Optimizing Age Penalty in Time-Varying Networks with Markovian and Error-Prone Channel State

1
Department of Electronic Engineering, Tsinghua University, Beijing 100084, China
2
Beijing National Research Center for Information Science and Technology (BNRist), Beijing 100084, China
3
Research Institute of Tsinghua University in Shenzhen, Shenzhen 518057, China
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(1), 91; https://0-doi-org.brum.beds.ac.uk/10.3390/e23010091
Submission received: 20 November 2020
/
Revised: 31 December 2020
/
Accepted: 8 January 2021
/
Published: 10 January 2021
(This article belongs to the Section Information Theory, Probability and Statistics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:In this paper, we consider a scenario where the base station (BS) collects time-sensitive data from multiple sensors through time-varying and error-prone channels. We characterize the data freshness at the terminal end through a class of monotone increasing functions related to Age of information (AoI). Our goal is to design an optimal policy to minimize the average age penalty of all sensors in infinite horizon under bandwidth and power constraint. By formulating the scheduling problem into a constrained Markov decision process (CMDP), we reveal the threshold structure for the optimal policy and approximate the optimal decision by solving a truncated linear programming (LP). Finally, a bandwidth-truncated policy is proposed to satisfy both power and bandwidth constraint. Through theoretical analysis and numerical simulations, we prove the proposed policy is asymptotic optimal in the large sensor regime.
1. Introduction
The requirements for data freshness in numerous emerging applications are becoming stricter [1,2]. However, the limited resources and bandwidth, together with the fading and error-prone channel characteristics, prevent the control terminal from obtaining the newest information. Moreover, the traditional optimization goals like low delay and high throughput cannot fully characterize the requirement of data freshness. Therefore, it is necessary to introduce new metrics to capture data freshness in such systems and design strategies to optimize the system performance in the presence of resource and environment restrictions.
Recently, a popular metric, Age of information (AoI), has been proposed in [3] to measure the data freshness. Since then, the optimization of age performance under different systems has been a research hotspot. The simple point-to-point system model has been studied in [3,4,5,6,7,8,9,10,11]. When update packets are generated by external sources and are queued in a buffer before transmission, queuing theory can be used to analyze the performance of such system, see, e.g., in, [3,4,5,6,7,8]. In [3], it is shown that the optimum packet generation rate of a first-come-first-served (FCFS) system should achieve a trade-off between throughput and delay. In [8], dynamic pricing is used as an incentive to balance the AoI evolution and the monetary payments to the users. Other studies [9,10,11] consider the generate-at-will system without a queue. Energy constraints are studied in [10,11] to find the trade-off between the age performance and energy consumption. In [11], both offline and online heuristic policies are proposed to optimize the average AoI, which outperform the greedy approach.
Apart from the point-to-point systems, scheduling strategies in the multi-user networks are studied in [12,13,14,15,16,17,18,19]. Different scheduling policies are studied in [12] to minimize the average AoI performance through unreliable channels, and Maatouk et al. verify the asymptotic optimality of Whittle’s index policy by setting an upper bound on the maximum AoI [13]. When each user has a minimum throughput requirement, the authors of [14] propose the Drift-Plus-Penalty policy using Lyapunov analysis to minimize the average AoI performance. In [17], a slotted ALOHA algorithm is proposed to minimize the average AoI, whose performance is verified in the large system regime.
Notice that in many general scenarios, like remote estimation [20,21], the proper evaluation of data freshness is a function of AoI instead of AoI itself. Therefore, the metric of Cost of Update Delay (CoUD) in [7] and age penalty function in [9] have been proposed to measure data freshness in a general setting. However, those works focus on minimizing data freshness in a single-user network, and the multi-user model is rarely considered. To fill this gap, we study a scenario where the base station (BS) collects time-sensitive data from multiple sensors through time-varying channels. We generalize our previous work [22] by considering a more realistic time-varying channel with packet loss and a more general age penalty measurement to model different application scenarios. The main contributions of the paper are listed as follows.
- We study the scheduling strategy for age penalty minimization in multi-sensor bandwidth constrained networks through time-varying and error-prone channel links with power limited sensors. To study a practical network, we model the channel to be a finite-state ergodic Markov chain. The packet loss probability and power consumption depend on the current channel state. Unlike previous work, we model the effect of data staleness in different scenarios via a class of monotone increasing function related to AoI.
- Through relaxing the hard bandwidth constraint and Lagrange multipliers, we decouple the multi-sensor optimization problem into several single-sensor constrained Markov decision process (CMDP) problems. To deal with the potential infinite age penalty, we deduce the threshold structure of the optimal policy and then obtain the approximate optimal single-sensor scheduling decision by solving a truncated linear programming (LP). We prove the solution to the LP is asymptotic optimal when the truncated threshold is sufficiently large.
- The sub-gradient ascend method is applied to find the optimal Lagrange multiplier to satisfy the relaxed bandwidth constraint. Finally, we propose the truncated stationary policy to meet the hard bandwidth constraint. The average performance of the strategy is verified through theoretical analysis and numerical simulations.
The remainder of this paper is organized as follows. The network model, the AoI metric, and the age penalty function are introduced in Section 2. In Section 3, we formulate the primal scheduling problem, and then decouple it into independent single-sensor problems through bandwidth relaxation and Lagrange multipliers. The approximate optimal policy for single-sensor problem is obtained in Section 4 by solving an LP. In Section 5, the asymptotic optimal truncated policy is proposed. Finally, Section 6 provides simulation results to verify the performance of the proposed truncated policy, and Section 7 draws the conclusion.
Notations: All the vectors and matrices are denoted in boldface. The probability of given is denoted as . Let be the expectation of variable X given . The cardinality of a set is written as .
2. System Model
2.1. Network Model
In this work, we consider a BS collecting update packets from N time-sensitive sensors through time-varying channels. The time is slotted, and is used to denote the current slot index. Define to be the scheduling decision for sensor n in slot t, where means the sensor n chooses to send the newest packet, while means idling the channel link. Assume all the scheduling behaviors take place at the beginning of each slot and the packet transmission delay through all the channel links is one slot. Due to the limited bandwidth capacity of the BS, the total number of sensors to be scheduled in one slot cannot be larger than M. Here, we assume so that the problem is nontrivial:
To model the time varying effect, we assume that the channel link connecting the BS and each sensor n is an ergodic Q-state Markov chain. Denote to be the channel state of link n in slot t. Without loss of generality, we assume that the channel state becomes more noisy as the state index becomes larger. Denote to be the Markov state transition matrix of link n, and the entry means the probability of changing into state j in the next slot given the current state i, i.e.,
Due to different channel states, the sensors should use different energy for both saving energy and successful decoding of the packet at the receiver. We denote to be the energy consumption for scheduling when the channel state is q. Notice that the energy consumption tends to be larger as the channel state becomes more noisy to combat the channel fading, i.e., . Besides, due to the power limit of each sensor n, the total average power consumption cannot exceed the upper bound, denoted by , i.e.,
where is a scheduling policy.
Given channel state q, we assume that there exists the probability of packet loss through link n due to decoding error or inaccurate estimation.
2.2. Age of Information and Age Penalty
In the network described above, the BS wishes to obtain the freshest information for further process or accurate prediction. We model the data staleness at the terminal end as a monotone increasing age penalty function of Age of information (AoI). By definition, AoI is the difference between the current time slot and the time slot that the freshest data received by the BS is generated by the sensor [3].
Let be the AoI of sensor n in slot t. According to the definition, if the sensor is scheduled in slot t and there is no packet loss, then ; otherwise, . In conclusion, the AoI evolves as follows,
3. Problem Formulation and Decomposition
3.1. Problem Formulation
For given network, we measure the data freshness at the terminal side by computing the average age penalty under scheduling policy , denoted by , i.e.,
where states the initial AoI of the system. In this work, we assume that the system is synchronized with all the sensors at the beginning, i.e., , and thus omit in the further analysis.
We denote to be the set of all possible causal policies whose decisions are only based on current and historic information while satisfying both bandwidth and power constraints. Then, our goal is to optimize Equation (5) by choosing a scheduling policy . Therefore, the primal optimization problem can be written as
Problem 1
(Primal Scheduling Problem).
3.2. Problem Decomposition
Notice that Equation (6b) is an integer programming where the exponential growth rate of state and action space set obstacles in solving Problem 1. Therefore, we formulate a relaxed version of Problem 1, where the primal bandwidth constraint in every slot is replaced by a time-average bandwidth constraint. We will then show that the relaxed problem can be solved by sensor level decoupling, which greatly reduces the cardinality of the state and action space.
Problem 2
(Relaxed Primal Scheduling Problem).
Denote to be the optimal policy of Problem 2. The following theorem ensures that the optimal policy of the relaxed problem is composed of several local optimal policies , each of which depends on its own channel state and AoI evolution regardless of others.
Theorem 1.
The optimal policy of Problem 2 can be decoupled into local optimal policies, i.e., . Each of the local policy has the following properties.
The proof of Theorem 1 is provided in Appendix A.
In order to find the local optimal polices, we introduce a Lagrange multiplier to eliminate the relaxed bandwidth constraint, and the Lagrange function is as follows,
where the Lagrange multiplier can be seen as a scheduling penalty which will increase the function value if there are more than M sensors to be scheduled per slot in average.
For fixed , we can now further decouple the relaxed scheduling problem into N single-sensor cross-layer designs, each of which has the corresponding power constraint in Equation (7c):
Problem 3
(Single-Sensor Decoupled Problem).
As the resolution of each decoupled problem is independent of n, we omit the subscript n in further analysis.
4. Single-Sensor Problem Resolution
4.1. Constrained Markov Decision Process Formulation
First, we notice that the decoupled problem is a constrained Markov decision process of which the elements and constraint are explained as follows.
- State Space: The state of each sensor consists of two parts: the current AoI and channel state . Thus, is infinite but countable.
- Action Space: There are two possible actions in the action space for the scheduling policy, denoted by . Action means the sensor chooses to schedule while means idling. Notice that here does not need to satisfy the bandwidth constraint.
- One-Step Cost: The one-step cost consists of two parts: the age penalty growth and scheduling penalty, which can be computed byAnd the one-step power consumption is
Now our goal is to optimize the following average one-step cost,
under the following average power constraint,
4.2. Characterization of the Optimal Policy
To search for the stationary optimal policy, we can further introduce another Lagrange multiplier to eliminate the power constraint, i.e.,
The multiplier can be viewed as a power penalty, which will increase the Lagrange function once the average power consumption exceeds the constraint. Then minimizing the above Lagrange function for fixed becomes an MDP problem without any constraint.
The following lemma ensures that the optimal stationary policy for the MDP problem has a threshold structure.
Lemma 1.
The optimal stationary policy of the unconstrained MDP problem has the threshold structure, i.e., given state , there exists a threshold such that if , then it is optimal to schedule the sensor; otherwise, idling is the optimal action.
Proof sketch: The complete proof is provided in Appendix B and Appendix C, which is similar to Theorem 2 in [23]. Despite the complex proof, the intuition is simple. As it is optimal to schedule the sensor in state , then it is also the optimal action in state because the AoI is much bigger.
4.3. Linear Programming Approximation
Now, we focus on finding the optimal stationary policy. Denote to be the scheduling probability given state and our goal is to find that minimizes the objective function. In this part, we will approximate by solving a truncated LP.
According to Lemma 1, for the optimal stationary policy, we can set a threshold and then we have . Next, we focus on searching for policies that possesses this threshold property as other policies are far from optimality.
Let be the steady distribution of state . Then, define a new variable . The following theorem converts the CMDP problem into an infinite LP problem.
Theorem 2.
The single-sensor decoupled problem is equal to the following infinite LP problem.
Proof.
Let us consider the average cost of Equation (8a) by using and . Invoking Equation (9), the one step cost of state is either when scheduling or when idling. Therefore, the time average cost can be computed as follows,
which is equivalent to Equation (13a).
Similarly, according to Equation (10), the time average power consumption is
which is exactly the LHS of Equation (13e).
Considering the property of steady probability distribution, Equation (13b,f) are verified.
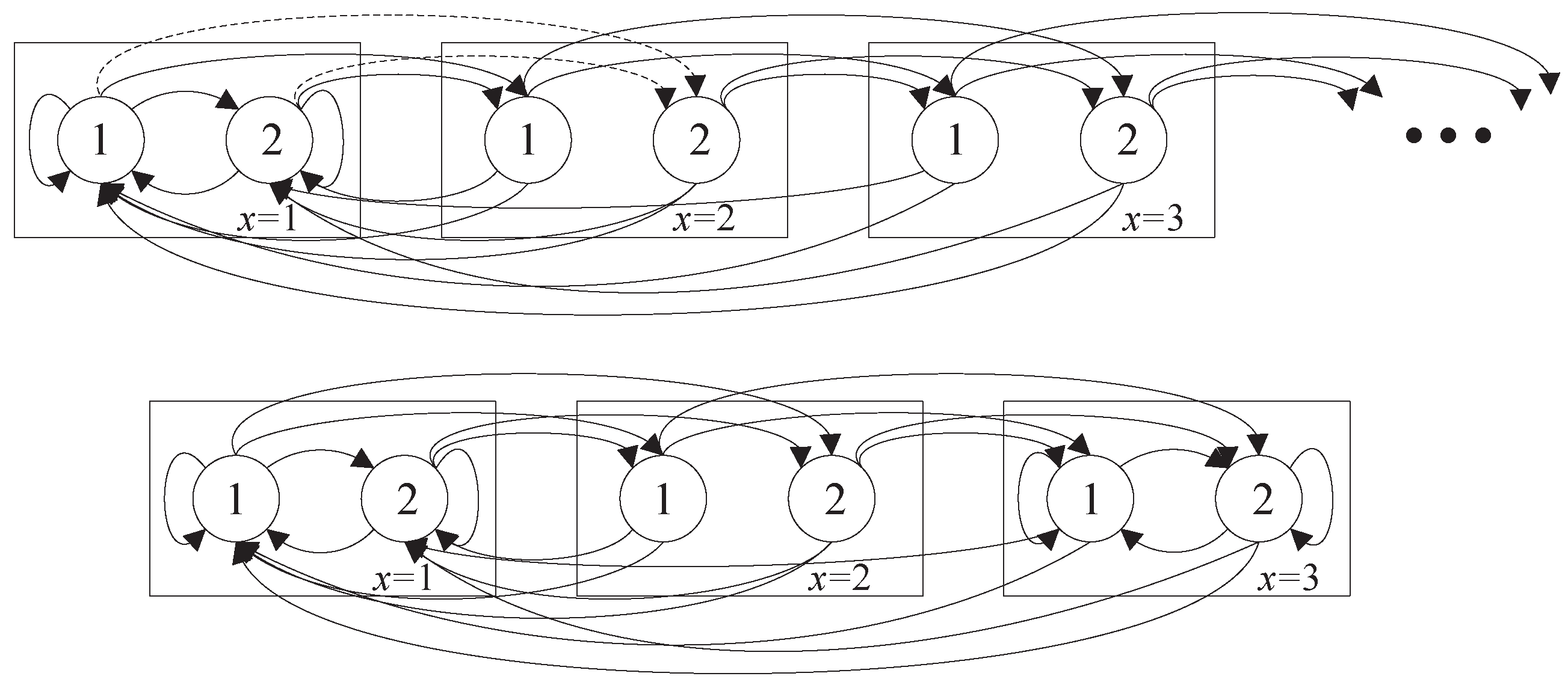
Finally, notice that the evolution of state forms a Markov chain as depicted in Figure 1 (top) for as an example. We use and to denote the transition probability between the states, which can be computed as follows,
According to the property of steady distribution, equals to the sum of the steady distribution which can be transferred to in the next slot times their transition probability. As depicted in Figure 1, (see the dashed lines). Therefore, we can compute as follows,
which is equivalent to Equation (13c,d). □
As the steady distribution is infinite, it is difficult to solve the problem exactly. Therefore, we approximate the optimization problem in Theorem 2 into a finite LP problem through truncation:
Problem 4
(Linear Programming Approximation).
After truncation, the optimal value of Equation (16a) is the lower bound of the objective function of the decoupled problem Equation (8a). The detailed proof is provided in Appendix D. The key concept is to set a threshold X and convert the Markov chain into a finite-state one (see Figure 1).
Moreover, the following theorem guarantees the lower bound obtained by the above LP problem is tight when X is sufficiently large. Thus, the approximate optimal solution performs close to the exact optimal solution . Before displaying the theorem, first denote and to be the scheduling policy according to the approximate optimal solution by setting threshold X and optimal one , respectively. Define to be the age and scheduling penalty of the primal problem under policy and is the approximate penalty when we set the age penalty . Then, according to Equations (13a) and (16a), we have
Theorem 3.
Assume satisfies the following property: and constant such that and , where . Then, we have the following property,
where . As we see the above inequality, the difference between optimal solution of Theorem 2 and Problem 4 converges to 0 as the threshold X becomes sufficiently large.
The entire proof is provided in Appendix E.
After solving the above LP problem, we can obtain the approximate optimal scheduling probability by setting a sufficiently large X and computing and . Moreover, analogical to the threshold structure described in Lemma 1, also has the following property.
Lemma 2.
For any state of each sensor, the optimal scheduling probability is non-decreasing with x, i.e.,
The proof technique is similar to Lemma 1, so it is omitted here.
5. Multi-Sensor Problem Resolution
By now, through relaxing, decoupling and truncation, we have obtained the approximate solution to the single-sensor decoupled problem for fixed scheduling penalty . In this section, we will go back to solve the multi-sensor problem, and propose a truncated policy to meet the hard bandwidth constraint in Equation (6b).
5.1. The Relaxed Problem Resolution
First, we should choose the optimal such that the relaxed bandwidth constraint can be fully leveraged. Denote to be the Lagrange dual function, where we choose the approximate optimal policy by solving LP. Then, the dual function can be computed as follows,
where is the decoupled dual function for sensor n. According to the LP approximation, can be further written out as follows,
where is the average age penalty bounded by , and is the average scheduling probability, which equals to .
According to the work in [24], the optimal Lagrange multiplier satisfies
If , then the optimal policy is just . Otherwise, the optimal policy is a mixture of two policies, denoted by and , which can be computed by
Then, we apply the sub-gradient ascend method to find the optimal solution, where the sub-gradient can be computed as follows,
where is the total scheduling probability.
Choose as the starting point, and compute the average scheduling probability . If , then it does not need to consider the bandwidth constraint, and thus the optimal solution has already been solved. Moreover, this optimal solution can also be viewed as the lower bound of the primal optimization problem, i.e.,
Otherwise, we need to increase the scheduling penalty through iterations. The update operation in iteration k can be written out as follows,
where is the step size in iteration k.
Moreover, the step size is determined as follows,
where is a constant.
The determination of the step size above guarantees the algorithm converges from both sides. Therefore, after running the whole algorithm, we can obtain two different scheduling probabilities and :
Their corresponding optimal polices are denoted as and . Then, the optimal stationary policy can be obtained by mixing these two policies:
where the mixed coefficient can be computed as follows,
Now, we have obtained the optimal stationary policy of the relaxed scheduling problem. The algorithm flow chart is listed in Algorithm 1. Once we obtain , the optimal scheduling probability can be computed as follows,
| Algorithm 1 Construction of the optimal stationary policy |
| Initialization: , , , , and |
| for each do |
| compute and |
| end for |
| if then |
| else |
| while or do |
| if then |
| else |
| end if |
| for each do |
| compute and |
| end for |
| if and then |
| end if |
| if and then |
| end if |
| end while |
| end if |
5.2. Truncation for the Hard Bandwidth Constraint
Finally, a bandwidth-truncated policy is derived from the optimal stationary policy to satisfy the hard bandwidth constraint in Equation (6b). Before introducing the truncated policy, first denote to be the set of sensors to be scheduled in slot t, and is the number of sensors to be scheduled in slot t. Then, the construction of is carried out as follows.
- In slot t, compute the scheduling set according to the optimal stationary policy .
- If , then schedules all these sensors as does.
- If , the hard bandwidth constraint is never satisfied. Therefore, randomly chooses M out of sensors to be scheduled in the current slot.
The following theorem guarantees the asymptotic performance of the truncated policy compared with on certain conditions.
Theorem 4.
Suppose the age penalty function is concave, and let be a constant. If all the sensors and their channels are identical, i.e., the power constraint and the channel transition matrix are the same, then the truncated policy and the optimal randomized policy have the following property,
The whole proof is provided in Appendix F.
6. Simulation Results
In this section, we provide simulation results to verify the performance of the proposed policy. First, we study the average age penalty performance with different types of sensors with different bandwidth constraint and AoI truncation threshold X. Next, we study the detailed scheduling decision of each sensor. The average performance is obtained by simulating consecutive slots.
6.1. Average Age Penalty Performance
In this part, we demonstrate the average performance of our proposed policy. We consider 4-state channel system, i.e., . The age penalty function is chosen as unless otherwise specified. The transition matrix for each sensor is the same:
Denote to be the steady distribution of the channel state. We consider that for each channel state q, the energy consumption . According to [12], the optimal policy to minimize the average AoI performance when all the sensors are identical is a greedy policy, which schedules the M sensors with the largest AoI and consumes the average power for each sensor . Therefore, define to be the power constraint factor which describes the effects of power consumption constraint .
Figure 2 demonstrates the average age penalty performance of the proposed policy as a number of sensors N, with bandwidth constraint , compared with the lower bound, the relaxed optimal policy and the greedy policy. Set the threshold , where is ceiling function. We assume that the probability of packet loss for each sensor is the same, denoted by :
The power constraint factor of sensor n is .
As seen in Figure 2, the proposed truncated policy performs closely to the relaxed optimal policy and the lower bound, and outperforms the greedy policy especially when N is large. According to Figure 2, the age penalty decreases by and from the greedy policy with sensors when and , respectively, under proposed policy. Moreover, as the threshold X becomes large, the difference between the average performance following policy and the lower bound becomes indistinguishable. Therefore, the asymptotic performance described in Theorem 3 can be verified.
Figure 3 compares the average performance of the proposed policy with the AoI-minimum policy to verify the improvement of considering different penalty function. The AoI-minimum policy is similar to the one proposed in our previous work [22] with the consideration of packet loss. The bandwidth constraint . The packet loss probability , and the energy consumption . Here the age penalty function is chosen as . From Figure 3, we can see that the AoI-minimum policy cannot guarantee a good age penalty performance. Thus, it is necessary to consider different demand for data freshness to achieve better performance.
Figure 4 and Figure 5 verify the asymptotic performance of the proposed policy with different age penalty function and different packet loss probability respectively when is a constant in symmetric networks. From both figures, it can be seen that the difference of average age penalty under proposed policy and the lower bound becomes small as N increases. Thus, the asymptotic performance described in Theorem 4 can be verified.
6.2. Sensor Level Analysis and Threshold Structure
Next, we analyze the scheduling decision of each sensor and their corresponding age penalty to provide some insights of optimal scheduling policies. We consider a system with and . The transition matrix of channel state is the same as Equation (21), and power consumption . We set the threshold to compute the proposed policy.
First we consider the system with and age penalty function . Figure 6 analyzes how the power constraint influences age penalty of each sensor. The power constraint of sensor n is . From Figure 6, we can see that the proposed policy outperforms the greedy policy when the required power consumption is scarce, and performs similarly or a little worse when the factor . This implies that our proposed policy chooses a more proper power allocation based on current channel state and AoI than the greedy policy by stimulating sources with scarce power budgets to be scheduled in better channel states.
As the packet loss influences age penalty as well, Figure 7 considers sensors with different probability of packet loss, which can be written out as the following matrix :
We fix the power constraint factor for all sensors. Figure 7 shows that the average age penalty increases with the probability of packet loss. Moreover, the proposed policy combats with the packet loss better than the greedy policy as the proposed policy considers when solving the LP problem, but the greedy policy does not.
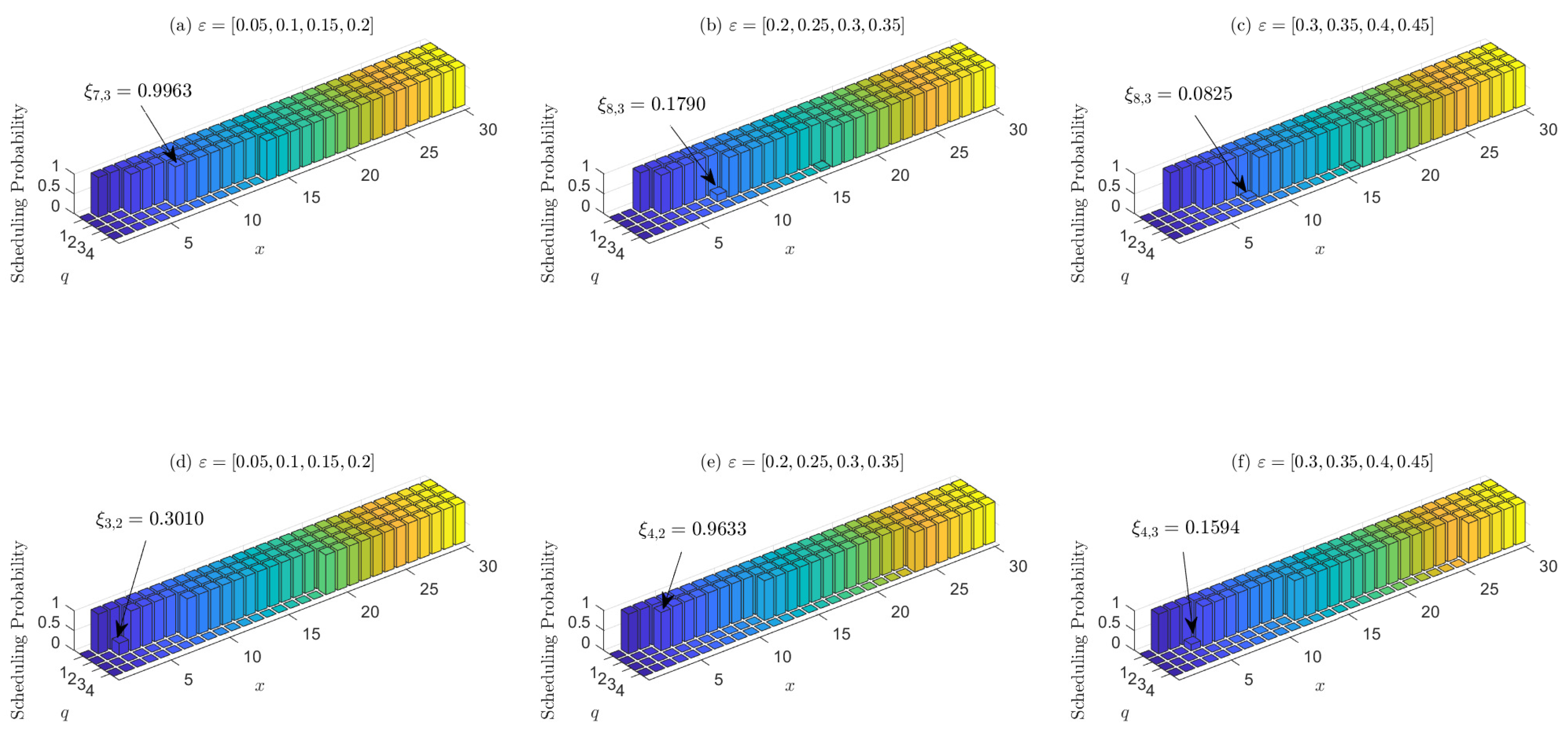
Next, we verify the threshold structure of the optimal scheduling policy. Figure 8 demonstrates the effect of bandwidth and packet loss on the scheduling threshold. The power constraint factor , and the packet loss probability is the same as Equation (22). Subfigures (a–c) demonstrate three of these sensors whose packet loss probability is as the title. For each of the three sensors, subfigures (d–f) consider the single-sensor system without bandwidth constraint and display their scheduling probability, respectively. Moreover, Figure 8 lists some of the thresholds given channel state q, e.g., in subfigure (a), the threshold of channel state is , and the corresponding optimal scheduling probability is . From Figure 8, first we can see that all the six figures verify the non-decreasing property of the scheduling probability with AoI described in Lemma 2. Second, subfigures (a–c) demonstrate that the sensor with higher packet loss probability also has higher scheduling threshold. This implies that the sensors with more reliable channel should be given higher priority to scheduling than unreliable ones to minimize the average age penalty, since scheduling the more reliable channel under the same AoI is more likely to reduce the current age penalty. Third, by comparing subfigures (a) and (d), (b) and (e), and (c) and (f), the scheduling threshold varies more significantly for different channel states if there exists no bandwidth constraint. The sensors tend to update more often when the channel state is good, and idle when the channel state is bad. This is because the sensors can choose to update packets more frequently in good channel state to both save energy and increase the success probability of transmission without bandwidth constraint.
Finally, we study the effects of age penalty function on threshold structure. Here, we consider a system with , and three different penalty function, i.e., , , and in Figure 9. We plot the scheduling decision of the sixth sensor. As is depicted in Figure 9, as the system has a higher restriction on data freshness such as exponential or quadratic function, the difference between thresholds of different states becomes small. In such situations, channel states play a weaker role because waiting for another slot to schedule tends to have unbearable age penalty.
7. Conclusions
In this paper, we consider the multi-sensor scheduling problem through an error-prone Markovian channel state. Through relaxing and decoupling, we propose a truncated policy to satisfy both the bandwidth and power constraints to minimize the average age penalty of all sensors in infinite horizon. We prove the asymptotic performance of the truncated policy in symmetric networks when the age penalty function is concave by choosing a sufficiently large threshold X. Through theoretical analysis and numerical simulations, we find that the age penalty function, packet loss probability, bandwidth constraint, and power constraint work altogether to influence the optimal scheduling decisions. Those who have more reliable channel state and enough power consumption tend to have higher scheduling priority.
Author Contributions
Conceptualization, Y.C. and H.T.; methodology, Y.C.; validation, Y.C. and H.T.; formal analysis, Y.C.; writing—original draft preparation, Y.C.; writing—review and editing, H.T., J.W., and J.S.; supervision, J.W. and J.S.; funding acquisition, J.W. and J.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Key R&D Program of China under Grant 2017YFE0112300, Beijing National Research Center for Information Science and Technology under Grant BNR2019RC01014 and BNR2019TD01001.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 1
First, we notice that Problem 2 is equivalent to the following optimization problem, where we further introduce variables to denote the local bandwidth constraint of sensor n.
Problem A1
(Equivalent Relaxed Primal Scheduling Problem).
For each feasible fixed local bandwidth constraint vector , we can transfer the above problem into the following one by removing constraint Equations (A1c) and (A1e).
Problem A2
(Relaxed Problem for Fixed ).
Then, according to the work in [25], the optimal policy of the Problem 6 given can be decoupled into several local policies. This is somewhat intuitive as the constraints and objective function of Problem 6 are decoupled for each sensor n. As for each feasible , the optimal scheduling policy can be decoupled, recall that , when takes the optimum value , the property also holds.
Appendix B. Proof of Lemma 1
Before we proceed to the proof, we make two definitions. For any two states and , define a partial order . We state that if and only if . Moreover, we also define a partial order on the action space . We state that if and only if .
The monotonicity of the optimal action on the state space is true if the four following conditions hold:
- If , for any ;
- If , for any , ,where is any monotone increasing function;
- If and , then ;
- If and , then:
Next, we consider a discounted cost MDP over a finite horizon:
where is discounted factor.
And the corresponding Bellman equation is
If the above four conditions are satisfied and the corresponding Bellman function is monotone increasing, then the one-step cost is monotone and sub-modular in s and u, which shows there exists an optimal monotone policy for any finite-time horizon MDP. Using the vanishing discount approach in Theorem 5.5.4 in [26], the property of monotonicity is propagated to the time-average MDP.
Before verifying the above four conditions, first we introduce the following lemma to ensure is monotone increasing with x, whose proof is provided in Appendix C.
Lemma A1.
For fixed channel state q and discounted factor β, is monotone increasing with x.
Therefore, we only need to show the decoupled unconstrained problem satisfies the above four conditions.
Notice that the one-step cost can be computed by
According to the definition of partial order and , and Equation (A6), we can easily verify condition 1 and 3.
Also, we have:
According to Equation (A7) and the fact that , it is also feasible to verify that both condition 2 and 4 hold.
Appendix C. Proof of Lemma A1
In this part, we will prove that in the finite-time horizon MDP is an increasing function with x. The key method of the proof is through induction.
Notice that is increasing with x. Suppose that is increasing with . For , we have
Denote to be the expected discounted cost if take action u at state . Then,
Similarly, we can derive that . According to the Bellman equation Equations (A4) and (A5), the value function can be computed as follows,
From the above, . Thus, . Therefore, through induction, we verify that is increasing with x.
Appendix D. Derivation of Problem 4
First, make the following variable substitution,
Similarly, let
Instead of solving and in Theorem 2, we solve the new finite variables and . Therefore, the constraints Equation (13b), Equation (13c), Equation (13e), and Equation (13f) become Equation (16b), Equation (16c), Equation (16f), and Equation (16g), respectively. Equation (16d) corresponds to Equation (13d) when . Otherwise, sum all the Equation (13d) from X to infinity, i.e.,
where (a) holds because we separate from the sum.
Invoking Equations (A8) and (A9), the above equality is equivalent to
which is exactly equal to Equation (16e).
Notice that the optimal action is to schedule when , i.e., . Thus, . Therefore, we have
which is equal to Equation (16h).
By now, through variable substitution, we have verified the constraints of the finite LP problem are equivalent to the ones of the original optimization problem. Therefore, the optimal solution to the finite LP problem is also feasible to the original problem. Now for the objective function, we have
Therefore, we have verified that the decoupled single-sensor problem is approximate to the LP problem, which has the same constraint but can be the lower bound of the original problem.
Appendix E. Proof of Theorem 3
Our aim is to bound . Recall that is the optimal solution to the primal problem. Thus, the difference can be bounded by .
To further bound the above term, first denote and to be the distribution and scheduling probability of state under policy , i.e.,
where is indicating function.
Let . Recalling the approximation solution to Problem 4, we have
Then, we can bound as
where (a) holds because of Equations (A11) and (A12). (b) holds because of Equations (A13) and (A14).
Next, we upper bound term . For simplicity, denote . Thus, we have
where the matrix can be computed according to Equation (14) and further bounded as follows,
Appendix F. Proof of Theorem 4
According to Lemma 2, the optimal policy for every decoupled single-sensor problem has the threshold structure. Let be the threshold of sensor n given channel state q. Denote to be the largest difference between different thresholds of sensor n, and . As all the sensors are identical, does not change with N. Moreover, let .
Suppose that the sensor n is not scheduled under when . Now consider the probability that it is still not scheduled in the next slot, which results from two reasons, i.e., it jumps into a state which has a higher scheduling threshold or there are still more than M sensors to be scheduled. Let p be the probability that the channel state jumps into a state having a higher scheduling threshold. Then, the probability of idling in the next slot, denoted by can be computed by
Notice that p can be upper bounded as
Therefore, can be upper bounded by z, which can be computed as
Therefore, it can be generalized that the probability that it is still not scheduled in the consecutive k slots is upper bounded by , where .
Now, we bound the different performance of and by introducing another policy . Under , when , all these sensors are scheduled like , but add an extra penalty for those sensors, which can be computed as
where (a) holds because is concave.
For simplicity, denote , which is a constant once the channel transition matrix and power constraint are fixed.
As the age penalty function is concave, the average age penalty cost under does not decrease compared with . Then, the difference between and can be bounded as
Notice that when , the optimal action is to schedule. Hence, the probability of is upper bounded by . For simplicity, let . Then, , there exists such that the steady distribution and n can be bounded as
Then, we have
As is concave, it can be upper bounded by a linear function, i.e., . Therefore, the second term in the above inequality can be further bounded as
By choosing and , the second term in Equation (A19) converges to 0 as N becomes large.
For the first term in Equation (A19), according to the work in [27], the expectation of has the following property,
In addition, as policy satisfies the relaxed bandwidth constraint, we have
Therefore, when , can be upper bounded by
As the threshold X does not increase with N, converges to 0 as N becomes infinite. Thus, the asymptotic performance of the truncated policy has been proven.
References
- Kaul, S.; Gruteser, M.; Rai, V.; Kenney, J. Minimizing age of information in vehicular networks. In Proceedings of the 2011 8th Annual IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks, Salt Lake City, UT, USA, 27–30 June 2011; pp. 350–358. [Google Scholar]
- Zhou, B.; Saad, W. Optimal Sampling and Updating for Minimizing Age of Information in the Internet of Things. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, UAE, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Kaul, S.; Yates, R.; Gruteser, M. Real-time status: How often should one update? In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 2731–2735. [Google Scholar]
- Chen, K.; Huang, L. Age-of-information in the presence of error. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 2579–2583. [Google Scholar]
- Costa, M.; Codreanu, M.; Ephremides, A. On the Age of Information in Status Update Systems with Packet Management. IEEE Trans. Inf. Theory 2016, 62, 1897–1910. [Google Scholar] [CrossRef]
- Najm, E.; Yates, R.; Soljanin, E. Status updates through M/G/1/1 queues with HARQ. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 131–135. [Google Scholar]
- Kosta, A.; Pappas, N.; Ephremides, A.; Angelakis, V. Age and value of information: Non-linear age case. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 326–330. [Google Scholar]
- Wang, X.; Duan, L. Dynamic Pricing for Controlling Age of Information. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 962–966. [Google Scholar]
- Sun, Y.; Uysal-Biyikoglu, E.; Yates, R.; Koksal, C.E.; Shroff, N.B. Update or wait: How to keep your data fresh. IEEE Trans. Inf. Theory 2017, 63, 7492–7508. [Google Scholar] [CrossRef]
- Ceran, E.T.; Gündüz, D.; György, A. Average Age of Information With Hybrid ARQ Under a Resource Constraint. IEEE Trans. Wirel. Commun. 2019, 18, 1900–1913. [Google Scholar] [CrossRef] [Green Version]
- Bacinoglu, B.T.; Ceran, E.T.; Uysal-Biyikoglu, E. Age of information under energy replenishment constraints. In Proceedings of the 2015 Information Theory and Applications Workshop (ITA), San Diego, CA, USA, 1–6 February 2015; pp. 25–31. [Google Scholar]
- Kadota, I.; Uysal-Biyikoglu, E.; Singh, R.; Modiano, E. Minimizing the Age of Information in broadcast wireless networks. In Proceedings of the 2016 54th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 27–30 September 2016; pp. 844–851. [Google Scholar]
- Maatouk, A.; Kriouile, S.; Assaad, M.; Ephremides, A. On the Optimality of the Whittle’s Index Policy for Minimizing the Age of Information. arXiv 2020, arXiv:2001.03096. [Google Scholar] [CrossRef]
- Kadota, I.; Sinha, A.; Modiano, E. Scheduling Algorithms for Optimizing Age of Information in Wireless Networks with Throughput Constraints. IEEE/ACM Trans. Netw. 2019, 27, 1359–1372. [Google Scholar] [CrossRef]
- Kadota, I.; Sinha, A.; Uysal-Biyikoglu, E.; Singh, R.; Modiano, E. Scheduling Policies for Minimizing Age of Information in Broadcast Wireless Networks. IEEE/ACM Trans. Netw. 2018, 26, 2637–2650. [Google Scholar] [CrossRef] [Green Version]
- Bedewy, A.M.; Sun, Y.; Shroff, N.B. Age-optimal information updates in multihop networks. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 576–580. [Google Scholar]
- Chen, X.; Gatsis, K.; Hassani, H.; Bidokhti, S.S. Age of Information in Random Access Channels. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020. [Google Scholar]
- Hsu, Y.; Modiano, E.; Duan, L. Age of information: Design and analysis of optimal scheduling algorithms. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 561–565. [Google Scholar]
- Talak, R.; Kadota, I.; Karaman, S.; Modiano, E. Scheduling Policies for Age Minimization in Wireless Networks with Unknown Channel State. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 2564–2568. [Google Scholar]
- Sun, Y.; Polyanskiy, Y.; Uysal, E. Sampling of the Wiener Process for Remote Estimation over a Channel with Random Delay. IEEE Trans. Inf. Theory 2019, 66, 1118–1135. [Google Scholar] [CrossRef]
- Wang, J.; Ren, X.; Mo, Y.; Shi, L. Whittle Index Policy for Dynamic Multichannel Allocation in Remote State Estimation. IEEE Trans. Autom. Control 2020, 65, 591–603. [Google Scholar] [CrossRef]
- Tang, H.; Wang, J.; Song, L.; Song, J. Minimizing Age of Information With Power Constraints: Multi-User Opportunistic Scheduling in Multi-State Time-Varying Channels. IEEE J. Sel. Areas Commun. 2020, 38, 854–868. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Han, D.; Cheng, P.; Shi, L. Optimal Scheduling of Multiple Sensors over Lossy and Bandwidth Limited Channels. arXiv 2018, arXiv:1804.05618. [Google Scholar] [CrossRef] [Green Version]
- Beutler, F.J.; Ross, K.W. Optimal policies for controlled Markov chains with a constraint. J. Math. Anal. Appl. 1985, 112, 236–252. [Google Scholar] [CrossRef] [Green Version]
- Tajan, R.; Ciblat, P. Information-theoretic multi-user power adaptation in retransmission schemes. In Proceedings of the 2016 IEEE 17th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Edinburgh, UK, 3–6 July 2016; pp. 1–5. [Google Scholar]
- Hernández-Lerma, O.; Lasserre, J.B. Discrete-Time Markov Control Processes: Basic Optimality Criteria; Springer Science & Business Media: Berlin, Germany, 2012; Volume 30. [Google Scholar]
- Diaconis, P.; Zabell, S. Closed form summation for classical distributions: Variations on a theme of de Moivre. Stat. Sci. 1991, 6, 284–302. [Google Scholar] [CrossRef]
Figure 1.
Illustration of the state transition graph for channel states without (top) and with (bottom) AoI truncation with AoI threshold . The numbers in circles are channel state index q, and the number in rectangles are AoI index x.
Figure 1.
Illustration of the state transition graph for channel states without (top) and with (bottom) AoI truncation with AoI threshold . The numbers in circles are channel state index q, and the number in rectangles are AoI index x.

Figure 2.
Average age penalty performance as a number of sensors N, .

Figure 3.
Average age penalty performance as a number of sensors N compared with AoI-minimum policy.
Figure 3.
Average age penalty performance as a number of sensors N compared with AoI-minimum policy.

Figure 4.
Asymptotic average age penalty performance with different age penalty function . .

Figure 5.
Asymptotic average age penalty performance with different packet loss probability.
. .

Figure 6.
Each sensor’s average penalty with different power constraint factor .

Figure 7.
Each sensor’s average penalty with different packet loss probability .

Figure 8.
Subfigures (a–c) demonstrate the scheduling probability of sensors whose packet loss probability is as the title when and . Subfigures (d–f) demonstrate their scheduling probability in single-sensor system respectively. All the power constraint is .
Figure 8.
Subfigures (a–c) demonstrate the scheduling probability of sensors whose packet loss probability is as the title when and . Subfigures (d–f) demonstrate their scheduling probability in single-sensor system respectively. All the power constraint is .

Figure 9.
Threshold comparison with different age penalty function.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chen, Y.; Tang, H.; Wang, J.; Song, J. Optimizing Age Penalty in Time-Varying Networks with Markovian and Error-Prone Channel State. Entropy 2021, 23, 91. https://0-doi-org.brum.beds.ac.uk/10.3390/e23010091
AMA Style
Chen Y, Tang H, Wang J, Song J. Optimizing Age Penalty in Time-Varying Networks with Markovian and Error-Prone Channel State. Entropy. 2021; 23(1):91. https://0-doi-org.brum.beds.ac.uk/10.3390/e23010091
Chicago/Turabian StyleChen, Yuchao, Haoyue Tang, Jintao Wang, and Jian Song. 2021. "Optimizing Age Penalty in Time-Varying Networks with Markovian and Error-Prone Channel State" Entropy 23, no. 1: 91. https://0-doi-org.brum.beds.ac.uk/10.3390/e23010091
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.