On the Rate-Distortion Function of Sampled Cyclostationary Gaussian Processes


1
Department of Electrical and Computer Engineering, Ben-Gurion University, Be’er-Sheva 8410501, Israel
2
Faculty of Mathematics and Computer Science, Weizmann Institute of Science, Rehovot 7610001, Israel
*
Author to whom correspondence should be addressed.
Entropy 2020, 22(3), 345; https://0-doi-org.brum.beds.ac.uk/10.3390/e22030345
Submission received: 14 February 2020
/
Revised: 8 March 2020
/
Accepted: 10 March 2020
/
Published: 17 March 2020
(This article belongs to the Special Issue Wireless Networks: Information Theoretic Perspectives)
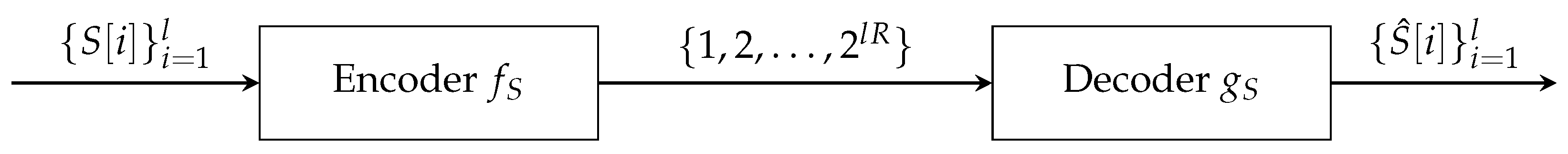{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Man-made communications signals are typically modelled as continuous-time (CT) wide-sense cyclostationary (WSCS) processes. As modern processing is digital, it is applied to discrete-time (DT) processes obtained by sampling the CT processes. When sampling is applied to a CT WSCS process, the statistics of the resulting DT process depends on the relationship between the sampling interval and the period of the statistics of the CT process: When these two parameters have a common integer factor, then the DT process is WSCS. This situation is referred to as synchronous sampling. When this is not the case, which is referred to as asynchronous sampling, the resulting DT process is wide-sense almost cyclostationary (WSACS). The sampled CT processes are commonly encoded using a source code to facilitate storage or transmission over wireless networks, e.g., using compress-and-forward relaying. In this work, we study the fundamental tradeoff between rate and distortion for source codes applied to sampled CT WSCS processes, characterized via the rate-distortion function (RDF). We note that while RDF characterization for the case of synchronous sampling directly follows from classic information-theoretic tools utilizing ergodicity and the law of large numbers, when sampling is asynchronous, the resulting process is not information stable. In such cases, the commonly used information-theoretic tools are inapplicable to RDF analysis, which poses a major challenge. Using the information-spectrum framework, we show that the RDF for asynchronous sampling in the low distortion regime can be expressed as the limit superior of a sequence of RDFs in which each element corresponds to the RDF of a synchronously sampled WSCS process (yet their limit is not guaranteed to exist). The resulting characterization allows us to introduce novel insights on the relationship between sampling synchronization and the RDF. For example, we demonstrate that, differently from stationary processes, small differences in the sampling rate and the sampling time offset can notably affect the RDF of sampled CT WSCS processes.
1. Introduction
Man-made signals are typically generated using a repetitive procedure, which takes place at fixed intervals. The resulting signals are thus commonly modeled as continuous-time (CT) random processes exhibiting periodic statistical properties [1,2,3], which are referred to as wide-sense cyclostationary (WSCS) processes. In digital communications, where the transmitted waveforms commonly obey the WSCS model [3], the received CT signal is first sampled to obtain a discrete-time (DT) received signal. In the event that the sampling interval is commensurate with the period of the statistics of the CT WSCS signal, cyclostationarity is preserved in DT ([3] Section 3.9). In this work, we refer to this situation as synchronous sampling. However, it is practically common to encounter scenarios in which the sampling rate at the receiver and the symbol rate of the received CT WSCS process are incommensurate, which is referred to as asynchronous sampling. The resulting sampled process in such cases is a DT wide-sense almost cyclostationary (WSACS) stochastic process ([3] Section 3.9).
This research aims at investigating lossy source coding for asynchronously sampled CT WSCS processes. In the source coding problem, every sequence of information symbols from the source is mapped into a sequence of code symbols, referred to as codewords, taken from a predefined codebook. In lossy source coding, the source sequence is recovered up to a predefined distortion constraint, within an arbitrary small tolerance of error. The figure-of-merit for lossy source coding is the rate-distortion function (RDF) which characterizes the minimum number of bits per source symbol required to compress the source sequence such that it can be reconstructed at the decoder within the specified maximal distortion [4]. For an independent and identically distributed (IID) random source process, the RDF can be expressed as the minimum mutual information between the source variable and the reconstruction variable, such that with the corresponding conditional distribution of the reconstruction symbol given the source symbol, the distortion constraint is satisfied ([5] Chapter 10). The source coding problem has been further studied in multiple different scenarios, including the reconstruction of a single source at multiple destinations [6] and the reconstruction of multiple correlated stationary Gaussian sources at a single destination [7,8,9].
For sampled stationary source processes, ergodicity theory and the asymptotic equipartition property (AEP) ([5] Chapter 3) were utilized for characterizing the RDF in different scenarios ([10] Chapter 9), ([4] Section I), [11]. However, as in a broad range of applications, including digital communications networks, the CT signals are WSCS processes, the sampling operation results in DT source signals whose statistics depends on the relationship between the sampling rate and the period of the statistics of the source signal. When sampling is synchronous, the resulting DT source signal is WSCS ([3] Section 3.9). The RDF for lossy compression of DT WSCS Gaussian sources with memory was studied in [12]. The work [12] used the fact that any WSCS signal can be transformed into a set of stationary subprocess [2]; thereby facilitating the application of information-theoretic results obtained for multivariate stationary sources to the derivation of the RDF; Nonetheless, in many digital communications scenarios, the sampling rate and the symbol rate of the CT WSCS process are not related in any way, and are possibly incommensurate, resulting in a sampled process which is a DT WSACS stochastic process. Such situations can occur as a result of the a-priori determined values of the sampling interval and the symbol duration of the WSCS source signal, as well as due to sampling clock jitters resulting from hardware impairments. A comprehensive review of trends and applications for almost cyclostationary signals can be found in [13]. Despite of their apparent frequent occurrences, the RDF for lossy compression of WSACS sources has not been characterized, which is the motivation for the current research. A major challenge associated with characterizing fundamental limits for asynchronously sampled WSCS processes stems from the fact that the resulting processes are not information stable, in the sense that their conditional distributions are not ergodic ([14] Page X), [15,16]. As a result, the standard information-theoretic tools cannot be employed, making the characterization of the RDF a very challenging problem.
Our recent study in [17] on channel coding reveals that for the case of additive CT WSCS Gaussian noise, capacity varies significantly with sampling rates, whether the Nyquist criterion is satisfied or not. In particular, it was observed that the capacity can change dramatically with minor variations in the sampling rate, causing it to switch from synchronous sampling to asynchronous sampling. This is in direct contrast to the results obtained for wide-sense stationary noise for which the capacity remains unchanged for any sampling rate above the Nyquist rate [18]. A natural fundamental question that arises from this result is how the RDF of a sampled Gaussian source process varies with the sampling rate. As a motivating example, one may consider compress-and-forward (CF) relaying, in which the relay samples at a rate which can be incommensurate with the symbol rate of the incoming communications signal.
In this work, we employ the information-spectrum framework [14] for characterizing the RDF of asynchronously sampled memoryless Gaussian WSCS processes, as this framework is applicable to the information-theoretic analysis of non information-stable processes ([14] Page VII). We further note that while rate characterizations obtained using information spectrum tools and its associated quantities may be difficult to evaluate ([14] Remark 1.7.3), here we obtain a numerically computable characterization of the RDF. In particular, we focus on the mean squared error (MSE) distortion measure in the low distortion regime, namely, source codes for which the average square of the difference between the source and the reproduction process is not larger than the minimal source variance. The results of this research lead to accurate modelling of signal compression in current and future digital communications systems. The derived RDF, which characterizes the fundamental performance limits in encoding sampled CT WSCS Gaussian processes into a digital representation, allows to evaluate source coding schemes associated with different levels of complexity in terms of their gap from optimality, when applied to this important class of signals.
Furthermore, we utilize our characterization of the RDF to examine how the RDF for a sampled CT WSCS Gaussian source varies with different sampling rates and sampling time offsets. We demonstrate that, differently from stationary sources, when applying a lossy source code to a sampled WSCS process, the achievable rate-distortion tradeoff can be significantly affected by minor variations in the sampling time offset and the sampling rate. Our results thus allow identifying the sampling rate and sampling time offsets which minimize the RDF in systems involving sampled WSCS processes.
The rest of this work is organised as follows: Section 2 provides a scientific background on cyclostationary processes and on rate-distortion analysis of DT WSCS Gaussian sources. Section 3 presents the problem formulation and auxiliary results, and Section 4 details the main result of RDF characterization for sampled WSCS Gaussian process. Numerical examples and discussions are provided in Section 5, and Section 6 concludes the paper.
2. Preliminaries and Background
In the following we review the main tools and framework used in this work: In Section 2.1 we detail the notations, and in Section 2.2 we review the basics of cyclostationary processes and the statistical properties of a DT process resulting from sampling a CT WSCS process. In Section 2.3 we recall some preliminaries of rate-distortion theory as well as the RDF for DT WSCS Gaussian source processes. This background creates a premise for the statement of the main result provided in Section 4 of this paper.
2.1. Notations
In this paper, random vectors are denoted by boldface uppercase letters, e.g., ; boldface lowercase letters denote deterministic column vectors, e.g., . Scalar RVs and deterministic values are denoted via standard uppercase and lowercase fonts respectively, e.g., X and x. Scalar random processes are denoted with for CT and with for DT. Uppercase Sans-Serif fonts represent matrices, e.g., , and the element at the row and the column of is denoted with . We use to denote the absolute value, , to denote the floor function and , to denote the . denotes the Kronecker delta function: for and otherwise, and denotes the stochastic expectation. The sets of positive integers, integers, rational numbers, real numbers, positive numbers, and complex numbers are denoted by , , , , and , respectively. The cumulative distribution function (CDF) is denoted by and the probability density function (PDF) of a CT random variable (RV) is denoted by . We represent a real Gaussian distribution with mean and variance by the notation . All logarithms are taken to base-2, and . Lastly, for any sequence , , and positive integer , denotes the column vector .
2.2. Wide-Sense Cyclostationary Random Processes
Here, we review some preliminaries from the theory of cyclostationarity. We begin by recalling the definition of wide-sense cyclostationary processes for CT and for DT:
Definition 1
(CT wide-sense cyclostationary processes ([3] Section 3.2.1)). A scalar stochastic process is called WSCS if both its first-order and its second-order moments are periodic with respect to with some period .
Definition 2
(DT wide-sense cyclostationary processes ([2] Section 17.2)). A scalar stochastic process is called WSCS if both its first-order and its second-order moments are periodic with respect to with some period .
WSCS signal are thus random processes whose first and second-order moments are periodic functions with the same period. To define WSACS signals, we first recall the definition of almost-periodic functions:
Definition 3
(Almost-periodic functions ([19] Definition 2.1)). A DT function , , is called an almost-periodic function if for every there exists a number with the property that for any and any , , such that
Definition 4
(DT wide-sense almost-cyclostationary processes ([2] Section 17.2)). A scalar stochastic process is called WSACS if its first and its second order moments are almost-periodic functions with respect to .
Remark 1.
Note that when the mean and the autocorrelation function are each periodic with periods which are incommensurate, the resulting processes is WSACS. We note that in many practical cases the mean is zero, see e.g., ([2] Section 17.2), hence the classification of the process will be determined by the periodicity of the autocorrelation function.
The DT WSCS model is commonly used in the communications literature, as it facilitates the the analysis of many problems of interest, such as fundamental rate limits analysis [20,21,22], channel identification [23], synchronization [24], and noise mitigation [25]. However, in many scenarios, the considered signals are WSACS rather than WSCS. To see how the WSACS model is obtained in the context of sampled signals, we briefly recall the discussion in [17] on sampled WSCS processes (please refer to ([17] Section II.B) for more details): Consider a CT WSCS random process , which is sampled uniformly with a sampling interval of and sampling time offset , resulting in a DT random process . It is well known that contrary to stationary processes, which have a time-invariant statistical characteristics, the values of and have a significant effect on the statistics of sampled WSCS processes ([17] Section II.B). To demonstrate this point, consider a CT WSCS process with variance for some . The sampled process for (no sampling time offset) and has a variance function whose period is : , for ; while the DT process obtained with the same sampling interval and with a sampling time offset of has a periodic variance with with values , for , which are different from the values of the DT variance for . It follows that both variances are periodic in discrete-time with the same period , although with different values within the period, which is a result of the sampling time offset, yet, both DT processes correspond to two instances of synchronous sampling. Lastly, consider the sampled variance obtained by sampling without a time offset (i.e., ) at a sampling interval of . For this case, is not an integer divisor of or of any of its integer multiples (i.e., ; where and ) resulting in the variance values , for . For this scenario, the DT variance is not periodic but is almost-periodic, corresponding to asynchronous sampling and the resulting DT process is not WSCS but WSACS ([3] Section 3.2). The example above demonstrates that the statistical properties of sampled WSCS processes depend on the sampling rate and the sampling time offset, implying that the RDF of such processes should also depend on these quantities, as we demonstrate in the sequel.
2.3. The Rate-Distortion Function for DT WSCS Processes
In this subsection we review the source coding problem and the existing results on the RDF of WSCS processes. We begin by recalling the definition of a source coding scheme, see, e.g., ([26] Chapter 30), ([5] Chapter 10):
Definition 5
(Source coding scheme). A source coding scheme with blocklength l consists of (see Figure 1):
- 1.
- An encoderwhich maps a block of l source samplesinto an index from a set ofindexes,.
- 2.
- A decoderwhich maps the received index into a reconstructed sequence of length l,,
The encoder-decoder pair is referred to as ansource code, where R is the rate of the code in bits per source symbol, defined as:
The RDF characterizes the minimal average number of bits per source symbol, denoted , that can be used to encode a source process such that it can be reconstructed from its encoded representation with a recovery distortion not larger than ([5] Section 10.2). In the current work, we use the MSE distortion measure, which measures the distortion due to decoding a source symbol S into via . The distortion for a sequence of source samples decoded into a reproduction sequence is given by and the average distortion in decoding a random source sequence into a random reproduction sequence is defined as:
where the expectation in Equation (2) is taken with respect to the joint probability distributions on the source and its reproduction . Using Definition 5 we can now define the achievable rate-distortion pair for a source , as stated in the following definition ([10] Pg. 471):
Definition 6
(Achievable rate-distortion pair). A rate-distortion pair is achievable for a process if for any and for all sufficiently large l it is possible to construct an source code such that
and
Definition 7.
The rate-distortion functionis defined as the infimum of all achievable rates R for a given maximum allowed distortion D.
Definition 6 defines a rate-distortion pair to be achievable if the rate and the distortion constraints are satisfied using source codes with any sufficiently large blocklength. In the following lemma, which will be used to characterize the RDF of DT WSCS signals, we state that it is sufficient to consider only source codes whose blocklength is an integer multiple of some fixed positive integer:
Lemma 1.
Consider the processwith a finite and bounded variance. For a given maximum allowed distortion D, the optimal reproduction processis also the optimal reproduction process when restricted to using source codes whose blocklengths are integer multiples of some fixed positive integer r.
Proof.
The proof of the lemma is detailed in Appendix A. □
This lemma facilitates switching between multivariate and scalar representations of the source and the reproduction processes.
The RDF obviously depends on the distribution of the source . Thus, statistically different sources have different RDFs. However, when a source is scaled by some positive constant, the RDF of the scaled process with the MSE distortion can be inferred from that of the original source process, as stated in the following theorem:
Theorem 1.
Letbe a source process for which the rate-distortion pairis achievable under the MSE distortion. Then, for every, it holds that the rate-distortion pairis achievable for the scaled source.
Proof.
The proof of the theorem is detailed in Appendix B. □
Lastly, in the proof of our main result, we make use of the RDF for DT WSCS sources derived in ([12] Theorem 1), repeated below for ease of reference. Prior to the statement of the theorem, we recall that for blocklenghts which are integer multiples of , a WSCS process with period can be represented as an equivalent -dimensional process via the decimated component decomposition (DCD) ([2] Section 17.2). The power spectral density (PSD) of the process is defined as ([12] Section II):
where ([2] Section 17.2). We now proceed to the statement of ([12] Theorem 1):
Theorem 2.
([12] Theorem 1) Consider a zero-mean real DT WSCS Gaussian sourcewith memory, and letdenote the period of its statistics. The RDF is expressed as:
where,denote the eigenvalues of the PSD matrix of the process, which is obtained fromby applying the-dimensional DCD, and θ is selected such that
We note that corresponds to a vector of stationary processes whose elements are not identically distributed; hence the variance function is different for each scalar stationary process. Using ([12] Theorem 1), we can directly obtain the RDF for the special case of a DT memoryless WSCS Gaussian process. This is stated in the following corollary:
Corollary 1.
Letbe a zero-mean DT memoryless real WSCS Gaussian source with period, and setfor. The RDF for compression ofis expressed as:
where, and θ is defined such that
Proof.
Applying Equations (6a) and (6b) to our specific case of a memoryless WSCS source, we obtain Equations (7a) and (7b) as follows: First, note that the corresponding DCD components for a zero-mean memoryless WSCS process are also zero-mean and memoryless; hence the PSD matrix for the multivariate process is a diagonal matrix, whose eigenvalues are the constant diagonal elements such that the mth diagonal element is equal to the variance : . Now, writing Equation (6a) for this case we obtain:
Now, from Lemma 1, we conclude that the RDF for compression of source sequences whose blocklength is an integer multiple of is the same as the RDF for compressing source sequences whose blocklength is arbitrary. We recall that from ([5] Chapter 10.3.3) it follows that for the zero-mean memoryless Gaussian DCD vector source process the optimal reproduction process which achieves the RDF is an memoryless process whose covariance matrix is diagonal with non-identically distributed elements. From [2], we can apply the inverse DCD to obtain a WSCS process. Hence, from Lemma 1 we can conclude that the optimal reproduction process for the DT WSCS Gaussian source is a DT WSCS Gaussian process.
3. Problem Formulation and Auxiliary Results
Our objective is to characterize the RDF for compression of asynchronously sampled CT WSCS Gaussian sources when the sampling interval is larger than the memory of the source. In particular, we focus on the minimal rate required to achieve a high fidelity reproduction, representing the RDF curve for distortion values not larger than the variance of the source. Such characterization of the RDF for asynchronous sampling is essential for comprehending the relationship between the minimal required number of bits and the sampling rate at a given distortion. Our analysis constitutes an important step towards constructing joint source-channel coding schemes for scenarios in which the symbol rate of the transmitter is not necessarily synchronized with the sampling rate of the source to be transmitted. Such scenarios arise, for example, when recording a communications signal for storage or processing, or in compress-and-forward relaying (([26] Chapter 16.7), [27]) in which the relay compresses the sampled received signal, which is then forwarded to the assisted receiver. As the relay operates with its own sampling clock, which need not necessarily be synchronized with the symbol rate of the assisted transmitter, sampling at the relay may result in a DT WSACS source signal. In the following we first characterize the sampled source model in Section 3.1. Then, as a preliminary step towards our characterization the RDF for asynchronously sampled CT WSCS Gaussian processes stated in Section 4, we recall in Section 3.2 the definitions of some information-spectrum quantities used in this study. Finally, in Section 3.3, we recall an auxiliary result relating the information-spectrum quantities of a collection of sequences of RVs to the information-spectrum quantities of its limit sequence of RVs. This result will be applied in the derivation of the RDF with asynchronous sampling.
3.1. Source Model
Consider a real CT, zero-mean WSCS Gaussian random process with period . Let the variance function of be defined as , and assume it is both upper bounded and lower bounded away from zero, and that it is continuous in . Let denote the maximal correlation length of , i.e., . By the cyclostationarity of , we have that . Let be sampled uniformly with the sampling interval such that for and yielding , where . The variance of is given by .
In this work, as in [17], we assume that the duration of temporal correlation of the CT signal is shorter than the sampling interval , namely, . Consequently, the DT Gaussian process is a memoryless zero-mean Gaussian process and its autocorrelation function is given by:
While we do not explicitly account for sampling time offsets in our definition of the sampled process , it can be incorporated by replacing with a time-shifted version, i.e., , see also ([17] Section II.C).
It can be noted from (10) that if is a rational number, i.e., , u and v are relatively prime, such that , then is a DT memoryless WSCS process with the period ([17] Section II.C). For this class of processes, the RDF can be obtained from ([12] Theorem 1) as stated in Corollary 1. On the other hand, if is an irrational number, then sampling becomes asynchronous and leads to a WSACS process whose RDF has not been characterized to date.
3.2. Definitions of Relevant Information-Spectrum Quantities
Conventional information theoretic tools for characterizing RDFs are based on an underlying ergodicity of the source. Consequently, these techniques cannot be applied to characterize the RDF of asynchronously sampled WSCS processes. To tackle this challenge, we use the information-spectrum framework, as this framework [14] can be utilized to obtain general formulas for rate limits for any arbitrary class of processes. The resulting expressions are not restricted to specific statistical models of the considered processes, and in particular, do not require information stability or stationarity. In the following, we recall the definitions of several information-spectrum quantities used in this study, see also ([14] Definitions 1.3.1 and 1.3.2):
Definition 8.
The limit-inferior in probability of a sequence of real RVsis defined as
Hence, is the largest real number satisfying that and there exists such that , .
Definition 9.
The limit-superior in probability of a sequence of real RVsis defined as
Hence, is the smallest real number satisfying that and , there exists , such that , .
The notion of uniform integrability of a sequence of RVs is a basic property in probability ([28] Chapter 12), which is not directly related to information spectrum methods. However, since it plays an important role in the information spectrum characterization of RDFs, we include its statement in the following definition:
Definition 10
The aforementioned quantities facilitate characterizing the RDF of arbitrary sources. Consider a general source process (stationary or non-stationary) taking values from the source alphabet and a reproduction process with values from the reproduction alphabet . It follows from ([14] Section 5.5) that for a distortion measure which satisfies the uniform integrability criterion, i.e., that there exists a deterministic sequence such that the sequence of RVs satisfies Definition 10 ([14] Page 336), then the RDF is expressed as ([14] Equation (5.4.2)):
where , denotes the joint CDF of and , and represents the limit superior in probability of the mutual information rate of and , given by:
In order to use the RDF characterization in (14), the distortion measure must satisfy the uniform integrability criterion. For the considered class of sources detailed in Section 3.1, the MSE distortion satisfies this criterion, as stated in the following lemma:
Lemma 2.
For any real memoryless zero-mean Gaussian sourcewith bounded variance, i.e.,such thatfor all, the MSE distortion satisfies the uniform integrability criterion.
Proof.
Set the deterministic sequence to be the all-zero sequence. Under this setting and the MSE distortion, it holds that . To prove the lemma, we show that the sequence of RVs has a bounded norm, which implies that it is uniformly integrable by ([28] Corollary 12.8). The norm of satisfies
where follows since for while ([29] Chapter 5.4). Equation (16) proves that is -bounded by for all , which in turn implies that the MSE distortion is uniformly integrable for the source . □
Since, as detailed in Section 3.1, we focus in the following on memoryless zero-mean Gaussian sources, Lemma 2 implies that the RDF of the source can be characterized using (14). However, (14) is in general difficult to evaluate, and thus does not lead to a meaningful understanding of how the RDF of sampled WSCS sources behaves, motivating our analysis in Section 4.
3.3. Information Spectrum Limits
The following theorem originally stated in ([17] Theorem 1) presents a fundamental result which is directly useful for the derivation of the RDF:
Theorem 3.
([17] Theorem 1) Letbe a set of sequences of real scalar RVs satisfying two assumptions:
- AS1
- For every fixed, every convergent subsequence ofconverges in distribution, as, to a finite deterministic scalar. Each subsequence may converge to a different scalar.
- AS2
- For every fixed, the sequenceconverges uniformly in distribution, as, to a scalar real-valued RV. Specifically, lettingand,, denote the CDFs ofand of, respectively, then by AS2 it follows that, there existssuch that for everyfor each,.
Then, forit holds that
Proof.
In Appendix C we explicitly prove Equation (17b). This complements the proof in ([17] Appendix A) which explicitly considers only (17a). □
4. Rate-Distortion Characterization for Sampled CT WSCS Gaussian Sources
4.1. Main Result
Using the information-spectrum based characterization of the RDF (14) combined with the characterization of the limit of a sequence of information spectrum quantities in Theorem 3, we now analyze the RDF of asynchronously sampled WSCS processes. Our analysis is based on constructing a sequence of synchronously sampled WSCS processes, whose RDF is given in Corollary 1. Then, we show that the RDF of the asynchronously sampled process can be obtained as the limit superior of the computable RDFs of the sequence of synchronously sampled processes. We begin by letting for and defining a Gaussian source process . From the discussion in Section 3.1 (see also ([17] Section II.C)), it follows that since is rational, is a WSCS process and its period is given by . Accordingly, the periodic correlation function of can be obtained similarly to (10) as:
Due to cyclostationarity of , we have that , , and we let denote its periodic variance.
We next restate Corollary 1 in terms of as follows:
Proposition 1.
Consider a DT, memoryless, zero-mean, WSCS Gaussian random processwith a variance, obtained fromby sampling with a sampling interval of. Letdenote the memoryless stationary multivariate random process obtained by applying the DCD toand let,, denote the variance of thecomponent of. The rate-distortion function is given by:
where forwe let, andis selected such that
We recall that the RDF of is characterized in Proposition 1 via the RDF of the multivariate stationary process obtained via a -dimensional DCD applied to . Next, we recall that the relationship between the source process and the optimal reconstruction process, denoted by , is characterized in ([5] Chapter 10.3.3) via a linear, multivariate, time-invariant backward channel with a additive vector noise process , and is given by:
It also follows from ([5] Section 10.3.3) that for the IID Gaussian multivariate process whose entries are independent and distributed via , , the optimal reconstruction vector process and the corresponding noise vector process each follow a multivariate Gaussian distribution:
where ; denotes the reverse waterfilling threshold defined in Prop. 1 for the index n, and is selected such that . The optimal reconstruction process, and the noise process are mutually independent, and for each it holds that , see ([5] Chapters 10.3.2 and 10.3.3). The multivariate relationship between stationary processes in (20) can be transformed into an equivalent linear relationship between cyclostationary Gaussian memoryless processes via the inverse DCD transformation ([2] Sec 17.2) applied to each of the processes, resulting in:
We are now ready to state our main result, which is the RDF of asynchronously sampled DT sources , in the low MSE regime, i.e., when the distortion D is not larger than the source variance. The RDF is stated in the following theorem, which applies to both synchronous sampling as well as to asynchronous sampling:
Theorem 4.
Consider a DT sourceobtained by sampling a CT WSCS source, whose period of statistics is, at intervals. Then, for any distortion constraint D such thatand any, the RDFfor compressingcan be obtained as the limit:
whereis defined Prop. 1.
Proof.
The detailed proof is provided in Appendix D. Here, we give a brief outline: The derivation of the RDF with asynchronous sampling follows three steps: First, we note that sampling at a rate of results in a sequence of DT WSCS sources whose sampling interval asymptotically approaches, as , the sampling interval for irrational given by . We define a sequence of rational numbers as ; Building upon this insight, we prove that the RDF with can be stated as a double limit where the outer limit is with respect to the blocklength and the inner limit is with respect to . Lastly, we use Theorem 3 to show that the order of the limits can be exchanged, obtaining a limit of expressions which are computable. □
Remark 2.
Theorem 4 focuses on the low distortion regime, defined as the values of D satisfying. This implies thathas to be smaller than; hence, from Prop. 1 it follows that for the corresponding stationary noise vectorin (20),and. We note that since every element of the vectorhas the same variancefor allandthen by applying the inverse DCD to, the resulting scalar DT processis wide sense stationary; and in fact IID with.
4.2. Discussion and Relationship with Capacity Derivation in Reference 17
Theorem 4 provides a meaningful and computable characterization for the RDF of sampled WSCS signals. We note that the proof of the main theorem uses some of the steps used in our recent study on the capacity of memoryless channels with sampled CT WSCS Gaussian noise [17]. It should be emphasized, however, that there are several fundamental differences between the two studies, which require the introduction of new treatments and derivations original to the current work. First, it is important to note that in the study on capacity, a physical channel model exists, and therefore the conditional PDF of the output signal given the input signal can be characterized explicitly for both synchronous sampling and asynchronous sampling for every input distribution. For the current study of the RDF we note that the relationship (21), commonly referred to as the backward channel [30], ([5] Chapter 10.3.2), characterizes the relationship between the source process and the optimal reproduction process, and hence is valid only for synchronous sampling and for the optimal reproduction process. Consequently, in the RDF analysis the limiting relationship (21) as is not even known to exist and, in fact, we can show it exists under a rather strict condition on the distortion (namely, the condition stated in Theorem 4). In particular, to prove the statement in Theorem 4, we had to show that from the backward channel (21), we can define an asymptotic relationship, as , which corresponds to the asynchronously sampled source process, denoted by , and relates with its optimal reconstruction process . This is done by showing that the PDFs for the reproduction process and noise process from (21), each converge uniformly as to a respective limiting PDF, which has to be defined as well. This enabled us to relate the RDFs for the synchronous sampling and for the asynchronous sampling cases using Theorem 3, eventually leading to (22). Accordingly, in our detailed proof of Theorem 4 given in Appendix D, Lemmas A6 and A8 as well as a significant part of Lemma A4 are largely new, addressing the special aspects of the proof arising from the fundamental differences between current setup and the setup in [17], while the derivations of Lemmas A3 and A7 follow similarly to ([17] Lemma B.1) and ([17] Lemma B.5), respectively, and parts of Lemma A4 coincide with ([17] Lemma B.2).
5. Numerical Examples
In this section we demonstrate the insights arising from our RDF characterization via numerical examples. Recalling that Theorem 4 states the RDF for asynchronously sampled CT WSCS Gaussian process, , as the limit supremum of a sequence of RDFs corresponding to DT memoryless WSCS Gaussian source processes , we first consider the convergence of in Section 5.1. Next, in Section 5.2 we study the variation of the RDF of the sampled CT process due to changes in the sampling rate and in the sampling time offset.
Similarly to ([17] Section IV), define a periodic continuous pulse function, denoted by , with equal rise/fall time , duty cycle , and period of 1, i.e., for all . Specifically, for the function is given by
In the following, we model the time varying variance of the WSCS source to be a linear periodic function of . To that aim, we define a time offset between the first sample and the rise start time of the periodic continuous pulse function; we denote the time offset by . This corresponds to the sampling time offset normalized to the period . The variance of is a periodic function with period which is defined as
with a period of secs.
5.1. Convergence of in n
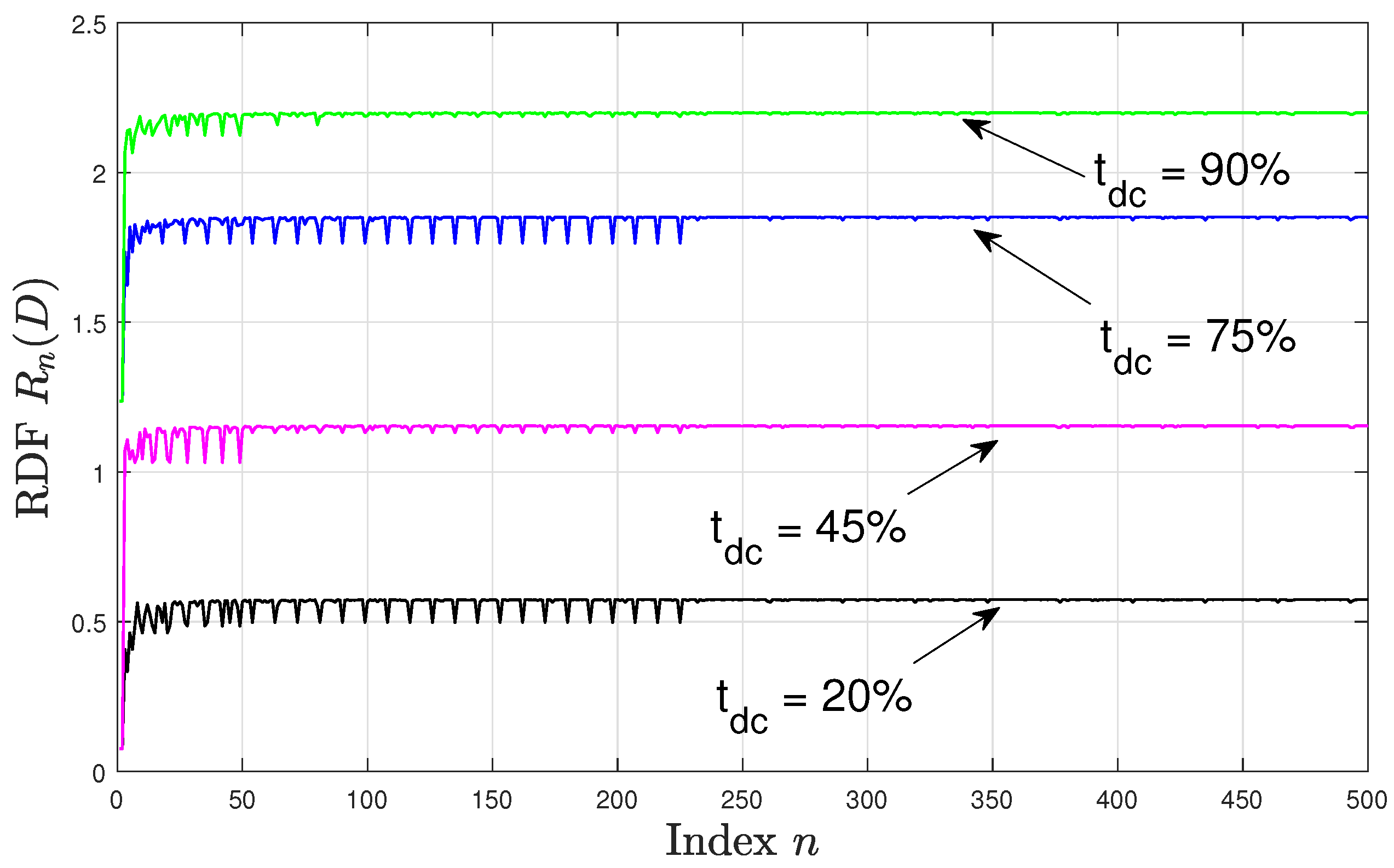
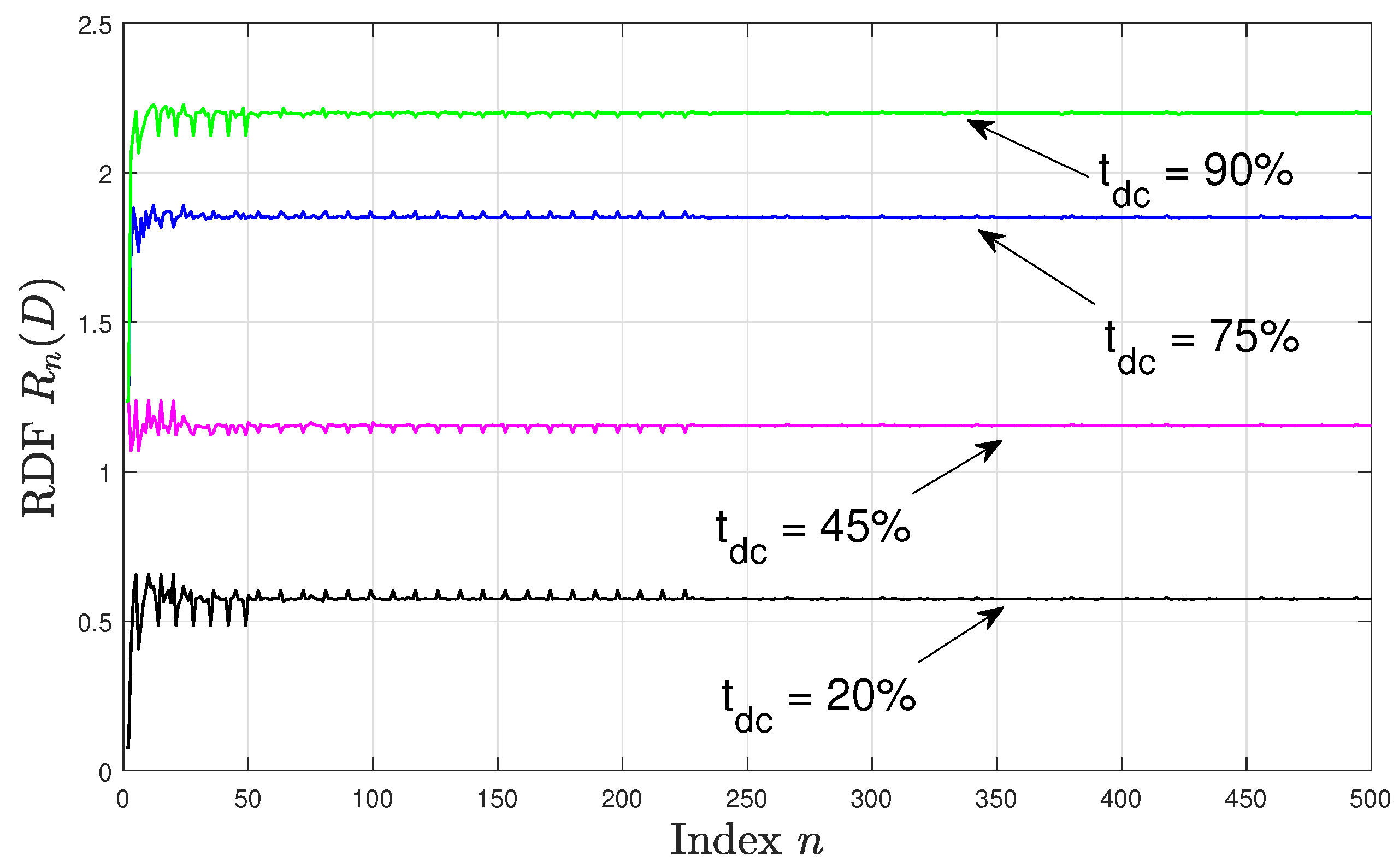
From Theorem 4 it follows that if the distortion satisfies , the RDF of the asynchronously sampled CT WSCS Gaussian process is given by the limit superior of the sequence ; where is defined in Proposition 1. In this subsection, we study the sequence of RDFs as n increases. For this evaluation setup, we fixed the distortion constraint at and set and . Let the variance of the CT WSCS Gaussian source process be modelled by Equation (24) for two sampling time offsets . For each offset , four duty cycle values were considered: . For each n we obtain the synchronous sampling mismatch , which approaches as , where . Since is a rational number, corresponding to a sampling period of , then for each n, the resulting dt process is WSCS with the period and its RDF follows from Proposition 1.
Figure 2 and Figure 3 depict for with the specified duty cycles and sampling time offsets, where in Figure 2 there is no sampling time offset, i.e., , and in Figure 3 the sampling time offset is set to . We observe that in both figures the RDF values are higher for higher . This can be explained by noting that for higher values, the resulting time-averaged variance of the DT source process increases, hence, a higher number of bits per source sample is required to encode the source process maintaining the same distortion value. Moreover, in all configurations, varies significantly for smaller values of n. Comparing Figure 2 and Figure 3, we see that the pattern of these variations depends on the sampling time offset . For example, when at , then for the rdf varies in the range bits per source sample, while for the RDF varies in the range bits per source sample. However, as n increases above 230, the variations in become smaller and are less dependent on the sampling time offset, and the resulting values of are approximately in the same range for each in both Figure 2 and Figure 3 for . This behaviour can be explained by noting that as n varies, the period also varies and hence the statistics of the DT variance differs over its respective period. This consequently affects the resulting RDF (especially for small periods). As n increases approaches the asynchronous sampling mismatch and the period takes a sufficiently large value such that the samples of the DT variance over the period are identically distributed irrespective of the value of ; leading to a negligible variation in the RDF as seen in the above figures.
5.2. The Variation of the RDF with the Sampling Rate
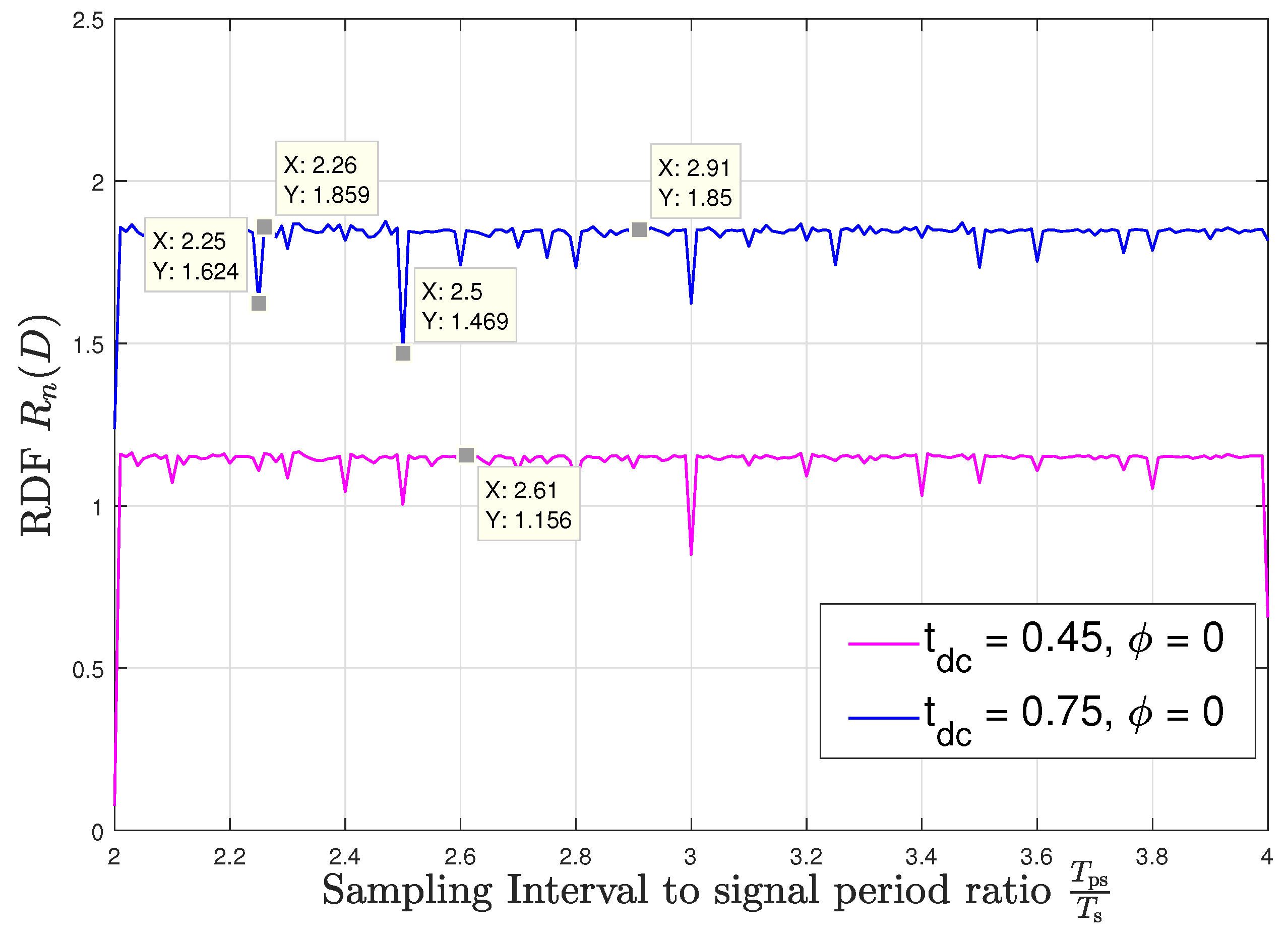
Next, we observe the dependence of the RDF for the sampled memoryless WSCS Gaussian process on the value of the sampling interval . For this setup, we fix the distortion constraint to and set the duty cycle in the source process (24) to . Figure 4 and Figure 5 demonstrate the numerically evaluated values for at sampling intervals in the range with the sampling time offsets and , respectively. We note that while the discussion which follows focuses on this range, as it corresponds to relatively low sampling rates—which are typically preferable in practice, the statements and observations regarding the relationship between the denominator of and the value of , and regarding the continuity the RDF in the parameter , are directly applicable to any range of values of , e.g., when higher sampling rates are preferable. A very important insight which arises from the figures is that the sequence of RDFs is not convergent; hence, for example, one cannot approach the RDF for by simply taking rational values of which approach . This verifies that the RDF for asynchronous sampling cannot be obtained by straightforward application of previous results, and indeed, the entire analysis carried out in the manuscript is necessary for the desired characterization.
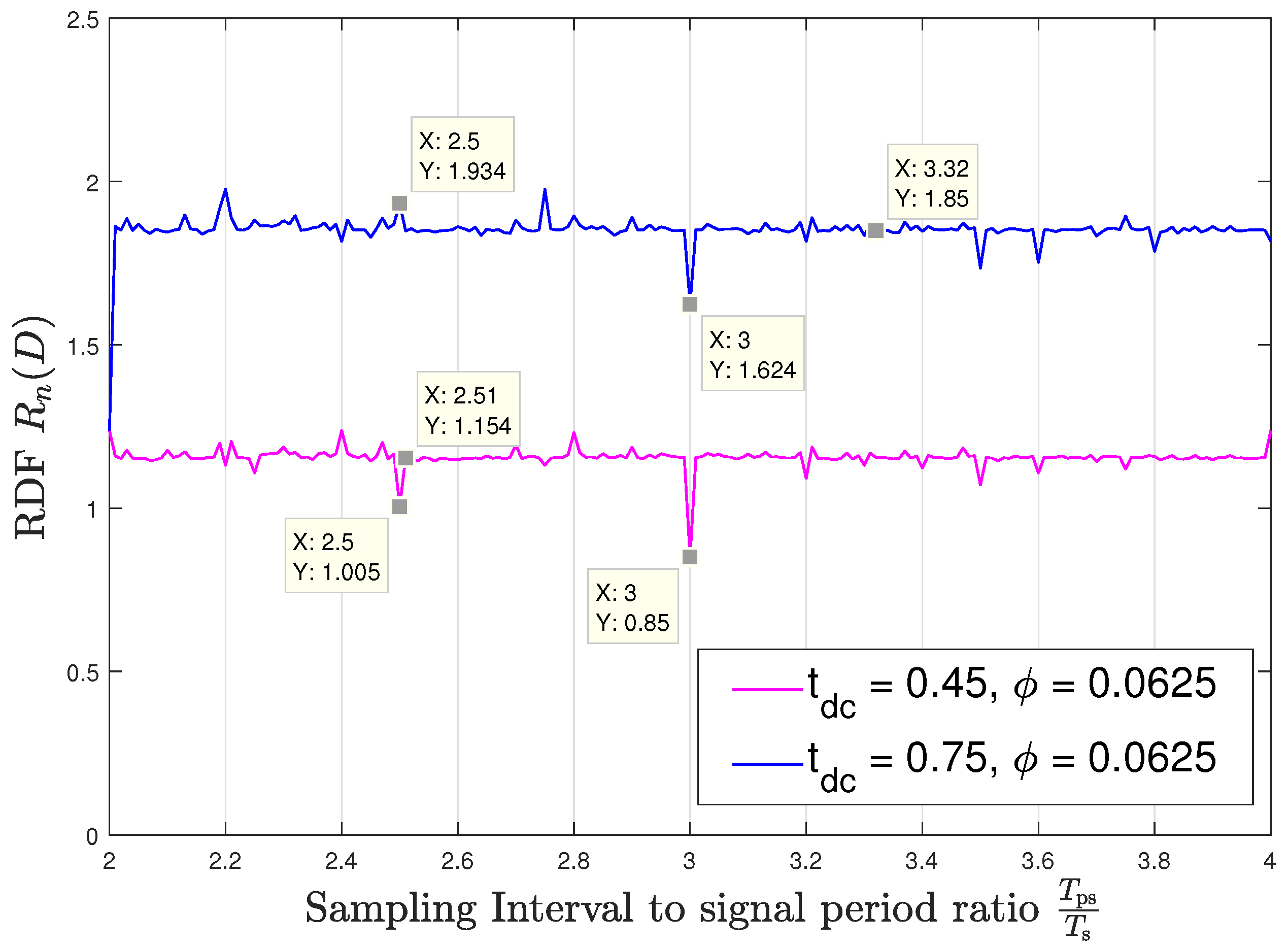
We observe in Figure 4 and Figure 5 that when has a fractional part with a relatively small integer denominator, the variations in the RDF are significant and depend on the sampling time offset. These variations can either degrade the ability to accurately represent the source, which are the observed peaks in Figure 4 and Figure 5, or alternatively, allow to encode the signal to within the same distortion with smaller code rates, corresponding to the deeps in these figures. However, when approaches an irrational number, the period of the sampled variance function becomes very long, and consequently, the RDF is approximately constant and independent of the sampling time offset. As an example, consider and : For sampling time offset the rdf takes a value of bits per source sample, as shown in Figure 4 while for the offset of the RDF peaks to bits per source sample as can be seen in Figure 5. On the other hand, when approaching asynchronous sampling, the RDF takes a nearly constant value of bits per source sample for all the considered values of and this value is invariant to the offset . This follows since when the denominator of the fractional part of increases, then the DT period of the resulting sampled variance, , increases and practically captures the entire set of values of the CT variance regardless of the sampling time offset. In a similar manner as with the study on capacity in [17], we conjecture that since asynchronous sampling captures the entire set of values of the CT variance, the respective RDF represents the RDF of the analog source, which does not depend on the specific sampling rate and offset. Figure 4 and Figure 5 demonstrate how slight variations in the sampling rate can result in significant changes in the RDF. For instance, at we observe in Figure 4 that when the sampling rate switches from to , i.e., the sampling rate switches from being synchronous to being nearly asynchronous, then the RDF changes from bits per source sample to bits per source sample for ; also, we observe in Figure 5 for , that when the sampling rate switches from to , i.e., the sampling rate also switches from being synchronous to being nearly asynchronous, then the rdf changes from bits per source sample to bits per source sample.
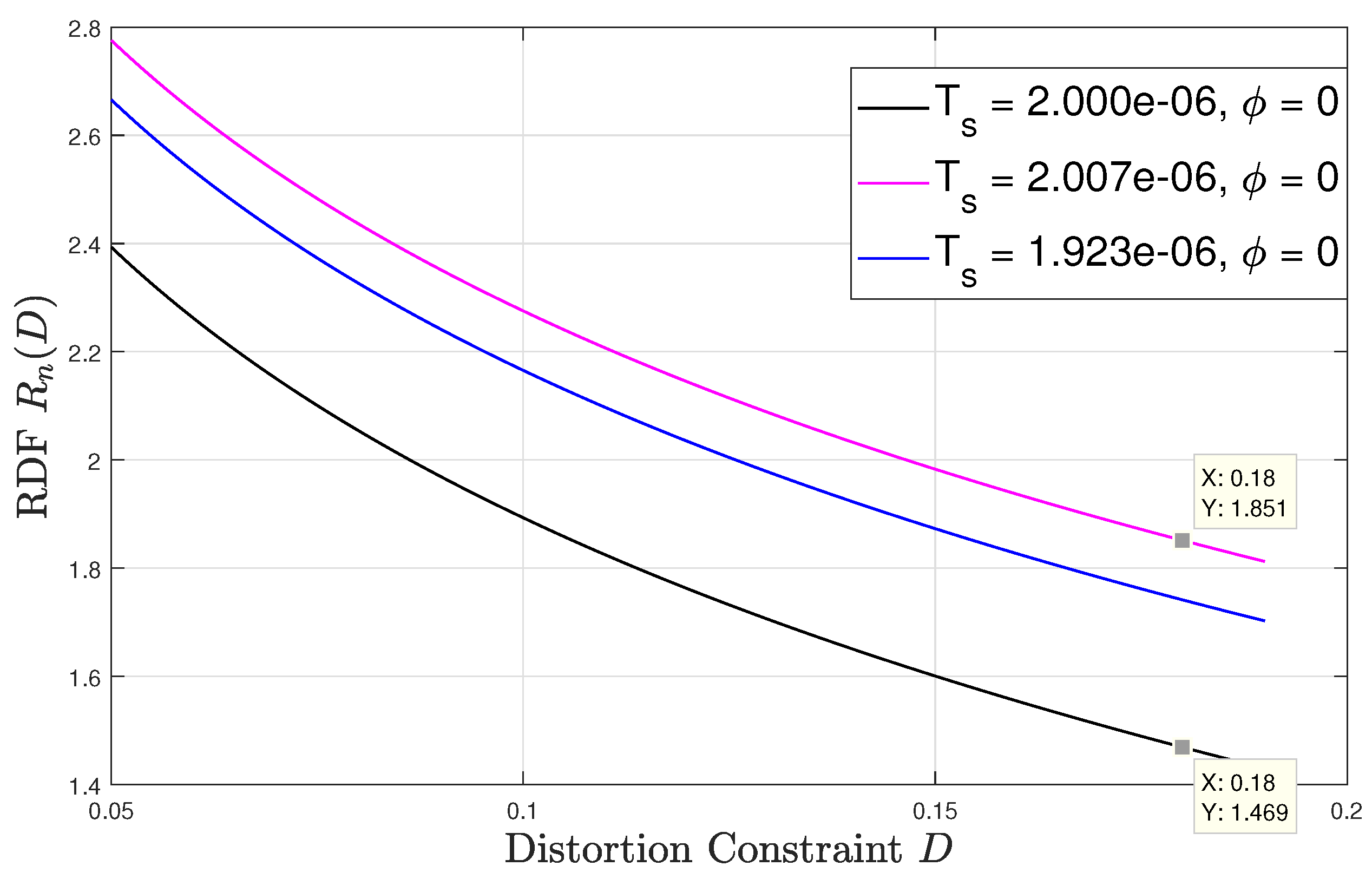
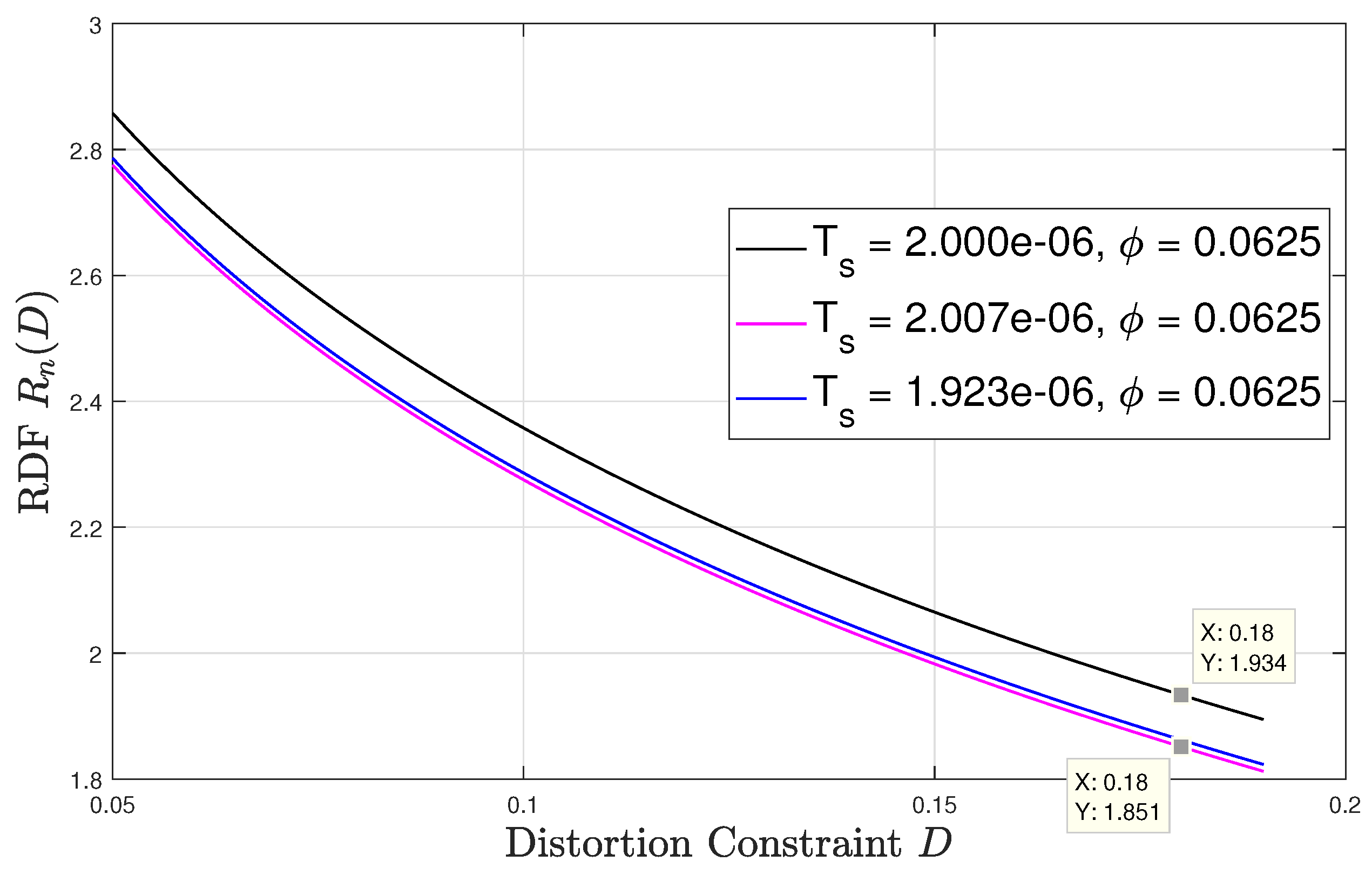
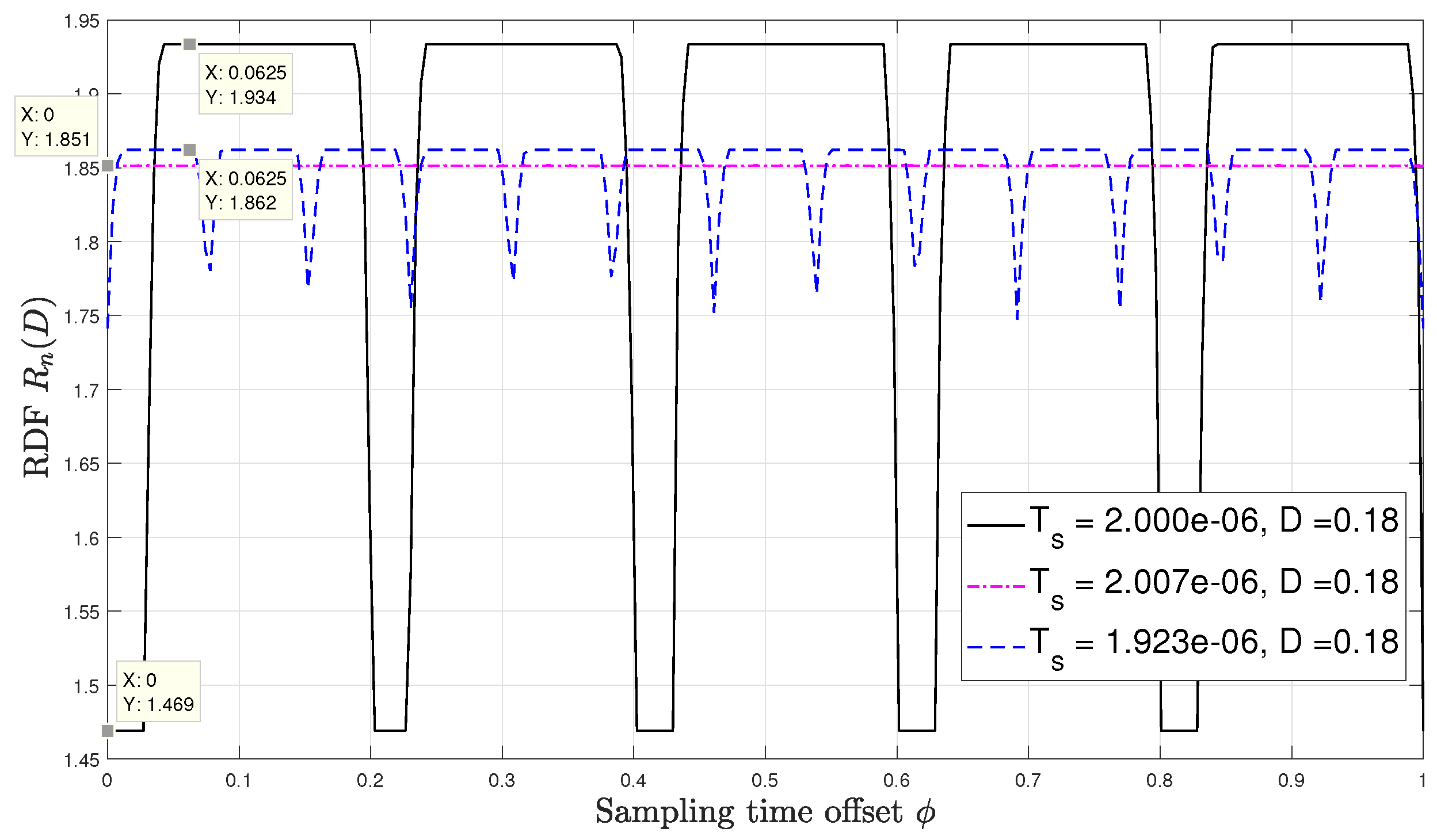
Lastly, Figure 6 and Figure 7 numerically evaluate the RDF versus the distortion constraint for sampling time offsets of 0 and respectively. At each , the result is evaluated at three different values of synchronization mismatch . For this setup, we fix , and . The only mismatch value that refers to the asynchronous sampling case is and its corresponding sampling interval is approximately secs, which is a negligible variation from the sampling intervals corresponding to , which are secs and secs, respectively. Observing both figures, we see that the rdf may vary significantly for very slight variation in the sampling rate. For instance, as shown in Figure 6 for , at , a slight change in the synchronization mismatch from (i.e., secs) to (i.e., secs) results to approximately decrease in the rdf. For the same change in the sampling synchronization mismatch at results in an increase in the RDF by roughly . These results demonstrate the unique and counter-intuitive characteristics of the RDF of sampled WSCS signals which arise from our derivation. It is also interesting to examine how the RDF varies with the sampling time offset . To that aim we plot in Figure 8 the RDF vs. for the three sampling rates used in Figure 6 and Figure 7 at . The points marked on the plot correspond to and considered in Figure 6 and Figure 7, respectively. We observe that the RDF is indeed periodic with . These variations in the RDF occur as by changing the number of high variance samples within a period of the variance of the DT process changes due to the duty cycle of the CT variance. Then, at the periodic variance of the DT process corresponding to has the smallest number of high variance values within a period, and when the periodic variance of the DT process corresponding to asynchronous sampling has the smallest number of high variance values within a period. For the asynchronous sampling rate the sampling time offset does not matter as in any case (nearly) all values of the CT variance are reflected in the variance of the DT process.
6. Conclusions
In this work the RDF of a sampled CT WSCS Gaussian source process was characterized for scenarios in which the resulting DT process is memoryless and the distortion is relatively small. This characterization shows the relationship between the sampling rate and the minimal number of bits per source sample required for compression at a given distortion. For cases in which the sampling rate is synchronized with the period of the statistics of the source process, the resulting DT process is WSCS and standard information theoretic framework can be used for deriving its RDF. For asynchronous sampling, information stability does not hold, and hence we resort to the information spectrum framework to obtain a characterization. To that aim we derived a relationship between some relevant information spectrum quantities for uniformly convergent sequences of RVs. This relationship was further applied to characterize the RDF of an asynchronously sampled CT WSCS Gaussian source process as the limit superior of a sequence of RDFs, each corresponding to the synchronous sampling of the CT WSCS Gaussian process. The results were derived in the low distortion regime, i.e., under the condition that the distortion constraint D is less than the minimum variance of the source, and for sampling intervals which are larger than the correlation length of the CT process. Our numerical examples give rise to non-intuitive insights which follow from the derivations. In particular, the numerical evaluation demonstrates that the RDF for a sampled CT WSCS Gaussian source can change dramatically with minor variations in the sampling rate and the sampling time offset. In particular, when the sampling rate switches from being synchronous to being asynchronous and vice versa, the RDF may change considerably as the statistical model of the source switches between WSCS and WSACS. The resulting analysis enables determining the sampling system parameters in order to facilitate accurate and efficient source coding of acquired CT signals.
Author Contributions
Conceptualization, E.A., N.S. and R.D.; Methodology, E.A., N.S. and R.D.; Derivation, E.A., N.S. and R.D.; Writing—original draft preparation, E.A., N.S. and R.D.; writing—review and editing, E.A., N.S. and R.D.; Supervision, N.S. and R.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Israel Science Foundation under Grants 1685/16 and 0100101, and by the Israeli Ministry of Economy through the HERON 5G consortium.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Lemma 1
Proof.
To prove that the minimum achievable rate at a given maximum distortion for a code with arbitrary blocklength can be achieved by considering only codes whose blocklength is an integer multiple of r, we apply the following approach: We first show that every rate-distortion pair achievable when restricted to using source codes whose blocklength is an integer multiple of r is also achievable when using arbitrary blocklenghts; We then prove that every achievable rate-distortion pair is also achievable when restricted to using codes whose blocklength is an integer multiple of r. Combining these two assertions proves that the rate-distortion function of the source can be obtained when restricting the blocklengths to be an integer multiple of r. Consequently, a reproduction signal which achieves the minimal rate for a given D under the restriction to use only blocklengths which are an integer multiple of r is also the reproduction signal achieving the minimal rate without this restriction, and vice versa, thus proving the lemma.
To prove the first assertion, consider a rate-distortion pair which is achievable when using codes whose blocklength is an integer multiple of r. It thus follows directly from Definition 6 that for every , such that for all there exists a a source code with rate satisfying . We now show that we can construct a code with an arbitrary blocklength where (i.e., the blocklength l is not an integer multiple of r) satisfying Definition 6 for all as follows: Apply the code to the first samples of and then concatenate each codeword by j zeros to obtain a source code having codewords of length . The average distortion (i.e., see (2)) of the resulting code is given by:
Thus, such that and hence, for all
The rate satisfies:
Consequently, any rate-distortion pair achievable with codes whose blocklength is an integer multiple of r can be achieved by codes with arbitrary blocklengths.
Next, we prove that any achievable rate-distortion pair can be achieved by codes whose blocklength is an integer multiple of r. To that aim, we fix . By Definition 6, it holds that there exists a code of blocklength l satisfying (3) and (4). To show that is achievable using codes whose blocklength is an integer multiple of r, we assume here that l is not an integer multiple of r, hence, there exist some positive integers b and j such that and . We denote this code by . It follows from Definition 6 that and . Next, we construct a code with codewords whose length is , i.e., an integer multiple of r, by adding zeros at the end of each codeword of the code . The average distortion can now be computed as follows:
Thus, since the variance is finite and bounded, such that for all . Hence, for all
The rate can be expressed as follows:
It follows that for any arbitrary by selecting a sufficiently large b. This proves that every rate-distortion pair achievable with arbitrary blocklengths (e.g., ) is also achievable when considering source codes whose blocklength is an integer multiple of r (i.e., ). This concludes the proof. □
Appendix B. Proof of Theorem 1
Recall that . To prove the theorem, we fix a rate-distortion pair that is achievable for the source . By Definition 6 this implies that for all there exists such that for all there exists a source code with rate and MSE distortion , where denotes the norm of a vector. Next, we use the code to define the source code , which operates in the following manner: The encoder first scales its input block by . Then, the block is encoded using the source code . Finally, the selected codeword is scaled by . Since the has the same number of codewords and the same blocklength as , it follows that its rate, denote , satisfied . Furthermore, by the construction of , it holds that its reproduction vector when applied to is equal to the output of applied to scaled by , i.e., . Consequently, the MSE of when applied to the source , denoted , satisfies .
It thus follows that for all there exists such that for all there exists a code with rate which achieves an MSE distortion of when applied to the compression of . Hence, is achievable for compression of by Definition 6, proving the theorem.
Appendix C. Proof of Theorem 3
In this appendix, we prove (17b) by applying a similar approach as used for proving (17a) in ([17] Appendix A). We first note that Definition 9 can also be written as follows:
For the equality , we note that the set of probabilities is non-negative and bounded in ; hence, for any for which , it also holds from ([31] Theorem 3.17) that the limit of any subsequence of is also 0, since non-negativity of the probability implies . Then, combined with the relationship , we conclude:
where follows from ([31] Example 3.18(c)). This implies exists and is equal to 0.
In the opposite direction, if then it follows from ([31] Example 3.18(c)) that . Next, we note that since is bounded in then is finite , even if does not exist. Equality follows since which according to ([32] Theorem 7.3.7) is equal to . By ([33] Chapter 1, page 29), this quantity is also equal to .
Next, we state the following lemma:
Lemma A1.
Given assumption AS2, for allit holds that
Proof.
To prove the lemma we first show that , and then we show . Recall that by AS2, for all and , converges as to , uniformly over k and , i.e., for all there exists , such that for every , and , it holds that . Consequently, for every subsequence such that exists for any , it follows from ([31] Theorem 7.11) that, as the convergence over k is uniform, the limits over n and l are interchangeable:
The existence of such a convergent subsequence is guaranteed by the Bolzano-Weierstrass theorem ([31] Theorem 2.42) as .
From the properties of the limit inferior ([31] Theorem 3.17) it follows that there exists a subsequence of , denoted , such that . Consequently,
where follows from (A9), and follows from the definition of the limit inferior ([31] Definition 3.16). Similarly, by ([31] Theorem 3.17), for any there exists a subsequence of which we denote by where satisfy , such that . Therefore,
where follows from (A9), and follows from the definition of the limit inferior ([31] Definition 3.16). Therefore, . Combining (A10) and (A11) proves (A8) in the statement of the lemma. □
Lemma A2.
Given assumptions AS1–AS2, the sequence of RVssatisfies
Proof.
Since by assumption AS1, for every , every convergent subsequence of converges in distribution as to a deterministic scalar, it follows that every convergent subsequence of converges as to a step function, which is the CDF of the corresponding sublimit of . In particular, the limit is a step function representing the CDF of the deterministic scalar , i.e.,
Since, by Lemma A1, AS2 implies that the limit exists (convergence to a discontinuous function is in the sense of ([31] Ex. 7.3)), then exists. Hence, we obtain that
and from the right-hand side of (A12) we have that
Next, from (A7) and (A13) we note that
Consequently, the left-hand side of (A12) is equal to . Combining with (A15) we arrive at the equality (A12) in the statement of the lemma. □
Substituting (A8) into (A7) results in
where follows from (A12). Equation (A16) concludes the proof for (17b).
Appendix D. Proof of Theorem 4
In this appendix we detail the proof of Theorem 4. The outline of the proof is given as follows:
- We first show in Appendix D.1 that for any , the PDF of the random vector , representing the first k samples of the CT WSCS source sampled at time instants , converges in the limit as and for any to the PDF of , which represents the first k samples of the CT WSCS source , sampled at time instants . We prove that this convergence is uniform in and in the realization vector . This is stated in Lemma A3.
- Next, in Appendix D.2 we apply Theorem 3 to relate the mutual information density rates for the random source vector and its reproduction with that of the random source vector and its reproduction . To that aim, let the functions and denote the joint distributions of an arbitrary dimensional source and reproduction vectors corresponding to the synchronously sampled and to the asynchronously sampled source process respectively. We define the following mutual information density rates:and. The RVs and in (A17) denote the mutual information density rates ([14] Definition 3.2.1) between the DT source process and the corresponding reproduction process for the case of synchronous sampling and for the case of asynchronous sampling, respectively.We then show that if the pairs of source process and optimal reproduction process and satisfy that uniformly with respect to and , and that uniformly in and , then uniformly in . In addition, Lemma A5 proves that every subsequence of k, indexed as converges in distribution, in the limit to a deterministic scalar.
- Lastly, in Appendix D.3 we combine the above results to show in Lemmas A7 and A8 that and respectively; implying that , which proves the theorem.
To facilitate our proof we will need uniform convergence in , of , and to , and , respectively. To that aim, we will make the following scaling assumption w.l.o.g.:
Assumption A1.
The variance of the source and the allowed distortion are scaled by some factorsuch that
Note that this assumption has no effect on the generality of the RDF for multivariate stationary processes detailed in ([5] Section 10.3.3), ([34] Section IV). Moreover, by Theorem 1, for every it holds that when any rate R achievable when compressing the original source with distortion not larger that D is achievable when compressing the scaled source with distortion not larger than . Note that if for the source the distortion satisfies , then for the scaled source and distortion we have .
Appendix D.1. Convergence in Distribution of to Uniformly with Respect to
In order to prove the uniform convergence in distribution, , uniformly with respect to , we first prove, in Lemma A3, that as the sequence of PDFs of , , converges to the PDF of , , uniformly in and in . Next, we show in Corollary A1 that uniformly in .
To that aim, let us define the set and consider the k- dimensional zero-mean, memoryless random vectors and with their respective diagonal correlation matrices expressed below:
Since it holds that ; therefore
Now we note that since is uniformly continuous, then by the definition of a uniformly continuous function, for each , the limit in (A20) implies that
From Assumption A1, it follows that satisfies ; Hence, we can state the following lemma:
Lemma A3.
The PDF of,, converges asto the PDF of,, uniformly inand in:
Proof.
The proof of the lemma directly follows from the steps in the proof of ([17] Lemma B.1), which was applied to random Gaussian processes with independent entries and variance larger than . □
Lemma A3 gives rise to the following corollary:
Corollary A1.
For anyit holds that, and convergence is uniform over k.
Proof.
The corollary holds due to ([35] Theorem 1): Since converges to then . In addition, since the convergence of the PDFs is uniform in , the convergence of the CDFs is also uniform in . □
Appendix D.2. Showing that and Satisfy the Conditions of Theorem 3
Let denote the joint distribution for the source process and the corresponding optimal reproduction process satisfying the distortion constraint D. We next prove that for , then and satisfy AS1–AS2. In particular, Lemma A4 proves that uniformly in for the optimal zero-mean Gaussian reproduction vectors with independent entries. Lemma A5 proves that for any fixed n, converges in distribution to a deterministic scalar as .
Lemma A4.
Letandbe two sets of mutually independent sequences ofzero-mean Gaussian random vectors related via the backward channel (20), each having independent entries and let PDFsand, respectively, denote their PDFs. Consider two other zero-mean Gaussian random vectorsandeach having independent entries with the PDFsand, respectively, such thatuniformly inand uniformly with respect to, anduniformly inand uniformly with respect to. Then, the RVsand, defined via (A17) satisfyuniformly over.
Proof.
To begin the proof, for , define
Now, we recall the backward channel relationship (20):
where and are mutually independent zero-mean, Gaussian random vectors with independent entries, corresponding to the optimal compression process and its respective distortion. From this relationship we obtain
where follows since , see (A23), and follows since and are mutually independent. The joint PDF of and can be expressed via the conditional PDF as:
where follows from (A24). Since and are Gaussian and mutually independent and since the product of two multivariate Gaussian PDFs is also a multivariate Gaussian PDF ([36] Section 3), it follows from (A25) that and are jointly Gaussian. Following the mutual independence of and , the right hand side (RHS) of (A25) is also equivalent to the joint PDF of denoted by . Now, from (A24), the assumption implies that a limit exists for the conditional PDF , this we denote by . Combining this with the assumption , we have that,
where follows from (A24), and follows since the limit for each sequence in the product exists ([31] Theorem 3.3); Convergence is uniform in and , as each sequence converges uniformly in ([31] Page 165). Observe that the joint PDF for the zero-mean Gaussian random vectors is given by the general expression:
where denotes the joint covariance matrix of . From (A27) we note that is a continuous mapping of with respect to the index n, see ([17] Lemma B.1). Hence the convergence in (A26) of as directly implies the convergence of as to a limit which we denote by . It therefore follows that the limit function corresponds to the PDF of a Gaussian vector with the covariance matrix .
The joint PDF for the zero-mean Gaussian random vectors can be obtained using their mutual independence as:
where denotes the joint covariance matrix of . Since the vectors and are zero-mean, mutually independent and, by the relationship (20), each vector has independent entries, it follows that is a diagonal matrix with each diagonal element taking the value of the corresponding temporal variance at the respective index . i.e.,
The convergence of , from (A26), implies a convergence of the diagonal elements in (A29) as . Hence converges as to a diagonal joint covariance matrix which we denote by . This further implies that the limiting vectors and are zero-mean, mutually independent and each vector has independent entries in .
Relationship (A26) implies that the joint limit distribution satisfies . Consequently, we can define an asymptotic backward channel that satisfies (A26) via the expression:
Next, by convergence of the joint PDF uniformly in and in , it follows from ([35] Theorem 1) that and the convergence is uniform in and in . Then, by the continuous mapping theorem (CMT) ([37] Theorem 7.7), we have
Now, using the extended CMT ([37] Theorem 7.24), we will show that for each , following the same approach as in the proof of ([17] Lemma B.2). Then, since and , we conclude that , where it also follows from the proof of ([17] Lemma B.2) that the convergence is uniform in . Specifically, to prove that , we will show that the following two properties hold:
- P1
- The distribution of is separable (as defined in ([37] Pg. 101)).
- P2
- For any convergent sequence such that , then .
To prove property P1, we show that (here we misuse the dimension notation as denotes a -dimensional vector) is separable ([37] Pg. 101), i.e., we show that , there exists such that . To that aim, recall first that by Markov’s inequality ([29] Pg. 114), it follows that . For the asynchronously sampled source process, we note that . By the independence of and , and by the fact that their mean is zero, we have, from (A30) that ; Hence , and . This further implies that ; therefore for each we have that , and thus is separable.
By the assumption in this lemma it follows that there exists such that for all we have that , , for all sufficiently large . Consequently, for all , and a sufficiently large , it follows from (A24) that
Following the continuity of and of , is also continuous ([31] Theorem 4.9); hence, when , then . This satisfies condition P2 for the extended CMT; Therefore, by the extended CMT, we have that . Since the RVs and , defined in (A17), are also continuous mappings of and of , respectively, it follows from the CMT ([37] Theorem 7.7) that .
Finally, to prove that the convergence is uniform in , we note that as and have independent entries, and the backward channels (21) and (A30) are memoryless. Hence, it follows from the proof of ([17] Lemma B.2), that the characteristic function of the RV which is denoted by converges to the characteristic function of , denoted by , uniformly over . Thus, for all sufficiently small , such that , and
Hence, following Lévy’s convergence theorem ([38] Theorem 18.1) we conclude that and that this convergence is uniform for sufficiently large k. Finally, since the CDFs of and obtained at are equivalent to the CDFs of and obtained at respectively, we can conclude that , uniformly in . □
The following convergence lemma A5 corresponds to ([17] Lemma B.3),
Lemma A5.
Letbe given. Every subsequence of, indexed by, converges in distribution, in the limit as, to a finite deterministic scalar.
Proof.
Recall that the RVs represent the mutual information density rate between k samples of the source process and the corresponding samples of its reproduction process , where these processes are jointly distributed via the Gaussian distribution measure . Further, recall that the relationship between the source signal and the reproduction process which achieves the RDF can be described via the backward channel in (21) for a Gaussian source. The channel (21) is a memoryless additive WSCS Gaussian noise channel with period , thus, by [21], it can be equivalently represented as a multivariate memoryless additive stationary Gaussian noise channel, which is an information stable channel ([39] Section 1.5). For such channels in which the source and its reproduction obey the RDF-achieving joint distribution , the mutual information density rate converges as k increases, almost surely, to the finite and deterministic mutual information rate ([14] Theorem 5.9.1). Since almost sure convergence implies convergence in distribution ([37] Lemma 7.21), this proves the lemma. □
Appendix D.3. Showing that
This section completes the proof to Theorem 4. We note from (14) that the RDF for the source process (for fixed length coding and MSE distortion measure) is given by:
where .
We now state the following lemma characterizing the asymptotic statistics of the optimal reconstruction process and the respective noise process used in the backward channel relationship (21):
Lemma A6.
Consider the RDF-achieving distribution with distortion D for compression of a vector Gaussian source processcharacterized by the backward channel (21). Then, there exists a subsequence in the indexdenoted, such that for the RDF-achieving distribution, the sequences of reproduction vectorsand backward channel noise vectorssatisfy thatuniformly inand uniformly with respect to, as well asuniformly inand uniformly with respect to, whereandare Gaussian PDFs.
Proof.
Recall from the analysis of the RDF for WSCS processes that for each , the marginal distributions of the RDF-achieving reproduction process and the backward channel noise is Gaussian, memoryless, zero-mean, and with variances and
respectively. Consequently, the sequences of reproduction vectors and backward channel noise vectors are zero-mean Gaussian with independent entries for each . Since , then, from (A34), it follows that is also bounded in the interval for all . Therefore, by Bolzano-Weierstrass theorem ([31] Theorem 2.42), has a convergent subsequence, and we let denote the indexes of this convergent subsequence and let the limit of the subsequence be denoted by . From the CMT, as applied in the proof of ([17] Lemma B.1), the convergence for each implies that the subsequence of PDFs corresponding to the memoryless Gaussian random vectors converges as to a Gaussian PDF which we denote by , and the convergence of is uniform in for any fixed . By Remark 2, it holds that is a memoryless stationary process with variance and by Equation (A34), . Hence by Assumption A1 and by the proof of ([17] Lemma B.1), it follows that for a fixed and , such that for all and for all sufficiently large k, it holds that for every . Since does not depend on k (only on the fixed ), this implies that the convergence is uniform with respect to .
The fact that is a zero-mean stationary Gaussian process with variance D for each , implies that the sequence of PDFs converges as to a Gaussian PDF which we denote by , hence its subsequence with indices also converges to . Since by Assumption A1 combined with the proof of ([17] Lemma B.1) it follows that this convergence is uniform in and in to .
Following the proof of Corollary A1, it holds that the subsequences of the memoryless Gaussian random vectors and converge in distribution as to a Gaussian distribution, and the convergence is uniform in for any fixed . Hence, as shown in Lemma A4 the joint distribution , and the limit distribution is jointly Gaussian. □
Lemma A7.
The RDF ofsatisfies, and the rateis achievable for the sourcewith distortion D when the reproduction process which obeys a Gaussian distribution.
Proof.
According to Lemma A6, we note that the sequence of joint distributions has a convergent subsequence, i.e., there exists a set of indexes such that the sequence of distributions with independent entries converges in the limit to a joint Gaussian distribution and the convergence is uniform in . Hence, this satisfies the condition of Lemma A4; This implies that uniformly in . Moreover, by Lemma A5 every subsequence of converges in distribution to a finite deterministic scalar as . Therefore, by Theorem 3 it holds that
Lemma A8.
The RDF ofsatisfies.
Proof.
To prove this lemma, we first show that for a joint distribution which achieves a rate-distortion pair it holds that : Recall that is an achievable rate-distortion pair for the source , namely, there exists a sequence of codes whose rate-distortion approach when applied to , This implies that for any there exists such that it holds that has a code rate satisfying by (3). Recalling Definition 5, the source code maps into a discrete index , which is in turn mapped into , i.e., form a Markov chain. Since is a discrete random variable taking values in , it holds that
where follows since which is not larger than as takes discrete values; while follows from the data processing inequality ([5] Chapter 2.8). Now, (A37) implies that for each , the reproduction obtained using the code satisfies . Since for every arbitrarily small , this inequality holds for all , i.e., for all sufficiently large l, it follows that . Hence, replacing the blocklength symbol from l to k, as ([5] Equation (2.3)), we conclude that
Next, we consider : Let be a subsequence of with the indexes such that its limit equals the limit superior. i.e., . Since by Lemma A4, the sequence of non-negative RVs convergences in distribution to as uniformly in , it follows from ([40] Theorem 3.5) that . Moreover, we define a family of distributions such that . Consequently, Equation (A38) can now be written as:
where follows since the convergence is uniform with respect to , thus the limits are interchangeable ([31] Theorem 7.11); follows since the limit of the subsequence exists in the index n, and is therefore equivalent to the limit superior, ([31] Page 57); and holds since mutual information is the expected value of the mutual information density rate ([5] Equation (2.30)). Finally, we recall that in the proof of Lemma A5 it was established that the backward channel for the RDF at the distortion constraint D, defined in (21), is information stable, hence for such backward channels, we have from ([41] Theorem 1) that the minimum rate is defined as and the limit exists; Hence, in the index k. Substituting this into Equation (A39) yields the result:
This proves the lemma. □
Combining the Lemmas A7 and A8 proves that and the rate is achievable with Gaussian inputs, completing the proof of the theorem.
References
- Gardner, W.; Brown, W.; Chen, C.K. Spectral correlation of modulated signals: Part II-digital modulation. IEEE Trans. Commun. 1987, 35, 595–601. [Google Scholar] [CrossRef]
- Giannakis, G.B. Cyclostationary signal analysis. In Digital Signal Processing Handbook; CRC PRESS: Boca Raton, FL, USA, 1998; pp. 17–21. [Google Scholar]
- Gardner, W.A.; Napolitano, A.; Paura, L. Cyclostationarity: Half a century of research. Signal Process. 2006, 86, 639–697. [Google Scholar] [CrossRef]
- Berger, T.; Gibson, J.D. Lossy source coding. IEEE Trans. Inf. Theory 1998, 44, 2693–2723. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: New York, NY, USA, 2006. [Google Scholar]
- Wolf, J.K.; Wyner, A.D.; Ziv, J. Source coding for multiple descriptions. Bell Syst. Tech. J. 1980, 59, 1417–1426. [Google Scholar] [CrossRef]
- Wyner, A.D.; Ziv, J. The rate-distortion function for source coding with side information at the decoder. IEEE Trans. Inf. Theory 1976, 22, 1–10. [Google Scholar] [CrossRef]
- Oohama, Y. Gaussian multiterminal source coding. IEEE Trans. Inf. Theory 1997, 43, 1912–1923. [Google Scholar] [CrossRef]
- Pandya, A.; Kansal, A.; Pottie, G.; Srivastava, M. Lossy source coding of multiple Gaussian sources: m-helper problem. In Proceedings of the IEEE Information Theory Workshop, San Antonio, TX, USA, 24–29 October 2004; pp. 34–38. [Google Scholar]
- Gallager, R.G. Information Theory and Reliable Communication; Springer: Berlin, Germany, 1968; Volume 588. [Google Scholar]
- Harrison, M.T. The generalized asymptotic equipartition property: Necessary and sufficient conditions. IEEE Trans. Inf. Theory 2008, 54, 3211–3216. [Google Scholar] [CrossRef] [Green Version]
- Kipnis, A.; Goldsmith, A.J.; Eldar, Y.C. The distortion rate function of cyclostationary Gaussian processes. IEEE Trans. Inf. Theory 2018, 64, 3810–3824. [Google Scholar] [CrossRef] [Green Version]
- Napolitano, A. Cyclostationarity: New trends and applications. Signal Process. 2016, 120, 385–408. [Google Scholar] [CrossRef]
- Han, T.S. Information-Spectrum Methods in Information Theory; Springer: Berlin, Germany, 2003; Volume 50. [Google Scholar]
- Verdú, S.; Han, T.S. A general formula for channel capacity. IEEE Trans. Inf. Theory 1994, 40, 1147–1157. [Google Scholar] [CrossRef] [Green Version]
- Zeng, W.; Mitran, P.; Kavcic, A. On the information stability of channels with timing errors. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Seattle, WA, USA, 9–14 July 2006; pp. 1885–1889. [Google Scholar]
- Shlezinger, N.; Abakasanga, E.; Dabora, R.; Eldar, Y.C. The Capacity of Memoryless Channels with Sampled Cyclostationary Gaussian Noise. IEEE Trans. Commun. 2020, 68, 106–121. [Google Scholar] [CrossRef]
- Shannon, C.E. Communication in the presence of noise. Proc. IEEE 1998, 86, 447–457. [Google Scholar] [CrossRef]
- Cherif, F. A various types of almost periodic functions on Banach spaces: Part I. Int. Math. Forum 2011, 6, 921–952. [Google Scholar]
- Shlezinger, N.; Dabora, R. On the capacity of narrowband PLC channels. IEEE Trans. Commun. 2015, 63, 1191–1201. [Google Scholar] [CrossRef] [Green Version]
- Shlezinger, N.; Dabora, R. The capacity of discrete-time Gaussian MIMO channels with periodic characteristics. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–16 October 2016; pp. 1058–1062. [Google Scholar]
- Shlezinger, N.; Zahavi, D.; Murin, Y.; Dabora, R. The secrecy capacity of Gaussian MIMO channels with finite memory. IEEE Trans. Inf. Theory 2017, 63, 1874–1897. [Google Scholar] [CrossRef]
- Heath, R.W.; Giannakis, G.B. Exploiting input cyclostationarity for blind channel identification in OFDM systems. IEEE Trans. Signal Process. 1999, 47, 848–856. [Google Scholar] [CrossRef] [Green Version]
- Shaked, R.; Shlezinger, N.; Dabora, R. Joint estimation of carrier frequency offset and channel impulse response for linear periodic channels. IEEE Trans. Commun. 2017, 66, 302–319. [Google Scholar] [CrossRef]
- Shlezinger, N.; Dabora, R. Frequency-shift filtering for OFDM signal recovery in narrowband power line communications. IEEE Trans. Commun. 2014, 62, 1283–1295. [Google Scholar] [CrossRef] [Green Version]
- El Gamal, A.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Wu, X.; Xie, L.L. On the optimal compressions in the compress-and-forward relay schemes. IEEE Trans. Inf. Theory 2013, 59, 2613–2628. [Google Scholar] [CrossRef] [Green Version]
- Zitkovic, G. Lecture Notes on the Theory of Probability Parts I and II. Available online: https://web.ma.utexas.edu/users/gordanz/lecture_notes_page.html (accessed on 12 March 2020).
- Papoulis, A. Probability, Random Variables, and Stochastic Processes; McGraw-Hill: New York, NY, USA, 2002. [Google Scholar]
- Zamir, R.; Kochman, Y.; Erez, U. Achieving the Gaussian rate–distortion function by prediction. IEEE Trans. Inf. Theory 2008, 54, 3354–3364. [Google Scholar] [CrossRef]
- Rudin, W. Principles of Mathematical Analysis; International series in pure and applied mathematics; McGraw-Hill: New York, NY, USA, 1976. [Google Scholar]
- Dixmier, J. General Topology; Springer: New York, NY, USA, 1984. [Google Scholar]
- Stein, E.M.; Shakarchi, R. Real Analysis: Measure Theory, Integration, and Hilbert Spaces; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Kolmogorov, A. On the Shannon theory of information transmission in the case of continuous signals. IRE Trans. Inf. Theory 1956, 2, 102–108. [Google Scholar] [CrossRef]
- Scheffé, H. A useful convergence theorem for probability distributions. Ann. Math. Stat. 1947, 18, 434–438. [Google Scholar] [CrossRef]
- Bromiley, P. Products and convolutions of Gaussian probability density functions. Tina-Vision Memo 2003, 3, 1. [Google Scholar]
- Kosorok, M.R. Introduction to Empirical Processes and Semiparametric Inference.; Springer: New York, NY, USA, 2008. [Google Scholar]
- Williams, D. Probability with Martingales; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar]
- Dobrushin, R.L. A general formulation of the fundamental theorem of Shannon in the theory of information. Uspekhi Matematicheskikh Nauk 1959, 14, 3–104. [Google Scholar]
- Billingsley, P. Convergence of Probability Measures; John Wiley & Sons: New York, NY, USA, 2013. [Google Scholar]
- Venkataramanan, R.; Pradhan, S.S. Source coding with feed-forward: Rate-distortion theorems and error exponents for a general source. IEEE Trans. Inf. Theory 2007, 53, 2154–2179. [Google Scholar] [CrossRef]
Figure 1.
Source coding block diagram.

Figure 2.
versus n; offset .

Figure 3.
versus n; offset .

Figure 4.
versus ; offset .

Figure 5.
versus ; offset .

Figure 6.
versus D; offset .

Figure 7.
versus D; offset .

Figure 8.
versus at .

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Abakasanga, E.; Shlezinger, N.; Dabora, R. On the Rate-Distortion Function of Sampled Cyclostationary Gaussian Processes. Entropy 2020, 22, 345. https://0-doi-org.brum.beds.ac.uk/10.3390/e22030345
AMA Style
Abakasanga E, Shlezinger N, Dabora R. On the Rate-Distortion Function of Sampled Cyclostationary Gaussian Processes. Entropy. 2020; 22(3):345. https://0-doi-org.brum.beds.ac.uk/10.3390/e22030345
Chicago/Turabian StyleAbakasanga, Emeka, Nir Shlezinger, and Ron Dabora. 2020. "On the Rate-Distortion Function of Sampled Cyclostationary Gaussian Processes" Entropy 22, no. 3: 345. https://0-doi-org.brum.beds.ac.uk/10.3390/e22030345
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.