
Geometric Insights into the Multivariate Gaussian Distribution and Its Entropy and Mutual Information

1
Department of Communications, Navigation and Control Engineering, National Taiwan Ocean University, 2 Peining Rd., Keelung 202301, Taiwan
2
Department of Business Administration, Asia University, 500 Liufeng Road, Wufeng, Taichung 41354, Taiwan
*
Author to whom correspondence should be addressed.
Entropy 2023, 25(8), 1177; https://0-doi-org.brum.beds.ac.uk/10.3390/e25081177
Submission received: 6 July 2023
/
Revised: 31 July 2023
/
Accepted: 4 August 2023
/
Published: 7 August 2023
(This article belongs to the Special Issue Entropy and Organization in Natural and Social Systems)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:In this paper, we provide geometric insights with visualization into the multivariate Gaussian distribution and its entropy and mutual information. In order to develop the multivariate Gaussian distribution with entropy and mutual information, several significant methodologies are presented through the discussion, supported by illustrations, both technically and statistically. The paper examines broad measurements of structure for the Gaussian distributions, which show that they can be described in terms of the information theory between the given covariance matrix and correlated random variables (in terms of relative entropy). The content obtained allows readers to better perceive concepts, comprehend techniques, and properly execute software programs for future study on the topic’s science and implementations. It also helps readers grasp the themes’ fundamental concepts to study the application of multivariate sets of data in Gaussian distribution. The simulation results also convey the behavior of different elliptical interpretations based on the multivariate Gaussian distribution with entropy for real-world applications in our daily lives, including information coding, nonlinear signal detection, etc. Involving the relative entropy and mutual information as well as the potential correlated covariance analysis, a wide range of information is addressed, including basic application concerns as well as clinical diagnostics to detect the multi-disease effects.
1. Introduction
Understanding the ways knowledge concerning an external variable or the reciprocal information of its parts can assist in characterizing and inferring the underlying mechanics and function of the system. This goal has driven the development of several techniques for dissecting the elements of a set of variables’ combined entropy or for dissecting the contributions of a set of variables to the mutual information about the variable of interest. In actuality, this association and its modifications exist for any input signal and the widest range of Gaussian pathways, comprising discrete-time and continuous-time pathways in scalar or vector forms.
In a more general way, mutual information and mean-square error (MSE) are the fundamental concepts of information theory and estimation theory, respectively. In contrast to the minimum MSE (MMSE), which determines how precisely each input sample can be restored using the channel’s outcomes, the input-output mutual information is an estimation of whether the information can be consistently delivered over a channel given a specific input signal. An inactive functioning characterization for mutual information is provided by the substantial relevance of mutual information to estimation and filtering. Therefore, the significance of identity is not only obvious, but the link is also fascinating and merits an in-depth explanation [1,2,3]. Relations between the MMSE of the approximation of the output given the input and the localized actions of the mutual information at diminishing signal-to-noise ratio (SNR) are presented in [4]. The authors of [5] give an idea about the probabilistic ratios of geometric characteristics of signal detection in Gaussian noise. Furthermore, whether in a continuous-time [5,6,7] or discrete-time [8] context, the likelihood ratio is difficult in the relationship between observation and estimation.
Considering the specific instance of parametric computation (or Gaussian inputs), correlations relating to causal and non-causal estimation errors have been investigated in [9,10], involving the limit on the loss owing to the causality restriction. Knowing how data pertaining to an external parameter, or inversely related data within its parts, distributes across the parts of a multivariate system can assist in categorizing and determining the fundamental mechanics and functionality of the structure. The mechanism served as the impetus for the development of various techniques for decomposing the various elements of a set of parameters’ joint entropy [11,12,13,14,15,16,17,18,19] or for deconvoluting the additions of a set of elements to the mutual information about a target variable [13]. The mutual information techniques can be used to examine a variety of intricate systems, including those in the physical distinction domain, such as gene networks [17] or brain coding [20], as well as those in the social domain, such as selection agents [21] and community behavior [22]. It can also be used to analyze artificial agents [23]. Furthermore, some new proposals deviated more significantly from the original framework by incorporating novel principles such as the consideration of the presence of harmful elements associated with errors and the use of joint entropy subdivisions in place of mutual information [24,25].
In the multivariate scenario, the challenges of breaking down mutual information into redundancy and complementary sections have nevertheless been significantly increased. The maximum entropy framework allows for a more straightforward generalization of the efficiency measurements to the multivariate case [26,27]. The novel redundancy determines that were initially developed are only defined for the bivariate situation or allow negative components [28], whereas measurements of coordination are more readily extended to the multivariate case, especially when using the maximum entropy architecture [29,30]. By either utilizing the associations between lattices formed by various numbers of parameters or utilizing the multiple interactions between redundant lattices and information loss lattices, for which collaborative efforts are more actually defined, the study in [31,32] established two analogous techniques for constructing multivariate redundant metrics. Information theory variables have a benefit compared to more known test results measurements in that they may be employed when numerous ailments are being considered as well as when a test of diagnosis can produce several or continuous findings [33].
Although there are some valuable references detailing entropy-related topics, both discrete and continuous, they may not be easily accessible to some readers from the existing publications. Therefore, in this present study, we propose an extension of the bivariate Gaussian distribution technique to calculate multivariate redundant metrics inside the maximum entropy context. The importance of the maximum entropy approach in the multivariate scenario, where it offers constraints for the actual redundancy, unique information, and efficiency terms under logical presumptions shared by additional criteria, acts as the motivation for this particular focus [26,34]. The maximum entropy measurements, specifically, offer a lower limit for the actual cooperation and redundant terms and a higher limit for the actual specific information if it is presumed that a bivariate non-negative disintegration exists and that redundancy can be calculated from the bivariate distributions of the desired outcome with every source. Furthermore, if these bivariate distributions are consistent with possibly having little interaction under the previous hypotheses, then the maximum entropy decomposition returns not only boundaries but also the precise actual terms. Here, in the proposed framework, we also demonstrated that, under similar presumptions, the maximum entropy reduction also plays this dominant role in the multivariate situation [35]. This paper intends to convey the important issues and inspire new applications of information theory to a number of areas, such as information coding, nonlinear signal detection, and clinical diagnostic testing.
The remainder of this paper is organized as follows. A brief review of the geometry of the Gaussian distribution is reviewed in Section 2. The three consecutive sections deal with various important topics on information entropy with illustrative examples, with an emphasis on visualization of the information and discussion. In Section 3, continuous entropy/differential entropy are presented. In Section 4, the relative entropy (Kullback–Leibler divergence) is presented. Mutual information is presented in Section 5. Conclusions are given in Section 6.
2. Geometry of the Gaussian Distribution
In this section, the background relations of the Gaussian distribution from different parametric points of view will be discussed. The exploratory objective of the fundamental analysis is to identify “the framework” in multivariate datasets. Ordinary least-squares regression and principal component analysis (PCA), respectively, analyze the measurements for dependency (the predicted connection between particular components) and rigidity (the degree of prominence of the probability density function (pdf) around a low-dimensional axis) for bivariate Gaussian distributions. Mutual information, an established measure of dependency, is not an accurate indicator of rigidity since it is not invariant with an opposite rotation of the parameters. For bivariate Gaussian distributions, a suitable rotating invariant compactness measure is constructed and demonstrated to reduce the corresponding PCA measure.
2.1. Standard Parametric Representation of an Ellipse
For the uncorrelated data, which has zero covariance, the ellipse is not rotated and the axis is aligned. The radii of the ellipse in both directions are the variances. Geometrically, a not-rotated ellipse at point (0, 0) and radii and for the - and -direction is described by:
The general probability density function for the multivariate Gaussian is given by the following:
where and is a symmetric, positive semi-definite matrix. If is the identity matrix, then the Mahalanobis distance reduces to the standard Euclidean distance between and .
For bivariate Gaussian distributions, the mean and covariance matrix are given by the following:
where the linear correlation coefficient .
Variance measures the variation of a single random variable, whereas covariance is a measure of the two random variables varying together. With the covariance, we can calculate the entries of the covariance matrix, which is a square matrix. In addition, the covariance matrix is symmetric. The diagonal entries of the covariance matrix are the variances; however, the other entries are the covariances. Due to this reason, the covariance matrix is often called the variance-covariance matrix.
2.2. The Confidence Ellipse
A typical way to visualize two-dimensional Gaussian-distributed data is by plotting a confidence ellipse. The distance is a constant value referred to as the Mahalanobis distance, which is a random variable distributed by the chi-squared distribution, denoted as .
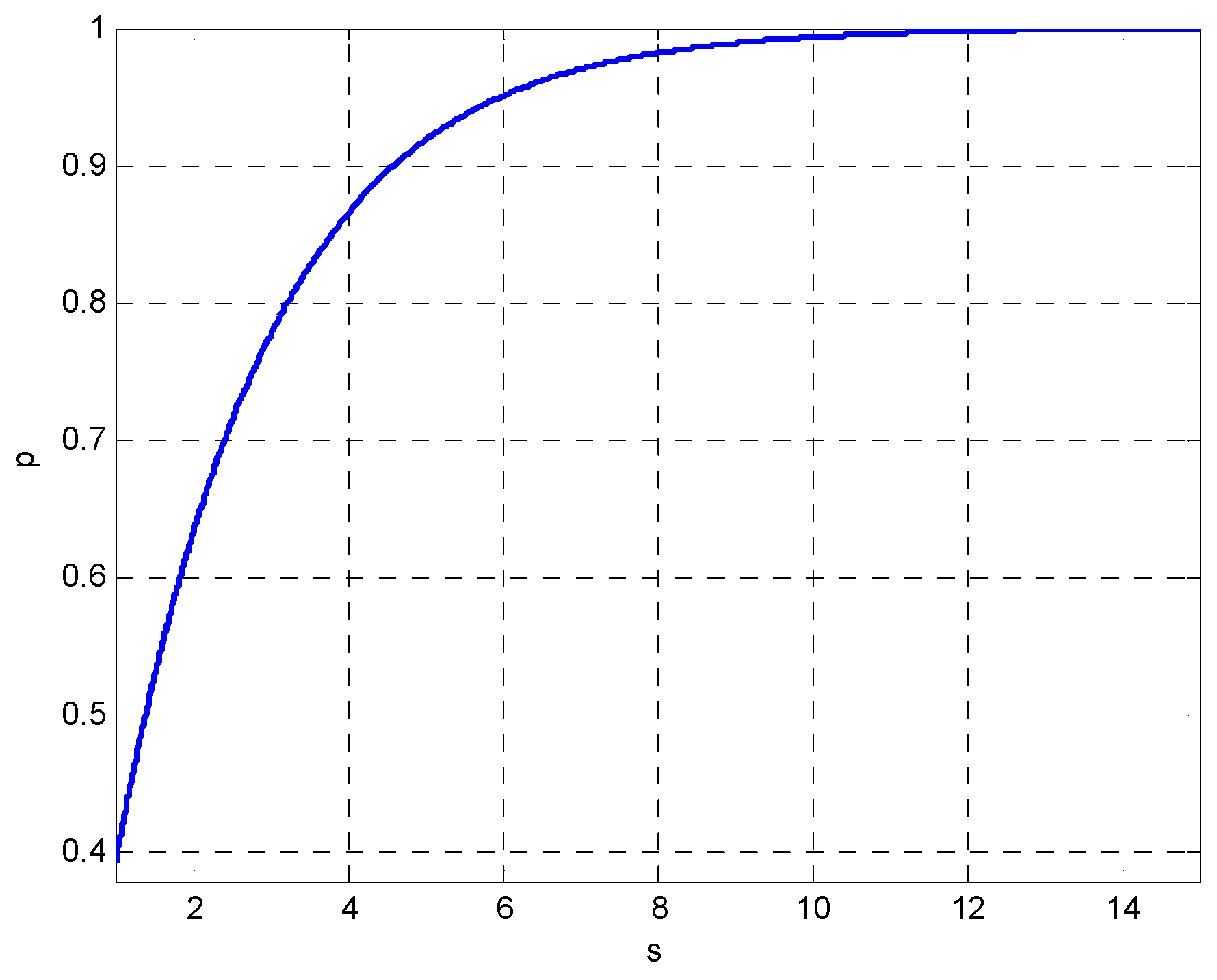
where is the number of degrees of freedom and is the given probability related to the confidence ellipse. For example, if 95% confidence ellipse is defined. Extension from Equation (1): the radius in each direction is the standard deviation and parametrized by a scale factor s, known as the Mahalanobis radius of the ellipsoid:
The goal is to determine the scale s such that confidence p is met. Since the data are multivariate Gaussian-distributed, the left-hand side of the equation is the sum of squares of Gaussian-distributed samples, which follows a χ2 distribution. A χ2 distribution is defined by the degrees of freedom, and since we have two dimensions, the number of degrees of freedom is two. Now, we have calculated the probability with the sum, and therefore s has a certain value under a χ2 distribution.
This ellipse with a probability contour defines the region of a minimum area (or volume in the multivariate case) containing a given probability under the Gaussian assumption. The equation can be solved using a χ2 table or simply using the relationship . The confidence interval can be evaluated through the following:
for we have . Furthermore, typical values include , , , and for , , , and , respectively. The ellipse can then be drawn with radii and . Figure 1 shows the relationship between the confidence interval and the scale factor s.
The Mahalanobis distance accounts for the variance of each variable and the covariance between variables.
Geometrically, it does this by transforming the data into standardized, uncorrelated data and computing the ordinary Euclidean distance for the transformed data. In this way, the Mahalanobis distance is like a univariate z-score: it provides a way to measure distances that takes into account the scale of the data.
In the general case, covariances and are not zero, and therefore the ellipse-coordinate system is not axis-aligned. In such a case, instead of using the variance as a spread indicator, we use the eigenvalues of the covariance matrix. The eigenvalues represent the spread in the direction of the eigenvectors, which are the variances under a rotated coordinate system. By definition, a covariance matrix is positive and definite; therefore, all eigenvalues are positive and can be seen as a linear transformation of the data. The actual radii of the ellipse are and for the two eigenvalues and of the scaled covariance matrix .
Based on Equations (2) and (7), the bivariate Gaussian distributions can be represented as follows:
and the level surface of are concentric ellipses:
where is the Mahalanobis distance possessing the following properties:
- ▪
- It accounts for the fact that the variances in each direction are different;
- ▪
- It accounts for the covariance between variables;
- ▪
- It reduces to the familiar Euclidean distance for uncorrelated variables with unit variance.
The length of the ellipse axes is a function of the given probability of the chi-squared distribution with 2 degrees of freedom , the eigenvalues and the linear correlation coefficient . If 95% confidence ellipse is defined by:
where
as denotes a symmetric matrix, the eigenvectors of is linearly independent (or orthogonal).
2.3. Similarity Transform
The simplest similarity transformation method for eigenvalue computation is the Jacobi method, which deals with the standard eigenproblems. In the multivariate Gaussian distribution, the covariance matrix can be expressed in terms of eigenvectors:
where are the eigenvectors of and is the diagonal matrix of the eigenvalues
replacing by , the square of the difference can be written as:
as . Denoting
the square of the difference can then be expressed as:
If the above equation is further evaluated, the resulting equation is the equation of an ellipse aligned with the axis and in the new coordinate system:
the axes of the ellipse are defined by axis with a length and axis with a length .
When , the eigenvectors are equal to and . Additionally, matrix whose elements are the eigenvectors, of becomes an identity matrix. The final equation of an ellipse is then defined by:
It is clear from the equation given above that the axes of the ellipse are parallel to the coordinate axes. The lengths of the axes of the ellipse are then defined as and .
The covariance matrix can be presented by its eigenvectors and eigenvalues: , where is the matrix whose columns are the eigenvectors of and is the diagonal matrix with diagonal elements given by the eigenvalues of . Transformation is performed based on the three steps involving scaling, rotation, and translation:
- Scaling
The covariance matrix can be written as , where is a diagonal scaling matrix ;
- 2.
- Rotation
is generalized from the normalized eigenvectors of the covariance matrix .
it can be noted that is an orthogonal matrix and . Here, we have calculated the matrix with rotation and scaling and . Thus, the covariance matrix can be written as and with diagonal eigenvalues . Since , we have .
The similarity transform is applied to obtain the relationship between , and the pdf of vector, which can be found by considering the below expression:
the ellipse in the transformed frame can be represented as:
where the eigenvectors are equal to and ;
- 3.
- Translation
2.4. Simulation with a Given Variance-Covariance Matrix
With the given data , an ellipse represents the confidence p, which can be plotted by calculating the radii, its center, and the rotation. Here, (by which can be obtained) and for generating the covariance matrix , from which can be derived. The inclination angle is calculated by:
which can be used in calculations with the values of
and the covariance can be evaluated by: if is specified. On the other hand, with the correlation coefficient and variances for generating the covariance matrix , can be obtained.
To generate the sampling points that meet the specified correlation, the following procedure can be followed. Given two random variables and , their linear combination is . For the generation of correlated random variables, if we have two Gaussian, uncorrelated random variables , then we can create two correlated random variables using the formula:
and then will have a correlation with :
Based on the relationship: , , the following equation can be employed to generate the sampling points for the scatter plots using the MATLAB software:
where the Cholesky decomposition of has a lower triangular matrix for , and is the vector of mean values.
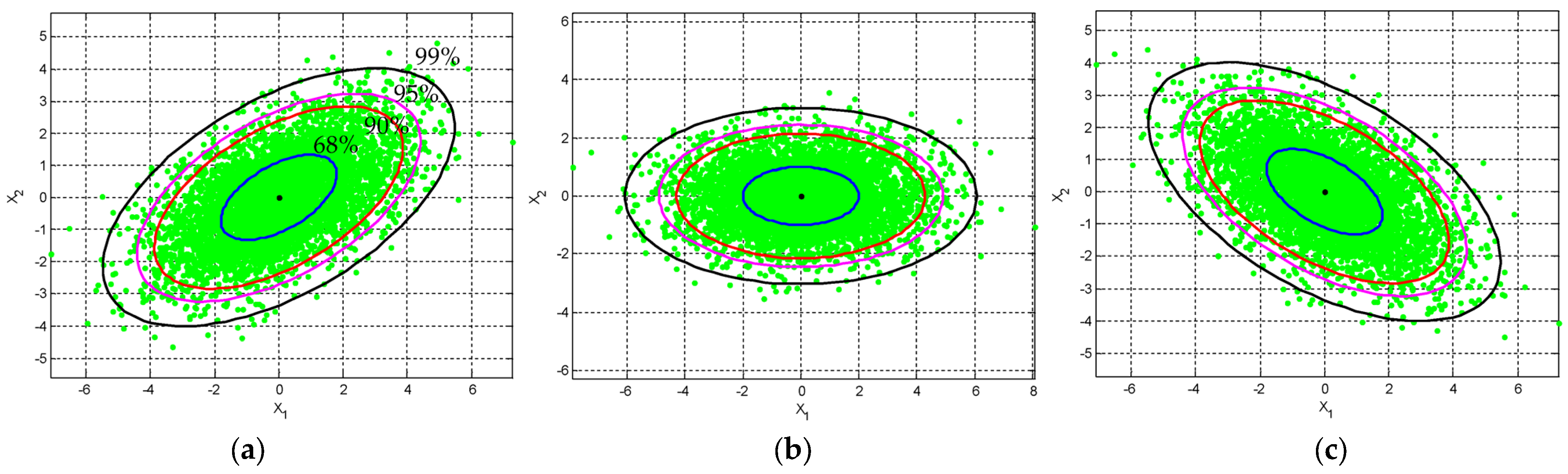
When , the axes of the ellipse are parallel to the original coordinate system, and when , the axes of the ellipse are aligned with the rotated axes in the transformed coordinate system. Figure 2 and Figure 3 show the ellipses for various levels of confidence. The plots provide the idea of confidence (error) ellipses with different confidence levels (i.e., 68%, ; 90%, ; 95%, ; and 99%, ) from inner to outer ellipses, respectively, by considering the cases where the random variables are: (1) positively correlated , (2) negatively correlated , and (3) independent . More specifically, in Figure 2, the position of the ellipse with various correlation coefficients given by the angle of inclination is specified to obtain , : (a) , ; (b) , ; and (c) , , respectively. On the other hand, in Figure 3, the position of the ellipse with various values of the correlation constant given the angle of inclination is specified to obtain : (a) , ; (b) , ; and (c) , , respectively. The rotation angle is measured with respect to the positive axis. When , the angle is in the first quadrant and when , the angle is in the second quadrant.
In the following, two case studies involve more illustrations:
(1) Equal variances for two random variables with nonzero :
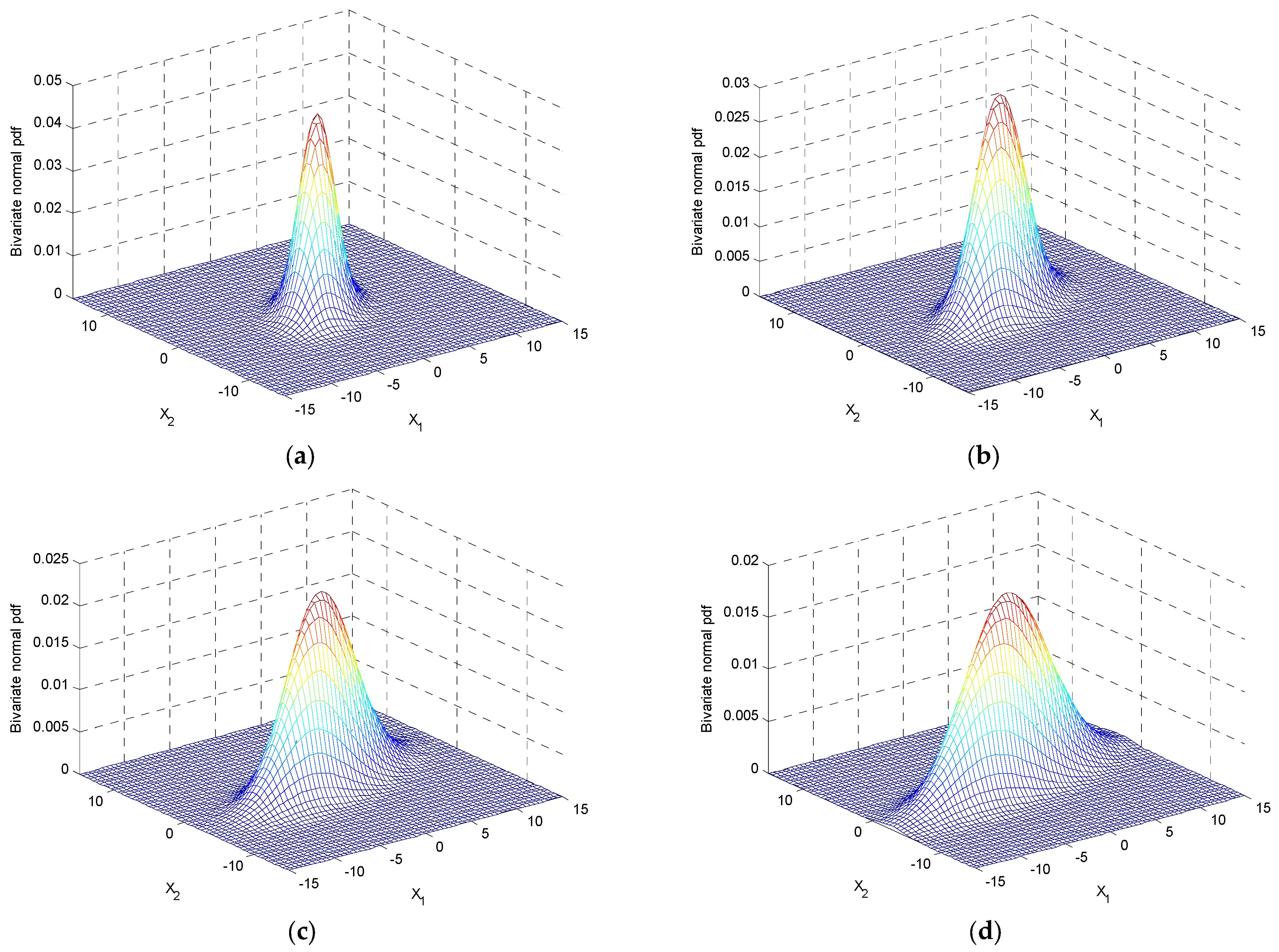
Case 1: fixed correlation coefficient. As an example, when , and the variances range from , as shown in Figure 4. As can be seen, the contours and the scatter plots are ellipses instead of circles.
Subplot (a) in Figure 5 shows the ellipses for with varying variances. Here and in subsequent illustrations, 95% confidence levels are shown;
Case 2: increasing the correlation coefficient from zero correlation. With fixed variance , the contour will initially be a circle when and then an ellipse as increases when . Subplot (b) in Figure 5 provides the contours with scatter plots for , respectively, when . The eccentricity of the ellipses increases with the increase of .
(2) Unequal variances for two random variables, with fixed correlation coefficient .
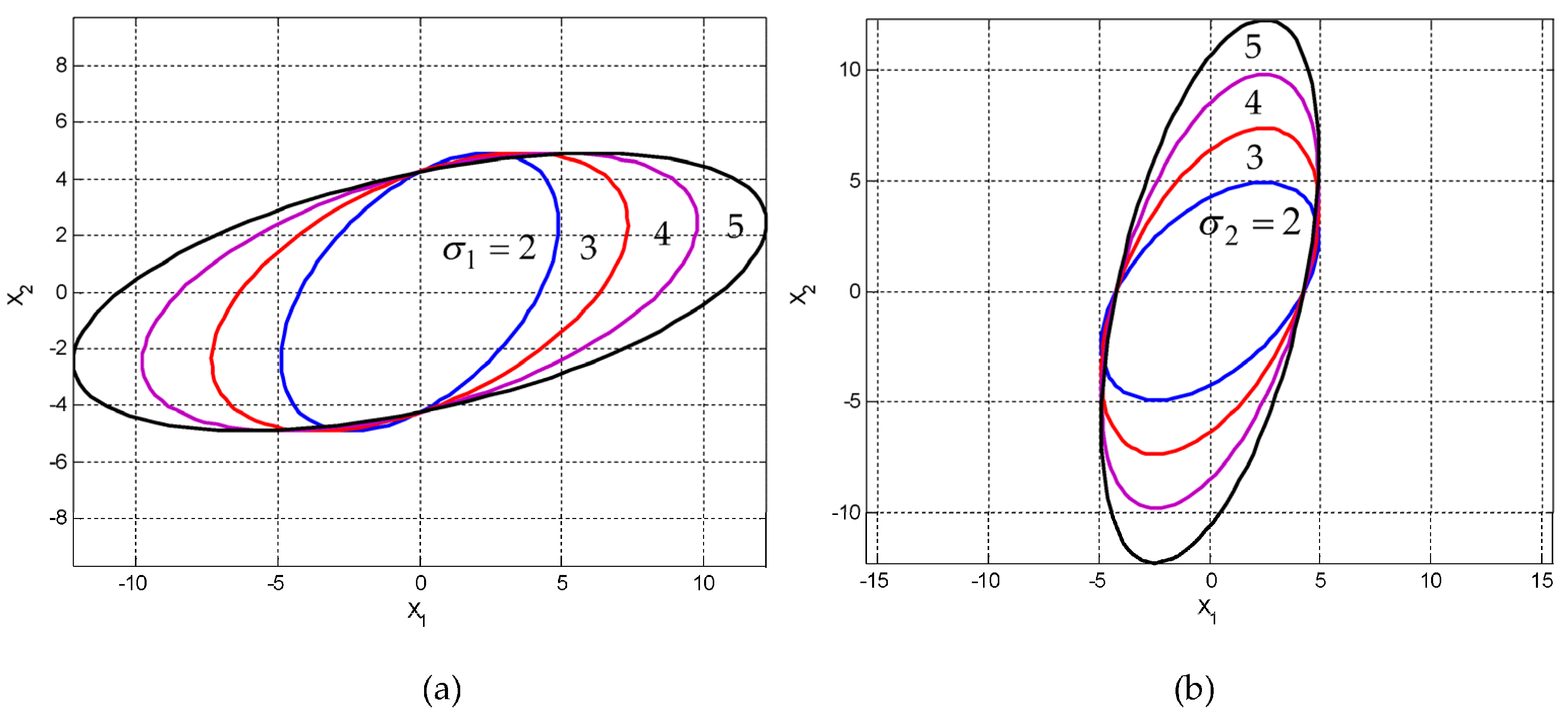
Case 1: . The variations of three-dimensional surfaces and ellipses are presented in Figure 6 and Figure 7a with the increase of , where and .
Case 2: . The variation of the ellipses is presented in Figure 7b with the increase of , where and . Figure 8 shows the variation of inclination angle as a function of and , for and for providing further insights on the variation of inclination angle with respect to and .
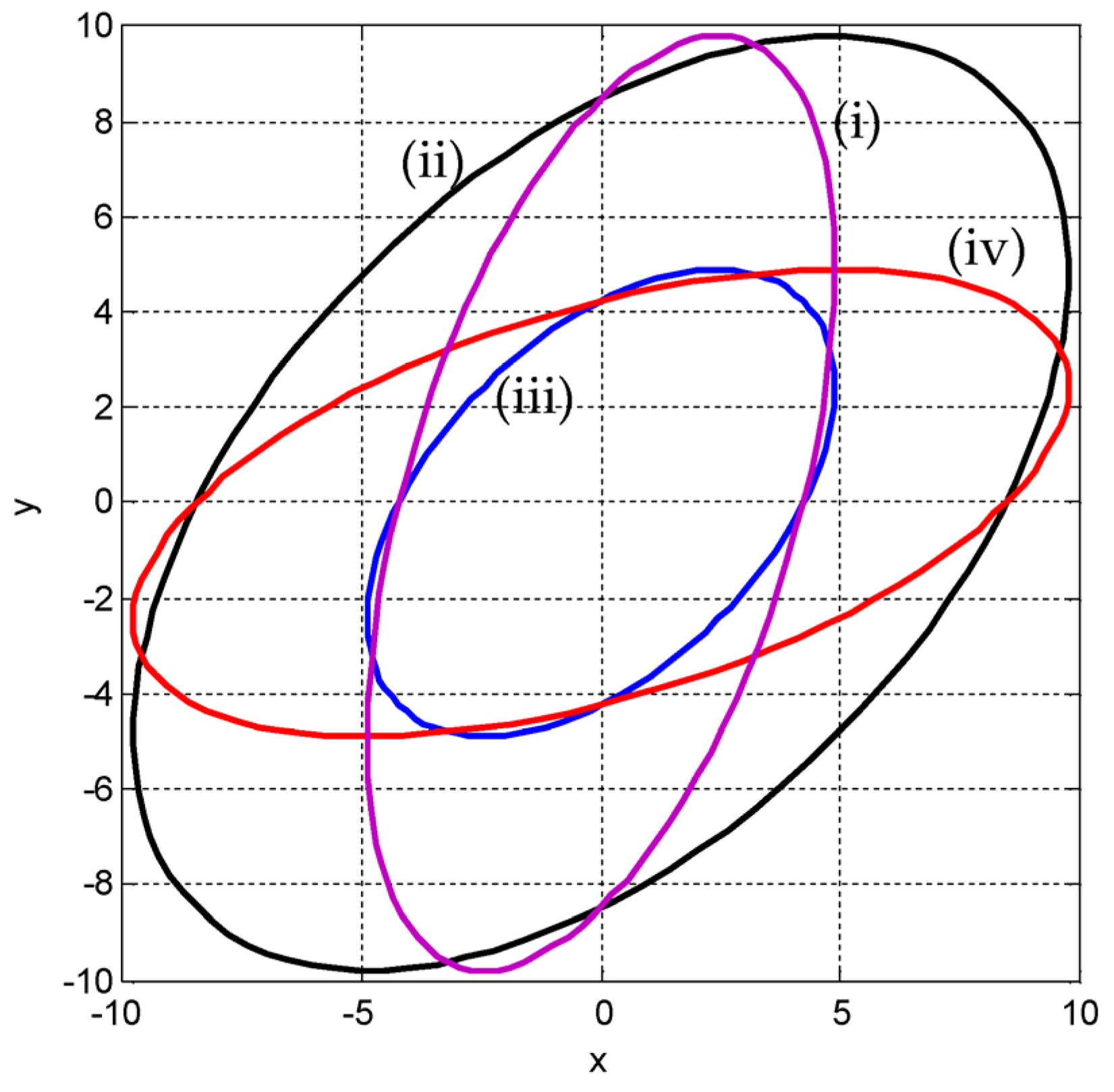
(3) Variation of the ellipses for the various positive and negative correlations. For a given variance, when is specified, the eigenvalues and the inclination angle are obtained accordingly. Figure 9 presents results for the cases of (, in this example) and (, in this example) with various correlation coefficients (namely, positive, zero, and negative), including and . In the figure, , are applied for the top plots, while , are applied for the bottom plots. On the other hand, are applied for the left plots, while are applied for the right plots. Furthermore, Figure 10 provides a comparison of the ellipses for various and for the following cases: (i) , ; (ii) , ; (iii) ; and (iv) , while .
3. Continuous Entropy/Differential Entropy
Differential entropy (also referred to as continuous entropy) is a concept in information theory that began as an attempt by Claude Shannon to extend the idea of (Shannon) entropy, a measure of the average surprise of a random variable, to continuous probability distributions. Unfortunately, Shannon did not derive this formula and rather just assumed it was the correct continuous analog of discrete entropy, but it is not [1]. The actual continuous version of discrete entropy is the limiting density of discrete points (LDDP). Differential entropy (described here) is commonly encountered in the literature, but it is a limiting case of the LDDP and one that loses its fundamental association with discrete entropy.
In the following discussion, differential entropy and relative entropy are measured in bits, which are used in the definition. Instead, if ln is used, it is then measured in nats, and the only difference in the expression is the factor.
3.1. Entropy of a Univariate Gaussian Distribution
If we have a continuous random variable with a probability density function (pdf) , the differential entropy of in bits is expressed as:
let be a Gaussian random variable
The differential entropy for this univariate Guassian distribution can be evaluated as follows:
Figure 11 shows the differential entropy as a function for the univariate Gaussian variable, which is concave downward and grows first very fast and then much more slowly at high values of .
3.2. Entropy of a Multivariate Gaussian Distribution
Let follow a multivariate Gaussian distribution , as given by Equation (2), then the differential entropy of in nats is:
and the differential entropy is given by Appendix B:
The above calculation involves the evaluation of expectations of the Mahalanobis distance as (Appendix C):
For a fixed variance, the normal distribution is the pdf that maximizes entropy. Let be a 2D Gaussian vector, and the entropy of can be calculated to be:
with a covariance matrix:
If , this becomes:
which is a function of concave downward and grows first very fast and then much more slowly for high values, as shown in Figure 12.
3.3. The Differential Entropy in the Transformed Frame
The differential entropy is invariant to a translation (change in the mean of the pdf):
and
For a random variable vector, the differential entropy in the transformed frame remains the same as the one in the original frame. It can be shown in general that:
For the case of a multivariate Gaussian distribution, we have:
It is known that the determinant of the covariance matrix is equal to the product of its eigenvalues:
For the case of a bivariate Gaussian distribution, , we have:
It can be shown that the entropy in the transformed frame is given by:
Detailed derivations are provided in Appendix D. As discussed, the determinant of the covariance matrix is equal to the product of its eigenvalues:
and thus, the entropy can be presented as:
The result confirms the statement that the differential entropy remains unchanged in the transformed frame.
4. Relative Entropy (Kullback–Leibler Divergence)
In this section, various important issues regarding relative entropy (Kullback–Leibler divergence) are discussed. Despite the aforementioned flaws, there is a possibility of information theory in the continuous case. A key result is that the definitions for relative entropy and mutual information follow naturally from the discrete case and retain their usefulness.
The relative entropy is a type of statistical distance that provides a measure of probability distribution , is different from a second reference probability distribution , denoted as:
A detailed derivation is provided in Appendix E. The relative entropy between two Gaussian distributions with different mean and variance is given by:
It is worth noting that the relative entropy measured in bits where is used in the definition. However, if ln is used, then it would be measured in nats. The only difference in the expression is the factor. Several conditions are discussed with examples of the characteristics of relative entropy:
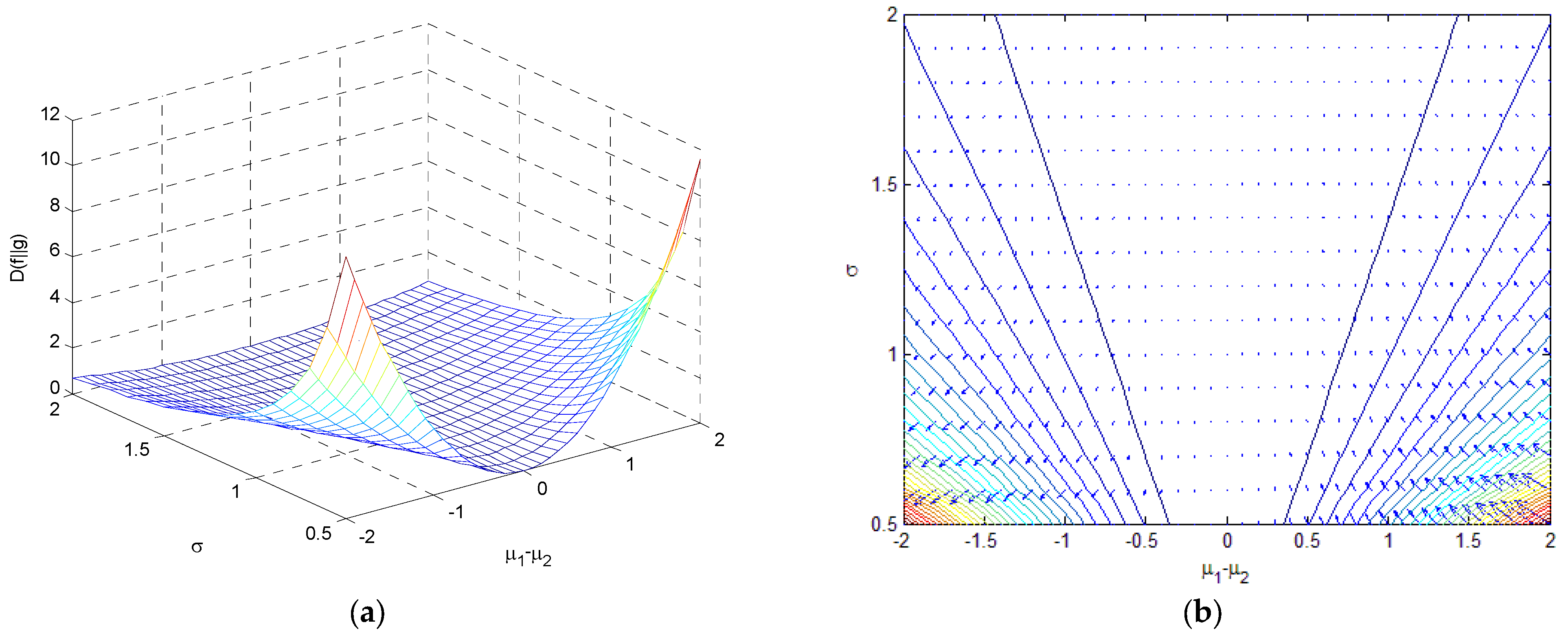
(1) If , , which is 0 when . Figure 13 shows the relative entropy as a function of and when , where a three-dimensional surface and a contour with an entropy gradient are provided.
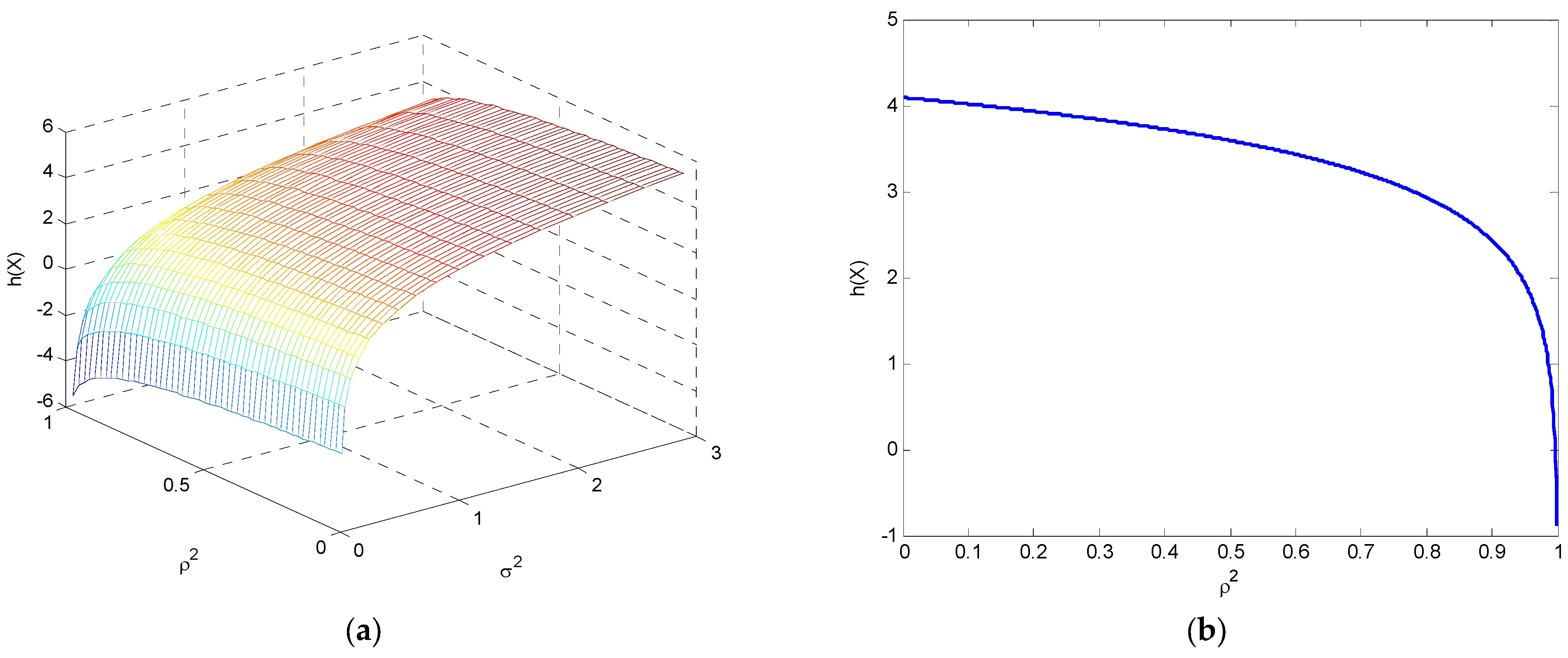
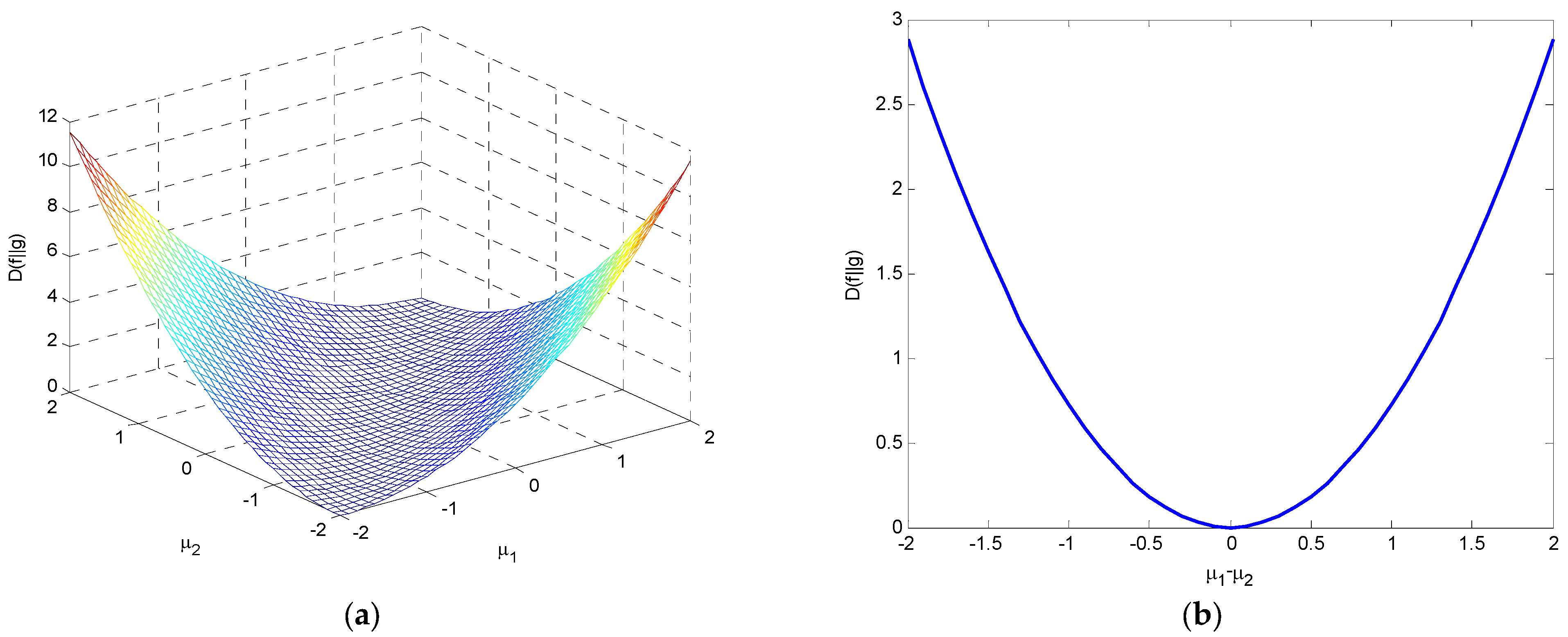
(2) If , , which is an even function with a minimum value of 0 when . Figure 14 illustrates the variations of relative entropy as a function of and and as a function of .
- –
- If , , it is a function of concave upward.
- –
- If , , it is a function of concave upward.
(3) If , . Figure 15 demonstrates relative entropy as a function of and when , where a three-dimensional surface and the contour with an entropy gradient are plotted.
When , .
When , .
Figure 16 illustrates the variations of relative entropy as a function of the variance when the other variance is unity under the condition .
A sensitivity analysis of the relative entropy due to changes in variance and mean is carried out. The gradient of given by:
can be calculated with the partial derivatives where the chain rule is involved. Based on the relationship , we have:
and the following expressions are obtained:
(1) ,
(2) ,
(3) ,
(4) .
The optimal condition for each of the above cases can be:
when ,
when ,
when ,
when .
5. Mutual Information
Mutual information is one of many quantities that measures one random variable and tells us about another. It is a dimensionless quantity with (generally) units of bits and can be thought of as the reduction in uncertainty about one random variable given knowledge of another. The mutual information between two variables with joint pdf is given by:
The mutual information between the random variables X and Y has the following relationships:
where
and
implying that and . The mutual information of a random variable with itself is self-information, which is entropy. High mutual information indicates a large reduction in uncertainty; low mutual information indicates a small reduction; and zero mutual information between two random variables, , meaning that the variables are independent. In such a case, and .
Let’s consider the mutual information between the correlated Gaussian variables X and Y given by:
Figure 17 presents the mutual information versus , where it grows first much slower and then very fast for high values of . If , the random variables X and Y are perfectly correlated, the mutual information is infinite. It can be seen that for and that for .
On the other hand, considering the additive white Gaussian noise (AWGN) channel, shown in Figure 18, the mutual information is given by:
where , and
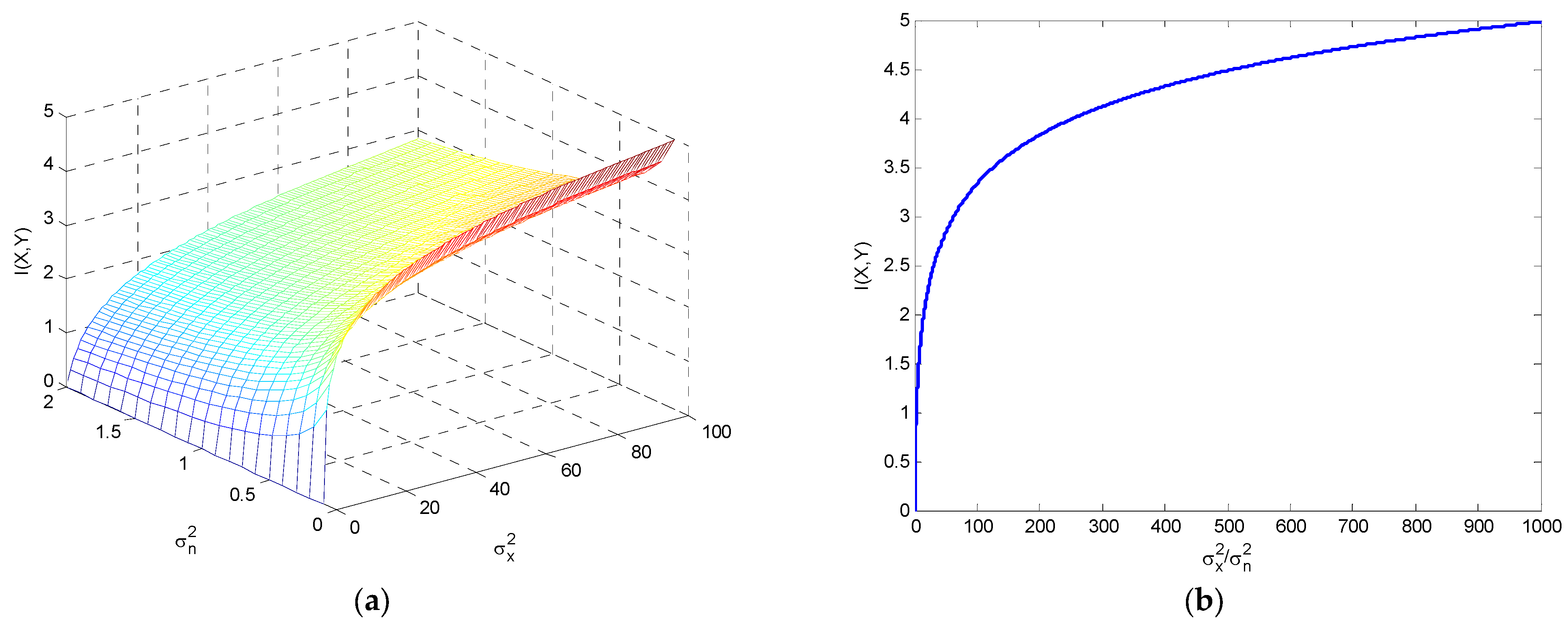
Mutual information for the additive white Gaussian noise (AWGN) channel is shown in Figure 19, including the three-dimensional surface as a function of and , and also in terms of the signal-to-noise ratio . It can be seen that the mutual information grows first very fast and then much more slowly for high values of the signal-to-noise ratio.
6. Conclusions
This paper intends to serve the readers as a supplement note for the multivariate Gaussian distribution with its entropy, relative entropy, and mutual information. The illustrative examples are discussed to provide further insights into the geometric interpretation and visualization, enabling the readers to correctly interpret the theory for future design. The fundamental objective is to study the application of multivariate sets of data to a Gaussian distribution. This paper examines broad measurements of structure for Gaussian distributions, which show that they can be described in terms of the information theory between the given covariance matrix and correlated random variables (in terms of relative entropy). To develop the multivariate Gaussian distribution with entropy and mutual information, several significant methodologies are presented through the discussion supported by illustrations, both technically and statistically. The content obtained allows readers to better perceive concepts, comprehend techniques, and properly execute software programs for future study on the topic’s science and implementations. It also helps readers grasp the themes’ fundamental concepts. Involving the relative entropy and mutual information as well as the potential correlated covariance analysis based on differential equations, a wide range of information is addressed, from basic to application concerns. Moreover, the proposed techniques of multivariate Gaussian distribution and mutual information are intended to inspire new applications of information theory to a number of areas, including information coding, nonlinear signal detection, and clinical diagnostic testing, particularly when data from improved testing equipment becomes accessible.
Author Contributions
Conceptualization, D.-J.J.; methodology, D.-J.J.; software, D.-J.J.; validation, D.-J.J. and T.-S.C.; writing—original draft preparation, D.-J.J. and T.-S.C.; writing—review and editing, D.-J.J., T.-S.C. and A.B.; supervision, D.-J.J. All authors have read and agreed to the published version of the manuscript.
Funding
The author gratefully acknowledges the support of the National Science and Technology Council, Taiwan, under grant number NSTC 111-2221-E-019-047.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Derivation of the Differential Entropy for the Univariate Gaussian Distribution
Appendix B. Derivation of the Differential Entropy for the Multivariate Gaussian Distribution
The calculation involves the evaluation of expectations of the Mahalanobis distance.
Appendix C. Evaluation of Expectations of the Mahalanobis Distance
A special case for
Appendix D. Derivation of the Differential Entropy in the Transformed Frame
The eigenvalues are the diagonal elements of the covariance matrix, namely variances, in the transformed frame. When , the eigenvectors are equal to .
Appendix E. Derivation of the Kullback–Leibler Divergence between Two Normal Distributions
References
- Verdú, S. On channel capacity per unit cost. IEEE Trans. Inf. Theory 1990, 36, 1019–1030. [Google Scholar] [CrossRef] [Green Version]
- Lapidoth, A.; Shamai, S. Fading channels: How perfect need perfect side information be? IEEE Trans. Inf. Theory 2002, 48, 1118–1134. [Google Scholar] [CrossRef]
- Verdú, S. Spectral efficiency in the wideband regime. IEEE Trans. Inf. Theory 2002, 48, 1319–1343. [Google Scholar] [CrossRef] [Green Version]
- Prelov, V.; Verdú, S. Second-order asymptotics of mutual information. IEEE Trans. Inf. Theory 2004, 50, 1567–1580. [Google Scholar] [CrossRef]
- Kailath, T. A general likelihood-ratio formula for random signals in Gaussian noise. IEEE Trans. Inf. Theory 1969, IT-15, 350–361. [Google Scholar] [CrossRef]
- Kailath, T. A note on least squares estimates from likelihood ratios. Inf. Control 1968, 13, 534–540. [Google Scholar] [CrossRef] [Green Version]
- Kailath, T. A further note on a general likelihood formula for random signals in Gaussian noise. IEEE Trans. Inf. Theory 1970, IT-16, 393–396. [Google Scholar] [CrossRef]
- Jaffer, A.G.; Gupta, S.C. On relations between detection and estimation of discrete time processes. Inf. Control 1972, 20, 46–54. [Google Scholar] [CrossRef] [Green Version]
- Duncan, T.E. On the calculation of mutual information. SIAM J. Appl. Math. 1970, 19, 215–220. [Google Scholar] [CrossRef] [Green Version]
- Kadota, T.T.; Zakai, M.; Ziv, J. Mutual information of the white Gaussian channel with and without feedback. IEEE Trans. Inf. Theory 1971, 17, 368–371. [Google Scholar] [CrossRef]
- Amari, S.I. Information Geometry and Its Applications; Springer: Berlin/Heidelberg, Germany, 2016; Volume 194. [Google Scholar]
- Schneidman, E.; Still, S.; Berry, M.J.; Bialek, W. Network information and connected correlations. Phys. Rev. Lett. 2003, 91, 238701. [Google Scholar] [CrossRef] [Green Version]
- Timme, N.; Alford, W.; Flecker, B.; Beggs, J.M. Synergy, redundancy, and multivariate information measures: An experimentalist’s perspective. J. Comput. Neurosci. 2014, 36, 119–140. [Google Scholar] [CrossRef]
- Ahmed, N.A.; Gokhale, D.V. Entropy expressions and their estimators for multivariate distributions. IEEE Trans. Inform. Theory 1989, 35, 688–692. [Google Scholar] [CrossRef]
- Misra, N.; Singh, H.; Demchuk, E. Estimation of the entropy of a multivariate normal distribution. J. Multivar. Anal. 2005, 92, 324–342. [Google Scholar] [CrossRef] [Green Version]
- Arellano-Valle, R.B.; Contreras-Reyes, J.E.; Genton, M.G. Shannon entropy and mutual information for multivariate skew-elliptical distributions. Scand. J. Stat. 2013, 40, 42–62. [Google Scholar] [CrossRef]
- Liang, K.C.; Wang, X. Gene regulatory network reconstruction using conditional mutual information. EURASIP J. Bioinform. Syst. Biol. 2008, 2008, 253894. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Novais, R.G.; Wanke, P.; Antunes, J.; Tan, Y. Portfolio optimization with a mean-entropy-mutual information model. Entropy 2022, 24, 369. [Google Scholar] [CrossRef]
- Verdú, S. Error exponents and α-mutual information. Entropy 2021, 23, 199. [Google Scholar] [CrossRef] [PubMed]
- Panzeri, S.; Magri, C.; Logothetis, N.K. On the use of information theory for the analysis of the relationship between neural and imaging signals. Magn. Reson. Imaging 2008, 26, 1015–1025. [Google Scholar] [CrossRef]
- Katz, Y.; Tunstrøm, K.; Ioannou, C.C.; Huepe, C.; Couzin, I.D. Inferring the structure and dynamics of interactions in schooling fish. Proc. Natl. Acad. Sci. USA 2011, 108, 18720–18725. [Google Scholar] [CrossRef] [PubMed]
- Cutsuridis, V.; Hussain, A.; Taylor, J.G. (Eds.) Perception-Action Cycle: Models, Architectures, and Hardware; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Ay, N.; Bernigau, H.; Der, R.; Prokopenko, M. Information-driven self-organization: The dynamical system approach to autonomous robot behavior. Theory Biosci. 2012, 131, 161–179. [Google Scholar] [CrossRef] [PubMed]
- Rosas, F.; Ntranos, V.; Ellison, C.J.; Pollin, S.; Verhelst, M. Understanding interdependency through complex information sharing. Entropy 2016, 18, 38. [Google Scholar] [CrossRef] [Green Version]
- Ince, R.A. The Partial Entropy Decomposition: Decomposing multivariate entropy and mutual information via pointwise common surprisal. arXiv 2017, arXiv:1702.01591. [Google Scholar]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. E 2013, 87, 012130. [Google Scholar] [CrossRef] [Green Version]
- Rauh, J.; Banerjee, P.K.; Olbrich, E.; Jost, J.; Bertschinger, N. On extractable shared information. Entropy 2017, 19, 328. [Google Scholar] [CrossRef] [Green Version]
- Ince, R.A. Measuring multivariate redundant information with pointwise common change in surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef] [Green Version]
- Perrone, P.; Ay, N. Hierarchical quantification of synergy in channels. Front. Robot. AI 2016, 2, 35. [Google Scholar] [CrossRef] [Green Version]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying unique information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef] [Green Version]
- Chicharro, D.; Panzeri, S. Synergy and redundancy in dual decompositions of mutual information gain and information loss. Entropy 2017, 19, 71. [Google Scholar] [CrossRef] [Green Version]
- Michalowicz, J.V.; Nichols, J.M.; Bucholtz, F. Calculation of differential entropy for a mixed Gaussian distribution. Entropy 2008, 10, 200. [Google Scholar] [CrossRef] [Green Version]
- Benish, W.A. A review of the application of information theory to clinical diagnostic testing. Entropy 2020, 22, 97. [Google Scholar] [CrossRef] [Green Version]
- Cadirci, M.S.; Evans, D.; Leonenko, N.; Makogin, V. Entropy-based test for generalised Gaussian distributions. Comput. Stat. Data Anal. 2022, 173, 107502. [Google Scholar] [CrossRef]
- Goethe, M.; Fita, I.; Rubi, J.M. Testing the mutual information expansion of entropy with multivariate Gaussian distributions. J. Chem. Phys. 2017, 147, 224102. [Google Scholar] [CrossRef]
Figure 1.
Relationship between the confidence interval and the scale factor s.

Figure 2.
The position of the ellipse with various correlation coefficients given by the angle of inclination is specified to obtain , : (a) , ; (b) ,; and (c) , , respectively.
Figure 2.
The position of the ellipse with various correlation coefficients given by the angle of inclination is specified to obtain , : (a) , ; (b) ,; and (c) , , respectively.

Figure 3.
The position of the ellipse for various values of the correlation constant with the angle of inclination is specified to obtain : (a) , ; (b) , ; and (c) , , respectively.
Figure 3.
The position of the ellipse for various values of the correlation constant with the angle of inclination is specified to obtain : (a) , ; (b) , ; and (c) , , respectively.

Figure 4.
The contours and the scatter plots of ellipses for equal variances with a fixed : (a) (b) (c) (d) .
Figure 4.
The contours and the scatter plots of ellipses for equal variances with a fixed : (a) (b) (c) (d) .

Figure 5.
Ellipses for (a) with varying variances ; and (b) equal variances with varying .

Figure 6.
The variations of surface plots in three-dimensional with the increase in for a fixed where : (a) ; (b) ; (c) ; and (d) .
Figure 6.
The variations of surface plots in three-dimensional with the increase in for a fixed where : (a) ; (b) ; (c) ; and (d) .

Figure 7.
Ellipses for a fixed correlation coefficient when for a fixed : (a) , increases where and ; and (b) , increases where and .
Figure 7.
Ellipses for a fixed correlation coefficient when for a fixed : (a) , increases where and ; and (b) , increases where and .

Figure 8.
The variation for inclination angle with a function of and , for (a) ; and (b) .

Figure 9.
(, ) with (a) ; (b) as compared to (, ) with (c) ; and (d) .

Figure 10.
Comparison of the ellipses for various (i) , ; (ii) , ; (iii) ; and (iv) , while .

Figure 11.
The differential entropy as a function of for a univariate Gaussian variable.

Figure 12.
The variation in differential entropy for the bivariate Gaussian distribution (a) as a function of and , and (b) as a function of when .
Figure 12.
The variation in differential entropy for the bivariate Gaussian distribution (a) as a function of and , and (b) as a function of when .

Figure 13.
The variation in relative entropy as a function of and when for (a) a three-dimensional surface; and (b) a contour with an entropy gradient.
Figure 13.
The variation in relative entropy as a function of and when for (a) a three-dimensional surface; and (b) a contour with an entropy gradient.

Figure 14.
The variations in relative entropy with for (a) a three-dimensional surface as a function of and ; and (b) as a function of .
Figure 14.
The variations in relative entropy with for (a) a three-dimensional surface as a function of and ; and (b) as a function of .

Figure 15.
The variation in relative entropy as a function of and with for (a) at the three-dimensional surface; and (b) contour with an entropy gradient.
Figure 15.
The variation in relative entropy as a function of and with for (a) at the three-dimensional surface; and (b) contour with an entropy gradient.

Figure 16.
Variations of relative entropy as a function of (a) when fixed and (b) when fixed , respectively ().
Figure 16.
Variations of relative entropy as a function of (a) when fixed and (b) when fixed , respectively ().

Figure 17.
Mutual information versus between the correlated Gaussian variables.

Figure 18.
Schematic illustration of the additive white Gaussian noise (AWGN) channel.

Figure 19.
The mutual information with the additive white Gaussian noise (AWGN) channel for (a) the three-dimensional surface as a function of and ; and (b) in terms of the signal-to-noise ratio.
Figure 19.
The mutual information with the additive white Gaussian noise (AWGN) channel for (a) the three-dimensional surface as a function of and ; and (b) in terms of the signal-to-noise ratio.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Jwo, D.-J.; Cho, T.-S.; Biswal, A. Geometric Insights into the Multivariate Gaussian Distribution and Its Entropy and Mutual Information. Entropy 2023, 25, 1177. https://0-doi-org.brum.beds.ac.uk/10.3390/e25081177
AMA Style
Jwo D-J, Cho T-S, Biswal A. Geometric Insights into the Multivariate Gaussian Distribution and Its Entropy and Mutual Information. Entropy. 2023; 25(8):1177. https://0-doi-org.brum.beds.ac.uk/10.3390/e25081177
Chicago/Turabian StyleJwo, Dah-Jing, Ta-Shun Cho, and Amita Biswal. 2023. "Geometric Insights into the Multivariate Gaussian Distribution and Its Entropy and Mutual Information" Entropy 25, no. 8: 1177. https://0-doi-org.brum.beds.ac.uk/10.3390/e25081177
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.