Application of Dynamic Fragmentation Methods in Multimedia Databases: A Review

 and
and
Abstract
:1. Introduction
- The database administrator (DBA) has to observe the system for a significant amount of time before the partitioning operation can take place until the probabilities of queries accessing certain database elements and their frequencies are collected, this is called an analysis stage.
- Even then, after the partitioning process is completed, nothing guarantees that the real trends in queries and data have been discovered. Thus the partitioning scheme may not be good. In this case, the database users may experience a very long query response time.
- In some dynamic (e.g., multimedia) applications, queries tend to change over time and a partitioning scheme is implemented to optimize the response time for one particular set of queries. Thus, if the queries or their relative frequencies change, the fragmentation result may no longer be adequate.
- In static partitioning methods, refragmentation is a heavy task and only can be performed manually when the system is idle
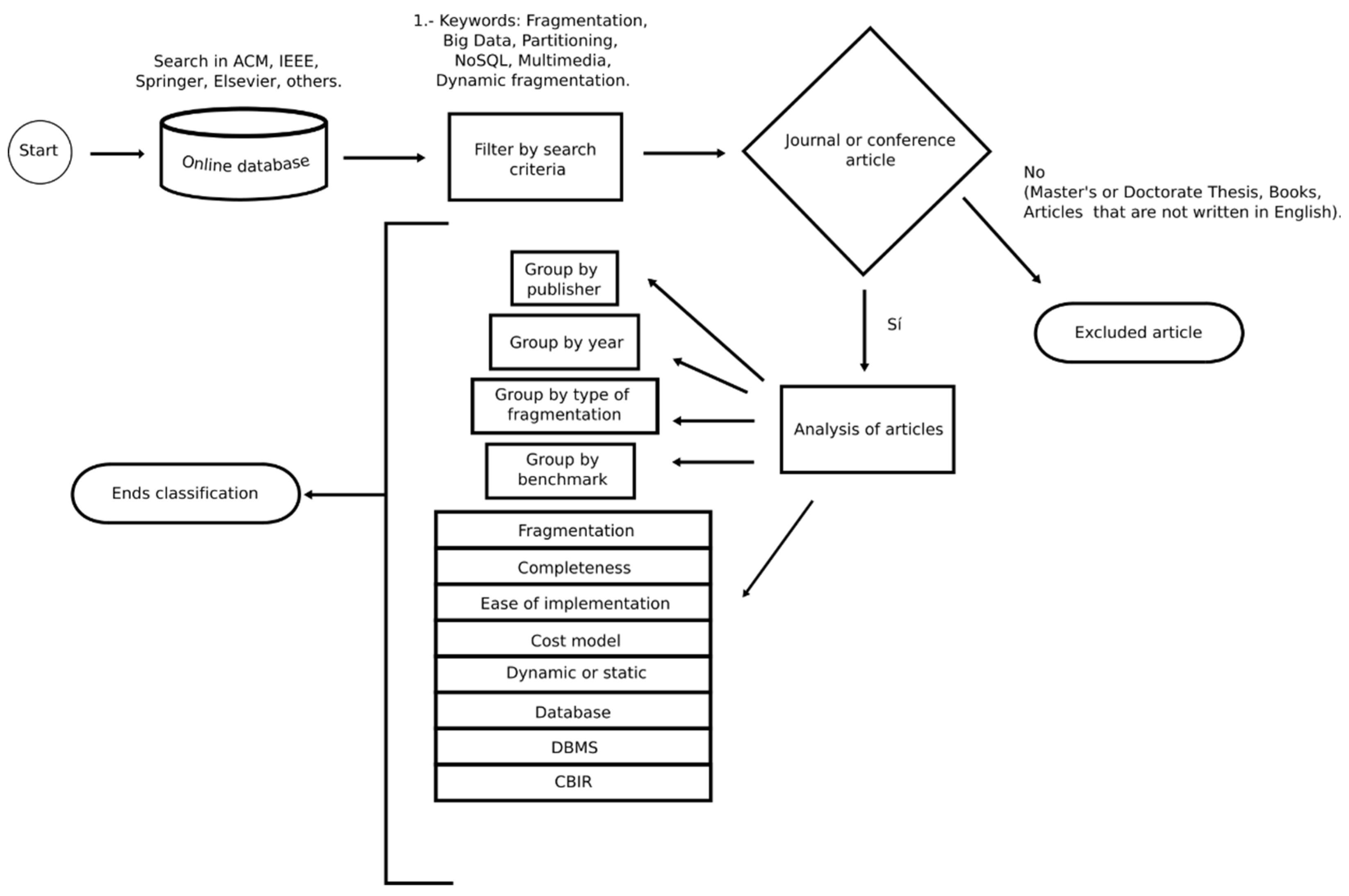
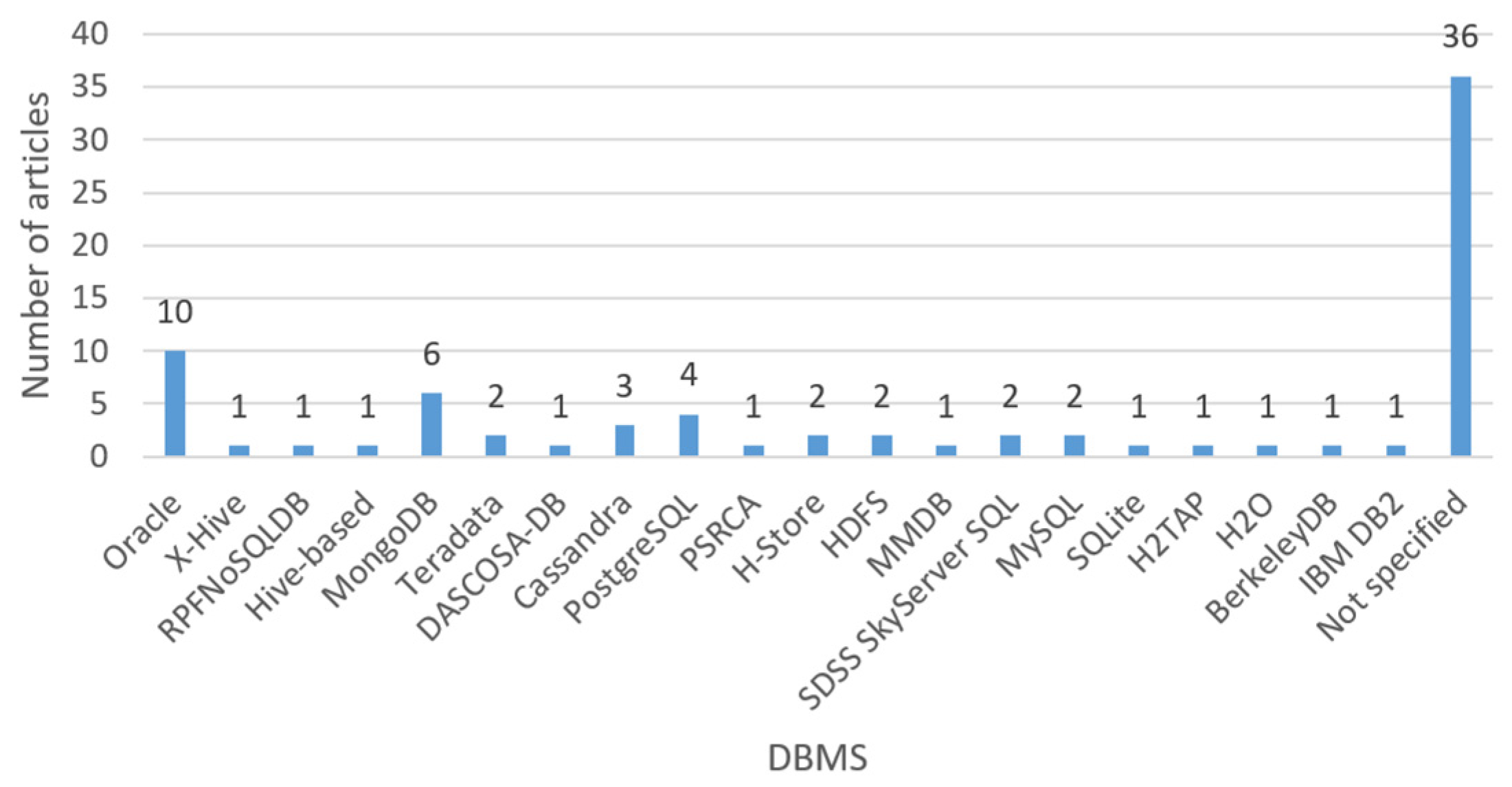
2. Research Methodology
3. Classification Method
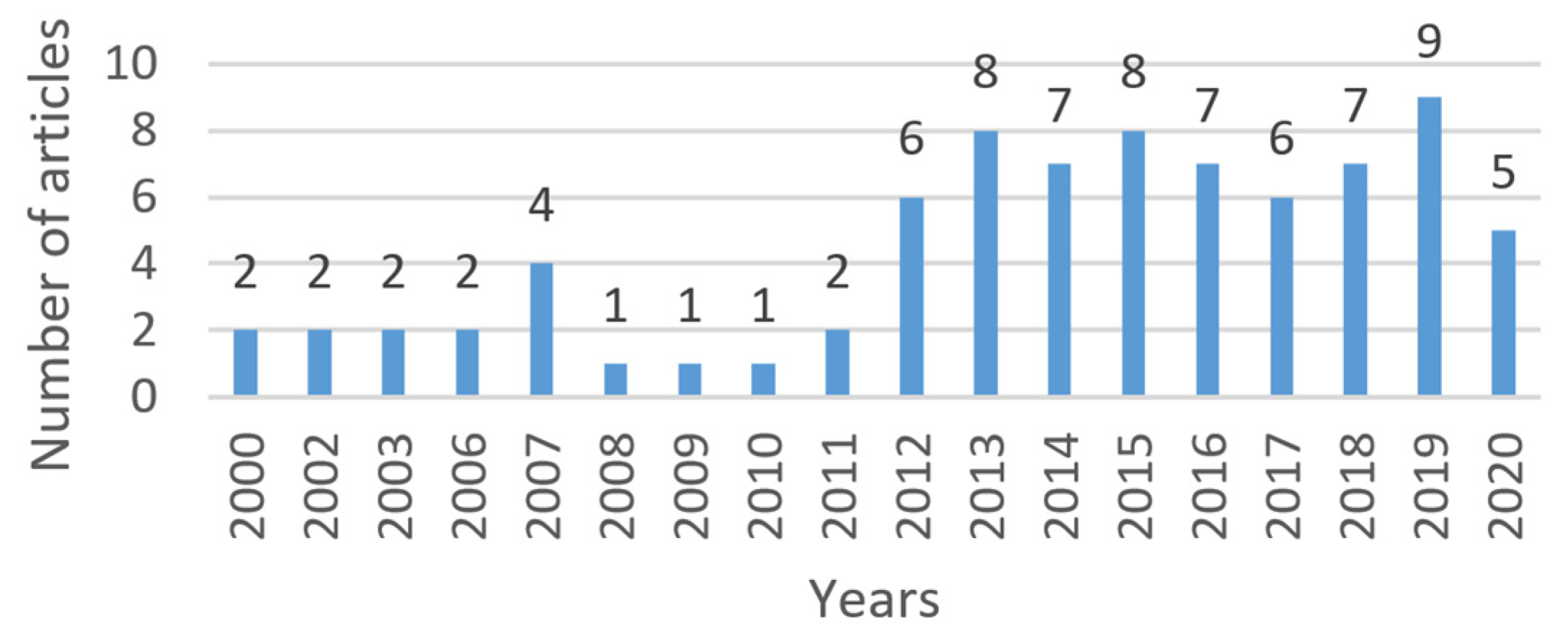
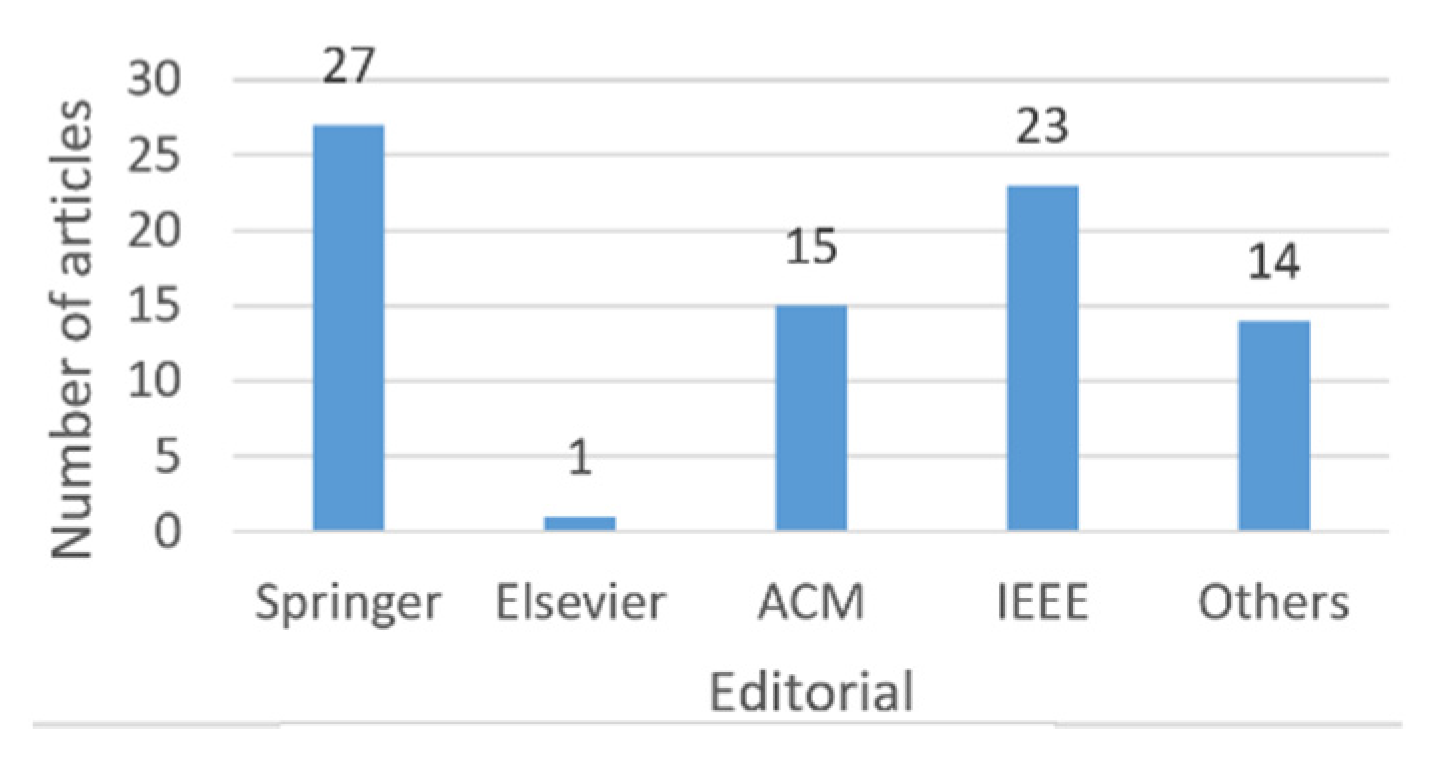
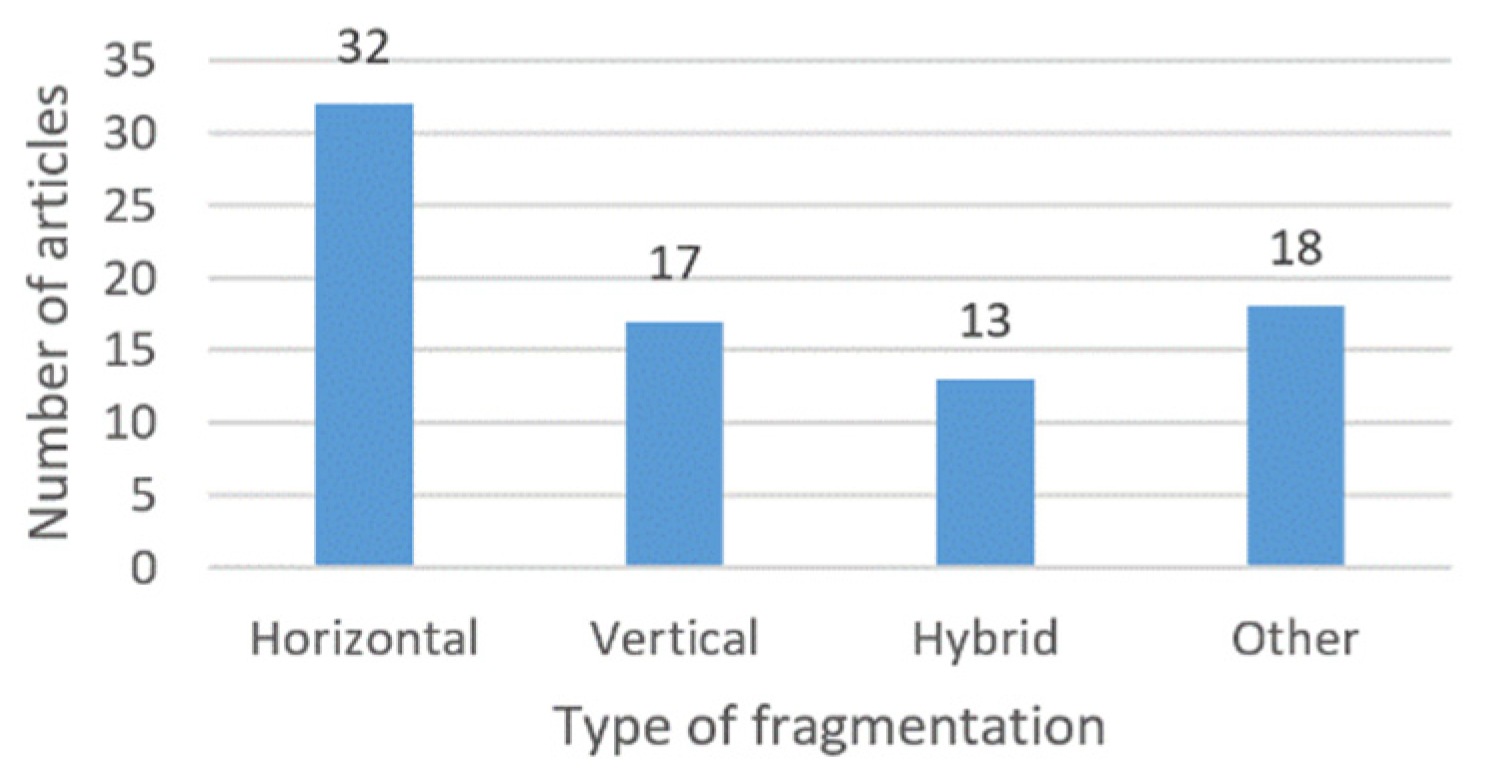
4. Classification of Research Papers
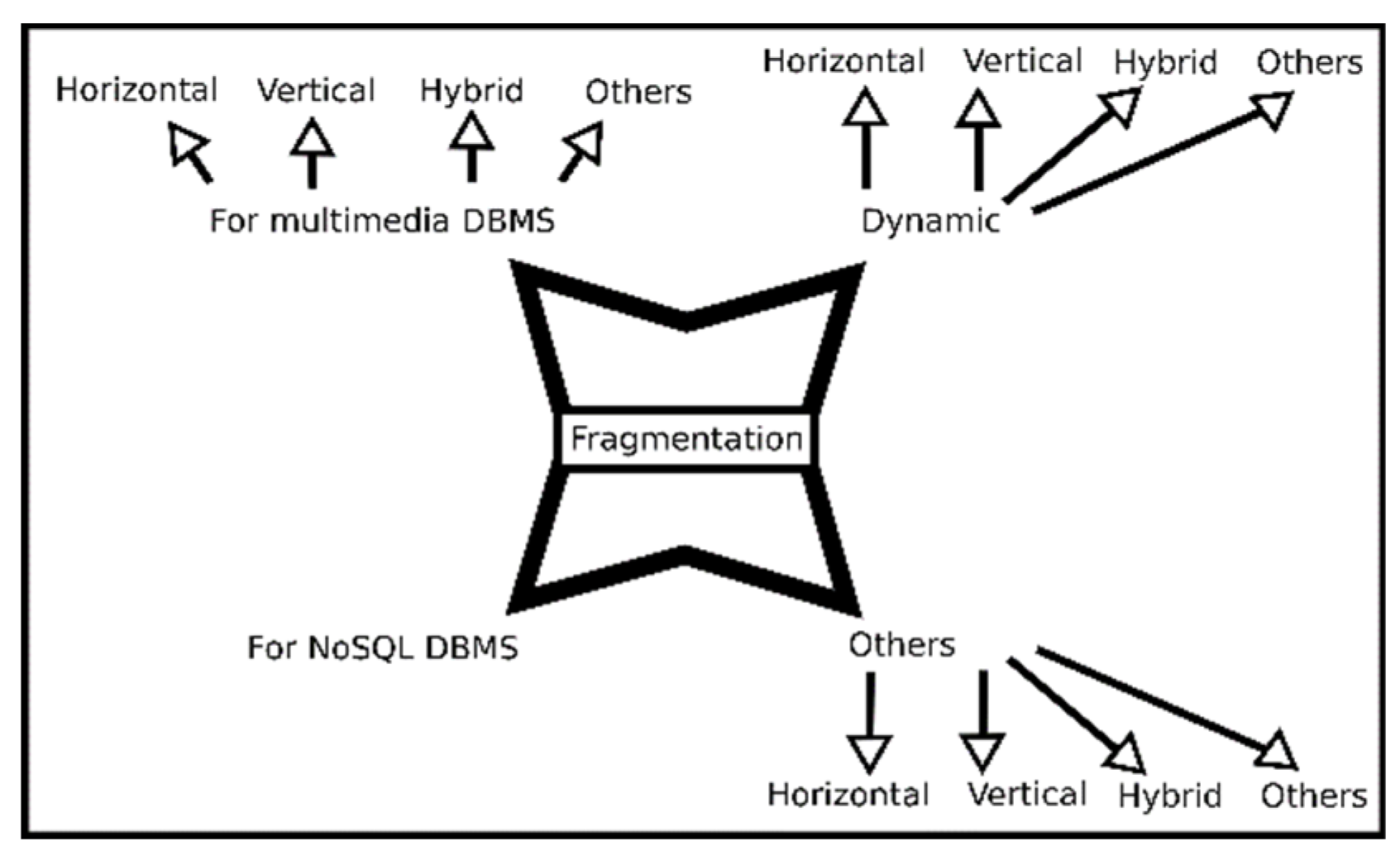
5. Description of the Set of Works by Category
5.1. Fragmentation of Multimedia Databases
5.1.1. Horizontal Fragmentation of Multimedia Databases
5.1.2. Vertical Fragmentation for Multimedia Databases
5.1.3. Hybrid Fragmentation for Multimedia Databases
5.1.4. Other Types of Fragmentation for Multimedia Databases
5.2. Dynamic Fragmentation
5.2.1. Dynamic Horizontal Fragmentation
5.2.2. Dynamic Vertical Fragmentation
5.2.3. Dynamic Hybrid Fragmentation
5.2.4. Other Dynamic Fragmentations
5.3. Fragmentation for NoSQL DBMS
5.4. Other Types of Fragmentation
5.4.1. Other Types of Horizontal Fragmentation
5.4.2. Other Types of Vertical Fragmentation
5.4.3. Other Types of Hybrid Fragmentation
5.4.4. Other Types of Fragmentation
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Saad, S.; Tekli, J.; Chbeir, R.; Yetongnon, K. Towards Multimedia Fragmentation. In Advances in Databases and Information Systems; Lecture Notes in Computer Science; Manolopoulos, Y., Pokorny, J., Sellis, T.K., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4152, pp. 415–429. [Google Scholar] [CrossRef]
- Vazquez, J. A dynamic virtual fragmentation method for query recovery optimization. In Proceedings of the 20th International Conference of the Chilean Computer Science Society, Santiago, Chile, 16–18 November 2000. [Google Scholar] [CrossRef]
- Castro-Medina, F.; Rodriguez-Mazahua, L.; Lopez-Chau, A.; Abud-Figueroa, M.; Alor-Hernandez, G. FRAGMENT: A Web Application for Database Fragmentation, Allocation and Replication over a Cloud Environment. IEEE Lat. Am. Trans. 2020, 18, 1126–1134. [Google Scholar] [CrossRef]
- Abdalla, H.; Artoli, A. Towards an Efficient Data Fragmentation, Allocation, and Clustering Approach in a Distributed Environment. Information 2019, 10, 112. [Google Scholar] [CrossRef] [Green Version]
- Tarun, S.; Batth, R.; Kaur, S. A Review on Fragmentation, Allocation and Replication in Distributed Database Systems. In Proceedings of the 2019 International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, UAE, 11–12 December 2019; pp. 538–544. [Google Scholar] [CrossRef]
- Rodríguez-Arauz, M.; Rodriguez-Mazahua, L.; Arrioja-Rodríguez, M.; Abud-Figueroa, M.; Peláez-Camarena, S.; Martínez-Méndez, L. Design of a Multimedia Data Management System that Uses Horizontal Fragmentation to Optimize Content-based Queries. In Proceedings of the Tenth International Conference on Advances in Information Mining and Management (IMMM 2020), Lisbon, Portugal, 27 September 2020; pp. 15–21. [Google Scholar]
- Rodriguez, L.; Li, X.; Cuevas-Rasgado, A.; Garcia-Lamont, F. DYVEP: An active database system with vertical partitioning functionality. In Proceedings of the 10th IEEE International Conference on Networking, Sensing and Control (ICNSC 2013), Evry, France, 10–12 April 2013. [Google Scholar] [CrossRef]
- Vu, M.; Lofstedt, T.; Nyholm, T.; Sznitman, R. A Question-Centric Model for Visual Question Answering in Medical Imaging. IEEE Trans. Med. Imaging 2020, 39, 2856–2868. [Google Scholar] [CrossRef] [PubMed]
- Bir, P.; Balas, V. A Review on Medical Image Analysis with Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Computing, Power and Communication Technologies (GUCON 2020), Greater Noida, India, 2–4 October 2020; pp. 870–876. [Google Scholar] [CrossRef]
- Tschandl, P.; Argenziano, G.; Razmara, M.; Yap, J. Diagnostic accuracy of content-based dermatoscopic image retrieval with deep classification features. Br. J. Dermatol. 2018, 181, 155–165. [Google Scholar] [CrossRef]
- Kucharczyk, M.; Hay, G.; Ghaffarian, S.; Hugenholtz, C. Geographic Object-Based Image Analysis: A Primer and Future Directions. Remote Sens. 2020, 12, 2012. [Google Scholar] [CrossRef]
- Lorek, D.; Horbiński, T. Interactive Web-Map of the European Freeway Junction A1/A4 Development with the Use of Archival Cartographic Sources. ISPRS Int. J. Geo-Inf. 2020, 9, 438. [Google Scholar] [CrossRef]
- Cybulski, P.; Horbiński, T. User Experience in Using Graphical User Interfaces of Web Maps. ISPRS Int. J. Geo-Inf. 2020, 9, 412. [Google Scholar] [CrossRef]
- Oroud, I. The annual surface temperature patterns across the Dead Sea as retrieved from thermal images. Arab. J. Geosci. 2019, 12, 695. [Google Scholar] [CrossRef]
- Kavitha, P.K.; Vidhya Saraswathi, P. Content based satellite image retrieval system using fuzzy clustering. J. Ambient Intell. Humaniz. Comput. 2020. [Google Scholar] [CrossRef]
- Oroud, I. The utility of thermal satellite images and land-based meteorology to estimate evaporation from large lakes. J. Great Lakes Res. 2019, 45, 703–714. [Google Scholar] [CrossRef]
- Du, A.; Wang, L.; Cheng, S.; Ao, N. A Privacy-Protected Image Retrieval Scheme for Fast and Secure Image Search. Symmetry 2020, 12, 282. [Google Scholar] [CrossRef] [Green Version]
- Li, D.; Bai, X. Criminal Investigation Image Retrieval Based on Deep Learning. In Proceedings of the International Conference on Computer Network, Electronic and Automation (ICCNEA 2020), Xi’an, China, 25–27 September 2020; pp. 72–77. [Google Scholar] [CrossRef]
- Rashid, A.; Yassin, A.; Abdel Wahed, A.; Yassin, A. Smart City Security: Face-Based Image Retrieval Model Using Gray Level Co-Occurrence Matrix. J. Inf. Commun. Technol. 2020, 19, 437–458. [Google Scholar] [CrossRef]
- Lew, M.; Sebe, N.; Djeraba, C.; Jain, R. Content-based multimedia information retrieval: State of the art and challenges. ACM Trans. Multimed. Comput. Commun. Appl. 2006, 2, 1–19. [Google Scholar] [CrossRef]
- Traina, A.; Brinís, S.; Pedrosa, G.; Avalhais, L.; Traina, C., Jr. Querying on large and complex databases by content: Challenges on variety and veracity regarding real applications. Inf. Syst. 2019, 86, 10–27. [Google Scholar] [CrossRef]
- Pérez, J.; Pazos, R.; Frausto, J.; Romero, D.; Cruz, L. Vertical Fragmentation and Allocation in Distributed Databases with Site Capacity Restrictions Using the Threshold Accepting Algorithm. In MICAI 2000: Advances in Artificial Intelligence; Lecture Notes in Computer Science; Cairó, O., Sucar, L.E., Cantu, F.J., Eds.; Springer: Berlin/Heidelberg, Germany, 2000; Volume 1793, pp. 75–81. [Google Scholar] [CrossRef]
- Fung, C.; Karlapalem, K.; Li, Q. An evaluation of vertical class partitioning for query processing in object-oriented databases. IEEE Trans. Knowl. Data Eng. 2002, 14, 1095–1118. [Google Scholar] [CrossRef]
- Fung, C.; Leung, E.; Li, Q. Efficient Query Execution Techniques in a 4DIS Video Database System for eLearning. Multimed. Tools Appl. 2003, 20, 25–49. [Google Scholar] [CrossRef]
- Fung, C.; Karlapalem, K.; Li, Q. Cost-driven vertical class partitioning for methods in object oriented databases. VLDB J. Int. J. Very Large Data Bases 2003, 12, 187–210. [Google Scholar] [CrossRef]
- Rodriguez, L.; Li, X. A Vertical Partitioning Algorithm for Distributed Multimedia Databases. In Database and Expert Systems Applications (DEXA 2011); Lecture Notes in Computer Science; Hameurlain, A., Liddle, S.W., Schewe, K.D., Zhou, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6861, pp. 544–558. [Google Scholar] [CrossRef]
- Gu, X.; Yang, X.; Wang, W.; Jin, Y.; Meng, D. CHAC: An Effective Attribute Clustering Algorithm for Large-Scale Data Processing. In Proceedings of the 2012 IEEE Seventh International Conference on Networking, Architecture, and Storage, Xiamen, China, 28–30 June 2012. [Google Scholar] [CrossRef]
- Li, L.; Gruenwald, L. Self-managing online partitioner for databases (SMOPD) a vertical database partitioning system with a fully automatic online approach. In Proceedings of the 17th International Database Engineering & Applications Symposium (IDEAS 2013), Barcelona, Spain, 9–13 October 2013; pp. 168–173. [Google Scholar] [CrossRef]
- Alagiannis, I.; Idreos, S.; Ailamaki, A. H2O: A hands-free adaptive store. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (SIGMOD 2014), Snowbird, UT, USA, 22–27 June 2014; pp. 1103–1114. [Google Scholar] [CrossRef]
- Li, L.; Gruenwald, L. SMOPD-C: An autonomous vertical partitioning technique for distributed databases on cluster computers. In Proceedings of the 2014 IEEE 15th International Conference on Information Reuse and Integration (IEEE IRI 2014), Redwood City, CA, USA, 13–15 August 2014. [Google Scholar] [CrossRef]
- Zhao, W.; Cheng, Y.; Rusu, F. Vertical partitioning for query processing over raw data. In Proceedings of the 27th International Conference on Scientific and Statistical Database Management (SSDBM 2015), La Jolla, CA, USA, 29 June–1 July 2015; pp. 1–12. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez-Mazahua, L.; Alor-Hernández, G.; Li, X.; Cervantes, J.; López-Chau, A. Active rule base development for dynamic vertical partitioning of multimedia databases. J. Intell. Inf. Syst. 2016, 48, 421–451. [Google Scholar] [CrossRef]
- Campero Durand, G.; Piriyev, R.; Pinnecke, M.; Broneske, D.; Gurumurthy, B.; Saake, G. Automated Vertical Partitioning with Deep Reinforcement Learning. ADBIS 2019: New Trends in Databases and Information Systems; Communications in Computer and Information Science; Welzer, T., Ed.; Springer: Cham, Switzerland, 2019; Volume 1064, pp. 126–134. [Google Scholar] [CrossRef]
- Costa, E.; Costa, C.; Santos, M. Evaluating partitioning and bucketing strategies for Hive-based Big Data Warehousing systems. J. Big Data 2019, 6, 34. [Google Scholar] [CrossRef] [Green Version]
- Sharify, S.; Lu, A.; Chen, J.; Bhattacharyya, A.; Hashemi, A.; Koudas, N.; Amza, C. An Improved Dynamic Vertical Partitioning Technique for Semi-Structured Data. In Proceedings of the 2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS 2019), Madison, WI, USA, 24–26 March 2019. [Google Scholar] [CrossRef]
- Amer, A. On K-means clustering-based approach for DDBSs design. J. Big Data 2020, 7. [Google Scholar] [CrossRef]
- Schroeder, R.; Penteado, R.; Hara, C. A data distribution model for RDF. Distrib. Parallel Databases 2020. [Google Scholar] [CrossRef]
- Pinto, D.; Torres, G. On Dynamic Fragmentation of Distributed Databases Using Partial Replication. In Advances in Systems Theory, Mathematical Methods and Applications; WSEAS: Cancun, Mexico, 2002; pp. 208–211. [Google Scholar]
- Ma, H.; Schewe, K.; Wang, Q. A heuristic approach to cost-efficient fragmentation and allocation of complex value databases. In Proceedings of the 17th Australasian Database Conference (ADC 2006), Hobart, Australia, 16–19 January 2006; Volume 49, pp. 183–192. [Google Scholar]
- Getahun, F.; Tekli, J.; Atnafu, S.; Chbeir, R. The use of semantic-based predicates implication to improve horizontal multimedia database fragmentation. In Proceedings of the Workshop on Multimedia Information Retrieval on the Many Faces of Multimedia Semantics (MS 2007), Augsburg, Germany, 23–29 September 2007; pp. 29–38. [Google Scholar] [CrossRef] [Green Version]
- Tekli, J.; Getahun, F.; Atnafu, S.; Chbeiru, R. Towards efficient horizontal multimedia database fragmentation using semantic-based predicates implication. In Proceedings of the XXII Simpósio Brasileiro de Banco de Dados, João Pessoa, Brasil, 15–19 October 2007; Volume 2007, pp. 68–82. [Google Scholar]
- Ma, H.; Schewe, K.; Wang, Q. A heuristic approach to cost-efficient derived horizontal fragmentation of complex value databases. In Proceedings of the eighteenth conference on Australasian database (ADC 2007), Ballarat, Australia, 29 January–2 February 2007; Volume 63, pp. 103–111. [Google Scholar]
- Hauglid, J.; Ryeng, N.; Nørvåg, K. DYFRAM: Dynamic fragmentation and replica management in distributed database systems. Distrib. Parallel Databases 2010, 28, 157–185. [Google Scholar] [CrossRef] [Green Version]
- Bellatreche, L.; Benkrid, S.; Ghazal, A.; Crolotte, A.; Cuzzocrea, A. Verification of Partitioning and Allocation Techniques on Teradata DBMS. In Algorithms and Architectures for Parallel Processing; Lecture Notes in Computer Sciences; Xiang, Y., Cuzzocrea, A., Hobbs, M., Zhou, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7016, pp. 158–169. [Google Scholar] [CrossRef]
- Abdalla, H.; Amer, A. Dynamic horizontal fragmentation, replication and allocation model in DDBSs. In Proceedings of the 2012 International Conference on Information Technology and e-Services, Sousse, Tunisia, 24–26 March 2012. [Google Scholar] [CrossRef]
- Liroz-Gistau, M.; Akbarinia, R.; Pacitti, E.; Porto, F.; Valduriez, P. Dynamic Workload-Based Partitioning for Large-Scale Databases. In Database and Expert Systems Applications; Lecture Notes in Computer Science; Liddle, S.W., Schewe, K.D., Tjoa, A.M., Zhou, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7447, pp. 183–190. [Google Scholar] [CrossRef] [Green Version]
- Bellatreche, L.; Bouchakri, R.; Cuzzocrea, A.; Maabout, S. Incremental Algorithms for Selecting Horizontal Schemas of Data Warehouses: The Dynamic Case. In Data Management in Cloud, Grid and P2P Systems; Lecture Notes in Computer Science; Hameurlain, A., Rahayu, W., Taniar, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8059, pp. 13–25. [Google Scholar] [CrossRef]
- Derrar, H.; Nacer, M.; Boussaid, O. Exploiting data access for dynamic fragmentation in data warehouse. Int. J. Intell. Inf. Database Syst. 2013, 7, 34–52. [Google Scholar] [CrossRef]
- Fasolin, K.; Fileto, R.; Krugery, M.; Kasterz, D.S.; Ferreirax, M.R.P.; Cordeirox, R.L.F.; Trainax, A.J.M.; Traina, C. Efficient Execution of Conjunctive Complex Queries on Big Multimedia Databases. In Proceedings of the 2013 IEEE International Symposium on Multimedia, Anaheim, CA, USA, 9–11 December 2013. [Google Scholar] [CrossRef]
- Lim, L. Elastic data partitioning for cloud-based SQL processing systems. In Proceedings of the 2013 IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013. [Google Scholar] [CrossRef]
- Liroz-Gistau, M.; Akbarinia, R.; Pacitti, E.; Porto, F.; Valduriez, P. Dynamic Workload-Based Partitioning Algorithms for Continuously Growing Databases. In Transactions on Large-Scale Data- and Knowledge-Centered Systems XII; Lecture Notes in Computer Science; Hameurlain, A., Küng, J., Wagner, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8320, pp. 105–128. [Google Scholar] [CrossRef] [Green Version]
- Herrmann, K.; Voigt, H.; Lehner, W. Cinderella—Adaptive online partitioning of irregularly structured data. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering Workshops, Chicago, IL, USA, 19 May 2014. [Google Scholar] [CrossRef]
- Kumar, R.; Gupta, N. An extended approach to Non-Replicated dynamic fragment allocation in distributed database systems. In Proceedings of the 2014 International Conference on Issues and Challenges in Intelligent Computing Techniques (ICICT 2014), Ghaziabad, India, 7–8 February 2014. [Google Scholar] [CrossRef]
- Baron, C.; Iacob, N. A New Dynamic Data Fragmentation and Replication Model in DDBMSs. Cost Functions. Knowl. Horiz. 2014, 6, 158–161. [Google Scholar]
- Rodríguez-Mazahua, L.; Alor-Hernández, G.; Abud-Figueroa, M.; Peláez-Camarena, S.G. Horizontal Partitioning of Multimedia Databases Using Hierarchical Agglomerative Clustering. In Nature-Inspired Computation and Machine Learning; Lecture Notes in Computer Science; Gelbukh, A., Espinoza, F.C., Galicia-Haro, S.N., Eds.; Springer: Cham, Switzerland, 2014; Volume 8857, pp. 296–309. [Google Scholar] [CrossRef]
- Fetai, I.; Murezzan, D.; Schuldt, H. Workload-driven adaptive data partitioning and distribution—The Cumulus approach. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 28 December 2015. [Google Scholar] [CrossRef]
- Sauer, B.; Hao, W. Horizontal cloud database partitioning with data mining techniques. In Proceedings of the 12th Annual IEEE Consumer Communications and Networking Conference (CCNC 2015), Las Vegas, NV, USA, 16 July 2015; pp. 796–801. [Google Scholar] [CrossRef]
- Abdel Raouf, A.; Badr, N.; Tolba, M. Distributed Database System (DSS) Design Over a Cloud Environment. In Multimedia Forensics and Security; Intelligent Systems Reference Library; Hassanien, A., Mostafa Fouad, M., Manaf, A., Zamani, M., Ahmad, R., Kacprzyk, J., Eds.; Springer: Cham, Switzerland, 2016; Volume 115, pp. 97–116. [Google Scholar] [CrossRef]
- Elghamrawy, S. An Adaptive Load-Balanced Partitioning Module in Cassandra Using Rendezvous Hashing. In Proceedings of the International Conference on Advances in Intelligent Systems and Informatics; Hassanien, A., Shaalan, K., Gaber, T., Azar, A., Tolba, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 587–597. [Google Scholar] [CrossRef]
- Serafini, M.; Taft, R.; Elmore, A.; Pavlo, A.; Aboulnaga, A.; Stonebraker, M. Clay: Fine-grained adaptive partitioning for general database schemas. Proc. VLDB Endow. 2016, 10, 445–456. [Google Scholar] [CrossRef]
- Wu, Q.; Chen, C.; Jiang, Y. Multi-source heterogeneous Hakka culture heritage data management based on MongoDB. In Proceedings of the Fifth International Conference on Agro-Geoinformatics (Agro-Geoinformatics 2016), Tianjin, China, 29 September 2016. [Google Scholar] [CrossRef]
- Khan, S. Efficient Partitioning of Large Databases without Query Statistics. Database Syst. J. 2016, 7, 34–53. [Google Scholar]
- Elghamrawy, S.; Hassanien, A. A partitioning framework for Cassandra NoSQL database using Rendezvous hashing. J. Supercomput. 2017, 73, 4444–4465. [Google Scholar] [CrossRef]
- Oonhawat, B.; Nupairoj, N. Hotspot management strategy for real-time log data in MongoDB. In Proceedings of the 19th International Conference on Advanced Communication Technology (ICACT 2017), Bongpyeong, Korea, 30 March 2017; pp. 221–227. [Google Scholar] [CrossRef]
- Zar Lwin, N.; Naing, T. Non-Redundant Dynamic Fragment Allocation with Horizontal Partition in Distributed Database System. In Proceedings of the International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS 2018), Bangkok, Thailand, 29 November 2018; pp. 300–305. [Google Scholar] [CrossRef]
- Olma, M.; Karpathiotakis, M.; Alagiannis, I.; Athanassoulis, M.; Ailamaki, A. Adaptive partitioning and indexing for in situ query processing. VLDB J. 2019, 29, 569–591. [Google Scholar] [CrossRef]
- Chbeir, R.; Laurent, D. Enhancing Multimedia Data Fragmentation. J. Multimed. Process. Technol. 2010, 1, 112–131. [Google Scholar]
- Jindal, A.; Dittrich, J. Relax and Let the Database Do the Partitioning Online. In BIRTE 2011: Enabling Real-Time Business Intelligence; Lecture Notes in Business Information Processing; Castellanos, M., Dayal, U., Lehner, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 126, pp. 65–80. [Google Scholar] [CrossRef]
- Wang, X.; Fan, X.; Chen, J.; Du, X. Automatic Data Distribution in Large-scale OLTP Applications. Int. J. Database Theory Appl. 2014, 7, 37–46. [Google Scholar] [CrossRef]
- Chen, K.; Cao, Y.; Zhou, Y. Online Data Partitioning in Distributed Database Systems. In Proceedings of the 18th International Conference on Extending Database Technology, Brussels, Belgium, 23–27 March 2015; pp. 1–12. [Google Scholar]
- Kulba, V.; Somov, S. Dynamic Fragment Allocation in Distributed System with Time-Varying Parameters of its Operation. In Proceedings of the 13th International Conference “Management of large-scale system development” (MLSD 2020), Moscow, Russia, 9 November 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Al-Kateb, M.; Sinclair, P.; Au, G.; Ballinger, C. Hybrid row-column partitioning in teradata®. Proc. VLDB Endow. 2016, 9, 1353–1364. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez-Mazahua, L.; Alor-Hernández, G.; Cervantes, J.; López-Chau, A.; Sánchez-Cervantes, J. A hybrid partitioning method for multimedia databases. DYNA 2016, 83, 59–67. [Google Scholar] [CrossRef]
- Mourão, A.; Magalhães, J. Balancing search space partitions by sparse coding for distributed redundant media indexing and retrieval. Int. J. Multimed. Inf. Retr. 2017, 7, 57–70. [Google Scholar] [CrossRef] [Green Version]
- Campero Durand, G.; Pinnecke, M.; Piriyev, R.; Mohsen, M.; Broneske, D.; Saake, G.; Sekeran, M.S.; Rodriguez, F. GridFormation Towards Self-Driven Online Data Partitioning using Reinforcement Learning. In Proceedings of the First International Workshop on Exploiting Artificial Intelligence Techniques for Data Management (aiDM 2018), Houston, TX, USA, 10 June 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Schreiner, G.; Duarte, D.; Santos Mello, R. An Autonomous Hybrid Data Partition for NewSQL DBs. In Proceedings of the 33rd Brazilian Symposium on Databases Companion, Rio de Janeiro, Brazil, 25–26 August 2018; pp. 95–101. [Google Scholar]
- Vogt, M.; Stiemer, A.; Schuldt, H. Polypheny-DB: Towards a Distributed and Self-Adaptive Polystore. In Proceedings of the IEEE International Conference on Big Data (Big Data 2018), Seattle, WA, USA, 10–13 December 2018; pp. 3364–3373. [Google Scholar] [CrossRef]
- Schreiner, G.; Duarte, D.; Dal Bianco, G.; Mello, R. A Hybrid Partitioning Strategy for NewSQL Databases. In Proceedings of the 21st International Conference on Information Integration and Web-based Applications & Services (iiWAS 2019), Muchich, Germany, 2–4 December 2019; pp. 353–360. [Google Scholar] [CrossRef]
- Pinnecke, M.; Campero Durand, G.; Broneske, D.; Zoun, R.; Saake, G. GridTables: A One-Size-Fits-Most H2TAP Data Store. Datenbank-Spektrum 2020, 20, 43–56. [Google Scholar] [CrossRef] [Green Version]
- Sleit, A.; AlMobaidee, W.; Al-Areqi, S.; Yahya, A. A Dynamic Object Fragmentation and Replication Algorithm in Distributed Database Systems. Am. J. Appl. Sci. 2007, 4, 613–618. [Google Scholar] [CrossRef] [Green Version]
- Hung, T.; Huang, C. A Dynamic Data Fragmentation and Distribution Strategy for Main-Memory Database Cluster. Adv. Mater. Res. 2012, 490–495, 1231–1236. [Google Scholar] [CrossRef]
- Torjmen, M.; Pinel-Sauvagnat, K.; Boughanem, M. Towards a structure-based multimedia retrieval model. In Proceedings of the 1st ACM international conference on Multimedia information retrieval (MIR 2008), Vancouver, GB, Canada, 27–31 October 2008; pp. 350–357. [Google Scholar] [CrossRef] [Green Version]
- Cuzzocrea, A.; Darmont, J.; Mahboubi, H. Fragmenting very large XML data warehouses via K-means clustering algorithm. Int. J. Bus. Intell. Data Min. 2009, 4. [Google Scholar] [CrossRef] [Green Version]
- Torjmen-Khemakhem, M.; Pinel-Sauvagnat, K.; Boughanem, M. Investigating the document structure as a source of evidence for multimedia fragment retrieval. Inf. Process. Manag. 2013, 49, 1281–1300. [Google Scholar] [CrossRef] [Green Version]
- Heni, H.; Gargouri, F. A Methodological Approach for Big Data Security: Application for NoSQL Data Stores. In Neural Information Processing; Lecture Notes in Computer Science; Arik, S., Huang, T., Lai, W., Liu, Q., Eds.; Springer: Cham, Switzerland, 2015; Volume 9492, pp. 685–692. [Google Scholar] [CrossRef]
- Santos, N.; Masala, G. Big Data Security on Cloud Servers Using Data Fragmentation Technique and NoSQL Database. In Intelligent Interactive Multimedia Systems and Services; De Prieto, G., Gallo, L., Howlett, R., Jain, L., Vlacic, L., Eds.; Springer: Cham, Switzerland, 2018; pp. 5–13. [Google Scholar] [CrossRef] [Green Version]
- Mourão, A.; Magalhães, J. Towards Cloud Distributed Image Indexing by Sparse Hashing. In Proceedings of the International Conference on Multimedia Retrieval (ICMR 2019), Ottawa, ON, Canada, 12 June 2019; pp. 288–296. [Google Scholar] [CrossRef]
- Mettes, P.; van Gemert, J.; Cappallo, S.; Mensink, T.; Snoek, C. Bag-of-Fragments: Selecting and encoding video fragments for event detection and recounting. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval (ICMR 2015), Shanghai, China, 23–26 June 2015; pp. 427–434. [Google Scholar] [CrossRef]
- Wycislik, L. Independent Data Partitioning in Oracle Databases for LOB Structures. In Man-Machine Interactions; Advances in Intelligent Systems and Computing; Gruca, A., Brachman, A., Kozielski, S., Czachórski, T., Eds.; Springer: Cham, Switzerland, 2015; Volume 391, pp. 687–696. [Google Scholar] [CrossRef]
- Turcu, A.; Palmieri, R.; Ravindran, B.; Hirve, S. Automated Data Partitioning for Highly Scalable and Strongly Consistent Transactions. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 106–118. [Google Scholar] [CrossRef]
- Chernishev, G. The design of an adaptive column-store system. J. Big Data 2017, 4, 5. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.; Lee, S. Optimizing MongoDB Using Multi-streamed SSD. In Proceedings of the 7th International Conference on Emerging Databases; Lecture Notes in Electrical Engineering; Lee, W., Choi, W., Jung, S., Song, M., Eds.; Springer: Singapore, 2017; Volume 461, pp. 1–13. [Google Scholar] [CrossRef]
- Khan, A.; Lee, C.; Hamandawana, P.; Park, S.; Kim, Y. A Robust Fault-Tolerant and Scalable Cluster-Wide Deduplication for Shared-Nothing Storage Systems. In Proceedings of the IEEE 26th International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS 2018), Milwaukee, WI, USA, 8 November 2018; pp. 87–93. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Bo, Y.; He, W.; Nabatchian, A. Dynamic Partition Forest: An Efficient and Distributed Indexing Scheme for Similarity Search based on Hashing. In Proceedings of the IEEE International Conference on Big Data (Big Data 2018), Seattle, WA, USA, 10–13 December 2018; pp. 1059–1064. [Google Scholar] [CrossRef]
- Le, T.; Kantere, V.; Orazio, L. Optimizing DICOM data management with NSGA-G. In Proceedings of the International Workshop on Design, Optimization, Languages and Analytical Processing of Big Data, Lisbon, Portugal, 26 March 2019. [Google Scholar]
- Santos, N.; Ghita, B.; Masala, G. Enhancing Data Security in Cloud using Random Pattern Fragmentation and a Distributed NoSQL Database. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics (SMC 2019), Bari, Italy, 28 November 2019; pp. 3735–3740. [Google Scholar] [CrossRef]
- Sharma, S.; Bawa, S. CBDR: An efficient storage repository for cultural big data. Digit. Scholarsh. Humanit. 2019, 35, 893–903. [Google Scholar] [CrossRef]
- Son, J.; Kim, M. An adaptable vertical partitioning method in distributed systems. J. Syst. Softw. 2004, 73, 551–561. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Type of Fragmentation | Cost Model | Dynamic | CBIR | Cost Equations |
|---|---|---|---|---|---|
| [22] | Vertical | Yes | Yes | No | |
| [23] | Vertical | Yes | No | No | Total_cost = IO_cost + CPU_cost |
| [24] | Vertical | Yes | No | No | Total cost = IO cost + CPU cost |
| [25] | Vertical | Yes | No | No | Total cost = Disk IO cost + CPU cost |
| [26] | Vertical | Yes | No | No | cost(vpsi) = IAAC(vpsi) + TC(vpsi) |
| [27] | Vertical | Yes | No | No | |
| [28] | Vertical | Yes | Yes | No | Not shown |
| [7] | Vertical | Yes | Yes | No | Not shown |
| [29] | Vertical | Yes | Yes | No | |
| [30] | Vertical | Yes | Yes | No | Not shown |
| [31] | Vertical | Yes | No | No | Not shown |
| [32] | Vertical | Yes | Yes | No | cost(vpsi) = IAAC(vpsi) + TC(vpsi) |
| [33] | Vertical | Yes | No | No | Not shown |
| [34] | Vertical | No | No | No | Not shown |
| [35] | Vertical | Yes | Yes | No | |
| [36] | Vertical | Yes | No | No | |
| [37] | Vertical | Yes | Yes | No | Not shown |
| [2] | Horizontal | No | Yes | No | Not shown |
| [38] | Horizontal | Yes | Yes | No | Not shown |
| [1] | Horizontal | Yes | No | Yes | Not shown |
| [39] | Horizontal | Yes | No | No | |
| [40] | Horizontal | No | No | Yes | Not shown |
| [41] | Horizontal | No | No | Yes | Not shown |
| [42] | Horizontal | Yes | No | No | |
| [43] | Horizontal | Yes | Yes | No | utilityMigrate = card(SW(Sr)) − card(SW(Sl)) − card(F) |
| [44] | Horizontal | Yes | No | No | Not shown |
| [45] | Horizontal | Yes | Yes | No | Minimize TC = RC+ UC + SC |
| [46] | Horizontal | No | Yes | No | Not shown |
| [47] | Horizontal | Yes | Yes | No | |
| [48] | Horizontal | Yes | Yes | No | |
| [49] | Horizontal | No | No | Yes | Not shown |
| [50] | Horizontal | Yes | No | No | Not shown |
| [51] | Horizontal | No | Yes | No | Not shown |
| [52] | Horizontal | Yes | Yes | No | Not shown |
| [53] | Horizontal | No | Yes | No | Not shown |
| [54] | Horizontal | Yes | Yes | No | |
| [55] | Horizontal | Yes | No | No | cost(hpsi) = ITAC(hpsi) + TC(hpsi) |
| [56] | Horizontal | Yes | Yes | No | |
| [57] | Horizontal | No | No | No | Not shown |
| [58] | Horizontal | Yes | Yes | No | CC(Si, Sj) = cost of creating the data packet + cost of transmitting the data packet from site Si to site Sj |
| [59] | Horizontal | No | No | No | Not shown |
| [60] | Horizontal | Yes | Yes | No | |
| [61] | Horizontal | No | No | No | Not shown |
| [62] | Horizontal | Yes | No | No | Not shown |
| [63] | Horizontal | Yes | No | No | Not shown |
| [64] | Horizontal | No | No | No | Not shown |
| [65] | Horizontal | Yes | Yes | No | Not shown |
| [66] | Horizontal | Yes | Yes | No | |
| [3] | Horizontal | Yes | No | No | Not shown |
| [67] | Hybrid | No | No | Yes | Not shown |
| [68] | Hybrid | Yes | Yes | No | Not shown |
| [69] | Hybrid | Yes | Yes | No | Not shown |
| [70] | Hybrid | Yes | Yes | No | |
| [71] | Hybrid | Yes | Yes | No | SOC = TSTF + CTR + RPC |
| [72] | Hybrid | Yes | No | No | Not shown |
| [73] | Hybrid | Yes | No | No | cost(hpsi) = IDAC(hpsi) + TC(hpsi) |
| [74] | Hybrid | No | No | Yes | Not shown |
| [75] | Hybrid | Yes | No | No | Not shown |
| [76] | Hybrid | No | No | No | Not shown |
| [77] | Hybrid | Yes | Yes | Yes | Not shown |
| [78] | Hybrid | No | No | No | Not shown |
| [79] | Hybrid | Yes | No | No | Not shown |
| [80] | Of objects | Yes | Yes | No | |
| [81] | Of objects | Yes | Yes | No | |
| [82] | Of documents | No | No | Yes | Not shown |
| [83] | Of documents | Yes | No | No | Not shown |
| [84] | Of documents | No | No | Yes | Not shown |
| [85] | Of documents | No | No | No | Not shown |
| [86] | Of documents | No | No | No | Not shown |
| [87] | Of documents | No | No | No | Not shown |
| [88] | Of video file | No | No | Yes | Not shown |
| [89] | Of Unstructured data | No | No | No | Not shown |
| [90] | K-way graph partitioning | Yes | No | No | Not shown |
| [91] | Of columns | No | Yes | No | Not shown |
| [92] | Internal | No | No | No | Not shown |
| [93] | Of metadata | No | No | Yes | Not shown |
| [94] | Of high dimensional vectors | No | Yes | Yes | Not shown |
| [95] | Grid fragmentation | No | No | No | Not shown |
| [96] | Random file fragmentation | No | No | No | Not shown |
| [97] | Of files | No | No | No | Not shown |
| Cost | Articles |
|---|---|
| Cost of access to irrelevant data | [26,55,73,83] |
| Query Processing Cost | [39,69,71,81,82] |
| Storage cost | [31,39,42,45,54,65,67,71,75,81,86,96] |
| Transport cost | [3,26,27,29,38,39,42,44,48,54,55,62,65,72,73,76,79,80,81,95] |
| Access cost | [22,23,24,25,26,29,31,32,35,36,38,43,48,60,66,79,81] |
| Execution cost | [23,24,25,29,30,32,33,35,37,41,47,48,52,56,68,70,73] |
| Update cost | [41,58,67,75,79,80] |
| Fragment creation computational cost | [1,50,56,68] |
| Network cost | [44] |
| Computational cost | [41,72] |
| Communication cost | [33,36,37,43,45,54,58,69,70,71,81,96] |
| Maintenance cost | [47] |
| Replication cost | [90] |
| Movement cost | [90] |
| Response time cost | [27,30] |
| Local access cost | [54,81] |
| Attribute usage cost | [28] |
| Operation type cost | [28] |
| Load cost | [66] |
| Migration cost | [60] |
| Distribution cost | [58] |
| Allocation cost | [77] |
| Overhead cost | [77] |
| Benchmark | Articles |
|---|---|
| XWeb | [83] |
| OO7 | [39,42] |
| THUMOS | [88] |
| TRECVID | [88] |
| CRM | [95] |
| TPC-E | [3] |
| TPC-H | [7,27,28,30,33,34,50,52,68,72,95] |
| SSB | [34,44,68] |
| Linkbench | [92] |
| YCSB | [59,63,76,92] |
| TPC-W | [76,90] |
| SPECWeb2009 | [57] |
| TPC-C | [56,60,69,78,79,90] |
| AuctionMark | [90] |
| EPinions | [90] |
| Re-Twis | [90] |
| APB-1 | [47,48] |
| Sloan Digital Sky | [29,31,46,51] |
| FIO | [93] |
| Fashion-MNIST | [94] |
| SIFT | [94] |
| GloVe | [94] |
| NoBench | [35] |
| OLTP-Bench | [78] |
| BSBM | [37] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Castro-Medina, F.; Rodríguez-Mazahua, L.; López-Chau, A.; Cervantes, J.; Alor-Hernández, G.; Machorro-Cano, I. Application of Dynamic Fragmentation Methods in Multimedia Databases: A Review. Entropy 2020, 22, 1352. https://0-doi-org.brum.beds.ac.uk/10.3390/e22121352
Castro-Medina F, Rodríguez-Mazahua L, López-Chau A, Cervantes J, Alor-Hernández G, Machorro-Cano I. Application of Dynamic Fragmentation Methods in Multimedia Databases: A Review. Entropy. 2020; 22(12):1352. https://0-doi-org.brum.beds.ac.uk/10.3390/e22121352
Chicago/Turabian StyleCastro-Medina, Felipe, Lisbeth Rodríguez-Mazahua, Asdrúbal López-Chau, Jair Cervantes, Giner Alor-Hernández, and Isaac Machorro-Cano. 2020. "Application of Dynamic Fragmentation Methods in Multimedia Databases: A Review" Entropy 22, no. 12: 1352. https://0-doi-org.brum.beds.ac.uk/10.3390/e22121352