally infinite representations as convex combination of the vertices, unless is on a face whose dimension plus 1 is equal to the number of vertices defining the face.
At first glance, the computational complexity of this problem seems intrinsically exponential, as the number of real variables defining is equal to . However, the dimension of the local polytope is and grows polynomially in the number of measurements and outcomes. Thus, by Carathéodory’s theorem, a (normalized) local distribution can always be represented as the convex combination of a number of vertices smaller than . This implies that there is a minimizer of F whose support contains a number of elements not greater than . Therefore, the minimizer can be represented by a number of variables growing polynomially in the input size. The main problem is to find a small set of vertices that are suitable for representing the closest local distribution . In the following, we will show that the computation of the distance from the local cone with an arbitrary fixed accuracy has polynomial complexity, granted the access to the following oracle.
Oracle Max: Given a function , the oracle returns the sequences and maximizing the function
and the corresponding maximal value.
Thus, Problem 1 is reduced to determining an efficient simulation of the oracle. Let us consider the case of binary outcomes, with r and s taking values (). The function takes the form
whose minimization falls into the class of spin-glass problems, which are notoriously computationally hard to handle. This suggests that the oracle is generally an intractable problem. Nonetheless, the oracle has a particular structure that can make the problem easier to be solved, in some instances. This will be discussed later, in Section 6.3 and Section 7. There, we will show that the oracle can be simulated efficiently in many relevant cases, by using a simple block-maximization strategy. Assuming for the moment that we have access to the oracle, let us introduce the algorithm solving Problem 1.
5. Computing the Distance
The distance from the local polytope can be computed efficiently, once we have a set of vertices that is small enough and suitable for representing the closest distribution . The algorithm introduced in this paper solves Problem 1 by iteratively generating a sequence of sets . At each step, the minimal distance is first computed over the convex hull of the given vertices. Then, the oracle is consulted. If the set does not contain the right vertices, the oracle returns a strictly positive maximal value and a vertex, which is added to the set (after possibly removing vertices with zero weight). The optimization Problem 1 is solved once the oracle returns zero, which guarantees that all the optimality conditions of the problem are satisfied. Before discussing the algorithm, let us derive these conditions.
5.1. Necessary and Sufficient Conditions for Optimality
Problem 1 is a convex optimization problem whose constraints satisfy Slater’s condition, requiring the existence of an interior point of the feasible region. This is the case, as a positive strictly satisfies all the inequality constraints. Thus, the four Karush–Kuhn–Tucker (KKT) conditions are necessary and sufficient conditions for optimality. Let us briefly summarize these conditions. Given an objective function of the variables and equality constraints , it is well known that the function F is stationary at if the gradient of the Lagrangian is equal to zero, for some value of the Lagrange multipliers . This is the first KKT condition. The second condition is the feasibility of the constraints; that is, the stationary point must satisfy the constraints . These two conditions are necessary and sufficient, as there are only equality constraints. If there are also inequalities, two additional conditions on the associated Lagrange multipliers are required. Given inequality constraints , with associated Lagrange multipliers , the third condition is the non-negativity of the multipliers; that is, . This condition says that the constraint acts only in one direction, like a floor acts on objects through an upward force, but not with a downward force. The last condition states that the Lagrange multiplier can differ from zero only if the constraint is active; that is, if . This is like stating that a floor acts on a body only if they are touching (contact force). This condition can concisely be written as .
Let us characterize the optimal solution of Problem 1 through the four KKT conditions.
- First KKT condition (stationarity condition): The gradient of the Lagrangian is equal to zero. The Lagrangian of Problem 1 iswhere are the Lagrange multipliers associated with the inequality constraints.
- Second KKT condition (feasibility of the constraints): The function is non-negative, .
- Third condition (dual feasibility): The Lagrange multipliers are non-negative; that is,
- Fourth condition (complementary slackness): If , then the multiplier is equal to zero; that is,
The stationarity condition on the gradient of the Lagrangian gives the equality
Eliminating , this equality and the dual feasibility yield the inequality
From Equation (18), we have that the complementary slackness is equivalent to the following condition,
that is, the left-hand side of the last inequality is equal to zero if is in the support of . The slackness condition (20), the primal constraint and Equation (19) provide necessary and sufficient conditions for optimality. Let us introduce the function
which is the opposite of the gradient of F with respect to , up to the factor . Summarizing, the conditions are
The second condition can be rewritten in the more concise form
Indeed, using Equations (22) and (24), it is easy to show that condition (23) is satisfied if and only if
which gives equality (25), by definition of (Equation (9)).
Condition (22) can be checked, by consulting the oracle with as the query. If the oracle returns a non-positive maximal value, then the condition is satisfied. Actually, at the optimal point, the returned value turns out to be equal to zero, as implied by the other optimality conditions.
Similar optimality conditions hold if we force to be equal to zero outside some set . Let us introduce the following minimization problem.
Problem 2.
The optimal value of this problem gives an upper bound on the optimal value of Problem 1. The two problems are equivalent if the support of a minimizer of Problem 1 is in . The necessary and sufficient conditions for optimality of Problem 2 are the same as of Problem 1, with the only difference that condition (22) has to hold only in the set . That is, the condition is replaced by the weaker condition
Thus, an optimizer of Problem 2 is solution of Problem 1 if the value returned by the oracle with query is equal to zero.
Hereafter, the minimizer and the minimal value of Problem 2 will be denoted by and , respectively. The associated optimal local distribution , defined by Equation (9), will be denoted by .
5.2. Overview of the Algorithm
Problem 1 can be solved iteratively by finding the solution of Problem 2 over a sequence of sets . The sets are built according to the answer of the oracle, which is consulted at each step of the iteration. The procedure stops when a desired accuracy is reached or contains the support of a minimizer , and the solution of Problem 2 is also the solution of Problem 1. Let us outline the algorithm. Suppose that we choose the initial as a set of sequences associated to linearly independent vertices ( being possibly equal to 1). Let us denote this set by . We solve Problem 2 with and get the optimal value with minimizer . Let us denote the corresponding (unnormalized) local distribution by . That is,
Since the cardinality of is not greater than and the problem is a convex quadratic optimization problem, the corresponding computational complexity is polynomial. Generally, a numerical algorithm provides an optimizer, up to some arbitrarily small but finite error. In Section 5.5, we will provide a bound on the accuracy required for the solution of Problem 2. For now, let us assume that Problem 2 is solved exactly. If the support of is in , is equal to the optimal value of Problem 1, and we have computed the distance from the local polytope. We can verify if this is the case by checking the first optimality condition (22), as the conditions (23) and (24) are trivially satisfied by the optimizer of Problem 2 for every . The check is made by consulting the oracle with the function as the query. If the oracle returns a maximal value equal to zero, then we have the solution of Problem 1. Note that if the optimal value of Problem 2 is equal to zero, then also the optimal value of the main problem is equal to zero and the conditional distribution is local. In this case, we have no need of consulting the oracle.
If the optimal value of Problem 2 is different from zero and the oracle returns a maximal value strictly positive, then the minimizer of Problem 2 satisfies all the optimality conditions of Problem 1, except Equation (22) for some . The next step is to add the pair of sequences returned by the oracle to the set and solve Problem 2 with the new set. Let us denote the new set and the corresponding optimal value by and , respectively. Once we have solved Problem 2 with , we consult again the oracle to check if we have obtained the solution of Problem 1. If we have not, we add the pair of sequences given by the oracle to the set and we solve Problem 2 with the new set, say . We continue until we get the solution of Problem 1 or its optimal value up to some desired accuracy. This procedure generates a sequence of sets and values . The latter sequence is strictly decreasing, that is, until contains the support of and the oracle returns zero as maximal value. Let us show that. Suppose that is the optimizer of Problem 2 with and is the new element in the set . Let us denote by the local distribution associated with , that is,
The optimal value of Problem 2 is bounded from above by the value taken by the function for every feasible , in particular, for
with positive. Let us set equal to the value minimizing F; that is,
which is equal to the value returned by the oracle. It is strictly positive, as the oracle returned a positive value—provided that does not contain the support of . Hence, is a feasible point and, thus, the corresponding value taken by F,
is an upper bound on . Hence,
that is, is strictly smaller than .
This procedure generates a sequence that converges to the optimal value of Problem 1, as shown in Section 6. For any given accuracy, the computational cost of the procedure is polynomial, provided that we have access to the oracle.
To avoid growth of the cardinality of beyond during the iteration and, thus, the introduction of redundant vertices, we have to be sure that the sets contain points associated to linearly independent vertices of the local polytope. This is guaranteed by the following procedure of cleaning up. First, after the computation of at step n, we remove the elements in where is equal to zero (this can be checked even if the exact is not known, as discussed later in Section 5.6). Let us denote the resulting set by . Then, the set is built by adding the point given by the oracle to the set . Let us denote by the set of vertices associated to the elements in the support of . The cleaning up ensures that the optimizer is in the interior of the convex hull of , up to a normalization constant, and the new vertex returned by the oracle is linearly independent of the ones in . Indeed, we have seen that the introduction of such a vertex allows us to lower the optimal value of Problem 2. This would not be possible if the added vertex was linearly dependent on the vertices in , as the (normalized) optimizer of Problem 2 is in the interior of the convex hull of .
This is formalized in Lemma 1.
Lemma 1.
Let be a sequence such that
If Ω is a set such that
then the vertex is linearly independent of the vertices associated to the sequences in Ω.
Proof.
The proof is by contradiction. Suppose that the vector is linearly dependent with the vectors with , then there is a real function such that
By definition of , this equation implies that . From this equation and Equation (34), we have
This lemma and the optimality conditions (22) and (23) imply that the sets , built through the previously discussed procedure of cleaning up, always contain points associated to independent vertices and, thus, never contain more than elements. Indeed, the set contains points where the minimizer is different from zero, for which
as implied by condition (23). Furthermore, given the sequence returned by the oracle, condition (22) implies that
until the set contains the support of and the iteration generating the sequence of sets is terminated.
The procedure of cleaning up is not strictly necessary for having a polynomial running time, but it can speed up the algorithm. Furthermore, the procedure guarantees that the distribution approaching the minimizer during the iterative computation is always represented as the convex combination of a minimal number of vertices. Thus, we have a minimal representation of the distribution at each stage of the iteration.
5.3. The Algorithm
In short, the algorithm for computing the distance from the local polytope with given accuracy is as follows.
Algorithm 1.
Input:
- 1.
- Set equal to the sequences given by the oracle with as query.
- 2.
- Set .
- 3.
- Compute the optimizers and of Problem 2. The associated F provides an upper bound of the optimal value .
- 4.
- Consult the oracle with as query. Set and α are equal to the sequences returned by the oracle and the associated maximal value, respectively. That is,
- 5.
- Compute a lower bound on the from ρ and α (see following discussion and Section 6.1). The difference between the upper and lower bounds provides an upper bound on the reached accuracy.
- 6.
- If a given accuracy is reached, stop.
- 7.
- Remove from Ω the points where χ is zero and add .
- 8.
- Go back to Step 3.
The algorithm stops at Step 6 when a desired accuracy is reached. To estimate the accuracy, we need to compute a lower bound on the optimal value . To guarantee that the algorithm eventually stops, the lower bound has to converge to the optimal value as the algorithm approaches the solution of Problem 1. We also need a stopping criterion for the numerical routine solving the optimization problem in Step 3. Let us first discuss the stopping criterion for Algorithm 1.
5.4. Stopping Criterion for Algorithm 1
The lower bound on , denoted by , is computed by using the dual form of Problem 1. As shown in Section 6.1, any local distribution induces the lower bound
where is the maximal value returned by the oracle with as query. An upper bound on is obviously
In the limit of equal to the local distribution minimizing F, the lower bound is equal to the optimal value . This can be shown by using the optimality conditions. Indeed, conditions (22) and (25) imply the limits
which imply as approaches the minimizer. This is made even more evident, by computing the difference between the upper bound and the lower bound. Indeed, given the local distribution computed at Step 3 and the corresponding returned by the oracle at Step 4, the difference is
which evidently goes to zero as goes to . Thus, the upper bound on the accuracy computed in Step 5 goes to zero as approaches the solution. This guarantees that the algorithm stops sooner or later at Step 6, provided that converges to the solution. If Problem 2 is solved exactly at Step 3, then the distribution satisfies condition (25), and the upper bound on the reached accuracy takes the form
Even if Condition (25) is not satisfied, we can suitably normalize so that the condition is satisfied.
In the following, we assume that this condition is satisfied.
5.5. Stopping Criterion for Problem 2 (Optimization at Step 3 of Algorithm 1)
In Algorithm 1, Step 3 is completed when the solution of Problem 2 with a given set is found. Optimization algorithms iteratively find a solution up to some accuracy. We can stop when the error is of the order of the machine precision. Here, we will discuss a more effective stopping criterion. This criterion should preserve the two main features previously described:
- The sequence of the exact optimal values of Problem 2, with , is monotonically decreasing.
- The sets contain points associated with linearly independent vertices of the local polytope, implying that the cardinality of is never greater than .
To guarantee that the first feature is preserved, it is sufficient to compute a lower bound on from a given so that the bound approaches as approaches the optimizer . If the lower bound with the set is greater than the upper bound on (see Equation (31)), then . Denoting by the lower bound on the optimal value , the monotonicity of the sequence is implied by the inequality
As shown later, by using dual theory, a lower bound on is
where
and is an unnormalized local distribution, associated to a function with support in . This bound becomes equal to in the limit of equal to the minimizer of Problem 2. Equation (43) gives the condition
where and is the local distribution computed in Step 3. If this condition is satisfied by the numerical solution found in Step 3, then the series is monotonically decreasing. As we will see, to prove that the series converges to the minimizer of Problem 1, we need the stronger condition
where is any fixed real number in the interval . A possible choice is . If this inequality is satisfied in each iteration of Algorithm 1, the sequence satisfies the inequality
which turns out to be equal to Equation (32) in the limit . The right-hand side of Equation (47) goes to zero as approaches the optimizer, as implied by the optimality conditions of Problem 2. Thus, if the set does not contain all the points where is different from zero, then the inequality is surely satisfied at some point of the iteration solving Problem 2, as tends to a strictly positive number. When the inequality is satisfied, the minimization at Step 3 of Algorithm 1 is terminated. If is the support of , the inequality will never be satisfied and the minimization at Step 3 will terminate when the desired accuracy on is reached.
5.6. Cleaning Up (Step 7)
As previously said, we should also guarantee that the sets contain only points associated with linearly independent vertices. This is granted if the procedure in Step 7 of Algorithm 1 successfully removes the points where the exact minimizer is equal to zero. How can we find the support of the minimizer from the approximate numerical solution computed in Step 3? Using dual theory, it is possible to prove the following.
Theorem 1.
Let be a non-negative function with support in Ω and be the associated unnormalized local distribution. Then, the inequality
holds.
A direct consequence of this theorem and the slackness condition (23) for optimality is the following.
Corollary 1.
Let be a non-negative function with support in Ω and the associated unnormalized local distribution. If the inequality
holds, with , then is equal to zero.
Condition (50) is sufficient for having equal to zero, but it is not necessary. A necessary condition can be derived by computing the lowest eigenvalue of the Hessian of the objective function . Both the necessary and sufficient conditions allow us to determine the support of the minimizer once the distribution is enough close to . Thus, the minimization in Step 3 should not stop until each sequence satisfies the sufficient condition or does not satisfy the necessary condition, otherwise the cleaning up could miss some points where the minimizer is equal to zero. However, numerical experiments show that the use of these conditions is not necessary, and the number of elements in the sets is generally bounded by , provided that Problem 2 is solved by the algorithm described in the following section.
5.7. Solving Problem 2
There are standard methods for solving Problem 2, and numerical libraries are available. The interior point method [19] provides a quadratic convergence to the solution, meaning that the number of digits of accuracy is almost doubled at each iteration step, once is sufficiently close to the minimizer. The algorithm uses the Newton method and needs to solve a set of linear equations. Since this can be computationally demanding in terms of memory, we have implemented the solver by using the conjugate gradient method, which does not use the Hessian. Furthermore, if the Hessian turns out to have a small condition number, the conjugate gradient method can be much more efficient than the Newton method, especially if we do not need to solve Problem 2 with high accuracy. This is the case in the initial stage of the computation, when the set is growing and does not contain all the points of the support of .
The conjugate gradient method iteratively performs a one-dimensional minimization, along directions that are conjugate with respect to the Hessian of the objective function [19]. The directions are computed iteratively, by setting the first direction equal to the gradient of the objective function. The conjugate gradient method is generally used with unconstrained problems, whereas Problem 2 has the inequality constraints . To adapt the method to our problem, we perform the one-dimensional minimization in the region where is non-negative. Whenever an inactive constraint becomes active, or vice versa, we set the search direction equal to the gradient and restart the generation of the directions from that point. Once the procedure terminates, the algorithm provides a list of active constraints with . Numerical simulations show that this list is generally complete, and corresponds to the points where the minimizer is equal to zero.
In general, the slackness condition (25) is not satisfied by the numerical solution. However, as previously pointed out, we can suitably normalize so that this condition is satisfied by . Thus, we will assume that the equality
holds with . This also implies that
6. Convergence Analysis and Computational Cost
Here, we provide a convergence analysis and show that the error on the distance from the local polytope is bounded above by a function decaying at least as fast as , where n is the number of iterations. The convergence of this function to zero is sublinear, but its derivation relies on a very rough estimate of a lower bound on the optimal value . Actually, the iteration converges to the solution in a finite number of steps (up to the accuracy of the solver of Problem 2). Indeed, since the number of vertices is finite, also the number of their sets is finite. Thus, the sequence converges to the support of the optimizer in a finite number of steps, as the accuracy goes to zero.
We expect that this finite number of steps is of the order of the dimension of the local polytope. Interestingly, the computed bound on the number of required iterations for given error does not depend on the number of measurements. Using this bound, we show that the computational cost for any given error on the distance grows polynomially with the size of the problem input; that is, with A, B, R, and S, provided that the oracle can be simulated in polynomial time.
To prove the convergence, we need to introduce the dual form of Problem 1 (see Ref. [19] for an introduction to dual theory). The dual form of a minimization problem (primal problem) is a maximization problem, whose maximum is always smaller than or equal to the primal minimum, the difference being called the duality gap. However, if the constraints of the primal problem satisfy some mild conditions, such as Slater’s conditions [19], then the duality gap is equal to zero. As previously said, this is the case of Problem 1.
The dual form is particularly useful for evaluating lower bounds on the optimal value of the primal problem. Indeed, the value taken by the dual objective function in a feasible point of the dual constraints provides such a bound. After introducing the dual form of Problem 1, we derive the lower bound on , given by Equation (37). Then, we use this bound and Equation (48) to prove the convergence.
6.1. Dual Problem
The dual problem of Problem 1 is a maximization problem over the space of values taken by the Lagrange multipliers subject to the dual constraints . The dual objective function is given by the minimum of the Lagrangian , defined by Equation (15), with respect to . The dual constraint is the non-negativity of the Lagrange multipliers, that is,
As this minimum cannot be derived analytically, a standard strategy for getting an explicit form of the dual objective function is to enlarge the space of primal variables and, correspondingly, to increase the number of primal constraints. The minimum is then evaluated over the enlarged space. In our case, it is convenient to introduce Equation (9) and as additional constraints and variables, respectively. Thus, F is made independent of and expressed as a function of . The new optimization problem, which is equivalent to Problem 1, has Lagrangian
where are the Lagrange multipliers associated with the added constraints. To find the minimum of the Lagrangian, we set its derivative, with respect to the primal variables and , equal to zero. We get the equations
The first equation does not depend on the primal variables and sets a constraint on the dual variables. If this constraint is not satisfied, the dual objective function is equal to . Thus, its maximum is in the region where Equation (55) is satisfied. Let us add it to the dual constraint (53). The second stationarity condition, Equation (56), gives the optimal . By replacing it in the Lagrangian, we get the dual objective function
Eliminating , which does not appear in the objective function, the dual constraints (53) and (55) give the inequality
Thus, Problem 1 is equivalent to the following.
Problem 3 (dual problem of Problem 1).
The value taken by at a feasible point provides a lower bound on . Given any function , a feasible point is
Indeed,
The lower bound turns out to be the optimal value , if the distribution given by Equation (56) in terms of is solution of the primal Problem 1. This suggests the transformation
where is some local distribution up to a normalization constant (in fact, can be any real function). Every local distribution induces a lower bound on the optimal value . This lower bound turns out to be an accurate approximation of if is close enough to the optimal local distribution. Using the last equation and Equation (59), we get the lower bound (37) from .
The dual problem of Problem 2 is similar to Problem 3, but the constraints have to hold for sequences in .
Problem 4 (dual problem of Problem 2).
This dual problem induces the lower bound on the optimal value of Problem 2 (Equation (44)).
6.2. Convergence and Polynomial Cost
Let be the local distribution computed in Step 3 of Algorithm 1. From the lower bound (37), we have
where is given by Equation (30), and . The part of the summation linear in is equal to zero, by Equation (51). The remaining part, linear in , is bounded from below by ( is positive). This can be shown by minimizing it under the constraint (51). Thus, we have that
As is not greater than 1, the factor in the right-hand side of the inequality can be replaced by , so that we have
which gives, with Equation (48), the following
This inequality implies that
This can be proved by induction. It is easy to prove that inequality holds for , if it holds for . Let us prove that it holds for . It is sufficient to prove that . Using the identity
we have
Thus, the error decreases at least as fast as . Although the convergence of the upper bound is sublinear, we derived this inequality by using Equation (63), which provides a quite loose bound on the optimal value . Nonetheless, the constraint set by Equation (66) on the accuracy is strong enough to imply the polynomial convergence of the algorithm, provided that the oracle can be simulated in polynomial time. Indeed, the inequality implies that the number of steps required to reach a given accuracy does not grow faster than . Since the computational cost of completing each step is polynomial, the overall algorithm has polynomial cost. More precisely, each step is completed by solving a quadratic minimization problem. If we do not rely on the specific structure of the quadratic problem, its computational cost does not grow faster than [19], where , , and D are the number of variables, the number of constraints, and the cost of evaluating the first and second derivatives of the objective and constraint functions. The numbers and are equal, and D is equal to . As the number of vertices in the set is not greater than the number of iterations (say, ), we have that . Furthermore, the number of vertices cannot be greater than . Thus, the number of variables is, in the worst case,
As implied by Equation (66), about iterations are sufficient for reaching an error not greater than . Let us set . Denoting the computational cost of Algorithm 1 with accuracy by , we have that
where K is some constant. Let us consider the two limiting cases with (high number of measurements) and (high accuracy).
In the first case, we have that , which also implies that (there are at least 2 measurements per party). We have
Thus, given a fixed error, the computational cost is asymptotically linear in the number of measurements. For and , this bound holds for a number of measurements per party greater than 800. If , the computation ends in few hours in the worst case by using available personal computers, provided that the bound is saturated in the most pessimistic scenario.
In the second case, we have that and . Thus,
Thus, for a fixed error and smaller than , the bound on the computational cost scales as the third power of the product ; that is, the sixth power of the number of measurments, provided that . This scaling is in good agreement with the numerical tests, as discussed later. However the tests indicate that the scaling and, thus, the sublinear convergence is too pessimistic. For example, for , , and , the bound gives a running time of the order of months, whereas the running time in the tests turns out to be less than one hour.
6.3. Simulation of the Oracle
We have shown that the cost of computing the distance from the local polytope grows polynomially, provided that we have access to the oracle. But what is the computational complexity of the oracle? In the case of measurements with two outcomes, we have seen that the solution of the oracle is equivalent to finding the minimal energy of a particular class of Ising spin glasses. These problems are known to be NP-hard. However, the oracle has a particular structure that can make many physically relevant instances numerically tractable. For example, the couplings of the Ising spin model are constrained by the nonsignaling conditions on and the optimality conditions (22)–(24). Furthermore, the Hamiltonian (14) is characterized by two classes of spins, described by the variables and , respectively, and each element in one class is coupled only to elements in the other class. This particular structure suggests the following block-maximization algorithm for solving the oracle.
Algorithm 2.
Input:
- 1.
- Generate a random sequence .
- 2.
- Maximize with respect to the sequence (see later discussion).
- 3.
- Maximize with respect to the sequence .
- 4.
- Repeat from Step 2 until the block-maximizations stop making progress.
Numerical tests show that this algorithm, when used for computing the distance from the local polytope, stops after a few iterations. Furthermore, only a few trials of the initial random sequence are required for convergence of Algorithm 1. We also note that the probability of a successful simulation of the oracle increases when is close to the optimal solution , suggesting that the optimality conditions (22)–(24) play some role in the computational complexity of the oracle. Pragmatically, we have chosen the number of trials equal to , such that the computational cost of simulating the oracle contributes to the overall running time with a constant multiplicative factor and, thus, the sixth-power law of the oracle-assisted algorithm is not affected.
Before discussing the numerical results, let us explain how the maximization on blocks is performed. Let us consider the maximization with respect to , as the optimization with respect to has an identical procedure. We have
Thus, the maximum is found by maximizing the function , with respect to the discrete variable r for every a. Taking into account the sum over b required for generating , the computational cost of the block-maximization is proportional to . Thus, it does not grow more than linearly with respect to the size of the problem input; that is, .
7. Numerical Tests
In the previous sections, we introduced an algorithm that computes the distance from the local polytope in polynomial time, provided that we have access to oracle Max. Surprisingly, in every simulation performed on entangled qubits, the algorithm implementing the oracle successfully finds the solution in polynomial time. More precisely, the algorithm finds a sequence sufficiently close to the maximum to guarantee convergence of Algorithm 1 to the solution of Problem 1. Interestingly, the probability of a successful simulation of the oracle increases as approaches the solution. This suggests that the optimality conditions (22)–(24) play a fundamental role in the computational complexity of the oracle. To check that the algorithm successfully finds the optimizer up to the desired accuracy, we have solved the oracle with a brute-force search at the end of the computation, whenever this was possible in a reasonable time. All of the checks show that the solution is found within the desired accuracy.
In the tests, we considered the case of maximally entangled states, Werner states, and pure non-maximally entangled states. The numerical data are compatible with a running time scaling as the sixth power of the number of measurements. This is in accordance with the theoretical analysis, given in Section 6.2. Furthermore, the simulations show that the sublinear convergence of the upper bound on the error is very loose, and the convergence turns out to be much faster. Let us discuss the case of entangled qubits in a pure quantum state.
7.1. Maximally Entangled State
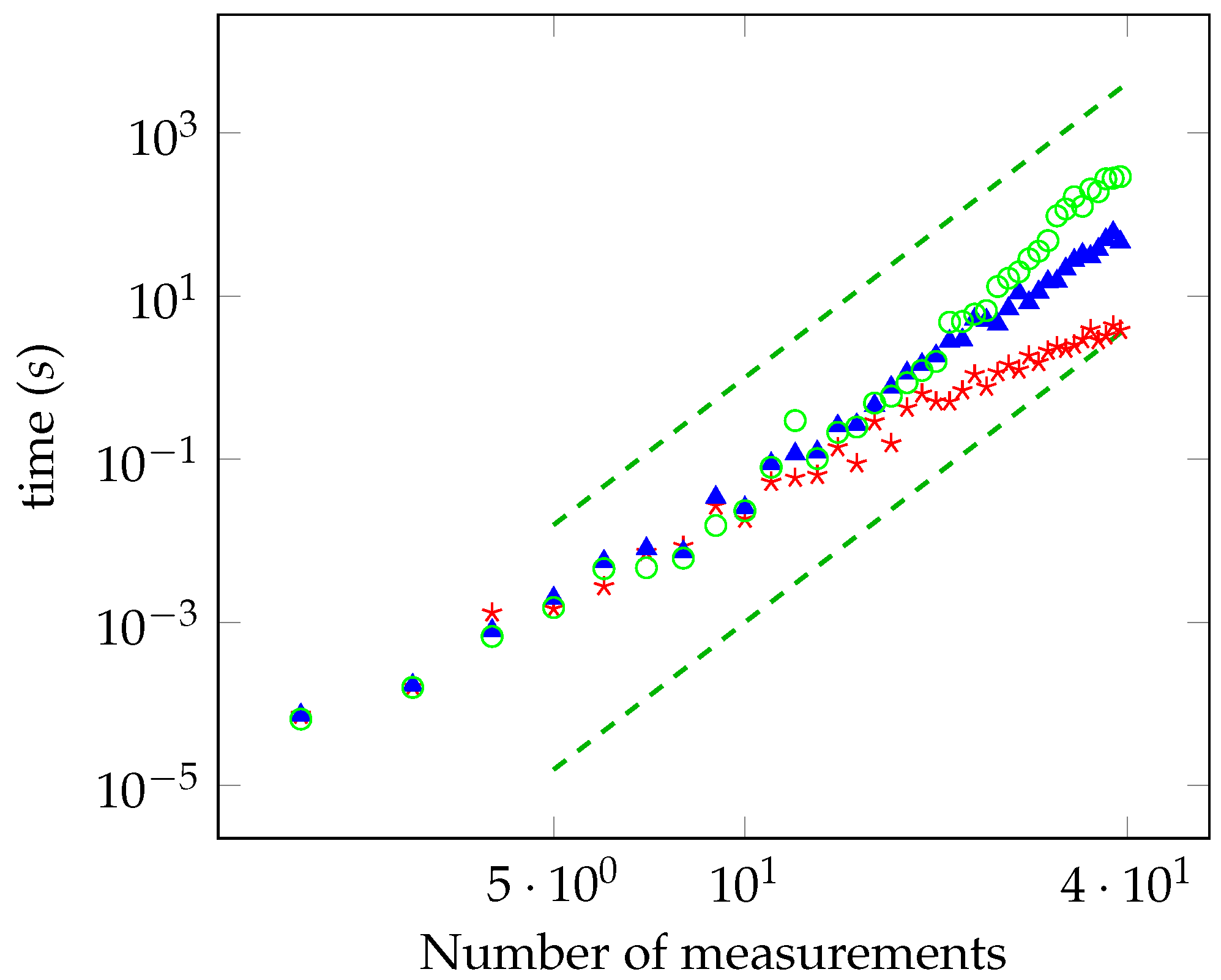
In Figure 1, we report the time required for computing the distance from the local polytope as a function of the number of measurements, M, in log-log scale. The distance has been evaluated with accuracy equal to , , and (red, blue, and green points, respectively). We have considered the case of planar measurements on the Bloch sphere. For the sake of comparison, we have also plotted the functions and (dashed lines). The data are compatible with the theoretical power law derived previously. They also show that the sublinear convergence of , derived in Section 6.2, is too pessimistic and the algorithm actually shows better performances. In particular, the bound says that the running time is not greater than years for and , whereas the observed running time is actually less than one hour. Other simulations have been performed with random measurements. We generated a set of measurements corresponding to random vectors on the Bloch sphere, by considering both the planar and non-planar case. Then, we computed the distance from the local polytope for a different number of measurements. We always observed that the running time scales with the same sixth power law. For a number of measurements below 28, we have solved the oracle with a brute-force search at the end of the computation, and we have always found that Algorithm 1 successfully converged to the solution within the desired accuracy.
7.2. Non-Maximally Entangled State
In the case of the non-maximally entangled state
with , we have considered planar measurements orthogonal to the Bloch vector (such that the marginal distributions are unbiased), as well as planar measurements lying in the plane containing (biased marginal distributions).
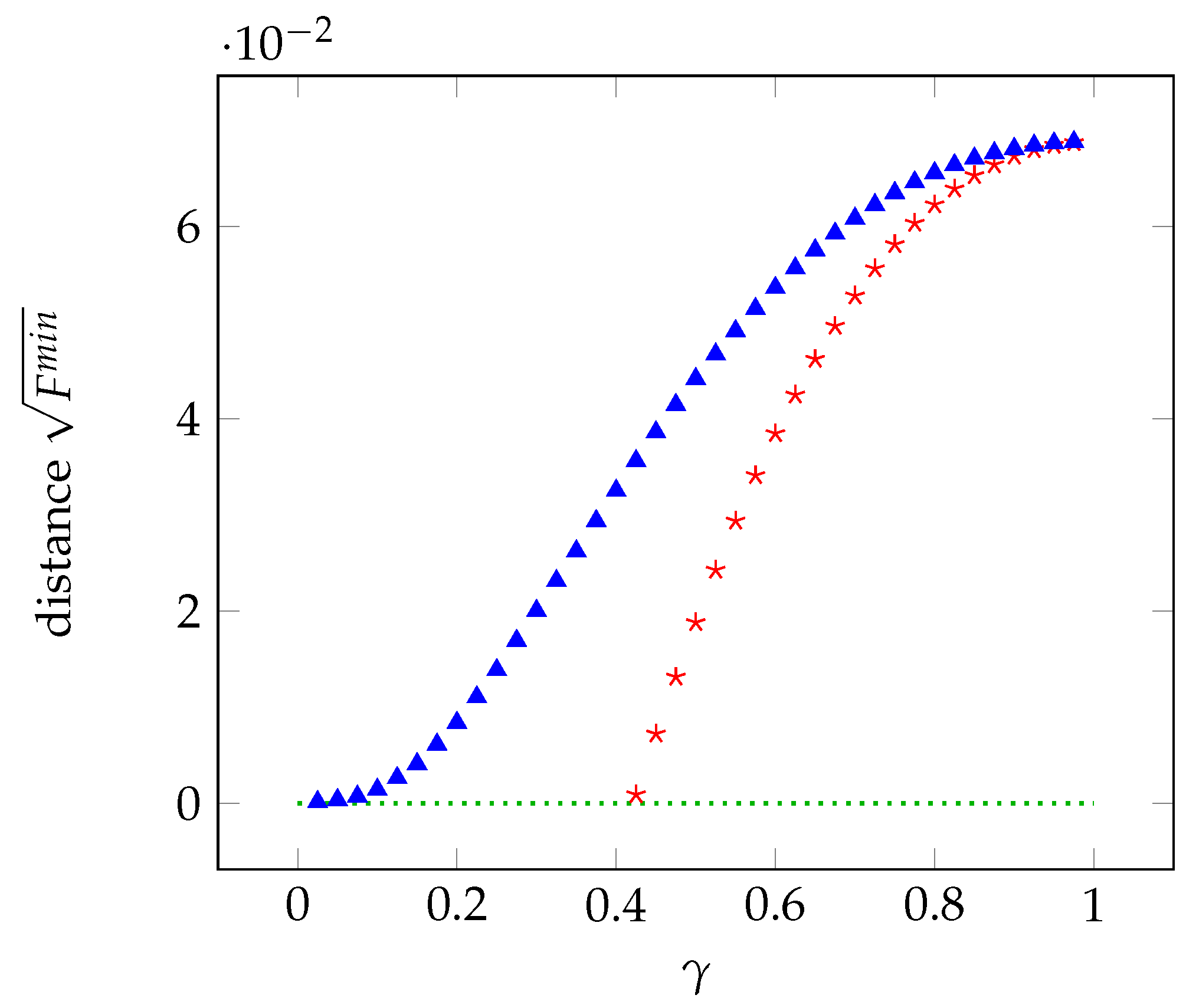
In Figure 2, we report the distance from the local polytope as a function of with 10 measurements. The distance changes slightly for higher numbers of measurements. In the unbiased case, the distance goes to zero for equal to about , whereas the correlations become local for in the biased case.
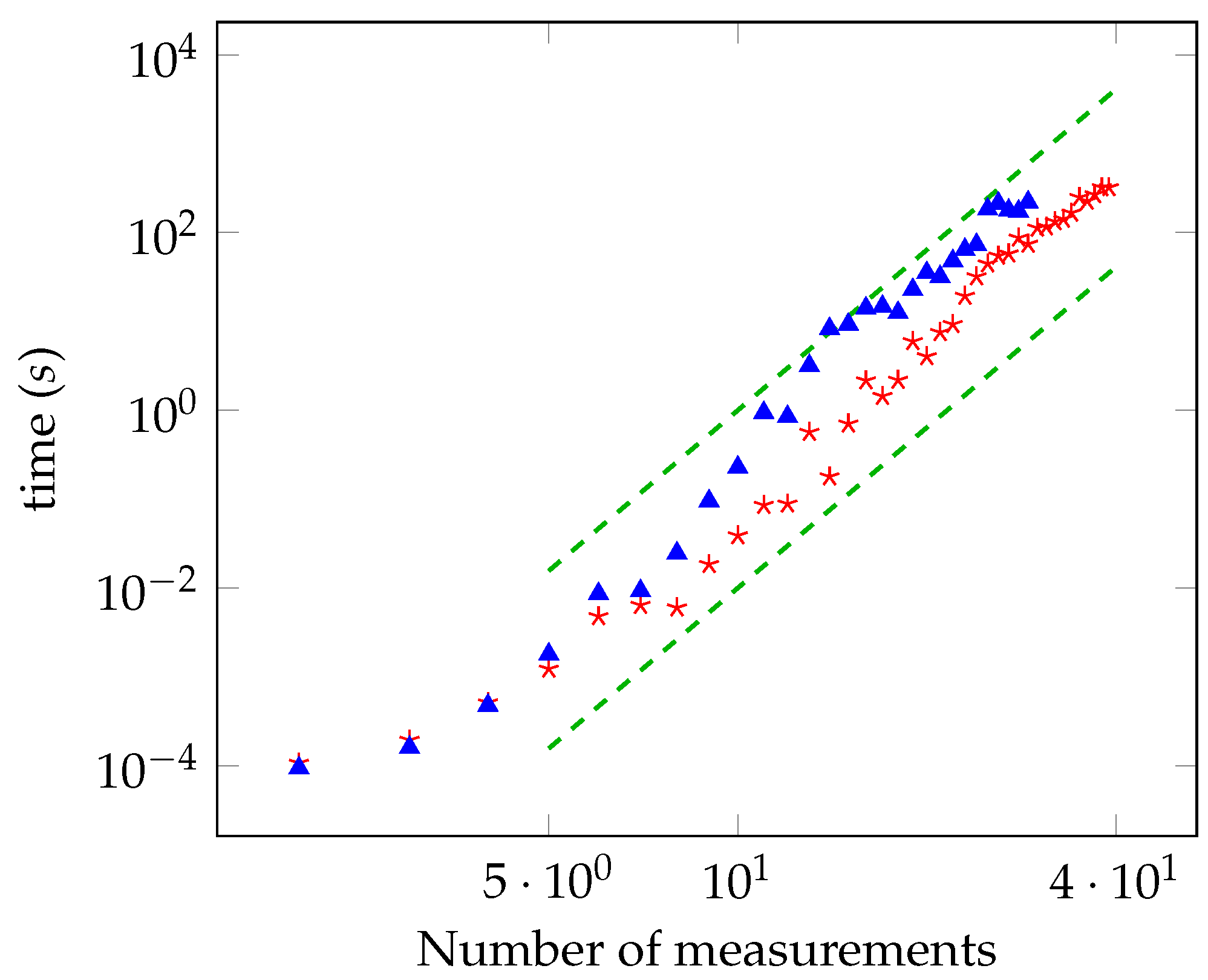
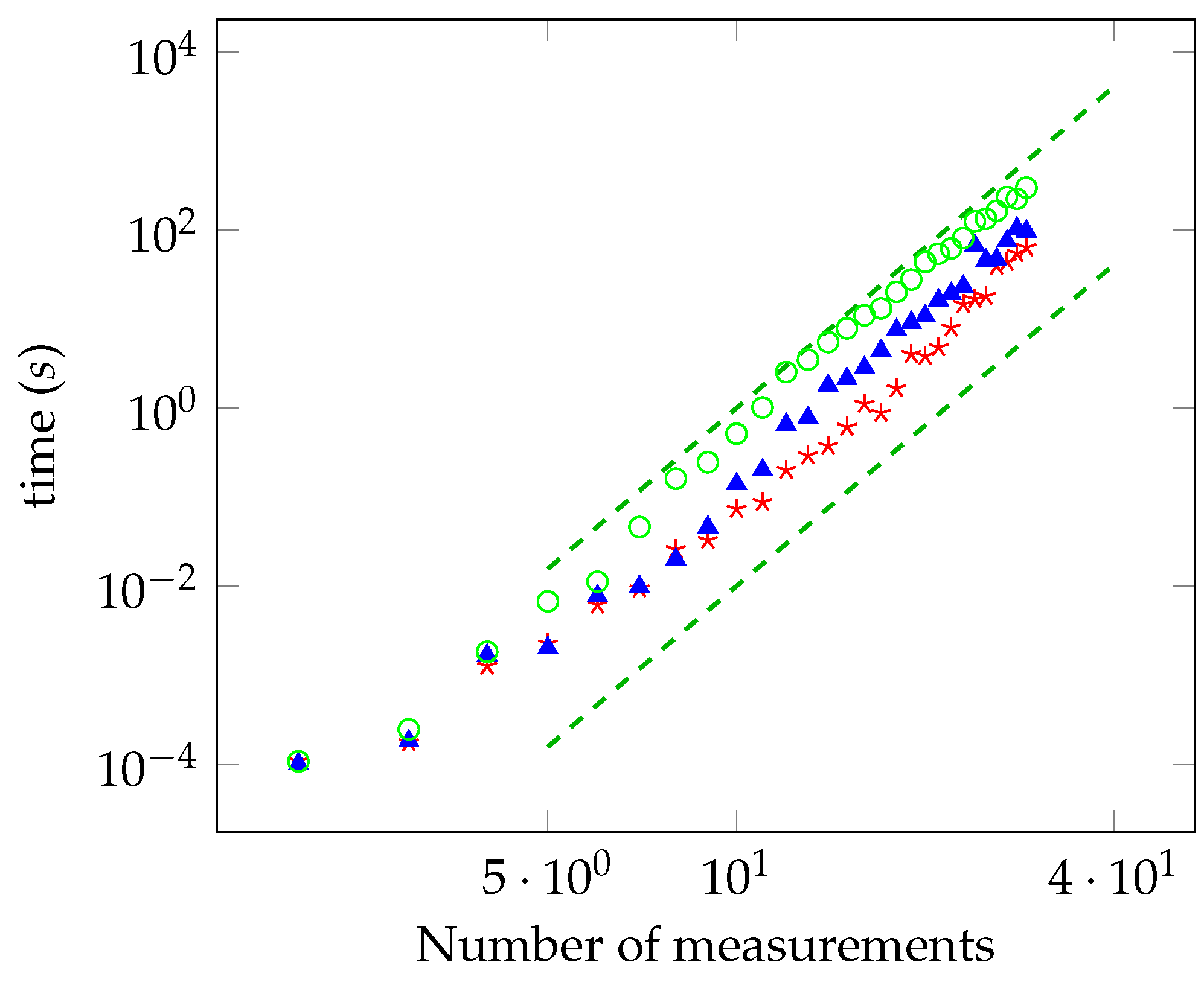
In Figure 3 and Figure 4, the running time as a function of the number of measurements is reported for the unbiased and biased cases, respectively. The power law is, again, in accordance with the theoretical analysis. As done for the maximally entangled case, we have checked the convergence to the solution by solving the oracle with a brute force search for a number of measurements up to 28.
8. Conclusions
In conclusion, we have presented an algorithm that computes the distance of a given non-signaling box to the local polytope. The running time, with given arbitrary accuracy, scaled polynomially, granted the access to an oracle determining the optimal locality bound of a Bell inequality. We also proposed an algorithm for simulating the oracle. In all of the numerical tests, the overall algorithm successfully computed the distance with the desired accuracy and a scaling of the running time, in agreement with the bound theoretically derived for the oracle-assisted algorithm. Our algorithm opens the way to tackle many unsolved problems in quantum theory, such as the non-locality of Werner states. Since the non-locality problem is NP-hard, our work and its further refinements could provide alternative algorithms to solve some instances of computationally hard problems.
Author Contributions
Conceptualization, formal analysis, investigation and software, A.M.; draft preparation, supervision, project administration, funding acquisition, A.M. and S.W.
Funding
This research was funded by Hasler Stiftung, grant number 16057, and Swiss National Science Foundation.
Acknowledgments
We wish to thank Arne Hansen for valuable comments and suggestions. This work is supported by the Swiss National Science Foundation, the NCCR QSIT, and the Hasler foundation through the project “Information-Theoretic Analysis of Experimental Qudit Correlations”.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bell, J. On the einstein podolsky rosen paradox. Physics 1964, 1, 195. [Google Scholar] [CrossRef]
- Barrett, J.; Hardy, L.; Kent, A. No signaling and quantum key distribution. Phys. Rev. Lett. 2005, 95, 010503. [Google Scholar] [CrossRef] [PubMed]
- Acín, A.; Gisin, N.; Masanes, L. From Bell’s theorem to secure quantum key distribution. Phys. Rev. Lett. 2006, 97, 120405. [Google Scholar] [CrossRef] [PubMed]
- Scarani, V.; Gisin, N.; Brunner, N.; Masanes, L.; Pino, S.; Acín, A. Secrecy extraction from no-signaling correlations. Phys. Rev. A 2006, 74, 042339. [Google Scholar] [CrossRef]
- Acín, A.; Massar, S.; Pironio, S. Efficient quantum key distribution secure against no-signalling eavesdroppers. New J. Phys. 2006, 8, 126. [Google Scholar] [CrossRef]
- Acín, A.; Brunner, N.; Gisin, N.; Massar, S.; Pironio, S.; Scarani, V. Device-independent security of quantum cryptography against collective attacks. Phys. Rev. Lett. 2007, 98, 230501. [Google Scholar] [CrossRef] [PubMed]
- Masanes, L.; Renner, R.; Christandl, M.; Winter, A.; Barrett, J. Full security of quantum key distribution from no-signaling constraints. IEEE Trans. Inf. Theory 2014, 60, 4973–4986. [Google Scholar] [CrossRef]
- Hänggi, E.; Renner, R.; Wolf, S. The impossibility of non-signaling privacy amplification. Theor. Comput. Sci. 2013, 486, 27–42. [Google Scholar] [CrossRef]
- Colbeck, R.; Renner, R. Free randomness can be amplified. Nat. Phys. 2012, 8, 450. [Google Scholar] [CrossRef]
- Gallego, R.; Masanes, L.; de la Torre, G.; Dhara, C.; Aolita, L.; Acín, A. Full randomness from arbitrarily deterministic events. Nat. Commun. 2013, 4, 2654. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buhrman, H.; Cleve, R.; Massar, S.; de Wolf, R. Nonlocality and communication complexity. Rev. Mod. Phys. 2010, 82, 665. [Google Scholar] [CrossRef]
- Pitowski, I. Quantum Probability—Quantum Logic; Academic Press: London, UK, 1989. [Google Scholar]
- Brierley, S.; Navascues, M.; Vertesi, T. Convex separation from convex optimization for large-scale problems. arXiv, 2016; arXiv:1609.05011. [Google Scholar]
- Montina, A.; Wolf, S. Can non-local correlations be discriminated in polynomial time? arXiv, 2016; arXiv:1609.06269v1. [Google Scholar]
- Fine, A. Hidden variables, joint probability, and the Bell inequalities. Phys. Rev. Lett. 1982, 48, 291. [Google Scholar] [CrossRef]
- Collins, D.; Gisin, N. A relevant two qubit Bell inequality inequivalent to the CHSH inequality. J. Phys. A Math. Theor. 2004, 37, 1775. [Google Scholar] [CrossRef]
- Montina, A.; Wolf, S. Information-based measure of nonlocality. New J. Phys. 2016, 18, 013035. [Google Scholar] [CrossRef]
- Bernhard, C.; Bessire, B.; Montina, A.; Pfaffhauser, M.; Stefanov, A.; Wolf, S. Non-locality of experimental qutrit pairs. J. Phys. A: Math. Theor. 2014, 42, 424013. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
Figure 1.
Time required for computing the distance from the local polytope for a maximally entangled state as a function of the number of measurements (log-log scale) with accuracy equal to , , and (red, blue, and green points, respectively).
Figure 1.
Time required for computing the distance from the local polytope for a maximally entangled state as a function of the number of measurements (log-log scale) with accuracy equal to , , and (red, blue, and green points, respectively).

Figure 2.
Distance from the local polytope as a function of in the unbiased case (red stars) and biased case (blue triangles).
Figure 2.
Distance from the local polytope as a function of in the unbiased case (red stars) and biased case (blue triangles).

Figure 3.
Time required for computing the distance from the local polytope as a function of the number of measurements (log-log scale) in the unbiased case, for (red stars) and (blue triangles). The green lines are the functions and . The accuracy is .
Figure 3.
Time required for computing the distance from the local polytope as a function of the number of measurements (log-log scale) in the unbiased case, for (red stars) and (blue triangles). The green lines are the functions and . The accuracy is .

Figure 4.
The same as Figure 3 in the biased case, for (red stars), (blue triangles), and (green circles).
Figure 4.
The same as Figure 3 in the biased case, for (red stars), (blue triangles), and (green circles).

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Montina, A.; Wolf, S. Discrimination of Non-Local Correlations. Entropy 2019, 21, 104. https://0-doi-org.brum.beds.ac.uk/10.3390/e21020104
AMA Style
Montina A, Wolf S. Discrimination of Non-Local Correlations. Entropy. 2019; 21(2):104. https://0-doi-org.brum.beds.ac.uk/10.3390/e21020104
Chicago/Turabian StyleMontina, Alberto, and Stefan Wolf. 2019. "Discrimination of Non-Local Correlations" Entropy 21, no. 2: 104. https://0-doi-org.brum.beds.ac.uk/10.3390/e21020104
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.