
Hybrid Basketball Game Outcome Prediction Model by Integrating Data Mining Methods for the National Basketball Association


Abstract
:1. Introduction
2. Literature Review
3. Methods
3.1. MARS Algorithm
3.2. ELM Algorithm
3.3. XGBoost Algorithm
3.4. KNN Algorithm
3.5. SGB Algorithm
3.6. Model Implementation
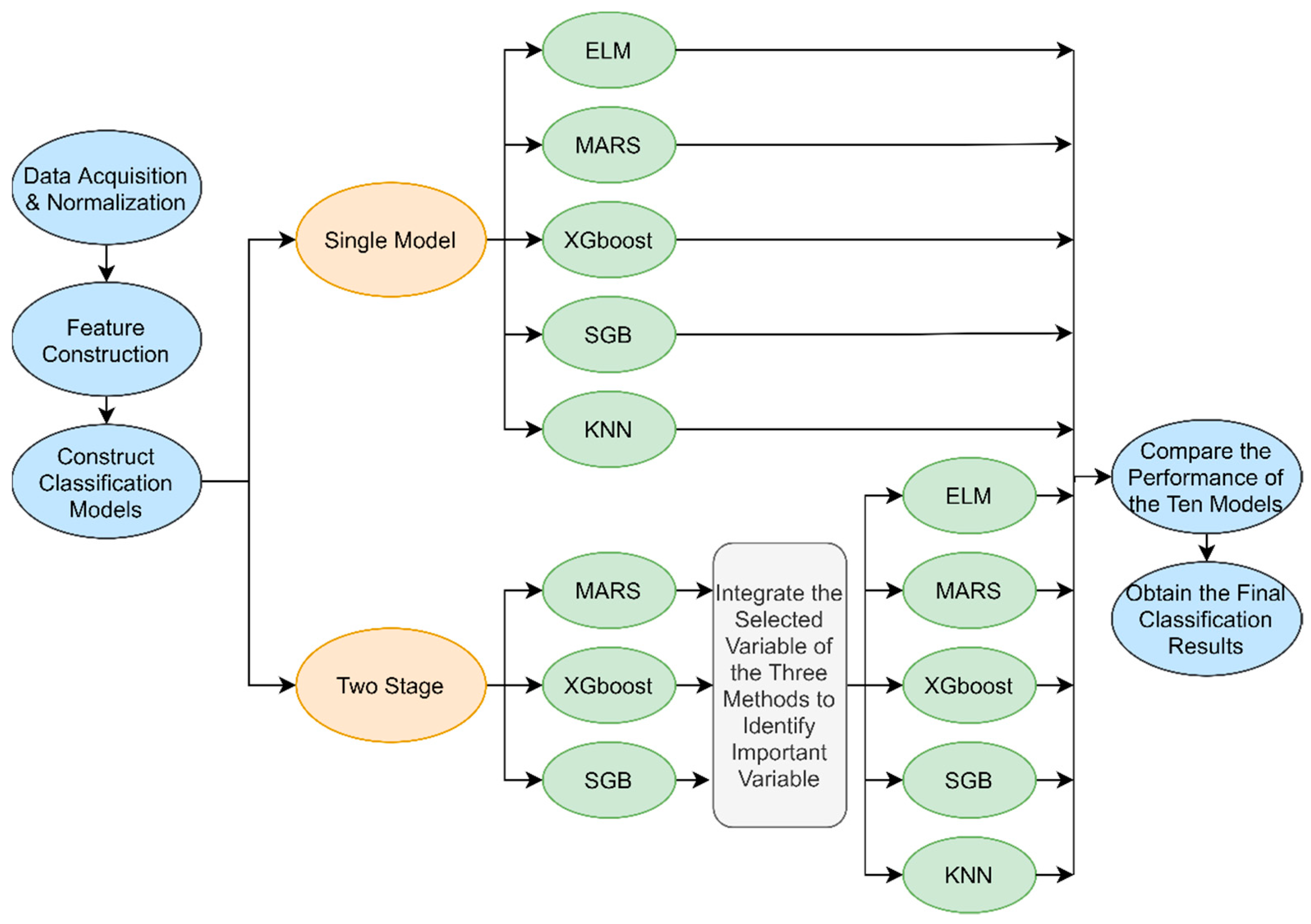
4. Proposed Basketball Game Score Prediction Scheme
5. Empirical Results
6. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Morgulev, E.; Azar, O.H.; Lidor, R. Sports Analytics and the Big-Data Era. Int. J. Data Sci. Anal. 2018, 5, 213–222. [Google Scholar] [CrossRef]
- Musa, R.M.; Majeed, A.P.A.; Taha, Z.; Chang, S.W.; Nasir, A.F.A.; Abdullah, M.R. A Machine Learning Approach of Predicting High Potential Archers by Means of Physical Fitness Indicators. PLoS ONE 2019, 14, e0209638. [Google Scholar] [CrossRef] [PubMed]
- Zuccolotto, P.; Manisera, M.; Sandri, M. Big Data Analytics for Modeling Scoring Probability in Basketball: The Effect of Shooting under High-Pressure Conditions. Int. J. Sports Sci. Coach. 2018, 13, 569–589. [Google Scholar] [CrossRef]
- Lam, M.W. One-Match-Ahead Forecasting in Two-Team Sports with Stacked Bayesian Regressions. J. Artif. Intell. Soft Comput. Res. 2018, 8, 159–171. [Google Scholar] [CrossRef] [Green Version]
- Baboota, R.; Kaur, H. Predictive Analysis and Modelling Football Results using Machine Learning Approach for English Premier League. Int. J. Forecast. 2019, 35, 741–755. [Google Scholar] [CrossRef]
- Horvat, T.; Havaš, L.; Srpak, D. The Impact of Selecting a Validation Method in Machine Learning on Predicting Basketball Game Outcomes. Symmetry 2020, 12, 431. [Google Scholar] [CrossRef] [Green Version]
- Dubbs, A. Statistics-Free Sports Prediction. Model Assist. Stat. Appl. 2018, 13, 173–181. [Google Scholar] [CrossRef]
- Loeffelholz, B.; Bednar, E.; Bauer, K.W. Predicting NBA Games using Neural Networks. J. Quant. Anal. Sports 2009, 5. [Google Scholar] [CrossRef]
- Cheng, G.; Zhang, Z.; Kyebambe, M.N.; Kimbugwe, N. Predicting the Outcome of NBA Playoffs Based on the Maximum Entropy Principle. Entropy 2016, 18, 450. [Google Scholar] [CrossRef]
- Pai, P.F.; ChangLiao, L.H.; Lin, K.P. Analyzing Basketball Games by A Support Vector Machines with Decision Tree Model. Neural Comput. Appl. 2017, 28, 4159–4167. [Google Scholar] [CrossRef]
- Song, K.; Zou, Q.; Shi, J. Modelling the Scores and Performance Statistics of NBA Basketball Games. Commun. Stat. Simul. Comput. 2018, 49, 2604–2616. [Google Scholar] [CrossRef]
- Thabtah, F.; Zhang, L.; Abdelhamid, N. NBA Game Result Prediction Using Feature Analysis and Machine Learning. Ann. Data Sci. 2019, 6, 103–116. [Google Scholar] [CrossRef]
- Huang, M.L.; Lin, Y.J. Regression Tree Model for Predicting Game Scores for the Golden State Warriors in the National Basketball Association. Symmetry 2020, 12, 835. [Google Scholar] [CrossRef]
- Song, K.; Gao, Y.; Shi, J. Making Real-Time Predictions for NBA Basketball Games by Combining the Historical Data and Bookmaker’s Betting Line. Phys. A Stat. Mech. Its Appl. 2020, 547, 124411. [Google Scholar] [CrossRef]
- Li, Y.; Wang, L.; Li, F. A Data-Driven Prediction Approach for Sports Team Performance and Its Application to National Basketball Association. Omega 2021, 98, 102123. [Google Scholar] [CrossRef]
- Tan, P.N.; Steinbach, M.; Kumar, V. Introduction to Data Mining, 1st ed.; Pearson Education Inc.: Taipei, Taiwan, 2006; pp. 1–3. [Google Scholar]
- Jordan, S.E.; Hovet, S.E.; Fung, I.C.H.; Liang, H.; Fu, K.W.; Tse, Z.T.H. Using Twitter for Public Health Surveillance from Monitoring and Prediction to Public Response. Data 2019, 4, 6. [Google Scholar] [CrossRef] [Green Version]
- Ting, W.C.; Chang, H.R.; Chang, C.C.; Lu, C.J. Developing a Novel Machine Learning-Based Classification Scheme for Predicting SPCs in Colorectal Cancer Survivors. Appl. Sci. 2020, 10, 1355. [Google Scholar] [CrossRef] [Green Version]
- Nobre, J.; Neves, R.F. Combining Principal Component Analysis, Discrete Wavelet Transform and Xgboost to Trade in the Financial Markets. Expert Syst. Appl. 2019, 125, 181–194. [Google Scholar] [CrossRef]
- Yu, H.; Ming, L.J.; Sumei, R.; Shuping, Z. A Hybrid Model for Financial Time Series Forecasting—Integration of EWT, ARIMA with the Improved ABC Optimized ELM. IEEE Access 2020, 8, 84501–84518. [Google Scholar] [CrossRef]
- Shariati, M.; Mafipour, M.S.; Mehrabi, P.; Zandi, Y.; Dehghani, D.; Bahadori, A.; Shariati, A.; Trung, N.T.; Salih, M.N.; Poi-Ngian, S. Application of Extreme Learning Machine (ELM) and Genetic Programming (GP) to Design Steel-Concrete Composite Floor Systems at Elevated Temperatures. Steel Compos. Struct 2019, 33, 319–332. [Google Scholar]
- Zhou, J.; Li, E.; Wang, M.; Chen, X.; Shi, X.; Jiang, L. Feasibility of Stochastic Gradient Boosting Approach for Evaluating Seismic Liquefaction Potential Based on SPT and CPT Case Histories. J. Perform. Constr. Facil. 2019, 33, 4019024. [Google Scholar] [CrossRef]
- Chau, V.H.; Vo, A.T.; Le, B.T. A Gravitational-Double Layer Extreme Learning Machine and its Application in Powerlifting Analysis. IEEE Access 2019, 7, 143990–143998. [Google Scholar] [CrossRef]
- Kapadia, K.; Abdel-Jaber, H.; Thabtah, F.; Hadi, W. Sport Analytics for Cricket Game Results Using Machine Learning: An Experimental Study. Appl. Comput. Inform. 2020. [Google Scholar] [CrossRef]
- Rajšp, A.; Fister, I. A Systematic Literature Review of Intelligent Data Analysis Methods for Smart Sport Training. Appl. Sci. 2020, 10, 3013. [Google Scholar] [CrossRef]
- Sarlis, V.; Chatziilias, V.; Tjortjis, C.; Mandalidis, D. A Data Science Approach Analysing the Impact of Injuries on Basketball Player and Team Performance. Inf. Syst. 2021, 99, 101750. [Google Scholar] [CrossRef]
- Friedman, J.H. Multivariate Adaptive Regression Splines. Ann. Stat. 1991, 1–67. [Google Scholar] [CrossRef]
- Harrington, P. Machine Learning in Action; Manning Publications Co.: Shelter Island, NY, USA, 2012. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme Learning Machine: Theory and Applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference and Prediction. Math. Intell. 2005, 27, 83–85. [Google Scholar]
- Yang, C.H.; Lin, H.Y. Is There Salary Discrimination by Nationality in the NBA? Foreign Talent or Foreign Market. J. Sports Econ. 2012, 13, 53–75. [Google Scholar] [CrossRef]
- Kopkin, N. Tax Avoidance: How Income Tax Rates Affect the Labor Migration Decisions of NBA Free Agents. J. Sports Econ. 2012, 13, 571–602. [Google Scholar] [CrossRef]
- Price, J.; Soebbing, B.P.; Berri, D.; Humphreys, B.R. Tournament Incentives, League Policy, and NBA Team Performance Revisited. J. Sports Econ. 2010, 11, 117–135. [Google Scholar] [CrossRef]
- Arel, B.; Tomas III, M.J. The NBA Draft: A Put Option Analogy. J. Sports Econ. 2012, 13, 223–249. [Google Scholar] [CrossRef]
- Pollard, R. Evidence of a Reduced Home Advantage When a Team Moves to a New Stadium. J. Sports Sci. 2002, 20, 969–973. [Google Scholar] [CrossRef] [PubMed]
- Pollard, R.; Pollard, G. Long-Term Trends in Home Advantage in Professional Team Sports in North America and England (1876–2003). J. Sport Sci. 2005, 23, 337–350. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Lorenzo, A.; Gómez, M.Á.; Mateus, N.; Gonçalves, B.S.V.; Sampaio, J. Clustering Performances in the NBA According to Players’ Anthropometric Attributes and Playing Experience. J. Sports Sci. 2018, 36, 2511–2520. [Google Scholar] [CrossRef]
- Morgulev, E.; Azar, O.H.; Bar-Eli, M. Searching for Momentum in NBA Triplets of Free Throws. J. Sports Sci. 2020, 38, 390–398. [Google Scholar] [CrossRef]
- Chou, J.S.; Pham, A.D. Smart Artificial Firefly Colony Algorithm-Based Support Vector Regression for Enhanced Forecasting in Civil Engineering. Comput. -Aided Civ. Infrastruct. Eng. 2015, 30, 715–732. [Google Scholar] [CrossRef]
- Guerard, J.B.; Xu, G.; Markowitz, H. A Further Analysis of Robust Regression Modeling and Data Mining Corrections Testing in Global Stocks. Ann. Oper. Res. 2020, 1–21. [Google Scholar] [CrossRef]
- Javed, M.F.; Amin, M.N.; Shah, M.I.; Khan, K.; Iftikhar, B.; Farooq, F.; Aslam, F.; Alyousef, R.; Alabduljabbar, H. Applications of Gene Expression Programming and Regression Techniques for Estimating Compressive Strength of Bagasse Ash Based Concrete. Crystals 2020, 10, 737. [Google Scholar] [CrossRef]
- Xie, K.; Liang, B.; Dulebenets, M.A.; Mei, Y. The Impact of Risk Perception on Social Distancing During the COVID-19 Pandemic in China. Int. J. Environ. Res. Public Health 2020, 17, 6256. [Google Scholar] [CrossRef] [PubMed]
- Chancellor, S.; De Choudhury, M. Methods in Predictive Techniques for Mental Health Status on Social Media: A Critical Review. Npj Digit. Med. 2020, 3, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abioye, O.F.; Dulebenets, M.A.; Ozguven, E.E.; Moses, R.; Boot, W.R.; Sando, T. Assessing Perceived Driving Difficulties under Emergency Evacuation for Vulnerable Population Groups. Socio Econ. Plan. Sci. 2020, 72, 100878. [Google Scholar] [CrossRef]
- Kao, L.J.; Chiu, C.C.; Lu, C.J.; Chang, C.H. A Hybrid Approach by Integrating Wavelet-Based Feature Extraction with MARS and SVR for Stock Index Forecasting. Decis. Support Syst. 2013, 54, 1228–1244. [Google Scholar] [CrossRef]
- Lu, C.J.; Kao, L.J. A Clustering-Based Sales Forecasting Scheme by Using Extreme Learning Machine and Ensembling Linkage Methods with Applications to Computer Server. Eng. Appl. Artif. Intell. 2016, 55, 231–238. [Google Scholar] [CrossRef]
- Zhang, W.; Goh, A.T. Multivariate Adaptive Regression Splines and Neural Network Models for Prediction of Pile Drivability. Geosci. Front. 2016, 7, 45–52. [Google Scholar] [CrossRef] [Green Version]
- Natekin, A.; Knoll, A. Gradient Boosting Machines, a Tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Torlay, L.; Perrone-Bertolotti, M.; Thomas, E.; Baciu, M. Machine Learning–XGBoost Analysis of Language Networks to Classify Patients with Epilepsy. Brain Inform. 2017, 4, 159–169. [Google Scholar] [CrossRef]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 Algorithms in Data Mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Wang, R. Efficient kNN Classification with Different Numbers of Nearest Neighbors. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 1774–1785. [Google Scholar] [CrossRef]
- Friedman, J. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Friedman, J. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Lawrence, R.; Bunn, A.; Powell, S.; Zambon, M. Classification of Remotely Sensed Imagery Using Stochastic Gradient Boosting as A Refinement of Classification Tree Analysis. Remote Sens. Environ. 2004, 90, 331–336. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Moisen, G.G.; Freeman, E.A.; Blackard, J.A.; Frescino, T.S.; Zimmermann, N.E.; Edwards Jr, T.C. Predicting Tree Species Presence and Basal Area in Utah: A Comparison of Stochastic Gradient Boosting, Generalized Additive Models, and Tree-Based Methods. Ecol. Model. 2006, 199, 176–187. [Google Scholar] [CrossRef]
- R Core Team. R: A language and Environment for Statistical Computing. R Foundation for Statistical Computing. Vienna, Austria. Available online: http://www.R-project.org (accessed on 1 February 2021).
- Milborrow, S.; Hastie, T.; Tibshirani, R. Earth: Multivariate Adaptive Regression Splines. R Package Version 5.3.0. Available online: https://www.rdocumentation.org/packages/earth (accessed on 1 February 2021).
- Chen, T.; He, T.; Benesty, M. XGBoost: Extreme Gradient Boosting. R Package Version 1.3.2.1. Available online: https://www.rdocumentation.org/packages/XGBoost (accessed on 1 February 2021).
- Kuhn, M.; Wing, J.; Weston, S. Caret: Classification and Regression Training. R Package Version, 6.0-86. Available online: https://www.rdocumentation.org/packages/caret (accessed on 1 February 2021).
- Greenwell, B.; Boehmke, B.; Cunningham, J. Gbm: Generalized Boosted Regression Models. R Package Version, 2.1.8. Available online: https://www.rdocumentation.org/packages/gbm (accessed on 1 February 2021).
- Gosso, A. ElmNN: Implementation of ELM (Extreme Learning Machine) Algorithm for SLFN (Single Hidden Layer Feedforward Neural Networks). R Package Version, 1.0. Available online: https://www.rdocumentation.org/packages/elmNN (accessed on 1 February 2021).
- Schliep, K.; Hechenbichler, K.; Lizee, A. Kknn: Weighted k-Nearest Neighbors. R Package Version, 1.3.1. Available online: https://www.rdocumentation.org/packages/kknn (accessed on 1 February 2021).
- Basketball Reference. Available online: https://www.basketball-reference.com (accessed on 15 December 2020).
- Tseng, C.J.; Lu, C.J.; Chang, C.C.; Chen, G.D.; Cheewakriangkrai, C. Integration of Data Mining Classification Techniques and Ensemble Learning to Identify Risk Factors and Diagnose Ovarian Cancer Recurrence. Artif. Intell. Med. 2017, 78, 47–54. [Google Scholar] [CrossRef] [PubMed]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. A Review of Feature Selection Methods on Synthetic Data. Knowl. Inf. Syst. 2013, 34, 483–519. [Google Scholar] [CrossRef]
- Lewis Colin, D. Industrial and Business Forecasting Methods; Butterwoth & Co Publishers Ltd.: London, UK, 1982. [Google Scholar]
- Juang, W.C.; Huang, S.J.; Huang, F.D.; Cheng, P.W.; Wann, S.R. Application of Time Series Analysis in Modelling and Forecasting Emergency Department Visits in A Medical Centre in Southern Taiwan. BMJ Open 2017, 7, e018628. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Diebold, F.X.; Mariano, R.S. Comparing Predictive Accuracy. J. Bus. Econ. Stat. 1995, 20, 134–144. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Variables | Definition | Description |
|---|---|---|
| 2PA | 2-Point Field Goal Attempts of a team in t-th game | |
| 2P% | 2-Point Field Goal Percentage of a team in t-th game | |
| 3PA | 3-Point Field Goal Attempts of a team in t-th game | |
| 3P% | 3-Point Field Goal Percentage of a team in t-th game | |
| FTA | Free Throw Attempts of a team in t-th game | |
| FT% | Free Throw Percentage of a team in t-th game | |
| ORB | Offensive Rebounds of a team in t-th game | |
| DRB | Defensive Rebounds of a team in t-th game | |
| AST | Assists of a team in t-th game | |
| STL | Steals of a team in t-th game | |
| BLK | Blocks of a team in t-th game | |
| TOV | Turnovers of a team in t-th game | |
| PF | Personal Fouls of a team in t-th game | |
| Score | Team Score of a team in t-th game |
| Designed Feature | MARS | XGBoost | SGB | Average Rank |
|---|---|---|---|---|
| 6 | 8 | 10 | 8.00 | |
| 2 | 1 | 3 | 2.00 | |
| 5 | 6 | 8 | 6.33 | |
| 8 | 7 | 5 | 6.67 | |
| 7 | 9 | 7 | 7.67 | |
| 3 | 4 | 4 | 3.67 | |
| 4 | 5 | 6 | 5.00 | |
| 1 | 2 | 2 | 1.67 | |
| 13 | 3 | 1 | 5.67 | |
| 13 | 13 | 13 | 13.00 | |
| 13 | 10 | 11 | 11.33 | |
| 13 | 11 | 12 | 12.00 | |
| 9 | 12 | 9 | 10.00 |
| Methods | ||||||
|---|---|---|---|---|---|---|
| S-ELM | 0.1020 | 0.0960 | 0.0915 | 0.0870 | 0.0931 | 0.0928 |
| S-MARS | 0.0910 | 0.0909 | 0.0897 | 0.0846 | 0.0917 | 0.0907 |
| S-XGBoost | 0.0919 | 0.0907 | 0.0911 | 0.0842 | 0.0927 | 0.0920 |
| S-SGB | 0.0910 | 0.0925 | 0.0913 | 0.0845 | 0.0923 | 0.0908 |
| S-KNN | 0.0992 | 0.1011 | 0.0947 | 0.0873 | 0.0934 | 0.0941 |
| Methods | ||||||
|---|---|---|---|---|---|---|
| T-ELM | 0.1206 | 0.0924 | 0.0951 | 0.0863 | 0.0972 | 0.0902 |
| T-MARS | 0.0917 | 0.0911 | 0.0912 | 0.0845 | 0.0928 | 0.0900 |
| T-XGBoost | 0.0918 | 0.0930 | 0.0916 | 0.0818 | 0.0929 | 0.0920 |
| T-SGB | 0.0909 | 0.0918 | 0.0912 | 0.0829 | 0.0930 | 0.0908 |
| T-KNN | 0.0998 | 0.0984 | 0.0973 | 0.0872 | 0.0993 | 0.0970 |
| Models (Lag = 4) | MAPE | RMSE | SSE |
|---|---|---|---|
| S-Linear | 0.0897 | 12.7324 | 75,868.89 |
| T-Linear | 0.0883 | 12.0904 | 68,410.85 |
| S-M5P | 0.0922 | 13.0613 | 79,839.95 |
| T-M5P | 0.0931 | 12.9102 | 78,,003.64 |
| S-SVR | 0.0914 | 13.0213 | 79,351.58 |
| T-SVR | 0.0889 | 12.2547 | 70,283.06 |
| T-XGBboost | 0.0818 | 11.4753 | 61,627.37 |
| T-XGBboost | Lag = 1 | Lag = 2 | Lag = 3 | Lag = 5 | Lag = 6 |
|---|---|---|---|---|---|
| Lag = 4 | −1.017 (0.007) ** | −1.044 (0.008) ** | −4.284 (0.001) ** | −6.115 (0.001) ** | −10.859 (0.001) ** |
| Lag = 4 | T-Linear | T-MARS | T-SVR | T-SGB | T-KNN | T-ELM | T-M5P |
|---|---|---|---|---|---|---|---|
| T-XGBboost | −1.239 (0.001) ** | −0.994 (0.010) ** | −0.997 (0.010) ** | −0.989 (0.011) ** | −0.885 (0.021) ** | −1.377 (0.000) ** | −1.043 (0.008) ** |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.-J.; Jhou, M.-J.; Lee, T.-S.; Lu, C.-J. Hybrid Basketball Game Outcome Prediction Model by Integrating Data Mining Methods for the National Basketball Association. Entropy 2021, 23, 477. https://0-doi-org.brum.beds.ac.uk/10.3390/e23040477
Chen W-J, Jhou M-J, Lee T-S, Lu C-J. Hybrid Basketball Game Outcome Prediction Model by Integrating Data Mining Methods for the National Basketball Association. Entropy. 2021; 23(4):477. https://0-doi-org.brum.beds.ac.uk/10.3390/e23040477
Chicago/Turabian StyleChen, Wei-Jen, Mao-Jhen Jhou, Tian-Shyug Lee, and Chi-Jie Lu. 2021. "Hybrid Basketball Game Outcome Prediction Model by Integrating Data Mining Methods for the National Basketball Association" Entropy 23, no. 4: 477. https://0-doi-org.brum.beds.ac.uk/10.3390/e23040477