Extracting Work Optimally with Imprecise Measurements


1
Grupo Interdisciplinar de Sistemas Complejos, Facultad de Ciencias Físicas, 28040 Madrid, Spain
2
Departamento de Estructura de la Materia, Física Térmica y Electrónica, Universidad Complutense de Madrid, 28040 Madrid, Spain
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(1), 8; https://0-doi-org.brum.beds.ac.uk/10.3390/e23010008
Submission received: 30 October 2020
/
Revised: 18 December 2020
/
Accepted: 19 December 2020
/
Published: 23 December 2020
(This article belongs to the Special Issue Recent Advances in Single-Particle Tracking: Experiment and Analysis)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Measurement and feedback allows for an external agent to extract work from a system in contact with a single thermal bath. The maximum amount of work that can be extracted in a single measurement and the corresponding feedback loop is given by the information that is acquired via the measurement, a result that manifests the close relation between information theory and stochastic thermodynamics. In this paper, we show how to reversibly confine a Brownian particle in an optical tweezer potential and then extract the corresponding increase of the free energy as work. By repeatedly tracking the position of the particle and modifying the potential accordingly, we can extract work optimally, even with a high degree of inaccuracy in the measurements.
1. Introduction
Modern techniques have allowed for the manipulation of objects at the microscale. A paradigmatic example are colloidal particles trapped by optical tweezers. At this scale—the scale of Brownian motion—not only the motion of particles, but the energy fluxes, work, or heat, become stochastic. Nevertheless, the combination of manipulation and imaging or other detection techniques allow for some degree of control [1]. For instance, in driven systems, the external driving may be modified based on outcomes of measurements, as in feedback control, leading, for example, to (efficient) confinement in small region of space [2] or to the reduction of thermal fluctuations, i.e., cooling, a technique that is implemented in both classical or quantum systems [3,4]. Another application of feedback is an increase of the performance of certain motors operating at the microscale, such as Brownian ratchets or micro-motors [5,6,7,8,9].
Feedback exploits the information that is acquired through measurement as a thermodynamic resource. It is now known that the work needed to perform an isothermal feedback process, for a system in contact with an environment at constant temperature T, is bounded by the following extension of the second law of thermodynamics [9,10]:
where is the free energy difference between the final and initial states of the process, k the Boltzmann’s constant, and I is the amount of information that is gained in the measurement, quantified by the mutual information from information theory. Information is always positive (or zero) and, thus, in a cycle () it is possible to extract work () from a single thermal bath with measurement and feedback.
Equation (1) also shows that a given level of accuracy in the measurement, quantified by the mutual information, limits the amount of work that can be extracted in one feedback operation. Some especially tailored protocols saturate that bound (1) and they may be used to convert all of the information acquired into useful work. These are processes that are reversible under feedback [11,12,13]. In this article, we first review these protocols and show how to use their special properties in order to extract energy with the same efficiency and even power when operating with higher measurement errors. In order to fix ideas, we use a well known model that we proceed to describe in the following section.
2. Model Description and Cycle Operation
As our system, we consider an overdamped Brownian particle that is in contact with a thermal bath, which acts as its environment. The particle feels a harmonic potential. This is a well proven theoretical model for an experimental system that was formed by a colloidal particle in water at constant temperature and trapped by optical tweezers. The potential has tunable parameters , the position of the center of the trap, and , the stiffness. As the Brownian particle position fluctuates, the energy transfers and thermodynamic potentials become also fluctuating; in fact, they are stochastic variables. The framework to analyze energetics for these fluctuating systems in the mesoscale is stochastic thermodynamics [14,15,16]. We review the main concepts in the following. The Brownian particle may, due to a collision with the solvent, absorb some energy and climb the potential well. Or it may transfer energy back to the thermal bath via viscosity and go down in the potential. These energy transfers with the thermal bath constitute heat and, and since this energy can be stored as potential energy, this is the internal energy of the particle. In our system then the internal energy is [17,18,19,20]. We will use to denote a stochastic variable and the regular letter a for the average over realizations, i.e., . Another form of energy transfer is work : an external agent may modify the harmonic potential (changing the parameters) and increase or decrease the potential energy of the particle. If the internal energy depends on a parameter that is modified from to then, formally, the definition of work is:
This is best seen with an example. For instance, consider a fast increase of the stiffness of the potential from to . If the increase is very fast, so that the particle does not modify its position x during the time, the stiffness is changing, the energy of the particle increases by an amount . This energy is supplied by the agent controlling the potential who has then performed a work . Consequently, the particle is in a tighter parabola and the equilibrium dispersion of the position of the particle decreases, so that this is commonly referred to as a compression. If the stiffness is decreased, work is exerted on the agent by the system and, since the distribution of particle positions will eventually widen, this corresponds to an expansion.
With these definitions, energy is conserved and the first law is fulfilled either at the level of trajectories or as averages [14,15,16,17,18,19,20].
In order to extract energy from the thermal bath, we propose the following cyclic operation in two stages:
- 1.
- Confinement of the Brownian particle by (repeated) measuring and feedback
- 2.
- Isothermal expansion
The system works as a motor if the work obtained in the isothermal expansion exceeds the work that is needed for confinement. During a compression, the free energy of the system increases (due to the entropy decrease). Using reversible feedback confinement [2], we can minimize the work that is needed for stage 1, which turns out to vanish, and extract all of the free energy increase of stage 1 as work during stage 2. Let us analyze each stage in more detail.
2.1. Optimal Confinement
The confinement of a system to a small region of the phase space (at constant temperature) implies a decrease of entropy of the system. For the entropy of a Brownian particle, we use the standard choice of Shannon’s entropy, , where is the probability distribution of the particle position. With this choice, the second law of thermodynamics is fulfilled on average and the thermodynamic relation is recovered for a system in contact with a thermal bath. Although, strictly speaking, this is a generalization of the free energy to non-equilibrium systems, in systems that are in contact to a thermal bath it plays a similar role as the standard thermodynamic free energy, and stochastic thermodynamics for our system closely resembles macroscopic thermodynamics [9].
Let us consider, for simplicity, that the internal energy change between the initial and final states of the confinement process vanishes (we will see later that this is the case in our particular system). A reduction of entropy then corresponds to an increase of free energy . This increase in free energy could then be extracted as work in an isothermal expansion. However, the whole process cannot operate as a motor, as this will defeat the second law (extracting work from a single thermal bath). Indeed, the second law states for the confinement
and then for the isothermal expansion back to the initial state ()
so that and the system dissipates energy into the thermal bath.
However, as explained above, when measuring and feeding back to the system, W is bounded by (1) instead. Thus, the work that is needed for the confinement may be reduced and the work output of the cyclic process () may be negative:
Notice that mutual information is always a positive quantity.
Following [2], we propose a reversible feedback confinement that can confine the particle with and, as will be shown later (see Equation (13)), without dissipating heat to the thermal bath, so that the increase in free energy that is produced by the confinement can later be completely recovered as work during a quasistatic expansion in stage 2.
For a system that is in contact with a thermal bath, a feedback process is reversible if the Hamiltonian is modified after the measurement, so that probability of the state of the system conditioned on the measurement outcome is the Gibbsian state of the new Hamiltonian. After a measurement, the probability to find a given state changes instantaneously, the new probability distribution takes into account the information obtained, and ut must be updated according to Bayesian inference. If the Hamiltonian also changes rapidly and the Gibbs state of the new Hamiltonian matches the posterior probability distribution, the system remains at equilibrium and no further evolution of the probability distribution ensues until a new measurement is taken.
In our model, we take the common assumption of Gaussian measurement errors. If the particle is located at a position x, then the measurement outcome m is Gaussian distributed around x and the dispersion quantifies the measurement error:
After a measurement, the probability distribution of the position of the particle updates according to Bayes’ theorem from the initial distribution :
where is the marginal distribution of the measurement outcome.
For a Brownian particle in a time-independent potential, the equilibrium distribution is its corresponding Gibbs distribution:
In a harmonic potential, it is a Gaussian, centered in the trap position and with variance being given by . It can be shown [7] that, after a measurement, the new distribution that is computed according to (7) remains Gaussian. If the initial distribution has mean and standard deviation , after a measurement, then the distribution updates to a Gaussian with the mean and deviation given by [2]:
We can make the post-measurement distribution an equilibrium distribution by setting a new center of the trap position and stiffness , as
Notice that ; hence, the particle is more tightly bound or confined after this change. Additionally, Equation (10) implies , so that every measurement and feedback step further reduces the variance of the particle distribution.
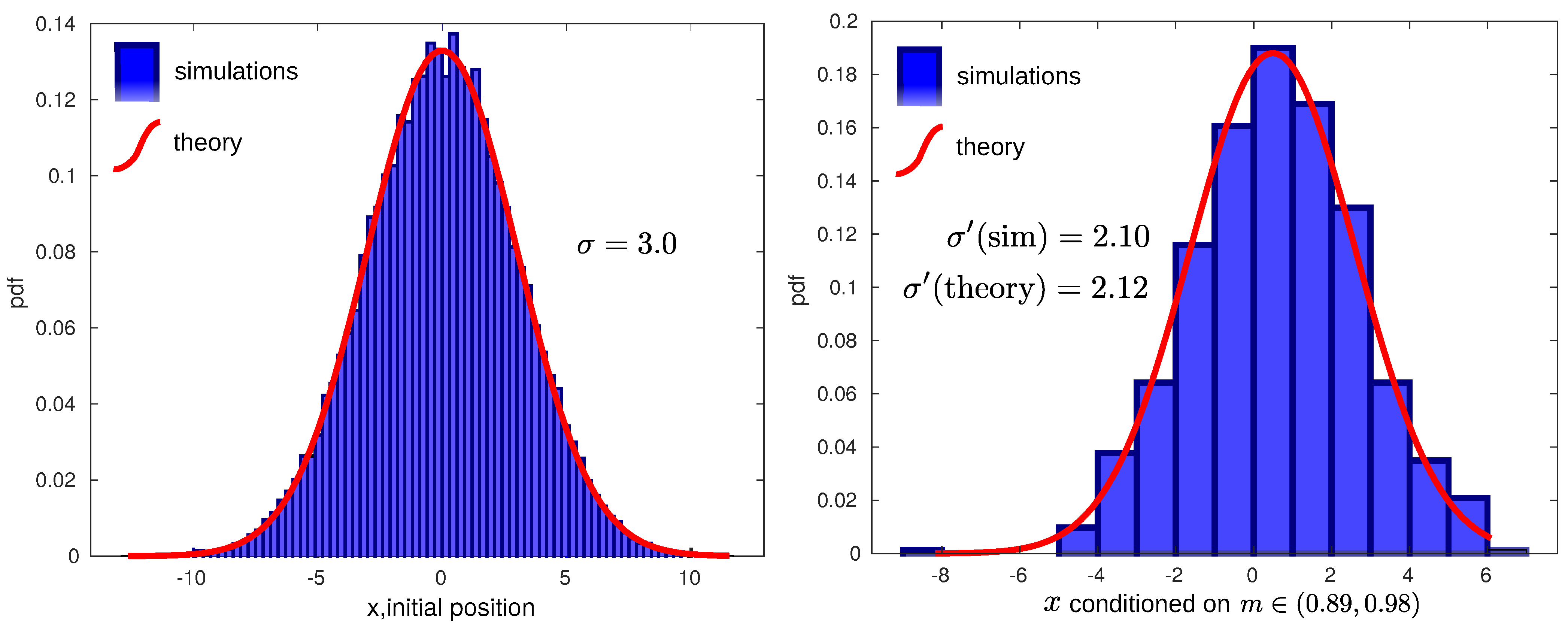
In order to check this reduction of variance in simulation, we have computed the particle distribution after a measurement. For this, we first generate a large number of trajectories, starting from an initial equilibrium distribution for a harmonic potential centered in position and corresponding dispersion , as depicted in Figure 1(left). After some time interval, for each trajectory, we measure its position by generating a (Gaussian) random measurement outcome m around the actual position x with dispersion (see the details in Section 5). We can then fix a small interval around a given measurement of the position of our choice, for instance (0.89, 0.98), and only check the realizations that gave a measurement in that interval. The distribution of the actual positions x of these particular realizations are distributed as in (7). In our case, a Gaussian with new reduced standard deviation is given by (10). This can be seen in Figure 1 (right).
This process of measurement and feedback can be repeated and a new, more confined state could be achieved. Figure 2 (top) shows the confining effect of repeating this procedure.
In every measurement and feedback step, the trapped Brownian particle stays in equilibrium with the thermal bath at temperature T. Consequently, the average energy is not modified by the feedback process. The average internal energy E of a trapped particle in one dimension is given by the equipartition theorem, as . Because the process is isothermal, . On the other hand, always being in equilibrium, there is no relaxation of the particle distribution and the heat that is transferred from the heat bath vanishes on average . Therefore, according to the first law, the average work done on the system also vanishes:
This has been checked in simulations, as shown in Figure 2 (bottom). Details about work computation during measurement and feedback can be found in Section 5.
In general, for other feedback protocols where the stiffness of the trap is suddenly changed, work is performed, on average [21], as in the simple example described after Equation (2). The feedback process used here is different (in addition to a sudden increase of stiffness, trap position is also modified in a precisely combined manner) and it is special in the sense that average work vanishes. As encoded in Equation (1), this can solely be achieved by using information regarding the position through measurement in the feedback (see Equation (9) for the new trap position). To see why this matters, consider our Brownian particle in a harmonic potential, where the observer happens to know that the particle is exactly at the bottom of the well. This would allow for this external agent to increase the stiffness of the potential well with an abrupt change, without performing work, since the energy of the particle is always zero at the bottom of the well, for any stiffness. The confining protocol is a refinement of this idea that works for any position of the particle, by displacing the bottom of the potential well towards the measured particle position and changing the stiffness in a suitable manner.
Furthermore, one can compute the mutual information that is obtained in the process of measurement and evaluate the increase in free energy for the confinement stage. From the definition of mutual information:
When considering that the measurement outcome distribution and the marginal distribution are Gaussian with variance and , respectively, the information that is acquired in a measurement is
Mutual information intuitively measures the decrease in uncertainty of variable x if we know the value of m, or vice versa [22]. In our case, from (10), if the measurement error is very large then and we extract almost no information from measuring (). Conversely, for infinite precise measurement , then , and we obtain infinite information from a measurement, as an infinite precise description of a position would require an infinite number of bits to store it.
The entropy of a Gaussian of variance is . In the measurement process, the distribution changes from a Gaussian of variance to a Gaussian of variance , and we have
Because , we finally obtain
This is valid for every measurement and feedback step while using the reversible feedback protocol. In a sequence of confinement steps with successive variances , the total information is
can be obtained from (10) by recursion, giving:
Finally, the free energy difference between the final and initial states in the confinement stage is
Every bit of information that is extracted in the measurement is turned into an increase of free energy during the confinement stage and it can be converted into useful work in the subsequent expansion.
2.2. Work Extraction by Isothermal Expansion
If an external agent changes the stiffness of the optical trap from to , energy is recovered as work, as explained above. In a quasistatic process, the work done by the system is given by the free energy difference. Because stage 2 completes the cycle of operation of the motor ending in the initial state, we have and
which corresponds to extracted work. In fact, it saturates expression (5) and it is the maximum possible work that can be extracted while using the information that was obtained in the measurements.
This result can also be recovered by the direct computation of the work of a process changing stiffness from to and while taking into account that, for a quasistatic process, one can use the equipartition theorem stating , with the instantaneous value of the stiffness. Subsequently, the average work during the expansion, according to (2), reads:
The expansion starts at the end of the confinement process with a distribution of variance and ends at . Subsequently, while using the relation between stiffness and variance in the confinement stage (11), we have
Notice that during both the confinement and expansion the system must be at equilibrium in order to transform every bit of information into useful work.
In practice, though, for a process changing the stiffness of the potential to be approximately quasistatic, it is enough that the time of the process is large compared to the inverse frequency of the trap given by . This is the criterion that we have used for simulations. Additionally, it is worth noting that, even though the work in every realization of the expansion may differ in principle in a stochastic system, work is—in this particular example—a self-averaging quantity: for a quasistatic expansion, the total work obtained in any realization is very similar to its average value. The argument for self-averaging of the work is the following: from work definition (2), work in a single realization when expanding is . If the expansion is very slow, in the time is modified a certain small amount, the particle position has time to fluctuate and sample the whole quasi-equilibrium distribution and approximately can be replaced by its average value (see the full computation in [14]).
Figure 3 depicts the complete diagram of the proposed cycle.
Finally, one could also define an efficiency as the ratio between the extracted thermodynamic resource (work) and the thermodynamic resource consumed to make the engine run, in this case information. With this definition, this reversible feedback engine attains the maximum efficiency:
as in a similar system [23], with just one measurement per cycle.
3. Results
3.1. Work Is Optimal
We have performed computer simulations of the model system that is described above. Figure 4 depicts part of two consecutive cycles, each of them with a confinement stage that is composed of 10 measurement and feedback steps, followed by an isothermal expansion. The top panel depicts the particle position (gray line), trap center (blue line), and measurement outcomes (red dots), whereas the bottom panel shows the evolution of the stiffness along the cycle.
Figure 5 shows the cumulative work that was done on the system along the time of a single cycle. The thick solid line represents the average over 200 cycles. Every cycle consists of a confinement that is achieved by measuring the particle position 10 times and the subsequent isothermal expansion. Average work extracted () by the end of the cycle approaches the expected result that is given by Equations (18), (19) and (21), marked with dashed black line. The shaded area represents the variance of the work, which is substantially large. As is apparent from the figure, most of the variance comes from the confinement step, with the quasistatic work being a self-averaging quantity. Finally, work that corresponds to two particular cycles is shown by thin blue lines.
3.2. Power and Efficiency with Higher Measurement Errors
Consider two setups, A and B, with different measurement errors being given by variances and . Suppose that only one measurement step is performed in each system before the expansion. According to our discussion above, the measurement information that can be later transformed into work is smaller in system B than in A:
However, we can obtain as much information in system B with two measurements as in system A with one measurement. After two measurements, while using the reversible confinement protocol, the variance of the equilibrium distribution in system B is equal to the variance in system A after one measurement :
Using (18), we obtain:
As explained above, this implies that the same work can be extracted in the subsequent quasistatic expansion. In fact, bothof the systems run with the same efficiency ; hence, every bit of information is turned into work in the expansion. Furthermore, system B can also be run in principle at the same power as system A. During the confinement process, after the adjustment of the potential, the particle distribution is at equilibrium. No relaxation occurs, as explained previously. Therefore, a new measurement and feedback step could, in principle, be taken immediately after, in rapid succession. Thus, halving the time between measurements in system B as compared to system A ensures the same cycle time. As the work obtained is also the same, both of the systems operate with the same power. Figure 6 depicts this, where we show the simulation results for system A with one measurement and expansion and system B with two (faster) measurements and expansion. Approximately the same work is obtained in both systems. For reference, we have also marked the expected extracted work for a system with tge measurement error given by , but using just one measurement.
4. Discussion
Reversible feedback confinement is an optimal way of reducing the entropy of a system to be later used for work extraction. Nevertheless, it requires a high degree of control over the Hamiltonian, to adapt it to the new probabilistic state after the measurement. This might be a limitation for experimental realizations, although a low dissipation is expected, even if a similar or approximate protocol is implemented. Theoretically, the dissipation could be accounted for by using the Kullback–Leibler distance between the post-measurement particle distribution and the equilibrium distribution of the potential after feedback [24], if they were different due to a less precise tuning of the potential.
In principle, for a measurement and feedback protocol, imprecision in the measurement, which will inevitably arise in an experimental setup, will limit the work extraction or power. Nevertheless, we have shown here that this limitation can be overcome by adding more measurement steps before the quasistatic expansion, as long as the reversible feedback confinement protocol is used. In principle, the application of this protocol is instantaneous. In practice, this means that the confinement may be applied in a very short time, limited maybe by the response time of the feedback mechanism or the measurement acquisition time. Thus, if the response times of measurement, feedback, and Hamiltonian modification are fast as compared to system’s relaxation time, optimal work extraction is feasible, even with a high degree of inaccuracy in the measurement, while using repeated optimal feedback.
5. Materials and Methods
The confined Brownian particle evolves according to Langevin equation:
with Gaussian white noise , T bath temperature and k Boltzmann’s constant. The potential is defined above and it is controlled through measurement and feedback. Model simulations were performed in C language, solving the Langevin evolution equation with the Heun method for a stochastic differential equation [25]. We provide, in the following, some details on work computation, measurement, and feedback steps. For full details, the code is available here: http://seneca.fis.ucm.es/ldinis/code/extract_optimal_work.zip.
- Measurement. In order to perform a measurement in the simulation, a Gaussian number “r” with zero average and standard deviation 1 is generated. Subsequently, if particle position is x, the measurement outcome m isNotice that m is then distributed according to Equation (6)
- Feedback. Immediately after measurement, and using the measurement outcome m just computed, the potential parameters and are recomputed according to Equations (9) to (12). Notice that the old values need to be stored in an auxiliary variable for the work computation, as explained in the following step.
- Work computation during feedback process. According to its definition for a trajectory, work is the difference in the potential energy when the potential is changed. If and as a result of measurement and feedback, then work is computed asThis is added to a variable W that stores the cumulative work that was done along the whole simulation.
- After the feedback, evolution equation resumes with the new potential parameters.
- Work during expansion. Work is also performed as a result of the change in during an expansion. In the simulation, during the expansion stage, changes an amount in every time step, where is the number of time steps of the expansion. Therefore, in a time step, a workis performed. Again, this has to be added to the variable W, which stores the total or cumulative work of the whole process.
Author Contributions
Conceptualization, L.D. and J.M.R.P.; methodology, L.D.; software, L.D.; validation, L.D.; formal analysis, L.D.; investigation, L.D.; writing—original draft preparation, L.D. and J.M.R.P.; writing—review and editing, L.D. and J.M.R.P.; visualization L.D. and J.M.R.P.; supervision, L.D. and J.M.R.P.; project administration, L.D. and J.M.R.P.; funding acquisition, L.D. and J.M.R.P. All authors have read and agreed to the published version of the manuscript.
Funding
L.D. and J.M.R.P. acknowledge financial support from Ministerio de Ciencia, Innovación y Universidades grant number FIS2017-83709-R.
Data Availability Statement
Data for this study was generated using custom computer code. The code and instructions are available at http://seneca.fis.ucm.es/ldinis/code/extract_optimal_work.zip.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Touchette, H.; Lloyd, S. Information-Theoreitc Limits of Control. Phys. Rev. Lett. 2000, 84, 1156–1159. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Granger, L.; Dinis, L.; Horowitz, J.M.; Parrondo, J.M.R. Reversible feedback confinement. EPL (Europhys. Lett.) 2016, 115, 50007. [Google Scholar] [CrossRef] [Green Version]
- Cohen, A.E. Control of Nanoparticles with Arbitrary Two-Dimensional Force Fields. Phys. Rev. Lett. 2005, 94, 118102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gieseler, J.; Deutsch, B.; Quidant, R.; Novotny, L. Subkelvin Parametric Feedback Cooling of a Laser-Trapped Nanoparticle. Phys. Rev. Lett. 2012, 109, 103603. [Google Scholar] [CrossRef] [PubMed]
- Cao, F.J.; Dinis, L.; Parrondo, J.M.R. Feedback control in a collective flashing ratchet. Phys. Rev. Lett. 2004, 93, 040603. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, F.J.; Feito, M.; Touchette, H. Information and flux in feedback controlled Brownian ratchet. Phys. A 2009, 338, 112–119. [Google Scholar] [CrossRef] [Green Version]
- Abreu, D.; Seifert, U. Extracting work from a single heat bath through feedback. Europhys. Lett. 2011, 94, 10001. [Google Scholar] [CrossRef]
- Sagawa, T.; Ueda, M. Nonequilibrium thermodynamics of feedback control. Phys. Rev. E 2012, 85, 021104. [Google Scholar] [CrossRef] [Green Version]
- Parrondo, J.M.R.; Horowitz, J.M.; Sagawa, T. Thermodynamics of information. Nat. Phys. 2015, 11, 131–139. [Google Scholar] [CrossRef]
- Sagawa, T.; Ueda, M. Minimal Energy Cost for Thermodynamic Information Processing: Measurement and Information Erasure. Phys. Rev. Lett. 2009, 102, 250602. [Google Scholar] [CrossRef] [Green Version]
- Horowitz, J.M.; Parrondo, J.M.R. Thermodynamic reversibility in feedback processes. Europhys. Lett. 2011, 95, 10005. [Google Scholar] [CrossRef] [Green Version]
- Horowitz, J.M.; Parrondo, J.M.R. Designing optimal discrete-feedback thermodynamic engines. New J. Phys. 2011, 13, 123019. [Google Scholar] [CrossRef]
- Horowitz, J.M.; Parrondo, J.M.R. Optimizing non-ergodic feedback engines. Acta Phys. Pol. B 2013, 44, 803–814. [Google Scholar] [CrossRef] [Green Version]
- Sekimoto, K. Stochastic Energetics; Lecture Notes in Physics; Springer: Berlin/Heidelberg, Germany, 2010; Volume 799. [Google Scholar]
- Seifert, U. Stochastic thermodynamics, fluctuation theorems, and molecular machines. Rep. Prog. Phys. 2012, 75, 126001. [Google Scholar] [CrossRef] [Green Version]
- Van den Broeck, C. Stochastic thermodynamics: A brief introduction. Proc. Int. Sch. Phys. Enrico Fermi 2013, 184, 155–193. [Google Scholar] [CrossRef]
- Blickle, V.; Bechinger, C. Realization of a micrometre-sized stochastic heat engine. Nat. Phys. 2012, 8, 143–146. [Google Scholar] [CrossRef] [Green Version]
- Blickle, V.; Speck, T.; Helden, L.; Seifert, U.; Bechinger, C. Thermodynamics of a Colloidal Particle in a Time-Dependent Nonharmonic Potential. Phys. Rev. Lett. 2006, 96, 070603. [Google Scholar] [CrossRef] [Green Version]
- Martínez, I.A.; Roldán, E.; Dinis, L.; Petrov, D.; Rica, R.A. Adiabatic Processes Realized with a Trapped Brownian Particle. Phys. Rev. Lett. 2015, 114. [Google Scholar] [CrossRef] [Green Version]
- Martínez, I.A.; Roldán, E.; Dinis, L.; Petrov, D.; Parrondo, J.M.R.; Rica, R.A. Brownian Carnot engine. Nat. Phys. 2015, 12, 67–70. [Google Scholar] [CrossRef]
- Schmiedl, T.; Seifert, U. Optimal Finite-Time Processes In Stochastic Thermodynamics. Phys. Rev. Lett. 2007, 98, 108301. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: New York, NY, USA, 2006. [Google Scholar]
- Bauer, M.; Abreu, D.; Seifert, U. Efficiency of a Brownian information machine. J. Phys. A-Math. Theor. 2012, 45. [Google Scholar] [CrossRef] [Green Version]
- Kawai, R.; Parrondo, J.M.R.; Van den Broeck, C. Dissipation: The phase-space perspective. Phys. Rev. Lett. 2007, 98, 080602. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mannella, R. A Gentle Introduction to the Integration of Stochastic Differential Equations. In Stochastic Processes in Physics, Chemistry, and Biology; Freund, J.A., Pöschel, T., Eds.; Lecture Notes in Physics; Springer: Berlin/Heidelberg, Germany, 2000; pp. 353–364. [Google Scholar] [CrossRef]
Figure 1.
Reduction of variance after measuring. Left: Initial distribution. Histogram of 40,000 random Gaussian numbers centered in 0 with standard deviation (blue bars) and a theoretical Gaussian distribution with the same parameters (red continuous line). Right: Posterior distribution. Histogram of particle positions with measurement outcomes in a given interval (0.89, 0.98) (blue bars) and prediction according to Bayes’ theorem (7) (red). Measurement outcomes were performed with measurement error . Using and in (10) gives , which matches the sample standard deviation of .
Figure 1.
Reduction of variance after measuring. Left: Initial distribution. Histogram of 40,000 random Gaussian numbers centered in 0 with standard deviation (blue bars) and a theoretical Gaussian distribution with the same parameters (red continuous line). Right: Posterior distribution. Histogram of particle positions with measurement outcomes in a given interval (0.89, 0.98) (blue bars) and prediction according to Bayes’ theorem (7) (red). Measurement outcomes were performed with measurement error . Using and in (10) gives , which matches the sample standard deviation of .

Figure 2.
Confinement. Top: particle trajectory (gray line), measurement outcome (red dots) and trap center position (blue line). Bottom: Cumulative work for different realizations (color lines) and its average over 200 realizations (thick black line) for confinement in 10 measurement steps. See the simulation details in Section 5. Initial trap stiffness and position . Initial condition is equilibrium with trap potential to avoid transient due to equilibration. Particle diffusion coefficient and friction .
Figure 2.
Confinement. Top: particle trajectory (gray line), measurement outcome (red dots) and trap center position (blue line). Bottom: Cumulative work for different realizations (color lines) and its average over 200 realizations (thick black line) for confinement in 10 measurement steps. See the simulation details in Section 5. Initial trap stiffness and position . Initial condition is equilibrium with trap potential to avoid transient due to equilibration. Particle diffusion coefficient and friction .

Figure 3.
Cycle for extracting work from a thermal bath with inaccurate measurements.

Figure 4.
Trajectories. (Top) Particle trajectory (gray continuous line), trap center (blue continuous line), measurement outcomes (red dots). (Bottom) Stiffness evolution during the cycle. Every cycle starts with , there are 10 measurement steps, followed by quasistatic expansion. , .
Figure 4.
Trajectories. (Top) Particle trajectory (gray continuous line), trap center (blue continuous line), measurement outcomes (red dots). (Bottom) Stiffness evolution during the cycle. Every cycle starts with , there are 10 measurement steps, followed by quasistatic expansion. , .

Figure 5.
Average cumulative work along the confinement-expansion cycle (thick blue line) computed from 200 realizations. The shaded area corresponds to one standard deviation from the average. Thin blue lines represent cumulative in two representative cycles. Simulation parameters are: , time between measurements , number of measurements before expansion is 10, measurement error , initial stiffness of the trap , diffusion coefficient , and drag coefficient .
Figure 5.
Average cumulative work along the confinement-expansion cycle (thick blue line) computed from 200 realizations. The shaded area corresponds to one standard deviation from the average. Thin blue lines represent cumulative in two representative cycles. Simulation parameters are: , time between measurements , number of measurements before expansion is 10, measurement error , initial stiffness of the trap , diffusion coefficient , and drag coefficient .

Figure 6.
Average work extraction for two different measurement errors, using one measurement with variance (blue thick line), and using two measurements with variance (red thick line). Dashed line represents expected work extraction and fine dashed line corresponds to expected work extraction with just 1 measurement of variance . Thin lines represent single realizations of the work in system A (blue) and B (red).
Figure 6.
Average work extraction for two different measurement errors, using one measurement with variance (blue thick line), and using two measurements with variance (red thick line). Dashed line represents expected work extraction and fine dashed line corresponds to expected work extraction with just 1 measurement of variance . Thin lines represent single realizations of the work in system A (blue) and B (red).

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Dinis, L.; Parrondo, J.M.R. Extracting Work Optimally with Imprecise Measurements. Entropy 2021, 23, 8. https://0-doi-org.brum.beds.ac.uk/10.3390/e23010008
AMA Style
Dinis L, Parrondo JMR. Extracting Work Optimally with Imprecise Measurements. Entropy. 2021; 23(1):8. https://0-doi-org.brum.beds.ac.uk/10.3390/e23010008
Chicago/Turabian StyleDinis, Luis, and Juan Manuel Rodríguez Parrondo. 2021. "Extracting Work Optimally with Imprecise Measurements" Entropy 23, no. 1: 8. https://0-doi-org.brum.beds.ac.uk/10.3390/e23010008
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.