Regularization Methods Based on the Lq-Likelihood for Linear Models with Heavy-Tailed Errors


1
Faculty of Information Science and Technology, Hokkaido University, Kita 14, Nishi 9, Kita-ku, Sapporo, Hokkaido 060-0814, Japan
2
Global Station for Big Data and Cybersecurity, Global Institution for Collaborative Research and Education, Hokkaido University, Hokkaido 060-0814, Japan
Entropy 2020, 22(9), 1036; https://0-doi-org.brum.beds.ac.uk/10.3390/e22091036
Submission received: 26 August 2020
/
Revised: 11 September 2020
/
Accepted: 13 September 2020
/
Published: 16 September 2020
(This article belongs to the Section Information Theory, Probability and Statistics)
Abstract
:We propose regularization methods for linear models based on the -likelihood, which is a generalization of the log-likelihood using a power function. Regularization methods are popular for the estimation in the normal linear model. However, heavy-tailed errors are also important in statistics and machine learning. We assume q-normal distributions as the errors in linear models. A q-normal distribution is heavy-tailed, which is defined using a power function, not the exponential function. We find that the proposed methods for linear models with q-normal errors coincide with the ordinary regularization methods that are applied to the normal linear model. The proposed methods can be computed using existing packages because they are penalized least squares methods. We examine the proposed methods using numerical experiments, showing that the methods perform well, even when the error is heavy-tailed. The numerical experiments also illustrate that our methods work well in model selection and generalization, especially when the error is slightly heavy-tailed.
1. Introduction
We propose regularization methods based on the -likelihood for linear models with heavy-tailed errors. These methods turn out to coincide with the ordinary regularization methods that are used for the normal linear model. The proposed methods work efficiently, and can be computed using existing packages.
Linear models are widely applied, and many methods have been proposed for estimation, prediction, and other purposes. For example, for estimation and variable selection in the normal linear model, the literature on sparse estimation includes the least absolute shrinkage and selection operator (LASSO) [1], smoothly clipped absolute deviation (SCAD) [2], Dantzig selector [3], and minimax concave penalty (MCP) [4]. The LASSO has been studied extensively and generalized to many models, including the generalized linear models [5]. As is well known, the regularization methods have many good properties. Many regularization methods are the penalized maximum likelihood estimators, that is, minimizing the sum of the negative log-likelihood and a penalty. The literature proposed various penalties. As described later, our regularization methods use another likelihood with existing penalties.
Because the regularization methods for the normal linear model are useful, they are sometimes used in linear models with non-normal errors. Here, popular errors include the Cauchy error and the t-distribution error, both of which are heavy-tailed errors. For example, Ref. [6] partly consider the Cauchy and t-distribution errors in their extensive experiments. These heavy-tailed distributions are known to be q-normal distributions, which are studied in the literature on statistical mechanics [7,8,9]. The q-normal model is also studied in the literature on the generalized Cauchy distribution. For example, see [10,11,12,13].
In this study, we consider the problem of a linear regression with a q-normal error. We propose sparse estimation methods based on the -likelihood, which is a generalization of the log-likelihood using a power function. The maximizer of the -likelihood, the maximum -likelihood estimator (MLqE), is investigated by [14] as an extension of the ordinary maximum likelihood estimator (MLE). Ref. [14] studies the asymptotic properties of the MLqE. However, we are interested in the regularization, not in the MLqE, because regularization estimators can be better than the MLqE. We examine the proposed methods using numerical experiments. The experiments show that our methods perform well in model selection and generalization, even when the error is heavy-tailed. Moreover, we consider the effects of the sample size, dimension and sparseness of the parameter, and value of the nonzero elements in the numerical experiments.
We also find that the proposed methods for linear models with q-normal errors coincide with the ordinary regularization methods that are applied to the normal linear model. This finding partly justifies the use of the ordinary regularization methods for linear regressions with heavy-tailed errors. Moreover, the proposed methods are penalized least squares methods, and can be efficiently computed by existing packages.
The rest of the paper is organized as follows. In Section 2, we introduce several tools, including the normal linear model, regularization methods, -likelihood, and q-normal models. In Section 3, we describe the problem under consideration, that is, estimations in linear models with q-normal errors. Moreover, we propose several regularization methods based on the -likelihood. In Section 4, we evaluate the proposed methods using numerical experiments. Section 5 concludes the paper.
2. Preliminaries
2.1. Normal Linear Model and Sparse Estimation
First, we introduce the normal linear model, the estimation of which is a basic problem in statistics and machine learning [15]. Furthermore, we briefly describe some well-known regularization methods.
The normal linear model is defined as follows. A response is represented by a linear combination of explanatory variables as
where is the response of the a-th sample, n is the sample size, d is the number of explanatory variables, is the i-th explanatory variable of the a-th sample, is a normal error with mean zero and known variance, and the regression coefficient is the parameter to be estimated. The normal linear model is equivalently given by
where is the expectation of the response , , and is a design matrix of size , with . Moreover, we define a row vector as , and a column vector as , which results in . Let be the response vector of length n. We assume that each column vector is standardized, as follows: and , for .
As is well known, some regularization methods for the normal linear model are formulated as an optimization problem in the form of
where is a penalty term, and is a regularization parameter. The LASSO [1] uses . The path of the LASSO estimator when varies can be made by the least angle regression (LARS) algorithm [16]. The SCAD [2] uses
and the MCP [4] uses
where and are tuning parameters.
The regularization problem given in (2) can be represented by
where is the probability density function of the statistical model. Note that is the log-likelihood.
2.2. -Likelihood
The -likelihood is a generalization of the log-likelihood that uses a power function instead of the logarithmic function. Let be a vector of independent and identically distributed (i.i.d.) observations, and let be a parameter of a statistical model. For , the -likelihood function is defined as
where is a probability density function of the statistical model, and
is the q-logarithmic function [9]. For , we define
which is the ordinary logarithmic function. When , the -likelihood is the log-likelihood.
The MLqE is defined as the estimator that maximizes the -likelihood. [14] studied the asymptotic performance of the MLqE, showing that it enjoys good asymptotic properties (e.g., asymptotic normality).
2.3. q-Normal Model
Before defining the q-normal distribution [7,8,9], we introduce the q-exponential function. For , the q-exponential function is the inverse function of the q-logarithmic function, and is given by
For , the 1-exponential function is the ordinary exponential function
Using the q-exponential function, the q-normal model is given by
where is a location parameter, is the parameter space, and is a dispersion parameter. The constant is a normalizing constant.
We assume that , which ensures that the sample space is the real line itself, not just part of it. Moreover, the parameter space is when .
For example, the 1-normal model is the ordinary normal model. Another example is the Cauchy distribution for :
where is the beta function. Furthermore, the t-distribution of the degree of freedom is obtained for :
3. Problem and Estimation Method
3.1. Linear Model with q-Normal Error
In this subsection, we formulate our problem, that is, a linear regression with a heavy-tailed error. The errors of the Cauchy and t-distributions in linear models have been studied by researchers in the context of heavy-tailed errors [17,18,19,20]. However, they focused mainly on the least squares methods, whereas we are interested in sparse estimators. Moreover, our approach is based on the -likelihood, not the ordinary log-likelihood.
We examine the problem of estimating the linear model given in (1) with i.i.d. errors from a q-normal distribution; henceforth, we refer to this as the q-normal linear model. In terms of probability distributions, we wish to estimate the parameter of the q-normal linear model :
where the dispersion parameter is assumed to be known (). The 1-normal linear model is identical to the normal linear model, as described in Section 2.1.
3.2. -Likelihood-Based Regularization Methods
We propose regularization methods based on the -likelihood. For q-normal linear models, the proposed methods coincide with the original regularization methods for the normal linear model. In other words, we apply the ordinary regularization methods as if the error distribution were a normal distribution. The literature describes how to compute the proposed methods efficiently. Moreover, our method calculates the MLqE.
We define the -likelihood for the q-normal linear model in (7) as (6), where is the regression coefficient. Note that the components of are not assumed to be identically distributed because their distributions are dependent on the explanatory variables.
The -likelihood for the q-normal linear model is
where the second term is a constant. The MLqE of the parameter is defined as the maximizer of the -likelihood. In the q-normal linear model, the MLqE is equal to the ordinary least square, the MLE for the normal linear model.
We propose a LASSO, SCAD, and MCP based on the -likelihood by replacing the log-likelihood with the -likelihood in the optimization problem in (5). That is, the -likelihood-based regularization methods are given in the form of
The penalty is for the LASSO, (3) for the SCAD, and (4) for the MCP. Note that the estimator for is the MLqE. As a special case, the proposed methods are the ordinary regularization methods when .
Because of (8) and (9), for the q-normal linear models, the -likelihood-based regularization methods are essentially the same as the penalized least square (2). In other words, we implicitly use the -likelihood-based regularization methods when we apply the ordinary LASSO, SCAD, and MCP to data with heavy-tailed errors.
4. Numerical Experiments
In this section, we describe the results of our numerical experiments and compare the proposed methods. Here, we focus on model selection and generalization.
Our methods do not require additional implementations because the LASSO, SCAD, and MCP are already implemented in software packages. In the experiments, we use the ncvreg package of the software R.
4.1. Setting
The procedure for the experiments is as follows. We fix the value q of the q-normal linear model and the -likelihood, the dimension d of the parameter , the ratio of nonzero components of , the true value of the nonzero components of , and the sample size n. The value of q is selected from , and , where is the t-distribution with degrees of freedom, is the t-distribution with degrees of freedom, and is the t-distribution with degrees of freedom. The sample size is or . The true parameter consists of s and zeros. All cases are illustrated in Table 1.
For each of trials, we create the design matrix X using the rnorm() function in R. The response is generated as q-normal random variables using the qGaussian package. For the estimation, we apply the ncvreg() function to with the default options; for example, the values of the tuning parameters are and .
To select one model and one estimate from a sequence of parameter estimates generated by a method, we use the AIC and BIC:
where is the dimension of parameters of the model under consideration. Moreover, we use other criteria based on the -likelihood:
For a sequence made by each of the methods, let and the MLE of the model . We call (10) with AIC1, and (10) with AIC2. Similarly, (11) with is BIC1, and (11) with is BIC2. The -AIC and -BIC are referred to in the same manner; for example, (12) with is -AIC1. Note that AIC1, BIC1, -AIC1, and -BIC1 are available only when the MLE exists; AIC2, BIC2, -AIC2, and -BIC2 are always applicable. Finally, we used cross-validation (CV) in addition to these information criteria.
4.2. Result
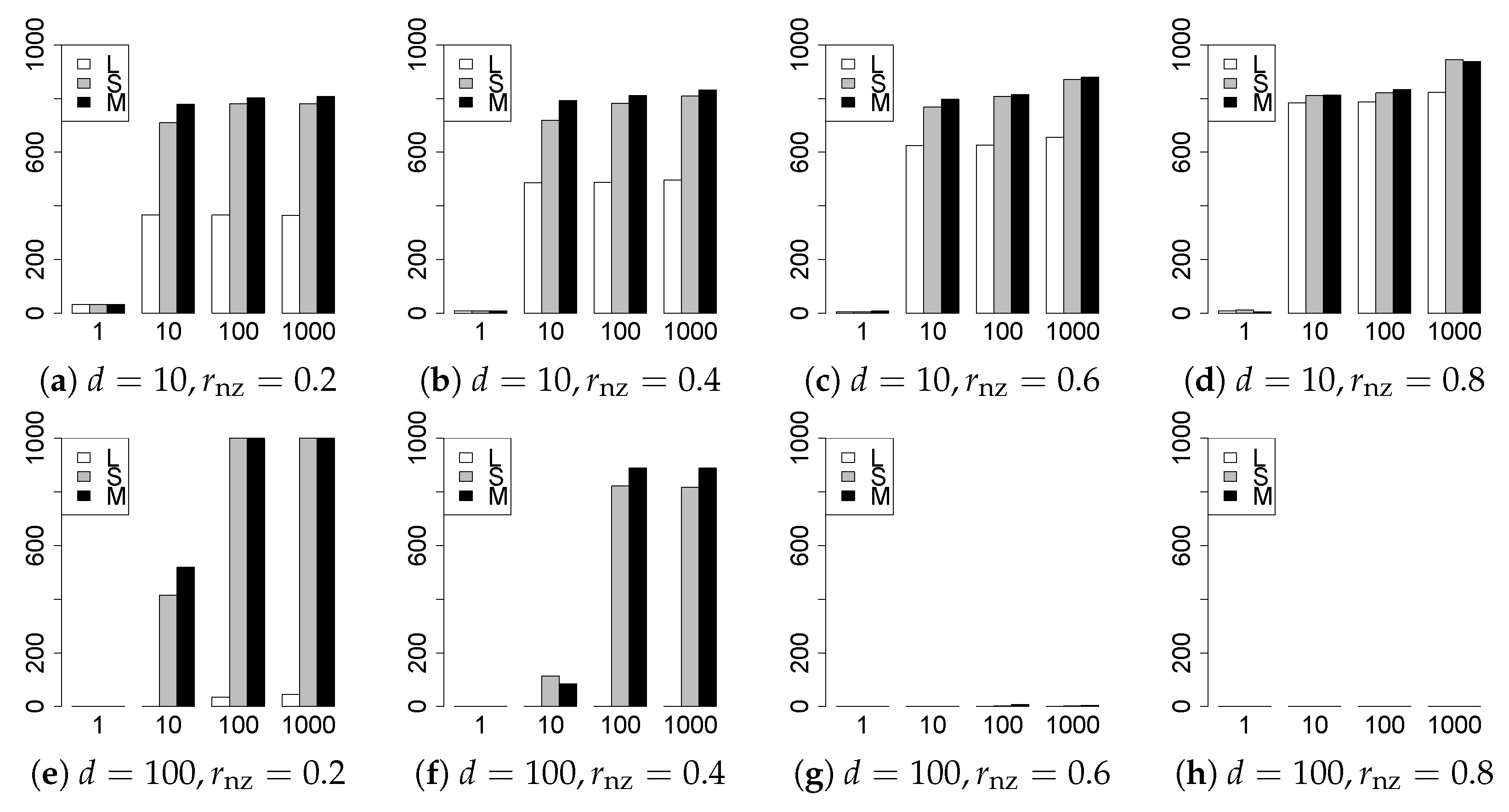
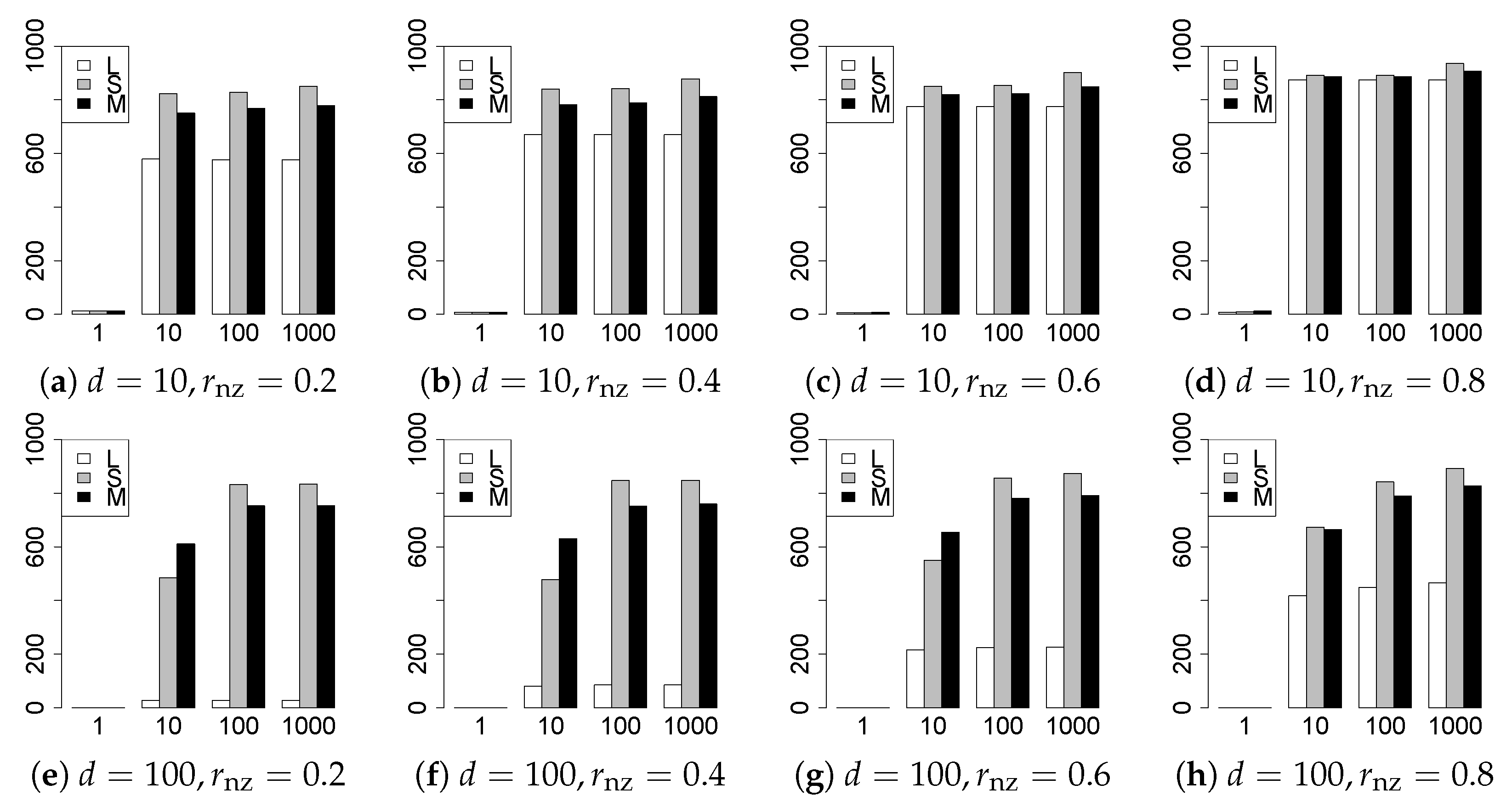
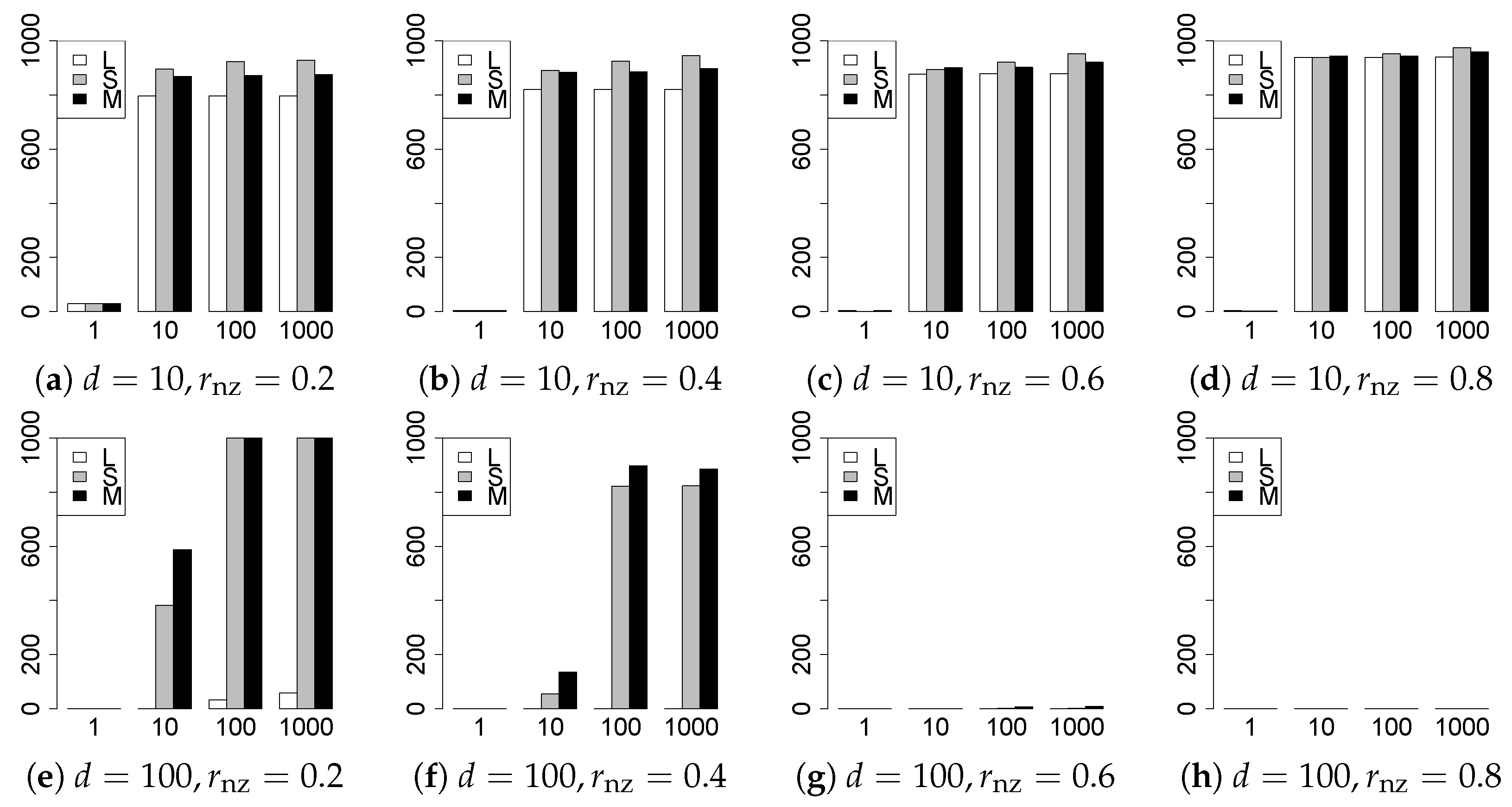
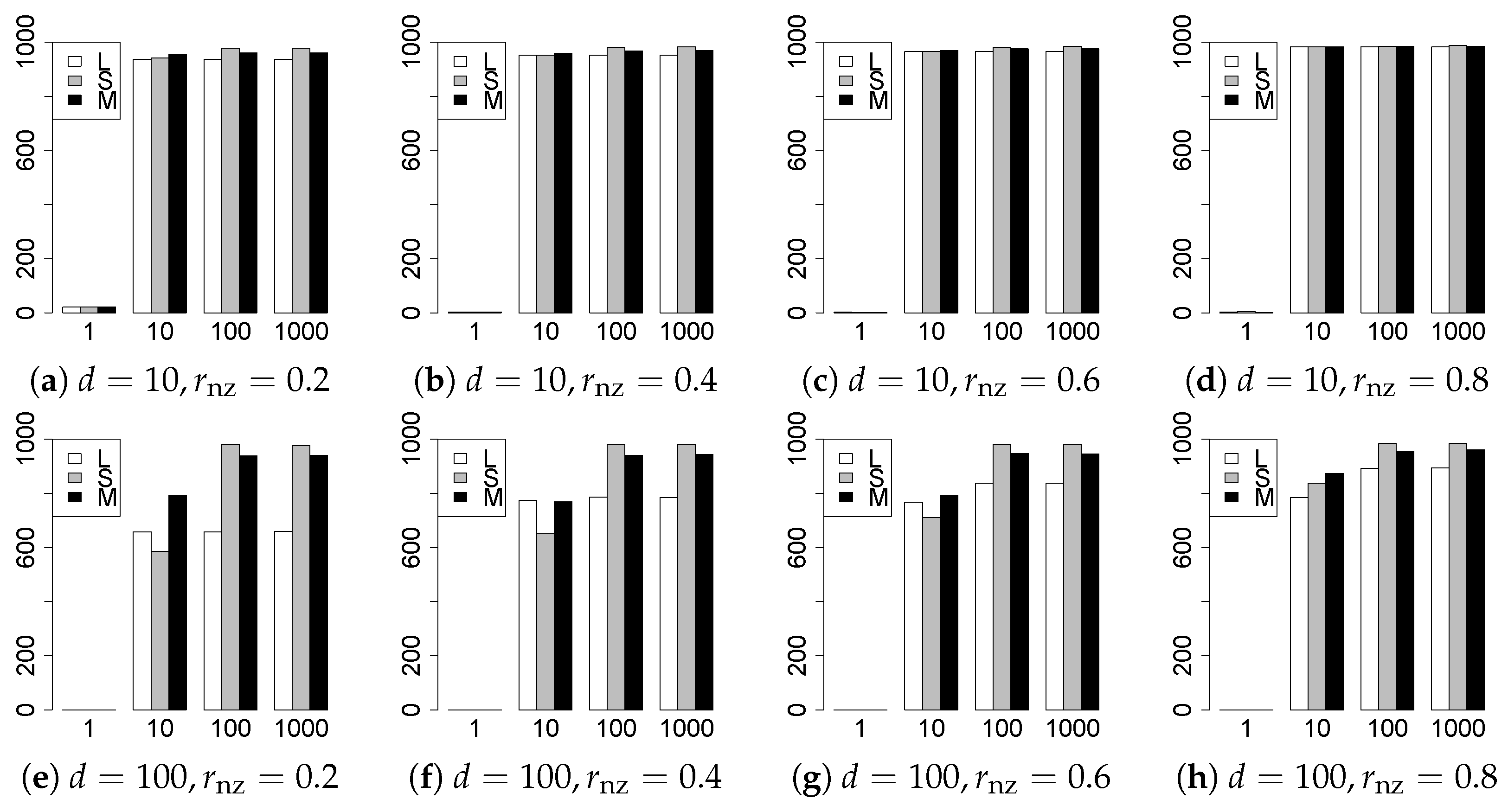
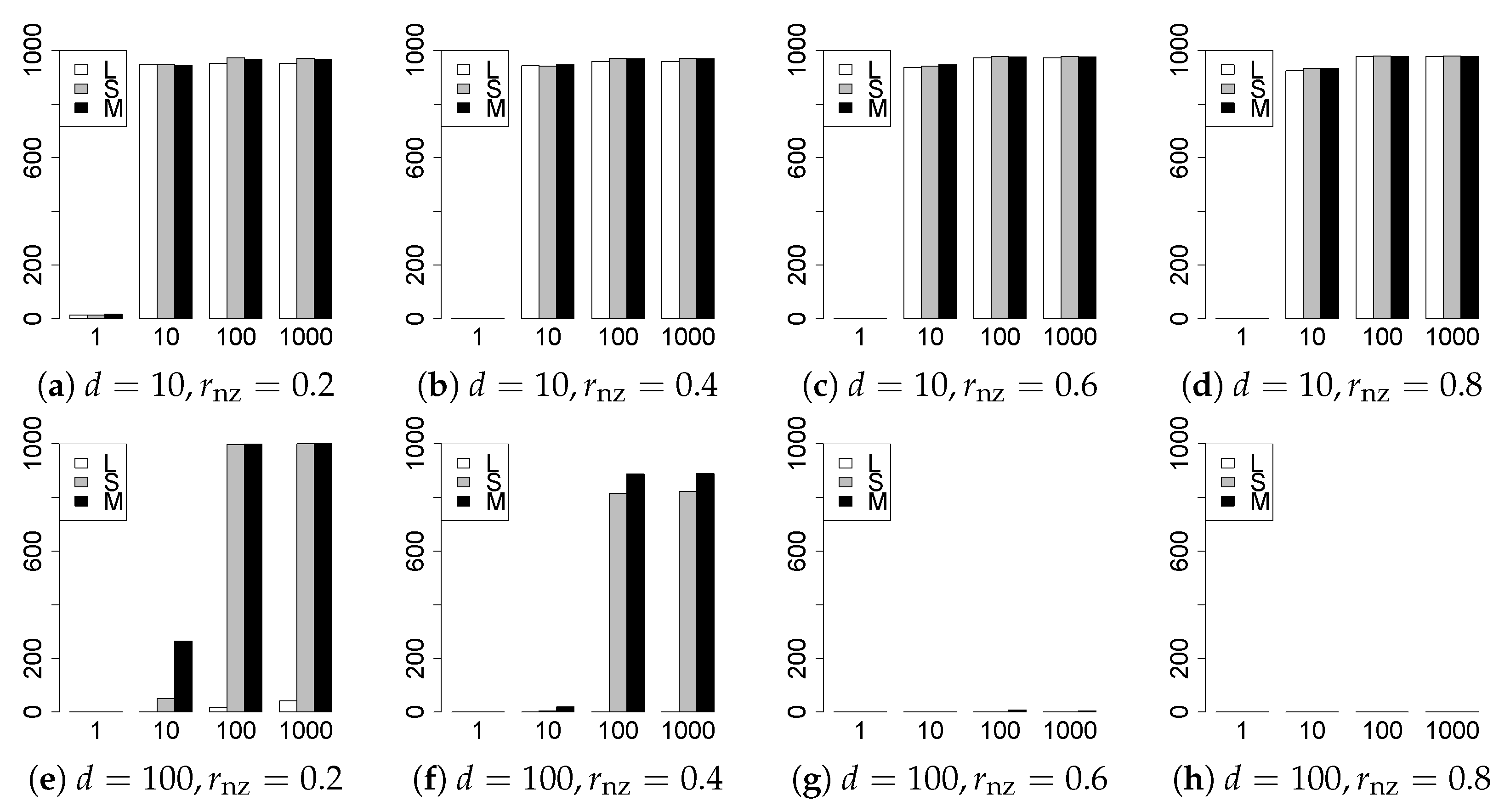
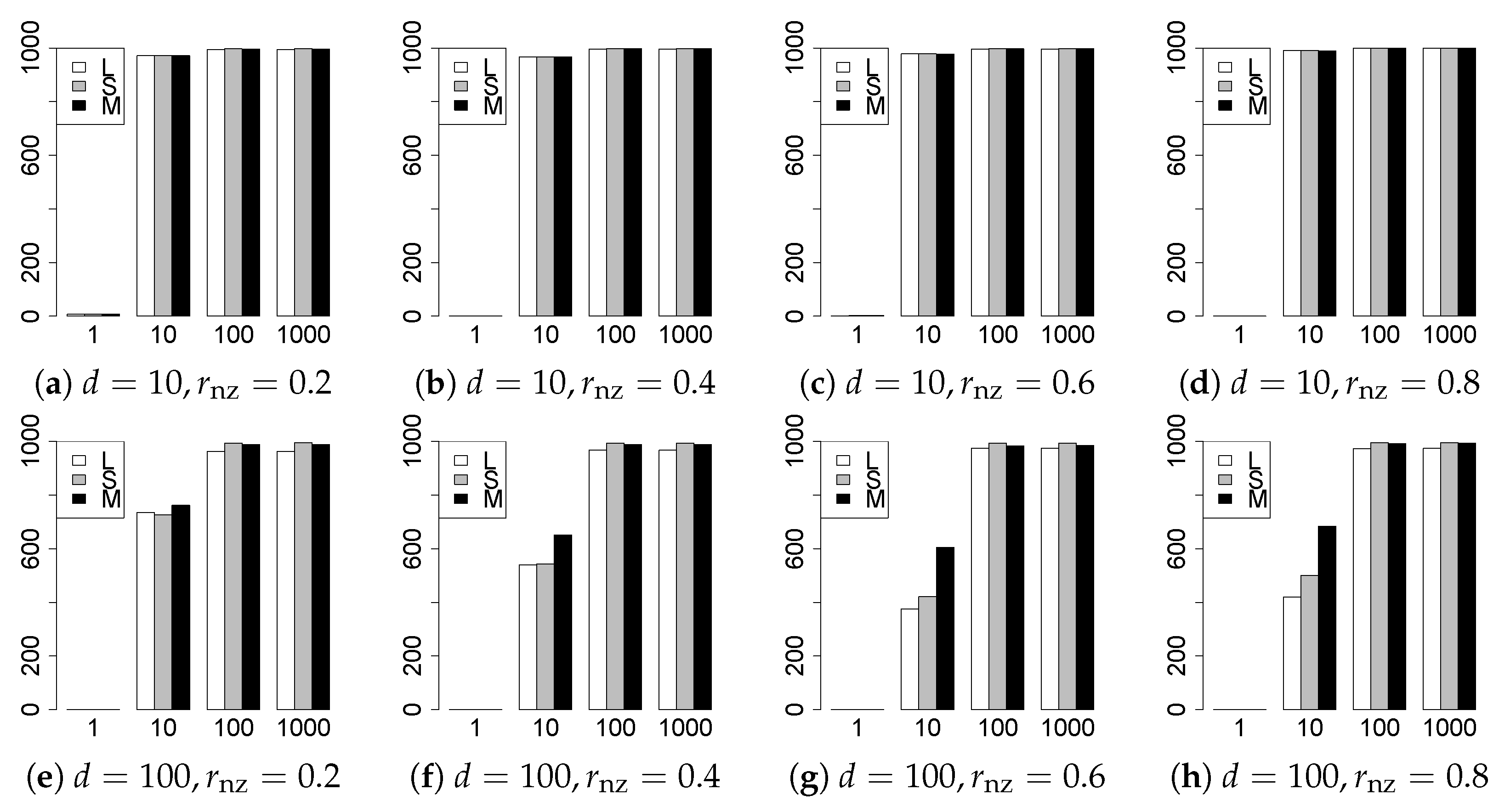
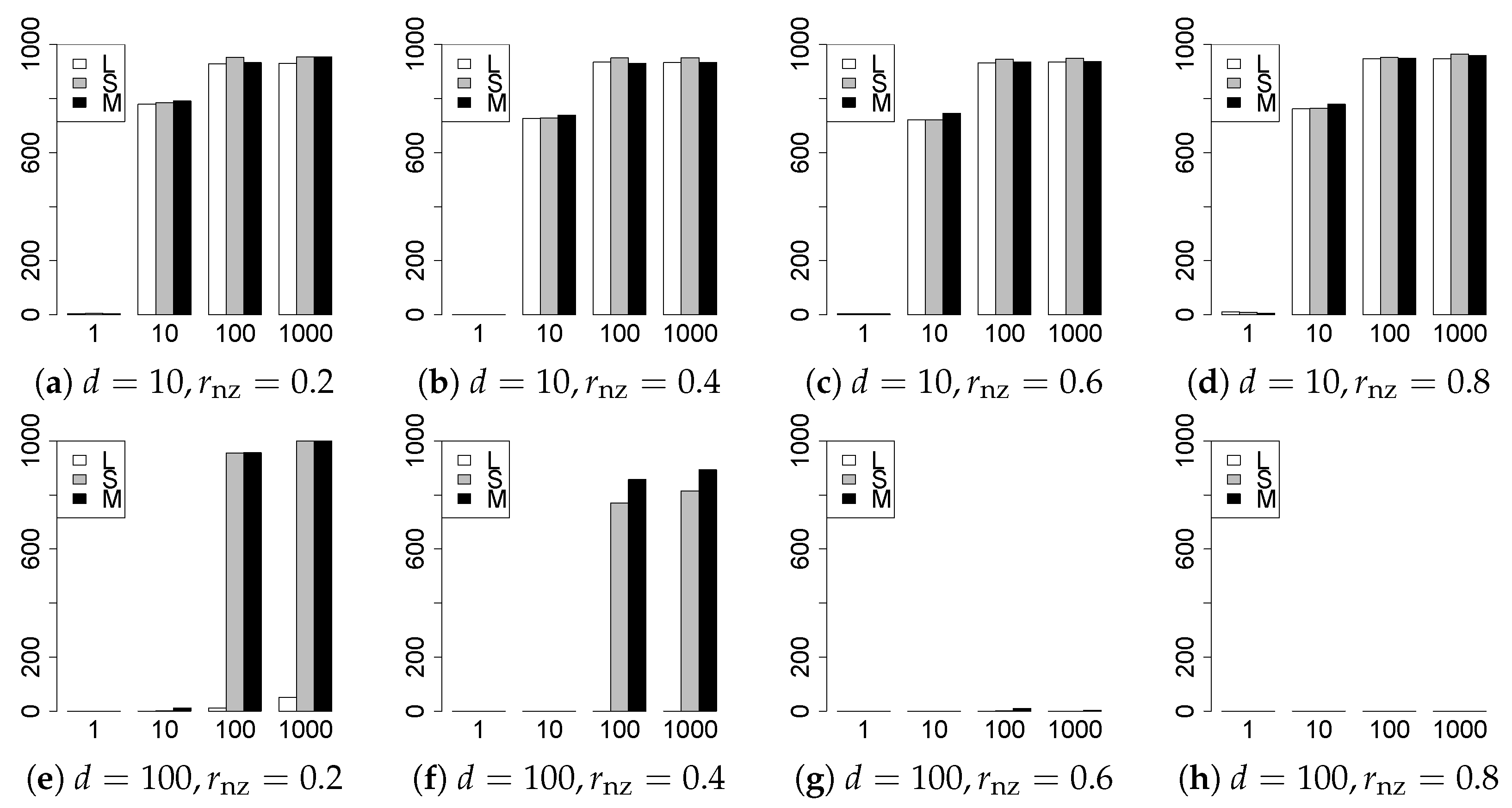
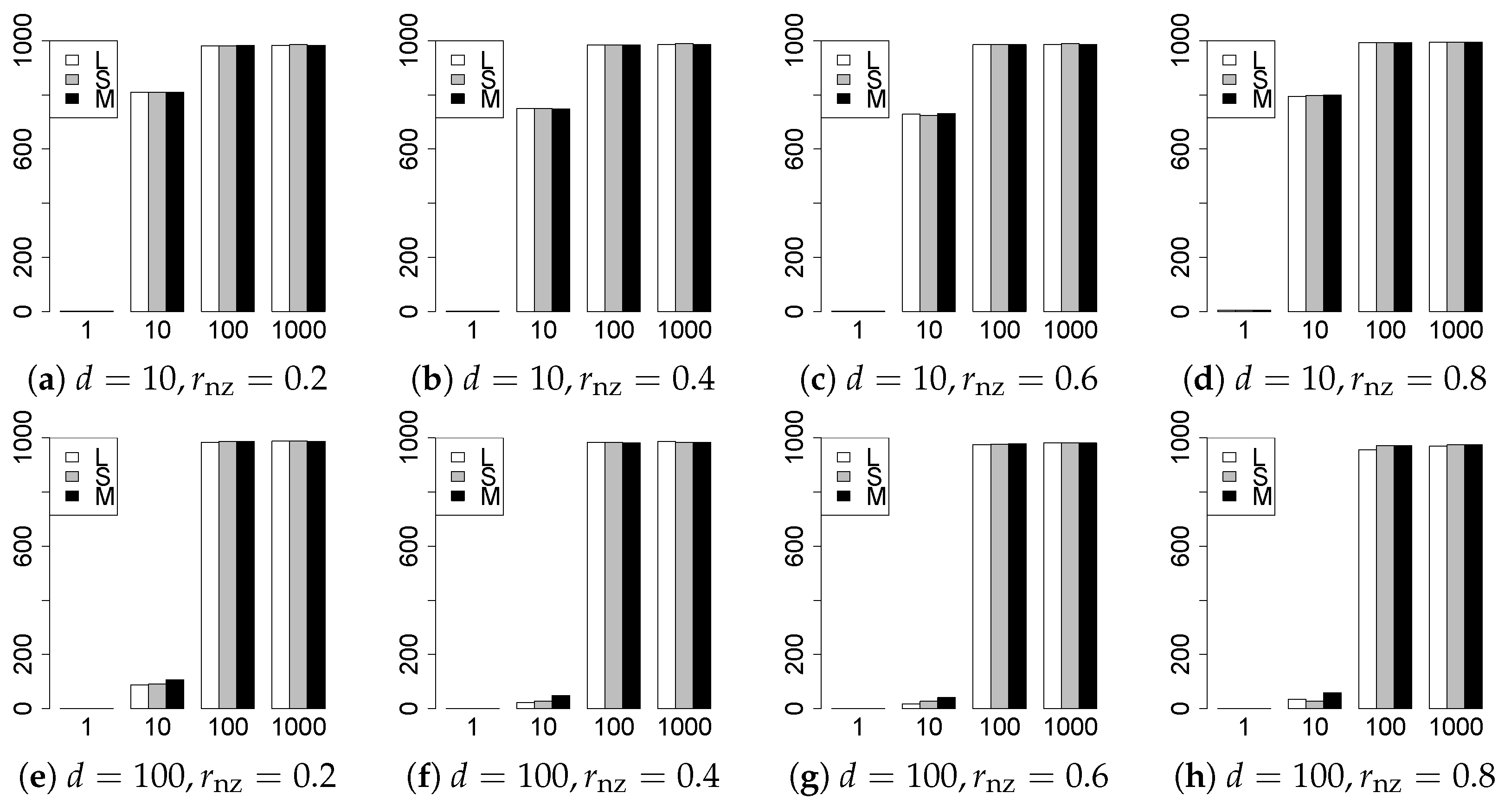
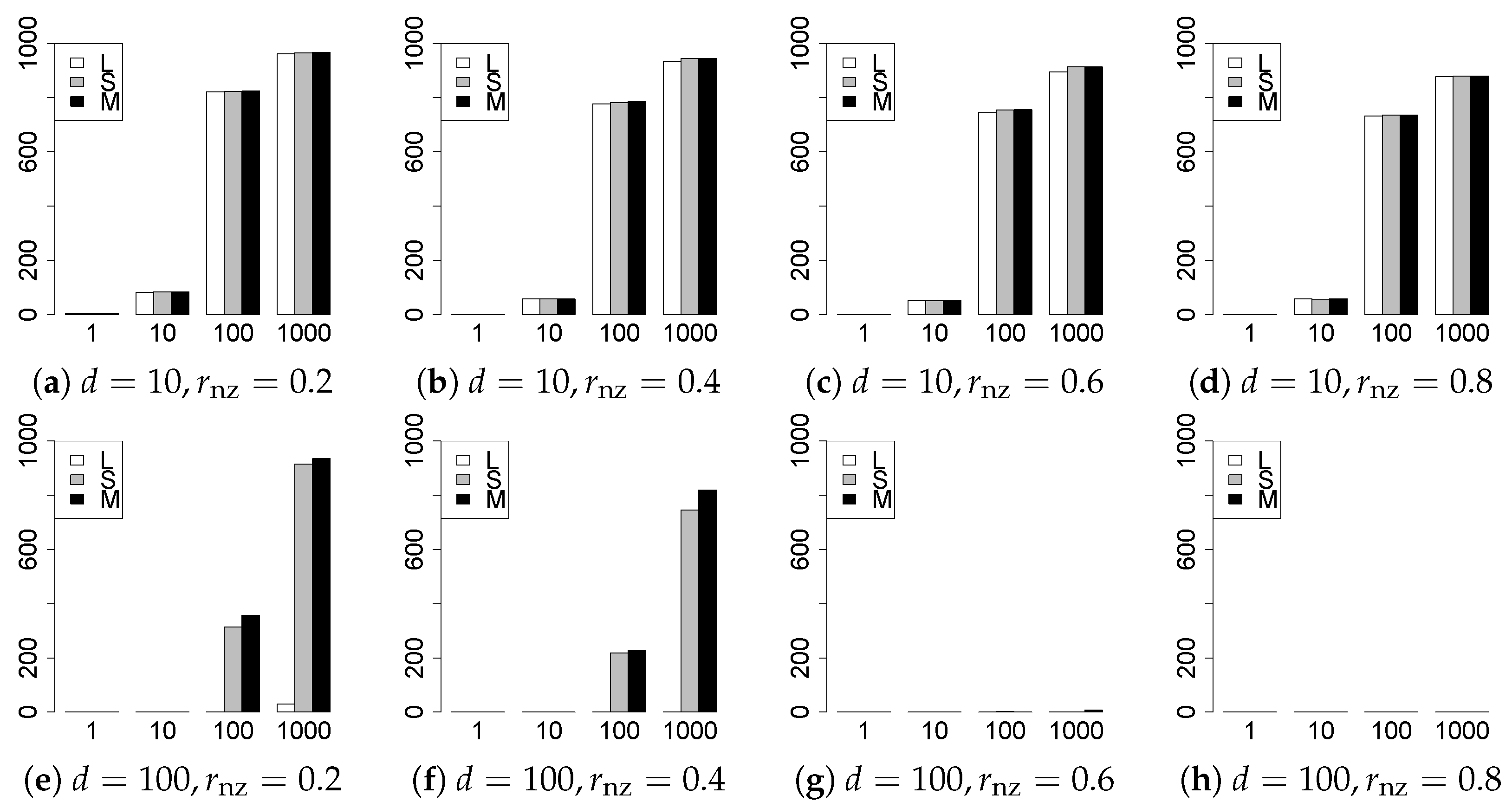
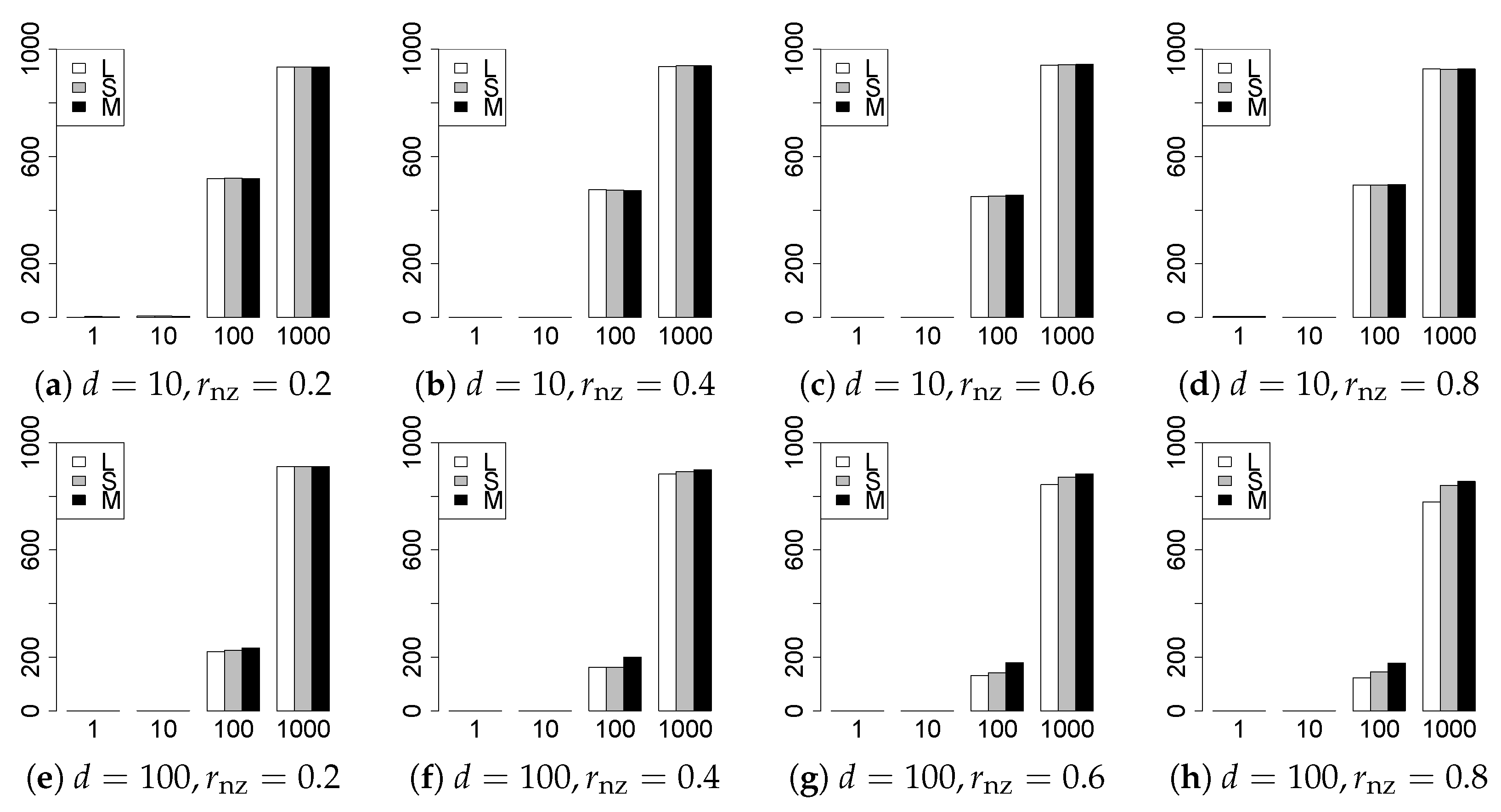
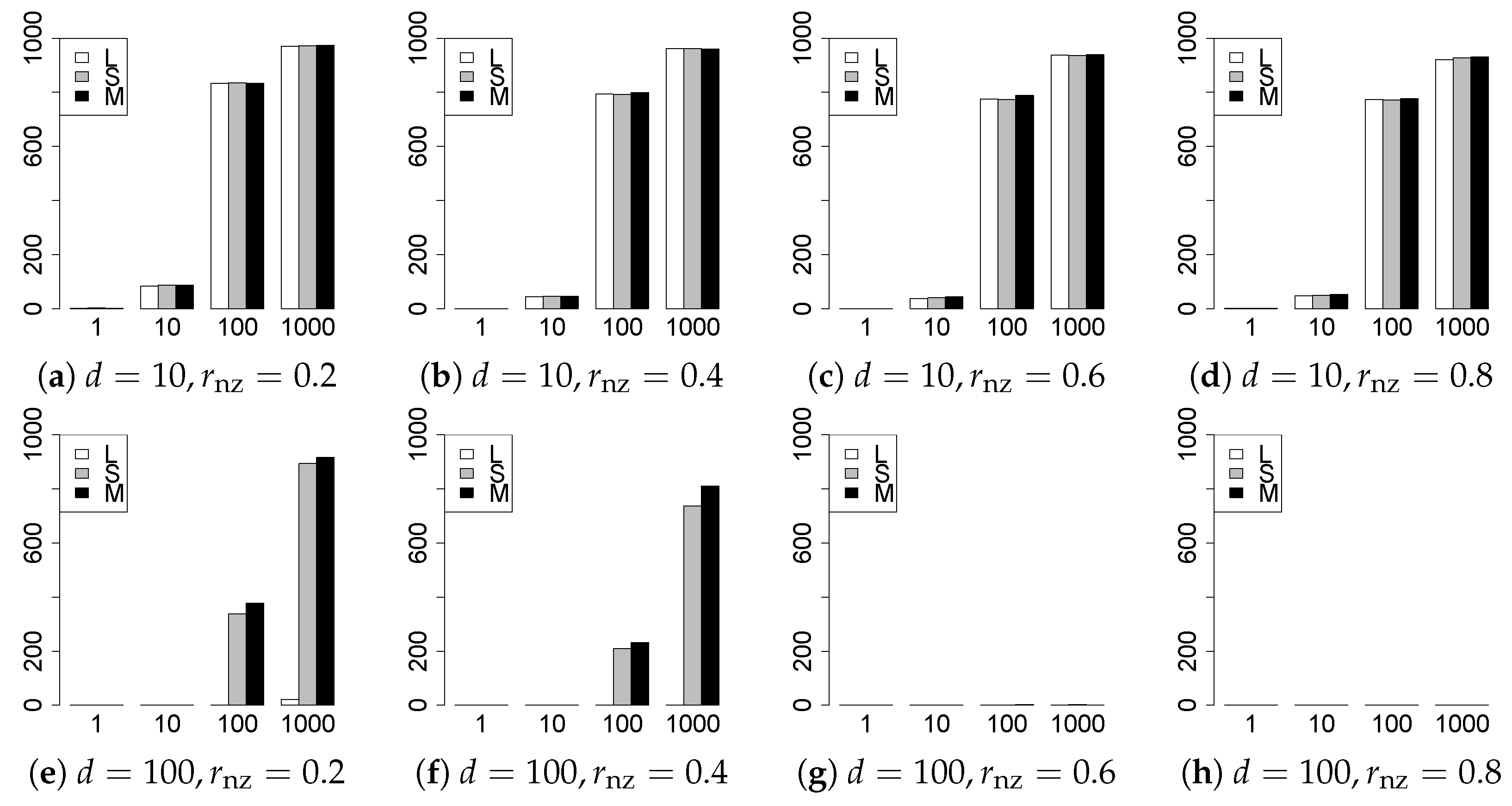
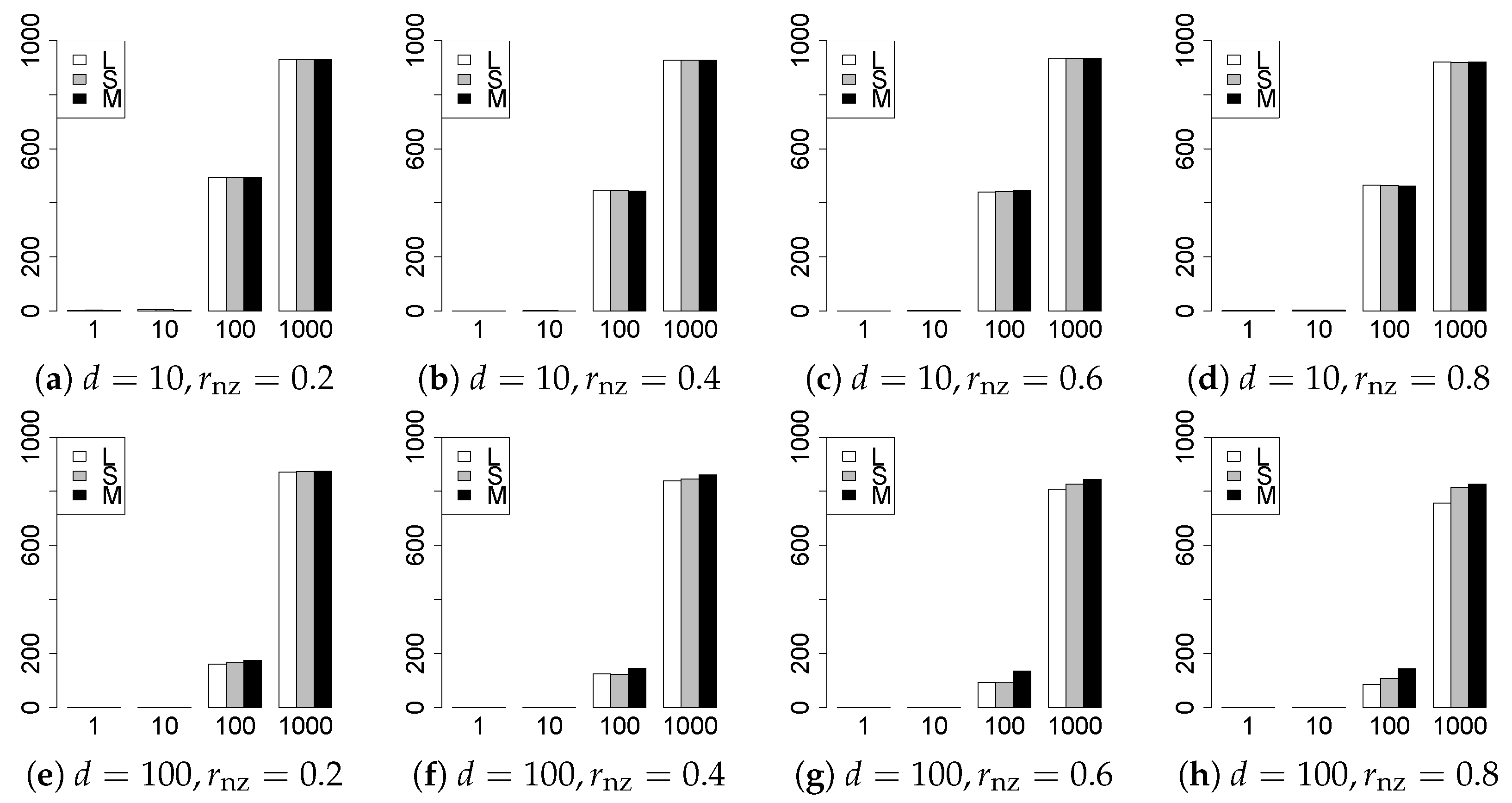
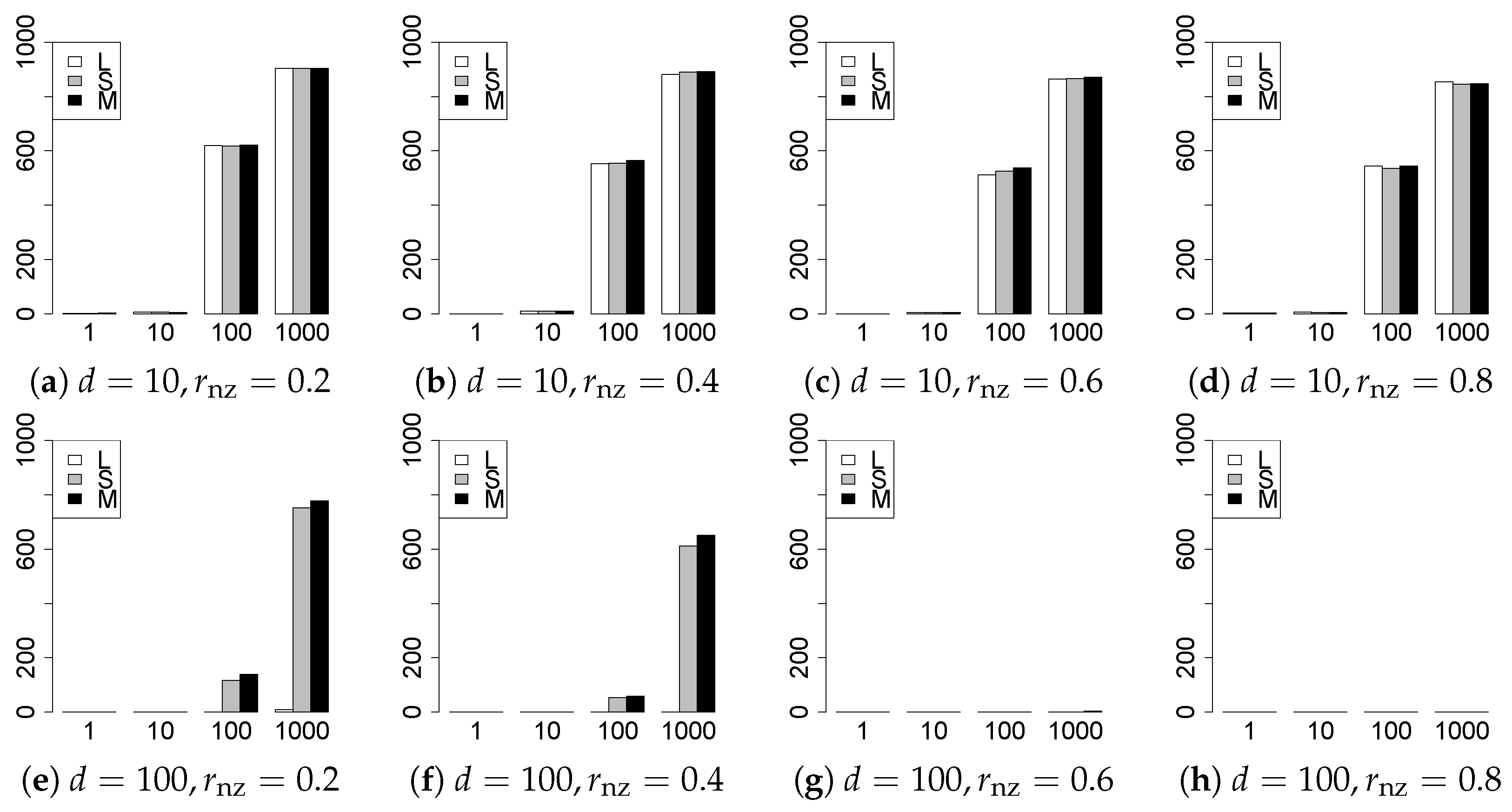
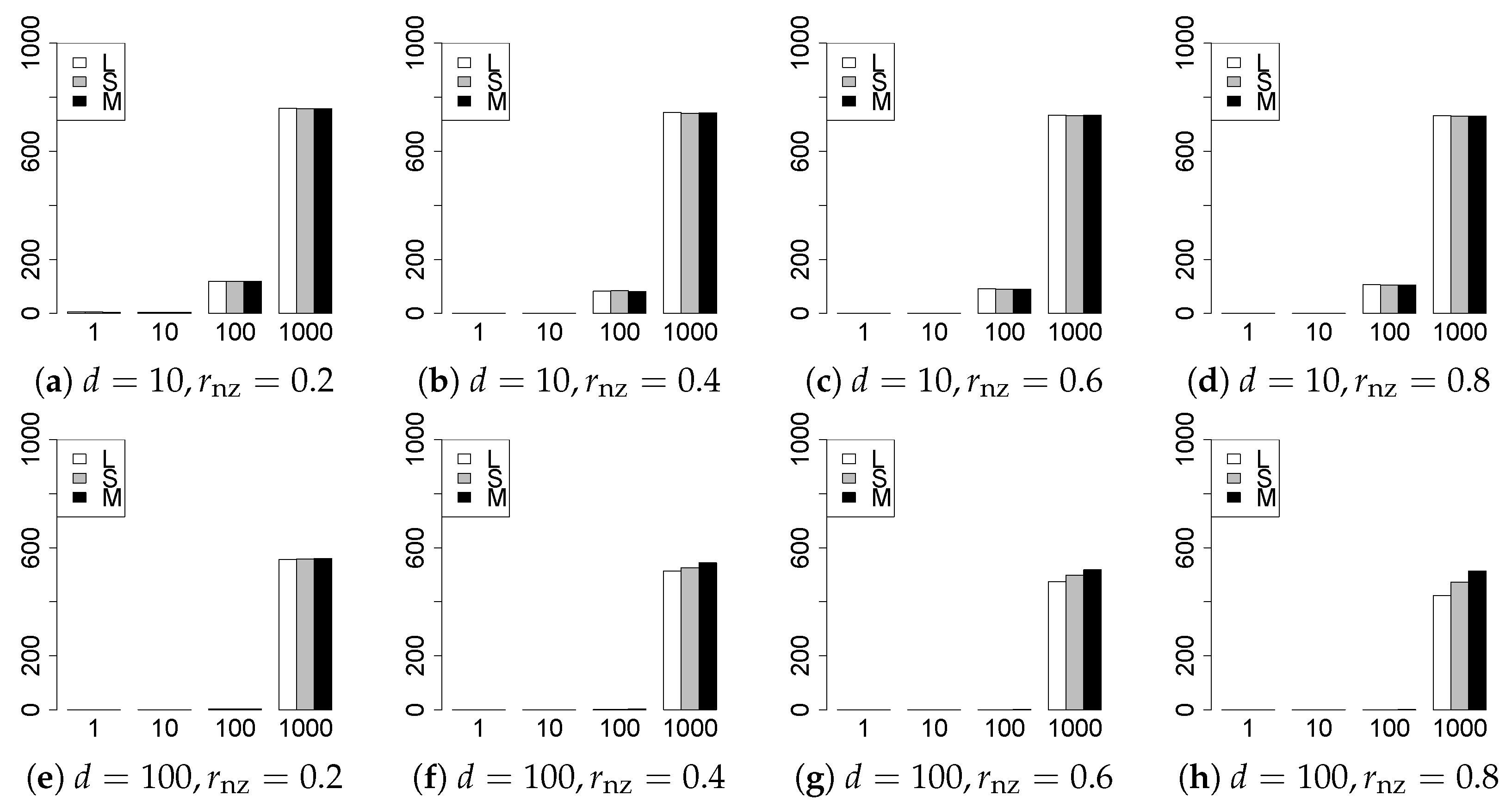
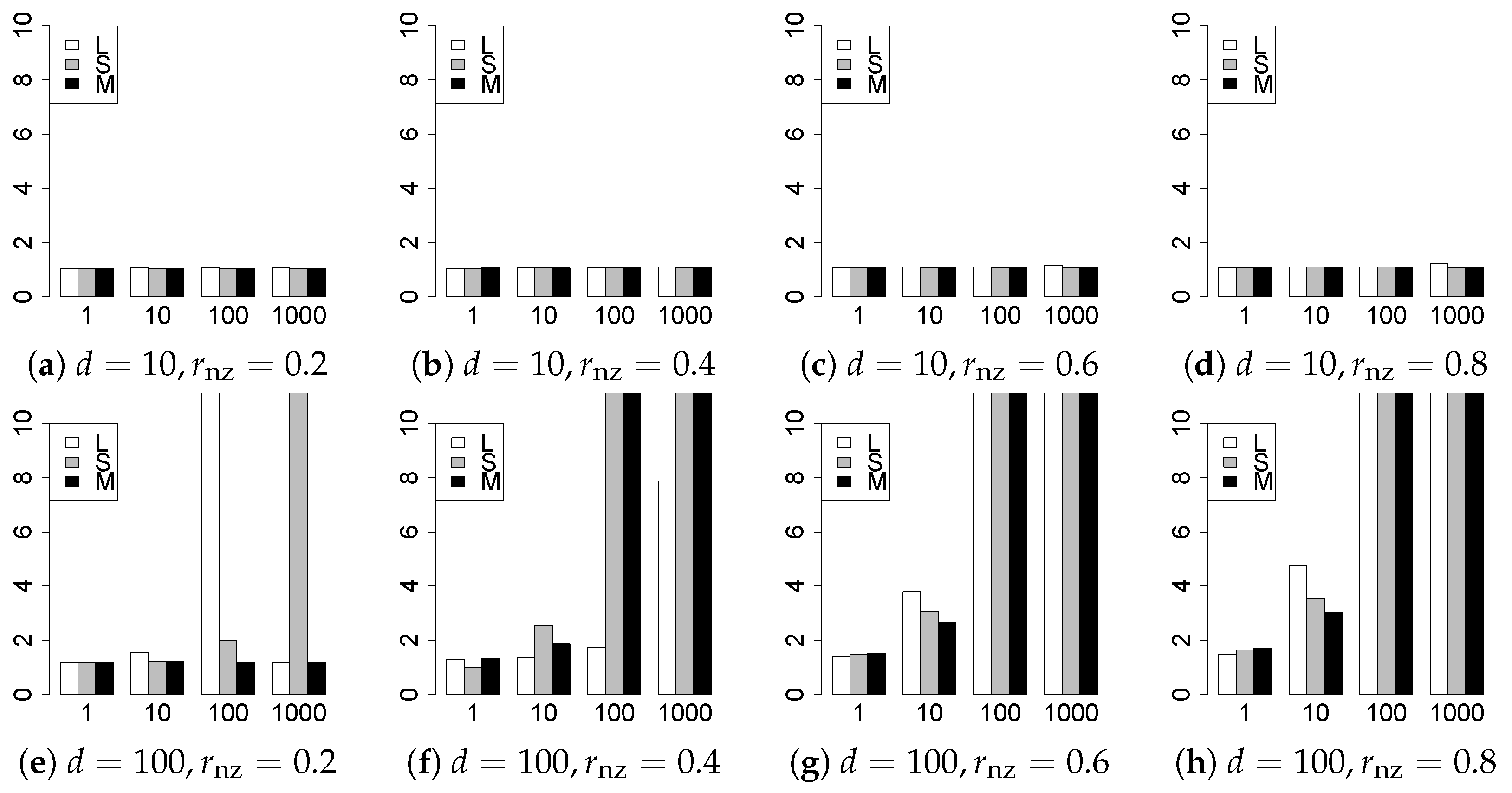
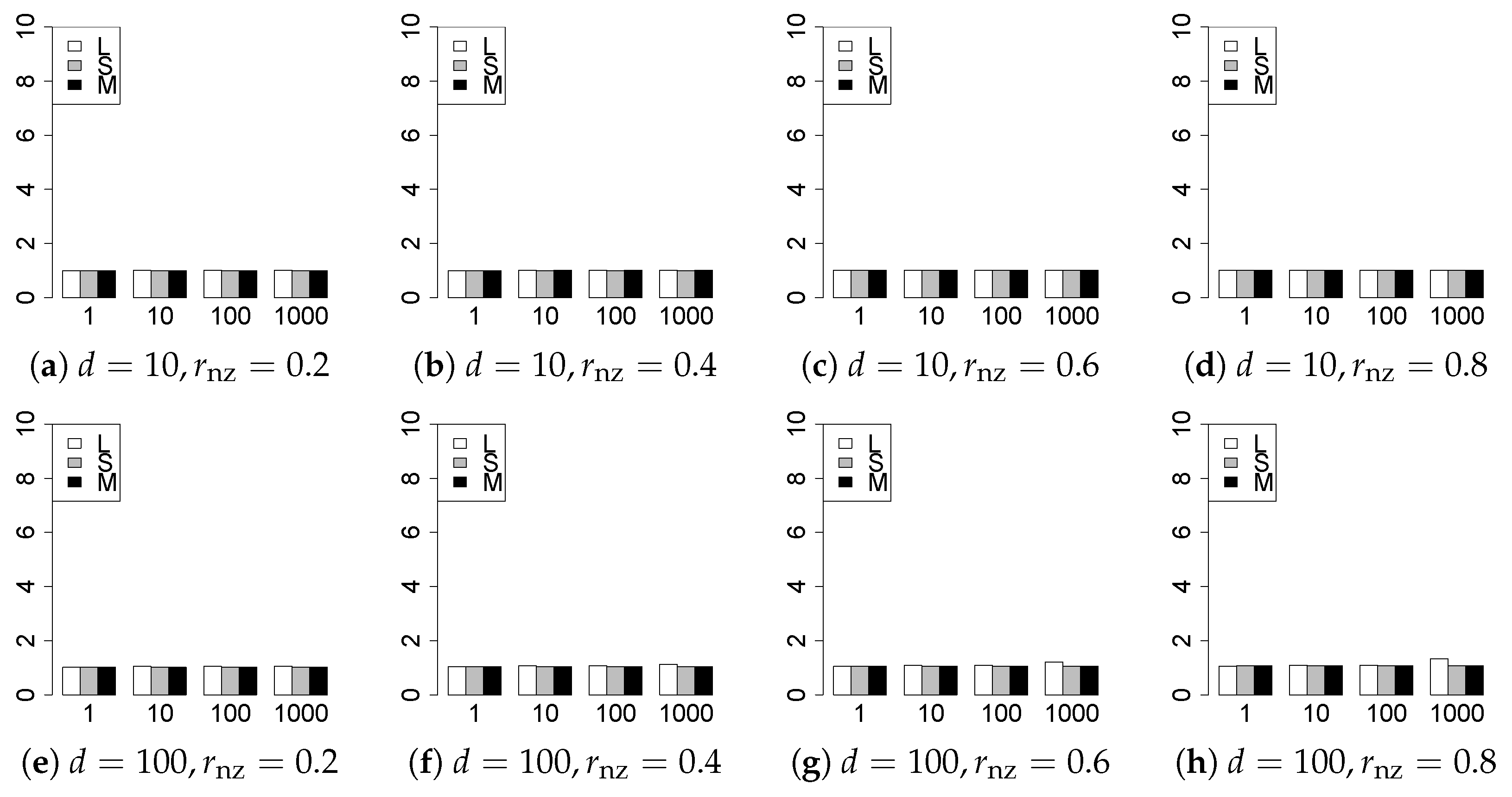
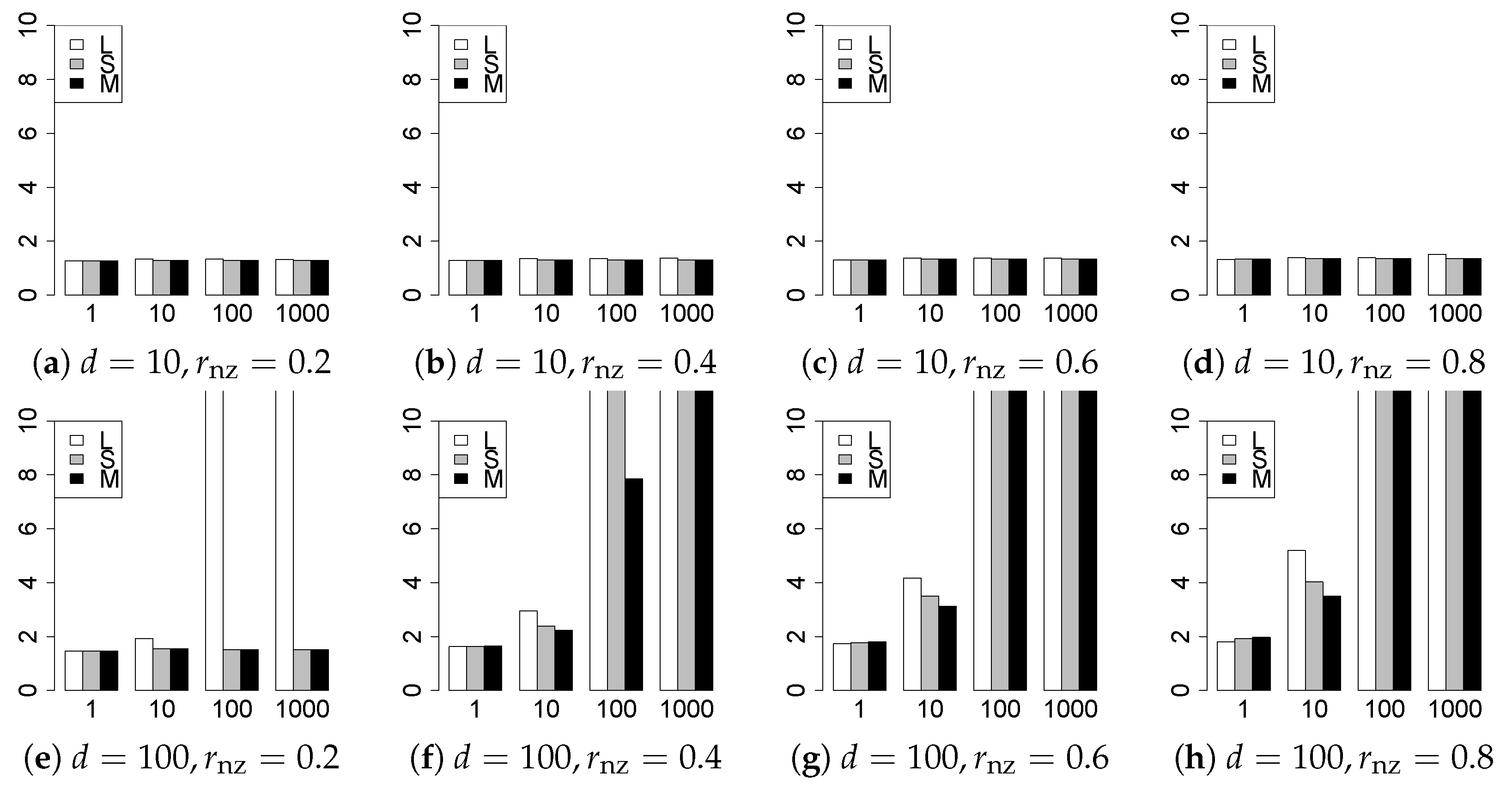
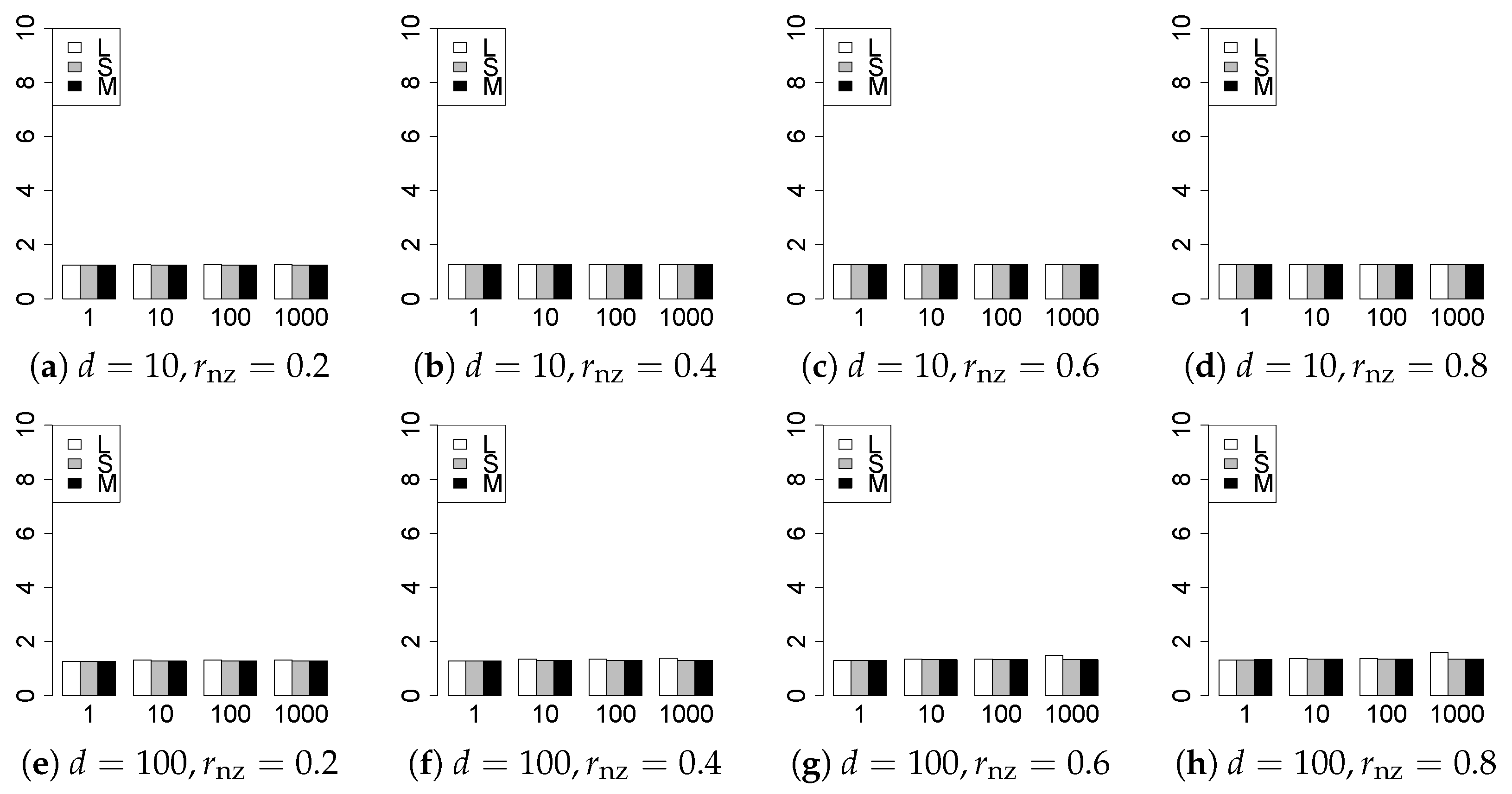
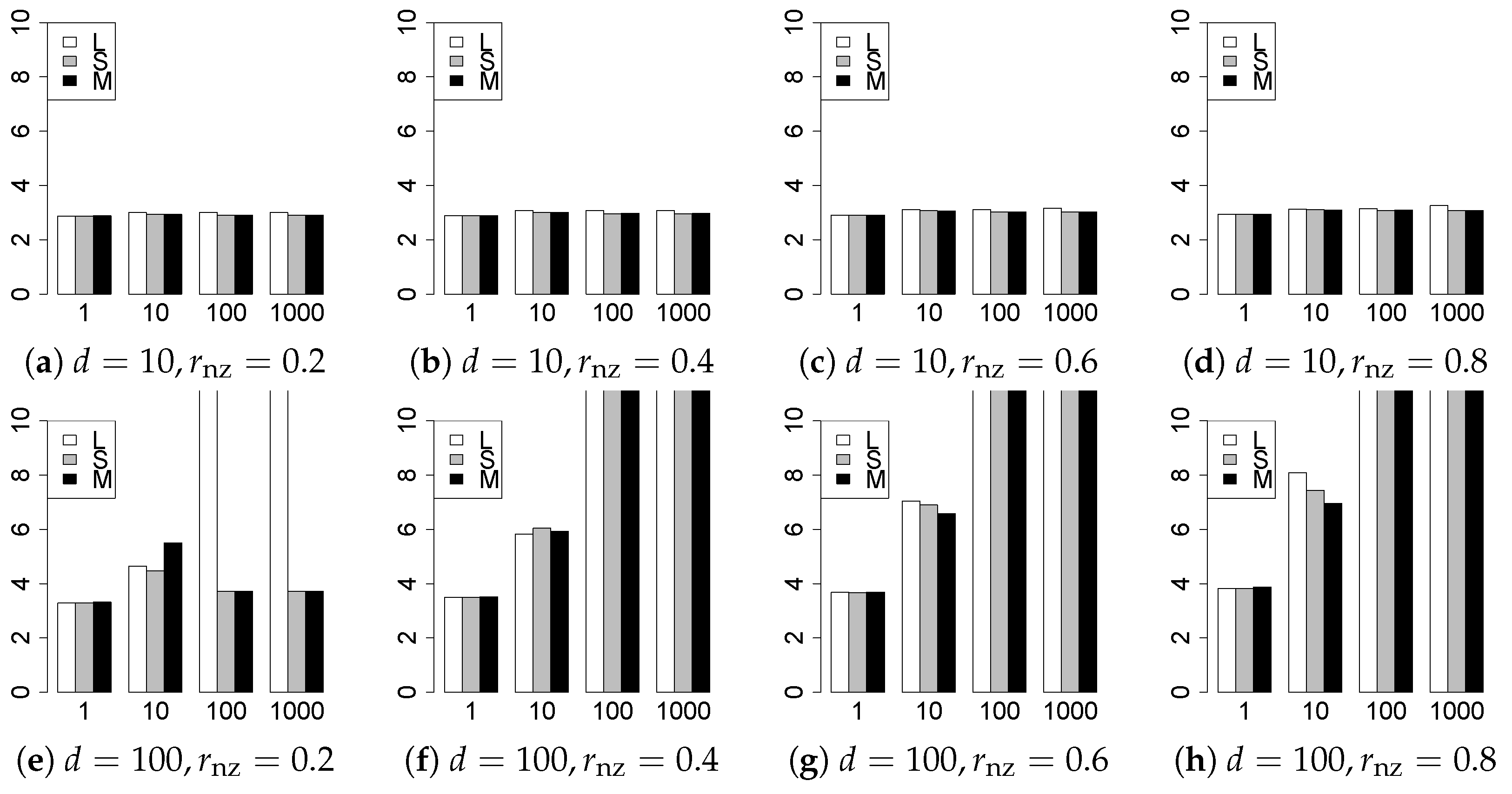
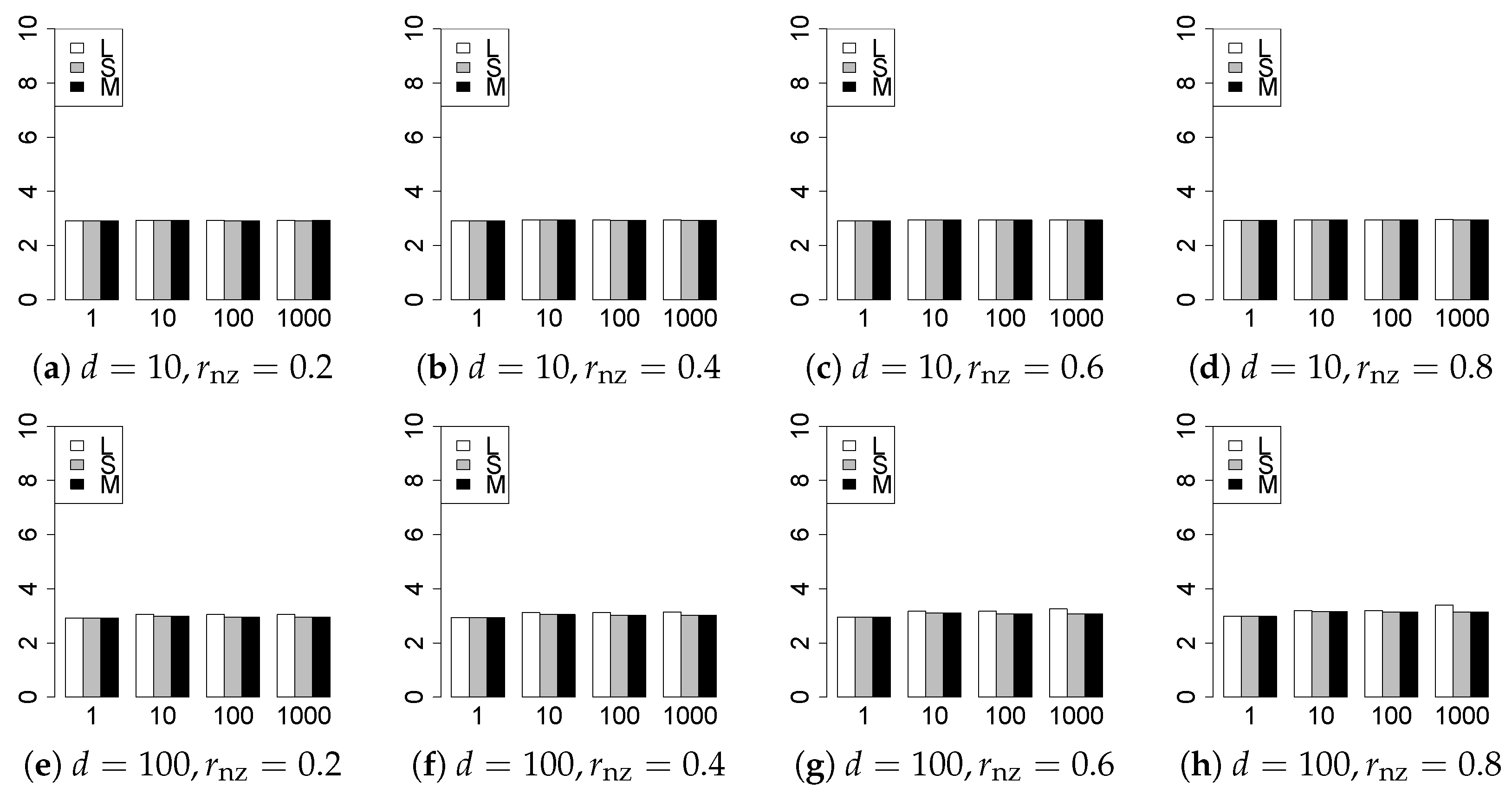
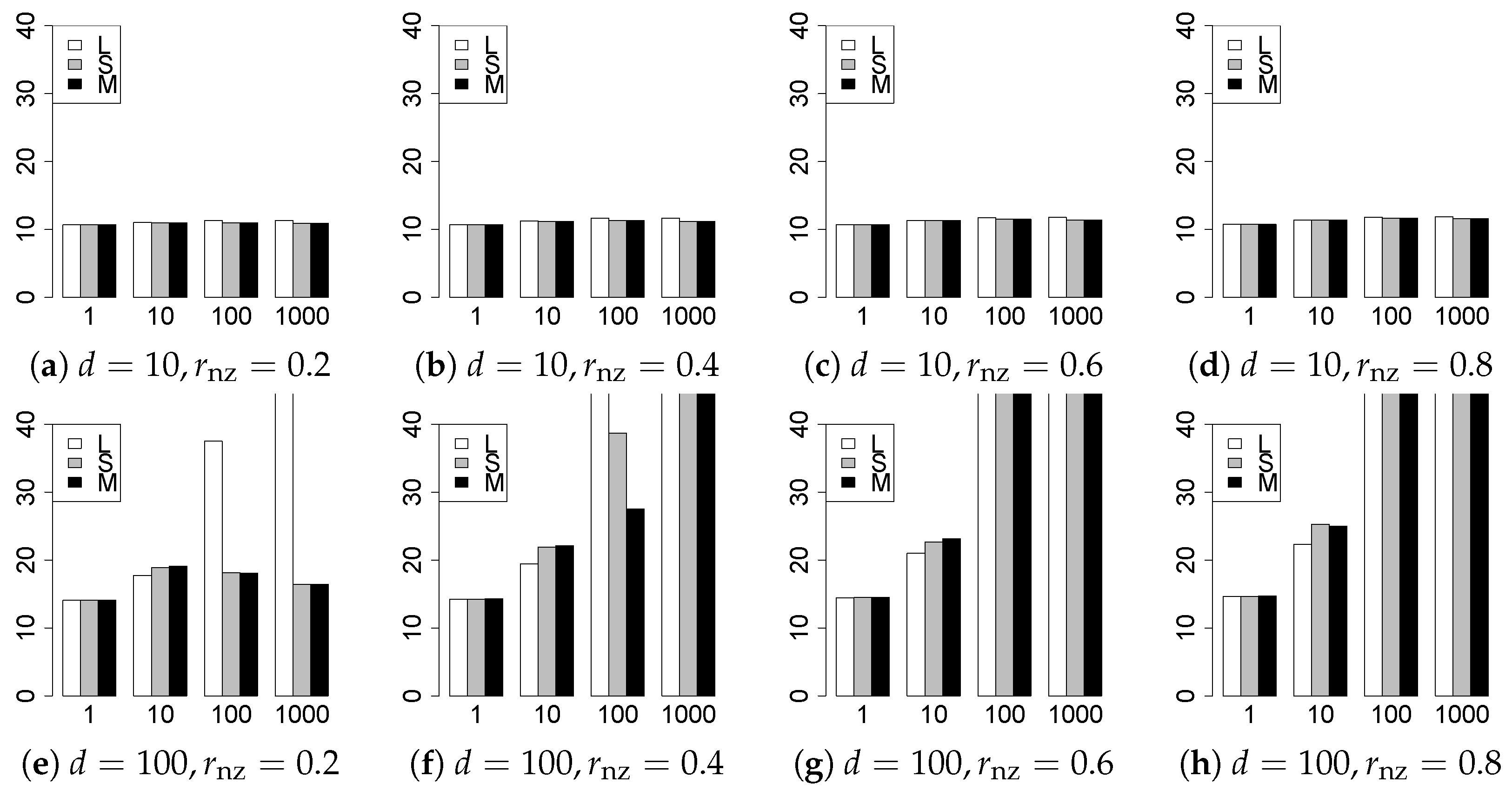
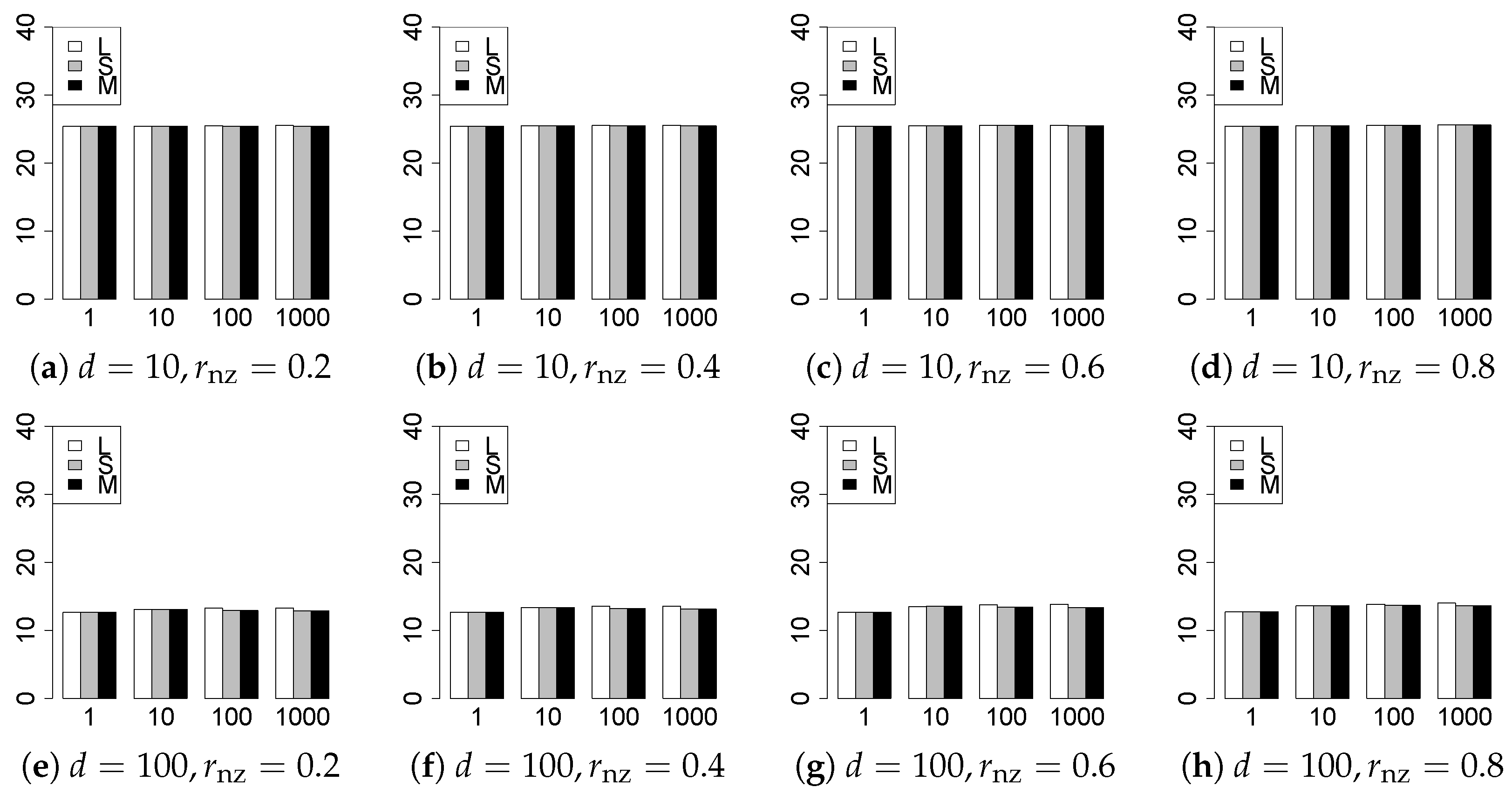
The results are presented in Figure 1, Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12, Figure 13, Figure 14, Figure 15, Figure 16, Figure 17, Figure 18, Figure 19, Figure 20, Figure 21 and Figure 22, which report the best result for each method based on the various information criteria. We present the tables of the results of the numerical experiments in the Supplementary Material. In the figures, white bars represent LASSO, gray bars represent SCAD, and black bars represent MCP.
The model selection results are reported in Figure 1, Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12, Figure 13 and Figure 14. The vertical axis indicates the number of trials (among trials) where a method selects the true model. Here, a larger value is better. The horizontal axis shows the value of .
The generalization results are reported in Figure 15, Figure 16, Figure 17, Figure 18, Figure 19, Figure 20, Figure 21 and Figure 22. To evaluate the generalization error of the proposed methods, we newly make independent copies in each trial. We computed the difference between and the m predictions using each of the methods. The vertical axis indicates the average prediction error over m trials. In this case, a smaller value is better. The scaling of Figure 21 and Figure 22 is different from that of the other figures.
Our first concern is whether the proposed methods work well. The results for can be regarded as a reference for the other values of q. The figures show that the proposed methods work well in both model selection and generalization, especially for . The methods also perform well in terms of model selection for , and . However, they perform poorly for in terms of model selection and for in terms of generalization. As anticipated, a large q makes the problem difficult.
Second, we evaluate the performance of the proposed methods, finding that the MCP performs best in most cases. In a few cases, the MCP performed similarly to or slightly worse than the other methods. For model selection, the cases with and large are exceptions. Furthermore, the LASSO performed worse than the SCAD and MCP.
Third, we consider the effect of , , d, and n, in addition to q. The cases with large and/or small are difficult. Moreover, a large d makes the problems difficult. However, if we have a small q (), large () and small , the problems with large d can be easier than those with small d. Furthermore, a small n makes the problems difficult in a similar manner to a large d. These observations imply that, for , small-sample problems can be easier than large-sample problems if is small and is large.
Fourth, the choice of information criterion changes the methods’ performance. In terms of model selection, BIC2 was mostly the best for many values of q. For , BIC1 was a little better than BIC2 if BIC1 was available. For and , BIC2 was better than BIC1. AIC1 and AIC2 were as good as BICs for . Moreover, the -BIC1 and -BIC2 were best only for , when BIC1 and BIC2 performed just as well. Overall, the -information criteria performed poorly.
Furthermore, in terms of generalization, BIC2 was mostly the best. AIC2 was as good as BIC2, whereas AIC2 was sometimes a little worse than BIC2. The information criteria using the -likelihood were poor for . For , and , the -information criteria worked as well as the ordinary criteria and CV, except for some cases. The performance of CV was mostly good, but was occasionally very poor.
In summary, using an appropriate criterion, the proposed methods perform well for linear models with slightly heavy-tailed errors (). Moreover, the proposed methods work in terms of model selection, even if the error is heavy-tailed (). Overall, we recommend using the MCP and BIC2.
5. Conclusions
We proposed regularization methods for q-normal linear models based on the -likelihood. The proposed methods coincide with the ordinary regularization methods. Our methods perform well for slightly heavy-tailed errors () in terms of model selection and generalization. Moreover, they work well in terms of model selection for heavy-tailed errors (). A theoretical analysis of the proposed methods is left to future work.
Supplementary Materials
The following are available online at https://0-www-mdpi-com.brum.beds.ac.uk/1099-4300/22/9/1036/s1, Tables S1–S34: The results of the numerical experiments.
Funding
This work was partly supported by JSPS KAKENHI Grant Number JP18K18008 and JST CREST Grant Number JPMJCR1763.
Conflicts of Interest
The author declares no conflict of interest.
References
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable Selection via Nonconcave Penalized Likelihood and its Oracle Properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Candes, E.; Tao, T. The Dantzig selector: Statistical estimation when p is much larger than n. Ann. Stat. 2007, 36, 2313–2351. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef] [Green Version]
- Park, M.Y.; Hastie, T. L1-Regularization Path Algorithm for Generalized Linear Models. J. R. Stat. Soc. B 2007, 69, 659–677. [Google Scholar] [CrossRef]
- Ahmed, S.E.; Kim, H.; Yildirim, G.; Yüzbasi, B. High-Dimensional Regression Under Correlated Design: An Extensive Simulation Study. In International Workshop on Matrices and Statistics; Springer: Cham, Switzerland, 2016; pp. 145–175. [Google Scholar]
- Furuichi, S. On the maximum entropy principle and the minimization of the Fisher information in Tsallis statistics. J. Math. Phys. 2009, 50, 013303. [Google Scholar] [CrossRef] [Green Version]
- Prato, D.; Tsallis, C. Nonextensive foundation of Lévy distributions. Phys. Rev. E 2000, 60, 2398–2401. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tsallis, C. Introduction to Nonextensive Statistical Mechanics; Springer: New York, NY, USA, 2009. [Google Scholar]
- Alzaatreh, A.; Lee, C.; Famoye, F.; Ghosh, I. The Generalized Cauchy Family of Distributions with Applications. J. Stat. Distrib. Appl. 2016, 3, 12. [Google Scholar] [CrossRef] [Green Version]
- Bassiou, N.; Kotropoulos, C.; Koliopoulou, E. Symmetric α-Stable Sparse Linear Regression for Musical Audio Denoising. In Proceedings of the 8th International Symposium on Image and Signal Processing and Analysis (ISPA 2013), Trieste, Italy, 4–6 September 2013; pp. 382–387. [Google Scholar]
- Carrillo, R.E.; Aysal, T.C.; Barner, K.E. Generalized Cauchy Distribution Based Robust Estimation. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2008, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 3389–3392. [Google Scholar]
- Carrillo, R.E.; Aysal, T.C.; Barner, K.E. A Generalized Cauchy Distribution Framework for Problems Requiring Robust Behavior. EURASIP J. Adv. Signal Process. 2010, 2010, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Ferrari, D.; Yang, Y. Maximum Lq-Likelihood Estimation. Ann. Stat. 2010, 38, 753–783. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar]
- Efron, B.; Hastie, T.; Johnstone, I.; Tibshirani, R. Least Angle Regression. Ann. Stat. 2004, 32, 407–499. [Google Scholar]
- Hinich, M.J.; Talwar, P.P. A Simple Method for Robust Regression. J. Am. Stat. Assoc. 1975, 70, 113–119. [Google Scholar] [CrossRef]
- Holland, P.W.; Welsch, R.E. Robust Regression Using Iteratively Reweighted Least-Squares. Commun. Stat. Theory Methods 1977, 6, 813–827. [Google Scholar] [CrossRef]
- Kadiyala, K.R.; Murthy, K.S.R. Estimation of regression equation with Cauchy disturbances. Can. J. Stat. 1977, 5, 111–120. [Google Scholar] [CrossRef]
- Smith, V.K. Least squares regression with Cauchy errors. Oxf. Bull. Econ. Stat. 1973, 35, 223–231. [Google Scholar] [CrossRef]
Figure 1.
Model selection for .

Figure 2.
Model selection for .

Figure 3.
Model selection for .

Figure 4.
Model selection for .

Figure 5.
Model selection for .

Figure 6.
Model selection for .

Figure 7.
Model selection for .

Figure 8.
Model selection for .

Figure 9.
Model selection for .

Figure 10.
Model selection for .

Figure 11.
Model selection for .

Figure 12.
Model selection for .

Figure 13.
Model selection for .

Figure 14.
Model selection for .

Figure 15.
Generalization error for .

Figure 16.
Generalization error for .

Figure 17.
Generalization error for .

Figure 18.
Generalization error for .

Figure 19.
Generalization error for .

Figure 20.
Generalization error for .

Figure 21.
Generalization error for .

Figure 22.
Generalization error for .


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
All cases in the experiments. Each case is studied for the values of q and n.
| 1 | 5 | 9 | 13 | 17 | 21 | 25 | 29 | |
| 2 | 6 | 10 | 14 | 18 | 22 | 26 | 30 | |
| 3 | 7 | 11 | 15 | 19 | 23 | 27 | 31 | |
| 4 | 8 | 12 | 16 | 20 | 24 | 28 | 32 | |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hirose, Y. Regularization Methods Based on the Lq-Likelihood for Linear Models with Heavy-Tailed Errors. Entropy 2020, 22, 1036. https://0-doi-org.brum.beds.ac.uk/10.3390/e22091036
AMA Style
Hirose Y. Regularization Methods Based on the Lq-Likelihood for Linear Models with Heavy-Tailed Errors. Entropy. 2020; 22(9):1036. https://0-doi-org.brum.beds.ac.uk/10.3390/e22091036
Chicago/Turabian StyleHirose, Yoshihiro. 2020. "Regularization Methods Based on the Lq-Likelihood for Linear Models with Heavy-Tailed Errors" Entropy 22, no. 9: 1036. https://0-doi-org.brum.beds.ac.uk/10.3390/e22091036
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.