Variational Information Bottleneck for Unsupervised Clustering: Deep Gaussian Mixture Embedding


1
Laboratoire d’informatique Gaspard-Monge, Université Paris-Est, 77454 Champs-sur-Marne, France
2
Mathematical and Algorithmic Sciences Lab, Paris Research Center, Huawei Technologies, 92100 Boulogne-Billancourt, France
*
Authors to whom correspondence should be addressed.
Entropy 2020, 22(2), 213; https://0-doi-org.brum.beds.ac.uk/10.3390/e22020213
Submission received: 3 December 2019
/
Revised: 4 February 2020
/
Accepted: 9 February 2020
/
Published: 13 February 2020
(This article belongs to the Special Issue Information Theory for Data Communications and Processing)
Abstract
:In this paper, we develop an unsupervised generative clustering framework that combines the variational information bottleneck and the Gaussian mixture model. Specifically, in our approach, we use the variational information bottleneck method and model the latent space as a mixture of Gaussians. We derive a bound on the cost function of our model that generalizes the Evidence Lower Bound (ELBO) and provide a variational inference type algorithm that allows computing it. In the algorithm, the coders’ mappings are parametrized using neural networks, and the bound is approximated by Markov sampling and optimized with stochastic gradient descent. Numerical results on real datasets are provided to support the efficiency of our method.
1. Introduction
Clustering consists of partitioning a given dataset into various groups (clusters) based on some similarity metric, such as the Euclidean distance, norm, norm, norm, the popular logarithmic loss measure, or others. The principle is that each cluster should contain elements of the data that are closer to each other than to any other element outside that cluster, in the sense of the defined similarity measure. If the joint distribution of the clusters and data is not known, one should operate blindly in doing so, i.e., using only the data elements at hand; and the approach is called unsupervised clustering [1,2]. Unsupervised clustering is perhaps one of the most important tasks of unsupervised machine learning algorithms currently, due to a variety of application needs and connections with other problems.
Clustering can be formulated as follows. Consider a dataset that is composed of N samples , which we wish to partition into clusters. Let be the set of all possible clusters and C designate a categorical random variable that lies in and stands for the index of the actual cluster. If is a random variable that models elements of the dataset, given that induces a probability distribution on C, which the learner should learn, thus mathematically, the problem is that of estimating the values of the unknown conditional probability for all elements of the dataset. The estimates are sometimes referred to as the assignment probabilities.
Examples of unsupervised clustering algorithms include the very popular K-means [3] and Expectation Maximization (EM) [4]. The K-means algorithm partitions the data in a manner that the Euclidean distance among the members of each cluster is minimized. With the EM algorithm, the underlying assumption is that the data comprise a mixture of Gaussian samples, namely a Gaussian Mixture Model (GMM); and one estimates the parameters of each component of the GMM while simultaneously associating each data sample with one of those components. Although they offer some advantages in the context of clustering, these algorithms suffer from some strong limitations. For example, it is well known that the K-means is highly sensitive to both the order of the data and scaling; and the obtained accuracy depends strongly on the initial seeds (in addition to that, it does not predict the number of clusters or K-value). The EM algorithm suffers mainly from slow convergence, especially for high-dimensional data.
Recently, a new approach has emerged that seeks to perform inference on a transformed domain (generally referred to as latent space), not the data itself. The rationale is that because the latent space often has fewer dimensions, it is more convenient computationally to perform inference (clustering) on it rather than on the high-dimensional data directly. A key aspect then is how to design a latent space that is amenable to accurate low-complexity unsupervised clustering, i.e., one that preserves only those features of the observed high-dimensional data that are useful for clustering while removing all redundant or non-relevant information. Along this line of work, we can mention [5], which utilized Principal Component Analysis (PCA) [6,7] for dimensionality reduction followed by K-means for clustering the obtained reduced dimension data; or [8], which used a combination of PCA and the EM algorithm. Other works that used alternatives for the linear PCA include kernel PCA [9], which employs PCA in a non-linear fashion to maximize variance in the data.
Thisby’s Information Bottleneck (IB) method [10] formulates the problem of finding a good representation that strikes the right balance between capturing all information about the categorical variable C that is contained in the observation and using the most concise representation for it. The IB problem can be written as the following Lagrangian optimization:
where denotes Shannon’s mutual information and s is a Lagrange-type parameter, which controls the trade-off between accuracy and regularization. In [11,12], a text clustering algorithm is introduced for the case in which the joint probability distribution of the input data is known. This text clustering algorithm uses the IB method with an annealing procedure, where the parameter s is increased gradually. When , the representation is designed with the most compact form, i.e., , which corresponds to the maximum compression. By gradually increasing the parameter s, the emphasis on the relevance term increases, and at a critical value of s, the optimization focuses on not only the compression, but also the relevance term. To fulfill the demand on the relevance term, this results in the cardinality of bifurcating. This is referred as a phase transition of the system. The further increases in the value of s will cause other phase transitions, hence additional splits of U until it reaches the desired level, e.g., .
However, in the real-world applications of clustering with large-scale datasets, the joint probability distributions of the datasets are unknown. In practice, the usage of Deep Neural Networks (DNN) for unsupervised clustering of high-dimensional data on a lower dimensional latent space has attracted considerable attention, especially with the advent of Autoencoder (AE) learning and the development of powerful tools to train them using standard backpropagation techniques [13,14]. Advanced forms include Variational Autoencoders (VAE) [13,14], which are generative variants of AE that regularize the structure of the latent space, and the more general Variational Information Bottleneck (VIB) of [15], which is a technique that is based on the information bottleneck method and seeks a better trade-off between accuracy and regularization than VAE via the introduction of a Lagrange-type parameter s, which controls that trade-off and whose optimization is similar to deterministic annealing [12] or stochastic relaxation.
In this paper, we develop an unsupervised generative clustering framework that combines VIB and the Gaussian mixture model. Specifically, in our approach, we use the variational information bottleneck method and model the latent space as a mixture of Gaussians. We derive a bound on the cost function of our model that generalizes the Evidence Lower Bound (ELBO) and provide a variational inference type algorithm that allows computing it. In the algorithm, the coders’ mappings are parametrized using Neural Networks (NN), and the bound is approximated by Markov sampling and optimized with stochastic gradient descent. Furthermore, we show how tuning the hyper-parameter s appropriately by gradually increasing its value with iterations (number of epochs) results in a better accuracy. Furthermore, the application of our algorithm to the unsupervised clustering of various datasets, including the MNIST [16], REUTERS [17], and STL-10 [18], allows a better clustering accuracy than previous state-of-the-art algorithms. For instance, we show that our algorithm performs better than the Variational Deep Embedding (VaDE) algorithm of [19], which is based on VAE and performs clustering by maximizing the ELBO. Our algorithm can be seen as a generalization of the VaDE, whose ELBO can be recovered by setting in our cost function. In addition, our algorithm also generalizes the VIB of [15], which models the latent space as an isotropic Gaussian, which is generally not expressive enough for the purpose of unsupervised clustering. Other related works, which are of lesser relevance to the contribution of this paper, are the Deep Embedded Clustering (DEC) of [20] and the Improved Deep Embedded Clustering (IDEC) of [21,22]. For a detailed survey of clustering with deep learning, the readers may refer to [23].
To the best of our knowledge, our algorithm performs the best in terms of clustering accuracy by using deep neural networks without any prior knowledge regarding the labels (except the usual assumption that the number of classes is known) compared to the state-of-the-art algorithms of the unsupervised learning category. In order to achieve the outperforming accuracy: (i) we derive a cost function that contains the IB hyperparameter s that controls optimal trade-offs between the accuracy and regularization of the model; (ii) we use a lower bound approximation for the KL term in the cost function, that does not depend on the clustering assignment probability (note that the clustering assignment is usually not accurate in the beginning of the training process); and (iii) we tune the hyperparameter s by following an annealing approach that improves both the convergence and the accuracy of the proposed algorithm.
Throughout this paper, we use the following notation. Uppercase letters are used to denote random variables, e.g., X; lowercase letters are used to denote realizations of random variables, e.g., x; and calligraphic letters denote sets, e.g., . The cardinality of a set is denoted by . Probability mass functions (pmfs) are denoted by and, sometimes, for short, as . Boldface uppercase letters denote vectors or matrices, e.g., , where context should make the distinction clear. We denote the covariance of a zero mean, complex-valued, vector by , where indicates the conjugate transpose. For random variables X and Y, the entropy is denoted as , i.e., , and the mutual information is denoted as , i.e., . Finally, for two probability measures and on a random variable , the relative entropy or Kullback–Leibler divergence is denoted as , i.e., .
2. Proposed Model
In this section, we explain the proposed model, the so-called Variational Information Bottleneck with Gaussian Mixture Model (VIB-GMM), in which we use the VIB framework and model the latent space as a GMM. The proposed model is depicted in Figure 1, where the parameters , , , for all values of , are to be optimized jointly with those of the employed NNs as instantiation of the coders. Furthermore, the assignment probabilities are estimated based on the values of latent space vectors instead of the observations themselves, i.e., . In the rest of this section, we elaborate on the inference and generative network models for our method.
2.1. Inference Network Model
We assume that observed data are generated from a GMM with components. Then, the latent representation is inferred according to the following procedure:
- One of the components of the GMM is chosen according to a categorical variable C.
- The data are generated from the cth component of the GMM, i.e., .
- Encoder maps to a latent representation according to .
- 3.1.
- The encoder is modeled with a DNN , which maps to the parameters of a Gaussian distribution, i.e., .
- 3.2.
- The representation is sampled from .
For the inference network, shown in Figure 2, the following Markov chain holds:
![Entropy 22 00213 i001]()

2.2. Generative Network Model
Since the encoder extracts useful representations of the dataset and we assume that the dataset is generated from a GMM, we model our latent space also with a mixture of Gaussians. To do so, the categorical variable C is embedded with the latent variable . The reconstruction of the dataset is generated according to the following procedure:
- One of the components of the GMM is chosen according to a categorical variable C, with a prior distribution .
- The representation is generated from the cth component, i.e., .
- The decoder maps the latent representation to , which is the reconstruction of the source by using the mapping .
- 3.1
- The decoder is modeled with a DNN that maps to the estimate , i.e., .
For the generative network, shown in Figure 3, the following Markov chain holds:
![Entropy 22 00213 i002]()

3. Proposed Method
In this section, we present our clustering method. First, we provide a general cost function for the problem of the unsupervised clustering that we study here based on the variational IB framework; and we show that it generalizes the ELBO bound developed in [19]. We then parametrize our model using NNs whose parameters are optimized jointly with those of the GMM. Furthermore, we discuss the influence of the hyperparameter s that controls optimal trade-offs between accuracy and regularization.
3.1. Brief Review of Variational Information Bottleneck for Unsupervised Learning
As described in Section 2, the stochastic encoder maps the observed data to a representation . Similarly, the stochastic decoder assigns an estimate of based on the vector . As per the IB method [10], a suitable representation should strike the right balance between capturing all information about the categorical variable C that is contained in the observation and using the most concise representation for it. This leads to maximizing the following Lagrange problem:
where designates the Lagrange multiplier and, for convenience, denotes the conditional distribution .
Instead of (4), which is not always computable in our unsupervised clustering setting, we find it convenient to maximize an upper bound of given by:
where is due to the definition of mutual information (using the Markov chain ![Entropy 22 00213 i003]() , it is easy to see that for all values of ). Noting that is constant with respect to , maximizing over is equivalent to maximizing:
For a variational distribution on (instead of the unknown ) and a variational stochastic decoder (instead of the unknown optimal decoder ), let . Furthermore, let:
, it is easy to see that for all values of ). Noting that is constant with respect to , maximizing over is equivalent to maximizing:
For a variational distribution on (instead of the unknown ) and a variational stochastic decoder (instead of the unknown optimal decoder ), let . Furthermore, let:
 , it is easy to see that for all values of ). Noting that is constant with respect to , maximizing over is equivalent to maximizing:
, it is easy to see that for all values of ). Noting that is constant with respect to , maximizing over is equivalent to maximizing: Lemma 1.
For given , we have:
In addition, there exists a unique that achieves the maximum and is given by:
Proof.
The proof of Lemma 1 is given in Appendix A.
Using Lemma 1, maximization of (6) can be written in term of the variational IB cost as follows:
Next, we develop an algorithm that solves the maximization problem (9), where the encoding mapping , the decoding mapping , as well as the prior distribution of the latent space are optimized jointly.
Remark 1.
As we already mentioned in the beginning of this section, the related work [19] performed unsupervised clustering by combining VAE with GMM. Specifically, it maximizes the following ELBO bound:
Let, for an arbitrary non-negative parameter s, be a generalization of the ELBO bound in (10) of [19] given by:
Investigating the right-hand side (RHS) of (11), we get:
where the equality holds since:
where can be obtained by expanding and re-arranging terms under the Markov chain ![Entropy 22 00213 i004]() (for a detailed treatment, please look at Appendix B); and follows from the definition of in (8).
(for a detailed treatment, please look at Appendix B); and follows from the definition of in (8).
 (for a detailed treatment, please look at Appendix B); and follows from the definition of in (8).
(for a detailed treatment, please look at Appendix B); and follows from the definition of in (8).Thus, by the non-negativity of relative entropy, it is clear that is a lower bound on . Furthermore, if the variational distribution is such that the conditional marginal is equal to , the bound is tight since the relative entropy term is zero in this case.
3.2. Proposed Algorithm: VIB-GMM
In order to compute (9), we parametrize the distributions and using DNNs. For instance, let the stochastic encoder be a DNN and the stochastic decoder be a DNN . That is:
where and are the weight and bias parameters of the DNNs. Furthermore, the latent space is modeled as a GMM with components with parameters , i.e.,
Using the parametrizations above, the optimization of (9) can be rewritten as:
where the cost function is given by:
Then, for given observations of N samples, i.e., , (18) can be approximated in terms of an empirical cost as follows:
where is the empirical cost for the ith observation and given by:
Furthermore, the first term of the RHS of (21) can be computed using Monte Carlo sampling and the reparametrization trick [13]. In particular, can be sampled by first sampling a random variable with distribution , i.e., , then transforming the samples using some function , i.e., . Thus,
where M is the number of samples for the Monte Carlo sampling step.
The second term of the RHS of (21) is the KL divergence between a single component multivariate Gaussian and a Gaussian mixture model with components. An exact closed-form solution for the calculation of this term does not exist. However, a variational lower bound approximation [24] of it can be obtained as:
In particular, in the specific case in which the covariance matrices are diagonal, i.e., and , with denoting the latent space dimension, (22) can be computed as follows:
where and are the mean and variance of the ith representation in the jth dimension of the latent space. Furthermore, and represent the mean and variance of the cth component of the GMM in the jth dimension of the latent space.
Finally, we train NNs to maximize the cost function (19) over the parameters , as well as those of the GMM. For the training step, we use the ADAM optimization tool [25]. The training procedure is detailed in Algorithm 1.
| Algorithm 1 VIB-GMM algorithm for unsupervised learning. |
|
Once our model is trained, we assign the given dataset into the clusters. As mentioned in Section 2, we do the assignment from the latent representations, i.e., . Hence, the probability that the observed data belongs to the cth cluster is computed as follows:
where indicates the optimal values of the parameters as found at the end of the training phase. Finally, the right cluster is picked based on the largest assignment probability value.
Remark 2.
It is worth mentioning that with the use of the KL approximation as given by (22), our algorithm does not require the assumption to hold (which is different from [19]). Furthermore, the algorithm is guaranteed to converge. However, the convergence may be to (only) local minima; and this is due to the problem (18) being generally non-convex. Related to this aspect, we mention that while without a proper pre-training, the accuracy of the VaDE algorithm may not be satisfactory, in our case, the above assumption is only used in the final assignment after the training phase is completed.
Remark 3.
In [26], it is stated that optimizing the original IB problem with the assumption of independent latent representations amounts to disentangled representations. It is noteworthy that with such an assumption, the computational complexity can be reduced from to . Furthermore, as argued in [26], the assumption often results only in some marginal performance loss; and for this reason, it is adopted in many machine learning applications.
3.3. Effect of the Hyperparameter
As we already mentioned, the hyperparameter s controls the trade-off between the relevance of the representation and its complexity. As can be seen from (19) for small values of s, it is the cross-entropy term that dominates, i.e., the algorithm trains the parameters so as to reproduce as accurately as possible. For large values of s, however, it is most important for the NN to produce an encoded version of whose distribution matches the prior distribution of the latent space, i.e., the term is nearly zero.
In the beginning of the training process, the GMM components are randomly selected; and so, starting with a large value of the hyperparameter s is likely to steer the solution towards an irrelevant prior. Hence, for the tuning of the hyper-parameter s in practice, it is more efficient to start with a small value of s and gradually increase it with the number of epochs. This has the advantage of avoiding possible local minima, an aspect that is reminiscent of deterministic annealing [12], where s plays the role of the temperature parameter. The experiments that will be reported in the next section show that proceeding in the above-described manner for the selection of the parameter s helps in obtaining higher clustering accuracy and better robustness to the initialization (i.e., no need for a strong pretraining). The pseudocode for annealing is given in Algorithm 2.
| Algorithm 2 Annealing algorithm pseudocode. |
|
Remark 4.
As we mentioned before, a text clustering algorithm was introduced by Slonim et al. [11,12], which uses the IB method with an annealing procedure, where the parameter s is increased gradually. In [12], the critical values of s (so-called phase transitions) were observed such that if these values were missed during increasing s, the algorithm ended up with the wrong clusters. Therefore, how to choose the step size in the update of s is very important. We note that tuning s is also very critical in our algorithm, such that the step size in the update of s should be chosen carefully, otherwise phase transitions might be skipped that would cause a non-satisfactory clustering accuracy score. However, the choice of the appropriate step size (typically very small) is rather heuristic; and there exists no concrete method for choosing the right value. The choice of step size can be seen as a trade-off between the amount of computational resource spared for running the algorithm and the degree of confidence about scanning s values not to miss the phase transitions.
4. Experiments
4.1. Description of the Datasets Used
In our empirical experiments, we applied our algorithm to the clustering of the following datasets.
MNIST: A dataset of gray-scale images of 70,000 handwritten digits of dimensions pixel.
STL-10: A dataset of color images collected from 10 categories. Each category consisted of 1300 images of size of (pixels) (RGB code). Hence, the original input dimension was 27,648. For this dataset, we used a pretrained convolutional NN model, i.e., ResNet-50 [27], to reduce the dimensionality of the input. This preprocessing reduced the input dimension to 2048. Then, our algorithm and other baselines were used for clustering.
REUTERS10K: A dataset that was composed of 810,000 English stories labeled with a category tree. As in [20], 4 root categories (corporate/industrial, government/social, markets, economics) were selected as labels, and all documents with multiple labels were discarded. Then, tf-idf features were computed on the 2000 most frequently occurring words. Finally, 10,000 samples were taken randomly, which were referred to as the REUTERS10K dataset.
4.2. Network Settings and Other Parameters
We used the following network architecture: the encoder was modeled with NNs with 3 hidden layers with dimensions , where is the input dimension and is the dimension of the latent space. The decoder consisted of NNs with dimensions . All layers were fully connected. For comparison purposes, we chose the architecture of the hidden layers, as well as the dimension of the latent space to coincide with those made for the DEC algorithm of [20] and the VaDE algorithm of [19]. All except the last layers of the encoder and decoder were activated with the ReLU function. For the last (i.e., latent) layer of the encoder, we used a linear activation; and for the last (i.e., output) layer of the decoder, we used the sigmoid function for MNIST and linear activation for the remaining datasets. The batch size was 100, and the variational bound (20) was maximized by the ADAM optimizer of [25]. The learning rate was initialized with 0.002 and decreased gradually every 20 epochs with a decay rate of 0.9 until it reached a small value (0.0005 in our experiments). The reconstruction loss was calculated by using the cross-entropy criterion for MNIST and the mean squared error function for the other datasets.
4.3. Clustering Accuracy
We evaluated the performance of our algorithm in terms of the so-called unsupervised clustering Accuracy (ACC), which is a widely used metric in the context of unsupervised learning [23]. For comparison purposes, we also present those of algorithms from the previous state-of-the-art.
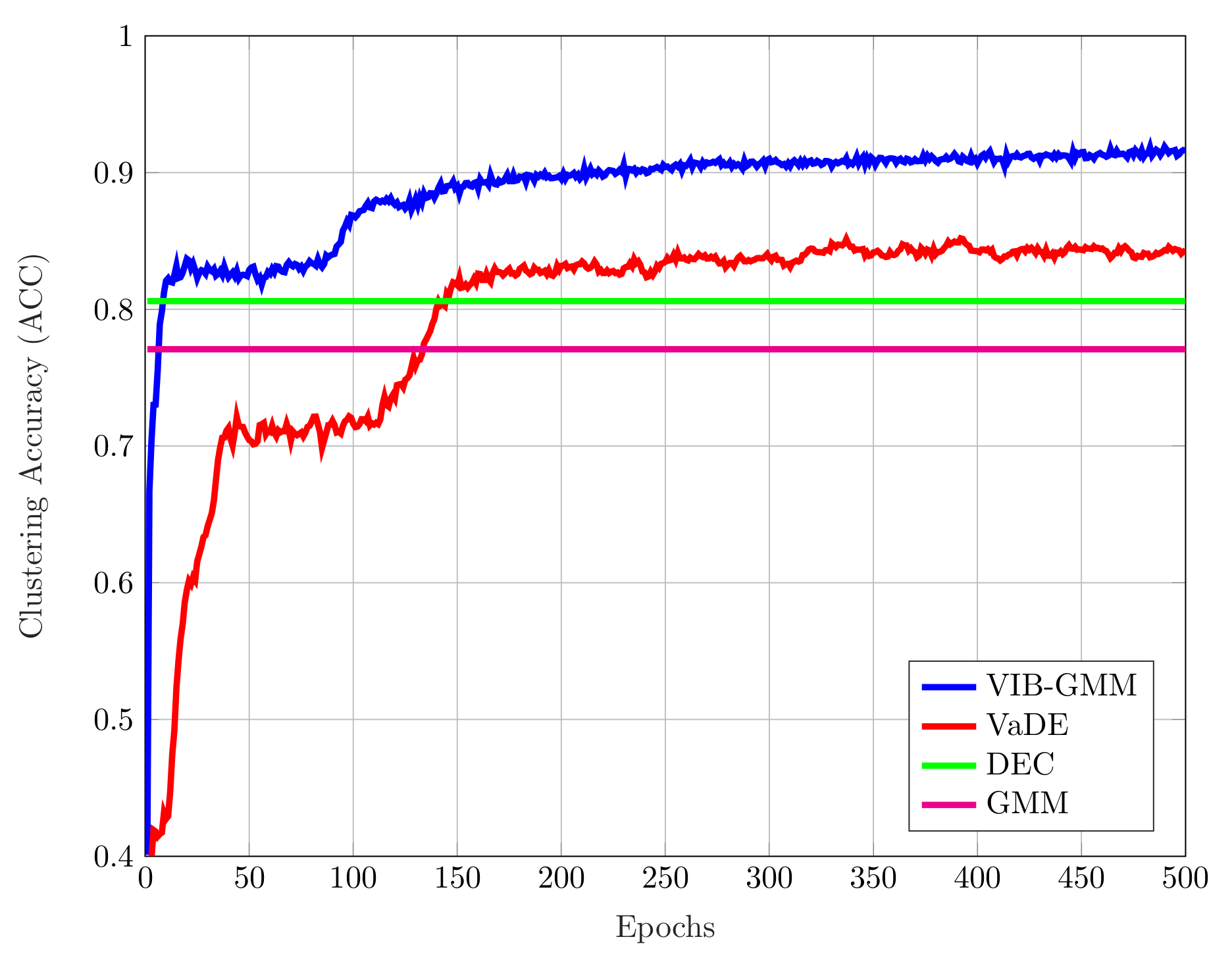
For each of the aforementioned datasets, we ran our VIB-GMM algorithm for various values of the hyper-parameter s inside an interval , starting from the smaller valuer and gradually increasing the value of s every epochs. For the MNIST dataset, we set ; and for the STL-10 dataset and the REUTERS10K dataset, we chose these parameters to be and , respectively. The obtained ACC accuracy results are reported in Table 1 and Table 2. It is important to note that the reported ACC results were obtained by running each algorithm ten times. For the case in which there was no pretraining (in [19,20], the DEC and VaDE algorithms were proposed to be used with pretraining; more specifically, the DNNs were initialized with a stacked autoencoder [28]), Table 1 states the accuracies of the best case run and average case run for the MNIST and STL-10 datasets. It was seen that our algorithm outperformed significantly the DEC algorithm of [20], as well as the VaDE algorithm of [19] and GMM for both the best case run and average case run. Besides, in Table 1, the values in parentheses correspond to the standard deviations of clustering accuracies. As seen, the standard deviation of our algorithm VIB-GMM was lower than the VaDE; which could be expounded by the robustness of VIB-GMM to non-pretraining. For the case in which there was pretraining, Table 2 states the accuracies of the best case run and average case run for the MNIST and REUTERS10K datasets. A stacked autoencoder was used to pretrain the DNNs of the encoder and decoder before running algorithms (DNNs were initialized with the same weights and biases of [19]). It was seen that our algorithm outperformed significantly the DEC algorithm of [20], as well as the VaDE algorithm of [19] and GMM for both the best case run and average case run. The effect of pretraining can be observed comparing Table 1 and Table 2 for MNIST. Using a stacked autoencoder prior to running the VaDE and VIB-GMM algorithms resulted in a higher accuracy, as well as a lower standard deviation of accuracies; therefore, supporting the algorithms with a stacked autoencoder was beneficial for a more robust system. Finally, for the STL-10 dataset, Figure 4 depicts the evolution of the best case ACC with iterations (number of epochs) for the four compared algorithms.
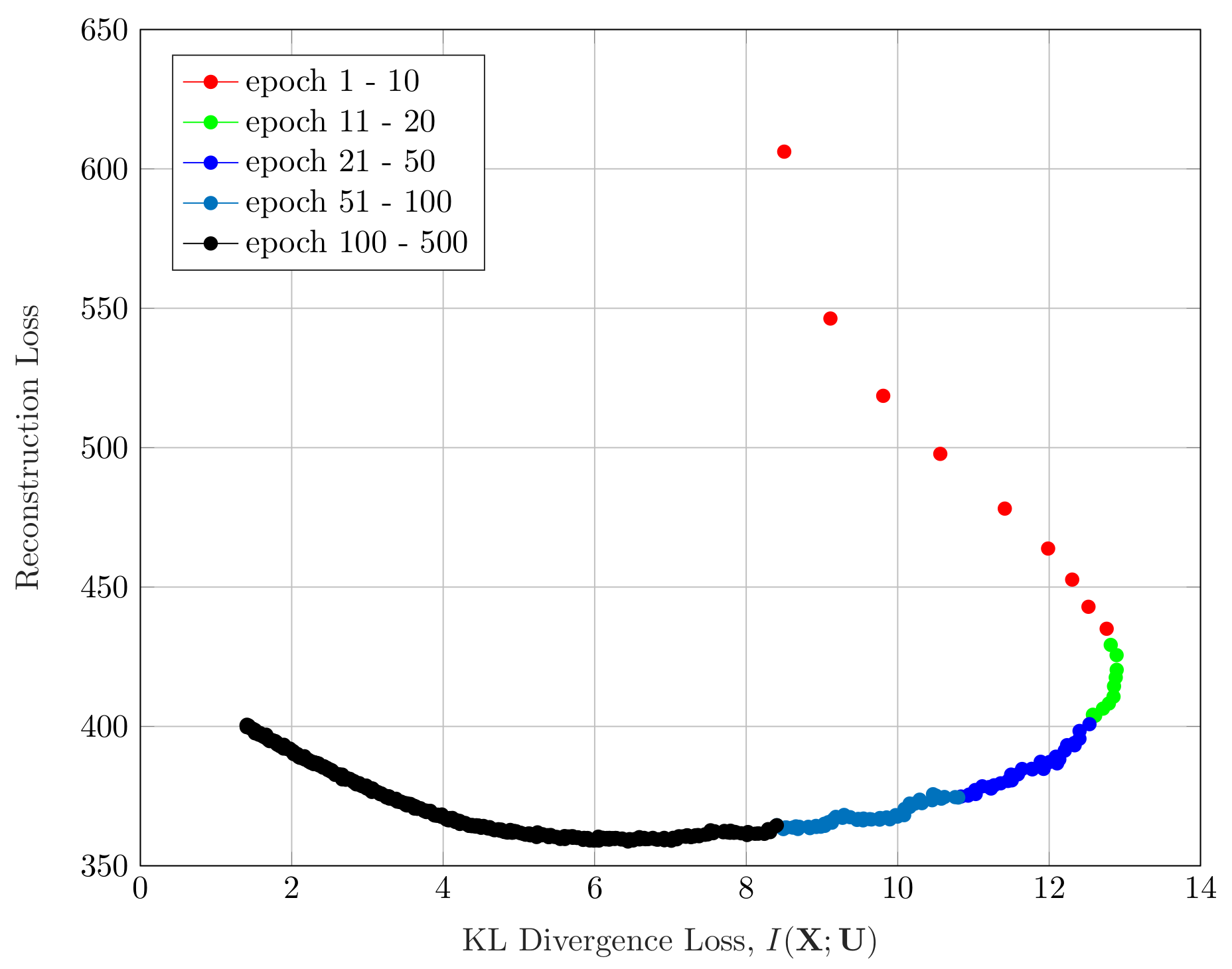
Figure 5 shows the evolution of the reconstruction loss of our VIB-GMM algorithm for the STL-10 dataset, as a function of simultaneously varying the values of the hyperparameter s and the number of epochs (recall that, as per the described methodology, we started with , and we increased its value gradually every epochs). As can be seen from the figure, the few first epochs were spent almost entirely on reducing the reconstruction loss (i.e., a fitting phase), and most of the remaining epochs were spent making the found representation more concise (i.e., smaller KL divergence). This was reminiscent of the two-phase (fitting vs. compression) that was observed for supervised learning using VIB in [29].
Remark 5.
For a fair comparison, our algorithm VIB-GMM and the VaDE of [19] were run for the same number of epochs, e.g., . In the VaDE algorithm, the cost function (11) was optimized for a particular value of hyperparameter s. Instead of running epochs for as in VaDE, we ran epochs by gradually increasing s to optimize the cost (21). In other words, the computational resources were distributed over a range of s values. Therefore, the computational complexity of our algorithm and the VaDE was equivalent.
4.4. Visualization on the Latent Space
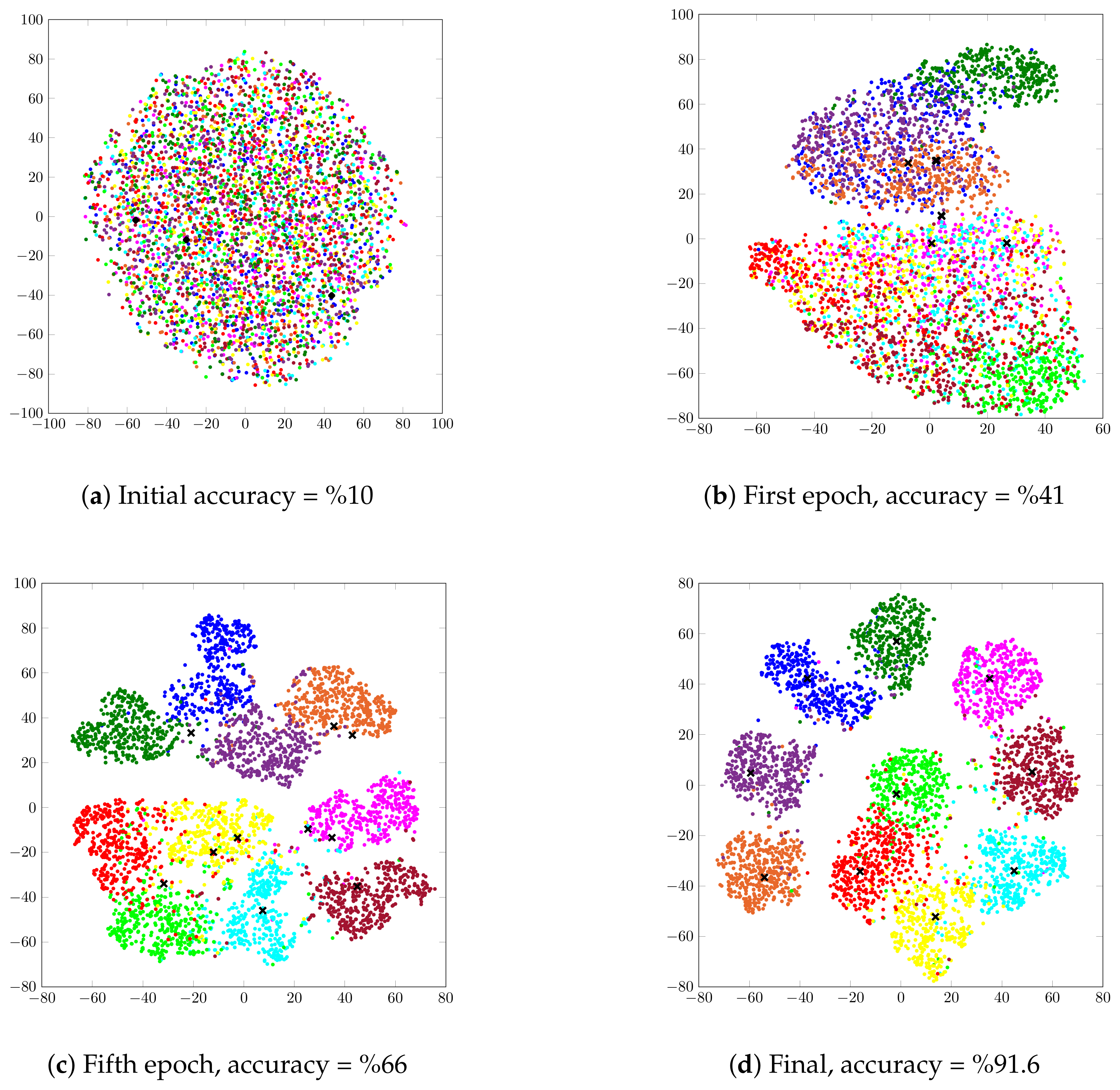
In this section, we investigate the evolution of the unsupervised clustering of the STL-10 dataset on the latent space using our VIB-GMM algorithm. For this purpose, we found it convenient to visualize the latent space through application of the t-SNEalgorithm of [30] in order to generate meaningful representations in a two-dimensional space. Figure 6 shows 4000 randomly chosen latent representations before the start of the training process and respectively after 1, 5, and 500 epochs. The shown points (with a · marker in the figure) represent latent representations of data samples whose labels are identical. Colors are used to distinguish between clusters. Crosses (with an marker in the figure) correspond to the centroids of the clusters. More specifically, Figure 6a shows the initial latent space before the training process. If the clustering is performed on the initial representations, it allows ACC as small as , i.e., as bad as a random assignment. Figure 6b shows the latent space after one epoch, from which a partition of some of the points starts to be already visible. With five epochs, that partitioning is significantly sharper, and the associated clusters can be recognized easily. Observe, however, that the cluster centers seem not to have converged yet. With 500 epochs, the ACC accuracy of our algorithm reached , and the clusters and their centroids were neater, as is visible from Figure 6d.
5. Conclusions and Future Work
In this paper, we proposed and analyzed the performance of an unsupervised algorithm for data clustering. The algorithm used the variational information bottleneck approach and modeled the latent space as a mixture of Gaussians. It was shown to outperform state-of-the-art algorithms such as the VaDE of [19] and the DEC of [20]. We note that although it was assumed that the number of classes was known beforehand (as was the case for almost all competing algorithms in its category), that number could be found (or estimated to within a certain accuracy) through inspection of the resulting bifurcations on the associated information-plane, as was observed for the standard information bottleneck method. Finally, we mention that among the interesting research directions in this line of work, one important question pertains to the distributed learning setting, i.e., along the counterpart, to the unsupervised setting, of the recent work [31,32,33], which contained distributed IB algorithms for both discrete and vector Gaussian data models.
Author Contributions
Software, Y.U.; Methodology, A.Z., Y.U. and G.A.; Supervision, A.Z.; Writing—original draft, A.Z., Y.U. and G.A. Writing—Review & Editing, Y.U. and A.Z. All authors have read and agreed to the published version of the manuscript.
Funding
The authors received no specific funding for this work.
Acknowledgments
The authors thank the reviewers for their comments that helped to improve the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. The Proof of Lemma 1
First, we expand as follows:
Then, is defined as follows:
Hence, we have the following relation:
where equality holds under equalities and . We note that .
Appendix B. Alternative Expression

References
- Sculley, D. Web-scale K-means clustering. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 1177–1178. [Google Scholar]
- Huang, Z. Extensions to the k-means algorithm for clustering large datasets with categorical values. Data Min. Knowl. Disc. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-means clustering algorithm. J. R. Stat. Soc. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. 1977, 39, 1–38. [Google Scholar]
- Ding, C.; He, X. K-means clustering via principal component analysis. In Proceedings of the 21st International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004. [Google Scholar]
- Pearson, K. On lines and planes of closest fit to systems of points in space. Philos. Mag. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Roweis, S. EM algorithms for PCA and SPCA. In Proceedings of the Advances in Neural Information Processing Systems 10, Denver, CO, USA, 1–6 December 1997; pp. 626–632. [Google Scholar]
- Hofmann, T.; Scholkopf, B.; Smola, A.J. Kernel methods in machine learning. Ann. Stat. 2008, 36, 1171–1220. [Google Scholar] [CrossRef] [Green Version]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. In Proceedings of the 37th Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 22–24 September 1999; pp. 368–377. [Google Scholar]
- Slonim, N.; Tishby, N. Document clustering using word clusters via the information bottleneck method. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, 24–28 July 2000; pp. 208–215. [Google Scholar]
- Slonim, N. The Information Bottleneck: Theory and Applications. Ph.D. Thesis, Hebrew University, Jerusalem, Israel, 2002. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. In Proceedings of the 2nd International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1278–1286. [Google Scholar]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep variational information bottleneck. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Lewis, D.D.; Yang, Y.; Rose, T.G.; Li, F. A new benchmark collection for text categorization research. J. Mach. Learn. Res. 2004, 5, 361–397. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 215–223. [Google Scholar]
- Jiang, Z.; Zheng, Y.; Tan, H.; Tang, B.; Zhou, H. Variational deep embedding: An unsupervised and generative approach to clustering. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 1965–1972. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 478–487. [Google Scholar]
- Guo, X.; Gao, L.; Liu, X.; Yin, J. Improved deep embedded clustering with local structure preservation. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 1753–1759. [Google Scholar]
- Dilokthanakul, N.; Mediano, P.A.M.; Garnelo, M.; Lee, M.C.H.; Salimbeni, H.; Arulkumaran, K.; Shanahani, M. Deep unsupervised clustering with Gaussian mixture variational autoencoders. arXiv 2017, arXiv:1611.02648. [Google Scholar]
- Min, E.; Guo, X.; Liu, Q.; Zhang, G.; Cui, J.; Long, J. A survey of clustering with deep learning: From the perspective of network architecture. IEEE Access 2018, 6, 39501–39514. [Google Scholar] [CrossRef]
- Hershey, J.R.; Olsen, P.A. Approximating the Kullback Leibler divergence between Gaussian mixture models. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Honolulu, HI, USA, 15–20 April 2007; pp. 317–320. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Achille, A.; Soatto, S. Information dropout: Learning optimal representations through noisy computation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2897–2905. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.-A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Schwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res 2008, 9, 2579–2605. [Google Scholar]
- Estella-Aguerri, I.; Zaidi, A. Distributed variational representation learning. IEEE Trans. Pattern Anal. Mach. Intell. 2020, in press. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Estella-Aguerri, I.; Zaidi, A. Distributed information bottleneck method for discrete and Gaussian sources. In Proceedings of the International Zurich Seminar on Information and Communication, Zürich, Switzerland, 21–23 February 2018. [Google Scholar]
- Zaidi, A.; Estella-Aguerri, I.; Shamai (Shitz), S. On the information bottleneck problems: Models, connections, applications and information theoretic views. Entropy 2020, 22, 151. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Variational Information Bottleneck with Gaussian mixtures.

Figure 2.
Inference network.

Figure 3.
Generative network.

Figure 4.
Accuracy vs. the number of epochs for the STL-10dataset.

Figure 5.
Information plane for the STL-10 dataset.

Figure 6.
Visualization of the latent space before training; and after 1, 5, and 500 epochs.


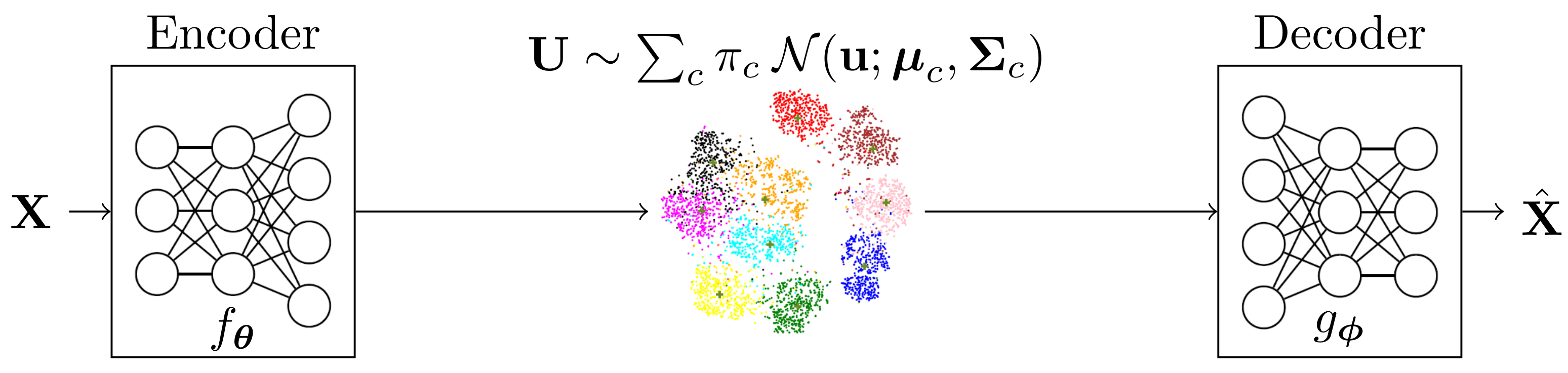{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparison of the clustering accuracy of various algorithms. The algorithms are run without pretraining. Each algorithm is run ten times. The values in correspond to the standard deviations of clustering accuracies. DEC, Deep Embedded Clustering; VaDE, Variational Deep Embedding; VIB, Variational Information Bottleneck.
Table 1.
Comparison of the clustering accuracy of various algorithms. The algorithms are run without pretraining. Each algorithm is run ten times. The values in correspond to the standard deviations of clustering accuracies. DEC, Deep Embedded Clustering; VaDE, Variational Deep Embedding; VIB, Variational Information Bottleneck.
| MNIST | STL-10 | ||||
|---|---|---|---|---|---|
| Best Run | Average Run | Best Run | Average Run | ||
| GMM | 44.1 | 40.5 (1.5) | 78.9 | 73.3 (5.1) | |
| DEC | 80.6 | ||||
| VaDE | 91.8 | 78.8 (9.1) | 85.3 | 74.1 (6.4) | |
| VIB-GMM | (5.9) | (5.6) | |||
Values are taken from VaDE [19].
Table 2.
Comparison of the clustering accuracy of various algorithms. A stacked autoencoder is used to pretrain the DNNs of the encoder and decoder before running algorithms (DNNs are initialized with the same weights and biases of [19]). Each algorithm is run ten times. The values in correspond to the standard deviations of clustering accuracies.
Table 2.
Comparison of the clustering accuracy of various algorithms. A stacked autoencoder is used to pretrain the DNNs of the encoder and decoder before running algorithms (DNNs are initialized with the same weights and biases of [19]). Each algorithm is run ten times. The values in correspond to the standard deviations of clustering accuracies.
| MNIST | REURTERS10K | ||||
|---|---|---|---|---|---|
| Best Run | Average Run | Best Run | Average Run | ||
| DEC | 84.3 | 72.2 | |||
| VaDE | 94.2 | 93.2 (1.5) | 79.8 | 79.1 (0.6) | |
| VIB-GMM | (0.1) | (0.4) | |||
Values are taken from DEC [20].
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Uğur, Y.; Arvanitakis, G.; Zaidi, A. Variational Information Bottleneck for Unsupervised Clustering: Deep Gaussian Mixture Embedding. Entropy 2020, 22, 213. https://0-doi-org.brum.beds.ac.uk/10.3390/e22020213
AMA Style
Uğur Y, Arvanitakis G, Zaidi A. Variational Information Bottleneck for Unsupervised Clustering: Deep Gaussian Mixture Embedding. Entropy. 2020; 22(2):213. https://0-doi-org.brum.beds.ac.uk/10.3390/e22020213
Chicago/Turabian StyleUğur, Yiğit, George Arvanitakis, and Abdellatif Zaidi. 2020. "Variational Information Bottleneck for Unsupervised Clustering: Deep Gaussian Mixture Embedding" Entropy 22, no. 2: 213. https://0-doi-org.brum.beds.ac.uk/10.3390/e22020213
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.