Computing Classical-Quantum Channel Capacity Using Blahut–Arimoto Type Algorithm: A Theoretical and Numerical Analysis †


1
School of Information Science and Technology, ShanghaiTech University, Shanghai 201210, China
2
Shanghai Institute of Microsystem and Information Technology, Chinese Academy of Sciences, Shanghai 201210, China
3
University of Chinese Academy of Sciences, Beijing 100049, China
*
Authors to whom correspondence should be addressed.
†
This paper is partially presented at 2019 International Symposium on Information Theory.
Entropy 2020, 22(2), 222; https://0-doi-org.brum.beds.ac.uk/10.3390/e22020222
Submission received: 15 January 2020
/
Revised: 5 February 2020
/
Accepted: 13 February 2020
/
Published: 16 February 2020
(This article belongs to the Collection Quantum Information)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Based on Arimoto’s work in 1972, we propose an iterative algorithm for computing the capacity of a discrete memoryless classical-quantum channel with a finite input alphabet and a finite dimensional output, which we call the Blahut–Arimoto algorithm for classical-quantum channel, and an input cost constraint is considered. We show that, to reach accuracy, the iteration complexity of the algorithm is upper bounded by where n is the size of the input alphabet. In particular, when the output state is linearly independent in complex matrix space, the algorithm has a geometric convergence. We also show that the algorithm reaches an accurate solution with a complexity of , and in the special case, where m is the output dimension, is the relative entropy of two distributions, and is a positive number. Numerical experiments were performed and an approximate solution for the binary two-dimensional case was analysed.
1. Introduction
The computation of channel capacity has always been a core problem in information theory. The very well-known Blahut-Arimoto algorithm [1,2] was proposed in 1972 to compute the discrete memoryless classical channel. Inspired by this algorithm, we propose an algorithm of Blahut-Arimoto type to compute the capacity of discrete memoryless classical-quantum channel. The classical-quantum channel [3] can be considered as a mapping of an input alphabet to a set of quantum states in a finite dimensional Hilbert space . The state of a quantum system is given by a density operator , which is a positive semi-definite operator with trace equal to one. Let denote the set of all density operators acting on a Hilbert space of dimension m. If the source emits a letter x with probability , the output would be , thus the output would form an ensemble: .
In 1998, Holevo showed [4] that the classical capacity of the classical-quantum channel is the maximization of a quantity called the Holevo information over all input distributions. The Holevo information of an ensemble is defined as
where is the von Neumann entropy, which is defined on positive semidefinite matrices:
Due to the concavity of von Neumann entropy [5], the Holevo information is always non-negative. The Holevo quantity is concave in the input distribution [5], and thus the maximization of Equation (1) over p is a convex optimization problem. However, it is not a straightforward convex optimization problem. In 2014, Sutter et al. [6] promoted an algorithm based on duality of convex programming and smoothing techniques [7] with a complexity of , where .
For discrete memoryless classical channels, the capacity can be computed efficiently by using an algorithm called Blahut–Arimoto (BA) algorithm [1,2,8]. In 1998, H. Nagaoka [9] proposed a quantum version of BA algorithm. In his work, he considered the quantum-quantum channel and this problem was proved to be NP-complete in 2008 [10]. Despite the NP-completeness, in [11], an example is given of a qubit quantum channel which requires four inputs to maximize the Holevo capacity. Further research of Nagaoka’s algorithm was presented in [12], where the algorithm was implemented to check the additivity of quantum channels. In [9], Nagaoka mentioned an algorithm concerning classical-quantum channel; however, its speed of convergence was not studied there and the details of the proof were not presented either. In this paper, we show that, with proper manipulations, the BA algorithm can be applied to computing the capacity of classical-quantum channel with an input constraint efficiently. The remainder of this article is structured as follows. In Section 2, we propose the algorithm and show how the algorithm works. In Section 3, we provide the convergence analysis of the algorithm. In Section 4, we show the numerical experiments of BA algorithm to see how well this algorithm performs. In Section 5, we propose an approximate solution for a special case, which is the binary input, two-dimensional output case.
Notations: The logarithm with basis 2 is denoted by . The space of all Hermitian operators of dimension m is denoted by . The set of all density matrices of dimension m is denoted by . Each letter is mapped to a density matrix , thus the classical-quantum channel can be represented as a set of density matrices . The set of all probability distributions of length n is denoted by . The von Neumann entropy of a density matrix is denoted by . The relative entropy between , if , is denoted by and otherwise. The relative entropy between , if , is denoted by and otherwise.
2. Blahut–Arimoto Algorithm for Classical-Quantum Channel
First, we write down the primal optimization problem:
where , is a positive real vector, . We denote the maximal value of Equation (3) as . In this optimization problem, we are to maximize the Holevo quantity with respect to the input distribution . Practically, the preparation of different signal state x has different cost, which is represented by . We would like to bound the expected cost of the resource within some quantity, which is represented by the inequality constraint in Equation (3).
Lemma 1.
[6] Let a set G be defined as and . Then, if , the inequality constraint in the primal problem is inactive; and, if , the inequality constraint in the primal problem is equivalent to .
Now, we assume that . The Lagrange dual problem of Equation (3) is
Proof.
The lemma follows from standard strong duality result of convex optimization theory ([13], Chapter 5.2.3). □
Define functions. Let
where .
Lemma 3.
For fixed p, .
Proof.
Lemma 4.
For fixed , we have
where and .
Proof.
Notice that, if we let in Equation (7), with some calculation, Equation (7) becomes Lemma 3. Thus, Lemma 3 is a straightforward corollary of Lemma 4
Theorem 1.
The dual problem in Equation (4) is equivalent to
Proof.
The BA algorithm is an alternating optimization algorithm, i.e., to optimize , each iteration step would fix one variable and optimize the function over the other variable. Now, we use BA algorithm to find . The iteration procedure is
where .
To get , we can use the Lagrange function:
setting the gradient with respect to to zero. By combining the normalization condition, we can have (taking the natural logarithm for convenience):
Thus, we can summarize the Algorithm 1 below.
| Algorithm 1 Blahut–Arimoto algorithm for discrete memoryless classical-quantum channel. |
|
Lemma 5.
Let for a given λ; then, is a decreasing function of λ.
Proof.
For convenience, we denote as . Notice that by definition of .
For , if , then, by the definition of , we have:
which is a contradiction to the fact that is an optimizer of . Thus, we must have if . □
We do not need to solve the optimization problem in Equation (8), because from Lemma 1 we can see that the statement “ is an optimal solution” is equivalent to “ and maximizes ”, which is also equivalent to “ and maximizes ", thus, if for some , a p maximizes and , then the capacity , and such is easy to find since is a decreasing function of , and, to reach an accuracy, we need
steps using bisection method.
3. Convergence Analysis
Next, we show that the algorithm indeed converges to and then provide an analysis of the speed of the convergence.
3.1. The Convergence Is Guaranteed
Corollary 1.
Proof.
Corollary 2.
For arbitrary distribution , we have
Proof.
Theorem 2.
converges to as .
Proof.
Let be an optimal solution that achieves ; then, we have the following inequality
The first equality follows from Equations (5), (6), and (1). The first inequality follows from Corollary 2. The last inequality follows from the non-negativity of relative entropy.
Thus, let and with , we have
Notice we take the initial to be uniform distribution, so the right hand side of Equation (15) is finite. Combine with the fact that is a non-decreasing sequence, this means converges to . □
Theorem 3.
The probability distribution also converges.
Proof.
Now that the sequence is a bounded sequence, there exists a subsequence that converges. Let us say it converges to . Then, clearly, we have (or would not converge). Substituting in Equation (16), we have
Thus, the sequence is a decreasing sequence and there exists a subsequence that converges to zero. Therefore, we can conclude that converges to zero, which means converges to . □
3.2. The Speed of Convergence
Theorem 4.
To reach ε accuracy to , the algorithm needs an iteration complexity less than .
Proof.
From the proof of Theorem 2, we know
and is non-increasing in t, thus
□
Next, we show that in some special cases the algorithm has a better convergence performance, which is a geometric speed of convergence.
Assumption 1.
The channel matrices are linearly independent, i.e., there does not exist a vector such that
Remark 1.
Assumption 1 is equivalent to: The output state is uniquely determined by the input distribution p.
Theorem 5.
Under Assumption 1, the optimal solution is unique.
Proof.
Notice that the von Neumann entropy in Equation (2) is strictly concave [14], thus, for distributions , , which is followed from Assumption refas1. Thus, this means is strictly concave in p. Thus, Holevo quantity in Equation (1) is strictly concave in p, which means the optimal solution is unique. □
We also need the following theorem:
Theorem 6.
[15] The relative entropy satisfies
Now, we state the theorem of convergence:
Theorem 7.
Suppose start from some initial point , then, under Assumption 1, the algorithm converges to the optimal point , and converges to at a geometric speed, i.e., there exist and , where N and δ are independent, such that, for any , we have
Proof.
Define and the real vector . Using Taylor expansion, we have
where . Now, converges to , i.e., converges to zero, thus there exists a such that, for any , we have
From Theorem 6, we have
where :
From Equation (18), we know that, under Assumption 1, M is positive definite. Thus, there exists a such that
Thus, for any , it follows from Equations (17) and (18) that
From Equation (12), we know
combined with Equation (19), we have
for any . □
Remark 2.
(Complexity). Denote as the size of input alphabet and output state dimension, respectively. A closer look at Algorithm 1 reveals that, for each iteration, a matrix logarithm needs to be calculated, and the rest are just multiplication of matrices and multiplication of numbers. The matrix logarithm can be done with complexity [16], thus, by Theorem 4 and Equation (11), the complexity to reach ε-close to the true capacity using Algorithm 1 is . With extra condition of the channel , which is Assumption 1, the complexity to reach an ε-close solution (i.e., ) using Algorithm 1 is . Usually, we do not need ε to be too small (no smaller than ), thus, in either case, the complexity is better than in [6] when is big, where .
4. Numerical Experiments on BA Algorithm
We only performed experiments on BA algorithm with no input constraint (BA algorithm with input constraint is some combination of BA algorithm with no input constraint.) We studied the relations between iteration complexity and (i.e., the input size and output dimension) when the algorithm reaches certain accuracy. Since we do not know the true capacity of a certain channel, we used the following theorem to bound the error of the algorithm.
Theorem 8.
With the iteration procedure in the BA Algorithm 1, converges to from above.
Proof.
Following from Algorithm 1, Corollary 1, and Theorem 3, we have
where , is an optimal distribution. The limit above is 1 if and does not exceed 1 if . Thus,
for every , with equality if . This proves
For any and any optimal distribution , we have
The first equality requires some calculation and the second equality follows since is an optimal distribution. This means converges to from above. □
Thus, our accuracy criterion was: for a given classical-quantum channel, we ran the BA algorithm (with no input constraint), until was less than , and recorded the number of iteration. At this time, the accuracy was of order at most since and converged to the true capacity from above and below, respectively.
We performed the following numerical experiments: for given values of input size n, output dimension m and accuracy, we generated 200 classical-quantum channels randomly, recorded the numbers of iterations, and then calculated the average number of iterations of these 200 experiments. The results are shown in Figure 1. Note that the accuracy in Figure 1 means we ran the BA algorithm until was less than , and the error between the true capacity and the computed value was of order at most.
We can see in Figure 1 that the iteration complexity scales better as accuracy and input dimension increase. We can also see for given input size n and accuracy, the output dimension has vary little influence on iteration complexity, which means the iteration complexity also scales better as the output dimension m increases. Compared with our theoretical analysis of iteration complexity in Theorem 4: to reach accuracy, we needed iterations; the numerical experiments showed that the number of iterations was far smaller than to reach accuracy, whether the output quantum states were independent or not (cases in ). The reason for this is that the inequalities in the proof of Theorem 4 are quite loose. Thus, Theorem 4 only provides a very loose upper bound on iteration complexity. We can also guess that maybe the relation in Equation (20) holds generally and we just cannot prove it yet.
Next, we needed to see the running time of the BA algorithm. There were three methods to compute the classical-quantum channel capacity: BA algorithm, the duality and smoothing technique [6], and the method created by Hamza Fawzi et al. [17]. In [17], a Matlab code package called CvxQuad is provided which accurately approximates the relative entropy function via semidefinite programming so that many quantum capacity quantities can be computed using a convex optimization tool called CVX. Here, we compared the running time of the above three methods. For different input size n and output dimension m, we generated a classical-quantum channel randomly and computed the channel capacity using the above three methods and then recorded the running time of each method. The results are shown in Figure 2.
In Figure 2, we can see the BA algorithm was the fastest method. The duality and smoothing method was rather slow and we did not record the running time of the duality and smoothing method when because it took too long. We can also notice that the running time of the CvxQuad method was extremely sensitive to the output dimension, which is not a surprise because CVX is a second-order method. Thus, our BA algorithm was significantly faster than the other two methods when n and m became big.
5. An Approximate Solution of p in Binary Two Dimensional Case
In this section, we provide an approximate optimal input distribution for the case of the input size and output dimension are both 2:
5.1. Use Bloch Sphere to Get an Approximate Solution
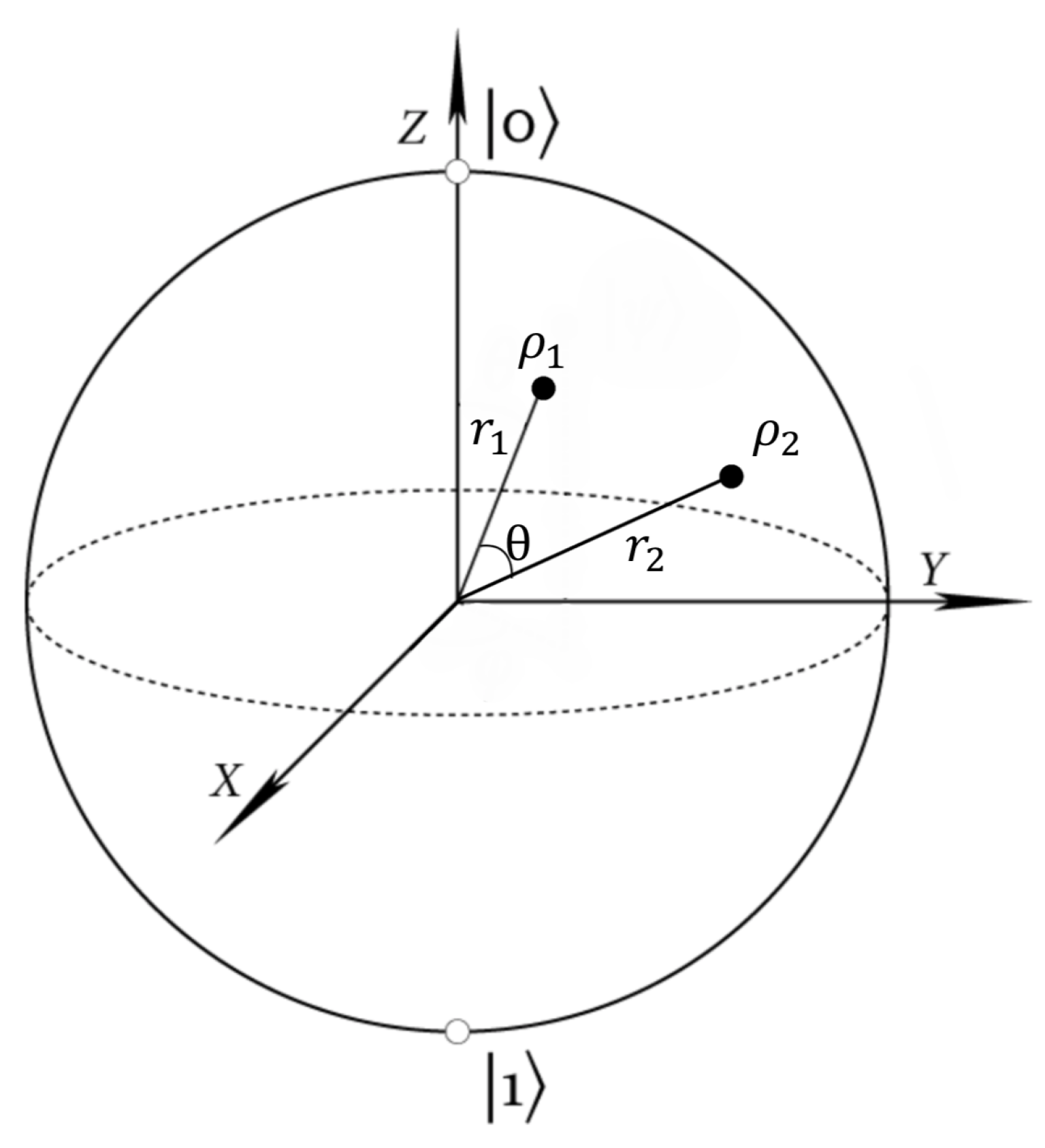
Any two-dimensional density matrix can be represented as a point in the Bloch sphere [5], as shown in the following:
Any density matrix can be represented as a vector in the Bloch sphere starting from the origin. Suppose can be represented as respectively, as shown in Figure 3; then, the two eigenvalues would be and , respectively. Extending , we get two intersections on the surface of the Bloch sphere; then, these two intersections represent the two eigenvectors of (the points on the surface of the sphere represent pure state and the interior points represent mixed states). A probabilistic combination of can be represented as ([5] Exercise 4.4.13). Any point on the surface of Bloch sphere can be represented as
where is the angle to the Z-axis and is the angle of the X-axis to the projection of the point on the X–Y plane.
By symmetry, it is obvious that the Holevo quantity is only related to , where is the angle between . One interesting result is that the angle has very little influence on , where is the optimal distribution that maximizes Holevo quantity. If we know (the bigger eigenvalues of , respectively), and , then the Holevo quantity can be written as
where is the binary entropy ( and .
Using Cosine Theorem to calculate , the gradient of with respect to can be calculated directly, denoted as
If we can find a such that , then this is the optimal solution (because is concave in ). However, we cannot solve the equation with respect to when . Now that has little influence on , let (this is actually the classical case), and let
the above equation is easy to solve and we get a solution :
where we assume . (It can be easily seen from the Bloch sphere that if , the optimal distribution would be .)
This can be used as an approximate optimal solution for all . Next, we need numerical experiments to see how accurate is.
5.2. Numerical Experiments on the Approximated Solution
It is obvious that the maximum of Holevo quantity only depends on and , thus, without loss of generality, we let be on the Z-axis and be on the X–Z plane:
where
which means the angle between and (i.e., and ) is [5].
In the numerical experiments, we let range from to 1, and range from 0 to . For each value of , we substituted into Equation (22) to compute . Then, we substituted into Equation (21) to get the approximate maximum of Holevo quantity over : . To see how accurate this approximate maximum is, we need a BA algorithm to provide an accurate maximum. The termination criterion for the iteration process of BA algorithm is stopping when is less than ; then, the BA algorithm outputs a value of Holevo quantity . We can compute the error of then take the maximum over
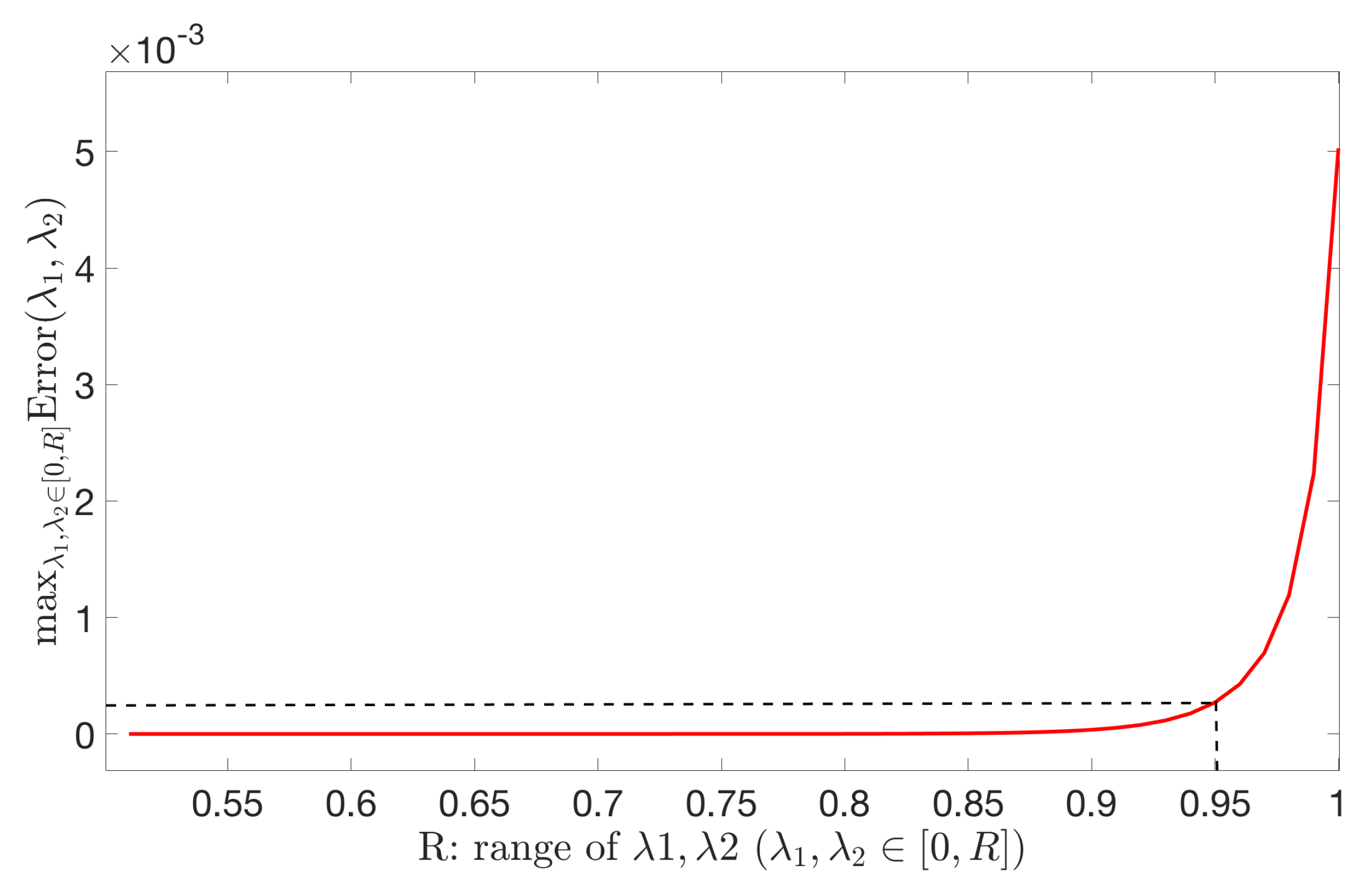
Figure 4 is the numerical result, which is a plot of .
In Figure 4, we can see that, if are not “too big", the error can be upper bounded by . To see this more directly, we take the maximum of for different ranges of :
Figure 5 is a plot of .
In Figure 5, we can see that, if , the error of approximate maximum of Holevo quantity can be upper bounded by . Thus, we can conclude that, when the bigger eigenvalues of are not too big (no bigger than ), Equation (22) can make the error of the maximum of Holevo quantity smaller than .
The approximate solution is an interesting phenomenon. The reason the angle has such little influence on the maximum of Holevo quantity is unclear.
6. Discussion
In this paper, we provide an algorithm which computes the capacity of classical-quantum channel. We analyzed the speed of convergence theoretically and numerical experiments showed that our algorithm outperforms the existing methods [6,17]. We also provide an approximated method to compute the capacity of binary two-dimensional classical-quantum channel, which shows high accuracy. As mentioned in the Introduction, for a general quantum-quantum channel, maximizing Holevo quantity with respect to both the input distribution and output quantum state is NP-complete and this is not a convex optimization problem because Holevo quantity is concave with respect to input distribution and convex with respect to output quantum states. Thus, it remains open whether there exists an efficient algorithm to solve this problem. However, for classical-quantum channel, Holevo quantity has an upper bound, thus one future work would be to maximize Holevo quantity with respect to output states with given input distribution. It remains open if alternating optimization algorithms, in particular of Blahut–Arimoto type, can also be given for other optimization problems in terms of quantum entropy.
The authors declare no conflict of interest.
Author Contributions
Formal analysis, H.L., N.C.; Investigation, H.L.; Project administration, H.L.; Supervision, N.C.; Writing—original draft, H.L.; Writing—review & editing, N.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Arimoto, S. An algorithm for computing the capacity of arbitrary discrete memoryless channels. IEEE Trans. Inf. Theory 1972, 18, 14–20. [Google Scholar] [CrossRef] [Green Version]
- Blahut, R. Computation of channel capacity and rate-distortion functions. IEEE Trans. Inf. Theory 1972, 18, 460–473. [Google Scholar] [CrossRef] [Green Version]
- Holevo, A. Problems in the mathematical theory of quantum communication channels. Rep. Math. Phys. 1977, 12, 273–278. [Google Scholar] [CrossRef]
- Holevo, A.S. The capacity of the quantum channel with general signal states. IEEE Trans. Inf. Theory 1998, 44, 269–273. [Google Scholar] [CrossRef] [Green Version]
- Wilde, M. From Classical to Quantum Shannon Theory; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Sutter, D.; Sutter, T.; Esfahani, P.M.; Renner, R. Efficient Approximation of Quantum Channel Capacities. IEEE Trans. Inf. Theory 2016, 62, 578–598. [Google Scholar] [CrossRef] [Green Version]
- Nesterov, Y. Smooth minimization of non-smooth functions. Math. Program. 2005, 103, 127–152. [Google Scholar] [CrossRef]
- Yeung, R.W. Information Theory and Network Coding; Springer: Berlin/Heidelberger, Germany, 2008. [Google Scholar]
- Nagaoka, H. Algorithms of Arimoto-Blahut type for computing quantum channel capacity. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Cambridge, MA, USA, 16–21 August 1998; p. 354. [Google Scholar]
- Beigi, S.; Shor, P.W. On the Complexity of Computing Zero-Error and Holevo Capacity of Quantum Channels. arXiv 2007, arXiv:0709.2090. [Google Scholar]
- Osawa, S.; Nagaoka, H. Numerical Experiments on the Capacity of Quantum Channel with Entangled Input States. IEICE TRANSACTIONS Fundam. Electron. Commun. Comput. 2001, E84-A, 2583–2590. [Google Scholar]
- Hayashi, M.; Imai, H.; Matsumoto, K.; Ruskai, M.B.; Shimono, T. Qubit Channels Which Require Four Inputs to Achieve Capacity: Implications for Additivity Conjectures. Quantum Inf. Comput. 2005, 5, 13–31. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Bengtsson, I.; Zyczkowski, K. GEOMETRY OF QUANTUM STATES: An Introduction to Quantum Entanglement; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Hiai, F.; Petz, D. Introduction to Matrix Analysis and Applications; Springer: Berlin/Heidelberger, Germany, 2014. [Google Scholar]
- Moler, C.; Van Loan, C. Nineteen Dubious Ways to Compute the Exponential of a Matrix, Twenty-Five Years Later. SIAM Rev. 2003, 45, 3–49. [Google Scholar] [CrossRef]
- Hamza Fawzi, O.F. Efficient optimization of the quantum relative entropy. J. Phys. A Math. Theor. 2018, 51, 409601. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
The number of iterations needed to reach certain accuracy.

Figure 2.
The caparison of the running time of three methods.

Figure 3.
Bloch sphere.

Figure 4.
Error of the approximated method.

Figure 5.
Error of the approximate method.

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Li, H.; Cai, N. Computing Classical-Quantum Channel Capacity Using Blahut–Arimoto Type Algorithm: A Theoretical and Numerical Analysis. Entropy 2020, 22, 222. https://0-doi-org.brum.beds.ac.uk/10.3390/e22020222
AMA Style
Li H, Cai N. Computing Classical-Quantum Channel Capacity Using Blahut–Arimoto Type Algorithm: A Theoretical and Numerical Analysis. Entropy. 2020; 22(2):222. https://0-doi-org.brum.beds.ac.uk/10.3390/e22020222
Chicago/Turabian StyleLi, Haobo, and Ning Cai. 2020. "Computing Classical-Quantum Channel Capacity Using Blahut–Arimoto Type Algorithm: A Theoretical and Numerical Analysis" Entropy 22, no. 2: 222. https://0-doi-org.brum.beds.ac.uk/10.3390/e22020222
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.