1. Introduction
Nipah virus (NiV) is a zoonotic notorious pathogen that belongs to the
Paramyxoviridae family. The first outbreak of this virus was recorded in Malaysia about 22 years ago; following that, successive outbreaks have been reported in many countries in the south-east Asia region [
1]. In a recent outbreak in 2018, the fatality rate was estimated to be 91% in a group of 23 cases in India [
2]. The journey of NiV transmission to various hosts starts from the fruit bat (
Pteropus species), which represents the viral reservoir, and when these bats drop their saliva or urine on fruits that would be consumed by humans and animals, viral infection occurs [
3]. In addition to that, humans can be infected with NiV through eating NiV infected pork or even through contacting the body fluids of infected humans where man-to-man transmission occurs [
4]. After the infection, cases usually suffer from mild to moderate symptoms of headache, vomiting, and fever where these symptoms may develop into severe encephalitis or acute harmful manifestations to the respiratory system, leading eventually to death [
5]. Because of the high virulence, the simple way of dissemination, and the continuously elevated rates of mortality and morbidity of the viral outbreaks, NiV was categorized as a biosafety level 4 virus [
6].
Exploration of the NiV genome revealed that it is composed of six essential genes, G, F, L, N, M, and P [
7]. Investigation of proteins that are expressed from these genes shows that G and F proteins have a significant role in the viral entry to the infected cell, where G protein helps the virus in attachment to the host cell, then F protein guides the fusion between the viral and the host cell membranes. Translation of L protein gives rise to an RNA-dependent RNA polymerase enzyme, which is required for viral genome replication. N and M genes code for nucleoprotein and matrix protein, respectively. The distinct P gene codes for four different proteins, namely phosphoprotein, V, W, and C proteins, where the last three proteins have a vital role in fighting against the host immune response [
8].
The absence of an effective drug or vaccine against NiV put this zoonotic virus on the WHO’s list for urgent need of research work to devise a solution for this emerging infectious pathogen [
9]. Several approaches for designing an effective vaccine against NiV have been followed, including: vaccines based on viral vectors such as vesicular stomatitis virus [
10] and rhabdovirus [
11], recombinant vaccines such as recombinant measles virus vaccine, which expresses envelope glycoprotein of NiV [
12], and Nipah virus-like particles composed of several NiV proteins [
13].
During the last decades, there has been a great revolution in the fields of bioinformatics and structural biology with continuous updates in the computational tools for analysis of genomic data, which aided in the development of new approaches for potential vaccine design [
14]. This progression led to the appearance of the immunoinformatics field, which can be defined as the interface between immunological data and computational tools that can handle these data [
15]. This new approach was tried successfully against several pathogens ranging from bacteria such as
Staphylococcus aureus [
16] and
Moraxella catarrhalis [
17] to viruses such as Zika virus [
18] and also fungi such as
Candida albicans [
19]. In the current study, the whole proteome of NiV was analyzed for antigenicity and virulence of each protein, where the best candidates were selected for B and T cell epitope prediction. Top ranking epitopes were assembled to construct the chimeric epitope vaccine against NiV, which was analyzed for its antigenicity and reactivity through computational tools.
2. Results
2.1. Nomination of Proteins as Vaccine Candidates
After the application of antigenicity score as the first step of NiV proteome screening, six out of nine proteins that represent the whole proteome of NiV were found to have an antigenicity score above 0.5. The functions of these six primary candidates were studied, and we selected the ones that had significant virulence roles. Consequently, we selected proteins G and F, which have roles in viral attachment to host cells, and proteins V and W that participate in combating host innate immune response. Before passing to the epitope prediction stage, we concluded that there is a high degree of similarity between the sequences of V and W proteins, therefore, we selected only protein V for epitope prediction, and one of the major criteria in the filtration of the predicted epitopes from V protein was that the epitope must show cross similarity between both V and W proteins.
2.2. Prediction of B Cell Epitopes
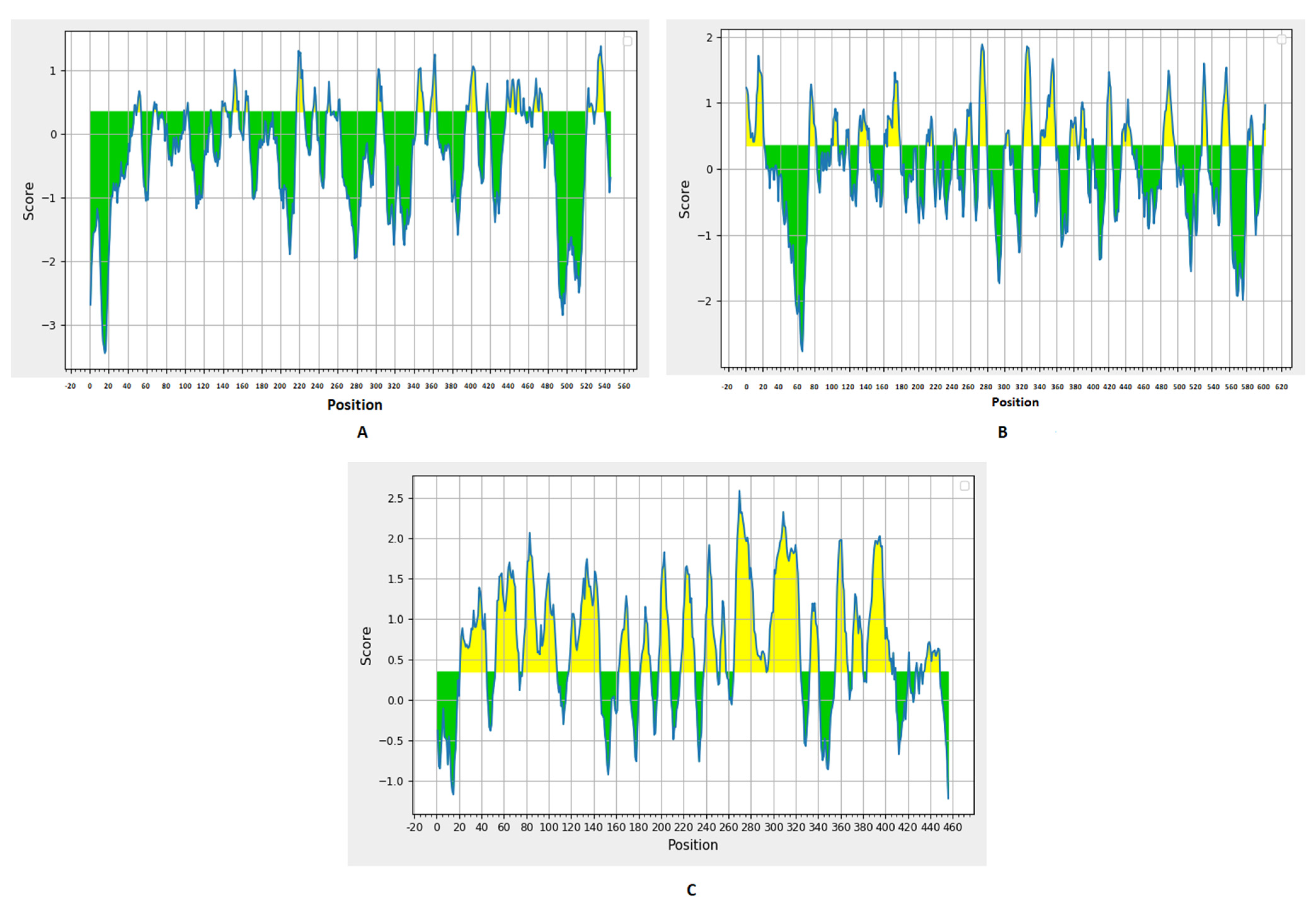
Prediction of B cell epitopes was performed through the BepiPred linear epitope prediction method (
Figure 1) with a threshold value of 0.35. There were 27, 24, and 22 predicted epitopes for F, G, and V proteins, respectively. This list was downsized by selecting epitopes sized between eight to 18 peptides (
Table 1 and
Table 2), and, finally, we selected the top two epitopes for each protein based on the antigenicity score predicted by VaxiJen 2.0 and the conservancy analysis in the nine studied proteomes from UniProt for designing the multitope vaccine with other T cell epitopes.
2.3. T Cell Epitopes Prediction
Regarding MHC-I epitopes, 29,025, 32,049, and 24,165 epitopes were predicted for F, G, and V proteins, respectively, with a percentile rank from 0.01 to 100, where epitopes that had a percentile rank less than two were analyzed for the selection of best candidates, as epitopes with small percentile rank are good binders. We selected MHC-I epitopes based on their antigenicity score and the number of reactions with different alleles (
Table 3 and
Table 4). Moving to MHC-II epitopes, there were14,364, 15,876, and 11,934 predictions for F, G, and V proteins, respectively, and the top 10% of these predictions were analyzed according to their antigenicity score, the number of reactions with different alleles, and their ability to induce interferon-gamma (
Table 5 and
Table 6). Again for epitopes of V protein, we analyzed the conservancy of epitopes in W protein. As a final point before assessment of epitope candidates through docking analysis, the conservancy of the selected 18 epitopes—the total number of epitopes to be assembled into the multitope vaccine—showed 100% conservancy through multiple sequence alignment of nine targeted NiV proteomes from UniProt. Therefore, selected epitopes were predicted to possess a cross-reactivity against Nipah M and Nipah B.
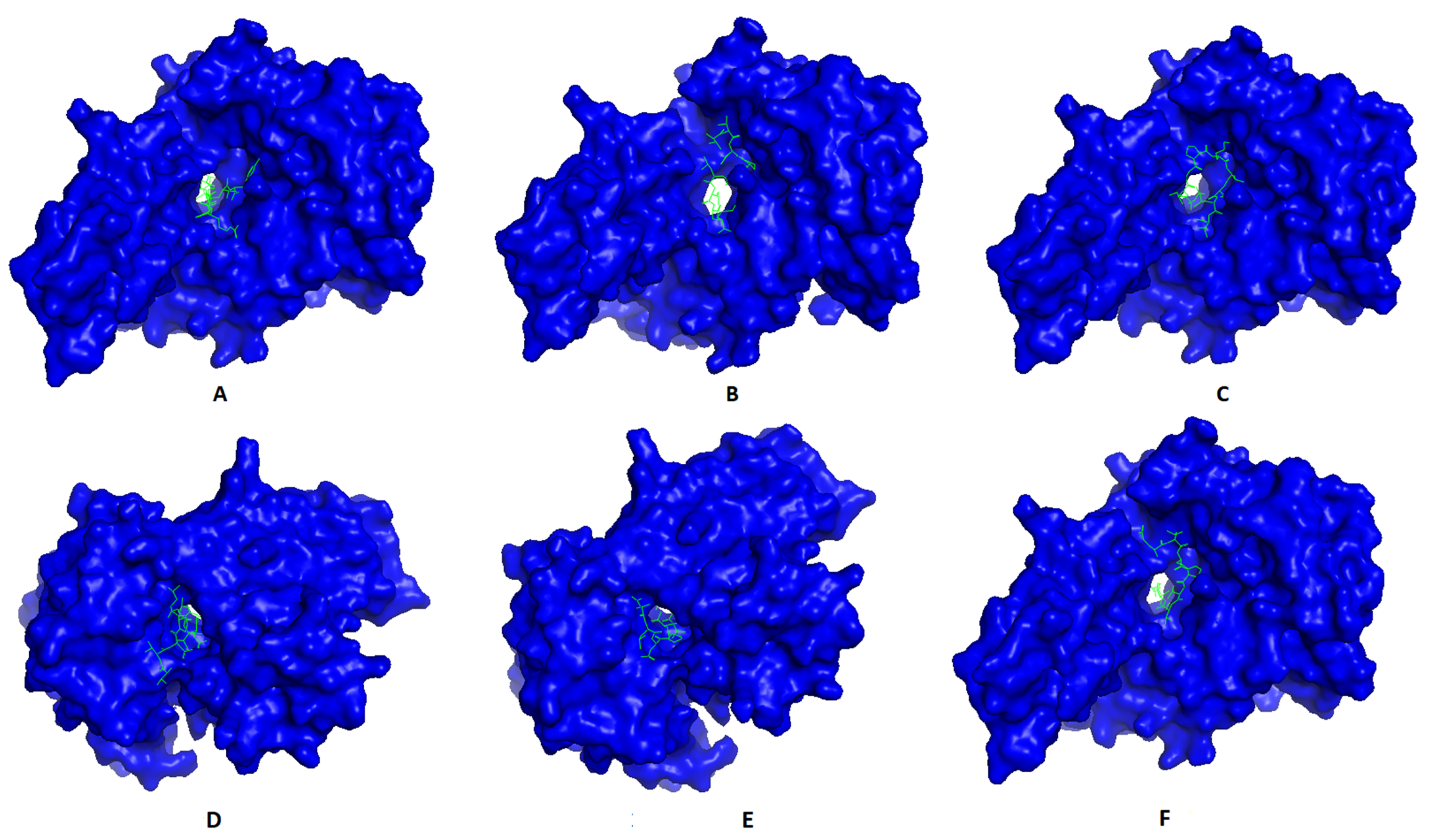
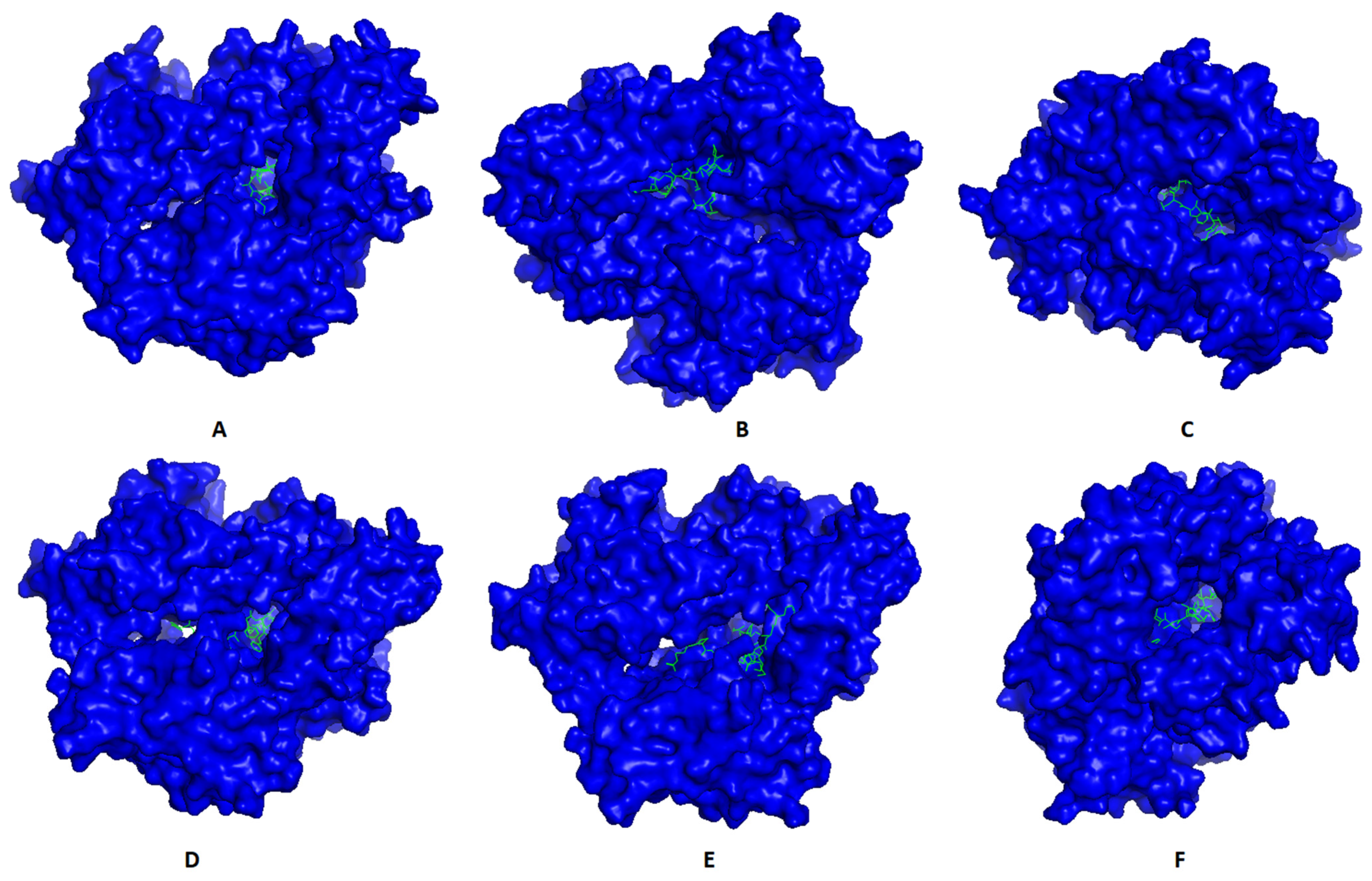
2.4. Molecular Docking of T Cell Epitopes
Most promising MHC-I and MHC-II epitopes were analyzed for their binding affinity to a representative allele to confirm their nomination for constructing the multitope vaccine.
Figure 2 shows the best docking sites of top predicted MHC-I epitopes in the receptor of HLA-A*11:01, while
Figure 3 shows those of MHC-II epitopes in the receptor of HLA-DRB1*04:01. The binding energy of the docking study for suggested epitopes of each protein is shown in
Table 7 where the values ranged from –7.1 to –9.1, confirming the nomination of these epitopes for constructing the multitope vaccine.
2.5. Multitope Vaccine Construction, Physicochemical Characteristics Assessment, and Secondary Structure Prediction
After the nomination of the best B and T cell epitopes from F, G, and V proteins, the multitope vaccine was designed based on six CTL epitopes (two from each protein), six HTL epitopes (two from each protein), and six BCL epitopes (two from each protein) linked together by GGGS, GPGPG, and KK linkers, respectively. Moreover, the beta-defensin adjuvant and the PADRE peptide sequence were also incorporated to constitute the final sequence of the designed multitope vaccine with a total length of 359 amino acids and sequenced as the following:
“EAAAKGIINTLQKYYCRVRGGRCAVLSCLPKEEQIGKCSTRGRKCCRRKKEAAAKAKFVAAWTLKAAAGGGSIVEKKRNTYGGGSTVNPSLISMGGGSEIGPKVSLIGGGSTVNPLVVNWGGGSQLDPVVTDVGGGSLSYAPEIAVGPGPGIILYVLSIASLCIGLGPGPG KYKIKSNPLTKDIVIGPGPGTLYFPAVGFLVRTEFGPGPGYQASFSWDTMIKFGDGPGPGRPGTPMPKSRGIPIKGPGPGDKLELVNDGLNIIDFKKNYNSEGIAIGKKRRVRPTSSGDKKVGQSGTCIKKLSIGSPSKIYDSKKIAVSKEDRETKKTSDDEEADQLEFKKAKFVAAWTLKAAAGGGS”.
The final predicted vaccine design was analyzed for allergenicity using the prediction approach of Blast search on allergen representative peptides (ARPs) and assessed as non-allergen. Following that, toxicity and antigenicity prediction demonstrated that the designed vaccine was non-toxic and antigenic with an antigenicity score of 0.71. Moreover, the final vaccine construction was found to be soluble upon overexpression with a SOLpro score of 0.96 (proteins with a score above 0.5 were assessed to be soluble upon overexpression). Other physicochemical characteristics of the designed vaccine, which were predicted by ProtParam online tools, are shown in
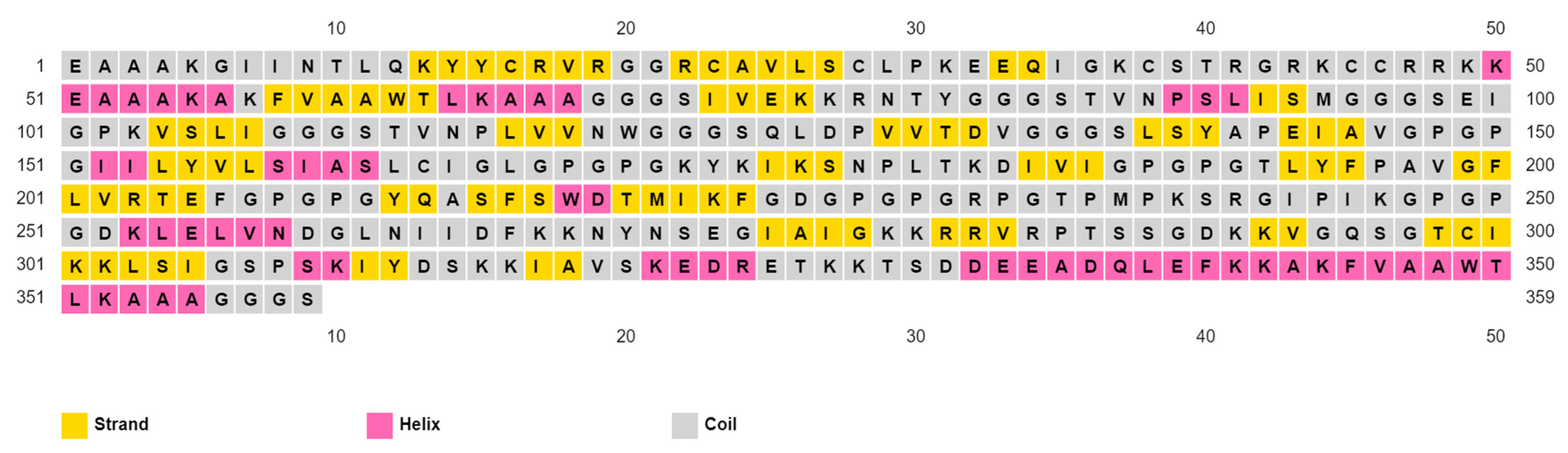
Table 8. Finally, prediction of the secondary structure demonstrated that the vaccine had a 16.44% helix, a 26.46% strand, and a 57.10% coil of its secondary structure (
Figure 4).
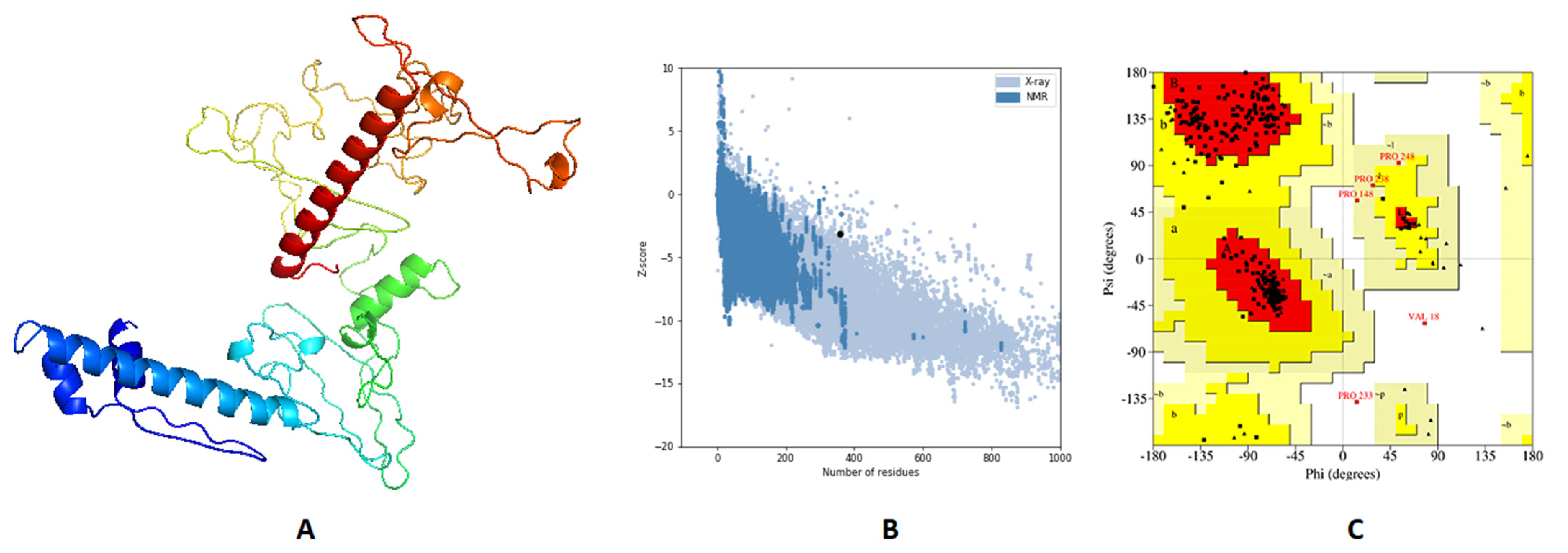
2.6. Tertiary Structure Prediction, Refinement, and Validation
The 3D primary structure of the predicted vaccine was modeled by 3Dpro webserver (
http://scratch.proteomics.ics.uci.edu/, accessed on 20 July 2021) and validation of this structure through Ramachandran plot analysis and Z-score estimation demonstrated that 89.8%, 9.8%, and 0.4% of residues were located in favored, allowed, and outlier regions, respectively, and the estimated Z-score was –2.84. Validation of the primary structure proved the need for structure refinement, which was processed by GalaxyRefine, where the best model (
Figure 5A) demonstrated an enhancement of Z-score from –2.84 to –3.17 (
Figure 5B). Moreover, Ramachandran plot analysis showed an improvement for the refined structure where 93.1%, 6.6%, and 0.4% of residues were in favored, allowed, and outer regions, respectively (
Figure 5C).
2.7. Vaccine Disulfide Engineering
After validating the refined vaccine structure, we performed disulfide engineering to increase the stability of the designed model. Regarding the current 3D structure and after analysis using the DbD2 server, 47 pairs of amino acids were found to be able to make disulfide bond, but after considering the accepted range of energy (which must be less than 2.2) and the Chi3 value (which must be between −87 and +97)), only three pairs (78ARG-84GLY), (94MET-99GLU), and (272SER-275ILE) were recommended for mutating with cysteine.
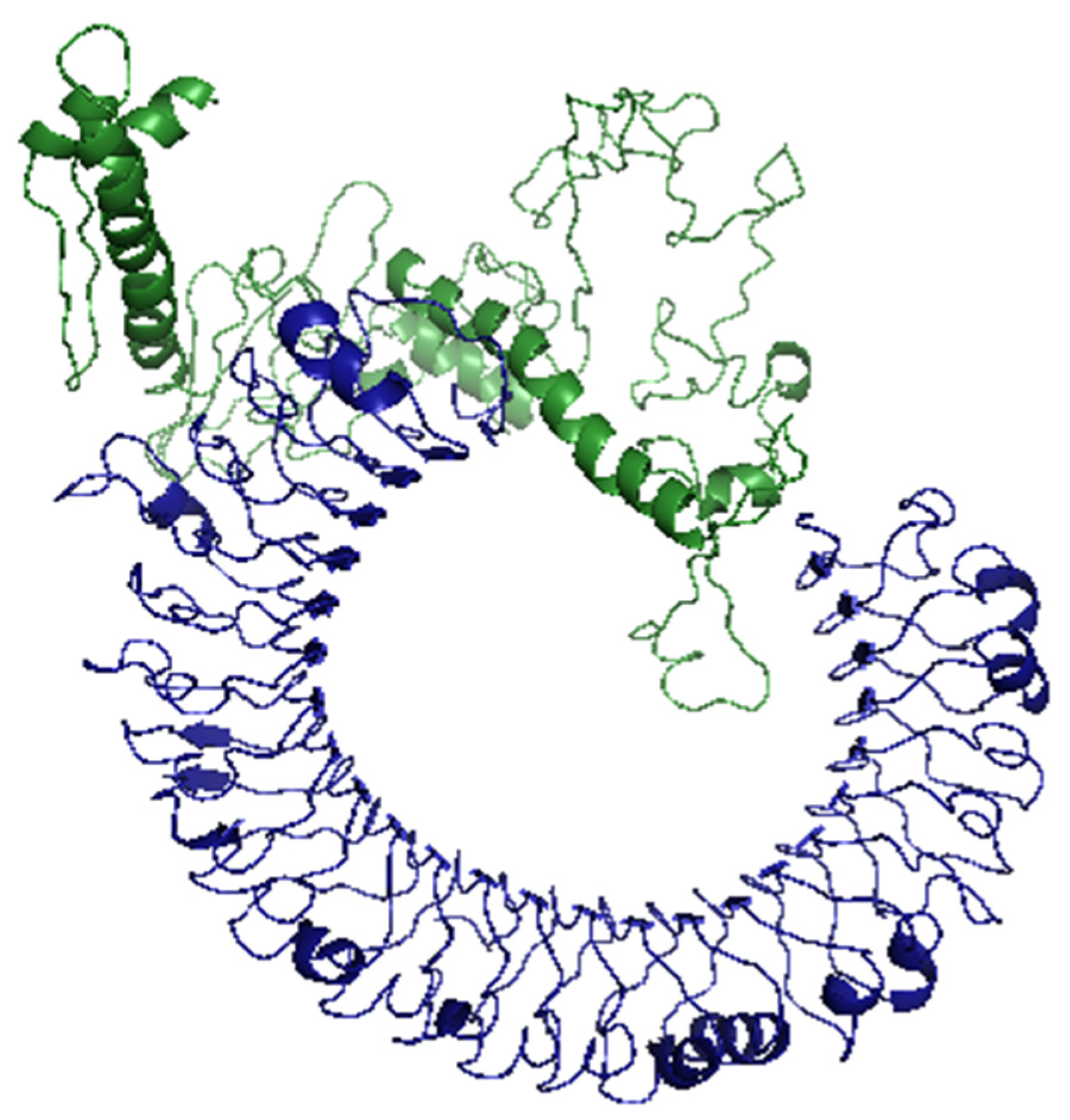
2.8. Molecular Docking of the Vaccine with TLR3
To validate the binding between the designed vaccine and its respective receptor through a computational approach, we ran molecular docking analysis through ClusPro 2.0 server. The server predicted 30 potential docking complexes of varying binding energies, where model number seven (
Figure 6) showed the lowest binding energy value (–1263.9), which was small enough to predict a strong binding between the designed vaccine and TLR3.
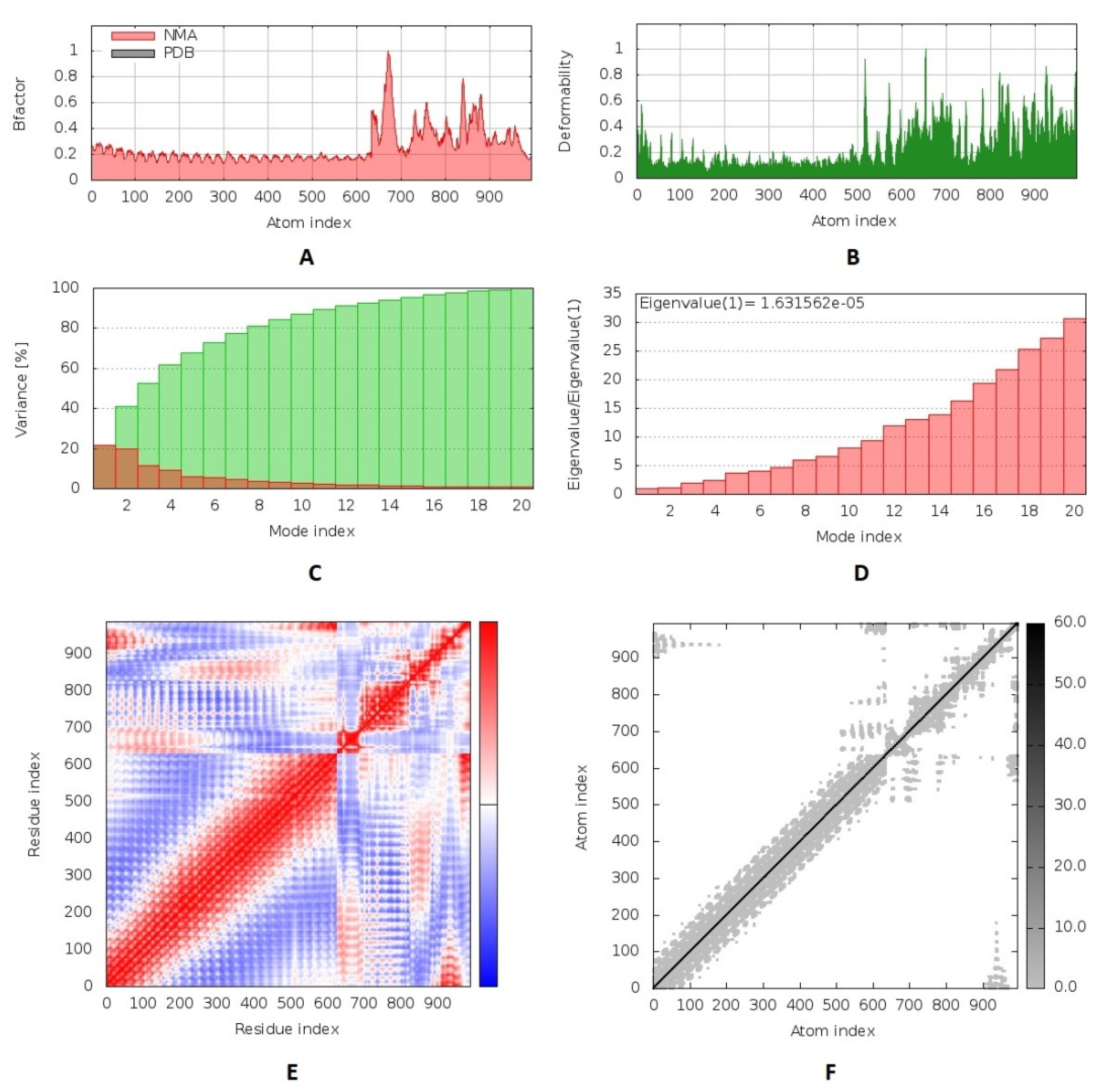
2.9. Molecular Dynamics Simulation
We performed a molecular dynamics simulation to analyze the stability of the vaccine–receptor complex where the iMODS server was employed to run this process. The deformability of the complex relied on the individual distortion of each residue, symbolized by hinges in the chain (
Figure 7B). The estimated eigenvalue of the complex was found to be 1.63 × 10
−5 (
Figure 7D). Generally, an inverse relationship was found between the eigenvalue and the variance related to each normal mode (
Figure 7C). The B-factor scores of normal mode analysis in the iMODS server were equivalent to RMS (
Figure 7A). The covariance matrix explained the coupling between pairs of residues where different pairs demonstrated correlated, anti-correlated, or uncorrelated motions represented by red, blue, and white colors, respectively (
Figure 7E). The server formed an elastic network model (
Figure 7F), as it showed the pairs of atoms linked through springs according to the degree of stiffness between them, and that was represented by color where it moved to darker gray with stiffer strings.
2.10. Vaccine Reverse Translation and Codon Optimization
The last stage of the current computational analysis was reverse translation and codon optimization on the amino acid sequence of the multitope vaccine where the JCat server was employed for this process. Regarding the submitted amino acid sequence of the multitope vaccine, the measured GC content was 50.23%, which was accepted as it was located within the accepted range (30%–70%). Furthermore, the Codon Adaptation Index (CAI) was calculated as 0.99, demonstrating a high probability of protein expression when we transferred our experiments to the wet lab; the value of CAI ranged 0–1, and the accepted range is between 0.8 and 1.
3. Discussion
Nipah virus is an emerging zoonotic pathogen with a wide range of pathogenesis and a high percentage of fatality [
20]. The antiviral drug, ribavirin, was used with the early diagnosed cases with NiV, where it showed some improvement with these cases, but the fatality rate was still high [
21]. Moreover, to assess the activity of ribavirin against NiV, it was administered along with chloroquine to Nipah infected hamster models, where they failed to prevent animal death [
22]. With successive outbreaks of NiV and the absence of an effective drug that can cure patients and reduce the high fatality rate of NiV, the development of an effective vaccine became a significant health priority. During the last decade, several trials that adopted different approaches were performed to provide a putative solution for this deadly virus. One of the early trials was performed in 2012 based on Hendra virus G glycoprotein to design a subunit vaccine against NiV [
23]. Unfortunately, a detailed analysis of that promising vaccine showed 100% relapse of encephalitis on tested African green monkeys [
24]. Other vector and virus-like particle vaccines were designed, but, until now, none of these vaccines have been approved for human usage.
Recently, there has been a revolution in the field of vaccine development as a result of the great progression in bioinformatics, structural biology, and computational tools that aided largely in the process of handling and analyzing genomic data of several microorganisms [
25]. The approach of predicting and designing vaccines through in silico studies has improved massively in the last few years, where its applications extended to involve bacteria, viruses, fungi, and even cancer [
26]. Multitope vaccine has been predicted through computational approaches against several microorganisms such as Mayaro virus [
27], Lassa virus [
28], COVID-19 [
29], and
E. coli [
30], where the predicted vaccine of the last study was expressed and analyzed through wet lab experimental validation and showed protection against urinary tract infection caused by uropathogenic
E. coli in animal models. The application of immunoinformatics for designing NiV vaccine through epitope prediction was shown in many studies. In 2014, a study predicted B and T cell epitopes of G and F proteins and analyzed their probability to act as vaccine candidates [
31]. With a similar approach, only T cell epitopes of all NiV proteins were predicted for designing peptide-based vaccines [
32]. Moreover, B and T cell epitopes of membrane proteins and RNA-dependent RNA polymerase (RdRp) proteins were also analyzed in the studies [
33] and [
34], respectively. The commonality between these studies is that proteins under investigation were selected without a clear rationale, and the candidates were single epitopes. In addition to that, some of these studies reported vaccines based on a single viral protein, and RNA viruses have a high mutation rate, as continuous mutations contribute largely to viral pathogenicity and early ineffectiveness of vaccine. This is a major disadvantage of a single viral protein vaccine [
35].
On the other hand, in the current study, we selected our protein candidates after the analysis of the whole proteome for the antigenicity score and the virulence role of every single protein. The primary list was composed of four proteins, G, F, V, and W, which had a high antigenicity score and possessed a vital role in NiV virulence. However, after careful analysis of the amino acid sequence of proteins V and W, we found that there was a high similarity in their sequences; therefore, we excluded W protein and used the factor of epitope cross-match between V and W proteins as a major one for selecting the most prominent epitopes from V protein. G protein has a vital role in the attachment of NiV to two cellular receptors, ephrin-B2 and ephrin-B3, and this subsequently triggers F-mediated membrane fusion between NiV and the infected cell [
36]. Viral surface proteins are potential targets for vaccine design [
37]. Moving to the contribution of V and W proteins in NiV virulence, it is known that signal transducers and activators of transcription (STAT) proteins are transcription factors that play key roles in interferon (IFN) and cytokine signaling. V and W proteins have a common N-terminal sequence that binds to STAT1 and STAT2 and blocks IFN-induced signal transduction, allowing the virus to evade the human immune response [
38].
Another major advantage of the current study is that the vaccine was constructed based on multitopes, which have superior efficacy and protection against infectious agents [
39] over a single epitope-based vaccine. Therefore, the current study did not end solely with prediction of B and T cell epitopes as did the above-mentioned studies; instead, top-ranked epitopes were selected to construct the multitope vaccine. Ranking criteria relied on percentile rank, antigenicity, ability to induce interferon-gamma, binding affinity to a representative allele, the conservancy of these epitopes (because, as we mentioned, NiV has a high rate of mutation), and the number of reactive alleles with the selected epitope to cover a high percentage in terms of population coverage. As mentioned, top-ranked epitopes were arranged together using appropriate linkers. Moreover, the beta-defensin adjuvant and the PADRE peptide were also incorporated into the final construct of the multitope vaccine to strengthen the stimulated immune response and reduce the HLA polymorphism in the population [
40].
Before predicting the three-dimensional structure of the designed multitope vaccine, the final vaccine amino acid sequence was analyzed regarding its physicochemical properties, antigenicity, allergenicity, solubility upon over-expression, and toxicity using computational tools. The analysis demonstrated that the proposed sequence of the vaccine is stable, hydrophilic, soluble upon over-expression, antigenic, non-allergen, and non-toxic. The next step was predicting the 3D structure, where structure validation using Ramachandran plot and ProSA demonstrated that a good-quality 3D structure was modeled and, for a better design, protein refinement was performed. The final refined structure was assessed, which proved generation of a high-quality 3D model. To provide more stability to the final designed model, we performed disulfide engineering, as disulfide bonds were proved to reduce the conformational entropy and increase the free energy of the denatured state of the designed protein, leading to an elevation in the stability of protein conformation [
41]. Finally, molecular docking between the designed vaccine and TLR-3 was performed to analyze the binding affinity between the complex components, where the docking score of the generated complex revealed that there was a good affinity between the vaccine and its receptor. To obtain a closer view of the docked complex, we employed normal mode analysis that was integrated into iMODS server and the output data, which described the collective functional motions of the complex and predicted that the designed vaccine can stimulate a specific immune response against NiV.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}