
Wireless Network Optimization for Federated Learning with Model Compression in Hybrid VLC/RF Systems †

 , ,
, , 
Abstract
:1. Introduction
1.1. Related Work
1.2. Contribution
- We propose a USBA-MC algorithm over a hybrid VLC/RF system. In the USBA-MC algorithm, each user obtains a local FL model by training through its own dataset and transmits the model parameters to a base station (BS). The BS aggregates the received local models to generate a global FL model and transmits it back to each user. For the considered FL model, the performance is significantly affected by wireless factors such as available bandwidth and users’ channel state information. This formulates a joint user selection and bandwidth allocation problem, whose goal is to minimize the FL training loss.
- To solve this problem, we first introduce a model compression method to reduce the size of FL model parameters that are transmitted over wireless links. To this end, we first sort the model parameters and design a threshold selection mechanism according to the sparsity rate. Then, we cut off the redundant model parameters based on the threshold and, thus, compress an FL model of each user.
- Following the model compression, we separate the joint user selection and bandwidth allocation problem into two subproblems. The first subproblem is a user selection problem with a given bandwidth allocation, which is solved by a traversal algorithm. The second subproblem is a bandwidth allocation problem with a given user selection, which is solved by a numerical method. The ultimate user selection and bandwidth allocation are obtained by iteratively compressing the model and solving these two subproblems.
2. System Model and Problem Formulation
2.1. FL Model
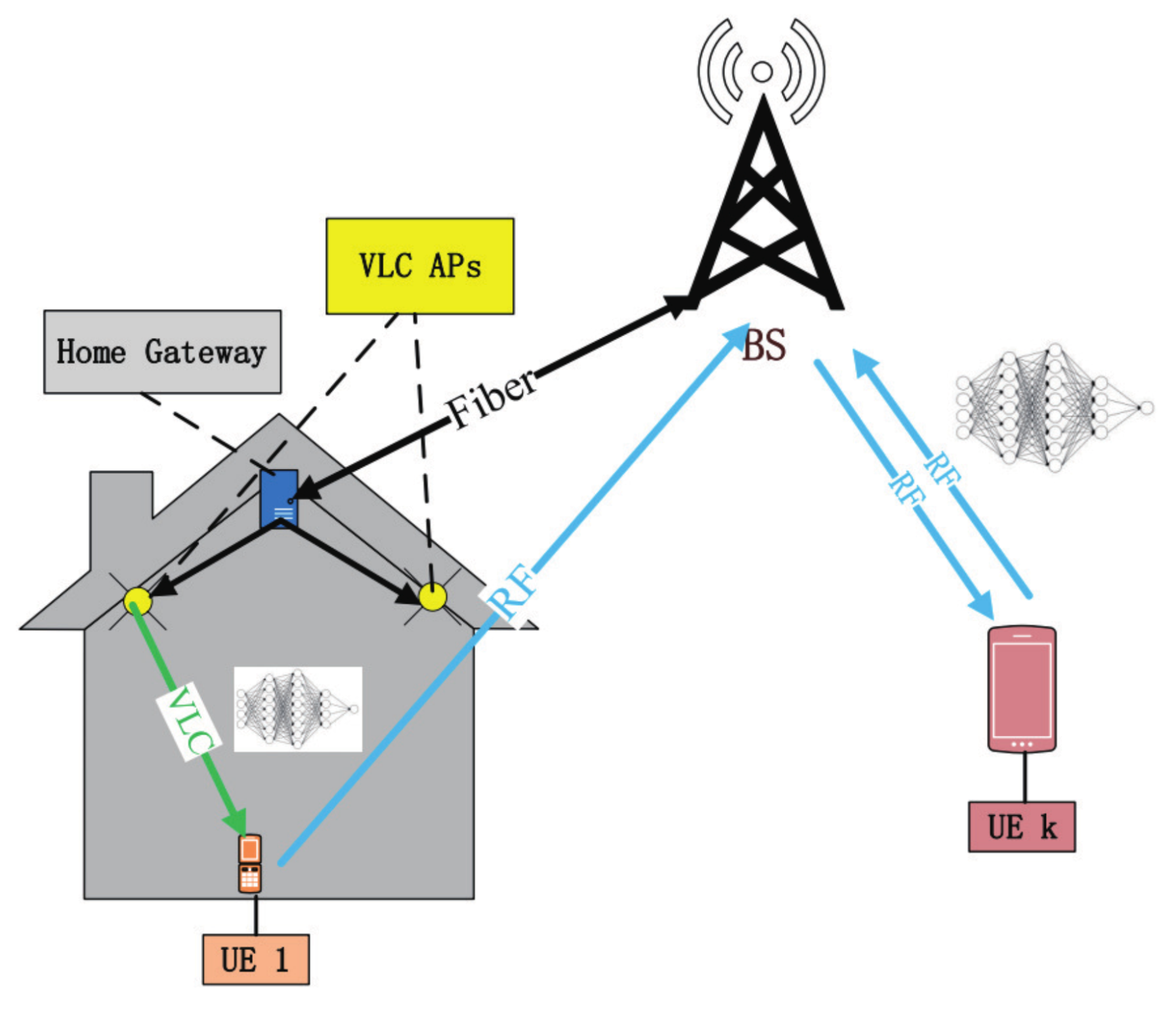
2.2. FL Based on Hybrid VLC/RF System
2.3. Computational Model
2.4. RF Transmission Model
2.5. VLC Transmission Model
2.6. Problem Formulation
3. Model Compression
3.1. Problem Analysis
3.2. Model Weights Compression
| Algorithm 1: FL Model Compression |
|
4. The Proposed Algorithm
4.1. Optimal User Selection
| Algorithm 2: User Selection Algorithm GetS(,,B) |
|
4.2. Optimal RB Bandwidth
4.3. Iterative Solution
| Algorithm 3: USBA-MC Algorithm |
|
4.4. Convergence, Implementation, and Complexity Analysis
5. Simulation Results and Analysis
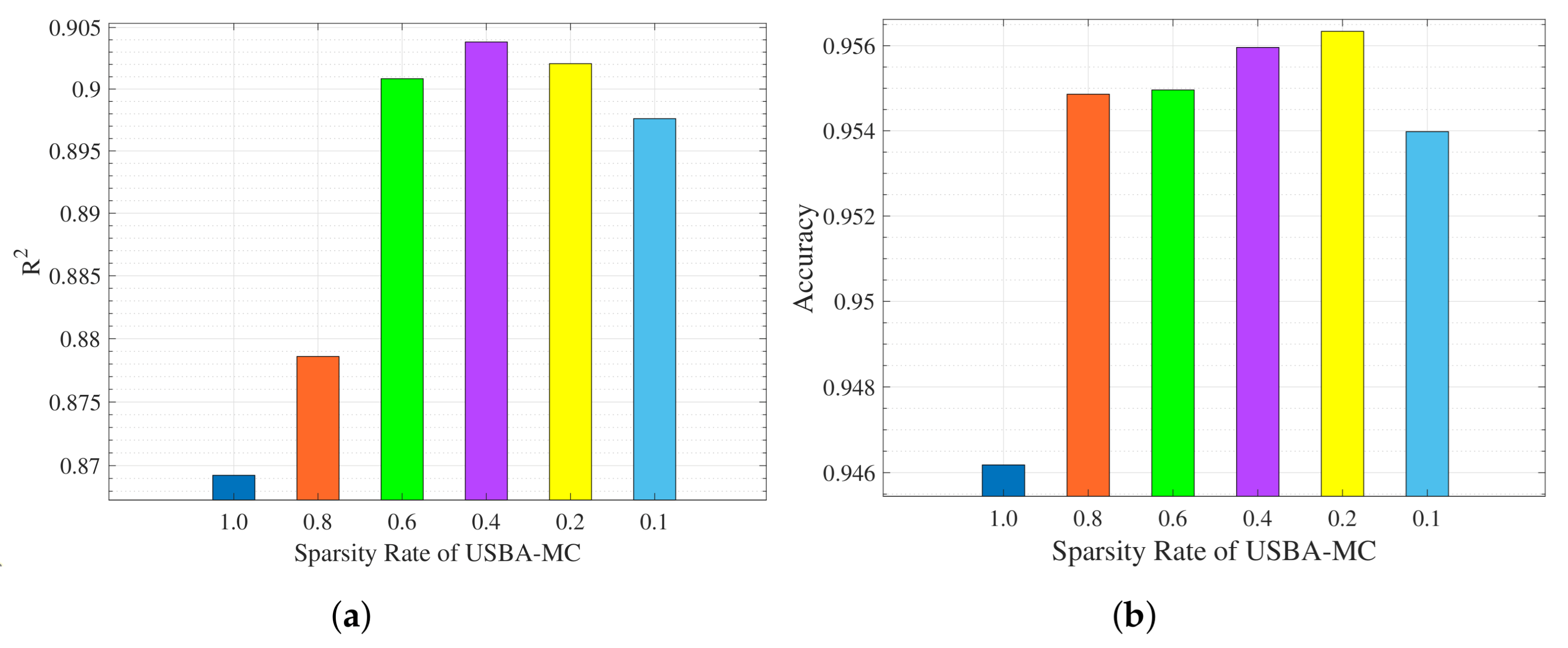
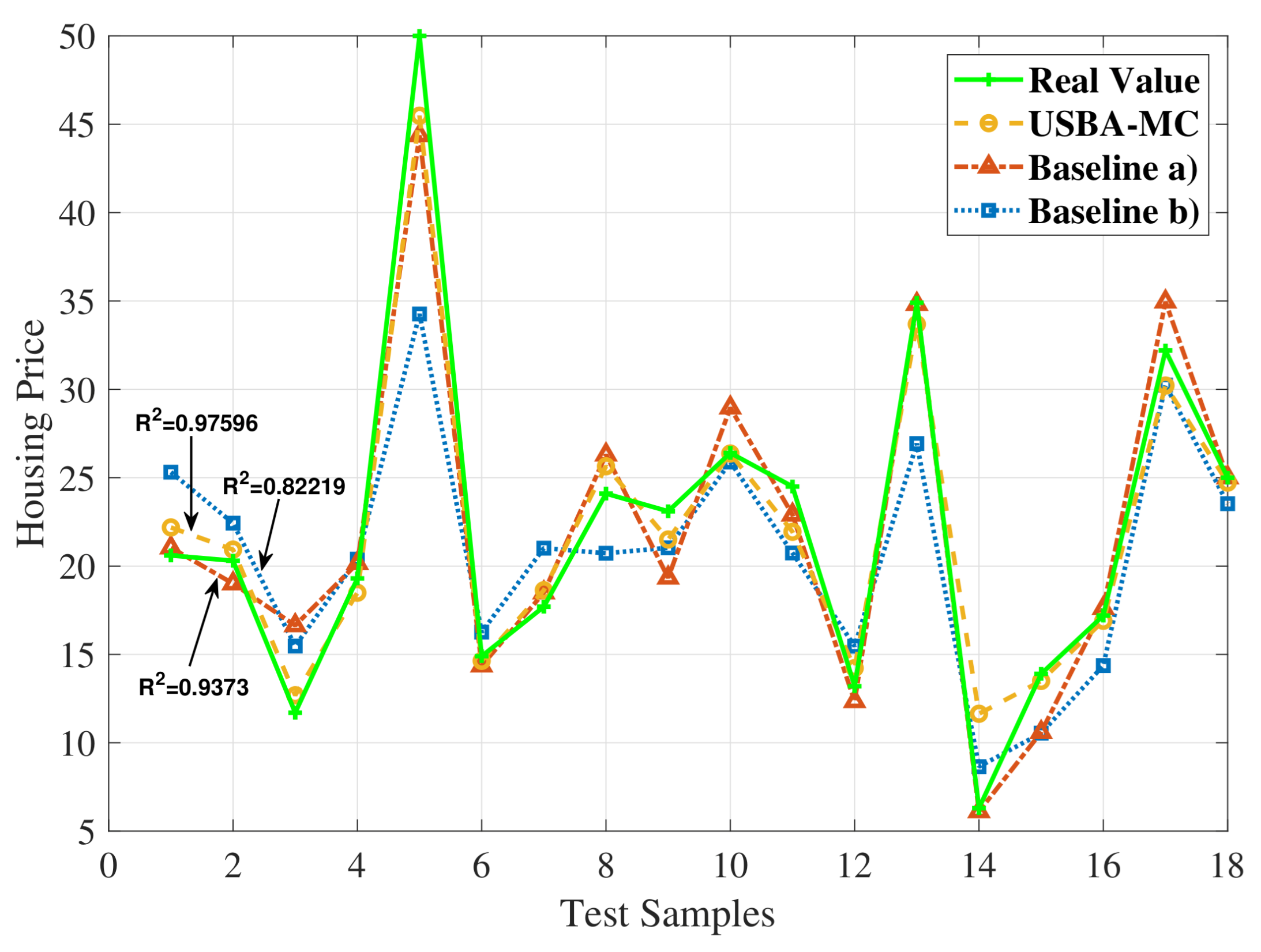
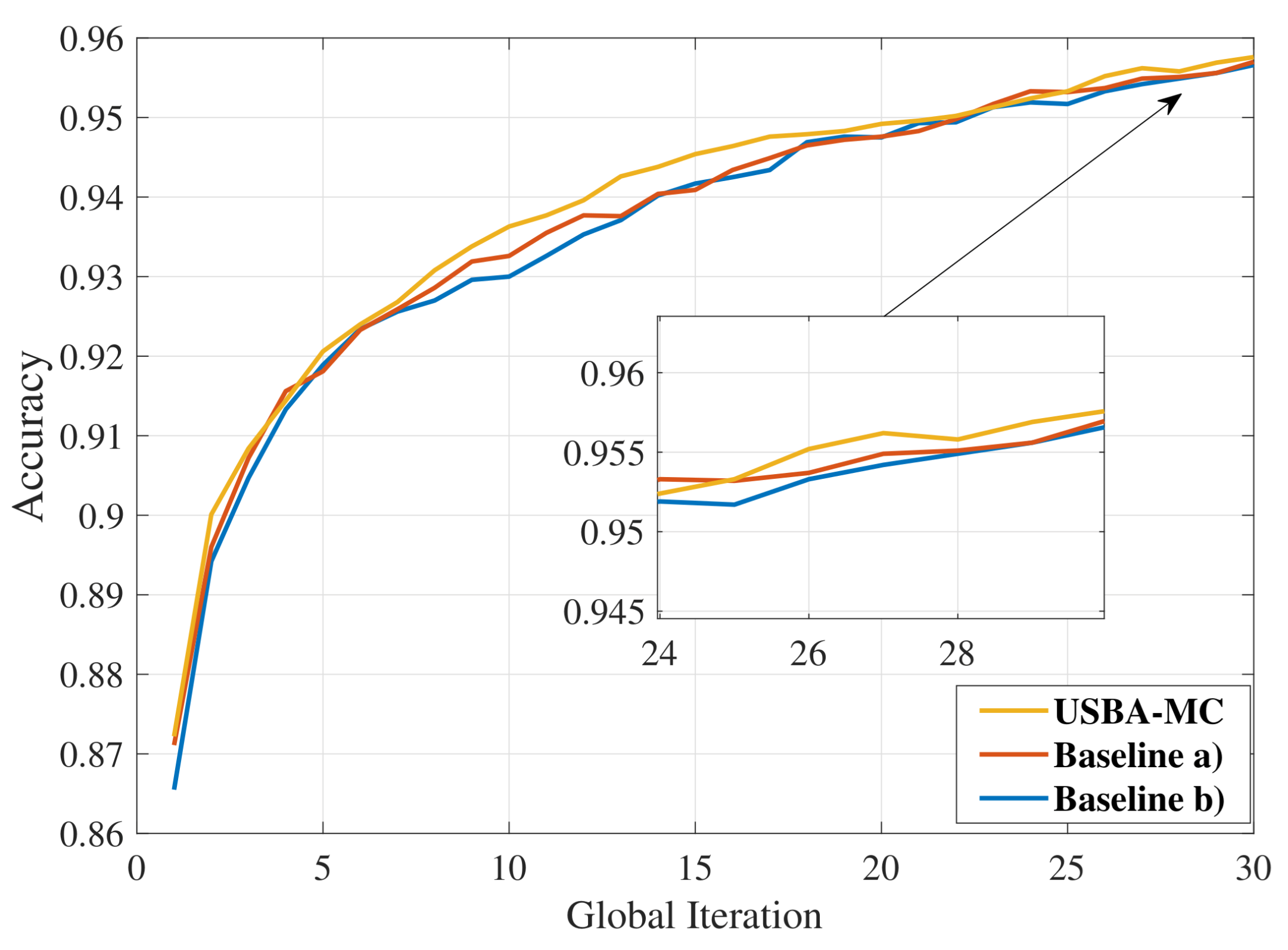
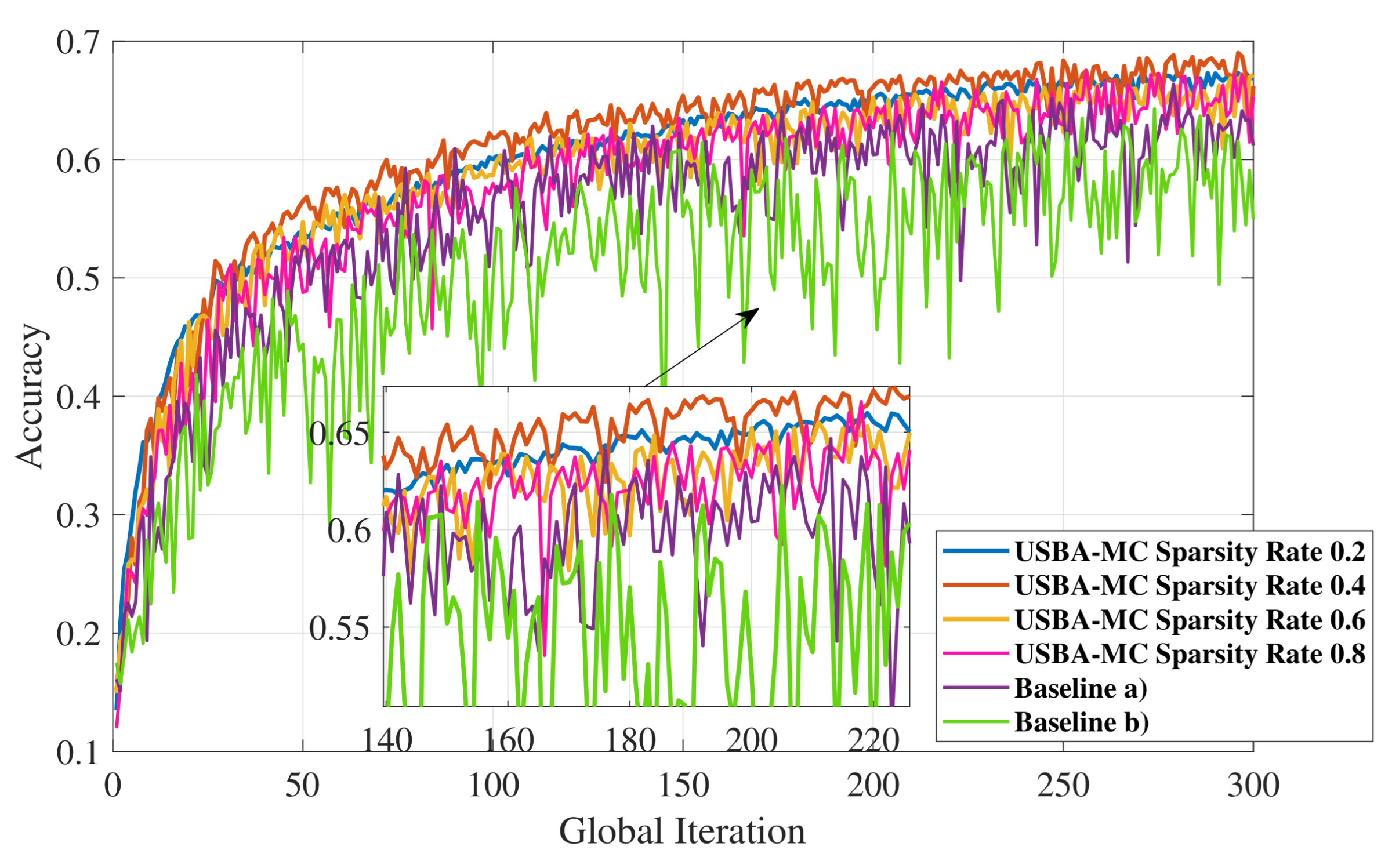
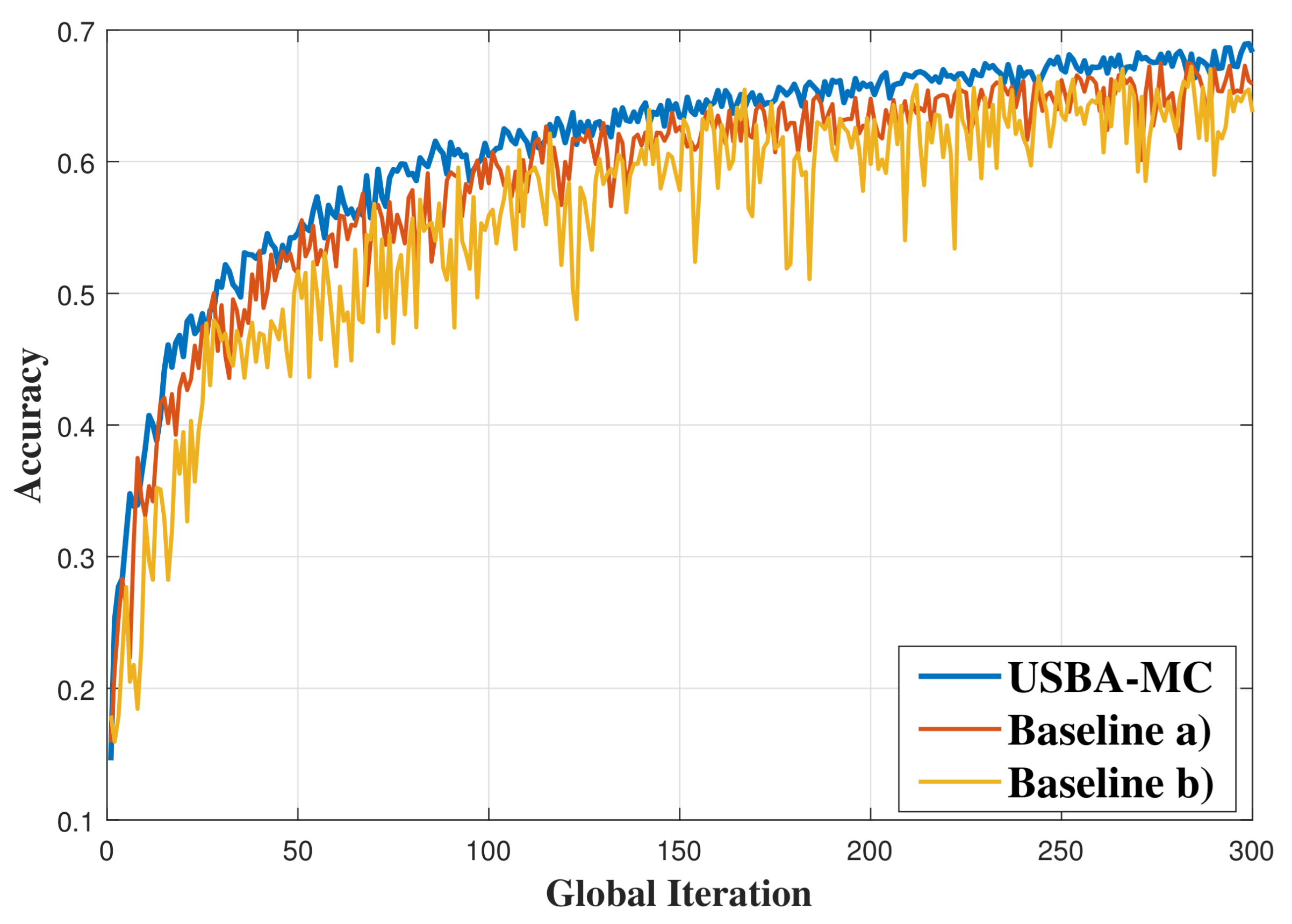
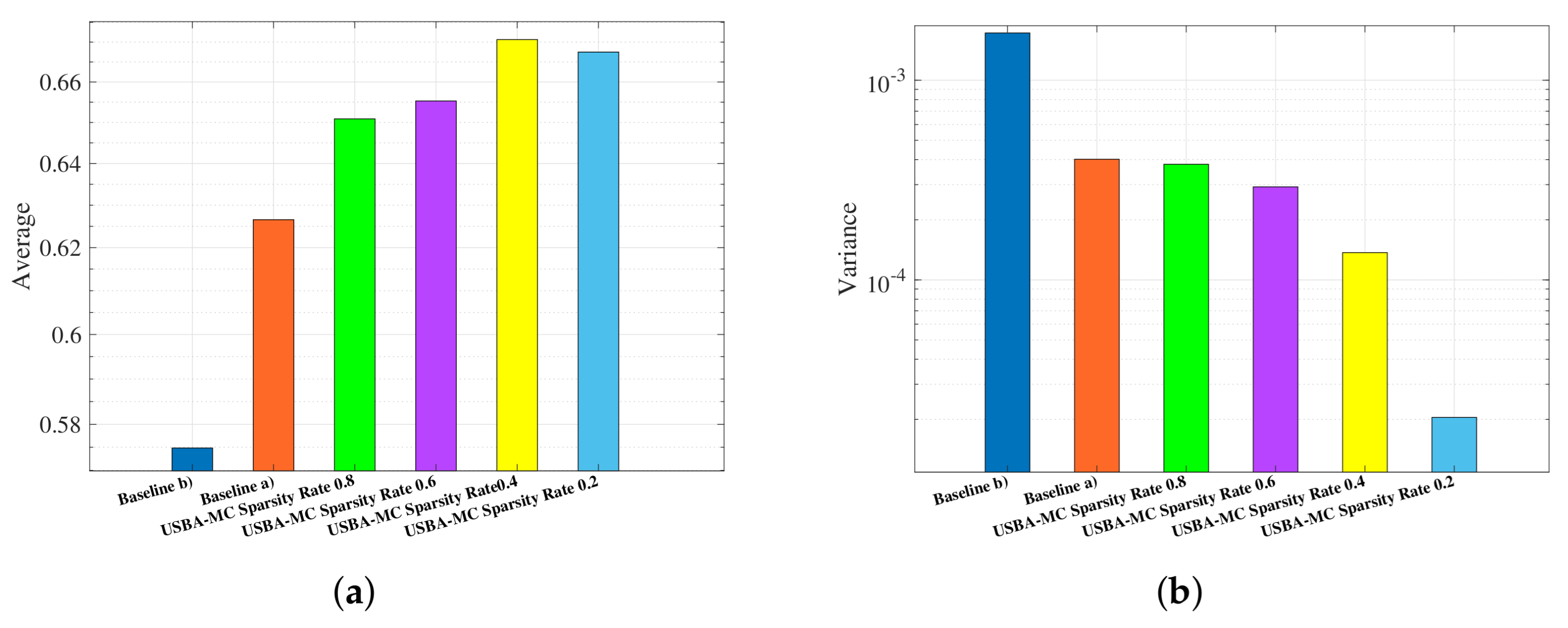
5.1. Performance over Different Sparsity Rates
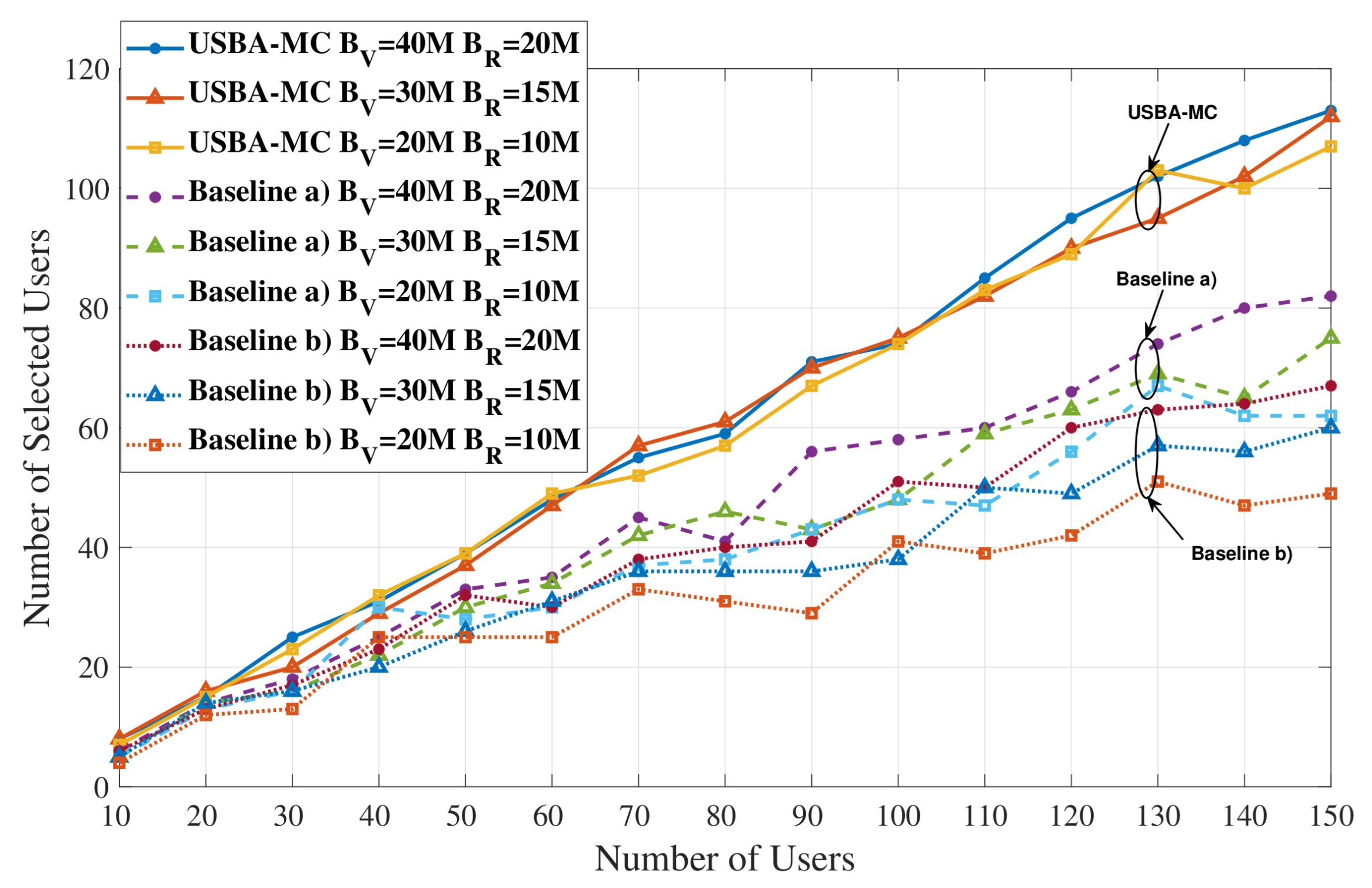
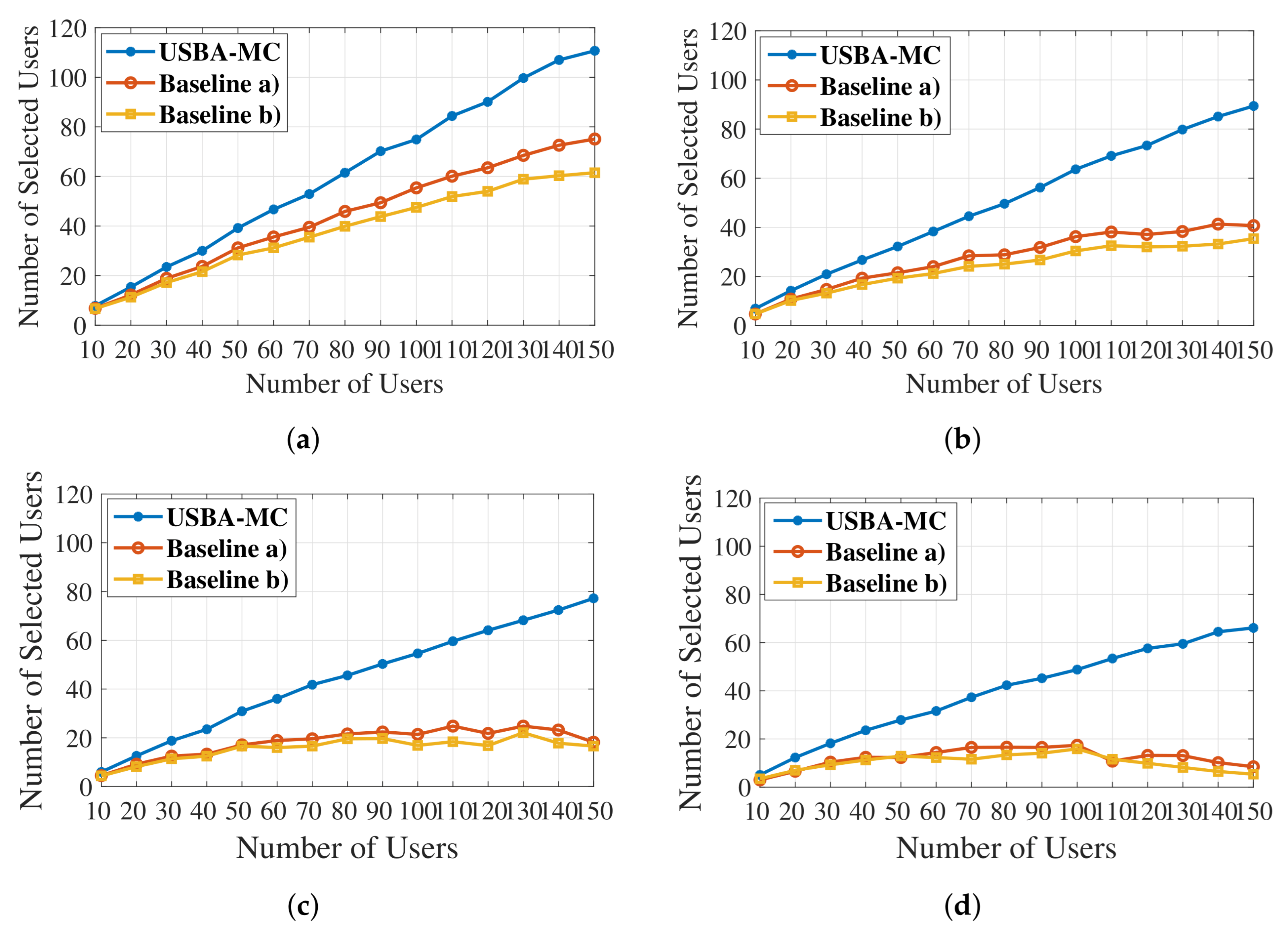
5.2. Number of Selected Users
5.3. Non-IID Data
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the International Comference on Artificial Intelligence and Statistics, Fort Lauderdate, FL, USA, 20–22 April 2017. [Google Scholar]
- Konecny, J.; McMahan, H.B.; Ramage, D.; Richtarik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Niknam, S.; Dhillon, H.S.; Reed, J.H. Federated learning for wireless communications: Motivation, opportunities and challenges. IEEE Commun. Mag. 2020, 58, 46–51. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Chen, M.; Gündüz, D.; Huang, K.; Saad, W.; Bennis, M.; Feljan, A.V.; Poor, H.V. Distributed learning in wireless networks: Recent progress and future challenges. arXiv 2021, arXiv:2104.02151. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Tsuzuku, Y.; Imachi, H.; Akiba, T. Variance-based gradient compression for efficient distributed deep learning. arXiv 2018, arXiv:1802.06058. [Google Scholar]
- Sattler, F.; Wiedemann, S.; Müller, K.R.; Samek, W. Robust and communication-efficient federated learning from non-iid data. IEEE Trans. Neural Netw. Learn Syst. 2019, 31, 3400–3413. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Du, W.; Jin, Y.; He, W.; Cheng, R. Ternary compression for communication-efficient federated learning. IEEE Trans. Neural Netw. Learn Syst. 2020, 1–15. [Google Scholar] [CrossRef]
- Shao, R.; Liu, H.; Liu, D. Privacy preserving stochastic channel-based federated learning with neural network pruning. arXiv 2019, arXiv:1910.02115. [Google Scholar]
- Chen, M.; Shlezinger, N.; Poor, H.V.; Eldar, Y.C.; Cui, S. Communication-efficient federated learning. Proc. Nat. Acad. Sci. USA 2021, 118, e2024789118. [Google Scholar] [CrossRef]
- Chen, M.; Yang, Z.; Saad, W.; Yin, C.; Poor, H.V.; Cui, S. A joint learning and communications framework for federated learning over wireless networks. IEEE Trans. Wireless Commun. 2021, 20, 269–283. [Google Scholar] [CrossRef]
- Tran, N.H.; Bao, W.; Zomaya, A.; Nguyen, M.N.H.; Hong, C.S. Federated learning over wireless networks: Optimization model design and analysis. In Proceedings of the IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019. [Google Scholar]
- Yang, Z.; Chen, M.; Saad, W.; Hong, C.S.; Bahaei, M.S. Energy efficient federated learning over wireless communication networks. IEEE Trans. Wireless Commun. 2021, 20, 1935–1949. [Google Scholar] [CrossRef]
- Chen, M.; Poor, H.V.; Saad, W.; Cui, S. Convergence time optimization for federated learning over wireless networks. IEEE Trans. Wireless Commun. 2021, 20, 2457–2471. [Google Scholar] [CrossRef]
- Ma, C.; Konečný, J.; Jaggi, M.; Smith, V.; Jordan, M.I.; Richtárik, P.; Takáč, M. Distributed optimization with arbitrary local solvers. Optim. Methods Softw. 2017, 32, 813–848. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Zeng, Z.; Cheng, J.; Guo, C.; Feng, C. A relay-assisted OFDM system for VLC uplink transmission. IEEE Trans. Commun. 2019, 67, 6268–6281. [Google Scholar] [CrossRef]
- Pham, T.V.; Pham, A.T. Coordination/cooperation strategies and optimal zero-forcing precoding design for multi-user multi-cell VLC networks. IEEE Trans. Commun. 2019, 67, 4240–4251. [Google Scholar] [CrossRef]
- Hsu, T.H.; Qi, H.; Brown, M. Measuring the effects of non-identical data distribution for federated visual classification. arXiv 2019, arXiv:1909.06335. [Google Scholar]
- Sattler, F.; Wiedemann, S.; Müller, K.R.; Samek, W. Sparse binary compression: Towards distributed deep learning with minimal communication. In Proceedings of the International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Xie, H.; Qin, Z. A lite distributed semantic communication system for internet of things. IEEE J. Sel. Areas Commun. 2020, 39, 142–153. [Google Scholar] [CrossRef]
- Aji, A.F.; Heafield, K. Sparse communication for distributed gradient descent. arXiv 2017, arXiv:1704.05021. [Google Scholar]
- Lin, Y.; Han, S.; Mao, H.; Wang, Y.; Dally, W.J. Deep gradient compression: Reducing the communication bandwidth for distributed training. arXiv 2017, arXiv:1712.01887. [Google Scholar]
- Friedlander, M.P.; Schmidt, M. Hybrid deterministic-stochastic methods for data fitting. SIAM J. Sci. Comput. 2012, 34, A1380–A1405. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Wang, S.; Valls, V.; Ko, B.J.; Lee, W.H.; Leung, K.K.; Tassiulas, L. Model pruning enables efficient federated learning on edge devices. arXiv 2019, arXiv:1909.12326. [Google Scholar]
- Cheung, T.Y. Graph traversal techniques and the maximum flow problem in distributed computation. IEEE Trans. Softw. Eng. 1983, SE-9, 504–512. [Google Scholar] [CrossRef]
- Liu, C.; Guo, C.; Yang, Y.; Chen, M.; Poor, H.V.; Cui, S. Optimization of user selection and bandwidth allocation for federated learning in VLC/RF systems. In Proceedings of the IEEE Wireless Communications and Networking Conference, Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE Inst. Electr. Electron. Eng. 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Nair, V.; Hinton, G. The CIFAR-10 Dataset. Available online: http://www.cs.toronto.edu/kriz/cifar.html (accessed on 27 March 2021).
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar]
- Rosenblatt, M. A central limit theorem and a strong mixing condition. Proc. Nat. Acad. Sci. USA 1956, 42, 43. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Transmitted optical power per VLC AP, | 9 W |
| Modulation bandwidth for LED lamp, B | 40 MHz |
| The physical area of a PD, | 1 cm |
| Half-intensity radiation angle, | 60 deg. |
| Gain of optical filter, | 1.0 |
| Receiver FOV semi-angle, | 90 deg. |
| Refractive index, n | 1.5 |
| Optical to electric conversion efficiency, | 0.53 A/W |
| Noise power spectral density, | A/Hz |
| RF total bandwidth, | 20 MHz |
| Transmit power of BS, | 1 W |
| The number of users, N | 50 |
| Delay requirement, | 2.5 s |
| Energy consumption requirement, | 2 J |
| Energy consumption coefficient, | |
| user update size, s | 1 Mb |
| Total Number of User | USBA-MC | Baseline (a) | Baseline (b) |
|---|---|---|---|
| 50 | 78% | 66% | 64% |
| 100 | 74% | 58% | 51% |
| 150 | 75.33% | 54.67% | 44.67% |
| Data Size | USBA-MC | Baseline (a) | Baseline (b) |
|---|---|---|---|
| 1 M | 73.8% | 50.07% | 41% |
| 3 M | 59.6% | 27.13% | 23.6% |
| 5 M | 51.47% | 12.13% | 11.07% |
| 7 M | 44.07% | 5.67% | 3.6% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Yang, Y.; Chen, M.; Liu, C.; Feng, C.; Poor, H.V. Wireless Network Optimization for Federated Learning with Model Compression in Hybrid VLC/RF Systems. Entropy 2021, 23, 1413. https://0-doi-org.brum.beds.ac.uk/10.3390/e23111413
Huang W, Yang Y, Chen M, Liu C, Feng C, Poor HV. Wireless Network Optimization for Federated Learning with Model Compression in Hybrid VLC/RF Systems. Entropy. 2021; 23(11):1413. https://0-doi-org.brum.beds.ac.uk/10.3390/e23111413
Chicago/Turabian StyleHuang, Wuwei, Yang Yang, Mingzhe Chen, Chuanhong Liu, Chunyan Feng, and H. Vincent Poor. 2021. "Wireless Network Optimization for Federated Learning with Model Compression in Hybrid VLC/RF Systems" Entropy 23, no. 11: 1413. https://0-doi-org.brum.beds.ac.uk/10.3390/e23111413