
Solving Schrödinger Bridges via Maximum Likelihood


1
The Computer Laboratory, Department of Computer Science and Technology, University of Cambridge, William Gates Building, 15 JJ Thomson Avenue, Cambridge CB3 0FD, UK
2
The Cavendish Laboratory, Deparment of Physics, The Old Schools, Trinity Ln, Cambridge CB2 1TN, UK
*
Authors to whom correspondence should be addressed.
Entropy 2021, 23(9), 1134; https://0-doi-org.brum.beds.ac.uk/10.3390/e23091134
Submission received: 21 July 2021
/
Revised: 11 August 2021
/
Accepted: 23 August 2021
/
Published: 31 August 2021
/
Corrected: 3 February 2023
(This article belongs to the Special Issue Information Theory Based Methods in Machine Learning and Bioinformatics)
Abstract
:The Schrödinger bridge problem (SBP) finds the most likely stochastic evolution between two probability distributions given a prior stochastic evolution. As well as applications in the natural sciences, problems of this kind have important applications in machine learning such as dataset alignment and hypothesis testing. Whilst the theory behind this problem is relatively mature, scalable numerical recipes to estimate the Schrödinger bridge remain an active area of research. Our main contribution is the proof of equivalence between solving the SBP and an autoregressive maximum likelihood estimation objective. This formulation circumvents many of the challenges of density estimation and enables direct application of successful machine learning techniques. We propose a numerical procedure to estimate SBPs using Gaussian process and demonstrate the practical usage of our approach in numerical simulations and experiments.
1. Introduction
Analysis of cross-sectional data is ubiquitous in machine learning and science. Temporal data are typically sampled at discrete intervals due to technological or physical constraints. This means information between time points is lost. This motivates the need to model the stochastic evolution of a process between sampled time points. The classical Schrödinger bridge problem [1,2] finds the most likely stochastic process that evolves a distribution to another distribution consistently with a pre-specified Brownian motion. We consider a more general dynamical Schrödinger bridge problem for any pre-specified diffusion prior. Practically, this generalization allows us to exploit domain knowledge, e.g., oceanic and atmospheric flows might be interpolated from empirical measurements using previously established dynamics as priors.
In the classical set up numerical approaches to solve the Schrödinger bridge are mainly based on the Sinkhorn–Knopp algorithm [3]; however, extending those algorithms to more general diffusion priors and marginals requires complex adaptations. We introduce an iterative proportional maximum likelihood (IPML) algorithm to solve the general Schrödinger bridge problem. The IPML algorithm also obtains a good approximation for the dynamics of the underlying physical process that solves the SBP. This contrasts to previous approaches [4,5,6] that estimate the value that extremises the SBP objective. Practically, this means we obtain physically interpretable solutions that we can leverage for downstream tasks.
IPML’s inspiration is from probabilistic numerics (PN) [7]. We combine a PN styled formulation with the iterative proportional fitting procedure (IPFP) [8,9]. The algorithm iteratively simulates trajectories that converge to the SBP. We prove that IPML converges in probability at each iteration. Our numerical experiments show the algorithm can be implemented with Gaussian process (GP) models of the drifts. GPs allow us to incorporate functional prior information. We demonstrate the practical use of our algorithm on real-world embryoid cells data (see Figure 4) by quantitatively and qualitatively comparing the performance of our algorithm to state-of-the-art deep learning methods and optimal transport techniques. To summarise, the main contributions of our work are:
- We recast the iterations of the dynamic IPFP algorithm as a regression-based maximum likelihood objective. This is formalised in Theorem 1 and Observation 1. This differs to prior approaches such as [10] where their maximum likelihood formulation solves a density estimation problem. This allows the application of many regression methods from machine learning that scale well to high dimensional problems. Note that this formulation can be parametrised with any method of choice. We chose GPs; however, neural networks would also be well suited,
- Finally we re-implement the approach by [10] and compare approaches across a series of numerical experiments. Furthermore we empirically show how our approach works well in dimensions higher than 2.
2. Technical Background
Our solution has three components. (1) We reformulate the SBP as a dynamical system giving a stochastic differential equation (SDE) with initial value (IV) and final value (FV) constraints [13]. (2) We reverse the system, reformulating the FV constraint as an IV constraint. Both IV problems are solved through a stochastic control formulation (Section 2.1.2). (3) We iterate the IV and FV constrained problems to converge to the full boundary value constrained SDEs.
2.1. Dynamic Formulation
The dynamic version of the Schrödinger bridge is written in terms of measures over the space of trajectories, which describe the stochastic dynamics defined over the unit interval.
Definition 1.
(Dynamic Schrödinger problem) The dynamic Schrödinger problem is given by
where is a measure with prescribed marginals of at times that is and . is a drift augmented Brownian motion with a scalar volatility γ acting as the prior, see Figure 1. Traditionally is a Wiener measure with volatility γ, however we consider the general setting in this work.
The prior can be written as a solution of the diffusion:
From here we use to denote the drift of the prior . Note that a finite KL implies and are both Itô SDEs with volatility . The diffusion coefficient is a time homogeneous constant and for the KL-divergence to be finite the process must have as its diffusion coefficient.
2.1.1. Time Reversal of Diffusions
When sampling solutions, IV constraints are trivially solved by initialisation of samples, but FV constraints are more problematic; however, if we can reformulate the SBP as a time reversed diffusion the FV constraint becomes an IV constraint (Section 3.2). Here we review how the diffusion is reversed. We reverse time (see Figure 1) in the random variable described by the diffusion in Equation (2) such that . The reverse time diffusion is also an Itô process. For a modern application of time reversal in machine learning see [14].
Lemma 1
([15]). If obeys the SDE
then obeys
where is a Brownian motion adapted to the reverse filtration , that is . Furthermore, the dual drift satisfies Nelson’s duality relation:
where solves the associated Fokker–Planck equation.
2.1.2. Stochastic Control Formulation
Now that the FV constraint has been converted to an IV constraint, we cast the problem into a stochastic control formulation to estimate the drift of each diffusion process. Following from the dynamic formulation, the control formulation casts the problem explicitly in terms of stochastic differential equations. The control formulation is used to enforce constraints as initial value problems. Furthermore, the drift based formulations of the SBP admit a reverse time formulation, which starts the chain at the end of the interval and progresses the dynamics backwards in time to the start.
Lemma 2
([20]). Let the measure be defined by solutions to the SDE
Then the KL divergence can be decomposed in terms of either the forward or reversed diffusion as
where is the time reversal of , and .
Proof.
This theorem follows by a direct application of the disintegration theorem (Appendix B) followed by Girsanov’s theorem. A detailed proof can be found in [20]. □
Using the above decompositions, we can solve the SBP by minimising either decomposition in Equation (4) over the space of random processes that satisfy a valid Itô SDE drift. The backwards and forwards objectives are respectively:
While we do not directly use the stochastic control formulations, the drift-based formulation serves as inspiration for our iterative scheme. Specifically, the existence and parametrisation of an optimal drift as shown in [10,20].
Lemma 3
This Lemma is key in formulating our ML approach to IPFP since it justifies our parametrisation of the drift in terms of a deterministic function i.e., . For a brief introduction to the Schrödinger system and potentials see Appendix A.
2.2. Iterative Proportional Fitting Procedure
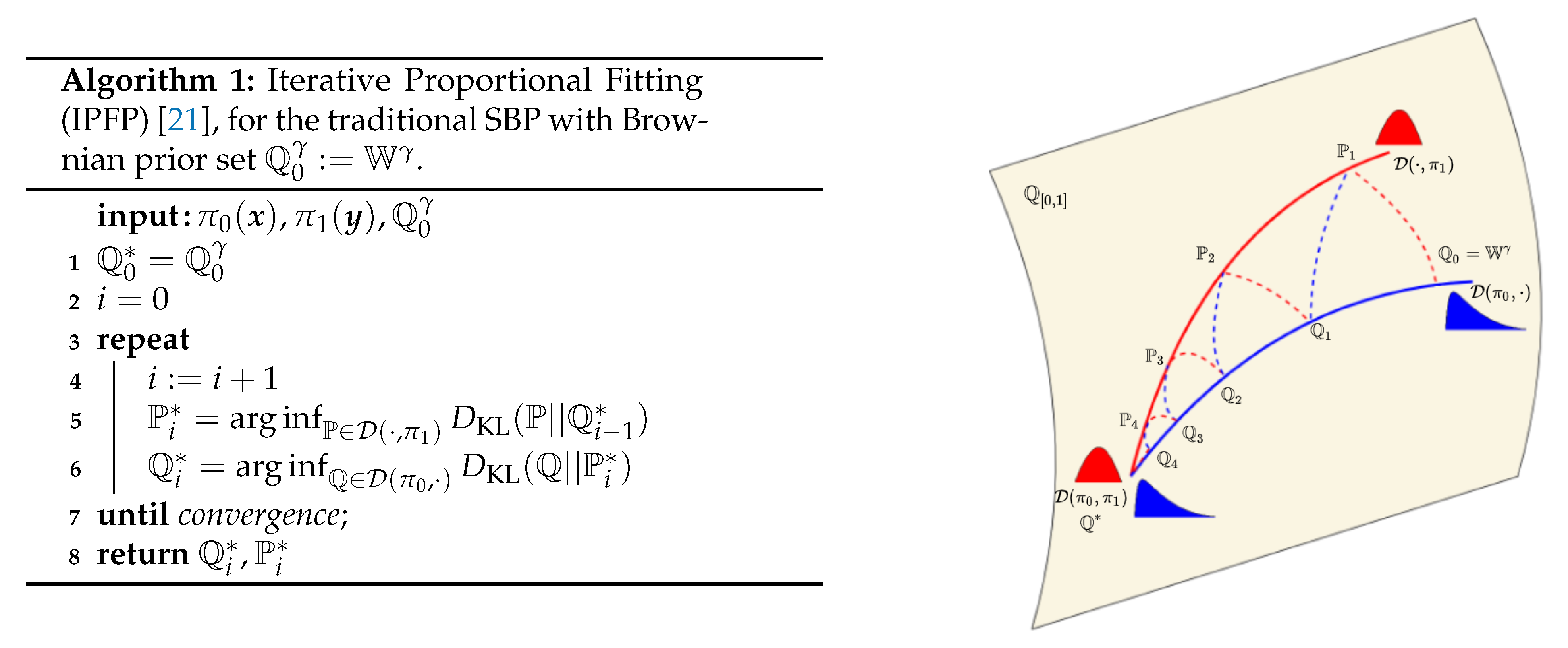
We now have two boundary value constrained diffusion processes solved through a stochastic control formulation. We use the iterative proportional fitting procedure (IPFP) to alternate between the forward and backward formulation with only one initial value constraint enforced at a time (see Figure 2), such that convergence to the full boundary value problem is guaranteed.
The measure theoretic version of IPFP we introduce is an extension of the continuous IPFP, initially proposed by [8] to a more general setting over general probability measures (see [21,22]). The convergence of IPFP has been shown in [9] and further extensions and results have been presented in [21,22]. The idea behind this family of approaches is to alternate minimising KL between the two marginal distribution constraints,
until convergence. The quantities and in the algorithm of Figure 2 are known as half bridges [10] and can be expressed in closed form in terms of known quantities,
where and are the marginals of and at times 1 and 0, respectively. While a closed form expression to estimate half bridges is known, its components are usually not available in closed form and require approximations. Note that the time reversed formulations (Section 2.1.2) and a simpler variant of Lemma 3 also apply to the half bridge problems. Applying the disintegration theorem (see Appendix B) we can reduce the IPFP introduced to the more popular instance of IPFP proposed by [8]. Furthermore for the case of discrete measures this algorithm reduces to the Sinkhorn–Knopp algorithm [3].
3. Methodology
In this section we introduce IPML by providing the theoretical foundations of our algorithm and convergence guarantees. Then, we propose a practical implementation of IPML based on a Bayesian non-parametric model (GP). These components allow us to solve the general SBP problem.
3.1. Approximate Half Bridge Solving as Optimal Drift Estimation
We present a novel approach to approximately solve the empirical Schrödinger bridge problem by exploiting the closed form expressions of the half bridge problem. Rather than parametrising the measures in the half bridge and solving the optimisation numerically, we seek to directly approximate the measure that extremises the half bridge objective. We achieve this by using Gaussian processes [11] to estimate the drift of the trajectories sampled from the optimal half bridge measure.
We start from the following observation, which tells us how to sample from the optimal half bridge distribution (see Appendix C for proof).
Observation 1.
We can parametrise a measure with its drift as either of the SDEs,
Then, we can sample from the solution to the half bridges,
via simulating trajectories (e.g., using the Euler–Maruyama (EM) method) following the SDEs
Solutions to the above SDEs are distributed according to and , respectively.
Intuitively, we are performing a cut-and-paste-styled operation by cutting the dynamics of the shortened (unconstrained) time interval and pasting the constraint to it at the corresponding boundary.
Theorem 1.
(Consistency of Reverse-MLE Formulations) Let be sampled/discretised trajectories from the SDE that represents the half bridge measure :
Then carrying out maximum likelihood estimation of the time reversed drift on time reversed samples:
where is the drift of our estimator SDE:
converges in probability to the to the true dual drift where is the optimal half bridge drift for as (see Appendix D for proof).
Note that w.l.o.g. the above result also holds for estimating the forward drift from backward samples. The combination of Observation 1 and Theorem 1 constitute one the main contributions of this work as they allow us to solve half bridges with a simple regression objective. Finally it is important to highlight that in practice for most interesting SDEs we can only sample approximately using schemes such as the Euler Mayurama (EM) method, for these settings our proof of Theorem 1 does not hold, however we believe it may be possible to extend/adapt the result for the approximate EM sample case.
3.2. On the Need for Time Reversal
We have already provided the intuition as to how time reversal enables the exchange of initial value constraints for final value constraints. In what follows we provide a more detailed technical review of this important simplification. Consider the first half bridge problem for a given IPFP iteration, . When formulated without time reversal in terms of the forward drift and the forward diffusion it reduces to a stochastic control problem which is subject to dynamics,
which is a forward SDE with a terminal hitting condition. Unlike a forward SDE with an initial value problem the above SDE is not trivial to sample from, one approach would be to solve the backwards Kolmogorov equation subject to the terminal condition; however, this approach requires (1) solving a parabolic PDE that typically involves mesh-based methods that do not scale well in high dimensions and (2) carrying out density estimation on the samples from , also problematic in high dimensions; however, if we consider the time reversed process, the terminal condition becomes an initial value problem, for which it is easy to sample consistent trajectories via the Euler–Maruyama (EM) discretisation without mesh-based methods or additional density estimations.
3.3. Iterative Proportional Maximum Likelihood (IPML)
Combining the KL minimisation routines in the original IPFP algorithm with our MLE-based drift estimation provides Figure 3. The routine DriftFit fits a dual drift on the EM sampled trajectories, and can be parametrised by any function estimation procedure with consistency guarantees. The SDESolve routine generates M trajectories using the EM method.
Drift Estimation with Gaussian Processes: One can choose any parametric or non parametric model to carry out the DriftFit routine. In this section, we briefly introduce our implementation. Our DriftFit routine is based on the work in [12,23] that uses GPs to estimate the drift of SDEs from observations. We refer to this routine as GPDriftFit. We can restate the regression problems given by Equation (8) and its reversed counterpart in the following form:
where . Placing GP priors on the drift functions and , we arrive at standard multi-output GP formulation. Following [12,24], we assume the dimensions of the drift function are independent (assuming that the drift dimensions are decoupled is the least restrictive assumption as coupling them would impose a form of regularization). (equivalent to imposing a block-diagonal kernel matrix on a multi-output GP) and thus we fit a separate GP for each dimension. See Appendix E.1 for the specification of the predictive means.
Similar to [12,23], we are not making use of the predictive variances (using the predictive mean as an estimate for the drift can also be interpreted as a form of kernel ridge regression under the empirical risk minimisation framework). Instead, we simply use the predictive mean as an estimate of the drift and subsequently use that estimate to perform the EM method, thus effectively we could interpret this approach as a form of kernel ridge regression under the empirical risk minimisation framework.
Note that the advantage of the Bayesian GP interpretation of this procedure is that the GP posterior under certain conditions is naturally conjugate to the posterior of the SDE drift when modelled with a GP prior [23,25]. Furthermore, the Bayesian non-parametric formulation allows for the encoding of the prior drift function as the mean function of the GP prior (i.e., ). This becomes helpful when trying to sample unlikely paths and evaluating the fitted drift at samples that were not observed by the GP during training, here we want the fitted drift to fall back to the prior rather than to a Brownian motion given by a GP prior with 0 mean.
We now have the relevant ingredients to carry out IPML as specified in Figure 3. The computational cost of IPML with a Gaussian process is detailed in Appendix H.5. The majority of the computation is spent fitting the GP in DriftFit at each iteration and scales as a function of the time discretization used as well as the size of and .
4. Related Methodology
In this section we carry out a conceptual comparison with two pre-existing numerical approaches for solving the static SBP. While our goal is to solve the dynamic SBP, the solution of the static SBP can be used to construct that of the dynamic SBP [10], and this connection is central to our discussion. We would also like to highlight that an algorithm akin to IPML has been proposed concurrently and independently by [26], the main difference with our algorithm is that they estimate the drifts of the SDEs using neural networks score matching while we use using Gaussian processes and maximum-likelihood-based ideas.
4.1. Sinkhorn–Knop Algorithms
Within the machine learning community the static SBP with a Brownian motion prior is popularly known as entropic optimal transport [4]. In this formulation there are no trajectories and the empirical distributions are treated as discrete measures and thus the objective is given by , where h is the discrete entropy, computes the dot product between two matrices. The cost matrix C corresponds to the log transition density induced by the prior SDE: , which in the case of a Brownian motion prior reduces to a scaled Euclidean distance.
Once the problem has been discretized as described, the Sinkhorn–Knopp algorithm [3] can be applied directly to fit an optimal discrete transport map (and discrete SBP potentials ) between the two distributions. Recent work [6] has showed empirical success in forming a continuous approximation of the SBP potentials using the logsumexp formula [6]; however, it still remains to formally analyse the accuracy of the logsumexp potentials.
Estimating the cost matrix required by the Sinkhorn algorithm requires a mixture of both density estimation and further simulation of the prior. Furthermore, once we have the logsumexp potentials, additional high dimensional integrals must be estimated every time we wish to evaluate the optimal drift. Details are discussed in Appendix F. In addition, the Sinkhorn–Knopp algorithm still faces challenges in high dimensional spaces, specially for small values of [27]. Many proposed enhancements and literature [4,5] have focused on cost functions that implicitly require a Brownian motion prior and thus do not apply to our general setting.
4.2. Data-Driven Schrödinger Bridge (DDSB)
The method proposed by [10] is perhaps the most similar approach to our approach and consists of iterating two coupled density estimation objectives (see Appendix G) fitted at the marginals until convergence. While conceptually similar to our approach, there are three key differences. As with Sinkhorn–Knopp-based methods, their approach aims to solve the static SBP. Once converged, it requires further approximation to estimate the optimal drift. The coupled maximum likelihood formulation of the static half bridges in [10] is based on un-normalised density estimation with respect to the SBP potentials . The coupling of in these objectives does not directly admit the application of modern methods in density estimation since it does not allow us to freely parametrise MLE estimators for the boundaries, and thus, neural density estimators such as [28,29,30] cannot be taken advantage of to circumvent the computation of the partition function. Regression problems are ubiquitous in machine learning (ML) and thus why we believe that this formulation can be very impactful as it allows us to leverage all these methods from ML. Experimentally, regression methods have been observed to scale better to high dimensional problems than density estimation methods, we observed similar evidence as we were unable to scale up the DDSB method beyond two dimensions.
Additionally, to compute the normalising term in the DDSB objective, we have to estimate a multidimensional integral that is not taken with respect to a probability distribution. This poses a difficult challenge in high dimensions. For a more detailed commentary, see Appendix G. Note that the method by [20] uses importance sampling to estimate these quantities which performs poorly beyond two dimensions.
It worth noting that we are interested in a method that can obtain a dynamic interpolation between two distributions. A downside of solving the static bridge either by Sinkhorn or [10] is that it does not directly provide us with an estimate of the optimal dynamics. In order to obtain an estimate of the optimal drift we require a series of approximations to estimate the integrals in Equations (A70) and (A71), thus every time we evaluate the optimal drift using these approaches we have to simulate the prior SDE times. This makes the runtime of obtaining the drift and dynamical interpolation expensive, since for each Euler step we take we have to simulate another SDE and backpropagate through it to evaluate the drift.
5. Numerical Experiments
In this section, we demonstrate the capability of IPML to solve the Schrödinger bridge while efficiently incorporating priors on a range of different tasks from synthetic experiments to embryo cells (code supporting experiments can be found at https://github.com/franciscovargas/GP_Sinkhorn, accessed on 22 August 2021).
5.1. Simple 1D and 2D Distribution Alignment
The first experiment considered is a simple alignment experiment where and are either unimodal or bimodal Gaussian distributions (see Appendix H.1 for exact details on the distributions). In Table 1 we compare the accuracy of the fitted marginals with our implementation of the Data-Driven Schrödinger Bridge (DDSB) by [10]. The scoring metrics used are the Earth mover’s distance (EMD) as well as a Kolmogorov–Smirnov (KS) statistic on both sample sets.
We were unable to get DDSB to work well when and were distant from each other. In these distant settings, DDSB collapses the mass of the marginals to a single data point (see Appendix H.1.1), as a result for the unimodal experiment we had to set for the DDSB approach to yield sensible results. We can observe IPML obtains better marginals overall and at a lower value of .
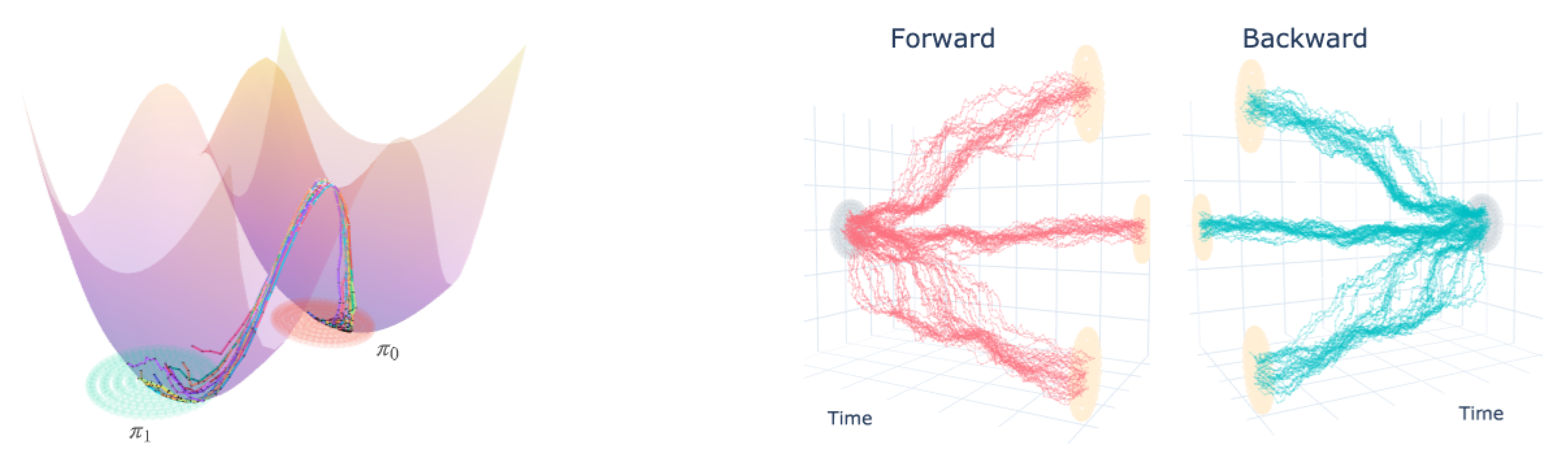
We carried out 2D experiments with our approach to show the ability of our method to diffuse from a simple uni-modal distribution to a multi-modal distribution as in Figure 1 where our learned bridge successfully splits. Furthermore, we can visually observe how the forward and backwards trajectories are mirror images of each other as expected.
5.2. 2D Double Well Experiments
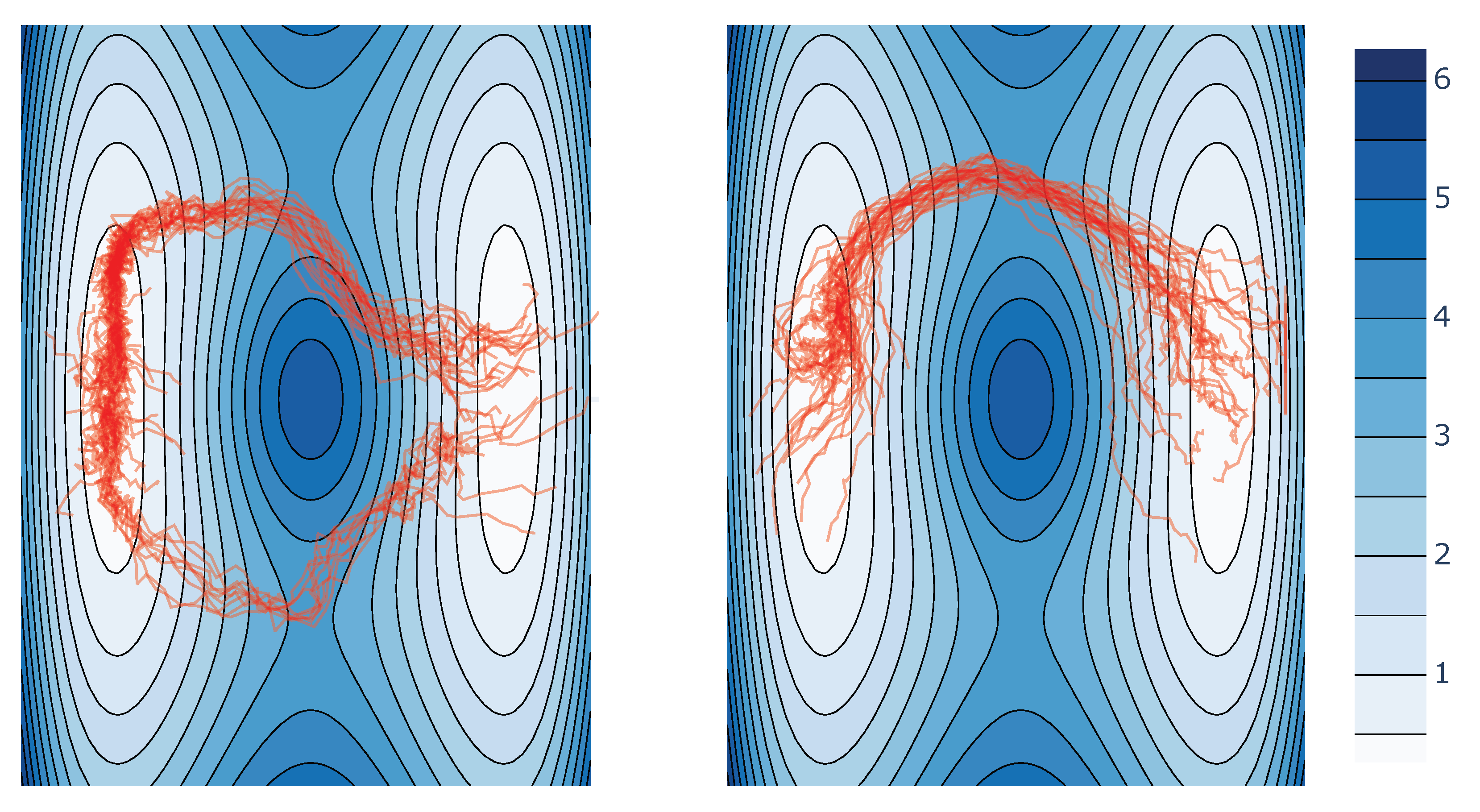
In the double well experiment, we illustrate how to incorporate an arbitrary functional prior and learn the distribution over paths connecting and . In order to encode prior information, we experiment with the potential well illustrated in Figure 1 and Figure A3. The boundary distributions are taken to be Gaussian distributions centred at the centre of each well, respectively (See Appendix H.2 for the experiment specification and IPML parameters).
The motivation behind this experiment is to show that the SBP with this prior follows low energy (according to the well’s potential function) trajectories for configurations of particles sampled at the wells. Intuitively, we can expect the learned trajectories to avoid the high energy peak located at and go via the “passes” on either side. Note that if we estimated the optimal transport (OT) geodesics between and or similarly ran IPML with a Brownian motion prior, the learned optimal trajectories would go right through the middle, which is the highest energy path between both wells.
The prior is incorporated in the algorithm in two different ways, (1) by having the first drift to follow the negative derivative of the potential function and (2) by setting the mean function of the GP used to fit the drift as the negative derivative of the potential function. As illustrated in Figure 1, the learned trajectories between the two wells avoid the main high energy region and go through via lower energy passes, thus respecting the potential prior; however, the behaviour of the trajectory will differ depending on the choice of kernel, as illustrated in Figure A3, underlying the need for its careful consideration. We compared our approach to DDSB using the mean squared error distance to the prior in our evaluation. The results were DDSB: 22.1, IPML (no prior): 19.9, IPML: (prior) 18.7. As we can see, IPML considerably outperforms DDSB.
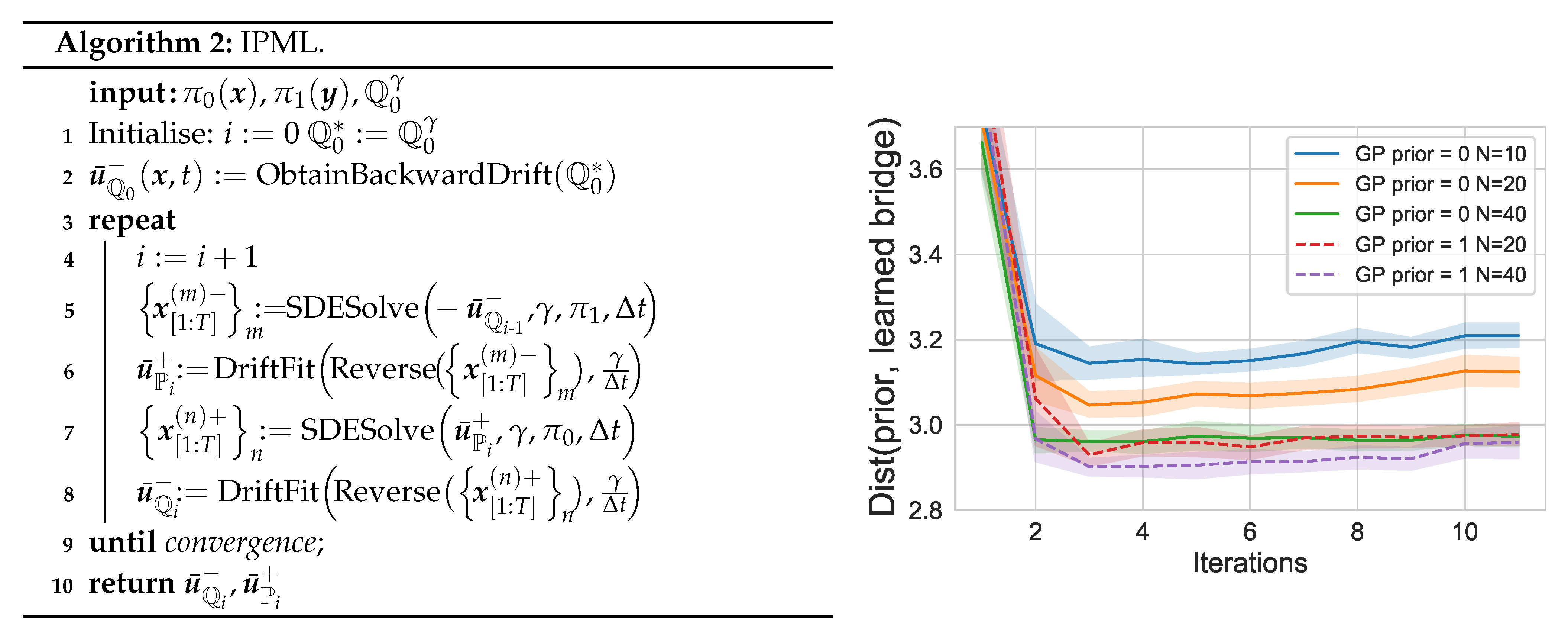
5.3. Finite Sample/Iteration Convergence
Theorem 1 provides us with asymptotic guarantees; however, it does not extend to the finite sample and discretisation case. To highlight the importance of finite effects on IPML, we carried out this analysis empirically. In Figure 3 we plot an empirical estimate of the error term in the control formulation of the SB (Equation (5)). This term is effectively the mean squared error between the learned drift and the prior drift (gradient field of the well). We analyse this metric for different values of N (number of samples) and (discretization factor). We observe that IPML quickly reaches a low error valley, then, the cumulative error from the successive finite sample MLE can be observed and the drift starts to slowly deviate from the prior, this motivates early stopping. As N is increased, IPML achieves lower error faster and deviates less from the prior in later iterations. Finally, we observe placing the drift prior via the GP has a significant effect in improving the error and its convergence. Additionally in Appendix E we detail how this question could be approached from a theoretical perspective while underlining its significance and difficulty as illustrated by the lack of such analyses in related algorithms [10,22].
5.4. Single Cell—Embryo Body (EB) Data Set
We perform an experiment on an embryoid body scRNA-seq time course [34]. Single-cell RNA sequencing enables accurate identification of cells at specific time points; however, all cells are destroyed by measurement. This prevents modelling single-cell trajectory and instead we rely on modelling the data-manifold at discrete time points. The datasets consist of 5 time points illustrated in Figure A4. To evaluate the performance of the algorithms, we fit the models at the endpoints () and predict the intermediate frames. The metric used is the Earth mover’s distance between the data at intermediate frames and the predicted distribution. We evaluate the performance at the endpoints by considering the prediction of the forward model at and the backward model at .
We compare the performance with two methods. The first one, TrajectoryNet [34], uses continuous normalising flows with a soft constraint based on optimal transport. The second leverages the McCann interpolant [35,36] to interpolate the discrete OT solution; this corresponds to the linear interpolation induced by the transport map.
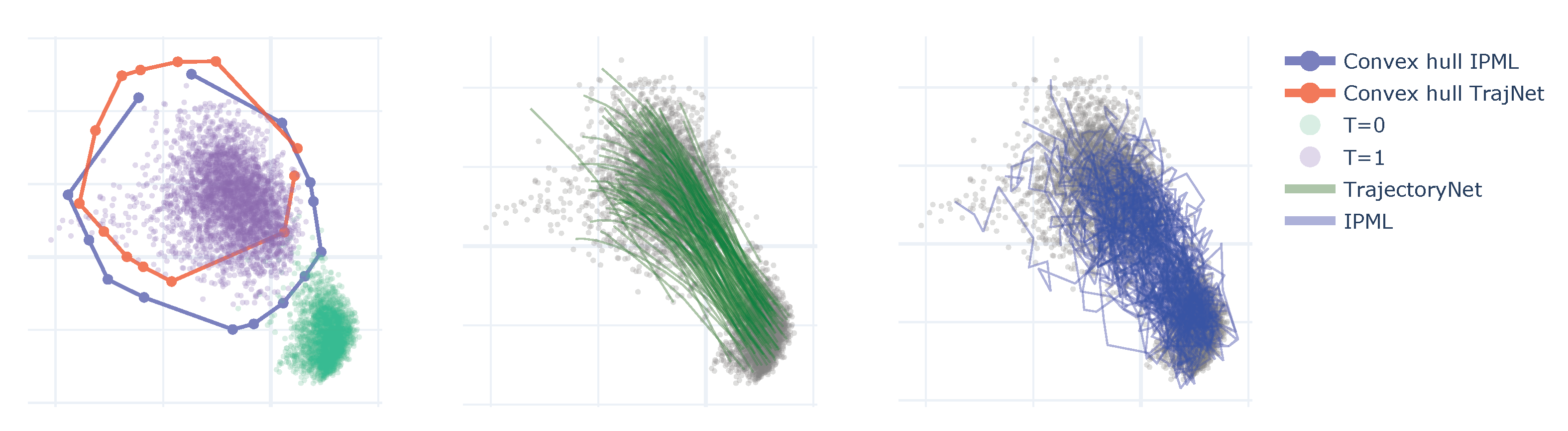
The results are summarised in Table 2. In most frames, IPML outperforms TrajectoryNet and performs similarly to OT. As the noise (volatility) in the trajectories goes to 0, IPML theoretically converges to the OT solution with linear geodesics. So without any additional prior information, we would not expect IPML to outperform OT; however, when dealing with finite data, the DriftFit procedure allows for some non-linearity in the trajectories if it improves the fit. As a result, we do see some differences in the convex hull displayed in Figure 4 where we observe a better coverage of the single cell observations. We hypothesize this explains the improvement in performance vs. OT for frame 4. The performance of IPML may be further improved by incorporating domain-specific knowledge as a prior. It would outperform OT in those settings.
5.5. Motion Capture
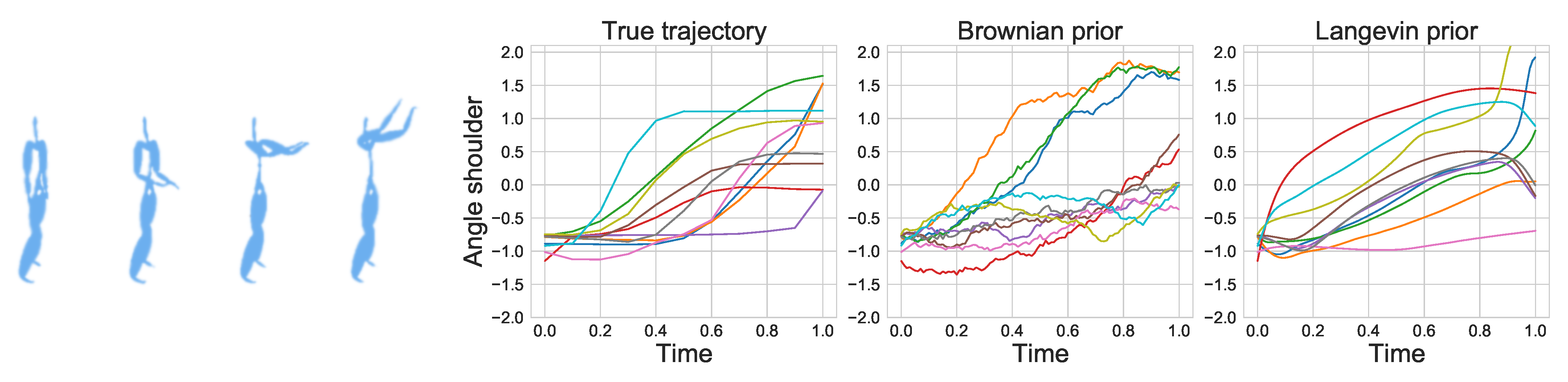
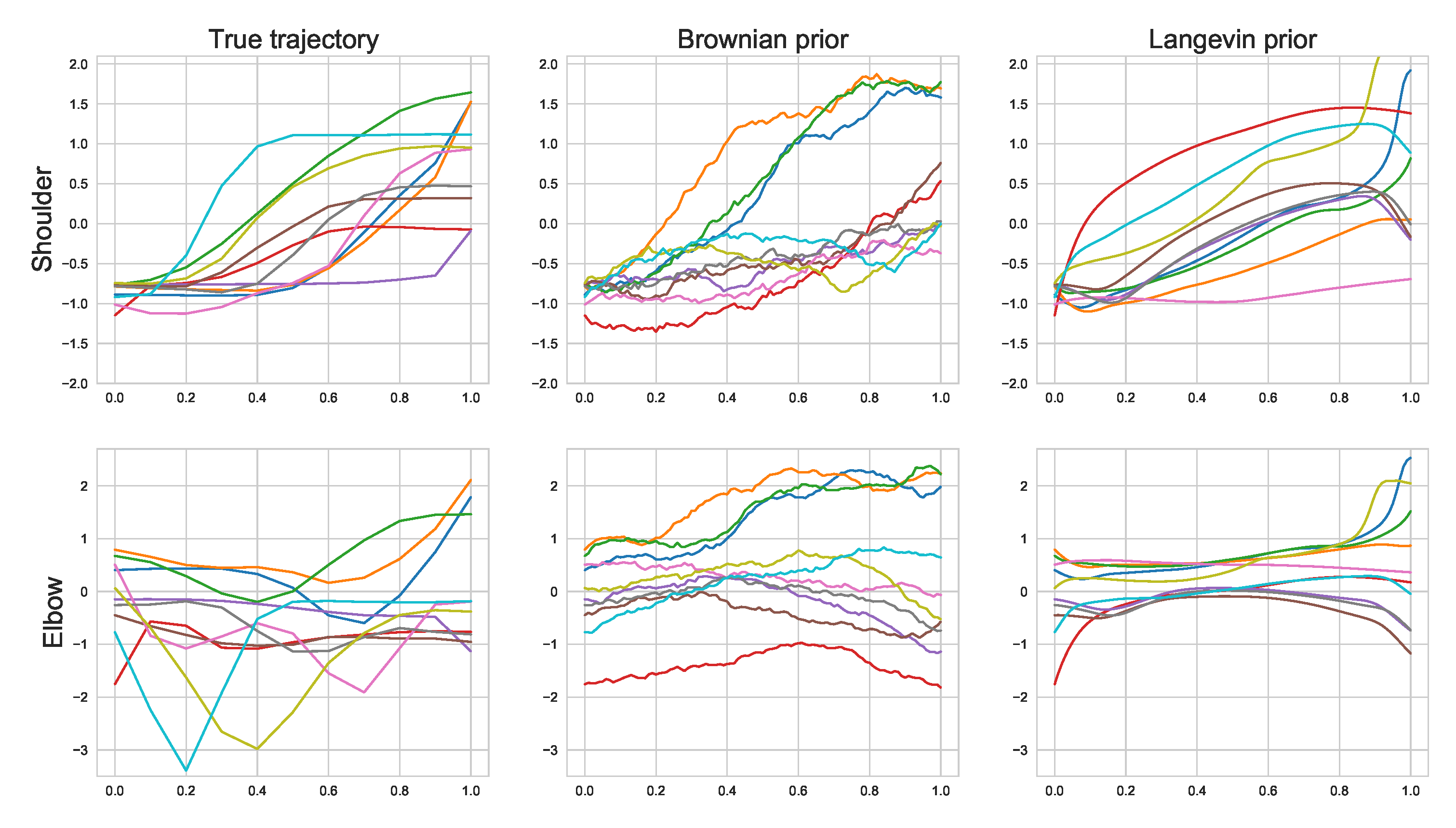
In this experiment, we demonstrate how IPML can be used to model human motion from sensor data (data from The CMU Graphics Lab Motion Capture Database funded by the NSF (http://mocap.cs.cmu.edu, accessed on 22 August 2021)). The motion corresponds to a basketball movement where the subject raises both arms simultaneously as illustrated in Figure 5 and each sensor corresponds to an oriented angle. We focus on modelling the right shoulder and elbow where the starting distribution corresponds to the leftmost image and the ending one the rightmost. This results in a 4-dimensional space as we model both position and velocity for each sensor. We compare the fit of IPML using a Brownian and a 2nd order linear ODE (Langevin) prior. The experimental details can be found in Appendix H.3. As illustrated in Figure 5, IPML is able to approximately model the dynamics using both priors. The Brownian prior displays noisy trajectories as expected in contrast to the Langevin prior that, by construction, smooths out the predicted positions (due to the 2nd order term). We observe that the Langevin prior approximates the step function nature of the true trajectory more closely than the Brownian prior, additionally, we can see that it also produces slightly better alignments.
6. Limitations and Opportunities
In this work, we propose to use GPs to estimate the drift; however, IPML could also be used with a parametric function estimator (e.g., a neural network). This could be useful with high-dimensional data where GPs may underperform. The main advantage of using a GP is its capacity to incorporate functional priors via the mean function. This can be useful in applications such as molecular dynamics where a potential function may be available. In contrast, implementing functional regularization in a neural network would require approximating a non-trivial high-dimensional integral to estimate the mean squared error between the parametric estimator and the functional prior.
A particular useful extension would be to adapt the SBP to work with more general forms of volatility functions that are not constant. This can be used, for example, in enforcing positivity constraints on a stochastic process via a geometric Brownian motion prior; this has applications in modelling biological signals such as transcription factors [37]. Work in this direction would require extending the theory of SBPs to non constant volatility functions.
Another promising setting is when multiple frames of data are available rather than just two boundary conditions. The IPFP algorithm trivially adapts to multiple constraints [21] rather than just initial and terminal distributions. Future work could explore experiments similar to the one presented in [34] where multiple frames are considered during training and the performance is measured using a leave-one-out procedure.
7. Conclusions
We have presented IPML, a method to solve the Schrödinger bridge for arbitrary diffusion priors. We presented theoretical results guaranteeing convergence in the limit of infinite data. We devised a practical application of the algorithm using Gaussian processes and presented several experiments on a variety of problems from synthetic to biological data. The approach opens up opportunities in science, where oftentimes, prior knowledge about the temporal evolution of a process has been developed but needs to be combined with data-driven methods to scale up to modern problems.
Author Contributions
Conceptualization, F.V., N.L. and A.L.; methodology, F.V. and P.T.; software, F.V. and P.T.; validation, P.T. and F.V.; formal analysis, F.V., P.T. and A.L.; investigation, F.V. and P.T.; resources, N.L.; data curation, F.V. and P.T.; writing—original draft preparation, F.V., P.T., N.L. and A.L.; writing—review and editing, F.V., P.T., N.L. and A.L.; visualization, P.T. and F.V.; supervision, N.L. and A.L.; project administration, N.L.; funding acquisition, N.L. All authors have read and agreed to the published version of the manuscript.
Funding
Francisco Vargas is Funded by Huawei Technologies Co. Pierre Thodoroff was funded by the Engineering and Physical Sciences Research Council (EPSRC) grant number EP/T517847/1. Neil Lawrence is funded by an Alan Turing Institute Senior Artificial Intelligence Fellowship.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analysed in this study. These datasets can be found here: Motion Capture Dataset: http://mocap.cs.cmu.edu. Mission statement for dataset: http://mocap.cs.cmu.edu/info.php. Instructions to download EB single cell dataset can be found at https://nbviewer.jupyter.org/github/KrishnaswamyLab/PHATE/blob/master/Python/tutorial/EmbryoidBody.ipynb. The dataset itself can be found at https://data.mendeley.com/datasets/v6n743h5ng/1. All websites were accessed on 22 August 2021.
Conflicts of Interest
The authors declare no conflict of interest.
Assumptions Across Proofs
For abstraction purposes we will list the set of assumptions assumed across all results in this appendix:
- All SDEs considered have –Lipchitz diffusion coefficients as well as satisfying linear growth
- The optimal drifts are elements of a compact space and thus satisfy the HJB equations. Note for the proposes of Theorem 1 this can be relaxed using notions of –convergence,
- All SDEs satisfy a Fokker–Plank equation and thus is differentiable with respect to ,
- The boundary distributions are bounded in that is .
Appendix A. Brief Introduction to the Schrödinger System and Potentials
The Schrödinger system and its potentials are mentioned when introducing some of the results and connections of the full Schrödinger bridge problem. In this section, we will provide a brief introduction to how the system arises from the original static Schrödinger bridge. For brevity we will use and to denote the boundaries.
The static Schrödinger bridge problem can be derived from the full dynamic bridge by marginalising out the dynamics via the Disintegration Theorem and focusing on the problem only concerning what is happening at the boundaries. The static SBP is formulated as:
where is the prior joint distribution for the boundary and can be obtained by solving the FPK equation corresponding to the prior SDE. Now if we write down the Lagrangian for the above problem we arrive at:
which via performing the appropriate variations wrt to q leads to the optimal solution:
which when relabeling the terms containing the Lagrange multipliers we obtain:
such that:
Furthermore, if we relabel the potentials to indicate the times they correspond to we arrive at the Schrödinger system:
where
The above functional system is refered to as the Schrödinger system and the Schrödinger potentials are given by . Furthermore the time interpolates for the potentials can be obtained by the propagations:
For a more rigorous and extensive introduction please see [20].
Appendix B. Disintegration Theorem—Product Rule for Measures
In this section, we present the Disintegration Theorem in the context of probability measures, which serves as the extension of the product rule to measures that do not admit the traditional product rule. Furthermore we will provide a proof for a direct lemma of the Disintegration Theorem that is more analogous to the standard product rule. Similar to the product rule these theorems are essential for decomposing and manipulating path measures and thus is needed for most results pertaining to the dynamic SBP.
Theorem A1.
(Disintegration Theorem for continuous probability measures):
For a probability space , where Z is a product space: and
- ,
- is a measurable function known as the canonical projection operator (i.e., and ),
there exists a measure , such that
where is a probability measure, typically referred to as a push-forward measure, and corresponds to the marginal distribution.
A direct consequence of the above instance of the disintegration theorem is, with ,
We can see that, in the context of probability measures, the above is effectively analogous to the product rule.
RN Derivative Disintegration
We now have the required ingredients to show the following:
Lemma A1.
(RN-derivative product rule) Given two probability measures defined on the same product space, and , the Radon–Nikodym derivative can be decomposed as
Proof.
Note that this is an instructive sketch for a well known result [10,20,38,39]. We assume that , which is not a trivial fact, yet it follows from the disintegration theorem in this particular setting (see Theorem 1.6 b in [39]). Starting from
we apply the Radon–Nikodym theorem to and then to :
Now, via the disintegration we have that
Thus, we conclude that
which, via the Radon–Nikodym theorem, implies
Note that swapping for the Lebesgue measure would result in the standard product rule for probability density functions. □
Appendix C. Proof Sketches for Half Bridges
In this section we provide a proof sketch for the closed form solution of the half bridges as well as a proof for Observation 1.
Theorem A2.
The forward half bridge admits the following solution:
Proof.
Via the disintegration theorem, we have the following decomposition of KL:
Thus, via matching terms accordingly, we can construct by setting and matching the constraints:
□
Observation A1.
We can parametrise a measure with its drift as the solution to either of the following SDEs:
Then, we can sample from the solution to the following half bridges:
via simulating trajectories following the SDEs
Paths sampled from the above SDEs will be distributed according to and , respectively.
Proof.
(Sketch) W.l.o.g., consider the decomposition of the KL divergence that follows from the disintegration Theorem (Appendix B):
Furthermore, the disintegration is a solution to the dynamics . We can make the term go to 0 by setting , it is clear the dynamics of follows . What is left is to attach the constraint via which brings to coinciding with the half bridge minima as per [20,22]. This is simply enforcing the constraints via the product rule (Disintegration Theorem) and then matching the remainder of the unconstrained interval with the disintegration for the reference distribution , following Equation (7). □
Appendix D. Proof Sketch for Reverse-MLE Consistency
The proof sketch for Theorem 1 will show how the likelihood converges in the large data and small time step limit to an optimisation of the KL divergence between two reverse time diffusions, from here one can use the standard arguments to show this quantity is minimised when the two measures describe the same stochastic process or equivalently when the drifts are equal.
Lemma A2.
Normalizing the time reversed likelihood with the true discretised backwards SDE density does not affect the maximum likelihood estimate. That is:
Proof.
The term does not depend on and thus is an additive constant. □
Theorem A3.
(Consistency of Reverse-MLE Formulations) Let be sampled/discretised trajectories from the SDE that represents the half bridge measure :
Then carrying out maximum likelihood estimation of the time reversed drift on time reversed samples:
where,
and is the drift of our estimator SDE:
converges in probability to the to the true dual drift where is the optimal half bridge drift for as . Under the assumptions:
- The density is differentiable with respect to ,
- The optimal drift lies in a compact space (this can be relaxed using notions of –convergence),
- The prior drift coefficient is –Lipchitz and satisfies linear growth.
Proof.
For the interest of brevity let . Taking logs and applying Lemma A2 to Equation (A19) yields:
where represents the terminal distribution of the forward SDE (i.e., ). Now we can equivalently write the above expression in terms of the time reversed samples (i.e., ):
Expanding the squares and re-arranging:
where . Now we can consider the limit of Equation (A25):
We can write the sum over the time grid as a stochastic integral if we express the inner terms using the continuous time approximation from Lemma A3:
From [15,16,18] it follows that is a semi-martingale (w.r.t. to the backwards filtration, see [17,40]) then in the limit the stochastic integrals are taken with respect to the true time reversed stochastic process adapted to the backwards filtration (see Theorem 2.13 in [41]):
now we have:
where by Lemma A3 each random function is sampled i.i.d from the SDE:
we can now apply the weak law of large numbers (WLLN):
Now using that the log RN derivative between the estimator SDE and the true SDE is given by Girsanov’s theorem [20,42,43]:
we arrive at:
Thus using to denote the negative normalized log-likelihood we have shown the following pointwise (i.e., for ) convergence in probability:
Then if , is compact plus additional continuity and boundedness assumptions on a stronger form of uniform convergence in probability can be attained:
from the above it directly follows that:
where is the MLE estimate of the dual drift at N samples. Which implies:
See Chapter 4.5 of [44] for a more detailed discussion on the required assumptions of . □
Extending Theorem 1 to EM Samples
Note that the above proof holds for discretised samples from the original SDE, however we have been unable to extend it to approximate sampling schemes such as EM. We believe that the following result motivates the possibility that Theorem 1 holds when the samples are obtained from a consistent scheme such as EM:
Lemma A3.
(Convergence of discrete time reversal) The time reversal of discrete Euler-Mayurama samples:
converges in probability to the solutions of the time reversed diffusion:
where .
Proof.
First let’s consider the continuous time step-wise approximation induced by the the EM samples:
From [45] it is a well known result that under the standard regularity assumptions on the drift (i.e., Lipchitz continuity in t and and ) that the above approximation converges in probability to the SDE solution as .
Observing that that the time reversal of the above corresponds to the approximation induced by the reverse samples we now consider the continuous time reversed approximation:
Using converges in probability to we have that :
we carry out the following substitution then :
□
Now it requires to be proved that is a semi-martingale which may follow from Lemma A3 as . Another potential proof strategy would be to try and exploit the strong convergence properties of the Euler scheme to show that the stochastic integral from Theorem 1 also converges in the case of Euler samples. It may be the case that a correction term needs to be introduced in order for the integrals built from the reversed EM sample to converge to the backwards integrals. This remains an interesting question for future work.
Appendix E. Towards a Finite Sample Analysis of Approximate IPFP Schemes
We use the term approximate IPFP schemes for methodologies such as the one we present in this paper (i.e., IPML) where steps 5, 6 of IPFP algorithm (Figure 2) are replaced with inexact approximations. In this section we will present a rough sketch that takes the first step towards formally analysing approximate IPFP schemes in the finite sample/discretisation regime. This will serve to illustrate many of the challenges that still remain in this analysis as well as provide some initial results.
Conjecture A1.
(Heuristic Finite Sample Bound)
Given that:
- The exact IPFP at the ith iteration can be bounded from above as:
- The approximate IPFP projection operators are –Lipchitz
- and the approximate finite sample projection error can be bounded by a constant:
Proof.
(Sketch) For notational simplicity we will relabel the half bridges in the algorithm of Figure 2 as projection operators in a function space . This leads to the following iterates:
For the approximate IPFP we have the iterates:
Furthermore, to simplify the analysis further we will consider the composition of the two projection operators (i.e., ) combined into a single operator (for both exact and approximate projections):
We will now proceed to bound the error:
From the assumptions it follows that:
yielding:
Now we will proceed to analyse the first term:
Now we can expand the recurrence until the first iteration, yielding:
When we attain the bound:
When the projection operator is non expansive this gives the bound:
□
Note that the above sketch is more of a strategy to outline the challenges and steps required for this analysis rather than a proof itself. We believe that the formal finite sample analysis on approximate IPFP schemes merits its own separate work and is thus not the focus of this work; however, in order to highlight its importance we have provided a template towards this formal analysis following a strategy similar to [46]. This analysis allows us to understand what conditions are needed to be shown and how they will affect the finite sample convergence rates.
We will now proceed to discuss each of the assumptions that are required as elements of the above analysis strategy.
Assumption A1.
The exact IPFP at the ith iteration can be bounded from above as:
This assumption/conjecture is somewhat reasonable since Proposition 2.1 in [22] proves formally that the sum of the KL errors of the ith marginals are bounded by , furthermore via the disintegration theorem one can show that the half bridge error terms are in fact bounded by the sum of the error of the ith marginals [20]. Thus it seems feasible to extend the result in [22] to the path error we use in our conjecture.
Assumption A2.
The approximate IPFP projection operators are –Lipchitz. Specifically we are interested in the cases where they may be non-expansive and contractive.
This assumption is specific to the approximation method used to estimate the half bridges. It requires going into rigorous details on the nature of the approximation and imposing suitable regularity assumptions. Not that ideally we want the operator to be contractive or at the very least not expansive since for Lipchitz constants greater than one the cumulative error would potentially accumulate exponentially.
It is interesting to note that in the contractive case we can attain the bound:
where the error term is constant with respect to the iteration number. Additionally the bound in Equation (A48) also trivially applies.
Assumption A3.
The approximate finite sample projection error can be bounded by a constant:
This should typically be something that one shows; however, as seen in [46], it is something that is often assumed in these proof strategies. The reason for assuming the result is that the projection varies depending on how we approximate the KL minimisation, in our case we combine our proposed IPML with drift estimation via Gaussian processes. The error of the drift estimation (i.e., ) via this approach is not straightforward to obtain and is still an area of active research see [23,25] for more details. As mentioned earlier this is not the focus of our work thus it is reasonable for us to assume that the drift estimation machinery proposed by prior authors is sound and should be possible to bound with a reasonable error.
Appendix E.1. GPDriftFit Implementation Details
In this section we provide the closed form predictive formulas used by our method to estimate the drift. Our GP formulation for the half bridge approximations yield the following mean per dimension d estimates of the drift:
where
where ⊕ is the concatenation operator, vec is the standard vectorisation operator, and is a valid kernel function.
Appendix E.2. Coupled vs. Decoupled Drift Estimators
A careful reader may enquire if the decoupled drift parametrisation we have used imposes any limitations on the generality of the drifts that our method can estimate in contrast to an approach that couples/correlates drift dimensions. While it may seem counter-intuitive, correlating the GP outputs (i.e., coupling the drift dimensions) is more restrictive than the decoupled approach we have taken. This point is discussed and motivated in [47,48], where it is illustrated that the coupling of the drift outputs correspond to regularising the RKHS hypothesis space. So in fact the decoupled approach we take in this work is more flexible (less limited) than coupling the drift outputs as discussed in [47,48]. It is important to note that the regularisation effects of coupling may be desirable in certain physical systems where we wish to impose a constraint; however, this would come at a large computational cost. Finally note that our method parametrises the drift with a function that depends on all dimensions of the dynamical process , that is each drift coordinate depends on the entire input space and thus no simplifying assumptions have been made in this setting.
Appendix F. Estimates Required by the Sinkhorn–Knop Algorithm
In order to adapt the Sinkhorn–Knop algorithm to a general prior we require the following considerations:
- The Sinkhorn–Knop algorithm requires computing the cost . For more general SDE priors whose transition densities are not available in closed form can be challenging:
- –
- First we have to estimate the empirical distribution for by generating multiple samples from the priors SDE for each in the dataset:
- –
- Once we have samples we must carry out density estimation for each j in order to evaluate .
- The Sinkhorn–Knop algorithm produces discrete potentials, which can be interpolated using the logsumexp formula; however, how do we go from these static potentials to time dependant trajectories?
- –
- From [10] we can obtain expressions for the optimal drift as a function of the time extended potentials:The first integral can be approximated using the Montecarlo approximation via sampling from the prior SDE to draw samples from ; however, computing the potential integral is less clear and requires careful thought.
- –
- Note that in order to estimate the drift we would have to simulate the SDE prior every time we want to evaluate the drift, which itself will be run in another SDE simulation to generate optimal trajectories.
Appendix G. Approximations Required by DDSB
The approach in [10] iterates the following two objectives.
and
where are parametric functions aimed at estimating the potentials, and:
Note that in Equation (A74) the outer most integral is not taken with respect to a probability distribution and thus does not admit standard approximations. The authors in [10] propose the method of importance sampling [49]; however, this does not scale well to higher dimensions. This is contrasting to our approach where all integrals are expectations with respect to the empirical distribution and the SDEs being fitted.
Figure A1.
Unimodal experiment on the left and bimodal on the right.

Appendix H. Experiments
In this section we provide in depth details regarding the parameter configurations of our approach plus our experimental setup. For all the experiments below, unless stated otherwise, we used the exponential kernel with a lengthscale set at the default value of 1. We ran IPML for 5 iterations with a discretization factor and . The iteration number (5) was selected by observing that the algorithm converged after that number in all experiments considered.
Appendix H.1. 1D Experiment
The prior in IPM (the practical implementation of will be added in the main paper during the revision period) is specified by a prior drift and an initial value distribution . We set and the prior to a Brownian motion unless stated otherwise. The initial value distribution does not affect the argmax of the SBP and is thus a free parameter. Note that is used in practice to estimate the backwards drift of the prior before entering the IPFP loop by first sampling from using the SDESolve subroutine. It is possible to encourage more exploration of the space by increasing the variance of .
For the unimodal boundary distributions we used:
and for the bimodal experiment we used:
Appendix H.1.1. Delta Collapse in DDSB
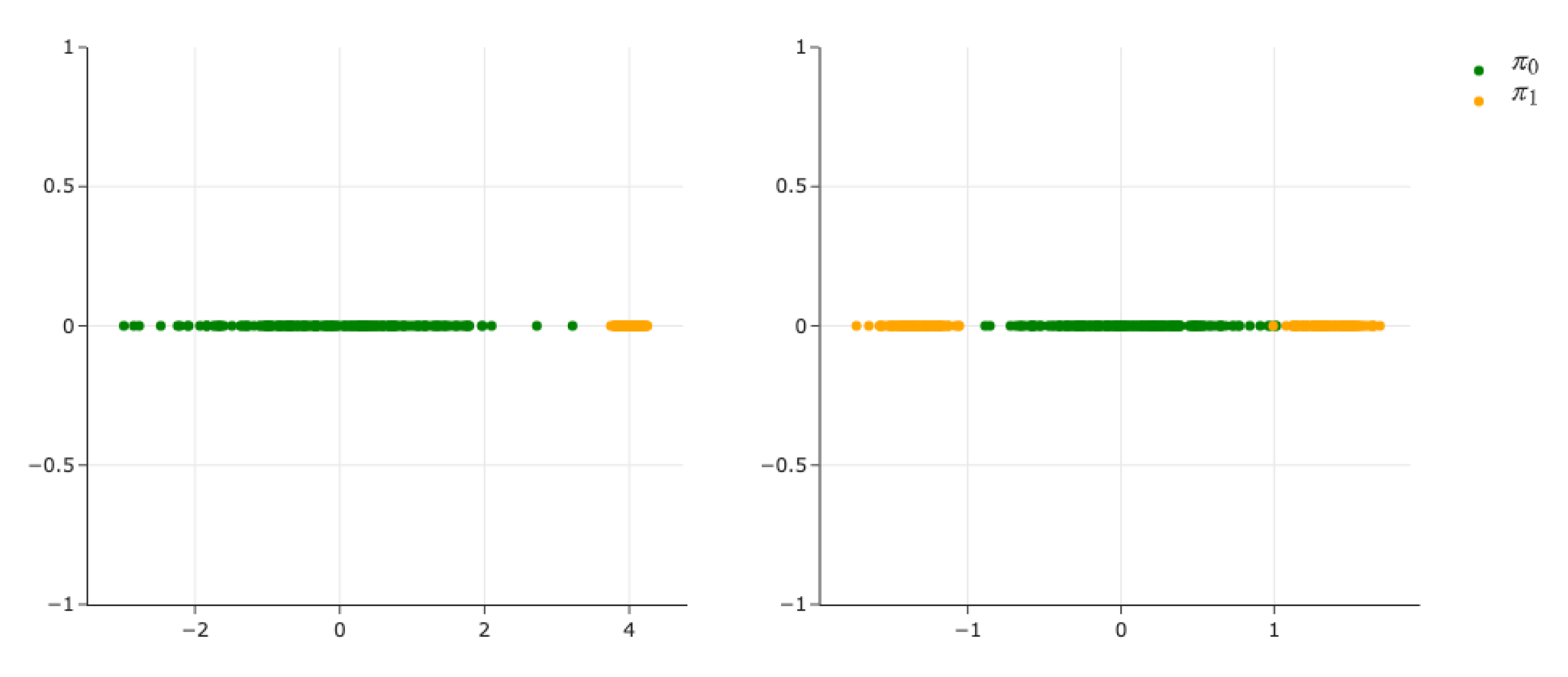
Here we will illustrate a common failure case of the approach in [10]. That is when the distributions and are distant from each other the methodology proposed in [10] breaks for suitable values of γ (i.e., ). Using the same marginals as in Experiment 1 we re-train the method by [10] with . In Figure A2 we can see the results of this experiment. We can see the marginals learned by DDSB collapse all the mass in a very small low density region for the true marginals. We found this phenomena to occur often and harder to overcome in 2-dimensional experiments and thus did not pursue further comparisons with this method. Note we normalised the delta spike of the DDSB marginals to have a range in so we could compare to the true density, its actual value is on the order of , which confirms that the model is collapsing to a point mass (dirac delta function).
Figure A2.
Schrödinger Bridge results using the method by [10] on unimodal to bimodal Gaussian 1D data. This example illustrates the Dirac delta collapse of the marginals.
Figure A2.
Schrödinger Bridge results using the method by [10] on unimodal to bimodal Gaussian 1D data. This example illustrates the Dirac delta collapse of the marginals.

Appendix H.2. Well Experiment
We used the following potential to model the double wells:
furthermore, we used the boundary distributions:
where we selected the boundary distributions to be located at the wells and visually follow a similar spread/curvature as the contour of the well. For these experiments we use . As highlighted previously is a free parameter, which in this section we set as:
we select this as the marginal prior since its samples cover the space over which the wells is defined well, and helps estimate the backwards drift of the prior more accurately. As mentioned in the paper, using different kernels as well as lengthscales resulted in slightly different behaviour on the well experiment where the trajectory would not split as illustrated in Figure A3. The splitting pattern was obtained using an exponential kernel with a lower lengthscale () underlying the need for careful consideration of the kernel and its parameters.
Figure A3.
IPML forward trajectories on potential well. Exponentiated kernel on the left and exponential quadratic on the right.
Figure A3.
IPML forward trajectories on potential well. Exponentiated kernel on the left and exponential quadratic on the right.

Discussion on Kernel Choice
We can observe that when using EQ kernel, the trajectories do not cross both passes but instead choose one. We conjecture that this is due to the fitted predictive means having a preference for simpler functions that send nearby particles in the same direction. We empirically verify this conjecture by experimenting with alternative kernels to EQ (i.e., exponential) that model a wider class of functions. We believe that these alternative kernels are less prone to discouraging splitting since, when viewed within the kernel ridge regression framework, they span an RKHS of functions that do not have the smoothness constraint of the EQ kernel.
The data used for this experiment were taken directly from the GitHub repository published by [34]. PCA is first applied to the data and the first five components are selected. We used the code available at https://github.com/KrishnaswamyLab/TrajectoryNet/tree/master/TrajectoryNet (accessed on 22 August 2021) to reproduce the performance of TrajectoryNet as well as the optimal transport baseline.
Appendix H.3. Motion Experiment
For this experiment we use a second order SDE prior (i.e., Langevin dynamics). This can be encoded in first order SDE using the companion/controllable form of a dynamical system:
For simplicity we set the dampening factor β to 0 and . As for the spring matrix we explored the following decoupled and coupled forms:
where k defines the frequency of the solution via in our setting we ignore the mass (imagine is at absorbed in the matrix and work directly with setting ω. Since the movement we select moves from rest to a high position and does not return to its starting point/or repeat itself we set that corresponds to Hz which describes half a revolution. We visually confirmed with the true trajectories that this seems like a reasonable prior.
Figure A4.
Fitted SBP distribution on the start and end data slices with Brownian prior on single-cell human Embryo data from [34]. Observations depicted as red point clouds. See Section 5.3 for experimental details.
Figure A4.
Fitted SBP distribution on the start and end data slices with Brownian prior on single-cell human Embryo data from [34]. Observations depicted as red point clouds. See Section 5.3 for experimental details.

Appendix H.4. Cell Experiment
For the Brownian motion prior that we use as a baseline comparison in Appendix H.3 we explored several values of γ and selected the best performing one (visually) of . Note we do pick a smaller value of γ for the Brownian motion and this is partly to compensate that the Langevin prior trajectories will always look smooth by construction thus we pick a not so noisy Brownian motion that still gives good results.
Note that the volatility term here is singular and in our mocap application setting it is exactly the vector:
where the dimension d is given by the number of sensors we use to fit the motion. A careful reader may wonder weather the SBP machinery still applies to such a sparsely structured diffusion and in fact it does. Following Theorem 4 of [43] we can see how the Radon–Nikodym derivative is finite and can be expressed in an almost identical fashion to the original controlled SBP formulation and thus justifying the existence of the SBP in this scenario as well as the application of the IPML algorithm and its derivatives.
Figure A5.
Trajectories of the shoulder and arm oriented angle sensor through the motion. The two plots on the right demonstrate IPML’s fit using a Brownian and Langevin prior.
Figure A5.
Trajectories of the shoulder and arm oriented angle sensor through the motion. The two plots on the right demonstrate IPML’s fit using a Brownian and Langevin prior.

Appendix H.5. Computational Resources
Appendix H.5.1. Computational Costs
The main computational cost of IPML comes from fitting a Gaussian process to model the drift (DriftFit). Assuming the cardinality of and a discretization factor , at each iteration, IPML requires fitting a Gaussian process on samples. It is a well-known fact that GPs have a cubic time complexity making the costs of the DriftFit subroutine . This could be scaled down by using GP approximations (Nystrom) and was successful in our preliminary results. The computational costs of the SDESolve sub-routine in comparison is due to the GP predictions costs. Finally, the memory complexity of the algorithm is due to the GP fitting in DriftFit. The running time of IPML on the machine described in the section below for the well experiment is around 5 min. For the cell experiment, the running time is between 1 and 2 h depending on the discretization factor chosen.
Appendix H.5.2. Infrastructure Used
The experiments were performed on Compute Canada clusters. Specifically, they ran on a CPU cluster composed of Intel CPUs. Each node contains 20 Intel Skylake cores (2.4 GHz, AVX512), for a total of 40 cores per node and 202 GB of RAM. The computational costs for the toy experiments (Well and 1D) was quite small; however, the RAM consumption of the cell experiment was significant due to the use of a Gaussian process.
References
- Schrödinger, E. Uber die Umkehrung der Naturgesetze; Akademie der Wissenschaften: Berlin, Germany, 1931; pp. 144–153. [Google Scholar]
- Schrödinger, E. Sur la théorie relativiste de l’électron et l’interprétation de la mécanique quantique. Annales de l’Institut Henri Poincaré 1932, 2, 269–310. [Google Scholar]
- Sinkhorn, R.; Knopp, P. Concerning nonnegative matrices and doubly stochastic matrices. Pac. J. Math. 1967, 21, 343–348. [Google Scholar] [CrossRef]
- Cuturi, M. Sinkhorn distances: Lightspeed computation of optimal transport. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Feydy, J.; Séjourné, T.; Vialard, F.X.; Amari, S.I.; Trouvé, A.; Peyré, G. Interpolating between optimal transport and MMD using Sinkhorn divergences. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Okinawa, Japan, 16 April 2019; pp. 2681–2690. [Google Scholar]
- Chizat, L.; Roussillon, P.; Léger, F.; Vialard, F.X.; Peyré, G. Faster Wasserstein Distance Estimation with the Sinkhorn Divergence. In Proceedings of the 2020 Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Volume 33. [Google Scholar]
- Hennig, P.; Osborne, M.A.; Girolami, M. Probabilistic numerics and uncertainty in computations. Proc. R. Soc. A Math. Phys. Eng. Sci. 2015, 471, 20150142. [Google Scholar] [CrossRef]
- Kullback, S. Probability densities with given marginals. Ann. Math. Stat. 1968, 39, 1236–1243. [Google Scholar] [CrossRef]
- Ruschendorf, L. Convergence of the iterative proportional fitting procedure. Ann. Stat. 1995, 23, 1160–1174. [Google Scholar] [CrossRef]
- Pavon, M.; Tabak, E.G.; Trigila, G. The Data Driven Schrödinger Bridge. arXiv 2018, arXiv:1610.02588v4. [Google Scholar]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Volume 2. [Google Scholar]
- Ruttor, A.; Batz, P.; Opper, M. Approximate Gaussian process inference for the drift function in stochastic differential equations. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2040–2048. [Google Scholar]
- Øksendal, B. Stochastic Differential Equations; Springer: Berlin/Heidelberg, Germany, 2003; pp. 65–84. [Google Scholar]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-Based Generative Modeling through Stochastic Differential Equations. arXiv 2020, arXiv:2011.13456. [Google Scholar]
- Nelson, E. Dynamical Theories of Brownian Motion; Princeton University Press: Princeton, NJ, USA, 1967; Volume 3. [Google Scholar]
- Anderson, B.D. Reverse-time diffusion equation models. Stoch. Process. Appl. 1982, 12, 313–326. [Google Scholar] [CrossRef]
- Elliott, R.J.; Anderson, B.D. Reverse time diffusions. Stoch. Process. Appl. 1985, 19, 327–339. [Google Scholar] [CrossRef]
- Follmer, H. An entropy approach to the time reversal of diffusion processes. Lect. Notes Control Inf. Sci. 1984, 69, 156–163. [Google Scholar]
- Haussmann, U.; Pardoux, E. Time reversal of diffusion processes. In Stochastic Differential Systems Filtering and Control; Springer: Berlin/Heidelberg, Germany, 1985; pp. 176–182. [Google Scholar]
- Pavon, M.; Wakolbinger, A. On free energy, stochastic control, and Schrödinger processes. In Modeling, Estimation and Control of Systems with Uncertainty; Springer: New York, NY, USA, 1991; pp. 334–348. [Google Scholar]
- Cramer, E. Probability measures with given marginals and conditionals: I-projections and conditional iterative proportional fitting. Stat. Decis.—Int. J. Stoch. Methods Models 2000, 18, 311–330. [Google Scholar]
- Bernton, E.; Heng, J.; Doucet, A.; Jacob, P.E. Schrödinger Bridge Samplers. arXiv 2019, arXiv:1912.13170. [Google Scholar]
- Papaspiliopoulos, O.; Pokern, Y.; Roberts, G.O.; Stuart, A.M. Nonparametric estimation of diffusions: A differential equations approach. Biometrika 2012, 99, 511–531. [Google Scholar] [CrossRef]
- Batz, P.; Ruttor, A.; Opper, M. Approximate Bayes learning of stochastic differential equations. Phys. Rev. E 2018, 98, 022109. [Google Scholar] [CrossRef]
- Pokern, Y.; Stuart, A.M.; van Zanten, J.H. Posterior consistency via precision operators for Bayesian nonparametric drift estimation in SDEs. Stoch. Process. Appl. 2013, 123, 603–628. [Google Scholar] [CrossRef]
- De Bortoli, V.; Thornton, J.; Heng, J.; Doucet, A. Diffusion Schrödinger Bridge with Applications to Score-Based Generative Modeling. arXiv 2021, arXiv:2106.01357. [Google Scholar]
- Feydy, J. Geometric Data Analysis, beyond Convolutions. Ph.D. Thesis, Université Paris-Saclay, Gif-sur-Yvette, France, 2020. Available online: https://www.math.ens.fr/$\sim$feydy (accessed on 22 August 2021).
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Papamakarios, G.; Pavlakou, T.; Murray, I. Masked autoregressive flow for density estimation. arXiv 2017, arXiv:1705.07057. [Google Scholar]
- Papamakarios, G. Neural density estimation and likelihood-free inference. arXiv 2019, arXiv:1910.13233. [Google Scholar]
- Wang, G.; Jiao, Y.; Xu, Q.; Wang, Y.; Yang, C. Deep Generative Learning via Schrödinger Bridge. arXiv 2021, arXiv:2106.10410. [Google Scholar]
- Huang, J.; Jiao, Y.; Kang, L.; Liao, X.; Liu, J.; Liu, Y. Schrödinger-Föllmer Sampler: Sampling without Ergodicity. arXiv 2021, arXiv:2106.10880. [Google Scholar]
- Kingma, D.P.; Salimans, T.; Poole, B.; Ho, J. Variational Diffusion Models. arXiv 2021, arXiv:2107.00630. [Google Scholar]
- Tong, A.; Huang, J.; Wolf, G.; Van Dijk, D.; Krishnaswamy, S. Trajectorynet: A dynamic optimal transport network for modeling cellular dynamics. In Proceedings of the International Conference on Machine Learning, Online. 12–18 July 2020; pp. 9526–9536. [Google Scholar]
- McCann, R.J.; Guillen, N. Five lectures on optimal transportation: Geometry, regularity and applications. In Analysis and Geometry of Metric Measure Spaces: Lecture Notes of the Séminaire de Mathématiques Supérieure (SMS) Montréal; American Mathematical Society: Providence, RI, USA, 2011; pp. 145–180. [Google Scholar]
- Schiebinger, G.; Shu, J.; Tabaka, M.; Cleary, B.; Subramanian, V.; Solomon, A.; Gould, J.; Liu, S.; Lin, S.; Berube, P.; et al. Optimal-transport analysis of single-cell gene expression identifies developmental trajectories in reprogramming. Cell 2019, 176, 928–943. [Google Scholar] [CrossRef]
- Sanguinetti, G.; Lawrence, N.D.; Rattray, M. Probabilistic inference of transcription factor concentrations and gene-specific regulatory activities. Bioinformatics 2006, 22, 2775–2781. [Google Scholar] [CrossRef]
- Léonard, C. A survey of the Schrödinger problem and some of its connections with optimal transport. arXiv 2013, arXiv:1308.0215. [Google Scholar] [CrossRef]
- Léonard, C. Some properties of path measures. In Séminaire de Probabilités XLVI; Springer: Cham, Switzerland, 2014; pp. 207–230. [Google Scholar]
- Kunitha, H. On backward stochastic differential equations. Stochastics 1982, 6, 293–313. [Google Scholar] [CrossRef]
- Revuz, D.; Yor, M. Continuous Martingales and Brownian Motion; Springer: Berlin/Heidelberg, Germany, 2013; Volume 293. [Google Scholar]
- Kailath, T. The structure of Radon-Nikodym derivatives with respect to Wiener and related measures. Ann. Math. Stat. 1971, 42, 1054–1067. [Google Scholar] [CrossRef]
- Sottinen, T.; Särkkä, S. Application of Girsanov theorem to particle filtering of discretely observed continuous-time non-linear systems. Bayesian Anal. 2008, 3, 555–584. [Google Scholar] [CrossRef]
- Levy, B.C. Principles of Signal Detection and Parameter Estimation; Springer: Boston, MA, USA, 2008. [Google Scholar]
- Gyöngy, I.; Krylov, N. Existence of strong solutions for Itô’s stochastic equations via approximations. Probab. Theory Relat. Fields 1996, 105, 143–158. [Google Scholar] [CrossRef]
- Sra, S. Scalable nonconvex inexact proximal splitting. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; Volume 25, pp. 530–538. [Google Scholar]
- Álvarez, M.A.; Rosasco, L.; Lawrence, N.D. Kernels for Vector-Valued Functions: A Review. Found. Trends Mach. Learn. 2012, 4, 195–266. [Google Scholar] [CrossRef]
- Evgeniou, T.; Micchelli, C.A.; Pontil, M.; Shawe-Taylor, J. Learning multiple tasks with kernel methods. J. Mach. Learn. Res. 2005, 6, 615–637. [Google Scholar]
- Martino, L.; Elvira, V.; Louzada, F. Effective sample size for importance sampling based on discrepancy measures. Signal Process. 2017, 131, 386–401. [Google Scholar] [CrossRef]
Figure 1.
Left: Learned SBP trajectories in the double well experiment of Section 5.1, with prior expressed in terms of an energy landscape as . Right: Forwards and backwards diffusion of learned SBP between unimodal and multimodal boundary distributions (see Section 5 for experimental details).
Figure 1.
Left: Learned SBP trajectories in the double well experiment of Section 5.1, with prior expressed in terms of an energy landscape as . Right: Forwards and backwards diffusion of learned SBP between unimodal and multimodal boundary distributions (see Section 5 for experimental details).

Figure 2.
Left: IPFP algorithm. Right: illustration of the convergence of the IPFP Algorithm.

Figure 3.
Distance between the prior and the learned bridge as a function of the iterations, number of samples used (N) and whether the prior is used for the GP ().
Figure 3.
Distance between the prior and the learned bridge as a function of the iterations, number of samples used (N) and whether the prior is used for the GP ().

Figure 4.
The left plot represent the first and last frame of the cell’s data and the convex hull of the forward model for TrajectoryNet and IPML. The right plots represent sample trajectories for Trajectorynet and IPML.
Figure 4.
The left plot represent the first and last frame of the cell’s data and the convex hull of the forward model for TrajectoryNet and IPML. The right plots represent sample trajectories for Trajectorynet and IPML.

Figure 5.
Left: 3D animation of the basketball signal motion modeled in Section 5.4 (motion from left to right). Right: Trajectories of the shoulder’s oriented angle sensor through the motion. The two plots on the right demonstrate IPML’s fit using a Brownian and Langevin prior.
Figure 5.
Left: 3D animation of the basketball signal motion modeled in Section 5.4 (motion from left to right). Right: Trajectories of the shoulder’s oriented angle sensor through the motion. The two plots on the right demonstrate IPML’s fit using a Brownian and Langevin prior.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Performance comparison of the fitted marginals between DDSB and IPML on unimodal and bimodal experiment.
Table 1.
Performance comparison of the fitted marginals between DDSB and IPML on unimodal and bimodal experiment.
| Unimodal | Bimodal | |||||||
|---|---|---|---|---|---|---|---|---|
| KS | EMD | KS | EMD | KS | EMD | KS | EMD | |
| DDSB | 0.17 | 0.34 | 0.19 | 0.13 | 0.18 | 0.12 | 0.07 | 0.04 |
| IPML | 0.06 | 0.10 | 0.13 | 0.04 | 0.05 | 0.04 | 0.07 | 0.15 |
Table 2.
Earth Moving Distance (EMD) on the EB data. EXP stands for the exponential kernel and EQ for exponentiated quadratic. The column “full” represents EMD averaged over all frames whereas “path” is averaged over the intermediate frames ().
Table 2.
Earth Moving Distance (EMD) on the EB data. EXP stands for the exponential kernel and EQ for exponentiated quadratic. The column “full” represents EMD averaged over all frames whereas “path” is averaged over the intermediate frames ().
| T = 1 | T = 2 | T = 3 | T = 4 | T = 5 | Mean | ||
|---|---|---|---|---|---|---|---|
| Path | Full | ||||||
| TrajectoryNet | 0.62 | 1.15 | 1.49 | 1.26 | 0.99 | 1.30 | 1.18 |
| IPML EQ | 0.38 | 1.19 | 1.44 | 1.04 | 0.48 | 1.22 | 1.02 |
| IPML EXP | 0.34 | 1.13 | 1.35 | 1.01 | 0.49 | 1.16 | 0.97 |
| OT | Na | 1.13 | 1.10 | 1.11 | Na | 1.11 | Na |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Vargas, F.; Thodoroff, P.; Lamacraft, A.; Lawrence, N. Solving Schrödinger Bridges via Maximum Likelihood. Entropy 2021, 23, 1134. https://0-doi-org.brum.beds.ac.uk/10.3390/e23091134
AMA Style
Vargas F, Thodoroff P, Lamacraft A, Lawrence N. Solving Schrödinger Bridges via Maximum Likelihood. Entropy. 2021; 23(9):1134. https://0-doi-org.brum.beds.ac.uk/10.3390/e23091134
Chicago/Turabian StyleVargas, Francisco, Pierre Thodoroff, Austen Lamacraft, and Neil Lawrence. 2021. "Solving Schrödinger Bridges via Maximum Likelihood" Entropy 23, no. 9: 1134. https://0-doi-org.brum.beds.ac.uk/10.3390/e23091134
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.