
Towards an Efficient and Exact Algorithm for Dynamic Dedicated Path Protection


1
Department of Computer Science, Częstochowa University of Technology, 42-200 Częstochowa, Poland
2
Institute of Telecommunications, UTP University of Sciences and Technology, 85-796 Bydgoszcz, Poland
3
Department of Mathematics and Computer Science, Jan Długosz University, 42-200 Częstochowa, Poland
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(9), 1116; https://0-doi-org.brum.beds.ac.uk/10.3390/e23091116
Submission received: 1 August 2021
/
Revised: 18 August 2021
/
Accepted: 24 August 2021
/
Published: 27 August 2021
(This article belongs to the Special Issue Advances in Computer Recognition, Image Processing and Communications, Selected Papers from CORES 2021 and IP&C 2021)
Abstract
:We present a novel algorithm for dynamic routing with dedicated path protection which, as the presented simulation results suggest, can be efficient and exact. We present the algorithm in the setting of optical networks, but it should be applicable to other networks, where services have to be protected, and where the network resources are finite and discrete, e.g., wireless radio or networks capable of advance resource reservation. To the best of our knowledge, we are the first to propose an algorithm for this long-standing fundamental problem, which can be efficient and exact, as suggested by simulation results. The algorithm can be efficient because it can solve large problems, and it can be exact because its results are optimal, as demonstrated and corroborated by simulations. We offer a worst-case analysis to argue that the search space is polynomially upper bounded. Network operations, management, and control require efficient and exact algorithms, especially now, when greater emphasis is placed on network performance, reliability, softwarization, agility, and return on investment. The proposed algorithm uses our generic Dijkstra algorithm on a search graph generated “on-the-fly” based on the input graph. We corroborated the optimality of the results of the proposed algorithm with brute-force enumeration for networks up to 15 nodes large. We present the extensive simulation results of dedicated-path protection with signal modulation constraints for elastic optical networks of 25, 50, and 100 nodes, and with 160, 320, and 640 spectrum units. We also compare the bandwidth blocking probability with the commonly-used edge-exclusion algorithm. We had 48,600 simulation runs with about 41 million searches.
1. Introduction
Optical networks, which are the backbone of communication networks, need to provide protection for the carried traffic to prevent large-scale disruptions due to fiber cuts, human errors, hardware failures, power outages, natural disasters or attacks [1,2,3]. From among the various ways of protecting traffic in optical networks, dedicated path protection (DPP) is the simplest, and the most effective, albeit the most expensive. In DPP, there are two paths established for a single demand: the working one, and the protecting one. When the working path fails, the protecting path delivers the traffic. DPP has been commonly used and studied for decades.
In a wavelength-division multiplexed (WDM) network, if a client signal does not fully utilize the fixed spectrum of the assigned wavelength, the spectrum of the precious erbium window is wasted, a problem addressed by elastic optical networks (EONs) which divide the spectrum into fine frequency slot units (of, e.g., 12.5 GHz width), or just units, and then allocating contiguous units to form a slot tailored to a specific demand [4].
Routing in WDM networks with the spectrum continuity constraint is called routing and wavelength assignment (RWA). Routing in EONs with the spectrum contiguity constraint added is called routing and spectrum assignment (RSA), and with the signal modulation constraint added is called routing, modulation, and spectrum assignment (RMSA). These routing problems can be dynamic or static. In dynamic (aka online) routing, a single demand is routed in a loaded network, as opposed to static (aka offline) routing, where many demands are routed in an unloaded network.
When finding an exact solution for a dynamic routing problem in optical networks, some path cost is minimized, and the spectrum and modulation constraints are met. The path cost can be defined in various ways, e.g., the path length, the number of edges, some signal quality measure, monetary cost, or a measure related to availability. The path cost can take into account the cost of traversing not only an edge, but a vertex, too. In routing with DPP, the cost of a path pair is minimized, and the spectrum and modulation constraints must be met for both paths.
Whether routing along paths of lowest cost leads to optimal network performance (as measured, for instance, with the bandwidth blocking probability over a series of established and terminated connections) is, to the best of our knowledge, an open research problem, which we do not address in this work. We research the problem of an exact algorithm, one which finds an optimal (i.e., of lowest cost) solution, and not of an optimal algorithm. An algorithm optimality could imply optimal network performance, or optimal computational complexity, and we address neither of these.
Our novel contribution is an algorithm which solves the dynamic routing problems with DPP for WDM networks and EONs without signal regeneration and spectrum conversion. The algorithm can take into account various spectrum allocation policies. With extensive simulations, we demonstrate the computational performance of the proposed algorithm, which can be polynomial, not exponential. We corroborate the optimality of the results found for networks up to 15 nodes. Finally, we provide under a liberal license our free and open-source implementation of the proposed algorithm [5].
2. Related Works
The proposed algorithm is based on the generic Dijkstra algorithm recently proposed [6]. The generic Dijkstra algorithm is a generalization of the Dijkstra algorithm, which takes into account the spectrum continuity and contiguity constraints by introducing the incomparability relation between solutions. Specifically, we modify the generic Dijkstra algorithm to work on a search graph, which is built using the input graph, and represents the possible ways of finding path pairs. Furthermore, we introduce the incomparability relation between pairs of paths.
To the best of our knowledge, no efficient and exact algorithm (at least demonstrated by simulations) for solving the dynamic routing problem with DPP in optical networks has been published. In [7], the authors offered a proof that the dynamic RWA with DPP is nondeterministic polynomial time complete (NP-complete). In Reference [8], the authors offered a proof that the dynamic RMSA with DPP is NP-complete. In contrast, we propose an algorithm with the efficiency and exactness demonstrated by simulations, which suggests the problem may be tractable.
Dynamic routing without DPP is simpler, but its status seemed unclear. In References [9,10], the problem was solved with exponential worst-case time and memory complexities. However, the dynamic routing problems in EONs can be solved exactly in polynomial time with the spectrum scan method [11], introduced in Reference [12]. The exact-routing concept of the spectrum scan method was introduced earlier for WDM networks in Reference [13] but was called a heuristic greedy algorithm. That concept was used under the name of the spectrum window planes [14], and the filtered-graphs algorithm [6]. In Reference [15], the authors solved efficiently (in polynomial time) and exactly the dynamic routing problem in WDM networks with their interconnected-layered-graph algorithm. That exact algorithm was later improved and applied to EONs in Reference [16] but was called heuristic.
In a very broad sense, dynamic routing problems are multicriteria shortest path problems, which, in turn, are multiobjective combinatorial optimization problems with a set of constraints given to define the combinatorial structure of the problem [17]. Whether a specific routing problem is tractable or not depends on the number and type of criteria (or objective functions) and constraints. Routing problems are defined for discrete or continuous criteria: discrete for, e.g., optical networks [9] and networks capable of advance resource reservation [18], continuous for, e.g., networks with quality-of-service requirements [19,20]. In Reference [21], ten bicriteria shortest path problems were studied, some of them were proven NP-complete, others were solved in polynomial time with a novel multilabeling algorithm. That bicriteria multilabeling algorithm was generalized to any number and type of criteria in Reference [22], which is now called the Martins algorithm.
The Martins algorithm is the basic algorithm for exactly solving any multicriteria shortest path problem, but with exponential worst-case memory and time complexities [23]. To use the Martins algorithm for dynamic routing in optical networks, we could consider available spectrum units as discrete criteria, but that would lead to exponential worst-case time and memory complexities. The generic Dijkstra is similar to the Martins algorithm in that it is also a multilabeling algorithm, but the generic Dijkstra algorithm is a single criterion shortest path algorithm, where the ordering between solutions (labels) is partial.
The efficient and exact algorithms for finding a shortest pair of edge-disjoint paths in a graph are: the Suurballe algorithm [24], the Bhandari algorithm [25], and any minimum-cost, maximum-flow algorithm (e.g., the successive shortest path algorithm) with edge capacities set to one [26], all of which use the path augmentation technique. These algorithms cannot be used for solving the stated problem because they do not consider the spectrum continuity and contiguity constraints.
In our simulations, we also used two well-known algorithms for solving the problem: the heuristic edge-exclusion algorithm, and the exact brute-force algorithm.
The edge-exclusion algorithm is a simple and commonly-used algorithm for finding a pair of edge-disjoint paths: find a shortest path, then remove from the graph the edges found, and then find a shortest path again. This heuristic performs quite well, but it often finds suboptimal solutions, and it can fail even when a solution exists (e.g., for the so-called trap topology).
The edge-exclusion algorithm usually employs the limited (i.e., with a limited K, e.g., ) K-shortest path (KSP) algorithm to find a shortest path, which is a heuristic algorithm whose blocking probability depends on the value of K. However, the edge-exclusion algorithm can perform better if an algorithm of lower blocking probabilities is used. The blocking probabilities of the generic Dijkstra algorithm can be even twice as low as the blocking probabilities of the limited KSP algorithm [27]. Therefore, in the edge-exclusion algorithm, we used the generic Dijkstra algorithm.
The brute-force algorithm enumerates the path pairs using a priority queue that sorts the pairs in increasing-cost order. After we retrieve a pair from the queue, we produce new path pairs by extending one of the paths in the pair with an available edge that was not used before because the two paths should be edge-disjoint and without loops. We put a new path pair into the queue, if its paths meet the spectrum continuity and contiguity constraints. We keep looking for path pairs until we find one whose paths end at the destination node, provided we have enough time and memory. We successfully used the brute-force algorithm only for very small networks (15 nodes), since this algorithm is very inefficient.
3. Problem Statement
Given:
- directed multigraph , where is a set of vertexes, and is a set of edges,
- available units function , which gives the set of available units of edge , which do not have to be contiguous,
- s and t are the source and target vertexes of the demand,
- a cost function , which returns the cost of path p,
- a monotonically nondecreasing cost function , which returns the (real or integer) cost of path pair l,
- a decision function of monotonically increasing requirements, which returns true if path p can support the demand, otherwise false,
- the set of all units on every edge.
Find:
- a cheapest (i.e., of the lowest cost) pair of edge-disjoint paths (a path is a sequence of edges), the cheaper being the working path, and the more expensive the protecting path,
- continuous and contiguous units for each of the two paths separately: the working path and the protecting path (i.e., each path can have different spectrum).
We denote a set of contiguous units (CU) which start at index a and end at index b inclusive as . For instance, denotes units 0, 1, and 2. We can treat a set of units as a set of CUs. For instance, and are the same. Two CUs are incomparable, when one is not included in the other. For instance, and are incomparable, which we denote with the ‖ relation, e.g., .
To state the problem generically, we intentionally introduced the cost, COST, and decide functions to consider the RWA, RSA, and RMSA problems with DPP at once. For example, for RWA, the function for path p could return the length of the path, for RSA, the product of the path length and the number of units requested by the demand, and, for RMSA, the product of the path length and the number of units required by the demand for the given path.
We require that the function for a path pair l be monotonically nondecreasing, i.e., for any path pair derived from l by appending an edge to one of the paths, . This requirement implies the proposed algorithm cannot be used for networks with regeneration, when the path cost is defined as the product of the path length and the required number of units. Regeneration would reduce the number of required units, and the cost of the path pair would be reduced, thus violating this requirement.
We also assume that an optimal path pair has the optimal substructure, i.e., it is built of optimal path pairs, which is required by the dynamic programming principle the proposed algorithm relies on. In our simulations, the defined problem meets this assumption: the path cost is the product of the path length and the number of units required, while the cost of a path pair is the sum of the costs of the two paths.
The decide function accepts or rejects a candidate path, and lets the user define an acceptable path. We require the function to have monotonically increasing requirements, i.e., if the function rejects path p, then any path derived from p by appending an edge should also be rejected. For RWA, the function should make sure that the CU has at least one unit (wavelength), for RSA, that the CU has at least the number of units requested by the demand, and, for RMSA, that a CU has at least the number of units required for the demand for the given path length.
The bitrate of a demand is not a given of the stated problem and, if needed, should be relegated to the decision function as an implementation detail. Likewise, the cost, COST, and decide functions remain undefined in the problem statement. In Section 5, to solve the RMSA problem with DPP, we define the cost, COST, and decide functions in Section 5.1.3. The decision function defined there by (7) checks for the required number of units, which depends on the path length.
4. Proposed Algorithm
We run the generic Dijkstra algorithm on a search graph. Searching for a cheapest solution in the search graph corresponds to searching for a pair of paths of lowest cost in the input graph. The algorithm grows the search tree for the search graph.
4.1. Preliminaries
Below, we describe the search graph, the search tree, the priority queue, and the related concepts of the solution, the path trait, and the solution label.
4.1.1. Search Graph
The search graph has a set of vertexes , where vertex indexes , and of the input graph satisfy . For vertex x, we find a set of solutions, where the solution is a pair of paths: one path leads to vertex , and the other to vertex . Which of the paths could eventually (when vertex t is reached by both paths) become working or protecting is unknown and unimportant at this stage.
An edge in the search graph from vertex x to vertex represents finding a solution for vertex based on a solution for vertex x by taking edge in the input graph from either vertex or . Therefore, the edge in the search graph connects vertex x to some other vertex which has one of the vertex indexes or taken from x. The other vertex index of is the index of the target vertex of edge . Vertex becomes either , or , with its vertex indexes swapped if necessary, because we require the first one be smaller than or equal to the second one.
Taking a single edge in the input graph is the simplest, and the only one needed, way of producing a new solution in the search graph. Taking at once two edges of the input graph, one edge for each of the two paths, should also work, but this would lead to a more complicated and less efficient algorithm. This is more complicated because we cannot always take two edges, and less efficient because, by taking two edges, we can reach a suboptimal solution, which we would avoid if we took one of those edges first.
4.1.2. Path Trait
A path trait p is a pair of a cost and a CU, which describes a path in the input graph. For a path trait p, function gives the path cost, and function the path CU. For example, assuming the cost is the path length, a path trait says the path is km long and has the CU of .
Path trait is better than or equal to path trait , denoted by , when the cost of is smaller than or equal to the cost of , and the CU of includes the CU of , i.e., . If , then we drop , since it offers no better path in comparison with , and so we perform the search more efficiently.
This definition of the path trait comparison allows for incomparability of path traits, which is needed when searching for paths with the spectrum continuity and contiguity constraints. For instance, path trait is incomparable with because neither nor is true. We are interested in path trait , even though its cost is higher than the cost of , because has a CU that is incomparable with the CU of .
4.1.3. Solution Label
Solution label for vertex x is a pair of path traits , , where the first path which ends at has trait , and the other path which ends at has trait .
We compare solution labels to drop those solutions which offer nothing better than we already have, thus limiting the search space, and performing the search more efficiently. Label is better than or equal to label , denoted by , when both path traits of are better than or equal to both path traits of , i.e., . If , then we should not be interested in because it offers no better solution in comparison with .
A solution label for vertex x with the same vertexes in the input graph, i.e., , should have its path traits ordered with the ≤relation, i.e., , so that, when we compare labels of two solutions for vertex x, we compare the working-path traits first, and the equal to or worse protecting-path traits next.
This definition of the label comparison allows for incomparability of labels, which is needed when searching for a pair of paths, when these paths can have incomparable traits. For instance, label of path traits , and is incomparable with label of path traits , and because neither nor is true.
4.1.4. Search Tree
The result of the search is the search tree, which is organized according to the dynamic-programming principle of reusing data from previous computation. Search-tree node represents a solution found for the search-graph vertex based on the solution found for node x. The solution is described by label : the first path of the solution which ends at has trait , and the other path which ends at has trait . We get the solution from the previous search-tree node for vertex x by taking edge in the input graph. For a search-tree node n, function returns its label, and function returns its search-graph vertex.
A tree node represents a solution which is either permanent or tentative. A permanent-solution node stays in the tree for good, while a tentative-solution node can be discarded. A tentative-solution node is always a leaf. A tentative solution wants to become permanent, but instead it can be discarded or never processed.
To ensure that a solution is edge-disjoint, we do not add to the search tree a solution node if its edge was already used by its ancestor in the search tree.
4.1.5. Priority Queue
The optimality of the solutions found is achieved with the priority queue, which provides the cheapest solutions. The priority queue stores pairs, where a pair has a cost and a reference to a search-tree node of a tentative solution. The cost in the pair is the cost of the solution, i.e., . The queue sorts the solutions in the increasing-cost order, with the cheapest solution at the top.
A tentative solution is waiting in the queue to be processed, but it also can be either discarded, if we find a better solution, or never processed, if the search finishes sooner. A tentative solution becomes permanent when it is retrieved from the queue.
4.2. Algorithm
The proposed algorithm has the main loop listed in Algorithm 1, and the relax procedure listed in Algorithm 2. The main loop iterates over the permanent solutions retrieved from the priority queue, while the relax procedure pushes tentative solutions to the priority queue.
The solutions for vertex x are maintained in the set of permanent solutions with incomparable labels, and the set of tentative solutions with incomparable labels. The set of all permanent solutions is P, and the set of all tentative solutions is T. Permanent solutions are optimal.
We start the search at vertex . We create the tentative solution (the root of the search tree) of two empty paths starting at vertex s with 0 costs and the CUs of . We insert into the set of tentative labels for vertex x, and push the pair of to the priority queue Q.
To cover the maximal part of the search space, we look for the paths with the maximal CU, which satisfy the requirements of the decision function decide used by the relax procedure. For this reason, we start the search with the CU of .
We stop searching when the priority queue is empty, or when we find a permanent solution for vertex . If we need a complete (i.e., for all vertexes x) search tree, we should let the algorithm run until the priority queue is empty.
In each iteration of the main loop, we process the cheapest of all tentative solutions, and make it permanent. When we retrieve a pair from the queue, we have to ensure the tentative solution was not discarded by the relax procedure, i.e., that the reference to is not null.
Next, we relax the out edges of vertex x in the search graph. An edge in the search graph represents taking an edge in the input graph from either vertex or , and so we iterate over the edges leaving vertex first, and over the edges leaving vertex next.
| Algorithm 1 Dedicated Path Protection Algorithm |
| In: graph G, source vertex s, target vertex t |
| Out: a cheapest pair of paths, and their CUs |
| Here, we concentrate on permanent solutions . |
|
The relax procedure relaxes a single edge in the search graph, which is described in the procedure parameters: the taken edge in the input graph, vertex and the corresponding path trait which both do not change, the other trait of the path to which we try to append edge , and the previous search-tree node .
The relaxation can find a number of tentative solutions, which would differ only by the CU of , because there may be a number of spectrum fragments available on edge which we can use for a tentative solution.
We build (if necessary, we swap the elements of pairs and with the swap function) and add a tentative solution to and Q, only when there is no solution with a better or equal label already found. Adding can make some tentative solutions invalid (since is better), so we discard them.
| Algorithm 2 relax |
| In: edge , const vertex , const trait , other trait , |
| previous search-tree node |
| Here, we concentrate on tentative solutions . |
|
Spectrum allocation policy should be taken into account in two places. First, the priority queue should choose the solution of the preferred spectrum allocation policy from among the tentative solutions of the same cost. Second, once the solution for the destination vertex is found, the preferred CUs should be allocated from the CUs found.
The trace function, using P, traces back the tree nodes from the node for vertex to the node for vertex . For each tree node there is an edge, which the function appends to one of the two paths. When appending an edge to a path, we have to ensure that not only the cost matches, but the CU matches, too. We have to consult the other path trait of the tree node, to ensure that we are not appending the edge to the wrong path, which coincidentally meets the conditions. The function returns the less expensive path as the working path, and the more expensive path as the protecting. For each of the paths, the function allocates the minimal CU, with the required number of units, from the maximal CU found for the permanent solution for vertex .
4.3. Example
We demonstrate how the algorithm works by finding a solution from the source vertex s to the destination vertex t for a single unit in the trap topology shown in Figure 1, where an edge label gives not only the name of the edge, but also its cost and available units. Not to complicate the example further, the signal modulation constraints are not considered, especially since they are not crucial to the algorithm as they only discard paths.
The trap topology is well-known since the edge-exclusion algorithm fails for it: when the edges of the shortest path from s to t through vertexes q and r are removed, a second path does not exist. However, the optimal solution does exist: one path goes through vertex q with the CU of , and the other through vertex r with .
Figure 2 shows the search graph generated, where the edge label gives the name of an input-graph edge to take to make a transition between the vertexes in the search graph. For example, the transition from vertex to vertex requires edge . Most edges are undirected, since the algorithm examines transitions in both directions. However, there are some directed edges (e.g., from to ), since their reverse transitions (e.g., from to ) are not examined. Because paths in the input graph have to be edge-disjoint, some paths in the search graph are disallowed, e.g., .
Figure 3 shows the search tree generated, where only the permanent (and not tentative) solutions are represented. The tree is rooted at node for vertex . The solution found is represented by node for vertex . A search-graph vertex can have a set of permanent incomparable solutions, which are represented by a set of search-tree nodes, e.g., for vertex there are two search-tree nodes: and .
The algorithm processes solution labels by taking actions on them, as reported in Table 1. A label can be produced and pushed into the queue, as in, e.g., action #0. A row represents an action on a label which was produced for the given search-graph vertex by making a transition with the given edge. For instance, action #2 reports a label that is pushed into the queue, and which was produced for the search-graph vertex by making a transition with edge (from vertex ).
A label can be retrieved from the queue, and made permanent, as in, e.g., action #1. A search-tree node for a permanent label has a name reported, e.g., as in action #1. A row for a label made permanent is colored gray to mark the beginning of a sequence of rows that report the actions of the relaxation based on the label from that gray row. For instance, the row for action #1 is gray, and the subsequent rows for actions from #2 to #5 report the actions of the relaxation that ensued.
A label can be pushed into the queue, or it can be dropped for two reasons: it is worse than or equal to an existing label (e.g., in action #4, a label is dropped because an equal label of action #2 exists), or it uses an edge twice (e.g., in action #7, a label is dropped because edge is used twice). A label can also be discarded from the queue if a better label is found (e.g., in action #17, a label is discarded because a better label was found in action #16).
As reported in Table 1, the search is booted with action #0. There are 14 permanent labels found for 10 vertexes of the search graph. The algorithm terminates, when the destination node is reached with the search-tree node . We can trace back from to to get the aforementioned optimal solution.
4.4. Worst-Case Analysis
We argue the size of the search space is polynomially upper bounded. We derive the upper bound L of the number of incomparable labels (i.e., the size of the search space) by considering the worst case where every vertex of all search graph vertexes has the maximum number S of incomparable labels. Therefore, . The problem is to derive and S.
The number of vertexes in the search graph is given by (1), since the input graph has vertexes, and since vertexes of the search graph satisfy . The number of vertexes with is , and the number of vertexes with is the number of combinations of two elements from the set of elements.
The maximum number S of incomparable labels a vertex can have is given by (2). Since a label describes a solution made up of two independent paths, S is the maximum number of incomparable path traits squared.
The maximum number of incomparable path traits depends only on . We get the largest set of incomparable path traits when the cost of path traits increases as the size of their CUs increases. The largest set has subsets: the first subset has traits with CUs of a single unit and the lowest cost, the second subset has traits with CUs of two units and a higher cost, …, and the last subset has a single trait with the CU of units and the highest cost. The largest set has incomparable path traits.
Therefore, the size of the search space is polynomially upper bounded, since .
5. Simulations
The simulations had two goals: the optimality corroboration, and the performance evaluation. We had 48,600 simulation runs: 32,400 corroborative runs, and 16,200 performance evaluation runs.
We corroborated the optimality of the results of our algorithm by comparing them with the results of the brute-force enumeration algorithm: for a single search either both algorithms returned results of the same cost, or both algorithms returned no results. Since there are billions of feasible solutions even in small networks, and since the brute-force algorithm enumerates them all, we were able to corroborate the results only for small networks.
We ran the corroborative simulations for networks of 10, 11, 12, 13, 14, and 15 nodes; for 160, 320, and 640 units; for offered loads ranging from light to heavy; and for demands requesting on average from 10 to 64 units. In total, we had 32,400 simulation runs, out of which 183 runs were killed, because they requested more than 120 GB of operating memory, which we did not have. In total, we carried out 17,590,624 searches, all successfully corroborated.
The remainder of this section is about the performance evaluation.
5.1. Simulation Setting
Below, we describe how we model the network, the traffic, and the signal modulation.
5.1.1. Network Model
A network model has an undirected graph, and . We randomly generated three groups of network graphs with 25, 50, and 100 vertexes, where each group had one hundred graphs. We generated Gabriel graphs because they have been shown to model the properties of the transport networks very well [28]. The vertexes were uniformly distributed over a square area with the density of one vertex per 10 thousand square km.
We used three spacings of 25 GHz, 12.5 GHz, and 6.25 GHz for the erbium band, which translated to three values for : 160, 320, and 640 units.
We present the results only for the first-fit spectrum allocation policy. The first-fit policy allocates units in the first CU that can support the demand, i.e., the CU with the units of the lowest indexes. We also considered the best-fit and random-fit policies. The best-fit policy performed comparably to the first-fit policy, and the random-fit policy performed markedly worse than the first-fit policy. We do not present the results for these alternative policies because they add little to the main results.
5.1.2. Traffic Model
We evaluate the algorithm performance as a function of the network utilization, which we define as the ratio of the number of units in use to the total number of units on all edges. We measure the network utilization in response to offered load a, which expresses the desired network utilization.
Demands arrive according to the exponential distribution with rate per day. The end nodes of a demand are different and chosen at random. The number of units a demand requests is described by distribution with the mean of , i.e., a shifted Poisson distribution, so that we do not get a zero. Parameter expresses the mean number of units that demands request relative to the number of all units on every edge, and so . We model the connection holding time with the exponential distribution with the mean of days. A connection is bidirectional: the same CU is allocated in both directions for a path.
We express as a function of a. The offered load is the ratio of the number of demanded units to the total number of units on all edges. For traffic intensity , the number of units demanded is , since a demand requests two paths, and we estimate they require units, and edges each, where is the average number of edges of a shortest path between the end nodes of the demand in the network being simulated. Therefore, , from which (3) follows.
Equation (3) underestimates the value of because we assume that every demand has a connection established. For this reason, does not yield a full network utilization.
5.1.3. Signal Modulation Model
We use the signal modulation model from Reference [6], with M modulations available. For a demand requesting g units for the most spectrally-efficient modulation, the number of units needed to establish a connection of length d is given by (4), where is the reach of the least spectrally-efficient modulation, and is the reach of the most spectrally-efficient modulation.
We describe a demand with the number of units g, instead of bitrate b, because the algorithm works with units, not bitrates. If the bitrate is given, we can calculate the number of units using (5), where R is a technology-dependent bitrate (e.g., Gb/s), and G is the number of guard-band units [29].
In the simulations, we assumed , and the reach of the least-spectrally efficient modulation equals to one and a half lengths of the longest path from among all the shortest paths (i.e., for every source-destination combination) in the network being simulated, which allows us to consider paths much longer than an average shortest path. Following Reference [6], we calculated .
5.1.4. The Cost and Decision Functions
5.2. Runs and Populations
A simulation run simulated 150 days of a network in operation, with the results from the first 50 days discarded. The parameters of a simulation run were: the network size, , , a, and . A simulation run reported the mean network utilization, the mean and maximum times taken, and the mean and maximum number of 64-bit memory words used by a search for a single demand.
We averaged the mean simulation results to calculate the sample mean results, which estimate the population mean results, and the average algorithm performance. We took the maximum of the maximum simulation results to get the sample maximum results, which estimate the population maximum results, and the worst-case algorithm performance.
In a given population, there were 100 simulation runs whose parameters differed only with the network model. We had 162 populations because we varied 3 network sizes (25, 50, 100 nodes), 3 values of (160, 320, 640 units), 9 values of a (0.05, 0.1, 0.15, 0.2, 0.45, 0.65, 1, 1.5, 2), and two runs for units, and of units available (i.e., 16 units for the case with 160 units, 32 for 320, and 64 for 640). For all populations, the mean connection holding time days was constant. In total, we carried out 16200 simulation runs (162 populations × 100 samples) with 24,043,157 searches. The sample means credibly estimate the population means, since their relative standard error was below 5%.
5.3. Simulation Results
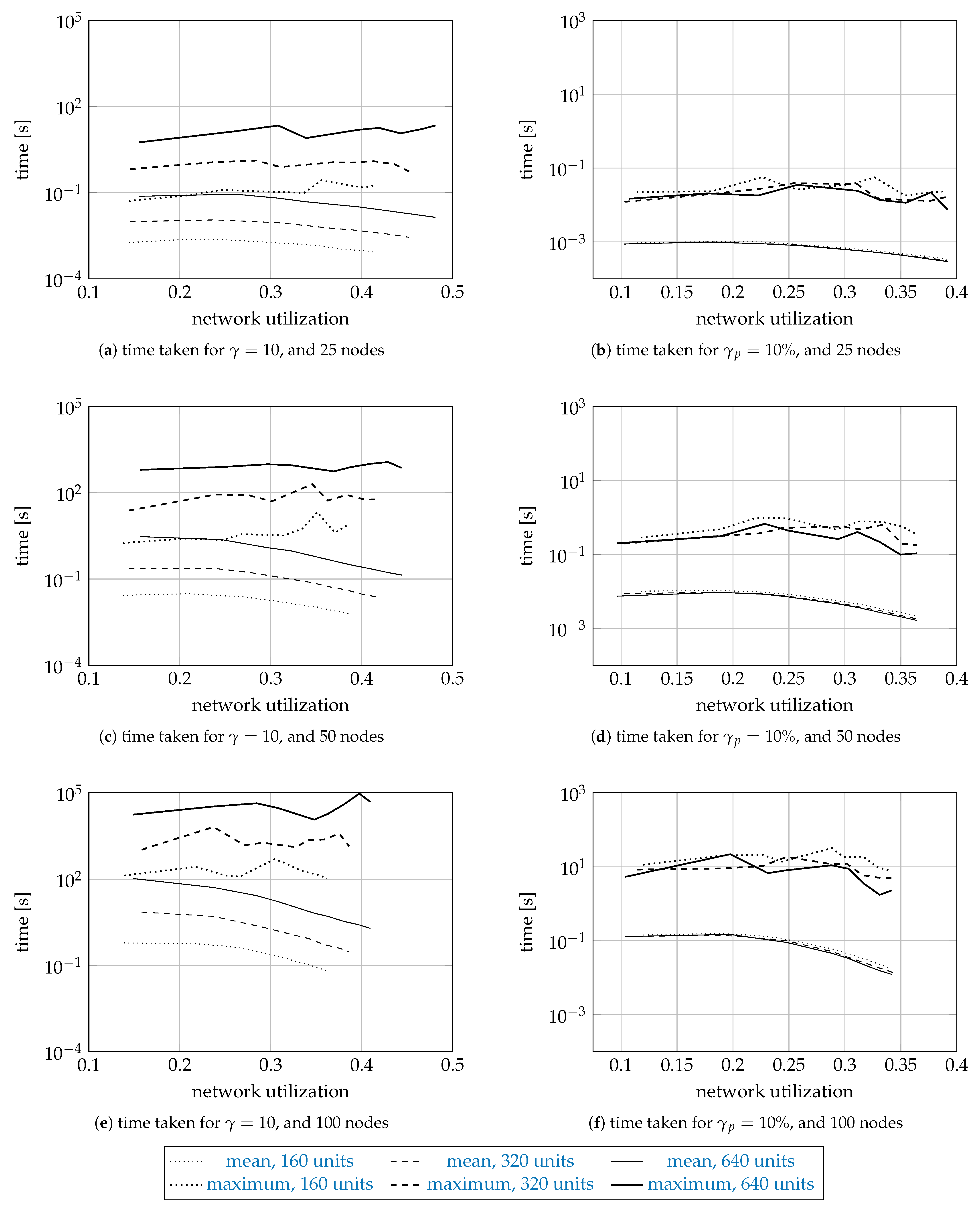
Figure 4 and Figure 5 show the sample means and the sample maxima of the time taken and memory used by a search, regardless of whether the search was successful or not. The results are shown on a logarithmic scale as a function of network utilization. The curves are plotted dotted for 160 units, dashed for 320 units, and solid for 640 units. The sample means are plotted thin, and the sample maxima thick. Each curve is drawn using 9 data points for different values of a. For the means, we do not report the error bars representing the standard error, since they were too small to plot.
Figure 4 and Figure 5 have three rows and two columns of subfigures. The first row shows the results for the networks with 25 nodes, the second for 50 nodes, and the third for 100 nodes. The first column shows the results for , and the second column the results for .
The mean times range from s (for 25 nodes, and 160 units) to s (100 nodes, 640 units). While the difference in scale is , we also note that the problem size increased 16 times. The mean time increases about ten times as we increase the network size by a factor of two. For , the mean time increases about five times as the number of units increases twice (from 160 to 320, and from 320 to 640 units). Interestingly, the time for is roughly the same for 160, 320, and 640 units, which suggests the time complexity depends on the number of units requested relative to the number of available units, and indirectly on the spectrum fragmentation. The mean time decreases as the network utilization increases, since the search space gets smaller. As for the sample maximum results, they were usually a hundred times larger than the mean results.
The memory results report the number of 64-bit memory words used by the permanent solutions, the tentative solutions, and the priority queue. The network size, , and affected the memory results similar to how they affected the time results. For the networks with 25 nodes, the mean number of words was about , while, for the networks with 100 nodes, about .
The memory used for is far larger than for because the spectrum (the available units) is more fragmented (since it is allocated in smaller fragments), and the algorithm finds more solutions as the search space is larger. Finding more solutions requires more time: simulations for take more time that the simulations for .
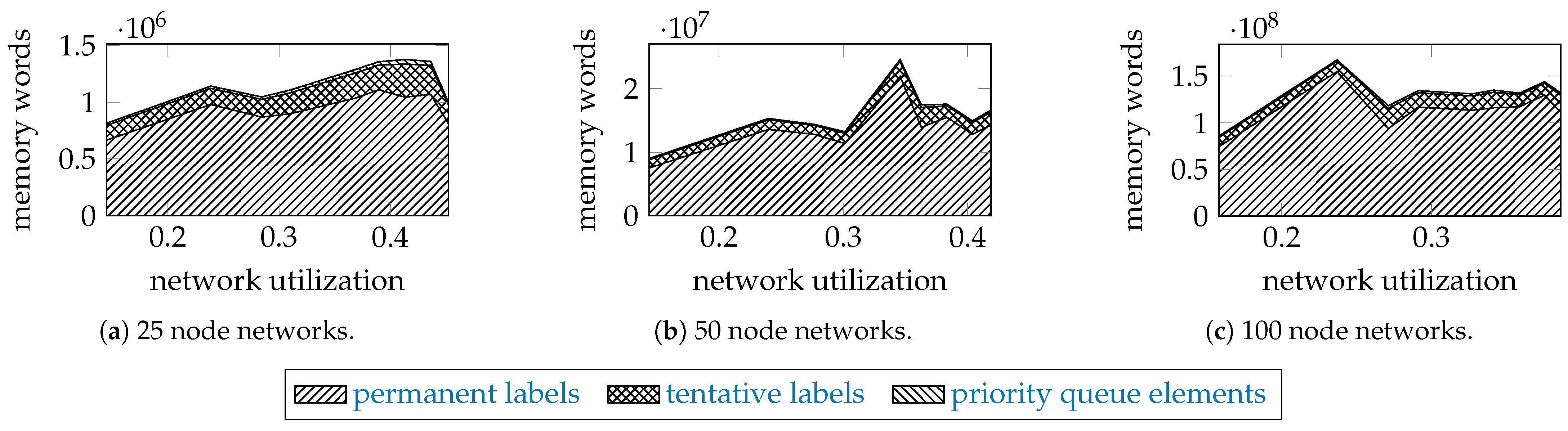
To examine how the incomparable permanent and tentative labels, and the elements of the priority queue contribute to the memory usage, Figure 6 shows as stack plots the maximal memory used by the proposed algorithm for the networks of 25, 50, and 100 nodes with 320 units, and .
The permanent labels take about 80% of memory, the tentative labels about 20%, and the elements of the priority queue take only a small fraction. We assumed that a label takes 15 64-bit words (implementation details: 4 words for a shared pointer, 1 word for a vertex pair, 4 words for a path trait, 2 words for an edge, 4 words for a shared pointer to the parent node in the search tree). An element of a priority queue is two words long (1 word for cost, 1 word for a weak pointer to its tentative label).
Most of the memory required by the algorithm is consumed by the permanent labels because of the large search space. A permanent label stores an optimal solution, and the results suggest that there are many of them for large networks. Furthermore, that large number of permanent labels helps to keep the number of tentative labels relatively much smaller through the edge relaxation.
To further validate the proposed algorithm, Figure 7 shows, for all populations of interest, the mean bandwidth blocking probabilities of the proposed algorithm as thin curves and of the edge-exclusion algorithm as thick curves. The figure has two rows and three columns of subfigures. The first row shows the results for , and the second for . The first column shows the results for the networks with 25 nodes, the second for 50 nodes, and the third for 100 nodes. We do not plot the error bars representing the standard error, since they were too small to plot.
Since the proposed algorithm can be exact, and the edge-exclusion algorithm is heuristic, the proposed algorithm should perform better, and indeed this is so. Interestingly, the edge-exclusion algorithm (which uses the generic Dijkstra algorithm) performs very well, at only about 5% worse.
We did not add the edge-exclusion algorithm to the time and memory performance comparison, since it is a heuristic algorithm with the worst-case computational complexity of the dynamic routing problem without DPP, i.e., [6]. In addition, we were unable to add the brute-force algorithm to the comparison because of its exponential complexity.
Admittedly, the reported time and memory consumption of the proposed algorithm seems large: for a network of 100 nodes and 640 units, the algorithm can run even for thousands of seconds, and use even 10 GBs of operating memory. However, to put these results in perspective, we report that, for a far smaller network of 15 nodes and 640 units, the brute-force algorithm ran for thousands of seconds, and it requested more than 120 GBs of operating memory in the corroborative runs.
6. Conclusions
The proposed algorithm is capable of solving various dynamic routing problems with dedicated path protection in optical networks, but not all of them, e.g., the algorithm cannot be applied when signal regeneration or spectrum conversion are used. However, the proposed algorithm can solve those routing problems that meet the minimal requirements of the stated research problem. If not, then perhaps the proposed algorithm and its novel principles could be used as a basis for devising more capable algorithms.
The proposed algorithm can also be used to find a pair of paths to different (primary, and secondary) data centers. The algorithm could even be useful in routing with inverse multiplexing, and multipath routing.
We are unable to compare the performance results of the proposed algorithm to some efficient and exact algorithm because, to the best of our knowledge, no such competing algorithm exists. For that large problem size, we could not have used the existing exact methods (e.g., the brute-force algorithm, integer linear programming) since they are inefficient, nor could we have used the existing efficient methods (e.g., the edge-exclusion algorithm, the tabu search), since they are suboptimal.
Dedicated path protection can be implemented at the multiplex section (fiber protection), the optical layer (optical signal protection), or the digital layer (the digital signal protection). We presented our algorithm in the setting of the optical signal protection, where we take into account the spectrum continuity and contiguity constraints, but the same principles could be used for other layers (e.g., the Internet protocol layer with multiprotocol label switching) and networks, too.
The algorithm can be adapted for further constraints, e.g., node-disjoint paths or the same spectrum fragments on both paths. Node-disjoint paths can be found if we do not relax the edges of the search graph that leave vertex when . The same spectrum fragment on both paths can be enforced by making sure during edge relaxation that the intersection of two fragments meet the requirements of a demand.
Future work could concentrate on applying the algorithm to related problems (e.g., establishing protected content-oriented connections to data centers), and further improving its performance with parallel computing.
Furthermore, perhaps the principle of the incomparability of solutions could be applied to the path augmentation technique, thus making, e.g., the Suurballe algorithm, even faster than the proposed algorithm.
The provided implementation does not require proprietary software, is implemented in modern C++ using the Boost Graph Library, and with modern functionality, such as concepts, smart pointers, in-place object creation, and move semantics. The implementation can be used to replicate the presented results, as well as stress-test the proposed algorithm.
Author Contributions
Conceptualization, I.S. and I.O.; methodology, I.S., I.O. and B.W.-S.; software, I.S.; validation, I.S., I.O. and B.W.-S., writing—original draft preparation, I.S.; writing—review and editing, I.S., I.O. and B.W.-S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Polish Ministry of Science and Higher Education grant number 020/RID/2018/19.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Acknowledgments
We ran the simulations using PL-Grid, the Polish supercomputing infrastructure.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shen, G.; Guo, H.; Bose, S.K. Survivable elastic optical networks: Survey and perspective. Photonic Netw. Commun. 2016, 31, 71–87. [Google Scholar] [CrossRef]
- Goścień, R.; Walkowiak, K.; Klinkowski, M.; Rak, J. Protection in elastic optical networks. IEEE Netw. 2015, 29, 88–96. [Google Scholar] [CrossRef]
- Simmons, J.M. Optical Network Design and Planning; Optical Networks; Springer: New York, NY, USA, 2014. [Google Scholar]
- Gerstel, O.; Jinno, M.; Lord, A.; Yoo, S. Elastic optical networking: A new dawn for the optical layer? IEEE Commun. Mag. 2012, 50, s12–s20. [Google Scholar] [CrossRef]
- Szcześniak, I. The Implementation of the Efficient and Optimal Algorithm for the Dynamic Dedicated Path Protection. 2019. Available online: http://www.irkos.org/ddpp (accessed on 26 August 2021).
- Szcześniak, I.; Jajszczyk, A.; Woźna-Szcześniak, B. Generic Dijkstra for optical networks. IEEE/OSA J. Opt. Commun. Netw. 2019, 11, 568–577. [Google Scholar] [CrossRef] [Green Version]
- Andersen, R.; Chung, F.; Sen, A.; Xue, G. On disjoint path pairs with wavelength continuity constraint in WDM networks. In Proceedings of the IEEE INFOCOM 2004, Hong Kong, China, 7–11 March 2004; pp. 524–535. [Google Scholar]
- Kishi, Y.; Kitsuwan, N.; Ito, H.; Chatterjee, B.C.; Oki, E. Modulation-Adaptive Link-Disjoint Path Selection Model for 1 + 1 Protected Elastic Optical Networks. IEEE Access 2019, 7, 25422–25437. [Google Scholar] [CrossRef]
- Christodoulopoulos, K.; Kokkinos, P.; Varvarigos, E.M. Indirect and direct multicost algorithms for online impairment-aware RWA. Trans. Netw. 2011, 19, 1759–1772. [Google Scholar] [CrossRef]
- Wang, X.; Kuang, K.; Wang, S.; Xu, S.; Liu, H.; Liu, G.N. Dynamic routing and spectrum allocation in elastic optical networks with mixed line rates. J. Opt. Commun. Netw. 2014, 6, 1115–1127. [Google Scholar] [CrossRef]
- Yang, L.; Nan, H.; Xiaoping, Z.; Hanyi, Z.; Bingkun, Z. Polynomial-time adaptive routing algorithm based on spectrum scan in dynamic flexible optical networks. China Commun. 2013, 10, 49–58. [Google Scholar] [CrossRef]
- Liu, Y.; Hua, N.; Wan, X.; Zheng, X.; Liu, Z. A spectrum-scan routing scheme in flexible optical networks. In Proceedings of the 2011 Asia Communications and Photonics Conference and Exhibition, Shanghai, China, 13–16 November 2011; pp. 1–6. [Google Scholar]
- Shen, G.; Bose, S.; Cheng, T.; Lu, C.; Chai, T. Efficient heuristic algorithms for light-path routing and wavelength assignment in WDM networks under dynamically varying loads. Comput. Commun. 2001, 24, 364–373. [Google Scholar] [CrossRef]
- Wang, C.; Shen, G.; Bose, S.K. Distance adaptive dynamic routing and spectrum allocation in elastic optical networks with shared backup path protection. J. Light. Technol. 2015, 33, 2955–2964. [Google Scholar] [CrossRef]
- Chen, C.; Banerjee, S. A new model for optimal routing in all-optical networks with scalable number of wavelength converters. In Proceedings of the GLOBECOM ’95, Singapore, 14–16 November 1995; Volume 2, pp. 993–997. [Google Scholar]
- Hsu, C.F.; Chang, Y.C.; Sie, S.C. Graph-model-based dynamic routing and spectrum assignment in elastic optical networks. J. Opt. Commun. Netw. 2016, 8, 507–520. [Google Scholar] [CrossRef]
- Ehrgott, M.; Gandibleux, X. A survey and annotated bibliography of multiobjective combinatorial optimization. OR Spektrum 2000, 22, 425–460. [Google Scholar] [CrossRef]
- Varvarigos, E.M.; Sourlas, V.; Christodoulopoulos, K. Routing and scheduling connections in networks that support advance reservations. Comput. Netw. 2008, 52, 2988–3006. [Google Scholar] [CrossRef] [Green Version]
- Mieghem, P.V.; Kuipers, F.A. Concepts of exact QoS routing algorithms. IEEE/ACM Trans. Netw. 2004, 12, 851–864. [Google Scholar]
- Wang, Z.; Crowcroft, J. Quality-of-service routing for supporting multimedia applications. IEEE J. Sel. Areas Commun. 1996, 14, 1228–1234. [Google Scholar] [CrossRef] [Green Version]
- Hansen, P. Bicriterion path problems. In Multiple Criteria Decision Making Theory and Application; Lecture Notes in Economics and Mathematical Systems; Springer: Berlin/Heidelberg, Germany, 1980; Volume 177, pp. 109–127. [Google Scholar]
- Martins, E.Q.V. On a multicriteria shortest path problem. Eur. J. Oper. Res. 1984, 16, 236–245. [Google Scholar] [CrossRef]
- Tarapata, Z. Selected multicriteria shortest path problems: An analysis of complexity, models and adaptation of standard algorithms. Int. J. Appl. Math. Comput. Sci. 2007, 17, 269–287. [Google Scholar] [CrossRef] [Green Version]
- Suurballe, J.W. Disjoint paths in a network. Networks 1974, 4, 125–145. [Google Scholar] [CrossRef]
- Bhandari, R. Survivable Networks: Algorithms for Diverse Routing; Kluwer Academic Publishers: Boston, MA, USA, 1999. [Google Scholar]
- Ahuja, R.K.; Magnanti, T.L.; Orlin, J.B. Network Flows: Theory, Algorithms, and Applications; Prentice Hall: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Szcześniak, I.; Woźna-Szcześniak, B. Adapted and constrained Dijkstra for elastic optical networks. In Proceedings of the 2016 International Conference on Optical Network Design and Modeling (ONDM), Cartagena, Spain, 9–12 May 2016; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Cetinkaya, E.; Alenazi, M.; Cheng, Y.; Peck, A.; Sterbenz, J. On the fitness of geographic graph generators for modelling physical level topologies. In Proceedings of the 2013 5th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Almaty, Kazakhstan, 10–13 September 2013; pp. 38–45. [Google Scholar] [CrossRef]
- Wan, X.; Hua, N.; Zheng, X. Dynamic routing and spectrum assignment in spectrum-flexible transparent optical networks. J. Opt. Commun. Netw. 2012, 4, 603–613. [Google Scholar] [CrossRef]
Figure 1.
A sample input graph: the trap topology.

Figure 2.
The search graph.

Figure 3.
The search tree.

Figure 4.
The sample means and maxima of the time taken by the proposed algorithm.

Figure 5.
The sample means and maxima of the memory used by the proposed algorithm.

Figure 6.
Simulation results: the maximum number of required words for networks with 320 units, and .
Figure 6.
Simulation results: the maximum number of required words for networks with 320 units, and .

Figure 7.
Simulation results: the sample means of the bandwidth blocking probability.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Solution labels processed.
| Action Number | Solution Cost | Search-Tree Node Name | Search-Graph Vertex | Solution Label | Edge | Action |
|---|---|---|---|---|---|---|
| 0 | 0 | push into queue | ||||
| 1 | 0 | make permanent | ||||
| 2 | 1 | push into queue | ||||
| 3 | 3 | push into queue | ||||
| 4 | 1 | drop (worse or equal) | ||||
| 5 | 3 | drop (worse or equal) | ||||
| 6 | 1 | make permanent | ||||
| 7 | 2 | drop (edge reuse) | ||||
| 8 | 4 | push into queue | ||||
| 9 | 2 | drop (worse or equal) | ||||
| 10 | 4 | push into queue | ||||
| 11 | 2 | push into queue | ||||
| 12 | 2 | make permanent | ||||
| 13 | 3 | drop (edge reuse) | ||||
| 14 | 5 | push into queue | ||||
| 15 | 3 | drop (worse or equal) | ||||
| 16 | 3 | push into queue | ||||
| 17 | 4 | discard from queue | ||||
| 18 | 3 | make permanent | ||||
| 19 | 4 | drop (edge reuse) | ||||
| 20 | 6 | push into queue | ||||
| 21 | 3 | make permanent | ||||
| 22 | 4 | drop (worse or equal) | ||||
| 23 | 6 | drop (edge reuse) | ||||
| 24 | 4 | push into queue | ||||
| 25 | 6 | drop (worse or equal) | ||||
| 26 | 4 | push into queue | ||||
| 27 | 4 | make permanent | ||||
| 28 | 5 | push into queue | ||||
| 29 | 7 | drop (edge reuse) | ||||
| 30 | 4 | make permanent | ||||
| 31 | 5 | drop (worse or equal) | ||||
| 32 | 7 | drop (worse or equal) | ||||
| 33 | 5 | drop (worse or equal) | ||||
| 34 | 5 | push into queue | ||||
| 35 | 7 | drop (worse or equal) | ||||
| 36 | 5 | drop (worse or equal) | ||||
| 37 | 4 | make permanent | ||||
| 38 | 5 | drop (worse or equal) | ||||
| 39 | 7 | drop (edge reuse) | ||||
| 40 | 7 | drop (worse or equal) | ||||
| 41 | 5 | drop (worse or equal) | ||||
| 42 | 5 | make permanent | ||||
| 43 | 6 | drop (worse or equal) | ||||
| 44 | 8 | push into queue | ||||
| 45 | 6 | push into queue | ||||
| 46 | 5 | make permanent | ||||
| 47 | 6 | drop (worse or equal) | ||||
| 48 | 8 | push into queue | ||||
| 49 | 6 | drop (edge reuse) | ||||
| 50 | 8 | drop (worse or equal) | ||||
| 51 | 6 | drop (worse or equal) | ||||
| 52 | 5 | make permanent | ||||
| 53 | 6 | drop (worse or equal) | ||||
| 54 | 6 | drop (worse or equal) | ||||
| 55 | 6 | drop (edge reuse) | ||||
| 56 | 8 | drop (worse or equal) | ||||
| 57 | 6 | drop (worse or equal) | ||||
| 58 | 6 | make permanent | ||||
| 59 | 7 | drop (worse or equal) | ||||
| 60 | 7 | drop (edge reuse) | ||||
| 61 | 6 | make permanent | ||||
| 62 | 7 | drop (edge reuse) | ||||
| 63 | 9 | drop (worse or equal) | ||||
| 64 | 7 | drop (edge reuse) | ||||
| 65 | 8 | make permanent |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Szcześniak, I.; Olszewski, I.; Woźna-Szcześniak, B. Towards an Efficient and Exact Algorithm for Dynamic Dedicated Path Protection. Entropy 2021, 23, 1116. https://0-doi-org.brum.beds.ac.uk/10.3390/e23091116
AMA Style
Szcześniak I, Olszewski I, Woźna-Szcześniak B. Towards an Efficient and Exact Algorithm for Dynamic Dedicated Path Protection. Entropy. 2021; 23(9):1116. https://0-doi-org.brum.beds.ac.uk/10.3390/e23091116
Chicago/Turabian StyleSzcześniak, Ireneusz, Ireneusz Olszewski, and Bożena Woźna-Szcześniak. 2021. "Towards an Efficient and Exact Algorithm for Dynamic Dedicated Path Protection" Entropy 23, no. 9: 1116. https://0-doi-org.brum.beds.ac.uk/10.3390/e23091116
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.