
Kolmogorov Entropy for Convergence Rate in Incomplete Functional Time Series: Application to Percentile and Cumulative Estimation in High Dimensional Data
 ,
,  , and
, and
Abstract
:1. Introduction
2. Model and Estimators
2.1. LLECCDF: Numerical Approximation of CCDF-Model
- (i)
- For all ,
- (ii)
- For all , ,
2.2. LLECQF: Numerical Approximation of CQF-Model
3. Uniform Convergence Rate
- (H1)
- The first-order derivative of exists and is bounded in . The function is such that
- (H2)
- There exists a non-random function satisfying
- (i)
- ,
- (ii)
- (iii)
- There exists a non-random function satisfying
- (H3)
- The distribution function and the kernel fulfill the following:
- (i)
- is a Lipschitz on its support satisfyingis a positive definite matrix.
- (ii)
- The function has a derivative satisfying
- (iii)
- We almost surely have
- (H4)
- The real sequence associated with satisfies
- (H5)
- The bandwidth is linked to and by
- (i)
- (ii)
- and and
- (iii)
- where is the law of X.
4. Asymptotic Normality
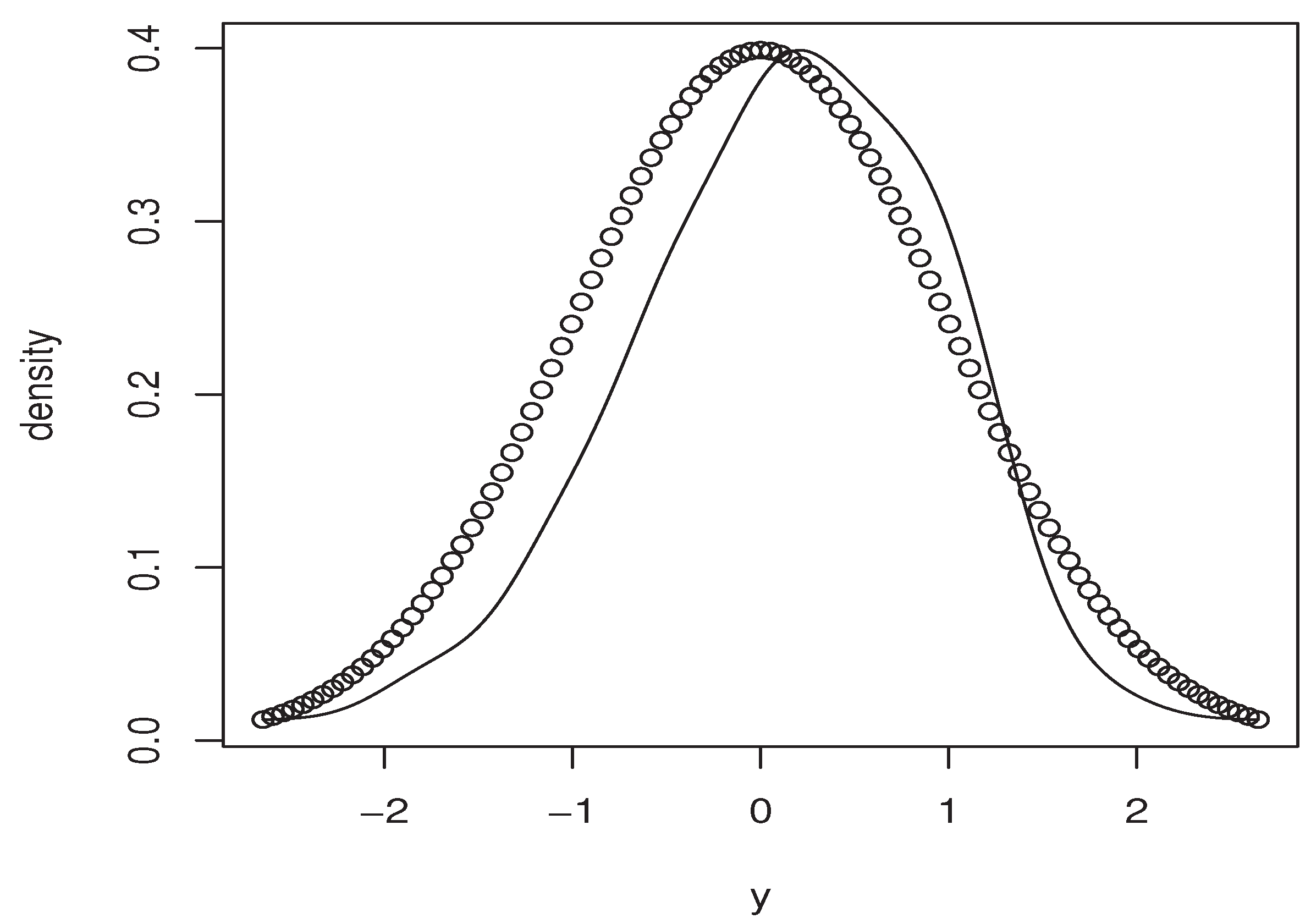
5. Numerical Results
6. Discussion and Comments
- Gap between the pointwise and uniform convergence in FDA: We specify the convergence rate over some known functional structures to highlight the gap between the pointwise and uniform convergence in functional statistics. The first one concerns the resealed version of Gaussian process . If we assume that the spectral measure of W such that, for some ,then the Kolmogorov’s -entropy of , the unit ball in reproducing kernel Hilbert spaces of the process as a subset of , is of the orderfor instance, see [66], implying an uniform convergence rate over asymptotically equal toSecondly, if we put as the closed unit ball of Cameron–Martin spaces associated with the covariance operator of the standard stationary Ornstein–Uhlenbeck process defined bythe Kolmogorov’s -entropy of this subset with respect to the norm of the Sobolev space is of orderfor instance, refer to [66], and the convergence rate isThirdly, it is shown in [67] that any closed ball in a Sobolev space endowed with the norm has a Kolmogorov’s -entropy of the orderimplying a uniform convergence rate asymptotically equal toSo, it is clear that the uniform convergence rate differs among functional subsets. However, in the nonfunctional case, where all norms are equivalent, the -entropy for any compact subset in is of the order , allowing us to keep the usual convergence rate in the finite-dimensional case, that iswhich also coincides with the pointwise convergence rate. In conclusion, unlike the finite-dimensional case, there is a real gap between the pointwise and the uniform convergence in FDA. Thus, treating uniform consistency in the FDA is a challenging question; refer to [9,68,69,70].
- The effect of the basis function on the Kolmogorov’s entropy:Similarly to the previous paragraph, Kolmogorov’s entropy is also affected by the spectral decomposition of the functional variable over specific basis functions. Of course, this relationship is justified by the fact that both tools have similar interpretations. In a sense, the Kolmogorov’s entropy of a given subset is the number of binary bits of information required to describe any with error , while the spectral decomposition of given a basis functions can be viewed as the reconstruction of . Furthermore, the minimal cardinal of elements of the basis , sufficient to reconstruct any with error , is so-called the sampling -entropy of ; for instance, see [71]. Theorem 4.1 in this cited work provides, under some general conditions, that the class of bounded piecewise smooth functions as a subspace of has a Kolmogorov’s -entropy of the orderIn contrast, Kolmogorov’s -entropy of the class of periodic real analytic functions on , as a subspace of isAs a consequence of this statement (see Corollary 4.2 in [71]), the sampling -entropy of the class spanned by the B-splines basis function is greater than the sampling -entropy of the class of periodic real analytic functions that is spanned for the Fourier basis function. In conclusion, in practice, the estimator’s accuracy is also affected by the choice of basis functions and the cardinal of the basis used in the metric.
- Estimation of the unconditional distribution of the MAR response: One of the fundamental applications of conditional modeling in the MAR structure is the possibility of reconstructing the feature of the MAR variable. In our context, we use the fact thatThus, the natural estimator of the cumulative distribution function iswhere is the estimator without the observation . An alternative estimator of can be obtained by replacing only the missing observation with the conditional expectation. Specifically, the second estimator is expressed by
7. Concluding Remarks
8. Proofs
8.1. Proof of the Main Theorems
8.2. Proof of the Technical Lemmas
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ramsay, J.O.; Silverman, B.W. Applied Functional Data Analysis: Methods and Case Studies; Springer Series in Statistics; Springer: New York, NY, USA, 2002; p. x+190. [Google Scholar] [CrossRef]
- Bosq, D. Linear Processes in Function Spaces: Theory and Applications; Lecture Notes in Statistics; Springer: New York, NY, USA, 2000; Volume 149, p. xiv+283. [Google Scholar] [CrossRef]
- Aneiros, G.; Bongiorno, E.G.; Cao, R.; Vieu, P. (Eds.) In Functional Statistics and Related Fields, Proceedings of the 4th International Workshop on Functional and Operatorial Statistics (IWFOS 2017), A Coruña, Spain, 15–17 June 2017; Springer: Cham, Switzerland, 2017; p. xxiv+288. [Google Scholar]
- Ferraty, F.; Laksaci, A.; Vieu, P. Estimating some characteristics of the conditional distribution in nonparametric functional models. Stat. Inference Stoch. Process. 2006, 9, 47–76. [Google Scholar] [CrossRef]
- Bongiorno, E.G.; Goia, A.; Salinelli, E.; Vieu, P. (Eds.) In Contributions in Infinite-Dimensional Statistics and Related Topics, Proceedings of the 3rd International Workshop on Functional and Operatorial Statistics (IWFOS’2014), Stresa, Italy, 19–21 June 2014; Società Editrice Esculapio: Bologna, Italy, 2014; p. xviii+280. [Google Scholar]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis: Theory and Practice; Springer Series in Statistics; Springer: New York, NY, USA, 2006; p. xx+258. [Google Scholar]
- Litimein, O.; Laksaci, A.; Mechab, B.; Bouzebda, S. Local linear estimate of the functional expectile regression. Stat. Probab. Lett. 2023, 192, 109682. [Google Scholar] [CrossRef]
- Bouzebda, S.; Laksaci, A.; Mohammedi, M. Single index regression model for functional quasi-associated time series data. Revstat 2022, 20, 605–631. [Google Scholar]
- Bouzebda, S.; Nezzal, A. Uniform consistency and uniform in number of neighbors consistency for nonparametric regression estimates and conditional U-statistics involving functional data. Jpn. J. Stat. Data Sci. 2022, 5, 431–533. [Google Scholar] [CrossRef]
- Bouzebda, S.; Chaouch, M. Uniform limit theorems for a class of conditional Z-estimators when covariates are functions. J. Multivar. Anal. 2022, 189, 104872. [Google Scholar] [CrossRef]
- Almanjahie, I.M.; Bouzebda, S.; Kaid, Z.; Laksaci, A. Nonparametric estimation of expectile regression in functional dependent data. J. Nonparametr. Stat. 2022, 34, 250–281. [Google Scholar] [CrossRef]
- Almanjahie, I.M.; Bouzebda, S.; Chikr Elmezouar, Z.; Laksaci, A. The functional kNN estimator of the conditional expectile: Uniform consistency in number of neighbors. Stat. Risk Model. 2022, 38, 47–63. [Google Scholar] [CrossRef]
- Mohammedi, M.; Bouzebda, S.; Laksaci, A. The consistency and asymptotic normality of the kernel type expectile regression estimator for functional data. J. Multivar. Anal. 2021, 181, 104673. [Google Scholar] [CrossRef]
- Wu, C.; Ling, N.; Vieu, P.; Liang, W. Partially functional linear quantile regression model and variable selection with censoring indicators MAR. J. Multivar. Anal. 2023, 197, 105189. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G., Jr. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Chernozhukov, V.; Fernández-Val, I.; Galichon, A. Quantile and probability curves without crossing. Econometrica 2010, 78, 1093–1125. [Google Scholar] [CrossRef]
- Angrist, J.; Chernozhukov, V.; Fernández-Val, I. Quantile regression under misspecification, with an application to the U.S. wage structure. Econometrica 2006, 74, 539–563. [Google Scholar] [CrossRef] [Green Version]
- Yu, K.; Jones, M.C. Local linear quantile regression. J. Am. Stat. Assoc. 1998, 93, 228–237. [Google Scholar] [CrossRef]
- Chaudhuri, P. Global nonparametric estimation of conditional quantile functions and their derivatives. J. Multivar. Anal. 1991, 39, 246–269. [Google Scholar] [CrossRef] [Green Version]
- Koenker, R.; Ng, P.; Portnoy, S. Quantile smoothing splines. Biometrika 1994, 81, 673–680. [Google Scholar] [CrossRef]
- Stone, C.J. Consistent nonparametric regression. Ann. Stat. 1977, 5, 595–645. [Google Scholar] [CrossRef]
- Bouzebda, S.; Taachouche, N. On the variable bandwidth kernel estimation of conditional U-statistics at optimal rates in sup-norm. Phys. A 2023, 625, 129000. [Google Scholar] [CrossRef]
- Bouzebda, S. General tests of conditional independence based on empirical processes indexed by functions. Jpn. J. Stat. Data Sci. 2023, 6, 115–177. [Google Scholar] [CrossRef]
- Crambes, C.; Gannoun, A.; Henchiri, Y. Support vector machine quantile regression approach for functional data: Simulation and application studies. J. Multivar. Anal. 2013, 121, 50–68. [Google Scholar] [CrossRef]
- Dabo-Niang, S.; Kaid, Z.; Laksaci, A. Asymptotic properties of the kernel estimate of spatial conditional mode when the regressor is functional. AStA Adv. Stat. Anal. 2015, 99, 131–160. [Google Scholar] [CrossRef]
- Wang, K.; Lin, L. Variable selection in semiparametric quantile modeling for longitudinal data. Commun. Stat. Theory Methods 2015, 44, 2243–2266. [Google Scholar] [CrossRef]
- Samanta, M. Nonparametric estimation of conditional quantiles. Stat. Probab. Lett. 1989, 7, 407–412. [Google Scholar] [CrossRef]
- Messaci, F.; Nemouchi, N.; Ouassou, I.; Rachdi, M. Local polynomial modelling of the conditional quantile for functional data. Stat. Methods Appl. 2015, 24, 597–622. [Google Scholar] [CrossRef]
- Demongeot, J.; Laksaci, A.; Rachdi, M.; Rahmani, S. On the local linear modelization of the conditional distribution for functional data. Sankhya A 2014, 76, 328–355. [Google Scholar] [CrossRef]
- Al-Awadhi, F.A.; Kaid, Z.; Laksaci, A.; Ouassou, I.; Rachdi, M. Functional data analysis: Local linear estimation of the L1-conditional quantiles. Stat. Methods Appl. 2019, 28, 217–240. [Google Scholar] [CrossRef]
- Fan, J.; Gijbels, I. Local Polynomial Modelling and Its Applications; Monographs on Statistics and Applied Probability; Chapman & Hall: London, UK, 1996; Volume 66, p. xvi+341. [Google Scholar]
- Rachdi, M.; Laksaci, A.; Demongeot, J.; Abdali, A.; Madani, F. Theoretical and practical aspects of the quadratic error in the local linear estimation of the conditional density for functional data. Comput. Stat. Data Anal. 2014, 73, 53–68. [Google Scholar] [CrossRef]
- Baíllo, A.; Grané, A. Local linear regression for functional predictor and scalar response. J. Multivar. Anal. 2009, 100, 102–111. [Google Scholar] [CrossRef] [Green Version]
- Barrientos-Marin, J.; Ferraty, F.; Vieu, P. Locally modelled regression and functional data. J. Nonparametr. Stat. 2010, 22, 617–632. [Google Scholar] [CrossRef]
- Contreras-Reyes, J.E. Information quantity evaluation of multivariate SETAR processes of order one and applications. Stat. Pap. 2023. [Google Scholar] [CrossRef]
- Bouzebda, S.; Keziou, A. New estimates and tests of independence in semiparametric copula models. Kybernetika 2010, 46, 178–201. [Google Scholar]
- Leucht, A.; Neumann, M.H. Degenerate U- and V-statistics under ergodicity: Asymptotics, bootstrap and applications in statistics. Ann. Inst. Stat. Math. 2013, 65, 349–386. [Google Scholar] [CrossRef] [Green Version]
- Leucht, A.; Neumann, M.H. Dependent wild bootstrap for degenerate U- and V-statistics. J. Multivar. Anal. 2013, 117, 257–280. [Google Scholar] [CrossRef]
- Neumann, M.H. Absolute regularity and ergodicity of Poisson count processes. Bernoulli 2011, 17, 1268–1284. [Google Scholar] [CrossRef] [Green Version]
- Bradley, R.C. Introduction to Strong Mixing Conditions; Kendrick Press: Heber City, UT, USA, 2007; Volume 3, p. xii+597. [Google Scholar]
- Benziadi, F.; Laksaci, A.; Tebboune, F. Recursive kernel estimate of the conditional quantile for functional ergodic data. Commun. Stat. Theory Methods 2016, 45, 3097–3113. [Google Scholar] [CrossRef]
- Chaouch, M.; Khardani, S. Randomly censored quantile regression estimation using functional stationary ergodic data. J. Nonparametr. Stat. 2015, 27, 65–87. [Google Scholar] [CrossRef]
- Rubin, D.B. Inference and missing data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Josse, J.; Reiter, J.P. Introduction to the special section on missing data. Stat. Sci. 2018, 33, 139–141. [Google Scholar] [CrossRef]
- Müller, U.U. Estimating linear functionals in nonlinear regression with responses missing at random. Ann. Stat. 2009, 37, 2245–2277. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Chen, S.X. Empirical likelihood for estimating equations with missing values. Ann. Stat. 2009, 37, 490–517. [Google Scholar] [CrossRef]
- Chen, X.; Hong, H.; Tarozzi, A. Semiparametric efficiency in GMM models with auxiliary data. Ann. Stat. 2008, 36, 808–843. [Google Scholar] [CrossRef] [Green Version]
- Ferraty, F.; Sued, M.; Vieu, P. Mean estimation with data missing at random for functional covariables. Statistics 2013, 47, 688–706. [Google Scholar] [CrossRef]
- Ling, N.; Liang, L.; Vieu, P. Nonparametric regression estimation for functional stationary ergodic data with missing at random. J. Stat. Plan. Inference 2015, 162, 75–87. [Google Scholar] [CrossRef]
- Ling, N.; Cheng, L.; Vieu, P.; Ding, H. Missing responses at random in functional single index model for time series data. Stat. Pap. 2022, 63, 665–692. [Google Scholar] [CrossRef]
- Ling, N.; Kan, R.; Vieu, P.; Meng, S. Semi-functional partially linear regression model with responses missing at random. Metrika 2019, 82, 39–70. [Google Scholar] [CrossRef]
- Rosenblatt, M. A strong mixing condition and a central limit theorem on compact groups. J. Math. Mech. 1967, 17, 189–198. [Google Scholar] [CrossRef]
- Rosenblatt, M. Uniform ergodicity and strong mixing. Z. Wahrscheinlichkeitstheorie Verwandte Geb. 1972, 24, 79–84. [Google Scholar] [CrossRef]
- Bouzebda, S.; Didi, S.; El Hajj, L. Multivariate wavelet density and regression estimators for stationary and ergodic continuous time processes: Asymptotic results. Math. Methods Stat. 2015, 24, 163–199. [Google Scholar] [CrossRef]
- Bouzebda, S.; Didi, S. Multivariate wavelet density and regression estimators for stationary and ergodic discrete time processes: Asymptotic results. Commun. Stat. Theory Methods 2017, 46, 1367–1406. [Google Scholar] [CrossRef]
- Bouzebda, S.; Didi, S. Additive regression model for stationary and ergodic continuous time processes. Commun. Stat. Theory Methods 2017, 46, 2454–2493. [Google Scholar] [CrossRef]
- Bouzebda, S.; Didi, S. Some asymptotic properties of kernel regression estimators of the mode for stationary and ergodic continuous time processes. Rev. Mat. Complut. 2021, 34, 811–852. [Google Scholar] [CrossRef]
- Bouzebda, S.; Chaouch, M.; Didi Biha, S. Asymptotics for function derivatives estimators based on stationary and ergodic discrete time processes. Ann. Inst. Stat. Math. 2022, 74, 737–771. [Google Scholar] [CrossRef]
- Didi, S.; Bouzebda, S. Wavelet Density and Regression Estimators for Continuous Time Functional Stationary and Ergodic Processes. Mathematics 2022, 10, 4356. [Google Scholar] [CrossRef]
- Didi, S.; Alharby, A.; Bouzebda, S. Wavelet Density and Regression Estimators for Functional Stationary and Ergodic Data: Discrete Time. Mathematics 2022, 10, 3433. [Google Scholar] [CrossRef]
- Kolmogorov, A.N.; Tihomirov, V.M. ε-entropy and ε-capacity of sets in function spaces. Usp. Mat. Nauk 1959, 14, 3–86. [Google Scholar]
- Ferraty, F.; Laksaci, A.; Tadj, A.; Vieu, P. Rate of uniform consistency for nonparametric estimates with functional variables. J. Stat. Plan. Inference 2010, 140, 335–352. [Google Scholar] [CrossRef]
- Kuelbs, J.; Li, W.V. Metric entropy and the small ball problem for Gaussian measures. J. Funct. Anal. 1993, 116, 133–157. [Google Scholar] [CrossRef] [Green Version]
- Nicoleris, T.; Yatracos, Y.G. Rates of convergence of estimates, Kolmogorov’s entropy and the dimensionality reduction principle in regression. Ann. Stat. 1997, 25, 2493–2511. [Google Scholar] [CrossRef]
- Hörmann, S.; Horváth, L.; Reeder, R. A functional version of the ARCH model. Econom. Theory 2013, 29, 267–288. [Google Scholar] [CrossRef] [Green Version]
- van der Vaart, A.; van Zanten, H. Bayesian inference with rescaled Gaussian process priors. Electron. J. Stat. 2007, 1, 433–448. [Google Scholar] [CrossRef] [Green Version]
- Shirikyan, A. Euler equations are not exactly controllable by a finite-dimensional external force. Phys. D 2008, 237, 1317–1323. [Google Scholar] [CrossRef] [Green Version]
- Bouzebda, S.; Nemouchi, B. Uniform consistency and uniform in bandwidth consistency for nonparametric regression estimates and conditional U-statistics involving functional data. J. Nonparametr. Stat. 2020, 32, 452–509. [Google Scholar] [CrossRef]
- Bouzebda, S.; Nezzal, A.; Zari, T. Uniform Consistency for Functional Conditional U-Statistics Using Delta-Sequences. Mathematics 2023, 11, 161. [Google Scholar] [CrossRef]
- Bouzebda, S.; Soukarieh, I. Non-Parametric Conditional U-Processes for Locally Stationary Functional Random Fields under Stochastic Sampling Design. Mathematics 2023, 11, 16. [Google Scholar] [CrossRef]
- Batenkov, D.; Friedland, O.; Yomdin, Y. Sampling, metric entropy, and dimensionality reduction. SIAM J. Math. Anal. 2015, 47, 786–796. [Google Scholar] [CrossRef] [Green Version]
- Ayad, S.; Laksaci, A.; Rahmani, S.; Rouane, R. Local linear modelling of the conditional distribution function for functional ergodic data. Math. Model. Anal. 2022, 27, 360–382. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Metric Type | op.norms | q or m | MSE | |
|---|---|---|---|---|
| Fourier Basis Functions | ||||
| 0.98 | 5 | 2 | 0.196 | |
| 0 | 0.193 | |||
| 0.5 | 2 | 0.184 | ||
| 0 | 0.187 | |||
| 0.05 | 2 | 0.156 | ||
| 0 | 0.155 | |||
| 0.48 | 5 | 2 | 0.172 | |
| 0 | 0.174 | |||
| 0.5 | 2 | 0.168 | ||
| 0 | 0.161 | |||
| 0.05 | 2 | 0.149 | ||
| 0 | 0.151 | |||
| B-spline Basis Functions | ||||
| 0.48 | 5 | 2 | 0.266 | |
| 0 | 0.264 | |||
| 0.5 | 2 | 0.257 | ||
| 0 | 0.259 | |||
| 0.05 | 2 | 0.251 | ||
| 0 | 0.248 | |||
| 0.08 | 5 | 2 | 0.243 | |
| 0 | 0.242 | |||
| 0.5 | 2 | 0.239 | ||
| 0 | 0.237 | |||
| 0.05 | 2 | 0.227 | ||
| 0 | 0.230 | |||
| PCA-metric | ||||
| 0.98 | 5 | 3 | 0.408 | |
| 1 | 0.407 | |||
| 0.5 | 3 | 0.398 | ||
| 1 | 0.394 | |||
| 0.05 | 3 | 0.387 | ||
| 1 | 0.376 | |||
| 0.08 | 5 | 3 | 0.143 | |
| 1 | 0.292 | |||
| 0.5 | 3 | 0.295 | ||
| 1 | 0.283 | |||
| 0.05 | 3 | 0.284 | ||
| 1 | 0.279 |
| The Metric Type | op.norms | q or m | MSE | |
|---|---|---|---|---|
| Fourier Basis Functions | ||||
| 0.98 | 5 | 2 | 0.091 | |
| 0 | 0.093 | |||
| 0.5 | 2 | 0.081 | ||
| 0 | 0.085 | |||
| 0.05 | 2 | 0.056 | ||
| 0 | 0.054 | |||
| 0.08 | 5 | 2 | 0.051 | |
| 0 | 0.04 | |||
| 0.5 | 2 | 0.033 | ||
| 0 | 0.039 | |||
| 0.05 | 2 | 0.031 | ||
| 0 | 0.023 | |||
| B-spline Basis Functions | ||||
| 0.98 | 5 | 2 | 0.128 | |
| 0 | 0.123 | |||
| 0.5 | 2 | 0.121 | ||
| 0 | 0.122 | |||
| 0.05 | 2 | 0.117 | ||
| 0 | 0.114 | |||
| 0.48 | 5 | 2 | 0.109 | |
| 0 | 0.107 | |||
| 0.5 | 2 | 0.099 | ||
| 0 | 0.095 | |||
| 0.05 | 2 | 0.085 | ||
| 0 | 0.074 | |||
| PCA-metric | ||||
| 0.48 | 5 | 3 | 0.104 | |
| 1 | 0.108 | |||
| 0.5 | 3 | 0.102 | ||
| 1 | 0.101 | |||
| 0.05 | 3 | 0.099 | ||
| 1 | 0.097 | |||
| 0.08 | 5 | 3 | 0.086 | |
| 1 | 0.092 | |||
| 0.5 | 3 | 0.081 | ||
| 1 | 0.078 | |||
| 0.05 | 3 | 0.064 | ||
| 1 | 0.061 |
| op.norms | ||
|---|---|---|
| 0.98 | 5 | 0.121 |
| 0.5 | 0.093 | |
| 0.48 | 5 | 0.109 |
| 0.5 | 0.091 |
| Method | op.norms | ||
|---|---|---|---|
| Local linear estimator | 0.98 | 5 | 0.051 |
| 0.5 | 0.042 | ||
| 0.48 | 5 | 0.044 | |
| 0.5 | 0.037 | ||
| Kernel method | 0.98 | 5 | 0.19 |
| 0.5 | 0.098 | ||
| 0.48 | 5 | 0.13 | |
| 0.5 | 0.067 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Litimein, O.; Alshahrani, F.; Bouzebda, S.; Laksaci, A.; Mechab, B. Kolmogorov Entropy for Convergence Rate in Incomplete Functional Time Series: Application to Percentile and Cumulative Estimation in High Dimensional Data. Entropy 2023, 25, 1108. https://0-doi-org.brum.beds.ac.uk/10.3390/e25071108
Litimein O, Alshahrani F, Bouzebda S, Laksaci A, Mechab B. Kolmogorov Entropy for Convergence Rate in Incomplete Functional Time Series: Application to Percentile and Cumulative Estimation in High Dimensional Data. Entropy. 2023; 25(7):1108. https://0-doi-org.brum.beds.ac.uk/10.3390/e25071108
Chicago/Turabian StyleLitimein, Ouahiba, Fatimah Alshahrani, Salim Bouzebda, Ali Laksaci, and Boubaker Mechab. 2023. "Kolmogorov Entropy for Convergence Rate in Incomplete Functional Time Series: Application to Percentile and Cumulative Estimation in High Dimensional Data" Entropy 25, no. 7: 1108. https://0-doi-org.brum.beds.ac.uk/10.3390/e25071108