
GUDM: Automatic Generation of Unified Datasets for Learning and Reasoning in Healthcare

Abstract
:1. Introduction

- (1)
- Automatically defines a global unified data model at run time from diverse data sources seamlessly.
- (2)
- Resolves the problem of overlapping attributes across multiple datasets by utilizing the proposed expert-centric priority based approach.
- (3)
- Produces the unified dataset in a consistent way and makes it easy for automatic learning and reasoning systems/tools to efficiently acquire knowledge from it that can be used for different types of reasoning and prediction services.
2. Related Work
3. Global Unified Data Model
- DS (Diverse data sources): the set of diverse datasets recording different information on the same individuals.
- PM (Preprocessing methods): a set of methods used for loading DS, finding missing values, finding intrinsic relationships across multiple datasets DS and making the datasets uniform using reduction technique.
- DM (Data modeling methods): the set of methods used to prioritize the datasets, define a unified structure for the data model and log data from the diverse DS.
- UD (Unified dataset): the dataset created from DS by exploiting PM and DM.
- LR (Learning and reasoning): the set of machine learning algorithms/tools used for learning the data stored in UD to enable reasoning and prediction services for new problems (this is beyond the scope of this study and will be considered in future work).


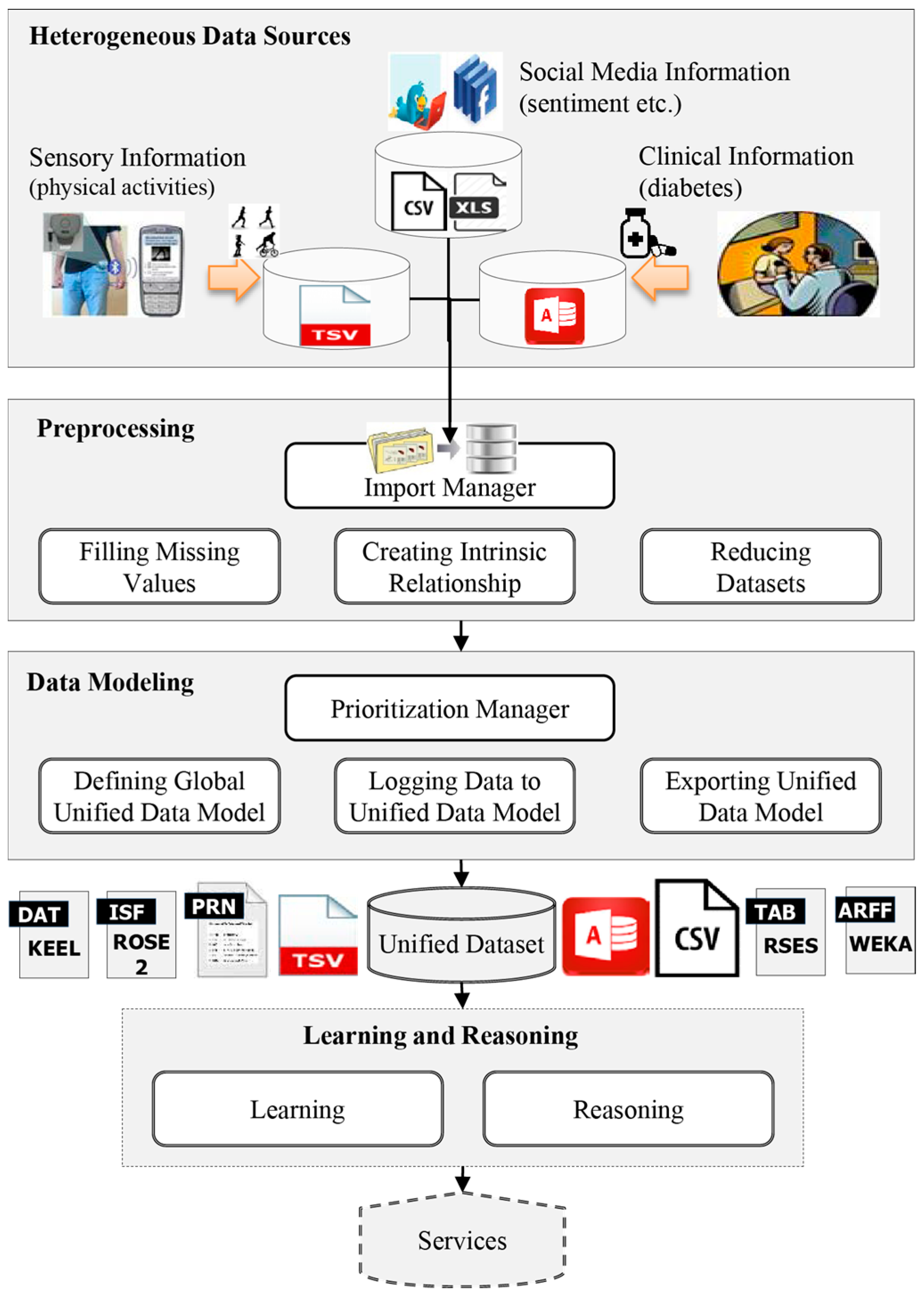
4. Methods: Generation of a Unified Dataset
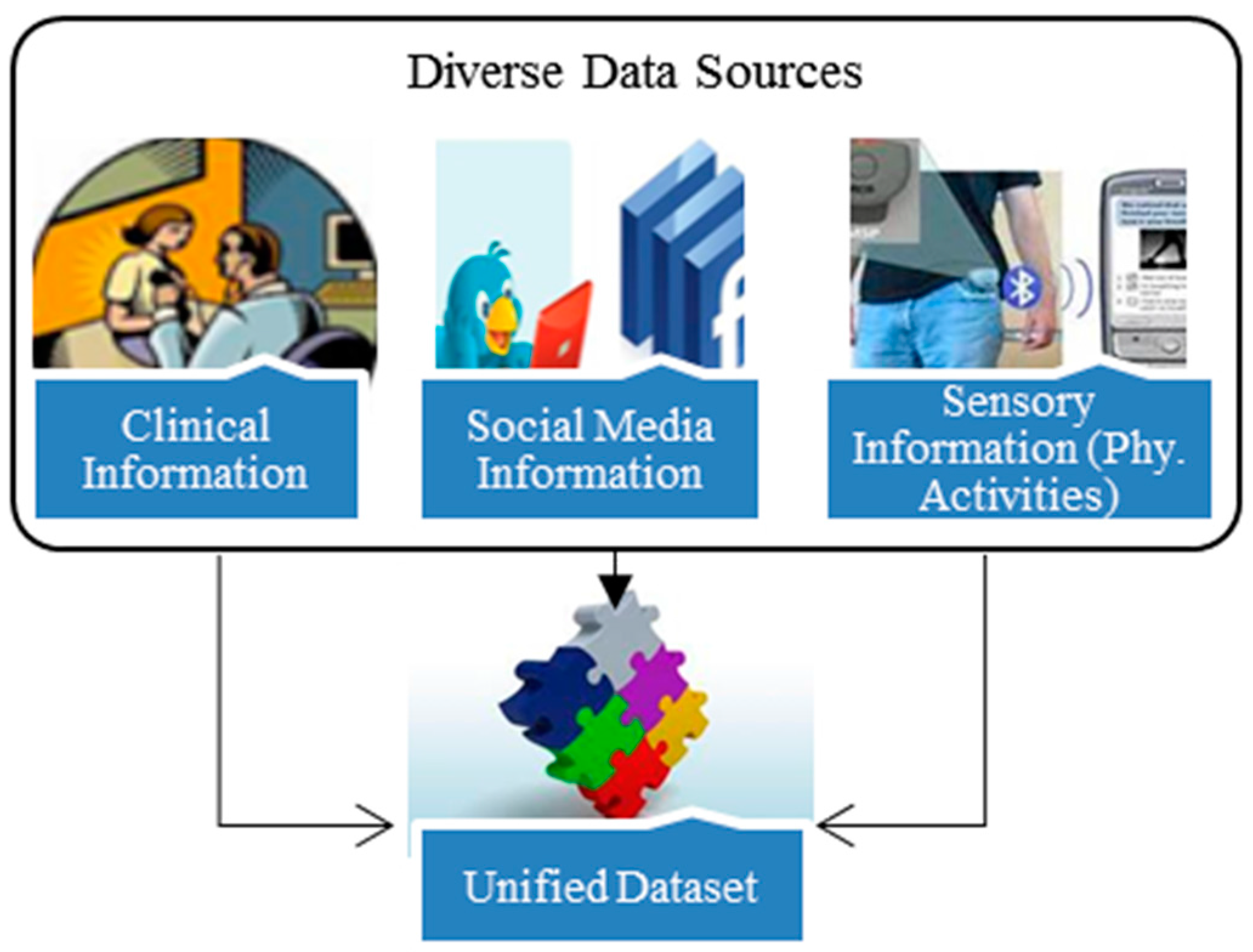
4.1. Heterogeneous Data Sources
- ClinicalDataset = {ID, Gender, TC, TG, LDL, HDL, SGOT, SGPT, FBS, SBP, DBP, Weight, Height, Hypoglycemia, HbA1c, diabetesType}
- SocialmediaDataset = {ID, Gender, Symptoms, Sentiments, Activities}
- SensoryDataset = {ID, Activities}
4.2. Preprocessing Phase
4.2.1. Import Phase
4.2.2. Filling Missing Values
4.2.3. Finding Intrinsic Relationships
4.2.4. Reduction
4.3. Generating a Unified Dataset
4.3.1. Prioritization Phase
4.3.2. Defining a Global Unified Data Model
4.3.3. Combining Datasets: Logging Data to the Unified Data Model
4.3.4. Exporting Unified Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) ROSE2 (.isf) | ||
| Type of Attribute | Description | Data Type |
| Decision | Used for class attribute | decision [val 1, val 2, ...] |
| Nominal (symbolic) | Used for ordered list | <val1,val2…,valN> |
| Nominal (symbolic) | Used for unordered list | [val1,val2…,valN] |
| Integer | Used for positive integer | (numbercoded) |
| Continuous | Used for continuous numbers | (continuous) |
| Donʼt care | To be omitted during analysis | (omit) |
| (b) WEKA (.arff) | ||
| Type of Attribute | Description | Data Type |
| Date | Used for date | date [<date-format>] |
| Nominal (symbolic) | Used for ordered list | {val1,val2…,valN} |
| Nominal (symbolic) | Used for unordered list | {val1,val2…,valN} |
| Integer | Used for positive integer | numeric |
| Continuous | Used for continuous numbers | numeric |
| String | Used for string | string |
| (c) KEEL (.dat) | ||
| Type of Attribute | Description | Data Type |
| Decision | Used for class attribute | outputs |
| Integer | Used for integers | integer [min, max] |
| Continuous | Used for continuous | real [min, max] |
| Nominal | Used for symbolic/strings | nominal {val1, val2, ...} |
| Inputs | Used for specification of input attributes | outputs |
| (d) RSES (.tab) | ||
| Type of Attribute | Description | Data Type |
| String | Used for symbolic | symbolic |
| Symbolic | Used for symbolic | symbolic |
| Nominal | Used for symbolic | symbolic |
| Integer | Used for integers | numeric 0 |
| Continuous | Used for continuous numbers. D denotes number of digits after decimal point | numeric D |
4.4. Unified Dataset: Algorithm for the Creation of Integrated Dataset
| Algorithm 1. Automatic Creation of Unified Dataset |
| Input DS–Set of n heterogeneous datasets |
| Output M’–A unified dataset |
| 1. [import datasets from the list of n available sources] |
| 2. [complete missing values, if any] |
| 3. [make the datasets uniform (i.e., equal size), if not] |
| (a) [find intrinsic relationship (i.e., sort the instances w.r.t their IDs), if not] |
| (b) [reduce the datasets to equal size] |
| , where |
| 4. [assign user-defined priorities to each dataset] |
| 5. [create unified data model] |
| 6. [log data to the unified dataset] |
| (a) [find the list of overlapped attributes] |
| (b) [find the list of unique attributes] |
| (c) [log data to the unique attributes of the unified data model] |
| (d) [log data to the overlapped attributes of the unified data model] |
| If (datasets of the overlapped attributes have different priorities) |
| Else |
| 7. [export unified dataset] |
| (a) [assign appropriate data type to each attribute] |
| (b) [export unified dataset in specific format] |
| 8. end |
4.5. Learning and Reasoning from Unified Dataset
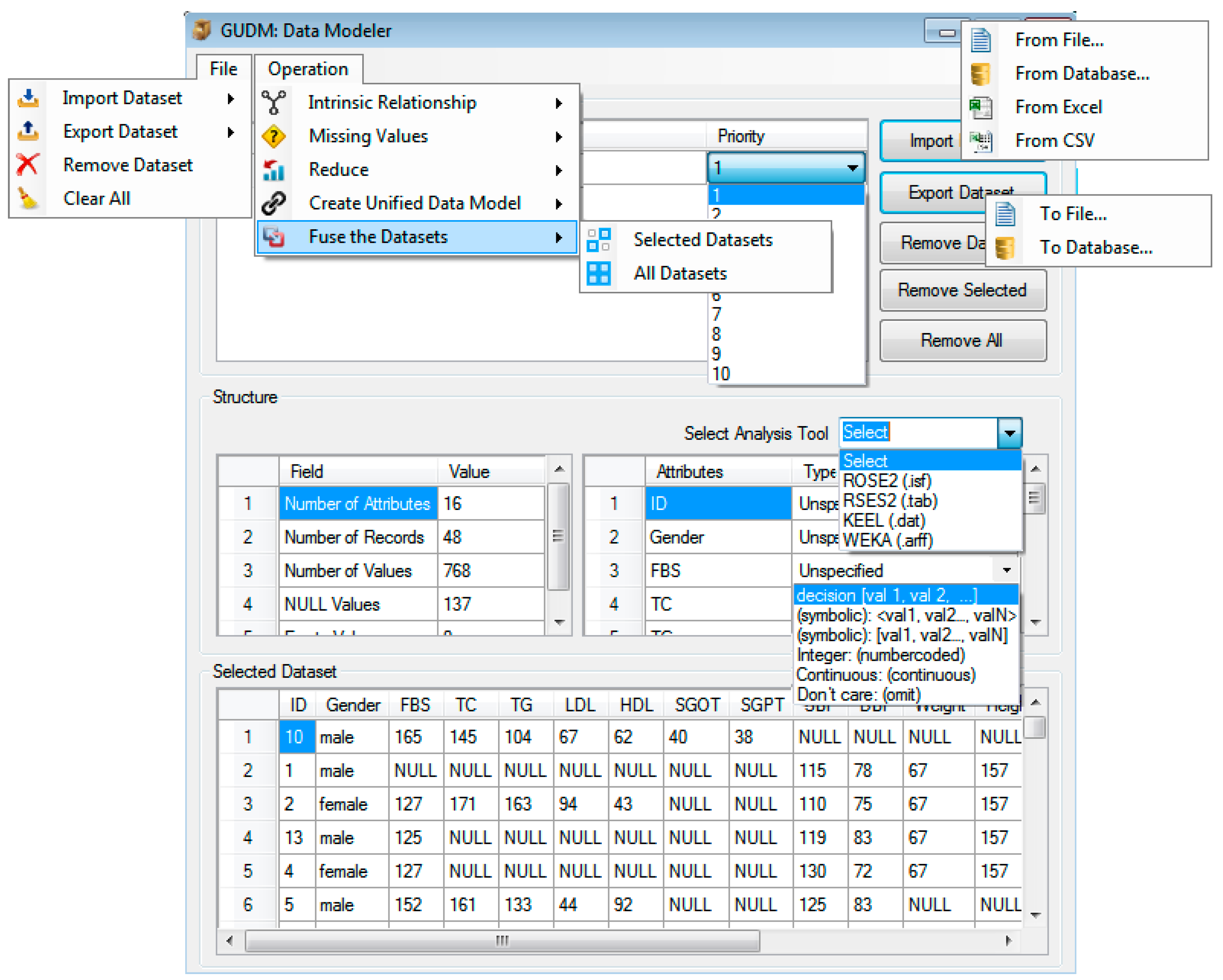
5. Working of the Data Modeler: Unified Dataset Creation

6. Simulation of “Data Modeler” for Unified Dataset Creation
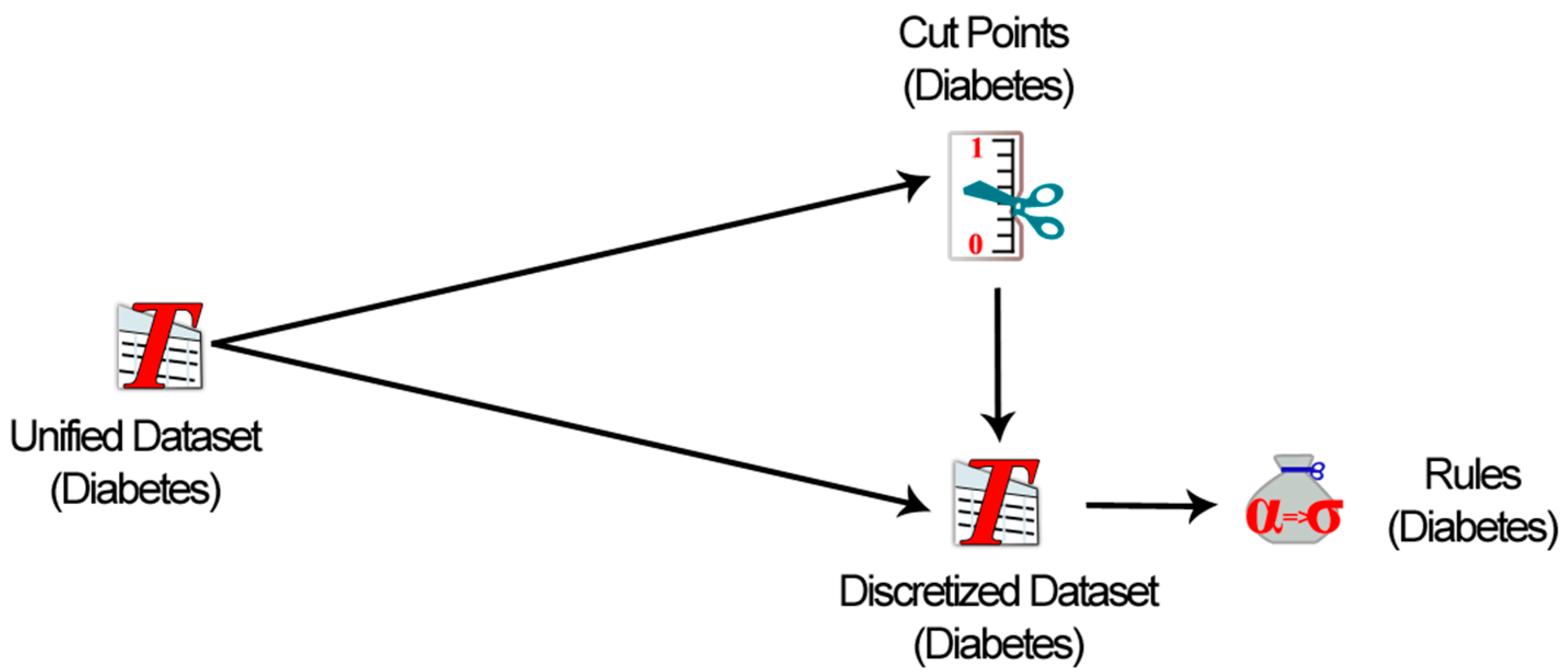
6.1. Case Study: Diabetes Mellitus
6.2. Working of the Data Modeler
- Selection of the target data analysis tool
- Assignment of the correct data types
- Support for specific file structure
- Support for multiple output file formats


| Rule # | Rules |
|---|---|
| 1 | If (BMI = [18.5–24.9]) & (Age = (50, Inf)) & (SBP = [120–139]) & (Hba1c = (7.4, Inf)) & (TC = (−Inf, 200)) & (SGPT = [7–56]) = > DiabetesType = 1 |
| 2 | If (Gender = M) & (SBP = (−Inf, 120)) & (Hba1c = (6.4–7.4]) & (LDL = [100–129]) =>DiabetesType = 2 |
| 3 | If (BMI = [18.5–24.9]) & (Age = [30–50]) & (SBP = (−Inf, 120)) & (TG = (−Inf, 150)) & (HDL = [40–60]) =>DiabetesType = 2 |
7. Data Modeler Evaluation
| Dataset Group | Dataset | No. of Attributes | No. Records | No. of Overlapping Attributes | %Age of Missing Values | Uniformity (Same Size) | Intrinsic Relationship (Sorted Records) | Evaluator |
|---|---|---|---|---|---|---|---|---|
| Gp1 | testDataset1 | 4 | 5 | 2 | 5 | yes | yes | Domain expert1 |
| testDataset2 | 3 | 5 | 2 | 6.5 | ||||
| Gp2 | testDataset3 | 9 | 10 | 3 | 30 | no | no | Domain expert2 |
| testDataset4 | 4 | 10 | 3 | 10 | ||||
| Gp3 | testDataset5 | 3 | 5 | 2 | 13.3 | yes | no | Domain expert3 |
| testDataset6 | 4 | 5 | 2 | 10 | ||||
| Gp4 | testDataset7 | 16 | 48 | 2 | 15 | no | no | Knowledge engineer1 |
| testDataset8 | 2 | 47 | 2 | 0 | ||||
| testDataset9 | 5 | 49 | 3 | 8.5 | ||||
| Gp5 | testDataset10 | 6 | 20 | 2 | 4.5 | no | no | Knowledge engineer2 |
| testDataset11 | 6 | 20 | 2 | 6.5 | ||||
| testDataset12 | 6 | 20 | 2 | 2 | ||||
| Gp6 | testDataset13 | 7 | 20 | 3 | 3 | no | no | Knowledge engineer2 |
| testDataset14 | 5 | 29 | 2 | 5 | ||||
| testDataset15 | 9 | 35 | 1 | 10 |
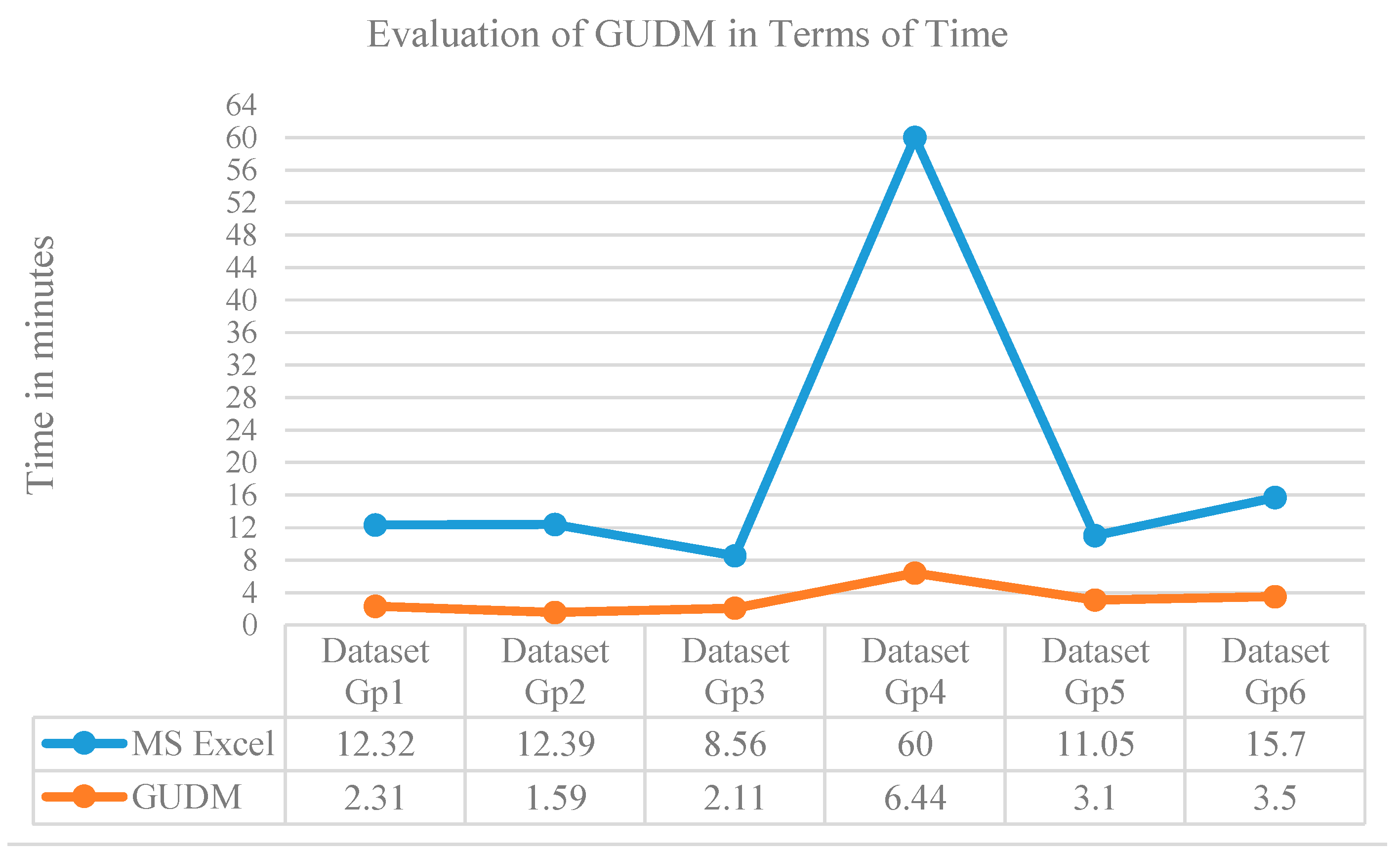
| Datasets Group | Unified Dataset | Evaluator | Unified Dataset Creation Time | |
|---|---|---|---|---|
| Traditional Tool (MS Excel) | GUDM (Data Modeler) | |||
| Gp1 | UD1 | Domain expert1 | 12.32 | 2.31 |
| Gp2 | UD2 | Domain expert2 | 12.39 | 1.59 |
| Gp3 | UD3 | Domain expert3 | 8.56 | 2.11 |
| Gp4 | UD4 | Knowledge engineer1 | 60 | 6.44 |
| Gp5 | UD5 | Knowledge engineer2 | 11.05 | 3.10 |
| Gp6 | UD6 | Knowledge engineer2 | 15.7 | 3.5 |
| Average time taken | 20.00333 | 3.175 | ||
| Average reduction of time | 16.82833 | |||
| Percent reduction of time | 84.12765 | |||

8. Discussion of Significance, Challenges and Limitations of the Work
9. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Branson, A.; Hauer, T.; McClatchey, R.; Rogulin, D.; Shamdasani, J. A data model for integrating heterogeneous medical data in the health-e-child project. Stud. Health Technol. Inform. 2008, 138, 13. [Google Scholar]
- Ziegler, P.; Dittrich, K.R. Data integration—Problems, approaches, and perspectives. In Conceptual Modelling in Information Systems Engineering; Springer: Berlin, Germany, 2007; pp. 39–58. [Google Scholar]
- Levy, A.Y. Logic-based techniques in data integration. In Logic-Based Artificial Intelligence; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2000; pp. 575–595. [Google Scholar]
- Gagnon, M.; Littenberg, B. The vermont diabetes information system: A cluster randomized trial of a population based decision support system. J. Gen. Int. Med. 2009, 24, 1303–1310. [Google Scholar]
- O’Connor, P.J.; Sperl-Hillen, J.M.; Rush, W.A.; Johnson, P.E.; Amundson, G.H.; Asche, S.E.; Ekstrom, H.L.; Gilmer, T.P. Impact of electronic health record clinical decision support on diabetes care: A randomized trial. Ann. Fam. Med. 2011, 9, 12–21. [Google Scholar] [CrossRef]
- Calhoun, Y.; Giam, P.; Kaplan, L.; Spasic, B. Diabetes Manager CDSS: A Diabetes Management Tool for PCPss and Patients. Available online: http://162389445480246740.weebly.com/uploads/1/4/5/9/14590780/final_project.pdf (accessed on 1 June 2015).
- CDS Starter Kit: Diabetes Follow-Up Care. Available online: http://www.healthit.gov/sites/default/files/del-3-7-condition-example-diabetes.pdf (accessed on 29 May 2015).
- Hussain, M.; Khattak, A.M.; Khan, W.A.; Fatima, I.; Amin, M.B.; Pervez, Z.; Batool, R.; Saleem, M.A.; Afzal, M.; Faheem, M. Cloud-based smart CDSS for chronic diseases. Health Technol. 2013, 3, 1–23. [Google Scholar] [CrossRef]
- Ahmad, M.; Pervez, Z.; Cheong, T.; Lee, S. Oblivious user management for cloud-based data synchronization. J. Supercomput. 2015, 71, 1–23. [Google Scholar] [CrossRef]
- Ahmad, M.; Pervez, Z.; Kang, B.H.; Lee, S. O-bin: Oblivious binning for encrypted data over cloud. In Proceedings of the 29th IEEE International Conference on Advanced Information Networking and Applications, Gwangju, Korea, 25–27 March 2015.
- Ali, R. GUDM—A tool for pre-processing and fusing heterogeneous datasets. Available online: https://sourceforge.net/projects/gudm/ (accessed on 27 September 2014).
- Viceconti, M.; Taddei, F.; Montanari, L.; Testi, D.; Leardini, A.; Clapworthy, G.; van Sint Jan, S. Multimod data manager: A tool for data fusion. Comput. Methods Progr. Biomed. 2007, 87, 148–159. [Google Scholar] [CrossRef]
- El Zanfaly, D.S.; Darwish, A.; Gomaa, A.G.G.; Youssif, A.A.A. Heterogeneous data reduction model for payment request file of direct debit processes. In Proceedings of the 8th International Conference on Informatics and Systems: Advances in Data Engineering and Management, Cairo, Egypt, 14–16 May 2012; pp. DE-8–DE-17.
- Chirathamjaree, C. A data model for heterogeneous data sources. In Proceedings of the IEEE International Conference on E-Business Engineering, Xi’an, China, 22–24 October 2008; pp. 121–127.
- Edwards, I.; Gros, X.E.; Lowden, D.W.; Strachan, P. Fusion of NDT data. Br. J. Non-Destr. Test. 1993, 35, 710–713. [Google Scholar]
- Milisavljevic, N.; Bloch, I. Sensor fusion in anti-personnel mine detection using a two-level belief function model. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2003, 33, 269–283. [Google Scholar] [CrossRef]
- SAS clinical data integration: Bringing repeatability and automation to analytical data preparation. Available online: http://www.sas.com/resources/factsheet/sas-clinical-data-integration-fact sheet.pdf (accessed on 31 May 2015).
- Klepper, K.; Drabløs, F. Motiflab: A tools and data integration workbench for motif discovery and regulatory sequence analysis. BMC Bioinform. 2013, 14, 9. [Google Scholar] [CrossRef] [Green Version]
- Ovaska, K.; Laakso, M.; Haapa-Paananen, S.; Louhimo, R.; Chen, P.; Aittomäki, V.; Valo, E.; Núñez-Fontarnau, J.; Rantanen, V.; Karinen, S.; et al. Large-scale data integration framework provides a comprehensive view on glioblastoma multiforme. Genome Med. 2010, 2, 65. [Google Scholar] [CrossRef]
- Lanckriet, G.R.G.; de Bie, T.; Cristianini, N.; Jordan, M.I.; Noble, W.S. A statistical framework for genomic data fusion. Bioinformatics 2004, 20, 2626–2635. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, H. Multi-source feature selection via geometry-dependent covariance analysis. In Proceedings of the Journal of Machine Learning Research, Workshop and Conference, Antwerp, Belgium, 15 September 2008; pp. 36–47.
- Ye, J.; Chen, K.; Wu, T.; Li, J.; Zhao, Z.; Patel, R.; Bae, M.; Janardan, R.; Liu, H.; Alexander, G. Heterogeneous data fusion for alzheimer’s disease study. In Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 1025–1033.
- Viangteeravat, T.; Anyanwu, M.N.; Nagisetty, V.; Kuscu, E.; Sakauye, M.; Wu, D. Clinical data integration of distributed data sources using health level seven (hl7) v3-rim mapping. J. Clin. Bioinform. 2011, 1, 32. [Google Scholar] [CrossRef]
- Megalooikonomou, V.; Kontos, D. Medical data fusion for telemedicine. IEEE Eng. Med. Biol. Mag. 2007, 26, 36–42. [Google Scholar] [CrossRef]
- Hristofis, K.; Potamias, G.; Tsiknakis, M.; Moustakis, V.; Orphanoudakis, S. Mining distributed and heterogeneous data sources: A project in the medical domain. In Proceedings of Machine Learning in the New Information Age, MLnet workshop, European Conference of Machine Learning, Barcelona, Spain, 30 May–2 June 2000.
- Goesmann, A.; Linke, B.; Rupp, O.; Krause, L.; Bartels, D.; Dondrup, M.; McHardy, A.C.; Wilke, A.; Pühler, A.; Meyer, F. Building a bridge for the integration of heterogeneous data from functional genomics into a platform for systems biology. J. Biotechnol. 2003, 106, 157–167. [Google Scholar] [CrossRef]
- Zitnik, M.; Zupan, B. Matrix factorization-based data fusion for gene function prediction in bakerʼs yeast and slime mold. Pac. Symp. Biocomput. 2014, 19, 400–411. [Google Scholar]
- Weng, Z.; Djuric, P. A bayesian approach to data fusion in sensor networks. arXiv Preprint arXiv 2013. 1303.2414. [Google Scholar]
- Lanckriet, G.R.G.; Cristianini, N.; Bartlett, P.; Ghaoui, L.E.; Jordan, M.I. Learning the kernel matrix with semidefinite programming. J. Mach. Learn. Res. 2004, 5, 27–72. [Google Scholar]
- Dimitrova, M.; Roumenin, C.; Nikolov, D.; Rotger, D.; Radeva, P. Multimodal data fusion for intelligent cardiovascular diagnosis and treatment in the active vessel medical workstation. J. Intell. Syst. 2009, 18, 33–50. [Google Scholar] [CrossRef]
- Grove, O.; Rajab, K.; Piegl, L.A. Heterogeneous modeling of medical image data using b-spline functions. Proc. Inst. Mech. Eng Part H: J. Eng. Med. 2012. [Google Scholar] [CrossRef]
- Madabhushi, A.; Agner, S.; Basavanhally, A.; Doyle, S.; Lee, G. Computer-aided prognosis: Predicting patient and disease outcome via quantitative fusion of multi-scale, multi-modal data. Comput. Med. Imaging Graph. 2011, 35, 506–514. [Google Scholar] [CrossRef]
- Larrabide, I.; Omedas, P.; Martelli, Y.; Planes, X.; Nieber, M.; Moya, J.A.; Butakoff, C.; Sebastián, R.; Camara, O.; de Craene, M. Gimias: An open source framework for efficient development of research tools and clinical prototypes. In Functional Imaging and Modeling of the Heart; Springer: Berlin, Germany, 2009; pp. 417–426. [Google Scholar]
- Mehmood, I.; Sajjad, M.; Baik, S.W. Video summarization based tele-endoscopy: A service to efficiently manage visual data generated during wireless capsule endoscopy procedure. J. Med. Syst. 2014, 38, 1–9. [Google Scholar] [CrossRef]
- Mehmood, I.; Sajjad, M.; Baik, S.W. Mobile-cloud assisted video summarization framework for efficient management of remote sensing data generated by wireless capsule sensors. Sensors 2014, 14, 17112–17145. [Google Scholar] [CrossRef]
- Tiwari, P.; Viswanath, S.; Lee, G.; Madabhushi, A. Multi-modal data fusion schemes for integrated classification of imaging and non-imaging biomedical data. In Proceedings of the IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Chicago, IL, USA, 30 March–2 April 2011; pp. 165–168.
- Zhou, D.; Burges, C.J.C. Spectral clustering and transductive learning with multiple views. In Proceedings of the 24th international conference on Machine learning, Corvallis, OR, USA, 20–24 June 2007; pp. 1159–1166.
- Mehmood, I.; Ejaz, N.; Sajjad, M.; Baik, S.W. Prioritization of brain MRI volumes using medical image perception model and tumor region segmentation. Comput. Boil. Med. 2013, 43, 1471–1483. [Google Scholar] [CrossRef]
- Mehmood, I.; Sajjad, M.; Ejaz, W.; Baik, S.W. Saliency-directed prioritization of visual data in wireless surveillance networks. Inform. Fusion 2015, 24, 16–30. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The weka data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Alcalá-Fdez, J.; Fernandez, A.; Luengo, J.; García, S.; Sánchez, L.; Herrera., F. Keel data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework. J. Mult. Valued Log. Soft Comput. 2011, 17, 255–287. [Google Scholar]
- Prędki, B.; Wilk, S. Rough set based data exploration using rose system. In Foundations of Intelligent Systems; Springer: Berlin, Germany, 1999; pp. 172–180. [Google Scholar]
- Bazan, J.G.; Szczuka, M. The rough set exploration system. In Transactions on Rough Sets III; Springer: Berlin, Germany, 2005; pp. 37–56. [Google Scholar]
- Almutiry, O.; Wills, G.; Alwabel, A. Toward a framework for data quality in cloud-based health information system. In Proceedings of the 2013 International Conference on Information Society (i-Society), Toronto, ON, USA, 24–26 June 2013; pp. 153–157.
- Grzymala-Busse, J.W.; Hu, M. A comparison of several approaches to missing attribute values in data mining. In Rough Sets and Current Trends in Computing; Springer: Berlin, Germany, 2001; pp. 378–385. [Google Scholar]
- Pawlak, Z. Rough set theory and its applications to data analysis. Cybern. Syst. 1998, 29, 661–688. [Google Scholar] [CrossRef]
- Grzymala-Busse, J.W. Knowledge acquisition under uncertainty—A rough set approach. J. Intell. Robot. Syst. 1988, 1, 3–16. [Google Scholar] [CrossRef]
- Bazan, J.G.; Szczuka, M.S.; Wroblewski, J. A new version of rough set exploration system. In Rough Sets and Current Trends in Computing; Springer: Berlin, Germany, 2002; pp. 397–404. [Google Scholar]
- Fatima, I.; Halder, S.; Saleem, M.A.; Batool, R.; Fahim, M.; Lee, Y.K.; Lee, S. Smart CDSS: Integration of social media and interaction engine (SMIE) in healthcare for chronic disease patients. Multimed. Tools Appl. 2013, 1–21. [Google Scholar] [CrossRef]
- Han, M.; Lee, Y.K.; Lee, S. Comprehensive context recognizer based on multimodal sensors in a smartphone. Sensors 2012, 12, 12588–12605. [Google Scholar] [CrossRef]
- Fahim, M.; Fatima, I.; Lee, S.; Lee, Y.K. EEM: Evolutionary ensembles model for activity recognition in smart homes. Appl. Intell. 2012, 38, 88–98. [Google Scholar] [CrossRef]
- Siddiqi, M.H.; Lee, S. Human facial expression recognition using wavelet transform and hidden markov model. In Ambient Assisted Living and Active Aging; Springer International Publishing: New York, NY, USA, 2013; pp. 112–119. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, R.; Siddiqi, M.H.; Idris, M.; Ali, T.; Hussain, S.; Huh, E.-N.; Kang, B.H.; Lee, S. GUDM: Automatic Generation of Unified Datasets for Learning and Reasoning in Healthcare. Sensors 2015, 15, 15772-15798. https://0-doi-org.brum.beds.ac.uk/10.3390/s150715772
Ali R, Siddiqi MH, Idris M, Ali T, Hussain S, Huh E-N, Kang BH, Lee S. GUDM: Automatic Generation of Unified Datasets for Learning and Reasoning in Healthcare. Sensors. 2015; 15(7):15772-15798. https://0-doi-org.brum.beds.ac.uk/10.3390/s150715772
Chicago/Turabian StyleAli, Rahman, Muhammad Hameed Siddiqi, Muhammad Idris, Taqdir Ali, Shujaat Hussain, Eui-Nam Huh, Byeong Ho Kang, and Sungyoung Lee. 2015. "GUDM: Automatic Generation of Unified Datasets for Learning and Reasoning in Healthcare" Sensors 15, no. 7: 15772-15798. https://0-doi-org.brum.beds.ac.uk/10.3390/s150715772