Regime-Switching Discrete ARMA Models for Categorical Time Series


Department of Mathematics and Statistics, Helmut Schmidt University, 22043 Hamburg, Germany
Entropy 2020, 22(4), 458; https://0-doi-org.brum.beds.ac.uk/10.3390/e22040458
Submission received: 18 March 2020
/
Revised: 14 April 2020
/
Accepted: 16 April 2020
/
Published: 17 April 2020
(This article belongs to the Special Issue Entropy Measures for Data Analysis II: Theory, Algorithms and Applications)
Abstract
:For the modeling of categorical time series, both nominal or ordinal time series, an extension of the basic discrete autoregressive moving-average (ARMA) models is proposed. It uses an observation-driven regime-switching mechanism, leading to the family of RS-DARMA models. After having discussed the stochastic properties of RS-DARMA models in general, we focus on the particular case of the first-order RS-DAR model. This RS-DAR model constitutes a parsimoniously parameterized type of Markov chain, which has an easy-to-interpret data-generating mechanism and may also handle negative forms of serial dependence. Approaches for model fitting are elaborated on, and they are illustrated by two real-data examples: the modeling of a nominal sequence from biology, and of an ordinal time series regarding cloudiness. For future research, one might use the RS-DAR model for constructing parsimonious advanced models, and one might adapt techniques for smoother regime transitions.
1. Introduction
Since the pioneering textbook on time series analysis by Box & Jenkins [1], this topic has attracted an immense interest in research and applications. To put it more precisely, real-valued time series (having a range consisting of real numbers or vectors) have been in the limelight of scientists and practitioners since that time. Besides many approaches for analyzing real-valued time series, also enumerable models have been developed, starting with the basic autoregressive moving-average (ARMA) models [1]. ARMA models are characterized by a linear conditional mean and an autocorrelation function (ACF) satisfying the so-called Yule–Walker equations. Their stochastic properties are well understood, but their actual potential for application is limited. Therefore, many alternatives and extensions have been developed, which cover more realistic time series patterns [2]. For example, if being concerned with a time series exhibiting sudden jumps and a piecewise behavior, then it is more appropriate to consider regime-switching models like the self-exciting threshold (SET) AR models proposed by Tong & Lim [3], also see the survey in Tong [4].
During the last decades, discrete-valued time series received more and more attention, see Weiß [5] for a recent survey. Especially count time series, i.e., quantitative time series with a range included in the set of non-negative integers, have been studied intensively. A large number of models have been developed for this type of discrete data, not only integer-valued counterparts to the basic ARMA model, but also to more advanced models like the aforementioned SETAR models. The latter include the proposals by Möller [6], Möller et al. [7], Monteiro et al. [8], Thyregod et al. [9], Wang et al. [10].
In this article, we consider another type of discrete-valued time series, which is somewhat neglected in the time series literature: categorical time series with and a qualitative range consisting of a finite number of categories [5]. There are fundamental differences between quantitative scales (interval or ratio) and qualitative scales (ordinal or nominal) of measurement, see Table 1 in Stevens [11]. In particular, quantitative scales (such as the aforementioned count data, or real-valued measurements such as temperatures or prices) allow us to use the basic arithmetic operations, which, however, is not permitted for qualitative scales. Qualitative (categorical) ranges are further distinguished into the cases that exhibits a natural order among the categories (ordinal range), and that the categories in are unordered (nominal range). In what follows, we are interested in both types of categorical time series. To simplify notations, we always assume the possible outcomes to be arranged in a certain order (either lexicographical or natural order), i.e., we denote the range as with some . Categorical time series require a tailor-made treatment in any sense. All the moment-based tools developed for quantitative time series cannot be applied due to the inadmissibility of the basic arithmetic operations. Instead, we have to express the location in terms of the mode (for ordinal time series, also the median can be used), and to use one of the customized measures of dispersion and serial dependence from Table 1, see Klein et al. [12], Weiß [13], [14] for further details. Even the basic time series plot can only be done in the ordinal case, whereas we may use the rate evolution graph as a substitute for nominal time series [5].
Finally, the selection of possible models for categorical time series is yet limited, see Weiß [5]. The quite flexible, higher-order Markov models suffer from a huge number of model parameters, which increases exponentially in the model order and polynomially in the number of categories, . The latter might be reduced by amalgamating some categories, but this causes a loss of information. The extremely parsimonious discrete ARMA models by Jacobs & Lewis [15], in contrast, have a rather narrow scope of application, see the discussion in Section 2 for further details. Therefore, as a compromise between flexibility and parsimony, we extend the discrete ARMA models for categorical time series by an observation-driven regime-switching mechanism, see Section 3. For ordinal time series, it might be implemented in analogy to the SET approach for quantitative time series. However, the regime-switching can also be applied to nominal time series to capture, e.g., structures or similarities within the categorical range. As an important special case, we obtain a family of parsimonious Markov chain (MC) models, see Section 4. The application potential of the new model family is demonstrated in Section 5 with two real-data applications, where we also illustrate how model fitting might be done. Finally, we conclude in Section 6 and outline issues for future research.
2. About Discrete ARMA Models
Jacobs & Lewis [15] proposed two families of discrete ARMA models. The first of these families (labeled by the acronym “DARMA”) is defined in a nested way and has therefore found less attention in the literature. The second family (labeled as “NDARMA”), in contrast, directly imitates the ordinary ARMA recursion and has been considered in several subsequent works. Both families agree in their boundary cases (i.e., pure AR- and pure MA-type models). We concentrate on the “NDARMA family” in the sequel, and we refer to these models simply as discrete ARMA models. The regime-switching mechanism to be proposed in Section 3 could be applied to the “DARMA family” in an analogous way. According to Weiß & Göb [16], the discrete ARMA models (“NDARMA”) by Jacobs & Lewis [15] might be defined as follows (Jacobs & Lewis [15] provide an equivalent definition based on backshift operators).
Definition 1.
Let and be categorical processes with range , where is independent and identically distributed (i. i. d.) with marginal distribution p (), and where is independent of . Let
be i. i. d. multinomial random vectors with , which are independent of and of . So the probabilities in , , sum up to one.
Then, is said to be a discrete ARMA process if it follows the recursion
(Here, if the range is not numerically coded, then we assume , and for each .)
The boundary cases and are referred to as a DAR process and DMA process, respectively. The probability vector p is contained in the -part unit simplex (recall that the range consists of categories),
and leads to m model parameters. Analogously, leads to further model parameters. Based on a Markov-chain representation of the discrete ARMA process according to Definition 1, Weiß [17] concluded on the ergodicity of the process as well as on the existence of a unique stationary distribution. The initial distribution for achieving stationarity is obtained by solving the invariance equation corresponding to the Markov-chain representation.
Although being denoted in an “ARMA style”, the model recursion of Equation (1) implies that is generated by doing nothing else than simply selecting either one of the past p observations , or one of the available innovations . As a consequence, and have the same stationary marginal distribution, namely p, i.e., for all . Furthermore, the random-selection mechanism leads to the following transition probabilities:
where empty sums (in case of or ) are assumed to take the value 0. Here, denotes the Kronecker delta, which takes the value 1 (0) iff ().
Despite their quite extraordinary data-generating mechanism, the discrete ARMA processes according to Definition 1 have an ARMA-like serial dependence structure. If serial dependence is expressed in terms of Cohen’s from Table 1, then the following Yule–Walker equations hold [16]:
where the are given by . Here, denotes the indicator function, which takes the value 1 (0) iff A is true (false). Furthermore, Weiß [17] showed that the discrete ARMA processes are -mixing with exponentially decreasing weights. As a consequence, one can apply the central limit theorem on p. 200 in Billingsley [18] to establish the asymptotic normality for statistics derived from such a process.
Remark 1.
Equation (3) also applies to the ordinal version of Cohen’s κ in Table 1. The reason for this is given by the fact that the bivariate probabilities at lag h, , satisfy for discrete ARMA processes. As a result, one obtains in the ordinal case, so . Thus, for discrete ARMA processes, the identity has to hold, whereas these measures usually differ from each other for other data-generating processes. It should be pointed out that further identities with other measures of serial dependence exist, see Weiß [13], Weiß & Göb [16] for details.
While the discrete ARMA models are very attractive in view of parameter parsimony (only parameters) and some of its model properties (e.g., Yule–Walker equations for ), they suffer from the fact that only positive forms of serial dependence are possible (in the sense that always ). Furthermore, because of the simple selection mechanism in Equation (1), the sample paths generated by discrete ARMA models are characterized by long constant segments being finished by abrupt changes, which will often be inappropriate for real applications. For quantitative time series, a possible remedy is to use additional variation operators, see Möller & Weiß [19]. However, this solution cannot be applied to qualitative time series. Therefore, in Section 3, the novel regime-switching discrete ARMA models are proposed to offer solutions to both of the above drawbacks, the limitation to positive dependence and the piecewise constant sample paths.
3. Regime-Switching Discrete ARMA Models
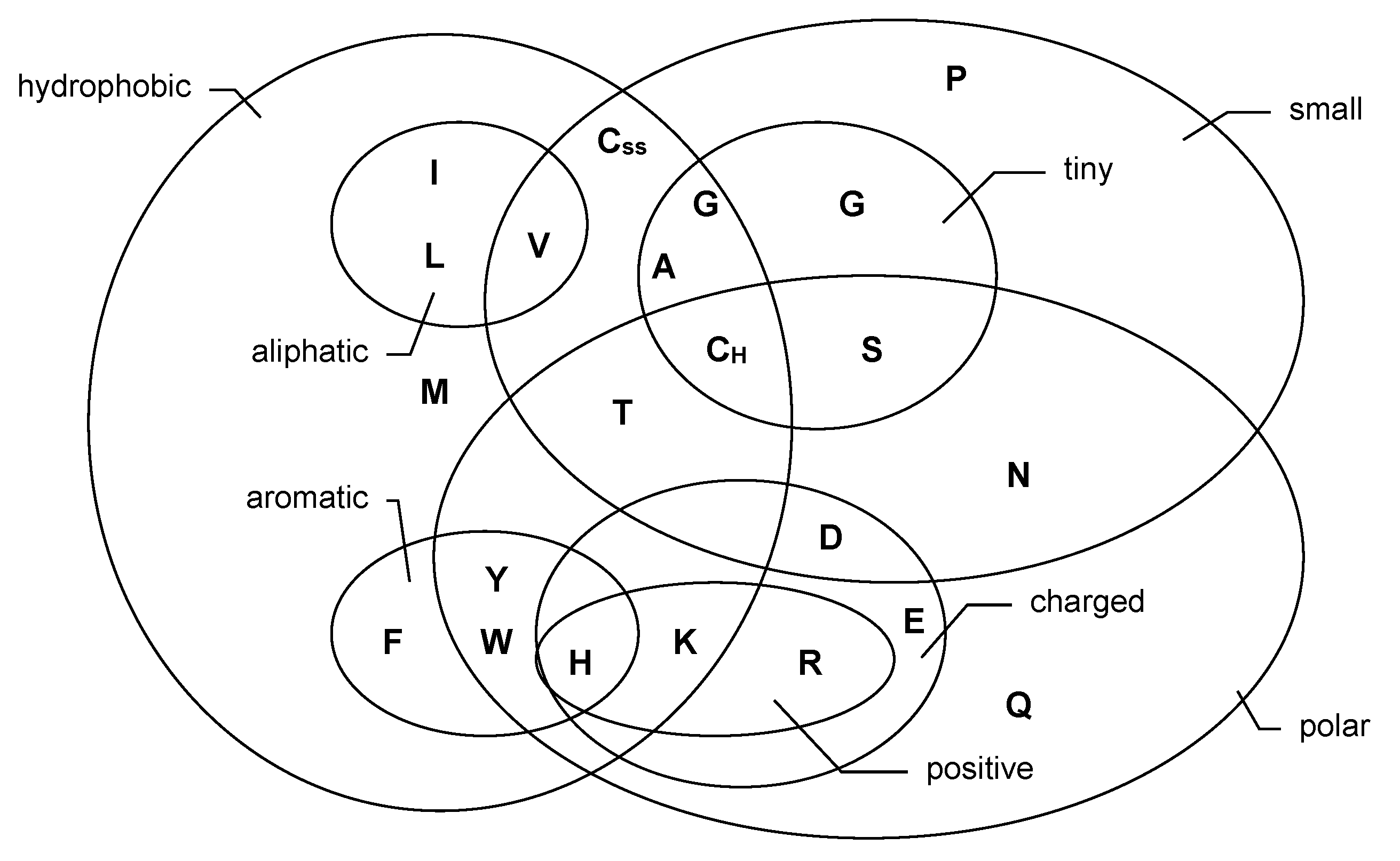
Let be a categorical process with range . If the range is ordinal, then the states are strictly ordered imposing a distinct structure on . Even for a nominal range, the states are not necessarily free of any relations, but similarities might exist within it. An example is given by biological sequences such as deoxyribonucleic acid (DNA) and protein sequences. The four DNA bases ‘a’, ‘c’, ‘g’, and ‘t’ (adenine, cytosine, guanine, and thymine, respectively) are divided into the group of pyrimidines (c, t) and purines (a, g). In this sense, c is more similar to t than to a or g. The twenty different amino acids exhibit an even more refined similarity structure, which is visualized by the Venn diagram in Figure 1, see Taylor [20] for further details. If developing a stochastic model for a biological sequence (also see Section 5.1 below), it is reasonable to try to account for the apparent structure within the range.
As a possible solution for this task, let us now introduce a novel regime-switching (RS) extension of the discrete ARMA model. It is defined with respect to a partition of the range into K non-empty subsets, where . Here, constitute a partition of iff these sets are pairwise disjoint and satisfy . The K regimes shall be used as a means to account for a structure within the categorical range, such as the grouping of the DNA bases in pyrimidines and purines, or the ordering of the categories in the case of an ordinal time series. The current regime is determined by the last (or even earlier) observation: if , then the process is in the kth regime at time t, and the upcoming observation is generated according to a regime-specific model. So we are concerned with an observation-driven (“self-exciting”) RS-mechanism, which is in contrast to, e.g., the Hidden-Markov model [21], where the regimes are defined by a latent process. As an example, for the ordinal cloudiness time series to be discussed in Section 5.2, we consider (among others) a two-regime model (so ), where the “lower regime” refers to a sky with at most scattered clouds, and the “upper regime” to broken clouds or an even overcast sky. Being in the lower regime, the upcoming cloudiness state follows a different model as if being in the upper regime.
Definition 2.
Like in Definition 1, let and be categorical processes, where the range is partitioned into , and let denote the multinomial mixture vectors.
Let and let be K state-dependent probability vectors. Then, the regime-switching discrete ARMA process (“RS-DARMA”) is defined by the recursive scheme
Note that the boundary case leads to the ordinary discrete ARMA model. In Definition 2, we stated the most basic type of RS-condition, where the last observation determines the current regime. Certainly, one may use other conditions as well, e.g., based on more delayed observations with .
If denotes a partition, then each belongs to exactly one of the . To simplify notations, we introduce the mapping defined by iff . So the element belongs to the -th subset. Then, the RS-condition in Equation (4) can be rewritten as and .
Note that the number of possible partitions of a set of size into K subsets is equal to , a Stirling number of the second kind [22], p. 5. These numbers can be computed recursively according to with and . The total number of all partitions of into non-empty subsets, , is the -th Bell number [22], p. 5.
Example 1.
Recall the DNA example mentioned in the beginning of Section 3. There, the range consists of different states, . Since , there are possible partitions, namely different partitions into subsets, respectively. One of them splits into the purines and pyrimidines, i.e., is partitioned into and . In this particular case, π maps , , , and .
Let us now discuss the stochastic properties of the RS-DARMA process according to Definition 2. The ordinary discrete ARMA’s transition probabilities from Equation (2) change to
i.e., depending on the outcome , another set of dependence parameters is plugged-in into Equation (2), otherwise, we just have the ordinary discrete-ARMA structure. Therefore, the MC-representation of the discrete ARMA process as well as the resulting proofs for existence, ergodicity, and mixing properties (-mixing with exponentially decreasing weights), as provided by Section 2.2 in Weiß [17], can be adapted to the RS-DARMA process, see Appendix A for details.
Example 2.
Let us consider the case , i.e., the purely autoregressive RS-DARMA model according to Definition 2. It can be understood as the direct counterpart to the popular SETAR model. The RS-DAR process constitutes a pth-order Markov process, where the transition probabilities compute as
These can now be used for likelihood computations or forecasting purposes.
4. A Class of Parsimonious Markov Chains
A particularly important special case of the RS-DARMA family is obtained by setting , because such a RS-DAR process constitutes a parsimoniously parameterized Markov chain (MC), also see Example 2. MCs, in turn, are of great relevance, because (1) such a first-order memory is often sufficient in practice, and because (2) MCs may constitute the starting point for defining more complex time series models [5]. Well-known examples regarding (2) are the so-called mixture transition distribution (MTD) model proposed by Raftery [23], which extends an underlying MC to a higher-order Markov model with only one additional parameter for each increment of the model order, or the hidden-Markov model (HMM), where the observable process is controlled by a latent MC [21]. Recall that an HMM can be interpreted as a parameter-driven RS-model, whereas we consider observation-driven RS-models in this article.
For any of the extensions in the sense of (2), it would be of relevance to start with a maximally parsimonious MC model to keep the overall number of model parameters at a feasible level. A full MC model on has model parameters, which increases quadratically in m. The lower bound of model parameters is determined through the i. i. d.-case, where only the marginal distribution p has to be specified (which requires m parameters). So any non-i. i. d. model with unspecified marginal distribution must have parameters. The ordinary DAR model with its parameters reaches this lower bound (and also the so-called “Negative Markov model”, see, e.g., Weiß [13] for details). It may sometimes be too simplistic for practice, recall the discussion in Section 2. In fact, an MTD model relying on a DAR-MC just leads to a DAR model. Thus, using a (true) RS-DAR model as a base for defining a HMM or MTD model, respectively, might turn out as a reasonable compromise between model flexibility and parameter parsimony.
The model recursion of an ordinary DAR process can be denoted as
where and according to Definition 1. Its transition probabilities equal . Let be a partition, then the RS-DAR model is generally defined by
see Example 2. For applications, however, it might be better to impose further restrictions such that the resulting model is better interpretable. Therefore, we shall now propose two special cases of Equation (7), where the regimes affect either the marginal distribution or the dependence parameter.
4.1. Marginal Regimes
A RS-DAR model with respect to the marginals is defined by
Here, are the K state-dependent probability vectors for the innovations , implying parameters for model Equation (8). would lead to a full MC model, but then would not be identifiable anymore. So model Equation (8) requires . The transition probabilities follow as , see Example 2. In contrast to the ordinary DAR model, the RS-DAR model Equation (8) also allows for negative serial dependence. This can be obtained by choosing the such that for all .
Example 3.
Let , and define the partition and . Furthermore, let us consider the boundary case
where . Then for all . The transition matrix equals
Solving the invariance equation , the stationary marginal distribution, , equals . From the diagonal of , it becomes clear that the bivariate probabilities . Furthermore, , so one computes Cohen’s κ at lag 1, see Table 1, as
This expression might also become negative, which is illustrated in Figure 2a, where is plotted against ϕ and p with .
Note that if the range is assumed ordinal, then differs from (in contrast to the case of ordinary DAR models). With analogous computations as before, one obtains
But like for , also might take negative values, see Figure 2b.
4.2. Dependence Regimes
As a possible alternative to Equation (8), a RS-DAR model with respect to the dependence parameter is defined by
Here, are the K state-dependent dependence parameters, so model Equation (9) has altogether parameters. The transition probabilities compute as , see Example 2.
Example 4.
As a possible application of model Equation (9), consider an ordinal range with , and let us assume individual dependence parameters for each state. More precisely, let us assume the partition with , and the corresponding state-dependent dependence parameters . So we have model parameters, whereas a full MC would have parameters. The transition probabilities equal . Then with
The formula for is easily verified by computing
The cumulative probabilities f of are given by . It follows that
which can be used to compute the dependence measures and from Table 1.
4.3. Statistical Inference
Let denote the vector of all model parameters, i.e., for the RS-DAR model Equation (8), we have , whereas for model Equation (9). To estimate from a given time series , we use the maximum likelihood (ML) approach. The (conditional) ML estimate is obtained by numerically maximizing the log-likelihood function,
We denote the maximized log-likelihood by , where the factor corrects for the conditioning on [5], p. 236. The existence, consistency, and asymptotic normality are easily established by proving that Condition 5.1 in Billingsley [24] holds. This condition requires that
- the set does not dependent on ;
- each has continuous partial derivatives in ;
- the Jacobian matrix of has full rank, i.e., the rank ;
- the MC is irreducible.
Since the transition probabilities are quadratic polynomials in the model parameters, part 2 is always satisfied. Part 1 holds by restricting the model parameters to the open interval , then all . This also implies the irreducibility of the transition matrix. Part 3 is ensured by an appropriate design of the model (identifiability of parameters).
Finally, if the model design is not fixed by the considered application scenario, then one will commonly try out multiple types of partitioning (between the boundary cases of an ordinary DAR model and a full MC). In this case, the model selection might be done based on a certain type of information criterion, such as Akaike’s information criterion (AIC) or the Bayesian information criterion (BIC), see Burnham & Anderson [25]. These are given by
respectively. The performance of AIC and BIC if selecting among general Markov models was investigated by Katz [26]. It was shown that only the BIC is consistent while the AIC tends to overfitting.
5. Real-Data Applications
In what follows, we apply the RS-DAR models to two data examples. The first one refers to a DNA sequence, which constitutes a nominal time series (Section 5.1). The second example, in contrast, is about an ordinal time series of cloudiness states (Section 5.2).
5.1. DNA Sequence Modeling
Let us pick up the discussion in the beginning of Section 3 as well as in Example 1, where we considered a nominal DNA sequence having the range (so ). Although such a sequence does not constitute a “time” series in the original sense, it is common practice to use models for stochastic processes as a tool for summarizing its main properties, see Churchill [27], Dehnert et al. [28]. In what follows, we consider the DNA sequence of the Bovine leukemia virus (length ), which is published by the National Center for Biotechnology Information at https://0-www-ncbi-nlm-nih-gov.brum.beds.ac.uk/nuccore/NC_001414?%3Fdb=nucleotide. Its rate evolution graph (a time series plot is not possible for nominal data, see Weiß [5]) and its sample Cohen’s (recall Table 1) are plotted in Figure 3.
The Bovine sequence was comprehensively analyzed in Section 7.2 of Weiß [5], where several types of models were fitted to the data. The most parsimonious model used was the ordinary DAR model (four parameters), but the best fit was actually obtained by a full MC model (12 parameters). Weiß [5] also tried out a 2-state HMM (eight parameters), which improved over the DAR model but was inferior to the full MC. Nevertheless, it is worth noting that the two hidden states that were constructed during model fitting closely matched the purines (a, g) and pyrimidines (c, t), respectively. This indicates a RS-approach might turn out to be appropriate for the data.
Therefore, we now fit several types of RS-DAR model to these data. As the criterion for model selection, we use the BIC, which is very suitable for time series of large length T. First, we try out the approach of Section 4.2, where the DAR’s dependence parameter depends on the current regime. The obtained BIC results are summarized in Table 2. The RS-DAR model with two regimes (purines and pyrimidines ) and, thus, five parameters, leads to a slight improvement compared to the DAR model, but the four-regime model (seven parameters) performs even worse in terms of the BIC. Any of these models is much worse than the full MC, so a regime-dependent dependence structure does not seem to be appropriate for the data.
Hence, let us now use the RS-DAR model with regime-dependent innovations’ distribution, see Section 4.1. Starting again with the two-regime model (purines vs. pyrimidines; seven parameters), we achieve a considerable improvement over the DAR model, but still do not reach the full MC’s BIC, see Table 3. Thus, we try splitting either the purine or the pyrimidine regime, leading to a three-regime model with ten parameters. If we split the purines into , then the BIC deteriorates again. However, if splitting the pyrimidines into , then the BIC improves and even becomes better than that of the full MC. So this type of RS-DAR model is best among all candidate models.
Thus, let us analyze this model fit in some more detail. The dependence parameter is estimated as , and the three regime-dependent innovations’ distributions are
This implies, for example, that if , then the probability for is quite large, whereas also leads to a rather large probability for . These “transition rules” can also be seen from the resulting transition matrix
which implies the following stationary marginal distribution for :
For the given three-digit rounding, this perfectly agrees with the vector of relative frequencies computed from the data. This excellent agreement between fitted and observed marginal distribution carries over to the measures of dispersion given in Table 1, with an IQV value of and an entropy of . Both values are very close to 1, because the marginal distribution is quite close to a uniform distribution, which is considered as the maximally dispersed scenario for nominal data [13].
Finally, let us do a diagnostic check of the serial dependence structure. On p. 146 in Weiß [5], it was pointed out that the sample value of Cohen’s at lag 1, , deviates from the corresponding sample value of Cramer’s v, . Here, Cramer’s v is defined by , constituting a so-called “unsigned” measure of serial dependence [5]. This discrepancy between and contradicts a DAR model, where and exactly agree, but it was reproduced by the fitted full MC. For the fitted three-regime model, we obtain and . The fitted RS-DAR model reproduces the discrepancy between and v, confirming its adequacy for the Bovine data.
5.2. Cloudiness Time Series
The amount of cloud coverage is measured in “okta”, i.e., in eighths of the sky being covered by clouds. Then, a common classification of cloudiness consists of the following five ordinal states (so ), ordered from lowest to highest: ‘SKC’ (sky clear, 0 oktas), ‘FEW’ (few, 1–2 oktas), ‘SCT’ (scattered, 3–4 oktas), ‘BKN’ (broken, 5–7 oktas), and ‘OVC’ (overcast, 8 oktas). We considered a time series obtained from the “DWD Climate Data Center” offered by the Deutscher Wetterdienst (German Weather Service) at https://cdc.dwd.de/portal/201912031600/mapview. The data refer to the hourly observations of cloudiness at the weather station in Schleswig (a town in the north of Germany) in May 2011. So the time series is of total length . A plot of the data as well as the corresponding sample ordinal Cohen’s (recall Table 1) are shown in Figure 4. We have a rather strong degree of serial dependence (). The marginal cumulative frequencies are given by , leading to the dispersion values 0.626 for the sample IOV and 0.689 for the CPE (recall Table 1). Note that in the ordinal case, maximal dispersion does not go along with a uniform distribution, but with an extreme two-point distribution, i.e., .
In analogy to Section 5.1, we now fit types of MC model to the cloudiness data. The most parsimonious model is again the DAR model, but this does not account for the ordinal structure of the range. Therefore, besides the full MC model, we also considered RS-DAR models (with respect to the marginal distribution), which are designed such that they account for the natural order within the range (the RS-DAR model with dependence regimes, see Example 4, performs clearly worse and is, thus, not reported here). This is achieved by imitating the threshold approach for quantitative time series: we considered the partitioning , corresponding to a threshold at , and the refinement , , corresponding to two thresholds at . The BICs of the four candidate models are summarized in Table 4.
According to the BIC, we select the two-regime model, where the dependence parameter is estimated as , and where the two regime-dependent innovations’ distributions are
According to this fitted model, we mainly produce innovations from the lower regime if staying in the lower regime, and vice versa. This type of “inertia” can also be seen from the right part of Figure 5, where a time series was simulated according to the fitted two-regime model. This sample path looks much more similar to the original time series in Figure 4 than the simulated DAR path in the left part of Figure 5, which does not exhibit a piecewise behavior. The (cumulative) stationary marginal distribution of the fitted two-regime model results as
which is reasonably close to . In fact, looking at the corresponding dispersion measures, we get and , which is only slightly below the above sample values. The dependence structure is captured quite well, with .
Remark 2.
Since is not that large, one might also think of using the AIC for model selection. In this case, the three-regime model () would be preferred over the two-regime model (). The parameter estimates are and
It is interesting to note that the innovations’ distribution of the central regime, , will hardly produce the value itself. Instead, there is a nearly fifty-fifty chance of falling either above or below this value. The four additional model parameters are outweighed by a closer fit of the marginal distribution, now
with stronger dispersion (, ), and by more serial dependence .
The fitted two-regime model can now be applied to forecasting the cloudiness. The one-step-ahead conditional mode or median is always equal to the given state, i.e., the point forecast for the next hour is equal to the current cloudiness state. But if using 95% prediction intervals for weather forecasting, then more complex rules of the form “” are obtained:
6. Conclusions
We extended the basic discrete ARMA model of Jacobs & Lewis [15] by an observation-driven regime-switching mechanism, leading to the family of RS-DARMA models. Particular attention was given to two instances of the RS-DAR model, because they constitute an easy-to-interpret type of parsimoniously parameterized MC model. Furthermore, in contrast to the ordinary DAR model, the RS-DAR model may even handle negative forms of serial dependence. Model fitting was illustrated by two real-data examples: a nominal DNA sequence, and an ordinal time series of cloudiness states. Besides such an immediate application of the novel models, it was also pointed out that types of RS-DAR model might serve as the base for constructing parsimonious advanced models, such as MTD models or HMMs. This direction deserves further attention by future research. Furthermore, the special case of regime-switching ordinal processes, which has various applications in practice, should be further elaborated. Due to the close connection to bounded-counts time series [14], one may try to adapt regime-switching techniques known from count processes, e.g., hysteresis zones for enabling smoother regime transitions.
Funding
This research received no external funding.
Acknowledgments
The author thanks the two reviewers for their useful comments on an earlier draft of this article.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. Markov-Chain Representation
In analogy to the argumentation in Section 2.2 of Weiß [17], the RS-DARMA process can be represented as the homogeneous MC defined by
For , no -terms need to be included in , but always has to be part of the vector . The corresponding transition probabilities are
see Equation (5). The crucial point in the derivations of Weiß [17] is the Lemma in Appendix A.1, where it is shown that all -step-ahead transition probabilities of are truly positive. From this property, it follows that is primitive, which implies the existence, ergodicity, and the mixing properties of .
For the RS-DARMA model considered here, we compute
for all . The first factor follows from (5) as
the second one is given by
The rest of the proof is done in the same way as in Appendix A.1 of Weiß [17], by using that all and have only non-zero entries.
References
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control, 1st ed.; Holden-Day: San Francisco, CA, USA, 1970. [Google Scholar]
- Holan, S.H.; Lund, R.; Davis, G. The ARMA alphabet soup: A tour of ARMA model variants. Stat. Surv. 2010, 4, 232–274. [Google Scholar] [CrossRef]
- Tong, H.; Lim, K.S. Threshold autoregression, limit cycles and cyclical data. J. R. Stat. Soc. Ser. B 1980, 42, 245–292. [Google Scholar] [CrossRef]
- Tong, H. Threshold models in time series analysis–30 years on. Stat. Its Interface 2011, 4, 107–118. [Google Scholar] [CrossRef] [Green Version]
- Weiß, C.H. An Introduction to Discrete-Valued Time Series; John Wiley & Sons, Inc.: Chichester, UK, 2018. [Google Scholar]
- Möller, T.A. Self-exciting threshold models for time series of counts with a finite range. Stoch. Model. 2016, 32, 77–98. [Google Scholar] [CrossRef]
- Möller, T.A.; Silva, M.E.; Weiß, C.H.; Scotto, M.G.; Pereira, I. Self-exciting threshold binomial autoregressive processes. AStA Adv. Stat. Anal. 2016, 100, 369–400. [Google Scholar] [CrossRef]
- Monteiro, M.; Scotto, M.G.; Pereira, I. Integer-valued self-exciting threshold autoregressive processes. Commun. Stat. Methods 2012, 41, 2717–2737. [Google Scholar] [CrossRef] [Green Version]
- Thyregod, P.; Carstensen, J.; Madsen, H.; Arnbjerg-Nielsen, K. Integer valued autoregressive models for tipping bucket rainfall measurements. Environmetrics 1999, 10, 395–411. [Google Scholar] [CrossRef]
- Wang, C.; Liu, H.; Yao, J.-F.; Davis, R.A.; Li, W.K. Self-excited threshold Poisson autoregression. J. Am. Stat. Assoc. 2014, 109, 777–787. [Google Scholar] [CrossRef] [Green Version]
- Stevens, S.S. Measurement, psychophysics and utility. In Measurement: Definitions and Theories; Churchman, C.W., Ratoosh, P., Eds.; John Wiley & Sons, Inc.: New York, NY, USA, 1959; pp. 18–63. [Google Scholar]
- Klein, I.; Mangold, B.; Doll, M. Cumulative paired ϕ-entropy. Entropy 2016, 18, 248. [Google Scholar] [CrossRef] [Green Version]
- Weiß, C.H. Measures of dispersion and serial dependence in categorical time series. Econometrics 2019, 7, 17. [Google Scholar] [CrossRef] [Green Version]
- Weiß, C.H. Distance-based analysis of ordinal data and ordinal time series. J. Am. Stat. Assoc. 2019. [Google Scholar] [CrossRef]
- Jacobs, P.A.; Lewis, P.A.W. Stationary discrete autoregressive-moving average time series generated by mixtures. J. Time Ser. Anal. 1983, 4, 19–36. [Google Scholar] [CrossRef]
- Weiß, C.H.; Göb, R. Measuring serial dependence in categorical time series. AStA Adv. Stat. Anal. 2008, 92, 71–89. [Google Scholar] [CrossRef]
- Weiß, C.H. Serial dependence of NDARMA processes. Comput. Stat. Data Anal. 2013, 68, 213–238. [Google Scholar] [CrossRef]
- Billingsley, P. Convergence of Probability Measures, 2nd ed.; John Wiley & Sons, Inc.: New York, NY, USA, 1999. [Google Scholar]
- Möller, T.A.; Weiß, C.H. Generalized discrete ARMA models. Appl. Stoch. Models Bus. Ind. 2020. [Google Scholar] [CrossRef] [Green Version]
- Taylor, W.R. The classification of amino acid conservation. J. Theor. Biol. 1986, 119, 205–218. [Google Scholar] [CrossRef]
- Zucchini, W.; MacDonald, I.L.; Langrock, R. Hidden Markov Models for Time Series: An Introduction Using R, 2nd ed.; Chapman & Hall/CRC Press: London, UK, 2016. [Google Scholar]
- Mansour, T. Combinatorics of Set Partitions; Chapman & Hall/CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Raftery, A.E. A model for high-order Markov chains. J. R. Stat. Soc. Ser. B 1985, 47, 528–539. [Google Scholar] [CrossRef]
- Billingsley, P. Statistical Inference for Markov Processes; University of Chicago Press: Chicago, IL, USA, 1961. [Google Scholar]
- Burnham, K.P.; Anderson, D.R. Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Katz, R.W. On some criteria for estimating the order of a Markov chain. Technometrics 1981, 23, 243–249. [Google Scholar] [CrossRef]
- Churchill, G.A. Stochastic models for heterogeneous DNA sequences. Bull. Math. Biol. 1989, 51, 79–94. [Google Scholar] [CrossRef]
- Dehnert, M.; Helm, W.E.; Hütt, M.-T. A discrete autoregressive process as a model for short-range correlations in DNA sequences. Physica A 2003, 327, 535–553. [Google Scholar] [CrossRef]
Figure 1.
Venn diagram for the classification of amino acids, adapted from Figure 3a in Taylor [20].
Figure 1.
Venn diagram for the classification of amino acids, adapted from Figure 3a in Taylor [20].

Figure 2.
Example 3: Plot of (a) and (b) against ϕ and p with . The black curves indicate those , where or , respectively.
Figure 2.
Example 3: Plot of (a) and (b) against ϕ and p with . The black curves indicate those , where or , respectively.

Figure 3.
Rate evolution graph of Bovine sequence and of against lag h.

Figure 4.
Plot of cloudiness time series and of against lag h.

Figure 5.
Plots of simulated cloudiness time series, generated according to the fitted DAR model (left) and two-regime RS-DAR model ((right); regimes separated by dotted line), respectively.
Figure 5.
Plots of simulated cloudiness time series, generated according to the fitted DAR model (left) and two-regime RS-DAR model ((right); regimes separated by dotted line), respectively.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Some measures of dispersion and serial dependence for categorical time series.
| Nominal Range | Ordinal Range | |
|---|---|---|
| Dispersion | Index of qualitative variation (Gini index): | Index of ordinal variation: |
| , | , | |
| Entropy: | Cumulative paired entropy: | |
| ; | ; | |
| where , | where , | |
| Serial dependence | Cohen’s κ: | Ordinal Cohen’s κ: |
| , | , | |
| where | where | |
| for time lag | for time lag |
Table 2.
Bovine DNA data: Bayesian information criterion (BIC) of RS-DAR models with respect to dependence parameter , compared to those of ordinary DAR and Markov chain (MC) model, respectively.
Table 2.
Bovine DNA data: Bayesian information criterion (BIC) of RS-DAR models with respect to dependence parameter , compared to those of ordinary DAR and Markov chain (MC) model, respectively.
| Model | DAR(1) | Full MC | ||
|---|---|---|---|---|
| BIC | 22927.4 | 22926.3 | 22928.9 | 22824.6 |
Table 3.
Bovine DNA data: BICs of RS-DAR models with respect to marginals , compared to those of ordinary DAR and MC model, respectively.
Table 3.
Bovine DNA data: BICs of RS-DAR models with respect to marginals , compared to those of ordinary DAR and MC model, respectively.
| Model | DAR(1) | Full MC | |||
|---|---|---|---|---|---|
| BIC | 22927.4 | 22869.6 | 22875.0 | 22822.0 | 22824.6 |
Table 4.
Cloudiness data: BICs of RS-DAR models with respect to marginals , compared to those of ordinary DAR and MC model, respectively.
Table 4.
Cloudiness data: BICs of RS-DAR models with respect to marginals , compared to those of ordinary DAR and MC model, respectively.
| Model | DAR(1) | Full MC | ||
|---|---|---|---|---|
| BIC | 1423.4 | 1345.5 | 1350.1 | 1392.6 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Weiß, C.H. Regime-Switching Discrete ARMA Models for Categorical Time Series. Entropy 2020, 22, 458. https://0-doi-org.brum.beds.ac.uk/10.3390/e22040458
AMA Style
Weiß CH. Regime-Switching Discrete ARMA Models for Categorical Time Series. Entropy. 2020; 22(4):458. https://0-doi-org.brum.beds.ac.uk/10.3390/e22040458
Chicago/Turabian StyleWeiß, Christian H. 2020. "Regime-Switching Discrete ARMA Models for Categorical Time Series" Entropy 22, no. 4: 458. https://0-doi-org.brum.beds.ac.uk/10.3390/e22040458
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.